




















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/HBaseGroup/BigDataNoSQLSystemApsaraDBHbaseandSpark79574?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
Big Data NoSQL System:Apsara DB Hbase and Spark
分享
点赞
8
收藏
2
下载 2
来自阿里巴巴的 Wei Li 介绍了基于阿里巴巴云 HBase 构建的融合了计算、存储和检索以及在线和离线的的大数据中台解决方案,同时结合云上的弹性伸缩能力,节省成本。针对扫描大表,造成在线的 HBase 服务不稳定的问题,他们做了一个工作是把在线存储和离线分析使用的数据分离开来,通过一键归档把离线的数据转成列存的格式,带来性能十倍以上的提升,同时也不会影响 HBase 在线服务的稳定性,列存的方式是把源数据通过WAL同步到Spark 集群,存储成列的方式。数据归档完成之后,处理完的数据还需要写回到 HBase,这些数据的具体细节没有说明,可能跟业务有关,猜测是一些经过处理之后的聚合类数据等。他们没有通过传统的使用 HBase API 的方式,而是直接加载 HFile.最后一点是成本,使用云端数据库能带来两个方面的成本节省。一个是计算资源,一个是存储。计算资源是因为不同的业务有不同的波峰和波谷;存储是因为可以利用云上的廉价存储。最后他根据具体的几个 case 详细讲述了这套方案的案例。
展开查看详情
1 .
2 .BigData NoSQL System:ApsaraDB HBase and Spark Wei Li ApsaraDB HBase X-Pack team
3 .Overview
4 . BigData processing scenario New New Finance E- manufactu Game Social News retail commerce ring Safety control Personalized Statistical Analysis Time&space timing Feeds recommendation ⽤户画像 ⽤户⾏为分析 监控数据 维表和结果表 海量帖⼦、⽂章 爬⾍抓取信息 ⽤户画像 轨迹、设备数据 离线分析 聊天、评论 反欺诈系统 推荐引擎 地理信息 海量实时数据存储 海量实时数据处理 订单数据 海量实时数据处理 区域分布统计
5 . System iterations and challenges Centralized database Distributed database Hadoop HBase X-Pack
6 . Architecture & Implementation
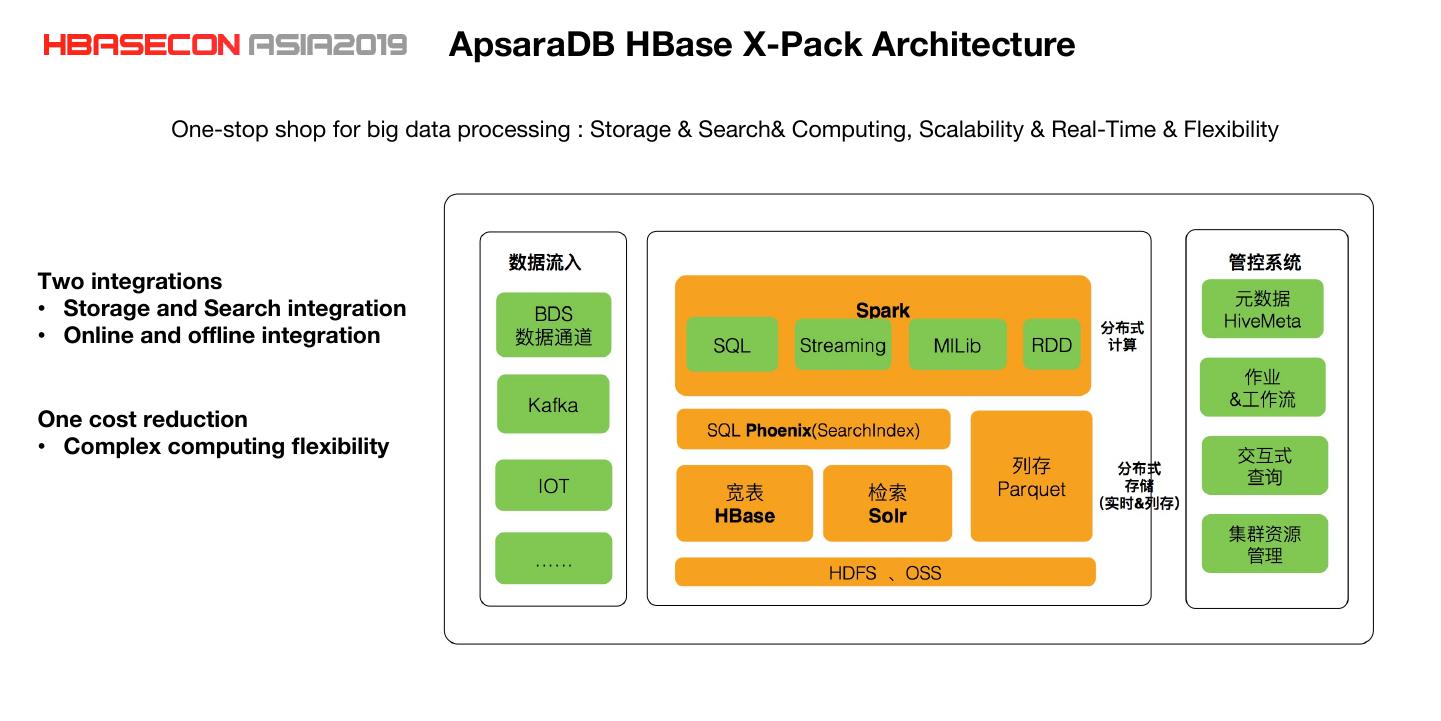
7 . ApsaraDB HBase X-Pack Architecture One-stop shop for big data processing : Storage & Search& Computing, Scalability & Real-Time & Flexibility Two integrations • Storage and Search integration • Online and offline integration One cost reduction • Complex computing flexibility
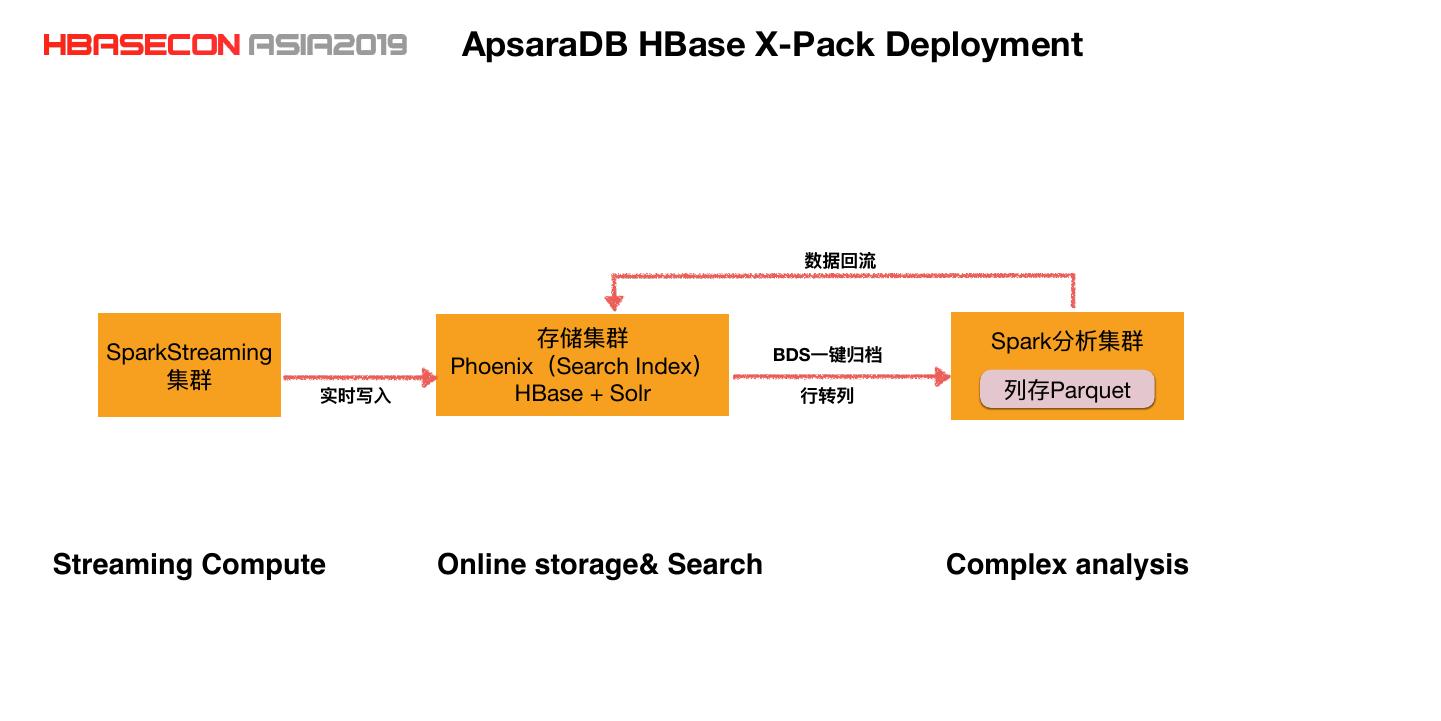
8 . ApsaraDB HBase X-Pack Deployment Spark SparkStreaming BDS Phoenix Search Index Parquet HBase + Solr Streaming Compute Online storage& Search Complex analysis
9 . Spark analysis HBase Data Spark on HBase Spark on HBase Spark Parser Performance DataSource API • distributed scan; Required • sql optimize like partition pruning column pruning predicate ! GetPartition! Columns PrunedFilter Schema ! pushdown ! • direct reading hifles Mapping! Filter • auto transform to column based storage filter Filter PhoenixInputFormat! Get Scan Snapshot ! Phoenix! put/create Get API Scan API newAPIHadoopRDD API TableSnapshot HBase ! Multi get Range Scan ! InPutFormat ! ! region Snapshot
10 . Spark analysis HBase Data One-click archiving • Row-Oriented To Column-Oriented • Performance improvement 20 times • HBase Cluster more stable start/stop config HBase BDS /tmp/20190606/00/15/ Spark /tmp/20190606/00/30/ hlog! …… Driver hlog! hlog /tmp/20190606/23/45/ ! ! /tmp/20190607/00/00/ Executor0 /data/20190606 ! ! region Executor1 …. ! ! ! ! ! hfile BulkLoad ExecutorX
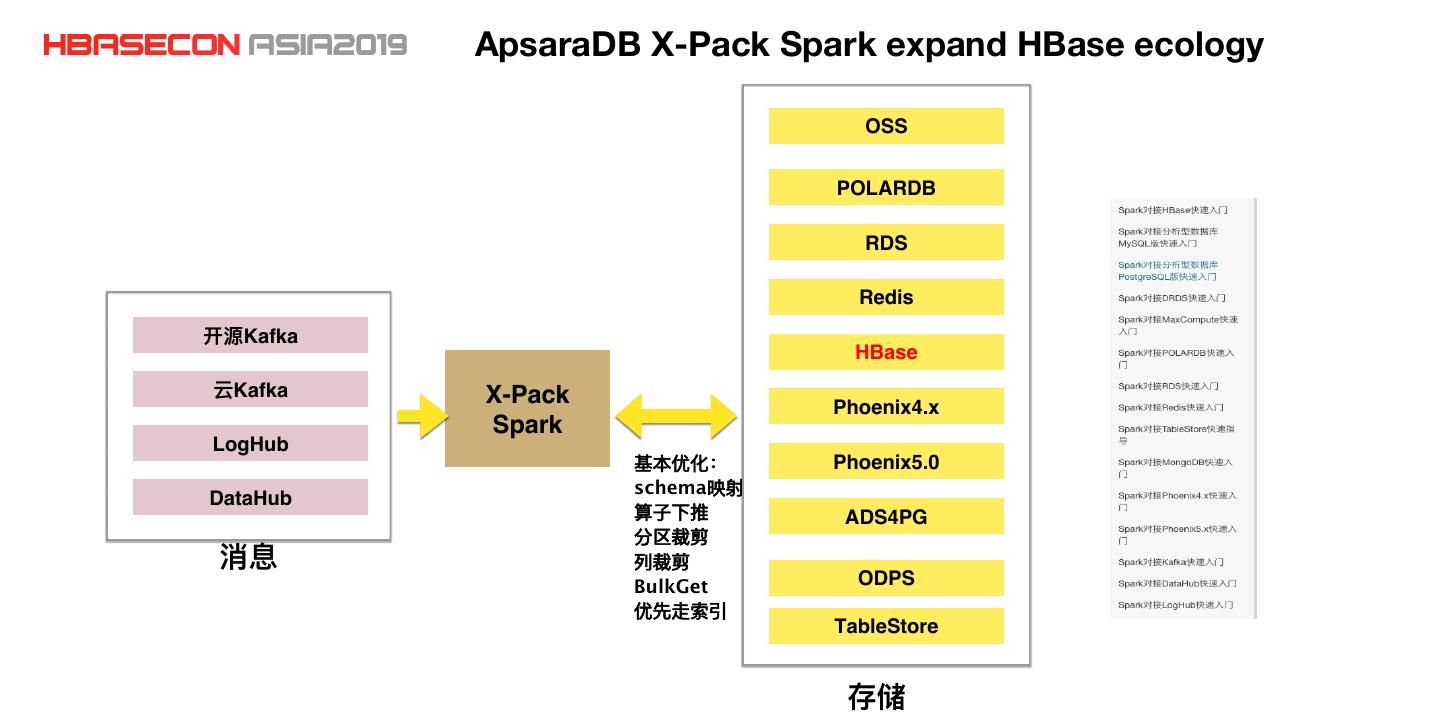
11 . ApsaraDB X-Pack Spark expand HBase ecology OSS POLARDB RDS Redis Kafka HBase Kafka X-Pack Phoenix4.x Spark LogHub Phoenix5.0 schema DataHub ADS4PG BulkGet ODPS TableStore
12 . ApsaraDB X-Pack Spark cost & dynamic ECS Master1 Master2 • Calculate resource elasticity(1 times lower) • OSS storage resource flexibility(3 times lower) Core Elastic Elastic ElasticNode! Core HDFS Elastic Elastic 300! 240! (node*h)! 180! 00:00-05:00 Core Elastic Elastic 5 node 10 node 120! 5 node 60! 0! OSS&DFS ElasticNode
13 . ApsaraDB X-Pack Spark data desktop Scheduling, relying, interactive
14 . ApsaraDB X-Pack Spark data desktop Scheduling, relying, interactive
15 .Solutions
16 . HBase X-Pack Product recommendation platform Scenario: With the increasing number of users accumulating in the APP, the customer is ready to launch the product recommendation function, which requires real-time ETL analysis, storage and model calculation of the user behavior log.
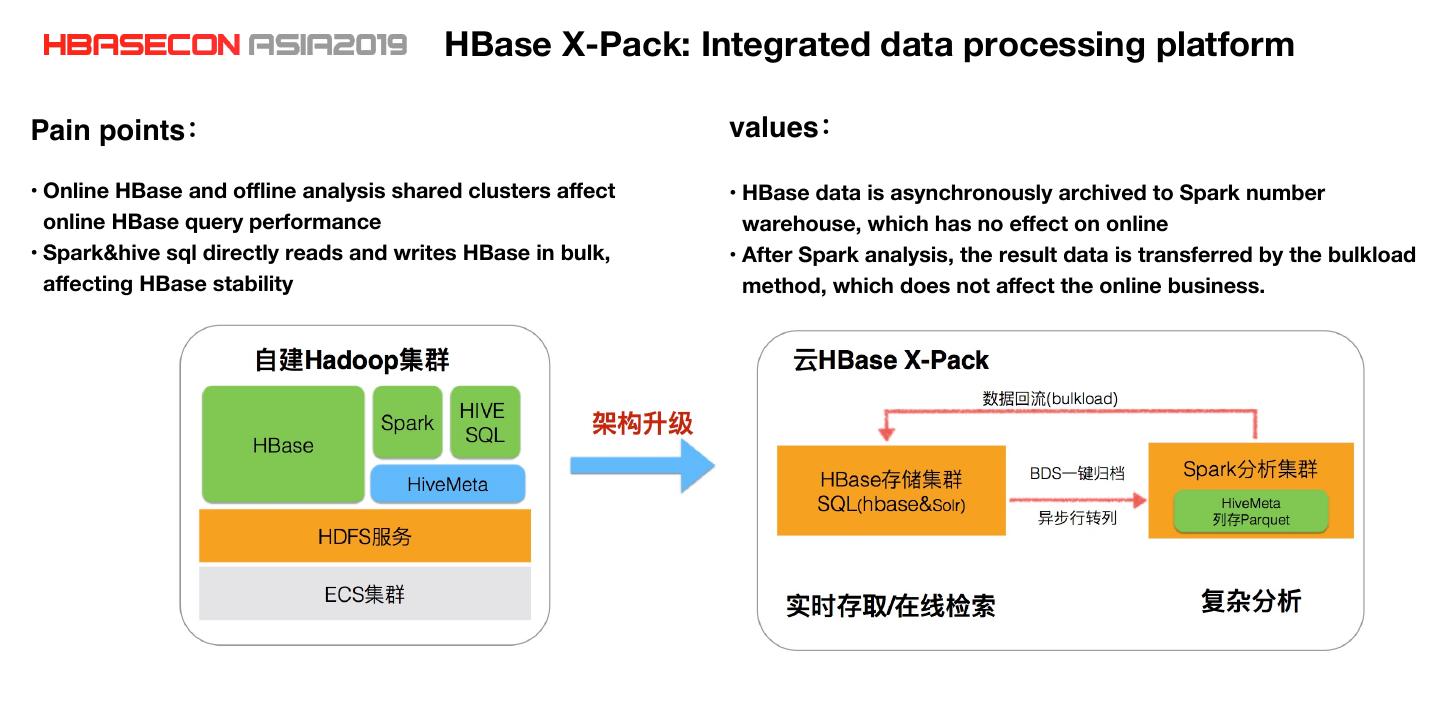
17 . HBase X-Pack: Integrated data processing platform Pain points values • Online HBase and offline analysis shared clusters affect • HBase data is asynchronously archived to Spark number online HBase query performance warehouse, which has no effect on online • Spark&hive sql directly reads and writes HBase in bulk, • After Spark analysis, the result data is transferred by the bulkload affecting HBase stability method, which does not affect the online business.
18 . HBase X-Pack: Big data risk control platform ( ) + + Spark Spark Streaming SQL MLlib Load ( HDFS) Kafka HBase Parquet (HDFS OSS) • Real-time news: Kafka accepts real-time collected messages, and can do simple things with smoke streaming • Archive by day increment: Data increments that are streamed to the storage service each day are archived to the spark offline warehouse • Offline data warehouse: used to store the full amount of data, the data is stored in HDFS on the column. • Full training model: spark supports complex computing, mlib, python is suitable for data computing training model • Model data Load: The new model Loaded to the model service for offline service to provide external control decision • Risk control simulation: When adding a heart rule or a new model at the training center, verify its good or bad, you can use the full amount of data to do training in the spark offline warehouse.
19 . HBase X-Pack: Game log processing platform https://yq.aliyun.com/articles/702337?spm=a2c4e.11163080.searchblog.27.154c2ec1x4glPb values • Support high performance offline computing and real-time computing; • Manage data job scheduling; • Support for elastic scaling calculations (cost savings) • Support hot and cold storage (cost saving) • Meet data lake scenarios and support high-throughput mass storage structured and unstructured data;
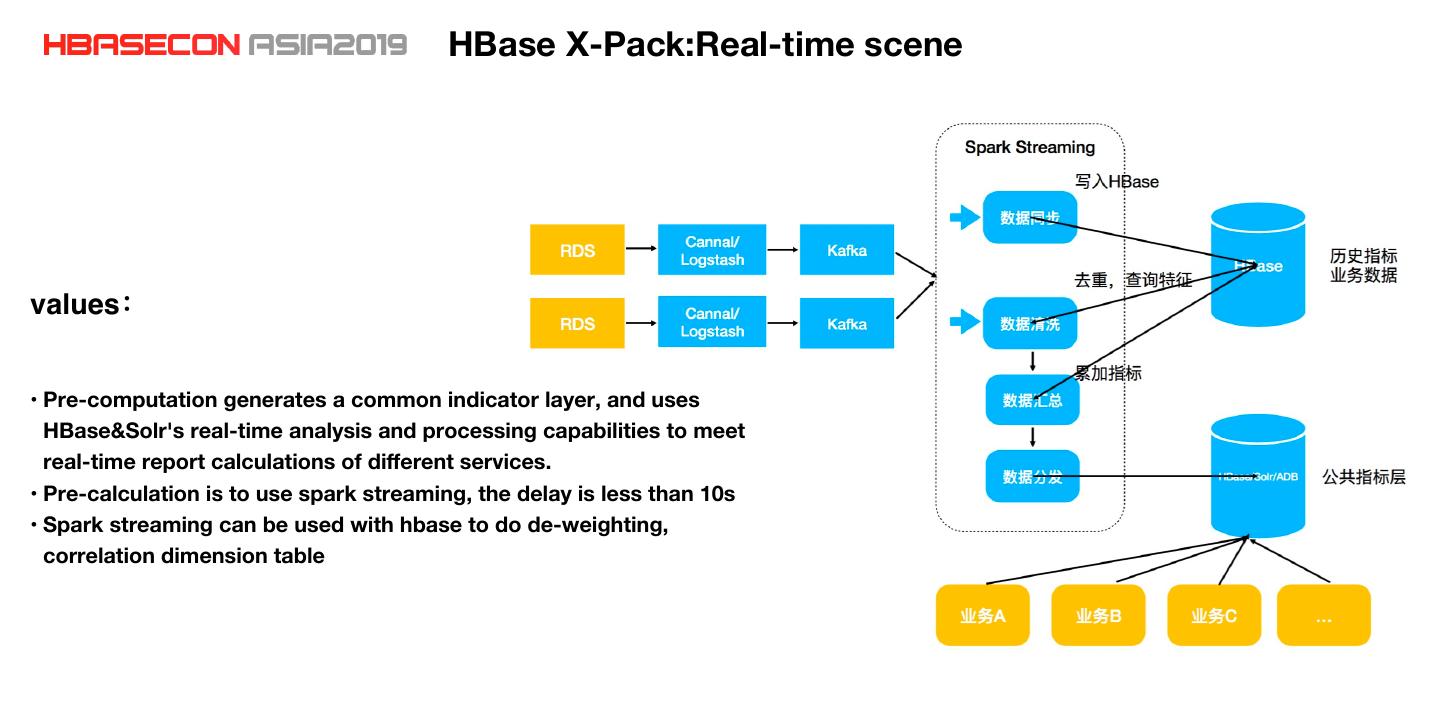
20 . HBase X-Pack:Real-time scene values • Pre-computation generates a common indicator layer, and uses HBase&Solr's real-time analysis and processing capabilities to meet real-time report calculations of different services. • Pre-calculation is to use spark streaming, the delay is less than 10s • Spark streaming can be used with hbase to do de-weighting, correlation dimension table
21 . HBase X-Pack:offline data warehouse PolarDB RDS ADB HBase Mongo Redis Spark Spark ( Parquet HIVEMeta) Spark ! Streaming - - ! ! ! ! ! ! ! ! Spark ! ! ! ! ! ! ! ! • Operational data layer: The most primitive data in the message middleware is similar to Kafka, LogHUB, or in online databases such as PolarDB, RDS, Mongo, HBase, etc. • Detail wide surface layer: Use the Spark batch ETL or Spark Streaming table to build a detailed wide table • Public summary wide surface layer: Classification and modeling in Spark according to certain business themes, such as daily/monthly reports, model training, etc. • Public dimension surface: static dimension table • Data application layer: high-level summary data processed by offline number bins is stored in the online library for query service.
22 .We are hiring! Ø If you are interested in the online sql analysis engine Ø If you are interested in the spark kernel and ecosystem ApsaraDB HBase X-Pack: https://help.aliyun.com/document_detail/93899.html
23 .Thanks!
3秒后跳转登录页面
去登陆

