展开查看详情
1 . HBase in Practice
- 性能、监控及问题解决
Yu Li
jueding.ly@alibaba-inc.com
�
2 .内容摘要
n 性能优化
l 针对IO的性能优化
l 不同版本值得注意的性能问题/优化
n 监控和问题排查
l Important metrics
l Logs and debugging
�
3 . 针对IO的性能优化
n Hard Drive Disk (HDD): IO能力较弱,很容易被打爆
l Compaction限流:HBASE-8329 (available in 1.1.0+)
n hbase.regionserver.throughput.controller
l 版本低于1.3.0 org.apache.hadoop.hbase.regionserver.compactions.PressureAwareCompactionThroughputController
l 版本高于1.3.0 org.apache.hadoop.hbase.regionserver.throttle.PressureAwareCompactionThroughputController
n hbase.hstore.compaction.throughput.[lower/upper].bound
n hbase.hstore.compaction.throughput.offpeak
l Flush限流:HBASE-14969 (available in 1.3.0+)
n hbase.regionserver.flush.throughput.controller =>
org.apache.hadoop.hbase.regionserver.throttle.PressureAwareFlushThroughputController
n hbase.hstore.flush.throughput.[lower/upper].bound
�
4 . 针对IO的性能优化 (cont’d)
n Hard Drive Disk (HDD): Per-CF Flush
l HBASE-10201: available in 1.1.0+
n hbase.regionserver.flush.policy =>
org.apache.hadoop.hbase.regionserver.FlushLargeStoresPolicy
n hbase.hregion.percolumnfamilyflush.size.lower.bound,默认16777216(16MB)
l HBASE-14906: available in 2.0.0+
n 默认的CF flush大小改进为hbase.hregion.memstore.flush.size/column_family_number
n hbase.hregion.percolumnfamilyflush.size.lower.bound.min控制flush下限
�
5 . 针对IO的性能优化 (cont’d)
n Hard Drive Disk (HDD): 多盘
l Multiple WAL: HBASE-5699 (available in 1.0.0+)
n 版本低于1.2.0:replication存在问题
n 写入性能较单WAL提升20%
n hbase.wal.provider => multiwal
n hbase.wal.regiongrouping.strategy => bounded
n 根据盘数设置hbase.wal.regiongrouping.numgroups
�
6 . 针对IO的性能优化 (cont’d)
n SSD
l WAL写SSD: HBASE-12848 (available in 1.1.0+)
n hbase.wal.storage.policy => ALL_SSD
n MultiWAL: 写入性能比单WAL提升40%以上
l CF级别Storage Policy配置: HBASE-14061 (available in 2.0.0+)
n create 'table',{NAME=>'f1',STORAGE_POLICY=>'ALL_SSD'}
n create 'table'
,{NAME=>'f1',CONFIGURATION=>{'hbase.hstore.block.storage.policy'=>’ALL_SSD'}}
l Bulkload支持StoragePolicy配置: HBASE-15172 (available in 2.0.0+)
n hbase.hstore.block.storage.policy => ALL_SSD
n hbase.hstore.block.storage.policy.<family_name> => ALL_SSD
l HBASE-19858: backport HBASE-14061/15172 to branch-1 (1.5.0+, not released yet)
�
7 . 针对IO的性能优化 (cont’d)
n SSD
l HDFS-9966: 允许HDFS client优先读远程SSD上的副本,dfs.client.pread.remote-ssd.first
l 未合入社区版本,需要手动backport
n Hybrid
l WAL策略
n ONE_SSD或ALL_SSD
n MultiWAL
l CF级别Storage Policy配置
n 根据SLA要求,分别配置ALL_SSD/ONE_SSD/HOT
n 配置好Bulkload
l 开启Compaction/Flush限流
�
8 . 不同版本值得注意的性能问题
n 写性能
l Merge MVCC and SequenceId引发的性能问题: HBASE-14460
n branch-1.0不要使用1.0.3以下版本,branch-1.1不要使用1.1.3以下版本
l 高负载下写入性能瓶颈: HBASE-16698/17471
n 如果线上发现wait在WALKey#getWriteEntry,建议升级到1.4.0以上版本
n 对ASYNC_WAL写入性能提升尤其明显
n 读性能
l BucketCache高并发读取单key的性能问题:HBASE-14463
n 1.2.0以上版本解决
�
9 . 问题排查:重要的监控指标
n RPC相关
l Server响应时间:hbase.regionserver.ipc.TotalCallTime (99th/999th_percentile)
l Server处理时间:hbase.regionserver.ipc.ProcessCallTime (99th/999th_percentile)
l 请求排队时间:hbase.regionserver.ipc.QueueCallTime (99th/999th_percentile)
l Active handler数:hbase.regionserver.ipc.numActiveHandler
n 读写分离的handler监控要求HBASE-16561,1.4.0以上版本
n Write rpc handler数:hbase.regionserver.ipc.numActiveWriteHandler
n Scan rpc handler数:hbase.regionserver.ipc.numActiveScanHandler
n 除Scan外的read rpc handler数:hbase.regionserver.ipc.numActiveReadHandler
l RPC队列长度:hbase.regionserver.ipc.numCallsInGeneralQueue
l RPC连接数:hbase.regionserver.ipc.numOpenConnections
�
10 . 问题排查:重要的监控指标(cont’d)
n RPC相关:示例
�
11 . 问题排查:重要的监控指标(cont’d)
n 请求相关指标
l 写入
n Put请求latency:hbase.regionserver.server.Mutate_999th_percentile
n WAL sync latency:hbase.regionserver.wal.SyncTime_999th_percentile
l 读取
n Get请求latency:hbase.regionserver.server.Get_999th_percentile
n HDFS pread latency:hbase.regionserver.io.FsPReadTime_999th_percentile
l HBASE-15160 required, 要求1.4.0以上版本
n Scan请求latency:hbase.regionserver.server.ScanTime_999th_percentile
n HDFS read latency: hbase.regionserver.io.FsReadTime_999th_percentile
l HBASE-15160 required, 要求1.4.0以上版本
�
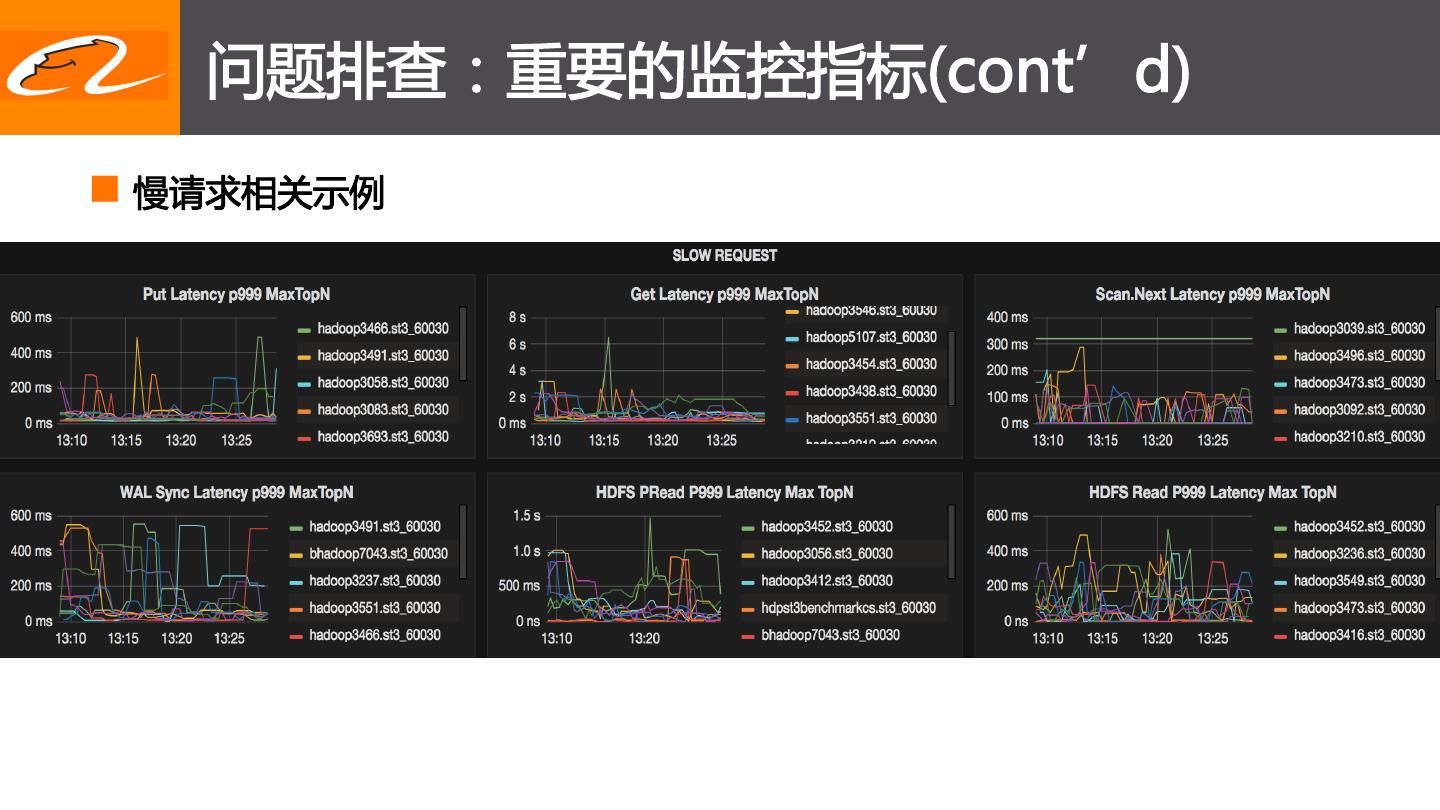
12 . 问题排查:重要的监控指标(cont’d)
n 慢请求相关示例
�
13 . 问题排查:重要的监控指标(cont’d)
n 内存相关指标
l GC
n GC时间:hbase.regionserver.jvmmetrics.GcTimeMillis
n GC次数:hbase.regionserver.jvmmetrics.GcCount
n pauseTimeWithoutGC:hbase.regionserver.server.PauseTimeWithoutGc_999th_percentile
l HBASE-15614 required, 要求1.4.0以上版本
l BlockCache/MemStore
n MemStore size:hbase.regionserver.server.memStoreSize
n BlockCache data block命中率:hbase.regionserver.server.blockCacheDataHitPercent
n BlockCache meta block命中率:hbase.regionserver.server.blockCacheMetaHitPercent
n 区分data和meta block的hit ratio要求HBASE-14983, 1.3.0以上版本
�
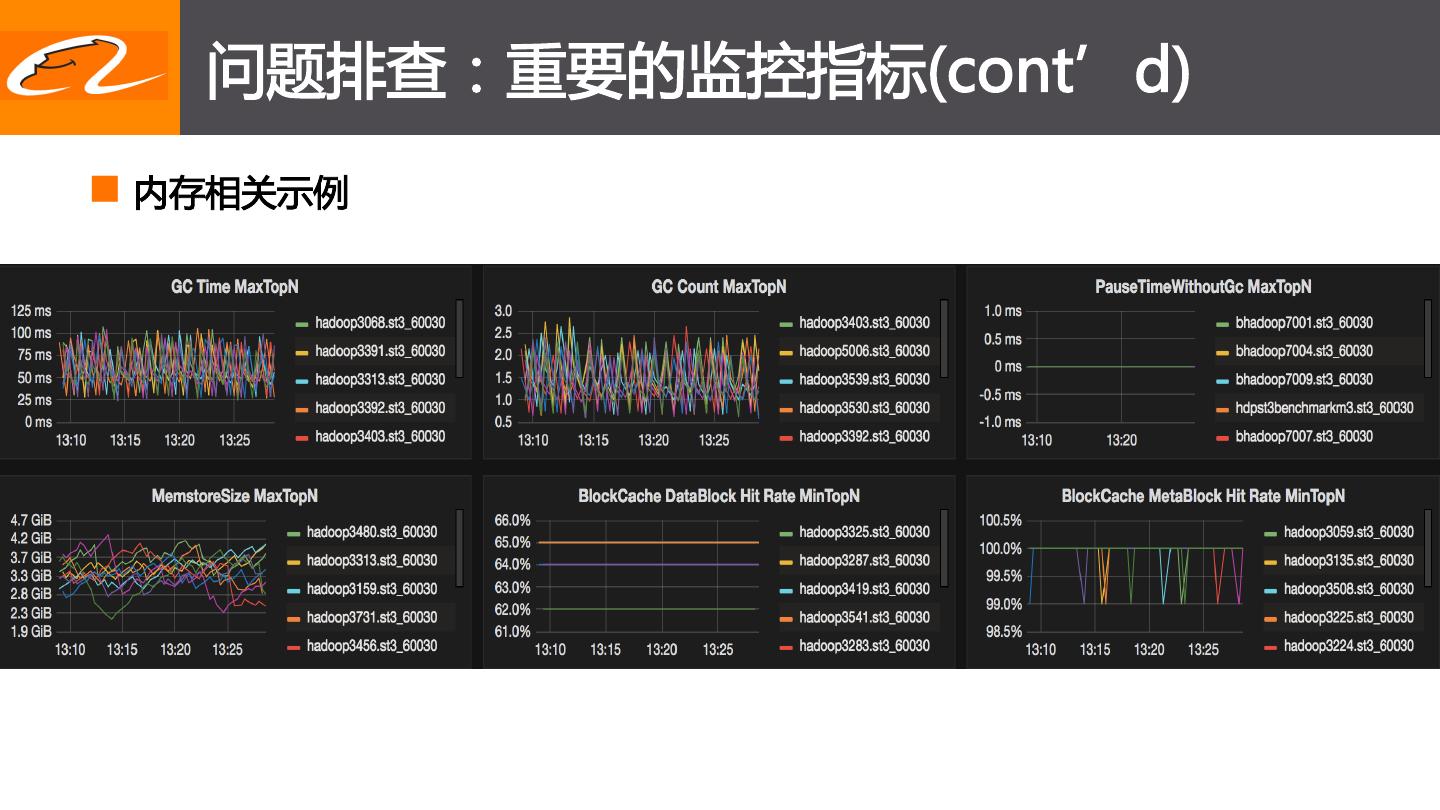
14 . 问题排查:重要的监控指标(cont’d)
n 内存相关示例
�
15 . 问题排查:重要的监控指标(cont’d)
n RegionServer单机指标
l Region大小:hbase.regionserver.regions.storeFileSize
l Region写操作数:hbase.regionserver.regions.
l Region get操作数:hbase.regionserver.regions.get_num_ops
l Region scan操作数:hbase.regionserver.regions.scanSize_num_ops
l Compaction队列长度:hbase.regionserver.server.compactionQueueLength
l Flush队列长度:hbase.regionserver.server.flushQueueLength
�
16 . 问题排查:重要的监控指标(cont’d)
n RegionServer单机示例
�
17 . 问题排查:重要的监控指标(cont’d)
n 发现stale的RegionServer
l 如果出现坏盘,请求卡在IO上一直无法返回,响应时间相关指标无法捕捉
l 如果机器资源耗尽,新的请求无法连接server,从响应时间等server metrics上也体现不出来
l HBASE-20158 增强health check
n 定期向自己发请求并设置超时时间,失败超过一定概率报警
n Upstreaming in progress
�
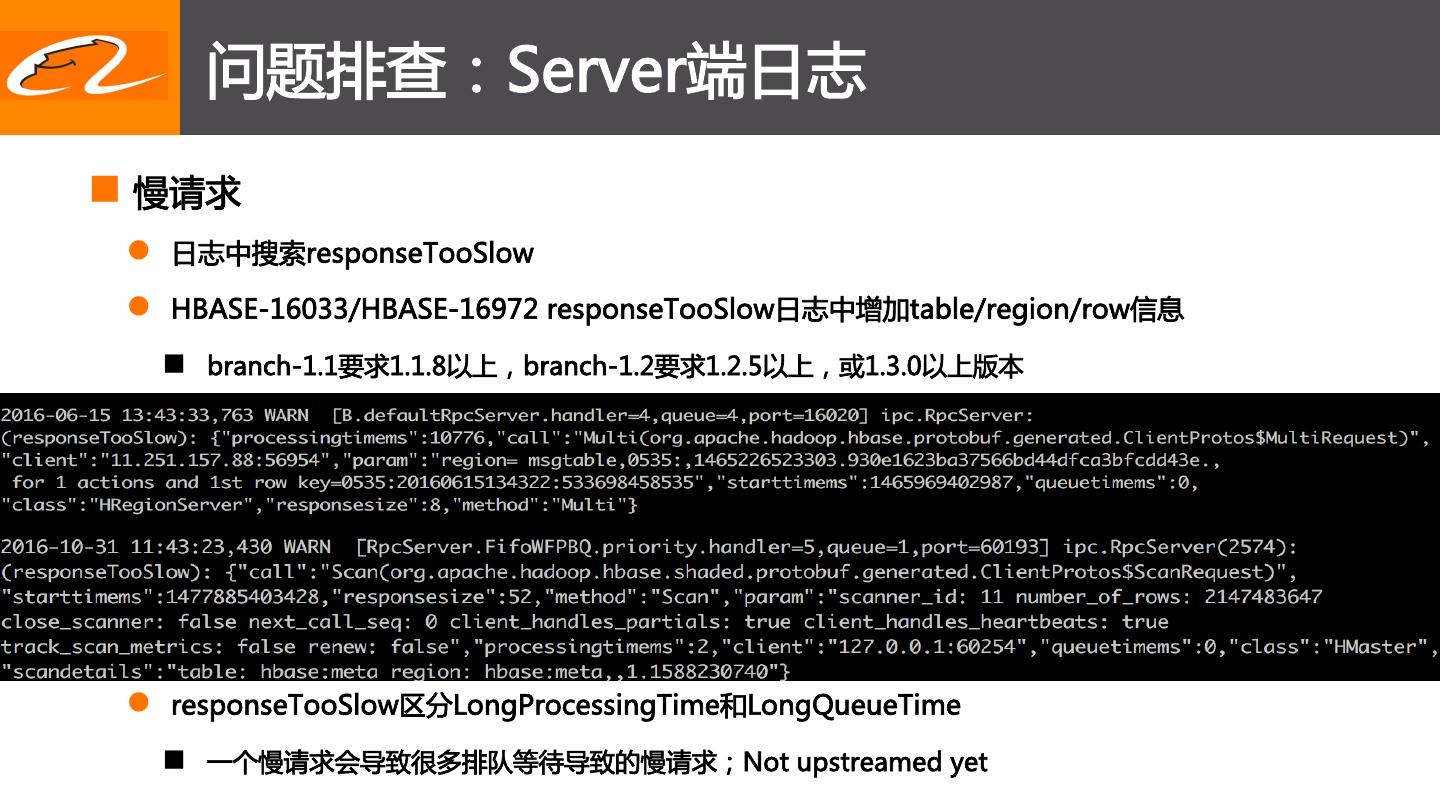
18 . 问题排查:Server端日志
n 慢请求
l 日志中搜索responseTooSlow
l HBASE-16033/HBASE-16972 responseTooSlow日志中增加table/region/row信息
n branch-1.1要求1.1.8以上,branch-1.2要求1.2.5以上,或1.3.0以上版本
l responseTooSlow区分LongProcessingTime和LongQueueTime
n 一个慢请求会导致很多排队等待导致的慢请求;Not upstreamed yet
�
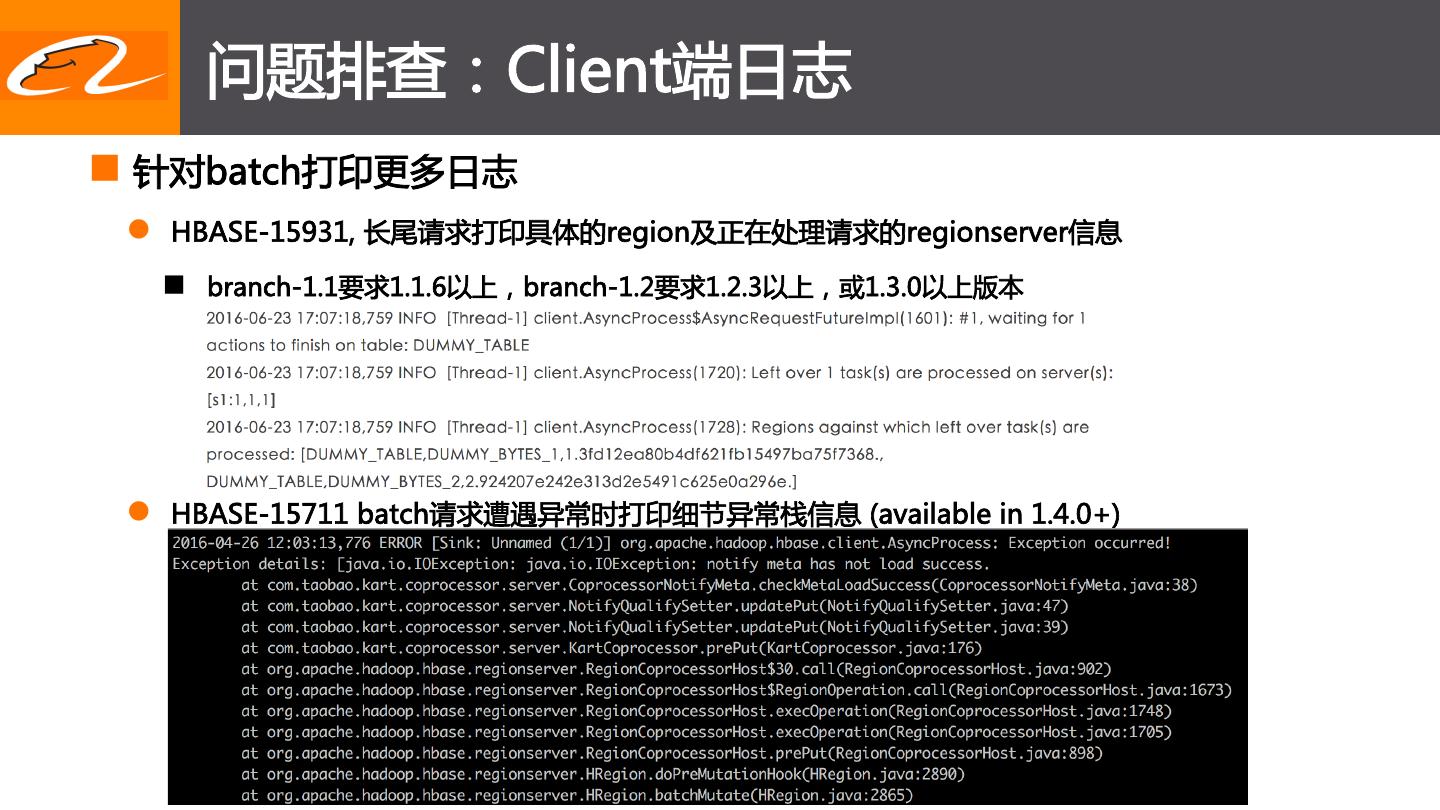
19 . 问题排查:Client端日志
n 针对batch打印更多日志
l HBASE-15931, 长尾请求打印具体的region及正在处理请求的regionserver信息
n branch-1.1要求1.1.6以上,branch-1.2要求1.2.3以上,或1.3.0以上版本
l HBASE-15711 batch请求遭遇异常时打印细节异常栈信息 (available in 1.4.0+)
�
20 . To Be Continued
n Will talk more in later meetups
l 如何排查GC、内存泄漏等复杂问题
l 如何定位疯狂访问RS的问题客户端应用
l 如何规避HDFS故障对HBase的影响
l 2.0黑科技在线上应用可能踩的坑
l 升级HBase版本有哪些必须的准备
l 线上升级操作有哪些注意事项
�
21 .Q & A
Thank You!
�