展开查看详情
1 .WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
�
2 .Using Spark MLlib Models in a
Production Training and Serving
Platform: Experiences and Extensions
Anne Holler, Michael Mui
Uber
#UnifiedAnalytics #SparkAISummit
�
3 .Introduction
● Michelangelo is Uber’s Machine Learning Platform
○ Supports training, evaluation, and serving of ML models in production
○ Uses Spark MLlib for training and serving at scale
● Michelangelo's use of Spark MLlib has evolved over time
○ Initially used as part of a monolithic training and serving platform, with
hardcoded model pipeline stages saved/loaded from protobuf
○ Initially customized to support online serving, with
online serving APIs added to Transformers ad hoc
#UnifiedAnalytics #SparkAISummit 3
�
4 .What are Spark Pipelines: Estimators and Transformers
Estimator: Spark
abstraction of a learning
algorithm or any algorithm
that fits or trains on data
Transformer: Spark
abstraction of an ML
model stage that includes
feature transforms and
predictors
#UnifiedAnalytics #SparkAISummit 4
�
5 .Pipeline Models Encode Operational Steps
#UnifiedAnalytics #SparkAISummit 5
�
6 .Pipeline Models Enforce Consistency
● Both Training and Serving involve pre- and post- transform stages in addition to raw
fitting and inferencing from ML model that need to be consistent:
○ Data Transformations
○ Feature Extraction and Pre-Processing
○ ML Model Raw Predictions
○ Post-Prediction Transformations
#UnifiedAnalytics #SparkAISummit 6
�
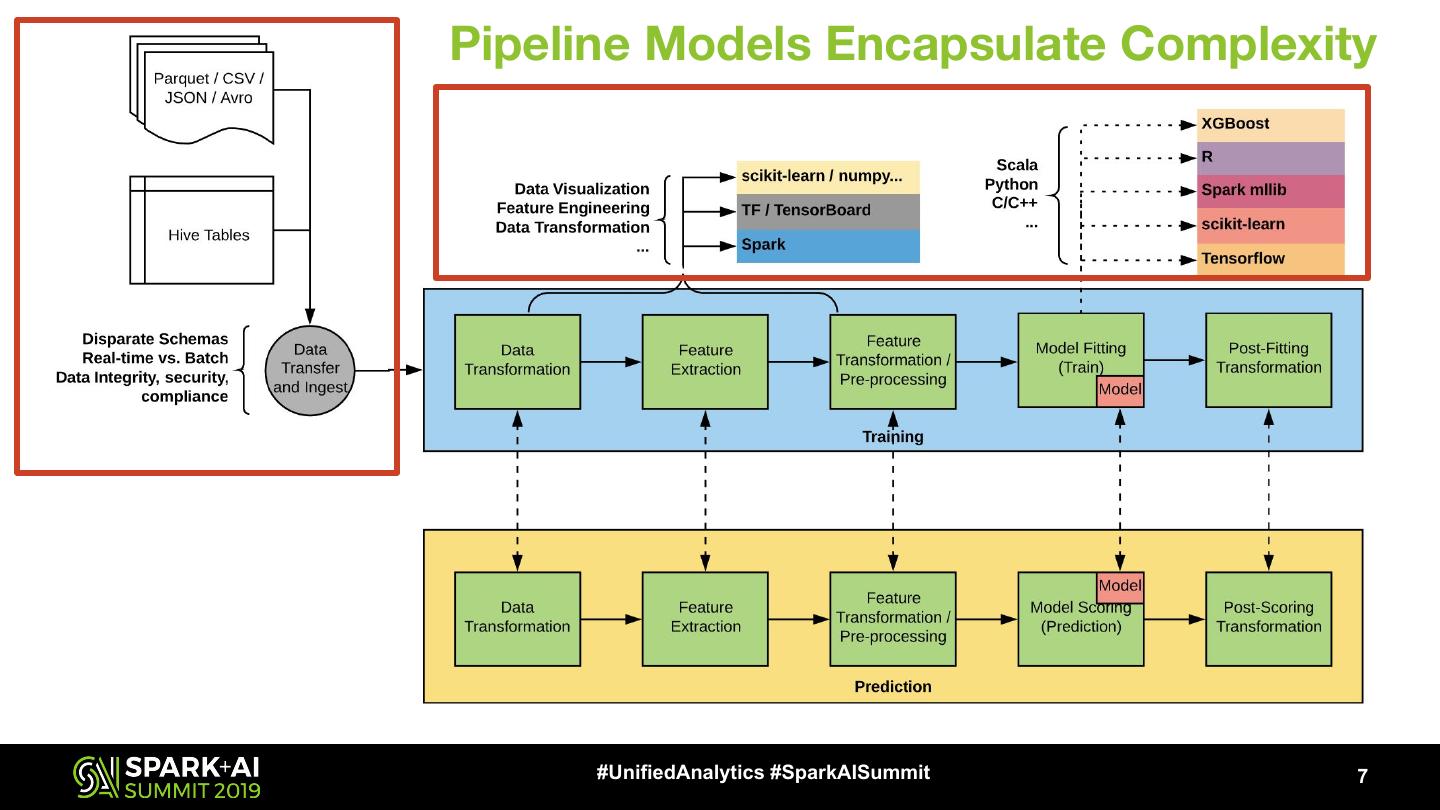
7 . Pipeline Models Encapsulate Complexity
ML Workflow In Practice
#UnifiedAnalytics #SparkAISummit 7
�
8 .Complexity arises from Different Workflow Needs
#UnifiedAnalytics #SparkAISummit 8
�
9 . Complexity arises from Different User Needs
Data Analysts / Data
Engineers / Software
Engineers
Research Scientists / Data Scientists / Research/ML Engineers
ML Engineers / Production Engineers
#UnifiedAnalytics #SparkAISummit 9
�
10 .Evolution Goal: Retain Performance and Consistency
● Requirement 1: Performant distributed batch serving that comes with the
DataFrame-based execution model on top of Spark’s SQL Engine
● Requirement 2: Low-latency (P99 latency <10ms), high throughput
solution for real-time serving
● Requirement 3: Support consistency in batch and real-time prediction
accuracy by running through common code paths whenever practical
#UnifiedAnalytics #SparkAISummit 10
�
11 .Evolution Goal: Increase Flexibility and Velocity
● Requirement 1: Flexibility in model definitions: libraries, frameworks
○ Allow users to define model pipelines (custom Estimator/Transformer)
○ Train and serve those models efficiently
● Requirement 2: Flexibility in Michelangelo use
○ Decouple its monolithic structure into components
○ Allow interoperability with non-Michelangelo components / pipelines
● Requirement 3: Faster / Easier Spark upgrade path
○ Replace custom protobuf model representation
○ Formalize online serving APIs
#UnifiedAnalytics #SparkAISummit 11
�
12 .Evolve: Replacing Protobuf Model Representation
● Considered MLeap, PMML, PFA, Spark PipelineModel: all supported in Spark MLlib
○ MLeap: non-standard, impacting interoperability w/ Spark compliant ser/de
○ MLeap, PMML, PFA: Lag in supporting new Spark Transformers
○ MLeap, PMML, PFA: Risk of inconsistent model training/serving behavior
● Wanted to choose Spark PipelineModel representation for Michelangelo models
○ Avoids above shortcomings
○ Provides simple interface for adding estimators/transformers
○ But has challenges in Online Serving (see Pentreath’s Spark Summit 2018 talk)
■ Spark MLlib PipelineModel load latency too large
■ Spark MLlib serving APIs too slow for online serving
#UnifiedAnalytics #SparkAISummit 12
�
13 .Spark PipelineModel Representation
● Spark PipelineModel format example file structure
├── 0_strIdx_9ec54829bd7c
│ ├── data part-00000-a9f31485-4200-4845-8977-8aec7fa03157.snappy.parquet
│ ├── metadata part-00000
├── 1_strIdx_5547304a5d3d
│ ├── data part-00000-163942b9-a194-4023-b477-a5bfba236eb0.snappy.parquet
│ ├── metadata part-00000
├── 2_vecAssembler_29b5569f2d98
│ ├── metadata part-00000
├── 3_glm_0b885f8f0843
│ ├── data part-00000-0ead8860-f596-475f-96f3-5b10515f075e.snappy.parquet
│ └── metadata part-00000
└── 4_idxToStr_968f207b70f2
├── metadata part-00000
● Format Read/Written by Spark MLReadable/MLWritable
trait MLReadable[T] {
def read : org.apache.spark.ml.util.MLReader[T]
def load(path : scala.Predef.String) : T
}
trait MLWritable {
def write: org.apache.spark.ml.util.MLWriter
def save(path : scala.Predef.String)
}
#UnifiedAnalytics #SparkAISummit 13
�
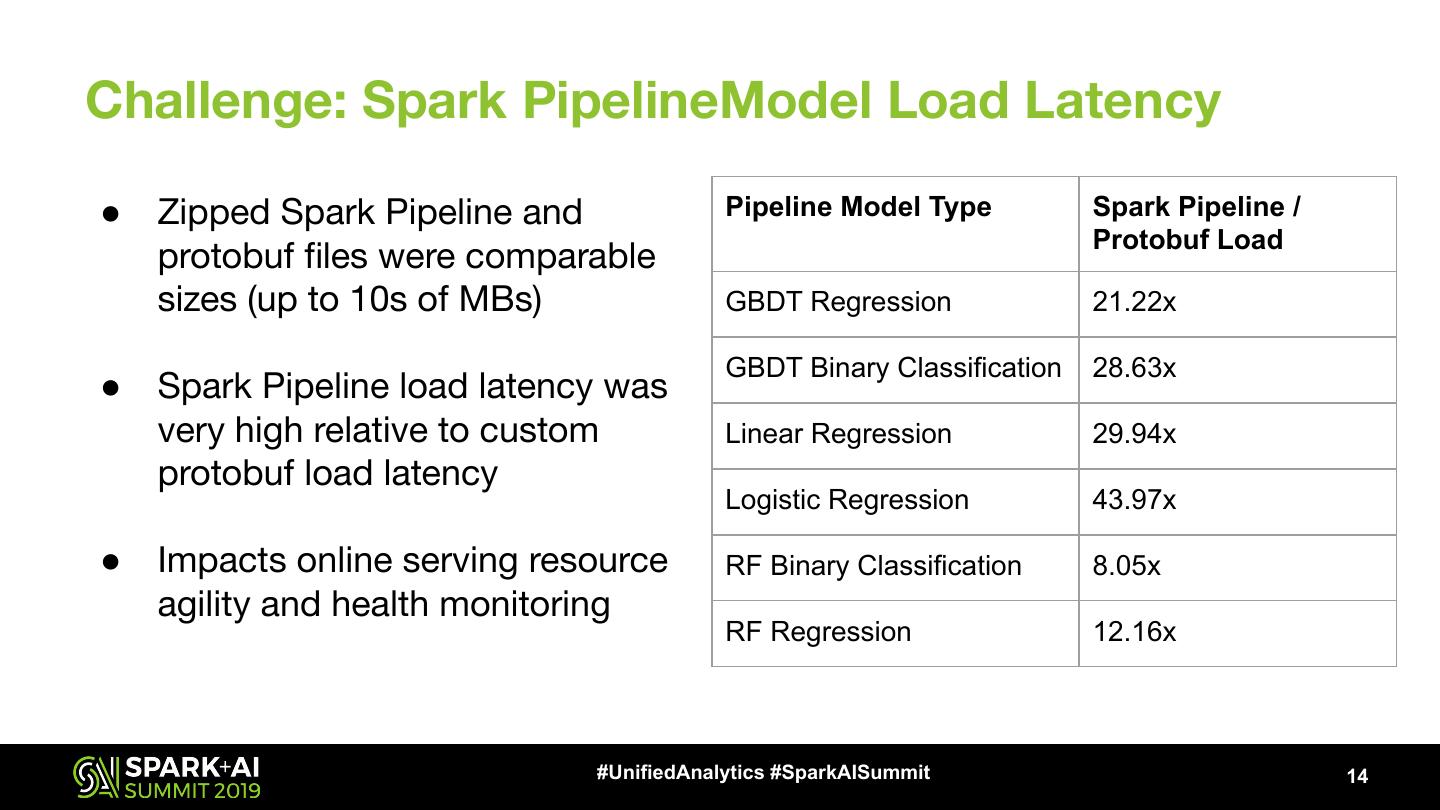
14 .Challenge: Spark PipelineModel Load Latency
● Zipped Spark Pipeline and Pipeline Model Type Spark Pipeline /
Protobuf Load
protobuf files were comparable
sizes (up to 10s of MBs) GBDT Regression 21.22x
GBDT Binary Classification 28.63x
● Spark Pipeline load latency was
very high relative to custom Linear Regression 29.94x
protobuf load latency
Logistic Regression 43.97x
● Impacts online serving resource RF Binary Classification 8.05x
agility and health monitoring
RF Regression 12.16x
#UnifiedAnalytics #SparkAISummit 14
�
15 .Tuning Load Latency: Part 1
Replaced sc.textfile with local metadata read
● DefaultParamsReadable.load uses sc.textfile
● Forming RDD of strings for small 1-line file was slower than simple load
● Replaced with java I/O for local file case, which was much faster
○ Updated loadMetadata method in
mllib/src/main/scala/org/apache/spark/ml/util/ReadWrite.scala
● Big reduction in latency of metadata read
#UnifiedAnalytics #SparkAISummit 15
�
16 .Tuning Load Latency: Part 2
Replaced sparkSession.read.parquet with ParquetUtil.read
● Spark distributed read/select for small Transformer data was very slow
● Replaced with direct parquet read/getRecord, which was much faster
○ Relevant to Transformers like LogisticRegression,
StringIndexer, LinearRegression
● Significant reduction in latency of Transformer data read
#UnifiedAnalytics #SparkAISummit 16
�
17 .Tuning Load Latency: Part 3
Updated Tree Ensemble model data save and load to use Parquet directly
● Coalesced tree ensemble node and metadata weights DataFrames at save
time to avoid writing large number of small files that are slow to read
● Loading Tree Ensemble models invoked a groupByKey,sortByKey
○ Spark distributed read/select/sort/collect was very slow
● Replaced with direct parquet read/getRecord, which was much faster
● Significant reduction in latency of tree ensemble data read
#UnifiedAnalytics #SparkAISummit 17
�
18 .Before and After: Tuned Pipeline Load Latency
Pipeline Model Type Spark Pipeline / Tuned Spark
Greatly improved MLLib load Protobuf Load Pipeline / Protobuf
latency, while retaining Load
current on-disk format! GBDT Regression 21.22x 2.05x
GBDT Binary 28.63x 2.50x
Classification
Linear Regression 29.94x 2.03x
Logistic Regression 43.97x 2.88x
RF Binary Classification 8.05x 3.14x
RF Regression 12.16x 3.01x
#UnifiedAnalytics #SparkAISummit 18
�
19 .Challenge: SparkContext Cleaner Performance
● Michelangelo online serving creates local SparkContext to handle load of
any unoptimized Transformers
● Periodic context cleaner runs induced non-trivial latency in serving request
responses
● Solution: Stopped SparkContext when models not actively being loaded.
○ Model load only happens at service startup or when new models are
deployed into production online serving
#UnifiedAnalytics #SparkAISummit 19
�
20 .Challenge: Serving APIs too slow for online serving
● Added OnlineTransformer trait to Transformers to be served online
○ Single & small list APIs which leverage low-level spark predict methods
trait OnlineTransformer {
def scoreInstances(instances: List[Map[String, Any]]): List[Map[String, Any]]
def scoreInstance(instance: Map[String, Any]): Map[String, Any]
}
○ Injected at Transformer load time, so pipeline models trained outside of
Michelangelo can be served online by Michelangelo
#UnifiedAnalytics #SparkAISummit 20
�
21 .Michelangelo Use of Spark MLlib Evolution Outcome
● Michelangelo is using updated Spark MLlib interface in production
○ Spark PipelineModel on-disk representation
○ Optimized Transformer loads to support online serving
○ OnlineTransformer trait to provide online serving APIs
#UnifiedAnalytics #SparkAISummit 21
�
22 .Example Use Cases Enabled by Evolved MA MLlib
● Flexible Pipeline Model Definition
○ Model Pipeline including TFTransformer
● Flexible Use of Michelangelo
○ Train Model in Notebook, Serve Model in Michelangelo
#UnifiedAnalytics #SparkAISummit 22
�
23 .Flexible Pipeline Model Definition
● Interoperability with non-Michelangelo components / pipelines
○ Cross framework, system, language support via Estimators /
Transformers
● Allow customizability of PipelineModel, Estimators, Transformers while
fully integrated into Michelangelo’s Training and Serving infrastructure
○ Combines Spark’s Data Processing with Training using custom
libraries e.g. XGBoost, Tensorflow
#UnifiedAnalytics #SparkAISummit 23
�
24 .Flexible Pipeline Definition Example: TFTransformer
● Serving TensorFlow Models with TFTransformer
https://eng.uber.com/cota-v2/
○ Spark Pipeline built from training contains both data processing
transformers and TensorFlow transformations (TFTransformer)
○ P95 serving latency < 10ms
○ Combines the distributed computation of Spark and low-latency serving
using CPUs and the acceleration of DL training using GPUs
#UnifiedAnalytics #SparkAISummit 24
�
25 .Serving TF Models
using TFTransformer
#UnifiedAnalytics #SparkAISummit 25
�
26 .Flexible Use Example: Train in DSW, Serve in MA
● Decouple Michelangelo into
functional components
● Consolidate custom data
processing, feature engineering,
model definition, train, and
serve around notebook
environments (DSW)
#UnifiedAnalytics #SparkAISummit 26
�
27 .Experiment in DSW, Serve in Michelangelo
#UnifiedAnalytics #SparkAISummit 27
�
28 .Key Learnings in Evolving Michelangelo
● Pipeline representation of models is powerful
○ Encodes all steps in operational modeling
○ Enforces consistency between training and serving
● Pipeline representation of models needs to be flexible
○ Model pipeline can encapsulate complex stages
○ Complexity stems from differing workflow and user needs
#UnifiedAnalytics #SparkAISummit 28
�
29 .Conclusion
● Michelangelo updated use of Spark MLlib is working well in production
● Propose to open source our changes to Spark MLlib
○ Submitted Spark MLlib Online Serving SPIP
■ https://issues.apache.org/jira/browse/SPARK-26247
○ Posted 2 patches
■ Patch to reduce spark pipeline load latency
■ Patch to add OnlineTransformer trait for online serving APIs
#UnifiedAnalytics #SparkAISummit 29
�