












- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
ChatGPT给语言大模型带来的启示和多模态大模型新的发展思路_
展开查看详情
1 .ChatGPT 给语言大模型带来的启示和多模态大模 * 型新的发展思路 赵朝阳 朱贵波 王金桥 (中国科学院自动化研究所 北京 100190) 摘要:【目的】剖析 ChatGPT 的基础技术原理,探讨其对大语言模型发展产生的影响,以及对多模态大模型发 【方法】通过分析 ChatGPT 的发展过程和技术原理,探讨指令微调、数据采集与标注、基 展思路产生的影响。 于人类反馈的强化学习等模型构建方法对大语言模型产生的影响。分析当前多模态大模型构建过程中遇到 的关键科学问题,并借鉴 ChatGPT 的技术方案,探讨多模态大模型未来的发展发展思路。 【结论】ChatGPT 为 预训练大模型向下游任务的发展提供了良好的参考技术路径,未来的多模态大模型构建以及下游任务实现 过程中,可以充分利用高质量的指令微调等技术来显著提升多模态大模型的下游任务性能。 关键词: 语言大模型 预训练大模型 多模态预训练模型 ChatGPT 分类号: TP393 G250 DOI: 10.11925/infotech.2096-3467.0216 引用本文: 赵朝阳,朱贵波,王金桥 . ChatGPT 给语言大模型带来的启示和多模态大模型新的发展思路[J]. 数 据 分 析 与 知 识 发 现 ,XXXX,XX(XX):1-11.(Zhao Chaoyang, Zhu Guibo, Wang Jinqiao. The Inspiration Brought by ChatGPT to LLM and the New Development Ideas of Multi-modal Large Model[J]. Data Analysis and Knowledge Discovery, XXXX, XX(XX): 1-11.) 1 引 言 自监督的语言模型,最初研究者们在自然语言处理 领域展开研究,2018 年 BERT[2]模型在 11 项 NLP 任 近 年 来 ,面 向 通 用 人 工 智 能(Artificial General 务基准上以远超第二名的性能打破了纪录,取得了 Intelligence,AGI)的探索已成为各国在人工智能领 巨大成功,自此基于自监督学习的语言模型成为基 在 AGI 领域研究的突破对各国抢占未 域的竞争焦点, 础性方法。这一技术观念上的转变与 2012 年基于 来技术战略制高点意义重大。而在这一探索进程当 卷 积 神 经 网 络 AlexNet 在 ImageNet 上 的 突 破 很 相 中,预训练基础模型(Pretrained Foundation Models, 似,标志着大模型时代的开始。目前,自然语言处理 PFMs) [1] 技术的发展,作为新一代人工智能技术的主 (Natural Language Processing,NLP)领 域 几 乎 所 有 流探索方向,在近年来备受学术界和工业界的关注。 的先进模型(State-Of-The-Art model,SOTA)都是基 受惠于各行业领域不断扩大的数据规模总量,计算 于 Transformer[3]的大模型架构进化而来的。随着生 硬件资源的持续发展,以及人工智能算法的不断创 成 式 预 训 练(Generative Pre-Train,GPT)、基 于 新突破,预训练基础大模型技术持续加速发展。 Transformer 的 双 向 编 码 器 表 达(Bidirectional 在预训练基础大模型的发展浪潮中,大语言模 Encoder Representation from Transformers,BERT)、 型的发展取得的成绩尤其瞩目。PFMs 起源于基于 GPT-3、DALL-E、Switch Transformer、华 为 盘 古 、智 通讯作者(Corresponding author):赵朝阳(Zhao Chaoyang),ORCID:0000-0002-0341-0166,E-mail:chaoyang.zhao@nlpr.ia.ac.cn。 *本文系国家自然科学基金项目 (项目编号:61976210, 62176254) 的研究成果之一。 The work is supported by the National Natural Science Foundation of China (Grants No. 61976210, 62176254). Data Analysis and Knowledge Discovery 1
2 . XXXX 源悟道、ERINE、M6 等大规模预训练模型快速涌现, 知识学习与表达的主动学习过程进行有效表达,不 人工智能研究领域正在经历一场有监督学习向无监 同模态之间的隐式交互信息并未被充分利用与学 督学习条件下“大数据+大模型”的大规模预训练范 习。因此,为实现更加通用的人工智能模型,预训练 式转变,即基于海量广域数据训练并且经过微调学 模型必然由单模态往多模态方向发展,需将文本、语 习自动适应广泛下游任务的模型。 音、图像、视频等多模态内容联合起来进行学习,并 在预训练基础大模型的发展浪潮下,ChatGPT [4] 专注多模态内容之间的关联特性与跨模态转换问 的横空出世,使得人们对大语言模型的通用能力有 题。这样一方面可以引入多维度的信息,另一方面 了全新的认识。ChatGPT 在自然语言处理领域展示 可以利用互联网上大量的多模态数据,使得模型能 了惊人的能力,其提供了通用的用户意图理解能力: 够学习更通用化的特征表示,以此增强模型的通用 无论是问答、分类、摘要、翻译等用户指令,ChatGPT 性和泛化能力。多模态预训练大模型架构与 GPT 尽管回复不一定完全正确,但是几乎都能够领会用 和 BERT 类似,也是基于自注意力机制 Transformer 户意图,对人类指令的意图理解能力远超预期。其 深度学习模型,其最大特点是模型的输入由单一模 提供了强大的大范围上下文连续对话能力: 态的文本拓展到文本、语音、图像、视频等多个模态 ChatGPT 可以实现几十轮连续对话,能够比较准确 数据同时作为输入,而不同模态数据之间信息量的 地识别省略、指代等细粒度语言现象、记录历史信 差异性,以及不同数据对信息抽取能力要求的差异 息,而且似乎都可以保持对话主题的一致性和专注 性,也对模型的构建提出更高的要求和挑战。本文 度。还提供了智能的交互修正能力:无论是用户更 将探讨在 ChatGPT 类模型的启发下,针对多模态预 改自己之前的说法还是指出 ChatGPT 的回复中存在 训练模型的新的构建思路。 的问题,都能够捕捉到修改意图,并准确识别出需要 2 大模型技术的国内外发展现状 修改的部分,最后做出正确的修改。ChatGPT 的成 功标志着人工智能从以专用小模型训练为主的“手 图灵奖获得者 Yann LeCun 在演讲时表示,如果 工作坊时代”迈入到以通用大模型预训练为主的“工 智能是一块蛋糕,那么蛋糕的主体是无监督学习,蛋 业化时代”,成为人工智能发展分水岭。 糕上的糖衣是监督学习,蛋糕上的樱桃是强化学习, ChatGPT 由 生 成 式 预 训 练 模 型(Generative 而人类对世界的理解主要来自于大量未标记的信 Pretrained Transformer,GPT)GPT-3.5 微 调 而 来 ,在 息。而同时不可忽视的是,无监督/自监督学习这类 GPT-3.5 的基础上,科学家们引入了基于人类反馈的 方 法 已 经 革 新 了 自 然 语 言 处 理 的 通 用 范 式 ,如 强化学习技术 (Reinforcement Learning from [5-6] BERT、GPT 系列在大规模语料上进行无监督预训 Human Feedback,RLHF)对模型进行微调,而这一方 练,在各类下游任务中均取得了令人惊艳的效果。 法提供了一种能够有效对齐预训练大模型和人类意 因此,无监督/自监督学习将是实现人类智能的关 图的良好范式。ChatGPT 的成功为生成式大模型的 键 ,被 广 泛 认 为 是 通 往 通 用 人 工 智 能 的 重 要 途 径 应用提供了一个明确的技术方向:即在微调阶段的 之一。 指令对齐(Instruct Alignment)技术。这其中包含了 2.1 单模态大模型 强化学习(RL),提示优化 (Prompt Tuning),思想 [7-9] (1)语言大模型 链[10-11] (Chain-of-thought)等技术手段。这些技术不 随着 ELMo[12]、 近年来, GPT-1[13]、 BERT、 GPT-2[14] 仅是在大语言模型中,在其他模态的预训练基础大 与 GPT-3[15]等预训练语言模型的发布,预训练技术 模型的应用场景中,同样起着指引性作用。 这场革新正在自然语言处理领域悄然展开,并迅速 另一方面,从人类接受信息的角度看,我们所接 影响各个子领域。顾名思义,预训练指的是使用通 收到真实世界的信息来自于多模态的数据源,如语 用性的任务和大规模的无标注数据进行第一阶段的 音、文本、图像等,而单模态预训练模型只涵盖了单 训练,让机器学习模型学习到具有较强泛化性的参 一模态的信息,无法对人类的信息获取、环境感知、 数。对于特定的下游任务,模型仅需对学习好的参 2 数据分析与知识发现
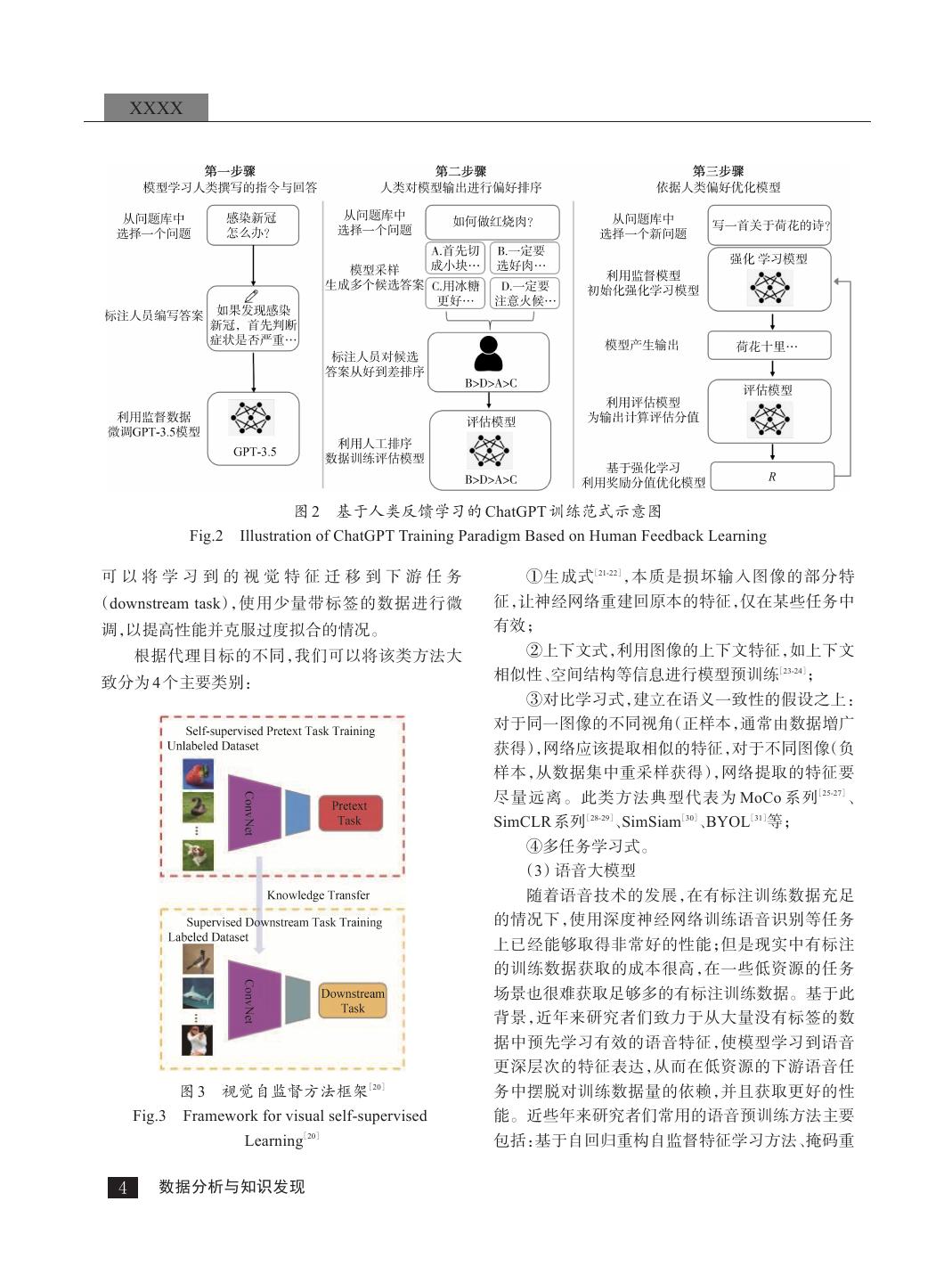
3 .数进行微小的调整(或训练)就能够完成高效迁移, 来了显著的改进,如文本分类、阅读理解、序列标注 达到显著的性能表现。上述方法被称作“预训练+微 和文本生成等,图 1 给出了预训练语言模型的主要 调”,该范式逐步覆盖自然语言处理的各大任务并带 发展脉络。 图1 预训练语言模型发展脉络 Fig.1 Development of Pretrained Language Model 预训练语言模型的发展呈指数型增强,参数规 个、生成游戏剧本等,几乎可以完成大多数的 NLP 模的增长也呈现出这种规律。GPT-3 是首个发布的 任务,但对生成内容的偏好性缺乏有效控制。2021 超大规模语言模型,使用自回归的方法和超大规模 年发布的 WebGPT 以及 2022 年发布的 InstructGPT[16] 的数据进行训练,呈现出了强大的通用性和少样本 使得模型逐步具备学习人类回答问题方式的能力。 学习的能力,为通用人工智能的实现打开了一个窗 研 究 人 员 在 模 型 的 训 练 过 程 中 引 入 人 类 作 为“ 教 口。在国内,清华大学和智源研究院合作发布悟道 师”,对模型训练进行反馈和指导,以此提高模型针 大模型,是中文超大规模预训练的排头兵;华为云由 对人类问题的理解能力。在此基础上,ChatGPT 进 底层向上逐步研发,开源了盘古大模型;中国科学院 一步通过改进模型多输出的能力,进一步获得更加 自动化研究所提出千亿规模的多模态预训练模型, 应 优异的上下文学习、对话能力,在生成的内容中,更 用场景广泛。参数量的增加不仅显著提升了模型通 加复合人类期待的反馈。图 2 给出了人类反馈学 用能力, 也彰显了中国人工智能发展的速度和水平。 习[17]的一个典型的处理流程。 ChatGPT 是 OpenAI 公司在 GPT 系列模型的基 (2)视觉大模型 础 上 ,历 经 四 年 迭 代 而 来 的 生 成 式 大 语 言 模 型 。 近些年,自监督学习越来越受到广大研究人员 GPT-1 诞生于 2018 年 6 月,侧重生成式任务,一经问 的关注,其设计与思想天生就适合训练视觉大模型: 世就证明了其在语言推理、文本生成、问答等任务中 利用大量的无标记数据训练模型构建通用的视觉表 的优异表现。GPT-1 以 1.17 亿参数展现了 GPT 系列 征,使得所有类型的下游任务受益。如图 3 所示,自 模型的特点:以生成式的方法,在庞大的数据及上通 监督学习常用方法是提出不同的上游任务(pretext 过无监督的方式训练大型语言模型。2019 年,GPT-2 task)。网络可以通过学习上游任务的目标函数来训 采用更大的网络容纳更大的数据量,同时引入文本 练,视觉特征也在这一过程中获得。在自监督的上 提示(Prompt)的输入方式。2020 年发布的 GPT-3 将 游任务训练阶段,自监督方法首先根据数据的某些 GPT 系列模型提升到了实用的高度,其能够将网页 属性自动生成该前置任务的伪标签,以此训练神经 描述转换为相应代码、模仿人类叙事、创作定制是 网络获得预训练模型。在自监督的训练完成之后, Data Analysis and Knowledge Discovery 3
4 . XXXX 图2 基于人类反馈学习的 ChatGPT 训练范式示意图 Fig.2 Illustration of ChatGPT Training Paradigm Based on Human Feedback Learning 可以将学习到的视觉特征迁移到下游任务 ①生成式[21-22],本质是损坏输入图像的部分特 (downstream task),使用少量带标签的数据进行微 征,让神经网络重建回原本的特征,仅在某些任务中 调,以提高性能并克服过度拟合的情况。 有效; 根据代理目标的不同,我们可以将该类方法大 ②上下文式,利用图像的上下文特征,如上下文 致分为 4 个主要类别: 相似性、空间结构等信息进行模型预训练[23-24]; ③对比学习式,建立在语义一致性的假设之上: 对于同一图像的不同视角(正样本,通常由数据増广 获得),网络应该提取相似的特征,对于不同图像(负 样本,从数据集中重采样获得),网络提取的特征要 尽量远离。此类方法典型代表为 MoCo 系列[25-27]、 SimCLR 系列[28-29]、SimSiam[30]、BYOL[31]等; ④多任务学习式。 (3)语音大模型 随着语音技术的发展,在有标注训练数据充足 的情况下,使用深度神经网络训练语音识别等任务 上已经能够取得非常好的性能;但是现实中有标注 的训练数据获取的成本很高,在一些低资源的任务 场景也很难获取足够多的有标注训练数据。基于此 背景,近年来研究者们致力于从大量没有标签的数 据中预先学习有效的语音特征,使模型学习到语音 更深层次的特征表达,从而在低资源的下游语音任 图3 视觉自监督方法框架 [20] 务中摆脱对训练数据量的依赖,并且获取更好的性 Fig.3 Framework for visual self-supervised 能。近些年来研究者们常用的语音预训练方法主要 Learning[20] 包括:基于自回归重构自监督特征学习方法、掩码重 4 数据分析与知识发现
5 .构方法、对比预测编码方法、掩码预测方法、多任务 (1)语 言 生 成 能 力 :模 型 能 够 遵 循 提 示 词 [32] 学习方法 等。 (Prompt)生成补全提示词的句子; 2.2 多模态大模型 (2)上下文学习能力(in-context learning):遵循 随着输入数据源模态的扩展,多模态大模型的 给 定 任 务 的 几 个 示 例 ,为 新 的 测 试 用 例 生 成 解 决 构建思路通样按照网络架构的不同,可以分为基于 方案; 理解模型的范式、基于生成式模型的范式,以及基于 (3)世界知识(world knowledge)获取能力:包括 编解码的模型构建方法。基于 Transformer Encoder 事实性知识和常识。 的 多 模 态 理 解 模 型 主 要 借 鉴 BERT 方 法 ,采 用 一方面,GPT3 能够合理地回应某些特定的查 Transformer 的 Encoder 部分作为模型架构,学习理 询,并在许多数据集中取得了较好的性能;另一方 解多模态数据的语义及其关联。当前研究方法可以 面,它在许多任务上的表现不及 T5 这样的小模型。 分为单流和双流两类。单流类方法将视觉和文本模 虽然初代的 GPT-3 可能表面上看起来很弱,但后来 态 一 起 输 入 到 编 码 器 ,代 表 性 工 作 包 括 VL- 的实验证明,初代 GPT-3 有着非常强的潜力。这些 BERT ,VideoBERT [33] ,UNITER [34] [35] 等。 潜力后来被代码训练、指令微调(instruction tuning) 随着 GPT 系列模型的发展,其强大的文本生成 和 基 于 人 类 反 馈 的 强 化 学 习(Reinforcement 能力受到越来越多的关注。该系列模型采用 Learning with Human Feedback,RLHF)解锁,最终展 Transformer 的解码部分。GPT-3 表明,语言可以用 示出极为强大的泛化表现能力。从 GPT3 到 GPT3.5 来指导大型神经网络执行各种文本生成任务。受此 的模型进化过程如图 4 所示。 启发,研究者开始研究大规模预训练的多模态生成 可以看到,在 GPT3 的基础上,OpenAI 通过引入 模型。近期,OpenAI 机构发布基于大规模预训练的 代码训练和指令微调对模型进行增强,指令微调很 [36] 文 本 到 图 像 生 成 模 型 —DALL-E 。该模型使用 可能降低了模型的上下文学习能力,但是增强了模 GPT-3 的 120 亿参数版本,可以通过文本直接生成对 型的零样本能力,使得模型拥有了与人类获取知识 应图像,被称作图像版 GPT。虽然 DALL-E 在一定 相对齐(alignment)的能力,使得模型生成的答案更 程度上提供了对少量物体属性和位置的可控性,但 加符合人类期待的反馈,如零样本问答、生成安全和 成功率取决于文字的措辞。当引入更多的对象时, 公正的对话回复、拒绝超出模型知识范围的问题,即 DALL-E 容易混淆对象及其颜色之间的关联,成功 得到 GPT3.5 模型。指令微调和代码训练两项关键 率会急剧下降。同期,清华大学和智源研究院提出 技术的引入,使得模型表现出了如下基础能力: CogView 模 型 [37] ,采 用 与 DALL-E 类 似 的 结 构 (1)响应人类指令:GPT-3 的输出主要训练常见 (VQVAE+GPT),只需微调就能执行超分辨率、风格 的句子,而 GPT3.5 的模型会针对指令/提示词生成 迁移等一系列任务。 更合理的答案(而不是相关但无用的句子); 基于 Transformer 编解码(Encoder-decoder)的多 (2)全新任务泛化:当用于调整模型的指令数量 模态模型通过引入解码器结构实现生成式预训练, 超过一定的规模时,模型就可以自动在从没见过的 更好地学习不同模态之间的关联,提升理解判别能 新指令上也能生成有效的回答; 力。代表性工作有 VL-T5 、E2E-VLP [38] 、M6 [30] [18] 等。 (3)利用思维链(chain-of-thought)进行复杂推 理:初代 GPT3 的模型思维链推理的能力很弱甚至 3 ChatGPT 对科学研究的影响 没有,而 GPT3.5 拥有足够强的思维链推理能力的 3.1 ChatGPT 对预训练大模型研究的影响 模型。 从算法框架上看,ChatGPT 是在 GPT3 的基础上 在 GPT3.5 的 基 础 上 ,RLHF 技 术 的 引 入 使 得 进行微调得到的。GPT3 在超过 3 000 亿单词的语料 ChatGPT 进一步触发了如下能力: 上预训练拥有 1 750 亿参数的模型,得到了三个重要 (1)翔 实 的 回 应 :ChatGPT 的 回 应 变 得 更 加 冗 的能力: 长,以至于用户必须明确要求“用一句话回答我”,才 Data Analysis and Knowledge Discovery 5
6 . XXXX 图4 GPT3 到 GPT3.5 模型的进化示意图 Fig.4 Evolution from GPT3 to GPT3.5 能得到更加简洁的回答,这是 RLHF 的直接产物; 在未来的大模型构建过程中,如何有效利用人 (2)公正的回应:ChatGPT 通常对涉及多个实体 类反馈进一步抽取有效知识,使得预训练模型在数 利益的事件(例如政治事件)给出非常平衡的回答, 据表达上进一步贴合人类认知,降低“对齐税”,是预 这也是 RLHF 的产物; 训练大模型面向下游任务的关键因素之一。 (3)拒绝不当问题:这是内容过滤器和由 RLHF 3.2 ChatGPT 对科研思路的影响 触发的模型自身能力的结合,过滤器过滤掉一部分, ChatGPT 的成功,进一步证明了大数据、高算力 然后模型再拒绝一部分; 和专业算法人才的有机结合在方向上的正确性,而 (4)拒绝其知识范围之外的问题:例如,拒绝在 这也将进一步使得从事大模型相关的科研工作产生 2021 年 6 月之后发生的新事件(因为它没在使用该 一定程度的变化。 时间点后的数据训练),RLHF 使模型能够隐式地区 (1)高校/科研机构研究思路的转变。由于训练 分哪些问题在其知识范围内,哪些问题不在其知识 资源不足,大量高校和科研机构的实验室将集中于 范围内。 Prompt 可解释性、即插即用方法、内部知识整合等方 在上述的模型变迁史中我们可以看到,相较于 向的探索。训练资源尤其稀缺的高校实验室将集中 GPT3 模型庞大的预训练数据量和计算量,无论是指 在比较偏小规模的任务。而与此同时,资源富集的 令微调,还是 RLHF,均依赖于高质量的有标签标注 实验室会开始进一步投入大模型竞争,短期内将会 数据以及持续的人类反馈来对模型进行微调。而针 以探索 RLHF 的不同方向和规模为主,未来以整合 对这一现象进行进一步分析,我们得到的结论是, 专业方向的外部知识为目标。实验室所产出的方法 “有效知识”是 ChatGPT 优于 GPT-3 的关键。GPT-3 和参数保密性将进一步提升,同时对系统架构和高 的训练数据没有任何标签,因此本质是一个无监督 效训练的人才的需求将迅速攀升。 学习;而 ChatGPT 使用 RLHF 生成符合人类指令要 (2)部分子任务的快速消失和被整合。大量之 求的知识信息,本质是一个有监督学习过程。有了 前存在的子任务/小任务会并入大任务,构造有监 RLHF 提供的监督信号,两个模型学习知识的质量 督数据集并微调不再是小任务的第一选择。大模 差异巨大,使得模型能够真正对齐人类知识获取和 型无法取得好结果的小任务将成为研究热点。部 表达模式,即 ChatGPT 使用了“质量高”的外部有效 分 科 研 机 构 会 将 研 究 重 点 转 换 为“ 大 模 型 做 不 到 知识,使得模型在生成数据时更具指向性。 什么”。 6 数据分析与知识发现
7 . (3)跨模态知识的挖掘和自监督学习将成为新 (3)自监督学习与模型优化训练 的热点研究方向。大量基于 RLHF 的跨模态知识的 对于大模型,除了设计更为合理的模型结构,还 生成方法将被快速提出并实践,相关成果将在短期 要设计更为高效的训练方式。现在的预训练都是基 内大量发表。主流热点将主要聚焦在知识的数量、 于 Softmax、回归或者对比损失等端到端训练方式。 质量以及运用知识的方法。 但实际上,人的学习是一个记忆再加上有外界环境 或者有老师指导的过程,是一个不断试错和积累的 4 ChatGPT 对多模态大模型发展的启示 过程。因此,可以研究如何将强化学习机制引入模 4.1 多模态大模型关键技术分析 型自监督学习过程中,把环境反馈引入进来。另外, 多模态大模型研究的焦点主要包括预训练数据 对于多模态大模型,需要设计单模态、部分模态和全 收集、基础模型构建、自监督学习与模型优化训练、 模态的混合训练方式,降低对多模态对齐数据的要 下游任务微调与迁移学习、大模型并行计算与推理 求,同时也能更好利用现有单模态、部分模态开源数 加速。 据。具体地,可以采用多流多模态编解码结构,其引 (1)预训练数据收集 入多层次多任务的自监督学习,可以支持图文音完 通常,大模型使用的预训练数据的质量越高,数 全匹配的数据,也可以支持图文部分模态匹配的信 量越多,越有利于模型性能的提高。但多模态大模 息 ,甚 至 可 以 只 使 用 一 种 模 态 的 信 息 来 进 行 模 型 型的训练需要多模态数据,其对数据的要求高于单 训练。 模态数据,实际中更难去获取质量高、数量多的训练 自然语言处理中大模型取得了很好的效果,而 数据 [19] 。因此需要研究如何以更低代价挖掘和构建 在视觉和多模态里面会有一些不尽人意的地方。这 不同模态之间对齐的数据。实际数据中噪音样本非 是因为语言本身就是一种语义符号,其语义鸿沟问 常多,为了获取大规模、高质量的数据来训练大模 题并不显著,而对图像、视频等多模态信息来说,从 型,目前一种简单有效的方法是维护一个基础词库 底层特征到高层语义具有天然难以跨越的语义鸿 对数据做基本的过滤,并在模型和数据更新的过程 沟。因此针对多模态大模型,需要研究如何有效建 中不断去扩展这个词库。但这种基于匹配过滤的方 模不同模态信息的细粒度语义对齐问题。 式不够灵活。人在面对具体任务时可以基于知识对 (4)下游任务微调与迁移学习 有用信息进行过滤,因此业界下一步研究重点会是 预训练模型通常需要领域标注数据进行微调实 如何引入知识来对数据进行筛选。 现具体下游任务,标注数据可以比全监督方式下得 (2)基础模型构建 更少、但性能可以比原来更好。微调相当于是对大 大模型具有很强的记忆能力,模型参数与数据 模型里记忆数据的一个检索,即给模型少量的样本 规模不断增加也带来了性能的显著提升,但终将会 来唤醒预训练时加入大量样本形成的知识。因此, 遇到瓶颈,所以需要设计能够更高效计算的网络模 高效的微调方法对大模型充分发挥性能至关重要。 型结构,改进甚至是替代 Transformer。大模型效果 另一方面,多模态大模型可以把文本、声音等模 好,除了对大数据有很强的拟合能力,也可以学到隐 态都嵌入到一个特征空间里,这个特征空间的几何 式知识,但这和人类理解的常识没有明确的关联。 形状以及它的距离度量应该符合人对这些知识的认 需要设计更好的模型实现将隐式知识与显式知识的 知先验,即两个概念比较近的事物的特征距离应该 关联,使预测更高效、准确。具体地,研究知识和数 比较近。如果对各种元素的特征空间都有一个比较 据混合驱动的方式,即把显式的知识,比如知识图谱 好的先验刻画,那么实际中只需要很少的样本就可 等,嵌入到模型结构中。例如实际中,CNN 每一层 以帮助模型迁移到下游的很多任务,比如专门领域 的作用都很清楚,知识可以较容易嵌入到各层,而 的分类任务等。 Transformer 没有 CNN 这么明确的从低到高的语义 (5)大模型并行计算与推理加速 抽象。如何嵌入,是下一步的研究方向。 大模型除了要从数据中有效学习,还要看能否 Data Analysis and Knowledge Discovery 7
8 . XXXX 快速学习。需要设计针对超大规模模型的分布式并 对如下能力进行拓展: 行训练方法。 (1)思维链 Chain of Thought:为了处理一个看 4.2 多模态大模型发展新思路 似简单的命令,可能需要多个单模态基础模型(如视 ChatGPT 吸引了各个领域的广泛关注,因其提 觉模型),如“根据该图像的预测深度生成一朵红花, 供了一个跨领域的具有卓越会话能力和推理能力的 然后使其像卡通一样”的查询需要深度估计、深度到 语言界面。然而,由于 ChatGPT 是一个语言模型,目 图像和风格转换模型; 前无法处理、生成来自视觉世界的图像。同时,视觉 (2)推理格式严格:多模态大模型通样必须遵循 基础模型(Visual Foundation Model,VFM,如视觉变 严格的推理格式。因此,使用复杂的正则表达式匹 换器或 Stable Diffusion,虽然显示出强大的视觉理 配算法解析中间推理结果,并为模型构建合理的输 解和生成能力,但只是具有一轮固定输入和输出的 入格式,以帮助确定下一次执行,同样是一个研究 特定任务的专家。如何将 ChatGPT 的上下文交互能 重点; 力同视觉、语音数据分析能力进行有效整合,将为多 (3)可靠性:作为跨模态的语言模型,未来的生 模态大模型训练提供新的思路,图 5 展示了跨模态 成模型可能会伪造图像文件名或事实,从而使系统 任务的交互形式和应用场景。 不可靠。为了处理这些问题,需要设计有效提示,要 求模型忠于用户的输出,而不是伪造图像内容或文 件名。 4.3 多模态大模型产业化分析 人工智能已广泛渗透入社会经济生产活动的主 要环节,但仍然处于商业落地早期。人工智能落地 仍然面临着诸多问题,行业数据隐私安全要求高,行 业(如医疗领域)数据获取困难,难以大规模收集并 用于训练人工智能模型;行业间与行业内数据的联 通与整合机制仍有待完善,数据来源繁杂、质量参差 不齐,行业内上下游机构的产业数据标准不统一。 大部分人工智能项目落地还停留在“手工作坊”阶 图5 多模态大模型的跨模态任务示例 段,即针对特定任务设计专用模型的阶段。 Fig.5 Illustration of Cross-modal Tasks for Multi- 多模态大模型还能更好地抽象人类处理现实问 modal Large Model 题的手段,提供了解决诸如医学影像诊疗这种单模 态学习难以处理的问题,为未来更大范围应用奠定 以视觉和文本任务结合为例,结合不同的视觉 了基础。多模态大模型加持下的人工智能平台逐渐 基 础 模 型(VFM),使 用 户 能 够 通 过 以 下 方 式 与 发展成为一种新范式。预计通过加大力度对其进行 ChatGPT 进行交互: 推进,在 3-5 年内大模型有望把人工智能众多方向 (1)发送和接收语言及图像; 加以融合发展,逐渐成熟,可落地应用服务于产业实 (2)给“复杂的视觉问题或视觉编辑”提供操作 体经济。 指南,通常此类操作需要多个 AI 模型通过多轮协作 未来的多模态大模型将实现图文音统一知识表 来完成; 示,成为人工智能基础设施。人工智能包含三个层 (3)提供反馈并询问正确结果。设计了一系列 次:基础层、技术层和应用层。基础层通常涵盖硬 提示,将视觉模型信息注入 ChatGPT,主要应用于多 件、算法和海量数据三部分;技术层包括计算机视 个输入/输出的模型或者需要视觉反馈的模型。 觉、语音、自然语言处理等技术;应用层主要是人工 在未来的多模态大模型训练过程中,将重点针 智能产品、服务和解决方案,适用于无人驾驶、智能 8 数据分析与知识发现
9 .家居、智慧金融、工业机器人、水下机器人、智慧医疗 arXiv Preprint, arXiv:1810.04805v2. [3] Vaswani A, Shazeer N, Parmar N, et al. Attention Is All You Need 等多个领域。作为人工智能基础层算法的重要组成 [OL]. PreprintarXiv, arXiv: 1706.03762. [4] ChatGPT[EB/OL]. 部分,多模态大模型及相应智能算法由于实现图、 (2022-11-30).https://openai.com/blog/chatgpt/. 文、音统一知识表示,正成为人工智能基础设施。 [5] Chen M, Tworek J, Jun H, et al. Evaluating Large Language “多模态+大模型+多任务”的统一学习,实现模 Models Trained on Code[OL]. arXiv Preprint, arXiv:2107.03374. 型研发的工业化。自动化所团队提出的视觉-文本- [6] Neelakantan A, Xu T, Puri R, et al. Text and Code Embeddings 语音三模态预训练模型采用分别基于词条级别 by Contrastive Pre-training[OL]. arXiv Preprint, arXiv: 2201.10005. (Token-level)、模 态 级 别(Modality-level)以 及 样 本 [7] Brown T B, Mann B, Ryder N, et al. Language Models are Few- 级别(Sample-level)的多层次、多任务子监督学习框 shot Learners[OL]. arXiv Preprint, arXiv:2005.14165. 架,更关注图-文-音三模态数据之间的关联特性以 [8] Lester B, Al-Rfou R, Constant N. The Power of Scale for 及跨模态转换问题。该模型不仅可实现跨模态理解 Parameter-Efficient Prompt Tuning[OL]. arXiv Preprint, arXiv: (比如图像识别、语音识别等任务),也能完成跨模态 2104.08691. [9] Schick T, Schütze H. Exploiting Cloze-questions for Few-shot 生成(比如从文本生成图像、图像生成文本、语音生 Text Classification and Natural Language Inference[OL]. arXiv 成图像等任务)。以多模态大模型为核心的通用人 Preprint, arXiv:2001.07676. 工智能平台上,可以让 AI 模型研发从“手工作坊”模 [10] Zhang Z, Zhang A, Li M, et al. Automatic Chain of Thought 式走向工业化协同的高效开发新范式,从而大大降 Prompting in Large Language Models[OL]. arXiv Preprint, arXiv: 低模型研发边际成本,提升模型的生产效率。 2210.03493. [11] Wei J, Wang X, Schuurmans D, et al. Chain of Thought 多模态大模型+小模型,必将成为行业应用的趋 Prompting Elicits Reasoning in Large Language Models[OL]. 势。人工智能想要真正规模化落地应用,核心在于 arXiv Preprint, arXiv:2201.11903. 要对落地行业有深刻的理解,找到真正懂行业场景 [12] Peters M E, Neumann M, Iyyer M, et al. Deep Contextualized 和关键痛点的人来做,通过多模态大模型+小模型模 Word Representations[OL]. arXiv Preprint, arXiv:1802.05365. 式解决了长尾场景的各种痛点需求,特别是解决边 [13] Radford A, Narasimhan K, Salimans T, et al. Improving Language Understanding by Generative Pre-Training[OL].https:// 际成本和碎片化问题,用户才愿意为此买单,实现 s3-us-west-2. amazonaws. com/openai-assets/research-covers/ AI 模型赋能各行各业。 language-unsupervised/language_understanding_paper.pdf. [14] Radford A, Wu J, Child R, et al. Language Models are 5 结 语 Unsupervised Multitask Learners[OL]. https://d4mucfpksywv. 本文针对预训练基础模型的发展状态进行了回 cloudfront.net/better-language-models/language-models.pdf. 顾,并分析了 ChatGPT 对大语言模型研究工作产生 [15] OpenAI. WebGPT:Brower-assisted question-answering with human feedback[EB/OL]. (2021-12-16). https://openai. com/blog/ 的影响。在当前主流的大模型发展路线中,针对多 webgpt/. 模态数据的基础预训练大模型构建工作将是其中的 [16] OpenAI. Aligning Language Models to Follow Instructions[EB/ 一个重要路径,ChatGPT 的成功所指明的针对有效 OL].(2022-01-27).https://openai.com/blog/instruction-following/. 数据的获取方法、指令微调等研究思路,将对多模态 [17] Christiano P, Leike J, Brown T B, et al. Deep Reinforcement 大模型的构建产生积极的作用,为多模态大模型未 Learning from Human Preferences [OL]. arXiv Preprint, arXiv: 1706.03741. 来在下游任务中的应用前景带来更多的启发。 [18] Lin J, Men R, Yang A, et al. M6: A Chinese Multimodal Pretrainer[OL]. arXiv Preprint, arXiv:2103.00823. 参考文献: [19] Liu Y, Zhu G, Zhu B, et. al. TaiSu: A 166M Large-scale High- [1] Zhou C, Li Q, Li C, et al. A Comprehensive Survey on Pretrained Quality Dataset for Chinese Vision-Language Pre-training[C]// Foundation Models: A History from BERT to ChatGPT[OL]. Proceedings of the 36th Conference on Neural Information arXiv Preprint, arXiv:2302.09419. Processing Systems Trank on Datasets and Benchmarks.2022. [2] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep [20] Jing L, Tian Y. Self-supervised Visual Feature Learning with Bidirectional Transformers for Language Understanding[OL]. Deep Neural Networks: A Survey[J]. IEEE Transactions on Data Analysis and Knowledge Discovery 9
10 . XXXX Pattern Analysis and Machine Intelligence, 2020, 43(11): 4037- [31] Grill J B, Strub F, Altché F, et al. Bootstrap Your Own Latent: A 4058. New Approach to Self-supervised Learning[OL]. arXiv Preprint, [21] Zhang R, Isola P, Efros A A. Colorful Image Colorization [OL]. arXiv:2006.07733. arXiv Preprint, arXiv:1603.08511. [32] Pascual S, Ravanelli M, Serrà J, et al. Learning Problem- [22] Caron M, Bojanowski P, Joulin A, et al. Deep Clustering for Agnostic Speech Representations from Multiple Self-Supervised Unsupervised Learning of Visual Features [OL]. arXiv Preprint, Tasks[OL]. arXiv Preprint, arXiv:1904.03416. arXiv:1807.05520. [33] Su W, Zhu X, Cao Y, et al. VL-BERT: Pre-training of Generic [23] Pathak D, Krahenbuhl P, Donahue J, et al. Context Encoders: Visual-Linguistic Representations[OL]. arXiv Preprint, arXiv: Feature Learning by Inpainting[C]. Proceedings of the 2016 1908.08530. IEEE Conference on Computer Vision and Pattern Recognition. [34] Sun C, Myers A, Vondrick C, et al. Videobert: A Joint Model for 2016: 2536-2544. Video and Language Representation Learning[C]. Proceedings of [24] He K, Chen X, Xie S, et al. Masked Autoencoders Are Scalable the 2019 IEEE/CVF International Conference on Computer Vision Learners[C]. Proceedings of the 2022 IEEE Conference Vision. 2019: 7464-7473. on Computer Vision and Pattern Recognition. 2021. [35] Chen Y C, Li L, Yu L, et al. Uniter: Universal Image-text [25] He K, Fan H, Wu Y, et al. Momentum Contrast for Unsupervised Representation Learning[OL]. arXiv Preprint, arXiv:1909.11740. Visual Representation Learning[C]. Proceedings of the 2020 [36] Ramesh A, Pavlov M, Goh G, et al. Zero-shot Text-to-Image IEEE/CVF Conference on Computer Vision and Pattern Generation[OL]. arXiv Preprint, arXiv:2102.12092. Recognition. 2020: 9729-9738. [37] Ding M, Yang Z, Hong W, et al. CogView: Mastering Text-to- [26] Chen X, Fan H, Girshick R, et al. Improved Baselines with Image Generation via Transformers[OL]. arXiv Preprint, arXiv: Momentum Contrastive Learning[OL]. arXiv Preprint, arXiv: 2105.13290. 2003.04297. [38] Cho J, Lei J, Tan H, et al. Unifying Vision-and-Language Tasks [27] Chen X, Xie S, He K. An Empirical Study of Training Self- via Text Generation[OL]. arXiv Preprint, arXiv:2102.02779. supervised Vision TRANSFORMERS[OL]. arXiv Preprint, arXiv:2104.02057. 作者贡献声明: [28] Chen T, Kornblith S, Swersky K, et al. Big Self-supervised 赵朝阳:提出研究思路,设计研究方案,论文起草,进行实验和分析; Models are Strong Semi-supervised Learners[OL]. arXiv 朱贵波,王金桥:论文最终版本修订。 Preprint, arXiv:2006.10029. [29] Chen T, Kornblith S, Norouzi M, et al. A Simple Framework for Contrastive Learning of Visual Representations[OL]. arXiv 利益冲突声明: Preprint, arXiv:2006.05709. 所有作者声明不存在利益冲突关系。 [30] Xu H, Yan M, Li C, et al. E2E-VLP: End-to-End Vision- Language Pre-training Enhanced by Visual Learning[OL]. arXiv 收稿日期:2023-03-13 Preprint, arXiv:2106.01804. 10 数据分析与知识发现
11 .The Inspiration Brought by ChatGPT to LLM and the New Development Ideas of Multi-modal Large Model Zhao Chaoyang Zhu Guibo Wang Jinqiao (Institute of Automation, Chinese Academy of Sciences, Beijing 100190, China) Abstract: [Objective] This paper analyzes the basic technical principles of ChatGPT, and discusses its influence on the development of large language model and the development of multi-modal pretrained model. [Methods] By analyzing the development process and technical principles of ChatGPT, this paper discusses the influence of model building methods such as instruct fine-tuning, data acquisition and annotation, and reinforcement learning based on human feedback on the large language model. At the same time, this paper analyzes several key scientific problems encountered in the construction of multi-modal model, and discusses the future development of multi-modal pretrained model by referring to ChatGPT’s technical scheme. [Conclusions] The success of ChatGPT provides a good reference technology path for the development of pretrained fundamental model to downstream tasks. In the future construction of multi-modal large model and the realization of downstream tasks, we can make full use of high-quality instruction fine-tuning and other technologies to significantly improve the performance of downstream tasks. Keywords: Large Language Model (LLM) Pretrained Foundation Model Multi-modal pretrained model ChatGPT Data Analysis and Knowledge Discovery 11
3秒后跳转登录页面
去登陆

