












































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Training Neural Networks
本课程将深入学习基础知识系列的第2部分讨论调整训练(包括超参数,过度拟合/欠拟合),训练算法(包括不同的学习率,反向传播),优化(包括随机梯度下降,动量,Nesterov加速梯度,RMSprop,自适应) 算法 - Adam,Adadelta等),以及卷积神经网络的入门。 这些PPT中包含的演示在Drasricks上使用TensorFlow后端在Keras上运行。
展开查看详情
1 .Training Neural Networks
2 .VISION Accelerate innovation by unifying data science, engineering and business PRODUCT Unified Analytics Platform powered by Apache Spark™ WHO WE ARE • Founded by the original creators of Apache Spark • Contributes 75% of the open source code, 10x more than any other company • Trained 100k+ Spark users on the Databricks platform
3 .About our speaker Denny Lee Technical Product Marketing Manager Former: • Senior Director of Data Sciences Engineering at SAP Concur • Principal Program Manager at Microsoft • Azure Cosmos DB Engineering Spark and Graph Initiatives • Isotope Incubation Team (currently known as HDInsight) • Bing’s Audience Insights Team • Yahoo!’s 24TB Analysis Services cube
4 .Deep Learning Fundamentals Series This is a three-part series: • Introduction to Neural Networks • Training Neural Networks • Applying your Convolutional Neural Network This series will be make use of Keras (TensorFlow backend) but as it is a fundamentals series, we are focusing primarily on the concepts.
5 .Previous Session: Introduction to Neural Networks • What is Deep Learning? • What can Deep Learning do for you? • What are artificial neural networks? • Let’s start with a perceptron… • Understanding the effect of activation functions
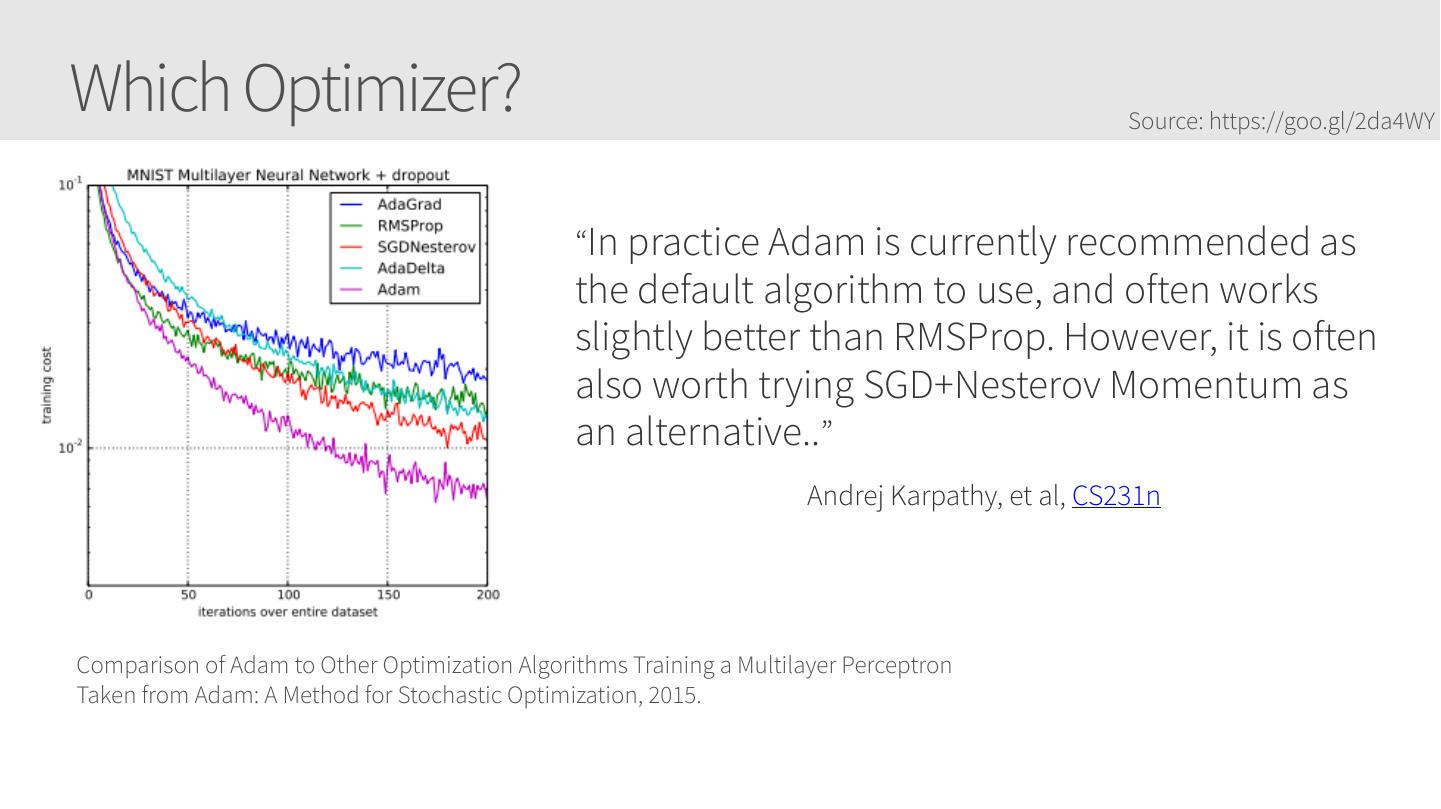
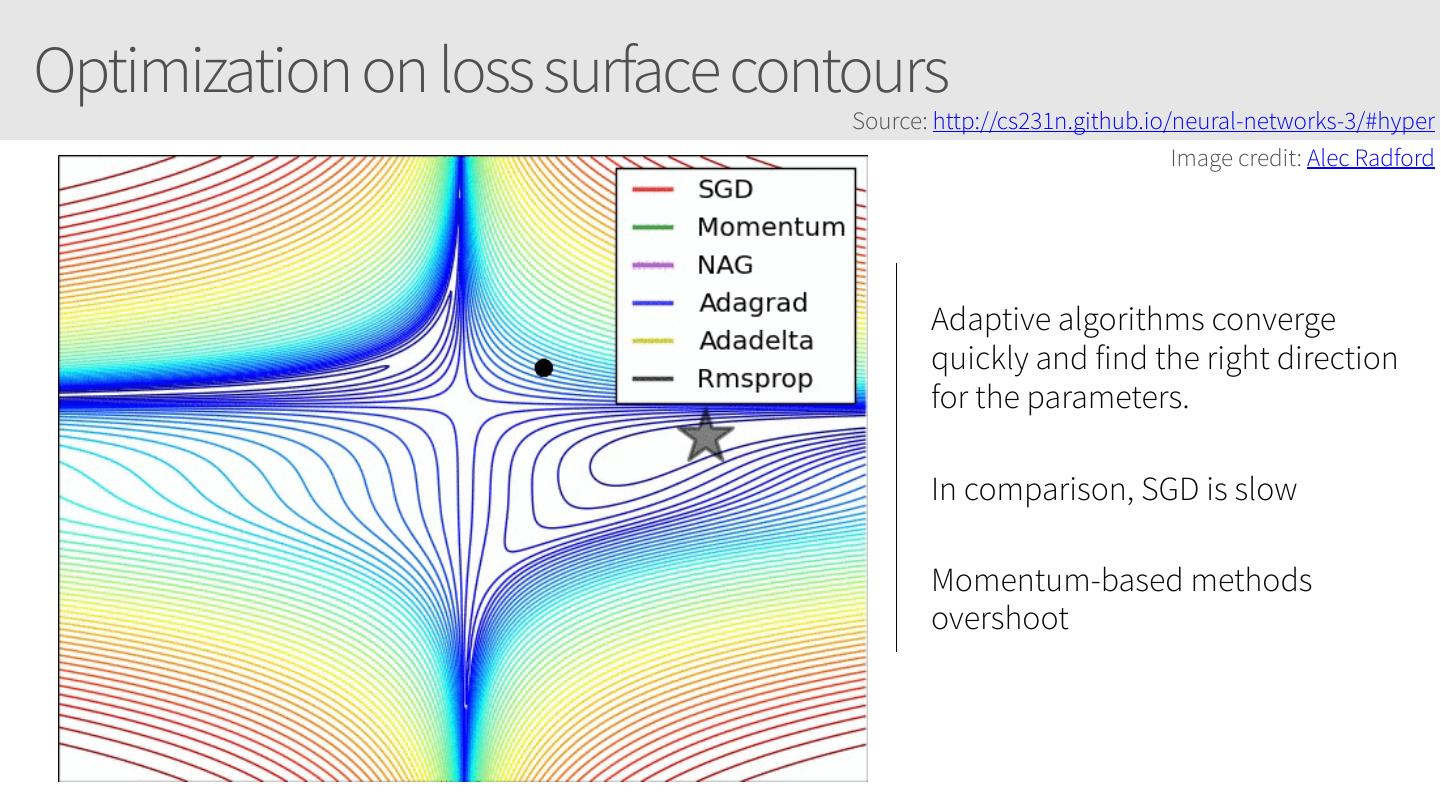
6 .Current Session: Training Neural Networks • Tuning training • Training Algorithms • Optimization (including Adam) • Convolutional Neural Networks
7 .Upcoming Session: Applying Neural Networks • Diving further into CNNs • CNN Architectures • Convolutions at Work!
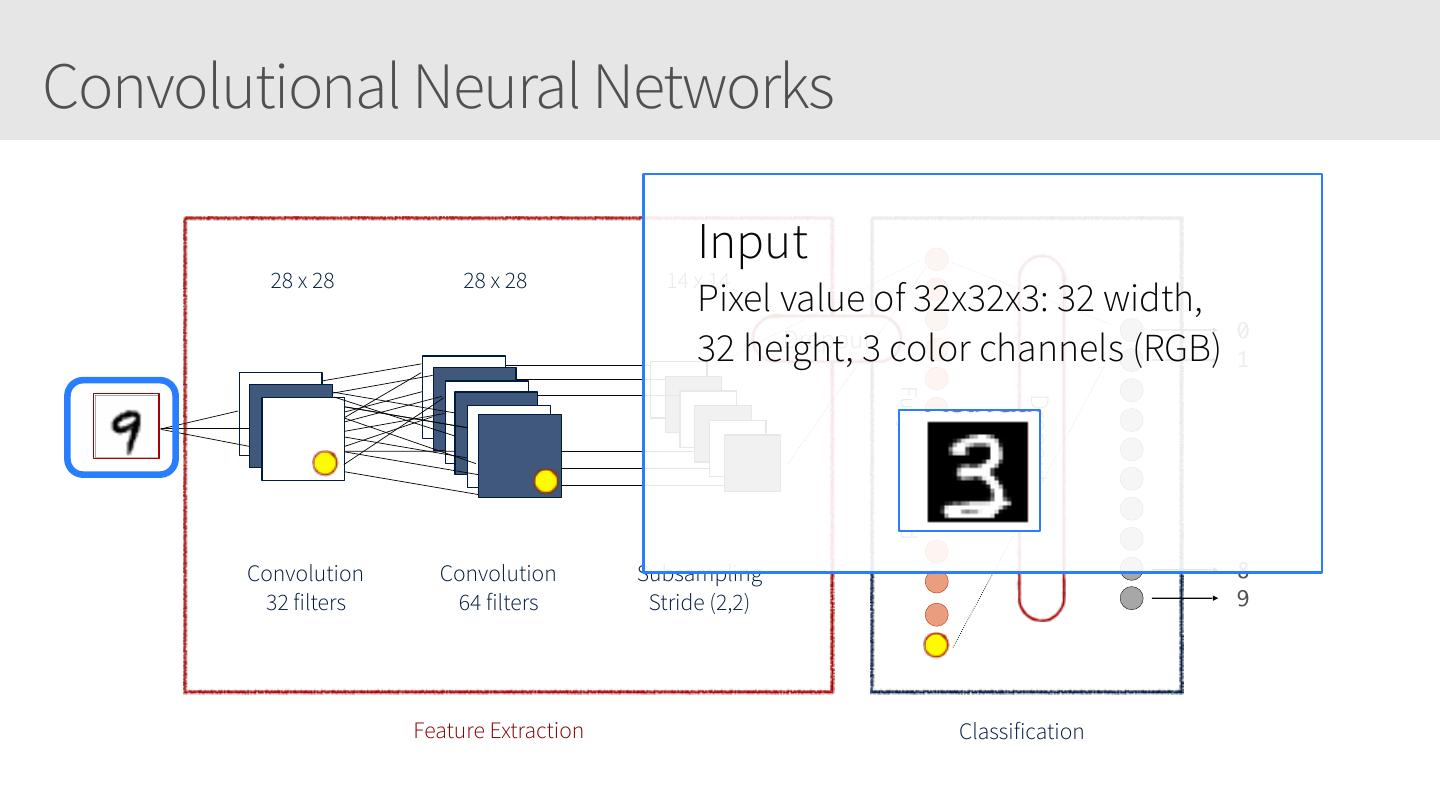
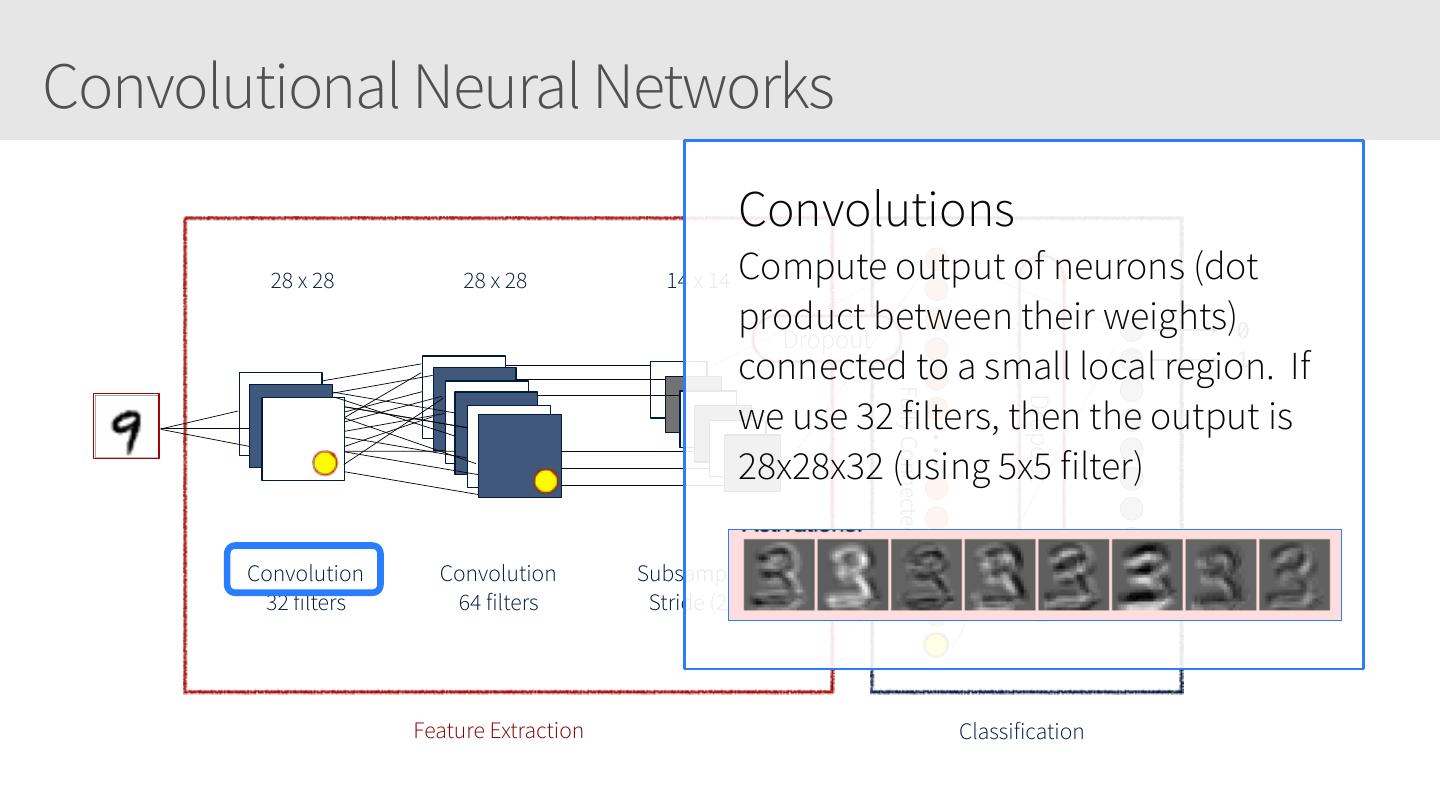
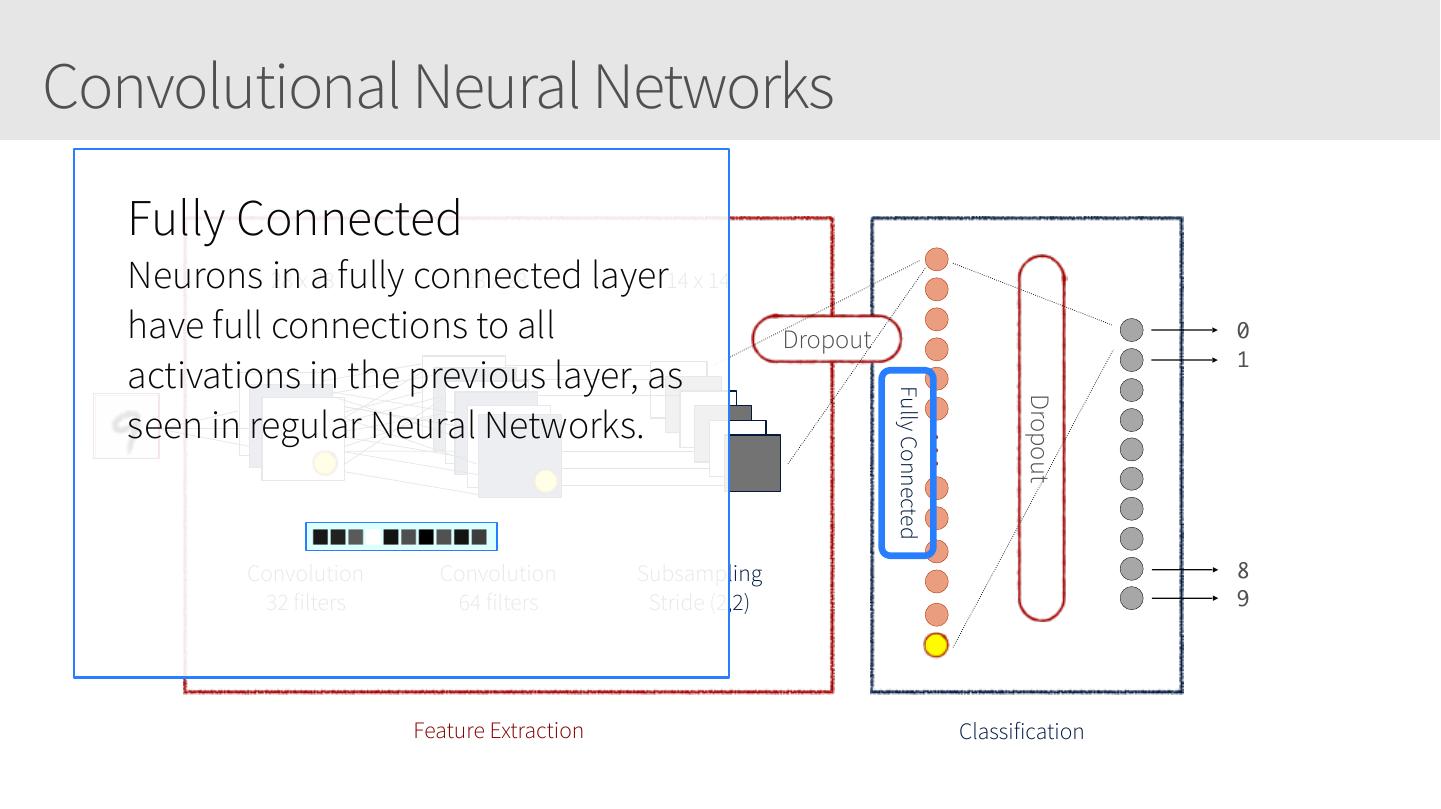
8 .Convolutional Neural Networks 28 x 28 28 x 28 14 x 14 0 Dropout 1 Fully Connected Dropout Convolution Convolution Subsampling 8 32 filters 64 filters Stride (2,2) 9 Feature Extraction Classification
9 .Tuning Training
10 .Hyperparameters • Network • How many layers? • How many neurons in each layer? • What activation functions to use? • Learning algorithm • What’s the best value of the learning rate? • How quickly decay the learning rate? Momentum? • What type of loss function should I use? • What batch size? • How many iterations is enough?
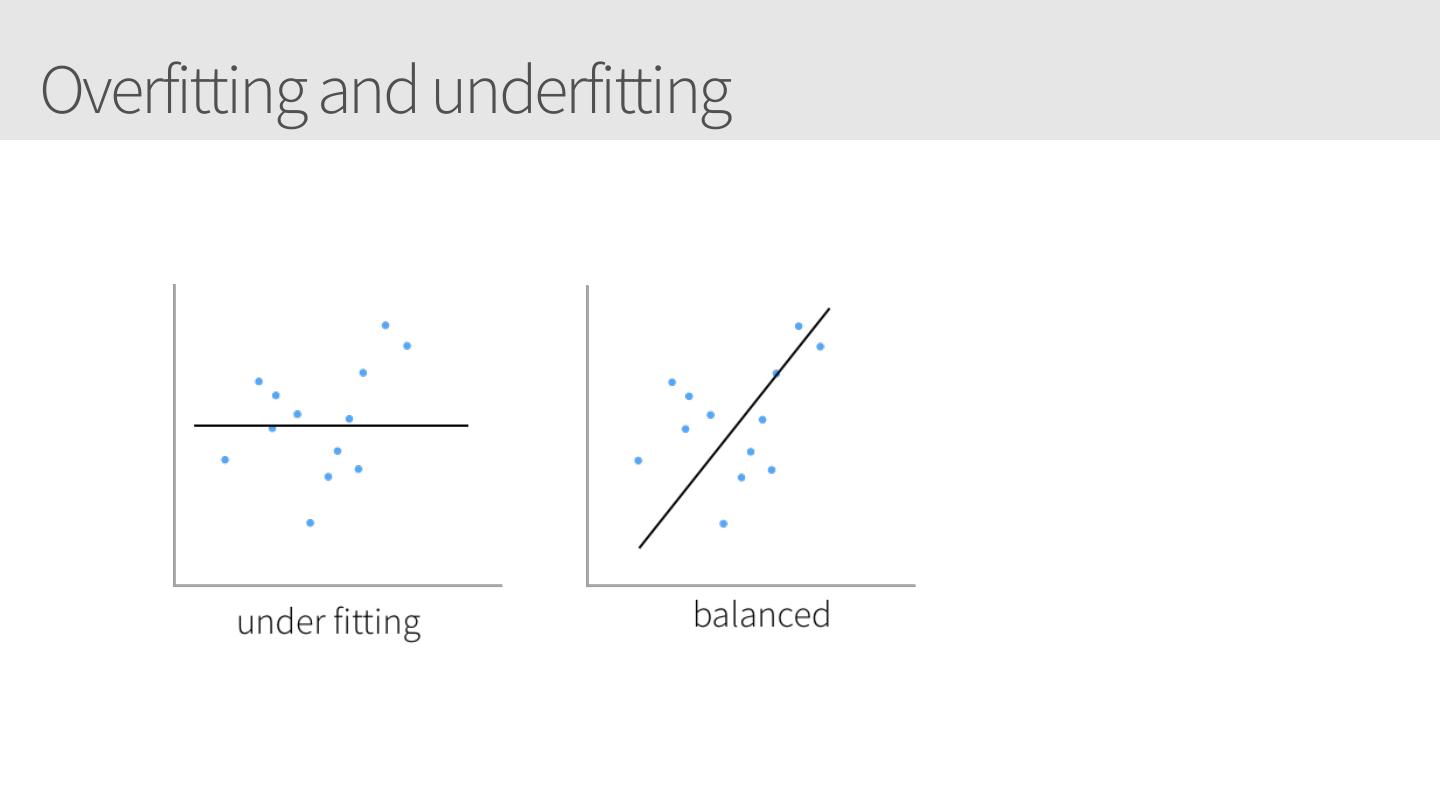
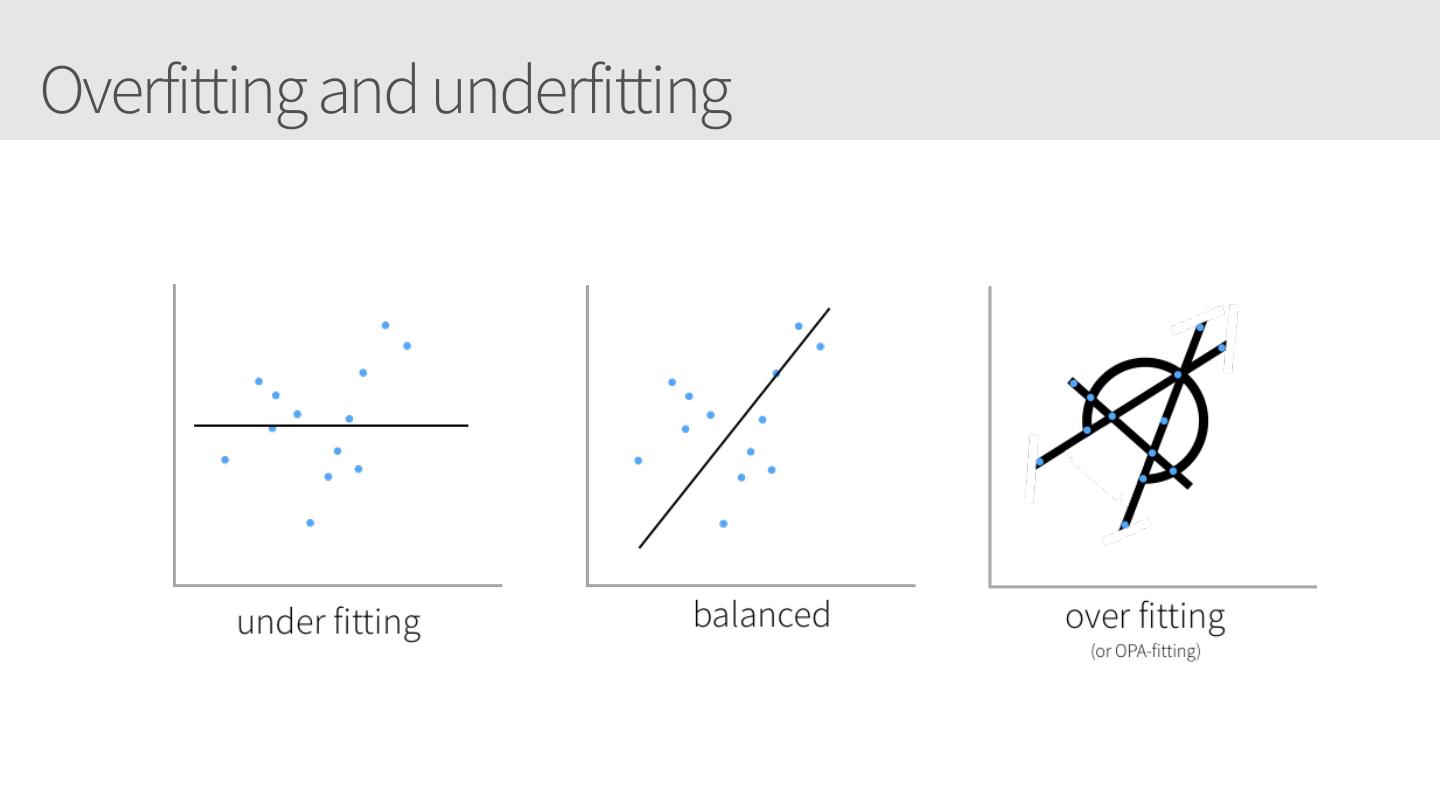
11 .Overfitting and underfitting
12 .Overfitting and underfitting
13 .Overfitting and underfitting
14 .Hyperparameters: Network Generally, the more layers and the number of units in each layer: • The greater the capacity of the artificial neural network • The risk is overfitting when your goal is to build a generalized model. From a practical perspective, a good starting point is: • The number of input units equals the dimension of features • The number of output units equals the number of classes (e.g. in the MNIST dataset, there are 10 possible values represents digits (0…9) hence there are 10 output units • Start with one hidden layer that is 2x the number of input units • A good reference is Andrew Ng’s Coursera Machine Learning course.
15 .Hyperparameters: Activation Functions? • Good starting point: ReLU • Note many neural networks samples: Keras MNIST, TensorFlow CIFAR10 Pruning, etc. • Note that each activation function has its own strengths and weaknesses. A good quote on activation functions from CS231N summarizes the choice well: “What neuron type should I use?” Use the ReLU non-linearity, be careful with your learning rates and possibly monitor the fraction of “dead” units in a network. If this concerns you, give Leaky ReLU or Maxout a try. Never use sigmoid. Try tanh, but expect it to work worse than ReLU/ Maxout.
16 . DEMO Neurons … Activate!
17 .Hyperparameters Learning algorithm • What’s the best value of the learning rate? • How quickly decay the learning rate? Momentum? • What type of loss function should I use? • What batch size? • How many iterations is enough?
18 .Training Algorithms
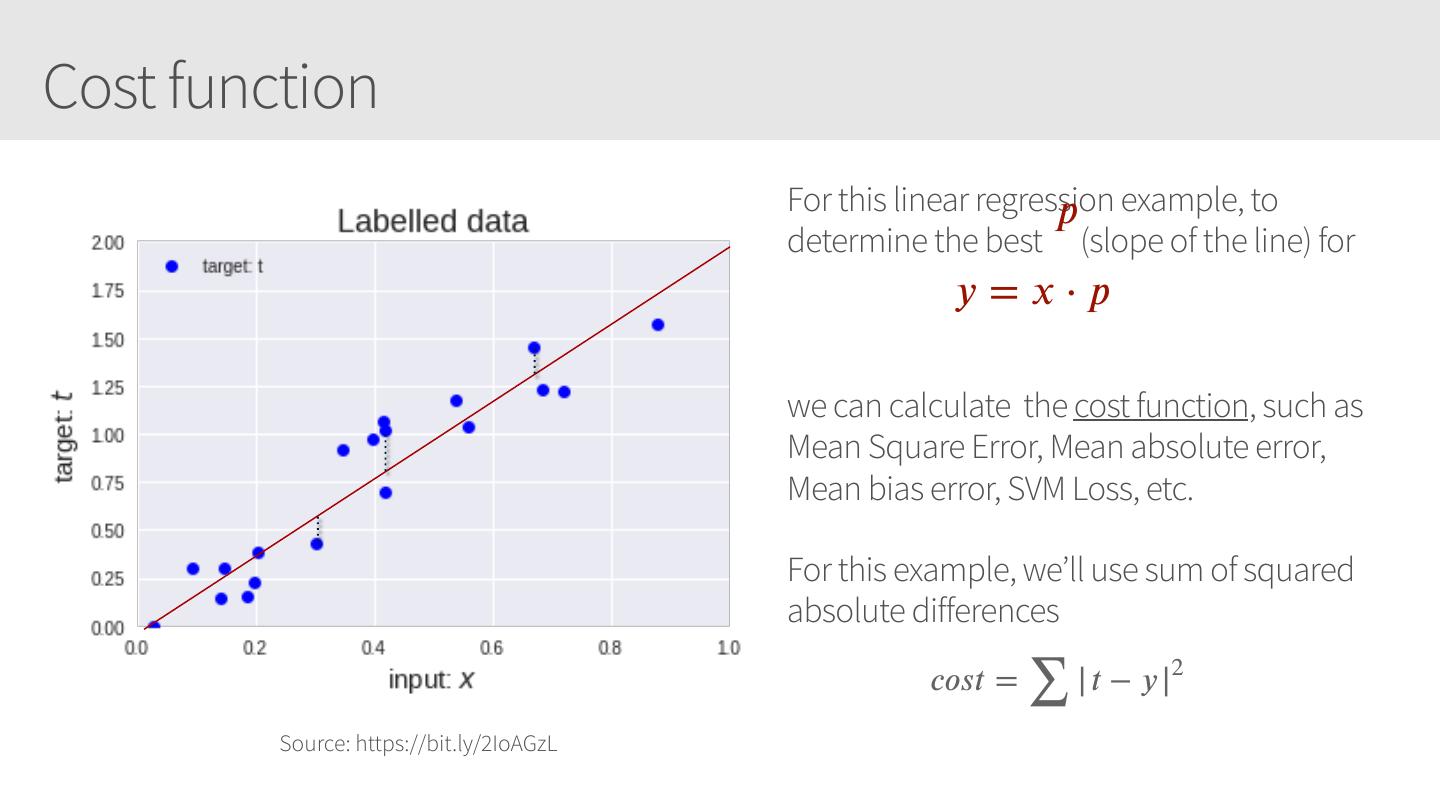
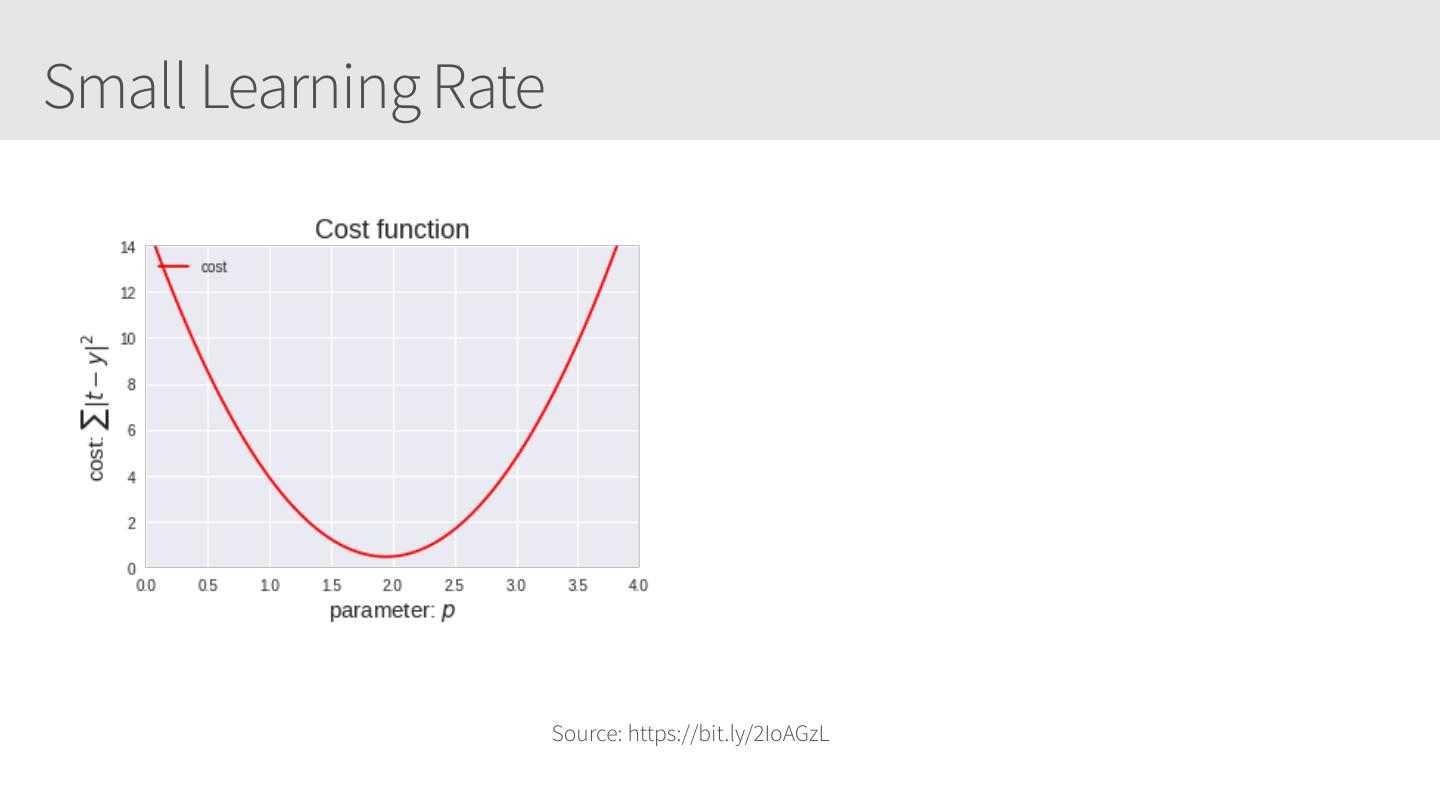
19 .Cost function 𝑝 example, to For this linear regression determine the best (slope of the line) for 𝑦 =𝑥⋅𝑝 we can calculate the cost function, such as Mean Square Error, Mean absolute error, Mean bias error, SVM Loss, etc. For this example, we’ll use sum of squared absolute differences | 𝑡 − 𝑦 |2 ∑ 𝑐𝑜𝑠𝑡 = Source: https://bit.ly/2IoAGzL
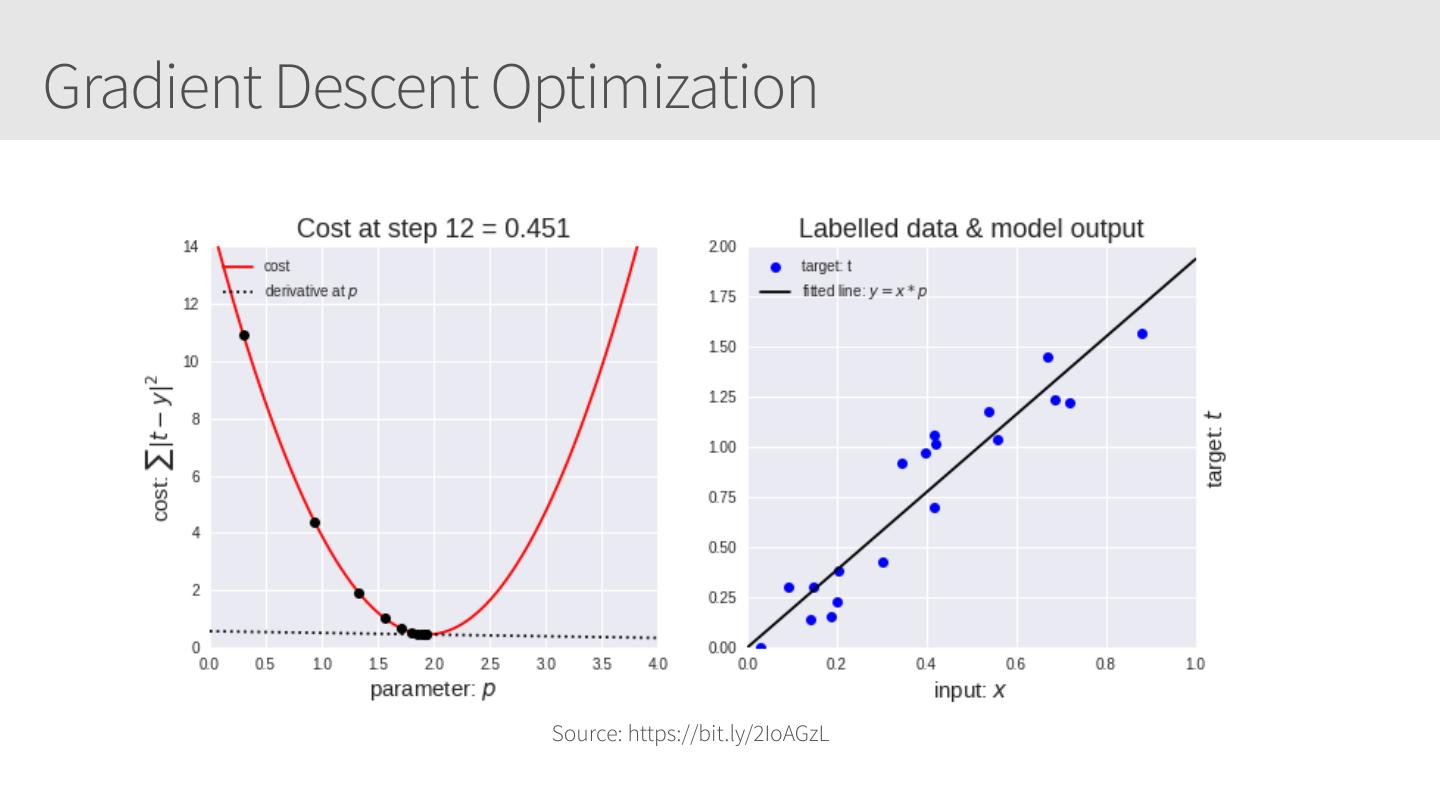
20 .Gradient Descent Optimization Source: https://bit.ly/2IoAGzL
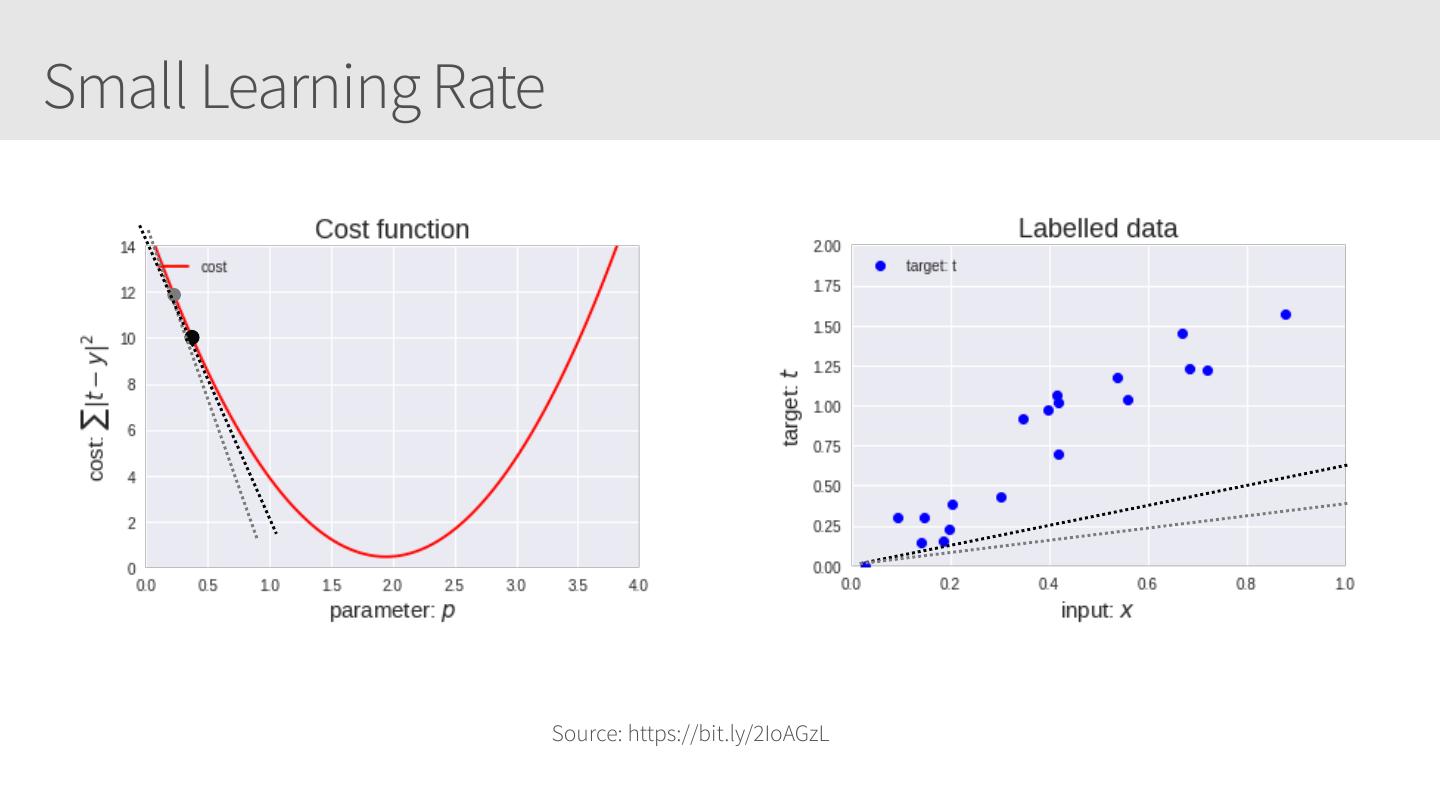
21 .Small Learning Rate Source: https://bit.ly/2IoAGzL
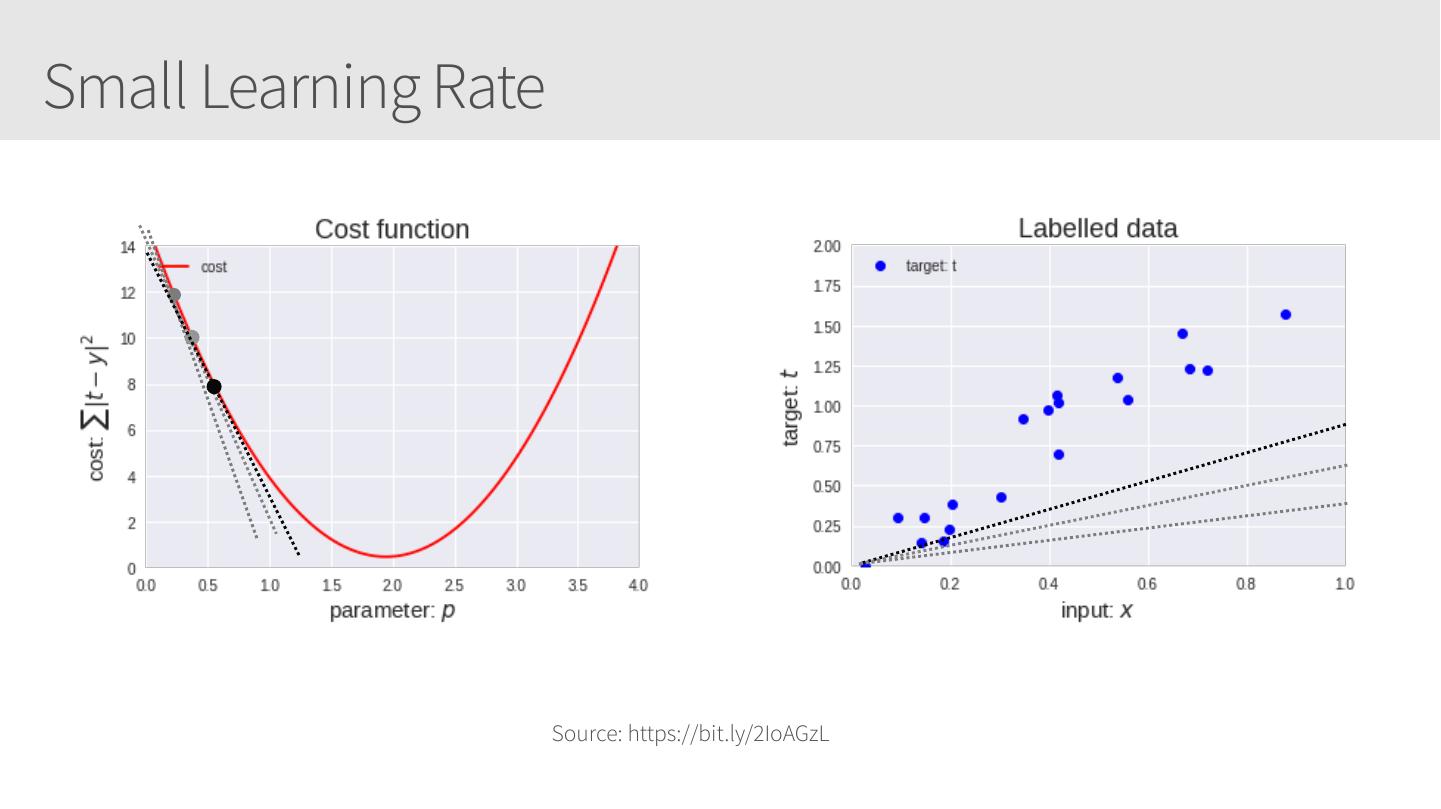
22 .Small Learning Rate Source: https://bit.ly/2IoAGzL
23 .Small Learning Rate Source: https://bit.ly/2IoAGzL
24 .Small Learning Rate Source: https://bit.ly/2IoAGzL
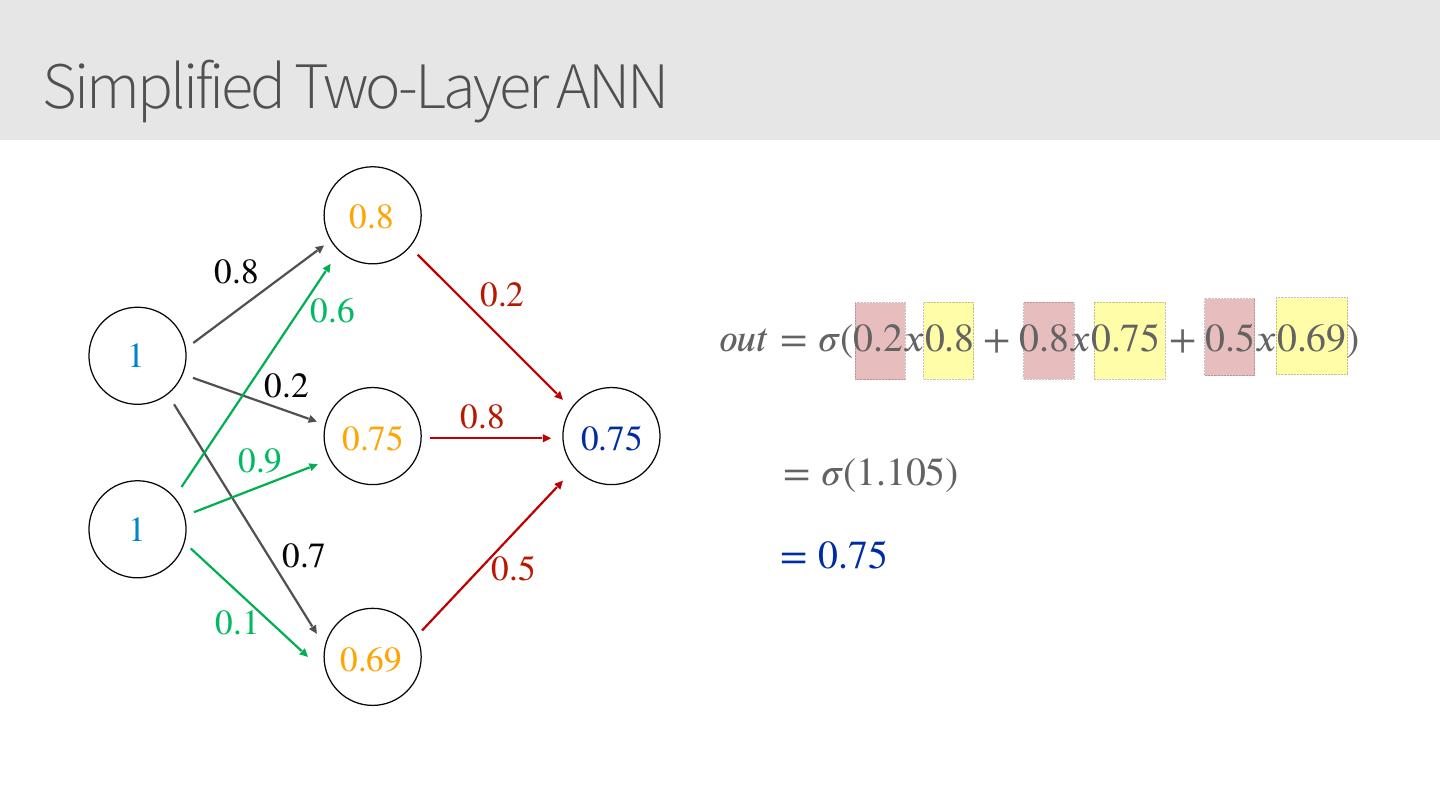
25 .Simplified Two-Layer ANN 0.8 0.8 0.6 1 0.2 h1 = 𝜎(1𝑥0.8 + 1𝑥0.6) = 0.80 0.9 0.75 h2 = 𝜎(1𝑥0.2 + 1𝑥0.9) = 0.75 h3 = 𝜎(1𝑥0.7 + 1𝑥0.1) = 0.69 1 0.7 0.1 0.69
26 .Simplified Two-Layer ANN 0.8 0.8 0.6 0.2 1 𝑜𝑢𝑡 = 𝜎(0.2𝑥0.8 + 0.8𝑥0.75 + 0.5𝑥0.69) 0.2 0.8 0.75 0.75 0.9 = 𝜎(1.105) 1 0.7 0.5 = 0.75 0.1 0.69
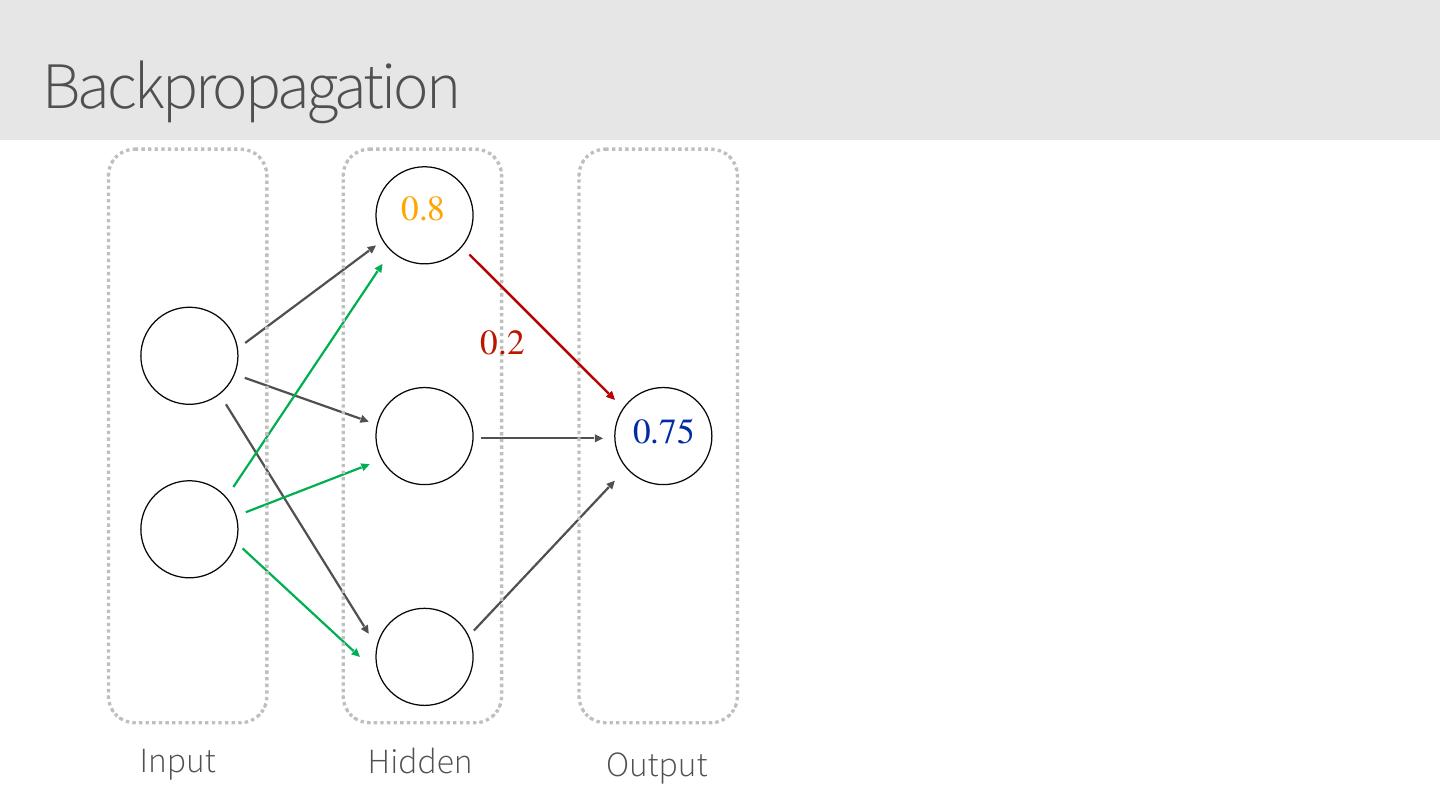
27 .Backpropagation 0.8 0.2 0.75 Input Hidden Output
28 .Backpropagation • Backpropagation: calculate the gradient of the cost function in a neural network • Used by gradient descent optimization 0.85 0.10 algorithm to adjust weight of neurons • Also known as backward propagation of errors as the error is calculated and distributed back through the network of layers Input Hidden Output
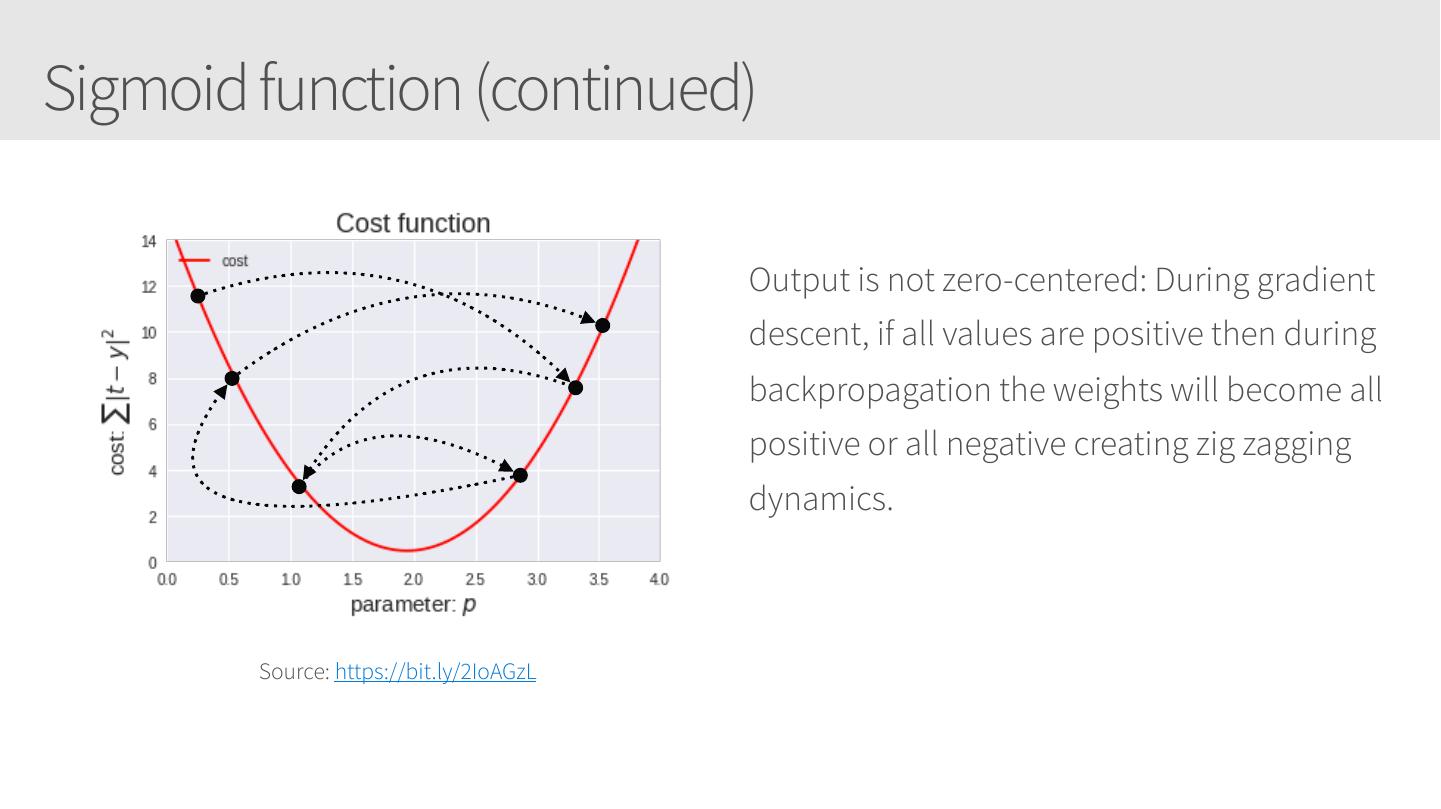
29 .Sigmoid function (continued) Output is not zero-centered: During gradient descent, if all values are positive then during backpropagation the weights will become all positive or all negative creating zig zagging dynamics. Source: https://bit.ly/2IoAGzL
3秒后跳转登录页面
去登陆

