展开查看详情
1 . 2023
DS 及 Spark 在
BIGO 的应用与改进
讲师:许名勇 BIGO计算平台
�
2 .目录
CONTENTS
01 DS 应用概况
02 DS 改进
未来计划
03 Spark 改进
�
3 . 01 为什么选择 DS
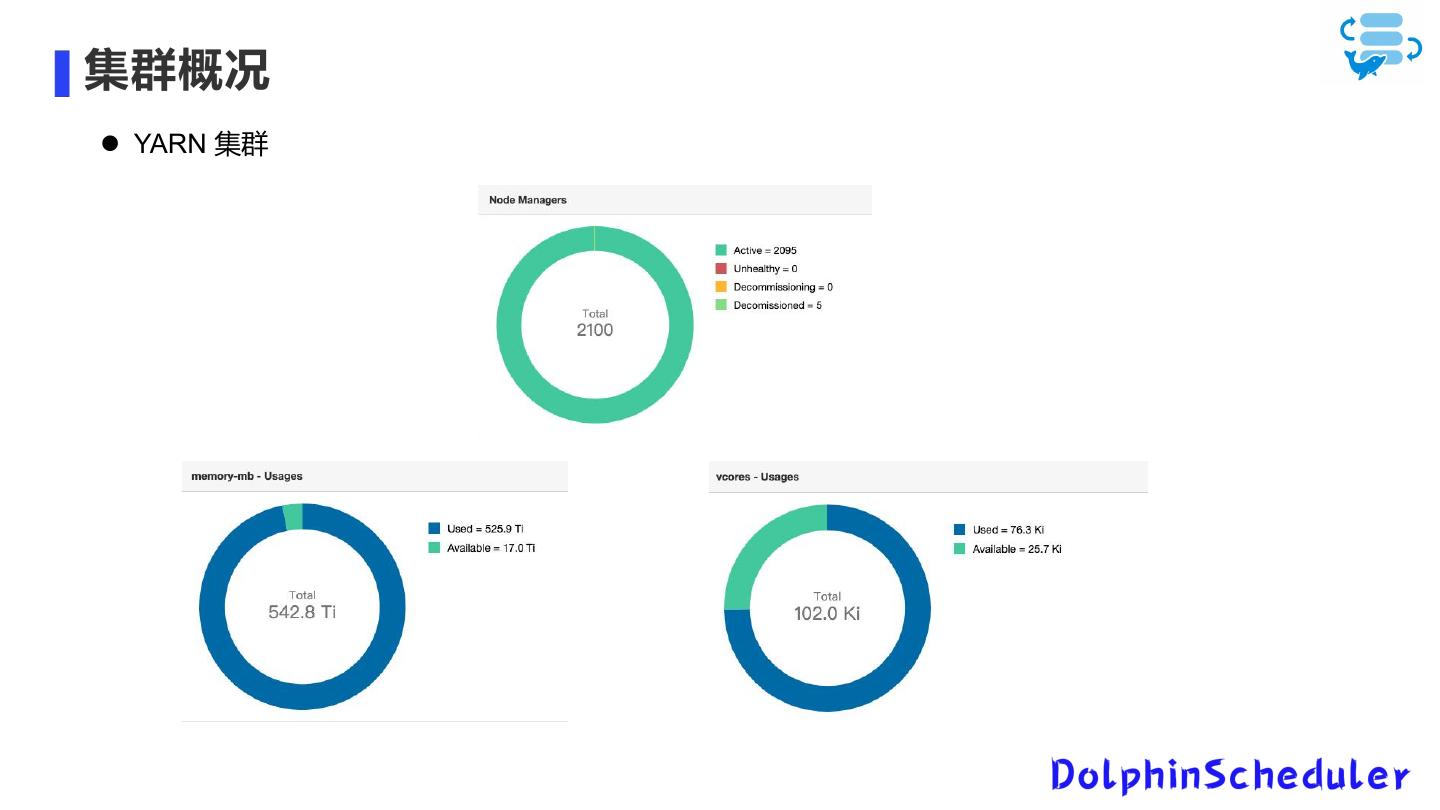
DS 应用概况 集群概况
作业概况
�
4 .为什么选择 DS
原有调度
• oozie:日志查看不便、缺少任务统计监控、调度存在压力
• airflow:需要 python 代码绘制 DAG,使用门槛高
• crontab:单点,管理不便
DS 优势
• 可视化 DAG 编辑,简单易用,日志查看方便
• 去中心化的多 Master/多 Worker 架构,线性扩展,保证高可用
• 任务类型丰富,契合大数据生态,方便定制和改造
• 支持补数
契机
• 自研一站式数据开发平台,需要一个新的工作流调度系统
�
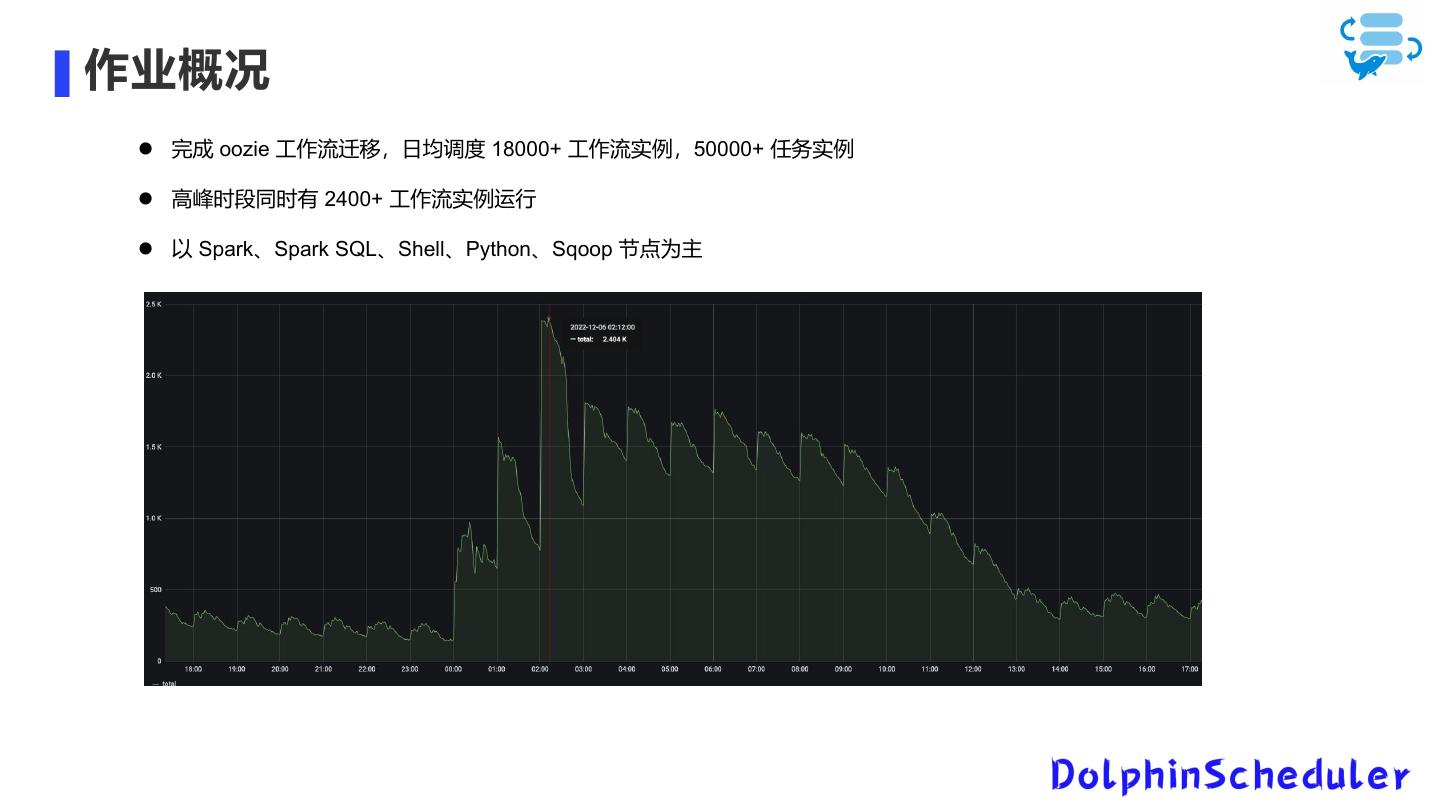
7 .作业概况
完成 oozie 工作流迁移,日均调度 18000+ 工作流实例,50000+ 任务实例
高峰时段同时有 2400+ 工作流实例运行
以 Spark、Spark SQL、Shell、Python、Sqoop 节点为主
�
8 .02 用户体验提升
DS 改进
系统层面改进
�
9 .用户体验提升
降低开发成本,简化任务配置
打通 OA,免去注册
DAG 编辑页面完成开发、上线、树形图查看、运行、定时管理一站式操作
树形图页面聚合单个工作流定义的所有实例列表
首页提供定时调度概况
增加页面分层级树形导航条,提供在项目、工作流、树形图页面快速切换
... ...
�
10 .用户体验提升
依赖选择
可直接按工作流 ID、工作流名称或 owner 搜索依赖工作流 依赖关系查看
便捷查看上游依赖情况
下游依赖批量替换
�
11 .用户体验提升
补数改进
补数支持触发下游
可查看补数进度
限制同一个调度时间的实例同时运行
�
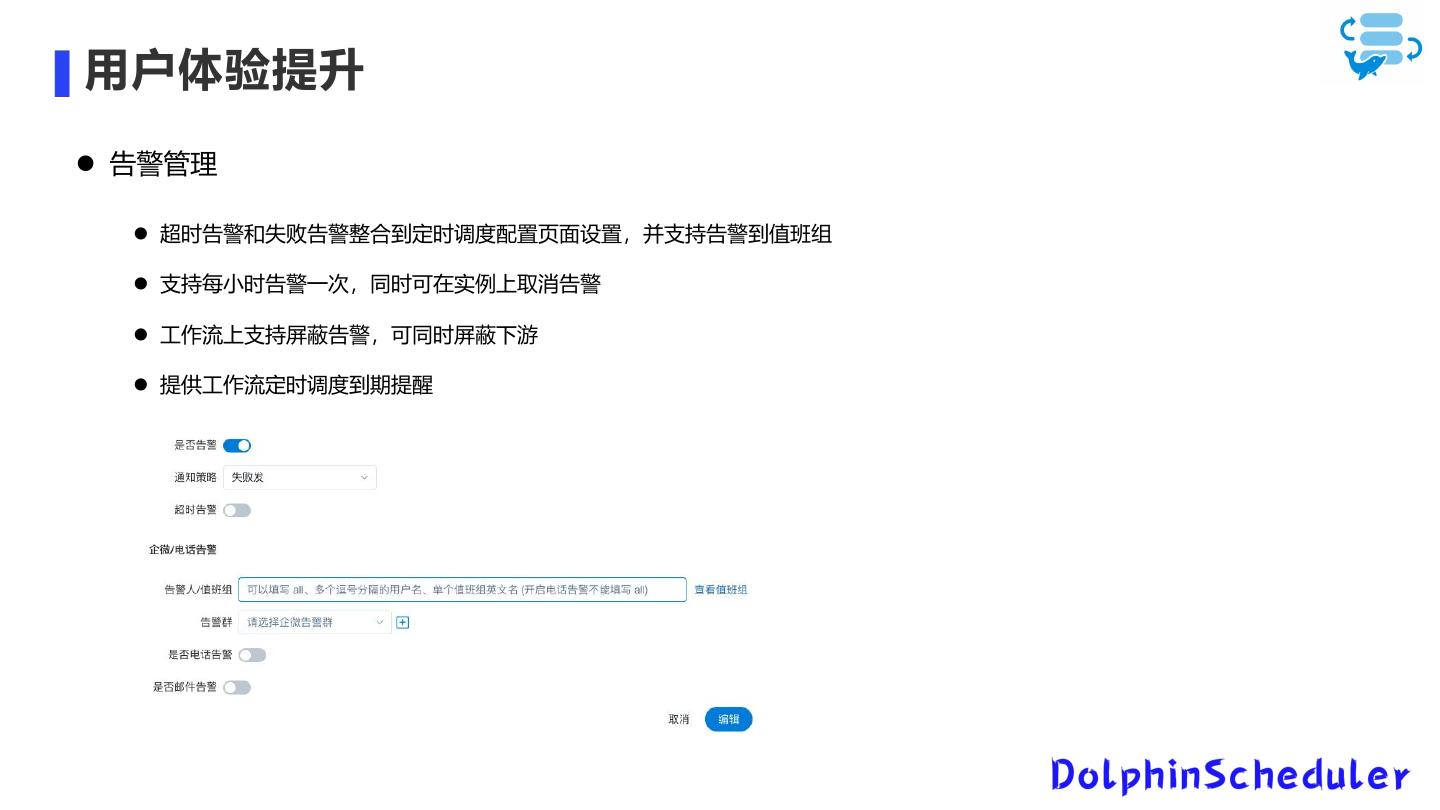
12 .用户体验提升
告警管理
超时告警和失败告警整合到定时调度配置页面设置,并支持告警到值班组
支持每小时告警一次,同时可在实例上取消告警
工作流上支持屏蔽告警,可同时屏蔽下游
提供工作流定时调度到期提醒
�
13 .系统层面改进
worker 支持任务无需重跑的 failover
现状: worker 重启后,正在运行的任务需要 kill 重新提交
问题
• 任务可能运行时间长,重跑代价大
• 重跑浪费集群资源
• 限制 worker 同时运行任务数量的上限
优化
• 改造任务提交方式,提交到 yarn 上执行,不在 worker 上执行
• 任务实例记录提交到 yarn 上后的 app id,开启异步任务 track 运行状态
• 若 worker 宕机,容错后由其他 worker 接管该 app 任务,继续 track 运行状态
�
14 .系统层面改进
确保 worker 任务只提交一次
问题: failover 时把 master/worker 启动后的实例也容错了,导致任务实例重复提交
• 工作流跑的数据不对
• 严重堵塞集群,影响工作流正常运行
优化
• 实例表增加 lastStartTime 字段,master/worker 容错时根据该字段判断实例是否需要容错
• master 端重试分发 task 时,优先分发至上一次分发的 worker
• 提交到 yarn 的 task 设置 yarn tags,failover 后的 task 重新分发到 worker 后如果没有 app id 信息,
则通过 yarn tags 检查 yarn 上该 task 是否已经提交或者在运行了
�
15 .系统层面改进
降低对数据库压力
现状: 1.3.8 版本 master 对线程使用过重,对数据库压力太大
• 每个工作流实例和任务实例都独占一个线程,状态轮询存在很多数据库 IO
• 依赖节点存在 24 小时依赖类型,每个小时实例查一次状态,夜里高峰时期可能打满数据库连接池
优化
• 增大工作流实例和任务实例状态轮询间隔
• 实例表增加索引,加快 sql 查询速度
• 依赖节点查询上游实例状态时通过随机化分散查询,降低同时查询的并发数
• 增加缓存,减少不必要的重复查询
�
16 .系统层面改进
支持 Spark 任务灰度
现状: 如果需要变更 Spark,Spark 任务灰度升级存在几个问题
• 单个任务灰度可添加参数 --conf spark.yarn.archive 指定 Spark 版本,但批量灰度不便
• worker 级别灰度,无法指定具体的工作流灰度,也不好控制灰度规模
优化
• 增加灰度管理功能,可批量添加一批工作流到灰度列表
• 灰度列表中的工作流在 master 分发任务到 worker 时,应用该灰度信息
• 可按照任务类型和工作流 owner 筛选工作流来灰度
• 工作流从灰度列表移除就取消灰度
�
17 . 03 小文件合并
Spark 改进 AQE 优化
�
18 .小文件合并
产生原因
• 取决于 RDD partition 数量,每个 partition 产生一个文件
• Spark 作业并行度高容易产生小文件
文件提交机制
�
19 .小文件合并
小文件合并方案
• 在 driver setup job 时,创建临时目录,将输出路径 outputPath 变为 outputPath/.merge-temp-${UUID}
• 数据写到临时目录
• 在 driver commit job 后,计算每个分区路径下数据文件平均大小
• 若只有一个文件或大于指定阈值,不需要合并直接移动到 outputPath
• 若小于指定阈值,则计算合并后文件数量:分区路径下文件大小之和 / 阈值
• 将分区路径下的文件读成 HadoopRDD 或 FileScanRDD,再按合并后文件数量 coalesce
• 启动一个 Spark Job 将 RDD 数据写到 outputPath 中
小文件合并收益
• 大大减少文件数量,减轻 NameNode 负载压力
• 降低 Spark 作业 driver OOM 出现的概率,提高数据读取效率,加快执行
�
20 .AQE 优化
AQE 实现的优化
• 动态合并 shuffle 分区
• 动态调整 join 策略
• 动态优化倾斜 join
�
21 .AQE 优化
AQE 进一步优化
• Expand 算子会导致数据膨胀,如果存在此类算子,不合并 shuffle 分区
• 扩展倾斜 join,支持收集行数信息,根据数据大小和行数判断分区是否倾斜
• 利用行数信息,在合并分区时根据数据大小和行数的比值决定是否合并分区
AQE 收益
• 对大部分作业缩短了运行时间,提高执行效率
• 集群整体作业平均运行时间缩短了 10%
�