





























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Spark+Alluxio在严选架构演进中的实践和探索
分享严选在Spark服务化建设的工作,以及我们在优化Spark计算引擎、存储格式等方面的优化探索,及严选大数据架构的演进方面的工作。Alluxio在严选大数据生态中同样扮演着重要的角色,Alluxio的特性能有效的帮助我们解决在spark优化,计算存储分离,计算混合部署等架构演进中遇到的困难。
展开查看详情
1 .Spark + Alluxio在严选⼤大数据架构演进的实践和探索 ⽹网易易严选数据平台 左琴 2019.7.27
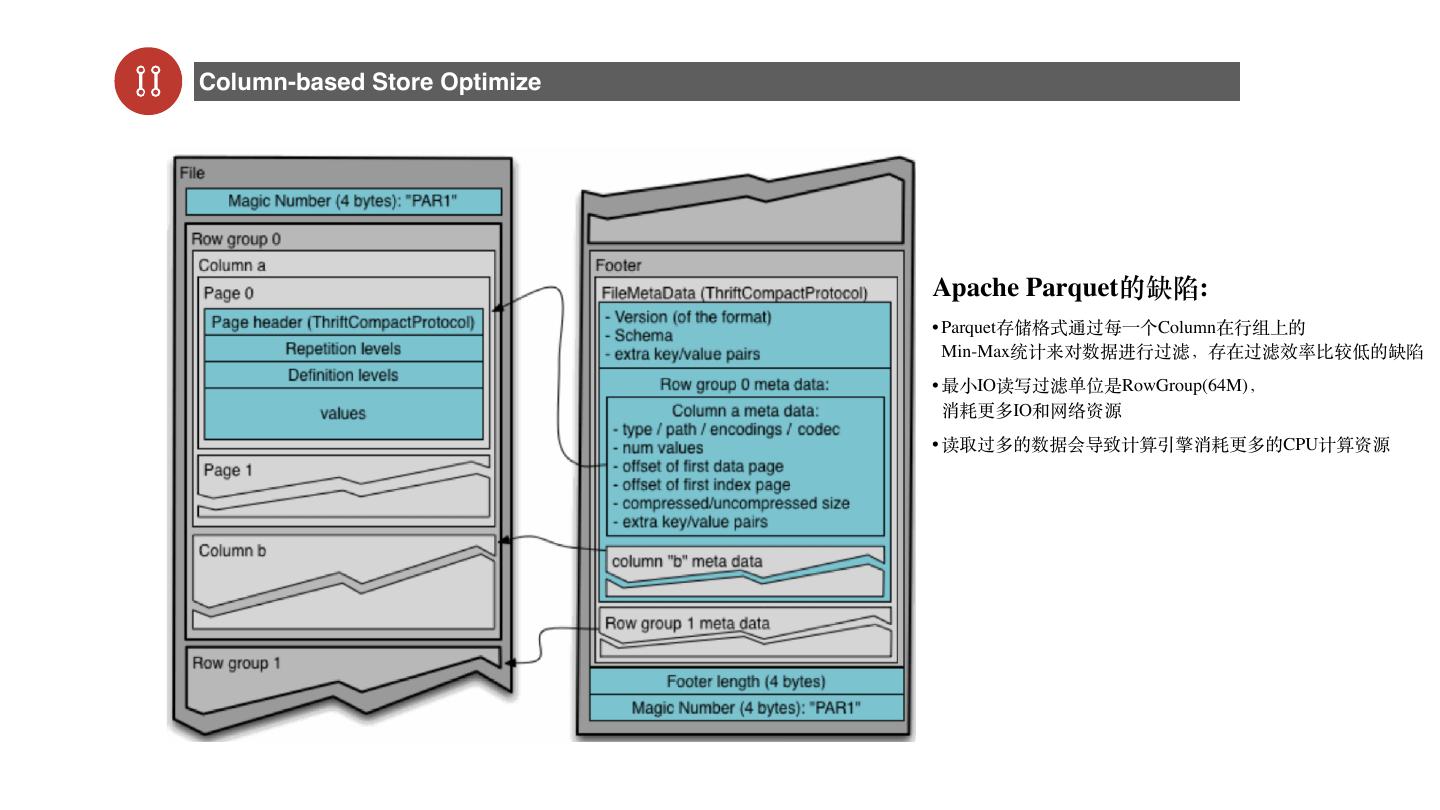
2 . Contents Data Infra Evolution @Netease YanXuan Spark As a Service Separation of Compute and Storage Data StorageFormate Optimize with Spark
3 .Data Infra Evolution @Netease YanXuan 2018年年末,我们有待解开的题 ??? $$$ ⼤大数据技术演进的未来在 ⼤大数据集群成本那么贵, 哪⾥里里? 我们如何去探索? 有优化空间么? 积⽊木 搭积⽊木⼀一样的解决⽅方案使⽤用成 本很⾼高,真的是最佳⽅方案么?
4 .Data Infra Evolution @Netease YanXuan ⼀一些想法 对⼤大数据平台问题的思考和解法,供讨论和修正 看现在 看未来 看过去 数据成为⽣生产资料料的前提: 社区的变化与演进: MapReduce: Simplified Data Processing on Large Clusters 1. Real time - TiDB?TP/AP 融合 - OSDI,2004 2. Reliable - 批流融合 - By Jeffrey Dean 3. Cheap Spark社区 赋能: Kafka社区 Kylin社区 1. 降低专业⻔门槛 现代的眼光来看过去的设计问 题. 2. ⼤大量量计算⽀支持
5 .Data Infra Evolution @Netease YanXuan 看过去: Jeff Dean’s Paper 本地化:移动计算程序⽐比移动数据更更容易易 拷问:Feature or Workaround?
6 . Data Infra Evolution @Netease YanXuan 看未来 数据⽣生态的演进决定平台⽣生态的演进 未来的数据⽣生态需要什什么样的平台? 在线 -离线计算成为⼀一个伪概念,被批处理理这样的概念替代,计算模型从批处理理/流处理理变成统 ⼀一的计算模型. 简单 – 不不需要搭积⽊木⼀一样的⼀一⼤大堆针对特定场景的解决⽅方法,尽量量⽤用⼀一致的概念和服务来解决 需求问题(策略略上还是要保持新概念的不不断引⼊入)。 ⽣生成资料料-低延迟 - 数据能在很低的时间内被⽣生成出来,同时能以很低的延迟提供给业务,满⾜足 在线⾃自动决策/在线智能决策的需要。 赋能 - 平台应该降低数据各个⽅方向的专业⻔门槛,将数据处理理能⼒力力,算法能⼒力力,分析思路路通过平 台的⽅方式提供给业务⼈人员(业务研发,产品经理理等);提升单⼈人的⼈人效,打破专业壁垒。 ----打破专业壁垒,是平台的该做的事情。
7 .Data Infra Evolution @Netease YanXuan 本地化的影响 问题: 1. 可能的不不经济 1. CPU/RAM/HDD的需求不不同时期不不⼀一致 2. 为了了解决其中CPU瓶颈,不不得不不买⼀一堆磁盘 2. 不不适合混合存储场景 3. 不不灵活 1. 计算资源(CPU/RAM)有临时性,但是⽆无法临时调配 2. ⼤大数据机器器资源与其他业务资源差别⽐比较⼤大 3. 存储容量量容易易预测,计算不不容易易预测(分析,ML/AI) 4. 磁盘需要同时承担HDFS读写和中间计算数据读写负载 5. ⼗十⼏几年年来是怎么解决这个问题的? 1. 买买买。 2. 采购计划不不精细 6. the rise of spark @ 严选 1. 严选正推进spark over hive 2. 存储本地化对spark意义不不⼤大(对MR意义⽐比较⼤大) 计算存储⼀一体化机器器/Hadoop经典机器器配置
8 .Data Infra Evolution @Netease YanXuan 新的问题 严选场景:存储采购量量降低导致集群整体IOPS 数据传输还是有⼀一点开销 下降 磁盘的Serving能⼒力力⽆无法跟存储容量量分离 HIVE/impala这类服务,计算需求跟IOPS需求是⼀一致的
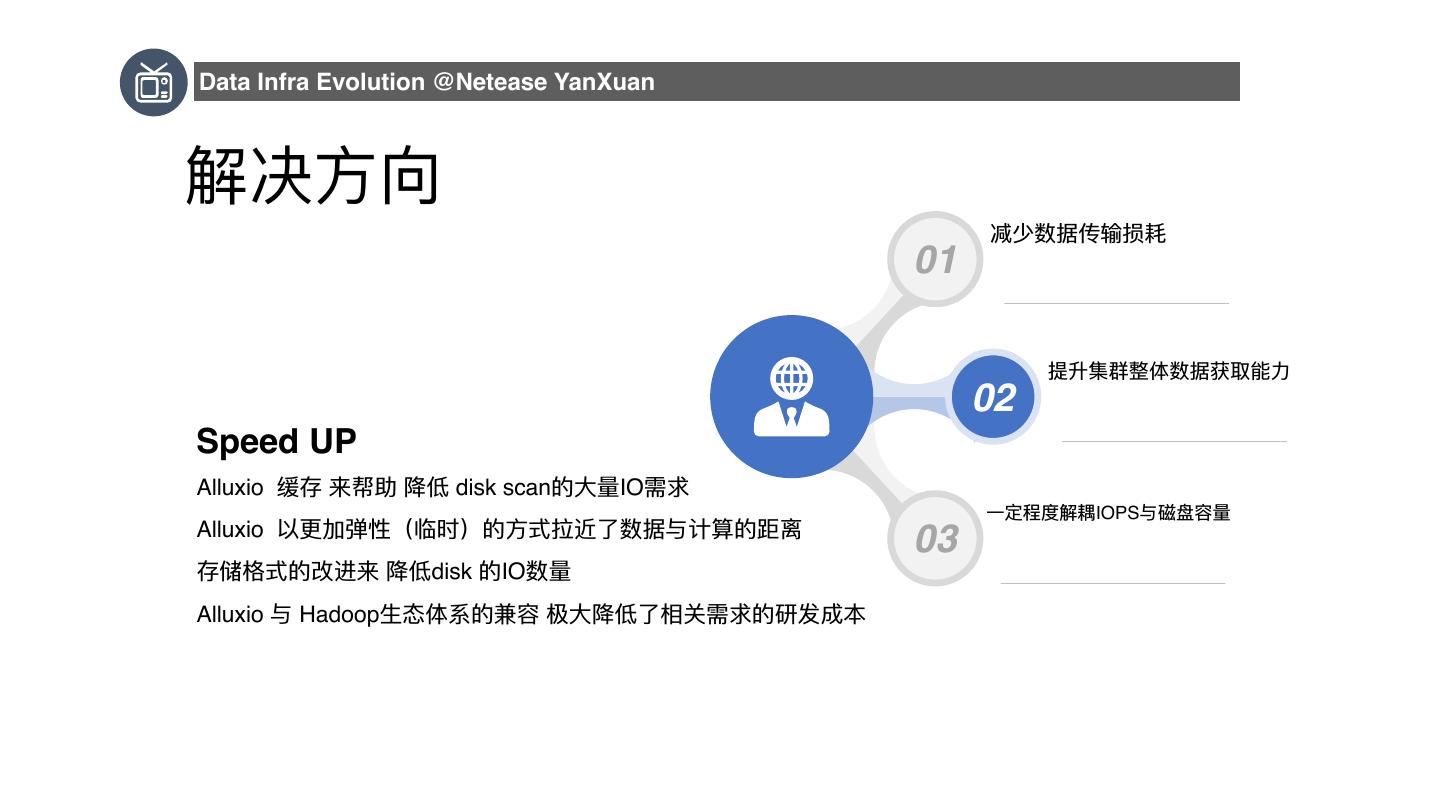
9 .Data Infra Evolution @Netease YanXuan 解决⽅方向 减少数据传输损耗 01 提升集群整体数据获取能⼒力力 02 Speed UP Alluxio 缓存 来帮助 降低 disk scan的⼤大量量IO需求 ⼀一定程度解耦IOPS与磁盘容量量 Alluxio 以更更加弹性(临时)的⽅方式拉近了了数据与计算的距离 03 存储格式的改进来 降低disk 的IO数量量 Alluxio 与 Hadoop⽣生态体系的兼容 极⼤大降低了了相关需求的研发成本
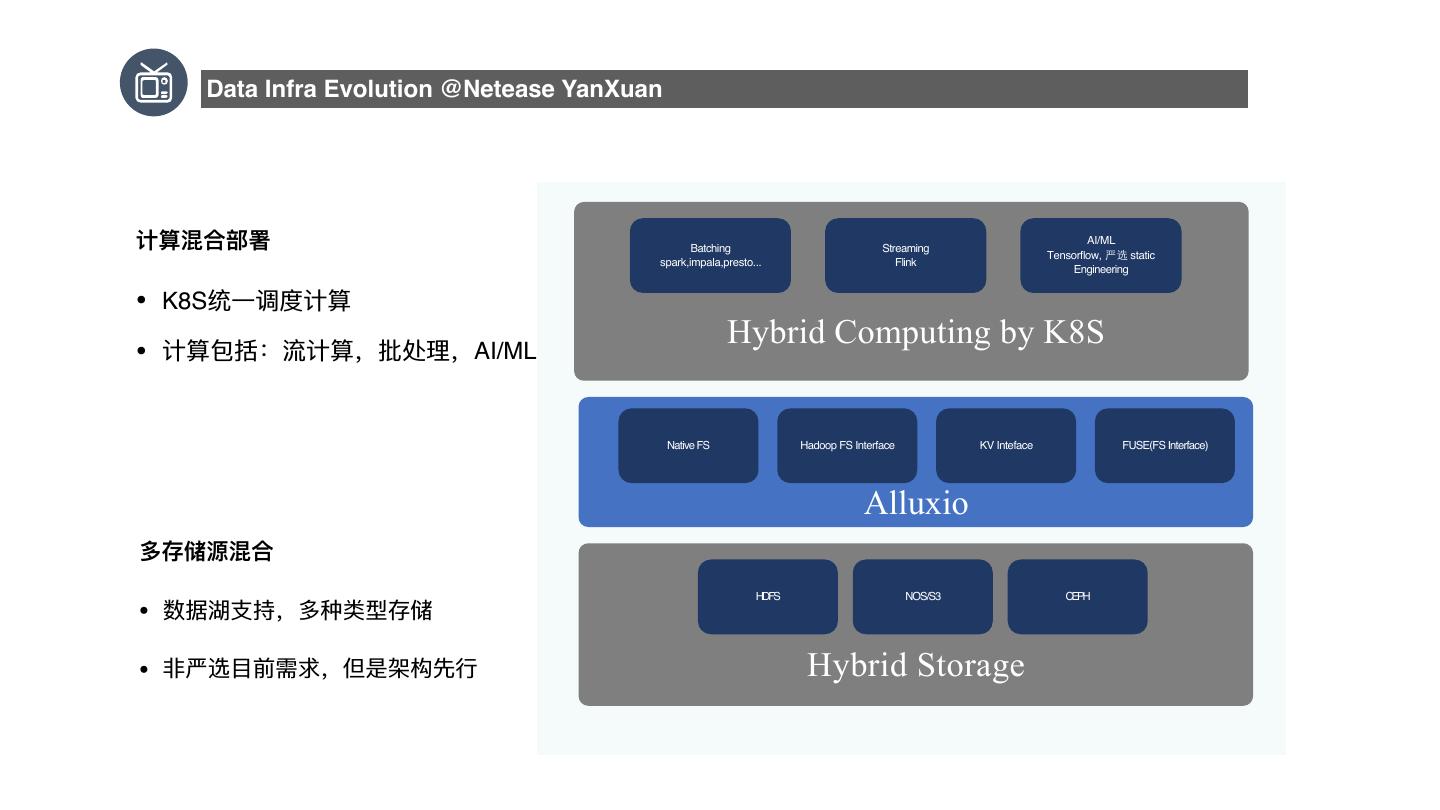
10 .Data Infra Evolution @Netease YanXuan Data Infra Evolution @ ⽹网易易严选 严选数据架构演进 主要关注⼤大数据使⽤用成本:采购成本,使⽤用⻔门槛,时间成本;我们不不断的演进来降低成本 2019年年主要⽅方向 计算存储分离 计算混合部署 Batch 任务与HDFS 分离 混合Batch,Streaming,AI/ML 等计算类任务 …… K8S管理理资源
11 . Data Infra Evolution @Netease YanXuan 计算混合部署 Batching Streaming AI/ML Tensorflow, static spark,impala,presto... Flink Engineering • K8S统⼀一调度计算 计算包括:流计算,批处理理,AI/ML Hybrid Computing by K8S • Native FS Hadoop FS Interface KV Inteface FUSE(FS Interface) Alluxio 多存储源混合 HDFS NOS/S3 CEPH • 数据湖⽀支持,多种类型存储 • ⾮非严选⽬目前需求,但是架构先⾏行行 Hybrid Storage
12 . Contents DataInfra @ YanXuan Spark As a Service Separation of Compute and Storage Data StorageFormate Optimize
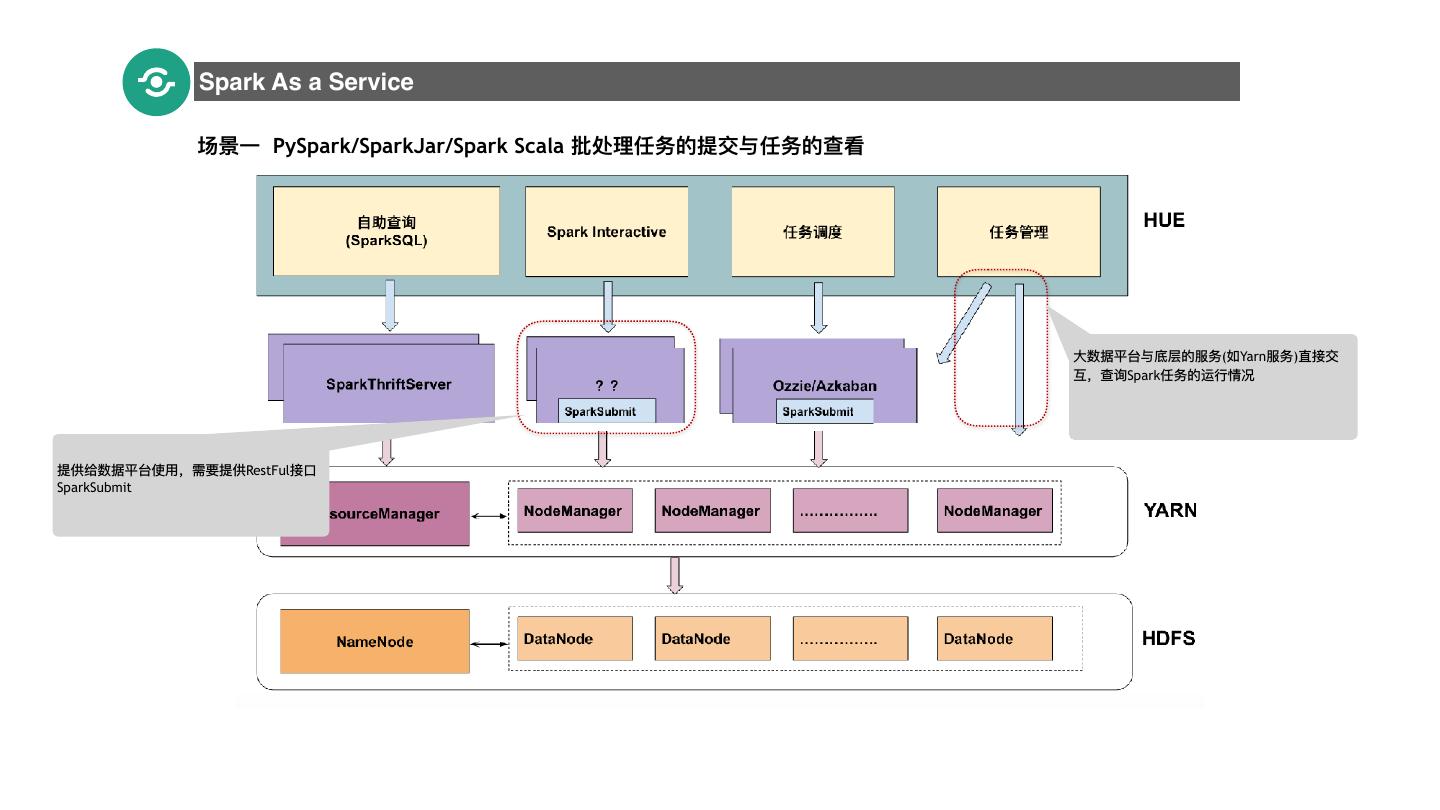
13 . Spark As a Service 场景⼀一 PySpark/SparkJar/Spark Scala 批处理理任务的提交与任务的查看 13 ⼤大数据平台与底层的服务(如Yarn服务)直接交 互,查询Spark任务的运⾏行行情况 提供给数据平台使⽤用,需要提供RestFul接⼝口 SparkSubmit
14 . Spark As a Service 场景⼆二 社区提供的SparkSQL Batch任务和Ad-Hoc查询使⽤用⽅方式 14 • Interactive和Batch任务需要Gateway节点 • Spark版本发布和权限难以集中管理控制 • Gateway节点上的部署细节及配置暴露 给⽤户 • ⽤户权限⽆法区分 • 计算资源⽆隔离 • 单点⽆HA⽅案
15 .Spark As a Service 场景三 访问Spark数据处理理能⼒力力和算法能⼒力力的需求 15 以服务的形式提供少量量临时数据的计算能⼒力力以及Spark的算法能⼒力力给业务系统或者平台 如: 严选统计分析引擎在SparkR的基础上封装和开发,提供统计分析的服务能⼒力力
16 . Spark As a Service 16 可靠性 可扩展 提供统⼀一的Spark服务 批处理理 • access and analyze data faster ⾼高性能 易易⽤用性 • performing graph computation 计算能⼒力力 Ad Hoc查询 • offering SQL on Hadoop • machine learning functionality 计算资源隔离 • can be easily used by both technical and business users
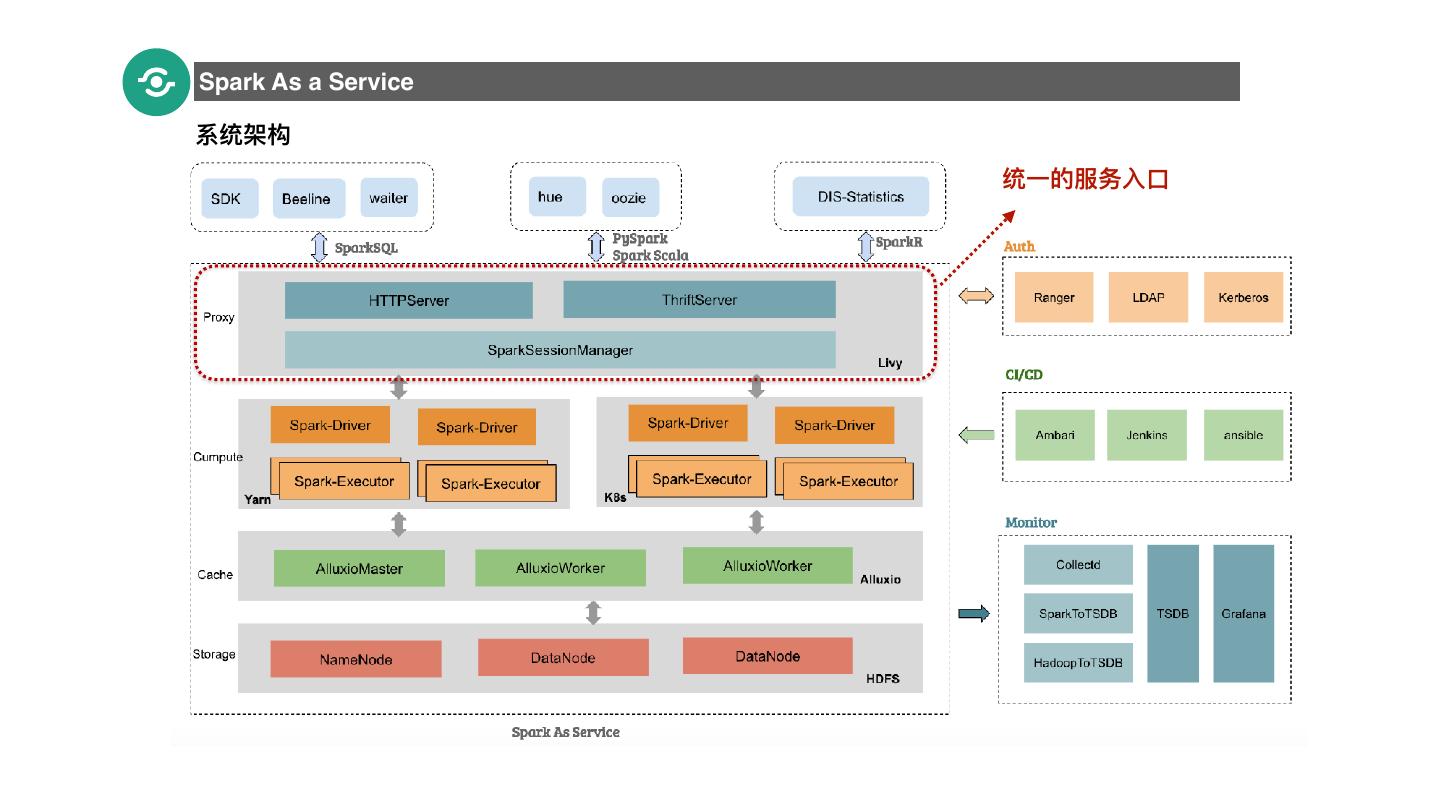
17 .Spark As a Service 系统架构 统⼀一的服务⼊入⼝口
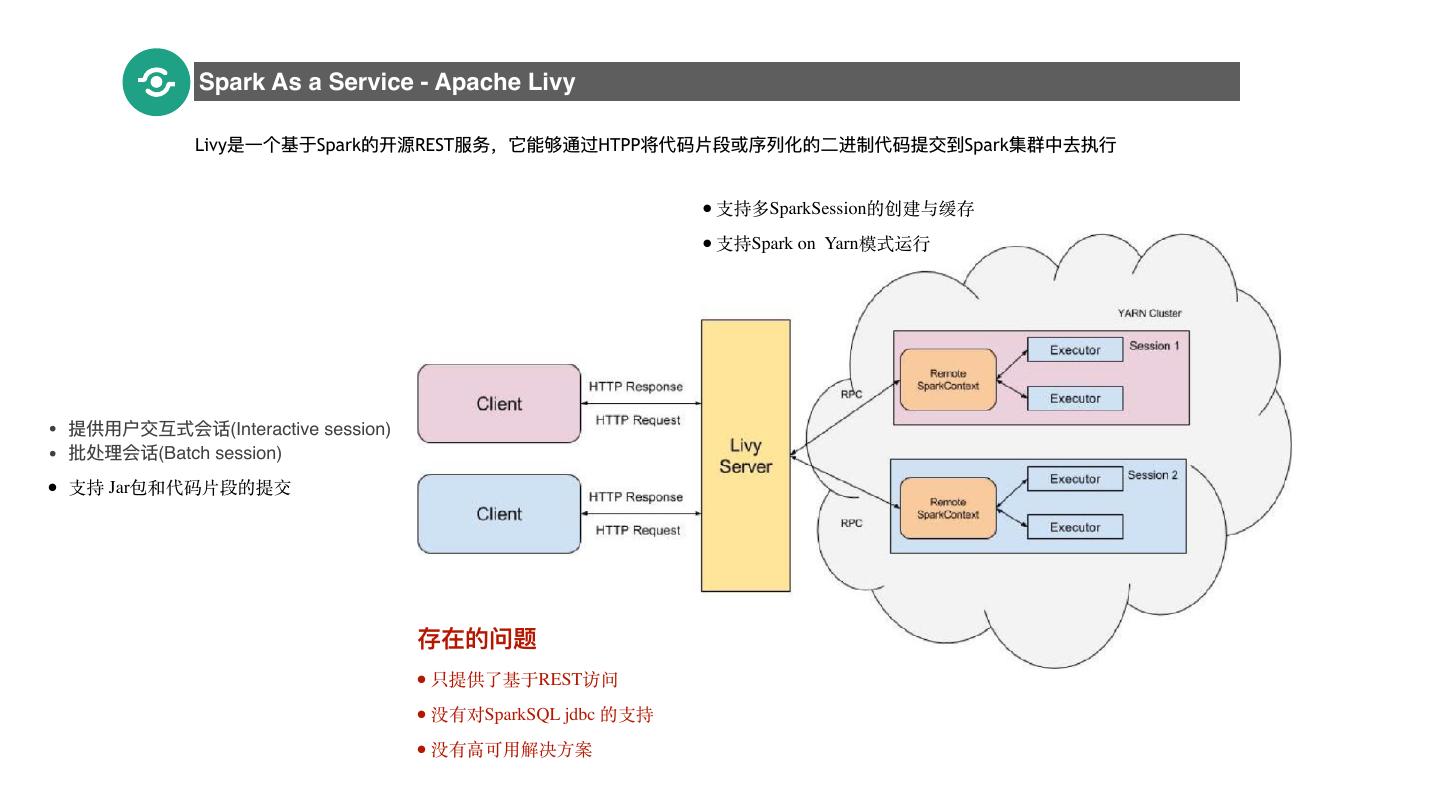
18 . Spark As a Service - Apache Livy Livy是⼀一个基于Spark的开源REST服务,它能够通过HTPP将代码⽚片段或序列列化的⼆二进制代码提交到Spark集群中去执⾏行行 18 • ⽀持多SparkSession的创建与缓存 • ⽀持Spark on Yarn模式运⾏ • 提供⽤用户交互式会话(Interactive session) • 批处理理会话(Batch session) • ⽀持 Jar包和代码⽚段的提交 存在的问题 • 只提供了基于REST访问 • 没有对SparkSQL jdbc 的⽀持 • 没有⾼可⽤解决⽅案
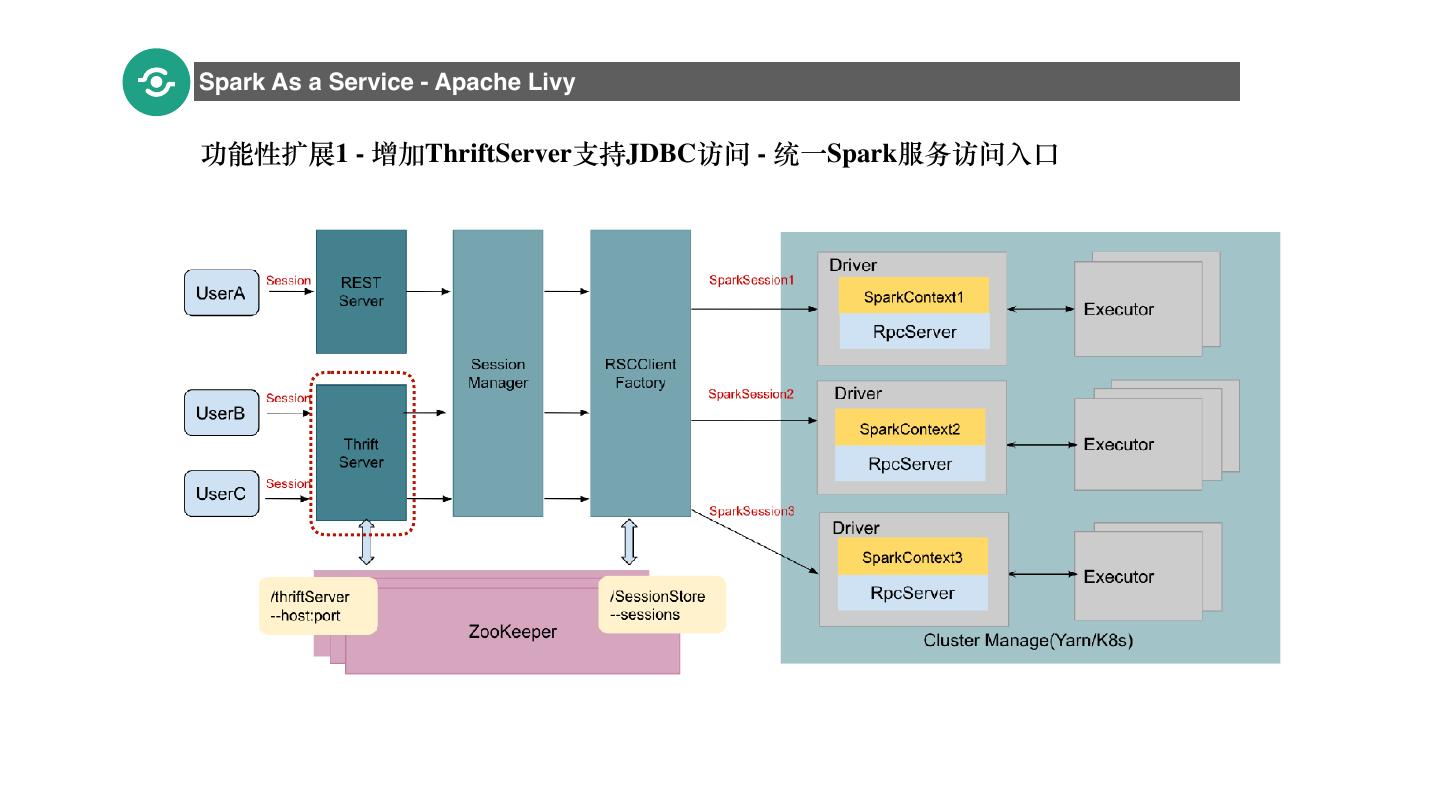
19 .Spark As a Service - Apache Livy 功能性扩展1 - 增加ThriftServer⽀持JDBC访问 - 统⼀Spark服务访问⼊⼜ 19
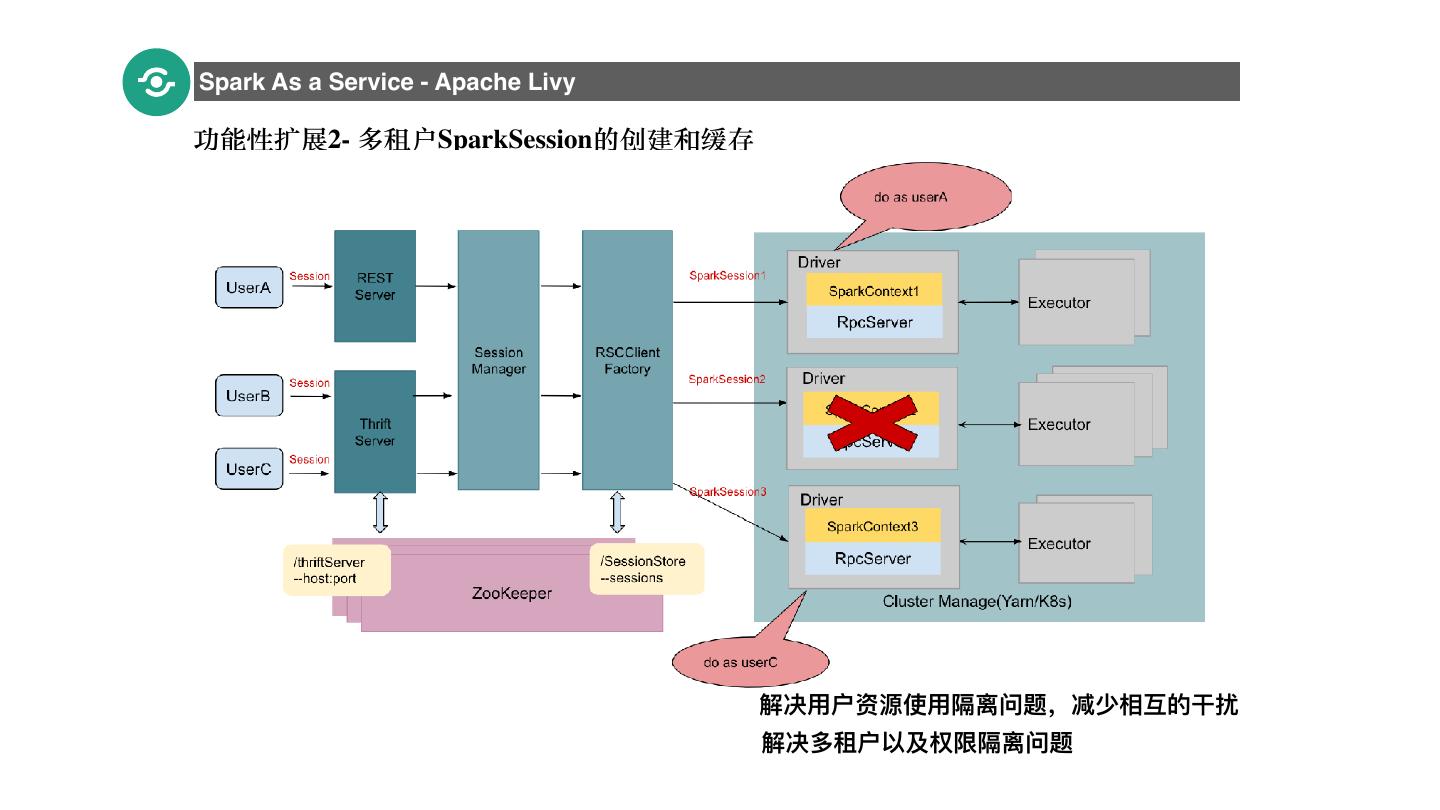
20 .Spark As a Service - Apache Livy 功能性扩展2- 多租户SparkSession的创建和缓存 20 解决⽤用户资源使⽤用隔离问题,减少相互的⼲干扰 解决多租户以及权限隔离问题
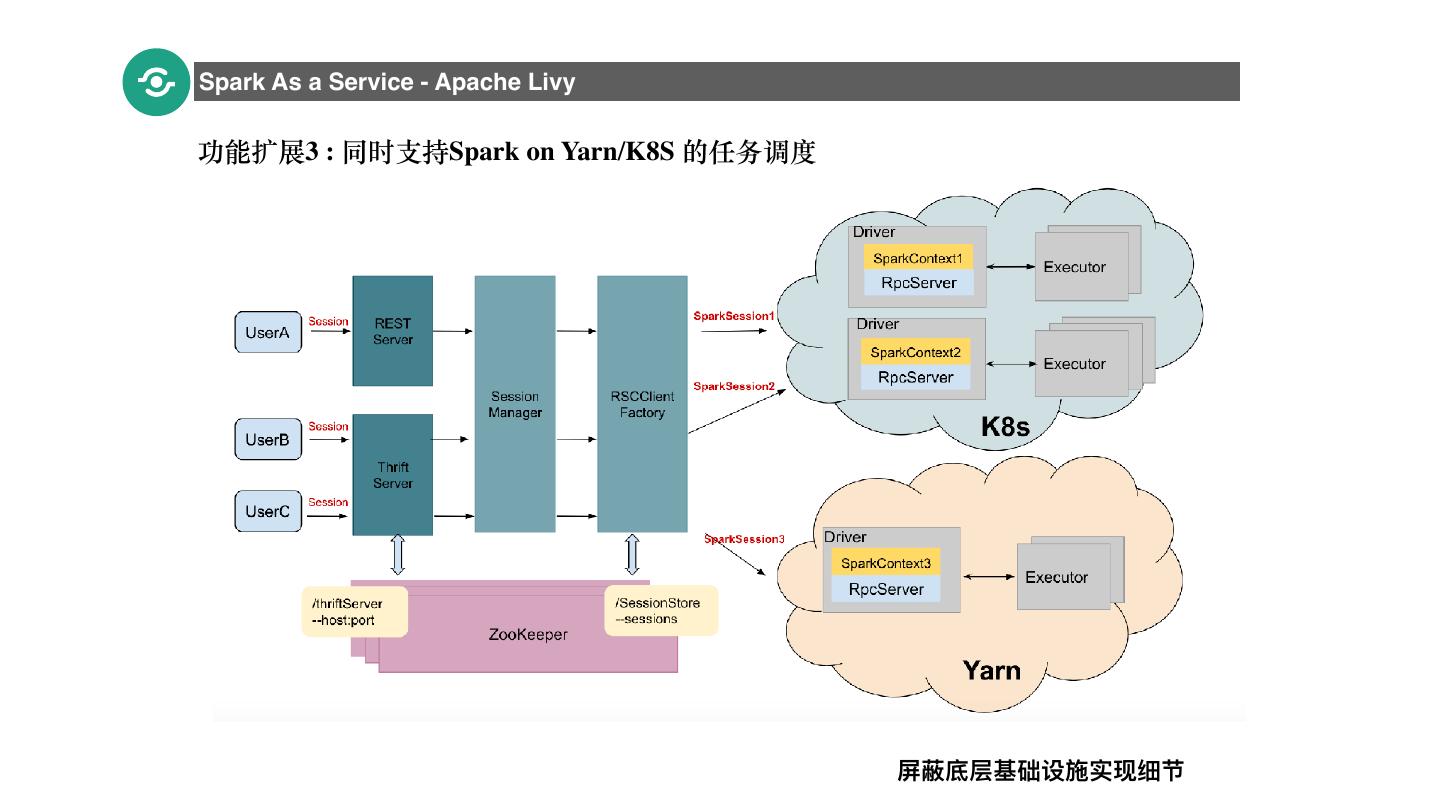
21 .Spark As a Service - Apache Livy 功能扩展3 : 同时⽀持Spark on Yarn/K8S 的任务调度 21 屏蔽底层基础设施实现细节
22 .Spark As a Service 功能扩展4: 统⼀提供查看任务监控的页⾯、SparkUI、运⾏⽇志 22 能够帮助⽤用户更更⽅方便便、更更快的排查SQL或程序的运⾏行行问题
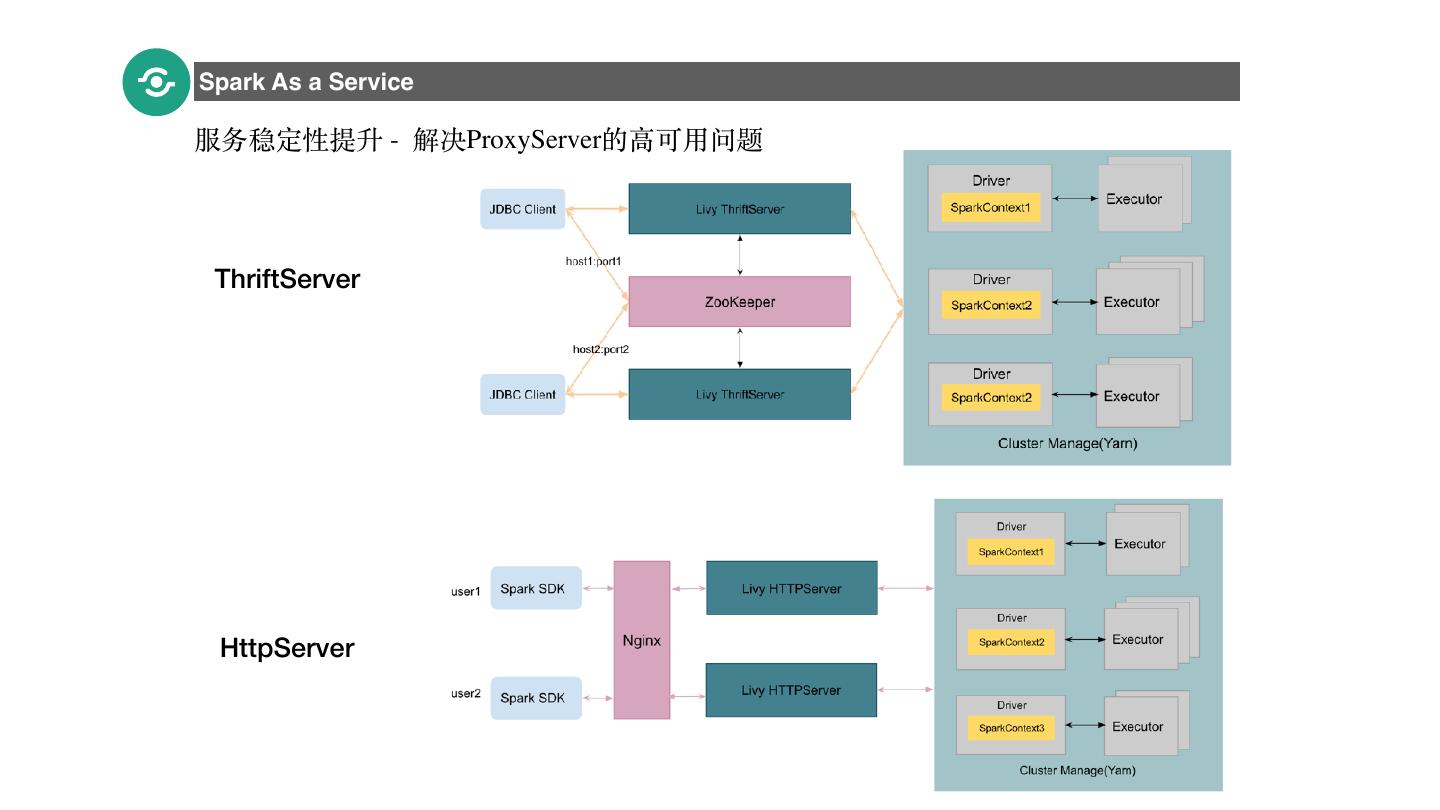
23 .Spark As a Service 服务稳定性提升 - 解决ProxyServer的⾼可⽤问题 23 ThriftServer HttpServer
24 .Spark As a Service 服务稳定性提升 - Session⾼高可⽤用 24 • YarnAppMonitorThread/K8sPodMonitorThread定时清理理异常和过期SparkSession • ⽤用户请求处理理时SessionState异常时清理理缓存 • ⽤用户请求查找seesion不不存在时,⾃自动重建SparkSession并缓存
25 .Spark As a Service 25 业务场景 上线效果 •严选⼤大数据平台Hue的⾃自助分析 •严选⼤大数据平台Spark任务开发调度 •严选JDBC⼯工具Waiter的SparkSQL查询 • Spark的发布和维护变得容易易 •严选千寻搜索中台 • 将数据处理理能⼒力力,算法能⼒力力以 •严选CRM系统 服务的⽅方式提供给业务⼈人员 •严选有数报表导出 •严选智能决策平台统计引擎服务
26 . Contents Data Infra Evolution @Netease YanXuan Spark As a Service Separation of Compute and Storage Data StorageFormate Optimize
27 . Separation of Compute and Storage Spark On K8S的⼯工作 27 平台任务调度和任务 管理理模块的重构 ⽀支持SparkOnK8s任务提交 SparkOnK8s access kerberos HDFS的开发 (Spark3.0会⽀支持)
28 .Separation of Compute and Storage SparkSQL + Alluxio AdHoc查询加速 • Batch任务计算节点 和 AdHoc查询计算节点 标签分离 • 读写分离,从Alluxio读,写HDFS
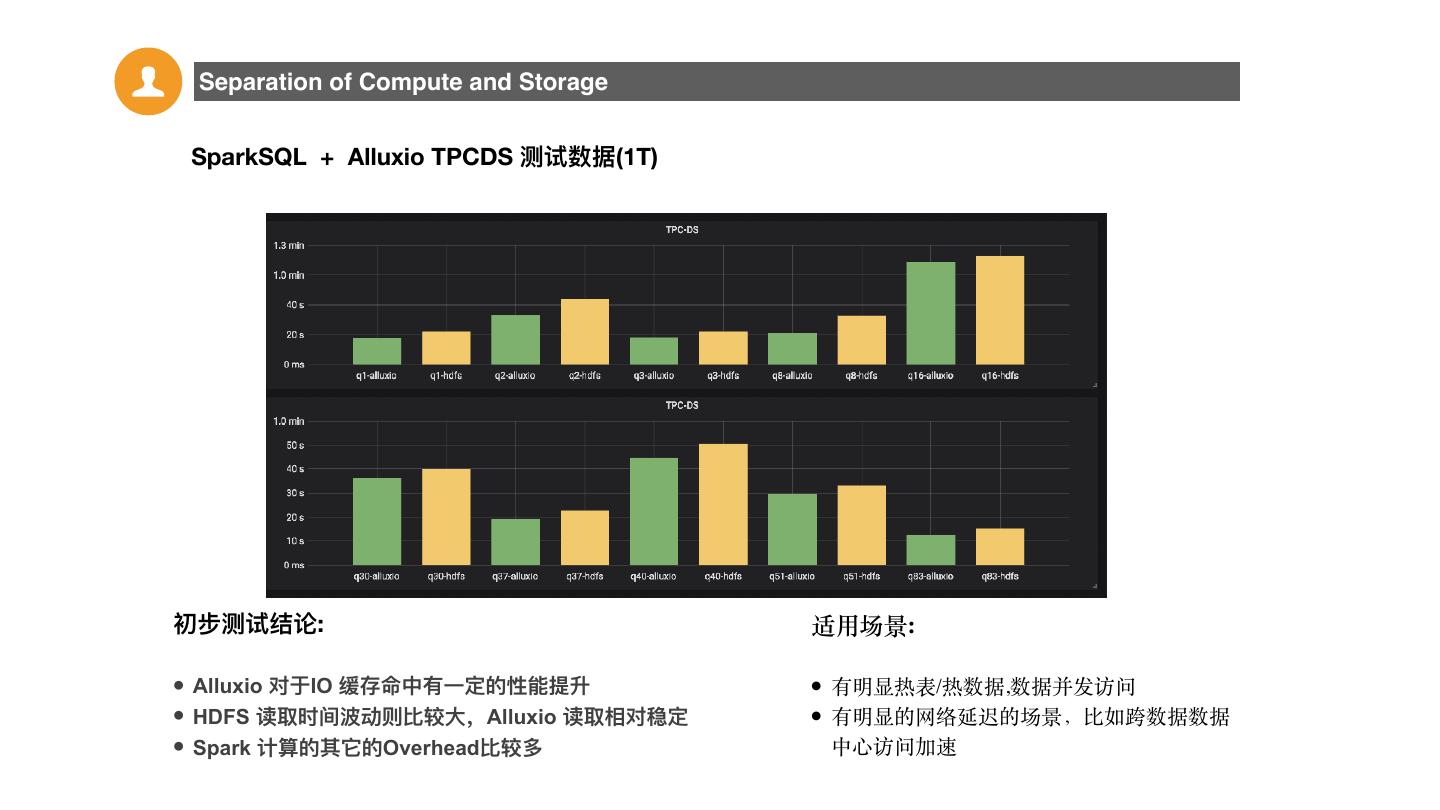
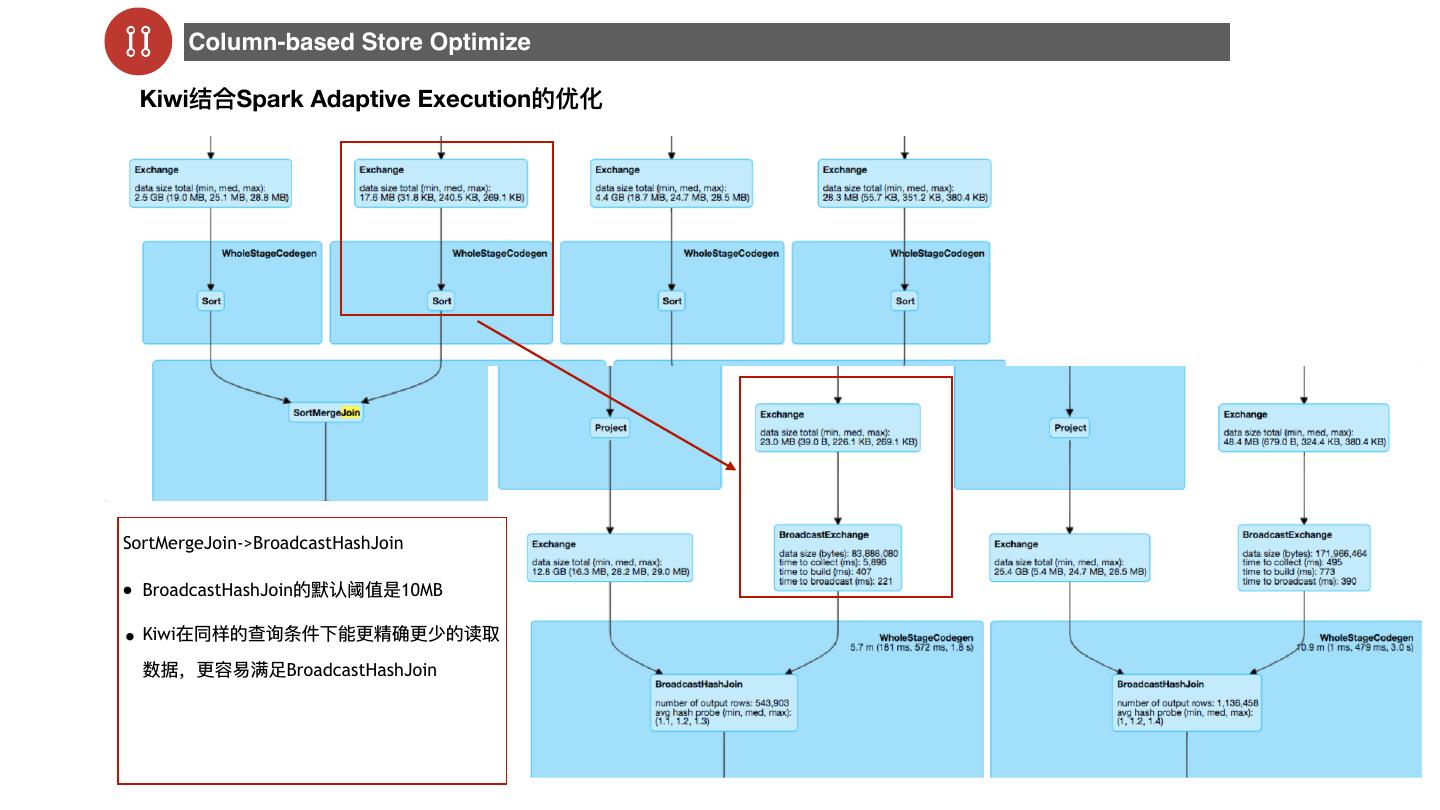
29 . Separation of Compute and Storage 29 SparkSQL + Alluxio TPCDS 测试数据(1T) 初步测试结论: 适⽤场景: • Alluxio 对于IO 缓存命中有⼀一定的性能提升 • 有明显热表/热数据,数据并发访问 • HDFS 读取时间波动则⽐比较⼤大,Alluxio 读取相对稳定 • 有明显的⽹络延迟的场景,⽐如跨数据数据 • Spark 计算的其它的Overhead⽐比较多 中⼼访问加速
3秒后跳转登录页面
去登陆

