

























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/Spark/ROCm_and_Distributed_Deep_Learning_on_Spark_and_TensorFlow?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
ROCm and Distributed Deep Learning on Spark and TensorFlow
分享
点赞
0
收藏
0
下载 2
ROCm, the Radeon Open Ecosystem, is an open-source software foundation for GPU computing on Linux. ROCm supports TensorFlow and PyTorch using MIOpen, a library of highly optimized GPU routines for deep learning. In this talk, we describe how Apache Spark is a key enabling platform for distributed deep learning on ROCm, as it enables different deep learning frameworks to be embedded in Spark workflows in a secure end-to-end machine learning pipeline. We will analyse the different frameworks for integrating Spark with Tensorflow on ROCm, from Horovod to HopsML to Databrick’s Project Hydrogen. We will also examine the surprising places where bottlenecks can surface when training models (everything from object stores to the Data Scientists themselves), and we will investigate ways to get around these bottlenecks. The talk will include a live demonstration of training and inference for a Tensorflow application embedded in a Spark pipeline written in a Jupyter notebook on Hopsworks with ROCm.
展开查看详情
1 .WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
2 .ROCm and Distributed Deep Learning on Spark and TensorFlow Jim Dowling, CEO @ Logical Clocks jim_dowling Ajit Mathews, VP Machine Learning @ AMD #UnifiedAnalytics #SparkAISummit
3 . [Image from Wikipedia] Great Hedge of India • East India Company was one of the industrial world’s first monopolies. • They assembled a thorny hedge (not a wall!) spanning India. • You paid customs duty to bring salt over the wall (sorry, hedge). In 2019, not all graphics cards are allowed to be used in a Data Center. Monoplies are not good for deep learning! 3
4 . Nvidia™ 2080Ti vs AMD Radeon™ VII ResNet-50 Benchmark Nvidia™ 2080Ti AMD Radeon™ VII Memory: 11GB Memory: 16 GB TensorFlow 1.12 TensorFlow 1.13.1 CUDA 10.0.130, cuDNN 7.4.1 ROCm: 2.3 Model: RESNET-50 Model: RESNET-50 Dataset: imagenet (synthetic) Dataset: imagenet (synthetic) ------------------------------------------------------------ ------------------------------------------------------------ FP32 total images/sec: ~322 FP32 total images/sec: ~302 FP16 total images/sec: ~560 FP16 total images/sec: ~415 https://lambdalabs.com/blog/2080-ti-deep-learning-benchmarks/ https://github.com/ROCmSoftwarePlatform/tensorflow-upstream/issues/173 https://www.phoronix.com/scan.php?page=article&item=nvidia- rtx2080ti-tensorflow&num=2 4/48
5 .AMD ML & HPC SOLUTIONS A M D M L S O F T W A R E S T R AT E G Y OPEN SOURCE FOUNDATION FOR MACHINE Data Platform Tools Spark / Machine Learning Apps LEARNING Latest Machine Learning Frameworks Frameworks Middleware and BLAS, FFT, Optimized Math & MIOpen RCCL Eigen Libraries RNG Communication Libraries OpenMP HIP OpenCL™ Python ROCm Dockers and Kubernetes Fully Open Source ROCm Platform support 5 Devices GPU CPU APU DLA Up-Streamed for Linux Kernel Distributions #UnifiedAnalytics #SparkAISummit
6 .Distro: Upstream Linux Kernel Support Linux Kernel 4.17 700+ upstream ROCm driver commits since 4.12 kernel https://github.com/RadeonOpenCompute/ROCK-Kernel- Driver
7 .Languages: Multiple Programming options LLVM Programming Models HIP OpenMP Python OpenCL LLVM -> AMDGCN Compiler AMDGPU Code LLVM: https://llvm.org/docs/AMDGPUUsage.html CLANG HIP: https://clang.llvm.org/doxygen/HIP_8h_source.html
8 .Libraries: Optimized Math Libraries Supports FP64, FP32, mixed precision, INT8, (INT4) Up to rocBLAS 98% rocSparse rocFFT rocSolver rocALUTION Software Efficiency rocRAND rocPrim https://github.com/ROCm-Developer-Tools
9 .Machine Learning Frameworks High performance FP16/FP32 AMD support in mainline training with up to 8 repository, including initial GPUs/node multi-GPU support for Caffe2 v1.13 – Available today as a Available today as a docker docker container container (or build from or as Python PIP wheel source)
10 . ROCm Distributed Training Multi-GPU Scaling (PCIe, CPU parameter-server, Optimized collective 1/2/4/8 GPU) 7.64X RCCL communication operations library 8.00X 7.00X 6.00X 5.00X Support for Infiniband and RoCE 3.98X ROCm w/ ROCnRDMA highspeed network fabrics 4.00X 3.00X 1.99X 2.00X 1.00X ROCm enabled UCX Easy MPI integration 1.00X 0.00X ResNet-50 RESNET50 1GPU 2GPU 4GPU 8GPU #UnifiedAnalytics #SparkAISummit 10
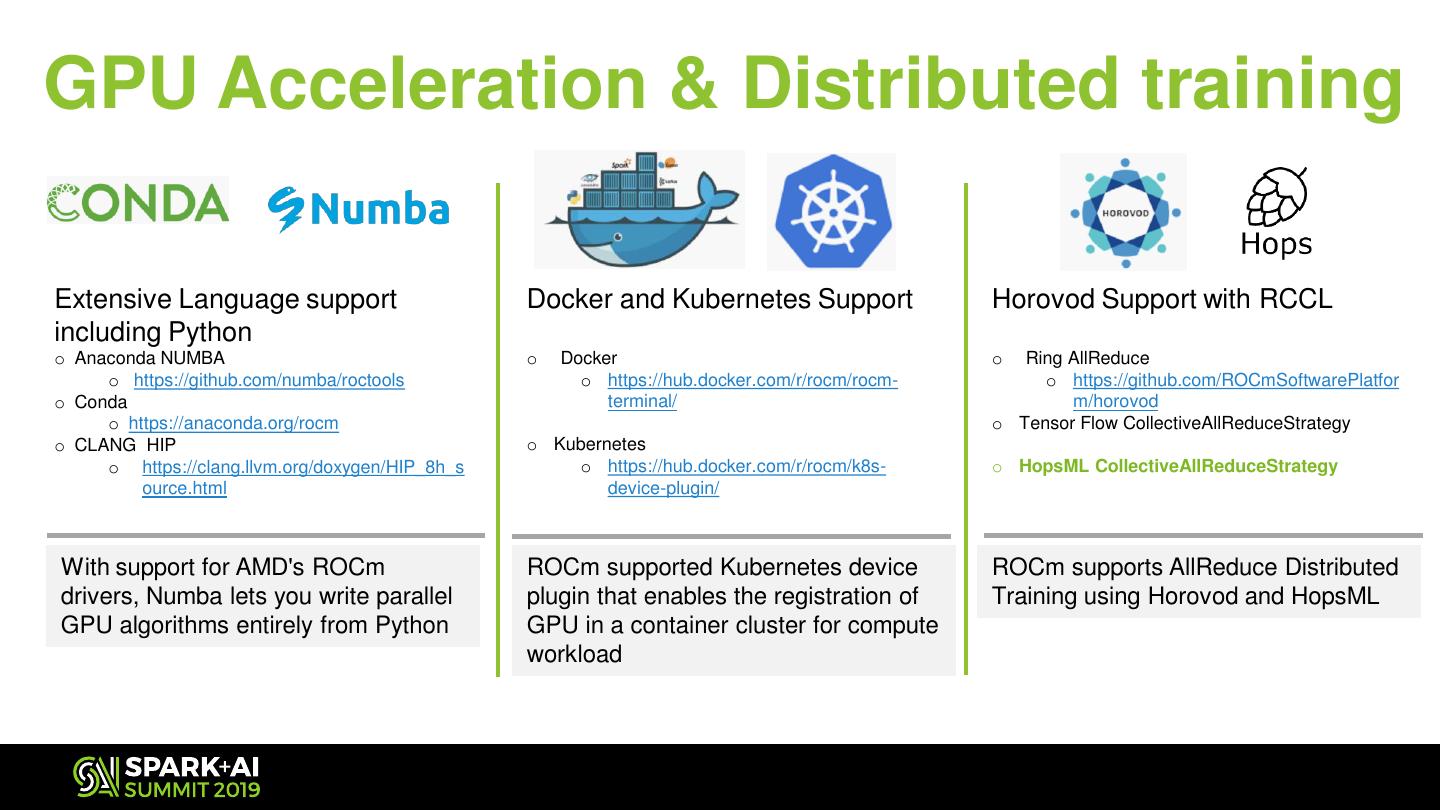
11 .GPU Acceleration & Distributed training Extensive Language support Docker and Kubernetes Support Horovod Support with RCCL including Python o Anaconda NUMBA o Docker o Ring AllReduce o https://github.com/numba/roctools o https://hub.docker.com/r/rocm/rocm- o https://github.com/ROCmSoftwarePlatfor o Conda terminal/ m/horovod o https://anaconda.org/rocm o Tensor Flow CollectiveAllReduceStrategy o CLANG HIP o Kubernetes o https://clang.llvm.org/doxygen/HIP_8h_s o https://hub.docker.com/r/rocm/k8s- o HopsML CollectiveAllReduceStrategy ource.html device-plugin/ With support for AMD's ROCm ROCm supported Kubernetes device ROCm supports AllReduce Distributed drivers, Numba lets you write parallel plugin that enables the registration of Training using Horovod and HopsML GPU algorithms entirely from Python GPU in a container cluster for compute workload
12 .Hopsworks Open-Source Data and AI Hopsworks BI Tools & HopsFS Spark Hive Reporting Data Feature Deep Elastic Notebooks Sources Store Learning Kafka Spark / Serving w/ Flink Kubernetes External Service Airflow Hopsworks Service On-Premise, AWS, Azure, GCE #UnifiedAnalytics #SparkAISummit 12
13 .Hopsworks Open-Source Data and AI Hopsworks HopsFS BATCH Spark ANALYTICS Hive BI Tools & Reporting Data Sources Elastic MLFeature & DEEP Store Deep LEARNING Learning Notebooks STREAMING Kafka Spark / Flink Serving w/ Kubernetes External Service Airflow Hopsworks Service On-Premise, AWS, Azure, GCE #UnifiedAnalytics #SparkAISummit 13
14 .Hopsworks Hides ML Complexity [Diagram adapted from “technical debt of machine learning”] Feature HopsML API Store MODEL TRAINING https://www.logicalclocks.com/feature-store/ https://hopsworks.readthedocs.io/en/latest/hopsml/hopsML.html# #UnifiedAnalytics #SparkAISummit 14
15 .ROCm -> Spark / TensorFlow • Spark / TensorFlow applications run unchanged on ROCm • Hopsworks runs Spark/TensorFlow on YARN and Conda #UnifiedAnalytics #SparkAISummit 15
16 .YARN support for ROCm in Hops Resource Manager Node Node Node Manager Manager Manager A Container is a CGroup Container Container Container Container that isolates CPU, memory, Driver Executor Executor Executor and GPU resources and has a conda environment and TLS certs. #UnifiedAnalytics #SparkAISummit 16
17 . Distributed Deep Learning Spark/TF # RUNS ON THE EXECUTORS def train(lr, dropout): Driver def input_fn(): # return dataset conda_env optimizer = … model = … model.add(Conv2D(…)) model.compile(…) Executor 1 Executor N model.fit(…) conda_env conda_env model.evaluate(…) # RUNS ON THE DRIVER HopsFS Hparams= {‘lr’:[0.001, 0.0001], ‘dropout’: [0.25, 0.5, 0.75]} experiment.grid_search(train,HParams) TensorBoard Checkpoints Training Data Models Logs https://github.com/logicalclocks/hops-examples More details: Spark Summit Europe 2018 talk https://www.youtube.com/watch?v=tx6HyoUYGL0 #UnifiedAnalytics #SparkAISummit 17
18 . Distributed Deep Learning Spark/TF # RUNS ON THE EXECUTORS def train(): Driver def input_fn(): # return dataset conda_env model = … optimizer = … model.compile(…) rc = tf.estimator.RunConfig( Executor 1 Executor N ‘CollectiveAllReduceStrategy’) conda_env conda_env keras_estimator = tf.keras.estimator. model_to_estimator(….) tf.estimator.train_and_evaluate( HopsFS keras_estimator, input_fn) # RUNS ON THE DRIVER experiment.collective_all_reduce(train) TensorBoard Checkpoints Training Data Models Logs https://github.com/logicalclocks/hops-examples More details: Spark Summit Europe 2018 talk https://www.youtube.com/watch?v=tx6HyoUYGL0 #UnifiedAnalytics #SparkAISummit 18
19 . Horizontally Scalable ML Pipelines with Hopsworks Airflow Raw Data Ingest Data Prep Feature Store Experiment/Train Deploy logs HopsFS Feature Store Serving Event Data Monitor logs Metadata Store #UnifiedAnalytics #SparkAISummit 19
20 .Pipelines from Jupyter Notebooks View Old Notebooks, Experiments and Visualizations Experiments & Tensorboard Interactive PySpark Kernel materialize certs, ENV variables Livy Server .ipynb (HDFS contents) HopsFS HopsYARN [logs, results] Jobs Service Convert .ipynb to .py Schedule using materialize certs, ENV variables REST API or UI Run .py or .jar #UnifiedAnalytics #SparkAISummit 20
21 .DEMO Distributed TensorFlow with Spark/TensorFlow and ROCm #UnifiedAnalytics #SparkAISummit 21
22 . OPEN SOURCE FOUNDATION FOR MACHINE LEARNING @logicalclocks www.logicalclocks.com 22
23 .DON’T FORGET TO RATE AND REVIEW THE SESSIONS SEARCH SPARK + AI SUMMIT
24 . Disclaimer & Attribution The information presented in this document is for informational purposes only and may contain technical inaccuracies, omissions and typographical errors. The information contained herein is subject to change and may be rendered inaccurate for many reasons, including but not limited to product and roadmap changes, component and motherboard version changes, new model and/or product releases, product differences between differing manufacturers, software changes, BIOS flashes, firmware upgrades, or the like. AMD assumes no obligation to update or otherwise correct or revise this information. However, AMD reserves the right to revise this information and to make changes from time to time to the content hereof without obligation of AMD to notify any person of such revisions or changes. AMD MAKES NO REPRESENTATIONS OR WARRANTIES WITH RESPECT TO THE CONTENTS HEREOF AND ASSUMES NO RESPONSIBILITY FOR ANY INACCURACIES, ERRORS OR OMISSIONS THAT MAY APPEAR IN THIS INFORMATION. AMD SPECIFICALLY DISCLAIMS ANY IMPLIED WARRANTIES OF MERCHANTABILITY OR FITNESS FOR ANY PARTICULAR PURPOSE. IN NO EVENT WILL AMD BE LIABLE TO ANY PERSON FOR ANY DIRECT, INDIRECT, SPECIAL OR OTHER CONSEQUENTIAL DAMAGES ARISING FROM THE USE OF ANY INFORMATION CONTAINED HEREIN, EVEN IF AMD IS EXPRESSLY ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. ATTRIBUTION © 2019 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, Radeon and combinations thereof are trademarks of Advanced Micro Devices, Inc. in the United States and/or other jurisdictions. Other names are for informational purposes only and may be trademarks of their respective owners. Use of third party marks / names is for informational purposes only and no endorsement of or by AMD is intended or implied.
3秒后跳转登录页面
去登陆

