





























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
HBase for Solr介绍
HBase 作为一个Key Value存储系统,对于多值查询,范围查询,模糊查询,分词等天然不支持,Solr作为非常优秀的搜索引擎,但是kv查询效率,数据膨胀等弱点也非常明显,如何结合两者,并且让运维更简单,支持典型等用户应用场景,来自阿里云多模式数据库技术组等天斯对这个话题进行了深入介绍。
展开查看详情
1 .HBase for Solr介绍 阿里云多模式数据库技术组 天斯 2018.09
2 .提纲 1 HBase查询需求背景 2 HBase检索增强思路路 3 HBase for Solr介绍 4 HBase for Solr发展前景 5 QA环节
3 .1 HBase查询需求背景
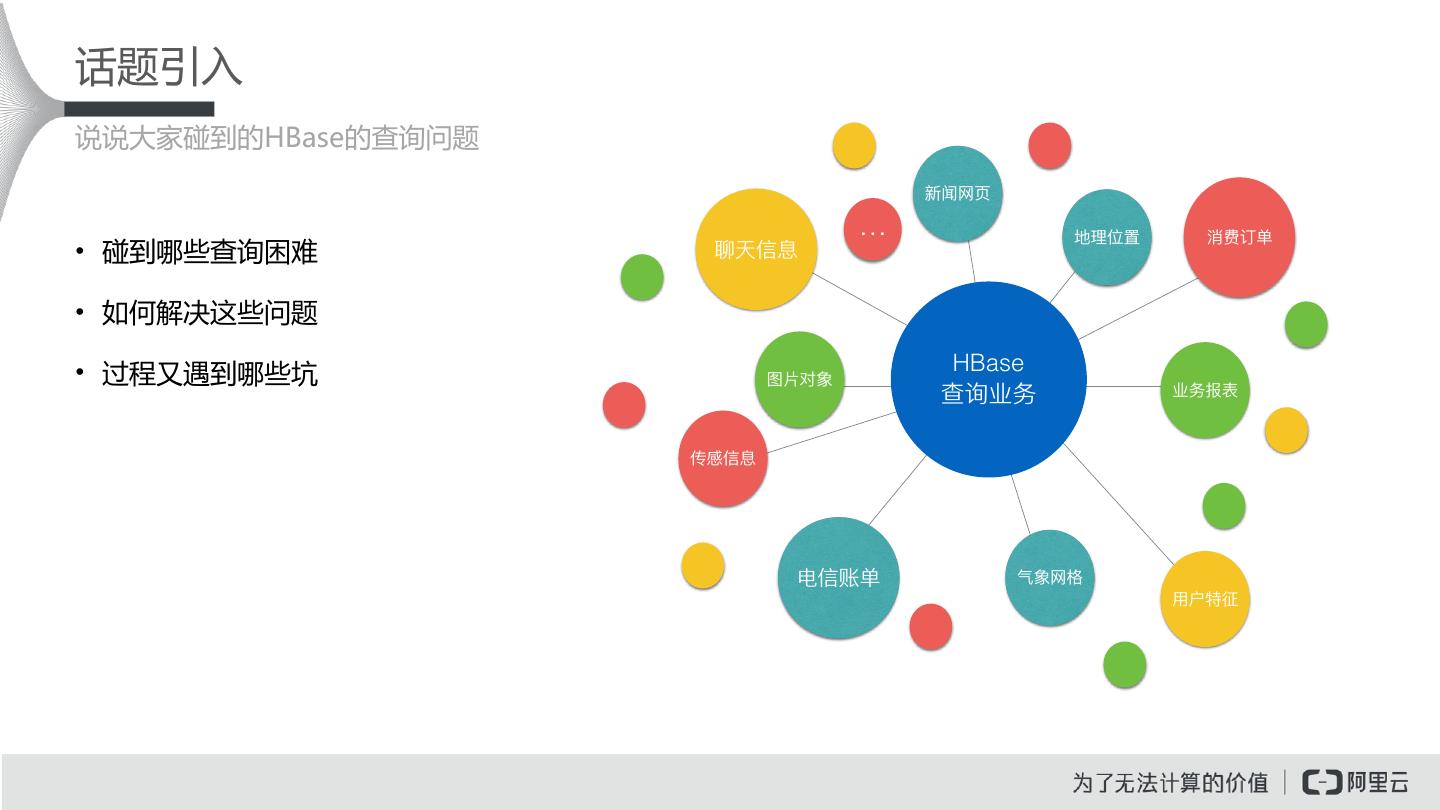
4 .话题引入 说说大家碰到的HBase的查询问题 新闻⽹网⻚页 ... 地理理位置 消费订单 • 碰到哪些查询困难 聊天信息 • 如何解决这些问题 • 过程又遇到哪些坑 HBase 图⽚片对象 查询业务 业务报表 传感信息 电信账单 ⽓气象⽹网格 ⽤用户特征
5 .话题引入 说说大家碰到的HBase的查询问题 • 碰到哪些查询困难 • HBase⽆无法满⾜足的查询: • 如何解决这些问题 • 模糊查询 • 任意条件and/or组合查询 • 过程又遇到哪些坑 • 空间查询 • 分组查询 • 分词检索 • ……
6 .话题引入 说说大家碰到的HBase的查询问题 • 碰到哪些查询困难 • 引入索引服务: • 如何解决这些问题 • 索引一致性问题 • 同步实现复杂 • 过程又遇到哪些坑 • ……
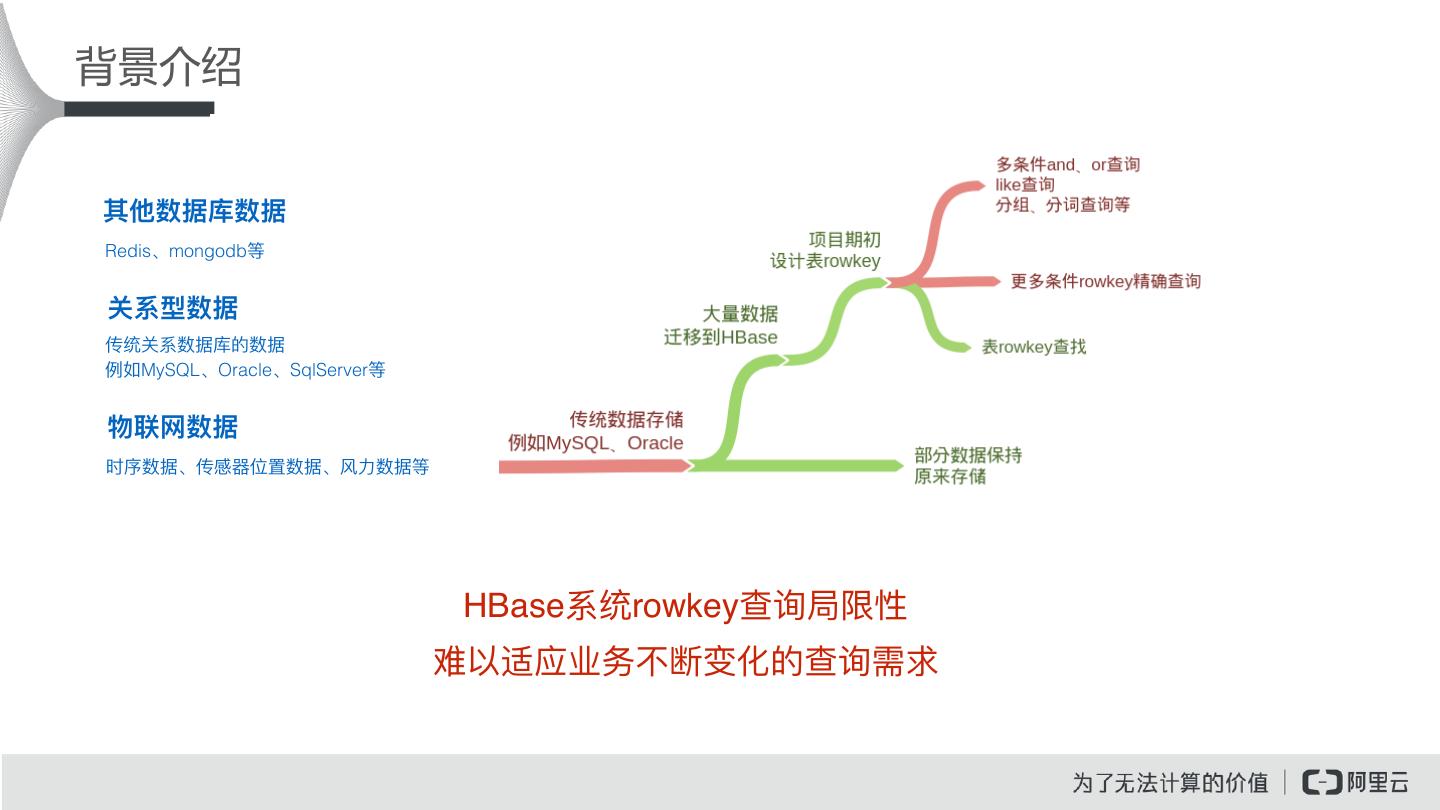
7 .背景介绍 ⼤大量量业务数据迁移到HBase存储,开始查询设计符合业务需求的rowkey,⽐比如从关系数据库迁移过来,有些数据关系通过 反规范化设计,使得整体查询在HBase中能符合rowkey⾼高效查询⽅方式. 其他数据库数据 Redis、mongodb等 HBase 查询业务 关系型数据 物联⽹网数据 传统关系数据库的数据 时序数据、传感器器位置数据、⻛风⼒力力数据等 例例如MySQL、Oracle、SqlServer等
8 .背景介绍 其他数据库数据 Redis、mongodb等 关系型数据 传统关系数据库的数据 例例如MySQL、Oracle、SqlServer等 物联⽹网数据 时序数据、传感器器位置数据、⻛风⼒力力数据等 1 2 3 4 传统数据库 HBase存储 HBase存储 HBase存储 数据量量太⼤大 》 rowkey查询 》 多条件rowkey查询 》 多条件组合 模糊like查询 分组、分词查询
9 .背景介绍 其他数据库数据 Redis、mongodb等 关系型数据 传统关系数据库的数据 例例如MySQL、Oracle、SqlServer等 物联⽹网数据 时序数据、传感器器位置数据、⻛风⼒力力数据等 HBase系统rowkey查询局限性 难以适应业务不不断变化的查询需求
10 .2 HBase检索增强思路路
11 .HBase检索能力增强思路 引入索引功能 Solr solr保存索引数据, 可以部署 与HBase共⽤用HDFS、共⽤用zk Lucene 每个regionserver使⽤用lucene 保存以及检索查询 Phoenix 在HBase之上建多个⼆二级索引 索引数据以及元数据存储在 HBase HBase表中 Elastisearch 建⽴立index保存在ES存储中 客户端双写、或者cp同步数据 ⾃自建HBase索引 其他DB保存索引 ⾃自建HBase表做全局索引 利利⽤用客户端双写实现同步 其他DB保存索引数据 ⼤大量量的原数据集合保存在HBase
12 .HBase检索能力增强思路 查询能力得到补充 HBase Phoenix/⾃自建HBase索引 Solr/ES 主表⼀一个rowkey,只能设计⼀一个 扩展更更多rowkey设计,允许更更多 任意条件 X、Y、Z..... rowkey=X|Y …这种场景 rowkey=X|Y rowkey=Y|Z 合适场景: 合适场景: rowkey=X|Z 。。。这种设计 1.X = a or Y= b (rowkey设计不不能实现的) X=a 2.X> a and Y < b (rowkey设计不不能实现的) X>=a, X>a 合适场景: 3. X like “%hbase%” X<=a,或者X<a ⼀一个表,允许更更多类似左边的场景。 4. Geo地理理距离检索 X=a and Y = b 更更多X、Y、Z...条件来组合来进⾏行行 5. ⽀支持分词查询 X=a and Y <= b 类似左边描述的条件查询 6. ⽀支持facet/group分类分组查询返回, X=a and Y>=b 例例如⼀一个关键词搜索新闻⽹网站,它可以分 优势: 政治、体育、经济等类别返回统计与结果 优点: 依然保持⾼高并发、⾼高效rowkey查询。允许有 7. 任意条件组合查询等 ⾼高并发、⾼高效快速 更更多rowkey设计,最⼤大化hbase rowkey检索 缺点: 优势 优点: 1.只有⼀一个rowkey设计,后期 缺点: 1. ⽀支持检索功能更更丰富; OR 组合查询, 业务变化不不能修改rowkey结构 1. 表变多,如果业务有U/V/W/X/Y/Z 6个条件 多个条件范围组合查询,like、分词等全⽂文检索, 2.检索场景简单,有局限性,⼀一个 两两组合的业务场景,就需要15个表,数据 这些查询使⽤用hbase rowkey设计是难以满⾜足的 rowkey必须由前缀X出现才能 膨胀,例例如这个时候,X在索引⾥里里被保存了了5 2. 对于类似U/V/W/X/Y/Z 6个条件两两组合的业务 快速查找,⽐比如上述 只提供 次。 场景,数据膨胀率远低于 hbase的rowkey⽅方案 Y=b的话,依然需要全表扫描 2. 查询也有局限性 缺点:类似hbase这种简单kv查询下,并发 不不如hbase⾼高效快速
13 .HBase检索能力增强思路 索引同步方法及其同时带来的问题 常⻅见索引同步⽅方法 客户端双写 客户端压⼒力力⼤大 依赖⽤用户客户端实现 客户端负责写原数据的同时 也负责写索引数据 异步索引 数据突增索引数据积压 异步索引常⻅见的有通过 异步同步延时太久 coprocessor和replication 两种实现⽅方式 同步索引 影响集群吞吐 通常在coprocessor hook中强同步索引 索引服务异常则原数据插⼊入受影响 只有写⼊入索引成功后才插⼊入原数据
14 .HBase检索能力增强思路 索引同步方法及其同时带来的问题 常⻅见索引同步⽅方法 索引同步问题 客户端双写 索引⼀一致性 客户端负责写原数据的同时 也负责写索引数据 异步索引 服务异常 异步索引常⻅见的有通过 coprocessor和replication 两种实现⽅方式 同步索引 索引数据积压 通常在coprocessor hook中强同步索引 只有写⼊入索引成功后才插⼊入原数据
15 .HBase检索能力增强思路 满⾜足了了查询,却带来了了新挑战 满⾜足了了查询需求,却同时带来别的挑战
16 .HBase检索能力增强思路 满⾜足了了查询,却带来了了新挑战 怀疑架构?换架构?
17 .3 HBase for Solr介绍
18 .HBase for Solr介绍 HBase rowkey查询已经不不能满⾜足复杂多变的⽤用户业务查询需求,HBase for Solr就是为了了满⾜足⼴广⼤大HBase⽤用户⽇日益变化的查询需求, 是HBase查询检索能⼒力力的补充,是⼤大数据多模式数据库发展趋势的基础之⼀一,⽐比如⼀一些图、时空等应⽤用,都可以使⽤用solr提供的索引 服务。 索引⼀一致性 复杂查询 监控管理理 多模式数据库 rowkey 时空查询 查询 复杂条件 图遍历 查询
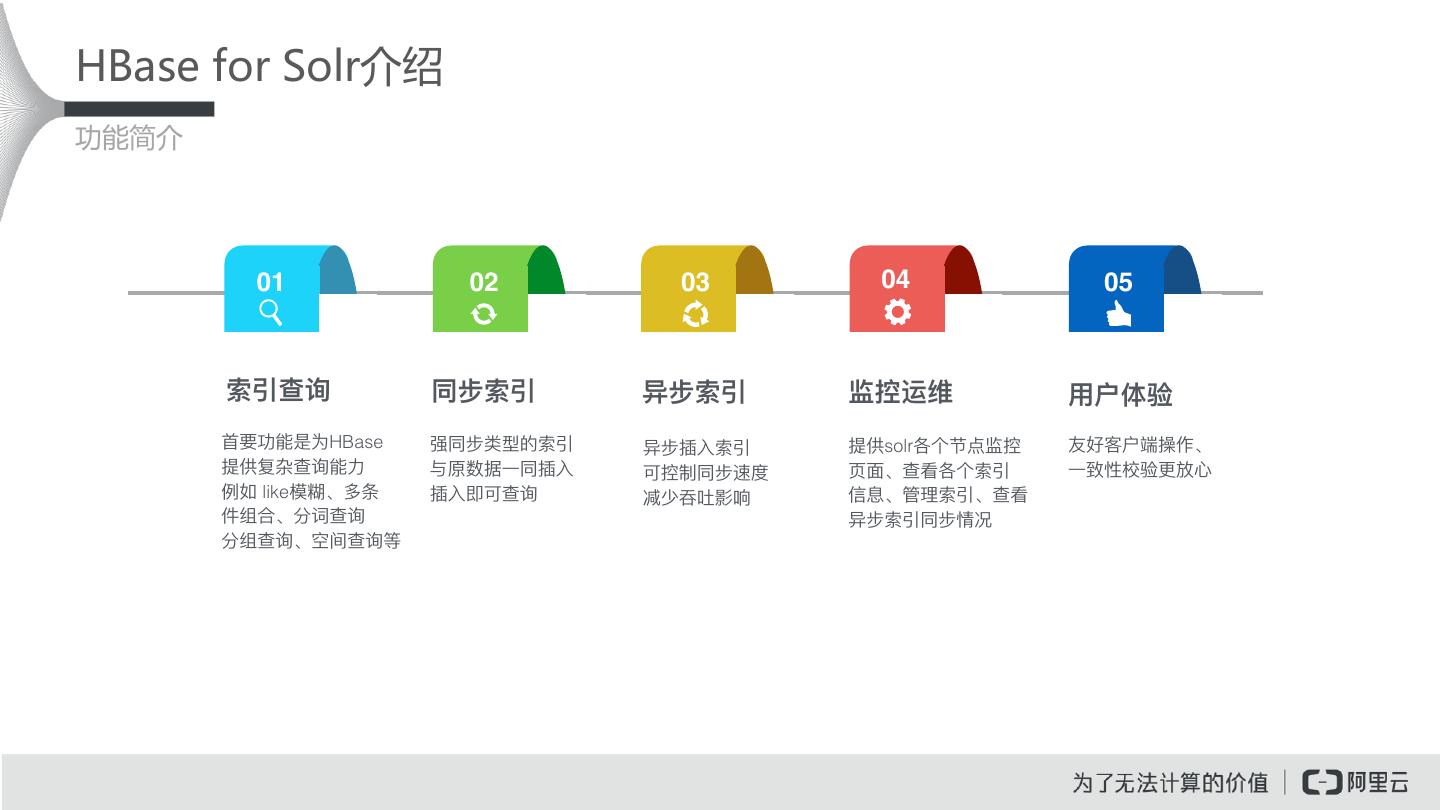
19 .HBase for Solr介绍 功能简介 01 02 03 04 05 索引查询 同步索引 异步索引 监控运维 ⽤用户体验 ⾸首要功能是为HBase 强同步类型的索引 异步插⼊入索引 提供solr各个节点监控 友好客户端操作、 提供复杂查询能⼒力力 与原数据⼀一同插⼊入 可控制同步速度 ⻚页⾯面、查看各个索引 ⼀一致性校验更更放⼼心 例例如 like模糊、多条 插⼊入即可查询 减少吞吐影响 信息、管理理索引、查看 件组合、分词查询 异步索引同步情况 分组查询、空间查询等
20 .HBase for Solr介绍 特性、改进、优化、贡献 异步索引直接写⼊入,兼容Lily-indexer 优化改进,fix 社区bug HBase 开发维护同步索引实现,⽀支持shell索引管理理、索引重建 稳定性运维脚本、crash⽬目录锁bug、ganglia监控信息 Solr request trace⽇日志、多副本共享⽬目录、multi data paths等 ⼀一致性 ⽀支持强同步、异步索引Lily indexer bug修复、⼀一致性校验等 HBase for Solr ⾼高效 读写solr on hdfs性能、索引同步优化 易易⽤用 hbase shell命令即可操作、lily indexer也⽀支持
21 .案例一、某物流企业新增物流管理业务 • 案例一:背景 • 碰到的问题 • 历史数据14亿条记录 • 单使用HBase的话,rowkey查询无法满 • 每行300列左右,15列会做为条件查询 足管理系统的查询业务 • 精确查询匹配要求30ms以内 • 选择传统数据库mysql等的话,数据量太 大,不合适 • 支持任意条件and/or组合查询 • 全部保存ES/solr的话,扩展性差,精确 • 存在模糊、类型、范围等大数据量匹配条 查找并发不高 件 • 自建HBase+es/solr维护人力成本大 • 每日增量约3500w条记录 • TPS峰值1700左右 • 保存查询最近3个月数据,约30亿左右
22 .案例一、某物流企业新增物流管理业务 • HBase for Solr解决方案 • 16c64g * 4节点 功能 性能 体验 • 3个月保留约32亿条记录,共13.5T原数 据,solr索引约1.4T左右 • rowkey精确查询延时平均小于1ms, 峰值 3w qps单台情况下,999延时小于3ms。 • 利用solr支持各种复杂条件组合查询 • 索引同步平均2w+行/每秒
23 .案例二、某企业零售消费信息业务 • 案例二:背景 • 集群现状存在问题 • 存量HBase数据约20T,100+张表,其中 • 维护成本高 4张表建立索引,索引数据约7500w • 一致性问题,存储漏数据现象 • 存在频繁的索引数据更新 • 任意条件查询索引 • 要求HBase写入50w~100w/s • 要求HBase读800/s~2.8w/s
24 .案例二、某企业零售消费信息业务 • 使用HBase for Solr情况 性能 • 运维成本下降 使⽤用体验 • 索引一致性问题得到保障 • 功能、性能满足需求 ⼀一致性
25 .4 HBase for Solr发展前景
26 .HBase for Solr发展前景 日益变化复杂查询需求推动 新闻⽹网⻚页 ... 地理理位置 消费订单 • 不断变化的业务背景 聊天信息 • 满足各种HBase复杂查询需求 • 提供查询类型更多丰富 HBase 图⽚片对象 查询业务 业务报表 传感信息 电信账单 ⽓气象⽹网格 ⽤用户特征
27 .HBase for Solr发展前景 多模式发展的重要方向 • 多模式数据库发展的重要方向 • 定位大数据索引服务 多模式 数据库 时空 时序 图 SQL 索引 KV
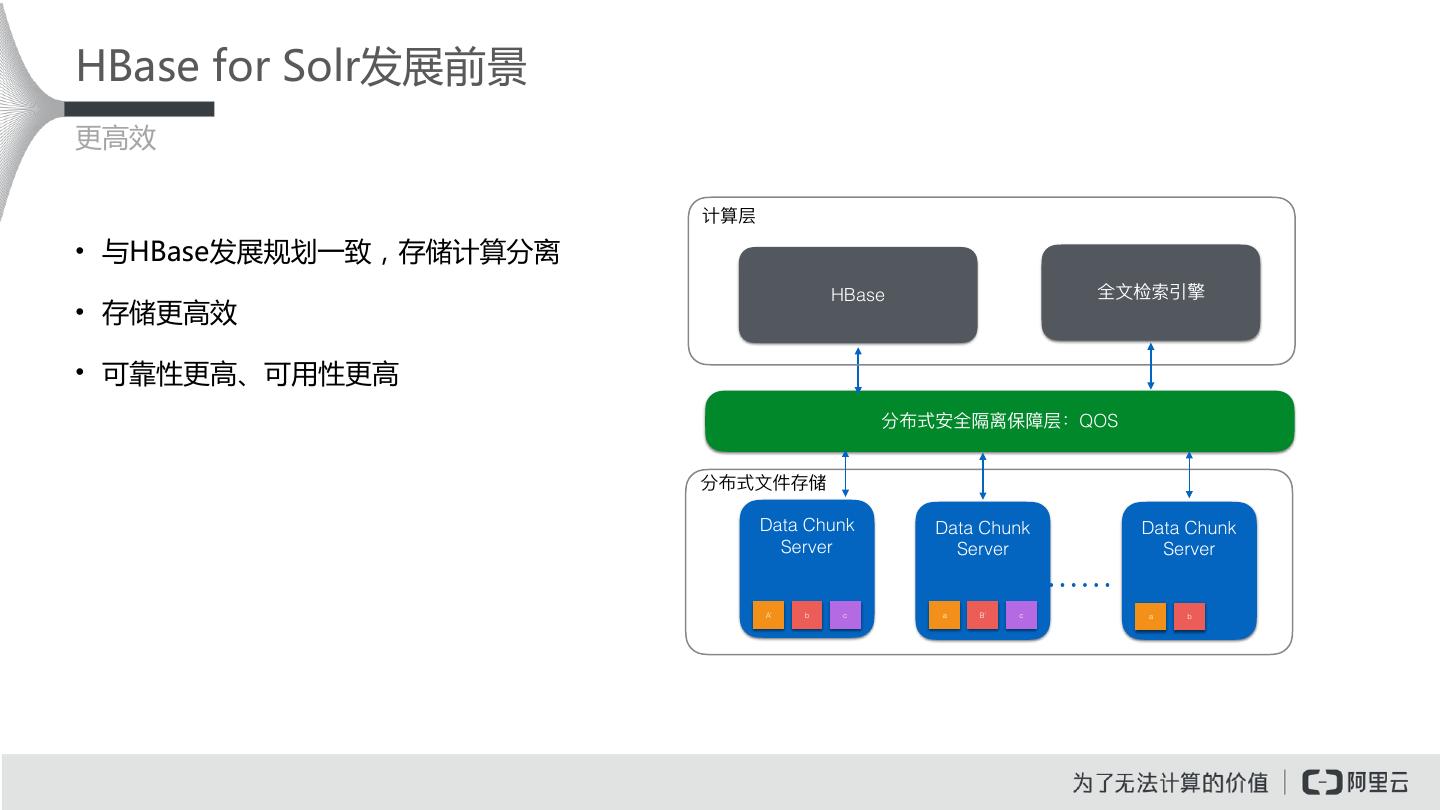
28 .HBase for Solr发展前景 更高效 计算层 • 与HBase发展规划一致,存储计算分离 HBase 全⽂文检索引擎 • 存储更高效 • 可靠性更高、可用性更高 分布式安全隔离保障层:QOS 分布式⽂文件存储 Data Chunk Data Chunk Data Chunk Server Server Server A’ b c a B’ c a b
29 .5 QA
3秒后跳转登录页面
去登陆

