
- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 微信扫一扫分享
- 已成功复制到剪贴板
ATorch:蚂蚁开源PyTorch分布式训练扩展库,助你将硬件算力压榨到极致
3
点赞
0
收藏


2023年上半年,蚂蚁AI Infra团队开源了DLRover项目,致力于通过提升深度学习训练过程的智能性,来解决整个系统的提效问题,目前DLRover支持了蚂蚁深度学习系统中的自动资源动态优化与分布式训练稳定性的提升,这次我们也在DLRover项目中开放了内部真实使用的大模型训练加速的工作ATorch,用户通过它可以快速get工业级千亿模型千卡级训练提效体验。

项目背景
2023年上半年,蚂蚁AI Infra团队开源了DLRover项目,致力于通过提升深度学习训练过程的智能性,来解决整个系统的提效问题,目前DLRover支持了蚂蚁深度学习系统中的自动资源动态优化与分布式训练稳定性的提升,相当于为一辆跑车提供了自动驾驶系统,那么如何让跑车跑的更快呢?我们还需要为跑车提供一个强劲的引擎,为此我们基于PyTorch开发了分布式训练加速扩展库ATorch。
PyTorch提供了很多训练优化的基础能力,包括分布式并行策略,显存优化,通讯计算优化等。业界基于PyTorch的开源扩展库已经有不少优秀项目,比如DeepSpeed,Megatron,Colossal-AI,Flash Attention,fastmoe等,这些已经被广泛使用。
作为服务公司无数业务五花八门需求的Infra团队,做自研开发的同时,还会面对用户使用很多开源框架的诉求,当他们的种类和数量开始暴增的时候,我们发现整个infra软件栈的治理问题开始突显:
- 开源库种类多迭代快,功能有overlap,学习成本高,接口很复杂,镜像环境依赖冲突,很多框架需要侵入用户代码
- 多种优化策略组合爆炸,如何达到最优配比,需要专家经验,普通用户很难有精力掌握
- 针对公司内部环境的存储和容器系统,没有存储/IO优化,快速容错恢复保障,故障检测隔离等基础能力
- 自研的优化特性同外部开源策略配合使用易发生冲突
- 大规模分布式训练无法开箱即用
为了解决上述问题,一种思路是像paddlepaddle,mindspore,oneflow等那样完全自研可控,但是这意味着更高的成本和落地难度。从更务实的角度,我们还是希望能够继续拥抱成熟活跃的PyTorch生态,这样如何能够优雅组合不同开源方案并且能够任意添加针对自身硬件与业务特点新策略,是我们对于自身软件框架的一个比较务实的需求。另一方面,针对不同的模型和硬件资源,仍然需要专家经验来针对性的配置出最优的策略,如何提升这一过程的效率,也是我们需要解决的问题。
基于上述需求,我们制定了ATorch的项目目标:
目标:
- 作为PyTorch框架的高性能扩展加速库,最少化用户代码侵入(one_api + 统一config实现性能优化)
- 为千亿级大模型训练提供千卡级高效大规模预训练能力
- 为千亿级大模型训练提供高效指令微调能力(SFT,RLHF,...)
- 针对开源优化技术和自研定制优化技术,提供统一的接入接口和用户使用组合配置模式,统一环境(包括分布式策略,通讯/计算/显存优化等环节)
- 针对多种优化策略等组合,提供自动搜索能力,给定单机模型和资源配置,自动通过试跑分析最优策略组合
- 配合DLRover项目提供大规模训练稳定性保障方案
- 国产卡AI加速卡适配最佳实践(待开源)
- 深度学习编译优化能力(待开源)
非目标:
- 完全自研一套深度学习框架
- 做一个封闭的PyTorch加速库,去对标deepspeed,megatron等作为类似PyTorch Lighting/Hugging face trainer 类似的trainer脚手架
地址:https://github.com/intelligent-machine-learning/dlrover/atorch
最近实践效果
大模型训练优化
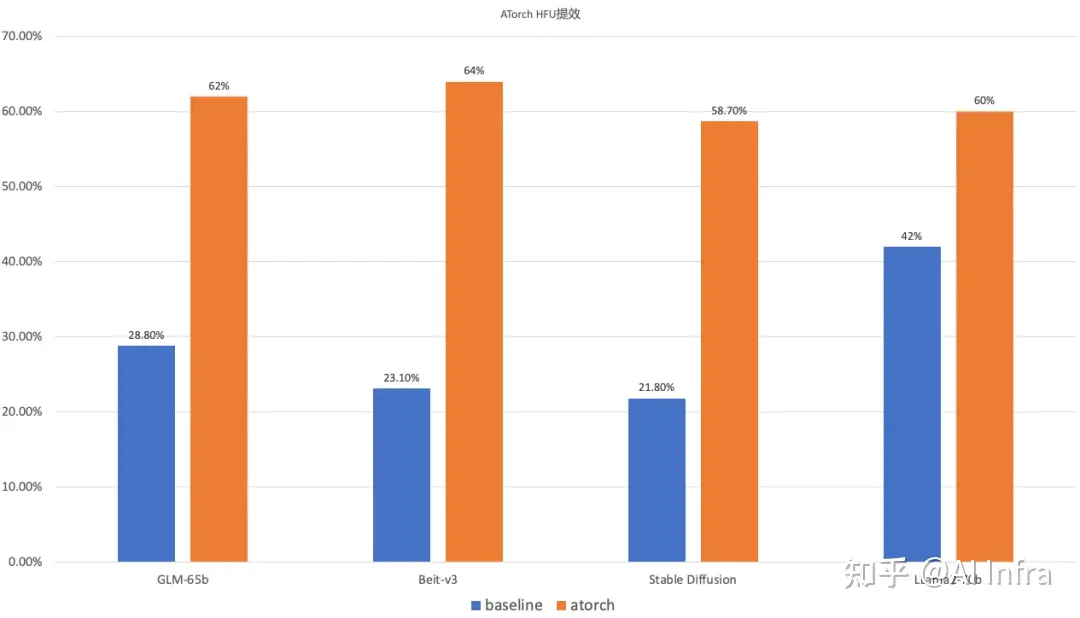
主要大模型预训练算力吞吐提效:
- GLM-65b:(A100*1536)
- LLama2-70b:(H800*1536)
- 多模态大模型:(A100*256)
- 视觉生成模型:(A100*128)
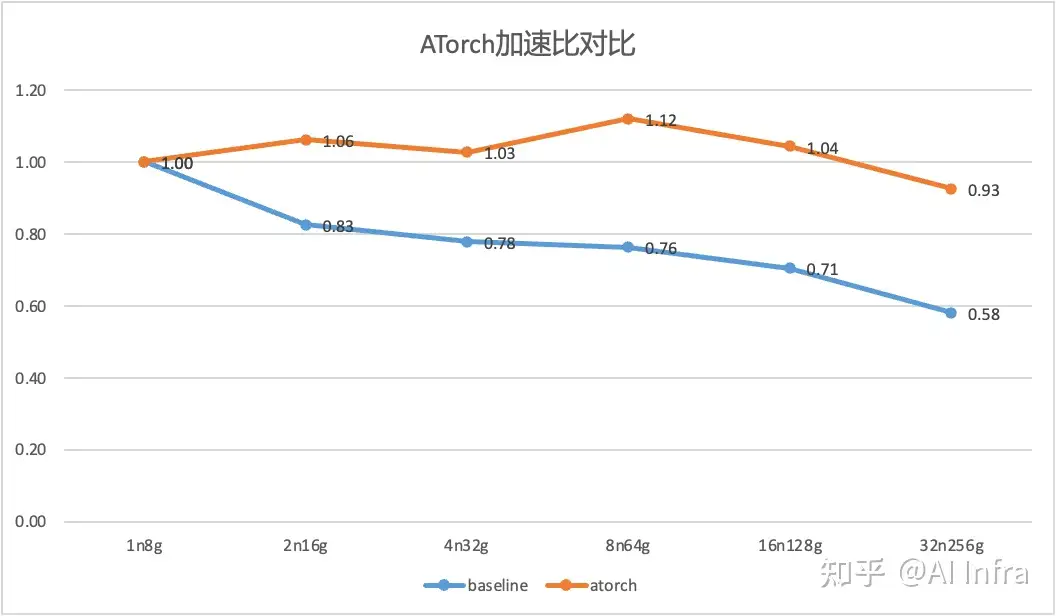
ATorch训练加速比
以antglm10B为实验模型,从1机8卡测试到32机256卡,基线为模型官方提供的Megatron+deepspeed实现
ATorch千卡训练稳定性
关键指标:
- 日均纯训练时常占比:40.7% -> 95%
- ckpt save耗时: 10min -> 1min
- 训练重启耗时:90 min -> 5 min
整体设计
系统架构
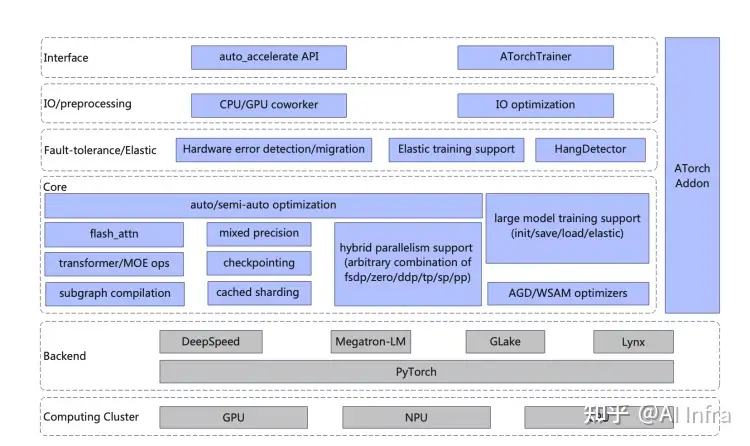
整体上ATorch采用了分层的架构设计:
- Interface层负责用户使用接口,支持极致精简的one api模式和trainer模式。
- IO和预处理层主要负责存储IO等相关的优化。
- 弹性容错层主要负责稳定性保障,主要配合DLRover使用来实现。
- 核心层是ATorch的主要代码,这里我们定义了优化策略的统一接入和表达,保障开源方法和自研策略统一管理,同时也包含了自动策略最优策略组合的功能。
- 最下层分别是PyTorch社区生态系统和底层的AIDC硬件。
核心功能
- 大模型训练关键关键技术
- 千亿参数大模型千卡级高性能预训练实践方案(算力利用率 > 50%)
- 显存/通信联合优化
- Flash Attention/Fused ops 等算子优化
- 千亿参数模型快速ckpt save/load的支持
- 支持千亿级模型RLHF高效微调
- 统一分布式优化策略配置接口
- 分布式算子,通信,显存优化
- 数据IO预处理优化
- 自动分布式策略搜索:
- 给定单机模型定义和硬件资源描述,自动搜索最优配置组合
- ATorch+DLRover自动弹性容错,提升大模型训练稳定性(有效训练时长大于95%)
- GLake高效动态显存管理库,显著提升batch size和端到端吞吐
- 国产硬件生态适配调优
- 自研优化器 AGD(加速收敛)和 WSAM(提升泛化,已被 KDD '23 接收,文章链接)
主要特性简介
ATorch自动分布式策略搜索
在剖析和优化模型性能的过程中,ATorch团队注意到以下现象:
- 调用训练优化方法对现有训练逻辑有一定侵入性,且不同优化方法存在兼容性问题。
- 训练优化方法的效果受特定参数的影响,依赖专家经验手工调优。
- 训练优化方法持续演进,算法工程师对优化方法了解较少。
- 不同业务模型的训练过程反复出现类似的、可解决的性能瓶颈。
- 需要团队付出大量人力做业务支持。
因此,ATorch提供了自动优化API auto_accelerate,综合了蚂蚁内部开发的和业界公布的训练优化方法,用一个API实现全自动优化策略的搜索、选择和实现。auto_accelerate是轻量级的wrapper API,不同于Trainer。对用户代码侵入性小、优化结果复用性好,不强制规定用户的训练逻辑,并开放了定制优化策略的接口。用户只要编写单机版本的模型训练代码,再调用auto_accelerate就能实现各种硬件环境下的自动优化。
auto_accelerate给出的优化策略将最大化训练吞吐量(throughput)。
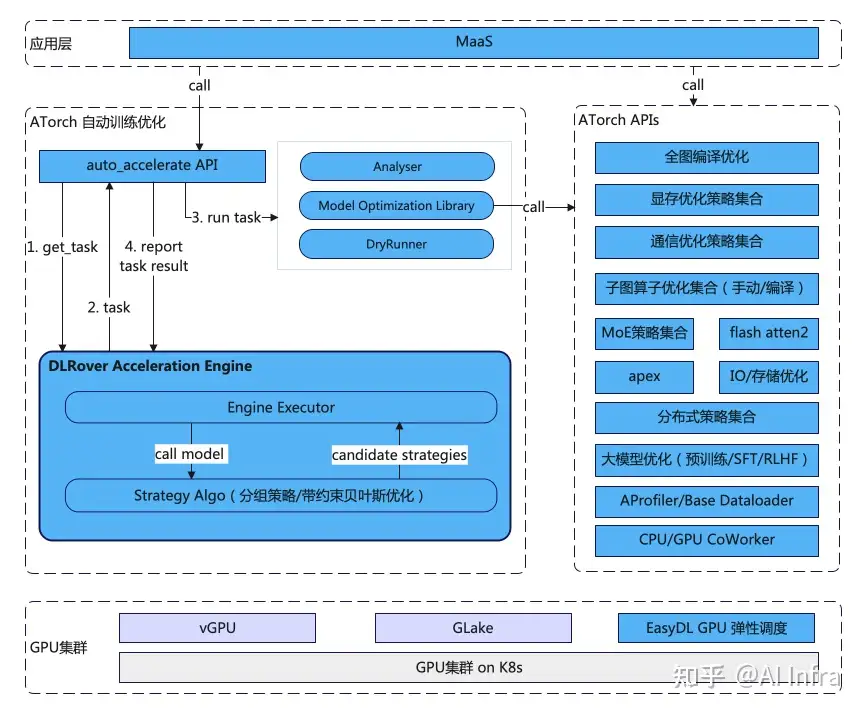
整体架构图如上所示,用户仅需要开发单机模型后,利用auto_accelerate api来完成分布式优化。
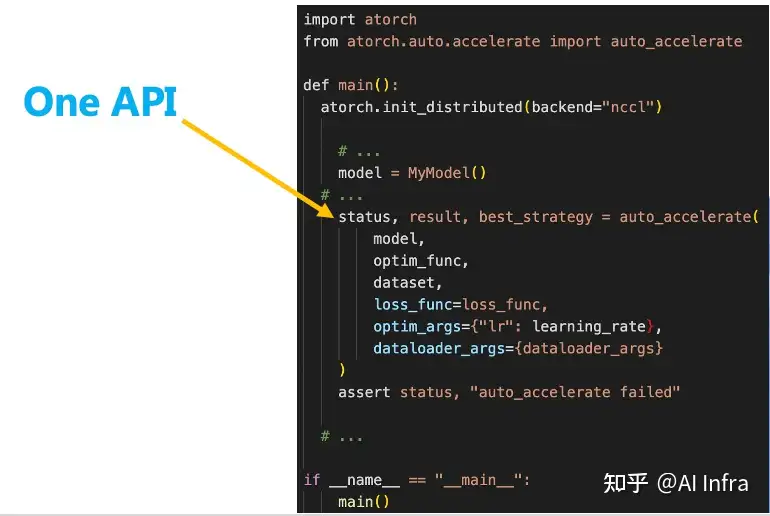
auto_accelerate 提供了2种使用方式:
- 全自动方式:自动生成优化策略,自动优化实现。(dry run需资源支持,目前百亿以下模型适合该方法)
- 半自动方式:用户通过 load_strategy 指定优化策略使用的方法组合后,自动完成优化方法的兼容实现。
使用方法参考:https://github.com/intelligent-machine-learning/dlrover/blob/master/atorch/docs/auto_accelerate_api.md
通过 auto_accelerate 接口,ATorch 可方便地实现大模型基于 FSDP 或者 3D 混合并行的分布式训练。
demo参考:https://github.com/intelligent-machine-learning/dlrover/tree/master/atorch/examples/llama2
GLake显存优化库
问题:大模型训练(百亿甚至更大)显存不足制约了batch size并影响训练性能与调试,典型显存问题包括:
- 显存碎片:Torch显存池reserve的物理显存足够,但地址连续的显存空间不足而引发OOM(类似磁盘碎片)。在一些大模型训练下碎片占比可能30%~85+%。
- 性能开销:在OOM之前,Torch会尝试1)释放一些整块空闲的显存(同步操作),2)然后重新分配。这2个操作有非常大的性能影响(几倍),类似Java GC。
- 多stream显存孤岛:多卡分布式训练时(如FSDP、pipeline并行),存在多个并发GPU stream,每个都需分配显存,为简化复用,Torch把多stream割裂形成了多个小显存池,互相无法复用。
优化:GLake重现优化实现了Torch底层核心的显存管理器,实测可显著提升batch size和端到端吞吐。
- 优化1(虚拟-物理显存):基于虚拟-物理显存的动态管理和映射,实现逻辑连续而物理地址不要求连续,优化碎片问题,提供更大可用显存,提高batch size(2~4X)。
- 优化2(动态映射):显存压力大时,不需释放物理显存(GC),而动态remap多个不连续物理地址,减少GC性能影响,提升吞吐50%。
- 优化3(跨stream复用):打破stream之间严格的内循环边界,显存压力大时,可在stream之间互相复用。
使用方法参考:https://github.com/intelligent-machine-learning/glake
ATorch+DLRover训练稳定性保障
在大规模分布式 GPU 集群上训练模型时,经常遇到硬件或者网络故障导致训练失败,常见的失败原因有:
- GPU 硬件问题导致机器故障,常见的 GPU 硬件问题有 GPU 掉卡和XID 问题。
- NCCL 通信超时。
- NVLINK 错误,比如 IB网络驱动问题和 nv_peer_mem error。
- PyTorch 组网失败,比如 TCP 端口被占用,Socket 超时导致组网超时等。
为了 ATorch 联合 DLRover 实现了 PyTorch 分布式训练的容错和弹性。通知两级容错来快速实现训练恢复。
- Pod 容错:对于故障机问题,DLRover 可以在机器失败后重新拉起一个新的 Pod 来替换失败的Pod,并让新启的 Pod 加入 PyTorch 训练。
- 进程容错:对于问题2、3、4,DLRover 和 ATorch 支持重启子进程来快速实现训练恢复。
在训练进程恢复后,DLRover 为了方便用户恢复训练dataset 的消费位点,提供了ElasticDistributedSampler方便用户在对模型做checkpoint时也对 Dataloader做checkpoint。从而实现模型和训练样本数据的一致性。
地址:https://github.com/intelligent-machine-learning/dlrover
后续计划
- ATorch RLHF:支持千亿模型高效指令微调,time/seq相对基线4x提升
- ATorch 大模型快速容错,ckpt 高速保存恢复方案
- 国产卡适配及优化
- Lynx全图编译优化
- 更多分布式优化策略细节连载
关于 DLRoverDLRover(Distributed Deep Learning System)是蚂蚁集团 AI Infra 团队维护的开源社区,是基于云原生技术打造的智能分布式深度学习系统。DLRover 使得开发人员能够专注于模型架构的设计,而无需处理任何工程方面的细节,例如硬件加速和分布式运行等;开发深度学习训练的相关算法,让训练更高效、智能,例如优化器。目前,DLRover 支持使用 K8s、Ray 进行自动化操作和维护深度学习训练任务。更多 AI Infra 技术请关注 DLRover 项目。
加入 DLRover 钉钉技术交流群:31525020959
DLRover Star 一下:https://github.com/intelligent-machine-learning/dlrover
3
点赞
0
收藏
3秒后跳转登录页面
去登陆

