


































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/IoTDB/202010ApacheIoTDBReporterXiangdongHuang11117?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
2020.10, Apache IoTDB 工业物联网数据管理. Reporter Xiangdong Huang.
分享
点赞
9
收藏
4
下载 20
展开查看详情
1 . Apache IoTDB 工业物联网数据库管理系统 清华大学 软件学院 大数据系统软件国家工程实验室 Apache IoTDB Team: Xiangdong Huang
2 . 目录 • 工业物联网数据管理需求 • Apache IoTDB • IoTDB设计细节 • 应用案例 • 开源解决方案
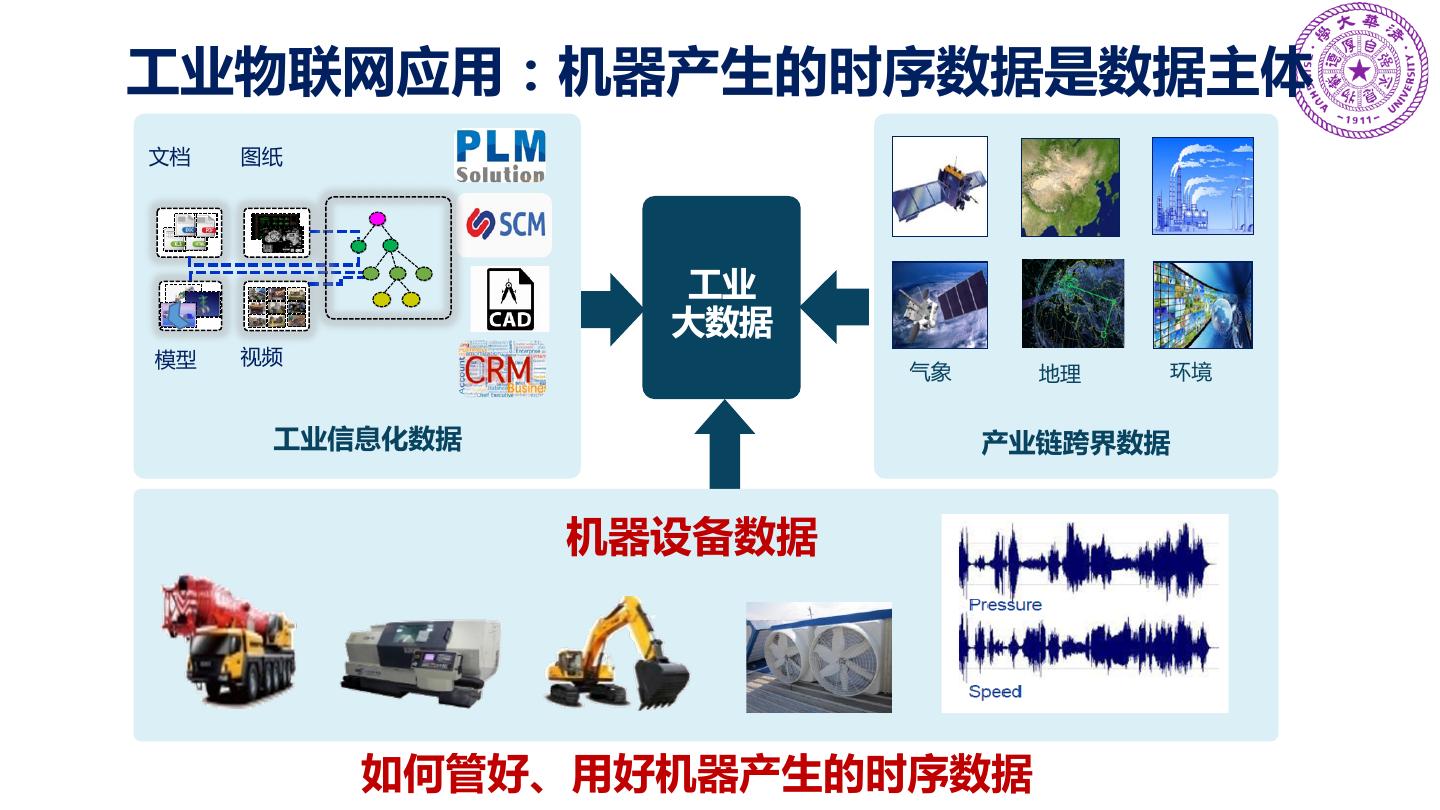
3 .工业物联网应用:机器产生的时序数据是数据主体 文档 图纸 工业 大数据 模型 视频 气象 地理 环境 工业信息化数据 产业链跨界数据 机器设备数据 如何管好、用好机器产生的时序数据
4 . 机器设备数据 • 风力发电厂(风能->电能) • 1、发电功率预测 • 2、风机故障预警(如叶片结冰) • 数据? • 1、静态关系数据:风机型号、叶片数量、坐标 • 2、动态时序数据:叶片转速、风力、温度
5 .工业物联网时序数据存储需求 大规模时序数据的特点 占用空间极大 数据总吞吐量大 时序数据存储的需求 产生速度快且不间断 【全时全量】 保证数据全时全量存储 【高效写入】 ~300列车 保证数据库可以承受高吞吐写入 >3000测点 【紧凑存储】 200 ms采样 对数据进行有效压缩减少磁盘空间占用 7x24 大数据应用 每天4140亿数据点 -> 410G * 10byte
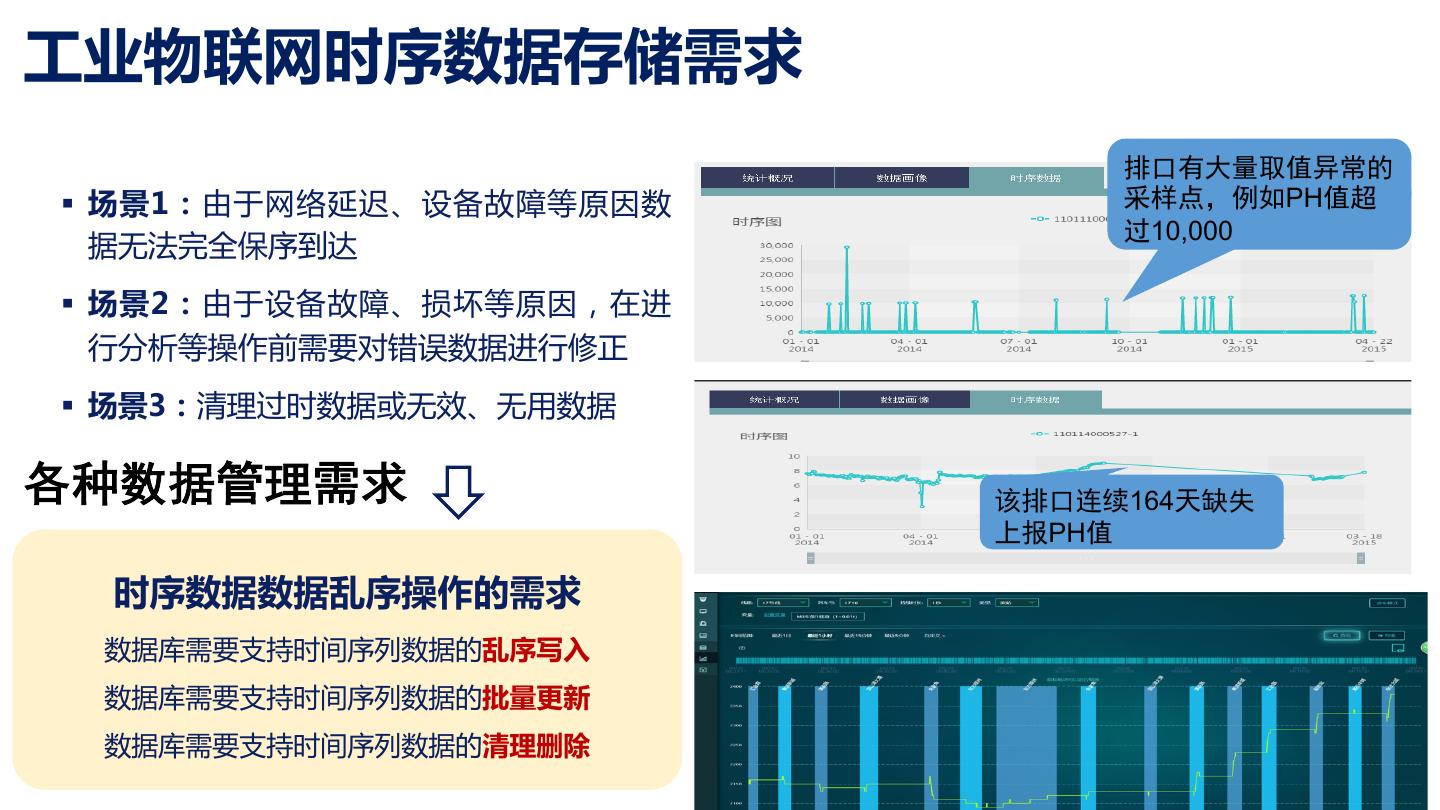
6 .工业物联网时序数据存储需求 排口有大量取值异常的 § 场景1:由于网络延迟、设备故障等原因数 采样点,例如PH值超 过10,000 据无法完全保序到达 § 场景2:由于设备故障、损坏等原因,在进 行分析等操作前需要对错误数据进行修正 § 场景3:清理过时数据或无效、无用数据 各种数据管理需求 该排口连续164天缺失 上报PH值 时序数据数据乱序操作的需求 数据库需要支持时间序列数据的乱序写入 数据库需要支持时间序列数据的批量更新 数据库需要支持时间序列数据的清理删除
7 .工业物联网时序数据查询需求 早高峰(7-9点)增加上行发车班次,减少下行发车班次 晚高峰(17-21点)增加下行发车班次,减少上行发车班次 多序列对齐比较 其他时间段运营班次存在压缩空间 ( join)
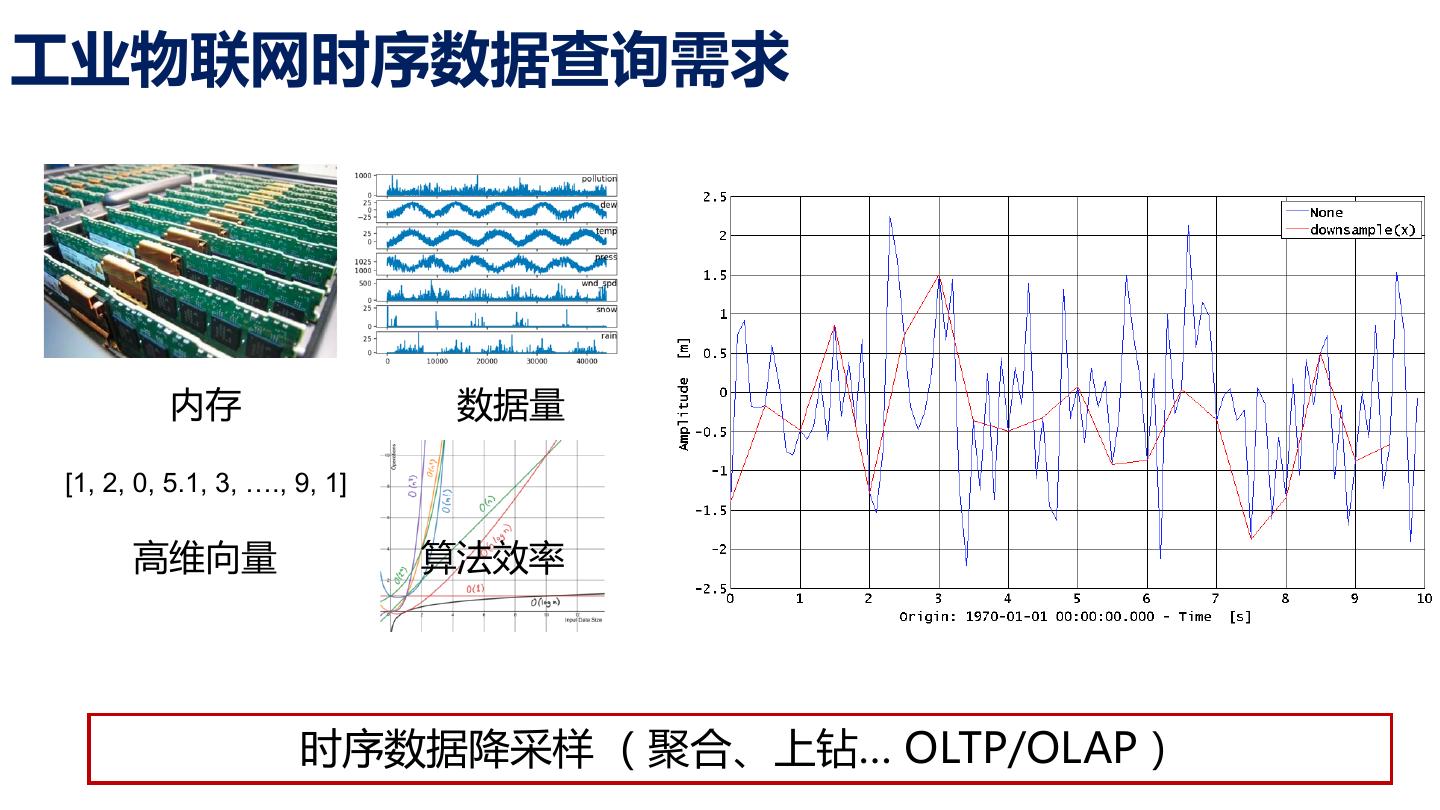
8 .工业物联网时序数据查询需求 内存 数据量 [1, 2, 0, 5.1, 3, …., 9, 1] 高维向量 算法效率 时序数据降采样 (聚合、上钻… OLTP/OLAP)
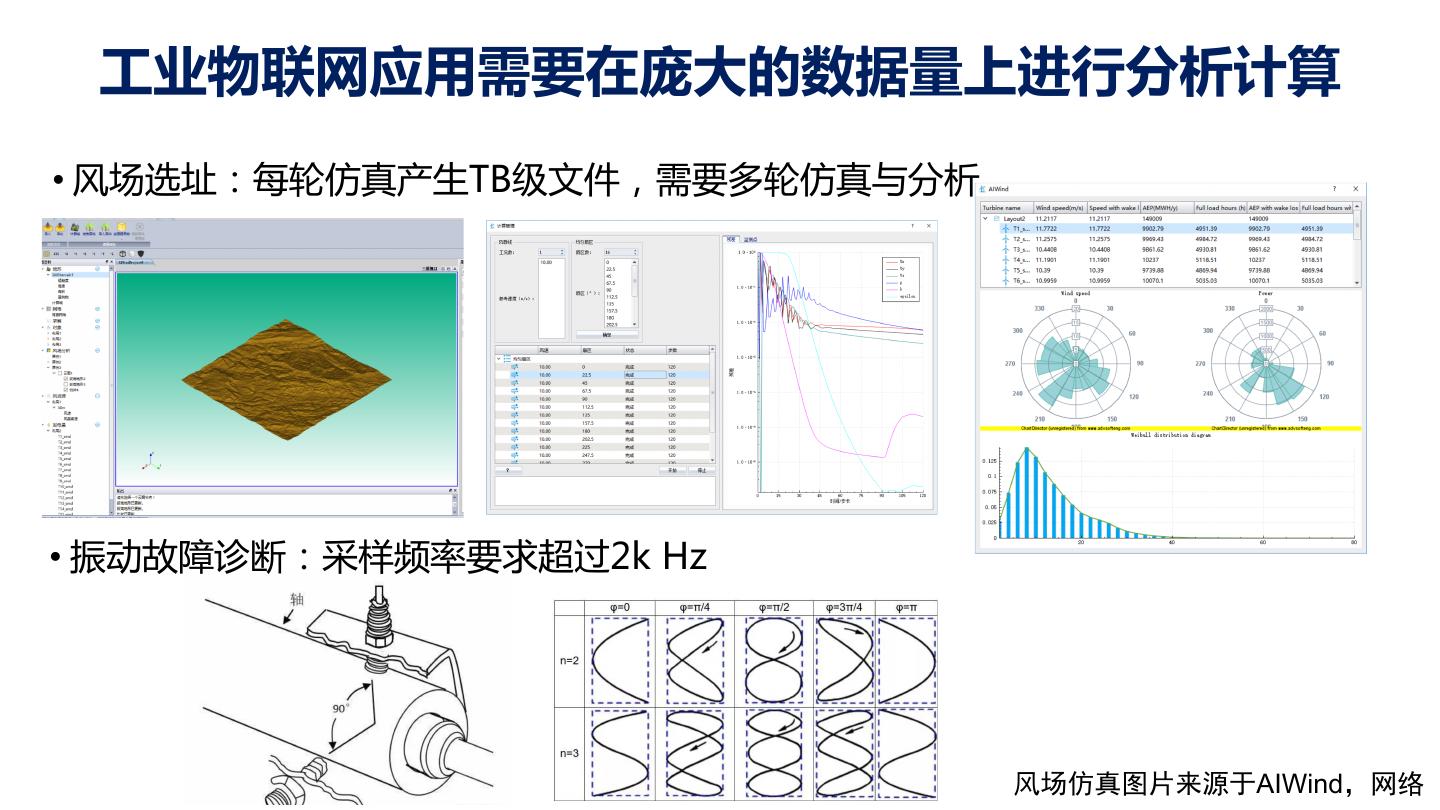
9 . 工业物联网应用需要在庞大的数据量上进行分析计算 • 风场选址:每轮仿真产生TB级文件,需要多轮仿真与分析 • 振动故障诊断:采样频率要求超过2k Hz 风场仿真图片来源于AIWind,网络
10 . 性能、功能与成本的权衡(存储) 性能 功能 ~300列车 • 不同设备类型,测点不同 >3000测点 200 ms采样 • 相同设备类型、不同实例, 7x24 测点不同 • 相同设备类型、相同实例、 不同时间段,测点不同 • 相同设备类型、相同实例、 >=500万数据点每秒的写入性能 一个时间段内,各测点采集时间对不齐
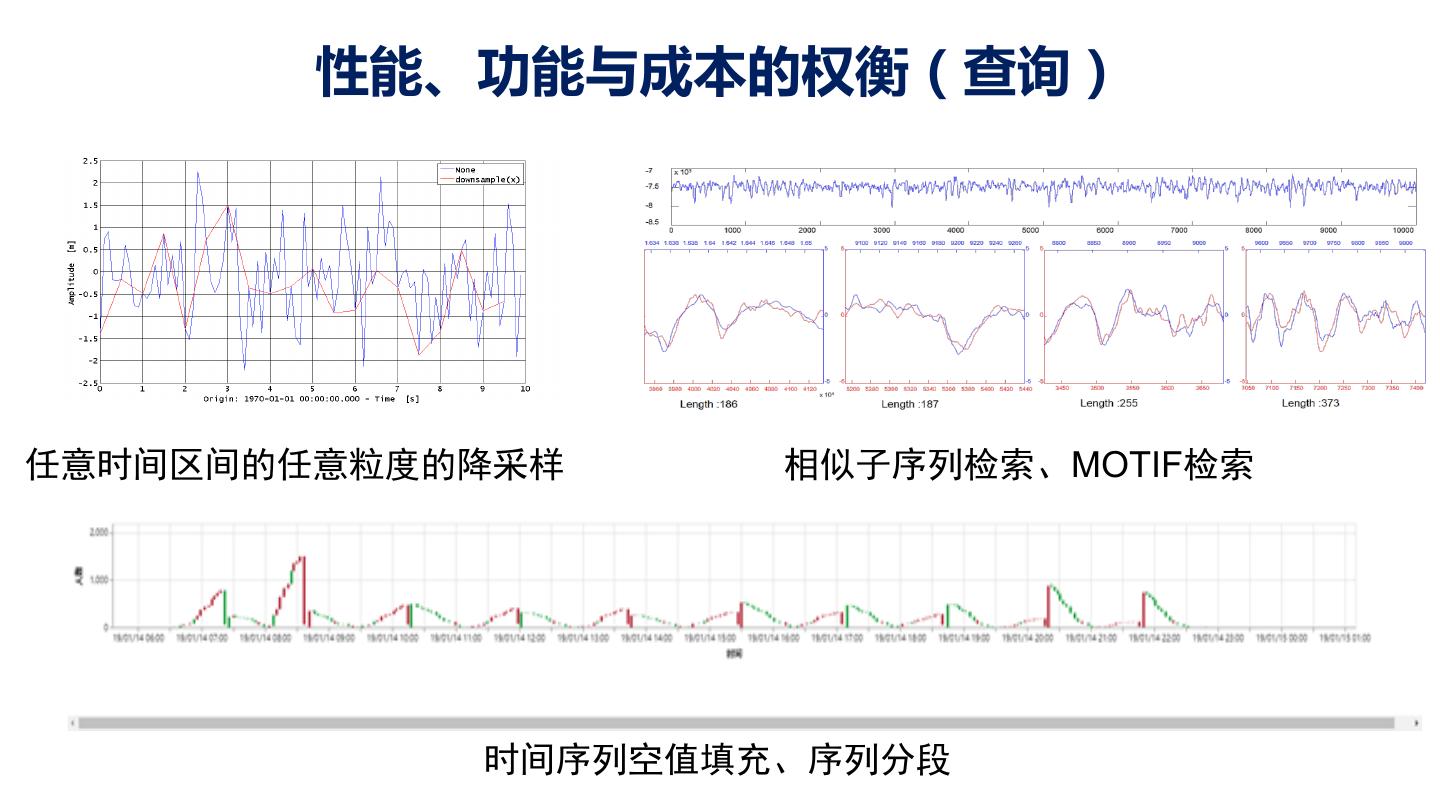
11 . 性能、功能与成本的权衡(查询) 任意时间区间的任意粒度的降采样 相似子序列检索、MOTIF检索 时间序列空值填充、序列分段
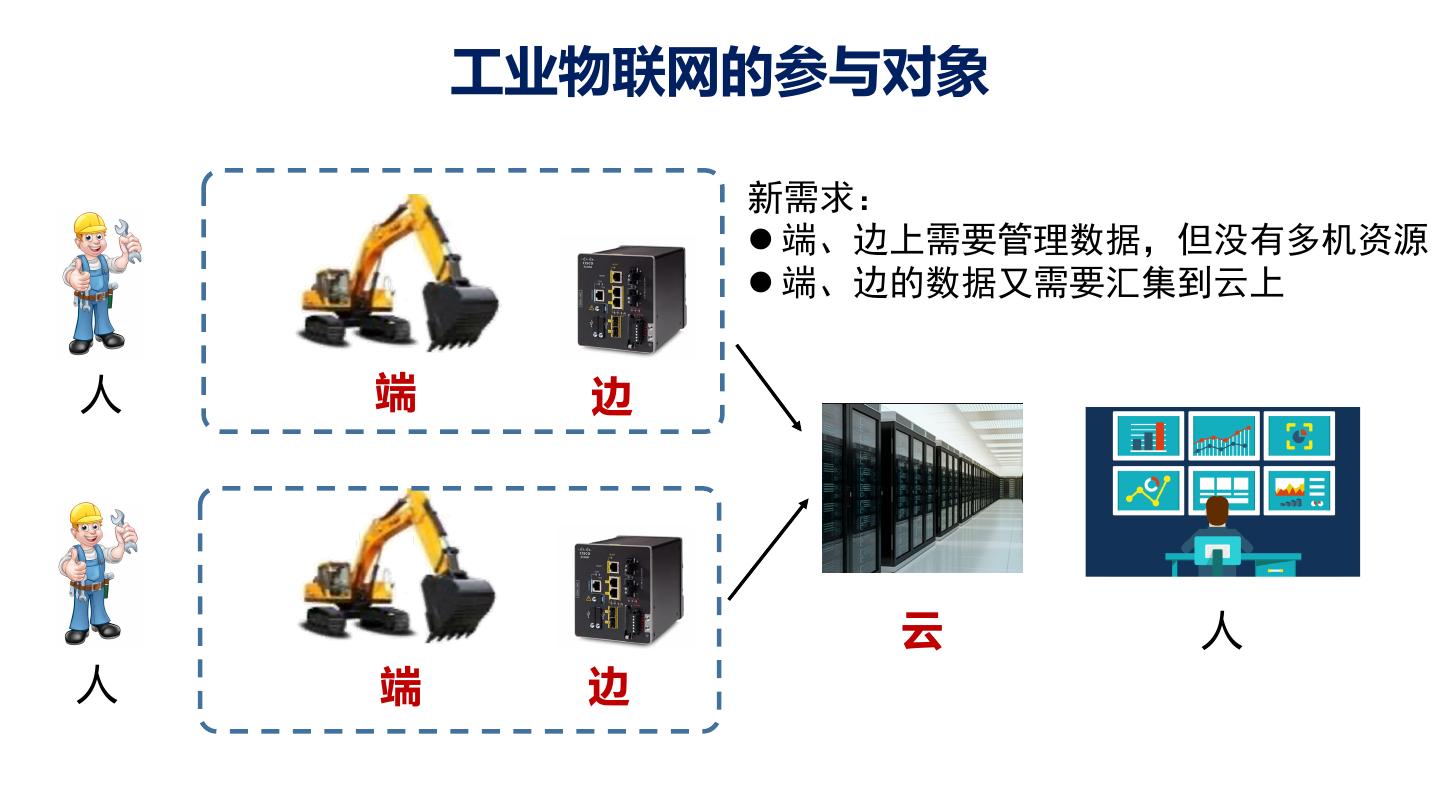
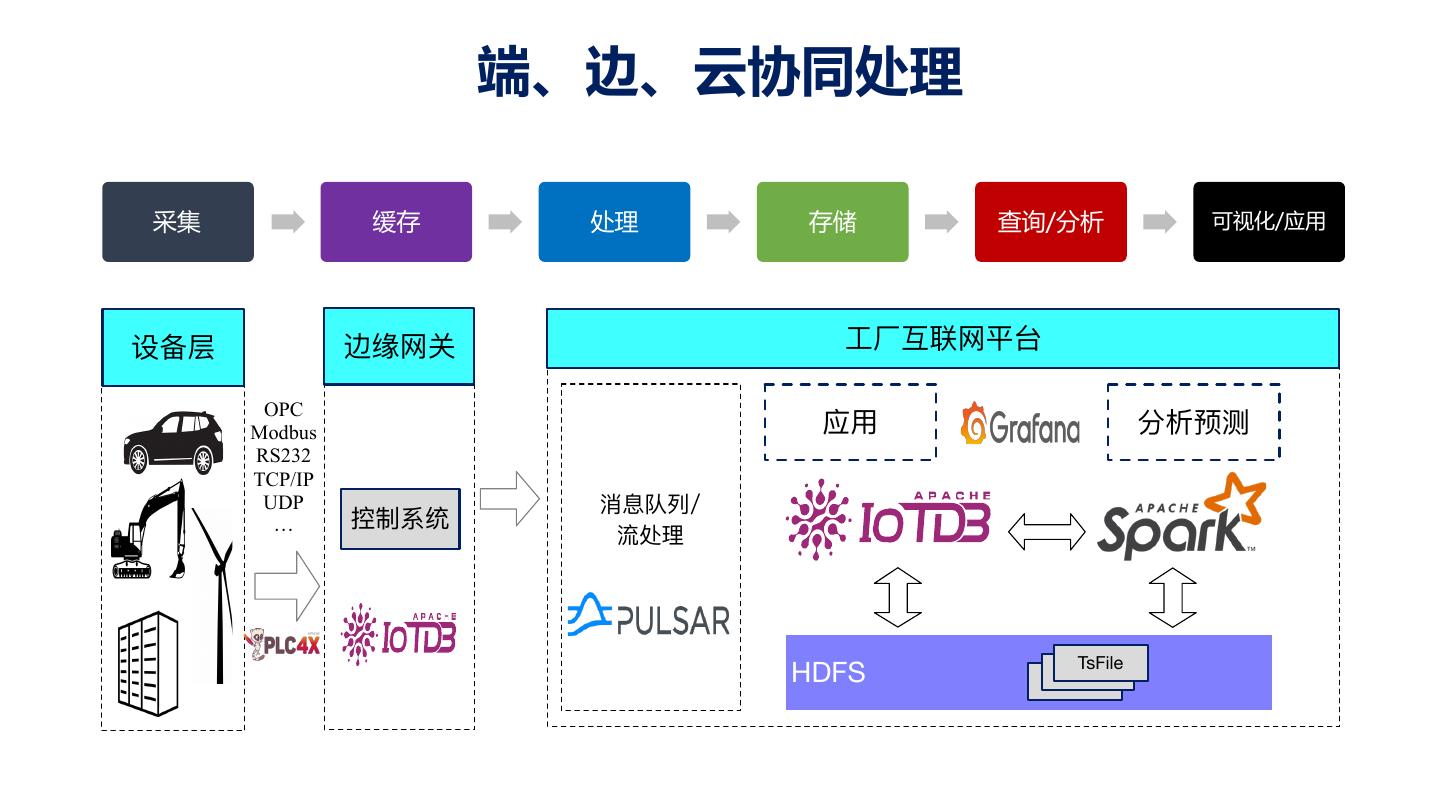
12 . 工业物联网的参与对象 新需求: l 端、边上需要管理数据,但没有多机资源 l 端、边的数据又需要汇集到云上 人 端 边 云 人 人 端 边
13 . 时序数据管理 (超高性能、超多序列) • 单表列数上限 基于关系数据库 • MySQL InnoDB 为1017列 关 基于PG开发的插件 系 •时序数据自动分区 • 单表行数不易过多 数 •查询计划做优化 原生时序数据库 • 小于1000万行 据 •定制并行查询 库 时 随着导入时间的增加 • 水平、垂直分表;分库 序 导入速率不断下降 基于LSM机制的时序库 数 基于键值数据库 •专属文件结构 • 可管理海量条时间序列 据 •专属查询优化 键 库 • 查询受限 值 基于Hbase/Cassandra • 按时间维度的查询 数 一些工业场景下 据 •时序分区键 性能下降 • 按值维度的查询 •定时任务构建索引 库 • 多序列的时间对齐查询 压缩不友好,查询不友好
14 . 目录 • 工业物联网数据管理需求 • Apache IoTDB • IoTDB设计细节 • 应用案例 • 开源解决方案
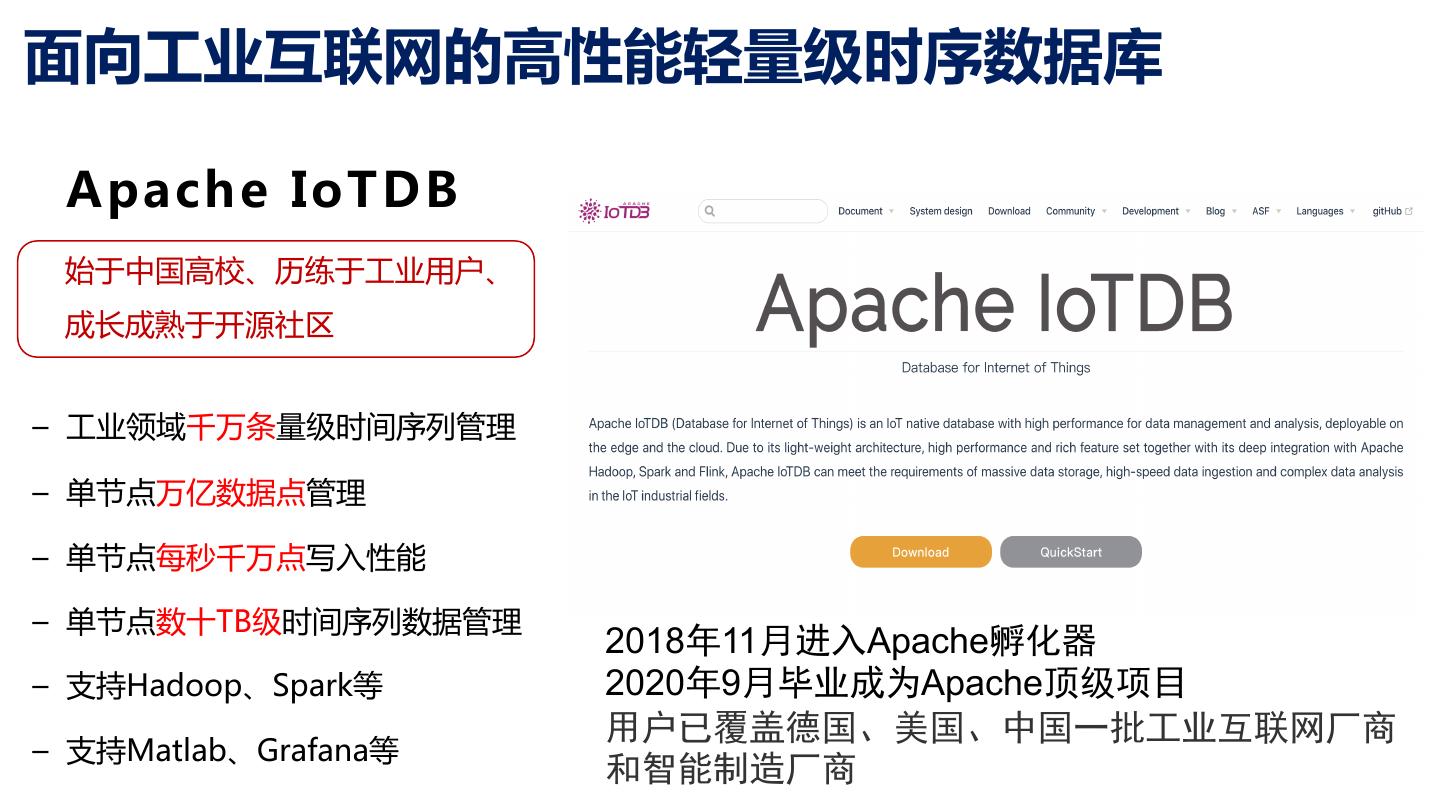
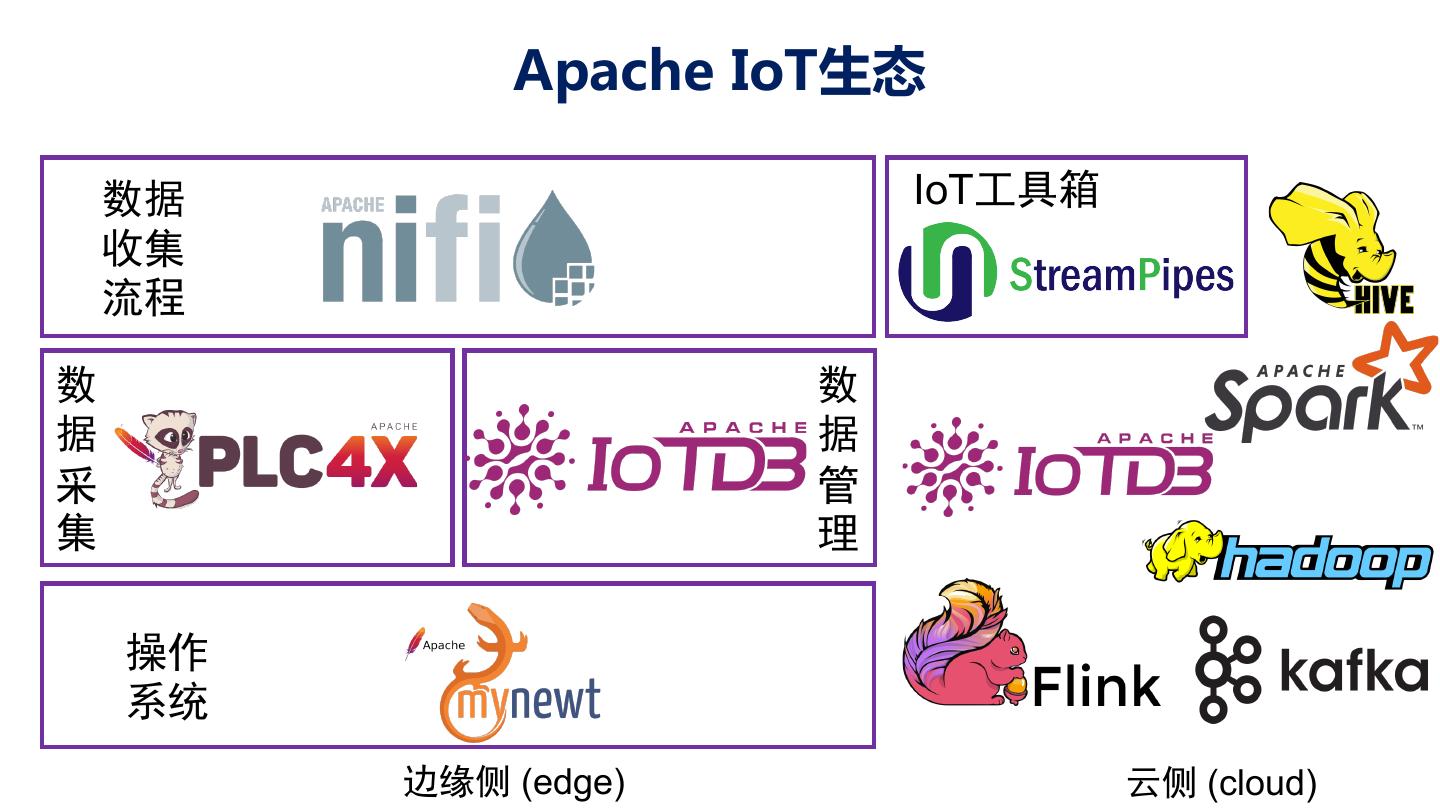
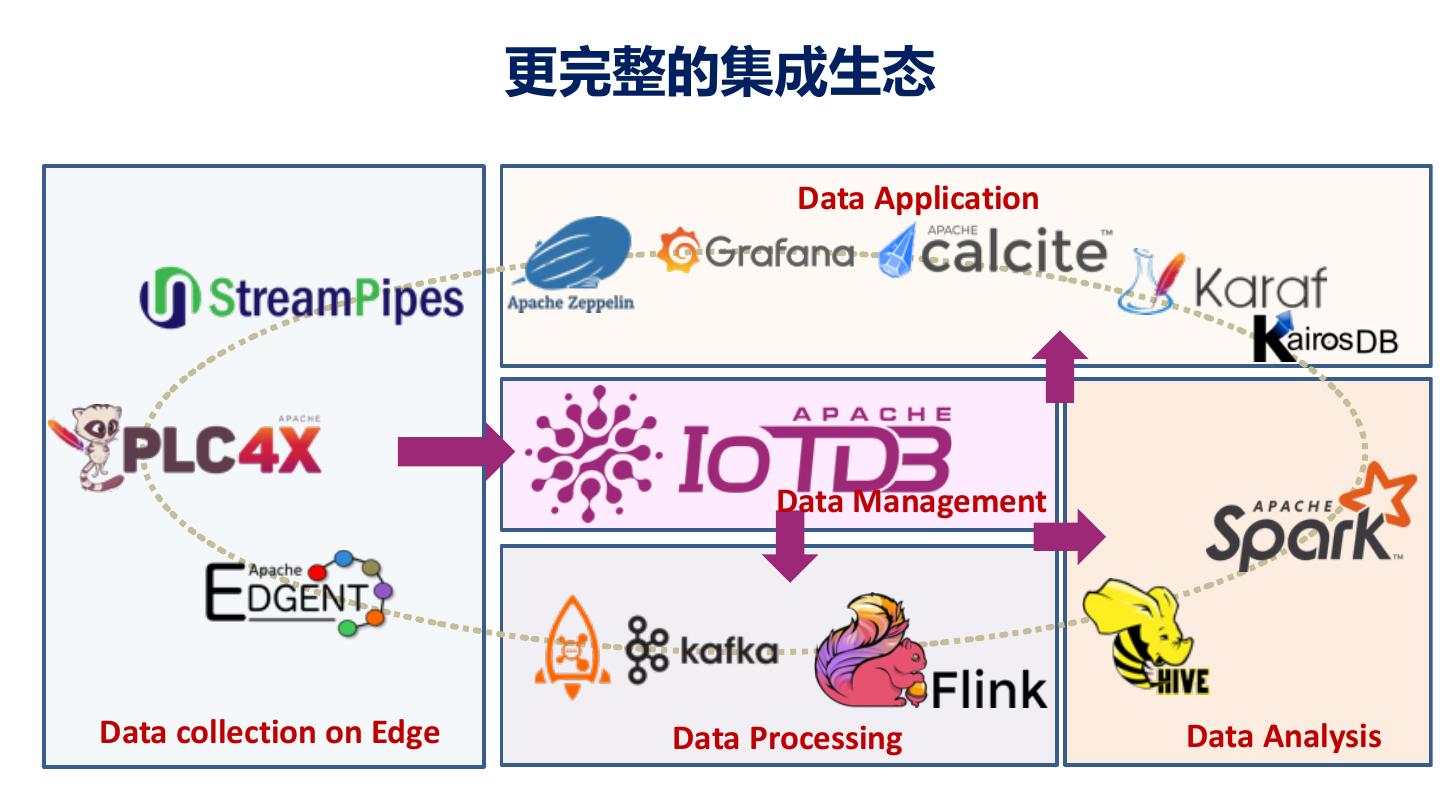
15 .面向工业互联网的高性能轻量级时序数据库 Apache IoTDB 始于中国高校、历练于工业用户、 成长成熟于开源社区 – 工业领域千万条量级时间序列管理 – 单节点万亿数据点管理 – 单节点每秒千万点写入性能 – 单节点数十TB级时间序列数据管理 2018年11月进入Apache孵化器 – 支持Hadoop、Spark等 2020年9月毕业成为Apache顶级项目 用户已覆盖德国、美国、中国一批工业互联网厂商 – 支持Matlab、Grafana等 和智能制造厂商
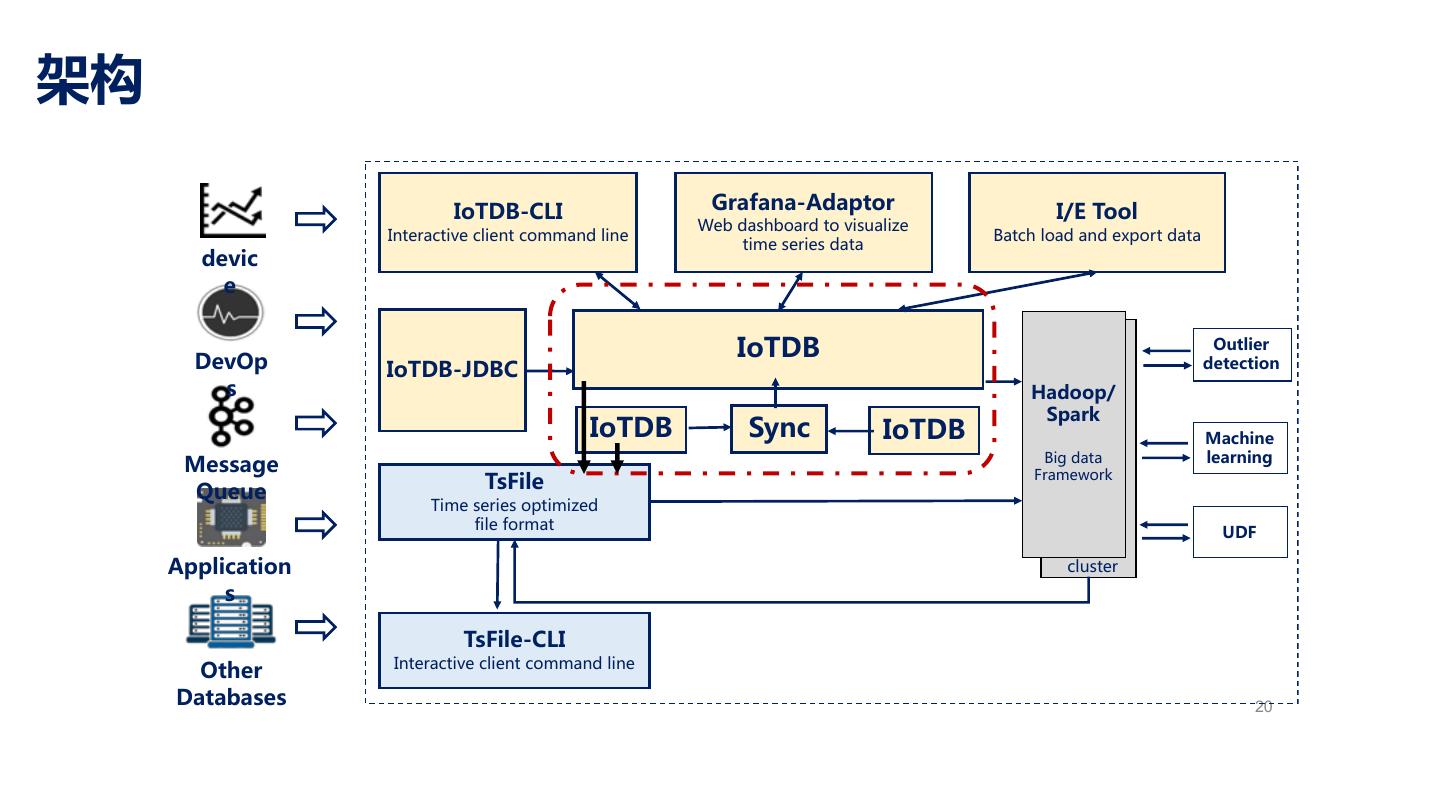
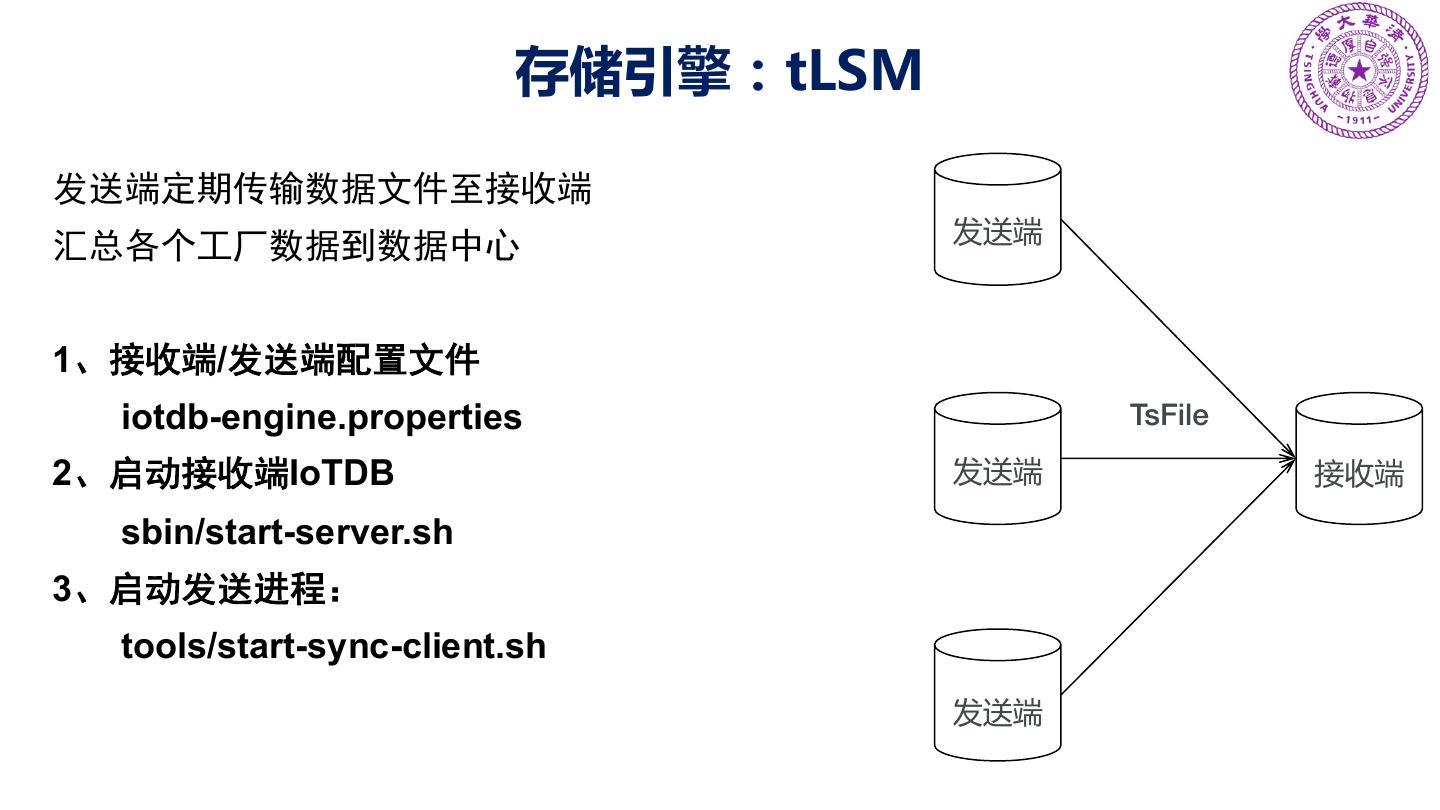
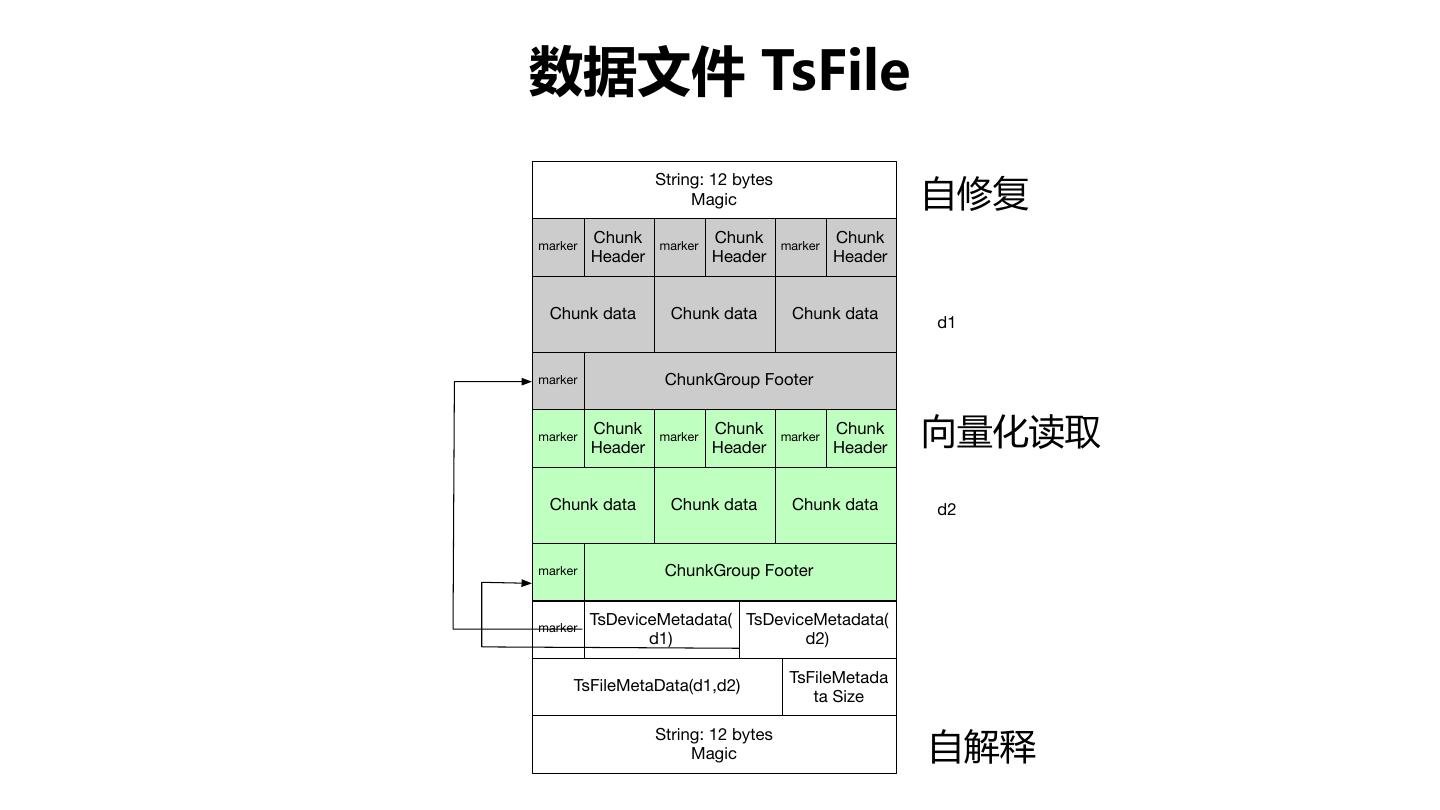
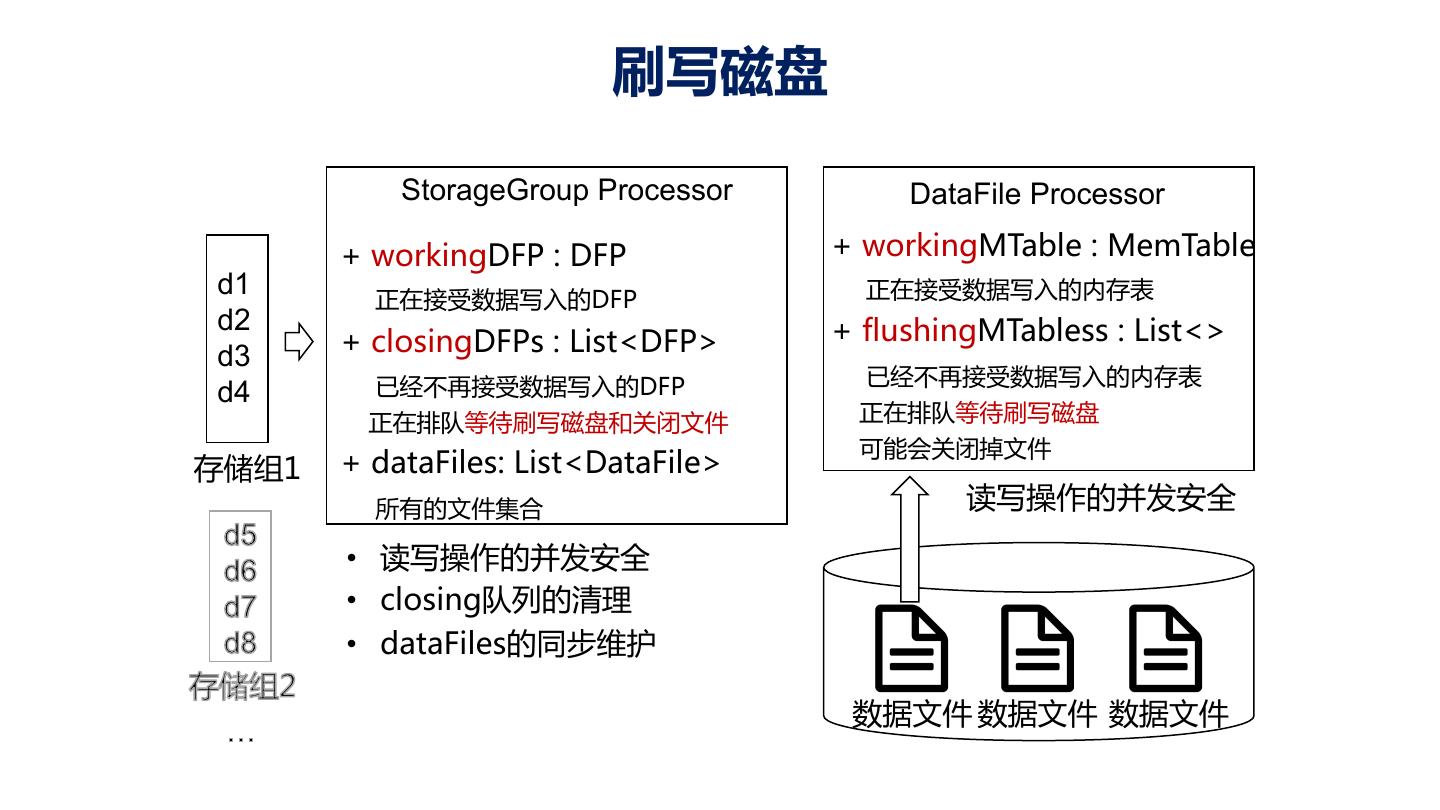
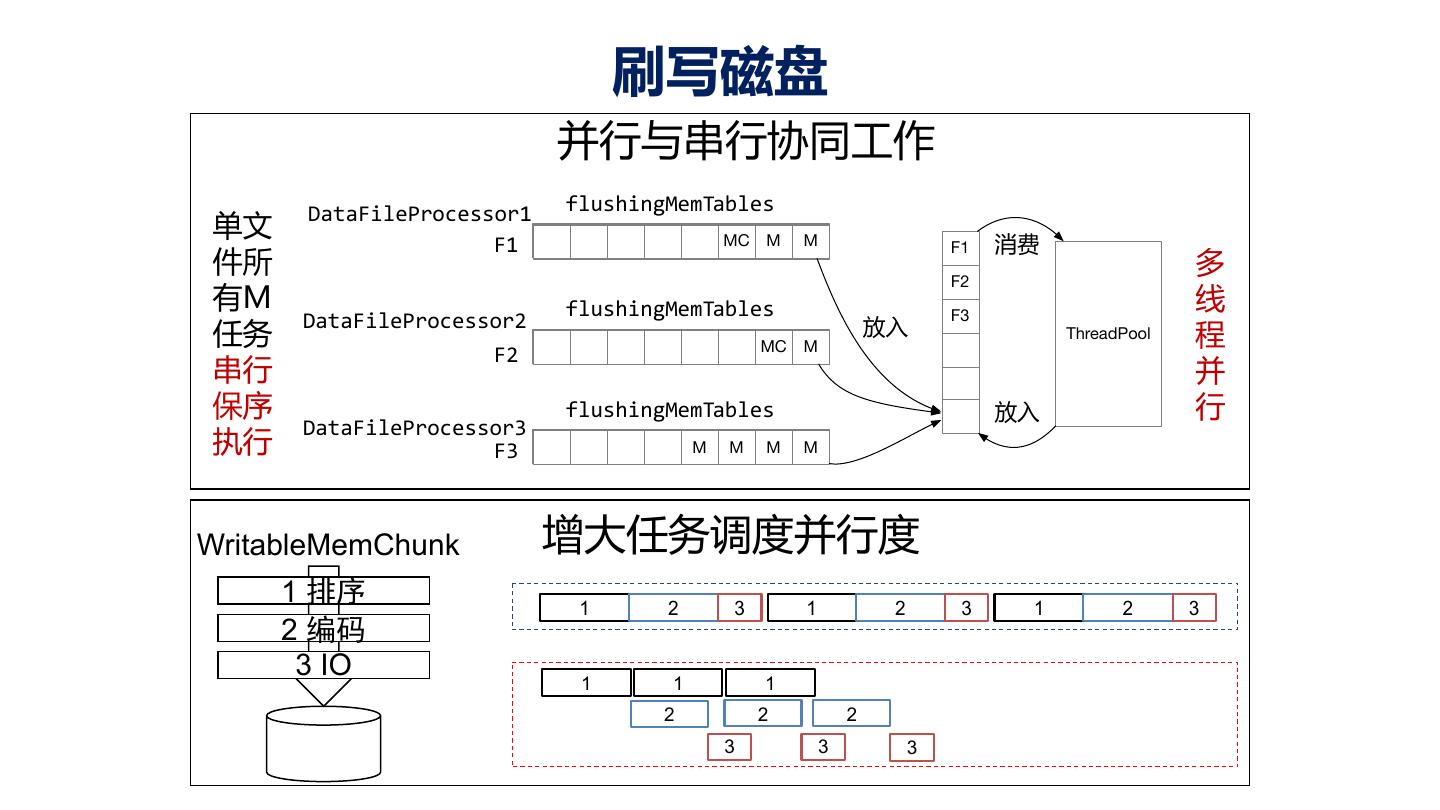
16 .架构 20
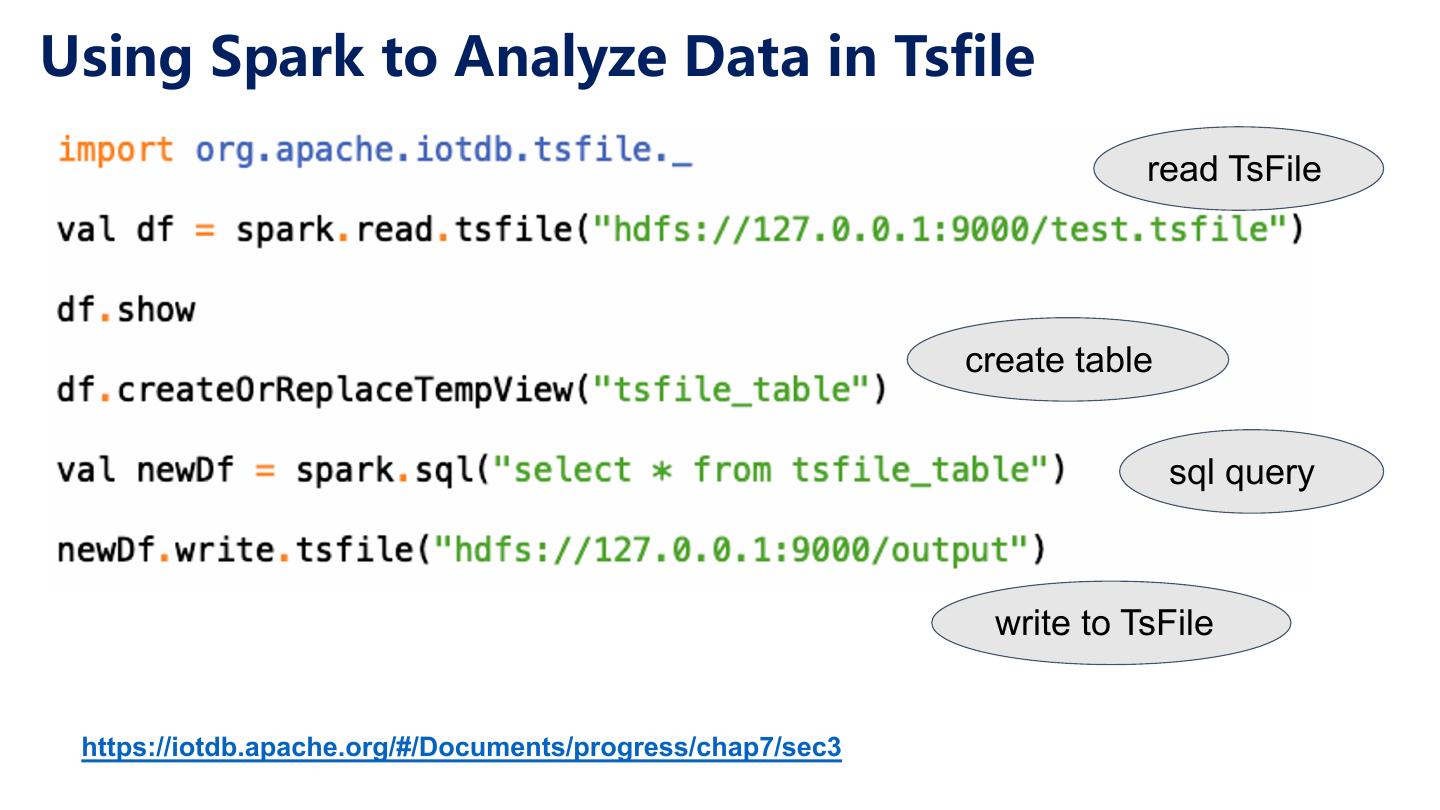
17 .产品形态:灵活适配“端-边-云”计算环境 部署在嵌入式终端设备的时序 部署在工控机等边缘计算设备 部署在云端数据中心的 “数据文件” 的时序“数据库” 时序“数据仓库” 终端(端) 场控(边) 数据中心(云) 为时序数据而生的zip文件 高效丰富的时间序列查询引擎 与大数据分析框架无缝集成 支持高性能写入,高压缩比存 提供增删改查,以及聚合查询 支持时序数据处理,挖掘分析 储,支持简单查询 时序对齐等高级功能 与机器学习
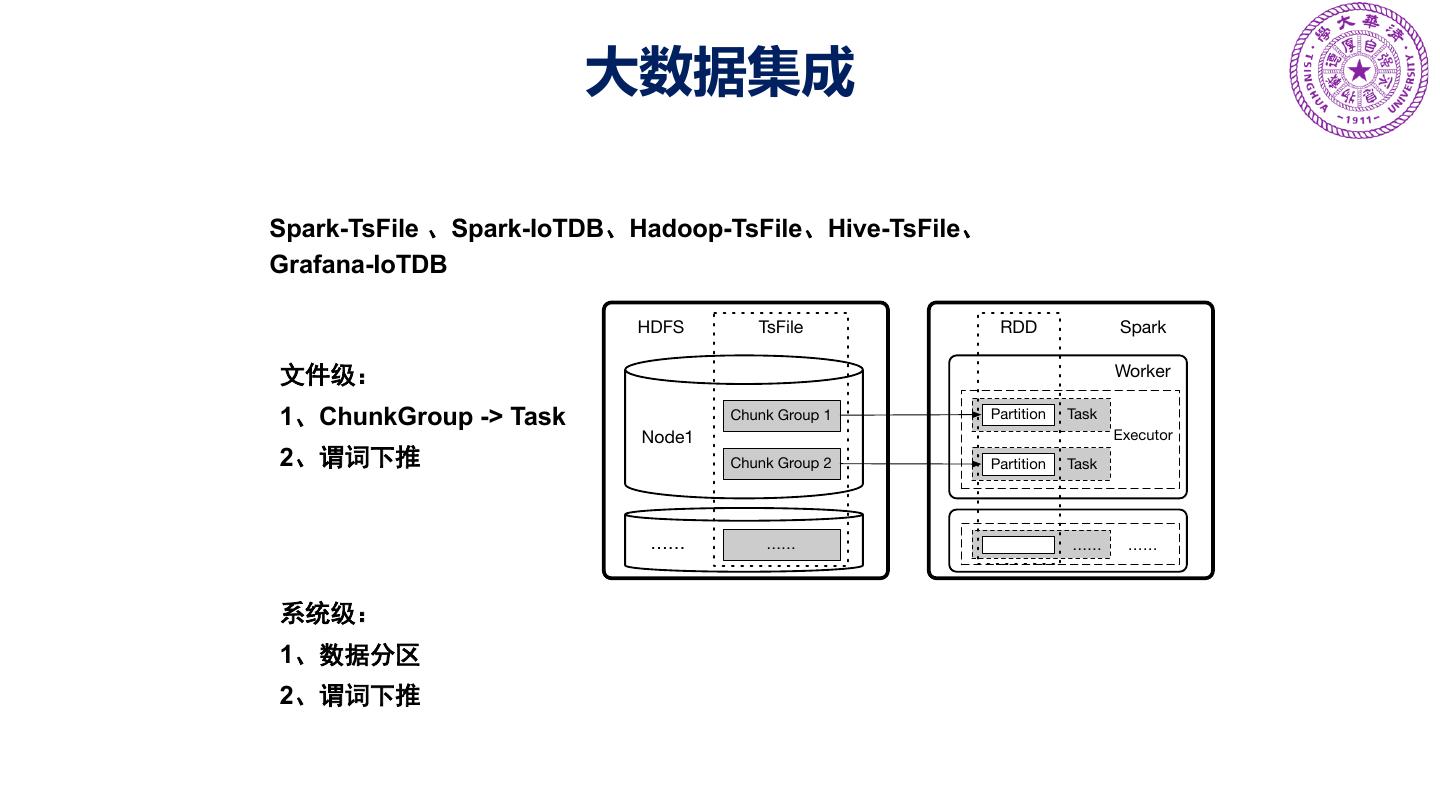
18 .生态集成 Analysis with Matlab Big data analysis Visualization (small data set) (Manual data explore) 18
19 . 基本概念 • Storage Group (存储组 / 数据库 / 设备类型) • 独立的物理存储和资源管理 Cadillac • 可管理多个设备 • root.Cadillac Device (设备) • 一个工业设备实例,可以有多个属性 • “root.Cadillac.id_7BTC409” Measurement (测点) • 部署在一个设备上的多个传感器 • “fuelRemain” 剩余油量 Time Series (时间序列) • Device + Measurement (设备+测点) • root.Cadillac.id_7BTC409.fuelRemain
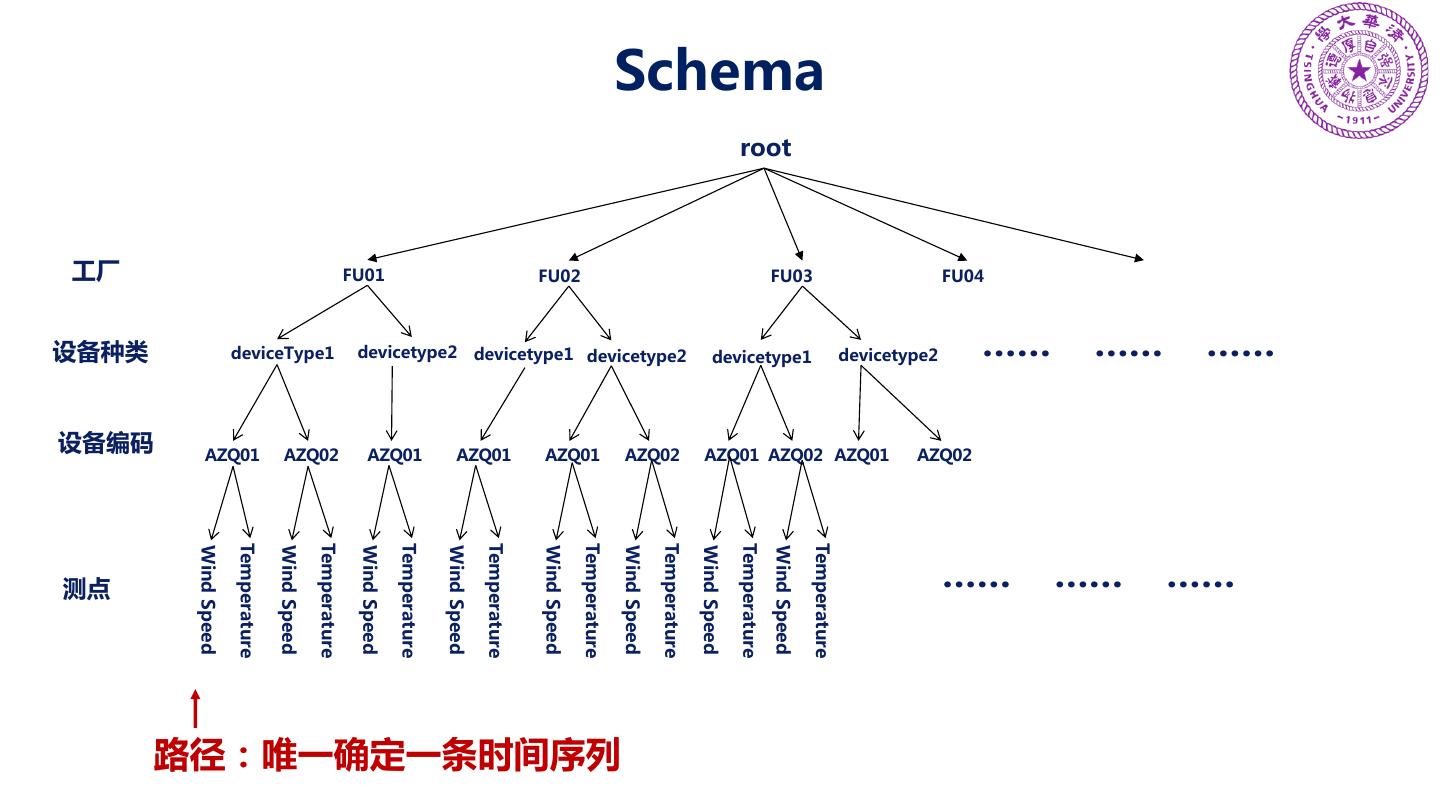
20 . Schema root 工厂 FU01 FU02 FU03 FU04 设备种类 deviceType1 devicetype2 devicetype1 devicetype2 devicetype1 devicetype2 …… …… …… 设备编码 AZQ01 AZQ02 AZQ01 AZQ01 AZQ01 AZQ02 AZQ01 AZQ02 AZQ01 AZQ02 Temperature Temperature Temperature Temperature Temperature Temperature Temperature Temperature Wind Speed Wind Speed Wind Speed Wind Speed Wind Speed Wind Speed Wind Speed Wind Speed 测点 …… …… …… 路径:唯一确定一条时间序列
21 . Schema • 场景:地铁数据管理 场景:电厂设备管理 • Storage group:地铁线路 • Storage group:设备类别(风机/ • Device:列车编号 太阳能板/逆变器) • Measurement:列车速度、开关量 • Device:设备编号 时间序列: • Measurement:风速、光照、电压 • 一号线的1701车的列车速度 时间序列: • root.metro.line1.1707.speed • 1号风机所在位置的风速 • root.turbine.1.windSpeed • 性能考虑: • root.metro.1.line1.1707.speed
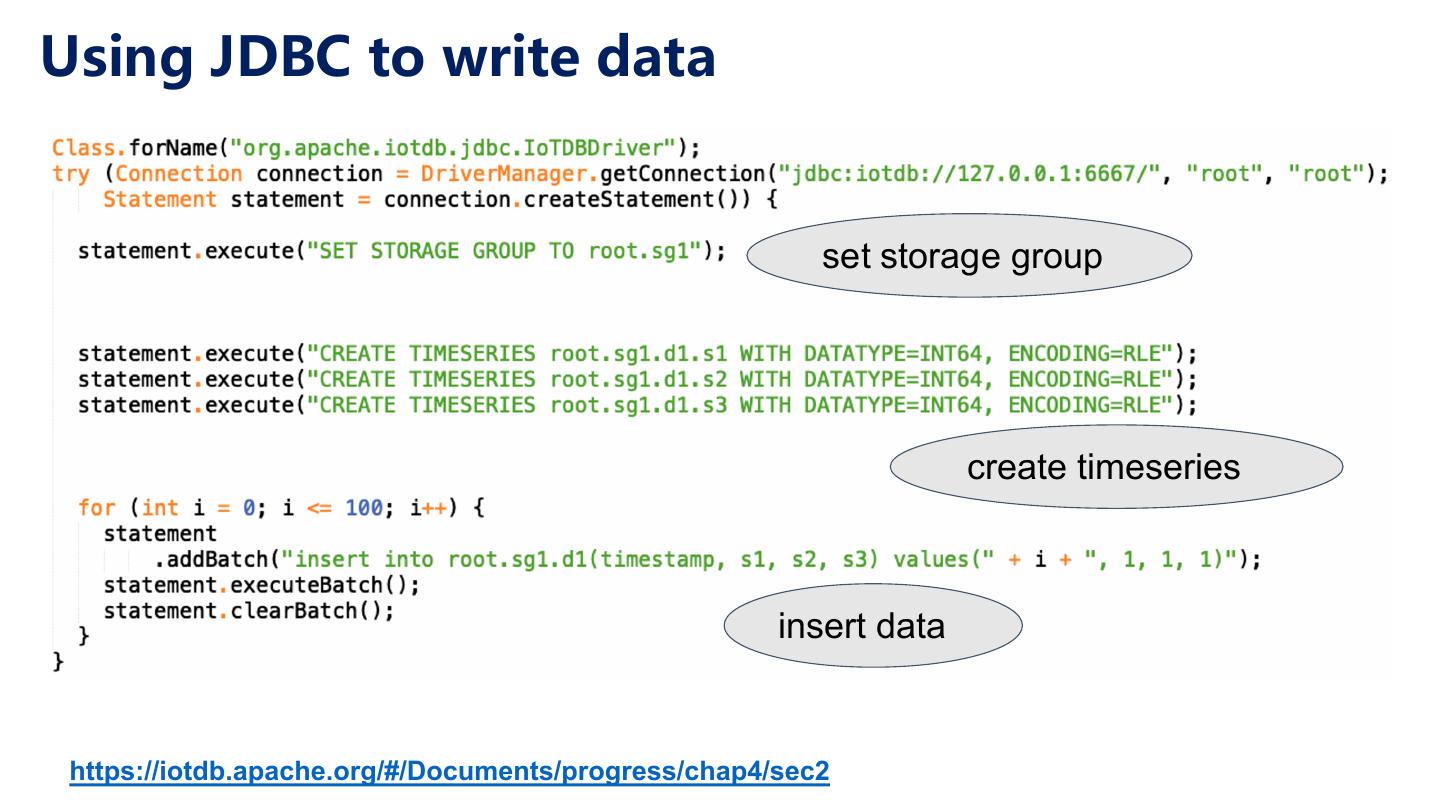
22 .SQL in IoTDB Set Storage Group SET STORAGE GROUP TO root.ln; Create Timeseries CREATE TIMESERIES root.ln.wf01.wt01.temperature WITH DATATYPE=FLOAT, ENCODING=RLE Insert Data INSERT INTO root.ln.wf02.wt02(timestamp, status) VALUES (1, true); Delete Data DELETE FROM root.ln.wf02.wt02.status WHERE time < 1000; Query Data (Filter, Aggregation, Group by time interval) SELECT count(status), max_value(temperature) FROM root.ln.wf01.wt01 GROUP BY (1h, [2017- 11-03T00:00:00, 2017-11-03T23:00:00]);
23 .Timeseries Statement Create Timeseries CREATE TIMESERIES root.ln.wf01.wt01.status WITH DATATYPE=BOOLEAN, ENCODING=PLAIN CREATE TIMESERIES root.ln.wf01.wt01.temperature WITH DATATYPE=FLOAT, ENCODING=RLE CREATE TIMESERIES root.ln.wf02.wt02.hardware WITH DATATYPE=TEXT, ENCODING=PLAIN CREATE TIMESERIES root.ln.wf02.wt02.status WITH DATATYPE=BOOLEAN, ENCODING=PLAIN CREATE TIMESERIES root.sgcc.wf03.wt01.status WITH DATATYPE=BOOLEAN, ENCODING=PLAIN CREATE TIMESERIES root.sgcc.wf03.wt01.temperature WITH DATATYPE=FLOAT, ENCODING=RLE Show Timeseries SHOW TIMESERIES root SHOW TIMESERIES root.ln Other Timeseries Operation COUNT TIMESERIES root DELETE TIMESERIES root.ln.wf01.wt01
24 .Insert and Delete Data Insert Data INSERT INTO root.ln.wf01.wt01(timestamp, status) VALUES (1, true); INSERT INTO root.ln.wf02.wt02(timestamp, status, hardware, temperature, software, type) VALUES (1, false, “v1”, 12.0, “v2”, 3); Delete Data DELETE FROM root.ln.wf02.wt02.status WHERE time < 1000; DELETE FROM root.ln.wf02.wt02.* WHERE time < 1000;
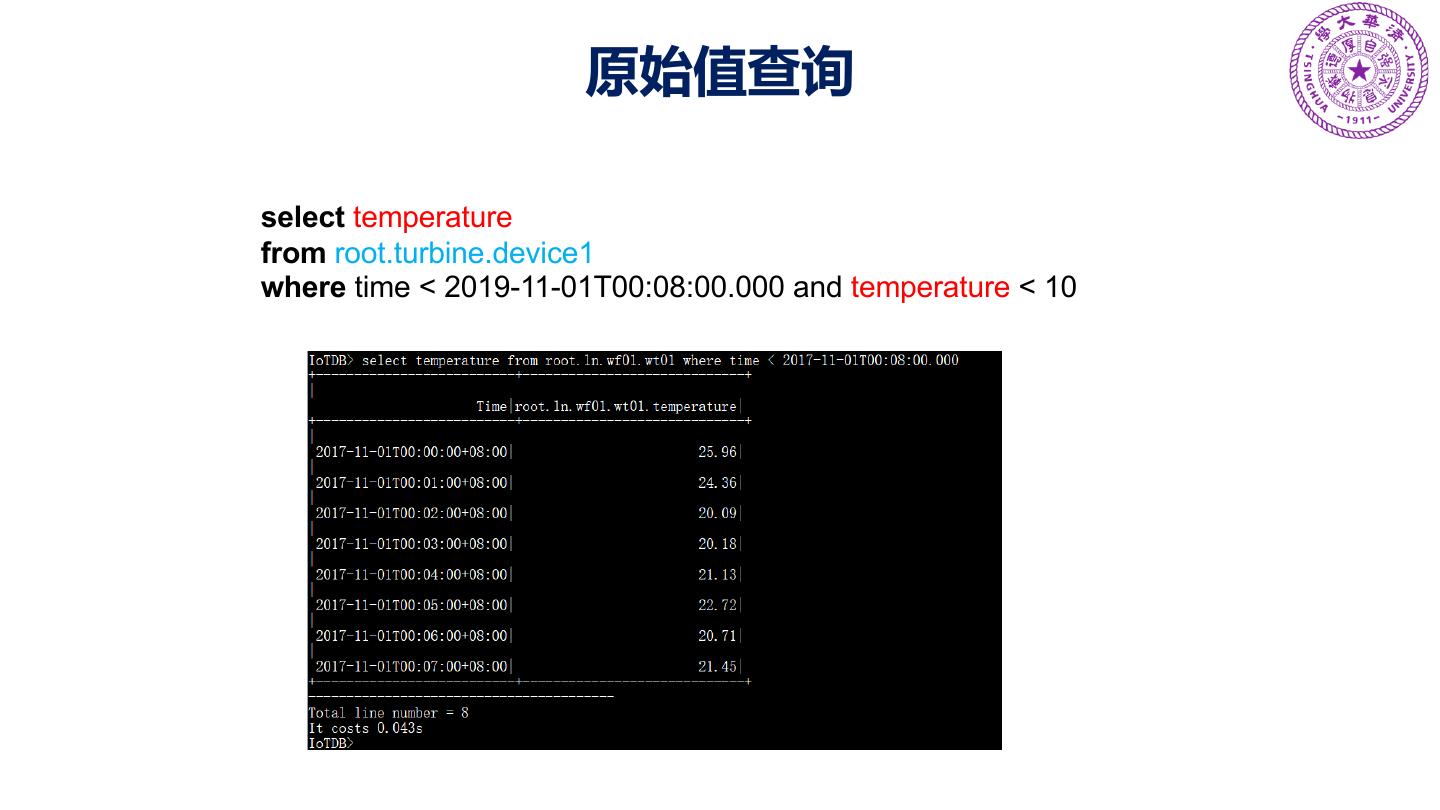
25 .Query Data Select a Column of Data Based on a Time Interval SELECT temperature FROM root.ln.wf01.wt01 WHERE time < 2017-11-01T00:08:00.000; Choose Multiple Columns of Data for Different Devices According to Multiple Time Intervals SELECT wf01.wt01.status, wf02.wt02.hardware FROM root.ln WHERE (time > 2017-11- 01T00:05:00.000 and time < 2017-11-01T00:12:00.000) or (time >= 2017-11-01T16:35:00.000 and time <= 2017-11-01T16:37:00.000);
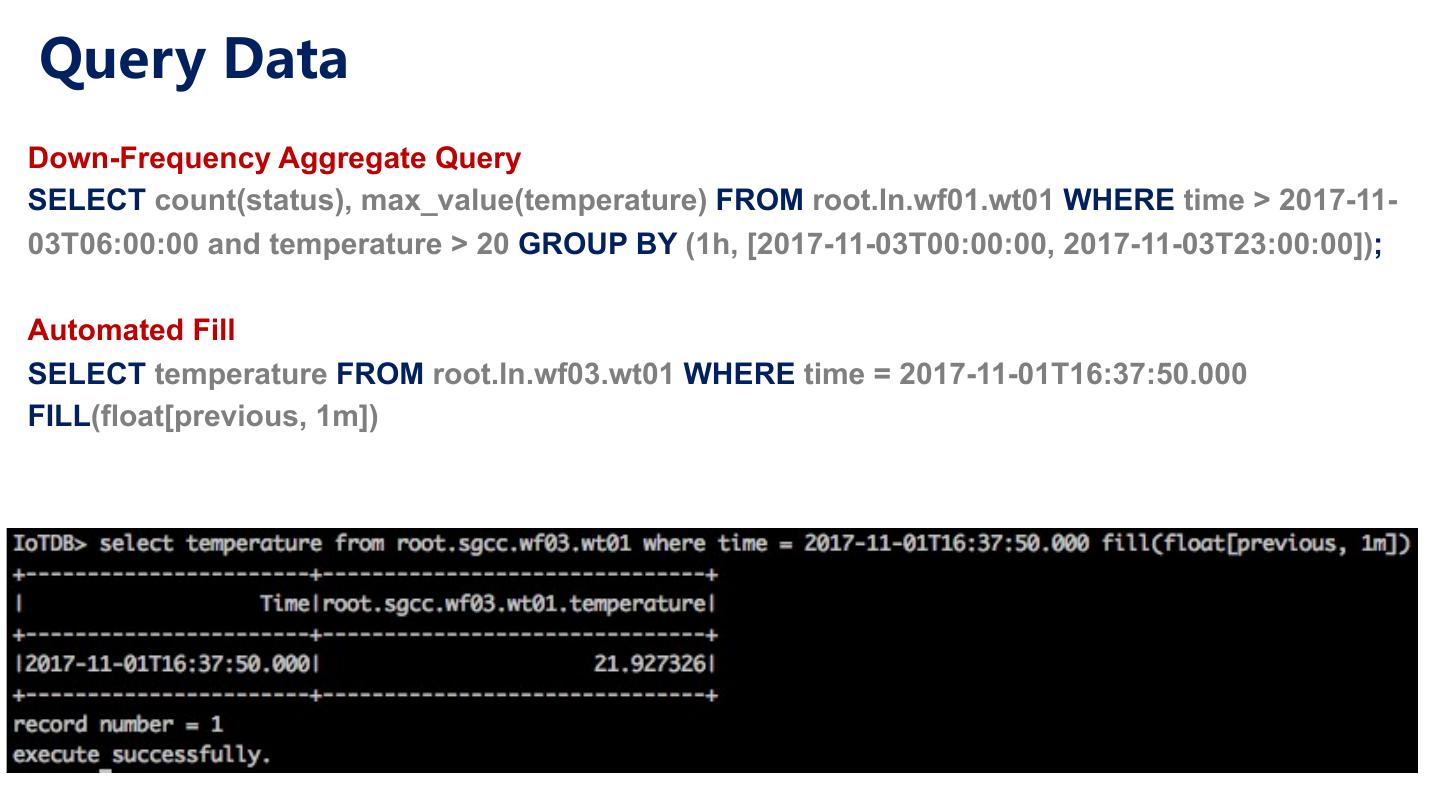
26 .Query Data Down-Frequency Aggregate Query SELECT count(status), max_value(temperature) FROM root.ln.wf01.wt01 WHERE time > 2017-11- 03T06:00:00 and temperature > 20 GROUP BY (1h, [2017-11-03T00:00:00, 2017-11-03T23:00:00]); Automated Fill SELECT temperature FROM root.ln.wf03.wt01 WHERE time = 2017-11-01T16:37:50.000 FILL(float[previous, 1m])
27 .Supported data type • Boolean • Int • Long • Float • Double • String • GPS (TODO) -> for trajectory data management • Array (TODO) -> for unstructured data management
28 .Metadata Related Statement Count Nodes Statement COUNT NODES root LEVEL=2 COUNT NODES root.ln.wf01 LEVEL=3 Show Devices Statement SHOW DEVICES Show Child Paths of Root Statement SHOW CHILD PATHS Show Child Paths Statement SHOW CHILD PATHS root SHOW CHILD PATHS root.ln.wf01
29 .TTL Statement Set TTL SET TTL to root.ln 3600000 Unset TTL UNSET TTL to root.ln
3秒后跳转登录页面
去登陆

