















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
HBase RowKey与索引设计
中国HBase技术社区第五届MeetUp:HBase RowKey与索引设计
展开查看详情
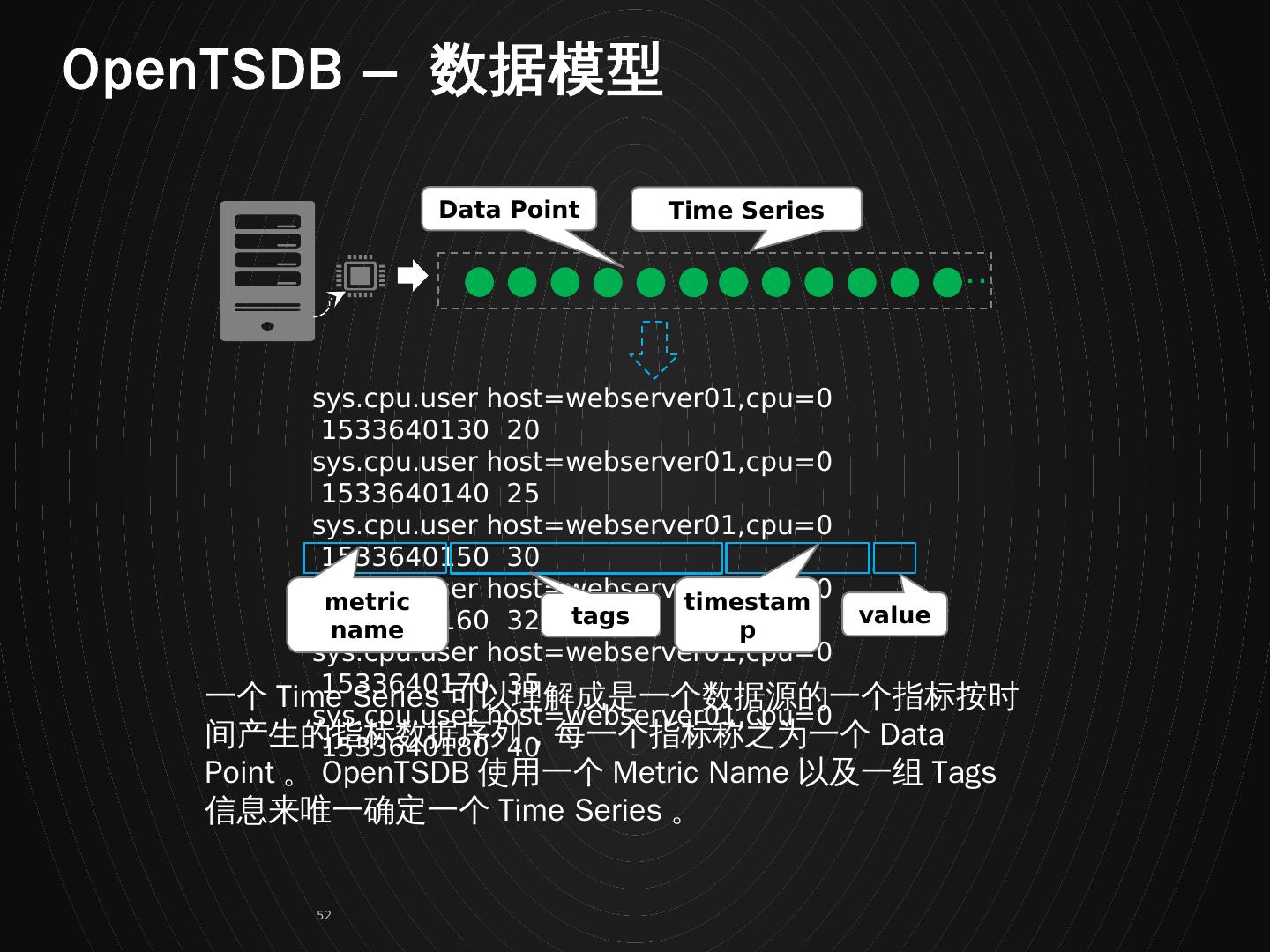
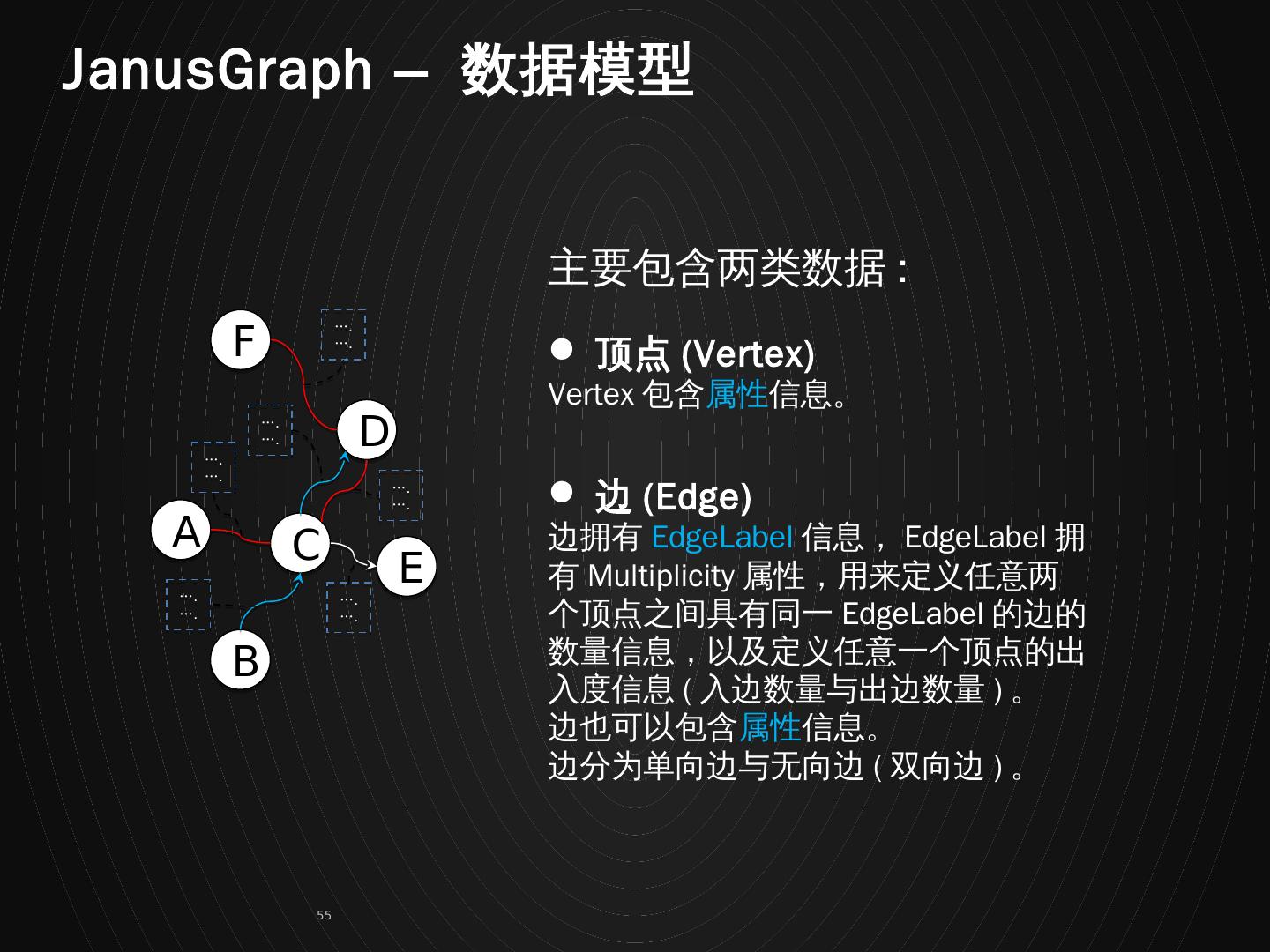
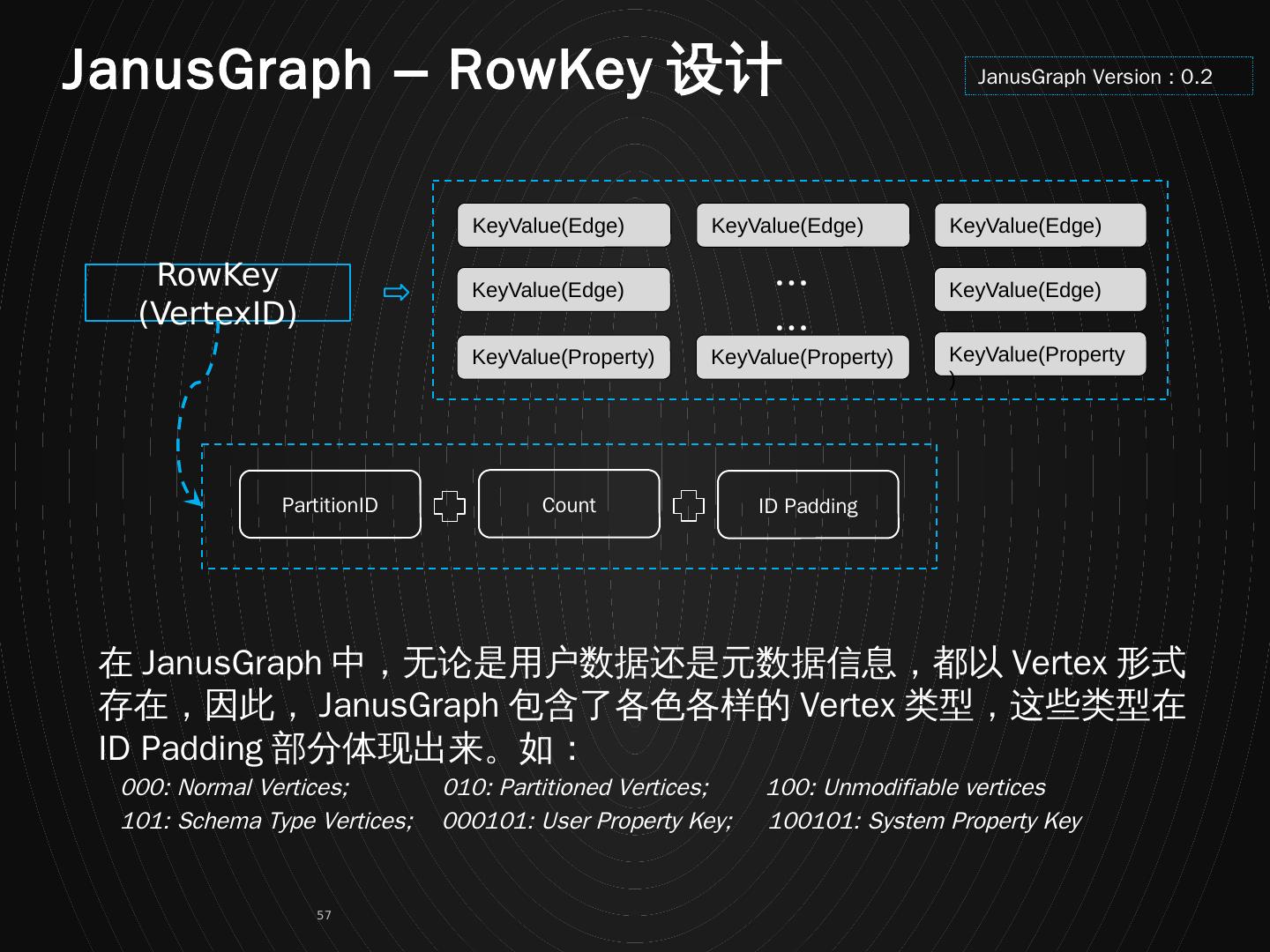
1 .HBase RowKey 与索引设计 设计技巧 / 原则 / 案例分享 毕杰山 http://www.nosqlnotes.com NoSQL 漫谈
2 .整体思路 第一部分: 15 分钟 HBase 基础知识 HBase 基础; RowKey 与 Region ;数据分片方式 第二部分: 合理的需求调研 设计目标;负载特点;查询场景;数据特点 第三部分: RowKey 与索引设计 技巧与原则;二级索引;组合索引设计原则 第四部分: RowKey 设计案例分享 OpenTSDB/JanusGraph/GeoMesa “ 无聊的话题,但多数 HBase 开发者却被时常困扰 …
3 .1 15 分钟 HBase 基础概念 2 合理的需求调研 目录 3 RowKey 与索引设计 4 设计案例分享
4 .提纲: 15 分钟 HBase 基础 基本概念与数据模型 KeyValue ; Region; 进程角色 ; 灵活的列设计 快速浏览读写流程 Write; Flush; Compaction; Read; HFile RowKey 与索引简介 RowKey 在读写流程中发挥的作用 ; 索引与 RowKey
5 .RegionServer RegionServer RegionServer Table Column Family A Column Family B Region Column Family HFile HFile HFile MemStore 基本概念 Table : 可理解成传统数据库中的一个表,但因为 SchemaLess 的设计,它较之传统数据库的表而言,在设计上可以更加灵活 Region :将 Table 横向切割成一个个子表,子表在 HBase 中被称之为 Region Column Family : 一些列的集合。不同的 Column Family 数据文件被存储在不同的路径中 HFile : HBase 数据在底层分布式文件系统中的文件组织格式 RegionServer : 数据服务进程。 Region 必须被部署在某一个 RegionServer 上才可以提供读写服务 MemStore : 用来在内存中缓存一定大小的数据,达到一定大小后批量写入到底层文件系统中。数据是有序的。
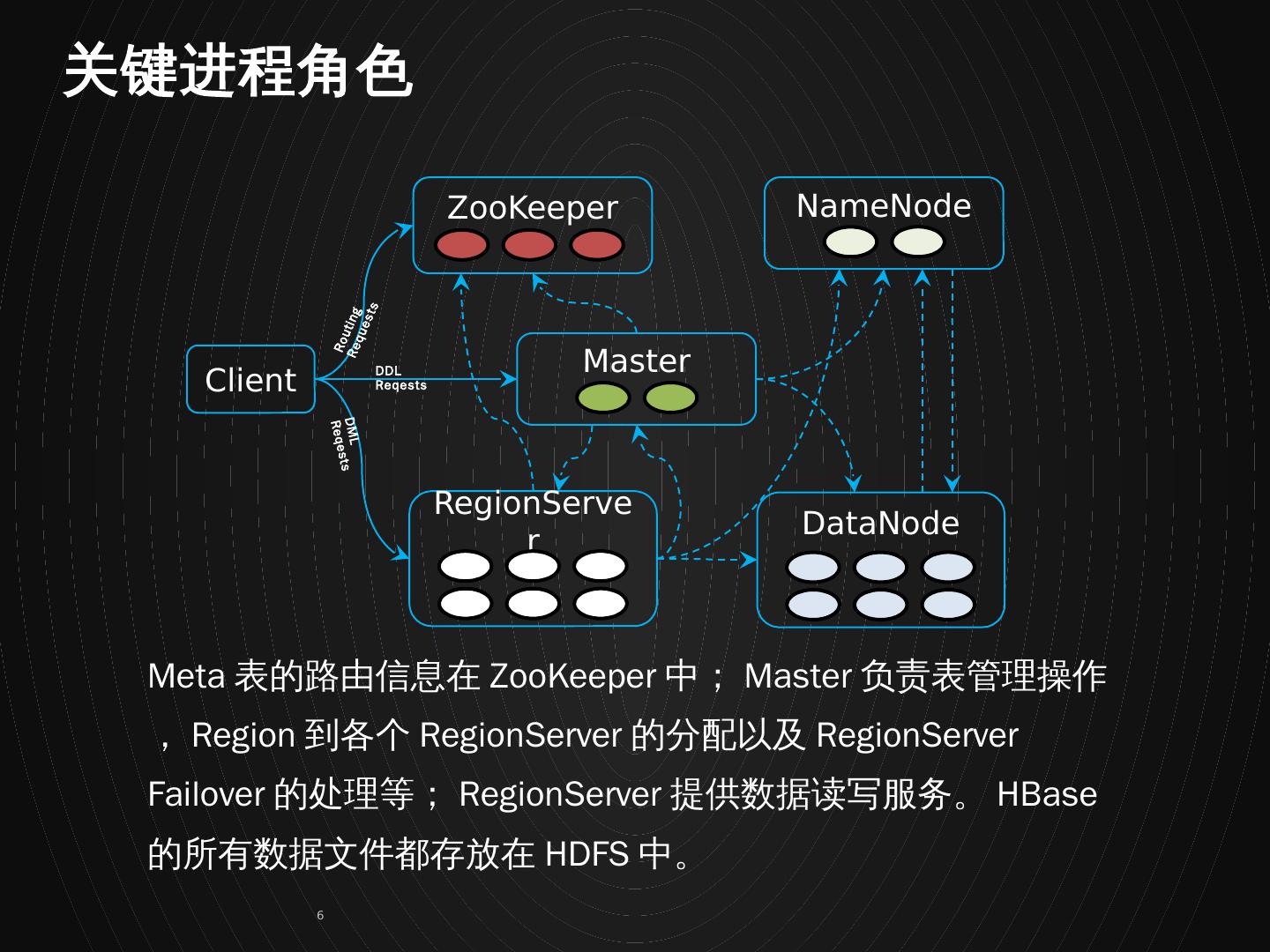
6 .Client ZooKeeper Master RegionServer NameNode DataNode DDL Reqests DML Reqests Routing Requests Meta 表的路由信息在 ZooKeeper 中; Master 负责表管理操作, Region 到各个 RegionServer 的分配以及 RegionServer Failover 的处理等; RegionServer 提供数据读写服务。 HBase 的所有数据文件都存放在 HDFS 中。 关键进程角色
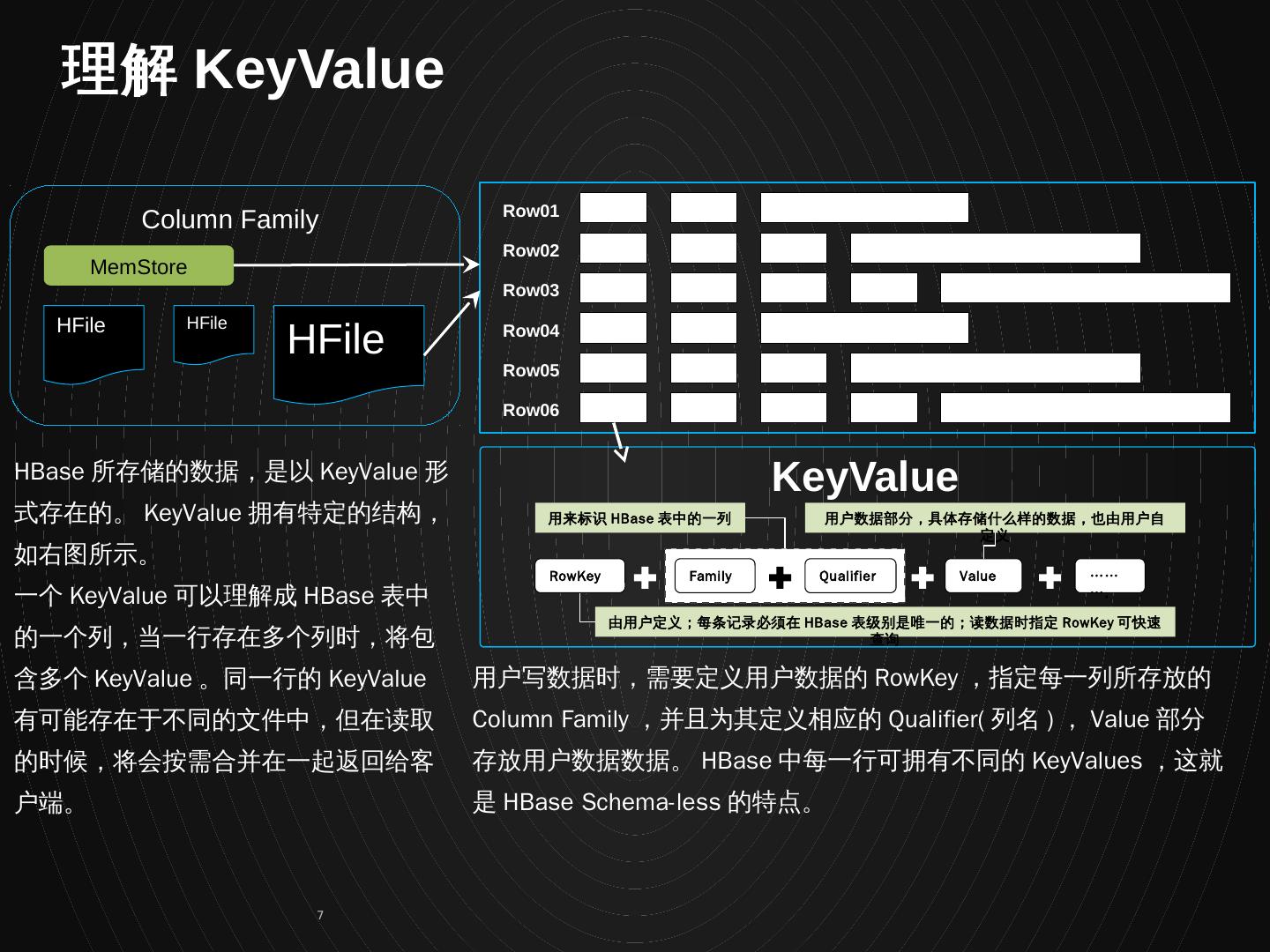
7 .Column Family HFile HFile HFile MemStore Row01 Row02 Row03 Row04 Row05 Row06 RowKey Family Qualifier Value ………. 由用户定义;每条记录必须在 HBase 表级别是唯一的;读数据时指定 RowKey 可快速查询 用户数据部分,具体存储什么样的数据,也由用户自定义 用来标识 HBase 表中的一列 HBase 所存储的数据,是以 KeyValue 形式存在的。 KeyValue 拥有特定的结构,如右图所示。 一个 KeyValue 可以理解成 HBase 表中的一个列,当一行存在多个列时,将包含多个 KeyValue 。同一行的 KeyValue 有可能存在于不同的文件中,但在读取的时候,将会按需合并在一起返回给客户端。 用户写数据时,需要定义用户数据的 RowKey ,指定每一列所存放的 Column Family ,并且为其定义相应的 Qualifier( 列名 ) , Value 部分存放用户数据数据。 HBase 中每一行可拥有不同的 KeyValues ,这就是 HBase Schema-less 的特点。 KeyValue 理解 KeyValue
8 .V3 V1 V1 V1 V1 Row01 Row02 V2 V1 V2 V1 V2 V1 Normal Scan Start Row01 Row02 Normal Scan End Row01 Row02 Multi-Version ScanStart Multi-Version Scan End HBase 中支持数据的多版本,通过带有不同时间戳的多个 KeyValue 版本来实现的。如左图所示。 HBase 所保存的版本数目是可配置的,默认存放 3 个版本。在普通的读取流程中,旧版本的数据是不可见的,但通过指定版本数或者版本号的读取,可以获取旧版本数据。下图是普通读取流程与多版本读取流程的对比。 KeyValue 多版本
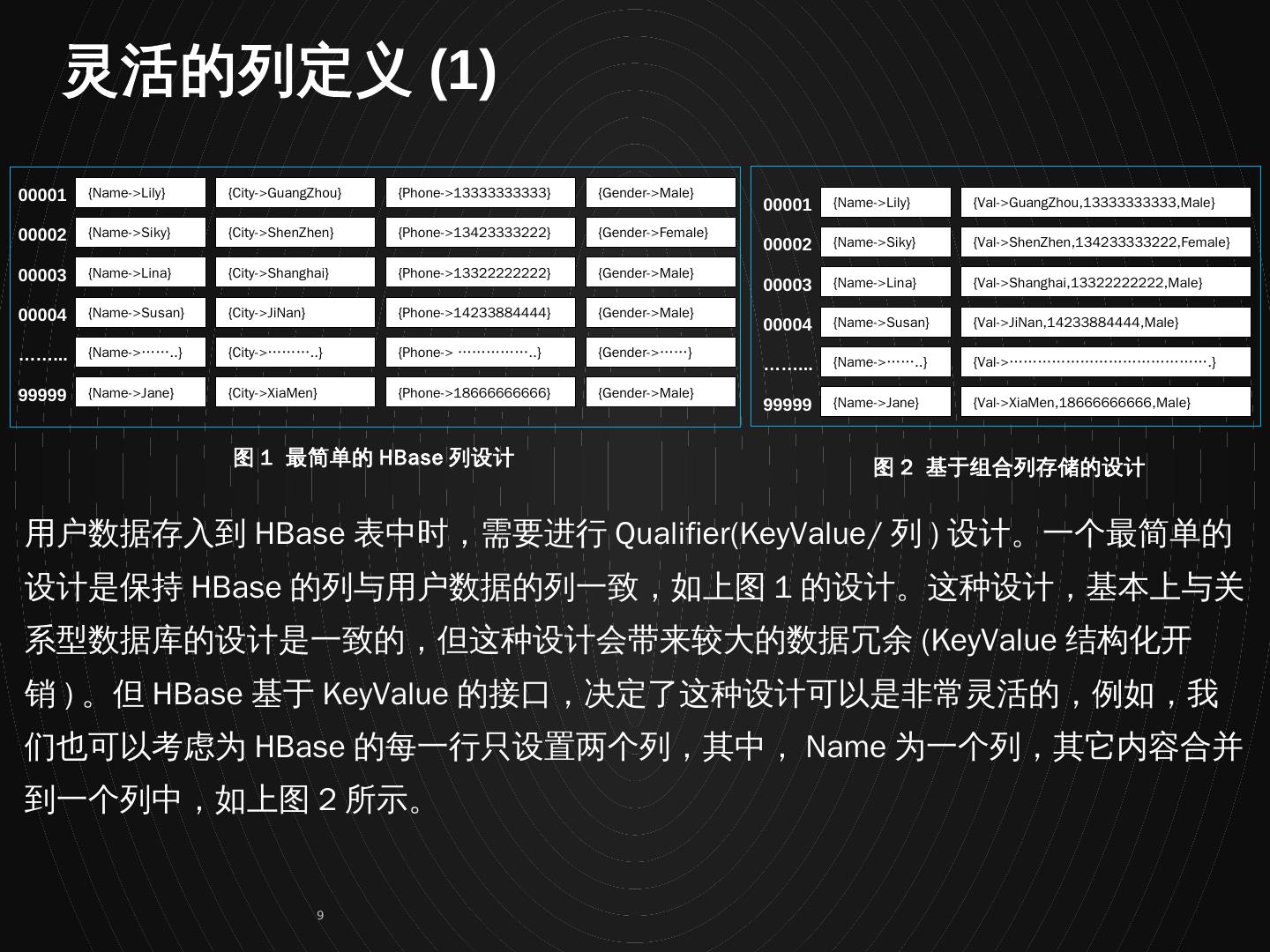
9 .{Name->Lily} 00001 00002 00003 00004 ……... 99999 {City->GuangZhou} {Phone->13333333333} {Gender->Male} {Name->Siky} {City->ShenZhen} {Phone->13423333222} {Gender->Female} {Name->Lina} {City->Shanghai} {Phone->13322222222} {Gender->Male} {Name->Susan} {City->JiNan} {Phone->14233884444} {Gender->Male} {Name->……..} {City->………..} {Phone-> ……………..} {Gender->……} {Name->Jane} {City->XiaMen} {Phone->18666666666} {Gender->Male} {Name->Lily} 00001 00002 00003 00004 ……... 99999 {Val->GuangZhou,13333333333,Male} {Name->Siky} {Val->ShenZhen,134233333222,Female} {Name->Lina} {Val->Shanghai,13322222222,Male} {Name->Susan} {Val->JiNan,14233884444,Male} {Name->……..} {Val->…………………………………….} {Name->Jane} {Val->XiaMen,18666666666,Male} 图 2 基于组合列存储的设计 图 1 最简单的 HBase 列设计 用户数据存入到 HBase 表中时,需要进行 Qualifier(KeyValue/ 列 ) 设计。一个最简单的设计是保持 HBase 的列与用户数据的列一致,如上图 1 的设计。这种设计,基本上与关系型数据库的设计是一致的,但这种设计会带来较大的数据冗余 (KeyValue 结构化开销 ) 。但 HBase 基于 KeyValue 的接口,决定了这种设计可以是非常灵活的,例如,我们也可以考虑为 HBase 的每一行只设置两个列,其中, Name 为一个列,其它内容合并到一个列中,如上图 2 所示。 灵活的列定义 (1)
10 .{Name->Lily} 00001 00002 00003 00004 ……... 99999 {City->GuangZhou} {Phone->13333333333} {Gender->Male} {Name->Siky} {City->ShenZhen} {Phone->13423333222} {Gender->Female} {Name->Lina} {City->Shanghai} {Phone->13322222222} {Gender->Male} {Name->Susan} {City->JiNan} {Phone->14233884444} {Gender->Male} {Name->……..} {City->………..} {Phone-> ……………..} {Gender->……} {Name->Jane} {City->XiaMen} {Phone->18666666666} {Gender->Male} {Age->20} {Age->22} {Birth->20} {Position->Engineer} {Age->35} 尽管我们在使用 HBase 表存放数据的时候,需要预先做好列的设计。但这个设计仅仅由应用层感知, HBase 并没有存放任何的 Schema 信息来描述这个设计。也就是说,应用层需要知道为每一个表 / 每一行设计了什么样的列( KeyValue ),然后在读取的时候做相应的解析。既然 HBase 中并没有 Schema 信息,那么,每一行中的列,也可以是任意添加的。如上图所示,绿色背景的 KeyValue 为后续增加的。 灵活的列定义 (2)
11 .Column Family - A HFile HFile MemStore Column Family - B HFile HFile MemStore {Name->Lily} 00001 00002 00003 00004 ……... 99999 {City->GuangZhou} {Phone->13333333333} {Gender->Male} {Name->Siky} {City->ShenZhen} {Phone->13423333222} {Gender->Female} {Name->Lina} {City->Shanghai} {Phone->13322222222} {Gender->Male} {Name->Susan} {City->JiNan} {Phone->14233884444} {Gender->Male} {Name->……..} {City->………..} {Phone-> ……………..} {Gender->……} {Name->Jane} {City->XiaMen} {Phone->18666666666} {Gender->Male} 假设为表设置了两个列族,而且,定义了每一个列族中要存放的列,如左图所示: {Name} -> Column Family-A, {City, Phone, Gender} -> Column Family-B 不同列族的数据会被存储在不同的路径中。即,设置多个列族时一行数据可能存在于两个路径中。 整行读取的时候,需要将两个路径中的数据合并在一起才可以获取到完整的一行记录。但如果仅仅读取 Name 一列的话,只需要读取 Column Family-A 即可。 Column Family
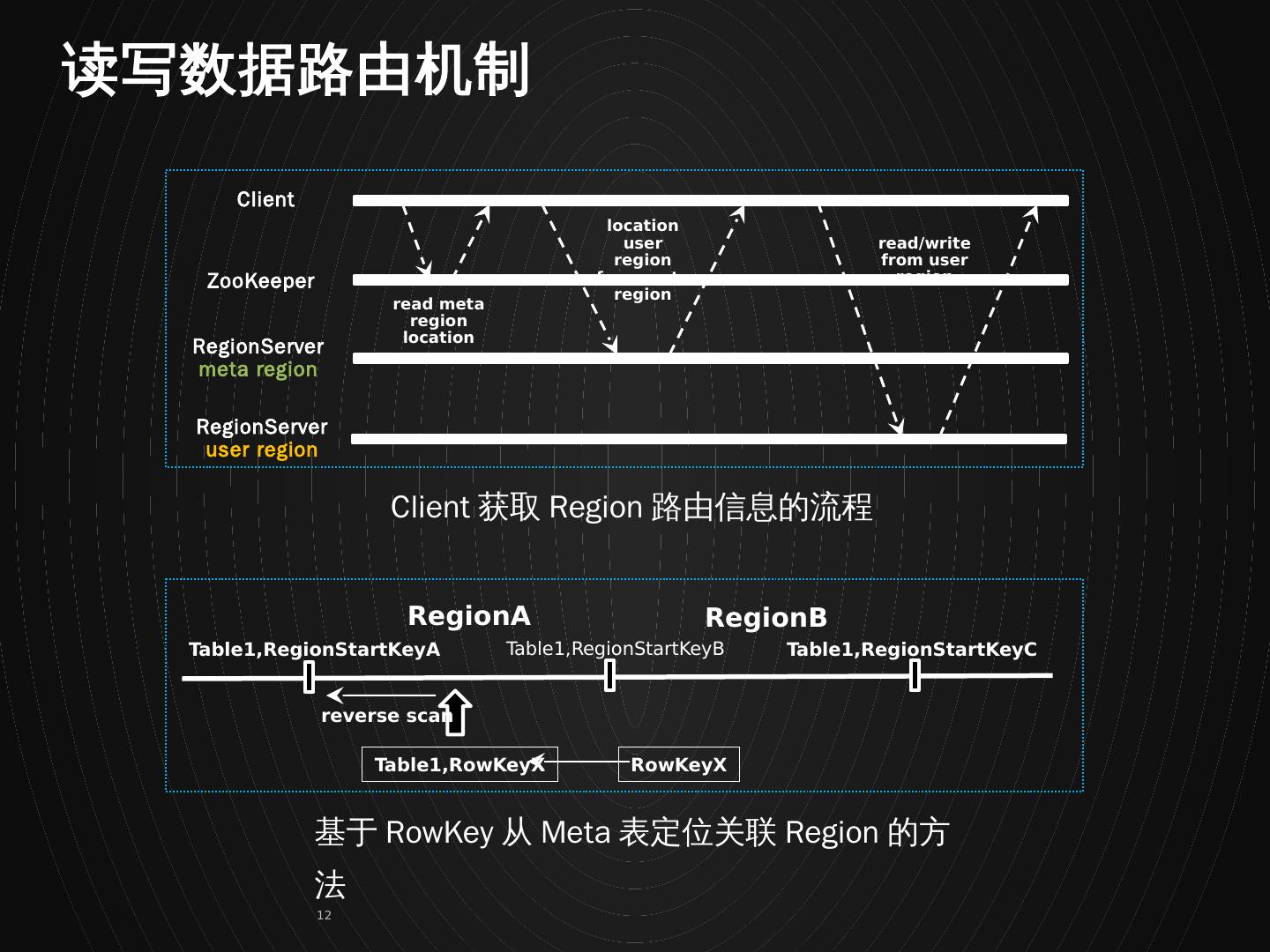
12 .Table1,RegionS t artKeyA Table1, RegionStartKeyB Table1, RegionStartKeyC RegionA RegionB RowKeyX Table1,RowKeyX reverse scan Client ZooKeeper RegionServer meta region RegionServer user region read meta region location location user region from meta region read/write from user region 读写数据路由机制 Client 获取 Region 路由信息的流程 基于 RowKey 从 Meta 表定位关联 Region 的方法
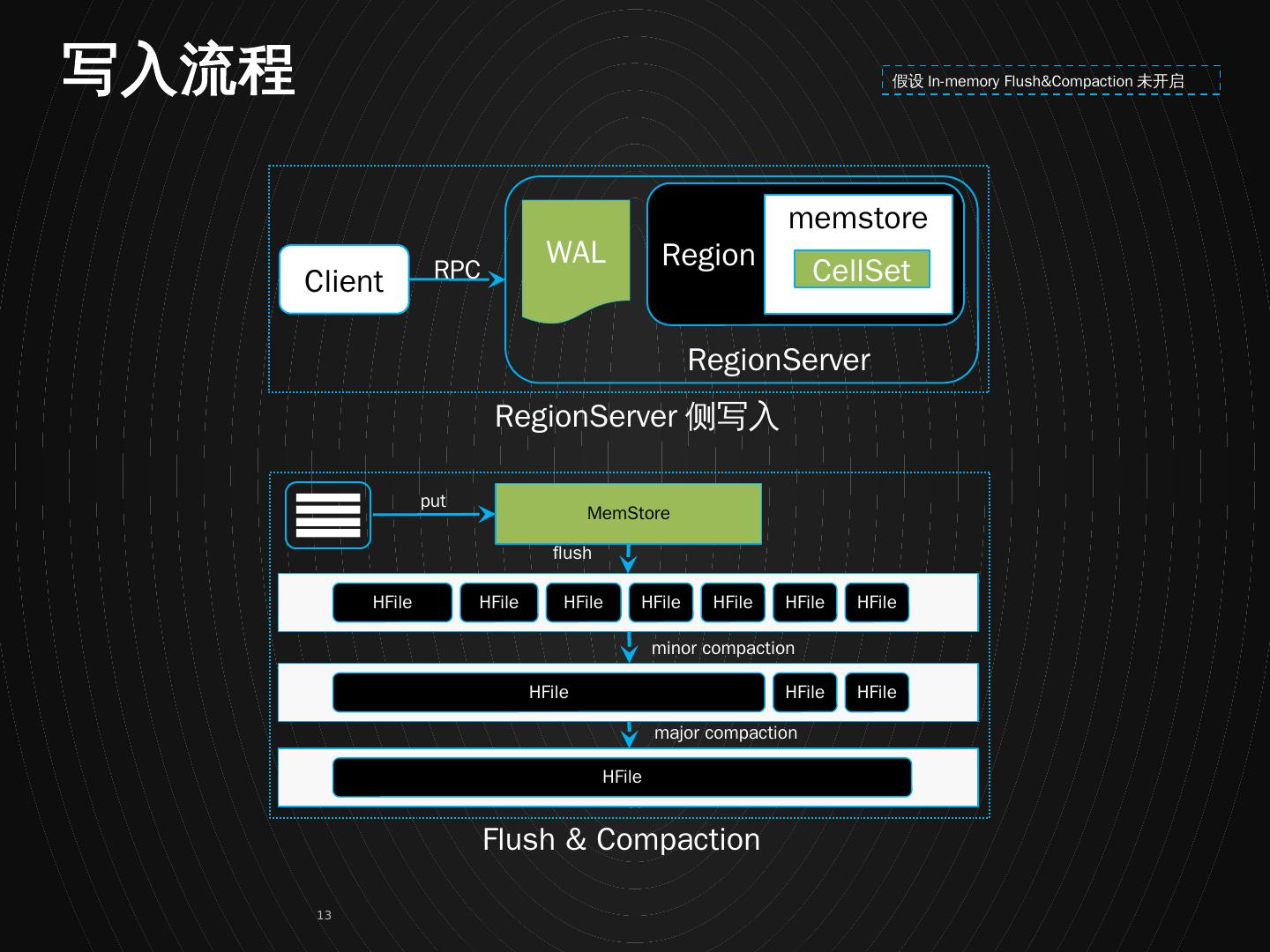
13 .memstore Region CellSet WAL RegionServer Client RPC HFile HFile HFile HFile HFile HFile HFile MemStore HFile HFile HFile HFile minor compaction major compaction flush put 假设 In-memory Flush&Compaction 未开启 写入流程 RegionServer 侧写入 Flush & Compaction
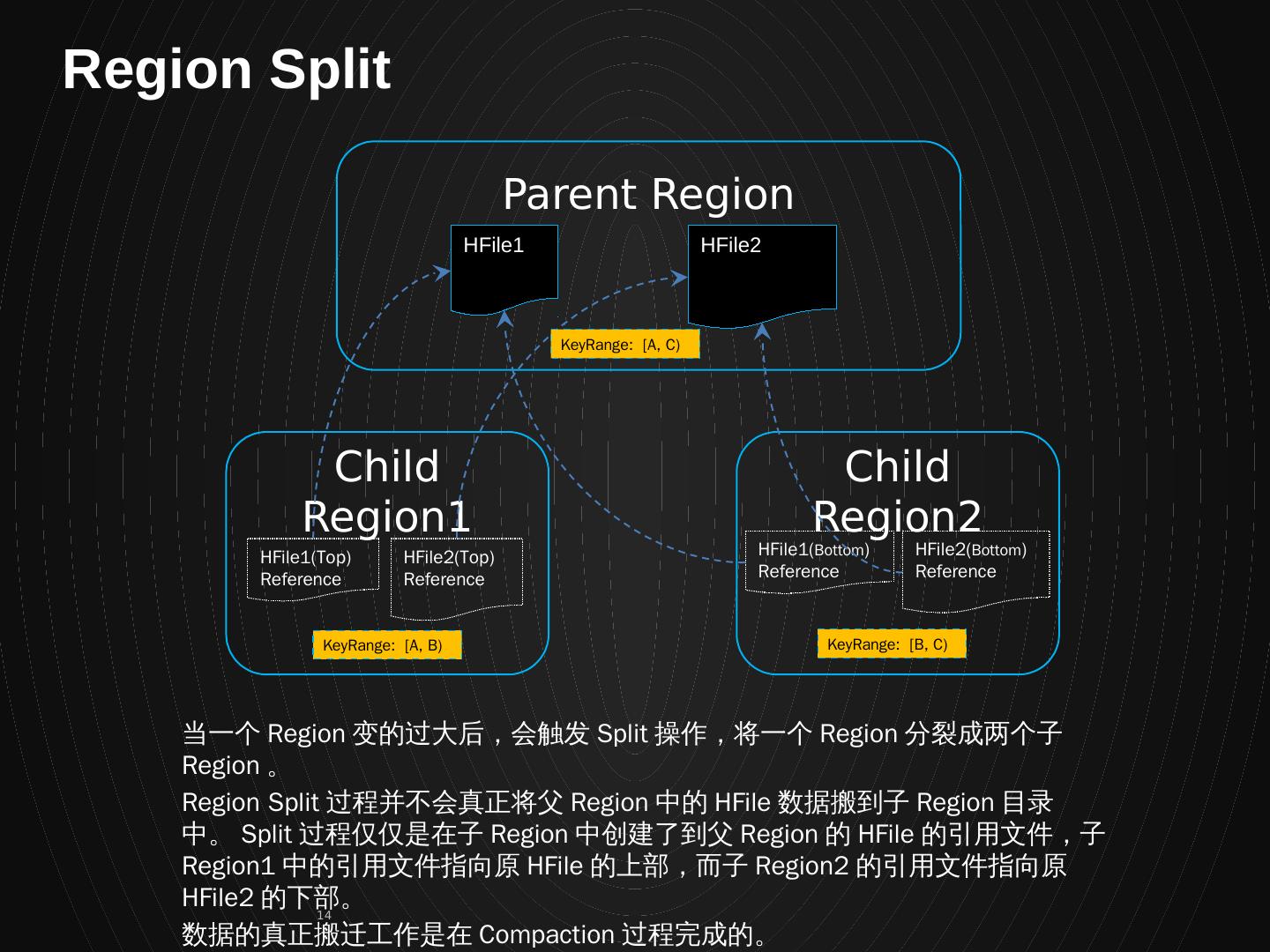
14 .Parent Region Child Region1 HFile1 HFile2 Child Region2 HFile1(Top) Reference HFile2(Top) Reference HFile1( Bottom ) Reference HFile2( Bottom ) Reference 当一个 Region 变的过大后,会触发 Split 操作,将一个 Region 分裂成两个子 Region 。 Region Split 过程并不会真正将父 Region 中的 HFile 数据搬到子 Region 目录中。 Split 过程仅仅是在子 Region 中创建了到父 Region 的 HFile 的引用文件,子 Region1 中的引用文件指向原 HFile 的上部,而子 Region2 的引用文件指向原 HFile2 的下部。 数据的真正搬迁工作是在 Compaction 过程完成的。 KeyRange: [A, C) KeyRange: [A, B) KeyRange: [B, C) Region Split
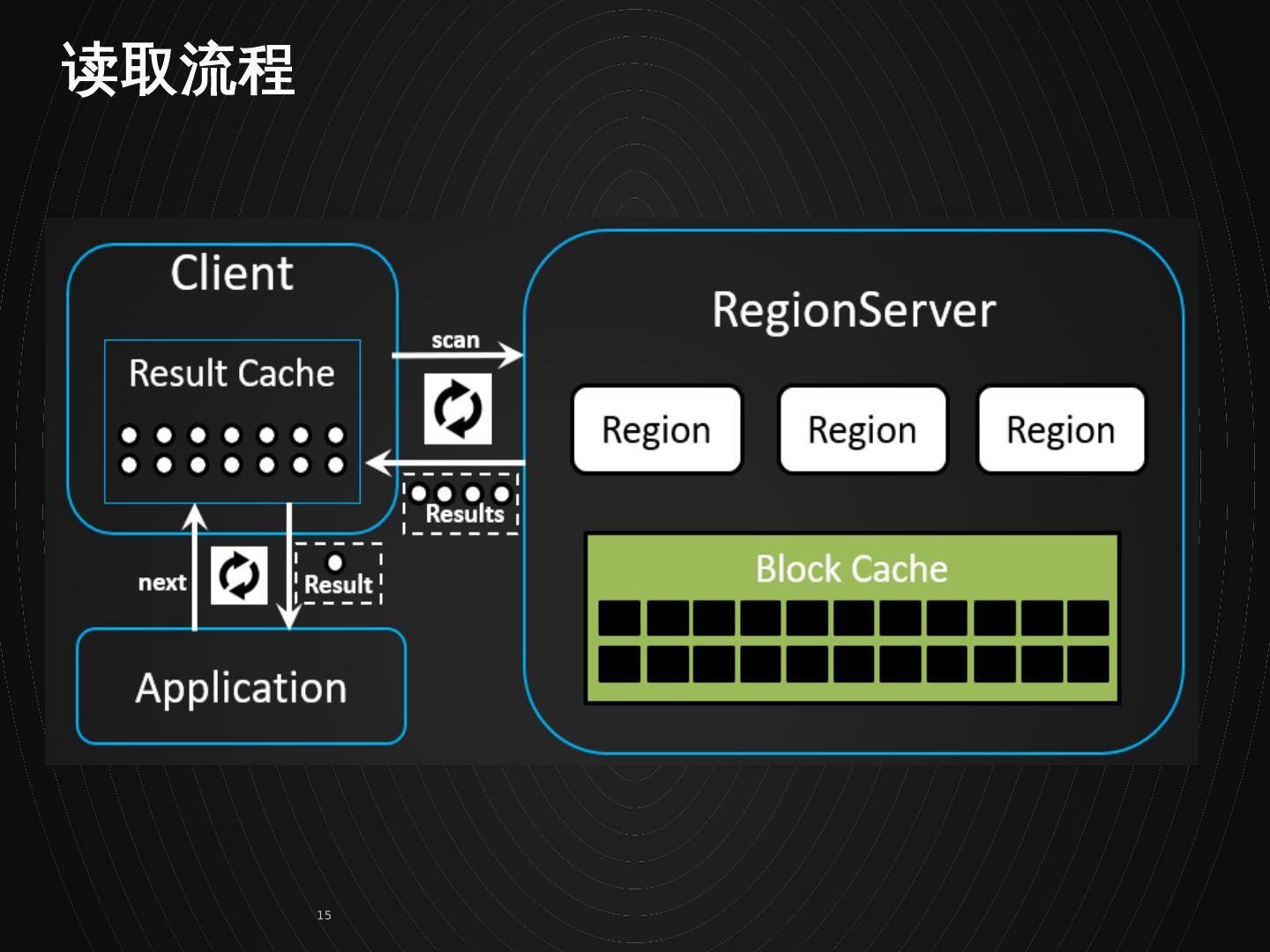
15 .读取流程
16 .StoreScanner StoreFileScanner SegmentScanner StoreScanner StoreFileScanner SegmentScanner StoreFileScanner StoreFileScanner StoreFileScanner StoreFileScanner StoreFileScanner StoreFileScanner SegmentScanner SegmentScanner StoreFileScanner StoreFileScanner StoreFileScanner StoreFileScanner 假设 In-memory Flush&Compaction 未开启 RegionScanner 读取流程 – Scanner 抽象 RegionScanner 的抽象 多个 Scanner 被组织在一个优先级队列中
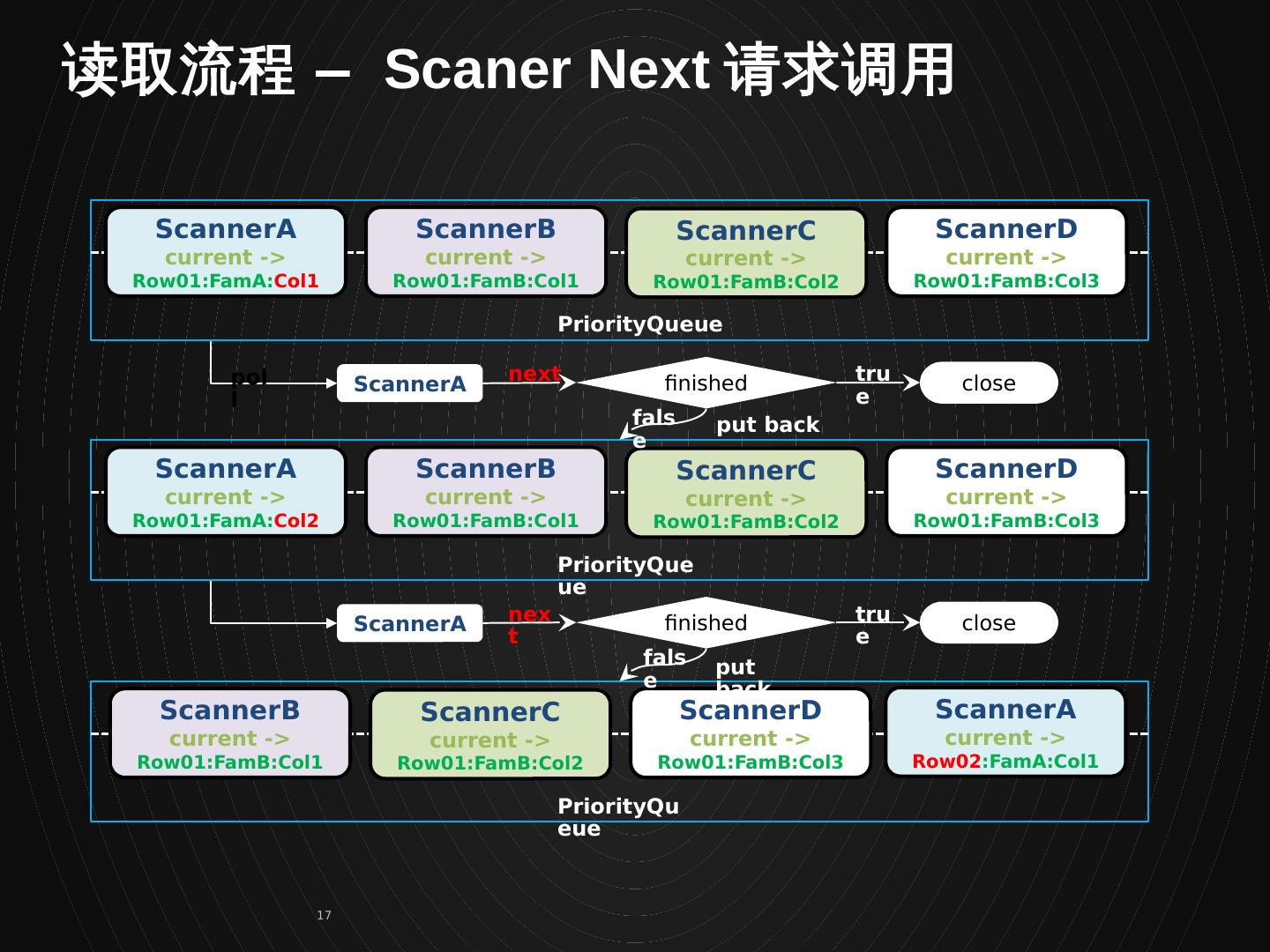
17 .ScannerA current -> Row01:FamA: Col1 ScannerB current -> Row01:FamB:Col1 ScannerD current -> Row01:FamB:Col3 ScannerA ScannerC current -> Row01:FamB:Col2 close finished next true PriorityQueue ScannerA current -> Row01:FamA: Col2 ScannerB current -> Row01:FamB:Col1 ScannerD current -> Row01:FamB:Col3 ScannerA ScannerC current -> Row01:FamB:Col2 close finished next true PriorityQueue ScannerA current -> Row02 :FamA:Col1 ScannerB current -> Row01:FamB:Col1 ScannerD current -> Row01:FamB:Col3 ScannerC current -> Row01:FamB:Col2 PriorityQueue poll false put back false put back 读取流程 – Scaner Next 请求调用
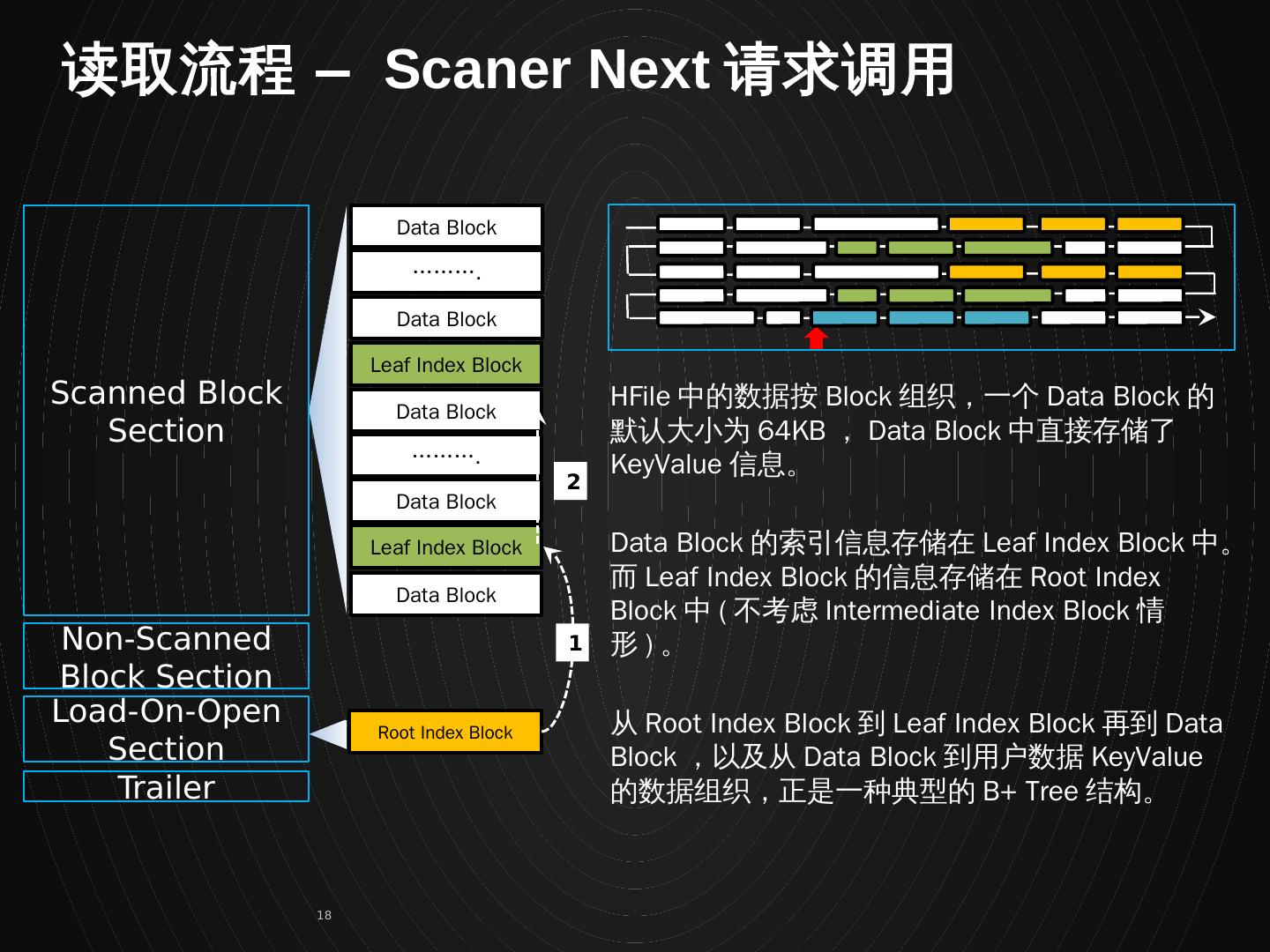
18 .Data Block ………. Data Block Leaf Index Block Data Block ………. Data Block Data Block Scanned Block Section Non-Scanned Block Section Load-On-Open Section Trailer Leaf Index Block Root Index Block 1 2 HFile 中的数据按 Block 组织,一个 Data Block 的默认大小为 64KB , Data Block 中直接存储了 KeyValue 信息。 Data Block 的索引信息存储在 Leaf Index Block 中。而 Leaf Index Block 的信息存储在 Root Index Block 中 ( 不考虑 Intermediate Index Block 情形 ) 。 从 Root Index Block 到 Leaf Index Block 再到 Data Block ,以及从 Data Block 到用户数据 KeyValue 的数据组织,正是一种典型的 B+ Tree 结构。 读取流程 – Scaner Next 请求调用
19 .回顾整个读写流程: 读写数据时通过 RowKey 路由到对应的 Region MemStore 中的数据按 RowKey 排序 HFile 中的数据按 RowKey 排序 “ HBase 的数据排序方式 HBase 中的数据按 RowKey 的字典数据存放,下面的例子将帮助你理解字典排序的原理: RowKey 列表: {“abc”, “a”, “bdf”, “cdf”, “defg”} 按字典排序后的结果为: {“a”, “abc”, “bdf”, “cdf”, “defg”} 也就是说,当两个 RowKey 进行排序时,先对比两个 RowKey 的第一个字节,如果相同,则对比第二个字节,依此类推 … 如果在对比到第 M 个字节时,已经超出了其中一个 RowKey 的字节长度,那么,短的 RowKey 要被排在另外一个 RowKey 的前面 RowKey 在读写流程中发挥的作用
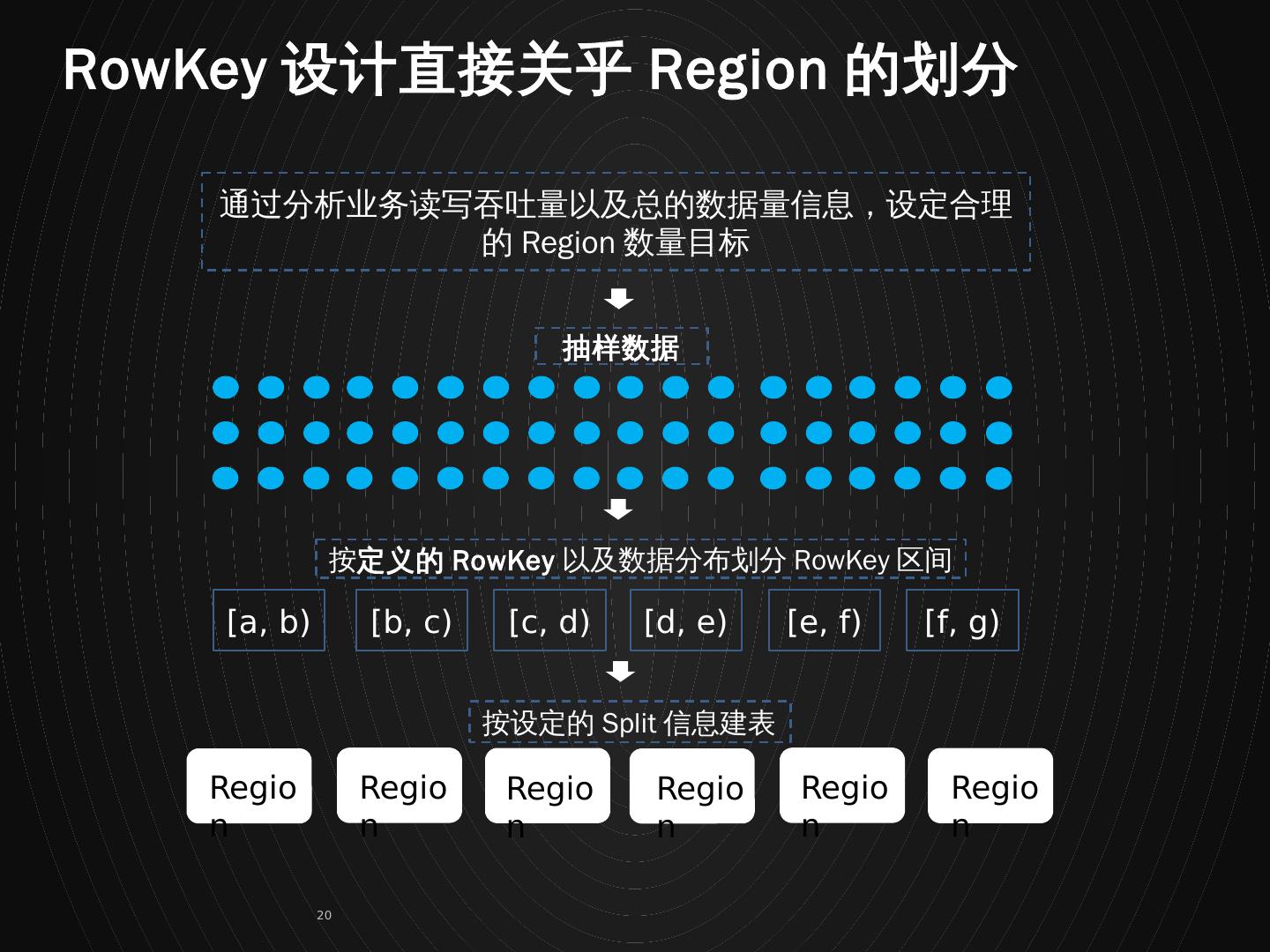
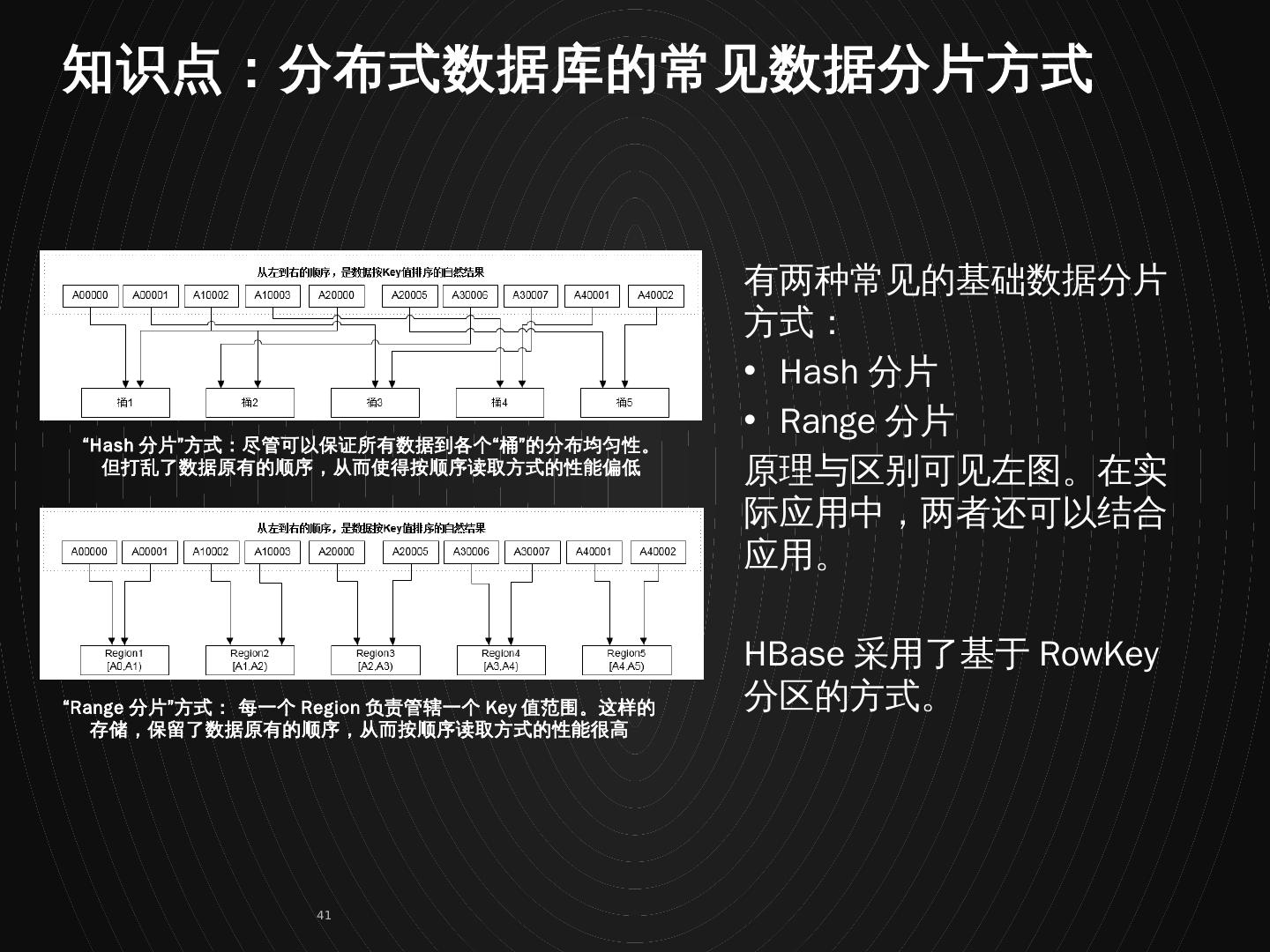
20 .Region Region Region Region Region Region [a, b) [b, c) [c, d) [d, e) [e, f) [f, g) 抽样数据 按 定义的 RowKey 以及数据分布划分 RowKey 区间 按设定的 Split 信息建表 通过分析业务读写吞吐量以及总的数据量信息,设定合理的 Region 数量目标 RowKey 设计直接关乎 Region 的划分
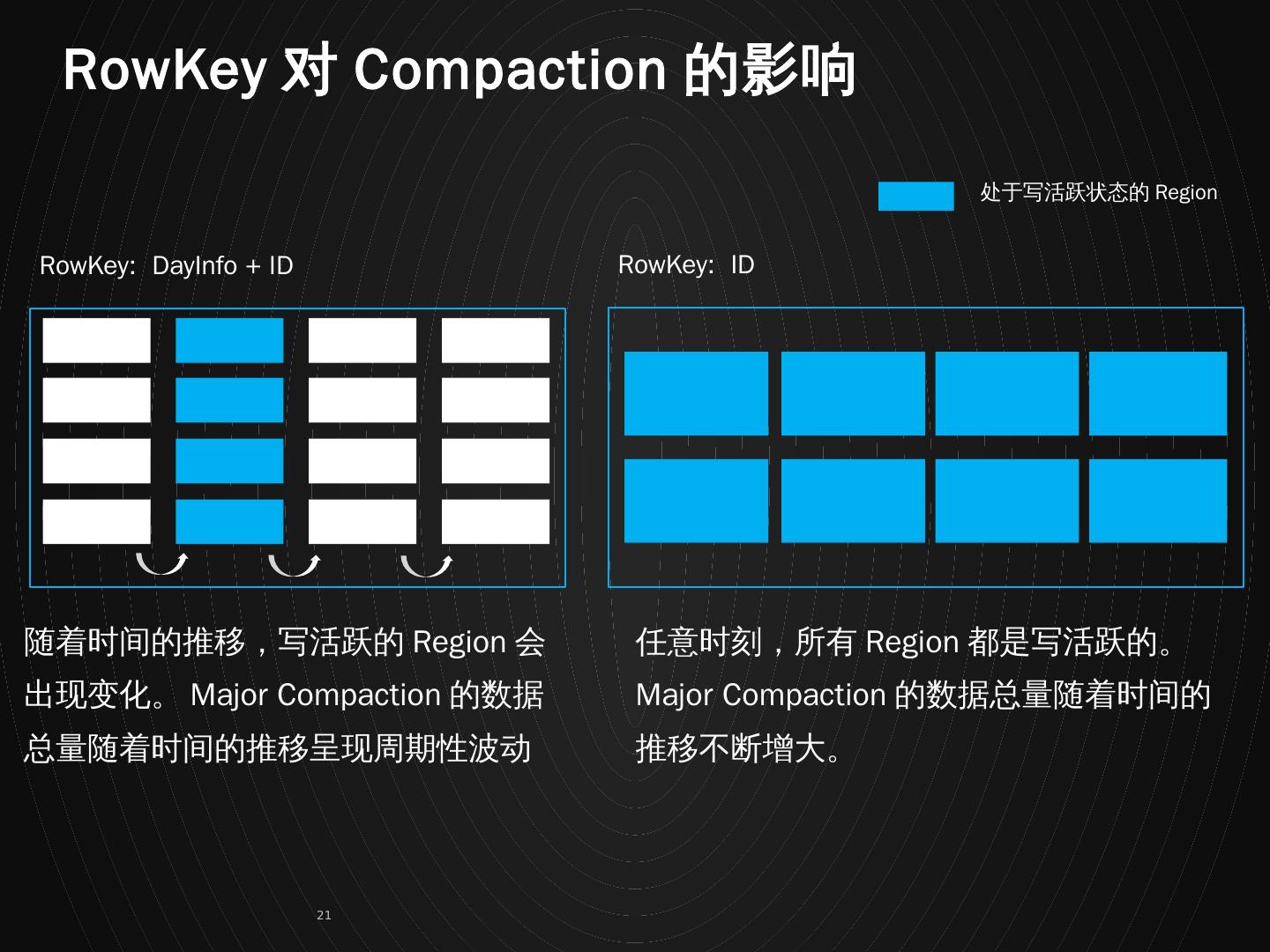
21 .处于写活跃状态的 Region RowKey: DayInfo + ID RowKey: ID 随着时间的推移,写活跃的 Region 会出现变化。 Major Compaction 的数据总量随着时间的推移呈现周期性波动 任意时刻,所有 Region 都是写活跃的。 Major Compaction 的数据总量随着时间的推移不断增大。 RowKey 对 Compaction 的影响
22 .基于 Name+Phone+ID 构建 RowKey Name Phone ID …… . Ariya 1332222 I0000005 … . … … … … . Li 1384444 I9999999 … . Li 1385555 I0000008 … . Wang 1332323 I0000007 … . Wang 1333232 I0000002 … . … … … … . Wang 1334988 I0012322 … . Wang 1335465 I0040007 … . Wang 1366134 I0070007 … . Wang 1397323 I0052322 … . Wang 1388866 I0112322 … . Wang 1388888 I0900007 … . … … … … . Xiao 1332222 I0000009 … . 可很好 / 较好支持的查询场景: 查询场景 1 : Name:Li AND Phone:1384444 AND ID:I9999999 查询场景 2 : Name:Wang AND Phone:1384444 查询场景 3 : Name:Wang 查询场景 4 : Name:Wang AND Phone: 133% 查询场景 2 : Name:Wang AND Phone: 133?323 难以支持的查询场景: 查询场景 5: Phone: 1384444 查询场景 6: ID: I9999999 RowKey 对查询的影响
23 .数据库查询可简单分解为两个步骤: 1 ) 键的查找 2 ) 数据的查找 因这两种数据组织方式的不同,在 RDBMS 领域有两种常见的数据组织表结构: 索引组织表 :键与数据存放在一起,查找到键所在的位置则意味着查找到数据本身。 堆表 :键的存储与数据的存储是分离的。查找到键的位置,只能获取到数据的物理地址,还需要基于该地址去获取数据。 HBase 数据表其实是一种 索引组织表结构 :查找到 RowKey 所在的位置则意味着找到数据本身。因此, RowKey 本身就是一种索引 。 RowKey 即索引 …
24 .Name Phone ID …… . Ariya 1332222 I0000005 … . … … … … . Li 1384444 I9999999 … . Li 1385555 I0000008 … . Wang 1332323 I0000007 … . Wang 1333232 I0000002 … . … … … … . Wang 1334988 I0012322 … . Wang 1335465 I0040007 … . Wang 1366134 I0070007 … . Wang 1397323 I0052322 … . Wang 1388866 I0112322 … . Wang 1388888 I0900007 … . … … … … . Xiao 1332222 I0000009 … . 如果提供的查询条件能够 尽可能丰富 的描述 RowKey 的 前缀信息 ,则 查询时延 越能得到保障。如下面几种组合条件场景 : Name + Phone + ID Name + Phone Name 如果查询条件不能提供 Name 信息,则 RowKey 的前缀条件是无法确定的,此时只能通过 全表扫描 的方式来查找结果。 一种业务模型的用户数据 RowKey ,只能采用单一结构设计。但事实上,查询场景可能是多维度的。例如,在上面的场景基础上,还需要单独基于 Phone 列进行查询。这是 HBase 二级索引出现的背景。即,二级索引是为了让 HBase 能够提供更多维度的查询能力。 注: HBase 原生并不支持二级索引方案,但基于 HBase 的 KeyValue 数据模型与 API ,可以轻易的构建出二级索引数据。 Phoenix 提供了两种索引方案,而一些大厂家也都提供了自己的二级索引实现 。 RowKey 查询的局限性 / 二级索引需求背景 基于 Name+Phone+ID 构建 RowKey
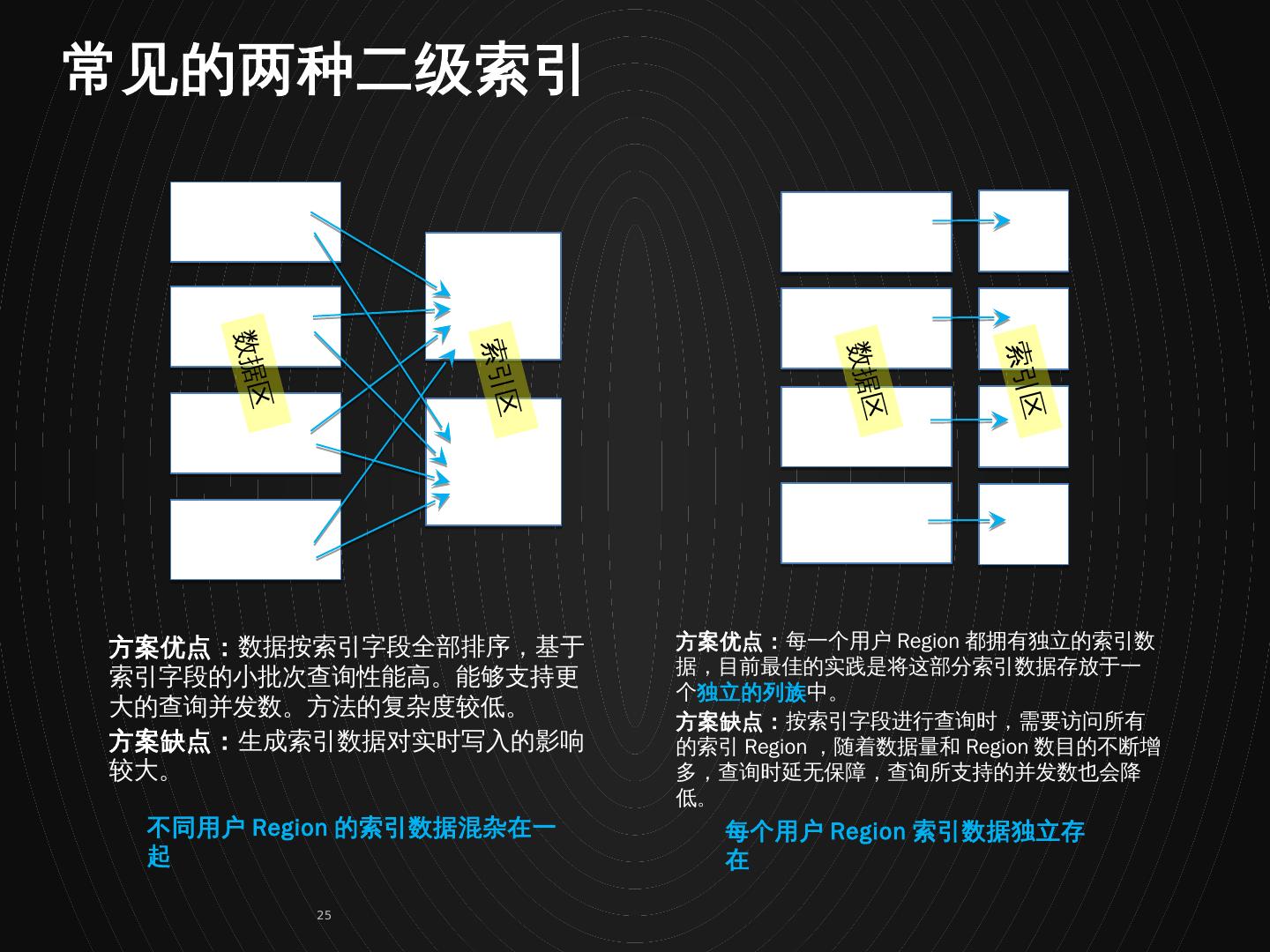
25 .方案优点: 数据按索引字段全部排序,基于索引字段的小批次查询性能高。能够支持更大的查询并发数。方法的复杂度较低。 方案缺点: 生成索引数据对实时写入的影响较大。 方案优点: 每一个用户 Region 都拥有独立的索引数据,目前最佳的实践是将这部分索引数据存放于一个 独立的列族 中。 方案缺点: 按索引字段进行查询时,需要访问所有的索引 Region ,随着数据量和 Region 数目的不断增多,查询时延无保障,查询所支持的并发数也会降低 。 ` 不同用户 Region 的索引数据混杂在一起 每个用户 Region 索引数据独立存在 数据区 数据区 索引区 索引区 常见的两种二级索引
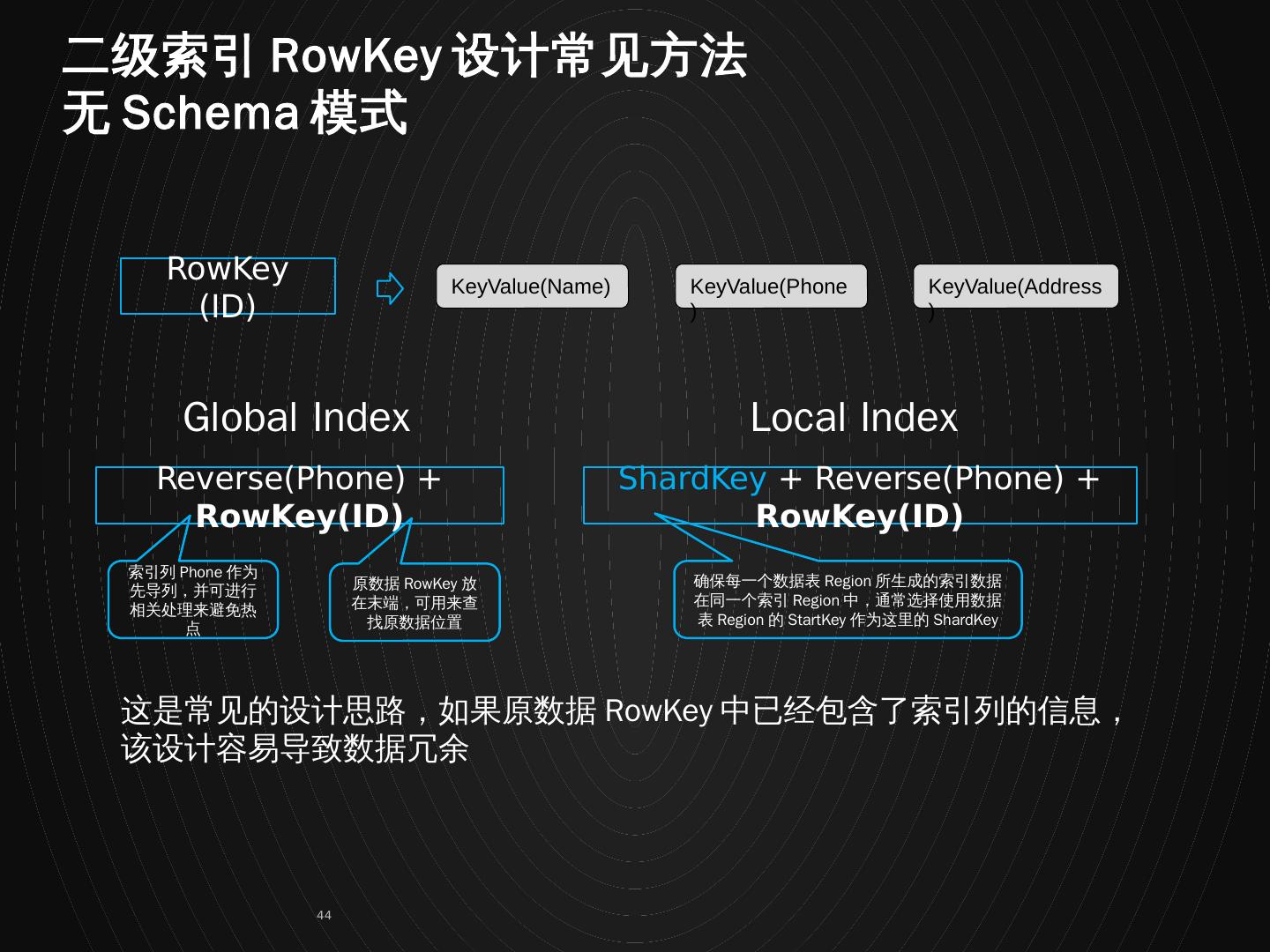
26 .举例说明如何基于 HBase 原生 API 构建二级索引的方法: 假设原始数据的 RowKey 与列定义如下: Put: RowKey -> ID , 列 -> {Name, Phone, Address, …….} 如果我们希望基于 Phone 列构建二级索引,我们可以基于原数据,构建一条新的记录,这个记录的 RowKey 为: Put: RowKey -> Phone + ID , 列 -> {…} 在二级索引的 RowKey 中,包含了数据的 RowKey 信息。这样,既能有效的从 Phone 索引到 ID 信息,又能保证索引 RowKey 的唯一性。 构建二级索引的核心在于 如何设计一个合理的索引 RowKey 。 索引即 RowKey…
27 .《 一条数据的 HBase 之旅 》 系列文章: 开篇基础内容 HBase 写数据流程 Flush 与 Compaction HBase 读取流程 HFile 原理剖析 …( 更多分享内容敬请期待 )… 更多 HBase 基础内容 …
28 .2 合理的需求调研 3 RowKey 与索引设计 目录 4 设计案例分享 1 15 分钟 HBase 基础知识
29 .结合业务特点,将数据合理的分配到每一个 Region 中,从而很好的满足业务的读写需求 Region Region Region Region Region Region RowKey 设计的目标
3秒后跳转登录页面
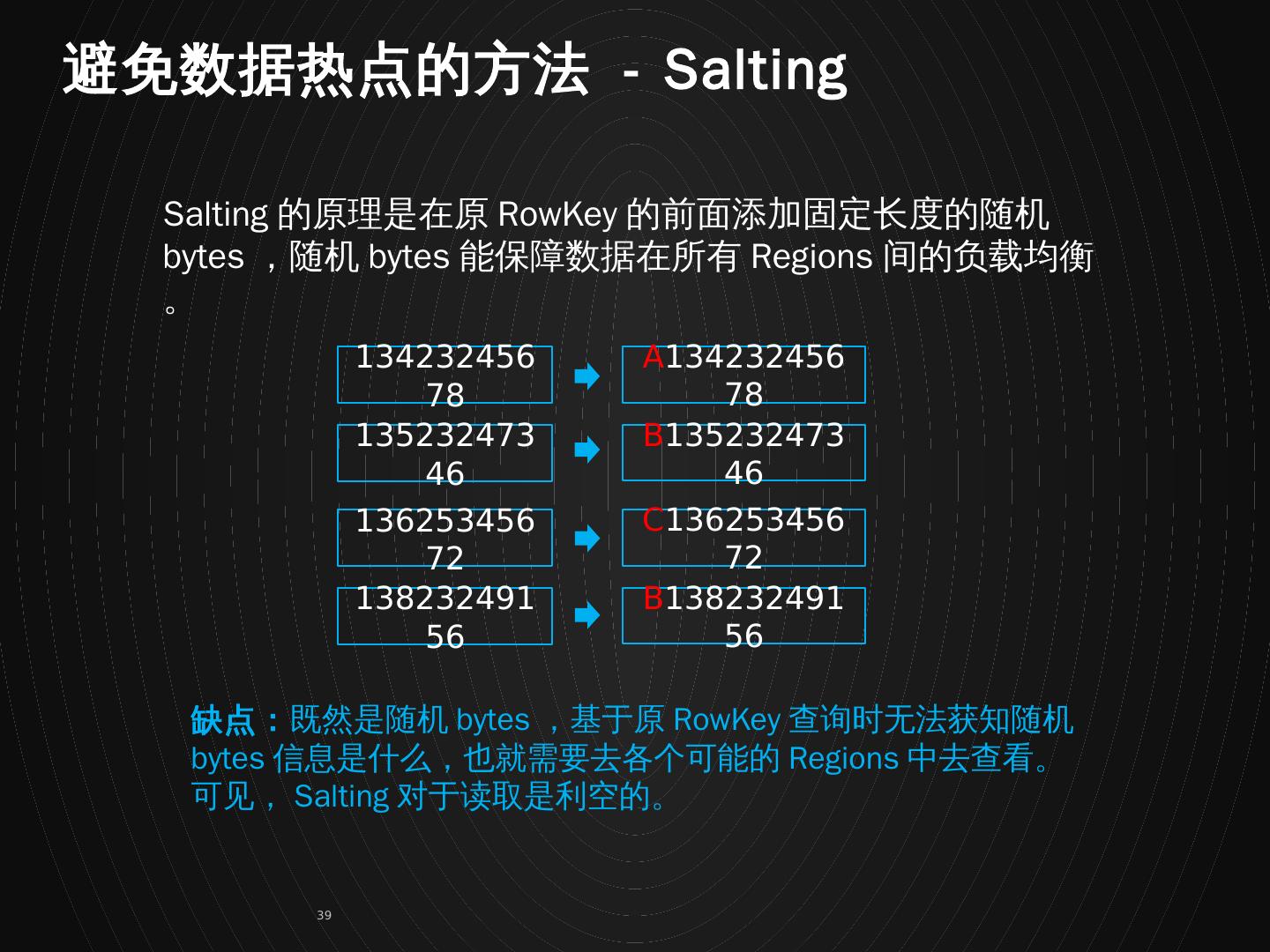
去登陆

