






































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
融合数据白皮书
Apache CarbonData参与的云计算开源产业联盟编写的融合数据白皮书,可以作为大数据应用的技术架构和解决方案参考。
展开查看详情
1 . 融合数据白皮书 第一部分 融合数据存储 云计算开源产业联盟 OpenSource Cloud Alliance for industry,OSCAR 2017 年 12 月
2 . 版 权声 明 本白皮书版权属于云计算开源产业联盟,并受法律保护。转载、摘 编或利用其它方式使用本调查报告文字或者观点的,应注明“来源:云 计算开源产业联盟”。违反上述声明者,本联盟将追究其相关法律责任。
3 . 前 言 大数据时代,电信、金融、公共安全等领域的数据与日俱增,海量数据的 体量可达总量达 PB 级、单表数据达百亿行级别。业务驱动下的数据分析灵活性 要求越来越高,一个具体业务的数据分析过程往往包含了多个分析步骤,分属 于不同的分析场景类型(如关系型分析,图查询,图分析等) 。行业应用中的业 务分析不仅数据体量大,而且分析的表属性维度较多,单表属性维度可达百维 以上。数据在不同的分析场景下上存在多份不同的存储形式,这导致了平台维 护成本、数据冗余和数据转换代价的与日俱增,严重阻碍了大数据分析技术的 应用和发展。 融合数据存储是指通过一份数据存储,来实现海量复杂数据(总量达到 EB 级的,单表数据达百亿行级别以上,单表属性维度达百维以上的数据)的归并, 并支持多维度任意组合查询和分析,支持多种快速查询需求(如过滤查询、快 速扫描、详单查询等)的统一响应。围绕基于 Hadoop 的大数据生态,出现了一 批能够与 HDFS 无缝集成,实现统一数据存储,并有效提升数据分析的效率的 高性能融合数据存储开源技术,其中以 Apache 社区的 ORC、Parquet 和 CarbonData 等为代表。 本白皮书主要介绍了产业对融合数据存储的需求,阐述了融合数据存储的 概念和技术基本要求;对典型的大数据系统存储方案进行分析,介绍并对比了 开源社区中主流的融合数据存储技术;从金融、电信、公共安全三个领域的应 用案例,描述了融合数据存储在实际生产建设中的使用情况;最后,对融合数 据存储的未来发展方向进行展望。
4 . 参与编写单位 中国信息通信研究院、华为技术有限公司、上海仪电(集 团)有限公司、中国电信股份有限公司北京研究院、无锡华 云数据技术服务有限公司、联通云数据有限公司、烽火通信 科技股份有限公司、中兴通讯股份有限公司 主要撰稿人 马飞、栗蔚、陈亮、周广成、高巍、刘超、陈凯、陈屹 力、刘如明、郭雪
5 . 目 录 1. 序言......................................................................................................................... 1 2. 融合数据存储概念................................................................................................. 2 3. 不同行业对融合数据存储的需求......................................................................... 3 3.1 金融行业.......................................................................................................... 3 3.1.1 场景描述................................................................................................... 3 3.1.1 技术需求................................................................................................... 5 3.2 电信行业.......................................................................................................... 5 3.2.1 场景描述 ...................................................................................................... 5 3.2.2 技术需求 ...................................................................................................... 6 3.3 公共安全行业.................................................................................................. 7 3.3.1 场景描述 ...................................................................................................... 7 3.3.2 技术需求 ...................................................................................................... 8 4. 融合数据存储的基本技术要求............................................................................. 8 5. 典型大数据系统存储方案分析........................................................................... 10 5.1 NOSQL 数据库 ................................................................................................ 10 5.2 并行数据库.................................................................................................... 10 5.3 搜索引擎........................................................................................................ 11 5.4 CUBE DATA ........................................................................................................ 12 5.5 小结................................................................................................................ 12 6. 典型开源融合数据存储技术分析....................................................................... 13 6.1 典型开源融合数据存储技术........................................................................ 13 6.1.1 ORC............................................................................................................... 13 6.1.2 Parquet ...................................................................................................... 14 6.1.3 CarbonData ............................................................................................... 15 6.2 融合数据存储技术功能对比........................................................................ 16 6.3 融合数据存储技术性能对比........................................................................ 17 6.3.1 测试数据准备 .......................................................................................... 17 6.3.2 过滤查询场景测试 .................................................................................. 17 6.3.2 聚合计算场景测试 .................................................................................. 18 6.4 小结................................................................................................................ 19 7. 应用案例............................................................................................................... 20 7.1 案例 1:金融审计业务 ................................................................................ 20 7.1.1 业务和数据介绍 ...................................................................................... 20 7.1.2 现有方案 .................................................................................................. 21 7.1.3 客户挑战 .................................................................................................. 21 7.1.4 技术应对方案 .......................................................................................... 21 7.1.5 为客户带来的有益效果 .......................................................................... 22
6 . 7.2 案例 2:电信用户统计信息业务 ................................................................ 23 7.2.1 业务和数据介绍 ...................................................................................... 23 7.2.2 现有方案 .................................................................................................. 24 7.2.3 客户挑战 .................................................................................................. 25 7.2.4 技术应对方案 .......................................................................................... 25 7.2.5 为客户带来的有益效果 .......................................................................... 26 7.3 案例 3:公共安全精确查询分析业务 ........................................................ 26 7.3.1 业务和数据介绍 ...................................................................................... 26 7.3.2 现有方案 .................................................................................................. 27 7.3.3 客户挑战 .................................................................................................. 28 7.3.4 技术应对方案 .......................................................................................... 28 7.3.5 为客户带来的有益效果 .......................................................................... 29 8. 融合数据存储未来发展展望............................................................................... 30
7 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 1. 序言 大数据时代,中大型企业数据爆发式增长,如国内某银行平均每 天有 3 亿笔业务,业务高峰期间每天可达 6 亿笔业务。在企业快速转 型过程中,企业数据处理场景日益丰富,数据分析要求越来越灵活, 从传统的报表分析、OLAP、OLTP 业务,到新兴的批处理、实时数 据分析、机器学习,新的数据分析模式层出不穷。 但是,不同数据处理架构对底层数据的存储/组织、检索(引擎), 乃至处理接口都提出不同要求,对一份数据需要配套构建多套不同结 构的数据集,导致数据冗余严重,数据不能共享。如何对浪涌式的大 数据实现统一存储和组织、统一分析、统一接口,形成高效的融合数 据技术体系,发挥数据最大价值,是产业各方在积极探索的方向。 金融 运营商 ... 制造 融合数据技术体系 融合数据接口 融合数据引擎 融合数据存储 图1 融合数据技术体系图 本白皮书以开源技术和应用为关注对象,主要介绍了产业对融合 数据存储的需求,阐述了融合数据存储的概念和技术基本要求;对典 型的大数据系统存储方案进行分析,介绍并对比了开源社区中主流的 融合数据存储技术;从金融、电信、公共安全三个领域的应用案例, 1
8 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 描述了融合数据存储在实际生产建设中的使用情况;最后,对融合数 据存储的未来发展方向进行展望。 大数据融合数据存储技术应用于生产建设中,在大数据系统中的 位臵如下: 数据应用 应用1 应用2 ... 应用3 互联网 数据 大数据计算平台 大数据管理平台 日志 处理引擎1 ... 处理引擎X 系统管理 数据 ... 大数据资源调度 数据导入 安全管理 大数据融合数据存储 应用系 统数据 大数据硬件存储系统 图2 融合数据存储技术在大数据系统中的位臵 2. 融合数据存储概念 目前实际的数据分析业务中,通常针对不同分析场景构建不同的 数据存储结构和存储系统,海量的数据往往在不同的存储系统中存在 多份不同结构的备份。 融合数据存储是指通过一份数据存储,来实现海量复杂数据(总 量达到 EB 级的,单表数据达百亿行级别以上,单表属性维度达百维 以上的数据)的归并,并支持多维度任意组合查询和分析,支持多种 快速查询需求(如过滤查询、快速扫描、详单查询等)的统一响应。 融合数据存储,也是一种面向分析的分布式海量数据统一管理的 2
9 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 方式,使得一份分布在不同数据存储系统中的多份业务相关但存储结 构不同且规模巨大的数据,可以支持不同业务分析的过程。 3. 不同行业对融合数据存储的需求 金融、电信、公共安全等领域的数据与日俱增,海量数据的体量 可达总量达 PB 级、单表数据达百亿行级别。业务驱动下的数据分析 灵活性要求越来越高,一个具体业务的数据分析过程往往包含了多个 分析步骤,分属于不同的分析场景类型(如关系型分析,图查询,图 分析等) 。行业应用中的业务分析不仅数据体量大,而且分析的表属 性维度较多,单表属性维度可达百维以上。数据在不同的分析场景下 上存在多份不同的存储形式,这导致了平台维护成本、数据冗余和数 据转换代价的与日俱增,严重阻碍了大数据分析技术的应用和发展。 3.1 金融行业 3.1.1 场景描述 随着数据的与日俱增,以及互联网金融等新业务的普及,金融领 域中来自互联网的新型数据内容和类型也在不断增加,如:某大型银 行进行交易流水记录的审计业务,涉及 1000 多张数据表百 TB 级别 数据;单表数据近 300 亿行的大数据量(8TB),每天更新加载一次, 一次加载 6000w 行数据;单表有 70 多个维度,多表关联可超过 20~30 张表。同时,业务驱动下的金融数据分析灵活性要求越来越高,需要 高效、统一的融合数据组织,加速金融业务快速转型,实现更多业务 创新、更好的用户体验。 3
10 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 融合数据存储在金融行业的主要应用场景包括: 1)历史交易明细查询 历史交易明细查询是对行内客户的账务、交易流水查询系统。系 统将全量和增量历史帐务数据进行归档,并提供统一在线的历史帐务 数据查询服务,如在线同步查询、在线异步查询、从逐级汇总视图到 明细钻取的交互式查询、开放给最终客户的公众自助查询等。 2)电子银行客户单一视图 整合、组织、分析电子银行客户数据,并展现基于单一客户号的 客户电子银行视图,提供两种视图;结构化数据视图,展现客户登陆 记录,客户交易记录,签约客户基本信息等内容;非结构化数据视图, 展现客户浏览行为,客户最感兴趣的一级或二级菜单,客户点击的按 钮功能等内容。 3)电子银行分析 宏观地分析网银网站的各项数据统计指标,并利用这些数据统计 指标优化客户体验。关键数据统计指标包括流量指标、转化指标、推 广指标、服务指标、用户指标等。 4)客户风险报告 通过分析咨询报告、年报、互联网数据,提供对公客户的产业趋 势、经营状态发生决策分析报告。 5)网银日志分析 通过电子银行系统运行日志分析用户访问行为,结果可支撑实时 营销业务如实时产品和服务推荐、商户促销和广告、个性化推荐等。 4
11 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 3.1.1 技术需求 金融行业对融合数据存储的技术要求如下: 1)支持海量数据存储,可支持单表数据达 100 亿行的处理。 2)支持数据统一存储,实现一份数据支持单表多维度、多表关 联查询,支持 order by,过滤、转换等能力。 3)支持高效的、实时的数据分析;支持每秒万级别并发,秒级 查询响应。 4)支持标准接口,提供开放的事实标准接口对数据进行操作, 应兼容主流的大数据技术,与企业已采购的工具和 IT 系统易无缝集 成,支撑老业务快速迁移。 5)支持资源水平扩展,扩展不应破坏原数据;能够支持不停机 动态添加以及删除节点,支持热扩展能力。 6)支持资源共享、统一的资源管理。 3.2 电信行业 3.2.1 场景描述 电信行业数据体量巨大且增长迅速,如某大运营商的用户统计信 息业务,涉及不同的业务总计大约 3000 多张数据表。单表的数据量 从百万级到百亿级不等;业务数据更新频率不同如每 15 分钟、每小 时和每天等,数据保存周期有 10 天、1 个月、1 年等,每天新增数据 总量大约 1T 左右。同时,不同业务要求多维度的数据分析,随着数 据分析的覆盖面、数据存储的高扩展性、数据分析快速响应要求越来 5
12 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 越高,需要一份数据拷贝支持不同业务,同时支持高线性扩展,匹配 企业业务的发展节奏。 融合数据存储在电信行业的主要应用场景包括: 1)实时清单分析场景 海量的原始话单数据作全量存储,进行基于话单的日汇总、月汇 总等轻度汇总的批处理,实现清单查询和分析,如详单统计分析、详 单分级归档存储、详单 Ad-hoc 查询、详单稽核等。 2)三域数据融合开放 以业务支撑域、网管支撑域、管理信息域三域进行数据融合,提 供位臵信息、流量和实名等价值数据为核心的服务产品,实现用户画 像和用户行为分析、网络优化、数据开放、个人征信服务等业务。 3)提升用户体验 融合三种信息,即业务信息如应用、类型等,用户信息如地域、 终端等,内容偏好如下载、评论等,进行客户关联模型分析,识别客 户,实现个性化推荐,如基于内容的推荐、基于产品的推荐、基于用 户的推荐等,并在合适的时间、合适的地点向用户推送有吸引力的广 告。 3.2.2 技术需求 电信行业对融合数据存储的技术要求如下: 1)一份数据,一份存储,消除冗余存储。 2)多应用并发处理速度快,大数据量时并发处理速度不减。 3)标准的数据共享访问接口和能力开放接口。 6
13 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 4)持水平线性扩容,满足数据存储能力达到 PB 级,单表容量 高达百 TB。 3.3 公共安全行业 3.3.1 场景描述 公共安全领域数据体量巨大,例如电信话单每天 200-300 亿条记 录,一般存储数据要求存 3 年,3 年数据量可达到大约 20 万亿级别 的量级。公共安全领域,除了需要存储储用户电信话单,还需要存储 用户车辆、用户行动轨迹等信息,用以支撑刑侦安全场景、行为统计 等。而且数据量级、数据的维度持续扩展,数据分析引擎需要满足万 亿量级的场景。巨大的数据量不但要求分析海量数据的响应速度,同 时也要数据存储的扩展从百节点起到千节点的能力。 融合数据存储在公共安全行业的主要应用场景包括: 1)警务信息关联分析 以人为线索,基于结构化信息(火车、民航、旅店、网吧、卡口、 通话、常口、暂口、银行等),分析目标人的同行人员、同住人员、 家庭关系、相互通话关系、同上网人员、财务异动等关系。 2)电子档案 以人为中心,整合公共安全资源、非公共安全资源,结构化数据、 非结构化数据,将人的信息全貌(包括基本信息、家庭信息、居住信 息、出入境信息、从业信息、活动轨迹、财产信息、缴费信息、参保 信息、纳税信息、违法违章信息、诚信信息等)进行集中展现,面向 7
14 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 公共安全所有警种使用。 3)大情报研判 面向公安安全情报领域,针对重点人员的预警模型及重大事件预 警模型的计算,对海量预警指令、活动轨迹进行统计、检索,并对历 史数据进行汇总和展示。 4)刑侦情报分析 面向公安安全刑侦领域,对重点案件、犯罪人员、犯罪团伙进行 分析计算,整合案件、人员、指纹、人像、DNA、足迹等信息,提 供关联查询、案件串并、比对碰撞、类案研判等大数据分析场景。 3.3.2 技术需求 公共安全行业对融合数据存储的技术要求如下: 1)支持高速数据入库、百亿记录查询秒级响应。 2)支持多节点支撑能力、PB 级数据容量、动态在线扩容。 3)支持标准应用接口,支持 SQL99 接口,提供图形化界面察看 SQL 运行状态。 4)支持资源共享,统一资源管理。 4. 融合数据存储的基本技术要求 基于以上各个垂直行业的场景和需求,整理出行业对融合数据存 储基础的、通用的功能和性能需求。 功能方面的需求包括: 1)统一存储:支持数据统一存储,实现一份数据支持任意维度 8
15 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 组合的过滤查询,支持单表多维度、多表关联查询,支持 order by, 过滤、转换等能力。 2)数据更新:支持加载历史数据以及增量加载新数据;支持数 据更新、删除等多种数据管理功能;支持流数据入库;支持实时查询。 3)兼容性:支持主流的技术规范、标准和产品,支持标准 SQL、 JDBC、ODBC;支持与主流 BI 工具无缝对接;支持大数据处理引擎 如批处理、内存计算等;兼容 Spark DataFrame/DataSet,支持复杂分 析应用。支持大数据标准编程接口,支持 JAVA,SCALA, Python, R 等 大数据常用的编程接口。 4)接口标准化:支持标准应用接口,支持 SQL99 接口,提供图 形化界面察看 SQL 运行状态。 5)资源水平扩展:扩展不应破坏原数据;能够支持不停机动态 添加以及删除节点,支持热扩展能力。支持资源共享、统一的资源管 理和调度。 性能方面的需求包括: 1)数据量多:支持总量达 PB 级以上,单表数据达 100 亿行的 数据存储和处理。 2)入库时间小:支持 PB 级数据入库延时时间小于秒级。 3)响应时间快:实现 PB 级以上级数据秒级响应,百维级别字 段任意组合查询支持快速查询秒级响应。 4)集群规模大:支持资源水平分布式扩展能力,动态扩展可达 到单集群支持 500 个以上的节点。 9
16 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 5. 典型大数据系统存储方案分析 目前,业界主要有四种典型的大数据系统存储方案,来支持实现 数据的分析处理。 5.1 NoSQL 数据库 NoSQL 数据库一般是用于数据分析的列式非关系型的分布式数 据库,这类数据库不同于一般的关系数据库,是一个适合与非结构化 数据存储的数据库,如:HBase、Cassandra、Redis 等。技术上,这 一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一 个指针指向特定的数据,这种 key value 型数据库,按 key 列查询能 达到毫秒级响应,但如果需按多个列组合查询,这类 key value 数据 库通常不太高效。所以,NoSQL 数据库较适合实时点查场景,很难 满足企业统一数据存储下多业务场景的诉求。 NoSQL 数据库主要擅长做基于 key 的 put 和 get。所谓 key value, 即通过 key 查询 value;这方面,HBase、Cassandra、Redis 都比较不 错,可以做到毫秒级的 get。key value 型数据库的问题在于是一键一 值,一个 Key 查询一个 Value,时间大概是 5 毫秒。这样,在面向分 析型应用的情况,需要基于大范围的数据做计算,甚至全表扫描,key value 型数据库的性能比较慢。 5.2 并行数据库 并行数据库是采用 share nothing 架构,将任务并行的分散到多个 服务器和节点上,通过并行计算提升性能的数据库系统。这类 share 10
17 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 nothing 数据库较多,比如:Greenplum、Vertica、Teradata 等。适合 计算型的且数据规模在 100 节点以内的数据分析场景,由于其采取的 是 pipeline 处理模式,如有任务数据处理失败时,需要对所有任务重 新计算,这导致并行数据库不能支持海量数据分析,不适合作为企业 的统一数据存储。此外,并行数据库技术不能有效与 Hadoop 大数据 生态集成,数据不能统一共享存储。 使用传统的 MPP 数据库,将数据库打散在每个节点上。数据的 计算是并发的,并且有着 pipeline 计算模型,在数据量规模不大的情 况下,它是一个比较合适的选择。它的问题在于,一方面是数据量过 大的情况下,自身的扩展性难以支撑超过一百个节点的规模;另外一 个方面是容错性,当执行时长较长的任务时,其中有机器宕机,计算 不能从中间步骤恢复,而需要将整个任务重头执行。 5.3 搜索引擎 搜索引擎通过将数据进行良好的组织和索引来支持快速找到数 据,从而支持用户低时延的数据分析体验,适合多维度的过滤查询, 文本分析等,但其无法完成复杂计算,数据膨胀一般在 2-4 倍左右, 不支持标准 SQL,不便于兼容已有业务。 搜索引擎的数据存储方案的主要优点是,性能非常快的,因为它 对每一列都建立了索引,适合多条件过滤,同时也能够做一些文本的 分析;搜索引擎的数据存储方案的主要缺点是它不能完成复杂的计算, 比如不能做多层级的聚集或者做关联 join;另外数据膨胀比较可观, 因为每一列都做了索引;最后是它没有对标准 SQL 的支持,很难对 11
18 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 接企业数据应用和 BI 工具,不便于与已有业务系统无缝集成,支撑 已有业务的快速迁移。 5.4 Cube Data 通过对数据进行预处理,通过空间和预处理换取查询效率,在数 据查询时,直接将预处理好的数据返回给用户,可以极大的提升性能, Cube Data 的数据存储方案,很适合 BI 类场景 KPI 固定,且维度不多 (一般 10 列左右)数据膨胀不大的情况下。但 Cube Data 的数据存储方 案,因为对数据做了预处理,只适合一部分场景,不适合作为企业的 统一数据存储。 这类引擎聚焦在计算层,帮解决分布式计算的问题。它们使用的 存储方式是 Hadoop 文件,这种文件在使用之前都是列存的,是面向 批处理设计的文件格式,主要是提供批处理所需要的全表扫描性能, 但由于没有索引支持,所以在过滤条件查询的情况下,性能表现很一 般。 5.5 小结 在应对 PB 级以上的数据量以及复杂数据分析时,以上四种典型 的大数据系统的存储方案只能满足用户在其所擅长的特定使用场景 下的分析需求,即在特定数据分析场景下要搭建一套最合适的存储。 这样,在导入数据前需要做一个数据复制,将其复制成多份,每一份 用一个系统存储,才能满足所有应用的性能要求。数据复制会带来存 储成本的较大开销,并且需要维护数据的一致性。 12
19 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 而现有的 HDFS 只是从文件系统角度将数据放在一起,实现了数 据的分布式、高可靠性等,并不能解决客户对所有查询场景的低时延 查询要求。 因此,需要围绕 Hadoop 大数据生态打造一个更高效的统一的数 据存储来满足客户大数据分析的需求,做到既利用计算和存储解耦的 架构,继承 HDFS 的统一数据存储下的高可靠性、分布式,又能提供 高性能的数据分析。 6. 典型开源融合数据存储技术分析 围绕基于 Hadoop 的大数据生态,出现了一批能够与 HDFS 无缝 集成,实现统一数据存储,并有效提升数据分析效率的高性能融合数 据存储开源项目,其中以 Apache 社区的 ORC、Parquet 和 CarbonData 为代表。 6.1 典型开源融合数据存储技术 6.1.1 ORC Apache ORC 是 Hadoop 生 态 中 的 一 种 存 储 源 自 于 RC (RecordColumnar File)存储格式、列式存储,支持数据的更新。ORC 是 Facebook 和 Hortonwork 合作开发的,最初围绕 Facebook 的场景, 用在 Apache Hive 上降低 Hadoop 数据存储空间和加速 Hive 查询速度, 因此 ORC 与 Hive 兼容性较好。2015 年,ORC 从 Apache 的孵化器里 毕业成为 Apache 顶级项目。 13
20 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 图3 ORC数据存储格式 6.1.2 Parquet Apache Parquet 是 Hadoop 生态圈中一种列式高性能存储格式, 支持存储嵌套数据类型,它可以兼容 Hadoop 生态圈中大多数计算框 架(Mapreduce、Spark 等),与 Spark 引擎集成效果较好。Parquet 是 twitter 和 cloudera 合作开发的,最初围绕 twitter 场景,2015 年 5 月从 Apache 的孵化器里毕业成为 Apache 顶级项目。 14
21 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 图4 Parquet数据存储格式 6.1.3 CarbonData Apache CarbonData 是一种索引列式高性能存储格式,支持索引、 全局字典编码、数据更新和删除、预聚合、实时数据导入等特性。 CarbonData 是华为开发的,不同于 ORC 和 Parquet 只围绕互联网场 景 , CarbonData 最 初 就 是 围 绕 企 业 统 一 数 据 存 储 场 景 , 因 此 CarbonData 不仅支持列式数据,还支持索引、全局字典编码、数据更 新等统一数据管理需要的特性。2016 年 6 月,CarbonData 进入 Apache 孵化器。2017 年 4 月,CarbonData 从 Apache 的孵化器里毕业成为 Apache 顶级项目。 15
22 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 图5 CarbonData数据存储格式 6.2 融合数据存储技术功能对比 下面从社区活跃度、大数据生态集成、开发语言、数据的操作以 及对数据分析的支持能力等方面,对开源融合数据存储技术进行比较。 表1 开源融合数据存储技术特性对比 ORC Parquet CarbonData 开源 Apache顶级项目 Apache顶级项目 Apache顶级项目 中 中 高 社区活跃度 (10 commits/month) (10 commits/month) (300+commits/month) 支持所有计算框架集 支持所有计算框架集 支持所有计算框架集 大数据生态集成 成,与Hive集成较好 成,与Spark集成较好 成,与Spark集成较好 开发语言 Java Java Java,Scala 粗粒度,不支持全局 粗粒度,不支持全局 索引 支持全局索引 索引 索引 全局字段编码、RLE、 编码 RLE、DELTA RLE、DELTA DELTA 数据更新、删除 支持 不支持 支持 数据分区 支持 支持 支持 数据压缩率 3-9倍 3-8倍 3-7倍 数据预聚合 不支持 不支持 支持 16
23 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 实时数据导入 不支持 不支持 支持 时序数据分析 部分支持 部分支持 支持 文本数据分析 不支持 不支持 支持 6.3 融合数据存储技术性能对比 因 ORC 只与 Hive 集成较好,但 Hive 的计算性能不如 Spark,所 以 ORC 的 性 能 不 如 Parquet 和 CarbonData 。 本 章 给 出 的 是 Parquet+Spark 和 CarbonData+Spark 在过滤查询场景和聚合计算场景 的性能测试结果,为体现公平公正,此测试方法应在任何环境复现。 6.3.1 测试数据准备 在 Spark-Shell 里由以下语句生成 10 亿条数据,每条数据四个字 段组成(ID, country,city,population): val r = new Random() //创建随机数 val df = spark.sparkContext.parallelize(1 to 1000 * 1000 * 1000).map(x => ("No."+r.nextInt(1000000), "country" + x%8, "city"+x%50, x%300)).toDF("ID","country","city","population") //创建 10 亿数据的 dataframe 6.3.2 过滤查询场景测试 Query1(第 1 个字段过滤查询) : select * from table where ID='No.xxx'; Query2(第 2 个字段过滤查询): select * from table where country='countryxxx'; Query3(大范围的 In 查询): 17
24 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 select * from table where ID in ('No.xxx','No.xxxx','No.xxx'); Query4(2 个字段组合过滤查询): select * from table where ID='No.xxx' and country='countryxxx; Query5(3 个字段组合过滤查询): select * from table where ID='No.xxx' and country='countryxxx' and city='cityxxx'; Query6(4 个字段组合过滤查询): select * from table where ID='No.xxx' and country='countryxxx' and city='cityxxx' and population < 10000; 图6 Parquet和CarbonData在过滤查询场景下的性能对比 6.3.2 聚合计算场景测试 Query1(第 1 个字段过滤和聚合查询) : select country,sum(population) from table where ID='No.xxx' group by country; 18
25 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 Query2(第 2 个字段过滤和聚合查询): select country,sum(population) from table where country='country5' group by country; Query3(基于第 1 个字段聚合查询) : select ID,sum(population) from table group by ID; Query4(基于第 2 个字段聚合查询) : select country,sum(population) from table group by country; Query5(2 个字段组合聚合查询) : select country,ID,sum(population) from table group by country,ID; Query6(通过 In 制定范围的聚合查询): select country,sum(population) from table where ID in ('No.xxx','No.xxxx','No.xxx') group by country; 图7 Parquet和CarbonData在聚合计算场景下的性能对比 6.4 小结 19
26 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 从主要开源融合数据存储技术的功能和性能对比来看,ORC 和 Pargquet 在产业应用相对较早,有较好的用户基础。CarbonData 在索 引、数据的基本操作能力、对数据分析的支持能力等方面具有明显优 势,CarbonData 在明细过滤场景下有明显的性能表现。此外,做为新 的大数据 Apache 顶级项目,CarbonData 社区的活跃度较好,技术更 新比较快,具有更大发展前景。 7. 应用案例 7.1 案例 1:金融审计业务 7.1.1 业务和数据介绍 XX 交行针对交易流水记录做审计业务,包括多维的详单查询场 景、部分聚合查询、模糊查询,并发查询低于 100,返回带 limit 查询 等; 在审计业务的数据类型是结构化为主,1000 多张数据表百 TB 级 别数据;单表数据最大 280 亿行的大数据量(8TB),超高基数达 5000 万,如身份证号,group by 效率较低;每天更新加载一次,一次加载 6000w 行数据;数据表常用 10 多个维度,整个表有 70 多个维度。 每天晚上 11 点左右加载 T+1 数据,文本格式存储在大数据系统, 早上 8:00 批量加工完成;日常工作中,审计部门员工登录审计查询 界面,连接到大数据系统进行交行查询。大约 2000 人左右有查询人 员,系统支持并发小于 100 tps。 根据查询语句的复杂度和数据量,秒级到分钟级都有。白天也有 20
27 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 少量数据入库,因此也会跑批加工。较复杂的查询,一般可达 5 个维 度以上的过滤,20~30 张以上的表做关联查询,传统技术 10 分钟级 别至小时级别,甚至查询失败。 7.1.2 现有方案 数据加载到 Hive 完毕后,启动批处理,加工增量数据后合并到 目标文件。Hive HQL 脚本数量 1000 个左右,使用 Hive1.2.1 做批量 加工,用于数据处理和加工;100 多个 Impala 批处理脚本,使用 Impala2.3 做批量加工,主要处理文本格式到为 Parquet 的格式转换; 跑批任务并发共计:30~50 tps。批处理加工的是每日增量数据,插入 到 Impala2.3 目标数据表;目标数据表文件为 Parquet 格式,包含全量 数据。 前端程序由 Java 编写,通过 JDBC 链接到 Impala 进行交互查询。 7.1.3 客户挑战 客户在技术和业务上挑战,主要有:1)Impala 集群需要独立分 配资源,无法与 hadoop 集群共享资源,不能用 Yarn 统一管理,无法 共享;2)经过多次优化查询,Impala 查询性能仍需 700 多秒;3) 交互查询存在稳定性问题 (impala 存在挂死情况) ;最多 20~30 表 Join, 一旦查询涉及更多多表关联,由于表数据量比较大,查询有时会失败。 7.1.4 技术应对方案 针对业务需求和挑战,采取基于融合数据存储的技术方案:批量 加 工 采 用 Hive , 历 史 库 查 询 采 用 SparkSQL+CarbonData , 替 代 21
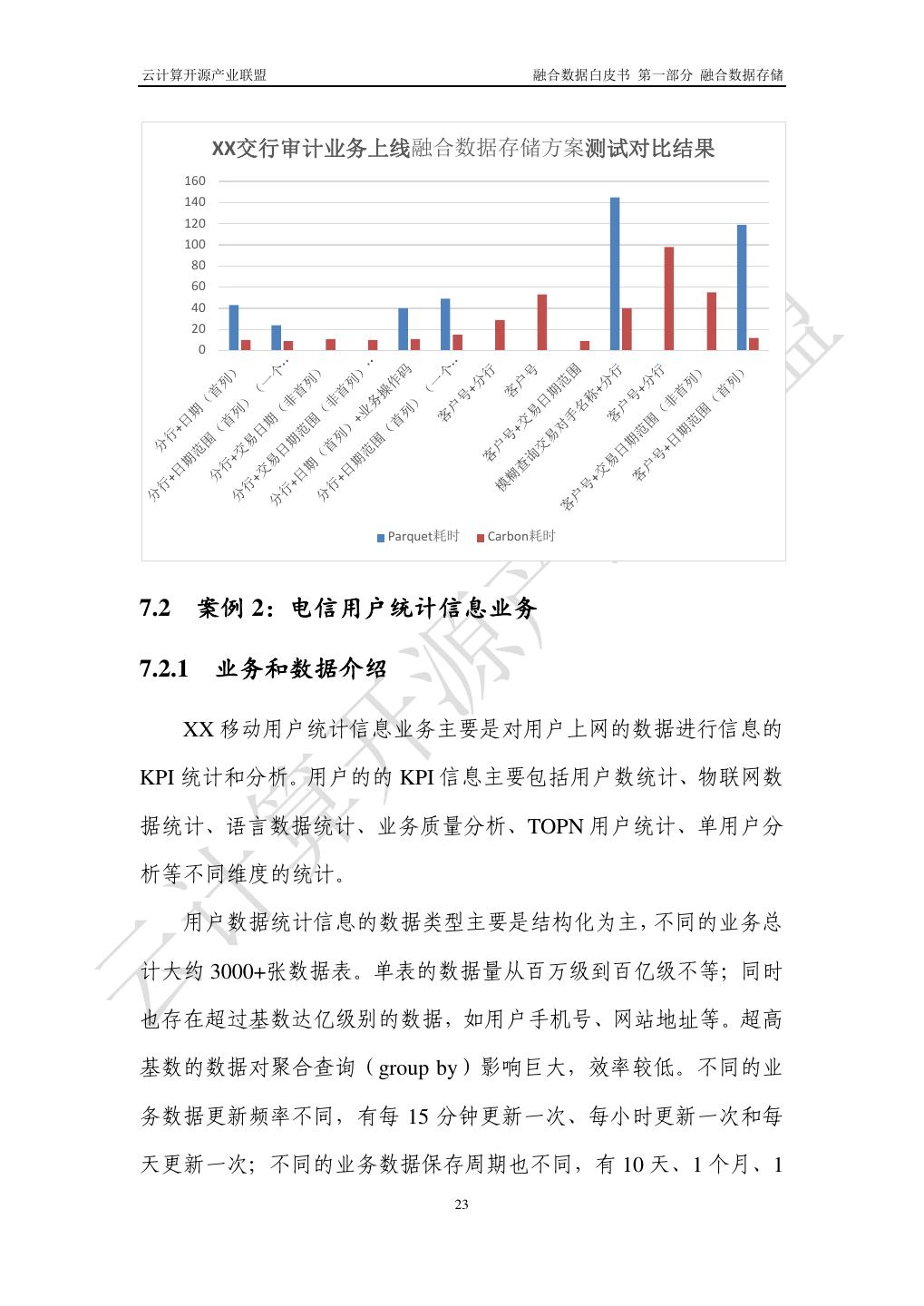
28 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 impala+Parquet;数据入库 parquet 格式改变为 Carbondata 格式,查询 从 impala 改变为 SparkSQL;资源统一由 Yarn 管理,灵活共享。业务 逻辑无需任何更改,一周内实现业务从旧方案迁移到新方案。 图8 金融审计业务系统的融合数据存储方案 7.1.5 为客户带来的有益效果 采用了融合数据存储方案后,压缩率与 Parquet 类似的情况下, 平均性能提升 10+倍,支持百亿行数据,多维过滤查询,秒级响应。 提升查询效率 10 倍以上,资源利用率更高。XX 交行的半年明细查 询平均在 10 秒内,一年明细查询平均在 20 秒内,从只支持半年的 详单查询扩展至五年以上的详单查询,用户满意度明显提升。 此外,资源采用 Yarn 统一管理,资源用户可配、可调,节省用 户资源 25%以上,取消 Impala 集群。从支持 100 台节点提升到可支 持 1000+台节点,为后续大数据业务系统弹性扩展提供基础。 22
29 .云计算开源产业联盟 融合数据白皮书 第一部分 融合数据存储 XX交行审计业务上线融合数据存储方案测试对比结果 160 140 120 100 80 60 40 20 0 Parquet耗时 Carbon耗时 7.2 案例 2:电信用户统计信息业务 7.2.1 业务和数据介绍 XX 移动用户统计信息业务主要是对用户上网的数据进行信息的 KPI 统计和分析。用户的的 KPI 信息主要包括用户数统计、物联网数 据统计、语言数据统计、业务质量分析、TOPN 用户统计、单用户分 析等不同维度的统计。 用户数据统计信息的数据类型主要是结构化为主,不同的业务总 计大约 3000+张数据表。单表的数据量从百万级到百亿级不等;同时 也存在超过基数达亿级别的数据,如用户手机号、网站地址等。超高 基数的数据对聚合查询(group by)影响巨大,效率较低。不同的业 务数据更新频率不同,有每 15 分钟更新一次、每小时更新一次和每 天更新一次;不同的业务数据保存周期也不同,有 10 天、1 个月、1 23
3秒后跳转登录页面
去登陆

