展开查看详情
1 .WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
�
2 .Distributed ML/DL with Ignite ML
module using Spark as a data
source
Zinovyev Alexey, GridGain
#UnifiedAnalytics #SparkAISummit
�
3 .Bio
• Java developer
• Distributed ML enthusiast
• Apache Spark user
• Apache Ignite Committer
• Happy father and husband
#UnifiedAnalytics #SparkAISummit 3
�
4 .ML/DL Most Popular Frameworks
#UnifiedAnalytics #SparkAISummit 4
�
5 .Training on PBs with scikit-learn
#UnifiedAnalytics #SparkAISummit 5
�
6 .Spark ML as an answer
• It supports classic ML algorithms
• Algorithms are distributed by nature
• Wide support of different data sources and sinks
• Easy building of Pipelines
• Model evaluation and hyper-parameter tuning
support
#UnifiedAnalytics #SparkAISummit 6
�
7 .What is bad with Spark ML?
• It doesn’t support model ensembles as stacking,
boosting, bagging
#UnifiedAnalytics #SparkAISummit 7
�
8 .What is bad with Spark ML?
• It doesn’t support model ensembles as stacking,
boosting, bagging
• It doesn’t support online-learning for all
algorithms
#UnifiedAnalytics #SparkAISummit 8
�
9 .What is bad with Spark ML?
• It doesn’t support model ensembles as stacking,
boosting, bagging
• It doesn’t support online-learning for all
algorithms
• A lot of data transformation/overhead from data
source to ML types
#UnifiedAnalytics #SparkAISummit 9
�
10 .What is bad with Spark ML?
• It doesn’t support model ensembles as stacking,
boosting, bagging
• It doesn’t support online-learning for all
algorithms
• A lot of data transformation/overhead from data
source to ML types
• The hard integration with TensorFlow/Caffee
#UnifiedAnalytics #SparkAISummit 10
�
11 .What is bad with Spark ML?
• A part of algorithms are using sparse matrix
#UnifiedAnalytics #SparkAISummit 11
�
12 .What is bad with Spark ML?
• A part of algorithms are using sparse matrix
• Several unfinished approaches of model
inference/model serving
#UnifiedAnalytics #SparkAISummit 12
�
13 .What is bad with Spark ML?
• A part of algorithms are using sparse matrix
• Several unfinished approaches of model
inference/model serving
• It doesn’t support Auto ML algorithms
#UnifiedAnalytics #SparkAISummit 13
�
14 .What is bad with Spark ML?
• A part of algorithms are using sparse matrix
• Several unfinished approaches of model
inference/model serving
• It doesn’t support Auto ML algorithms
• It doesn’t support ML operators in Spark SQL
• ML algorithms internally uses Mllib on RDD
#UnifiedAnalytics #SparkAISummit 14
�
15 .The main problem
with Spark ML
You grow old before
your PR will be
merged
#UnifiedAnalytics #SparkAISummit 15
�
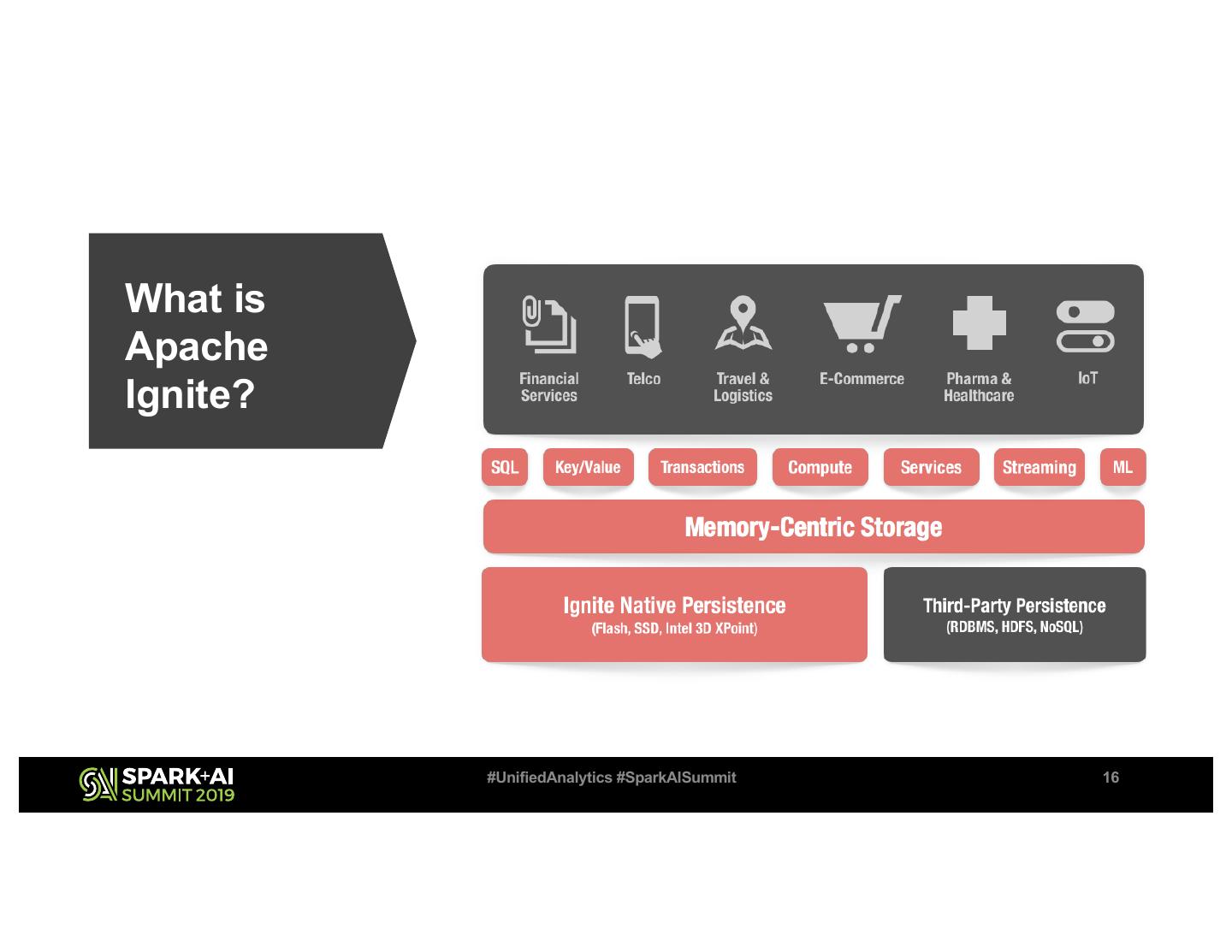
16 .What is
Apache
Ignite?
#UnifiedAnalytics #SparkAISummit 16
�
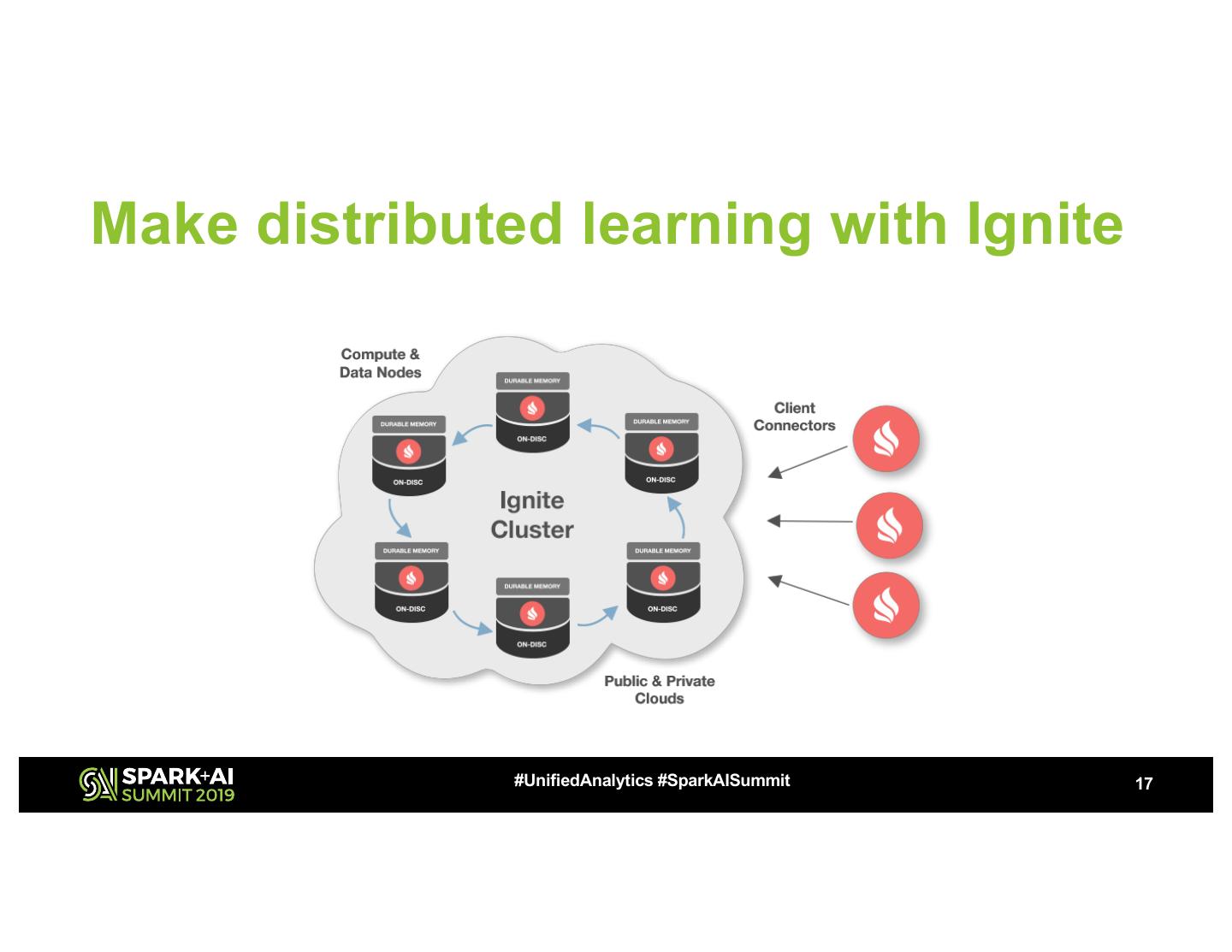
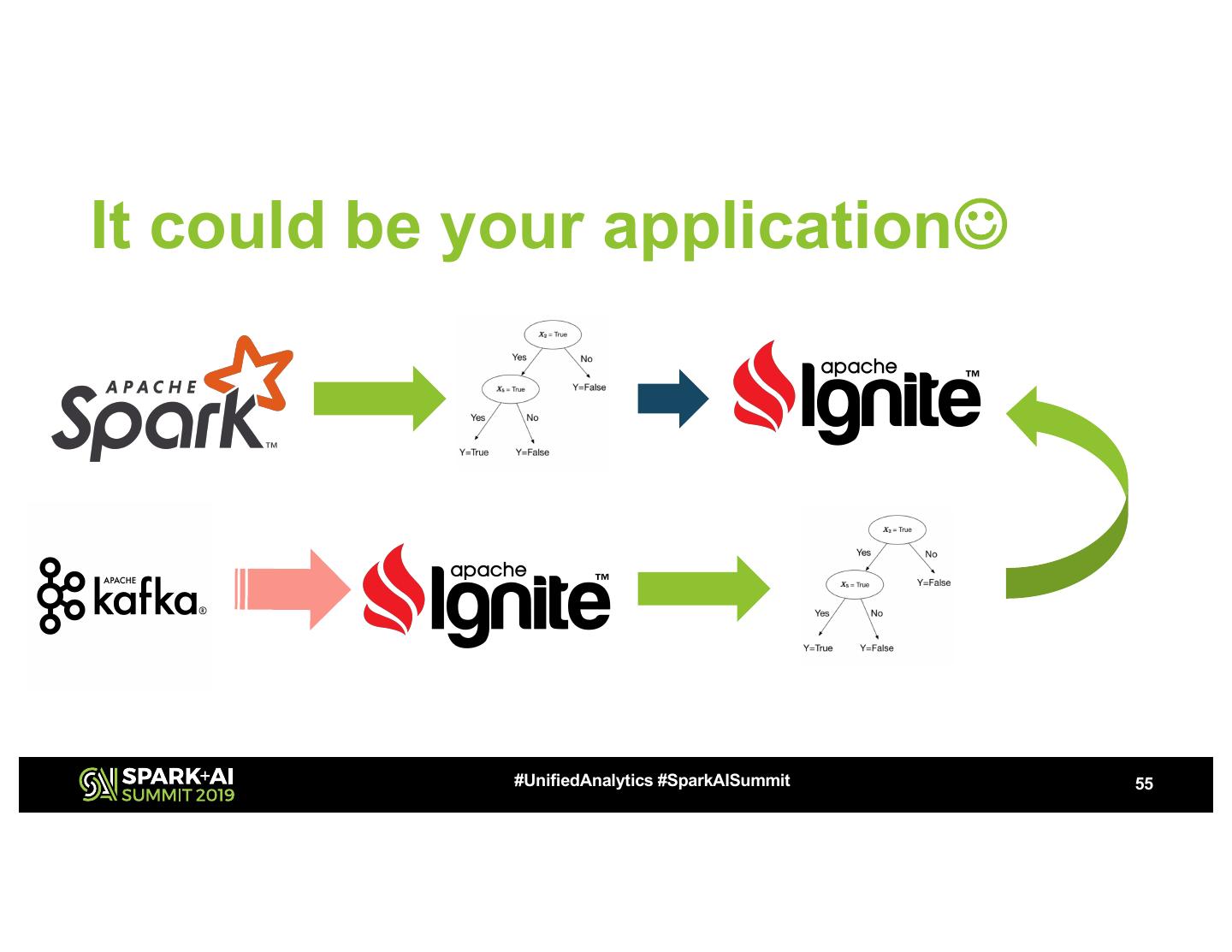
17 .Make distributed learning with Ignite
#UnifiedAnalytics #SparkAISummit 17
�
18 .Spark Cluster as data-source
#UnifiedAnalytics #SparkAISummit 18
�
19 . Via .write.format('ignite')
bin/pyspark --jars $IGNITE_HOME/libs/ignite-spring/*.jar,
$IGNITE_HOME/libs/optional/ignite-spark/ignite-*.jar,
$IGNITE_HOME/libs/*.jar,
$IGNITE_HOME/libs/ignite-indexing/*.jar
#UnifiedAnalytics #SparkAISummit 19
�
20 . Via .write.format('ignite')
bin/pyspark --jars $IGNITE_HOME/libs/ignite-spring/*.jar,
$IGNITE_HOME/libs/optional/ignite-spark/ignite-*.jar,
$IGNITE_HOME/libs/*.jar,
$IGNITE_HOME/libs/ignite-indexing/*.jar
Dataset<Row> passengers = spark.read().format("json").load("filename.json");
employees.filter("age is not null")
.drop("weight")
.write().format("ignite")
.option("config", "default-config.xml")
.option("table", "employees")
.mode("overwrite")
.save();
#UnifiedAnalytics #SparkAISummit 20
�
21 . Via .write.format('ignite')
bin/pyspark --jars $IGNITE_HOME/libs/ignite-spring/*.jar,
$IGNITE_HOME/libs/optional/ignite-spark/ignite-*.jar,
$IGNITE_HOME/libs/*.jar,
$IGNITE_HOME/libs/ignite-indexing/*.jar
Dataset<Row> passengers = spark.read().format("json").load("filename.json");
employees.filter("age is not null")
.drop(“fare")
.write().format("ignite")
.option("config", "default-config.xml")
.option("table", “passengers")
.mode("overwrite")
.save();
#UnifiedAnalytics #SparkAISummit 21
�
22 .Implement CacheStore interface
public class SparkCacheStore implements CacheStore<Integer, Object[]>, Serializable {
private SparkSession spark;
private Dataset<Row> ds;
private static IgniteBiInClosure<Integer, Object[]> staticClo;
{
spark = SparkSession ....getOrCreate();
ds = spark.read()....csv(“data-file");
ds = ds.withColumn("index", functions.monotonically_increasing_id());
}
#UnifiedAnalytics #SparkAISummit 22
�
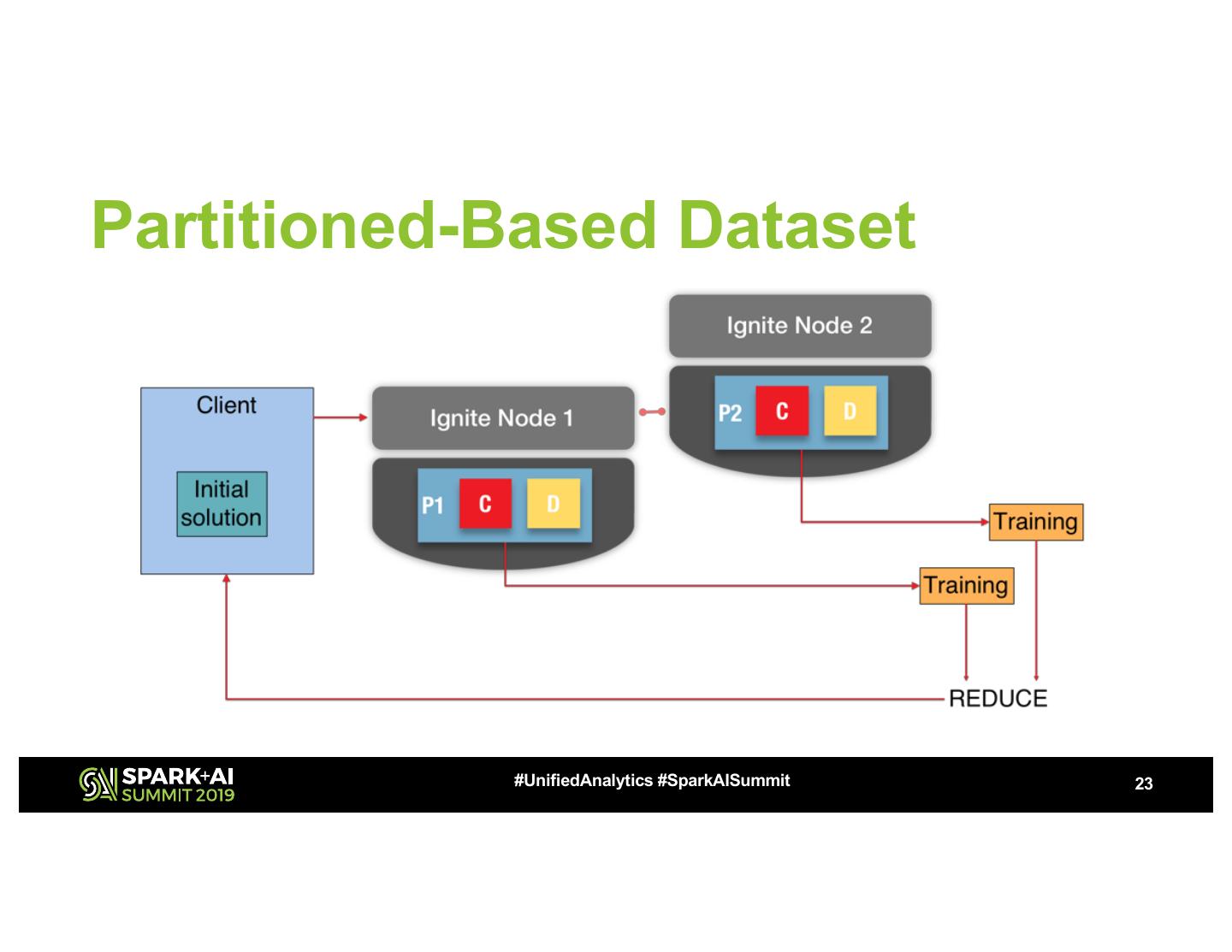
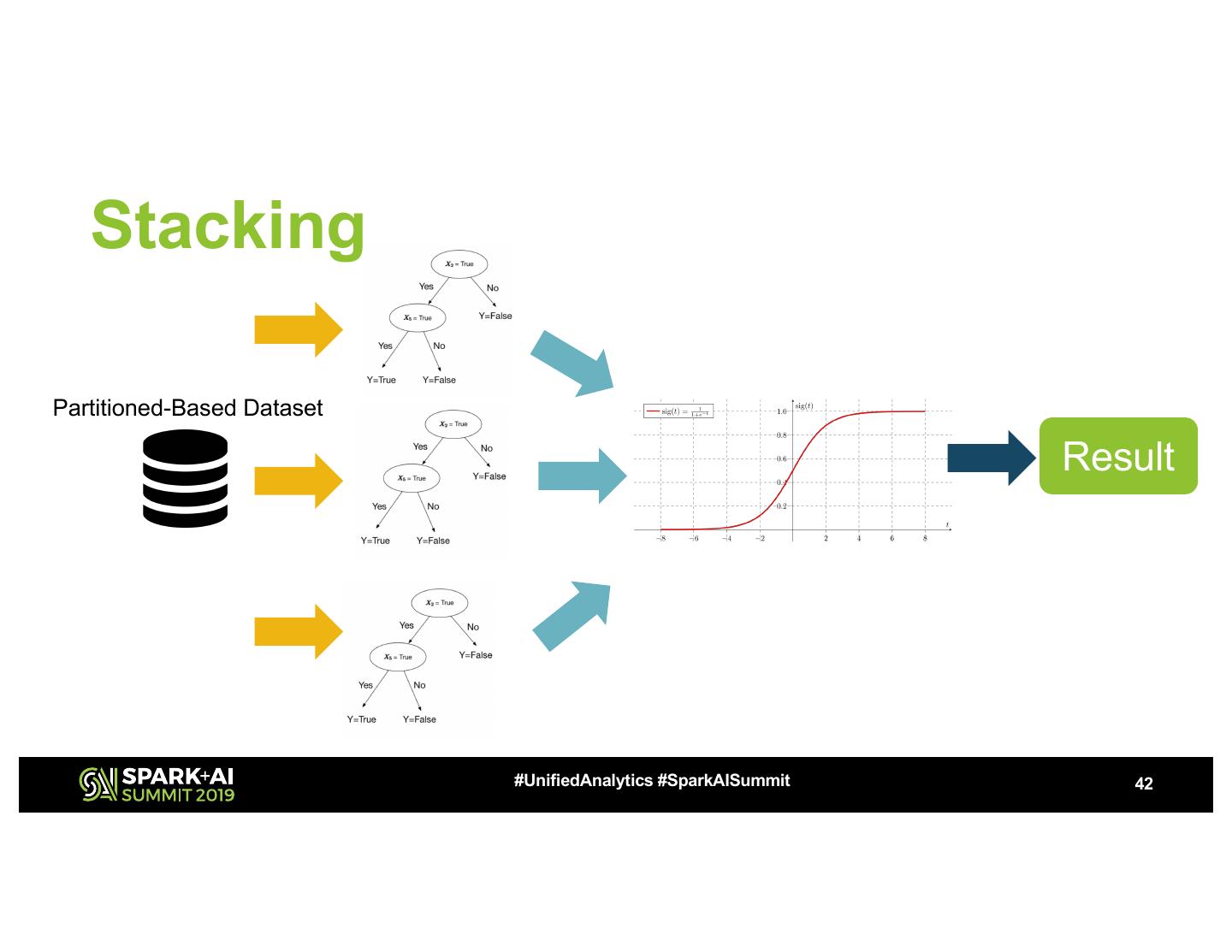
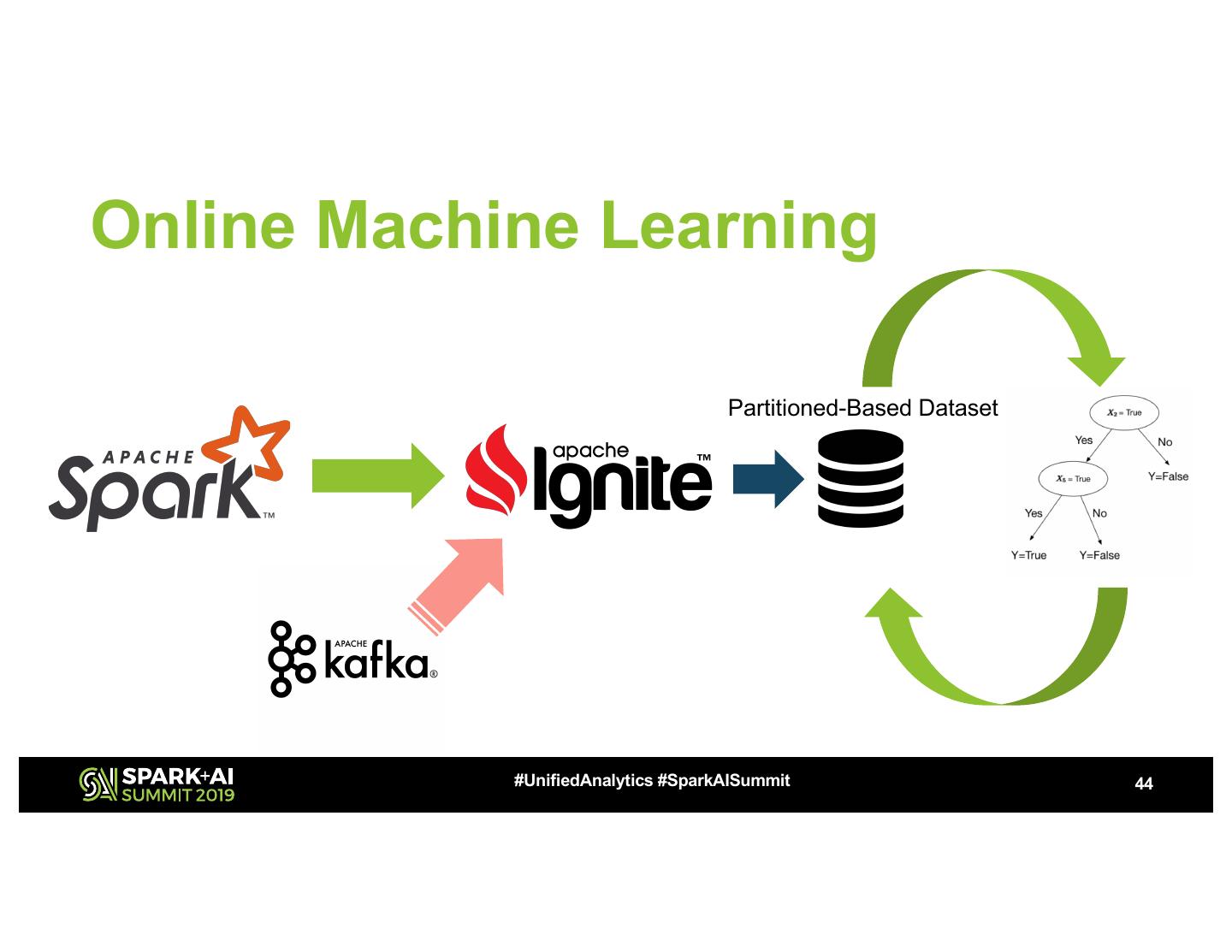
23 .Partitioned-Based Dataset
#UnifiedAnalytics #SparkAISummit 23
�
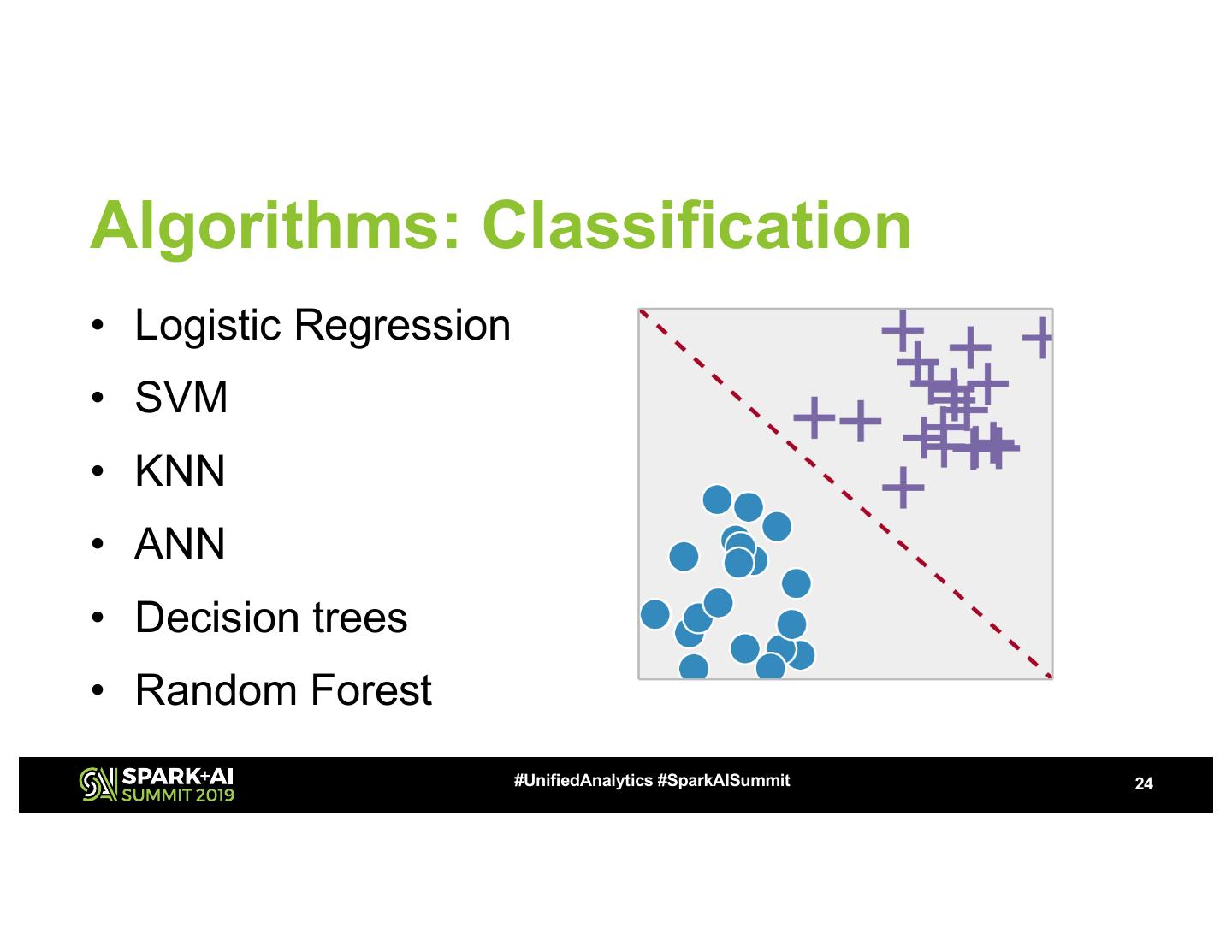
24 .Algorithms: Classification
• Logistic Regression
• SVM
• KNN
• ANN
• Decision trees
• Random Forest
#UnifiedAnalytics #SparkAISummit 24
�
25 .Algorithms: Regression
• KNN Regression
• Linear Regression
• Decision tree
regression
• Random forest
regression
• Gradient-boosted tree
regression
#UnifiedAnalytics #SparkAISummit 25
�
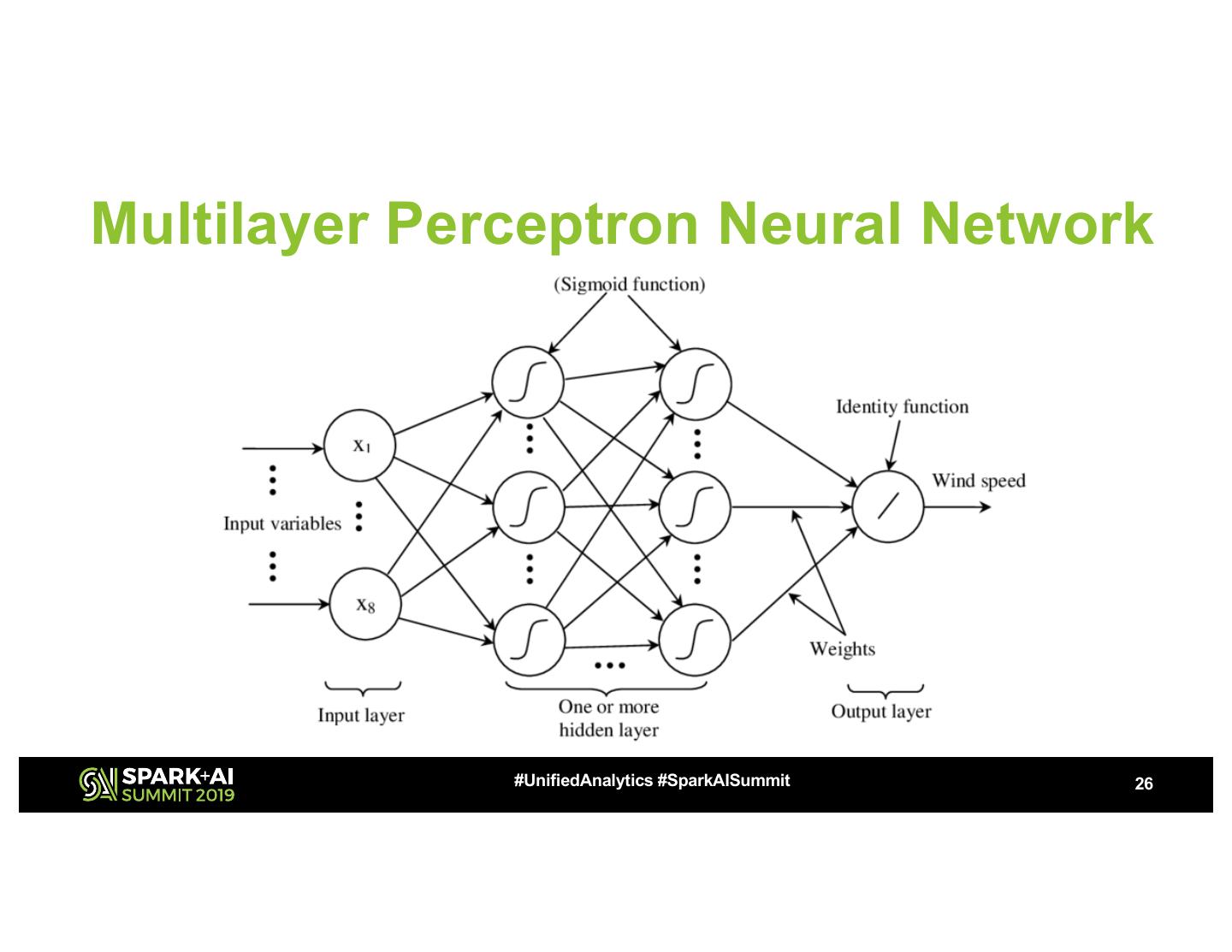
26 .Multilayer Perceptron Neural Network
#UnifiedAnalytics #SparkAISummit 26
�
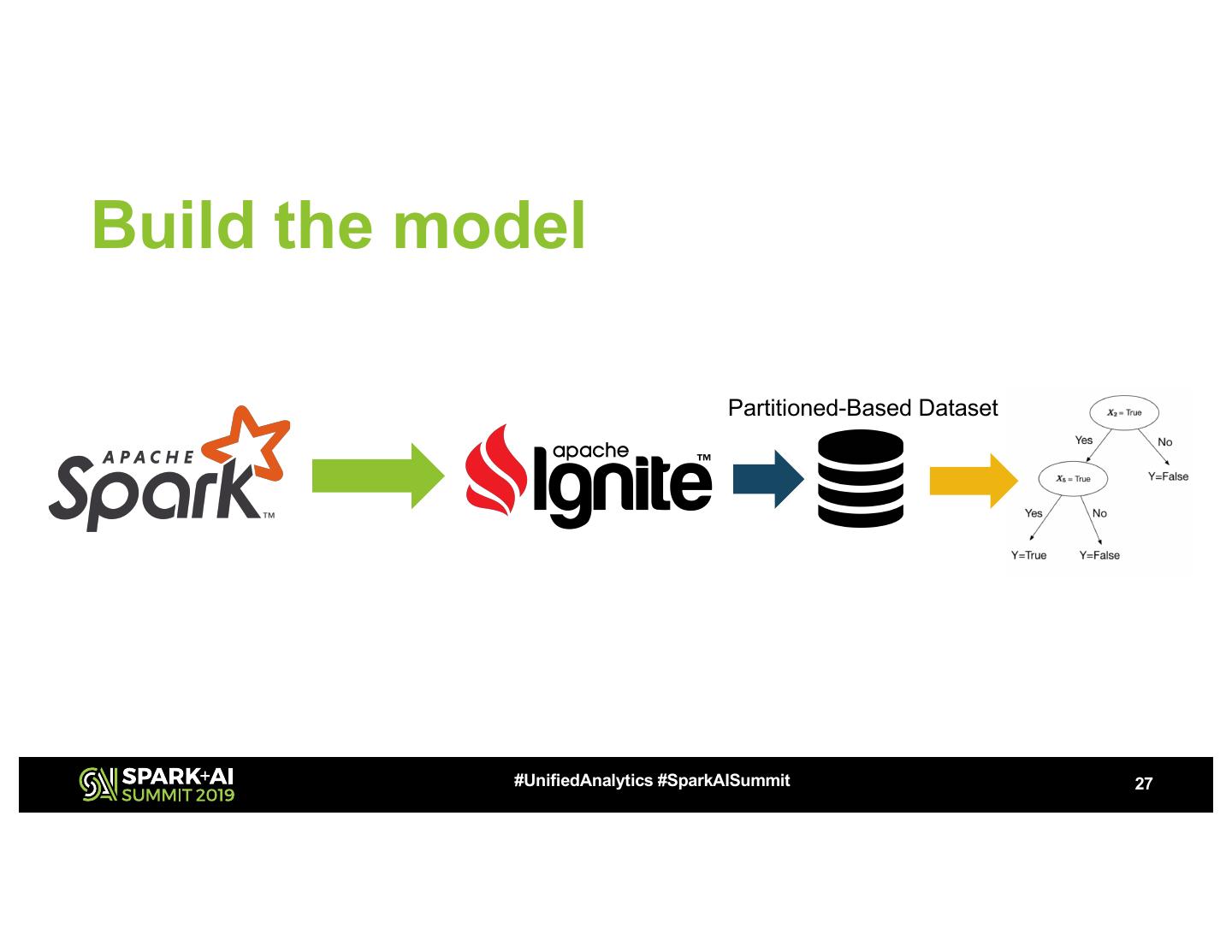
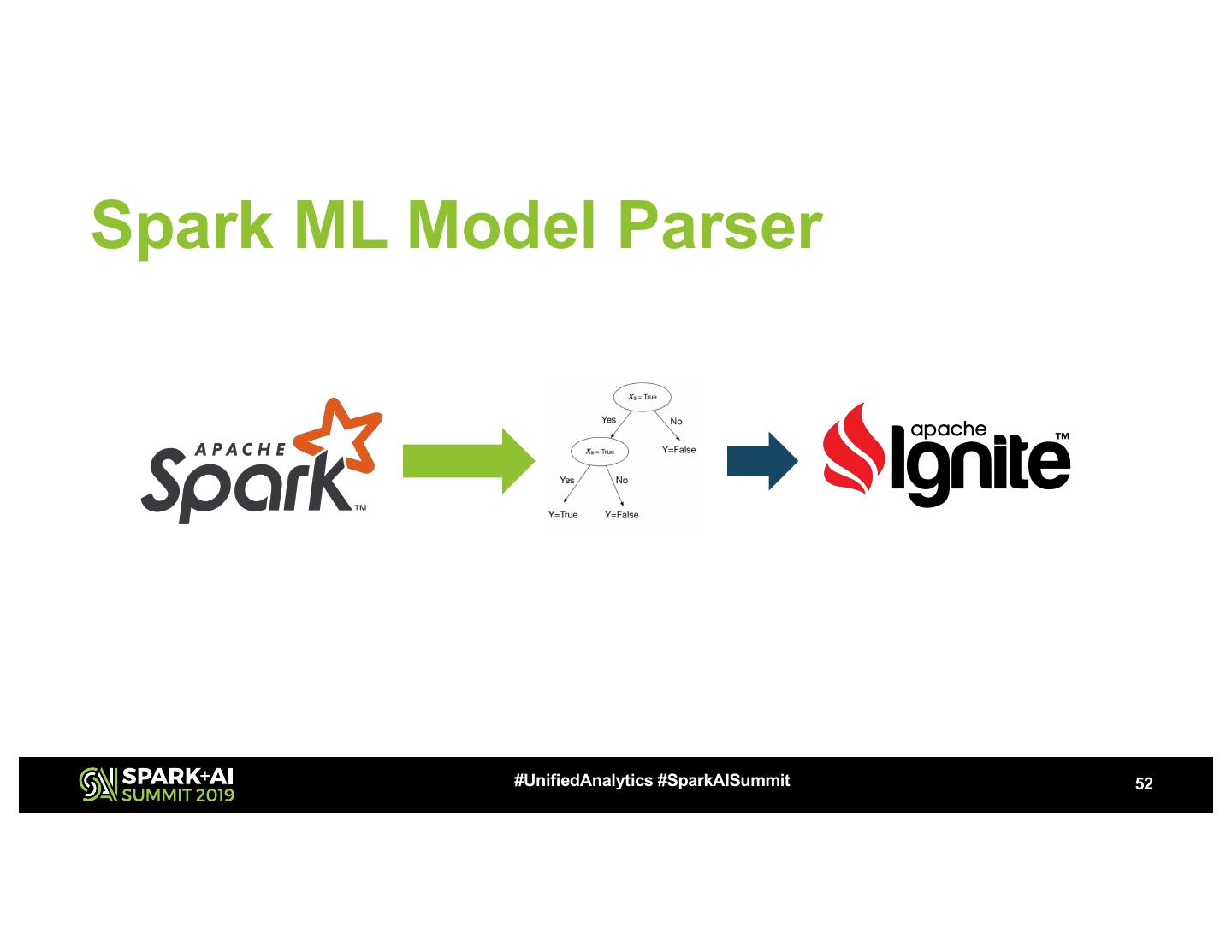
27 .Build the model
Partitioned-Based Dataset
#UnifiedAnalytics #SparkAISummit 27
�
28 .Fill the cache
IgniteCache<Integer, Vector> dataCache = TitanicUtils.readPassengers (ignite);
Vectorizer vectorizer = new DummyVectorizer(0, 5, 6).labeled(1);
DecisionTreeClassificationTrainer trainer = new DecisionTreeClassificationTrainer(5, 0);
DecisionTreeNode mdl = trainer.fit(ignite, dataCache, vectorizer);
double accuracy = Evaluator.evaluate(dataCache, mdl, vectorizer, new Accuracy<>());
#UnifiedAnalytics #SparkAISummit 28
�
29 .Build Labeled Vectors
IgniteCache<Integer, Vector> dataCache = TitanicUtils.readPassengers (ignite);
Vectorizer vectorizer = new DummyVectorizer(0, 5, 6).labeled(1);
DecisionTreeClassificationTrainer trainer = new DecisionTreeClassificationTrainer(5, 0);
DecisionTreeNode mdl = trainer.fit(ignite, dataCache, vectorizer);
double accuracy = Evaluator.evaluate(dataCache, mdl, vectorizer, new Accuracy<>());
#UnifiedAnalytics #SparkAISummit 29
�