































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/Spark/TuneIn_HowtogetyourjobstunedwhileyouaresleepingPresentation?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
TuneIn: How to get your jobs tuned while you are sleeping Present
点赞
0
收藏
1
下载 14
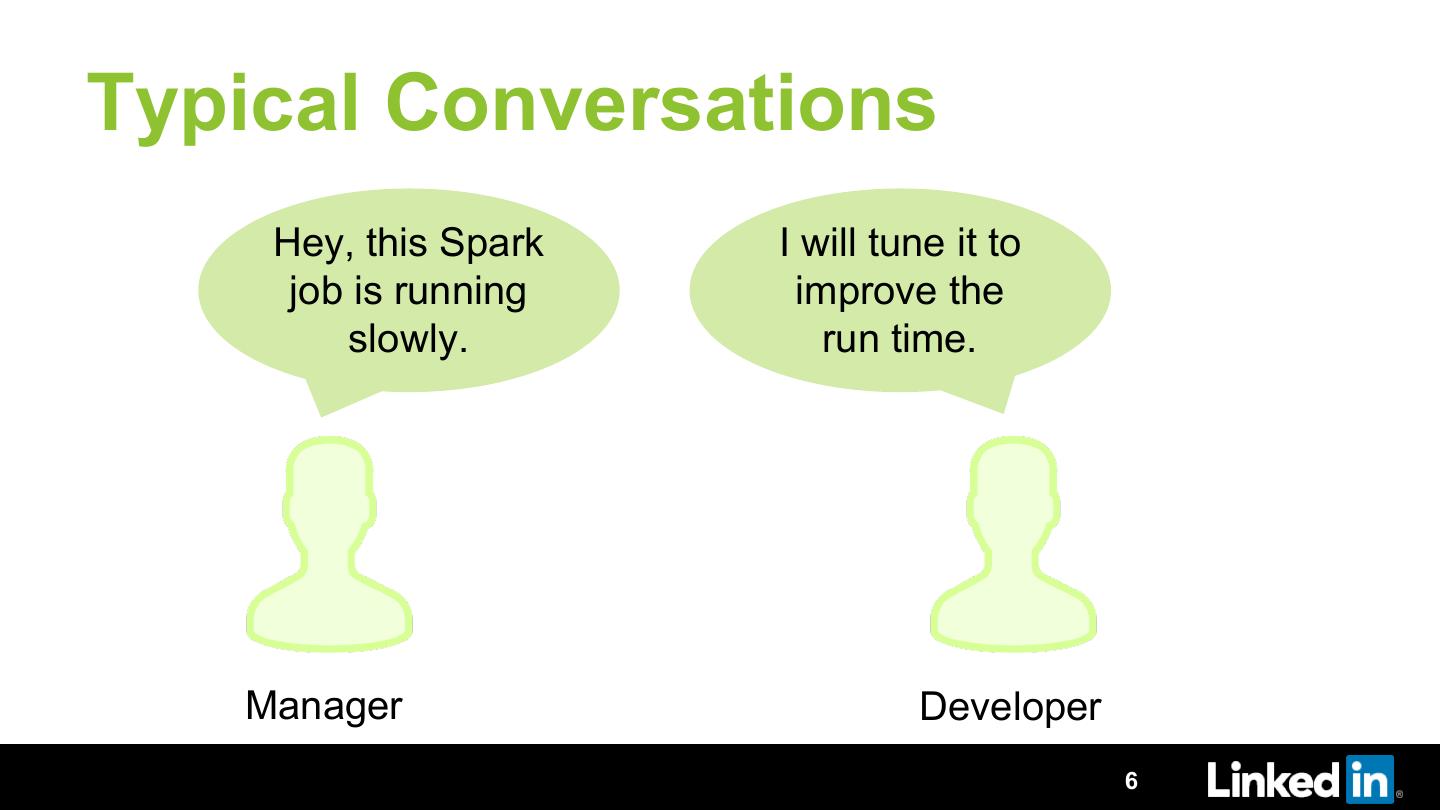
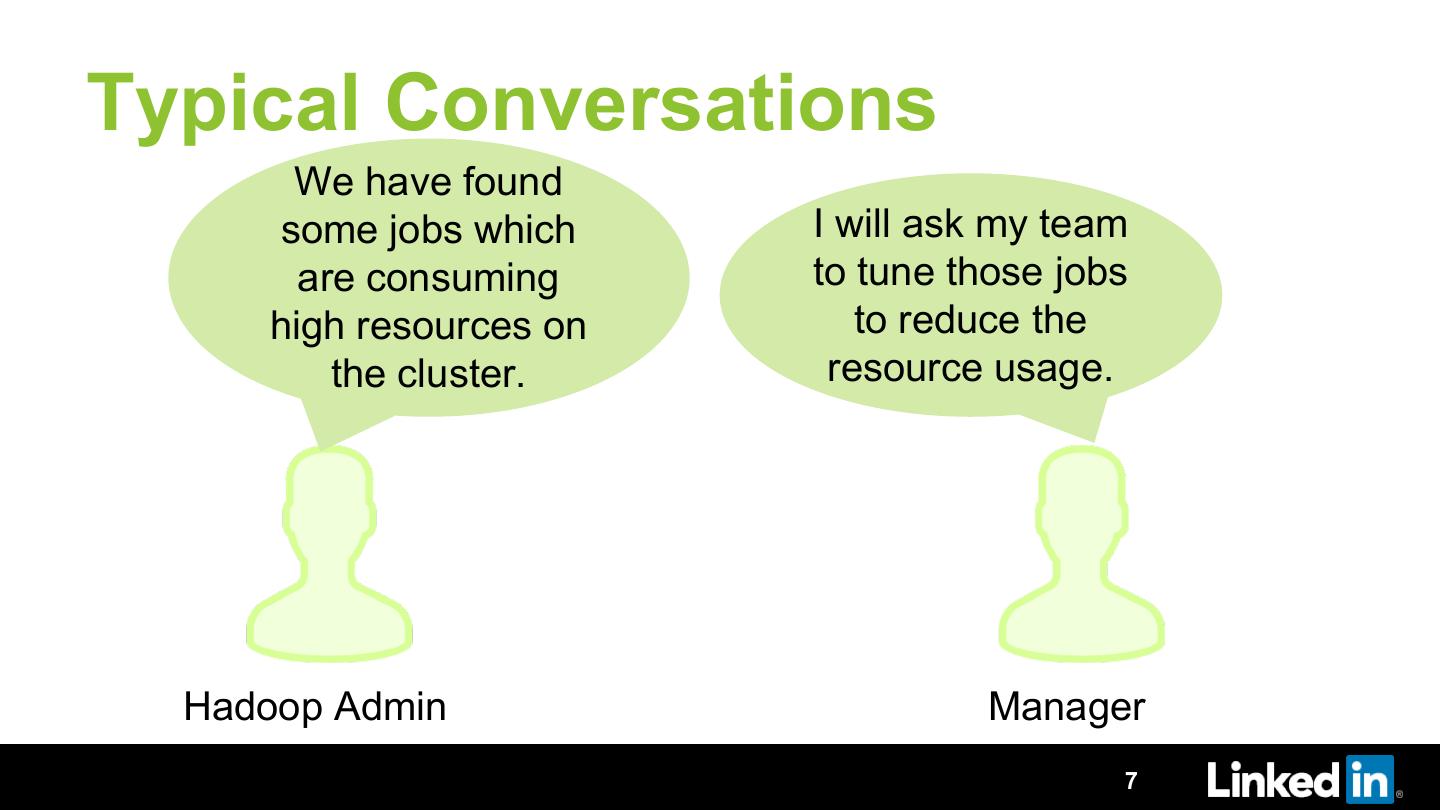
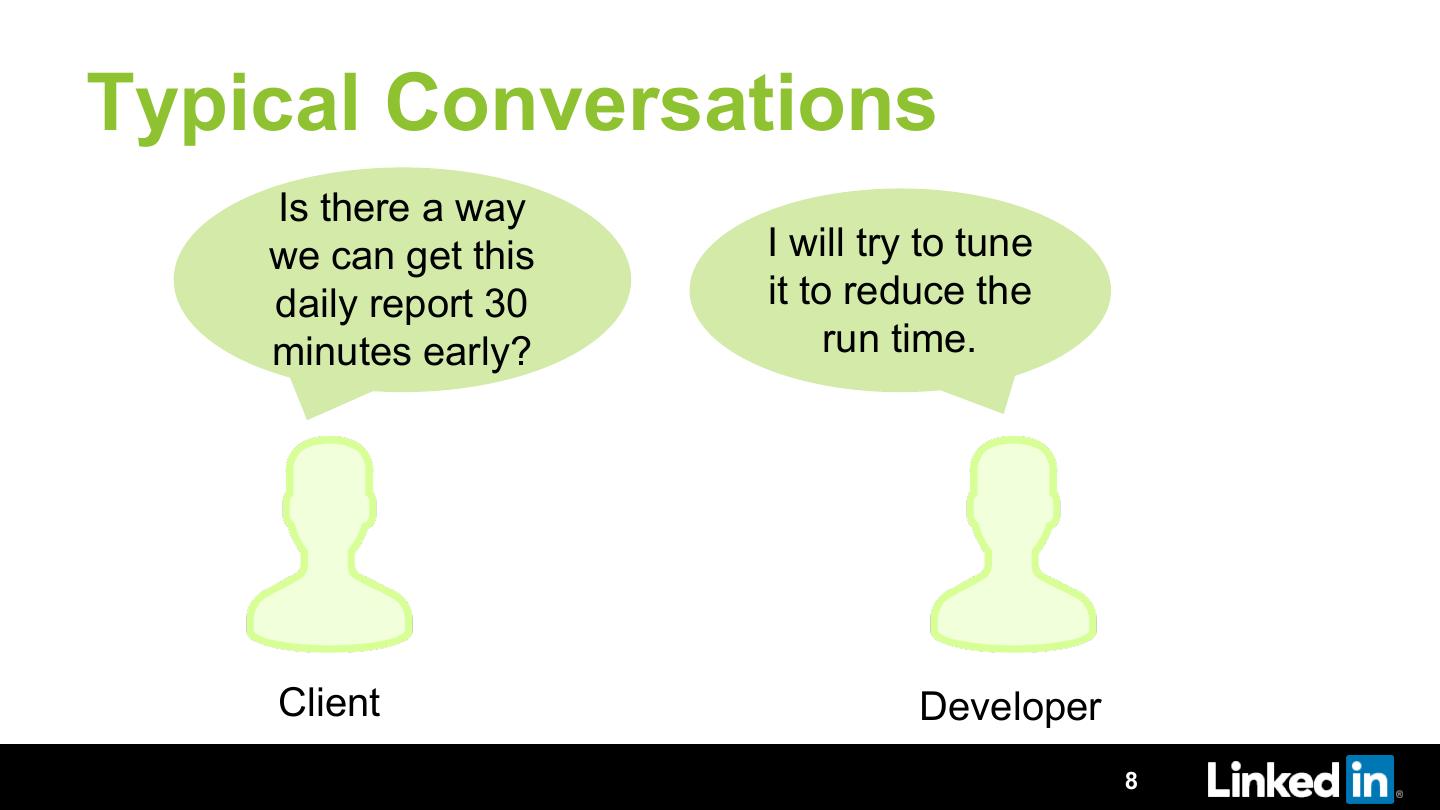
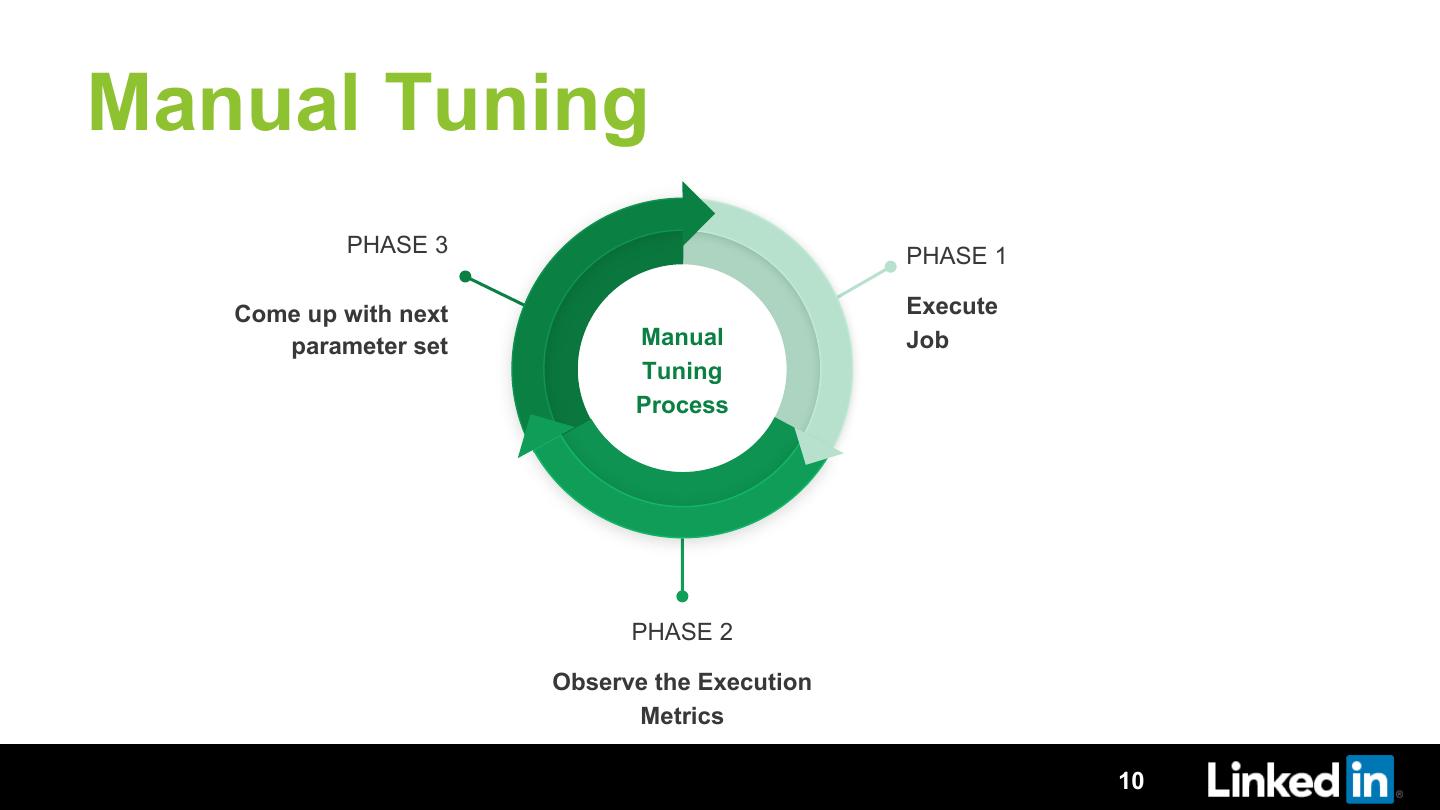
Have you ever tuned a Spark, Hive or Pig job? If yes, then you must know that it is a never ending cycle of executing the job, observing the running job, making sense out of hundreds of metrics and then re-running it with the better parameters. Imagine doing this for tens of thousands of jobs. Performance optimization at this scale manually is tedious, requires significant expertise and results into wasting a lot of resources to do the same task again and again.
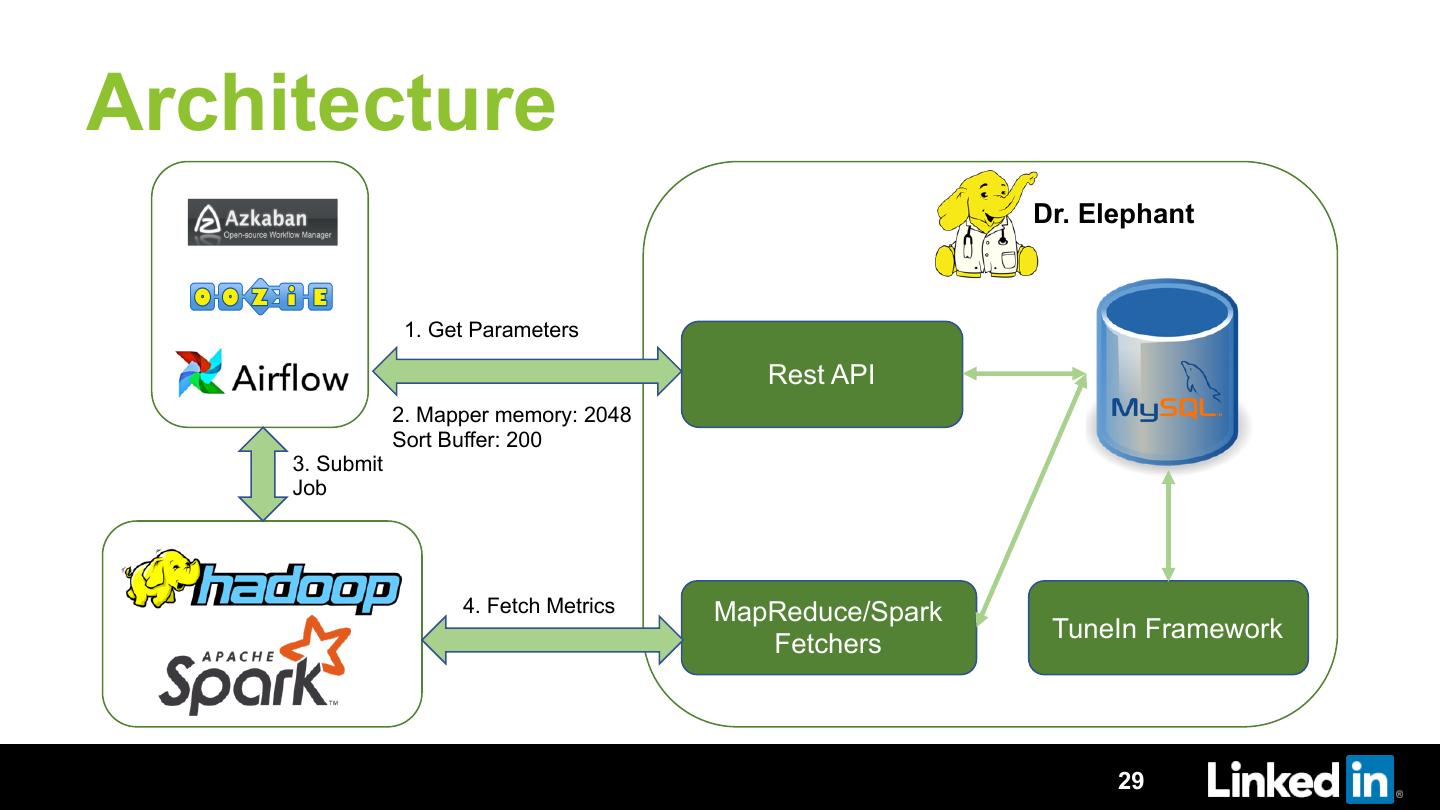
As Hadoop/Spark is the natural choice for any data processing with many naive users, it becomes important to develop a tool to automatically tune Hadoop/Spark jobs. At LinkedIn we tried to solve the problem using Dr. Elephant, an open-sourced self-serve performance monitoring and tuning tool for Hadoop and Spark, used at LinkedIn and various other companies. While it has proven to be very successful, it relies on the developers’ initiative to check and apply the recommendation manually. It also expects some expertise from developers to arrive at the optimal configuration from the recommendations.
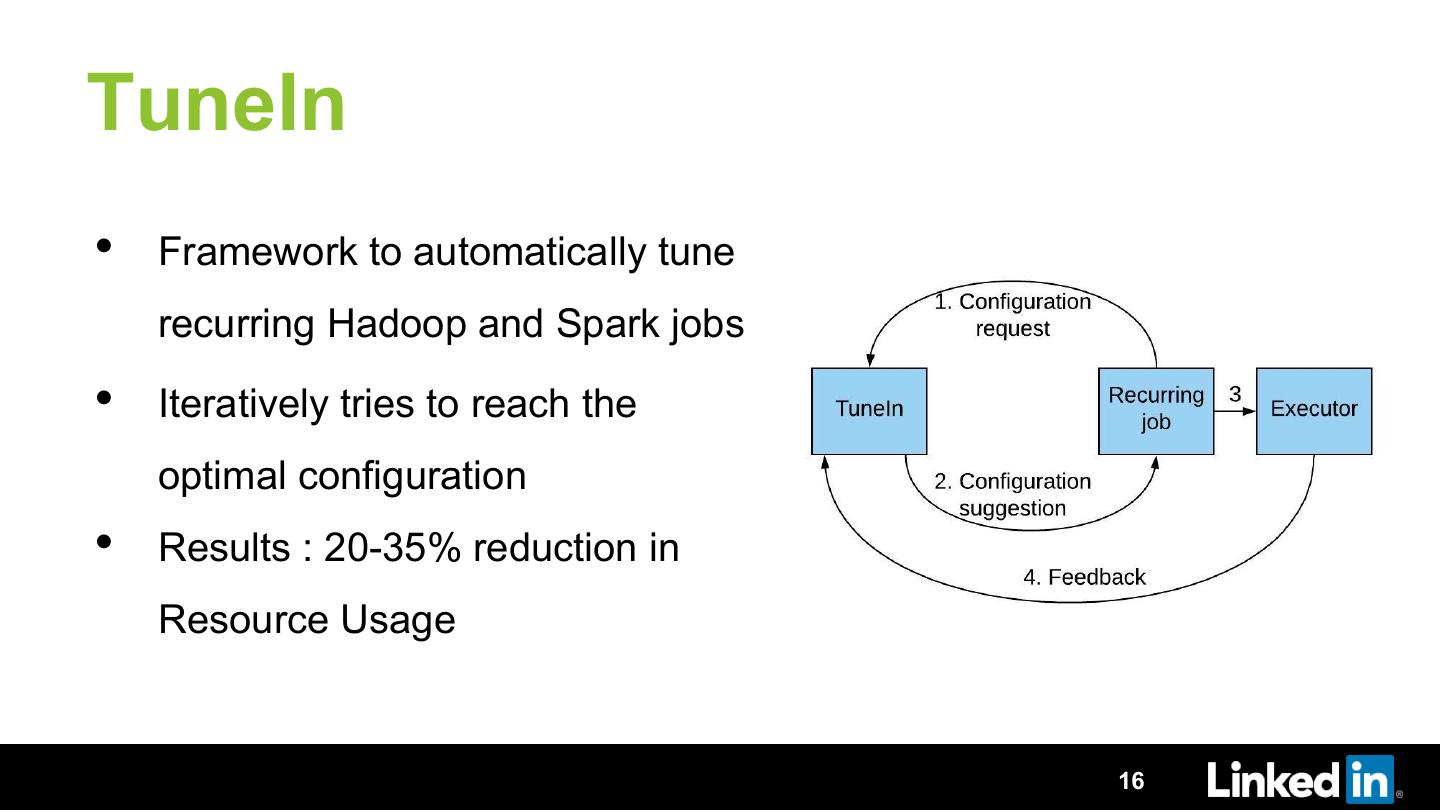
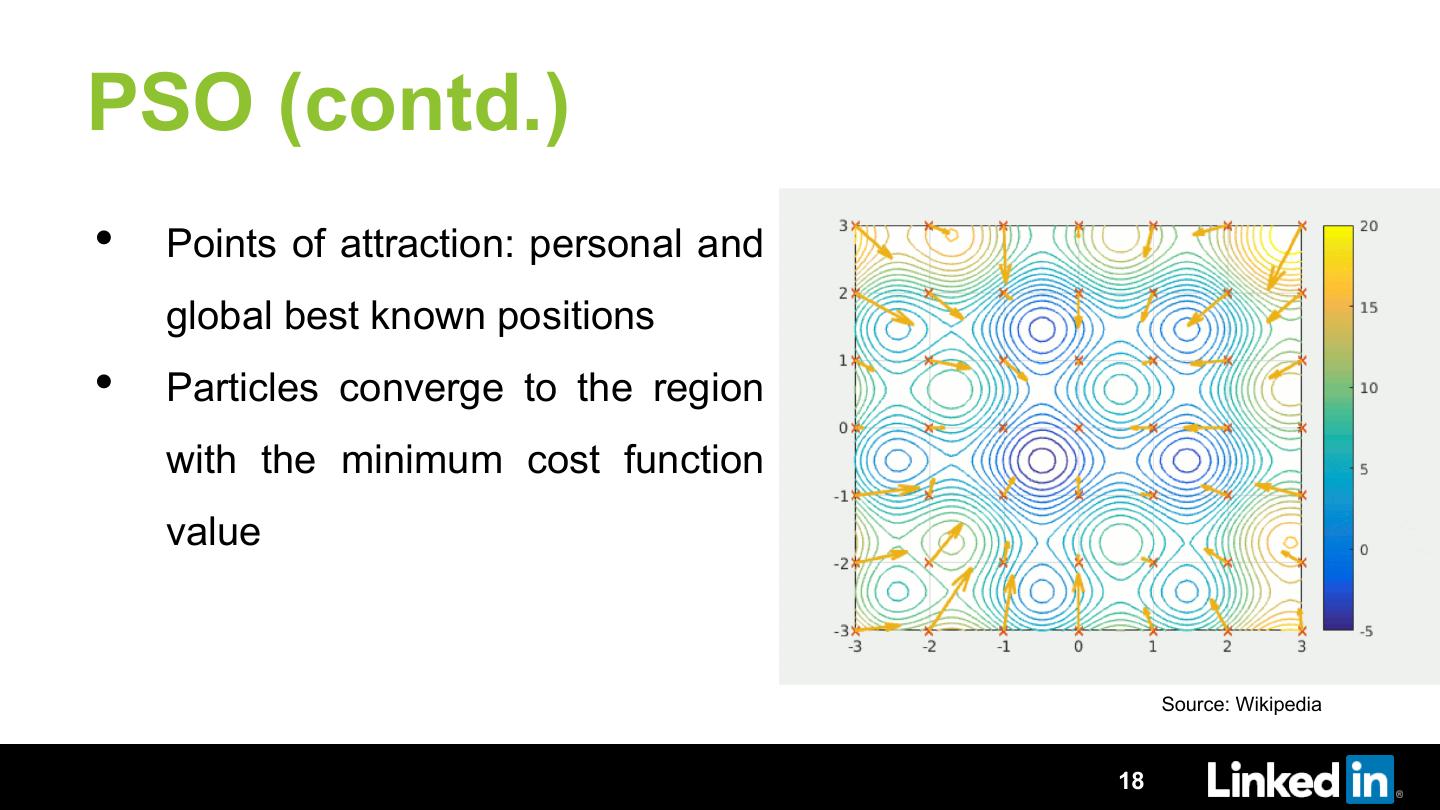
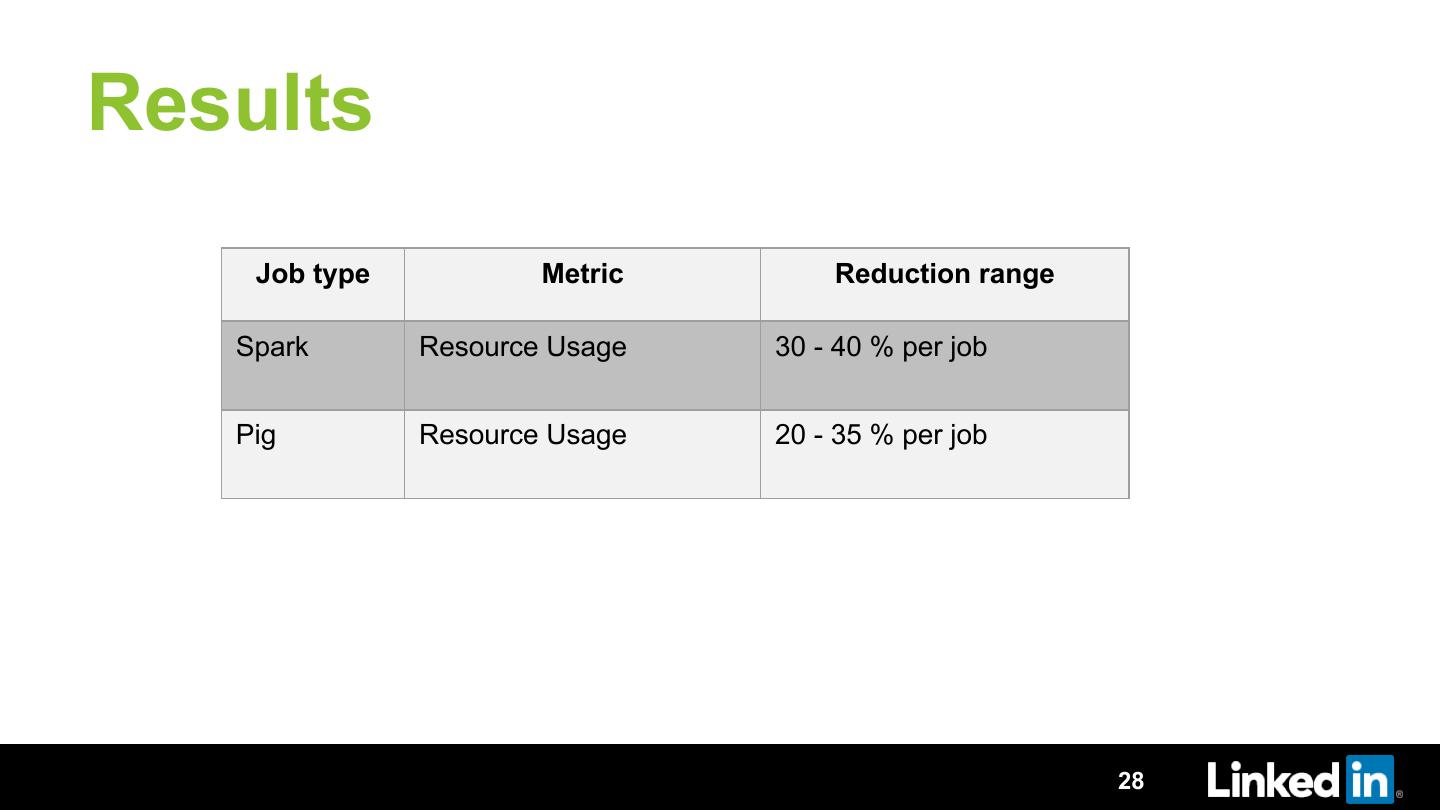
In this talk we will discuss TuneIn, an auto tuning framework developed on top of Dr. Elephant. We will describe how we are using an iterative approach of optimization to find optimal parameters. We will discuss the various optimization algorithms we tried and why we found Particle Swarm Optimization algorithm to give best results. We will talk about how we avoided using any extra execution and tuned the jobs during their regular scheduled execution. We go into detail on techniques employed to ensure faster convergence and zero failed executions while tuning. We will showcase how we achieved more than 50% gain in resource usage by tuning a small set of parameters. We will also talk about the lessons learned and the future roadmap.

