展开查看详情
1 . Apache Hudi:
解析记录级索引
许世彦
Apache Hudi PMC,Onehouse 创始团队成员
�
2 .提纲
● Hudi的索引机制简介
● 多模索引
● 解析记录级索引
● 社区动态 - Hudi 1.x
�
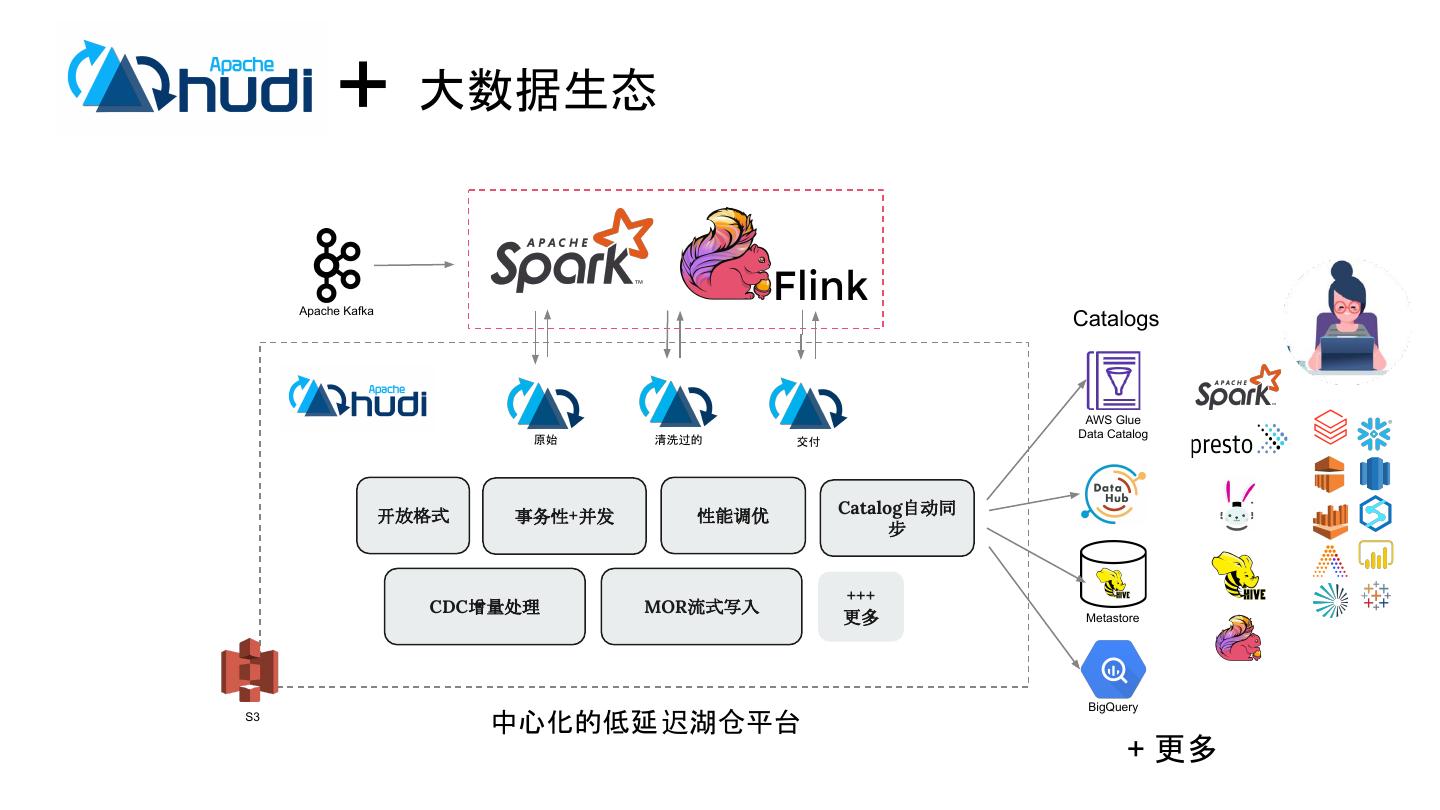
3 . + 大数据生态
Apache Kafka
Catalogs
AWS Glue
原始 清洗过的 Data Catalog
交付
开放格式 事务性+并发 性能调优 Catalog自动同
步
+++
CDC增量处理 MOR流式写入
更多 Metastore
BigQuery
S3
中心化的低延 迟湖仓平台
+ 更多
�
4 . 读侧流程 Hudi 表
解析SQL
读取 Hudi 索引
SELECT…
WHERE…
返回
裁剪过的分区和文件 对应分区和文件组
→ 生成计划
读取(谓词下推,列裁剪、动态裁剪)
�
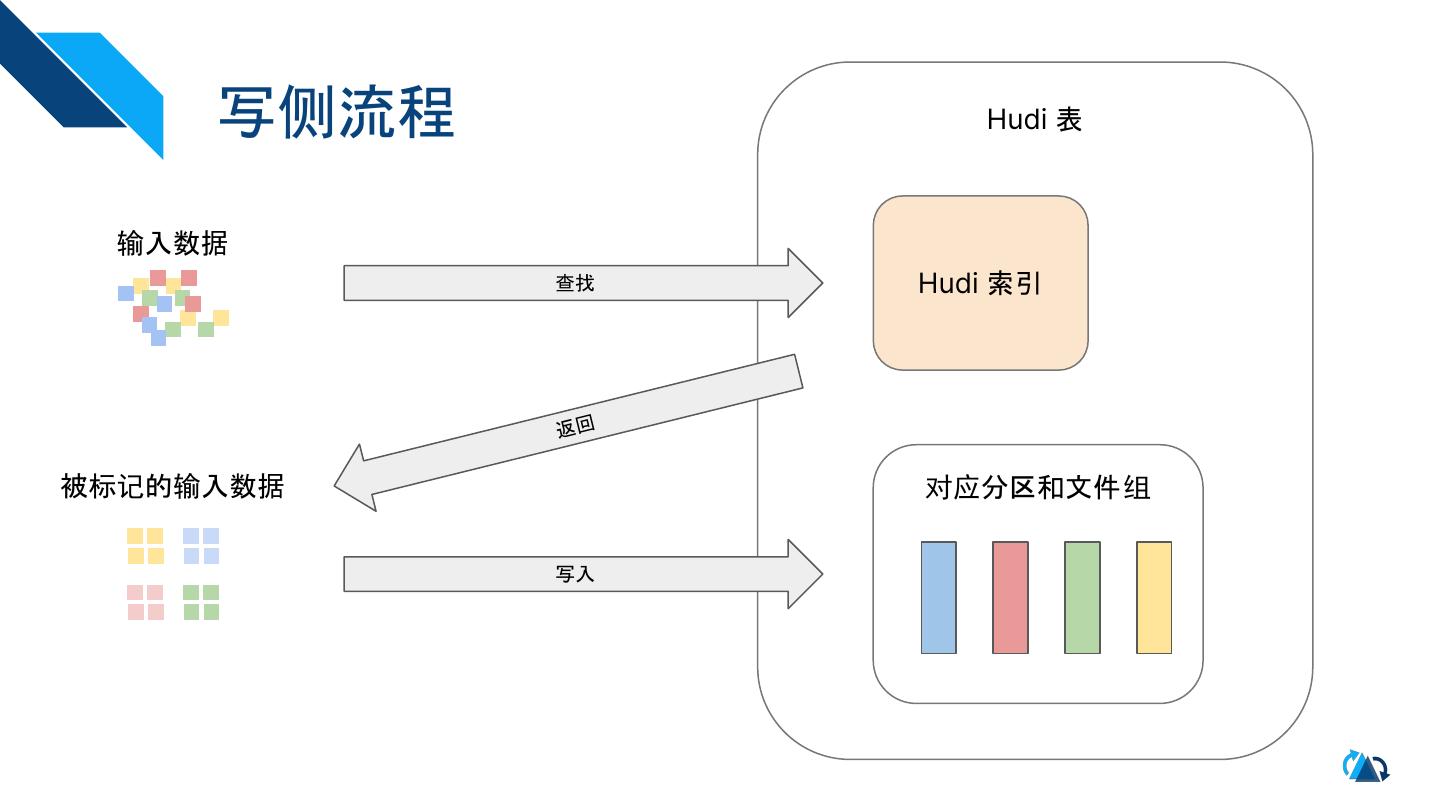
5 . 写侧流程 Hudi 表
输入数据
查找 Hudi 索引
返回
被标记的输入数据 对应分区和文件组
写入
�
6 . Hudi的索引类型
● Hudi 支持不同的索引 类型
● Bloom/Simple
● 全局 Bloom/Simple
● HBase/其他拓展(全局)
● Bucket/Consistent hashing
● 多模索引(元数据表)
○ Files分区
○ Column stats分区
○ Bloom filter分区
○ Record level index分区
https://hudi.apache.org/blog/2020/11/11/hudi-indexing-mechanisms/
�
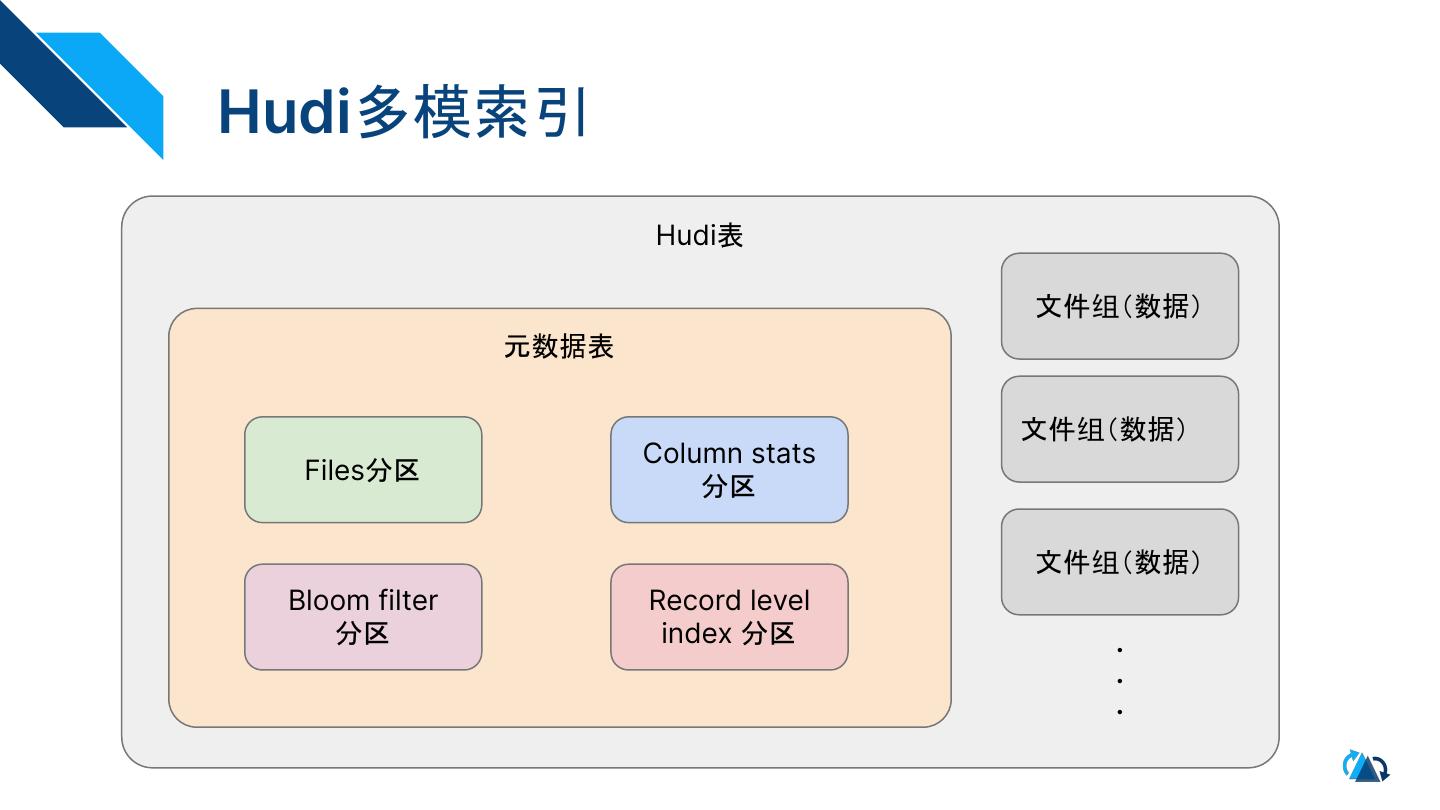
7 .Hudi多模索引
Hudi表
文件组(数据)
元数据表
文件组(数据)
Column stats
Files分区
分区
文件组(数据)
Bloom filter Record level
分区 index 分区 .
.
.
�
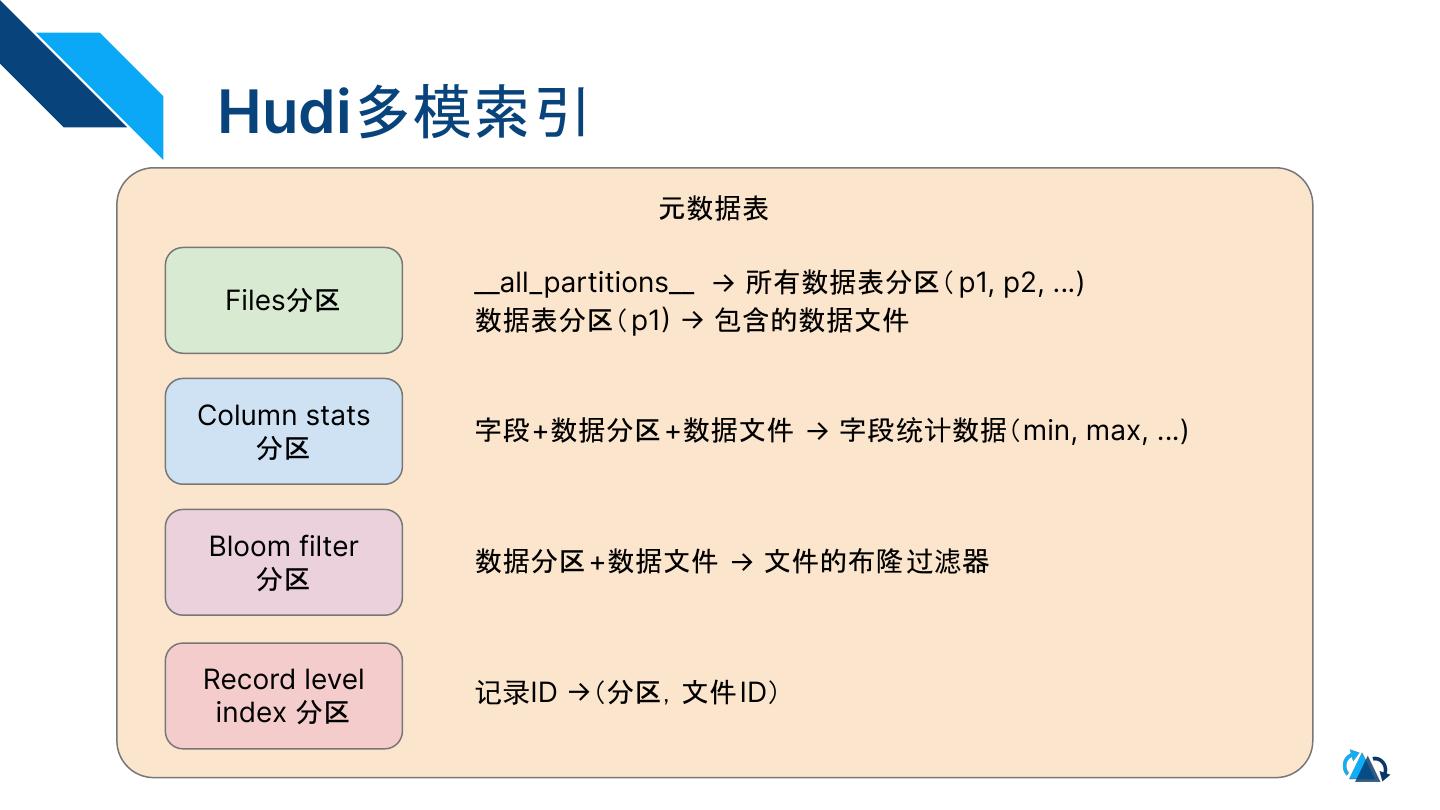
8 . Hudi多模索引
元数据表
__all_partitions__ → 所有数据表分区( p1, p2, …)
Files分区
数据表分区(p1) → 包含的数据文件
Column stats
字段+数据分区+数据文件 → 字段统计数据(min, max, …)
分区
Bloom filter
数据分区+数据文件 → 文件的布隆过滤器
分区
Record level 记录ID →(分区,文件ID)
index 分区
�
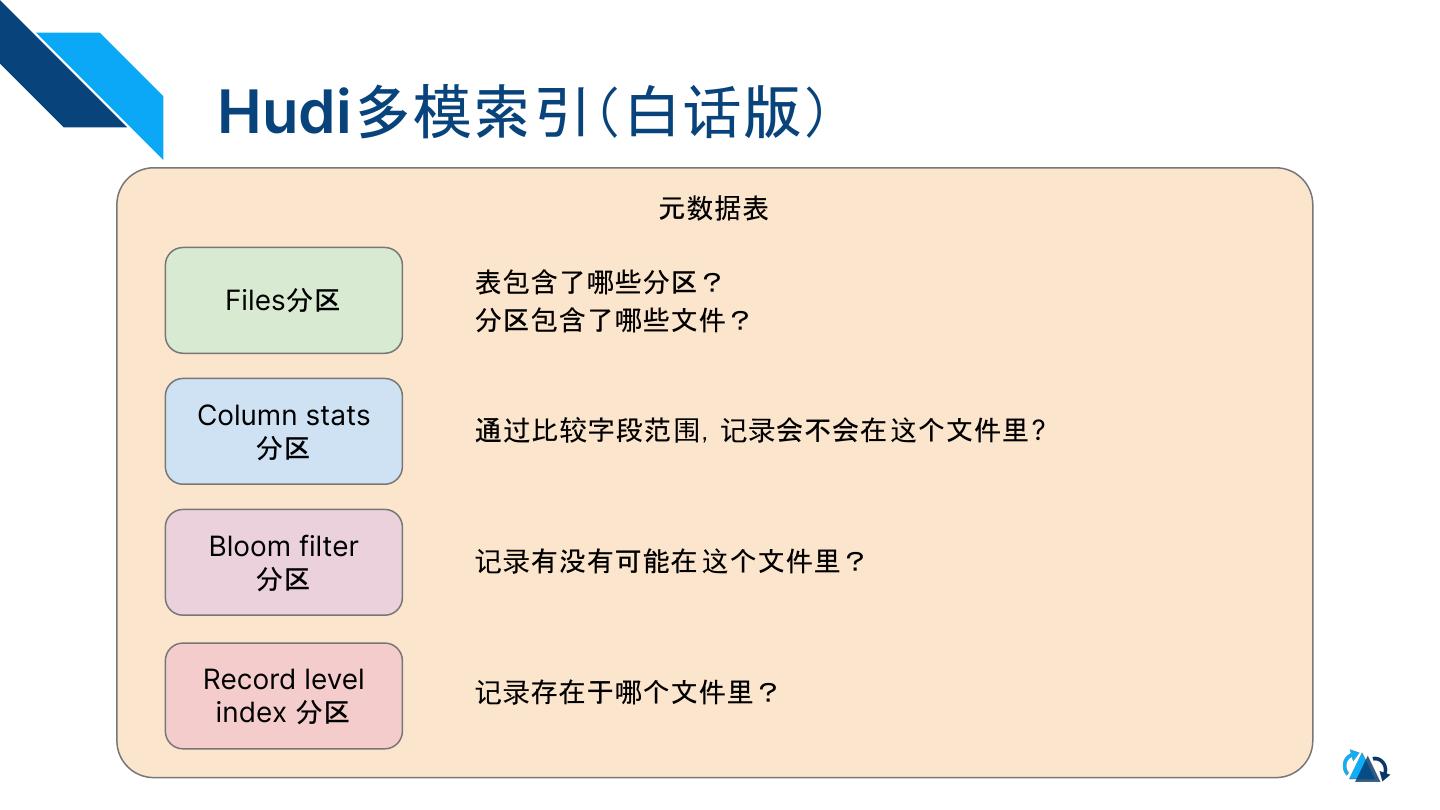
9 . Hudi多模索引(白话版)
元数据表
表包含了哪些分区?
Files分区
分区包含了哪些文件?
Column stats
通过比较字段范围,记录会不会在这个文件里?
分区
Bloom filter
记录有没有可能在 这个文件里?
分区
Record level 记录存在于哪个文件里?
index 分区
�
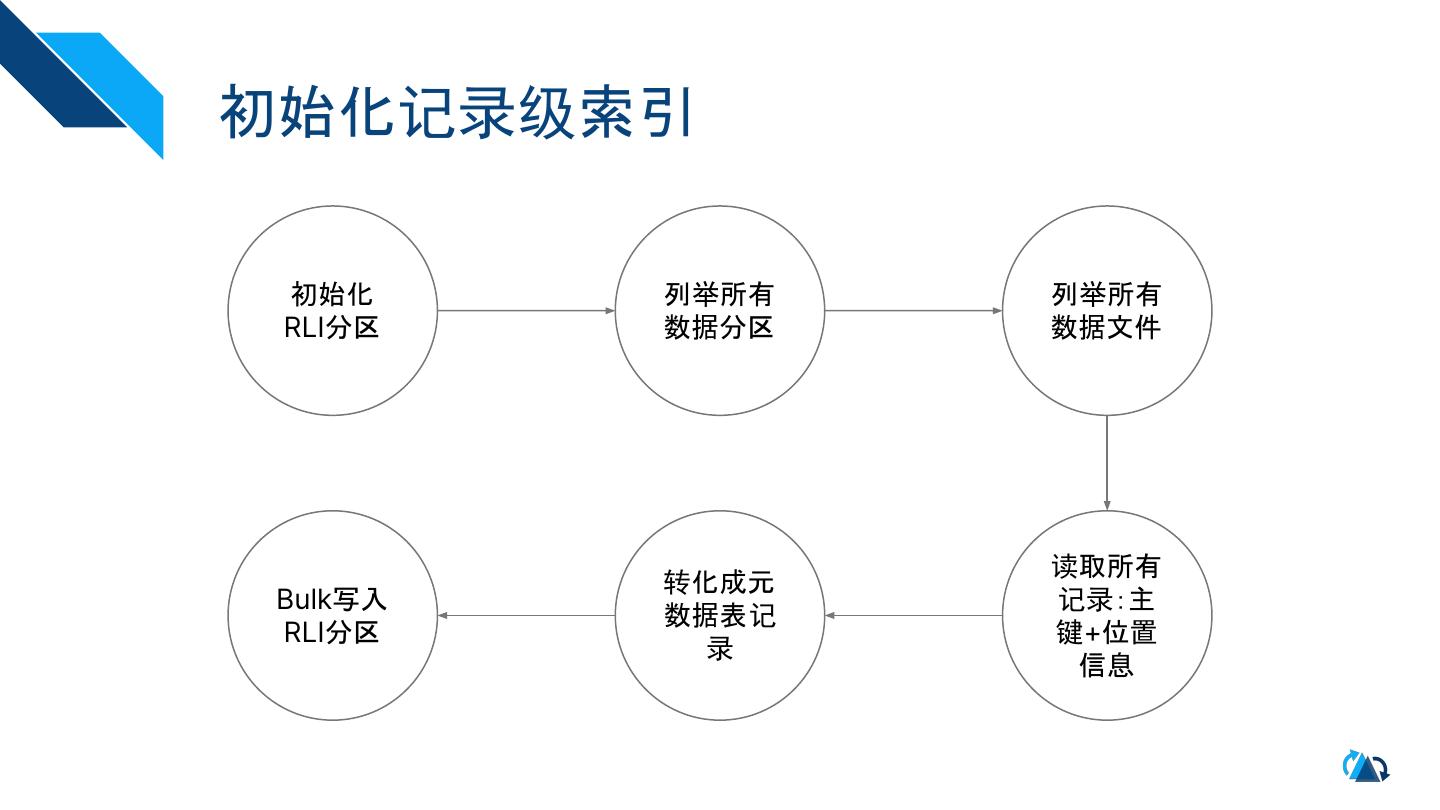
10 .初始化记录级索引
初始化 列举所有 列举所有
RLI分区 数据分区 数据文件
读取所有
转化成元
Bulk写入 记录:主
数据表记
RLI分区 键+位置
录
信息
�
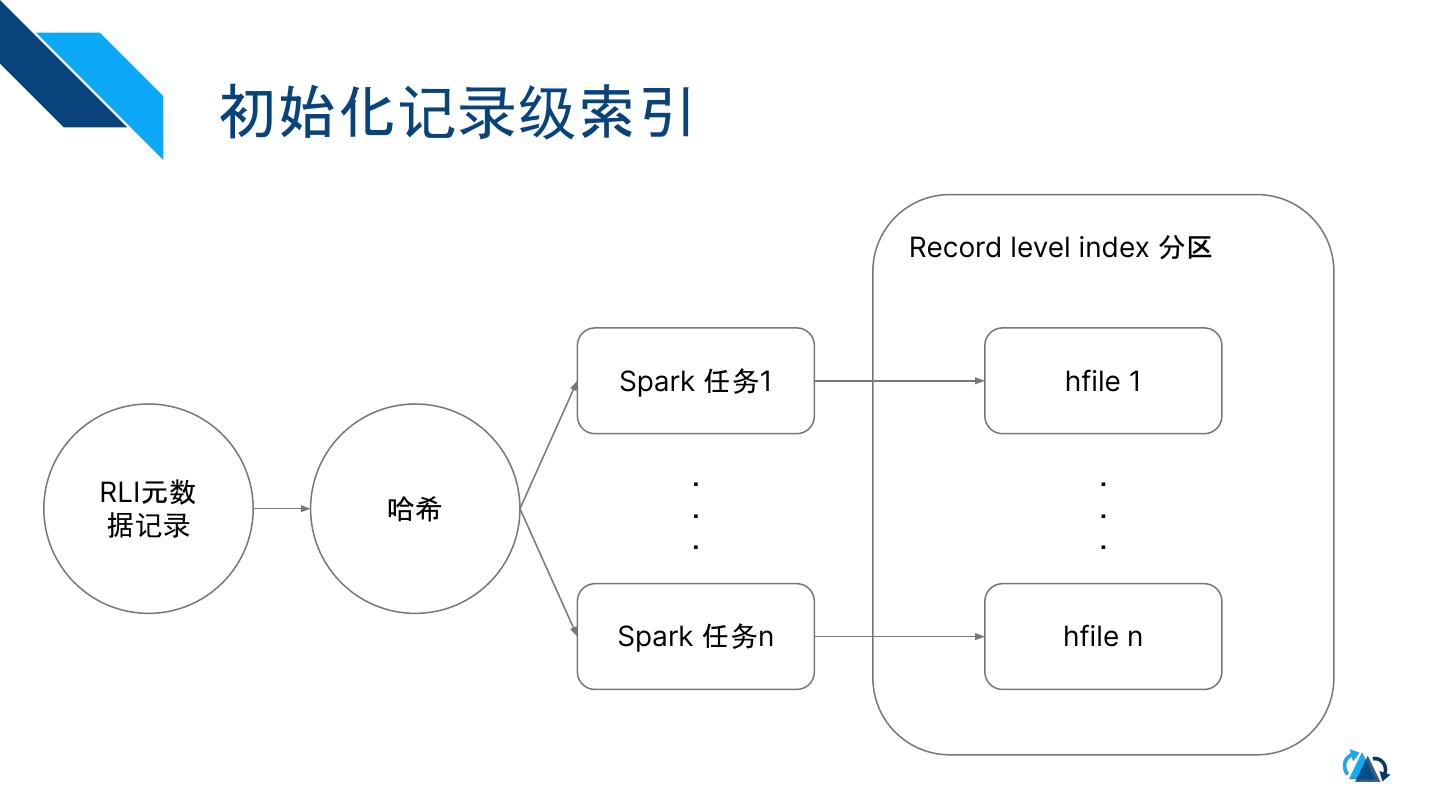
11 . 初始化记录级索引
Record level index 分区
Spark 任务1 hfile 1
. .
RLI元数
哈希 . .
据记录 . .
Spark 任务n hfile n
�
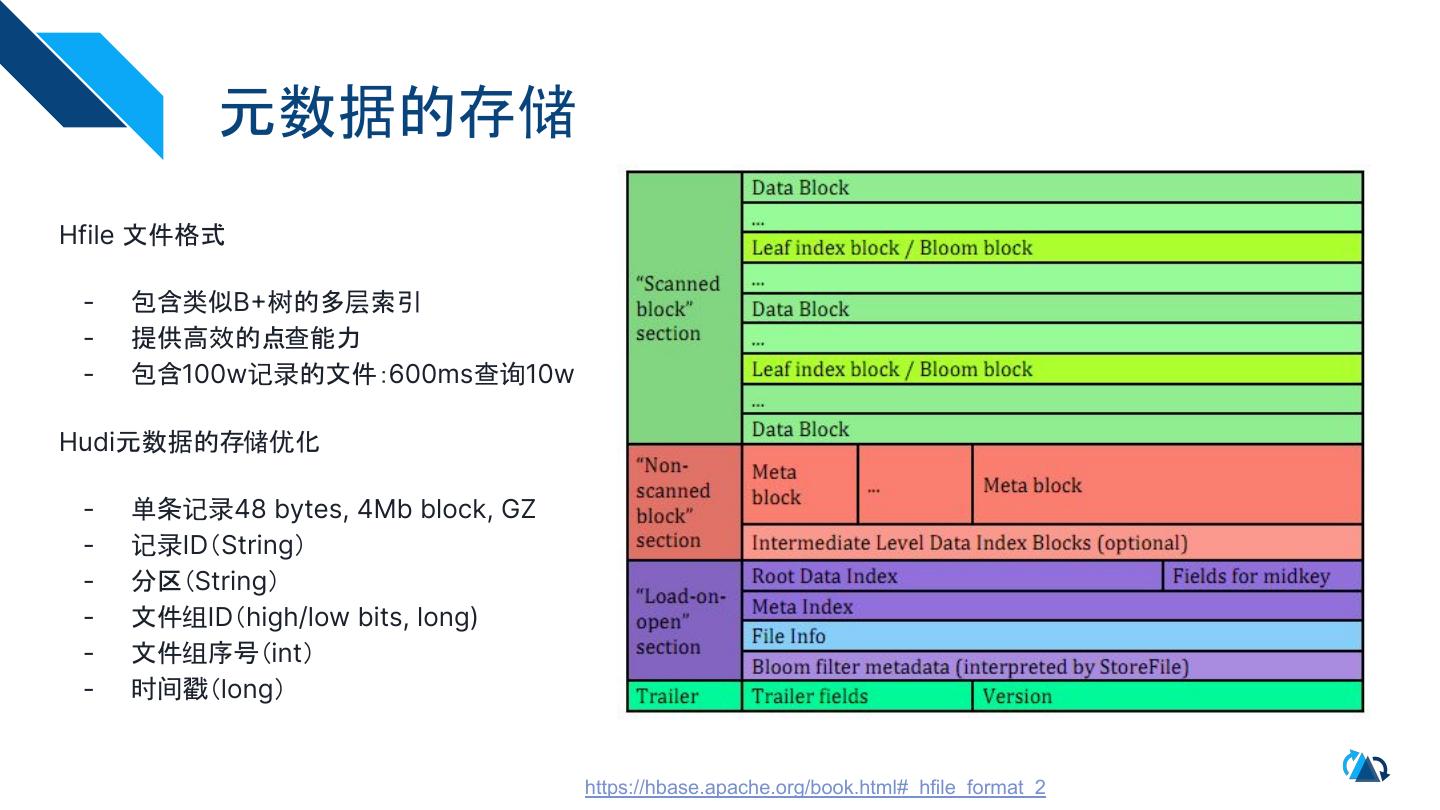
12 . 元数据的存储
Hfile 文件格式
- 包含类似B+树的多层索引
- 提供高效的点查能力
- 包含100w记录的文件:600ms查询10w
Hudi元数据的存储优化
- 单条记录48 bytes, 4Mb block, GZ
- 记录ID(String)
- 分区(String)
- 文件组ID(high/low bits, long)
- 文件组序号(int)
- 时间戳(long)
https://hbase.apache.org/book.html#_hfile_format_2
�
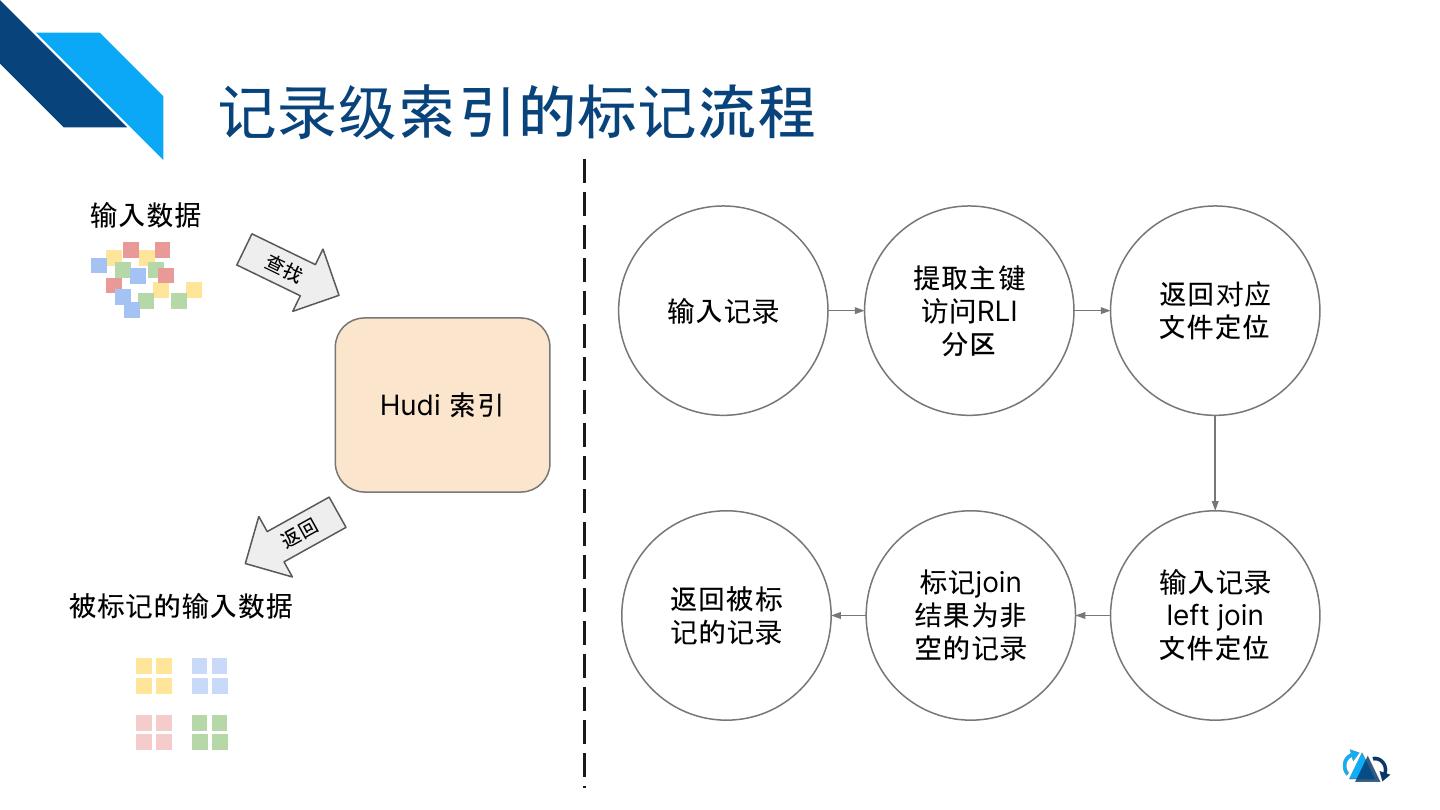
13 . 记录级索引的标记流程
输入数据
查找
提取主键
返回对应
输入记录 访问RLI
文件定位
分区
Hudi 索引
返回
标记join 输入记录
被标记的输入数据 返回被标
结果为非 left join
记的记录
空的记录 文件定位
�
14 . 记录级索引的优势
Hudi表
● 更优化的全局索引
元数据表
○ 利用记录ID → 文件组的映射
○ 精确定位文件,减少 IO
Column stats
● 避免了例如Hbase的外部依赖 Files分区
分区
● 充分利用存储空间的优势
●
Bloom filter Record level
分区 index 分区
�
15 . 记录级索引在Uber的实践
1.6T+
总索引映射数
6万+
总索引分片数
80TB+ 3k亿+
总索引存储 最大单表索引映射数
7小时
最大索引初始化 时间(8k
1.2万 1ms
最大单表索引分片数 单条平均点查耗时
executor)
�
16 .Hudi的用户群
https://hudi.apache.org/powered-by
�
17 . RFC-69 - Hudi 1.x
https://github.com/apache/hudi/pull/8679
In all, we propose Hudi 1.x as a reimagination of Hudi, as the
transactional database for the lake, with polyglot persistence,
raising the level of abstraction and platformization even higher
for Hudi data lakes.
○ 全新的记录合并APIs
○ 查询引擎和索引的全面集成
○ 多语言支持
○ 非阻塞并发
○ 无限时间线
○ Metaserver - 向数仓性能靠近
○ 缓存 - 用于平摊合并的开销,全面提升 查询性能
�
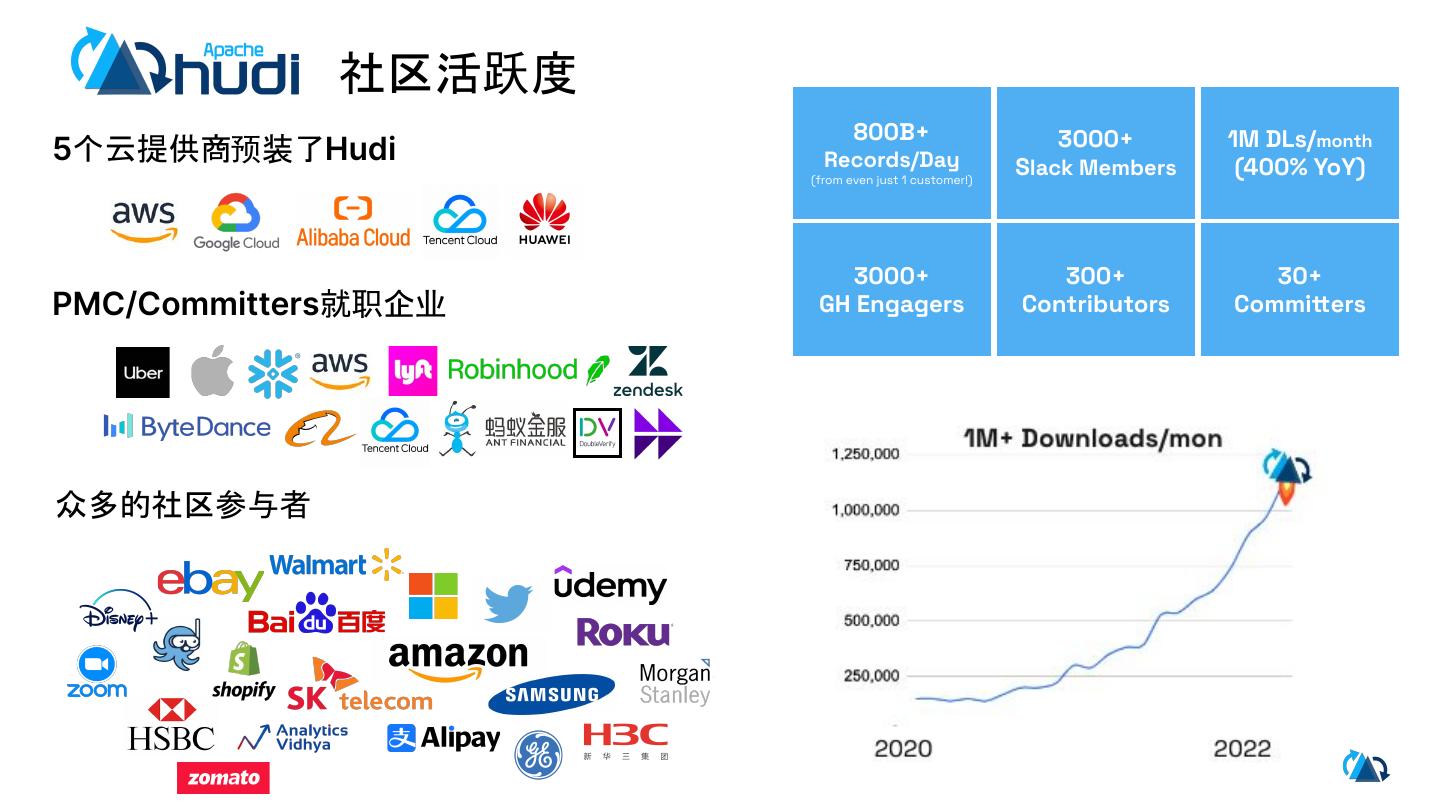
18 . 社区活跃度
800B+ 3000+ 1M DLs/month
5个云提供商预装了Hudi Records/Day Slack Members (400% YoY)
(from even just 1 customer!)
3000+ 300+ 30+
PMC/Committers就职企业 GH Engagers Contributors Committers
众多的社区参与者
�
19 .欢迎参与构建社区!
Docs : https://hudi.apache.org
Blogs : https://hudi.apache.org/blog
Slack : https://join.slack.com/t/apache-hudi/shared_invite/zt-1e94d3xro-JvlNO1kSeIHJBTVfLPlI5w
Join Hudi Slack
Twitter : https://twitter.com/apachehudi
Github: https://github.com/apache/hudi/ Give us a star ⭐!
Mailing list(s) :
dev-subscribe@hudi.apache.org (send an empty email to subscribe)
�