



















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/DolphinScheduler/DSK8S42668?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
基于DolphinScheduler和K8S大数据平台的应用实践-李建军
分享
点赞
1
收藏
6
下载 8
展开查看详情
1 . 2022 基于DS和K8S大数据 平台的应用实践 讲师 李建军
2 .目录 CONTENTS 01 JDL-BDP介绍 02 BDP容器化 03 基于K8S的BDP 04 展望
3 . 01 平台定位 JDL-BDP介绍 平台简介 平台架构 核心功能描述
4 .1 .1 平台定位 JDL-BDP支持重计算场景*大数据量的集中存储、计算资源的统一管理、高效的数据开发、即席数据 查询。在大数据平台之上,用户可以快速落地数据分析挖掘应用,以数据驱动业务价值实现,提升企 业竞争力。 *重计算场景:在供应链企业数据驱动业务场景中十分常见,以预测算法、数据模型等计算为核心需求,对数据计算资源和性能要求较高。
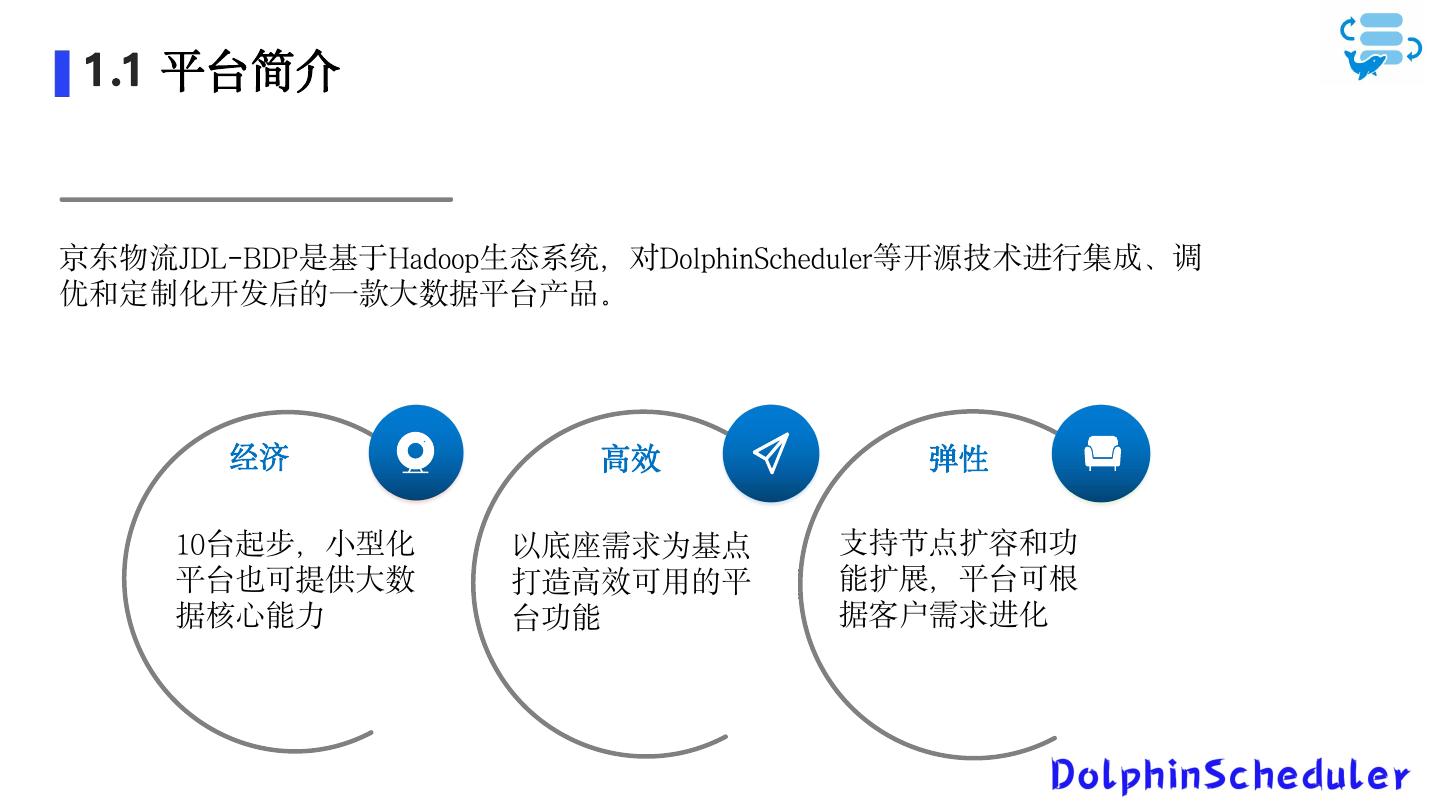
5 . 1 .1 平台简介 京东物流JDL-BDP是基于Hadoop生态系统,对DolphinScheduler等开源技术进行集成、调 优和定制化开发后的一款大数据平台产品。 经济 高效 弹性 10台起步,小型化 以底座需求为基点 支持节点扩容和功 平台也可提供大数 打造高效可用的平 能扩展,平台可根 据核心能力 台功能 据客户需求进化
6 .1 .2 平台架构 数据应用 智慧供应链 库存仿真 实时大屏 物流控制塔 ...... 多租户管理 分析工具 PowerBI Teablue EasyBI 管控平台 数据分析与服务 API数据服务 Doris 日志管理 Batch Compute Real Time Compute 任 数据计算 MR Tez Spark Flink Spark Streaming Structured Streaming 务 服务监控 调 资源管理 yarn 度 组件管理 数据存储 平 HDFS KAFKA 台 数据权限 数据集成 接入方式管理 接入数据源管理 接入运维管理 DS 管理 离线数据同步(增量/全量) 实时数据同步 多数据源支持 数据一致性校验 数据资产 管理 数据源 RDBMS NOSQLS LOGS BinLogs ......
7 .1 .3 核心功能描述 数据 集 成 数据 开发 工 作 流 调度 支持多种数据源接入; 脚本创建与保存,支持脚本目录 可视化拖拽方式进行工作流编辑 支持全量和增量数据同步,支持周期性同 支持基于Hive、Spark的离线数据开发 支持计算任务调度、周期性执行 步; 支持基于FlinkSQL的实时数据开发 支持状态订阅通知 支持实时数据同步; 入前后数据一致性检查; 数据 资产管 理 资源 管 理 &监控 统计 权限 管 理 支持本地数仓元数据查询 资源上传下载 多用户、多租户管理 支持外部数据源元数据查询 任务执行情况统计 队列管理、接口令牌管理等 支持自动元数据采集 节点运行监控、日志可视化运维 支持手动元数据采集
8 .1 .3 核心功能描述-离线数据开发 支持sql脚本创建与保存 支持sql计算引擎,包含hive、spark引擎 支持DML、DDL语言操作
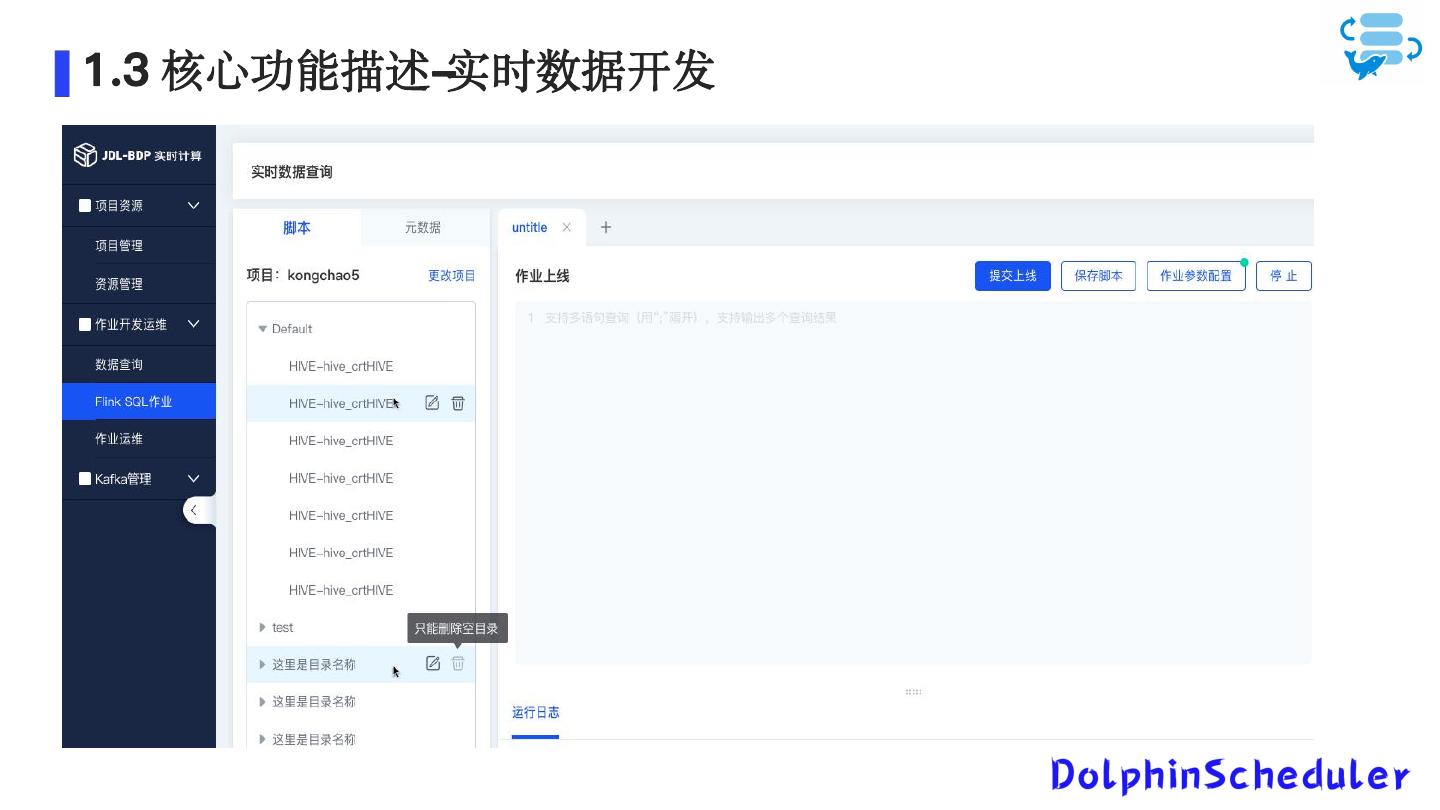
9 .1 .3 核心功能描述-实时数据开发 基于Flink的进行开发 支持创建FlinkSQL作业 支持消息队列Kafka的topic管理、消费组管理、消息查看等等
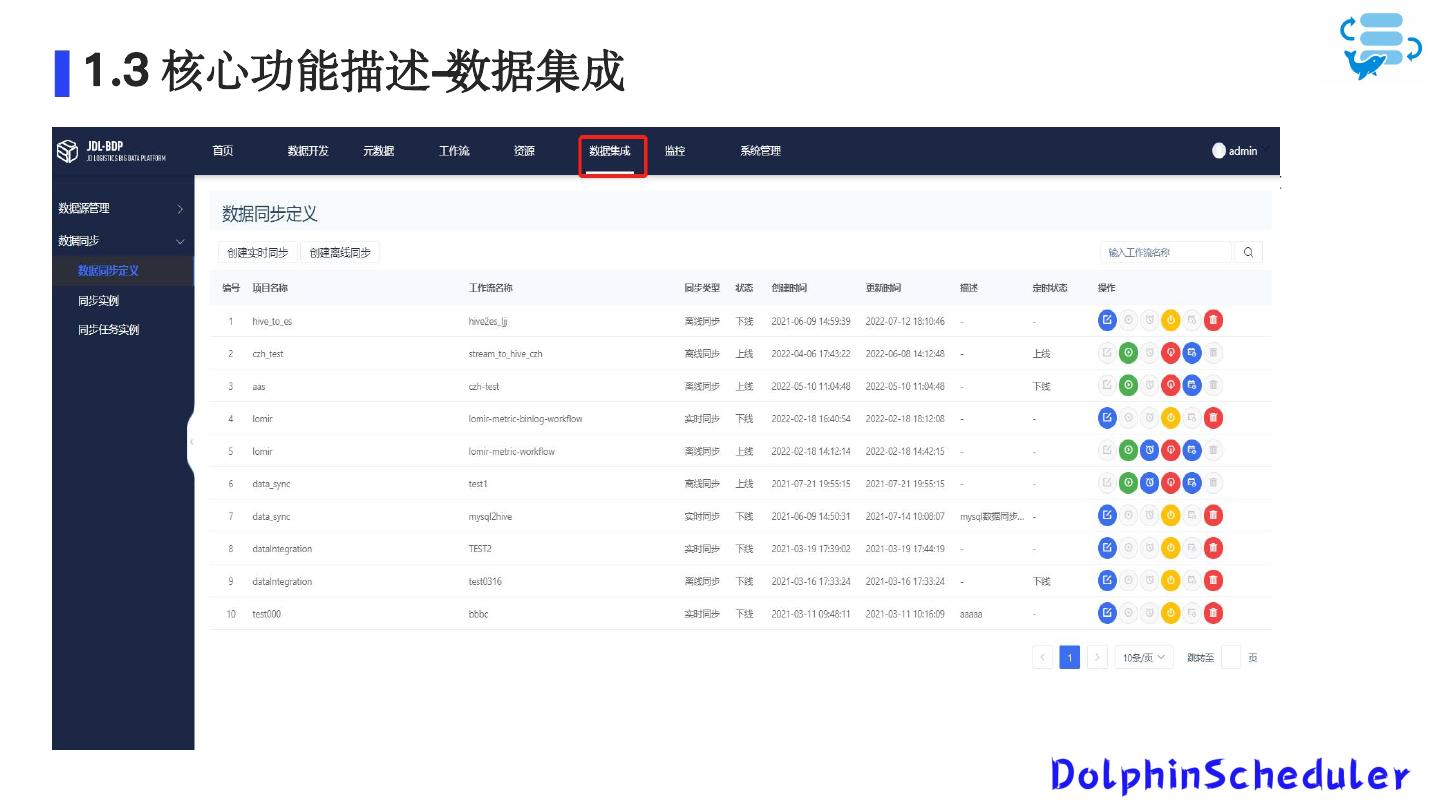
10 .1 .3 核心功能描述-数据集成 数据集成服务 基于袋鼠云开源的flinkx(现更名为ChunJun),是一款稳定、易用、高效、批流一体的数据集成框架,目前基于实时计算引擎Flink实现多种异构数 据源之间的数据同步与计算。 我们数据集成服务目前支持 1. 离线数据同步服务,支持MySQL、SQLSever、Hive、Oracle、SAP Hana、ElasticSearch的数据同步 2. 离线全量和增量数据同步,支持周期性同步 3. 实时数据同步,支持MySQL、SQL Sever、KafKa
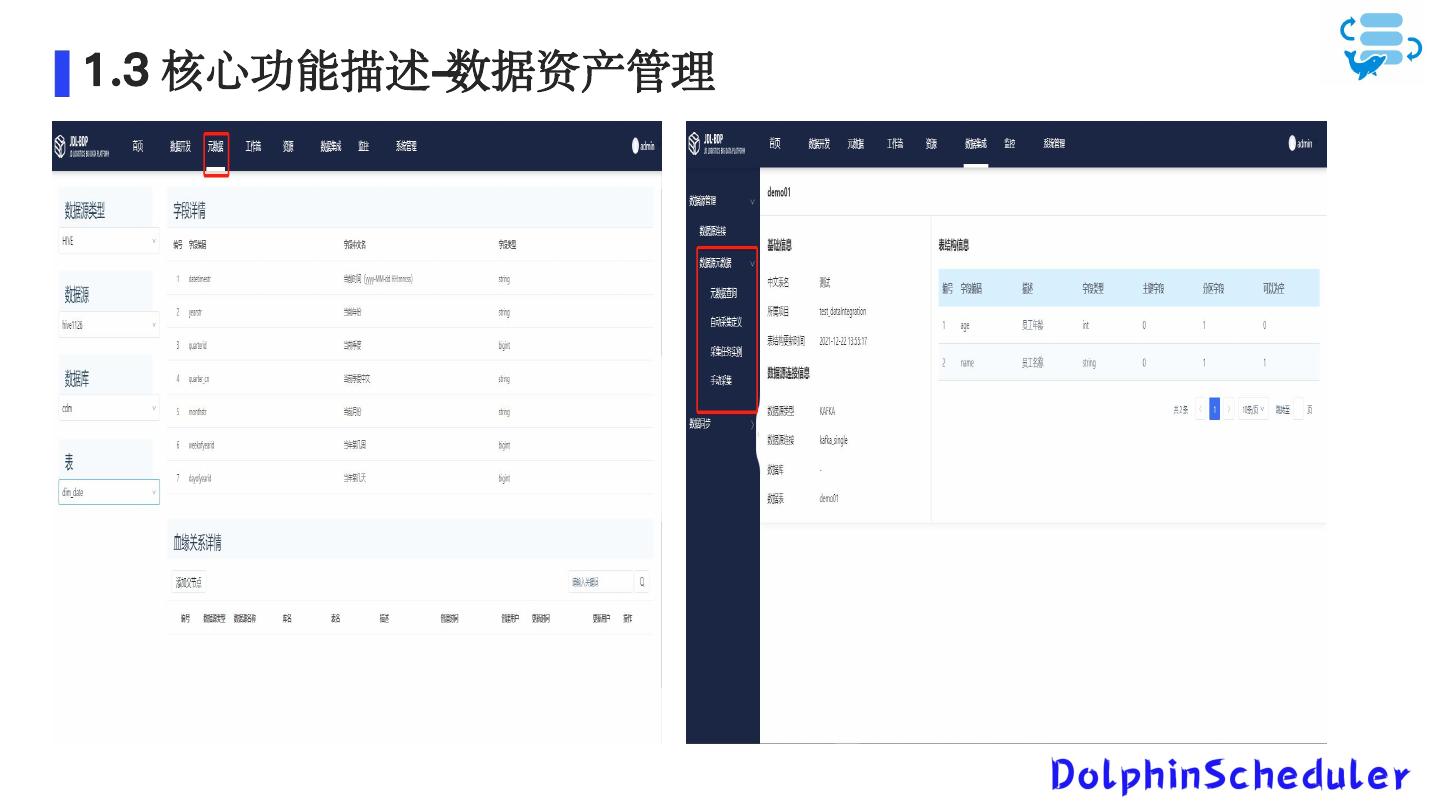
11 .1 .3 核心功能描述-数据资产管理 支持本地数仓元数据查询 支持外部数据源元数据查询 支持自动元数据采集 支持手动元数据采集
12 . 02 背景介绍 BDP容器化 镜像构建 整体介绍
13 .2.1 背景介绍 业务痛点在面向ToB项目时,由于上云的大趋势下,我们的bdp服务与第三方的大 数据平台对接时,需要定制化开发,定制化部署,复杂的环境适配,各种问题频出不穷。 例如:大数据组件版本适配的问题、网络问题等等。解决这种问题的时间成本非常高, 每一次对接就相当于一次定制化开发。有时还受限于第三方大数据平台的权限限制,对 我们排查问题产生了诸多困扰。 容器化优势 容器化部署相对于物理机或者虚拟机部署,部署上线快,由于都是构建好成熟的镜像, 只需要针对不同的容器化环境进行配置的微调;发生故障的概率大大减小,因为都是 容器内部环境,几乎不依赖外部服务。同时的运维也会变得很简单。 容器化方案相对与第三方的hadoop大数据平台对接,能节省90%的时间与人力(以联通 项目为例);相对于第三方物理机或虚拟机部署,能节省80%以上的时间与人力成本。
14 .2.2 ambari-base镜像构建 build entrypoint layer(/usr/sbin/init) build expose layer(8080,8088,50070,1 9888,1 8081 ,etc.) build volume layer(/sys/fs/cgroup,/data,/var/log,/hadoop,etc.) build Algorithm dependency package layer build system config(limits,time zone,etc.) build nginx layer build tools layer(mysql-client,expect,curl,etc.) Image layers RO build ambari layer build env layer(java_home etc.) build jdk layer build systemctl layer build copy/add layer(ambari-init.sh) centos:7 ambari-base:v1
15 .2.2 bdp镜像构建 build entrypoint layer(startup.sh) build expose layer(1 2345,8888,8082,etc.) Image layers RO build env layer(app_home etc.) build copy/add layer(bdp,startup.sh) ambri-base:v1 bdp:v1
16 .2.2 doris镜像构建 build entrypoint layer(startup.sh) build expose layer build volume layer build system config(limits,time zone,etc.) Image layers RO build jdk layer build env layer(doris_home etc.) build copy/add layer(DORIS-xx-release.tar.gz,startup.sh ) centos:7 doris:v1
17 . 2.3 容器化整体介绍 hdp01 master queen proxy fe hdp02 worker wasp be01 hdp03 api be02 container layers hdp04 frontend be03 hdp05 flink … … bdp:v1 ambri-base:v1 doris:v1 Image layers Centos:7 BDP容器化 mysql container layers centos7repos ambarirepos container layers mysql:5.7 Image layers centos7-yumrepos:v1 ambari-yumrepos:v1 Image layers tomcat:latest
18 . 03 集群编排 基于K8S的BDP 关键技术支撑 编排模型
19 .3.1 Ambari Hadoop集群编排 第一步:创建PV(挂载卷)和PVC(挂载卷映射) 指定PV读写类型为:ReadWriteOnce 指定PV存储大小 指定PV驱动 PVC与PV一一绑定 第二步:配置并启动ambari hadoop集群yum源 使用Deployment控制器 第三步:ConfigMap配置,配置yum源和proxy map 第四步:配置并启动mysql元数据服务 配置Service:对外提供服务 磁盘挂载:将容器内部的mysql数据挂载到外部分布式存储,第一步创建的mysql PVC 使用Deployment控制器 第五步:配置并启动Ambari Hadoop集群 Ambari Server(逻辑管理节点) 指定bdp镜像 资源控制:限制容器内部CPU和内存的使用阈值 磁盘挂载:绑定PVC和configmap 配置mysql链接信息 配置Headless Service 使用StatefulSet控制器 第六步:配置并启动Ambari Hadoop集群 Ambari Agent(逻辑计算节点),根据需要配置多个 指定bdp镜像 资源控制:限制容器内部CPU和内存的使用阈值(注意QoS级别) 磁盘挂载:绑定第一步创建的PVC和第三步创建的configmap yum源文件 配置mysql链接信息(Hive Metastore服务所在节点需要配置) 配置Headless Service 使用StatefulSet控制器 开启容器privileged=true 获取宿主机root权限(特殊权限,可以运行守护进程) 第七步:配置代理,转发Ambari Hadoop集群 Ambari Server服务到外部
20 .3.2 关键技术支撑 关键技术 StatefulSet 固定IP
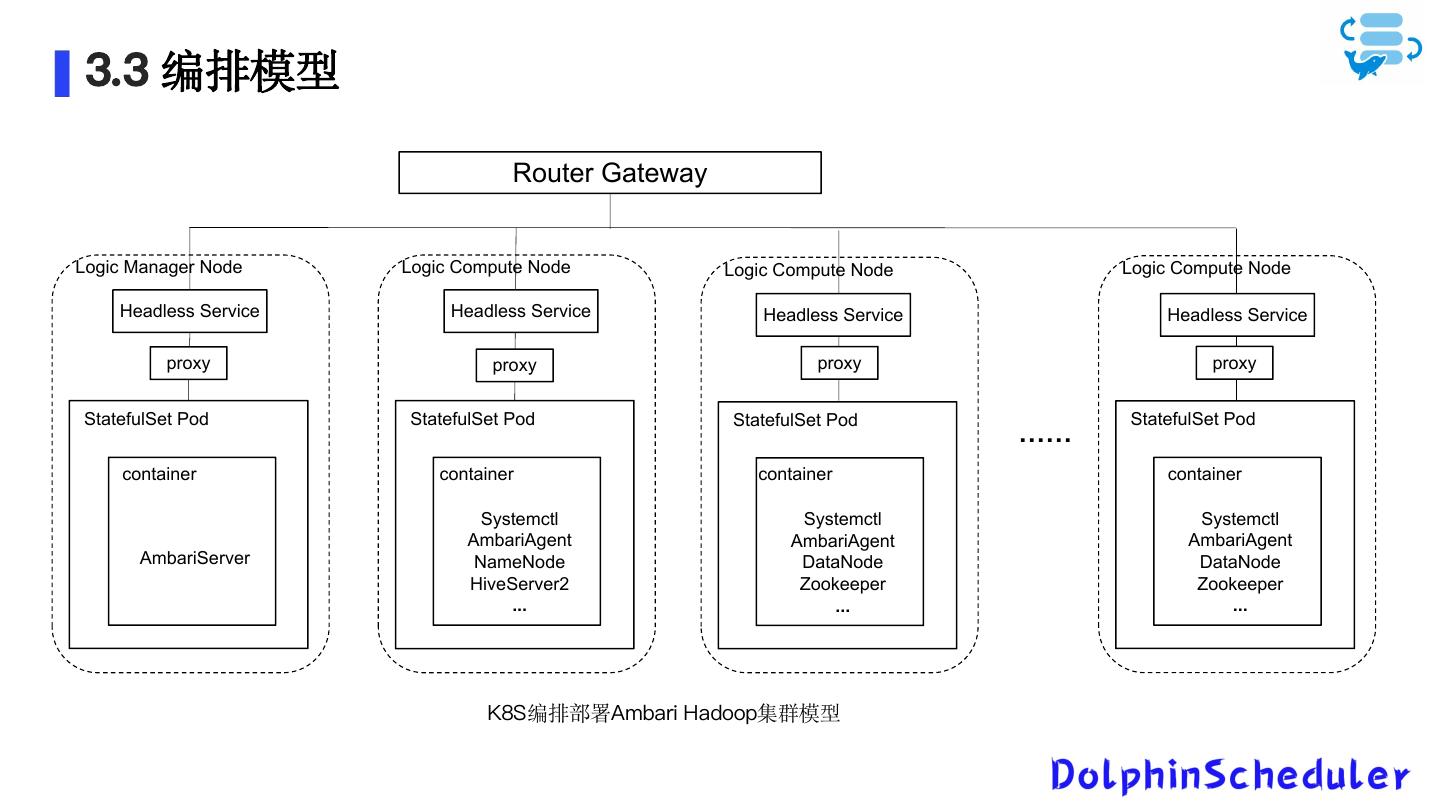
21 . 3.3 编排模型 Router Gateway Logic Manager Node Logic Compute Node Logic Compute Node Logic Compute Node Headless Service Headless Service Headless Service Headless Service proxy proxy proxy proxy StatefulSet Pod StatefulSet Pod StatefulSet Pod StatefulSet Pod …… container container container container Systemctl Systemctl Systemctl AmbariAgent AmbariAgent AmbariAgent AmbariServer NameNode DataNode DataNode HiveServer2 Zookeeper Zookeeper ... ... ... K8S编排部署Ambari Hadoop集群模型
22 .04 编排模型 展望 理论支撑
23 . 4.1 K8S编排模型展望 Router Gateway Logic Manager Node Logic Compute Node Logic Compute Node Logic Compute Node Headless Service Headless Service Headless Service Headless Service proxy proxy proxy proxy StatefulSet Pod StatefulSet Pod StatefulSet Pod StatefulSet Pod …… Ambari Ambari Ambari NameNode DataNode DataNode Agent Agent Agent Ambari container container container container container container Server container HiveServer2 ... Zookeeper ... Zookeeper ... container container container
24 .4.1 理论支撑 稳定的网络标识和IP 容器间的通信 解决了这些技术难题,就可以解决Kubernetes部署 Ambari Hadoop集群存在的组件间的进程通信、不稳定 的数据持久化和节点宕机故障恢复问题。Kubernetes部 基于K8S的大数据平台 组件间的进程通信 署Ambari Hadoop集群的基本模型为:一个Pod类比为一 稳定的数据持久化 个节点(管理节点或计算节点),Pod内部一个容器类 节点宕机故障恢复 比为节点内的一个进程或组件。 稳定的持久化存储 细粒度的资源控制
25 . THANKS! Ending
3秒后跳转登录页面
去登陆

