展开查看详情
1 .基于HBase实时数仓
探索实践
上海久耶--武基鹏
�
2 .About me
武基鹏,现就职于上海久耶供应链
主要从事大数据平台的技术工作
�
3 .1.第一代离线数仓
2.第二代实时数仓
3.业务场景
4.业务开发
5.集群调优监控
6.分享2个生产案例
�
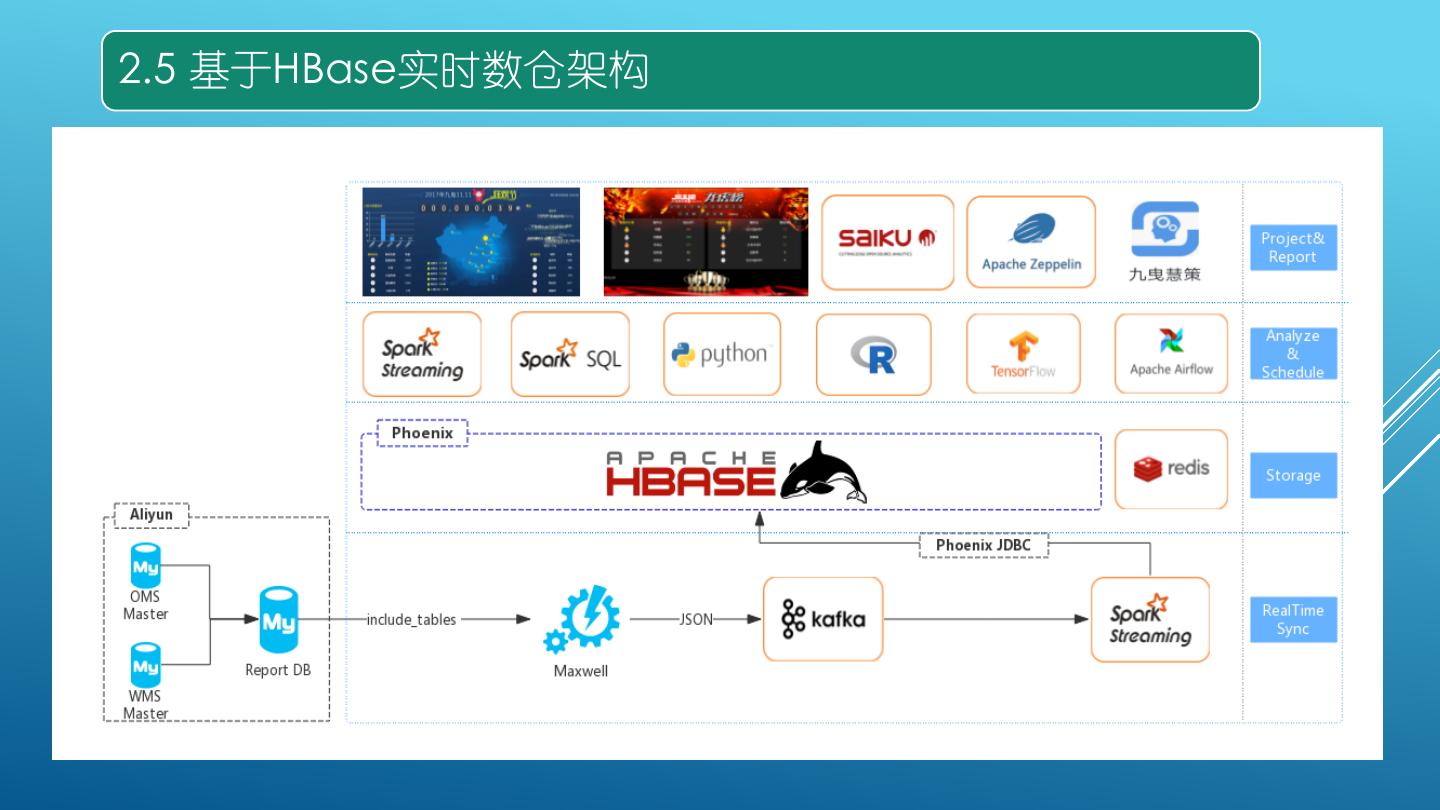
5 .2.第二代实时数仓
实时采集:
Maxwell
数仓存储:
HBase
�
6 .2.1 为什么会选择Maxwell
1. Can do SELECT * from table (bootstrapping) initial
loads of a table.
2. supports automatic position recover on master
promotion.
3. flexible partitioning schemas for Kafka - by
database, table, primary key, or column.
4. Maxwell pulls all this off by acting as a full mysql
replica, including a SQL parser for create/alter/drop
statements (nope, there was no other way).
�
7 .2.2 为什么会选择HBase
1. Apache HBase™ is the Hadoop database,
a distributed, scalable, big data store.
2. Use Apache HBase™ when you need random,
realtime read/write access to your Big Data.
3. This project's goal is the hosting of very large tables --
billions of rows X millions of columns.
�
8 .2.3 为什么会选择Phoenix
1. Support SQL
1. Salted Tables
2. Secondary Indexes
3. Support Spark
�
9 .2.4 基于CDH HBase版本构建Phoenix
版本历程:
phoenix-for-cloudera-4.9-HBase-1.2-cdh5.9
+apache-phoenix-4.11.0-HBase-1.2
----------》phoenix-for-cloudera-4.10-HBase-1.2-
cdh5.12
�
10 .为什么要编译?
1. 支持特定版本CDH
2. 支持特定版本SPARK
3. PHOENIX-3826
4. PHOENIX-3333
5. PHOENIX-3603
�
11 . 6. 修复SYSTEM.MUTEX表在分布式的计算时,
多次创建错误
7. QUERYSERVICESOPTIONS.JAVA文件修改参数
DEFAULT_IS_NAMESPACE_MAPPING_ENABLED=TRUE
�
12 .8. 修改DateUtil.java文件timezone为”Asia/Shanghai”
PHOENIX-4629
�
14 .2.5.1 数据仓库:
A. 模型建设:
第一层: 基础表
第二层: 事实表 维度表
第三层: 领域表
B.数据校验: 数据量比对
�
15 .2.5.2 当前只采集OMS、WMS的18库:
QPS: 2000
1条数据: 平均60列 495b
�
16 .3. 业务场景
1.业务报表(客诉妥投、ABC订单、商业季度等)
2.BI自助分析(saiku)
3.双十一大屏、龙虎榜
4.BMS清分系统
5.慧策IDSS(钉钉应用)
�
17 .4. 业务开发
1. Build Phoenix Table
2. Kafka+Spark Streaming+Phoenix
3. Spark Develop Read
4. Spark Develop Write
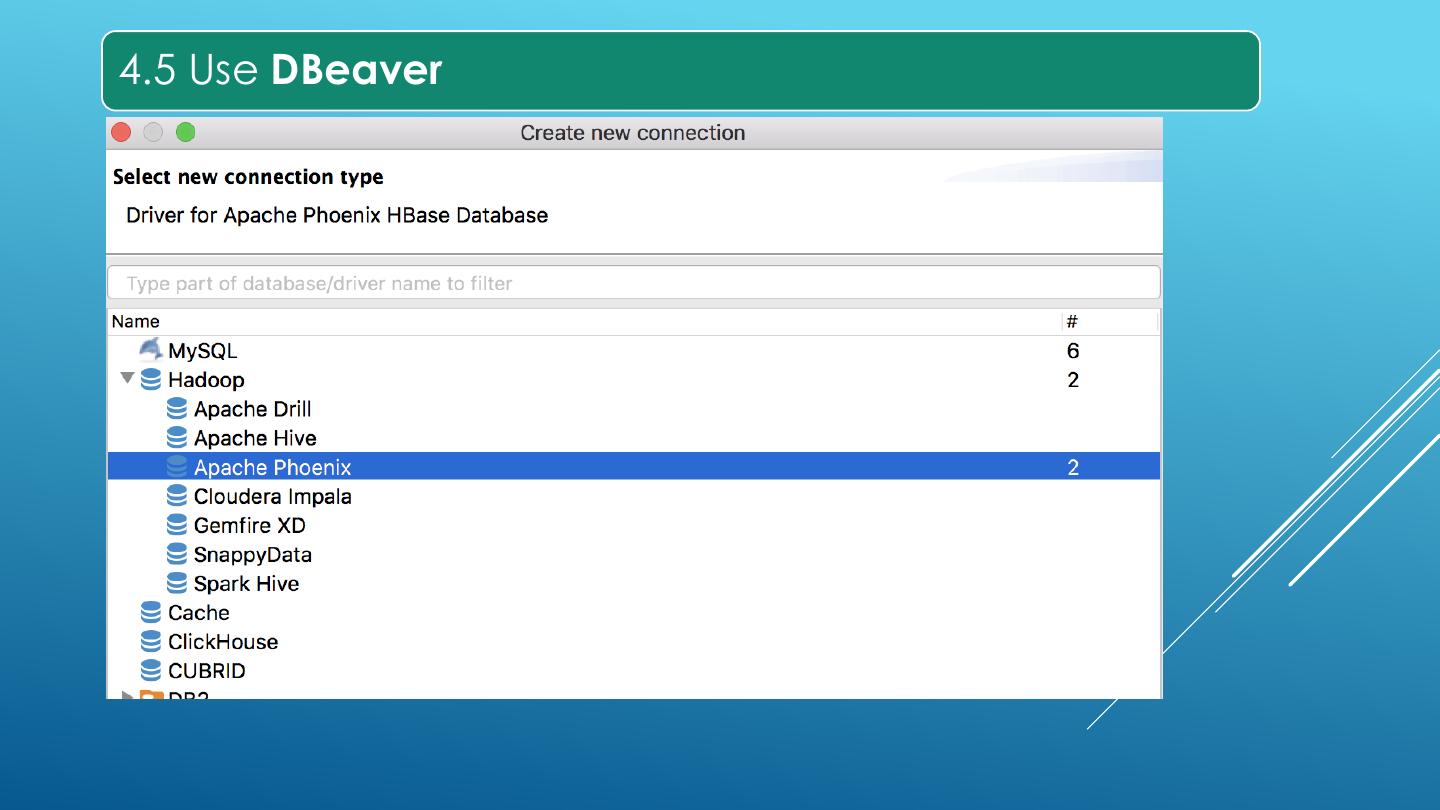
5. Use DBeaver
�
18 .4.1 Build Phoenix Table
CREATE TABLE JYDW.BIGDATA(
id bigint(20) NOT NULL,
warehouse_no varchar(10) NOT NULL,
a_col varchar(256),
.............
.............
cretime timestamp,
CONSTRAINT pk PRIMARY KEY (id, warehouse_no)
) SALT_BUCKETS = 36, COMPRESSION = 'SNAPPY’;
�
19 .4.2 Kafka+Spark Streaming+Phoenix
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(
record => connection.send(record)
)
connection.close()
}
}
�
20 .4.3 Spark Develop Read
val bigdataDF =
spark.sqlContext.phoenixTableAsDataFrame(
"JYDW.BIGDATA",
Array(”ID", ”WAREHOUSE_NO”,”A_COL”),
predicate = Some(
"""
|CRETIME > CAST(TO_DATE('2018-02-10 00:00:01',
'yyyy-MM-dd HH:mm:ss') AS TIMESTAMP)
""".stripMargin),
conf = configuration
)
�
21 .4.4 Spark Develop Write
bigdataDF.write
.format("org.apache.phoenix.spark")
.mode(SaveMode.Overwrite)
.option("table", "JYDW.OMS_ORDER")
.option("zkUrl",zkUrl)
.save()
�
23 .5. 集群调优监控
1. Linux parameters
2. HDFS parameters
3. HBase parameters
4. GC parameters
5. Monitor
6. Bug
�
24 .5.1 Linux Parameters
5.1.1.句柄数 文件数 线程数
echo "* soft nofile 196605" >> /etc/security/limits.conf
echo "* hard nofile 196605" >> /etc/security/limits.conf
echo "* soft nproc 196605" >> /etc/security/limits.conf
echo "* hard nproc 196605" >> /etc/security/limits.conf
重新登录,检查是否生效
# ulimit -a
open files (-n) 196605
max user processes (-u) 196605
�
25 .5.1.2.网络、内核、进程能拥有的最多内存区域
echo net.core.somaxconn=32768 >> /etc/sysctl.conf
echo "kernel.threads-max=196605" >> /etc/sysctl.conf
echo "kernel.pid_max=196605" >> /etc/sysctl.conf
echo "vm.max_map_count=393210" >> /etc/sysctl.conf
#生效
sysctl -p
�
26 .5.1.3.swap
more /etc/sysctl.conf | vm.swappiness
echo vm.swappiness = 10 >> /etc/sysctl.conf
#生效
sysctl –p
5.1.4.关闭大页面
echo never >
/sys/kernel/mm/redhat_transparent_hugepage/defrag
echo 'echo never >
/sys/kernel/mm/redhat_transparent_hugepage/defrag'
>> /etc/rc.local
�
27 .5.2 HDFS Parameters
5.2.1 handler参数
dfs.datanode.handler.count 64
dfs.datanode.max.xcievers,
dfs.datanode.max.transfer.threads 12288
dfs.namenode.handler.count 256
dfs.namenode.service.handler.count 256
4.2.2 timeout参数
dfs.socket.timeout 1800000ms
�
28 .5.2.3 HDFS-12936
2017-12-17 23:58:14,422 INFO org.apache.hadoop.hdfs.server.datanode.DataNode:
PacketResponder: BP-1437036909-192.168.17.36-1509097205664:
blk_1074725940_987917, type=HAS_DOWNSTREAM_IN_PIPELINE terminating
2017-12-17 23:58:31,425 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode:
DataNode is out of memory. Will retry in 30 seconds.
java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:714)
at org.apache.hadoop.hdfs.server.datanode.DataXceiverServer.run
(DataXceiverServer.java:154)
at java.lang.Thread.run(Thread.java:745)
�
29 .5.3 HBase Parameters
5.3.1 handler参数
hbase.master.handler.count 256
hbase.regionserver.handler.count 256
5.3.2 timeout参数
dfs.socket.timeout 1800000ms
�