
























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
丁香园基于 Tableau 的 Apache Kylin 应用实践
这是2018年10月 Apache Kylin meetup@杭州站,丁香园大数据工程师所做的结合 Tableau 和 Kylin 进行大数据分析的实践。
展开查看详情
1 . 丁⾹香园 基于 TABLEAU 的 KYLIN 应⽤用实践 分享⼈人:周天鹏
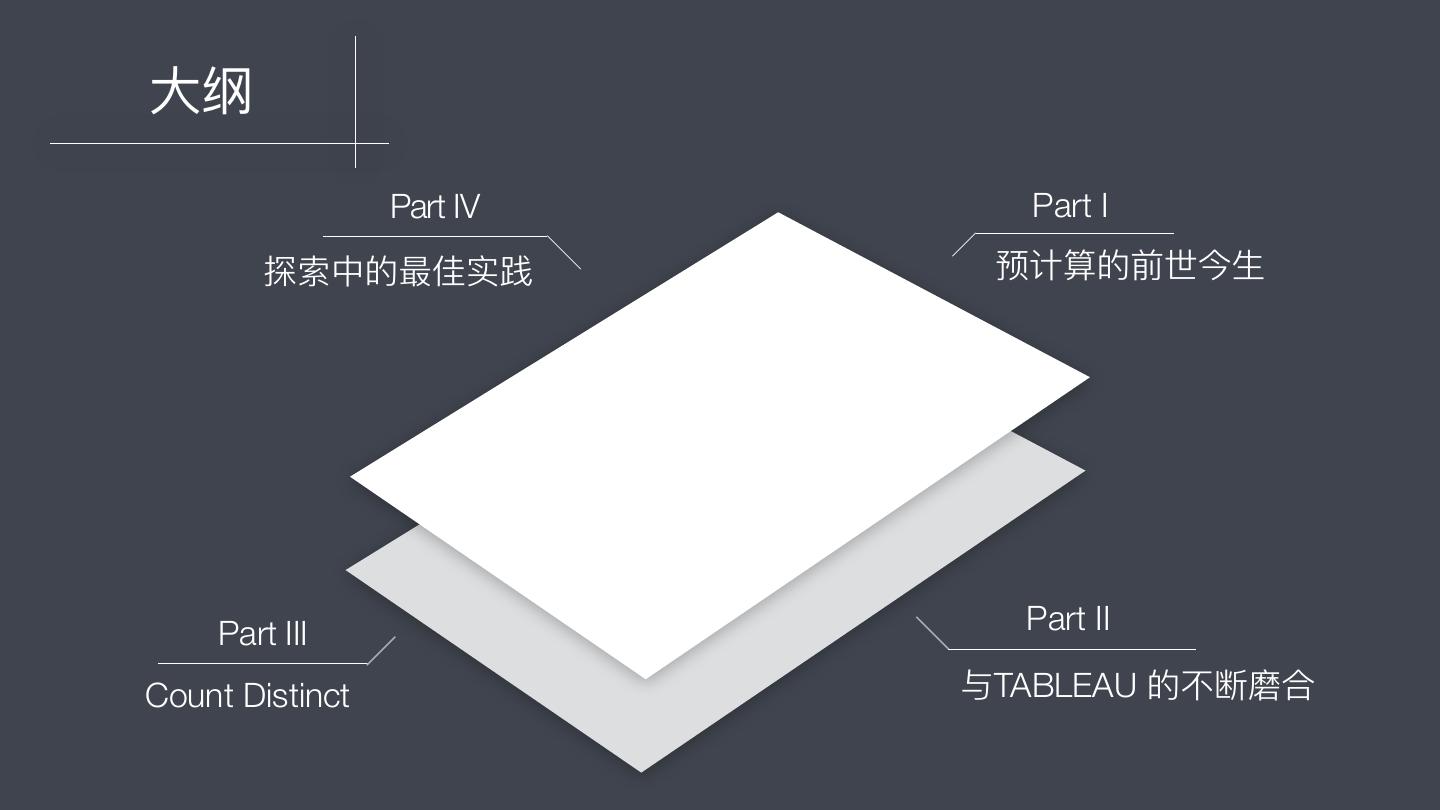
2 .⼤大纲 Part IV Part I 探索中的最佳实践 预计算的前世今⽣生 Part III Part II Count Distinct 与TABLEAU 的不不断磨合
3 . Part 01 预计算的前世今⽣生 I
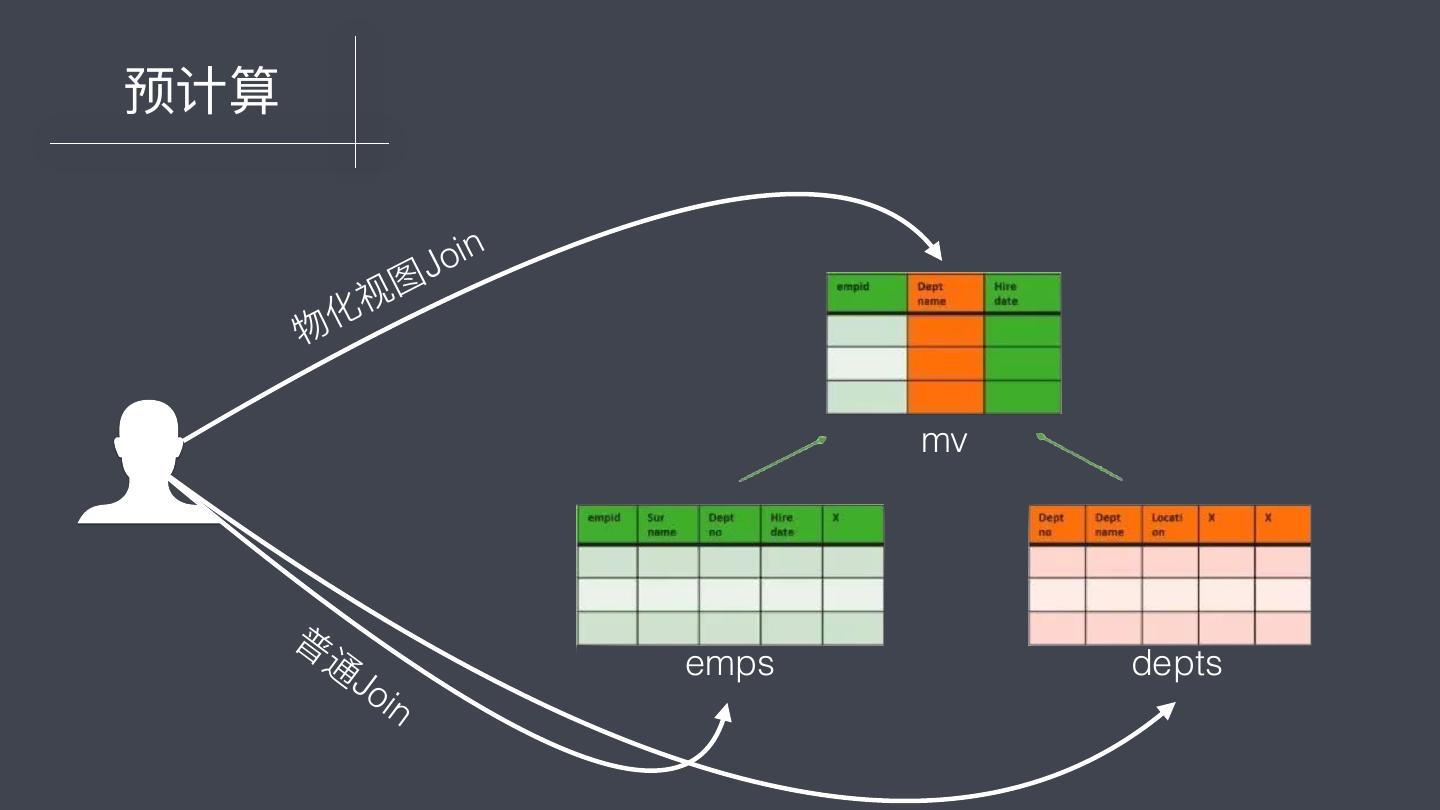
4 .预计算 Optimizing Queries Using Materialized Views: A Practical, Scalable Solution. Jonathan Goldstein & Per-Ake Larson (Microsoft), 2001
5 . 预计算 物化视图 物化视图(Materialized View)在Oracle 9i以前的版本叫做快照(SNAPSHOT), 从9i开始改名叫做物化视图。它是⽤用于预先计算并保存表连接或聚集等耗时较多 的操作的结果,这样,在执⾏行行查询时,就可以避免进⾏行行这些耗时的操作,从⽽而快 速的得到结果。 Oracle 9i 发布时间:2000 年年 10 ⽉月
6 .预计算 i n 图 Jo 化 视 物 mv 普 通 emps depts Jo in
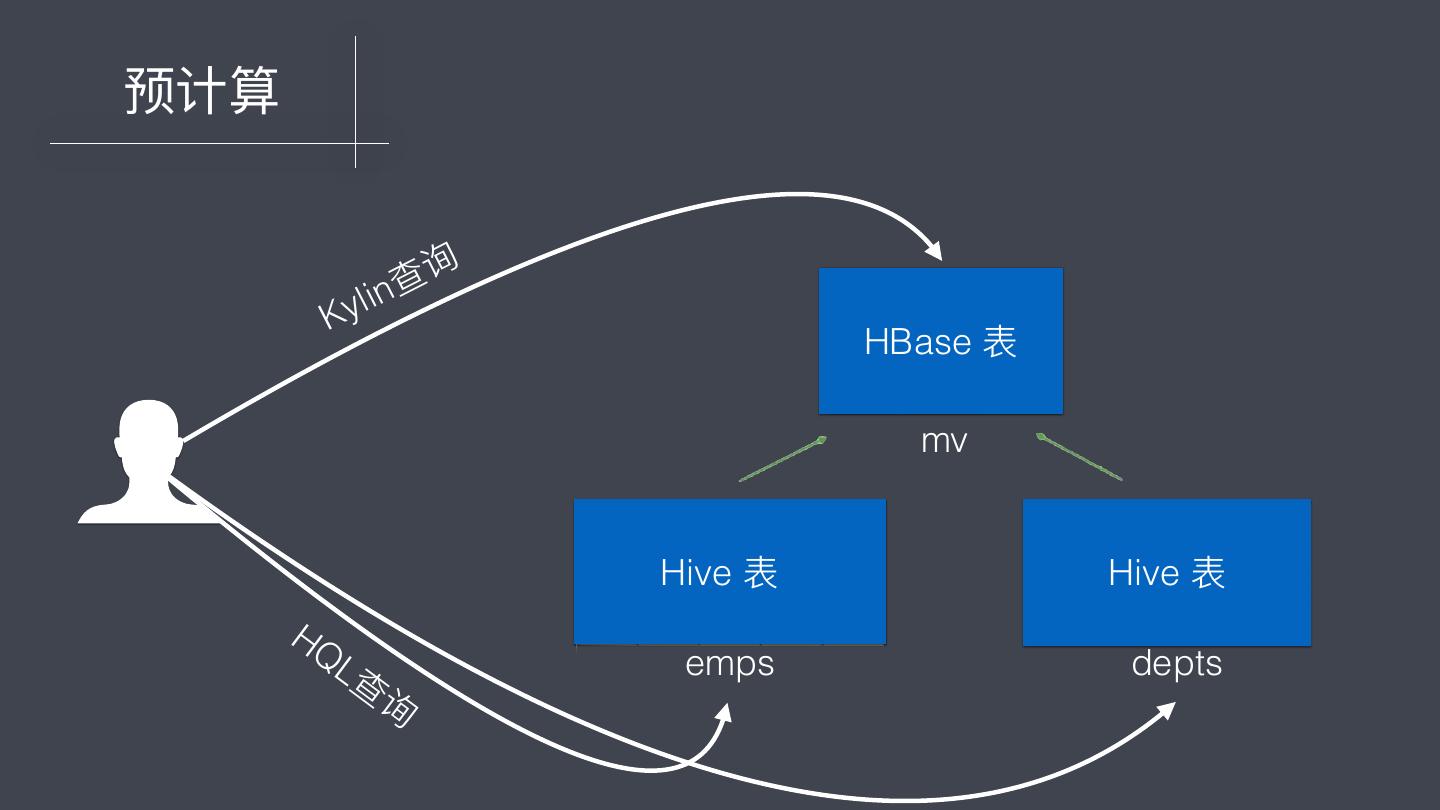
7 .预计算 查 询 y l i n K HBase 表 mv Hive 表 Hive 表 HQ L查 emps depts 询
8 .预计算
9 . Part 02 与TABLEAU的不不断磨合 II
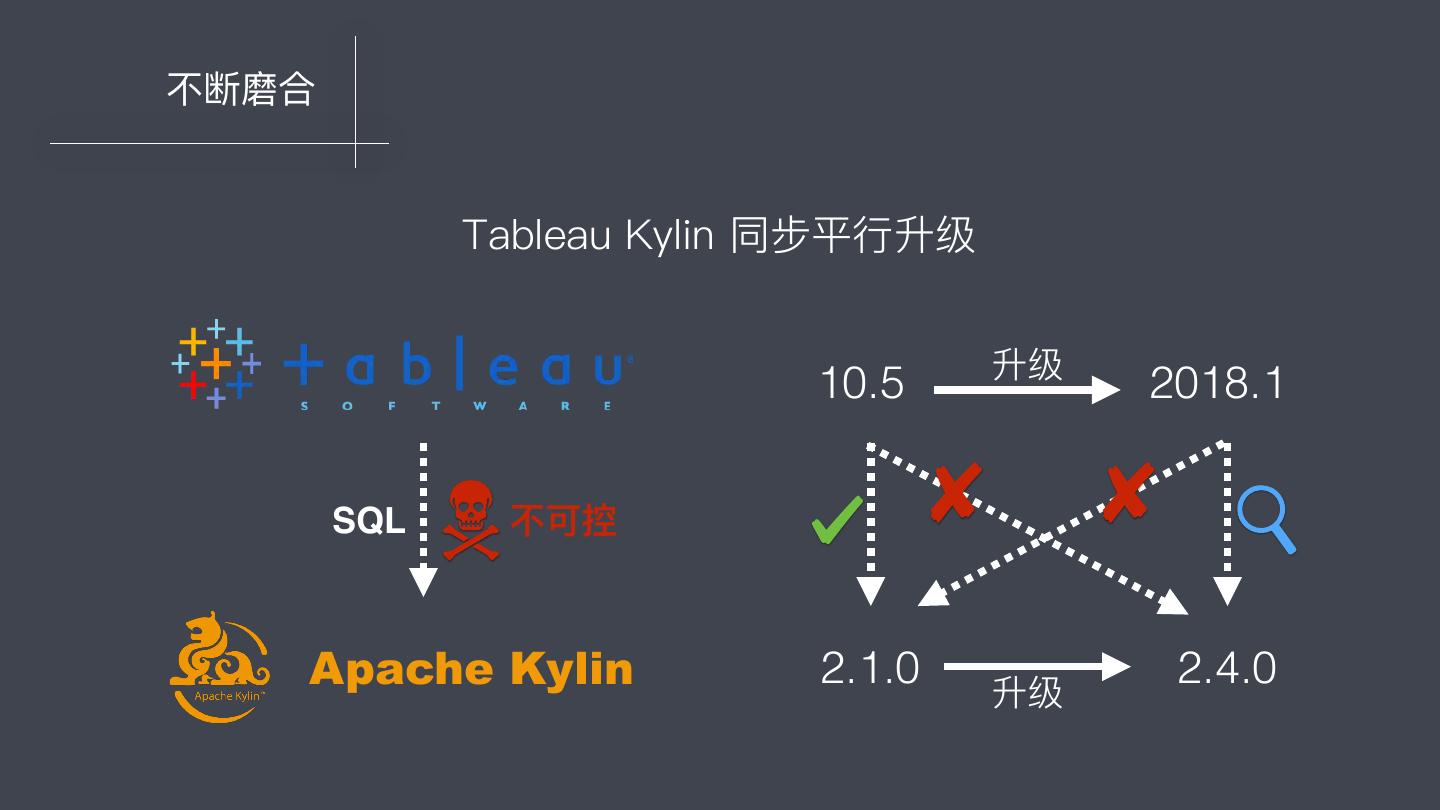
10 .不不断磨合 Tableau Kylin 同步平⾏行行升级 升级 10.5 2018.1 SQL 不不可控 Apache Kylin 2.1.0 升级 2.4.0
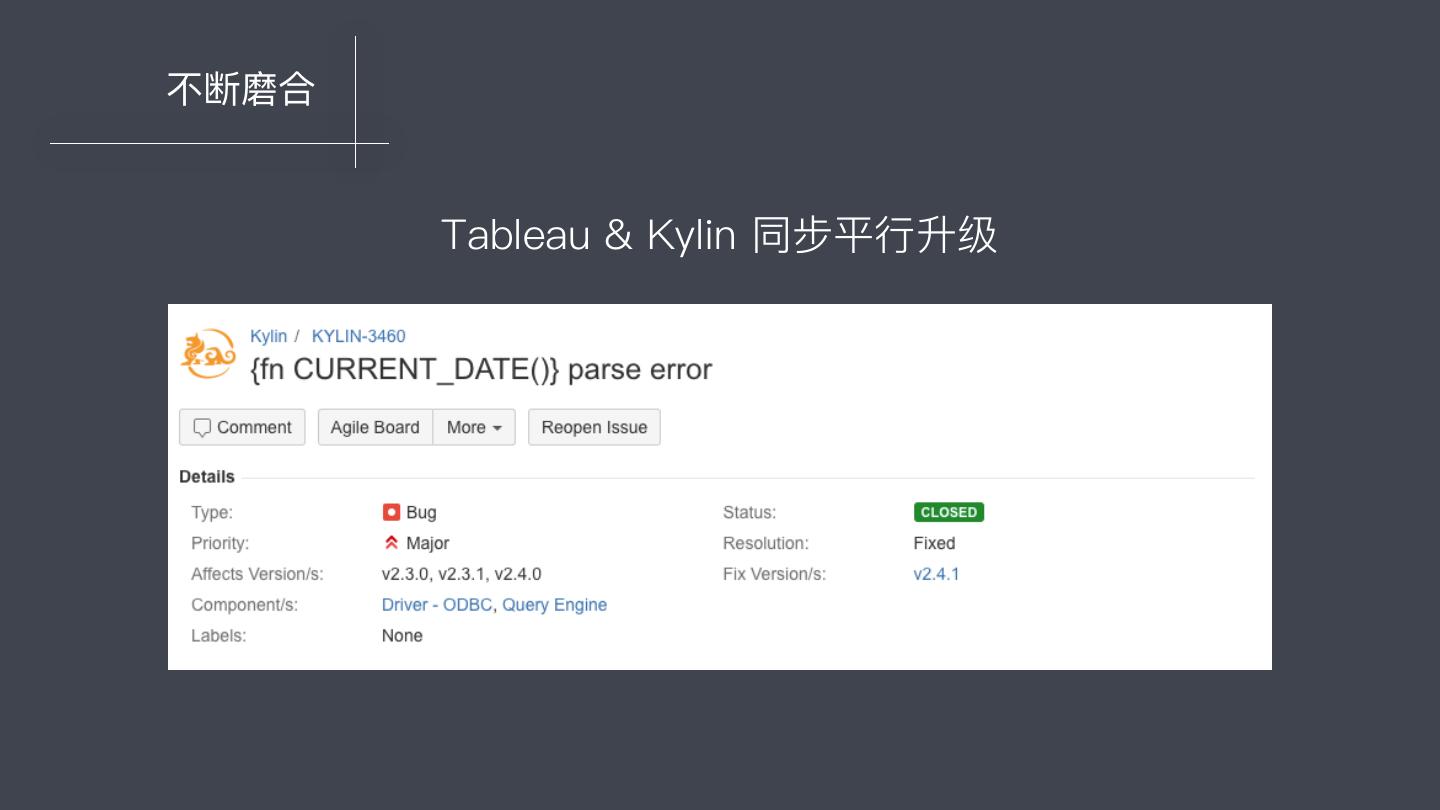
11 .不不断磨合 Tableau & Kylin 同步平⾏行行升级
12 . 不不断磨合 Tableau ⽣生成的 SQL SELECT {fn CURRENT_TIMESTAMP(0)} AS "COL" 经过 Kylin 预处理理转交给 Calcite SQL 解析引擎的 SQL SELECT CURRENT_TIMESTAMP(0) AS “COL"
13 .不不断磨合 使⽤用 Tableau 过程中 SQL 不不兼容的解决思路路: 1. 找到引起不不兼容的部分 SQL; 2. 尝试简单改写; 3. 观察 org.apache.kylin.query.util.DefaultQueryTransformer 类的 源码,尝试进⾏行行浅度定制。
14 .不不断磨合 升级后 SQL 能兼容 就万事⼤大吉? 不不⼀一定! ACL 信息处理理妥当 就万事⼤大吉? 也不不⼀一定!
15 . 不不断磨合 刚升级完的启动⽇日志 2018-08-02 11:00:34,903 DEBUG [localhost-startStop-1] hbase.HBaseConnection:306 : HTable 'kylin_metadata' already exists 2018-08-02 11:00:34,979 INFO [localhost-startStop-1] Configuration.deprecation:1274 : hadoop.native.lib is deprecated. Instead, use io.native.lib.available 2018-08-02 11:00:35,226 DEBUG [localhost-startStop-1] cachesync.CachedCrudAssist:118 : Reloading AclRecord from kylin_metadata(key='/acl')@kylin_metadata@hbase 2018-08-02 11:02:30,744 DEBUG [localhost-startStop-1] cachesync.CachedCrudAssist:127 : Loaded 123742 AclRecord(s) out of 123742 resource 2018-08-02 11:02:30,793 INFO [localhost-startStop-1] common.KylinConfig:428 : Creating new manager instance of class org.apache.kylin.metadata.cachesync.Broadcaster 2018-08-02 11:02:30,796 DEBUG [localhost-startStop-1] cachesync.Broadcaster:101 : 4 nodes in the cluster: [t1:7070, t2:7070, t3:7070, t4:7070]
16 .不不断磨合 Cube 级 ACL 信息膨胀问题的解决思路路: 扫描 HBase 中存储 Kylin 元数据的 kylin_metadata 表中以 /acl 开 头的所有记录并解析: Loaded 123742 AclRecord(s) out of 123742 resource cube: 122477 project: 1210 直接删除废弃的 12w 条 Cube 级 ACL 信息即可
17 . 不不断磨合 清理理掉废弃的 Cube 级 ACL 信息后的启动⽇日志 2018-08-02 18:50:27,402 DEBUG [localhost-startStop-1] hbase.HBaseConnection:306 : HTable 'kylin_metadata' already exists 2018-08-02 18:50:27,478 INFO [localhost-startStop-1] Configuration.deprecation:1274 : hadoop.native.lib is deprecated. Instead, use io.native.lib.available 2018-08-02 18:50:27,674 DEBUG [localhost-startStop-1] cachesync.CachedCrudAssist:118 : Reloading AclRecord from kylin_metadata(key='/acl')@kylin_metadata@hbase 2018-08-02 18:50:30,541 DEBUG [localhost-startStop-1] cachesync.CachedCrudAssist:127 : Loaded 1265 AclRecord(s) out of 1265 resource 2018-08-02 18:50:30,582 INFO [localhost-startStop-1] common.KylinConfig:428 : Creating new manager instance of class org.apache.kylin.metadata.cachesync.Broadcaster 2018-08-02 18:50:30,585 DEBUG [localhost-startStop-1] cachesync.Broadcaster:101 : 4 nodes in the cluster: [t1:7070, t2:7070, t3:7070, t4:7070]
18 . Part 03 Count Distinct III
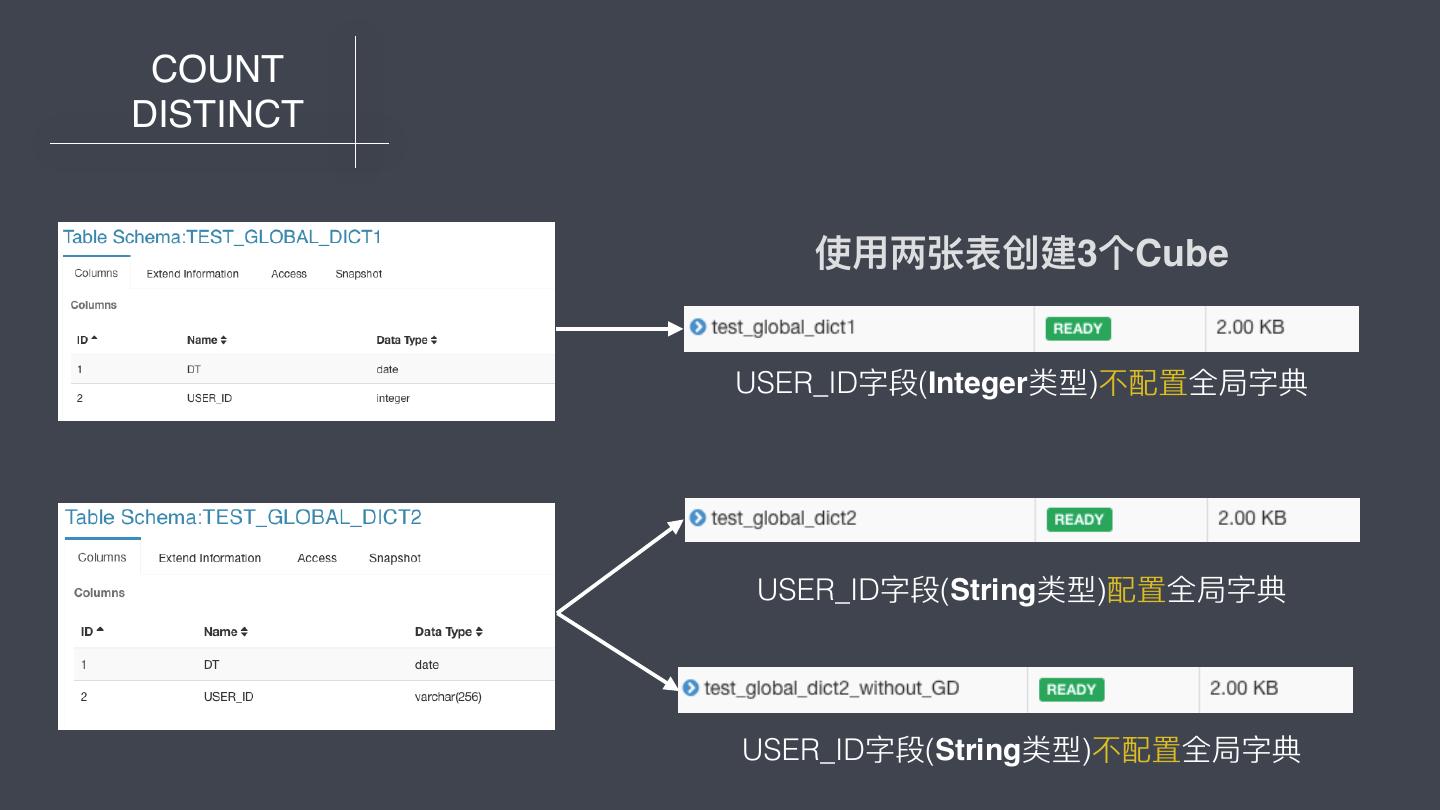
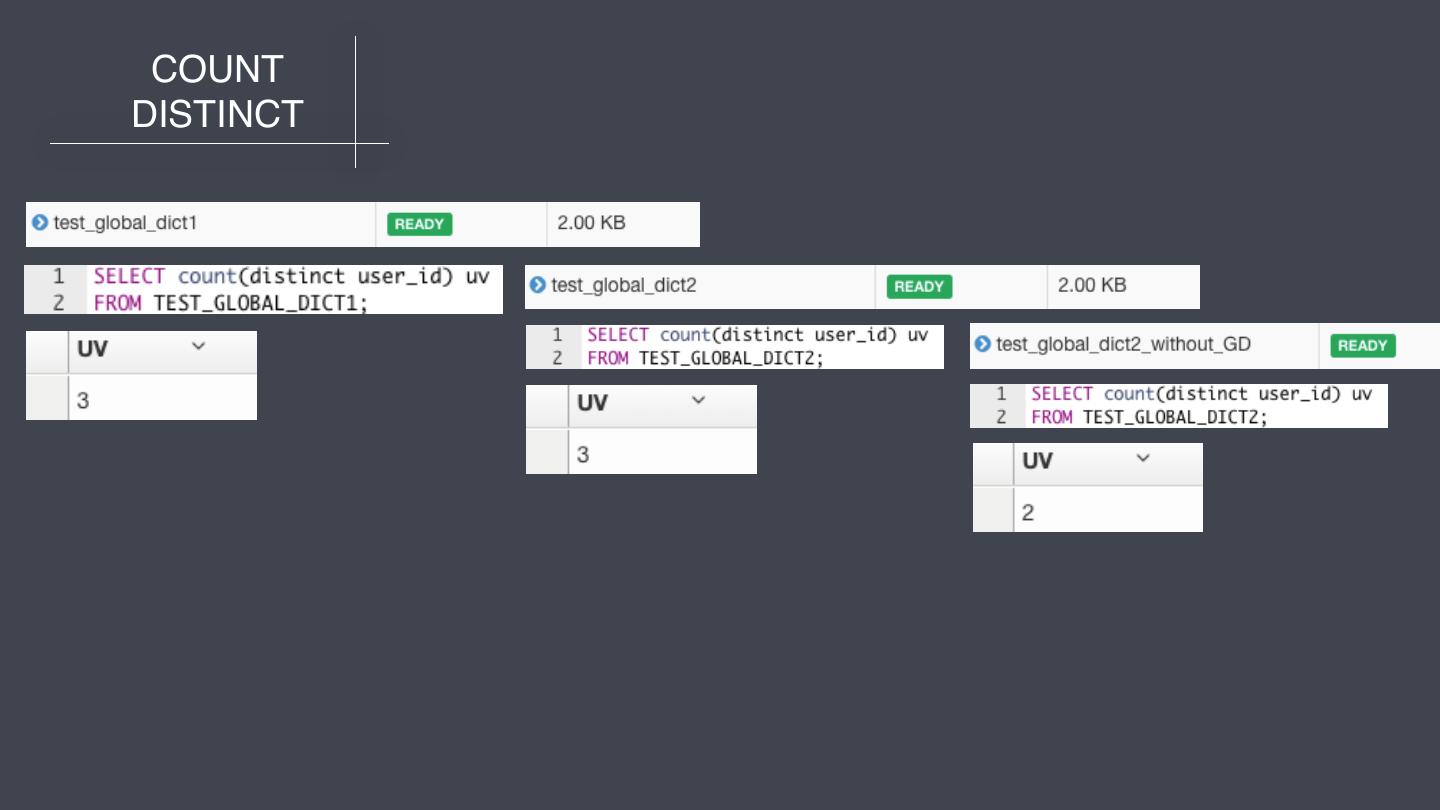
19 . COUNT DISTINCT 两表中的数据如下所示,完全相同 分区:2016-06-08 分区:2016-06-09 DT USER_ID DT USER_ID 2016-06-08 1 2016-06-09 2 2016-06-08 2 2016-06-09 3 2016-06-08 1 2016-06-09 2 2016-06-08 2 2016-06-09 3
20 . COUNT DISTINCT 使⽤用两张表创建3个Cube USER_ID字段(Integer类型)不不配置全局字典 USER_ID字段(String类型)配置全局字典 USER_ID字段(String类型)不不配置全局字典
21 . COUNT DISTINCT
22 . COUNT DISTINCT
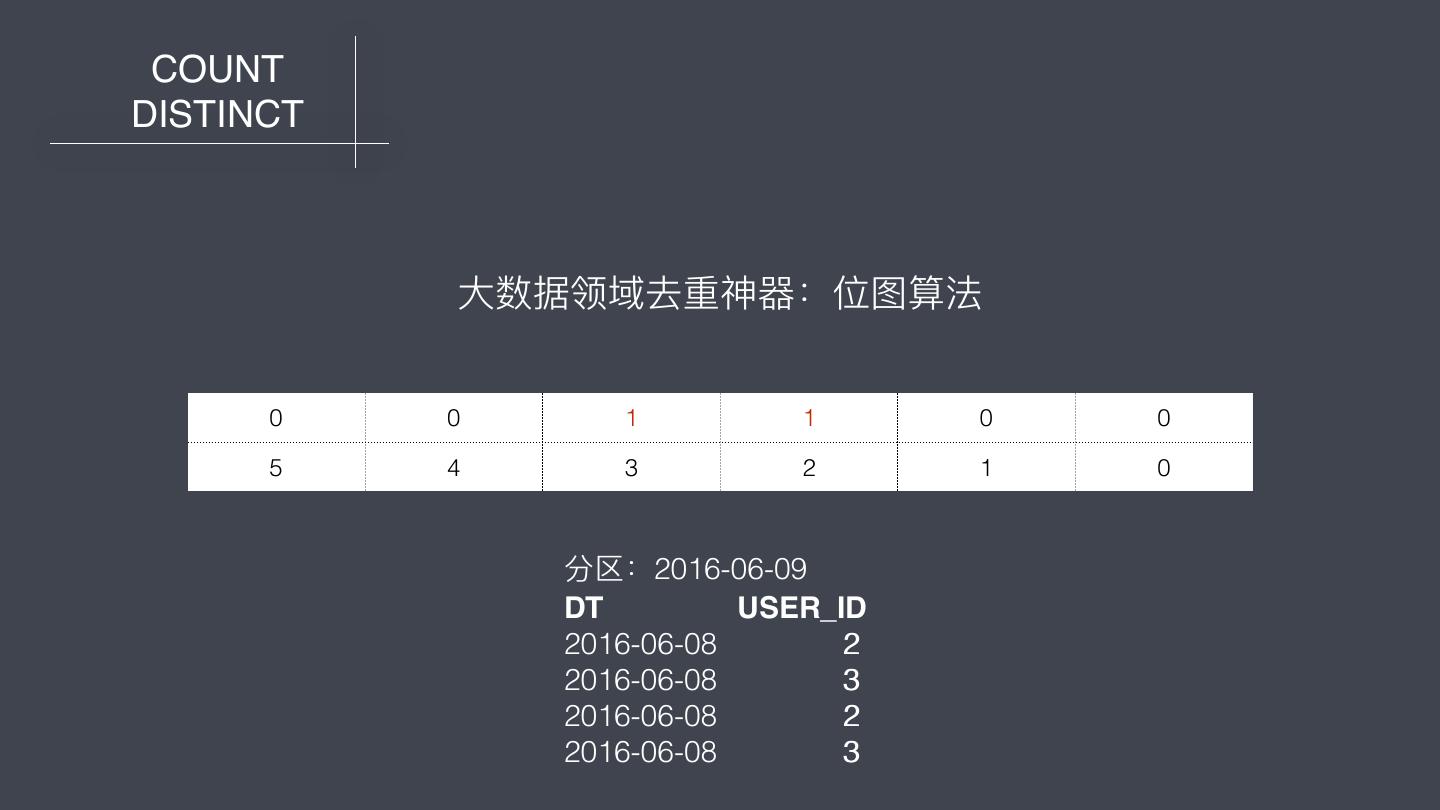
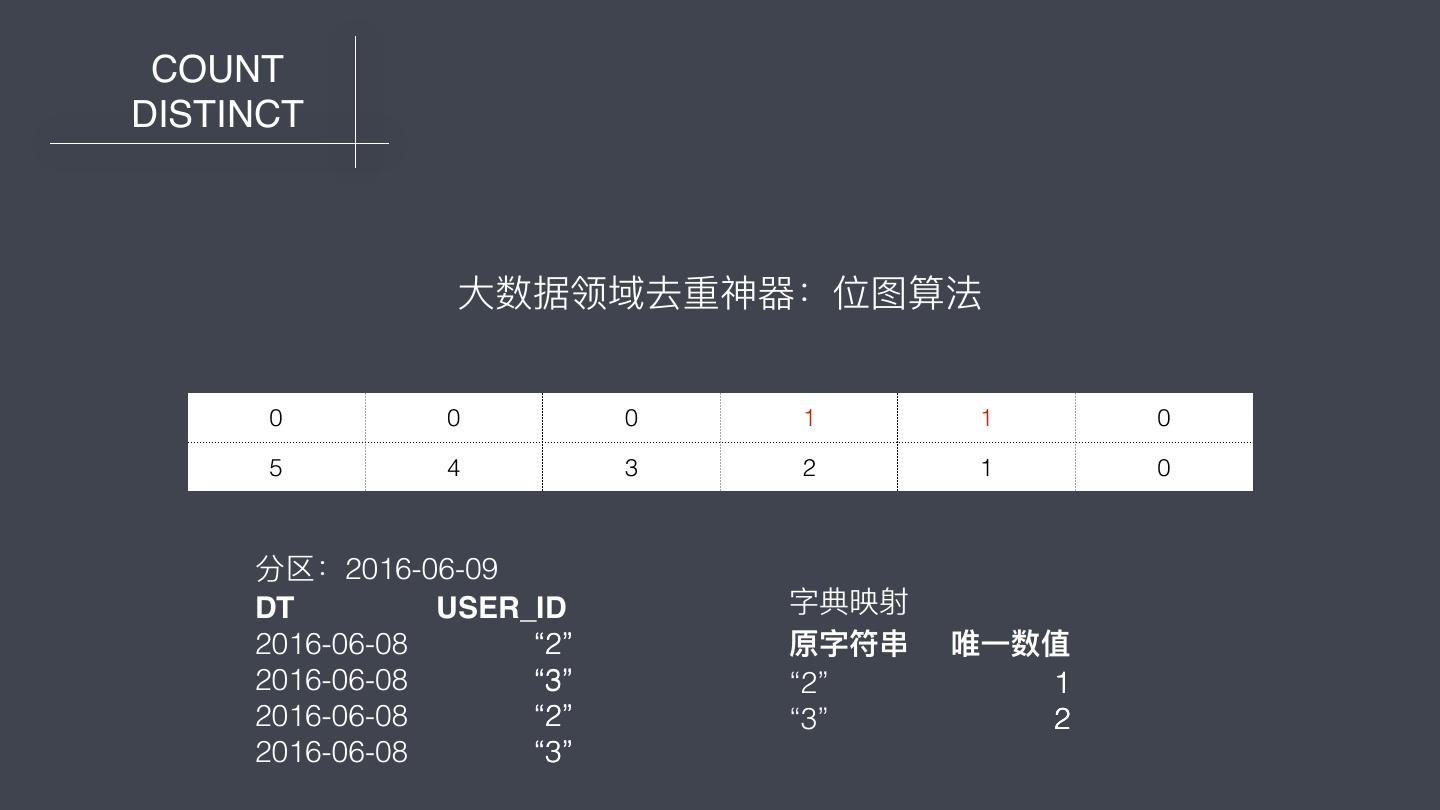
23 . COUNT DISTINCT ⼤大数据领域去重神器器:位图算法 0 0 0 1 0 1 0 0 5 4 3 2 1 0 分区:2016-06-09 DT USER_ID 2016-06-08 2 2016-06-08 3 2016-06-08 2 2016-06-08 3
24 . COUNT DISTINCT USER_ID字段(Integer类型)不不配置全局字典 分区:2016-06-08 0 0 0 1 1 0 5 4 3 2 1 0 分区:2016-06-09 0 0 1 1 0 0 5 4 3 2 1 0 跨分区上卷聚合后的位图 0 0 1 1 1 0 5 4 3 2 1 0
25 . COUNT DISTINCT ⼤大数据领域去重神器器:位图算法 0 0 0 0 1 0 1 0 5 4 3 2 1 0 分区:2016-06-09 DT USER_ID 字典映射 2016-06-08 “2” 原字符串串 唯⼀一数值 2016-06-08 “3” “2” 1 2016-06-08 “2” “3” 2 2016-06-08 “3”
26 . COUNT DISTINCT USER_ID字段(String类型)不不配置全局字典 分区:2016-06-08 原字符串串 唯⼀一数值 本 地 0 0 0 1 1 0 “1” 1 字 5 4 3 2 1 0 “2” 2 典 分区:2016-06-09 原字符串串 唯⼀一数值 本 地 0 0 0 1 1 0 “2” 1 字 5 4 3 2 1 0 “3” 2 典 跨分区上卷聚合后的位图 0 0 0 1 1 0 5 4 3 2 1 0
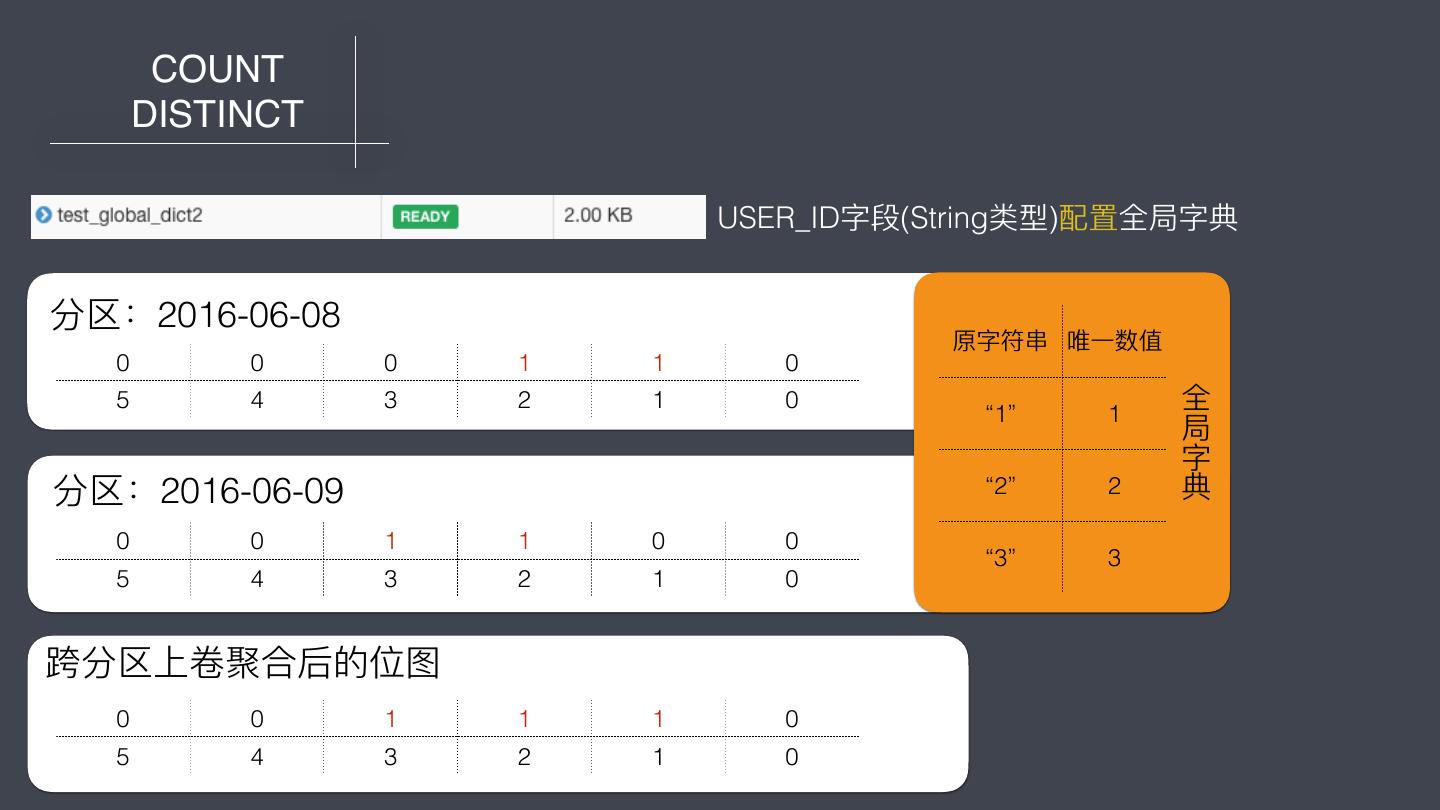
27 . COUNT DISTINCT USER_ID字段(String类型)配置全局字典 分区:2016-06-08 原字符串串 本 原字符串串 唯⼀一数值 唯⼀一数值 地 0 0 0 1 1 0 “1” 1 字 5 4 3 2 1 0 “2” “1” 2 1 全 典 局 字 分区:2016-06-09 “2” 2 原字符串串 唯⼀一数值 典 本 地 0 0 1 1 0 0 “2” 1 字 “3” 3 5 4 3 2 1 0 “3” 2 典 跨分区上卷聚合后的位图 0 0 1 1 1 0 5 4 3 2 1 0
28 .不不断磨合 全局字典使⽤用注意事项: 1. 精确去重的字段,能使⽤用 int 类型尽量量使⽤用 int 类型。由于位图 算法的特性,即使不不使⽤用全局字典也可以实现跨分区精确去重 的效果; 2. 如果精确去重的字段类型只能是 string,那么如果查询需要跨 分区上卷聚合则务必使⽤用全局字典,如果查询不不需要跨分区上 卷聚合则不不必使⽤用全局字典; 3. 全局字典只有在 Build Cube 时才会⽤用到,查询时只需要⽤用到 Build 好的位图。
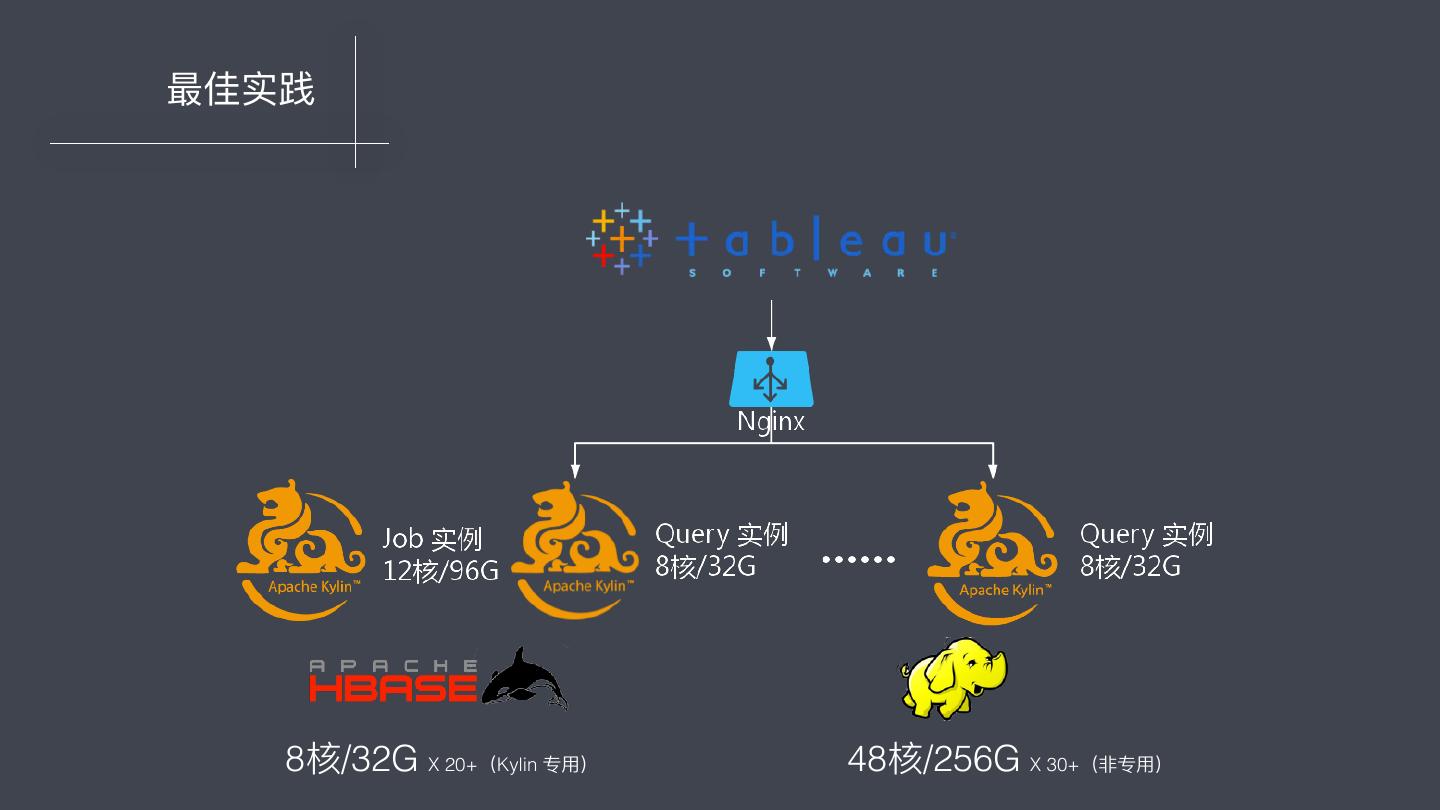
29 . Part 04 探索中的最佳实践 IV
3秒后跳转登录页面
去登陆

