


































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/Spark/AutoPilotforApacheSparkUsingMachineLearning?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
Auto-Pilot for Apache Spark Using Machine Learning
分享
点赞
6
收藏
2
下载 0
• Motivation
• Approach
• Scope
• Previous Work
• Gaussian Process
• Domain based Model
• Uchit - Spark Auto Tuner
• Demo
• Experimental Evaluation
• Open Source
展开查看详情
1 .Auto-Pilot for Apache Spark using Machine Learning Amogh Margoor, Qubole Inc Mayur Bhosale, Qubole Inc #UnifiedDataAnalytics #SparkAISummit
2 .Agenda • Motivation • Approach • Scope • Previous Work • Gaussian Process • Domain based Model • Uchit - Spark Auto Tuner • Demo • Experimental Evaluation • Open Source #UnifiedDataAnalytics #SparkAISummit 2
3 .Motivation 3
4 .Tuning a Spark Application Benefits • Performance • Resource Efficiency On Public Cloud translates to $$ saved. #UnifiedDataAnalytics #SparkAISummit 4
5 .Tuning is a Hard Problem !! ● Manual ● Requires Domain Knowledge ● Too many Knobs to configure 5
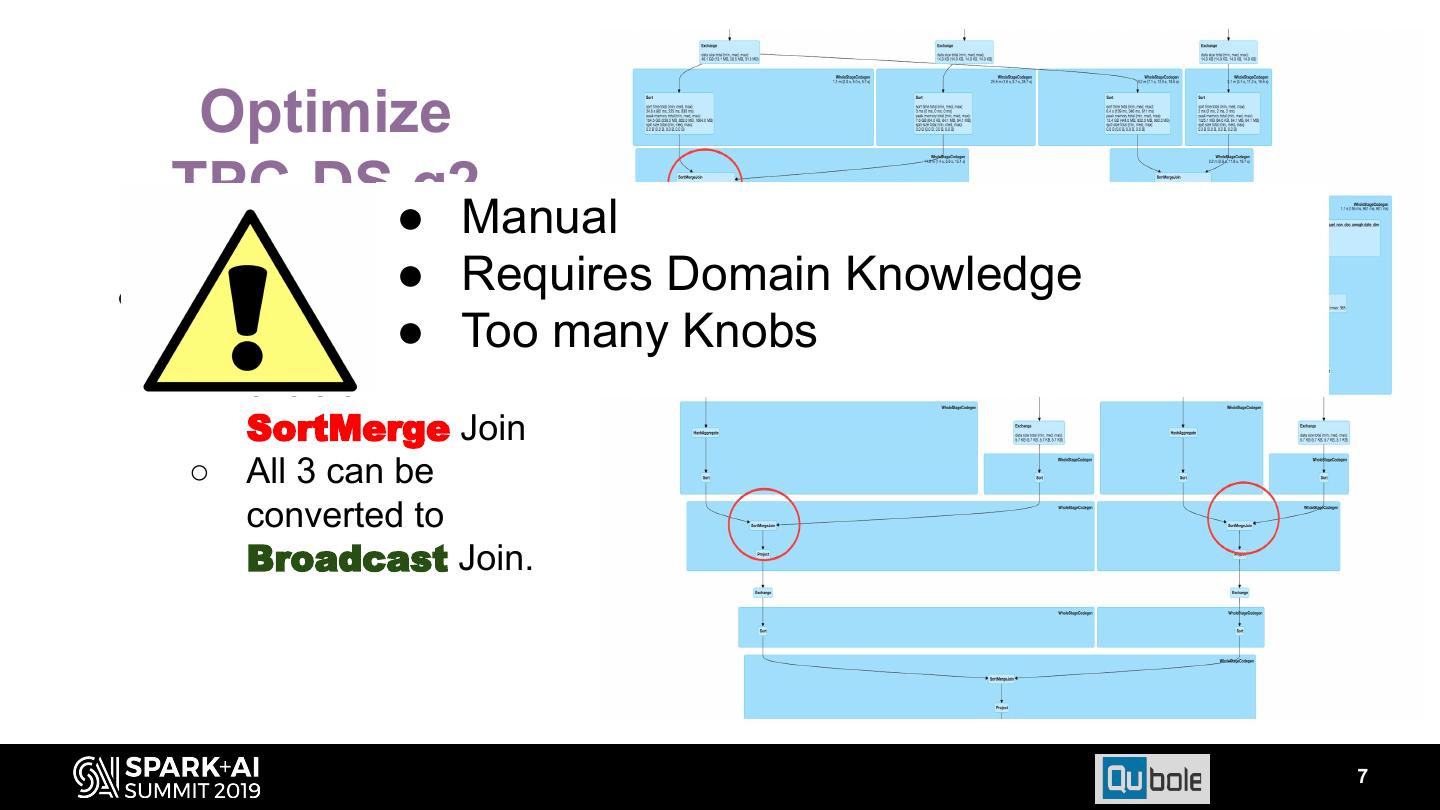
6 . Optimize TPC-DS q2 ● Analyze query plan ○ 3 Joins in Red circle are SortMerge Join ○ All 3 can be converted to Broadcast Join. 6
7 . Optimize TPC-DS●q2Manual ● ● Requires Domain Knowledge Analyze query plan ○ 3 Joins in●RedToo many Knobs circle are SortMerge Join ○ All 3 can be converted to Broadcast Join. 7
8 .Approach 8
9 .Scope – Goals: Improve Runtime or Cloud Cost. – Insights through SparkLens are quite helpful (demo). Can we also Auto Tune the Spark Configuration for above goals ? – Target Repetitive Queries - ETL, Reporting etc. 9
10 .Previous Work • “Standing of the shoulder of Giants” – S. Kumar, S. Padakandla, C. Lakshminarayanan, P. Parihar, K. Gopinath, S. Bhatnagar, Performance tuning of hadoop mapreduce: A noisy gradient approach, vol. abs/1611.10052, 2016. – H. Herodotou, S. Babu, "Profiling what-if analysis and cost-based optimization of mapreduce programs", Proceedings of the VLDB Endowment, vol. 4, no. 11, pp. 1111-1122, 2011. – H. Herodotou, H. Lim, G. Luo, N. Borisov, L. Dong, F. B. Cetin, S. Babu, "Starfish: A self-tuning system for big data analytics", Cidr, no. 2011, pp. 261-272, 2011. – A. J. Storm, C. Garcia-Arellano, S. Lightstone, Y. Diao, and M. Surendra. Adaptive Self-tuning Memory in DB2. In VLDB, 2006. – D. G. Sullivan, M. I. Seltzer, and A. Pfeffer. Using probabilistic reasoning to automate software tuning. In SIGMETRICS, 2004. – D. N. Tran, P. C. Huynh, Y. C. Tay, and A. K. H. Tung. A new approach to dynamic self-tuning of database buffers. ACM Transactions on Storage, 4(1), 2008. – B. Zhang, D. Van Aken, J. Wang, T. Dai, S. Jiang, et al. A Demonstration of the OtterTune Automatic Database Management System Tuning Service. PVLDB – S. Duan, V. Thummala, and S. Babu. Tuning Database Configuration Parameters with iTuned, VLDB, August 2009 – Prasad M. Deshpande, Amogh Margoor, Rajat Venkatesh, Automatic Tuning of SQL-on-Hadoop Engines on Cloud Platforms. IEEE CLOUD 2018 #UnifiedDataAnalytics #SparkAISummit 10
11 .Tuning a Spark Application • Machine Learning Based: – B. Zhang, D. Van Aken, J. Wang, T. Dai, S. Jiang, et al. A Demonstration of the OtterTune Automatic Database Management System Tuning Service. PVLDB – S. Duan, V. Thummala, and S. Babu. Tuning Database Configuration Parameters with iTuned, VLDB, August 2009 • Domain Knowledge Based: – Prasad M. Deshpande, Amogh Margoor, Rajat Venkatesh, Automatic Tuning of SQL-on-Hadoop Engines on Cloud Platforms. IEEE CLOUD 2018 #UnifiedDataAnalytics #SparkAISummit 11
12 .Machine Learning Approach 12
13 .Machine Learning Approaches • Based on previous works, our approach is also: – Iterative approaches: • Step 1: Predict good config based on Previous runs • Step 2: Run with predicted config and add the result to Previous runs. • Repeat Step1 and Step 2 for `n` iterations – Gaussian Process based approaches. #UnifiedDataAnalytics #SparkAISummit 13
14 .Gaussian Process ● Gaussian is non-parametric approach. ● Other parametric regression techniques start with fixed assumption of parameters. Problems: ○ y = 𝛳0 + 𝛳1x Linear Equation with 2 parameters is not enough for data. ○ y = 𝛳0 + 𝛳1x + 𝛳2x2 Quadratic equation with 3 parameters will be more appropriate. ● Gaussian Process is non-parametric i.e., it assumes all the possibilities. ● Image Source: https://katbailey.github.io/post/gaussian-processes-for-dummies/ #UnifiedDataAnalytics #SparkAISummit 14
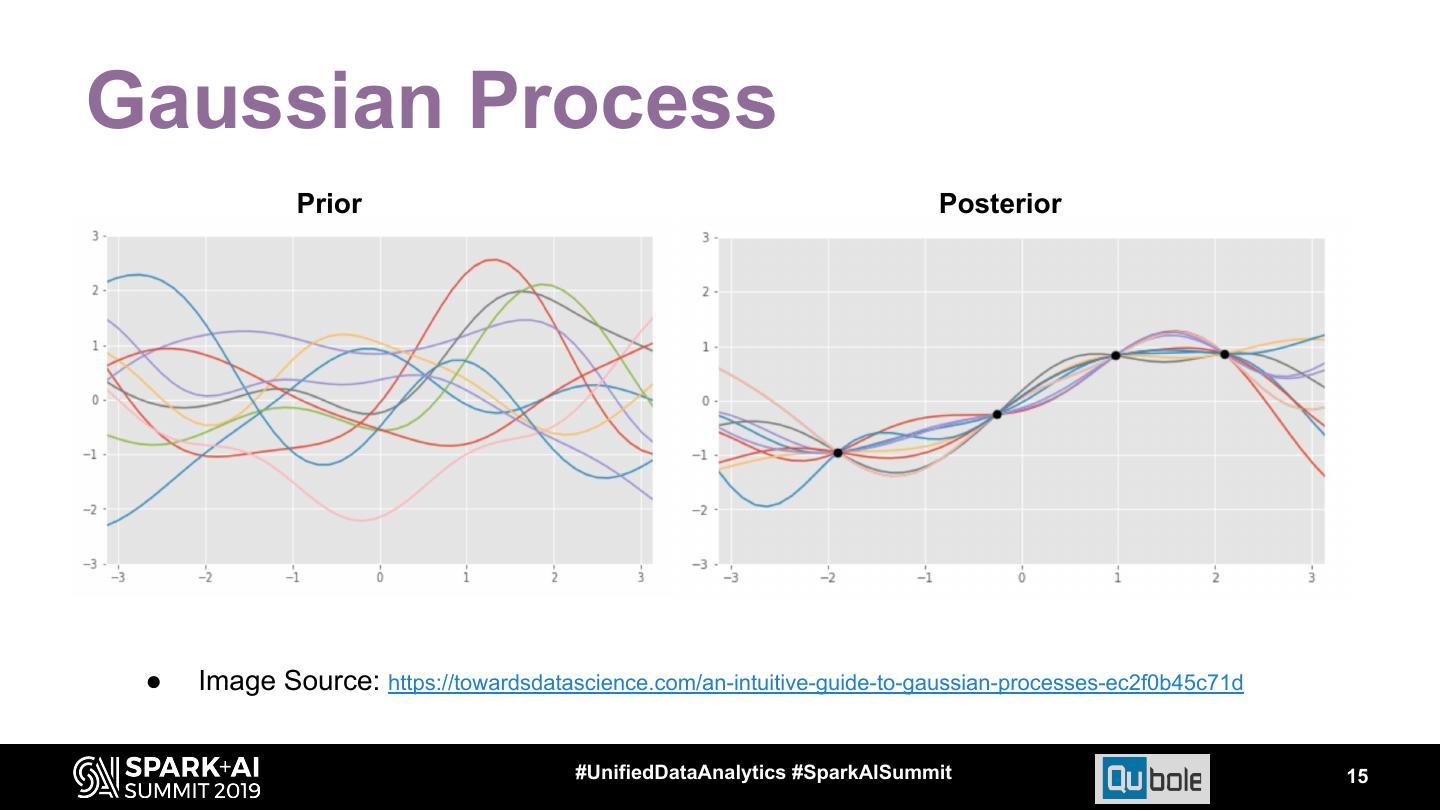
15 .Gaussian Process Prior Posterior ● Image Source: https://towardsdatascience.com/an-intuitive-guide-to-gaussian-processes-ec2f0b45c71d #UnifiedDataAnalytics #SparkAISummit 15
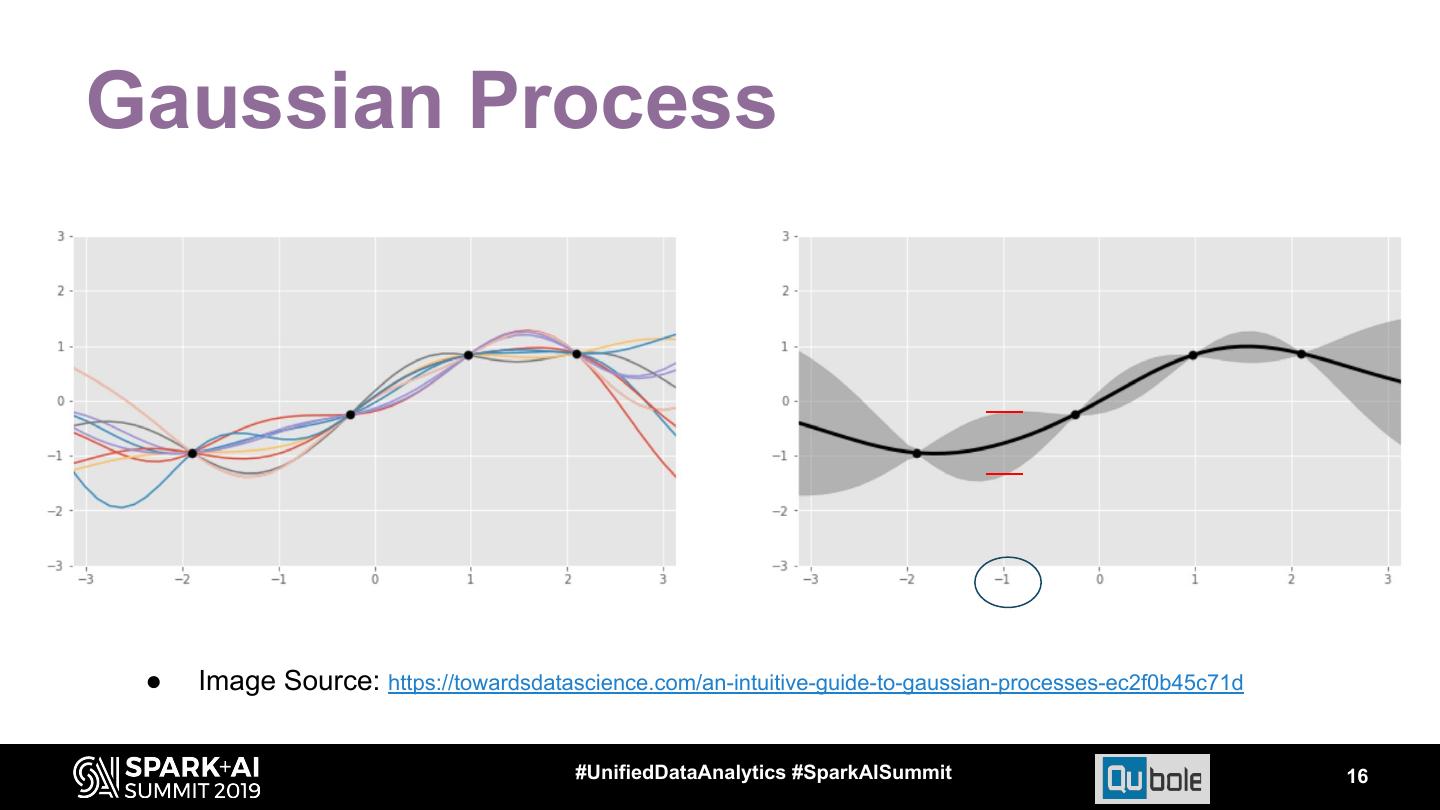
16 .Gaussian Process ● Image Source: https://towardsdatascience.com/an-intuitive-guide-to-gaussian-processes-ec2f0b45c71d #UnifiedDataAnalytics #SparkAISummit 16
17 .Gaussian Process - Advantage How does Gaussian Process help in finding good configs iteratively ? GP tells degree of certainty of it’s prediction: low and high. Results in balancing Exploitation and Exploration. Exploration: Explore configs with low Exploitation: Predict configs from degree certainty i.e., configs different high degree certainty of from training data. improvement. ● Image Source: https://towardsdatascience.com/an-intuitive-guide-to-gaussian-processes-ec2f0b45c71d #UnifiedDataAnalytics #SparkAISummit 17
18 .ML Model Issues • Training data is actual run of a job. Learning over multiple runs might be required: – Correlation between configs. – Sensitiveness of individual config for a particular job. – Explore large config space for global optimal. – Domain specific insights like cloud insights etc. • Too many runs can be expensive. 18
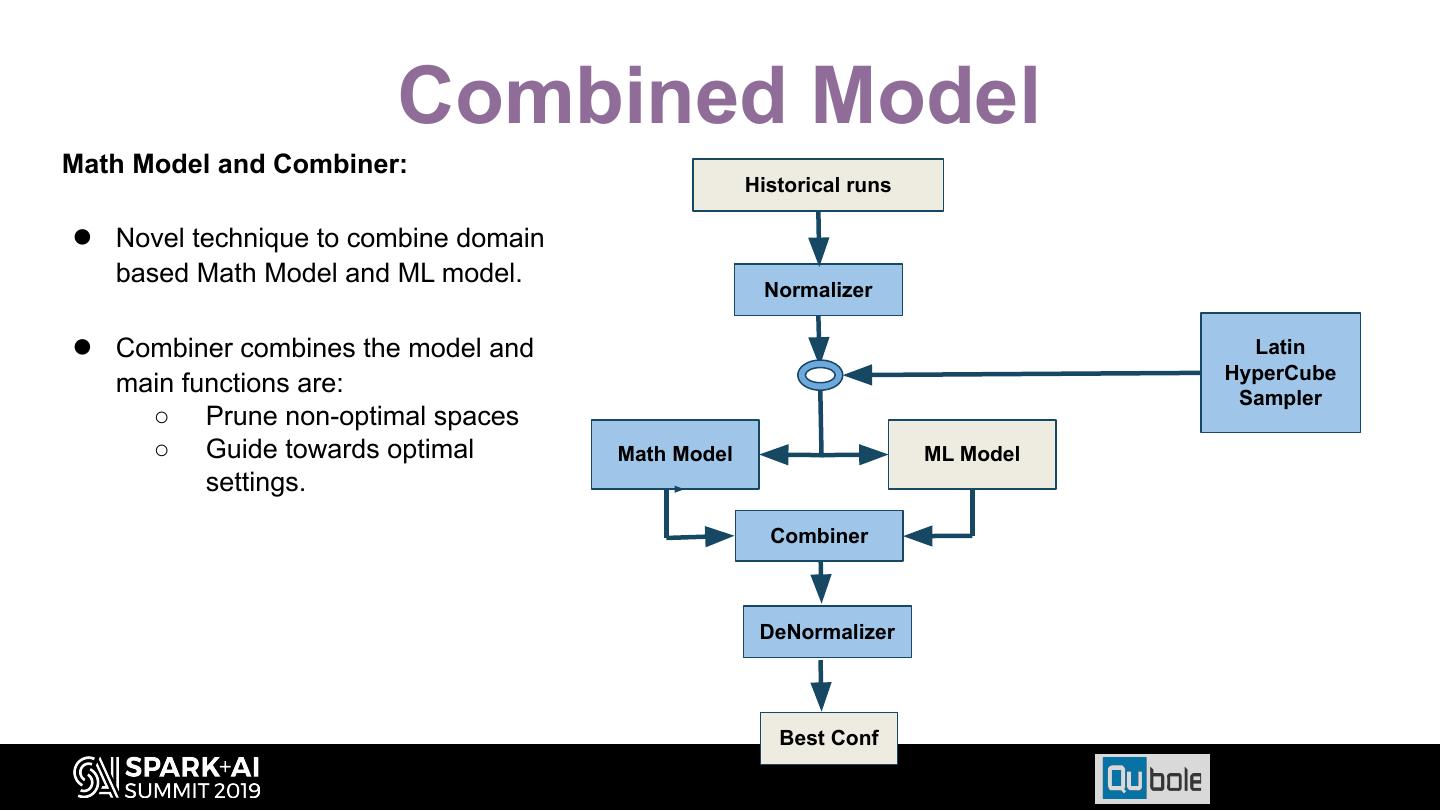
19 .ML Model Issues • Model searches for the optimal config using historical data. – Problem: Might need multiple iterations to prune out obvious non-optimal configs. – Solution: To converge sooner, Domain based knowledge can be used to prune non-optimal configs. 19
20 .Domain based model 20
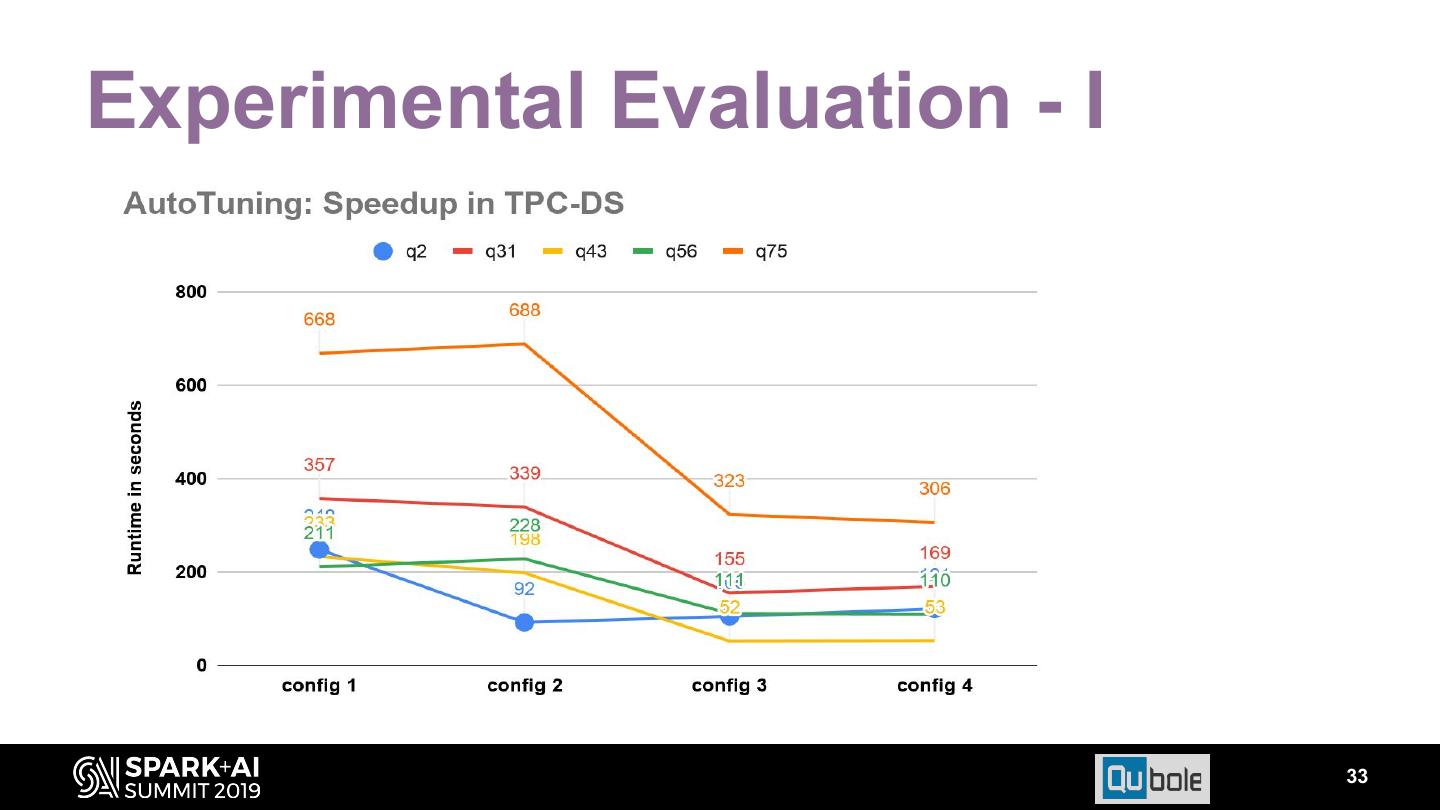
21 . Spills are expensive and should be avoided at all Insight 1 cost. Spill increases Disk I/O significantly Avoided by: ○ Increasing memory of task/containers. ○ More fine grained tasks i.e., increased parallelism. For e.g., decreasing split sizes or increasing shuffle partitions. Evaluation Time reduces for TPC DS q46 by almost 30% on increasing shuffle partitions from 100 to 200.
22 . For Spark, use single fat executor which uses all Insight 2 cores in node. Reasons for improvements are: ● Improved memory consumption between cores ● Reduced replicas of broadcast tables ● Reduced overheads. Evaluation ● Figure besides show effect of increasing cores per executor. ● Increased spark.executor.cores from 1 to 8 and correspondingly varying spark.executor.memory from 1152MB to 11094MB, thus keeping memory per core constant. ● Saw performance benefit up to 25% with fatter executor.
23 . Memory/vCPU ratio Insight 3 Yarn allocates containers on two dimensions - memory and vcpu Each container is given 1 vcpu and some memory The memory/vcpu of the containers should match the memory/vcpu ratio of the machine type Otherwise resources are wasted!
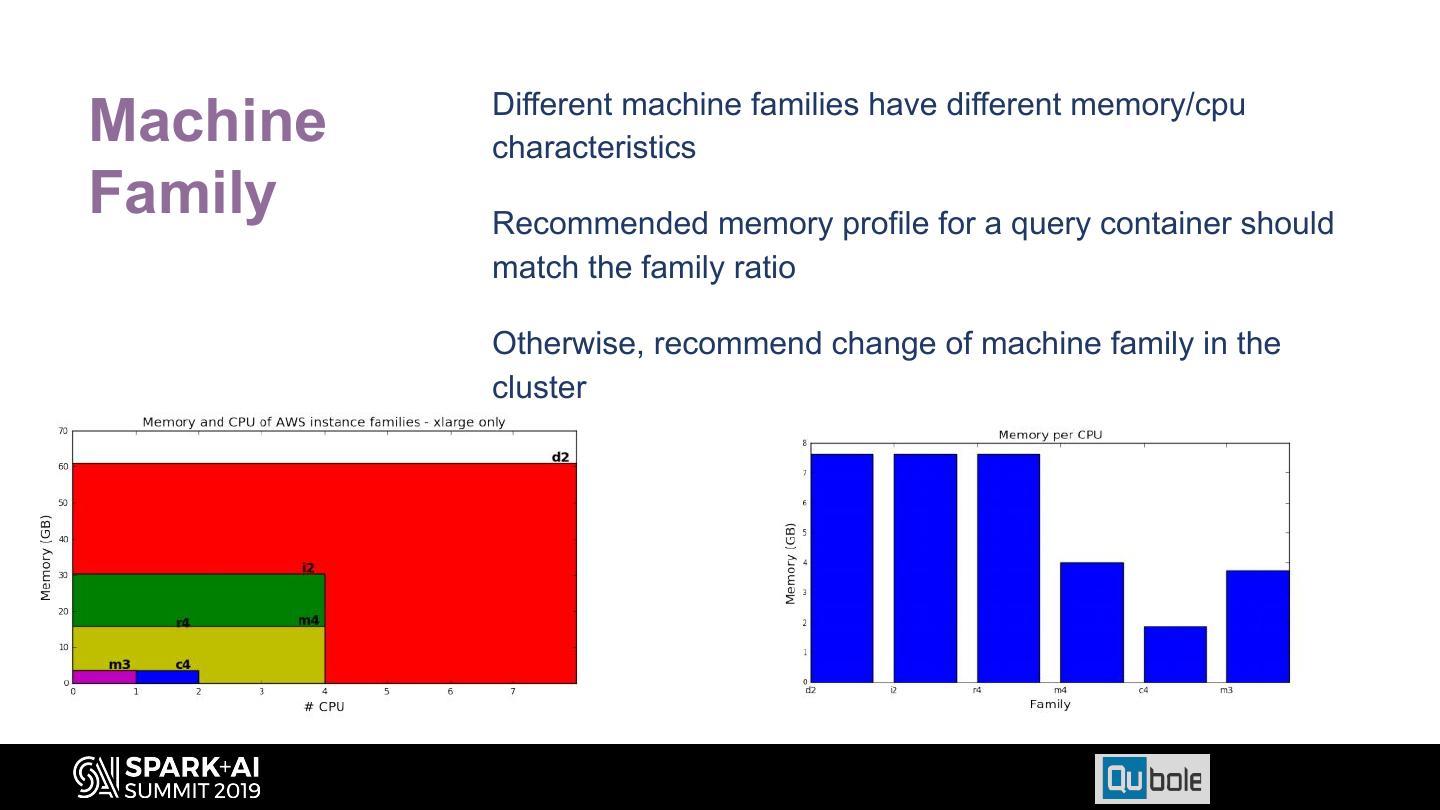
24 . Different machine families have different memory/cpu Machine characteristics Family Recommended memory profile for a query container should match the family ratio Otherwise, recommend change of machine family in the cluster
25 . Generate better SQL plans Insight 4 ● Collect statistics for Catalyst Optimizer. ● Tune configurations for better plans: e.g., more broadcast joins in TPC-DS q2
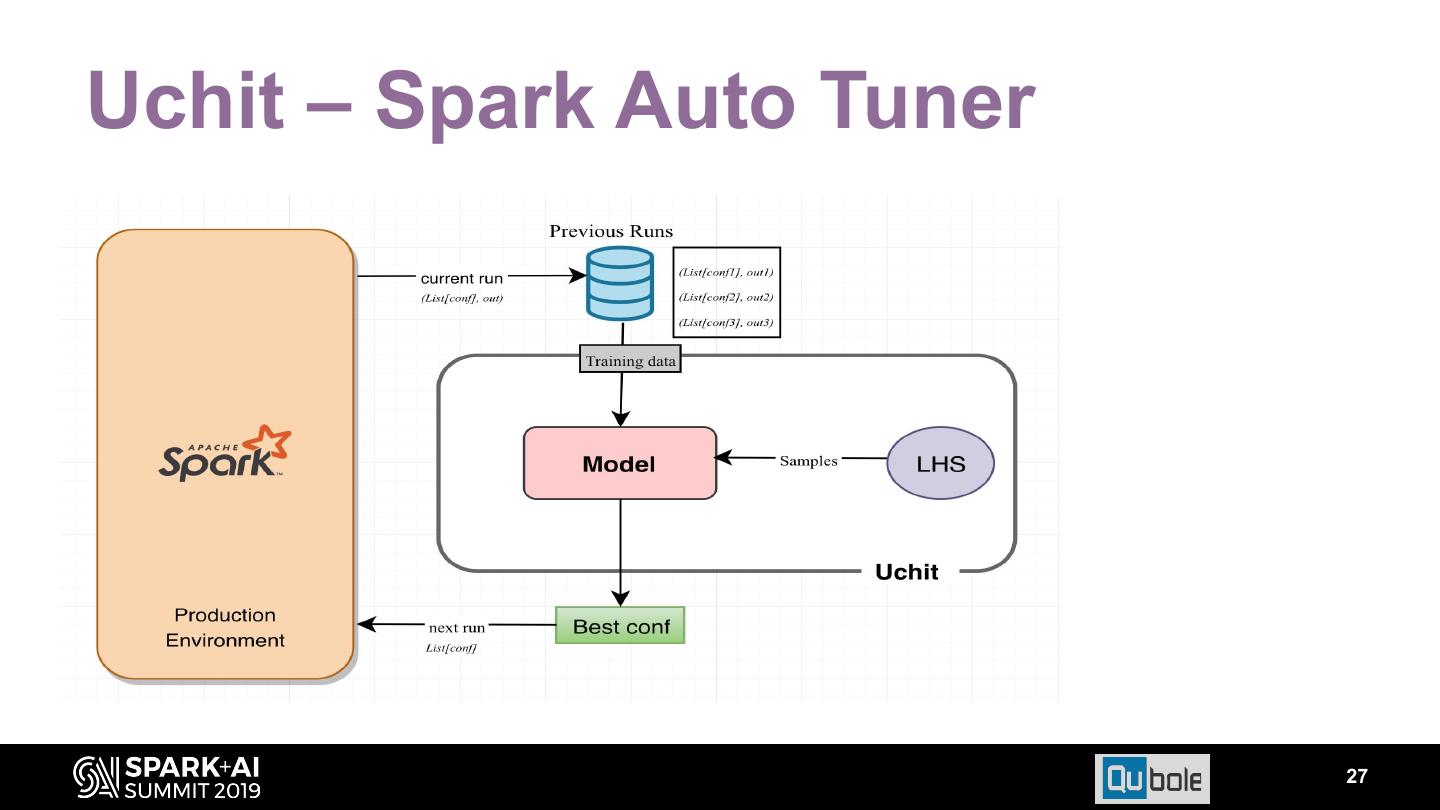
26 .Uchit – Spark Auto Tuner 26
27 .Uchit – Spark Auto Tuner 27
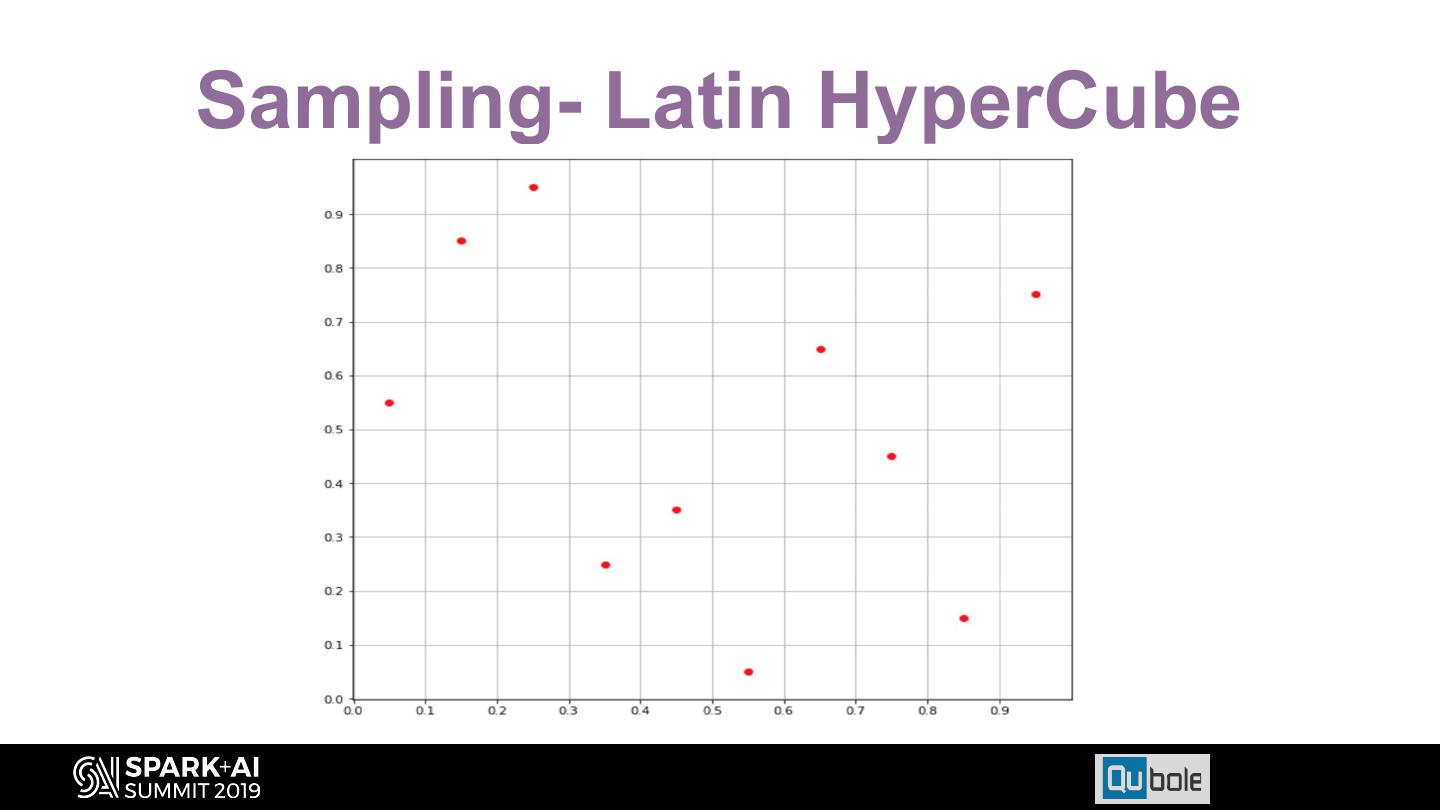
28 . Config Sampling • Discretize configuration. For e.g., if spark.executor.memory for r3.xlarge can vary between 2GB and 24 GB Discretized values = {2, 4, 6, 8, … 24} • Possible configs for 5 configs ≃ 29 million. • With sampling we could reduce it to 2000 config space: Latin Hypercube Sampling.
29 .Sampling- Latin HyperCube
3秒后跳转登录页面
去登陆

