


















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
开源大数据存储系统Alluxio的新特性介绍与缓存性能优化
分布式文件系统处于大数据系统中基础地位,在行业大数据应用中发挥着重要作用。Alluxio(原名Tachyon)是世界上首个以内存为中心的层次化分布式文件系统。它为上层计算框架和底层存储系统构建了桥梁,应用可以通过Alluxio提供的统一数据访问方式访问底层任意存储系统中的数据。在本报告中,我将首先介绍Alluxio系统的基本原理,以及Alluxio 2.0的新特性;然后,我将介绍我们在Alluxio缓存优化方面的一些工作,包括通用的分层式大数据缓存调度框架,缓存替换策略及其自适应调度算法,以及内存读性能优化等。
展开查看详情
1 .开源大数据存储系统Alluxio 的新特性介绍与缓存性能优化 顾荣 Alluxio PMC 南京大学 PASA大数据实验室助理研究员,博士 gurong@nju.edu.cn 2019-6-2 上海
2 . 1 Alluxio项目&系统简介 Agenda 2 Alluxio 2.0新特性概览 3 Alluxio缓存性能优化
3 . 数据处理的四大趋势 驱动了新型基础架构的需求 Separation of Hybrid – Multi Rise Self-service Compute & cloud of the object data across the Storage environments store enterprise
4 .Data Ecosystem - Beta Data Ecosystem 1.0 COMPUTE COMPUTE STORAGE STORAGE
5 . 大数据之路与企业创新的选择 混合云化部署HDFS Burst HDFS data in the cloud, 同置 分散 public or private (Co-located ) (Disaggregated) 支持更多计算框架 Co-located Disaggregated compute & HDFS compute & HDFS Support Presto, Spark on the same cluster on the same cluster and other computes without app changes 向对象存储过渡 MR / Hive Hive HDFS Enable & accelerate HDFS big data on object stores
6 . 技术转变中的挑战 混合云部署HDFS 支持更多计算框架 向对象存储过渡 Accessing data over WAN too Copying data to multiple Object stores performance for slow compute clouds time consuming big data workloads can be very and error prone poor Copying data to compute cloud time consuming and complex Migrating applications for new No native support for popular storage systems is complex & frameworks Using another storage system like time consuming S3 means expensive application Expensive metadata operations changes Storing and managing multiple reduce performance even more copies of the data becomes Using S3 via HDFS connector expensive No support for hybrid leads to extremely low environments directly performance
7 . 计算与存储实现独立可扩展性 Java File API HDFS Interface FUSE Interface S3 Interface REST API Alluxio: a Virtual Distributed File System (VDFS) HDFS Driver S3 Driver Swift Driver NFS Driver 6/3/2019 7
8 . Alluxio数据编排赋能的几类场景 Accelerate big data frameworks Burst big data workloads in Dramatically speed-up big data on the public cloud hybrid cloud environments on object stores on premise On-premise Spark Hive Presto Alluxio Alluxio Alluxio Same container / machine Same instance / container Same instance / container On premise or or
9 . 高级使用场景 Spark Presto Spark Hive Presto Alluxio Alluxio Standalone Any public / Same data private cloud center / region Any Cloud / Multi Cloud or or Enable big data on object stores Orchestrate data frameworks on across single or multiple clouds the public cloud
10 . Alluxio的核心创新 数据本地性 数据可访问性 数据伸缩性 Data Locality Data Accessibility Data Elasticity with Intelligent for popular APIs & with a unified Multi-tiering API translation namespace Accelerate big data Run Spark, Hive, Presto, ML Abstract data silos & storage workloads with transparent workloads on your data systems to independently scale tiered local data located anywhere data on-demand with compute
11 .基于智能多层缓存实现数据本地性 Local performance from remote data using multi-tier storage Read & Write Buffering Transparent to App RAM SSD HDD Hot Warm Cold Policies for pinning, promotion/demotion, TTL
12 .通过提供流行APIs和API转换实现数据可访问性 Convert from Client-side Interface to native Storage Interface Java File API HDFS Interface S3 Interface FUSE Interface REST API HDFS Driver S3 Driver Swift Driver NFS Driver
13 .通过统一命名空间实现数据可伸缩性 Enables effective data management across different Under Store - Uses Mounting with Transparent Naming
14 .统一命名空间(Unified Namespace) Transparent access to understorage makes all enterprise data available locally HDFS #1 SUPPORTS IT OPS FRIENDLY Object Store • HDFS • Storage mounted into Alluxio • NFS by central IT NFS • OpenStack • Security in Alluxio mirrors • Ceph source data • Amazon S3 • Authentication through HDFS #2 • Azure LDAP/AD • Google Cloud • Wireline encryption
15 .100+ Known Production Deployments 6/3/2019 15
16 . Incredible Open Source Momentum with growing community 1000+ contributors & Apache 2.0 Licensed growing Hundreds of Thousands 4170+ Git Stars of downloads Join the conversation on Slack alluxio.org/slack
17 .Alluxio适用场景分析 Finding high-fit use-cases Compute Zone Standalone or managed with Mesos or Yarn Example First Projects Spark Tensorflow Presto Enterprise Storage & Big Data Teams • Virtual Data Lakes • Gradual transition to low cost storage • Unify hybrid-cloud storage HDFS Machine Learning & Data Science Teams • Accelerate training Storage in Different Availability Zone • Improve productivity Either on-prem or cloud Alluxio is installed with or near compute to unify data stores, stage remote data, and improve system performance. 6/3/2019 17
18 .Machine Learning Case Study – SPARK SPARK TERADATA TERADATA Challenge – Solution – Gain end to end view of business ETL Data from Teradata to Alluxio with large volume of data Impact – Faster Time to Market – “Now we Queries were slow / not don’t have to work Sundays” interactive, resulting in operational inefficiency Use Case: http://bit.ly/2oMx95W 6/3/2019 18
19 .Machine Learning Use Case – MESOS MESOS SPARK SPARK Public Internet Public Internet HDFS HDFS Challenge – Solution – Slow training of model for With Alluxio, data access are 10- algorithmic trading in $50B data 30X faster driven Hedge Fund Impact – Increased efficiency on training of Data access was slow, costing ML algorithm, lowered compute cost them $$ in compute cost and and increased modeler productivity, lower modeler productivity resulting in 14 day ROI of Alluxio 6/3/2019 19
20 .Analytics Use Case – Top Retailer SPARK SPARK HDFS HDFS Challenge – Solution – Bottleneck in Trend Analysis of With Alluxio, data queries are 10X mission critical daily sales and faster inventory management Impact – Higher operational efficiency Queries were slow / not interactive, resulting in Use case: http://bit.ly/2ook8Nh operational inefficiency 6/3/2019 20
21 .Consumer Intelligence Use Case – HADOOP HDFS ML HADOOP ML ETL HDP CDH MAPR HDFS HDFS HDFS HDFS HDFS HDFS Challenge – Solution – Desired a central view of Alluxio integrates data into central consumer information in near catalog for fast access to consumer real time for proactive support. interaction records. Many HDFS, different Impact – Reduced integration time distributions, many incompatible Faster data speed & freshness versions. On-prem & cloud. Integration through heavy ETL. 6/3/2019 21
22 .Machine Learning / Deep Learning – Maximizes GPU investment: • Self-serve data access for data scientists • Rapid integration of new data sources • Improved memory management & performance 6/3/2019 22
23 . 1 Alluxio项目&系统简介 Agenda 2 Alluxio 2.0新特性 3 Alluxio缓存性能优化
24 . 支持超大规模数据工作负载 支持超过10亿个文件 2.0引入了分层元数据管理(tiered metadata management)这一新选 项,以支持包含超过10亿个文件的单群集部署。 我们现在默认使用RocksDB进行堆外存储。 热数据的元数据继续存储在堆内的进程内存中,而其余元数据由 Alluxio在进程内存外进行管理。 alluxio.master.metastore可以配置为仅使用堆内存储。 高度分布式数据服务 2.0引入了Alluxio作业服务(Job Service),这是一种分布式集群服务, 可以实现复制、持久化、跨存储移动和分布式加载等数据操作,从 而实现高性能和大规模扩展。 6/3/2019 24
25 . 支持超大规模数据工作负载 自适应副本以增强数据本地性 该功能为Alluxio配置一定数量范围的自动管理的存储数据副本数。 alluxio.user.file.replication.max和alluxio.user.file.replication.min可用 于指定该范围。 内嵌式日志以达到高可用性 2.0设计了一种称为内嵌式日志(embedded journal)的面向文件/对象 元数据的新容错和高可用模式。 内嵌式日志使用RAFT共识算法,并且实现方面独立于任何其他外部 存储系统。这对于抽象对象存储特别有用。 6/3/2019 25
26 .支持超大规模数据工作负载-自适应副本以增强数据本地性 Application Application Application Application Alluxio Alluxio Alluxio Alluxio Client Client Client Client Alluxio Alluxio Alluxio Alluxio Alluxio Master Worker Worker Worker Worker Block-1 Block-1 Block-1 Block-1 Pros: data layout is adaptive based on demand Cons: some data (e.g., common tables to join) Under Store Block-1 gets excessive copies
27 .支持超大规模数据工作负载-自适应副本以增强数据本地性 Application Application Application Application Alluxio Alluxio Alluxio Alluxio SetReplicaMax(2) Client Client Client Client Alluxio Alluxio Alluxio Alluxio Alluxio Master Worker Worker Worker Worker Block-1 Block-1 Block-1 Block-1 Under Store Block-1
28 .支持超大规模数据工作负载-自适应副本以增强数据本地性 Application Application Application Application Alluxio Alluxio Alluxio Alluxio SetReplicaMin(3) Client Client Client Client Alluxio Alluxio Alluxio Alluxio Alluxio Master Worker Worker Worker Worker Block-1 Block-1 Block-1 Under Store Block-1
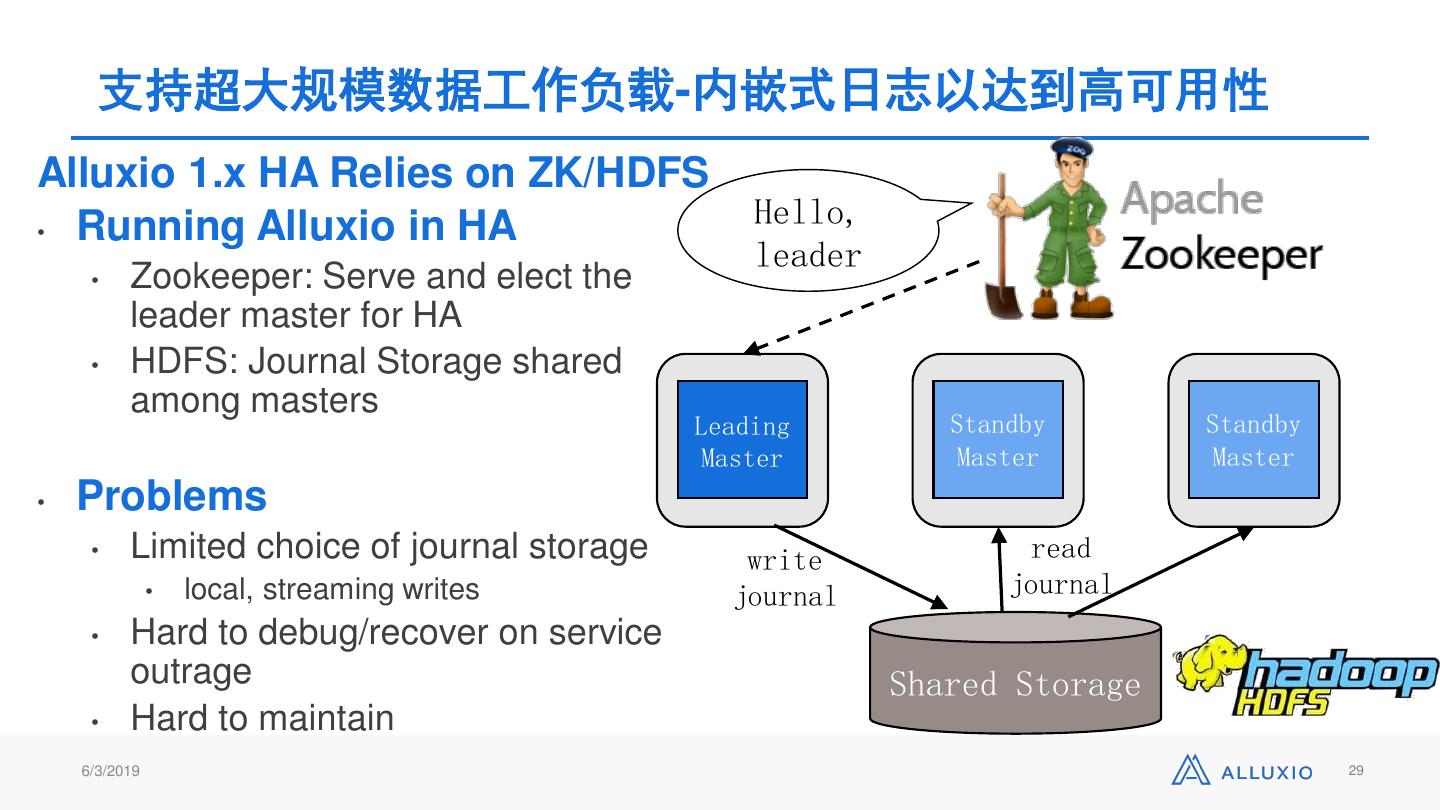
29 . 支持超大规模数据工作负载-内嵌式日志以达到高可用性 Alluxio 1.x HA Relies on ZK/HDFS • Running Alluxio in HA Hello, leader • Zookeeper: Serve and elect the leader master for HA • HDFS: Journal Storage shared among masters Leading Standby Standby Master Master Master • Problems • Limited choice of journal storage write read • local, streaming writes journal journal • Hard to debug/recover on service outrage Shared Storage • Hard to maintain 6/3/2019 29
3秒后跳转登录页面
去登陆

