


















































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
AIGC深度报告:新一轮内容生产力革命的起点
展开查看详情
1 . 证券研究报告 传媒 2023年03月02日 AIGC深度报告:新一轮内容生产力革命的起点 评级:推荐(维持) 姚蕾(证券分析师) 方博云(证券分析师) S0350521080006 S0350521120002 yaol02@ghzq.com.cn fangby@ghzq.com.cn
2 .最近一年走势 相关报告 沪深300 传媒 《国海证券_行业研究:元宇宙系列深度报告:下一代互联网前瞻*传媒*姚 5% 蕾》——2022/01/05 《国海证券_行业研究:元宇宙系列深度报告之二:数字虚拟人——科技人文 0% 的交点,赋能产业的起点*传媒*姚蕾 》——2022/03/10 -5% 《国海传媒_行业研究:元宇宙系列深度报告之三:NFT的本质思考及破圈之 -10% 路*传媒*姚蕾 》——2022/03/11 -15% -20% -25% -30% 相对沪深300表现 表现 1M 3M 12M 传媒 8.51% 19.59% 0.33% 沪深300 -1.31% 10.55% -9.92% 请务必阅读报告附注中的风险提示和免责声明 2
3 .重点关注公司及盈利预测 2023/3/1 EPS PE 股票代码 股票名称 投资评级 股价 2021A 2022E 2023E 2021A 2022E 2023E 300002.SZ 神州泰岳 6.7 0.2 0.3 0.3 33.6 23.7 19.2 未评级 300418.SZ 昆仑万维 25.2 1.3 1.0 1.1 19.2 25.7 23.1 未评级 300364.SZ 中文在线 12.3 0.1 -0.1 0.2 90.3 - 52.3 未评级 000681.SZ 视觉中国 15.8 0.2 0.2 0.3 72.5 87.7 57.2 未评级 300058.SZ 蓝色光标 6.2 0.2 -0.1 0.3 29.5 - 23.5 未评级 002555.SZ 三七互娱 23.0 1.3 1.4 1.6 17.6 16.8 14.4 买入 603444.SH 吉比特 366.6 20.4 18.4 24.1 17.9 19.9 15.2 买入 002624.SZ 完美世界 14.5 0.2 0.7 0.9 76.5 20.3 16.7 买入 300413.SZ 芒果超媒 34.8 1.2 1.0 1.3 29.7 35.4 26.8 买入 003032.SZ 传智教育 18.6 0.2 0.5 0.6 97.7 38.3 32.5 买入 注:盈利预测除芒果超媒、三七互娱、完美世界、吉比特、传智教育外均来自Wind一致预期 单位:元 资料来源:wind,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 3
4 .核心要点 ◆ 数据、算法、算力共振推动AIGC发展,模型开源及商业化带来的产品化浪潮及通用人工智能领域的初探推动AIGC破圈。AIGC传媒相关应用有望超千亿。 ✓ 复盘AIGC算法迭代:竞争中发展,模型开源及商业化推动应用破圈。2017年推出的Transformer架构的并行训练优势奠定了大模型训练的基础,以GPT 为代表的预训练模型,通过使用无标注数据预训练及微调,缓解了标注数据不足的问题,并不断提升参数量级及模型通用性,ChatGPT在此基础上加入 了利用人类反馈强化学习的训练方法。扩散模型取代GAN成为图像生成领域的主流模型,CLIP模型推动跨模态生成技术的发展。GPT3的商业化及CLIP 及Stable Diffusion模型的开源推动文本生成、文生图产品化的浪潮。谷歌、Meta持续探索文字生成视频领域模型。 ✓ 国内传媒领域应用有望超千亿。Gartner预测至2023年将有20%的内容被生成式AI所创建;至2025年生成式AI产生的数据将占所有数据的10%(目前 不到1%)。红杉预测生成式ai将产生数万亿美元经济价值。2025年,国内生成式ai应用规模有望突破2000亿,我们预测国内传媒领域应用空间超1000 亿。 ◆ AIGC应用于文本、音频、跨模态、策略生成,在设计、内容创作、广告营销、游戏、企业服务等领域开启商业化,有望开启新一轮内容生产力革命。 ✓ 文本生成:应用于辅助写作、营销、社交、浏览器、企业级服务、心理咨询等领域。代表公司Jasper.ai,通过SaaS订阅收费模式,获得B端客户认可, 率先实现规模化收入;OpenAI旗下ChatGPT由于其通用性被集成至浏览器、办公自动化软件、企业级服务产品中,作为增值服务项目。 ✓ 音频生成:应用于智能客服、有声读物制作、配音、导航、虚拟歌手、作曲等领域。代表公司喜马拉雅、倒映有声、标贝科技、StarX MusicX Lab等。 ✓ 跨模态生成:包括文生图、文生视频,图片视频生成文字等应用。AI绘画代表产品Midjourney、DALL-E2、Dream studio、文心一格,主要按生成次 数收费。 ✓ 策略生成:应用于游戏、自动驾驶、机器人控制、智能交互数字人等领域。游戏领域代表性公司腾讯AI Lab、网易伏羲、启元世界、rct.ai、超参数等。 ◆ 投资建议:AIGC的快速发展源于数据、算法、算力的共振。在此基础上,AIGC的出圈源于模型商业化及开源带来的产品化浪潮,及ChatGPT在通用 人工智能领域投射的曙光带来的震撼。AIGC目前在营销、社交、内容创作、游戏等领域均有应用,并开启商业化变现。随着算法迭代、算力提升, AIGC将开启新的内容生产力革命,为传媒行业发展提供新动力。基于此,我们维持行业“推荐”评级。建议重点关注三类公司: 一、拥有自有算法及模型的公司,建议关注昆仑万维、神州泰岳; 二、拥有海量内容及版权储备的公司,建议关注视觉中国、中文在线; 三、相关应用领域龙头公司,重点推荐游戏、影视、营销板块。相关标的三七互娱、吉比特、完美世界、芒果超媒、蓝色光标。 ◆ 风险提示:技术发展演进不及预期、商业化进程不及预期、企业技术管理能力建设不足风险、企业内容审核能力不足风险、版权保护风险、新技术增加 监管难度风险、技术滥用风险、核心人才流失风险、创作伦理风险、法律政策监管风险、估值中枢下移风险等。 请务必阅读报告附注中的风险提示和免责声明 4
5 .目录 1 AIGC破圈元年 1.1 AIGC破圈 1.2 AIGC定义 1.3 发展历程 1.4 市场空间 1.5 商业模式 2 AIGC应用场景 3 产业链及相关公司 请务必阅读报告附注中的风险提示和免责声明 5
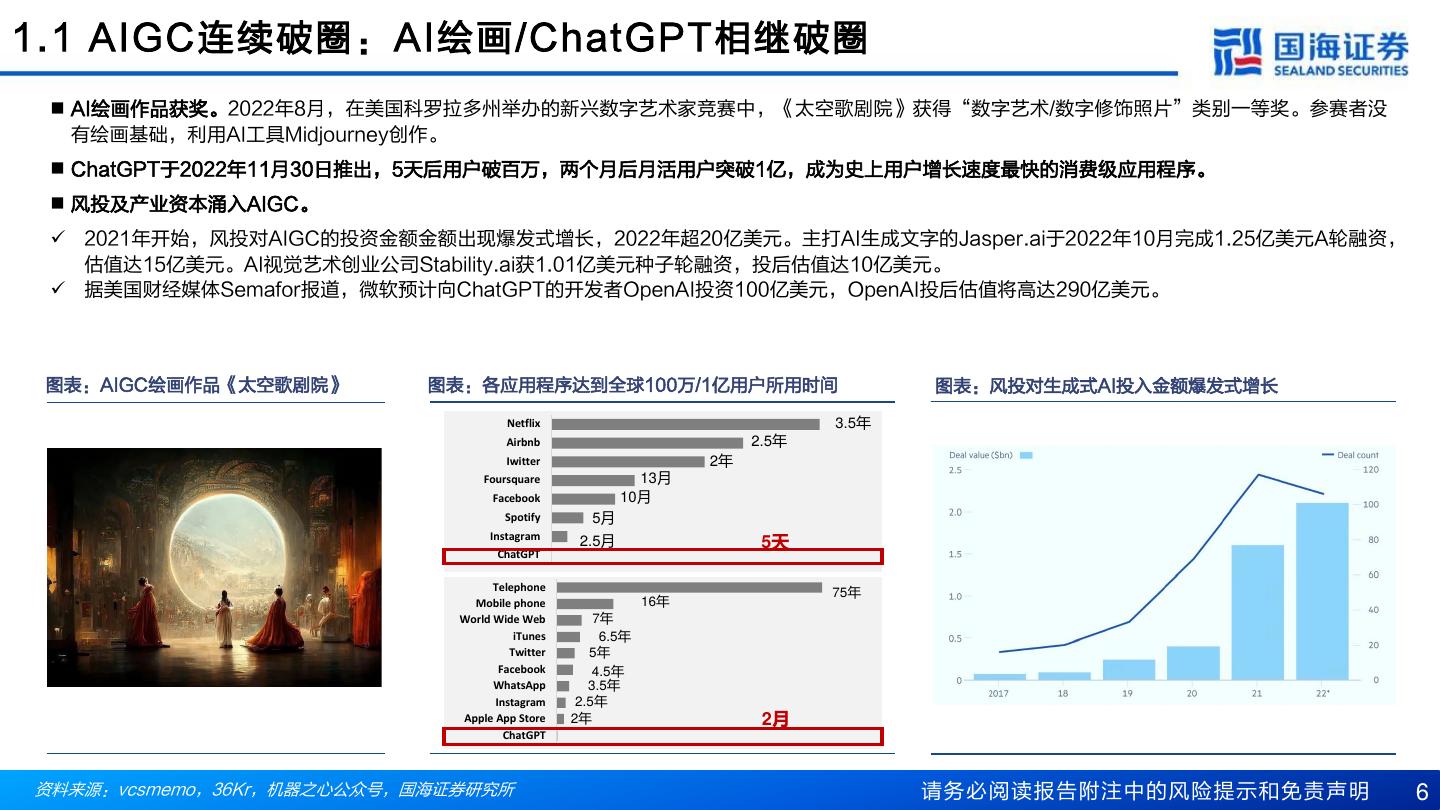
6 .1.1 AIGC连续破圈:AI绘画/ChatGPT相继破圈 ◼ AI绘画作品获奖。2022年8月,在美国科罗拉多州举办的新兴数字艺术家竞赛中,《太空歌剧院》获得“数字艺术/数字修饰照片”类别一等奖。参赛者没 有绘画基础,利用AI工具Midjourney创作。 ◼ ChatGPT于2022年11月30日推出,5天后用户破百万,两个月后月活用户突破1亿,成为史上用户增长速度最快的消费级应用程序。 ◼ 风投及产业资本涌入AIGC。 ✓ 2021年开始,风投对AIGC的投资金额金额出现爆发式增长,2022年超20亿美元。主打AI生成文字的Jasper.ai于2022年10月完成1.25亿美元A轮融资, 估值达15亿美元。AI视觉艺术创业公司Stability.ai获1.01亿美元种子轮融资,投后估值达10亿美元。 ✓ 据美国财经媒体Semafor报道,微软预计向ChatGPT的开发者OpenAI投资100亿美元,OpenAI投后估值将高达290亿美元。 图表:AIGC绘画作品《太空歌剧院》 图表:各应用程序达到全球100万/1亿用户所用时间 图表:风投对生成式AI投入金额爆发式增长 Netflix 3.5年 Airbnb 2.5年 Iwitter 2年 Foursquare 13月 Facebook 10月 Spotify 5月 Instagram 2.5月 5天 ChatGPT Telephone 75年 Mobile phone 16年 World Wide Web 7年 iTunes 6.5年 Twitter 5年 Facebook 4.5年 WhatsApp 3.5年 Instagram 2.5年 Apple App Store 2年 2月 ChatGPT 资料来源:vcsmemo,36Kr,机器之心公众号,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 6
7 .1.2 AIGC 定义:新的内容生成方式、基于人工智能的技术集合 ◼ AIGC(AI Generated Content)即利用人工智能技术自动生成内容,受制于AI技术成熟度,目前AI仍为内容制作的辅助型角色(AIUGC),待技术突破, AI可真正作为内容创作者(AIGC)。 AIGC是技术集合,基于生成对抗网络GAN、大型预训练模型等人工智能技术,通过已有数据寻找规律,并通过适 当的泛化能力生成相关内容的技术集合。 ✓ 相关叫法:合成式媒体(Synthetic Media),即基于AI生成的文字、图像、音频等;Gartner提出的生成式AI(Generative AI),即由人工智能自动生 成新的编程、内容或商业活动,让文字、音乐、图像、视频、场景等都可由AI算法自动生成。 ◼ 从PGC到UGC,从UGC到AIGC。Web1.0时代“只读”模式催生出“PGC”;Web2.0时代,社交媒体兴起,人与人通过网络交互,催生出以用户生 产和分享内容的“UGC”模式;Web3.0时代,内容消费需求进一步增长,个性化需求凸显,“AIGC”将成为重要的新内容生成方式。 图表:内容生产方式的变更 图表:从Web1.0到Web3.0的内容生成方式 生 产 PGC 接收内容 AI技术发展尚未关键性突破 AIGC (Web 1.0) 的 内 人 平台 容 内容质量参差不齐 AIUGC 数 创作内容 UGC 量 (Web 2.0) 接收内容 产能不足 UGC 人 平台 PGC 创作内容 AIGC 单人体验 小范围多人交 大范围多人交 元宇宙的自然 (Web 3.0) 互 互的新兴体验 社交网络 接收内容 人 机器 平台 Web 3.0时代 资料来源:a16z,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 7
8 .1.2 AIGC 定义:机器对信息认知分三阶段,从学习到超越经验 ◼ 机器对信息的认知处于第一或第二阶段。人在遇到新问题时,会通过以往类似经历总结规律,并将新的问题套用到规律中,以推测可能的结果。相应地, 机器学习基于对历史数据的归纳和学习,构建出事件模型,并将合适的新数据输入到相应的模型来预测未来。人类能够超越观察达到干预及想象阶段,而 对于AI来说,目前还处于第一或第二阶段,一些复杂的信息还没办法处理,人类需要将其简化后再投喂给机器处理。 ◼ UGC为AIGC提供了发展的数据基础,AIGC满足更个性化的内容消费需求。 ✓ 用户不再满足于专业团队和用户创造,对内容质量要求更高,AI在提高内容生产效率、丰富内容多样性及提供更加动态且可交互的内容上大有可为。 ✓ UGC生成的规模化内容,创造了大量学习素材,帮助AI实现从学习经验到超越并重构已有经验的飞跃性转变。 人脑思考过程 机器对信息的认知三阶段 未来 阶段三:在想象中对外界环境进行干 AI逐渐具备了想象能力, 预,在反事实中寻找规律 AI能自主创造多样的 超越并重构已有经验 内容 让计算机在对战中去想象如果执行这一 步会怎么样 阶段二:对外界环境进行干预,在改 现阶段 AI主动创造数据,逐渐 变中寻找规律 超越已有经验 用UGC的方式去做 机器学习过程 若改变现有围棋对战中的执行策略,让 人设和规则,为 计算机去进一步判断能否取得胜利 AI“编码”人体基因。 阶段一:对外界环境进行观察,在观 AI被动接受数据,停留 察中寻找规律 在统计意义上对规律的 早期阶段 理解,无法超越已有经 计算机研究了数百万量级的围棋对战数 验 通过既定的图片或者 据后,就能够找出哪些对战的策略会导 语音来生成风格一致 致更高的胜率 的内容。 资料来源:rct AI,《2022AI营销白皮书》,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 8
9 .1.3 AIGC为何爆发?数据、算法、算力共振 ◼ AIGC发展核心三要素:数据、算力、算法。 ✓ 算法持续迭代。2017年推出的Transformer架构的并行训练优势奠定了大模型训练的基础,GPT为代表的预训练模型,通过使用无标注数据预训练及微调, 缓解了标注数据不足的问题,并不断提升参数量级及模型通用性,ChatGPT在此基础上加入了利用人类反馈强化学习的训练方法。扩散模型取代GAN成 为图像生成领域的主流模型,CLIP模型推动跨模态生成技术的发展。 ✓ 模型商业化及开源释放创造力。GPT3的商业化及CLIP及Stable Diffusion模型的开源推动文本生成、文生图产品化浪潮。 图表:深度学习模型的发展 图表:训练模型的计算量(左图)以及AI模型参数量(右图) 模型 类别 发布年份 特点 影响 图像 对输出结果的控制力较弱,容易产 GAN 2014 - 生成 生随机图像、分辨率比较低。 自然语言理解飞跃 引入自注意力机制,能够基于两个 性发展,平行训练 单词间的关系进行建模,有效理解 Transfor 自然语 优势逐步发展出超 2017 单词在上下文中的意思,支持并行 mer 言模型 亿规模的大模型, 训练,使语言模型训练效果达到新 ChatGPT打开AI新 高度。 纪元 对文字、图像分别进行训练,不断 文本-图 调整两个模型内部参数,使得模型 多模态技术推动 CLIP 2021 像生成 分别输出文字特征值和图像特征值 AIGC内容多样性 并确认匹配 通过增加噪声破坏训练数据来学习, 图像 然后找出如何逆转这种噪声过程以 图像生成技术突破, Diffusion 2022 生成 恢复原始图像,高效地解决GAN无 AI绘画点燃AIGC 法训练、训练不稳定的问题。 注:计算结果15000x为WuDao2.0中的参数数量除以GPT 1中的参数数量的比值 资料来源:腾讯科技公众号,谷歌研究,《Generative AI: A Creative New World》,《AI 2022: The Explosion》,国 海证券研究所 请务必阅读报告附注中的风险提示和免责声明 9
10 .1.3 AIGC 算法发展历程:早期受制于算法、算力瓶颈 阶段 萌芽阶段(1950s-1990s) 沉淀积累阶段(1990s-2010s) 特点 从实验性向实用性转变,但受限于算法瓶颈,无法直 受限于技术水平,仅限于小范围实验 接进行内容生成 ◆ 艾伦图灵提出著名 ◆ 第一支由计算 ◆ 世界第一款自然 ◆ 80 年 代 中 期 , ◆ 声龙发布了第一款 ◆ 世界第一部完全由人工 ◆微软展示全自动 事件 的“灵图测试” , 机创作的弦乐 语言聊天机器人 IBM创造语音控 消费级语音识别产 智 能 创 作 的 小 说 《1 同传系统 给出判断机器是否 四重奏《依利 Eliza问世 制 打 字 机 品Dragon Dictate, the road》问世 亚克组曲》完 具有“智能”的实 成 Tangora,处理 售价高达9000美元 验方法 20000个单词 2007 1980 2010 1950 1957 技术 1966 ◆ 通过关键字扫描 和重组完成交互 任务 ◆ 连续语音的识别迅速发展,统计模型 逐步取代模板匹配的方法,隐马尔科 夫模型(HMM)成为语音识别系统的 ◆ 图形处理器GPU、张 量 处 理器 TPU等 算力 设备性能不断提升, ◆深 度 神 经 网 路 算法(DNN) 基础模型 互联网数据规模快速 人物 膨胀 事件 ◆ 首次提出判断机器 ◆ 只有文本界面,自然 ◆ 算法不断完善,语音识别技术快速发 ◆ 可读性不强,拼写错 ◆ 基本深层神经网络 影响 是否是人工智能的 语言理解尚未取得真 展 误、辞藻空洞、缺乏 可以将英文语音翻 方法,灵图被称作 正突破 逻辑等缺点明显 译转化成中文语言 “人工智能”之父 资料来源:信通院《人工智能成内容(AIGC)白皮书》,中国移动雄安产业研究院,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 10
11 .1.3 AIGC算法发展历程:模型持续迭代 阶段 快速发展阶段(2010s-2021年) 特点 深度学习算法不断迭代,人工智能生成内容百花齐放,效果逐渐逼真至难以分辨 ◆ Ian J. ◆ “小冰”推出 ◆ 英 伟 达 发 布 ◆ 人工智能生成 ◆ DeepMind 发 布 ◆ 2020 年 , 伯 克 利 ◆ Open AI 推 出 了 ◆ Open AI 推 出 事件 Goodfellow 世 界 首 部 StyleGan 模 型 画作在佳士得 DVD-GAN 模 的 Pieter Abbeel GPT-3 , 拥 有 超 过 DALL-E,主要应用 提出生成对 100%由人工 可自动生成高 以43.25万美元 型用以生成连续 等人提出去噪扩散 1750 亿 的 训 练 参 数 于文本与图像交互生 抗网络GAN 智能创作的诗 质量图片,几 成交,成为首 视频 概率模型(DDPM) 量,被誉为“万能生 成内容,同年将跨模 集《阳光失了 个月后发布了 个出售的人工 成器” 态深度学习模型 玻璃窗》 StyleGan2 智能艺术品 CLIP开源 2020 2014 2021 2018 2017 2019 ◆ GAN ◆ Transformer ◆ StyleGan ◆ GAN ◆ DVD-GAN ◆ DDPM ◆自然语言生成模型 ◆ 关联文字和图像,并 技术 架构提出 GPT-3 且关联特征非常丰富 人物 事件 ◆ 被 广 泛 应 ◆ Transformer ◆ 在 图像 生成 方面 ◆ 文本生成迎来重大突破, ◆ CLIP 模型 搜集 了 大 影响 用在图像 架构推动深度 比GAN更优,扩 GPT-3 庞 大 的 运 行 规 量数据,为输入文本 生成、语 学习算法突破 散 模型 威望 大幅 模使得它不仅能答题、 生成图像 /视 频应用 音生成等 发展,迸发出 提升 写论文和生成代码等, 的落地奠定了基础 场景中 大模型 还能编写曲谱、写小说 等 资料来源:信通院《人工智能成内容(AIGC)白皮书》,机器之心Pro,腾讯新闻,《Denoising Diffusion Probabilistic Models》,《Attention is All You Need!》,腾讯云,环球网,搜狐新闻,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 11
12 .1.3 AIGC算法发展历程:从模型到应用 井喷式发展阶段:2022年——AIGC元年 ▲以色列AI服务 ▲ Stability.ai ▲ Jasper. ▲小冰公司获 ▲AI图片视频服 ▲微软宣布 商 Hour One 宣 融 资 1.01 亿 美 ai 完 成 了 10亿元人民币 务商Runway完 向 OpenAI 布将2000万美元 元 , 估 值 达 10 1.25亿美元 融资,估值超 成 5000 万 美 元 投资数十亿 A轮融资用于投 亿美元 融资 20亿美元 C轮融资,投后 美元(可能 入研发文本-视 估值5亿美元 高 达 100 亿 频模型 美元) ▲ 上 线 于 2021 ▲ OpenAI 推 出 文 本 ▲谷歌在2022年 ▲ Stability AI 推 ▲谷歌研究院等 年10月的文本- - 图 像 模 型 DALL- I/O大会上公布了 出文本-图像模型 提出了视频生成 图像模型Disco E2 , 可 以 从 自 然 语 对话式人工智能 Stable Diffusion 模型—Dreamix Diffusion 开 始 言的描述中创建逼真 模型LaMDA2 并开源 流行 的图像,超过150万 用户测试 ▲ DeepMind 推 ▲ GitHub 开 放 能 ▲微软将DALL-E2 ▲ OpenAl 的 大 语 言 模 出了AI编码引擎 够实时提供代码建 集 成 到 Bing 搜 索 、 型聊天机器人ChatGPT AlphaCode 议 的 Copilot 的 访 Edge浏览器和新的 上线,建立在GPT-3.5 问权限 Office中 模型之上 2月 4月 5月 6月 8月 10月 11月 12月 1月 2月 ◆扩散模型是 ◆ Stable Diffusion模 ◆ ChatGPT 对GAN的彻底 型 助 力 AIGC 破 圈 , 文 火爆全球 革新 字生成图像取得跨越式 发展 注:曲线图为百度搜索指数,橙色的曲线代表AI绘画;蓝色曲线代表chatGPT,绿色曲线代表AIGC 资料来源:36Kr,百度指数,华尔街见闻,谷歌研究,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 12
13 .1.3 AIGC算法发展历程:OpenAI VS Google ◼ OpenAI:非盈利性转向封顶盈利性公司,估值达290亿美金。 图表:OpenAI核心人员 ✓ 2015年由马斯克等人创立的非盈利人工智能研究公司,启动资金10亿 美金,成立初衷是与其它机构合作进行AI相关研究,并开放研究成果 以促进AI技术发展,防止垄断。 ✓ 核心团队为CEO Sam Altman、Greg Brockman、IIya Sutskever,大 都技术出身,在通用AI领域经验丰富。 ✓ 2019年宣布从“非盈利”性质过度到“封顶盈利性”,之后获微软10 亿美元战略投资,并开启与微软在产品上的合作。 ✓ 据美国财经媒体Semafor报道,微软预计向ChatGPT的开发者OpenAI Sam Altman Greg Brockman Mira Murati IIya Sutskever 投资100亿美元,OpenAI投后估值将高达290亿美元。 CEO、创始人 总裁(原CTO) CTO 首席科学家 图表:OpenAI融资过程 图表:OpenAI部分对外投资 序号 日期 融资轮次 融资金额 投资机构 序号 被投公司 主营业务 投资阶段 1 2021年 A轮 2.5亿美元 - 1 Anysphere AI工具 种子轮 2 2021年 种子轮延期 - - 2 Atomic Semi 芯片制造 种子轮 3 2020年 种子轮 - Matthew Brown Companies 3 Cursor 代码编辑 种子轮 4 2019年 战略融资 10亿美元 微软 4 Diagram 设计工具 种子轮 5 2019年 pre-种子轮 - ReidHoffman 慈善基金、Khosla Ventures 5 Harvey AI法律顾问 种子轮 Gabe Newell、Jaan Tallinn、Ashton Eaton 6 Kick 会计软件 种子轮 6 2018年 天使轮 - 和Brianne Theisen-Eaton等 7 Milo 家长虚拟助理 种子轮 8 qqbot.dev 开发者工具 种子轮 7 2017年 亲友轮 - - 9 EdgeDB 开源数据库 A轮 Elon Musk 、 Sam Altman 、Linkdin 的联合创 10 Mem Labs 记笔记应用 A轮 8 2016年 亲友前轮 10亿美元 始人 Reid Hoffman、Paypal 联合创始人 Peter 11 Speak AI英语学习平台 B轮 Thiel 、YC 联合创始人Jessica Livingston等 12 Descript 音视频编辑应用 C轮 注:数据截止到2023年1月 注:数据截止到2023年1月 资料来源:datalearner,OpenAI官网,澎湃新闻,华尔街见闻,腾讯新闻,金融界,智东西微信公众号等,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 13
14 .1.3 AIGC算法发展历程:OpenAI推动AI算法模型发展 ⚫ OpenAI技术发展历史 发布CLIP,能有效地从 发布 发布Whisper, 开源一个重现强化 自然语言监督中学习视 InstructGPT, 一个语音识别 学习算法的工具 发布拥有15亿参数 发布Microscope, 觉概念,可以应用于任 大量使用了人类 预训练模型, OpenAI Baselin GPT-2,基于800万网 一个用于分析神经 何视觉分类基准,只需 反馈与指导,在 结果逼近人类 es,提供用于正确 页数据、40GWebText 网络内部特征形成 提供要识别的视觉类别 GPT3的基础上, 水平,支持多 的强化学习算法实 作为训练数据。 过程的可视化工具 的名称 进一步精调,使 种语言 现的最佳实践 得输出更加可控 2016年4月 2018年6月 2019年4月 2020年5月 2021年1月 2022年4月 2022年11月 2017年5月 2019年2月 2020年4月 2021年1月 2022年1月 2022年9月 发 布 GPT , 一 个 首次将生成模型从自 发布GPT-3模型,对 在诸多语言处理 然语言处理领域拓展 于所有任务,无需进 第一个项目 发布DALL·E模型, 任务上都取得了 到其它领域:公布 行任何梯度更新或微 发 布 DALL·E OpenAI 一个120亿个参数 发布ChatGPT, 很好结果的算法, MuseNet , 一 个 深 调,仅通过与模型的 2.0 , 其 效 果 比 Gym Beta 的 GPT-3 版 本 , 一个AI对话系 首 个 将 度神经网络,可以用 文本交互指定任务和 第一个版本更 发布,以开 少量示例即可获得很 被训练成使用文 统,可以写代 Transformer 与 10种不同的乐器生成 加逼真,细节 发和比较不 好的效果;一个月后, 本-图像对的数据 码、写博客、 无监督预训练技 4分钟的音乐作品, 更加丰富且解 写短剧等等 同强化学习 发布Image GPT模型, 集,从文本描述 术相结合的算法, 并且可以结合从乡村 析度更高 算法 将GPT的成功引入计 中生成图像 其取得的效果好 到莫扎特到披头士的 算机视觉领域 于已知算法 风格 资料来源:datalearner,机器之心Pro,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 14
15 .1.3 AIGC算法发展历程:OpenAI携手微软 ◼ OpenAI携手微软,获得资金支持,落地场景,借力微软云计算领域布局。 ✓ 资金+算力:2019年7月,OpenAI 接受了微软10亿美元的战略投资,同时将把微软的Azure作为其独家云计算供应商;2021年,微软加注投资,具体 金额未公布;2023年,微软预计向OpenAI再投资100亿美元,在满足首批投资者收回初始资本后,微软将获得OpenAI75%利润,直到收回投资。 ✓ 业务协作:2021年,微软推出了Azure OpenAI服务预览;2022年,微软将DALL-E2模型集成到了Azure OpenAI、Microsoft Designer、Bing Image Creator中。2023年1月,Azure OpenAI服务正式发布,企业可以申请访问包括GPT-3.5、Codex和DALL-E2等AI模型,之后还可能通过 Azure OpenAI服务访问ChatGPT。2023年2月,微软推出ChatGPT支持的最新版本Bing搜索引擎与Edge浏览器,增加聊天写作功能。此外,微软计 划将ChatGPT引入Office产品中,进一步提升市场份额。 图表:OpenAI盈利后利润分配的四阶段 图表:Azure OpenAI服务官网 优先保证埃隆马斯克、彼得泰尔、雷德霍夫曼等 微软无分成 首批投资者收回初始资本 微软将有权获得OpenAl 的利润,直至收回其 微软获得 130亿美元投资 75%利润 在 OpenAI 的 利 润 达 到 920 亿 美 元 后 , 微 软 在 微软获得 OpenAI的持股比例将下降到49%,剩余的利润 49%利润 由其他风险投资者和OpenAI的员工分享 在利润达到1500亿美元后,微软和其他风险投资 微软无分成 者的股份将无偿转让给OpenAI的非营利基金 资料来源:中国新闻网,搜狐新闻,Azure官网,腾讯网,微软科技公众号,Azure OpenAI服务官网等,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 15
16 .1.3 AIGC 算法发展历程:谷歌持续重注 AIGC研究 ◼ 2022年11月在AI年度活动上谷歌发布四项最新成果,其能够根据文本提示生成高分辨率的长视频、3D模型、音乐、代码、文字内容等。 ✓ 结合Imagen Video和Phenaki两大模型的优势,推出超长连贯性视频生成模型:Imagen Video是基于级联视频扩散模型的文本条件视频生成系统,即给出文本提示, 就可以通过一个由frozen T5文本编码器、基础视频生成模型、级联时空视频超分辨率模型组成的系统来生成高清视频。Phenaki模型可通过一系列提示在开放域中生 成所有时间段的视频,是谷歌首次以时间变量提示生成视频。 ✓ LaMDA Wordcraft:在大语言模型LaMDA基础上开发的、能辅助专业作家写作的AI写文工具,帮助创作者突破“创作瓶颈”。 ✓ Audio LM:具备“长期连贯性”的高质量音频生成框架,不需要任何文字或音乐符号表示的情况下,只在极短(三四秒即可)的音频样本基础上训练,可生成自然、 连贯、真实的音频结果,不限语音或者音乐。 ✓ 文字生成3D模型:通过结合Imagen和最新的神经辐射场 (Neural Radiance Field) 技术,谷歌开发出了DreamFusion技术,可根据现有文字描述,生成具有高保真 外观、深度和法向量的3D模型,支持在不同光照条件下渲染。 ◼ 将推出Bard对话机器人。2023年2月,谷歌宣布将推出Bard AI聊天机器人,由谷歌大型语言模型LaMDA支持,但参数量更少,使公司能够以更低的成本提供该技术, Bard能在获得简单提示的情况下生成详细答案。 图表:谷歌Imagen模型架构 图表:谷歌Phenaki模型架构 整个架构共有7个子模型(1 个T5文本编码器、1 个基础视频扩散模型、3 个 SSR扩散模型、 3 个 TSR扩散模型),共116亿个参数 ✓ 文本编码器——将文本prompt编码为text_embedding; ✓ 基础视频扩散模型——以文本为条件,生成初始视频; ✓ SSR——提高视频的分辨率; ✓ TSR——提高视频的帧数 主要包含两大部分:一个将视频压缩为离散嵌入(即 token)的编码器-解码器模型 和一个将文本嵌入转换为视频token的transformer模型 资料来源:腾讯新闻,网易新闻,谷歌research官网,github,《AudioLM: a Language Modeling Approach to Audio Generation》, 《PHENAKI: VARIABLE LENGTH VIDEO GENERATION FROM OPEN DOMAIN TEXTUAL DESCRIPTIONS》,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 16
17 .1.3 AIGC 算法发展历程:谷歌持续重注 AIGC研究 ◼ 2023 年 2 月 2 日 , 谷 歌 研 究 院 等 提 出 了 一 种 视 频 生 成 新 模 型 —— 图表:Dreamix模型原理 Dreamix,受到了AI作图UniTune的启发,将文本条件视频扩散模型 (video diffusion model, VDM)应用于视频编辑。核心是通过两种 在应用程序预处理的基础上(左 图),将输入内容转换为统一的 主要思路使文本条件VDM保持对输入视频的高保真度:(1)不使用 视频格式。对于图像到视频,输 纯噪声作为模型初始化,而是使用原始视频的降级版本,通过缩小尺 入图像被复制并被变换,合成带 有一些相机运动的粗略视频;对 寸和添加噪声仅保留低时空信息;(2)通过微调原始视频上的生成模 于目标驱动视频生成,其输入被 省略,,单独进行微调以维持保 型来进一步提升对原始视频保真度。微调确保模型了解原始视频的高 真度,然后使用 Dreamix Video 分辨率属性,对输入视频的简单微调会促成相对较低的运动可编辑性, Editor(右图)编辑这个粗糙的 视频(首先通过采样破坏视频, 这是因为模型学会了更倾向于原始运动而不是遵循文本prompt。 添加噪声,然后应用微调的文本 引导视频扩散模型,将视频升级 到最终的时间空间分辨率)。 图表: Dreamix模型应用于视频编辑 图表: Dreamix模型应用于图像生成视频 “单一图像+文字”生成视频:在一个静态图像中注入复杂的运动,比如添加一个移动的鲨鱼, 并让海龟游泳,在这种情况下,对物体位置和背景的视觉保真度被保留了下来 将吃东西的猴子(上面一排)变成跳舞的熊(最下面排),改变外观和运动,但保持对颜色、 “多图像+文字”生成视频:在给定主题下,能够提取给定多个图像的主题的视觉特征,然后在 姿势、物体大小和拍摄角度的保真度,从而产生了一个时间上一致的视频 不同的场景中制作动画 资料来源:谷歌研究《Dreamix: Video Diffusion Models are General Video Editors》,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 17
18 .1.3 AIGC算法发展历程:谷歌持续重注 AIGC研究 超长连贯性视频生成模型 Audio LM 刘宇昆在Wordcraft撰写的短篇小说《Evaluative Soliloquies》 DreamFusion生成的3D模型 资料来源:量子位,github,appspot,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 18
19 .1.3 AIGC算法发展历程:你追我赶,持续迭代 基 于 自 我 注 意 力 机 制 ( self-attention ) 的 变 换 器 (transformer)模型:首次将其用于理解人类的语言, 使用了经典的大型书籍文本数据集进行模型预训 能够同时并行进行数据计算和模型训练,训练时长更 transformer 练,又针对四种不同的语言场景使用不同的特定 2017年6月 短,并且训练得出的模型可用语法解释。当时在包括 6500万 GPT-1 数据集对模型进行进一步训练,最终训练所得的 2018年6月 翻译准确度、英语成分句法分析等各项评分上都达到 1.17亿 模型在问答、文本相似性评估、语义蕴含判定、 以及文本分类这四种语言场景,都取得了比基础 了业内第一。 Transformer模型更优的结果,成为了新的业内 第一。 BERT(Transformers的双向编码表示模型):在机器 阅读理解顶级水平测试中表现出惊人的成绩,成为 BERT NLP发展史上的里程碑式的模型成就,在同等参数规 3亿 在文本内容生成方面表现出了强大的天赋,最 2018年10月 模下,BERT的效果好于GPT-1,因为双向模型可以利 大贡献是验证了通过海量数据和大量参数训练 2019年2月 用上下文来分析。 出来的词向量模型可迁移到其它类别任务中, GPT-2 而不需要额外的训练,由于GPT-2的性能和生 15亿 T5作为一个文本到文本的统一框架,可以将同一模型、 成文本能力获得了很高赞誉,OpenAI又扳回一 局。 目标、训练流程和解码过程,直接应用于实验中的每 T5 一项任务,T5在摘要生成、问答、文本分类等诸多基 110亿 2019年10月 准测试中都取得了不错的效果,一举超越现有最强模 在 一 些 NLP 任 务 的 数 据 集 中 使 用 少 量 样 本 的 型。 GPT-3 Few-shot方式甚至达到了最好效果,省去了模 2020年5月 1750亿 型微调,也省去了人工标注的成本,GPT-3的 神经网络是在超过45TB的文本上进行训练的, 有效地利用了为稠密矩阵乘法(广泛用于语言模型的 Switch 数据相当于整个维基百科英文版的160倍。 数 学 运 算 ) 而 设 计 的 硬 件 —— 例 如 GPU 和 Google Transformer 2021年1月 TPU,新模型在翻译等领域获得了绝对的胜利,但模 1.6万亿 型越大,部署的难度越高,成本也越高,效率更低。 使用了遮掩语言模型的训练方法。在这种方法 ChatGPT 中,模型被要求预测被遮盖的词,并通过上下 2022年11月 约20亿 宣布将推出Bard的AI聊天机器人,由谷歌大型语言模 文来做出预测,以用更接近人类的思考方式参 Bard 型LaMDA支持,是LaMDA的“轻量级”版本,能够 与用户的查询过程,推出两个月后月活用户已 (LaMDA) 以更低的成本提供该技术,Bard能在获得简单提示的 1370亿 破亿。 2023年2月 情况下生成详细答案。 资料来源:做AI做的事儿公众号,网易新闻,澎湃新闻,谷歌研究论文《LaMDA: Language Models for Dialog Applications》,国海证券研究所 注:模型后面的数据为模型的参数数量 请务必阅读报告附注中的风险提示和免责声明 19
20 .1.4 AIGC市场空间:从决策走向创造 推动内容生产向高效率和更富创造力方向发展,与多产业融合。 ◼ 不仅是降本增效,更是个性化内容生成。AI不仅能够以优于人类的制造能力和知识水平承担信息挖掘、素材调用、复刻编辑等基础性机械劳动,从技术层 面实现以低边际成本、高效率的方式满足海量个性化需求。根据Sequoiacap,近年来AI模型在手写、语音和图像识别、阅读理解和语言理解方面的表现 逐渐超过了人类的基准水平。而且AI让所有人都能够成为“艺术家”,可无时无刻生成更有创造力、更个性化的内容。 ◼ 通过支持AI生成式内容与其他产业的多维互动、融合渗透从而孕育新业态新模式,为各行各业创造新的商业模式,提供价值增长新动能。 图表:内容生成及创建的评价指标 图表:AI模型在语音识别、图像识别、阅读理解、语言理解等方面的表现 注:内容生成及创建的评估指标根据行业公允评估方法设计,采用影谱科技AI智能影像生成引擎AGC为 数测平台 资料来源:《中国AI数字商业展望2021-2025》,Sequoiacap《Generative AI: A Creative New World》 请务必阅读报告附注中的风险提示和免责声明 20
21 .1.4 AIGC市场空间:2025年国内市场应用规模有望超2000亿元 生成式AI居于Gartner2022年战略技术首位,2030年全球市场规模有望超万亿元美元,2025年国内应用规模有望突破2000亿元。 ◼ 2021年,Gartner发布了12项2022年重要战略技术趋势,生成式AI居于战略首位。Gartner预测至2023年将有20%的内容被生成式AI所创建;至2025年 生成式AI产生的数据将占所有数据的10%(目前不到1%)。 ✓ 根据2022年红杉《Generative AI:A Creative New World》,未来2-3年AIGC初创公司和商业落地方案将持续增加,将产生数万亿美元经济价值。 ✓ 根据Gartner“2022年人工智能技术成熟度曲线”,生成式AI仍处于技术萌芽期,预计将在2-5年内实现规模化应用。 ◼ 根据《中国AI数字商业展望2021-2025》,到2025年中国生成式AI技术应用规模预计上升至2070亿元,2020-2025年年均复合增长率高达84.1%。 图表:Gartner2022年人工智能技术成熟度曲线 图表:中国生成式AI技术应用规模(单位:亿元) 2070 250.0% 1606 1077 66393.3% 343 62.4% 49.1% 98 28.9% 2020 2021E 2022E 2023E 2024E 2025E 不超过2年 ⚫ 2-5年 ⚫ 5-10年 超过10年 生成式AI技术应用规模(亿元) yoy 注:生成式 AI 应用规模的统计口径为应用生成式AI技术生成的数字内容的市场规模,统计方式 为数字内容市 场规模乘以生成式 AI 渗透率,以上规模的推导考虑国家商务局、GARTNER,第三方调研机构等多个数据源。 资料来源:量子位,Gartner官网,《中国AI数字商业展望2021-2025》, 《Generative AI: A Creative New World》, 国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 21
22 .1.4 AIGC市场空间:国内传媒领域潜在应用空间超 1000亿元 ◼ AIGC市场空间 = 各代表性行业内容成本*对应的AI辅助制作比例 ✓ 内容成本测算=各代表性行业的市场规模*预计的内容/版权成本占收入比重。电影行业参考博纳影业投资业务毛利率(约40%)和投资方的分账比例(约 38%),计算得出电影制作成本占票房的23%;在线音乐参考腾讯音乐/网易云的内容服务成本占收比,并按照二者的市场份额进行加权。 ✓ AI辅助制作的比例:图片生成、音乐生成领域的应用相对较成熟,预计未来AI辅助生成的比例分别为65%/60%,游戏领域的AI生成主要集中在图片/音 乐/NPC上,预计占比30%;AI辅助视频类(长视频/电影/IPTV+OTT)内容生成还在初始阶段,预计AI辅助生成比例较低(15%-20%);目前网络直 播行业虚拟主播应用较广,预计AI辅助制作比例35%。综上,我们匡算国内AIGC市场的理论空间超1000亿元。 图表:AIGC在国内传媒领域潜在市场空间测算 2022年市场规模 内容/版权成本占收 AIGC市场空间匡算 内容 内容成本(亿元) AI辅助制作的比例 *注 (亿元) 入比重* (亿元) 游戏(国内) 2658.8 20.0% 531.8 30% 159.5 参考游戏行业的研发费用占收比20% 游戏(出海) 173.5 20.0% 34.7 30% 10.4 参考游戏行业的研发费用占收比20% 参考博纳影业投资业务毛利率40%和投资方的票房 电影 641.0 22.8% 146.1 20% 29.2 分账比例38% 参考爱奇艺内容成本占收比74%和芒果超媒的互联 长视频 1626.3 73.8% 1200.4 15% 180.1 网视频业务毛利率31% 参考新媒股份内容成本占收比36%、芒果超媒运营 IPTV+OTT 279.9 30.8% 86.2 15% 12.9 商业务毛利率74% 短视频 3055.0 5.0% 152.8 40% 61.1 参考快手内容成本占收比5% 在线音乐 495.0 64.4% 319.0 60% 191.4 参考腾讯音乐/网易云音乐的内容服务成本60%/80% 图片版权 264.7 31.5% 83.3 65% 54.2 参考视觉中国的版权费占收比32% 参考中文在线、阅文集团的内容分销成本占收比 网络文学 214.0 13.4% 28.7 15% 4.3 16%/11% 网络直播 1936.6 50.0% 968.3 35% 338.9 参考直播行业主播分成比例大概为5:5 合计 11344.8 31.3% 3551.3 29% 1042.0 注:电影行业市场规模参考疫情前2019年电影市场票房,AI辅助制作的比例均为匡算值 资料来源:艺恩,各公司公告,《2022年中国游戏产业报告》,Mob研究院,中国新闻网,中商产业研究院,中国演出行 业协会等,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 22
23 .1.5 商业模式:按调用量收费、SaaS订阅收费、增值服务、解决方案等 ◼ AIGC的潜在客户主要包括2B端内容生产公司和2C端用户: ✓ 2B:在PGC领域实现内容创作高效化,提高PGC活跃度和灵活性。AIGC能够克服人力不足,降低内容生产成本。客户主要为资讯媒体、音乐流媒体、 游戏公司、视频平台、影视制作公司等,如协助影视公司制作电影/剧集视频片段。 ✓ 2C:在UGC领域实现内容创作低门槛和较高专业度,扩充UGC人群。AIGC能够激发C端用户灵感,且不需要用户具有极强的专业知识,每个人都可以 成为创作者。客户主要为画家、写手、歌手等,如协助音乐小白创作专属于个人的歌曲。 ◼ 国内AIGC商业模式尚未成型。以写作机器人、自动配音等场景为例,大部分产品仍处在免费试用的“流量吸引+平台改良”阶段。此外,部分公司将 AIGC用于协助自身原有商业体系,如腾讯开发的AI Bot应用于腾讯游戏中,阿里的智能语音服务主要应用于微信,字节跳动则主要基于短视频场景研究AI 赋能。 图表:AIGC商业模式 版本 Explore Create Build Scale 通过API方式接入其他产品,按照数 用户 入门用户 普通用户 VIP用户 大规模生产 如GPT-3对外提供API接口,采用四种模型收费 级用户 据请求量和实际计算量收费 100美元 400美元 免费试用 (200万 (1000万 GPT-3 定价 3个月/10 token)/月, token)/月, 定制价格 定价方式 万token 超出部分1k 超出部分1k 如DALL-E、Deep Dream Generator等AI图像生成平台 token/8美分 token/6美分 按产出内容量收费 大多按照图像张数收费 如个性化营销文本写作工具AX Semantics,分普通编辑器、 直接对外提供软件 Deep Dream 电商套装、定制定价三种定价方式 Generator 定价方式 模型训练费用 适用于NPC训练等个性化定制需求较强的领域 如版权授予(支持短期使用权、长期使用权、排他性使用权和所 AX 根据具体属性收费 有权多种合作模式,拥有设计图案的版权)、是否支持商业用途 Semantics (个人用途、企业使用、品牌使用等)等 定价方式 资料来源:量子位,Deep Dream Generator官网,AX Semantics官网,新浪科技,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 23
24 .目录 1 AIGC破圈元年 2 AIGC应用场景 2.1 文本生成 2.2 音频生成 2.3 图像生成 2.4 视频生成 2.5 跨模态生成 2.6 策略生成 3 产业链及相关公司 请务必阅读报告附注中的风险提示和免责声明 24
25 .AIGC场景一览 ◼ 较为广泛地实际应用、技 术细节仍待进一步提升 ◼ 底层技术原理基本明确, 预计1-2年内将规模化应用 ◼ 底层技术原理仍待完善 资料来源:量子位《AIGC/AI生成内容》,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 25
26 .2.1 文本生成:基于NLP技术,受益于预训练语言模型突破发展 ◼ 自然语言处理技术(NLP)是文本生成的基础。NLP探索计算机和人类(自然)语言之间相互作用,研究实现人与计算机之间用自然语言进行有效通信的 各种理论和方法。最早的自然语言处理研究工作是机器翻译,后逐渐向文本摘要、分类、校对、信息抽取、语音合成、语音识别等方面深入。 ◼ 从基于规则的经验主义到基于统计的理性主义,再到基于深度学习的方法,NLP在70年历程中逐渐发展进步。受益于预训练语言模型的突破发展, Transformer等底层架构不断精进,NLP取得跨越式提升。 图表:自然语言处理的两种解释 图表:NLP发展阶段 ①释义: 1950s-1970s 1970s-2000s 2000-至今 自然语言处理 自然语言 处理 采用基于规则的 采用基于统计的 采用基于神经网络的方 用计算机对字、词、句、 人类社会约定俗成 输入、输出、识别、 方法 方法 法 篇章等自然语言的输入、 的,区别于如程序 分析、理解、生成 输出、识别、分析、理解、 设计的人工语言 等计算机操作过程 生成等的操作和加工,实 现人机间的信息交流 √1950 年 , “ 图 灵 √ 从数学统计的角度 √模型开始像人脑一样学 测试”被提出,自然 预测下个词的出现概 习,2017年以前主要是小 ②构成: 语言处理思想诞生 率 , 代 表 模 型 如 N- 模型阶段, 2017年 √认为自然语言处理 Gram等,推理过程非 Transformer发布之后, 自然语言处理 自然语言理解 自然语言产生 过程和人类学习认知 常直观,但是推理结 模型开始尝试大量数据的 一门语言类似,NLP 果非常受数据集的影 训练学习,进入大语言模 让机器具备正常 将非语言格式的数 停留在经验主义思潮 响,容易出现数据稀 型阶段,在加入人工干预 人的语言理解能 据转换成人类可以 阶段 疏(即空值)等问题 的反馈基础上,模型效果 力(识别人讲的 理解的语言格式 √只能基于手写规则, 攀上新的台阶 话) (输出为人讲的话) 处理少量数据 资料来源:easyai,罗兰贝格管理咨询微信公众号,央广网,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 26
27 .2.1 文本生成:难点在于自然语言的复杂性及如何生成富有“人味”的语言 ◼ NLP技术分为自然语言理解(NLU)和自然语言生产(NLG)两个核心任务,目前难点在于自然语言的复杂性使AI的理解程度不高以及如何生成富有“人 味”的语言。 图表:自然语言理解层次逐渐加深 图表:自然语言生成从低等级到高等级 语音分析 词法分析 句法分析 语义分析 语用分析 Level1 Level2 Level3 简单的数据合并 模板化的 NLG 高级 NLG 从语音 流中 区 找出词汇的各 对句子和短语的 找出词义、结构 研究语言所存在 分出独 立的 音 个词素,从中 结构进行分析, 意义及其结合意 的外界环境对语 将数据合并并转换 使用模板驱动模式 理解意图,添加智能, 素,再 根据 音 获得语言学的 找出词、短语等 义,从而确定语 言使用者所产生 为简单文本 来显示输出 考虑上下文,并将结 位形态 规则 找 信息 的相互关系以及 言所表达的真正 的影响 果呈现在⽤户可以轻 出音节 及其 对 各自在句中的作 含义或概念 松阅读和理解的富有 应的词素或词 用 洞察力的叙述中 图表:自然语言理解的五大难点 图表:自然语言生成的六大步骤 ⾃然语言的组合方式非常灵活:字、词、短语、句子、段落 多样性 等不同的组合可以表达出很多的含义 参考表达 语言实现 式生成 歧义性 同一个语言可能在不同情境下表达的意思完全不一样 语法化 组合形 成一 个 N 句子聚合 选择对 应领 域 结构良 好的 自 L 自然语言在输入的过程中,尤其是通过语音识别获得的文本, 然语言 鲁棒性 会存在多字、少字、错字、噪音等问题 将多个信息 的单词 和短 语 U 文本结构 组织成 自然 语 难 通过连接词 语言除字面意思,还有基于知识的特殊意义,如7天可以表 将多个 信息 合 言 知识依赖 内容确定 组织成自然 点 示时间也可以表示为酒店 并到一 个句 子 确定合理的 语言 里表达 可能 会 决定哪 些信 息 组织文本的 更加流 畅 , 也 上下文 从同一个语言出发很难揣测上下文 顺序 要包含 在正 在 更易于阅读 构建的文本中 资料来源:easyai,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 27
28 .2.1 文本生成:预训练语言模型发展推动NLP研究 ◼ 预训练语言模型(PTM):在大规模无监督的语料上进行长时间的无监督或自监督预先训练,获得通用的语言建模和表示能力。应用到实际任务上时不需 要做大改动,只需增加针对特定任务获得输出结果的输出层,并使用任务语料对模型进行少许训练。 ◼ Transformer架构的并行化训练优势,促进预训练语言模型突破发展。2017年,Google发布文章《Attention is all you need》,提出了解决sequence to sequence问题的transformer架构,引入了自注意力机制,能够基于两个单词间的关系进行建模,按输入数据各部分重要性的不同分配不同的权重, 有效理解单词在上下文中的意思,支持并行训练,使语言模型训练效果达到新高度。 ◼ 2020年,1750亿参数的GPT-3在问答、摘要、翻译、续写等语言类任务上均展现出了优秀的通用能力,证明了“大力出奇迹”在语言类模型上的可行性, 其文本生成能力已被直接应用于Writesonic、 Conversion.ai、 Snazzy AI、 Copysmith、 Copy.ai、 Headlime等文本写作/编辑工具中。 图表:Transformer整体结构 图表:百度ERNIE2.0预训练语言模型结构 4.输出 自注意力机制 3.Decod er block 2.Encode r block 1.输入 资料来源:《ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding》,《Attention is All You Need!》,量子位,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 28
29 .2.1 文本生成:Transformer 凭自注意力机制取代RNN ◼ RNN的局限:RNN模型(LSTM等)的限制在于相关算法只能从左向右或从右向左依次计算,带来了两个问题:(1)时刻t的计算依赖时刻t-1的计算结 果,限制了模型的并行能力;(2)顺序计算的过程中信息会丢失,尽管LSTM等模型结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现 象,LSTM依旧无能为力。 ◼ Transformer的自注意力机制解决了RNN的两个问题:首先,自注意力机制可按输入数据各部分重要性不同分配不同权重;其次,自注意力机制可以为输 入序列中的任意位置提供上下文,支持并行训练。并行优势允许其在更大数据集上训练,促进了BERT、GPT等预训练大模型的发展。 图表:RNN和Transformer处理上的区别 图表:RNN结构 示例:“I arrived at the bank after crossing the……” A.road or √ B.river RNN Transformer 方法:一步一步地阅读“bank”和“river”之 方法:比较”bank”和其他单词,得到每个其 间的每个单词,来确定“bank”的意思 他单词的注意力分数,获得较高注意力分数 的单词“river”可能就是确定的结果 图表:Transformer在英语-德语、英语-法语翻译精度上明显优于RNN 英语-德语 英语-法语 输入层为 X,隐藏层为 S,输出层为 O。U 是输入层到隐藏层的权重,V 是隐藏层到 输出层的权重。从公式看出,隐藏层的值 S 不仅取决于当前时刻的输入 X,还取决于 上一时刻的输入 Xt-1。 资料来源:谷歌研究,《Attention is All You Need!》,机器之心,国海证券研究所 请务必阅读报告附注中的风险提示和免责声明 29
3秒后跳转登录页面
去登陆

