展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Cosmos DB Real-time advanced analytics workshop
Cosmos DB Real-time
Advanced Analytics
Workshop
Sri Chintala, Microsoft
#UnifiedDataAnalytics #SparkAISummit
�
3 .Today’s customer scenario
Woodgrove Bank provides payment processing services
for commerce.
Want to build PoC of an innovative online fraud detection
solution.
Goal: Monitor fraud in real-time across millions of
transactions to prevent financial loss and detect
widespread attacks.
#UnifiedDataAnalytics #SparkAISummit 3
�
4 .Part 1: Customer Scenario
• Woodgrove Banks’ customers – end merchants
– are all around the world.
• The right solution would minimize any latencies
experienced by using their service by
distributing the solution as close as possible to
the regions used by customers.
4
�
5 .Part 1: Customer scenario
• Have decades-worth of historical transactional data, including transactions
identified as fraudulent.
• Data is in tabular format and can be exported to CSVs.
• The analysts are very interested in the recent notebook-driven approach
to data science & data engineering tasks.
• They would prefer a solution that features notebooks to explore and
prepare data, model, & define the logic for scheduled processing.
5
�
6 .Part 1: Customer needs
• Provide fraud detection services to merchant customers, using incoming
payment transaction data to provide early warning of fraudulent activity.
• Schedule offline scoring of “suspicious activity” using trained model, and make
globally available.
• Store data from streaming sources into long-term storage without interfering
with read jobs.
• Use standard platform that supports near-term data pipeline needs and long-
term standard for data science, data engineering, & development.
6
�
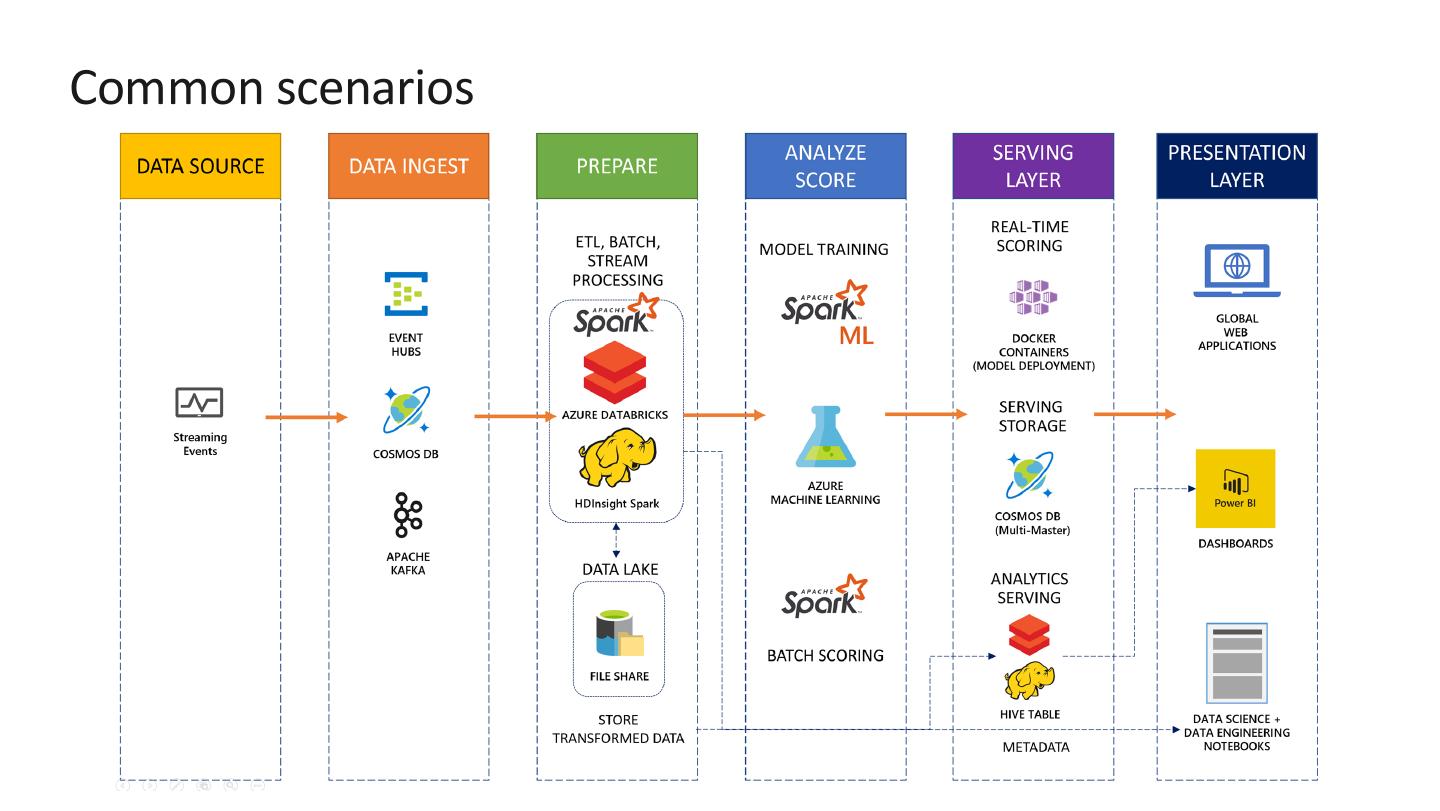
8 .Part 2: Design the solution (10 min)
• Design a solution and prepare to present the
solution to the target customer audience in a
chalk-talk format.
8
�
9 .Part 3: Discuss preferred solution
9
�
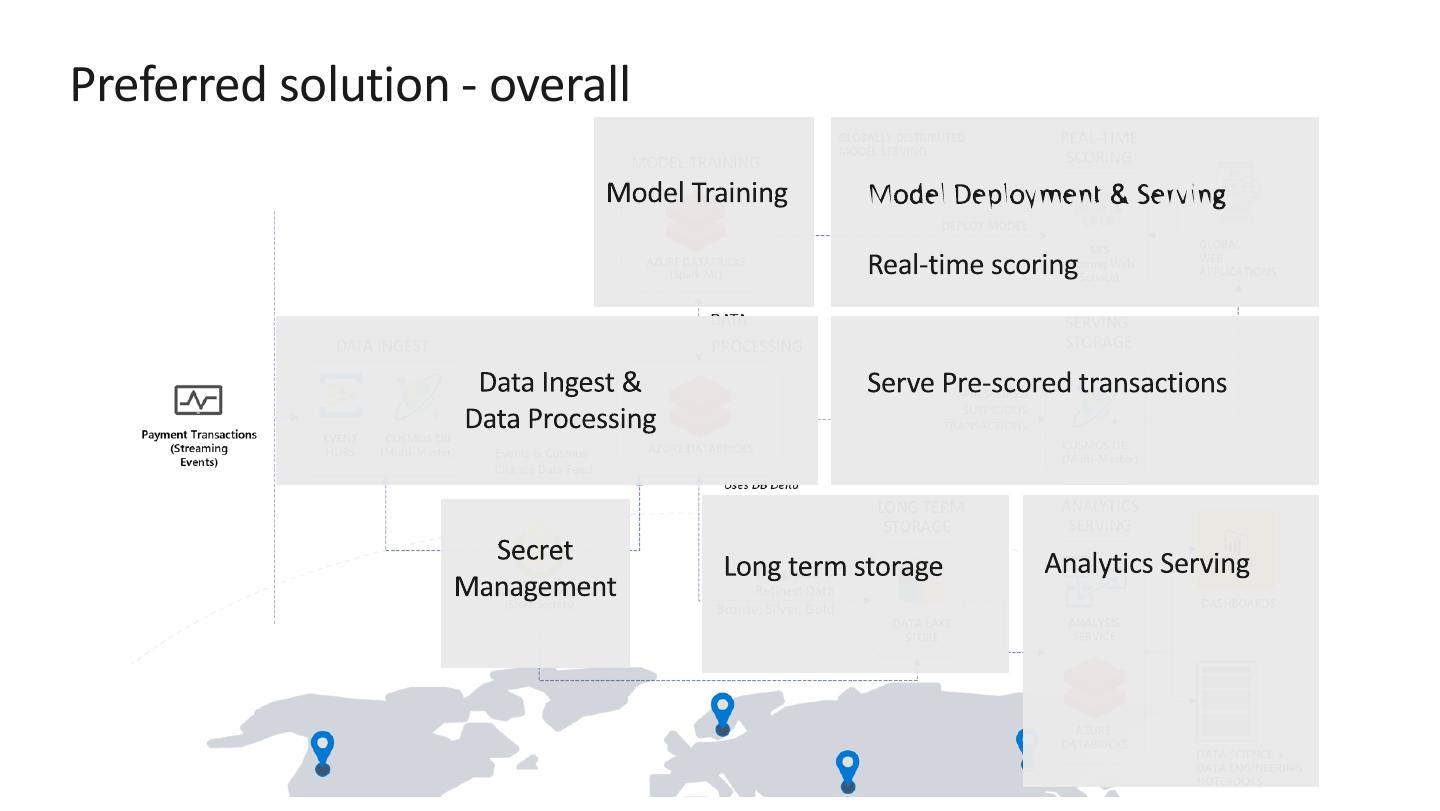
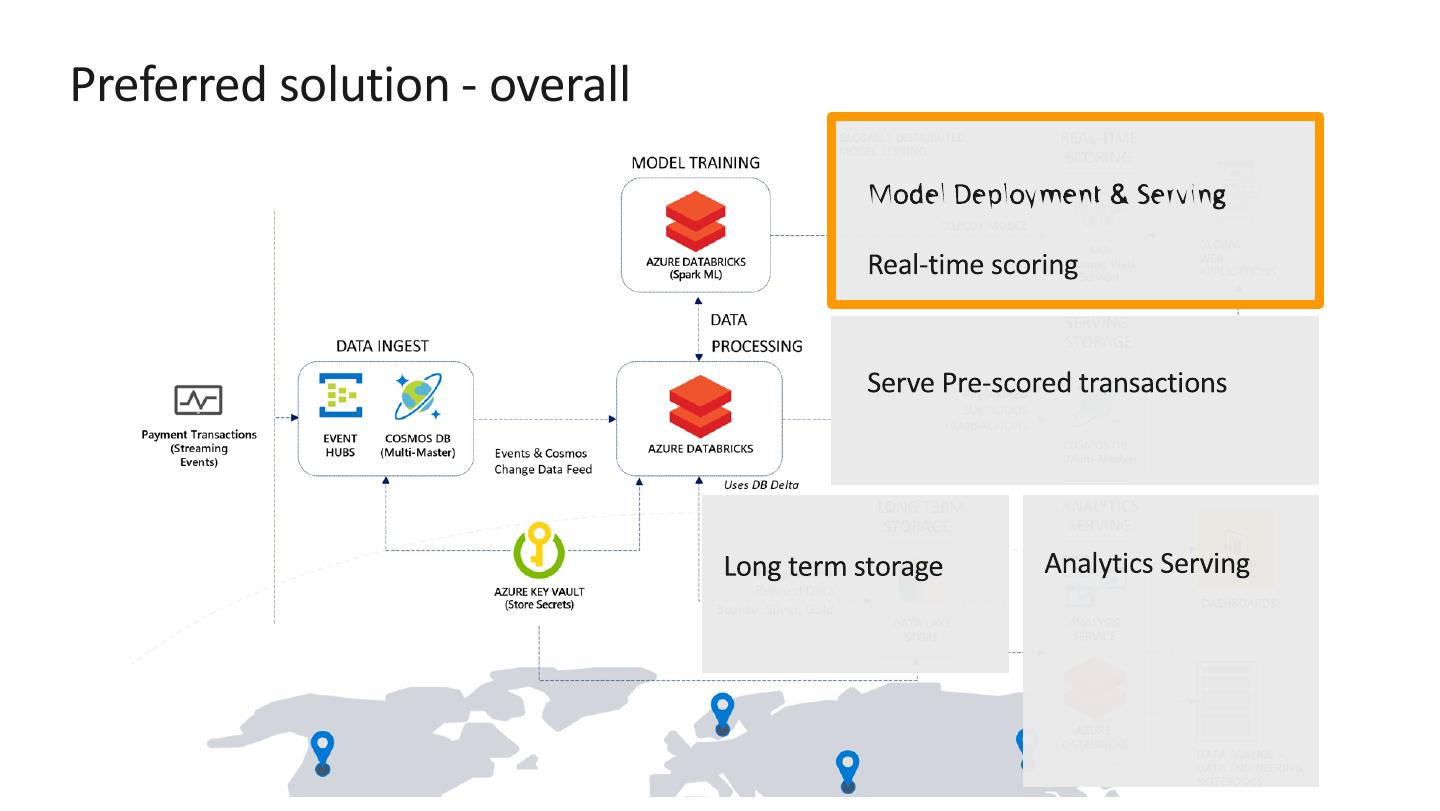
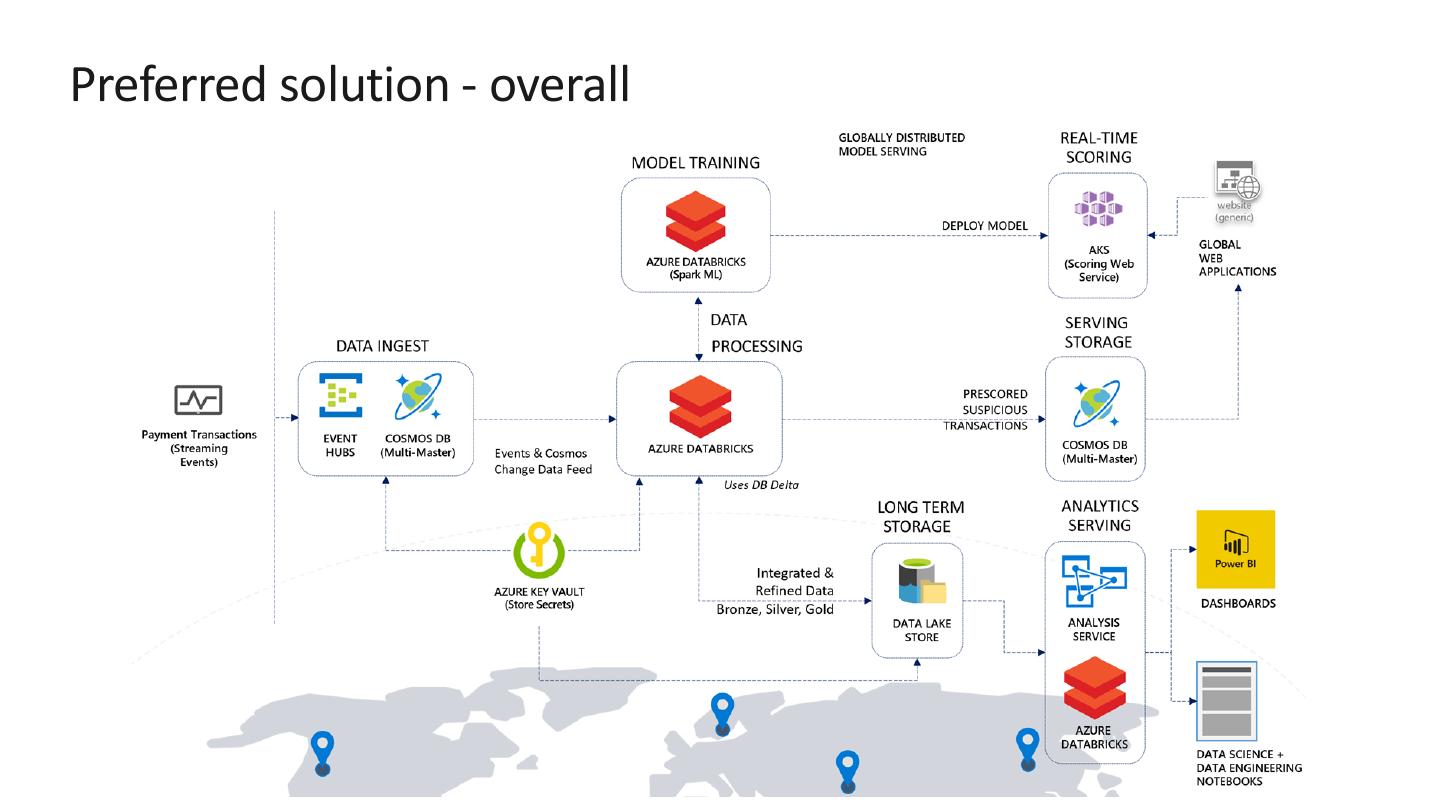
10 .Preferred solution - overall
�
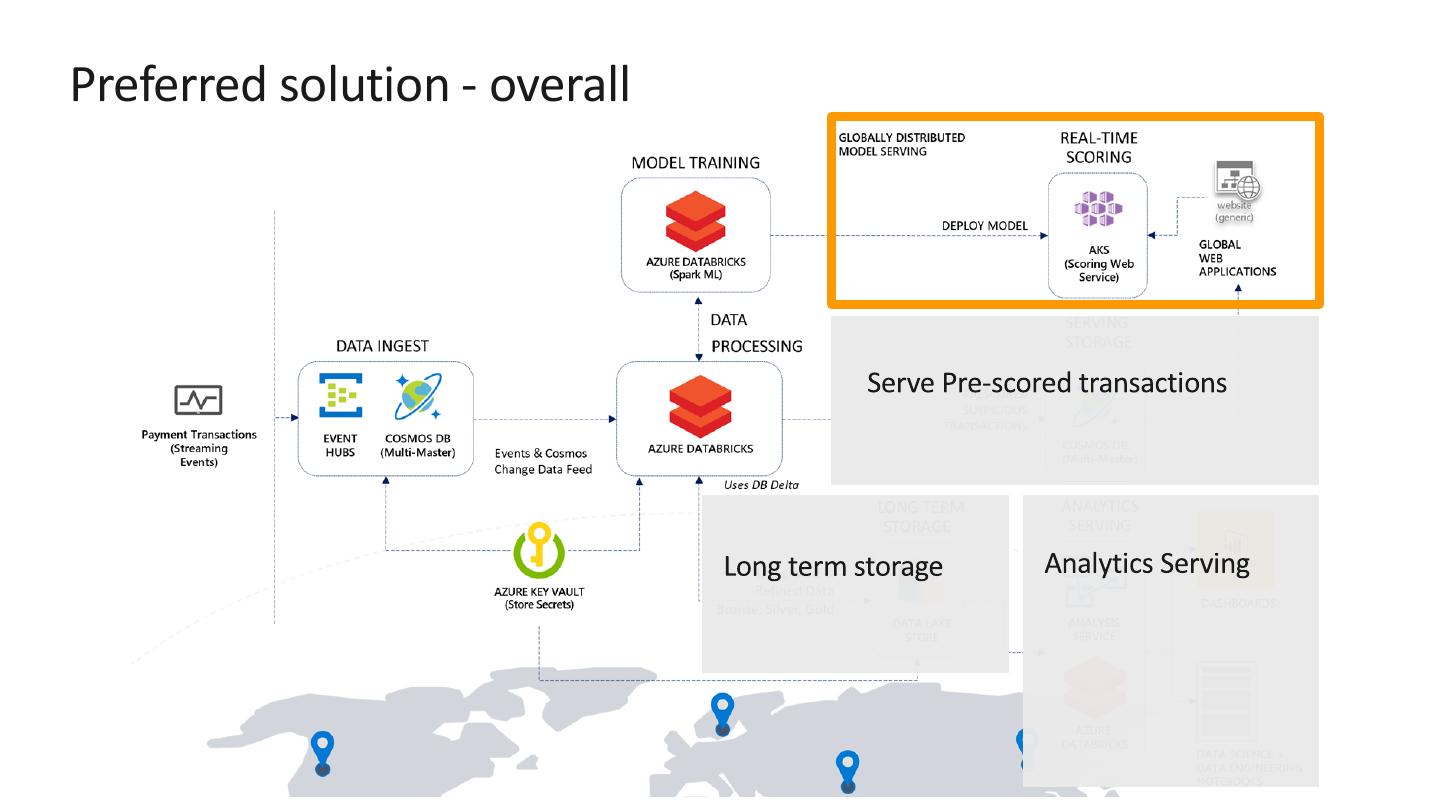
11 .Preferred solution - overall
�
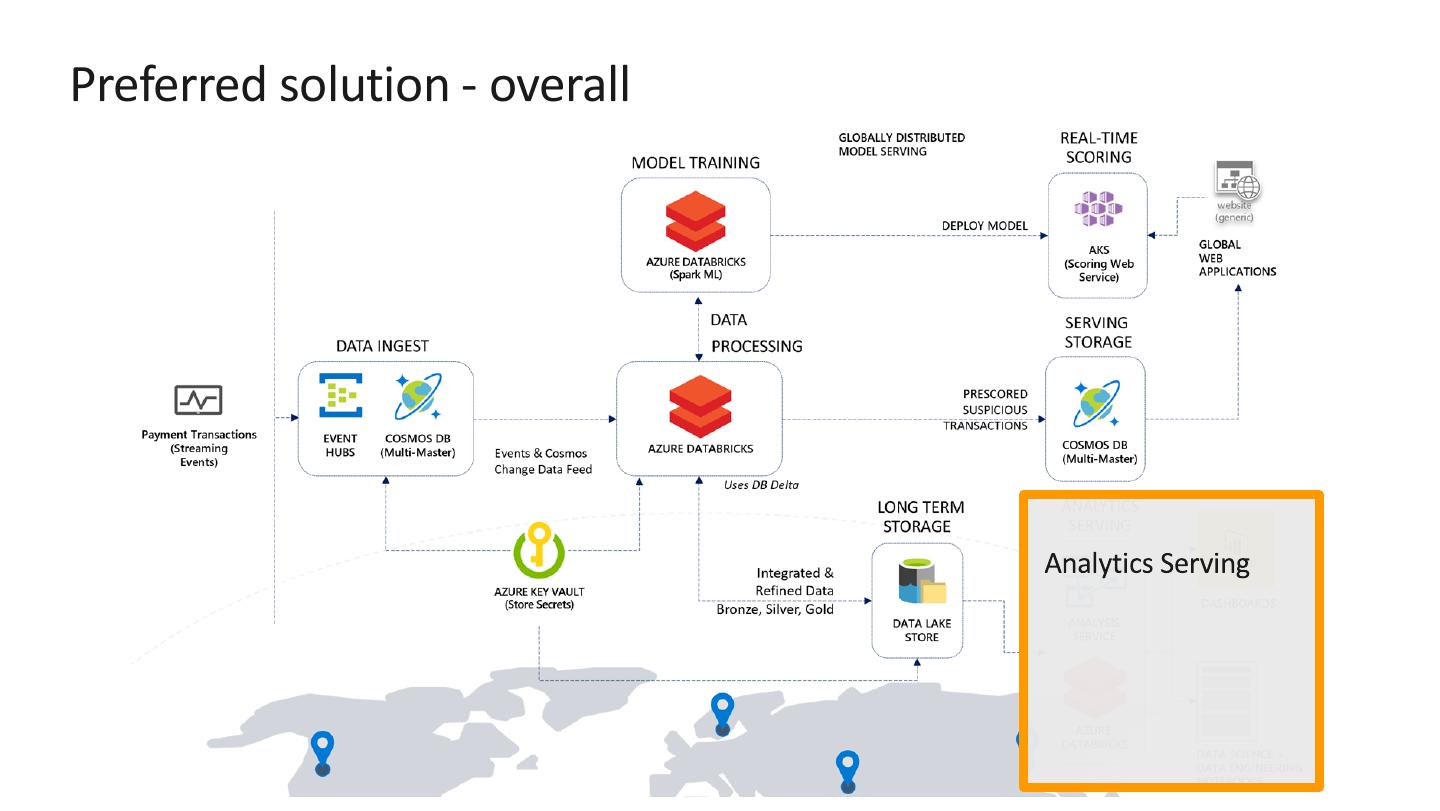
12 .Preferred solution - overall
�
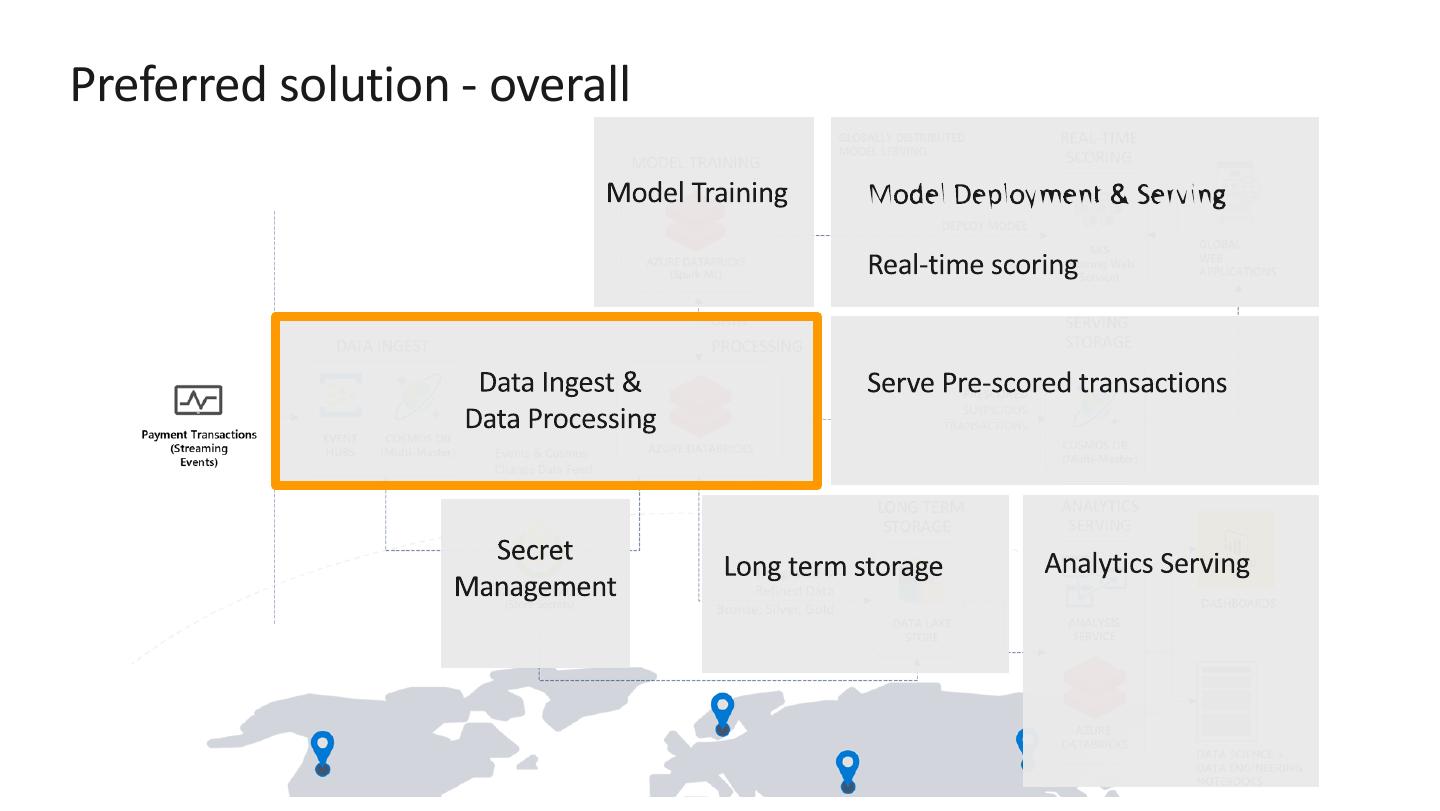
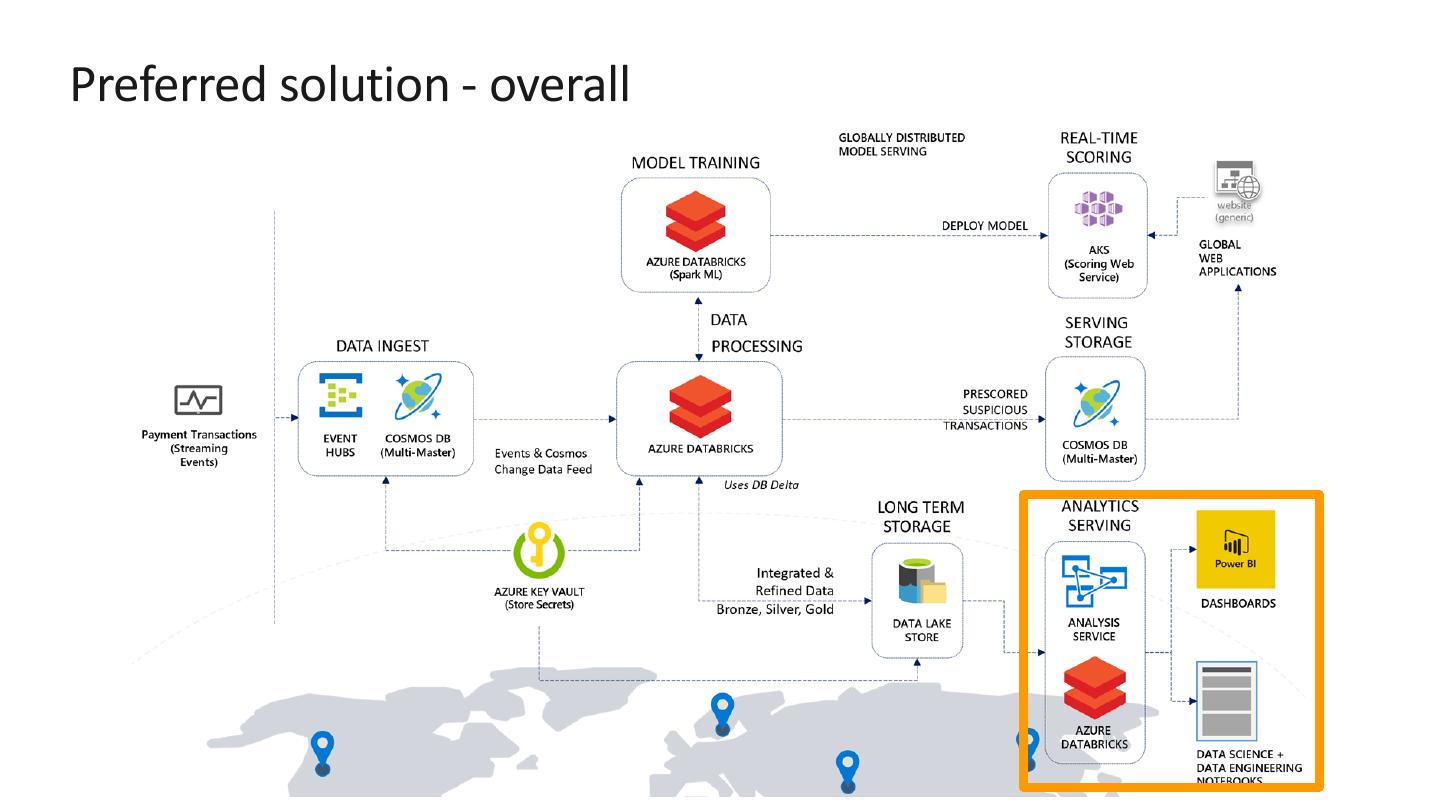
13 .Preferred solution – Data Ingest
Payment transactions can be ingested in real-time using Event Hubs
or Azure Cosmos DB.
Factors to consider are:
rate of flow (how many transactions/second)
data source and compatibility
level of effort to implement
long-term storage needs
�
14 .Preferred solution – Data Ingest
Cosmos DB:
Is optimized for high write throughput
Provides streaming through its change feed.
TTL (time to live) – automatic expiration & save in storage cost
Event Hub:
Data streams through, and can be persisted (Capture) in Blob or ADLS
Both guarantee event ordering per-partition. It is important how you
partition your data with either service.
�
15 .Preferred solution – Data Ingest
Cosmos DB likely easier for Woodgrove to integrate because they
are already writing payment transactions to a database.
Cosmos DB multi-master accepts writes from any region (failover
auto redirects to next available region)
Event Hub requires multiple instances in different geographies
(failover requires more planning)
Recommend: Cosmos DB – think of as “persistent event store”
�
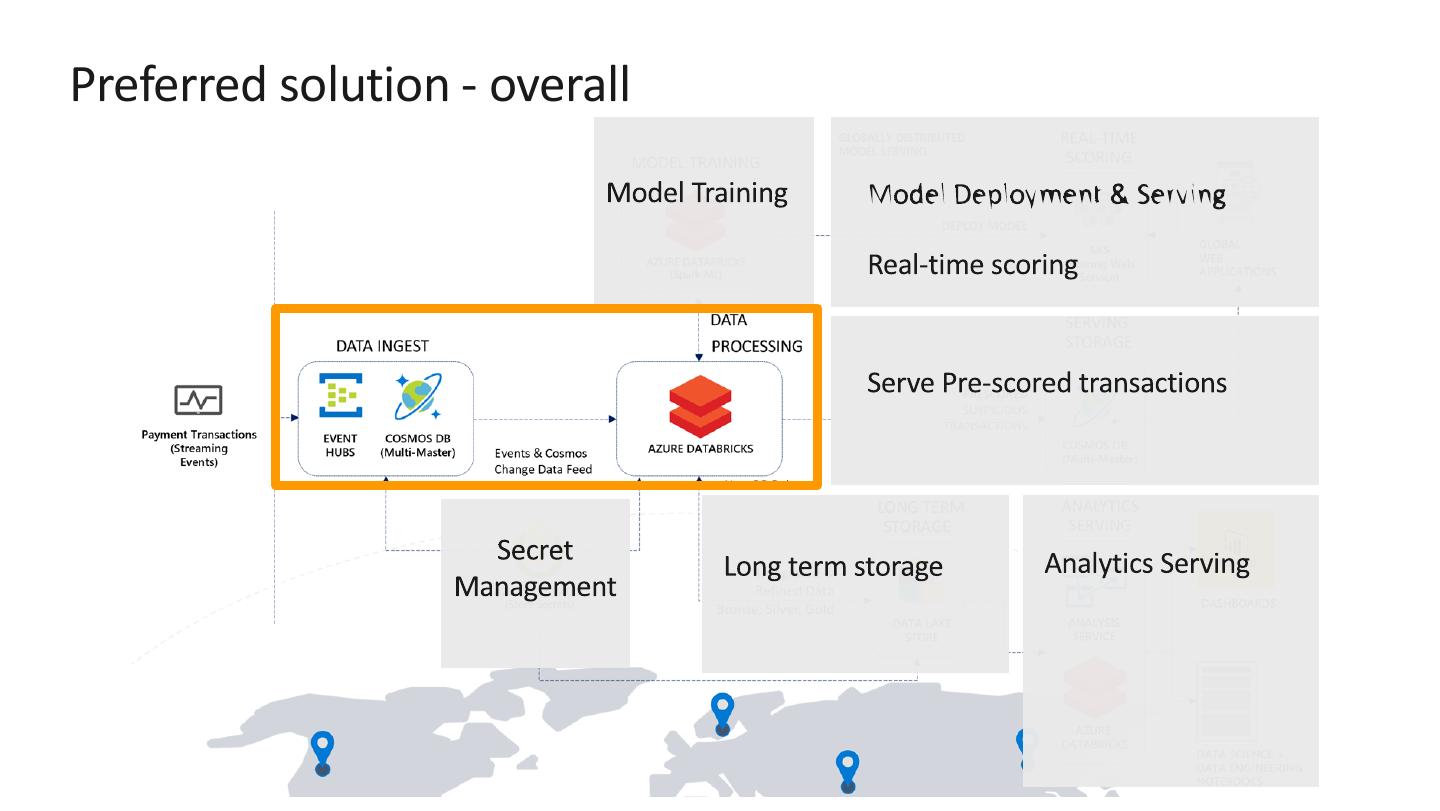
16 .Preferred solution – Data pipeline processing
Azure Databricks:
Managed Spark environment that can process streaming & batch data
Enables data science, data engineering, and development needs.
Features it provides on top of standard Apache Spark include:
AAD integration and RBAC
Collaborative features such as workspace and git integration
Run scheduled jobs for automatic notebook/library execution
Integrates with Azure Key Vault
Train and evaluate machine learning models at scale
�
17 .Preferred solution – Data pipeline processing
Azure Databricks can connect to both Event Hubs and Cosmos DB, using
Spark connectors for both.
Spark Structured Streaming to process real-time payment transactions into
Databricks Delta tables.
Be sure to set a checkpoint directory on your streams. This allows you to
restart stream processing if the job is stopped at any point.
�
18 .Preferred solution – Data pipeline processing
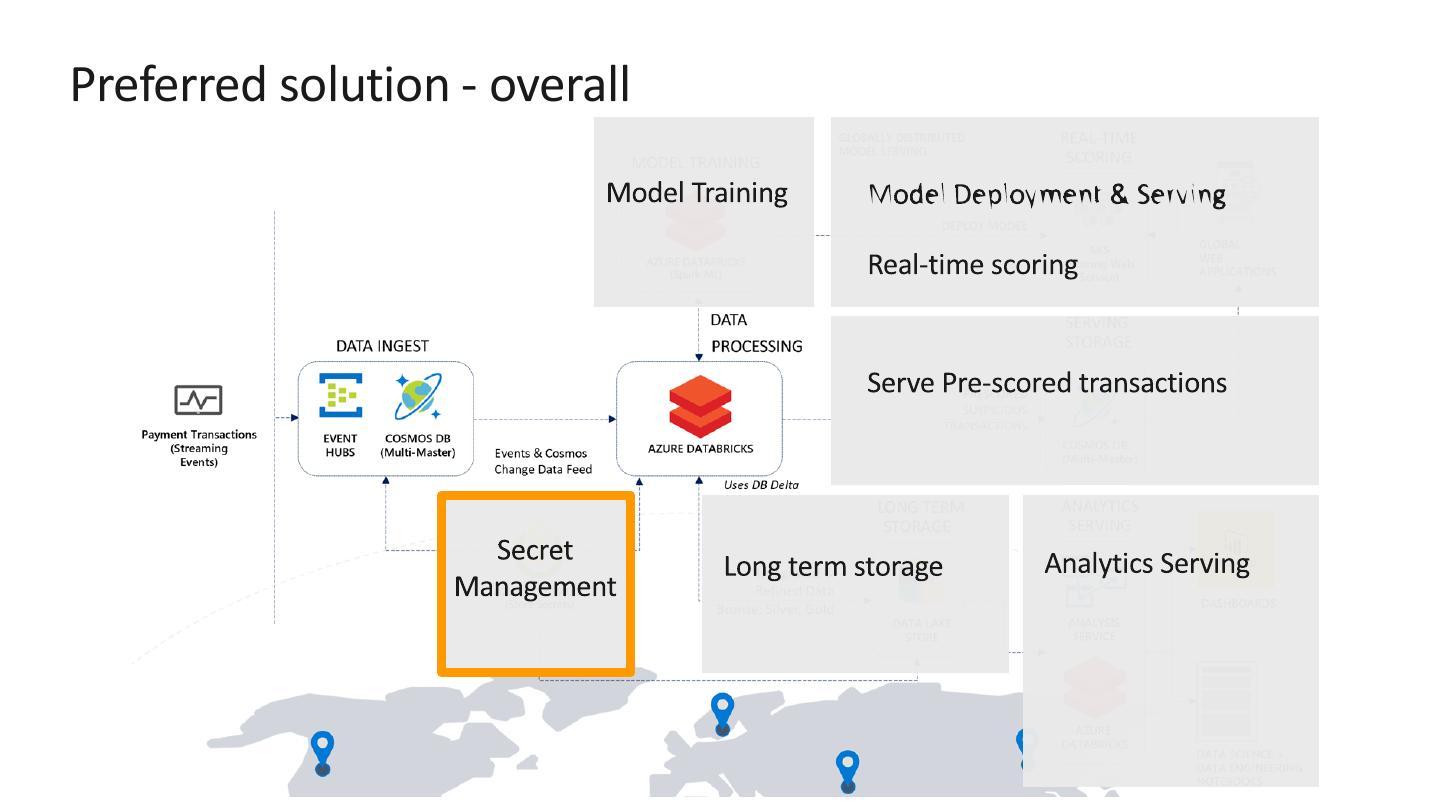
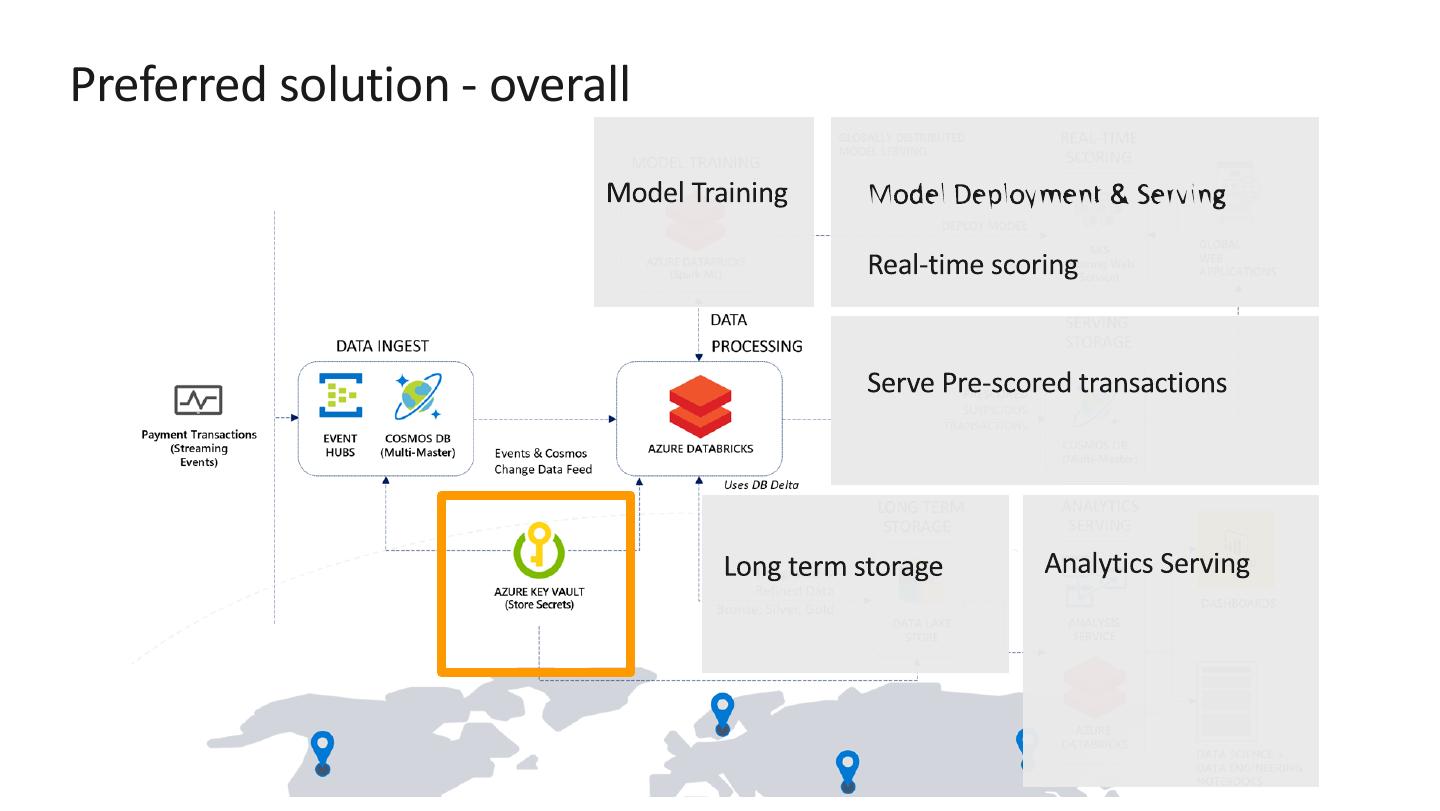
Store secrets such as account keys and connection strings centrally in
Azure Key Vault
Set Key Vault as the source for secret scopes in Azure Databricks. Secrets
are [REDACTED].
�
19 .Preferred solution – Data pipeline processing
Databricks Delta tables are Spark tables with built-in reliability
and performance optimizations.
Supports batch & streaming with additional features:
ACID transactions: Multiple writers can simultaneously modify data,
without interfering with jobs reading the data set.
DELETES/UPDATES/UPSERTS:
Automatic file management: Data access speeds up by organizing data into
large files that can be read efficiently
Statistics and data skipping: Reads are 10-100x faster when statistics are
tracked about data in each file, avoiding irrelevant
information
�
20 .Preferred solution - overall
�
21 .Preferred solution - overall
�
22 .Preferred solution - overall
�
23 .Preferred solution - overall
�
24 .Preferred solution – Model training &
deployment
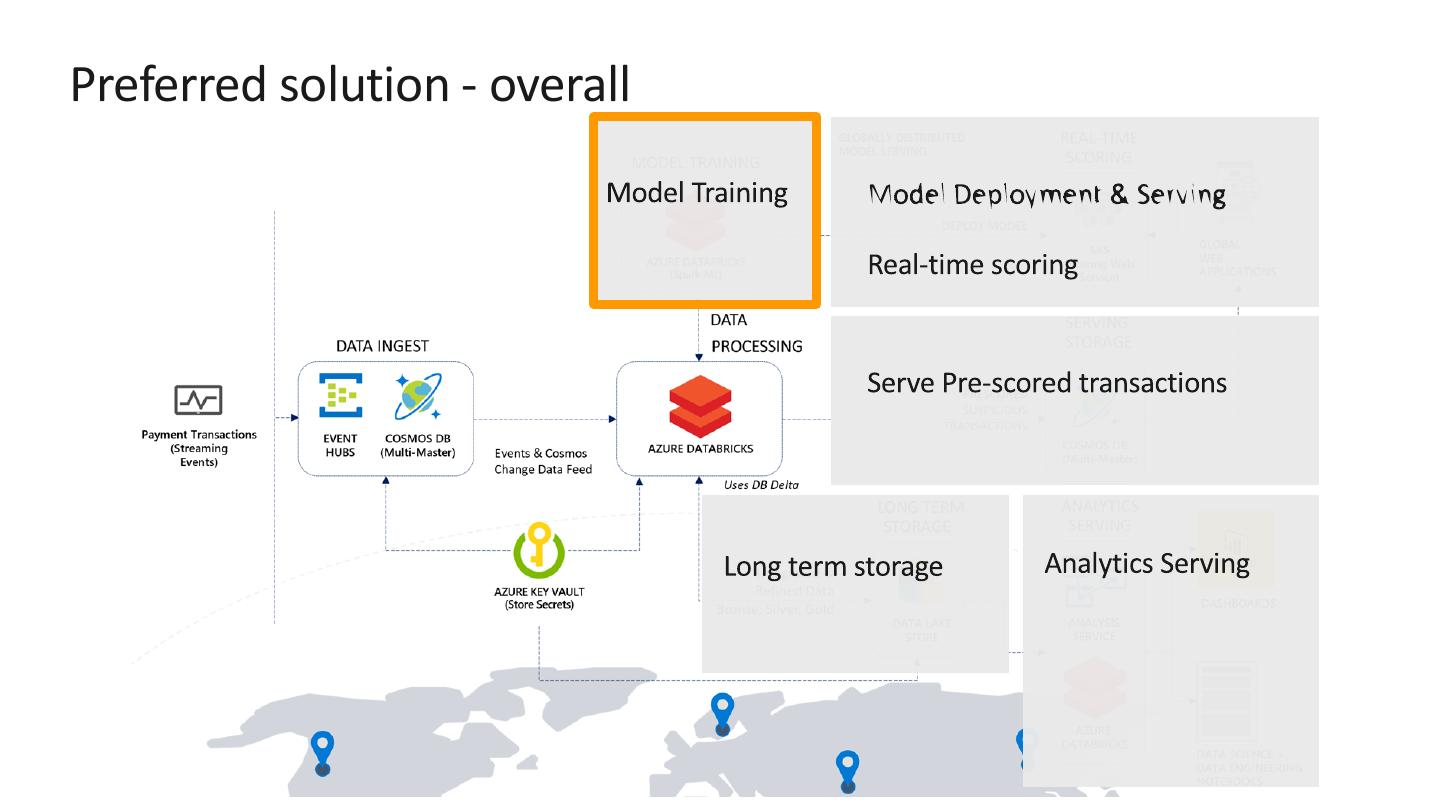
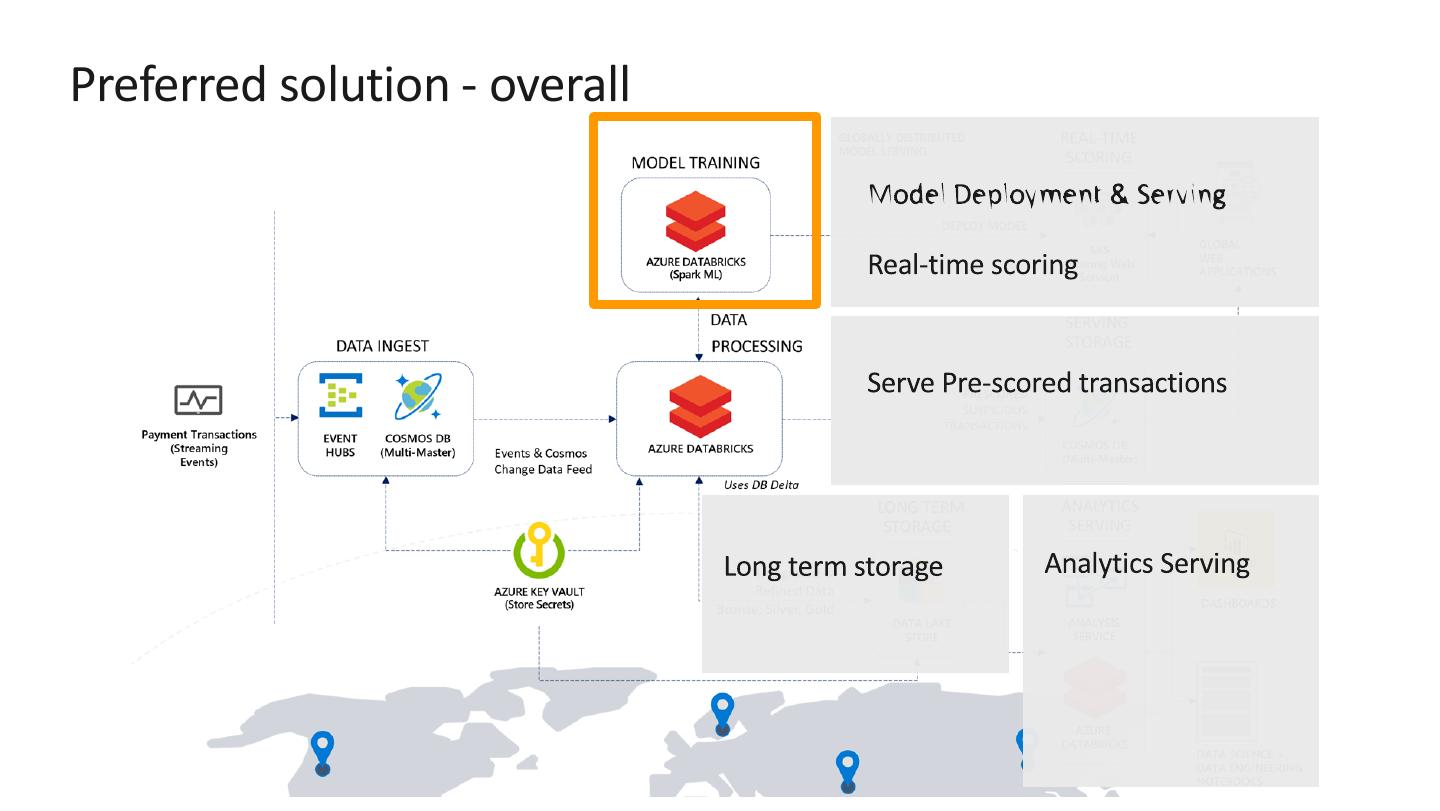
Azure Databricks supports machine learning training at scale.
Train model using historical payment transaction data
�
25 .Preferred solution - overall
�
26 .Preferred solution - overall
�
27 .Preferred solution – Model training &
deployment
Use Azure Machine Learning service (AML) to:
Register the trained model
Deploy it to Azure Kubernetes Service (AKS) cluster for easy web
accessibility and high availability.
For scheduled, batch scoring, Access model from notebook and
write results to Cosmos via Cosmos DB Spark connector.
�
28 .Preferred solution - overall
�
29 .Preferred solution - overall
�