


























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Kylin on HBase
介绍了Apache Kylin的应用范围,作为其核心组件之一的HBase,来自Kylin的工程师也分享了基于HBase来完成OLAP优势和原理。
展开查看详情
1 .Apache Kylin on HBase Extreme OLAP Engine for Big Data Shaofeng Shi | 史少锋 Apache Kylin Committer & PMC August 17,2018
2 .Content 01 What is Apache Kylin Apache Kylin introduction, architecture and relationship with others 02 Why Apache HBase Key factors that Kylin selects HBase as the storage engine 03 How to use HBase in OLAP How Kylin works on HBase 04 Use Cases Apache Kylin typical use cases
3 .01 What is Apache Kylin
4 .What is Apache Kylin OLAP engine for Big Data Apache Kylin is an extreme fast OLAP engine for big data.
5 .What is Apache Kylin Key characters Real Interactive Ease of Use Trillion rows data, 99% queries < 1.3 seconds, No programing; User-friendly Web GUI; from Meituan.com ANSI-SQL MOLAP Cube SQL on Hadoop, supports most ANSI SQL User can define a data model and pre-build in Kylin query functions with more than 10+ billions of raw data records Hadoop Native Seamless BI Integration Compute and store data with JDBC/ODBC/REST API; Supports Tableau, MSTR, Qlik MapReduce/Spark/HBase, fully scalable architecture; Sense, Power BI, Excel and others
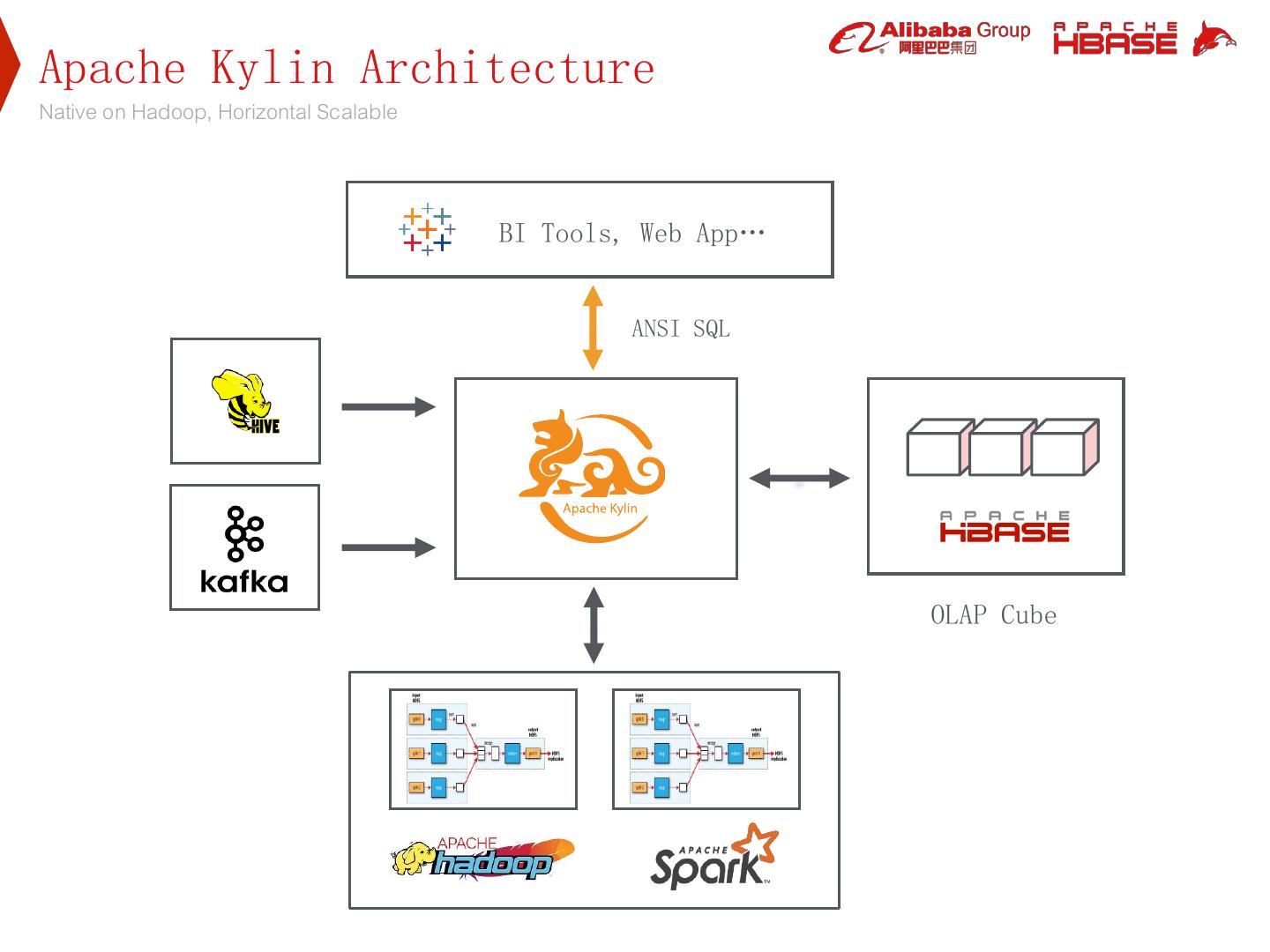
6 .Apache Kylin Architecture Native on Hadoop, Horizontal Scalable BI Tools, Web App… ANSI SQL OLAP Cube
7 .Why Kylin is fast Pre-calculation + Random access Join and aggregate data to Cube in offline Convert SQL query to Cube visiting No join at query time Filter with index and do online calculation within memory Sort Sort Aggr Filt Online er calculation Filt er Offline build Cuboid Join Aggregated Data Tables O(1)
8 .02 Why Apache HBase
9 .Criteria of the Storage engine for Kylin Hadoop Native Low Latency High Capacity Wide Adoption Easy to use API Active User Community
10 .Only HBase Can Hadoop Native Low Latency Block cache and Bloom HBase is built on Hadoop Filters for real-time technologies; It Integrates queries. well with HDFS, MapReduce and other components. High Capacity Wide Adoption Supports very large data Most Hadoop users are volume, TB to PB data in running HBase; one table. Easy to use API Active User Community HBase has many active users, which provides many good articles and best practices.
11 .HBase in Kylin HBase acts four roles in Kylin Massive Storage for Cube Kylin persists OLAP Cube in HBase, for low latency Metadata access. MPP for online calculation Kylin pushes down calculations to HBase region HBase Master servers for parallel Scan & computing. pushdown Meta Store Kylin uses HBase to persist Coprocess Coprocess its metadata. or … or Cache Kylin caches big lookup HBase HBase table in HBase. Region Server Region Server
12 .03 How to use HBase in OLAP
13 .How Cube be Built Cube building process Kylin uses MR or Spark to aggregate source data into Cube; The typical algorithm is by-layer cubing; Calculate N-Dimension cuboid first, and then calculate N-1. 0-D cuboid MR 1-D cuboid MR 2-D cuboid MR 3-D cuboid MR 4-D cuboid MR Full Data
14 .How Cube be Built The whole Cube building process Hive 临时 Hive Hive Hbase Query 表 Table Bulk Load Build Build Dimension Cubing Fast HDFS MR Dimension Cube Hfiles Dictionary 算法选择 Cubing Files Job Dictionary Job Layer Cubing N D(Base) Cuboid N-1 D(Base) Cuboid 0 D(Base) Cuboid MR HDFS MR HDFS MR HDFS … Job Files Job Files Job Files
15 .Cube in HBase Cube Structure Cube is partitioned into multiple segments by time range Each segment is a HBase Table Table is pre-split into multiple regions Cube is converted into HFile in batch job, and then bulk load to HBase Cube Seg 1 Seg 2 … Seg N Table 1 Table N Rowkey Value Rowkey Value
16 .HBase Table Format Rowkey + Value Dimension values are encoded to bytes (via dictionary or others) Measures are serialized into bytes HBase Rowkey format: Shard ID (2 bytes) + Cuboid ID (8 bytes) + Dimensions HBase Value: measures serialized bytes Table is split into regions by Shard ID User can group measures into 1 or multiple column families Shard ID Cuboid Dim 1 Dim 2 … Dim N Measure 1 … Measure N ID (long) 2 bytes 8 bytes Rowkey Value
17 .How Cube be Persisted in HBase Example: a Tiny Cube 2 dimensions and 1 measure; total 4 cuboids: 00,01,10,11 Please note the Shard ID is not appeared here Source Table Dictionary Encoding Aggregated Table (Cube) HBase KV Format
18 .How Cube be Queried Kylin parses SQL to get the dimension and measures; Identify the Model and Cube; Identify the Cuboid to scan; Identify the Cube segments; Leverage filter condition to narrow down scan range; Send aggregation logic to HBase coprocessor, do storage-side filtering and aggregation; On each HBase RS returned, de-code and do final processing in Calcite Dimension: city, year select city , Cuboid ID: 00000011 sum(price) from table Filter: year=1993 (encoded value: 0) where year= 1993 group by year Scan start: 00000011|0 Scan end: 00000011|1
19 .Good and not-good of HBase for OLAP HBase is a little complicated for OLAP scenario; HBase supports both massive write + read; while OLAP is read-only. Native on Hadoop. Great performance Not a columnar storage (when search pattern No secondary index matches Downtime for upgrade row key design) (update coprocessor need to High concurrency disable table first)
20 .04 Use Cases
21 .1000+ Global Users Internet FSI Telecom Manufacturing Others • eBay • CCB 建设银行 • China • SAIC 上汽集 • MachineZone • CMB 招商银行 Mobile 团 • Yahoo! Japan • Glispa • SPDB 浦发银 • China • Huawei 华为 • Baidu 百度 行 Telecom • Inovex • Lenovo 联想 • Meituan 美团 • CPIC 太平洋 • China • Adobe 保险 • OPPO • NetEase 网易 Unicom • iFLY TEK科大讯 • CITIC BANK • XiaoMi 小米 飞 • Expedia 中信银行 • AT & T • … • VIVO • … • JD 京东 • UnionPay 中 国银联 • MeiZu 魅族 • VIP 唯品会 • HuaTai 华泰 • … • 360 证券 • TOUTIAO 头条 • GuoTaiJunAn 国泰君安证券 • … • …
22 .Use Case – OLAP on Hadoop Meituan: Top O2O company in China Challenge Solution • Slow performance with previous MySQL • Apache Kylin as core OLAP on option Heavy development efforts with Hadoop solution Hive solution • SQL interface for internal • Huge resources for Hive job users • Analysts can’t access directly for • Active participate in open data on Hadoop source Kylin community 973 Cubes, 8.9+ trillion rows, Cube size 971 TB 3,800,000 queries/day, TP90 < 1.2 second (Data in 2018/08) Supporting all Meituan business lines
23 .Use Case – Shopping Reporting Yahoo! Japan: the most visited website in Japan We provide a reporting system that show statistics for store owners. e. g. impressions, clicks and sales. Our reporting system used Impala as a backend database previously. It took a long time (about 60 sec) to show Web UI. Thanks to low latency with Kylin, In order to lower the we become possible to focus on latency, we moved to Apache Kylin. adding functions for users. Average latency < 1sec for most cases
24 . We Are Hiring WeChat: Kyligence WeChat: Apache Kylin
25 .Thanks
3秒后跳转登录页面
去登陆

