展开查看详情
2 .强化学习在Tensorflow中的应用
主讲人:江岸青
�
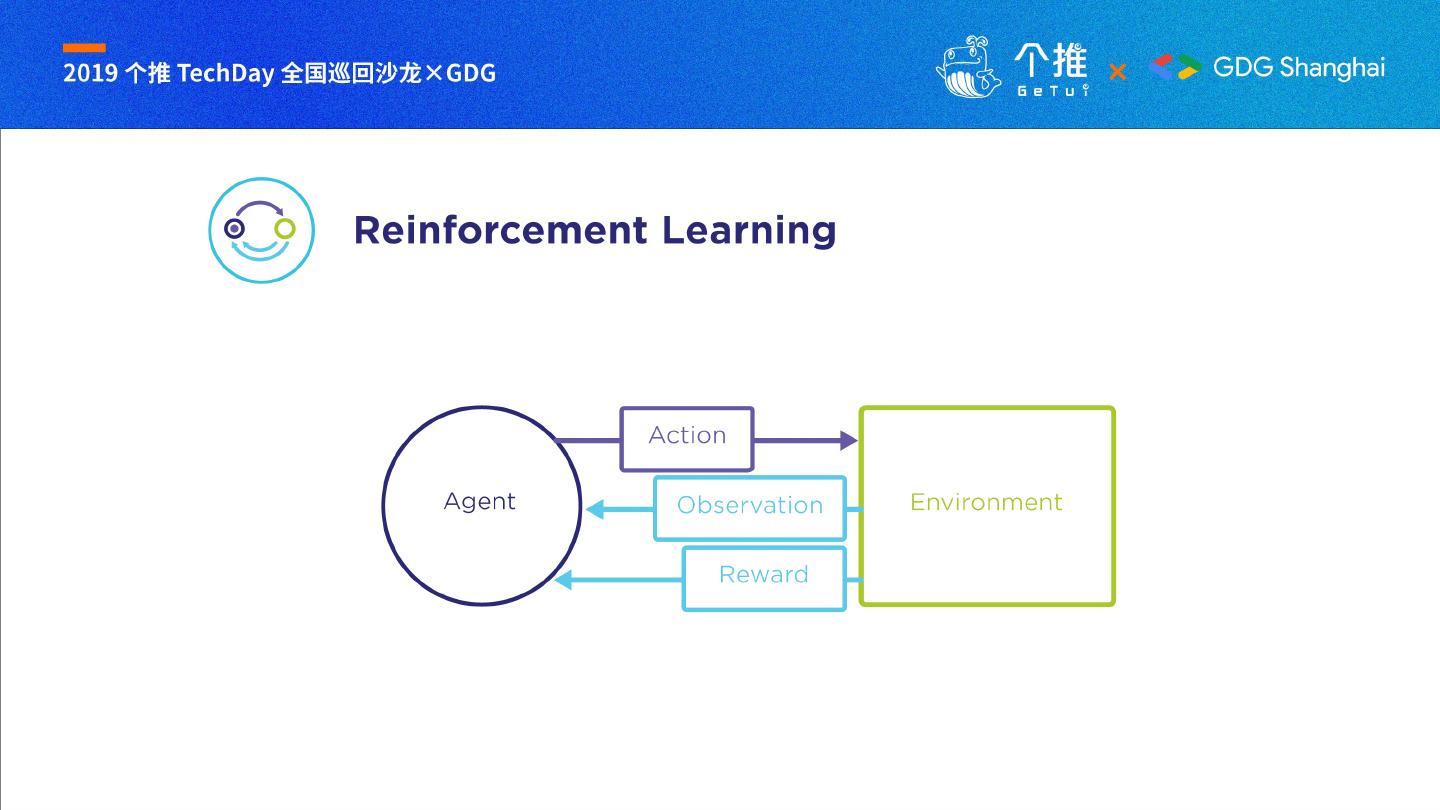
3 . 什么是强化学习?
What is reinforcement learning?
�
4 . • 尝试探索
人的成长 • 反馈总结
• 学习成长
�
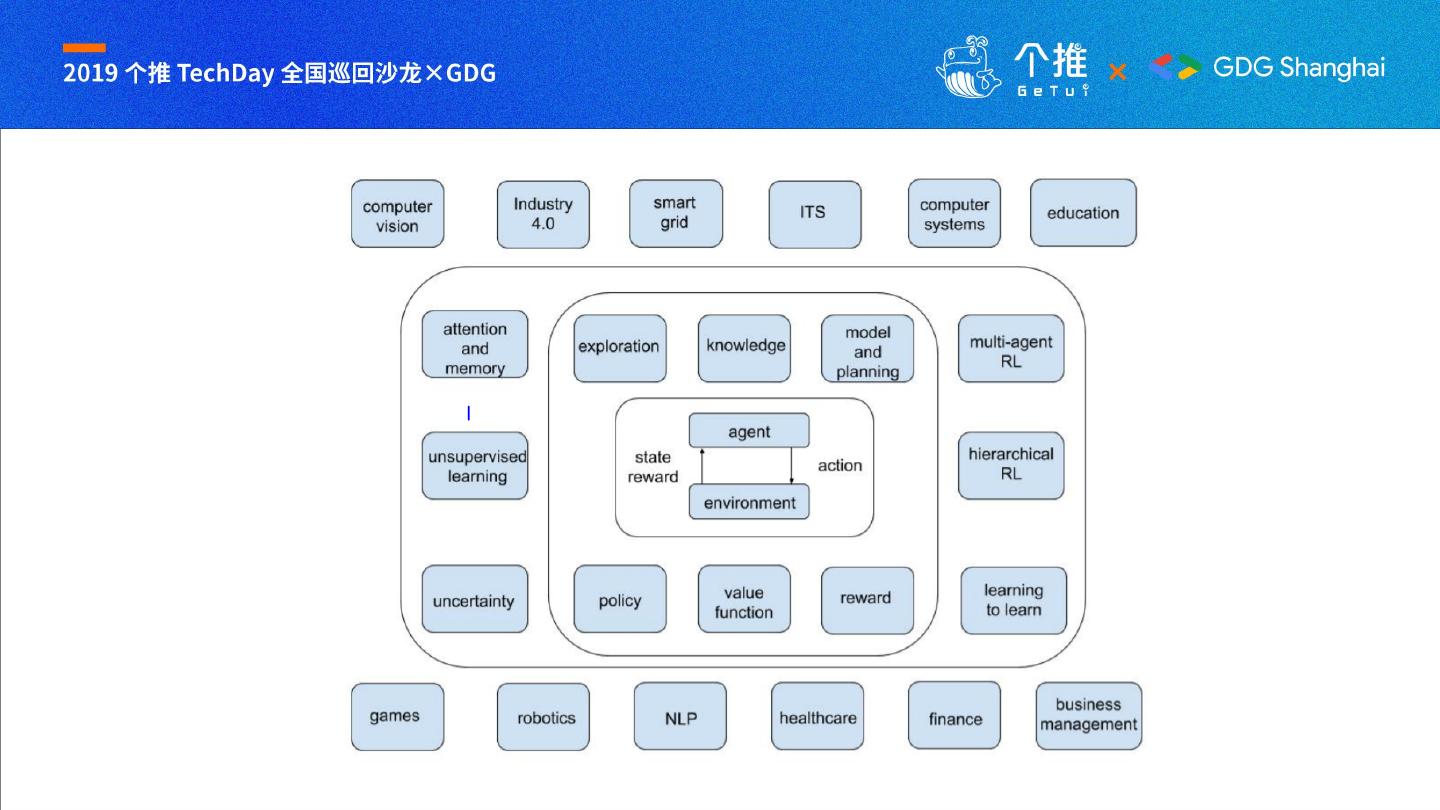
8 . • 智慧交通 • 游戏
• 集群资源管理 • 广告
强化学习的应用
• 材料学 • 个性化推荐
• 机器人 • 量化投资
�
9 . • 滴滴智能派单
智慧交通
• 智能红绿灯
* 1. https://arxiv.org/abs/1802.06444
* 2.https://github.com/Ujwal2910/Smart-Traffic-Signals-in-India-using-Deep-Reinforcement-Learning-and-Advanced-Computer-Vision
�
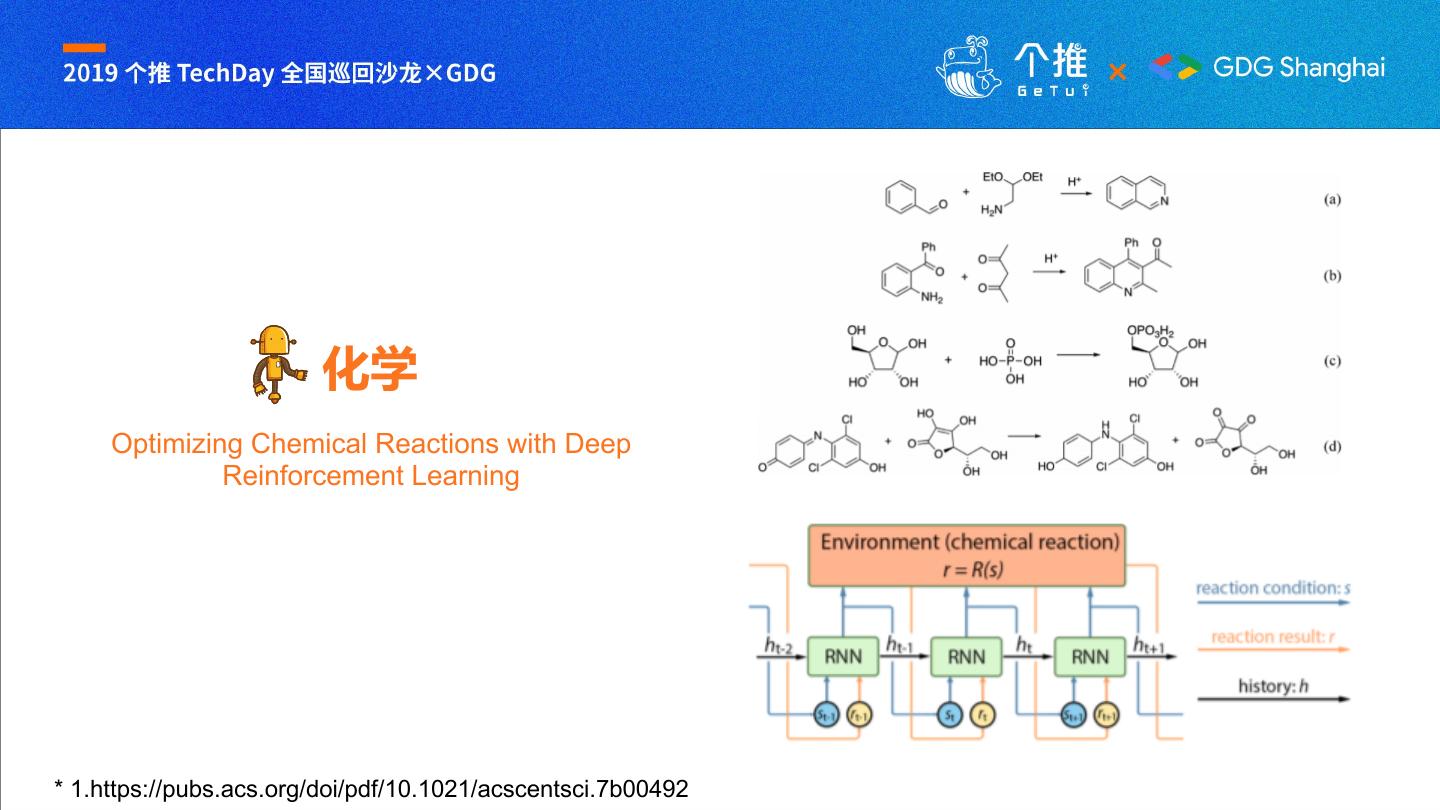
10 . 化学
Optimizing Chemical Reactions with Deep
Reinforcement Learning
* 1.https://pubs.acs.org/doi/pdf/10.1021/acscentsci.7b00492
�
11 . 推荐系统
Generative Adversarial User Model for
Reinforcement Learning Based Recommendation
System
* 1. https://arxiv.org/pdf/1812.10613.pdf
�
12 . 游戏
Open AI Five
* 1.https://openai.com/blog/openai-five/
�
13 . 量化投资
Trading Gym
* 1. https://github.com/Yvictor/TradingGym
�
14 . 构建强化学习的要素
AGENT ENV REWARD
• 算法 • 模拟 • 回报函数
• 训练 • 现实
�
15 . • Q-Learning, DQN, DDQN, DQN-RNN
• DDPG, TD3
强化学习的算法
• PPO, PPO-RNN
• SAC(soft actor critic)
• ….
�
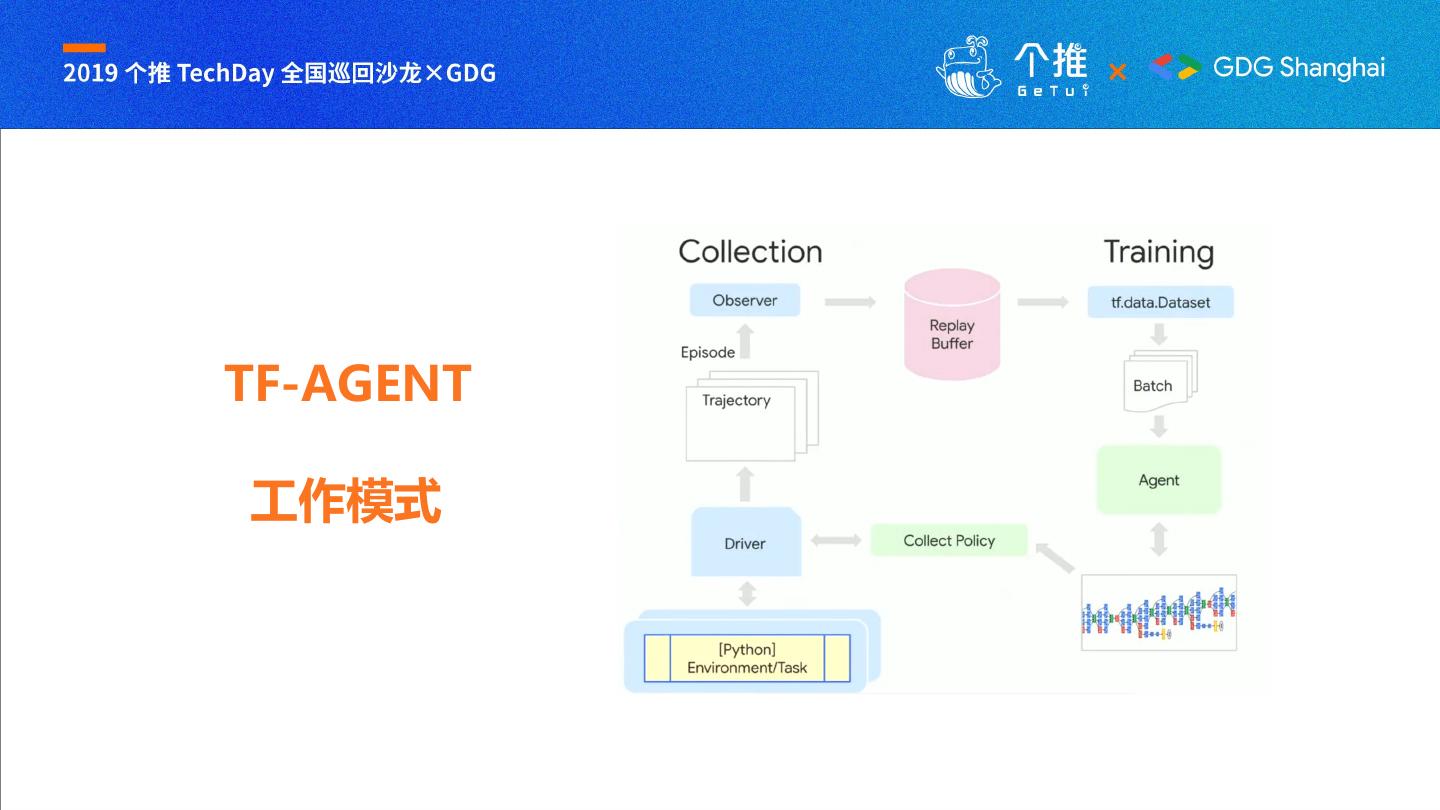
16 . Tensorflow 强化学习库
TF-AGENT
https://github.com/tensorflow/agents
�
18 . import tensorflow as tf
tf.compat.v1.enable_v2_behavior()
AGENT from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import suite_pybullet
ENV from tf_agents.environments import tf_py_environment
from tf_agents.eval import metric_utils
from tf_agents.metrics import tf_metrics
from tf_agents.networks import actor_distribution_ne
NET twork
from tf_agents.networks import normal_projection_net
work
from tf_agents.policies import greedy_policy
POLICIES from tf_agents.policies import random_tf_policy
from tf_agents.replay_buffers import tf_uniform_repl
REPLAY ay_buffer
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
�
19 . env_name = 'CartPole-v0’
环境建立 env = suite_gym.load(env_name)
�
20 . fc_layer_params = (100,)
q_net = q_network.QNetwork( train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=fc_layer_params)
AGENT
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
agent = dqn_agent.DqnAgent( train_env.time_step_spec(), train_env.action_spec(),
q_network=q_net, optimizer=optimizer,
td_errors_loss_fn=common.element_wise_squared_loss,
train_step_counter=train_step_counter)
agent.initialize()
�
21 .METRICS 评价指标 def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
�
22 .TRAIN 训练
for _ in range(num_iterations):
for _ in range(collect_steps_per_iteration):
collect_step(train_env, agent.collect_policy, replay_buffe
r)
experience, unused_info = next(iterator)
agent.train = common.function(agent.train)
train_loss = agent.train(experience).loss
# Reset the train step
step = agent.train_step_counter.numpy()
agent.train_step_counter.assign(0)
if step % log_interval == 0:
# Evaluate the agent's policy once before training.
print('step = {0}: loss = {1}'.format(step, train_loss))
avg_return = compute_avg_return(eval_env, agent.policy, num_ev
al_episodes)
if step % eval_interval == 0:
returns = [avg_return]
avg_return = compute_avg_return(eval_env, agent.policy, nu
m_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_
return))
returns.append(avg_return)
�