展开查看详情
1 .WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
�
2 .Spark Streaming
Headaches and Breakthroughs in Building
Continuous Applications
Landon Robinson & Jack Chapa
#UnifiedAnalytics #SparkAISummit
�
3 .Who We Are
Landon Robinson Jack Chapa
Data Engineer Data Engineer
Big Data Team @ SpotX
#UnifiedAnalytics #SparkAISummit 3
�
4 .But first… why are we here?
Because Spark Streaming...
• is very powerful
• can supercharge your infrastructure
• … and can be very complex!
Lots of headaches and breakthroughs!
#UnifiedAnalytics #SparkAISummit 4
�
5 .Takeaways
Leave with a few actionable items that we wish we knew
when we started with Spark Streaming.
Focus Areas
● Streaming Basics ● Helpful Configurations
● Testing ● Backpressure
● Monitoring & Alerts ● Data Enrichment &
● Batch Intervals & Resources Transformations
�
6 .Our Company
The Trusted Platform For
Premium Publishers and
Broadcasters
#UnifiedAnalytics #SparkAISummit 6
�
7 .We Process a Lot of Data
Data:
- 220 MM+ Total Files/Blocks
- 8 PB+ HDFS Space
- 20 TB+ new data daily
- 100MM+ records/minute
- 300+ Data Nodes
Apps:
- Thousands of daily Spark apps
- Hundreds of daily user queries
- Multiple 24/7 Streaming apps
�
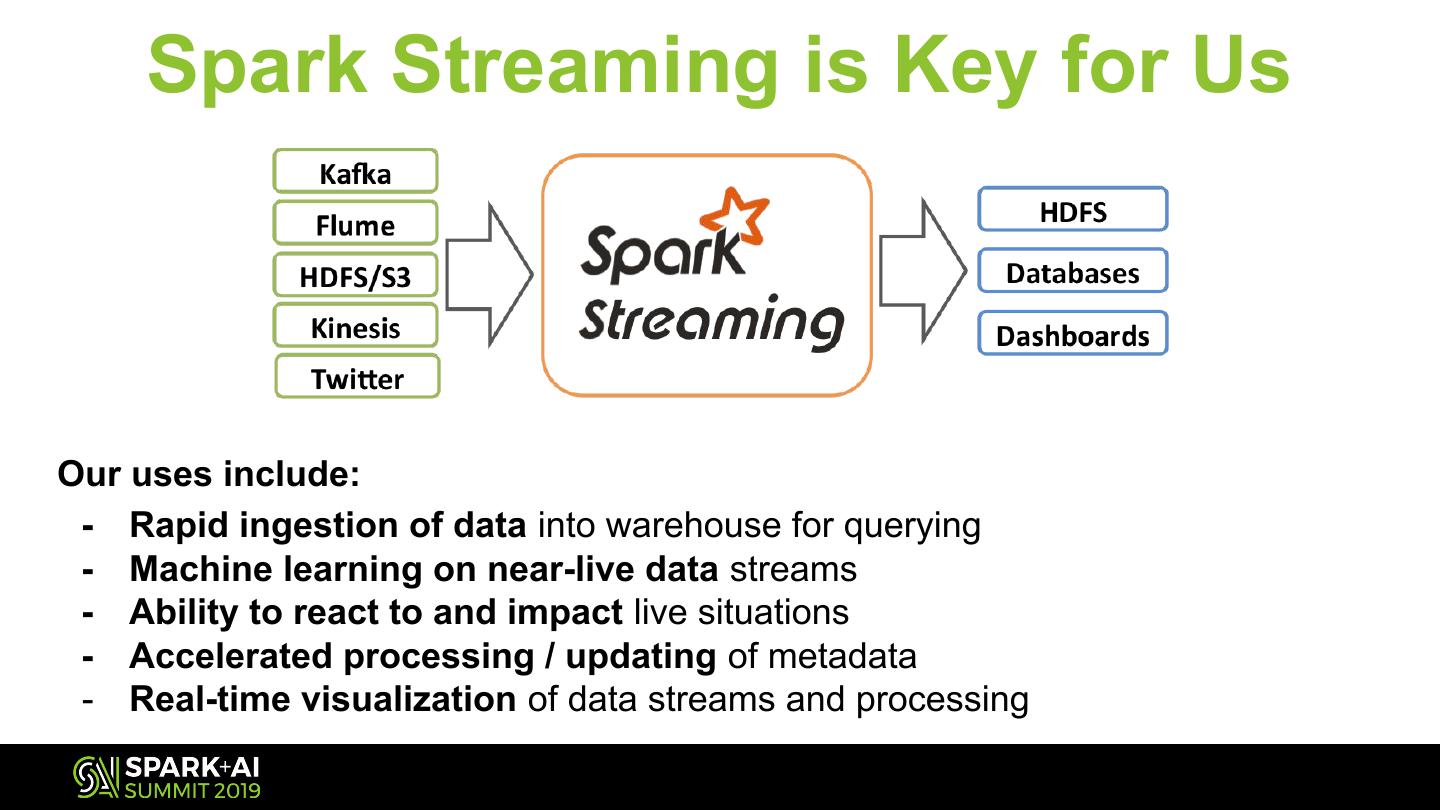
8 . Spark Streaming is Key for Us
Our uses include:
- Rapid ingestion of data into warehouse for querying
- Machine learning on near-live data streams
- Ability to react to and impact live situations
- Accelerated processing / updating of metadata
- Real-time visualization of data streams and processing
�
9 .Spark Streaming Basics
a brief overview
�
10 . Spark Streaming Basics
Spark Streaming is an extension of Spark that
enables scalable, high-throughput, fault-tolerant
processing of live data streams.
• Stream == live data stream
– Topic == Kafka’s name for a stream
•
DStream == sequence of RDDs formed
from reading a data stream
• Batch == a self-contained job within your
Streaming app that processes a segment of
the stream.
�
11 . Testing
Rapid development and
testing of Spark apps
�
12 .Use Spark in Local Mode
You can start building Spark Streaming apps
in minutes, using Spark locally!
On your local machine
• No cluster needed!
• Great for rough testing
We Recommend:
IntelliJ Community Edition
• with SBT: For dependency management
�
13 .Use Spark in Local Mode
The Scala Build Tool is your friend!
Simply: In your build.sbt:
• Import Spark libraries • src/test/scala => “provided”
• Invoke a Context and/or Session • src/main/scala => “compiled”
• Set master to local[*] or local[n]
�
14 . Example Unit Test using just a SparkContext
Invoke a local session:
• In your unit test classes Add to your deployment pipeline
• Test logic on small datasets for a nice pre-release gut check!
�
15 . Unit Testing
Spark Streaming Apps can easily be unit tested
- Using .queueStream()
- Using a spark testing library
Libraries Use Cases
- spark-testing-base - DStream actions
- sscheck - Business Logic
- spark-tests - Integration
�
16 . Example Library: spark-testing-base
- Easy to Use
- Helpful wrappers
- Integrates w/ scalatest
- Minimal code required
- Clock management
- Runs alongside other tests
GitHub: https://github.com/holdenk/spark-testing-base
�
17 .Monitoring
Tracking and visualizing
performance of your
app
�
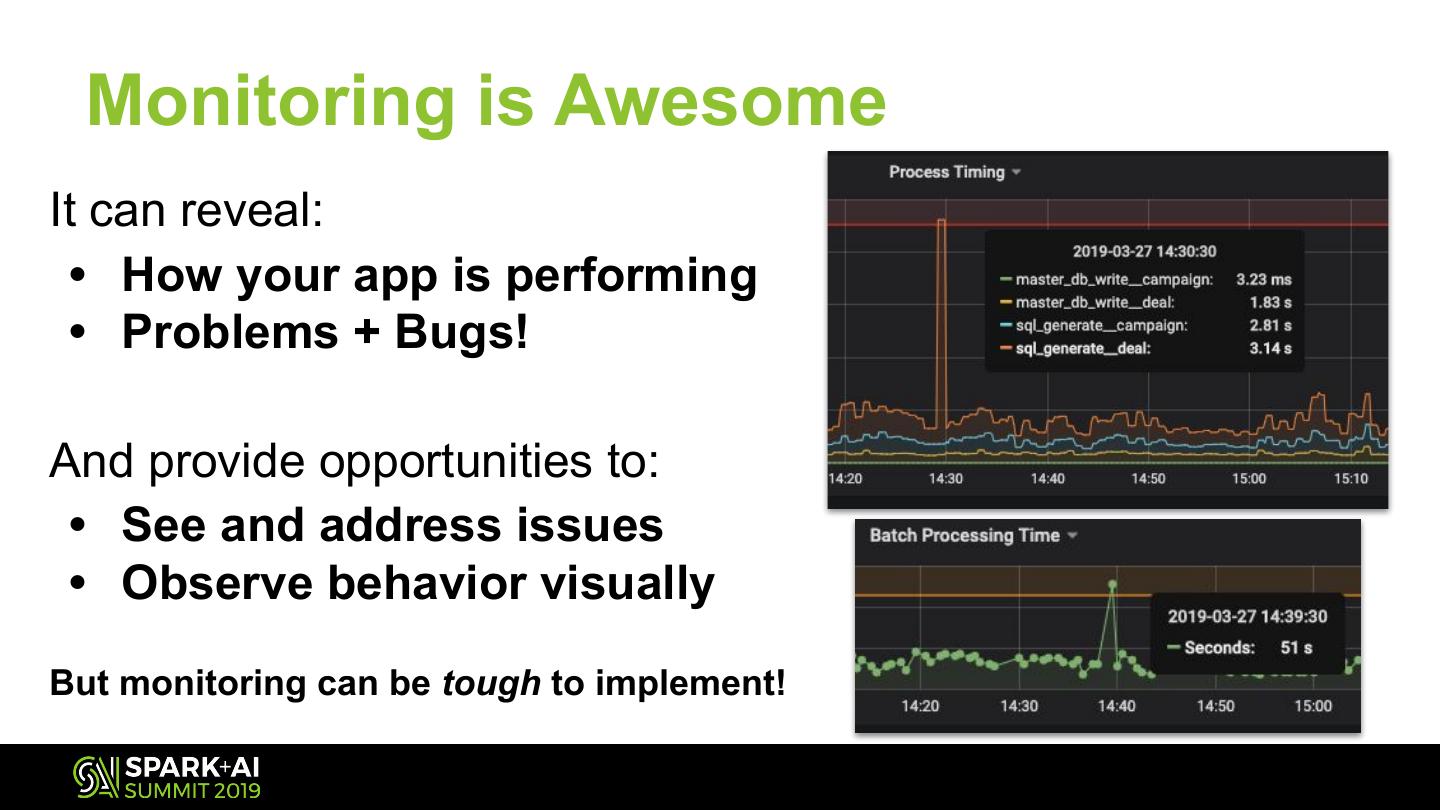
18 . Monitoring is Awesome
It can reveal:
• How your app is performing
• Problems + Bugs!
And provide opportunities to:
• See and address issues
• Observe behavior visually
But monitoring can be tough to implement!
�
19 .Monitoring (a less than ideal approach)
You could do it all in the app...
Example: Looping over RDDs to:
• Count records
• Track Kafka offsets
• Processing time / delays
But it’s less than ideal...
• Calculating performance significantly
impacts performance… not great.
• All these metrics are calculated by
Spark!
�
20 .Monitoring and Visualization (using Listeners)
Use Spark Listeners to access
metrics in the background!
Let Spark do the hard work:
• Batch duration, delays
• Record throughput
• Stream position recovery
Come to our talk: Spark Listeners:
A Crash Course in Fast, Easy
Monitoring!
• Room 3016 | Today @ 5:30 PM
�
21 .Kafka Offset Recovery
Saving your place
elsewhere
�
22 . Writing Offsets to MySQL
Inside the Spark
Listener class, after a
batch completes...
You can access an
object generated by
Spark containing your
offsets processed.
Take those offsets and
back them up to a
DB...
�
23 .Reading Offsets from MySQL
Your offsets are now
stored in a DB after
each batch completes.
Whenever your app
restarts, it reads those
offsets from the DB...
And starts processing
where it last left off!
�
24 .Getting Offsets from the Database
�
25 .Example: Reading Offsets from MySQL
�
26 .Example: Reading Offsets from MySQL
�
27 . Timing Logging (around actions)
- Record timing info for fast
troubleshooting
- Escalate alarms to the
appropriate team
- Quickly resolve while
app continues running
�
28 .React
How do I react to this monitoring?
● Heartbeats
● Scheduled Monitor Jobs
○ Version Updates
○ Ensure Running
○ Act on failure/problem
● Monitoring Alarms
● Look at them!
�
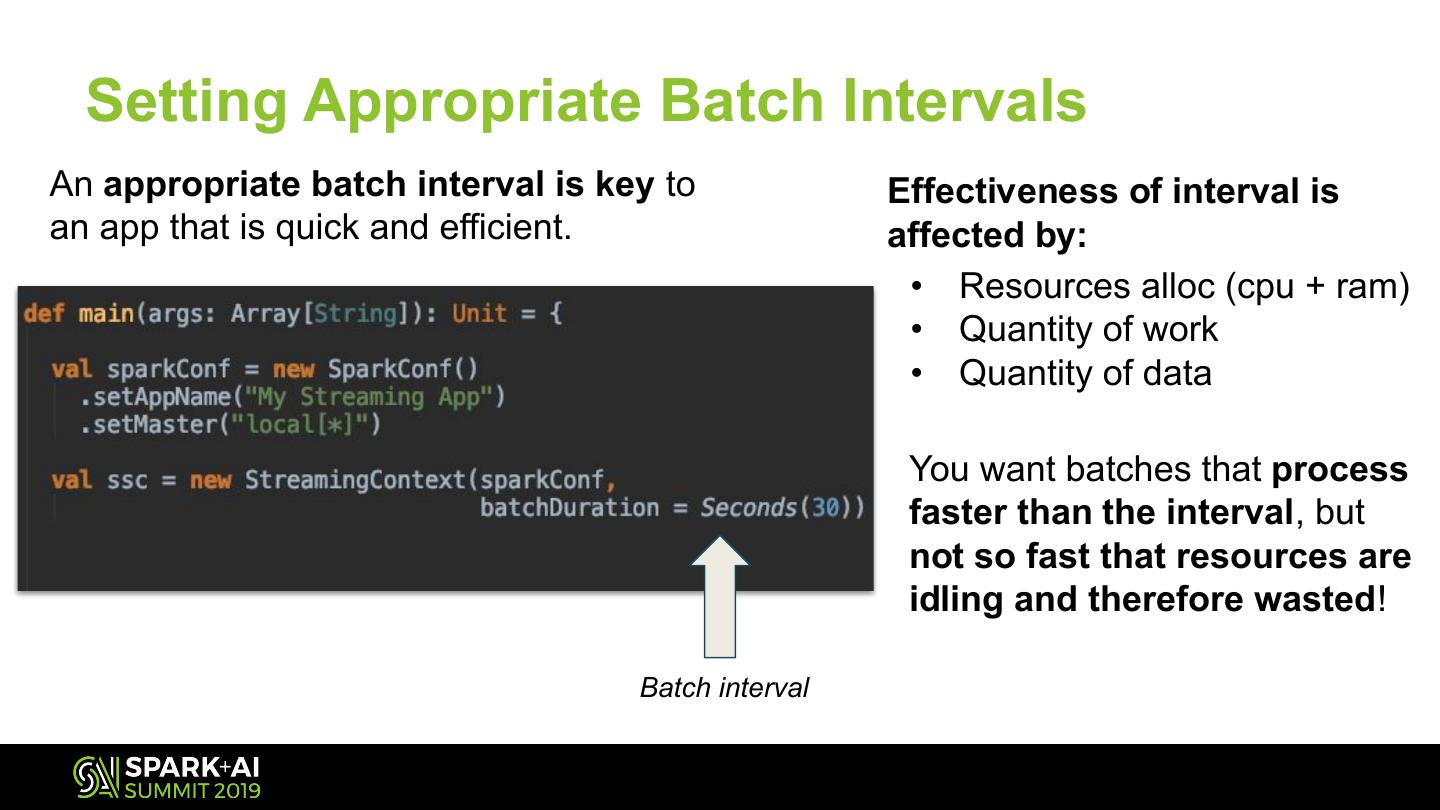
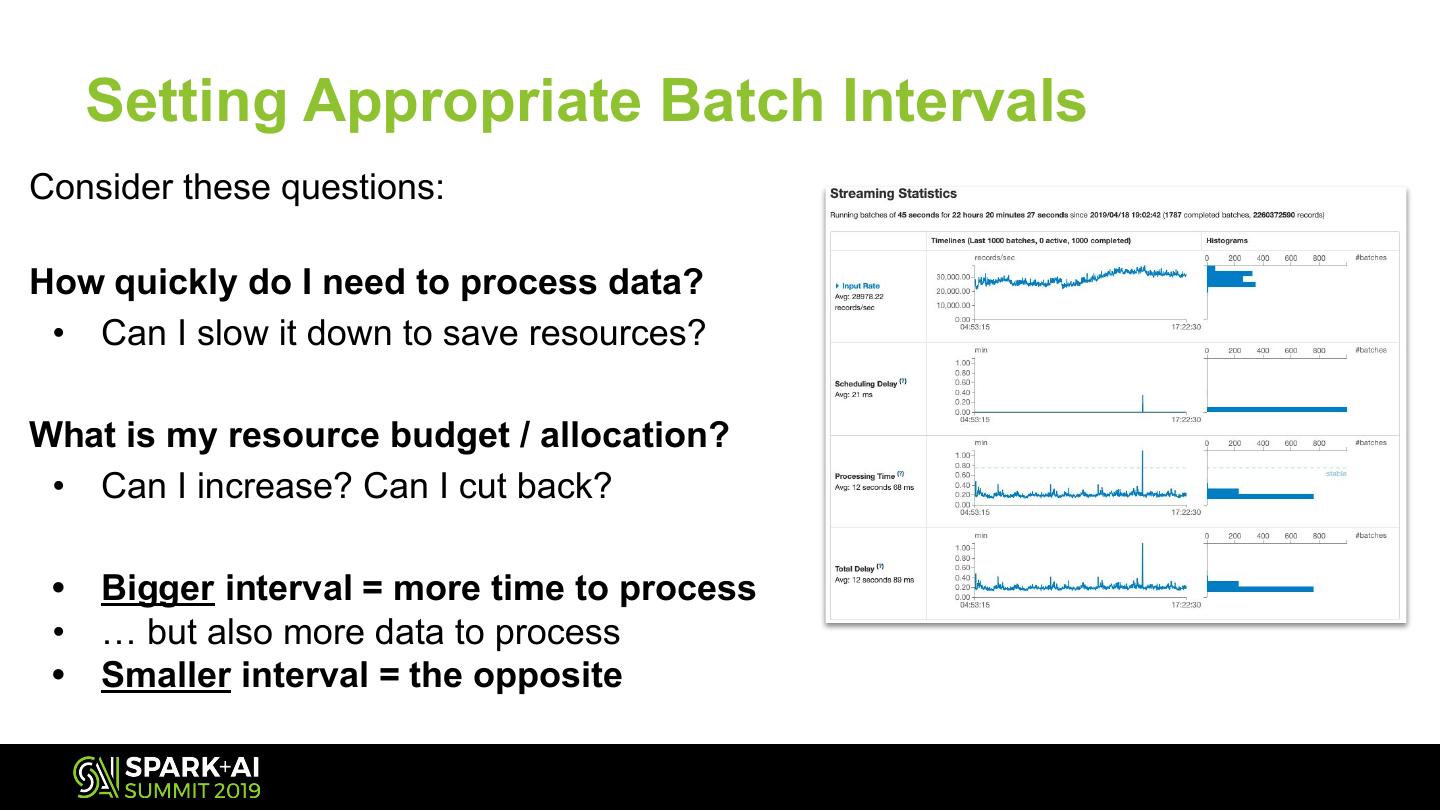
29 .Batch Intervals
Optimizing for speed
and resource efficiency
�