展开查看详情
1 . ⽬
CONTENT
01
深度学习实战进阶
基于Milvus的开源语义检索系统&实践
02
讲师信息/副标题信息:
百度⾼级研发⼯程师 吴⾼升
字号24 录 03
�
2 . ⽬
CONTENT
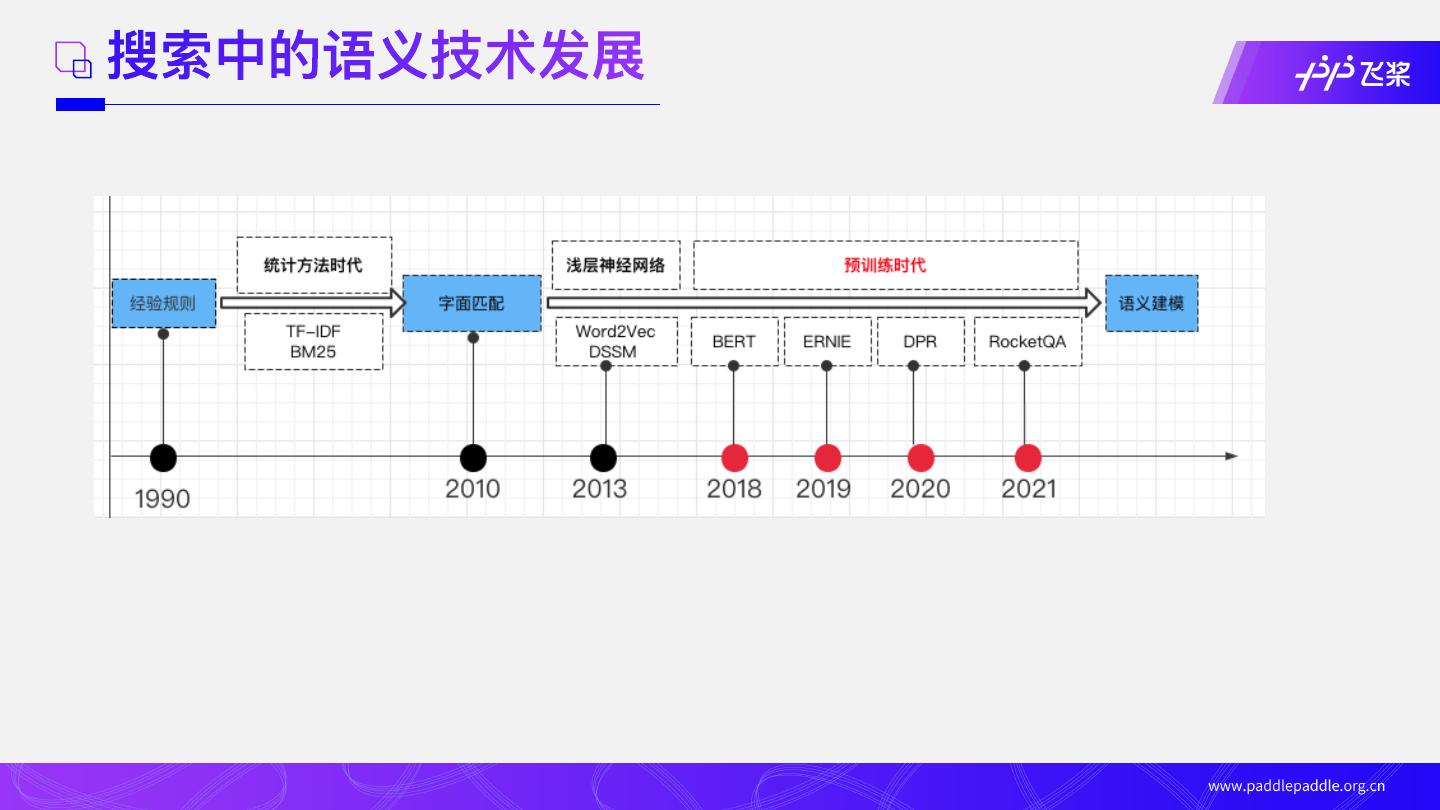
01 搜索核⼼技术发展
02 基于PaddleNLP 语义检索系统
语义检索应⽤案例
录 03
04 实践: 快速搭建语义检索系统
�
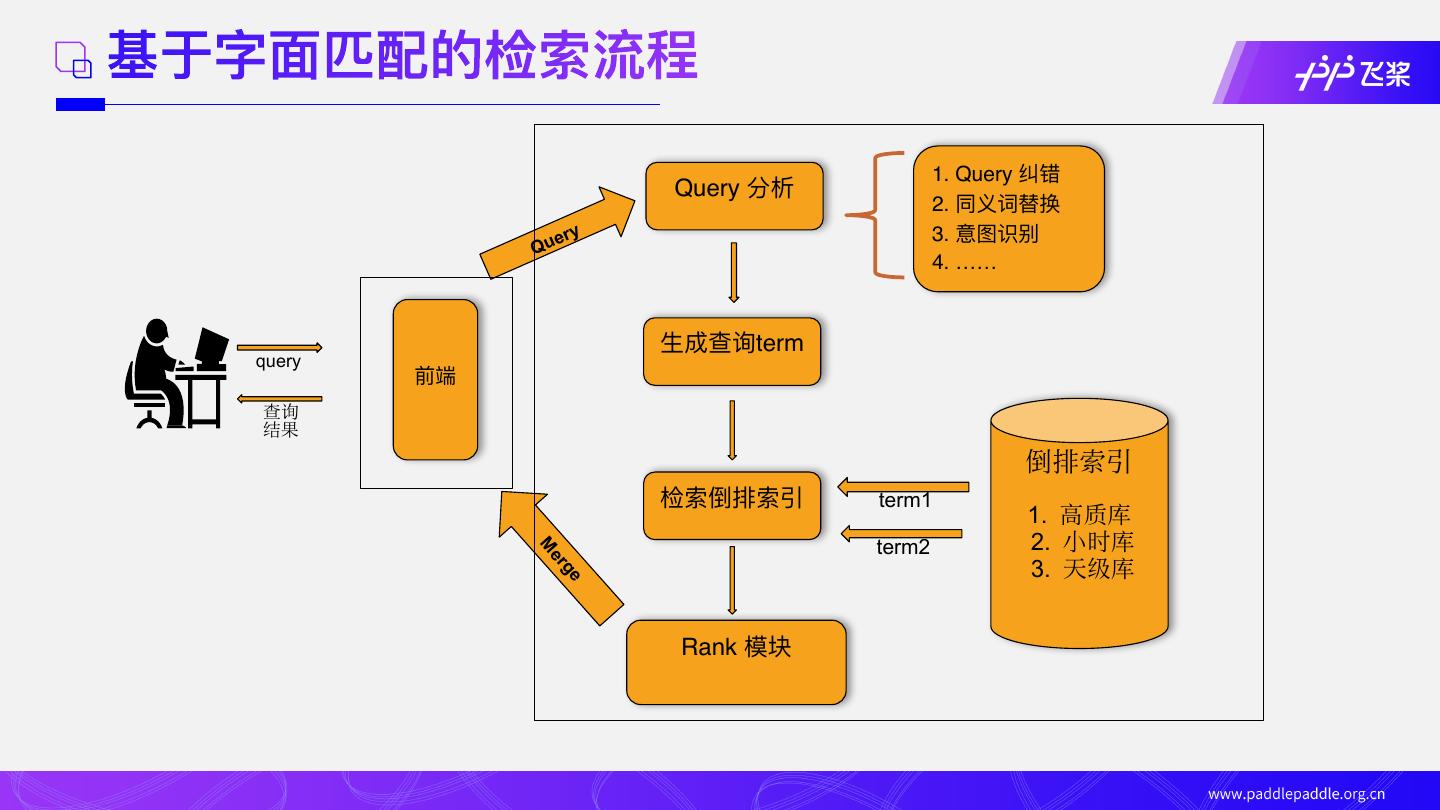
6 .基于字⾯匹配的检索流程
1. Query 纠错
Query 分析
2. 同义词替换
ery 3. 意图识别
Qu
4. ……
⽣成查询term
query
前端
查询
结果
倒排索引
检索倒排索引 term1
1. 高质库
M
er term2 2. 小时库
3. 天级库
ge
Rank 模块
�
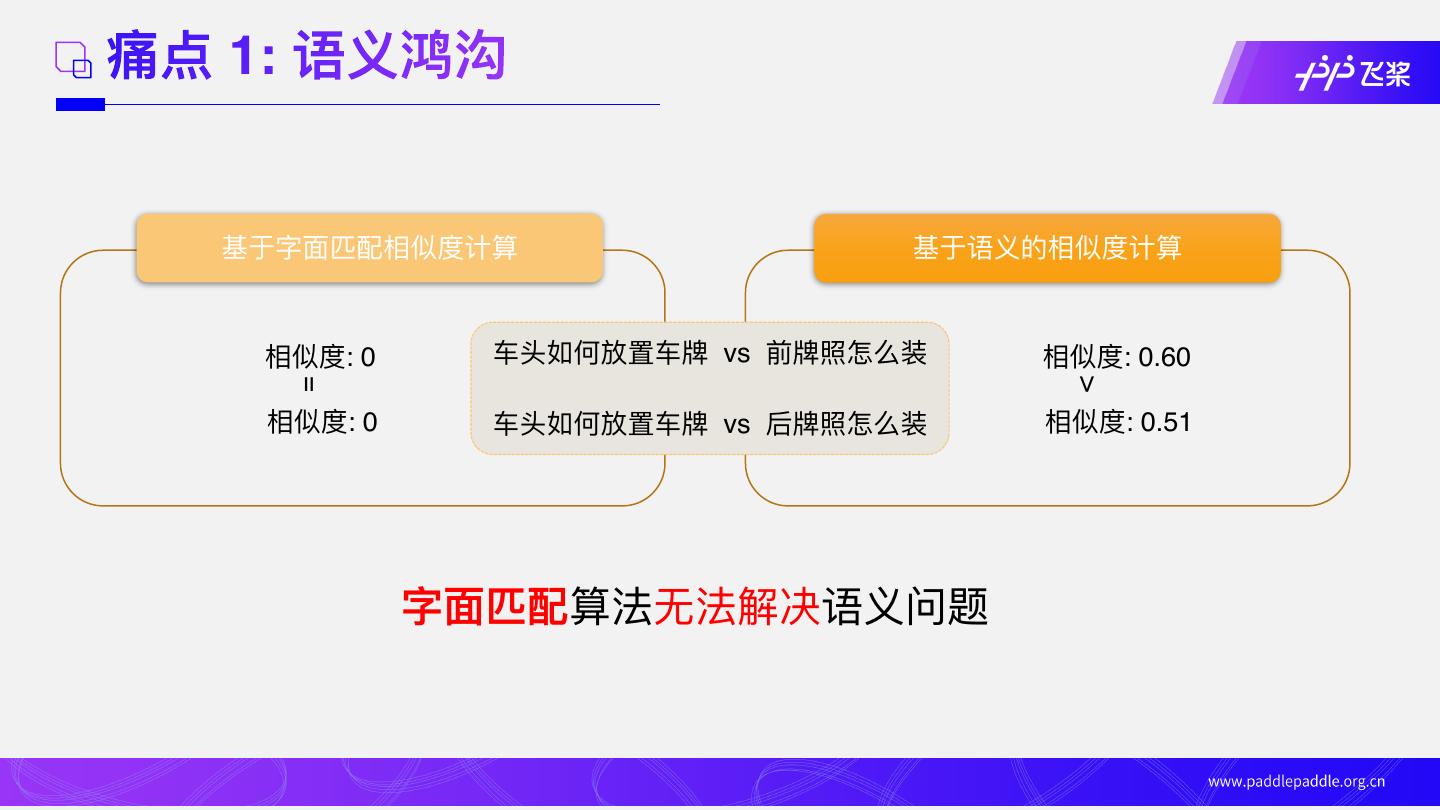
7 .痛点 1: 语义鸿沟
基于字⾯匹配相似度计算 基于语义的相似度计算
相似度: 0 ⻋头如何放置⻋牌 vs 前牌照怎么装 相似度: 0.60
=
>
相似度: 0 ⻋头如何放置⻋牌 vs 后牌照怎么装 相似度: 0.51
字⾯匹配算法⽆法解决语义问题
�
8 .痛点 2: 没有标注数据
➢ 没有标注数据
➢ 只有⽆监督数据
没有标注数据如何训练语义模型?
�
9 .痛点 3: 不清楚语义检索系统⽅案
➢ 语义检索系统架构?
➢ 各模块采⽤什么模型?
➢ 模型如何调优?
➢ 多少训练数据?训练数据的形式?
➢ 语义检索的效果如何⾃动化评估?
从字⾯匹配升级到 语义检索 ⽅案&路径?
�
10 .Part2:基于PaddleNLP 语义检索系统
�
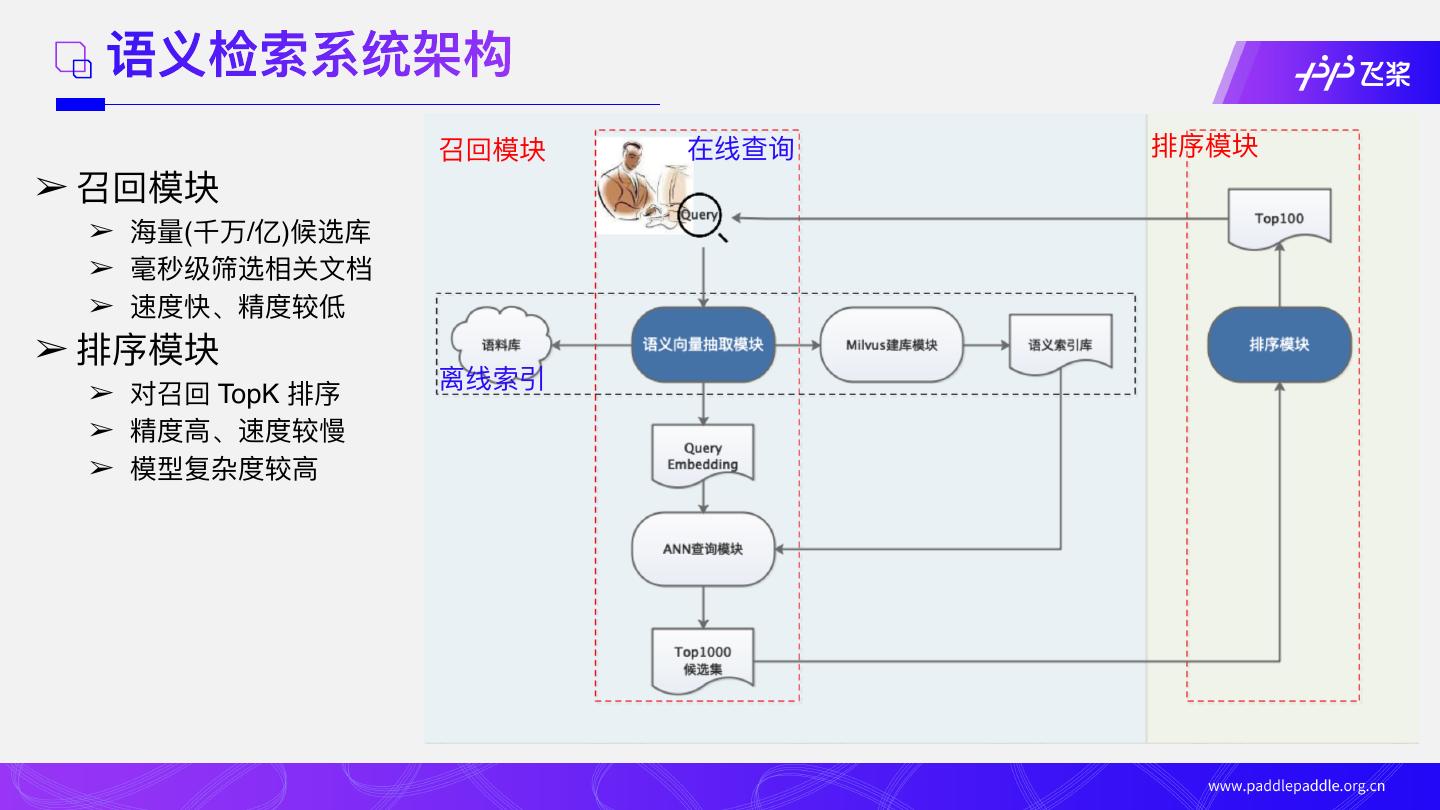
11 . 语义检索系统架构
召回模块 在线查询 排序模块
➢ 召回模块
➢ 海量(千万/亿)候选库
➢ 毫秒级筛选相关⽂档
➢ 速度快、精度较低
➢ 排序模块
➢ 对召回 TopK 排序 离线索引
➢ 精度⾼、速度较慢
➢ 模型复杂度较⾼
�
12 .特⾊ 1: 简单易⽤且全⾯开源
➢ ⼀步步搭建语义检索系统详细案例
➢ 代码的运⾏配置了bash脚本,每个功能⼏乎可以达到脚本直接运⾏
➢ README⾥⾯展示了关键步骤的预测输出,⽅便⽤户对照运⾏复现
➢ 数据开源且给出了⼀些优化⽅案
➢ ⼀站式⽀持训练、预测、ANN 引擎、部署
�
13 .特⾊ 2: 没有标注数据也能做语义检索
⽆监督数据 有监督数据 技术⽅案
多 ⽆ ⽆监督技术 SimCSE
⽆ 多 有监督技术 In-Batch Negatives
多 少 ⽆监督 SimCSE + 有监督 In-Batch Negatives
�
14 .特⾊ 3: ⾼性能
➢ 基于 Paddle Inference ⾼性能抽取
语义向量
➢ 抽取向量 8w/s (256维语义向量)
➢ 基于 Paddle Serving ⾼性能线上推
理服务
➢ 基于百度开源的RPC⽹络框架,具有⾼并发、
低时延等特点
➢ 基于 Milvus 向量检索引擎⾼性能查
询和建库
➢ 查询 Latency: 1.5 ms
➢ 建⽴索引库 QPS: 1.3万/s (256 维语义向量)
�
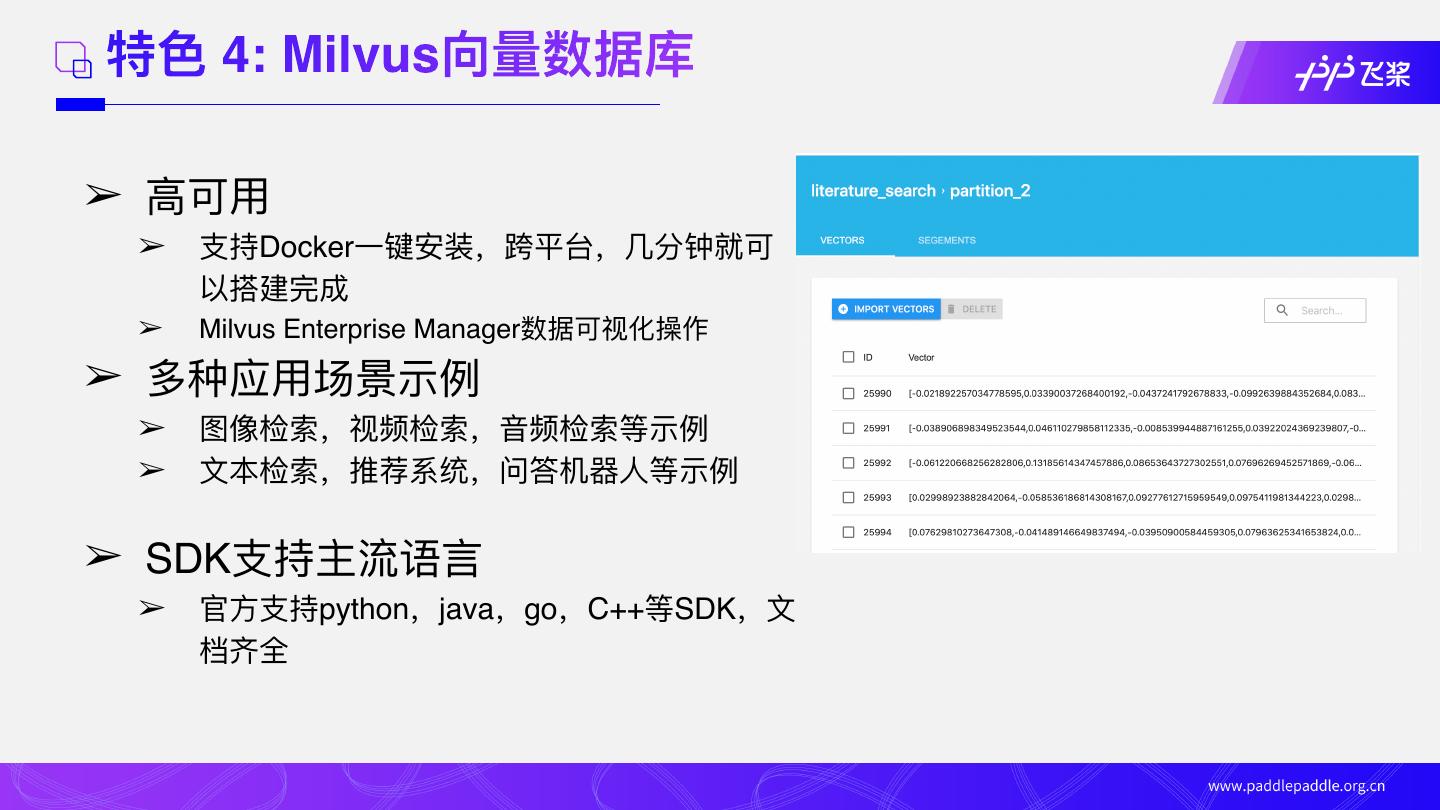
15 .特⾊ 4: Milvus向量数据库
➢ ⾼可⽤
➢ ⽀持Docker⼀键安装,跨平台,⼏分钟就可
以搭建完成
➢ Milvus Enterprise Manager数据可视化操作
➢ 多种应⽤场景示例
➢ 图像检索,视频检索,⾳频检索等示例
➢ ⽂本检索,推荐系统,问答机器⼈等示例
➢ SDK⽀持主流语⾔
➢ 官⽅⽀持python,java,go,C++等SDK,⽂
档⻬全
�
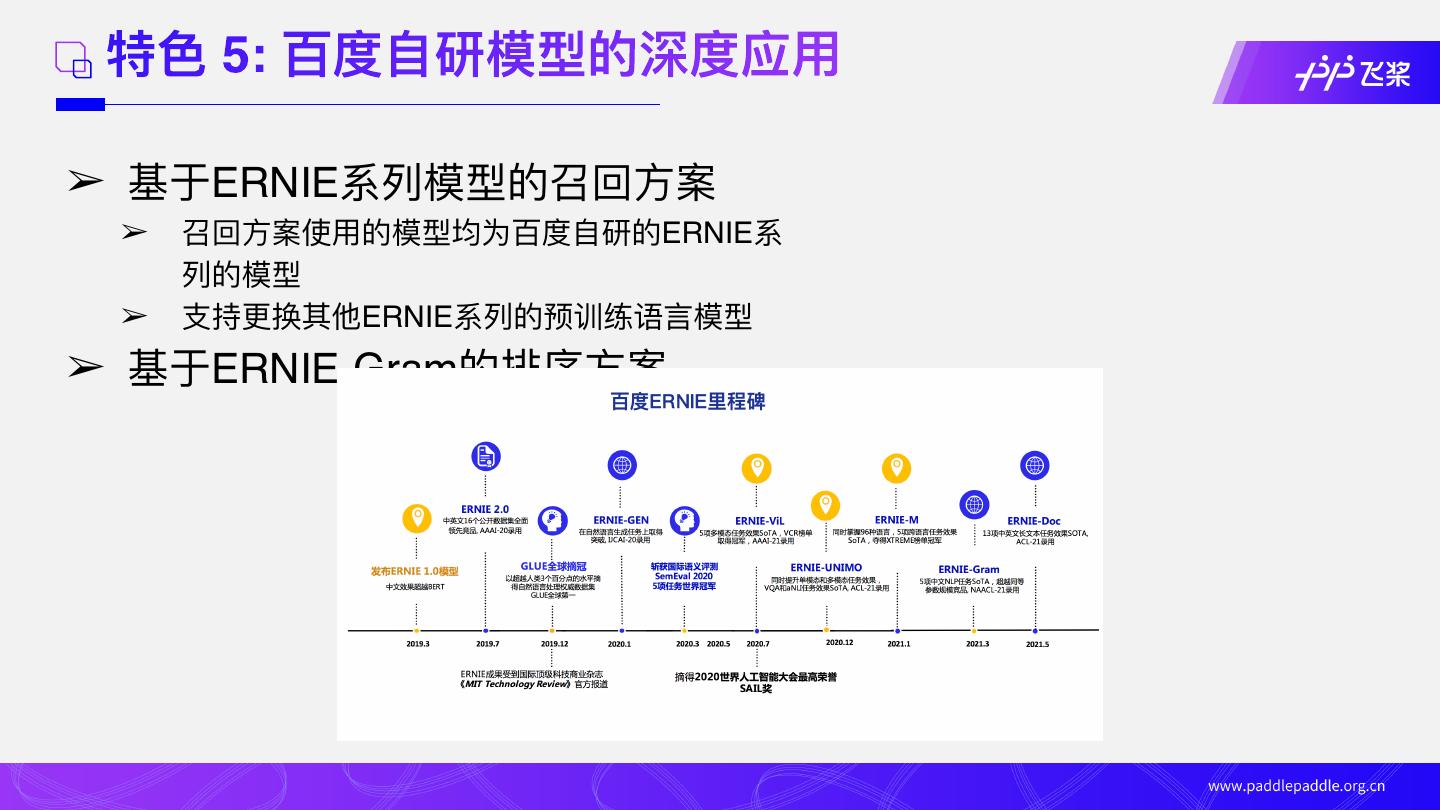
16 . 特⾊ 5: 百度⾃研模型的深度应⽤
➢ 基于ERNIE系列模型的召回⽅案
➢ 召回⽅案使⽤的模型均为百度⾃研的ERNIE系
列的模型
➢ ⽀持更换其他ERNIE系列的预训练语⾔模型
➢ 基于ERNIE-Gram的排序⽅案
�
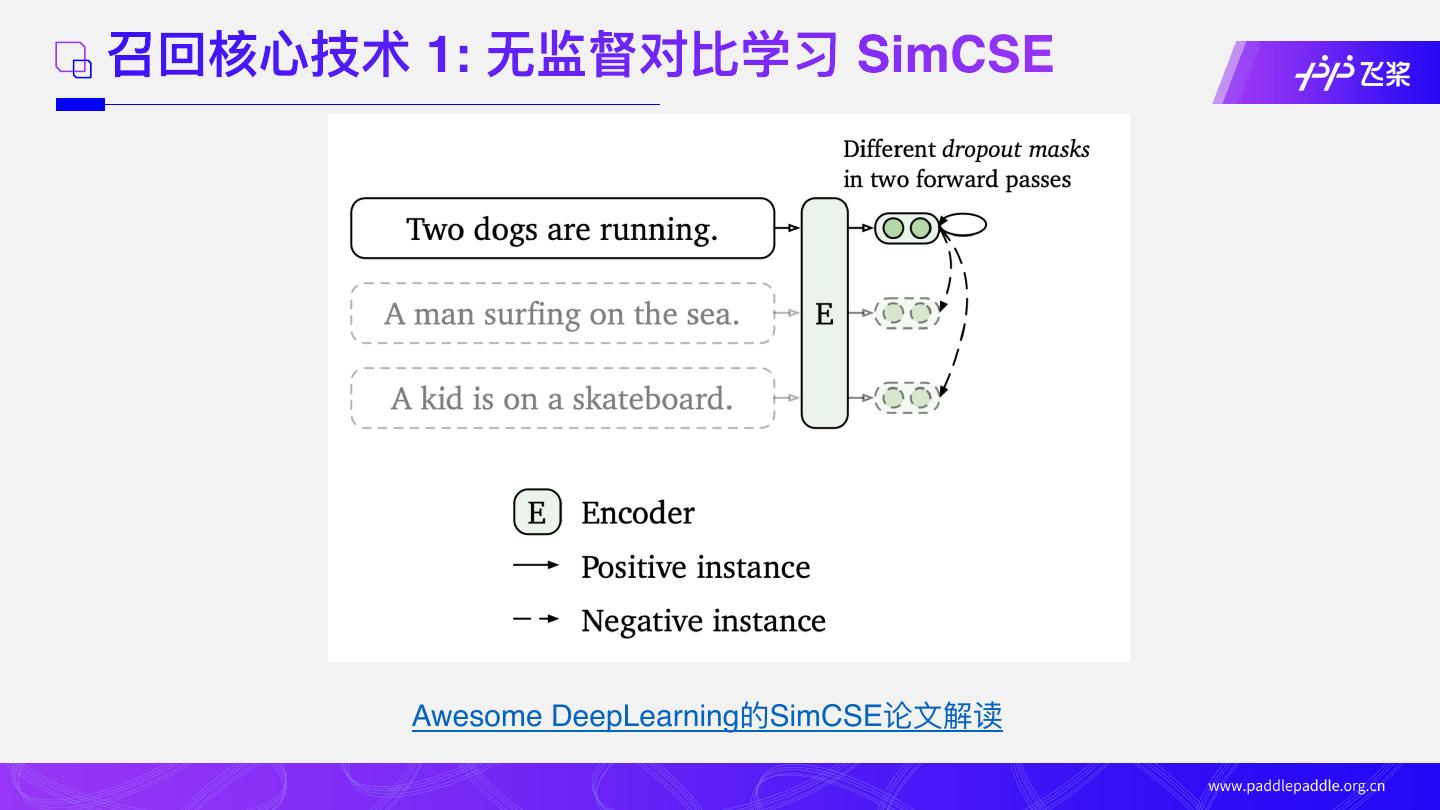
17 . 召回核⼼技术 1: ⽆监督对⽐学习 SimCSE
SimCSE 核⼼思想: 基于随机性因素在特征空间 隐式数据增强,构造监督信号
原始⽂本: 今天我感到很开⼼
同义词替换: 今天我感到很⾼兴
随机增/删: 今天我感到很开⼼
回译(中->英, 英->中):我今天感到⾮常⾼兴
Shuffle: 我今天感到很开⼼
图像显式数据增强 ⽂本显式数据增强
�
18 .召回核⼼技术 1: ⽆监督对⽐学习 SimCSE
Awesome DeepLearning的SimCSE论⽂解读
�
19 . 召回核⼼技术 2: 有监督 In-Batch 负采样
训练数据: N
➢ 正例对
t1 t2 t3 t4
➢ ⼀般为业务点击数据, 例如: query、点击 title q1 q1 q1 q1
q1
t1 t2 t3 t4
q2 q2 q2 q2
q2
t1 t2 t3 t4
N
q3 q3 q3 q3
q3
t4 t2 t3 t4
q4 q4 q4 q4
q4
t1 t2 t3 t4
优化⽬标:
➢转化成分类任务
➢Cross Entropy 交叉熵损失
�
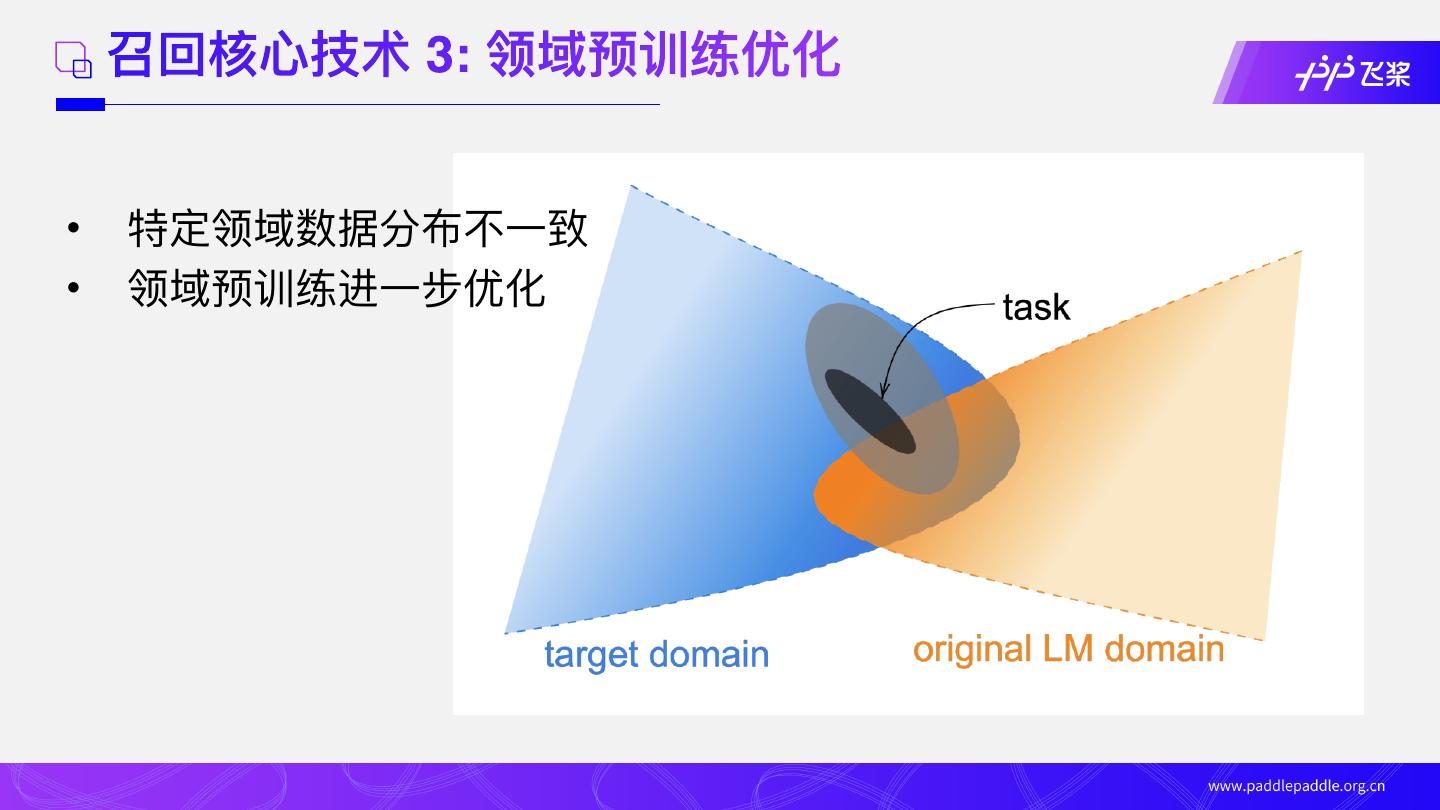
20 . 召回核⼼技术 3: 领域预训练优化
• 特定领域数据分布不⼀致
• 领域预训练进⼀步优化
�
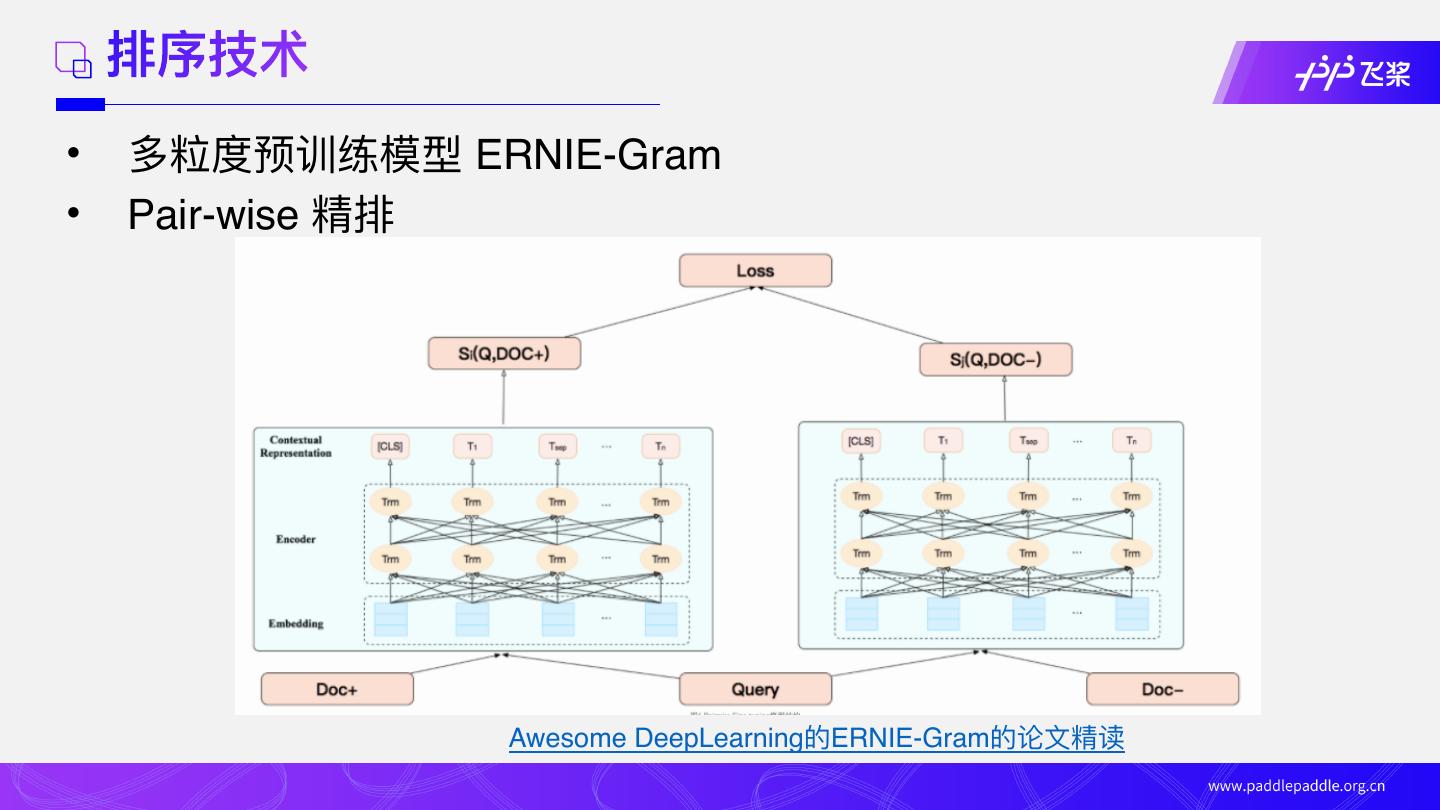
21 . 排序技术
• 多粒度预训练模型 ERNIE-Gram
• Pair-wise 精排
Awesome DeepLearning的ERNIE-Gram的论⽂精读
�
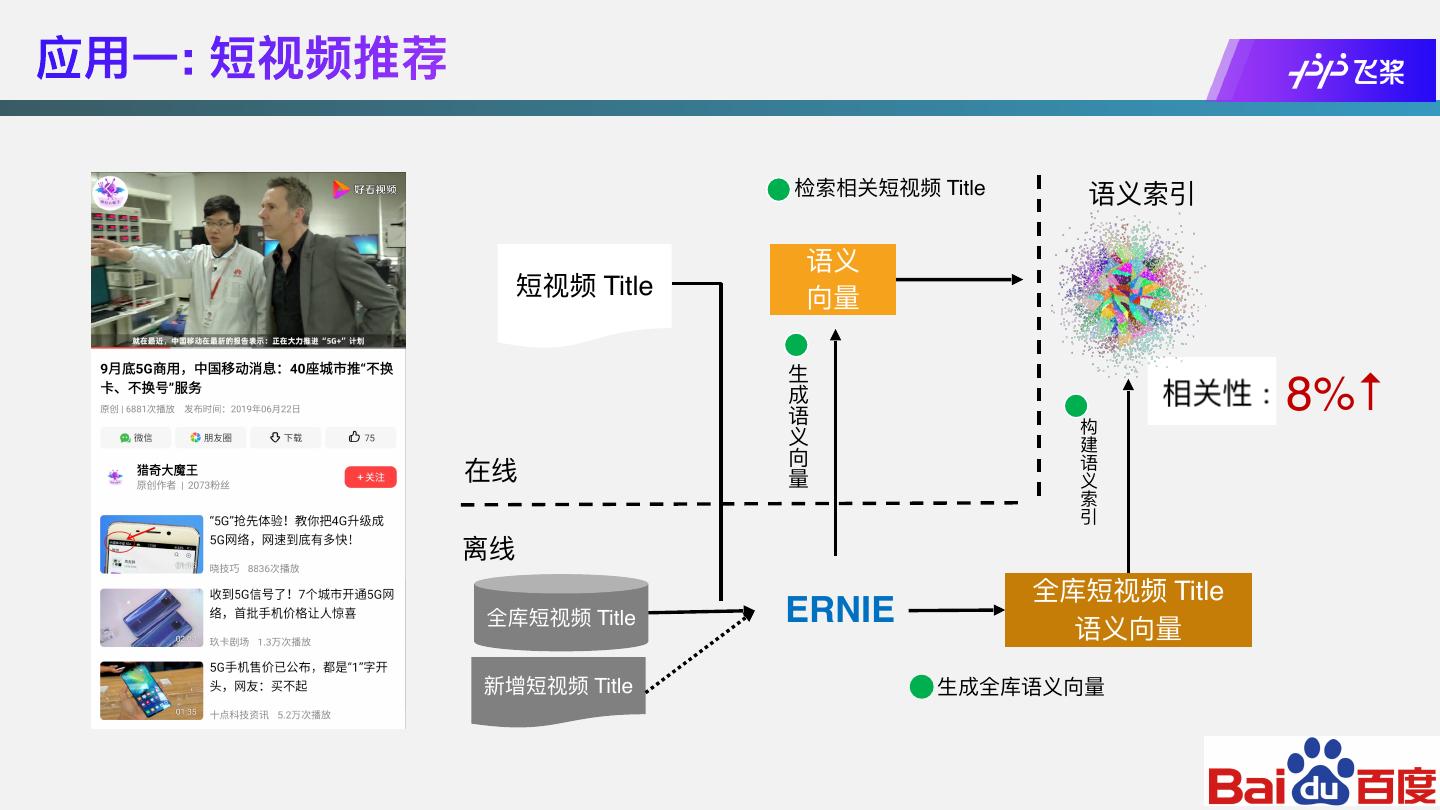
23 .应⽤⼀: 短视频推荐
检索相关短视频 Title 语义索引
语义
短视频 Title 向量
⽣
成
语 构
8%↑
义 建
向 语
在线 量 义
索
引
离线
全库短视频 Title
全库短视频 Title ERNIE 语义向量
新增短视频 Title ⽣成全库语义向量
�
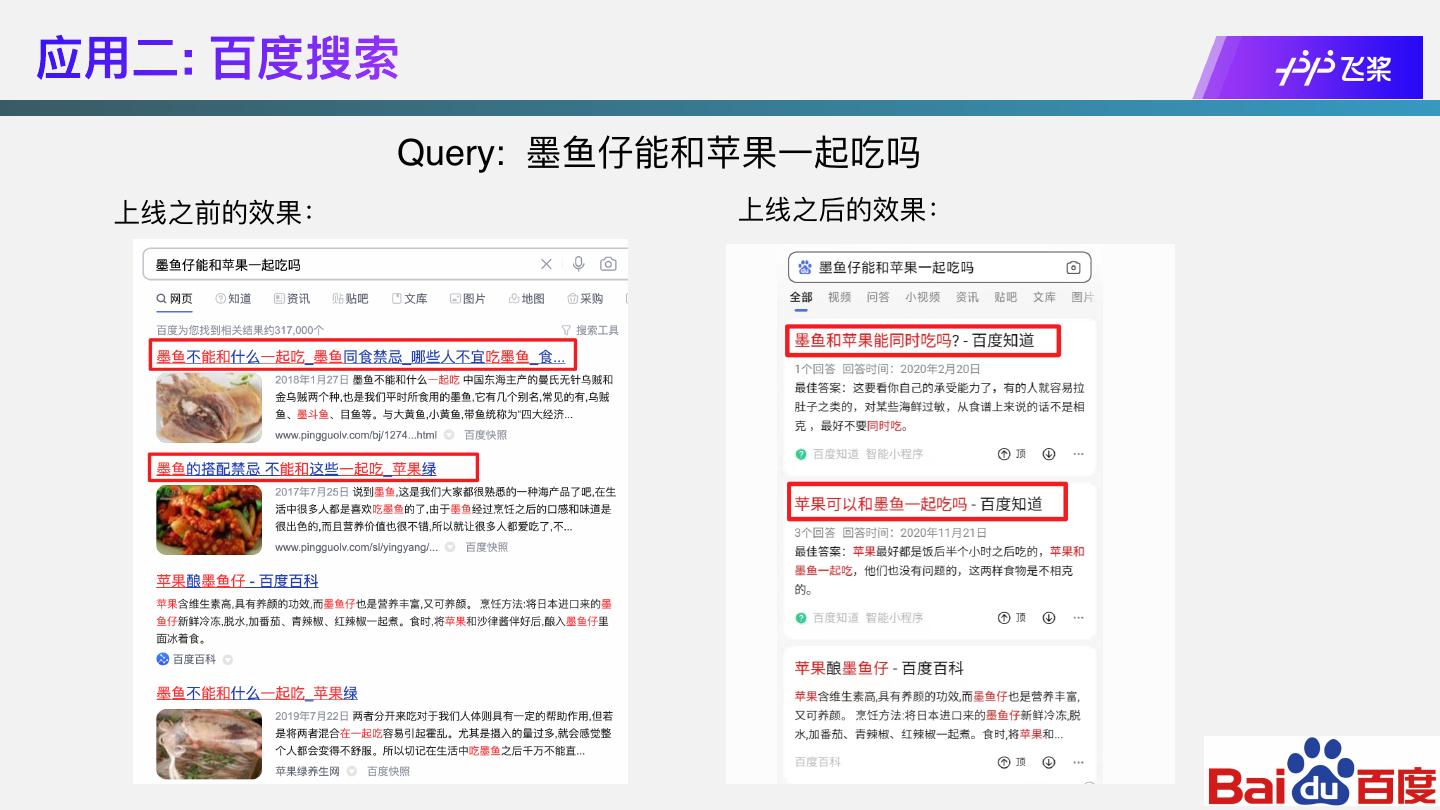
24 .应⽤⼆: 百度搜索
Query: 墨⻥仔能和苹果⼀起吃吗
上线之前的效果: 上线之后的效果:
�
25 .应⽤三: ⽂献语义检索
➢数据场景
➢⽆监督数据: 千万级
➢有监督数据: 4000 (⼈⼯标注)
➢解决⽅案
1. 领域预训练,产出⽂献检索领域预训练模型
2. ⽆监督训练 SimCSE: 学习⽆监督语义知识
3. 有监督训练 In-Batch Negatives: 提升语义模型精准度
4. 基于 ERNIE-Gram Pair-wise Ranking: 提升排序精准度
�
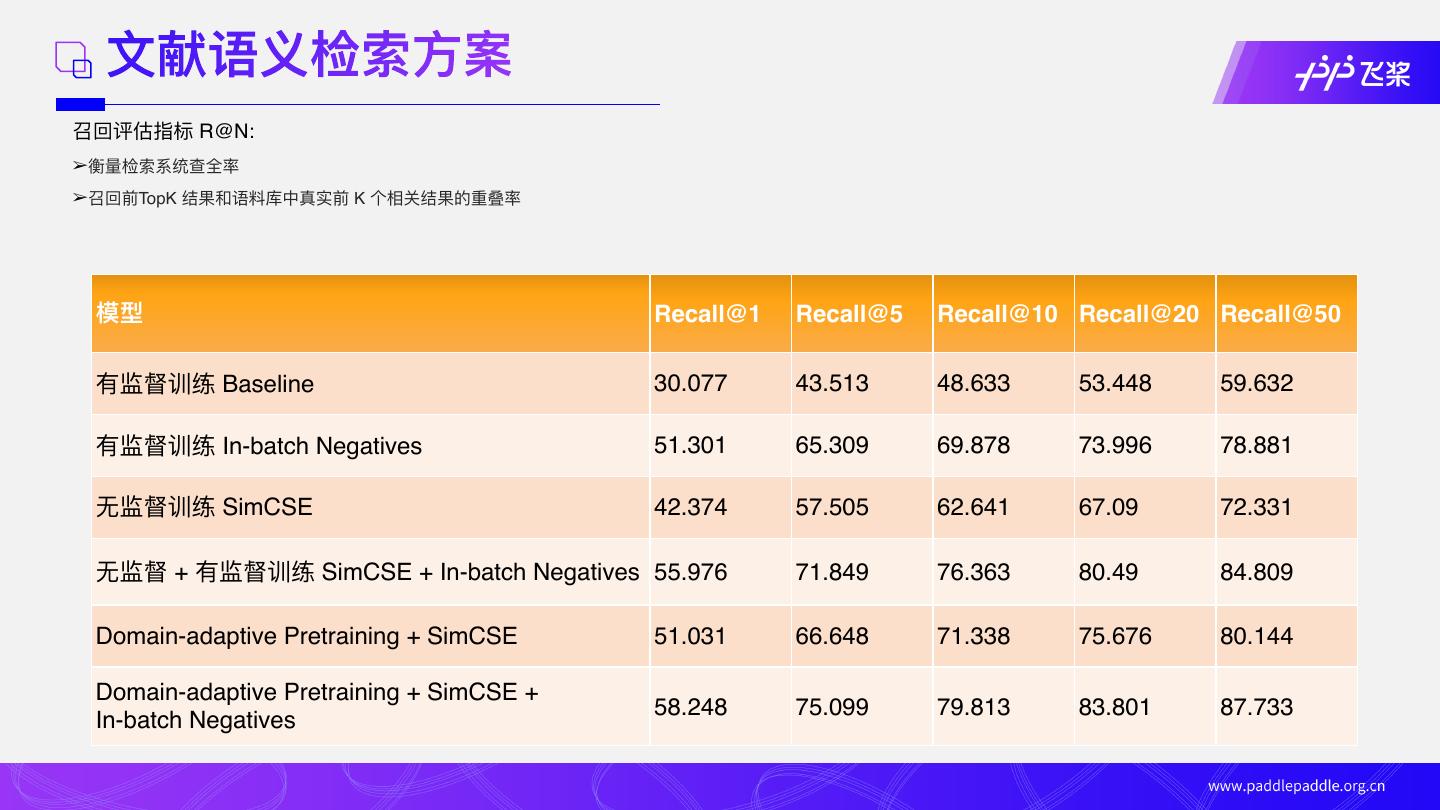
26 . ⽂献语义检索⽅案
召回评估指标 R@N:
➢衡量检索系统查全率
➢召回前TopK 结果和语料库中真实前 K 个相关结果的重叠率
模型 Recall@1 Recall@5 Recall@10 Recall@20 Recall@50
有监督训练 Baseline 30.077 43.513 48.633 53.448 59.632
有监督训练 In-batch Negatives 51.301 65.309 69.878 73.996 78.881
⽆监督训练 SimCSE 42.374 57.505 62.641 67.09 72.331
⽆监督 + 有监督训练 SimCSE + In-batch Negatives 55.976 71.849 76.363 80.49 84.809
Domain-adaptive Pretraining + SimCSE 51.031 66.648 71.338 75.676 80.144
Domain-adaptive Pretraining + SimCSE +
58.248 75.099 79.813 83.801 87.733
In-batch Negatives
�
27 . ⽂献语义检索⽅案
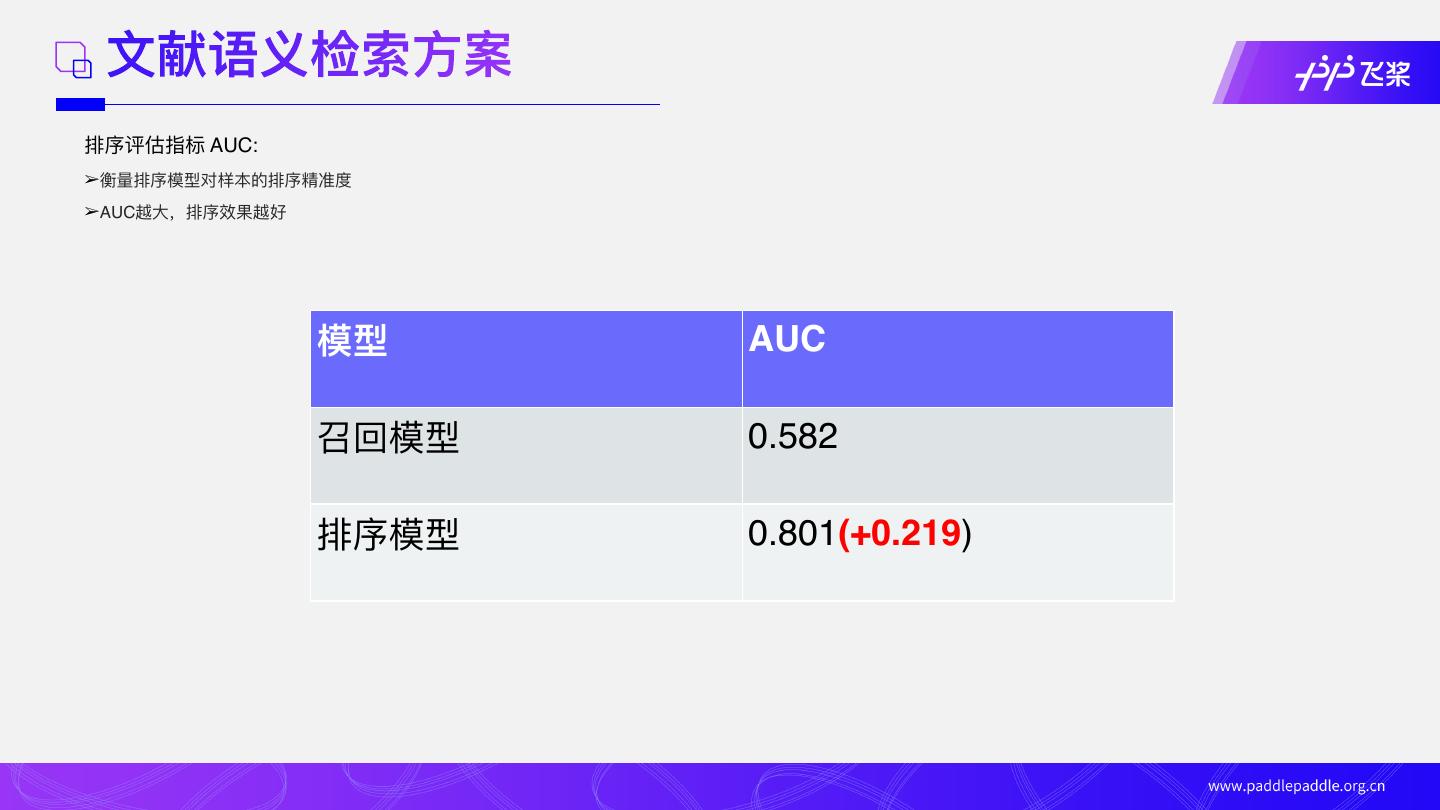
排序评估指标 AUC:
➢衡量排序模型对样本的排序精准度
➢AUC越⼤,排序效果越好
模型 AUC
召回模型 0.582
排序模型 0.801(+0.219)
�
29 .典型数据场景下语义检索实践
➢数据场景:
➢⽆监督数据: 多(⼗万+)
➢有监督数据: 少(千数量级)
➢解决⽅案
1. ⽆监督训练 SimCSE: 学习⽆监督语义知识
2. 有监督训练 In-Batch Negatives: 提升语义模型精准度
3. 基于 ERNIE-Gram Pair-wise Ranking: 提升排序精准度
4. 使⽤Milvus快速向量检索引擎
语义⽂献检索系统核⼼实践
�