展开查看详情
1 .TiDB 的 HTAP 之路
过去,现在和将来
�
2 .About Me
● 分析产品负责人@PingCAP
● 曾就职于网易杭研,担任 BigData Infra Team Lead
● 主要关注大数据,分布式数据库,SQL on Hadoop 等领域
�
3 .TiDB 有很多故事
● 每个故事都可以有多个视角
● 这是一个从 AP 视角讲 HTAP 故事的分享,当然还有技术讨论
�
4 .TiDB for HTAP
100% TP 和 80% AP
很久以前,这曾经是我们的 Slogan
�
5 .TiDB for HTAP
100% TP 和 80% AP
用户:为什么是 80% 不是 75%,也不是 85% ?
�
6 .TiDB for HTAP
TiDB 是一款 HTAP 数据库
所以,后来我 们改用比较精确(时髦)的说法...
�
7 .TiDB for HTAP
TiDB for HTAP
It’s a long long journey
�
8 .从 TiDB 的上古时代说起
● 受到 Google Spanner 启发,我们做了 TiDB
● 在 Pre GA 版本,TiDB 是
○ 一个可自由扩容(算力,存储)的数据库
○ 兼容支持 MySQL 语法和协议
○ 透明的数据分片策略 - Range 分片
○ 强一致,无视分片的分布式事务支持
�
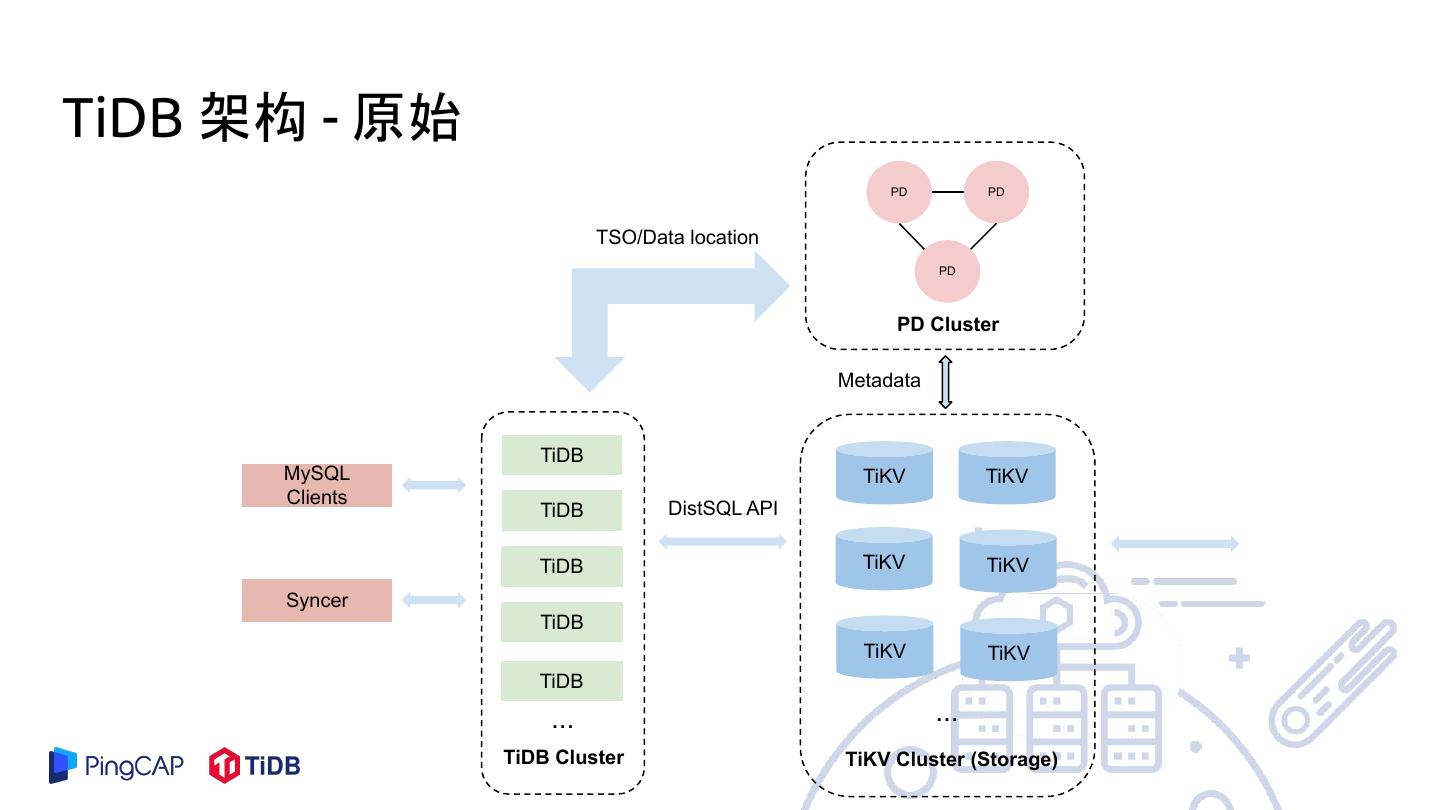
9 .TiDB 架构 - 原始
PD PD
TSO/Data location
PD
PD Cluster
Metadata
TiDB
MySQL TiKV TiKV
Clients
TiDB DistSQL API
TiDB TiKV TiKV
Syncer
TiDB
TiKV TiKV
TiDB
... ...
TiDB Cluster TiKV Cluster (Storage)
�
10 .简单说:同款不同尺寸
S
XXXXXXXXXXXL
�
11 .TP 处女秀
● 我们:TiDB 很好用的啦,可以替换分库分表 MySQL 做 TP 业务。
● 客户:我咋知道你们够稳定呢?我们先把生产库同步到 TiDB 集群测测看吧。
�
13 .TP 处女秀
● 我们:用的咋样?
● 客户:同步数据之后做实时分析真的挺方便的...
● 我们:...
�
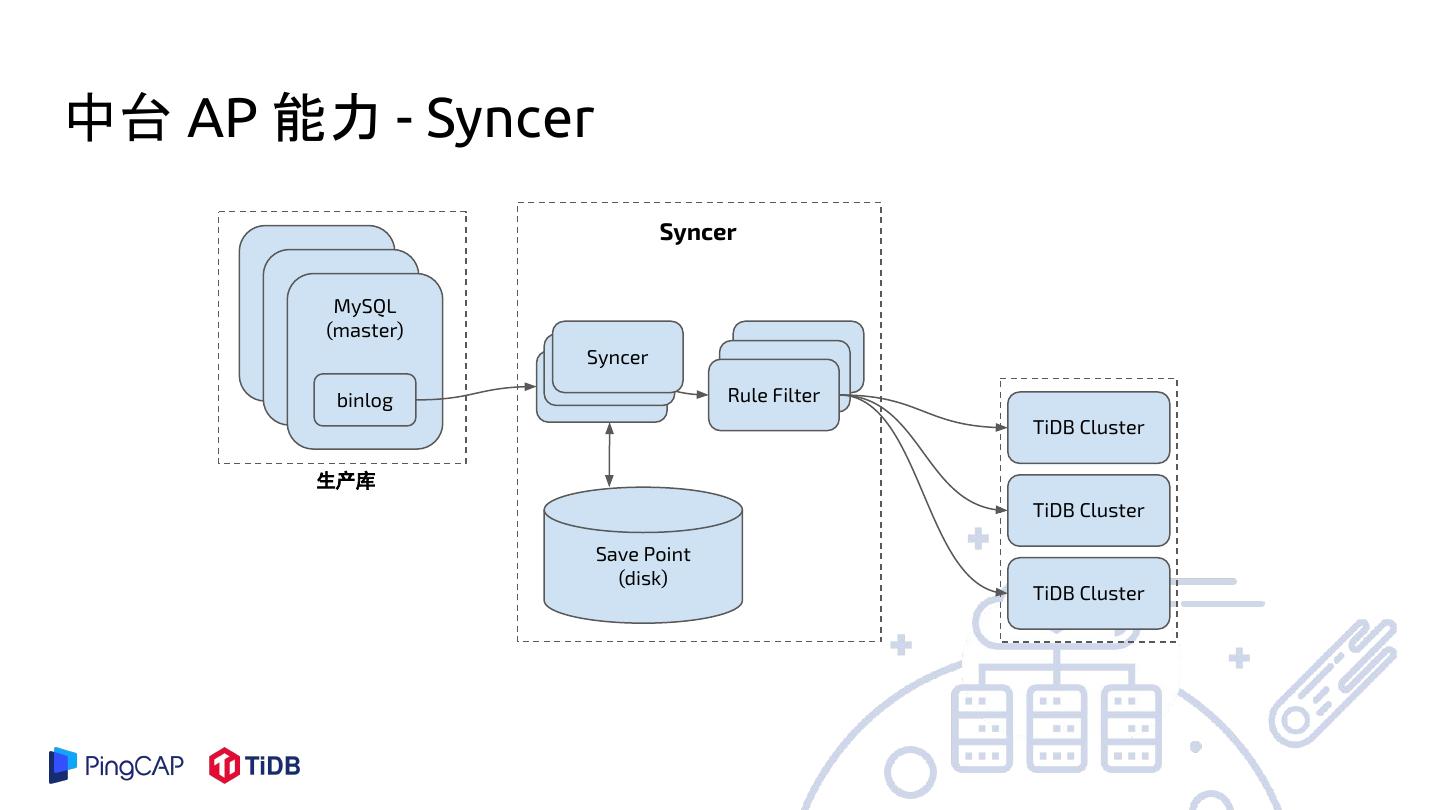
14 .中台 AP 能力 - Syncer
Syncer
MySQL
MySQL
(master)
(master)
MySQL
(master)
binlog Syncer
binlog Syncer
binlog
Syncer Rule Filter
TiDB Cluster
生产库
TiDB Cluster
Save Point
(disk)
TiDB Cluster
�
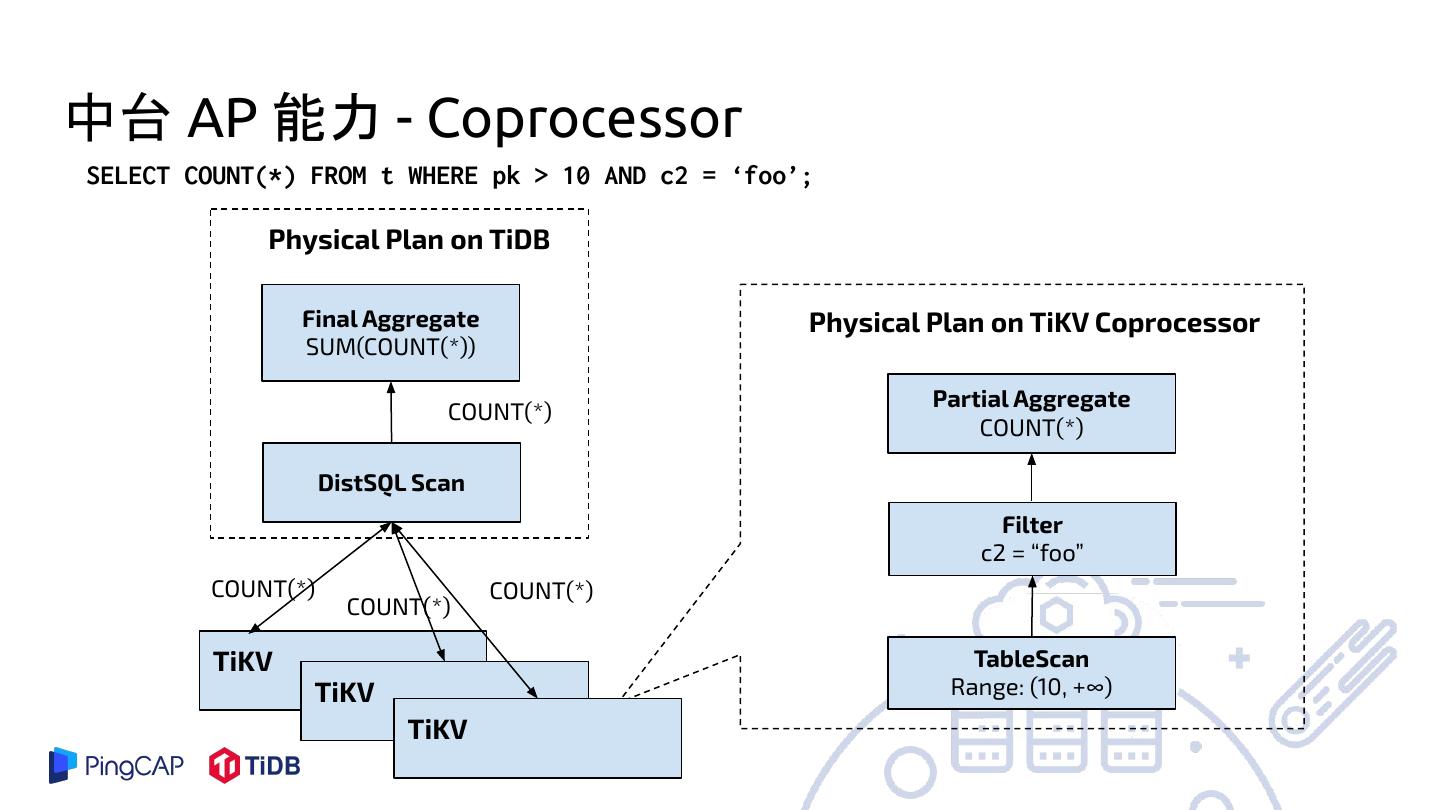
15 .中台 AP 能力 - Coprocessor
SELECT COUNT(*) FROM t WHERE pk > 10 AND c2 = ‘foo’;
Physical Plan on TiDB
Final Aggregate Physical Plan on TiKV Coprocessor
SUM(COUNT(*))
Partial Aggregate
COUNT(*)
COUNT(*)
DistSQL Scan
Filter
c2 = “foo”
COUNT(*) COUNT(*)
COUNT(*)
TiKV TableScan
TiKV Range: (10, +∞)
TiKV
�
16 .中台 AP 能力
● TiDB 非常适合中台场景
● 协议兼容,轻松同步 MySQL 生产库
● 透明无障碍的跨分片查询
● 数据实时落地
● 海量存储允许多数据源汇聚
● 备库 - 中台分析二合一
�
17 .Everyone Happy Now?
? ? ? ?
?
�
18 .一年以后
● TP 场景
○ 客户:虽然还有各种问题...真香!
● AP 场景
○ 客户1:年度报表算的好慢!
○ 客户2:老是 OOM!
○ 客户3:没法和大数据平台结合!
�
19 .不匹配的算力
https://tinyheadedkingdom.com/
�
20 .不匹配的算力
● TiDB 之间无法直接交换数据
● TiKV 之间也无法在计算过程中交换数据
● 海量存储(TiKV),半单机计算(TiDB)
○ 只能通过 TiDB 服务器 Scale-Up 改善
● Coprocessor 无法处理需要数据交换的算子
○ Join,Full Aggregation,Distinct
�
21 .抉择
● 要么将 TiDB 或 TiKV 串起来
○ 完全重构优化器和执行器,打造 MPP Engine
○ 风险大,时间长
● 要么,借助外力,拥抱生态
○ 需要一个开源分布式计算框架
○ 成熟度高,用户群广泛
�
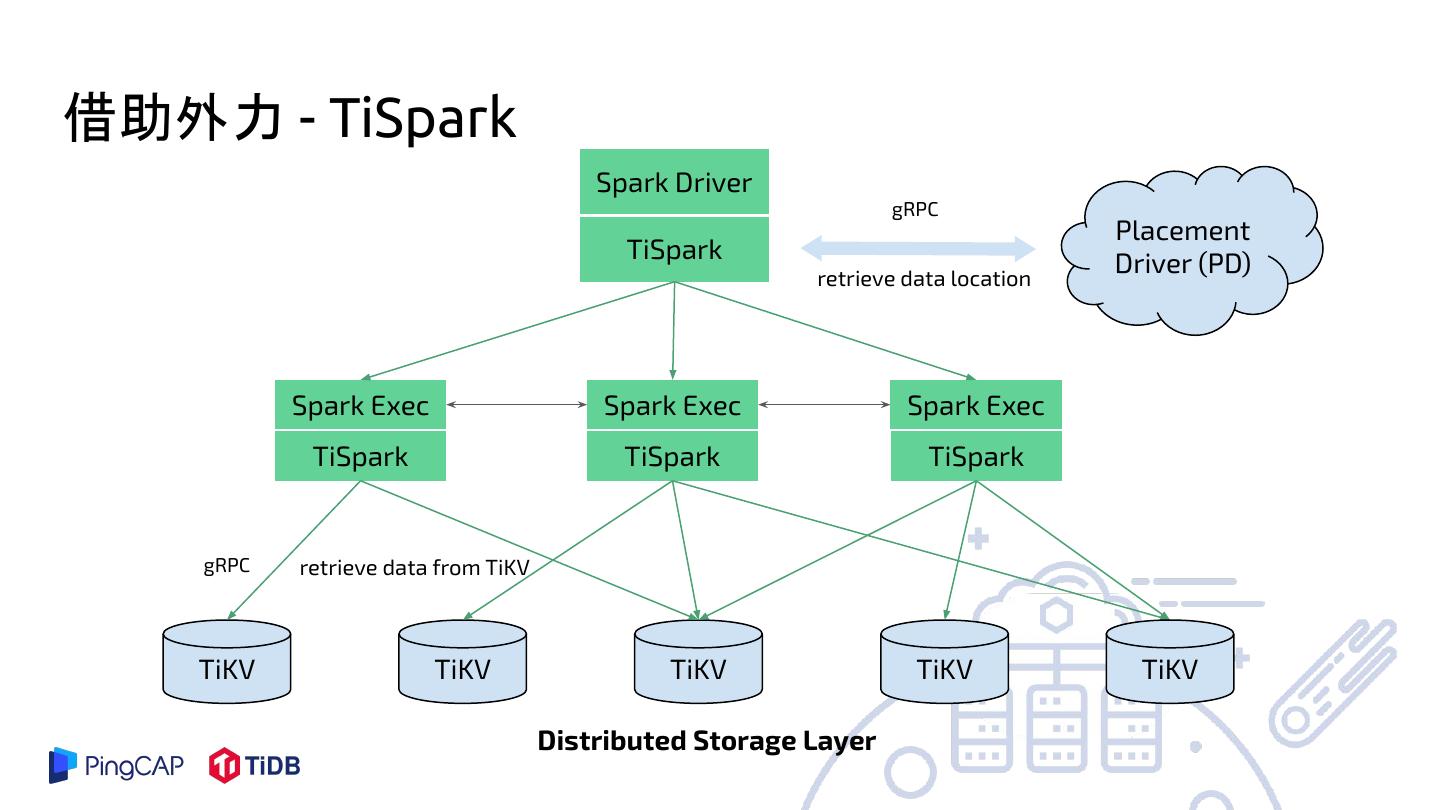
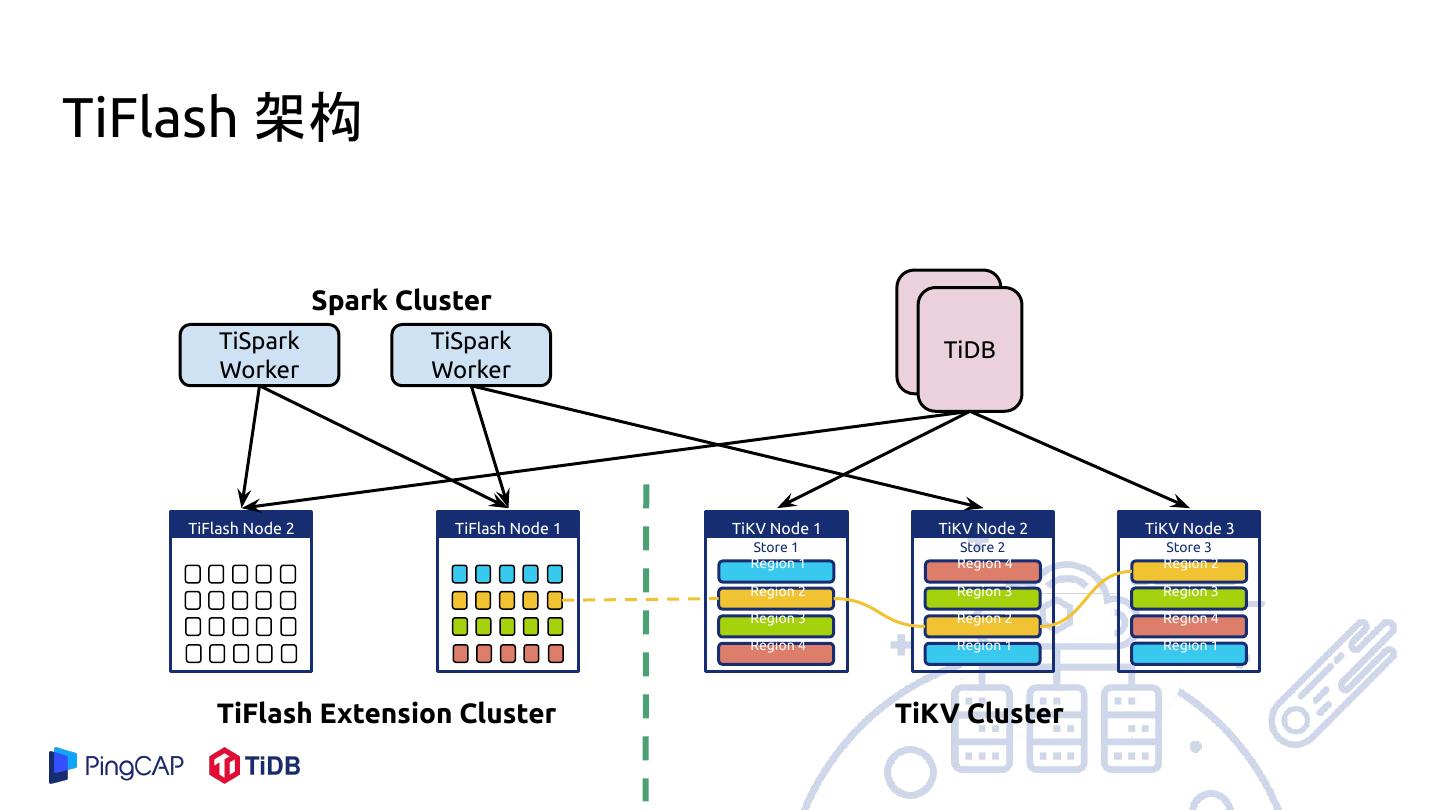
22 .借助外力 - TiSpark
Spark Driver
gRPC
Placement
TiSpark Driver (PD)
retrieve data location
Spark Exec Spark Exec Spark Exec
TiSpark TiSpark TiSpark
gRPC retrieve data from TiKV
TiKV TiKV TiKV TiKV TiKV
Distributed Storage Layer
�
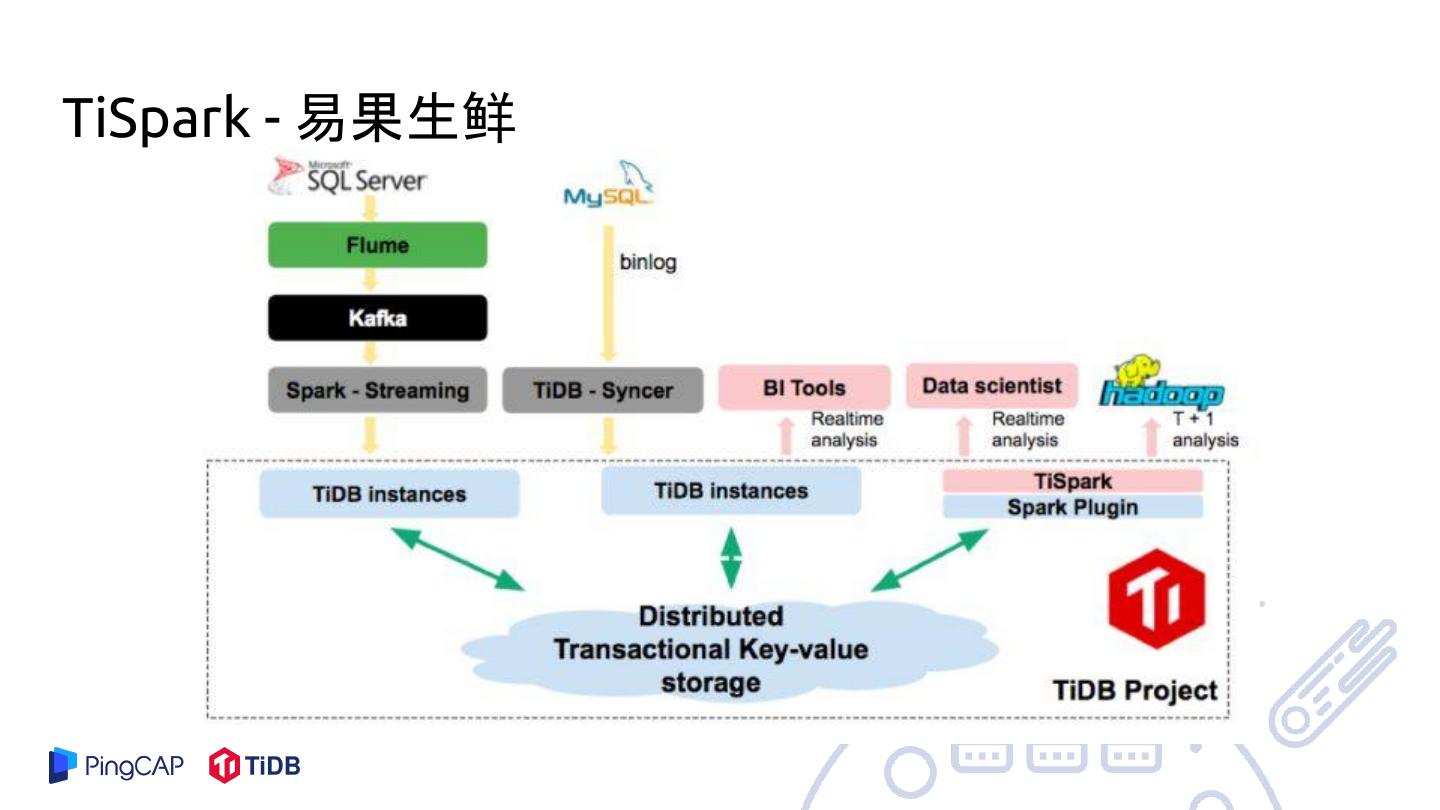
23 .TiSpark
● Spark 帮我们做分布式计算
○ 成熟的分布式计算平台
○ 更快(?),更多,更稳(?)
● 完整继承 Apache Spark 生态圈
○ 无痛衔接大数据生态圈
○ 脚本,JDBC,Python,R,Apache Zeppelin,衔接 Hadoop 数仓...
�
25 .Everyone Happy Now?
? ? ? ?
?
�
26 .TiSpark
● Apache Spark 只能提供低并发的粗暴计算
○ 计算模型重,资源消耗高
○ 更合适报表和重量级 Adhoc 查询
● 用户在很多场合下仍需要高并发中小规模 AP 能力
○ 低消耗低延迟的复杂查询能力
○ TiDB 运维远比 Spark 集群简单
�
28 .与此同时...
● 我们也在围绕单机 TiDB 进行各种优化
○ 在中小规模场景更聪明,更高效,更迅速
● 优化器
○ 你叫它优化器? → RBO + CBO 优化器 → Cascades 优化器(WIP)
● 执行器
○ 经典火山模型 → JIT Batch Execution → Vectorized Execution(WIP)
○ 更好的并发与 Pipeline
● 分区表,Index Merge 等等
�
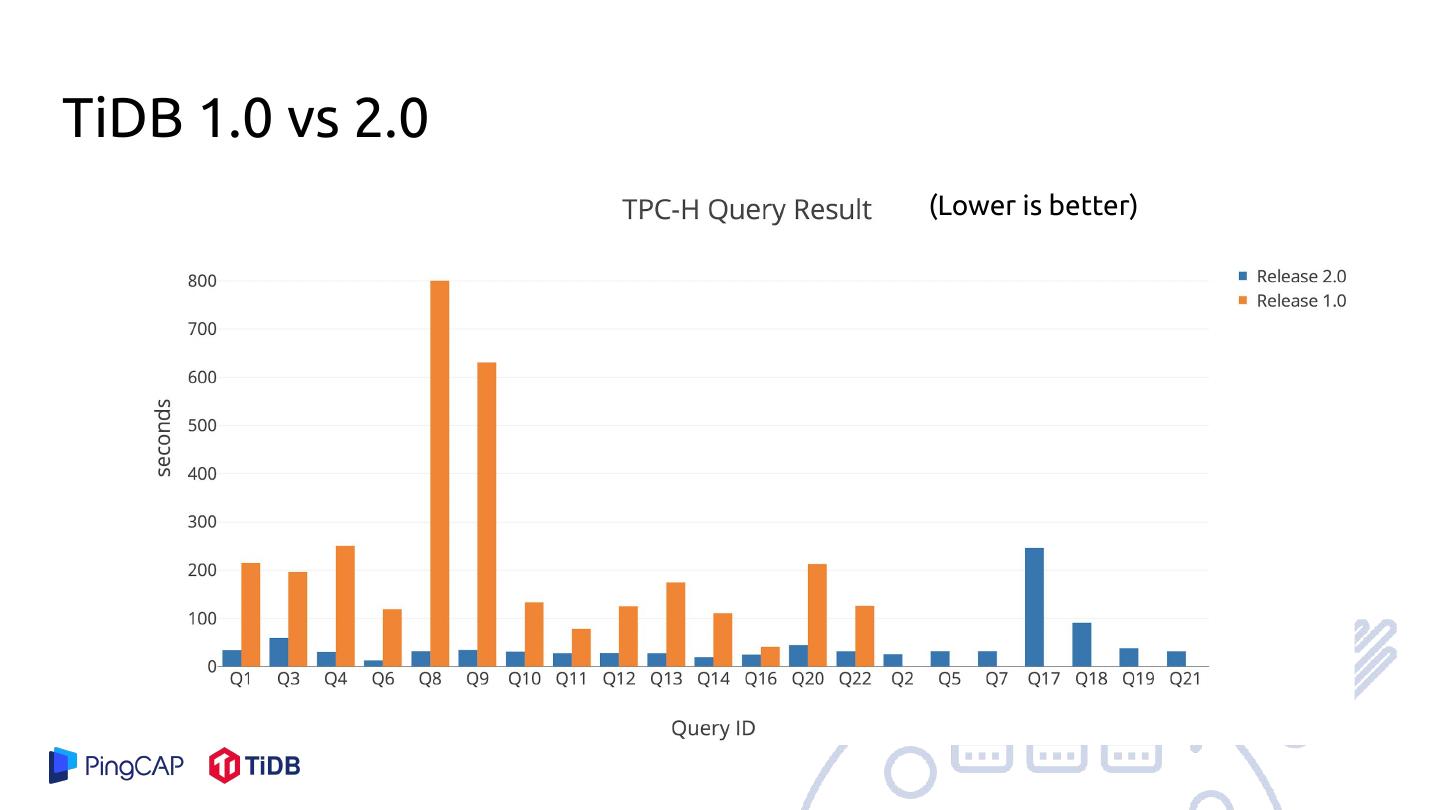
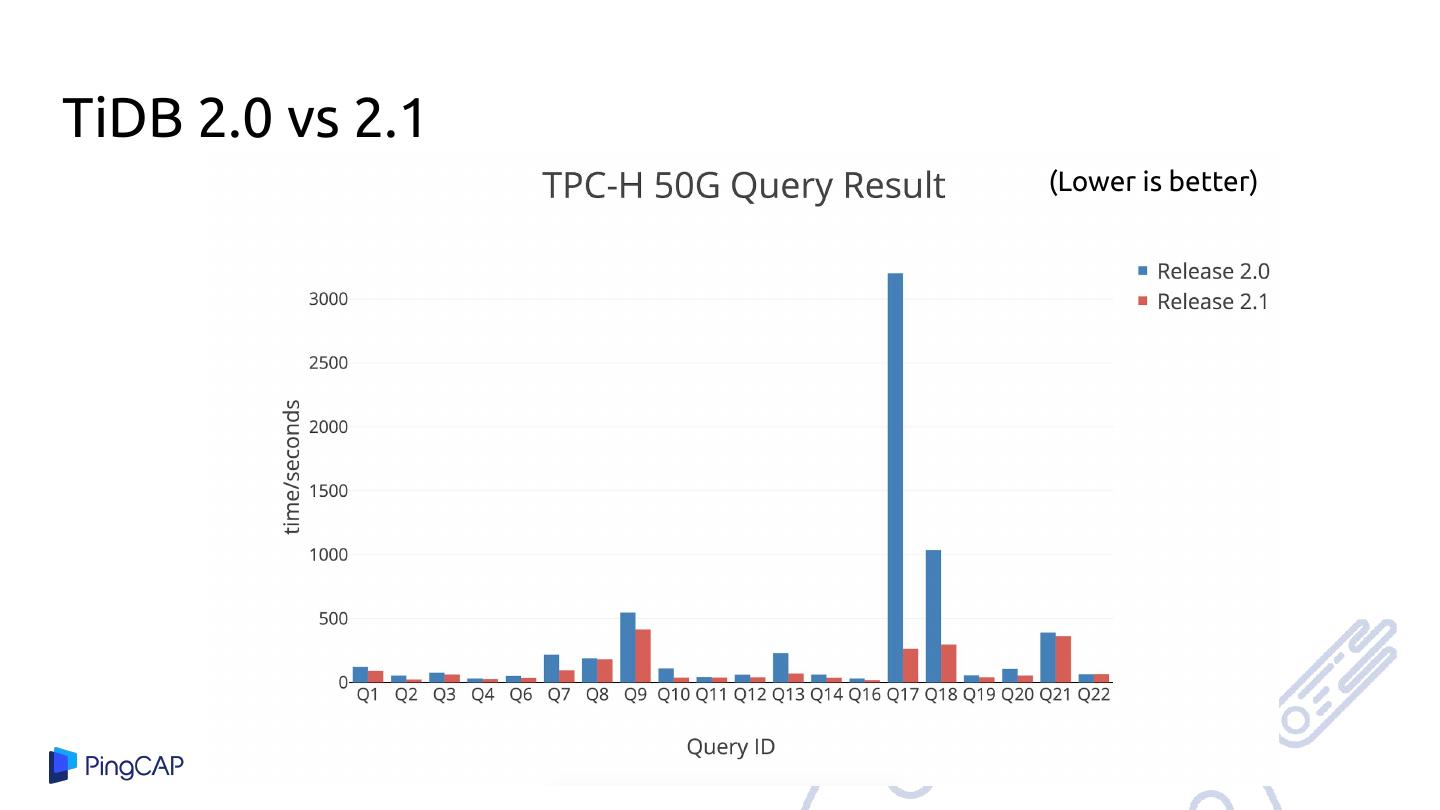
29 .TiDB 1.0 vs 2.0
(Lower is better)
�