


































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Cortex-A 系列处理器Cortex-A77文档分享 |arm_cortex_A77_software_optimization_guide
Cortex-A77相关文档 ARM Cortex-A 系列的Cortex-A77的 ARM 文档集 TARM Cortex-A 系列是一系列用于复杂操作系统和用户应用程序的应用程序处理器。Cortex-A 系列处理器支持 ARM、Thumb 和 Thumb-2 指令集。
Cortex-A77文档集:
Revision: r0-r1 revisions Arm Cortex-A77 MP074 Software Developers Errata Notice Arm Cortex-A77 Core Software Optimization Guide Software Optimization Guide Revision: r1p1 Arm Cortex‑A77 Core Cryptographic Extension Technical Reference Manual Arm Cortex‑A77 Core Technical Reference Manual
包含文档如下:
arm_cortex_a77_mp074_software_developer_errata_notice_v9.0 arm_cortex_A77_software_optimization_guide arm_cortex_a77_crypto_trm_101113_0101_02_en arm_cortex_a77_trm_101111_0101_04_en
展开查看详情
1 .Arm® Cortex®-A77 Core Revision: r1p1 Software Optimization Guide Non-Confidential Issue 3.0 Copyright © 2018, 2019 Arm Limited (or its affiliates). PJDOC-466751330-11050 All rights reserved.
2 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Arm® Cortex®-A77 Core Software Optimization Guide Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Release information Document history Issue Date Confidentiality Change 1.0 9 May 2018 Confidential First release for r0p0 2.0 28 Sept 2018 Confidential First release for r1p0 3.0 10 May 2019 Non-Confidential First release for r1p1 Non-Confidential Proprietary Notice This document is protected by copyright and other related rights and the practice or implementation of the information contained in this document may be protected by one or more patents or pending patent applications. No part of this document may be reproduced in any form by any means without the express prior written permission of Arm. No license, express or implied, by estoppel or otherwise to any intellectual property rights is granted by this document unless specifically stated. Your access to the information in this document is conditional upon your acceptance that you will not use or permit others to use the information for the purposes of determining whether implementations infringe any third party patents. THIS DOCUMENT IS PROVIDED “AS IS”. ARM PROVIDES NO REPRESENTATIONS AND NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, INCLUDING, WITHOUT LIMITATION, THE IMPLIED WARRANTIES OF MERCHANTABILITY, SATISFACTORY QUALITY, NON-INFRINGEMENT OR FITNESS FOR A PARTICULAR PURPOSE WITH RESPECT TO THE DOCUMENT. For the avoidance of doubt, Arm makes no representation with respect to, and has undertaken no analysis to identify or understand the scope and content of, patents, copyrights, trade secrets, or other rights. This document may include technical inaccuracies or typographical errors. TO THE EXTENT NOT PROHIBITED BY LAW, IN NO EVENT WILL ARM BE LIABLE FOR ANY DAMAGES, INCLUDING WITHOUT LIMITATION ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, PUNITIVE, OR CONSEQUENTIAL DAMAGES, HOWEVER CAUSED AND REGARDLESS OF THE THEORY OF LIABILITY, ARISING OUT OF ANY USE OF THIS DOCUMENT, EVEN IF ARM HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. This document consists solely of commercial items. You shall be responsible for ensuring that any use, duplication or disclosure of this document complies fully with any relevant export laws and regulations to assure that this document or any portion thereof is not exported, directly or indirectly, in violation of such export laws. Use of the word “partner” in reference to Arm's customers is not intended to create or refer to any partnership relationship with any other company. Arm may make changes to this document at any time and without notice. Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 2 of 68
3 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 If any of the provisions contained in these terms conflict with any of the provisions of any click through or signed written agreement covering this document with Arm, then the click through or signed written agreement prevails over and supersedes the conflicting provisions of these terms. This document may be translated into other languages for convenience, and you agree that if there is any conflict between the English version of this document and any translation, the terms of the English version of the Agreement shall prevail. The Arm corporate logo and words marked with ® or ™ are registered trademarks or trademarks of Arm Limited (or its subsidiaries) in the US and/or elsewhere. All rights reserved. Other brands and names mentioned in this document may be the trademarks of their respective owners. Please follow Arm's trademark usage guidelines at http://www.arm.com/company/policies/trademarks. Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Arm Limited. Company 02557590 registered in England. 110 Fulbourn Road, Cambridge, England CB1 9NJ. LES-PRE-20349 Confidentiality Status This document is Non-Confidential. The right to use, copy and disclose this document may be subject to license restrictions in accordance with the terms of the agreement entered into by Arm and the party that Arm delivered this document to. Unrestricted Access is an Arm internal classification.Product Status The information in this document is Final, that is for a developed product. Web Address 33T http://www.arm.com 33T Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 3 of 68
4 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Contents 1 Introduction 6 1.1 Product revision status 6 1.2 Intended audience 6 1.3 Conventions 6 1.3.1 Glossary 6 1.3.2 Typographical conventions 7 1.4 Additional reading 8 1.5 Feedback 8 1.5.1 Feedback on this product 8 1.5.2 Feedback on content 8 2 About this document 9 2.1 Scope 9 2.2 Product overview 9 2.2.1 Pipeline overview 9 3 Instruction characteristics 12 3.1 Instruction tables 12 3.2 Legend for reading the utilized pipelines 12 3.3 Branch instructions 13 3.4 Arithmetic and logical instructions 13 3.5 Move and shift instructions 16 3.6 Divide and multiply instructions 17 3.7 Saturating and parallel arithmetic instructions 19 3.8 Miscellaneous data-processing instructions 22 3.9 Load instructions 23 3.10 Store instructions 28 3.11 FP data processing instructions 30 3.12 FP miscellaneous instructions 33 3.13 FP load instructions 34 3.14 FP store instructions 36 3.15 ASIMD integer instructions 39 3.16 ASIMD floating-point instructions 45 3.17 ASIMD miscellaneous instructions 50 Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 4 of 68
5 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 3.18 ASIMD load instructions 53 3.19 ASIMD store instructions 57 3.20 Cryptography extensions 60 3.21 CRC 61 4 Special considerations 62 4.1 Dispatch constraints 62 4.2 Dispatch stall 62 4.3 Optimizing general-purpose register spills and fills 62 4.4 Optimizing memory copy 62 4.5 Load/Store alignment 63 4.6 AES encryption/decryption 63 4.7 Region based fast forwarding 64 4.8 Branch instruction alignment 65 4.9 FPCR self-synchronization 65 4.10 Special register access 65 4.11 Register forwarding hazards 67 4.12 IT blocks 67 4.13 Instruction fusion 68 Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 5 of 68
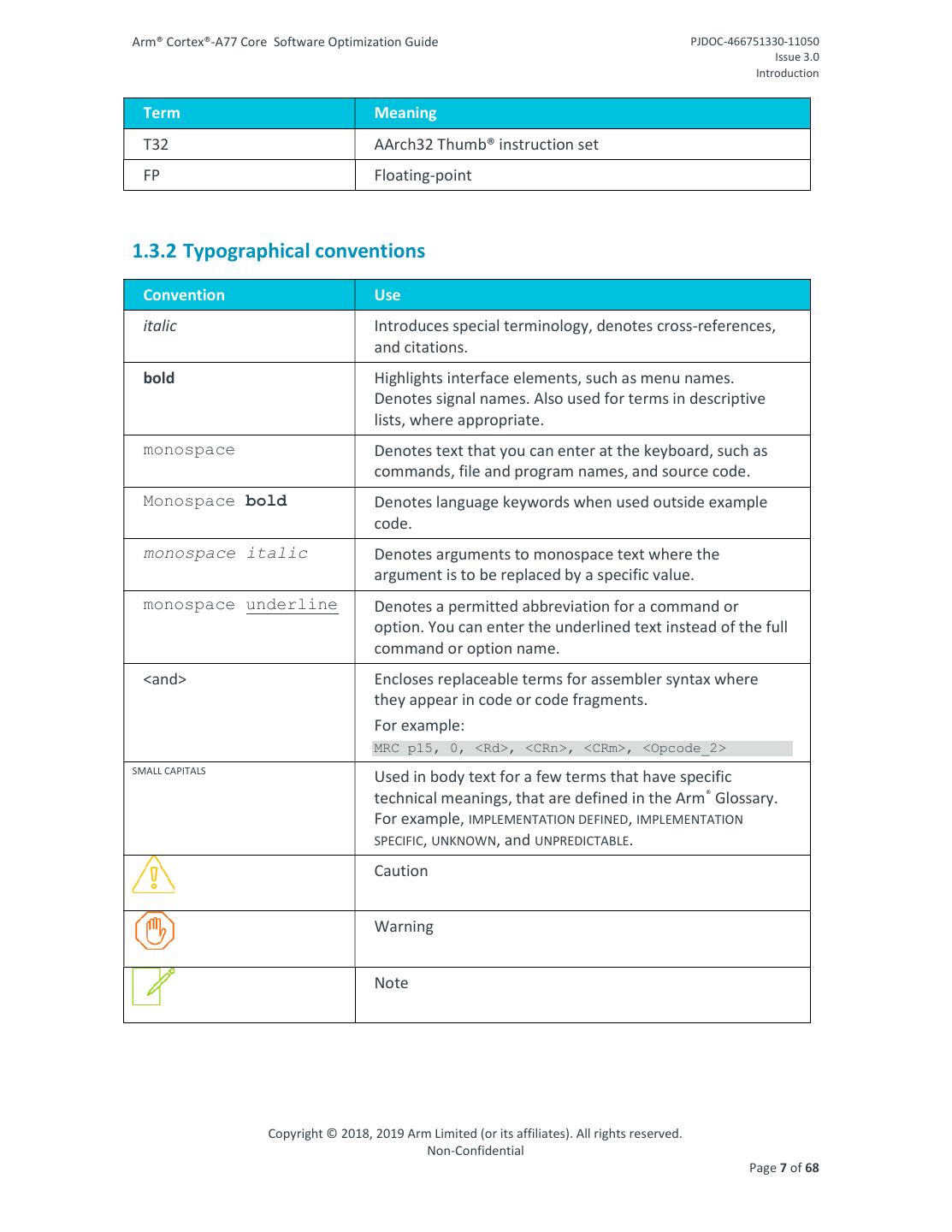
6 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Introduction 1 Introduction 1.1 Product revision status The rmpn identifier indicates the revision status of the product described in this book, for example, r1p2, where: rm Identifies the major revision of the product, for example, r1. pn Identifies the minor revision or modification status of the product, for example, p2. 1.2 Intended audience This document is for system designers, system integrators, and programmers who are designing or programming a System-on-Chip (SoC) that uses an Arm core. 1.3 Conventions The following subsections describe conventions used in Arm documents. 1.3.1 Glossary The Arm Glossary is a list of terms used in Arm documentation, together with definitions for those terms. The Arm Glossary does not contain terms that are industry standard unless the Arm meaning differs from the generally accepted meaning. See the Arm® Glossary for more information. 1.3.1.1 Terms and Abbreviations This document uses the following terms and abbreviations. Term Meaning ALU Arithmetic and Logical Unit ASIMD Advanced SIMD DSU DynamIQ™ Shared Unit MOP Macro-OPeration µOP Micro-OPeration SQRT Square Root Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 6 of 68
7 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Introduction Term Meaning T32 AArch32 Thumb® instruction set FP Floating-point 1.3.2 Typographical conventions Convention Use italic Introduces special terminology, denotes cross-references, and citations. bold Highlights interface elements, such as menu names. Denotes signal names. Also used for terms in descriptive lists, where appropriate. monospace Denotes text that you can enter at the keyboard, such as commands, file and program names, and source code. Monospace bold Denotes language keywords when used outside example code. monospace italic Denotes arguments to monospace text where the argument is to be replaced by a specific value. monospace underline Denotes a permitted abbreviation for a command or option. You can enter the underlined text instead of the full command or option name. <and> Encloses replaceable terms for assembler syntax where they appear in code or code fragments. For example: MRC p15, 0, <Rd>, <CRn>, <CRm>, <Opcode_2> SMALL CAPITALS Used in body text for a few terms that have specific technical meanings, that are defined in the Arm ® Glossary. For example, IMPLEMENTATION DEFINED, IMPLEMENTATION SPECIFIC, UNKNOWN, and UNPREDICTABLE. Caution Warning Note Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 7 of 68
8 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Introduction 1.4 Additional reading This document contains information that is specific to this product. See the following documents for other relevant information: Table 1: Arm publications Document name Document ID Licensee only Y/N Arm® Architecture Reference Manual, DDI 0487 Y Armv8, for Armv8-A architecture profile Arm® Cortex®-A77 Core Technical 101111 Y Reference Manual 1.5 Feedback 1.5.1 Feedback on this product If you have any comments or suggestions about this product, contact your supplier and give: The product name. The product revision or version. An explanation with as much information as you can provide. Include symptoms and diagnostic procedures if appropriate. 1.5.2 Feedback on content If you have comments on content, send an e-mail to errata@arm.com and give: The title: Arm® Cortex®-A77 Core Software Optimization Guide. The number: PJDOC-466751330-8482. If applicable, the page number(s) to which your comments refer. A concise explanation of your comments. Arm also welcomes general suggestions for additions and improvements. Arm tests the PDF only in Adobe Acrobat and Acrobat Reader, and cannot guarantee the quality of the represented document when used with any other PDF reader. Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 8 of 68
9 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 About this document 2 About this document This document contains a guide to the Cortex-A77 core micro-architecture with a view to aiding software optimization. 2.1 Scope This document describes aspects of the Cortex-A77 core micro-architecture that influence software performance. Micro-architectural detail is limited to that which is useful for software optimization. This documentation extends only to software visible behavior of the Cortex-A77 core and not to the hardware rationale behind the behavior. 2.2 Product overview The Cortex-A77 core is a high-performance and low-power Arm product that implements the Armv8-A architecture with support for the Armv8.2-A extension, including the RAS extension, the Load acquire (LDAPR) instructions introduced in the Armv8.3-A extension, and the dot product instructions introduced in the Armv8.4-A extension. The Cortex-A77 core has a Level 1 (L1) memory system and a private, integrated Level 2 (L2) cache. It also includes a superscalar, variable-length, out-of-order pipeline. The Cortex-A77 core is implemented inside the DynamIQ™ Shared Unit (DSU) cluster. For more information, see the Arm® DynamIQ™ Shared Unit Technical Reference Manual. 2.2.1 Pipeline overview The following figure describes the high-level Cortex-A77 instruction processing pipeline. Instructions are first fetched and then decoded into internal Macro-OPerations (MOPs). From there, the MOPs proceed through register renaming and dispatch stages. A MOP can be split into two Micro-OPerations (µOPs) further down the pipeline after the decode stage. Once dispatched, µOPs wait for their operands and issue out-of-order to one of twelve issue pipelines. Each issue pipeline can accept one µOP per cycle. Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 9 of 68
10 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 About this document Figure 1: Cortex-A77 core pipeline Branch 0 Branch 1 Fetch Decode, Rename, Integer Single-Cycle 0 Dispatch Integer Single-Cycle 1 Integer Single /Multi-Cycle 0 Integer Single /Multi-Cycle 1 Issue FP/ASIMD 0 FP/ASIMD 1 Load/Store 0 Load/Store 1 Store data 0 Store data 1 IN ORDER OUT OF ORDER The execution pipelines support different types of operations, as shown in the following table. Table 2: Cortex-A77 core operations Instruction groups Instructions Branch 0/1 Branch µOPs Integer Single-Cycle Integer ALU µOPs 0/1 Integer Single/Multi- Integer shift-ALU, multiply, divide, CRC and sum-of-absolute- cycle 0/1 differences µOPs Load/Store 0/1 Load, Store address generation and special memory µOPs Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 10 of 68
11 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 About this document Instruction groups Instructions Store data 0/1 Store data µOPs FP/ASIMD-0 ASIMD ALU, ASIMD misc, ASIMD integer multiply, FP convert, FP misc, FP add, FP multiply, FP divide, FP sqrt, crypto µOPs, store data µOPs FP/ASIMD-1 ASIMD ALU, ASIMD misc, FP misc, FP add, FP multiply, ASIMD shift µOPs, store data µOPs, crypto µOPs. Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 11 of 68
12 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics 3 Instruction characteristics 3.1 Instruction tables This chapter describes high-level performance characteristics for most Armv8.2-A A32, T32, and A64 instructions. A series of tables summarize the effective execution latency and throughput (instruction bandwidth per cycle), pipelines utilized, and special behaviors associated with each group of instructions. Utilized pipelines correspond to the execution pipelines described in chapter 2. In the tables below, Exec Latency is defined as the minimum latency seen by an operation dependent on an instruction in the described group. In the tables below, Execution Throughput is defined as the maximum throughput (in instructions per cycle) of the specified instruction group that can be achieved in the entirety of the Cortex-A77 microarchitecture. 3.2 Legend for reading the utilized pipelines Table 3: Cortex-A77 core pipeline names and symbols Pipeline name Symbol used in tables Branch 0/1 B Integer single Cycle 0/1 S Integer single Cycle 0/1 and single/multicycle 0/1 I Integer single/multicycle 0/1 M Integer multicycle 0 M0 Load/Store 0/1 L Store data 0/1 D FP/ASIMD 0/1 V FP/ASIMD 0 V0 FP/ASIMD 1 V1 Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 12 of 68
13 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics 3.3 Branch instructions Table 4: AArch64 Branch instructions Instruction Group AArch64 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Branch, immed B 1 2 B - Branch, register BR, RET 1 2 B - Branch and link, immed BL 1 2 B - Branch and link, register BLR 1 2 B - Compare and branch CBZ, CBNZ, 1 2 B - TBZ, TBNZ Table 5: AArch32 Branch instructions Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Branch, immed B 1 2 B - Branch, register BX 1 2 B - Branch and link, immed BL, BLX 1 2 B - Branch and link, register BLX 1 2 B - Compare and branch CBZ, CBNZ 1 2 B - 3.4 Arithmetic and logical instructions Table 6: AArch64 Arithmetic and logical instructions Instruction Group AArch64 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Arithmetic, basic ADD, ADC, 1 4 I - SUB, SBC Arithmetic, basic, flag set ADDS, ADCS, 1 3 I - SUBS, SBCS Arithmetic, extend and ADD{S}, 2 2 M - shift SUB{S} Arithmetic, LSL shift, shift ADD, SUB 1 4 I - <= 4 Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 13 of 68
14 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics Instruction Group AArch64 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Arithmetic, flag set, LSL ADDS, SUBS 1 3 I - shift, shift <= 4 Arithmetic, LSR/ASR/ROR ADD{S}, 2 2 M - shift or LSL shift > 4 SUB{S} Conditional compare CCMN, CCMP 1 3 I - Conditional select CSEL, CSINC, 1 3 I - CSINV, CSNEG Logical, basic AND{S}, 1 3 I - BIC{S}, EON, EOR, ORN, ORR Logical, shift, no flagset AND, BIC, 1 4 I - EON, EOR, ORN, ORR Logical, shift, flagset ANDS, BICS 2 2 M - Table 7: AArch32 Arithmetic and logical instructions Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines ALU, basic, no flagset ADD, ADC, 1 4 I - ADR, AND, BIC, EOR, ORN, ORR, RSB, RSC, SUB, SBC ALU, basic, flagset ADDS, ADCS, 1 3 I - ANDS, BICS, CMN, CMP, EORS, ORNS, ORRS, RSBS, RSCS, SUBS, SBCS, TEQ, TST ALU, basic, shift by (same as ALU 2 1 I, M0 - register, conditional basic, flagset and no flagset) Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 14 of 68
15 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines ALU, basic, shift by (same as 2 1 M0 - register, unconditional, ALU, basic, flagset flagset) Arithmetic, shift by ADD, ADC, 2 1 M0 - register, unconditional, RSB, RSC, no flagset SUB, SBC Logical, shift by register, AND, BIC, 1 1 M0 - unconditional, no flagset EOR, ORN, ORR Arithmetic, LSL shift by ADD, ADC, 1 4 I - immed, shift <= 4, RSB, RSC, unconditional, no flagset SUB, SBC Arithmetic, LSL shift by ADDS, ADCS, 1 3 I - immed, shift <= 4, RSBS, RSCS, unconditional, flagset SUBS, SBCS Arithmetic, LSL shift by ADD{S}, 1 1 M0 - immed, shift <= 4, ADC{S}, conditional RSB{S}, RSC{S}, SUB{S}, SBC{S} Arithmetic, LSR/ASR/ROR ADD{S}, 2 2 M - shift by immed or LSL ADC{S}, shift by immed > 4, RSB{S}, unconditional RSC{S}, SUB{S}, SBC{S} Arithmetic, LSR/ASR/ROR ADD{S}, 2 1 M0 - shift by immed or LSL ADC{S}, shift by immed > 4, RSB{S}, conditional RSC{S}, SUB{S}, SBC{S} Logical, shift by immed, AND, BIC, 1 4 I - no flagset, unconditional EOR, ORN, ORR Logical, shift by immed, AND, BIC, 1 1 M0 - no flagset, conditional EOR, ORN, ORR Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 15 of 68
16 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Logical, shift by immed, ANDS, BICS, 2 2 M - flagset, unconditional EORS, ORNS, ORRS Logical, shift by immed, ANDS, BICS, 2 1 M0 - flagset, conditional EORS, ORNS, ORRS Test/Compare, shift by CMN, CMP, 2 2 M - immed TEQ, TST Branch forms +1 2 +B 1 Branch forms are possible when the instruction destination register is the PC. For those cases, an additional branch µOP is required. This adds 1 cycle to the latency. 3.5 Move and shift instructions Table 8: AArch32 Move and shift instructions Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Move, basic MOV, 1 4 I - MOVW, MVN Move, basic, flagset MOVS, MVNS 1 3 I Move, shift by immed, no ASR, LSL, LSR, 1 4 I - flagset ROR, RRX, MVN Move, shift by immed, ASRS, LSLS, 2 2 M - flagset LSRS, RORS, RRXS, MVNS Move, shift by register, ASR, LSL, LSR, 1 4 I - no flagset, unconditional ROR, RRX, MVN Move, shift by register, ASR, LSL, LSR, 2 2 I - no flagset, conditional ROR, RRX, MVN Move, shift by register, ASRS, LSLS, 2 1 M0 - flagset LSRS, RORS, RRXS, MVNS Move, top MOVT 1 4 I - Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 16 of 68
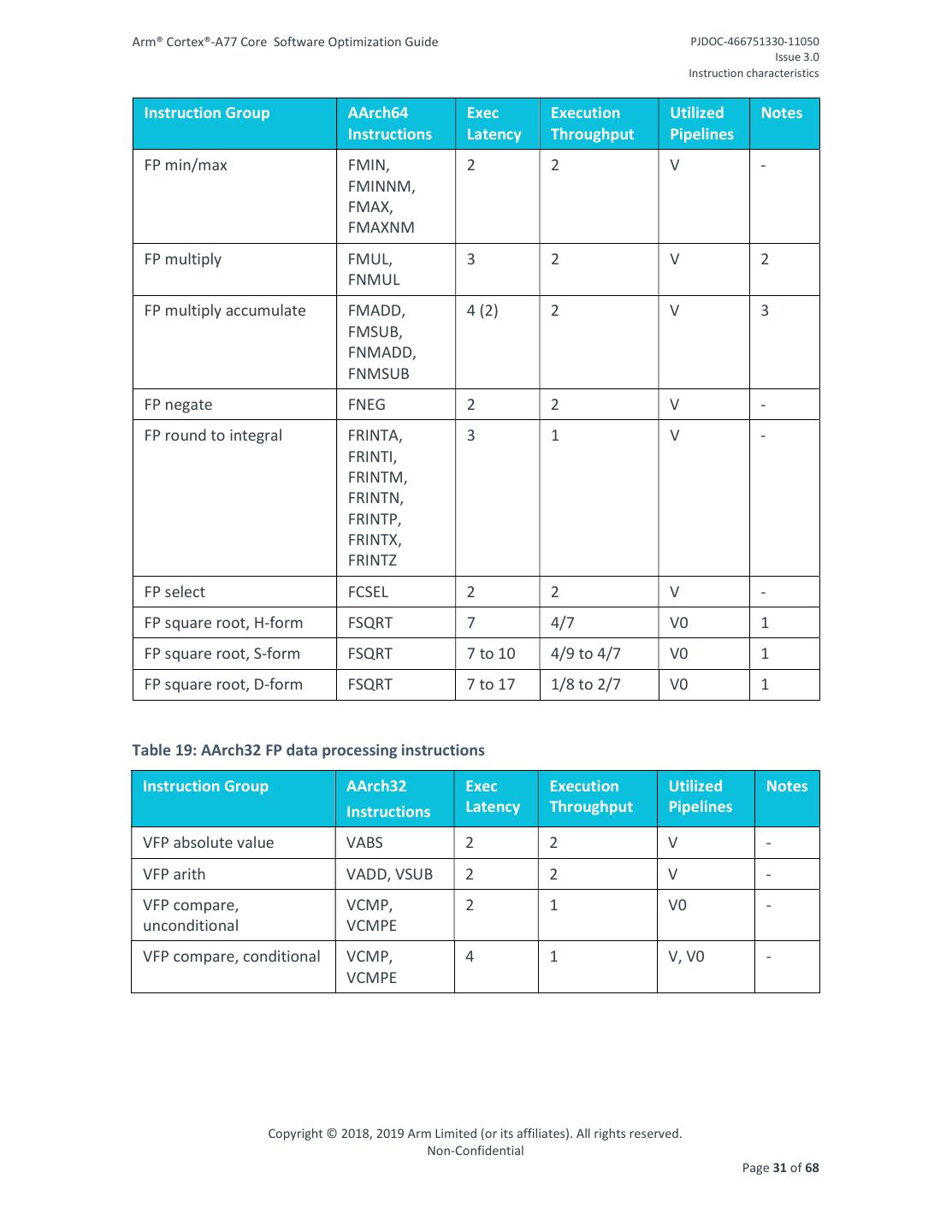
17 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Move, branch forms +1 2 +B - 3.6 Divide and multiply instructions Table 9: AArch64 Divide and multiply instructions Instruction Group AArch64 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Divide, W-form SDIV, UDIV 5 to 12 1/12 to 1/5 M0 1 Divide, X-form SDIV, UDIV 5 to 20 1/20 to 1/5 M0 1 Multiply accumulate, W- MADD, 2(1) 1 M0 2 form MSUB Multiply accumulate, X- MADD, 2(1) 1 M0 2 form MSUB Multiply accumulate long SMADDL, 2(1) 1 M0 2 SMSUBL, UMADDL, UMSUBL Multiply high SMULH, 3 1 M0 2 UMULH Table 10: AArch32 Divide and multiply instructions Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Divide SDIV, UDIV 5 to 12 1/12 to 1/5 M0 1 Multiply MUL, 2 1 M0 - SMULBB, SMULBT, SMULTB, SMULTT, SMULWB, SMULWT, SMMUL{R}, SMUAD{X}, SMUSD{X} Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 17 of 68
18 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Multiply accumulate, MLA, MLS, 3 1 M0, I - conditional SMLABB, SMLABT, SMLATB, SMLATT, SMLAWB, SMLAWT, SMLAD{X}, SMLSD{X}, SMMLA{R}, SMMLS{R} Multiply accumulate, MLA, MLS, 2(1) 1 M0 2 unconditional SMLABB, SMLABT, SMLATB, SMLATT, SMLAWB, SMLAWT, SMLAD{X}, SMLSD{X}, SMMLA{R}, SMMLS{R} Multiply accumulate UMAAL 4 1 I, M0 - accumulate long, conditional Multiply accumulate UMAAL 3 1 I, M0 - accumulate long, unconditional Multiply accumulate long, SMLAL, 2 1 M0, I - no flagset SMLALBB, SMLALBT, SMLALTB, SMLALTT, SMLALD{X}, SMLSLD{X}, UMLAL Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 18 of 68
19 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Multiply accumulate long, SMLAL, 2 1 M0, I, M - flagset SMLALBB, SMLALBT, SMLALTB, SMLALTT, SMLALD{X}, SMLSLD{X}, UMLAL Multiply long, SMULL, 2 1 M0 - unconditional, no flagset UMULL Multiply long, SMULLS, 3 1 M0, I - unconditional, flagset UMULLS Multiply long, conditional SMULL{S}, 3 1 M0, I - UMULL{S} 1. Integer divides are performed using an iterative algorithm and block any subsequent divide operations until complete. Early termination is possible, depending upon the data values. 2. Multiply-accumulate pipelines support late-forwarding of accumulate operands from similar µOPs, allowing a typical sequence of multiply-accumulate µOPs to issue one every N cycles (accumulate latency N shown in parentheses). Accumulator forwarding is not supported for consumers of 64 bit multiply high operations. 3. Multiplies that set the condition flags require an additional integer µOP. 3.7 Saturating and parallel arithmetic instructions Table 11: AArch32 Saturating and parallel arithmetic instructions Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Parallel arith, SADD16, 2 1 M - unconditional SADD8, SSUB16, SSUB8, UADD16, UADD8, USUB16, USUB8 Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 19 of 68
20 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Parallel arith, conditional SADD16, 2(4) 1 M0, I 1 SADD8, SSUB16, SSUB8, UADD16, UADD8, USUB16, USUB8 Parallel arith with SASX, SSAX, 3 2 I, M - exchange, unconditional UASX, USAX Parallel arith with SASX, SSAX, 3(5) 1 I, M0 1 exchange, conditional UASX, USAX Parallel halving arith, SHADD16, 2 2 M - unconditional SHADD8, SHSUB16, SHSUB8, UHADD16, UHADD8, UHSUB16, UHSUB8 Parallel halving arith, SHADD16, 2 1 M0 - conditional SHADD8, SHSUB16, SHSUB8, UHADD16, UHADD8, UHSUB16, UHSUB8 Parallel halving arith with SHASX, 3 1 I, M0 - exchange SHSAX, UHASX, UHSAX Parallel saturating arith, QADD16, 2 2 M - unconditional QADD8, QSUB16, QSUB8, UQADD16, UQADD8, UQSUB16, UQSUB8 Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 20 of 68
21 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Parallel saturating arith, QADD16, 2 1 M0 - conditional QADD8, QSUB16, QSUB8, UQADD16, UQADD8, UQSUB16, UQSUB8 Parallel saturating arith QASX, QSAX, 3 2 I, M - with exchange, UQASX, unconditional UQSAX Parallel saturating arith QASX, QSAX, 3(5) 1 I, M0 - with exchange, UQASX, conditional UQSAX Saturate, unconditional SSAT, 2 2 M - SSAT16, USAT, USAT16 Saturate, conditional SSAT, 2 1 M0 - SSAT16, USAT, USAT16 Saturating arith, QADD, QSUB 2 2 M - unconditional Saturating arith, QADD, QSUB 2 1 M0 - conditional Saturating doubling arith, QDADD, 4 1 M, M - unconditional QDSUB Saturating doubling arith QDADD, 4 1 M, M0 - conditional QDSUB Branch forms are possible when the instruction destination register is the PC. For those cases, an additional branch µOP is required. This adds 1 cycle to the latency. Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 21 of 68
22 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics 3.8 Miscellaneous data-processing instructions Table 12: AArch64 Miscellaneous data-processing instructions Instruction Group AArch64 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Address generation ADR, ADRP 1 4 I - Bitfield extract, one reg EXTR 1 4 I - Bitfield extract, two regs EXTR 3 2 I, M - Bitfield move, basic SBFM, UBFM 1 4 I - Bitfield move, insert BFM 2 2 M - Count leading CLS, CLZ 1 4 I - Move immed MOVN, 1 4 I - MOVK, MOVZ Reverse bits/bytes RBIT, REV, 1 4 I - REV16, REV32 Variable shift ASRV, LSLV, 1 4 I - LSRV, RORV Table 13: AArch32 Miscellaneous data-processing instructions Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Bit field extract SBFX, UBFX 1 4 I - Bit field insert/clear, BFI, BFC 2 2 M - unconditional Bit field insert/clear, BFI, BFC 2 1 M0 - conditional Count leading zeros CLZ 1 4 I - Pack halfword, PKH 2 2 M - unconditional Pack halfword, PKH 2 1 M0 - conditional Reverse bits/bytes RBIT, REV, 1 4 I - REV16, REVSH Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 22 of 68
23 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Select bytes, SEL 1 4 I - unconditional Select bytes, conditional SEL 2 2 I - Sign/zero extend, normal SXTB, SXTH, 1 4 I - UXTB, UXTH Sign/zero extend, SXTB16, 2 2 M - parallel, unconditional UXTB16 Sign/zero extend, SXTB16, 2 1 M0 - parallel, conditional UXTB16 Sign/zero extend and SXTAB, 2 2 M - add, normal, SXTAH, unconditional UXTAB, UXTAH Sign/zero extend and SXTAB, 2 1 M0 - add, normal, conditional SXTAH, UXTAB, UXTAH Sign/zero extend and SXTAB16, 4 1/2 M - add, parallel, UXTAB16 unconditional Sign/zero extend and SXTAB16, 4 1/2 M, M0 - add, parallel, conditional UXTAB16 Sum of absolute USAD8, 2 1 M0 - differences, USADA8 unconditional Sum of absolute USAD8, 2 1 M0, I - differences, conditional USADA8 3.9 Load instructions Table 14: AArch64 Load instructions Instruction Group AArch64 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Load register, literal LDR, LDRSW, 4 2 L - PRFM Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 23 of 68
24 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics Instruction Group AArch64 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Load register, unscaled LDUR, 4 2 L - immed LDURB, LDURH, LDURSB, LDURSH, LDURSW, PRFUM Load register, immed LDR, LDRB, 4 2 L, I - post-index LDRH, LDRSB, LDRSH, LDRSW Load register, immed pre- LDR, LDRB, 4 2 L, I - index LDRH, LDRSB, LDRSH, LDRSW Load register, immed LDTR, LDTRB, 4 2 L - unprivileged LDTRH, LDTRSB, LDTRSH, LDTRSW Load register, unsigned LDR, LDRB, 4 2 L - immed LDRH, LDRSB, LDRSH, LDRSW, PRFM Load register, register LDR, LDRB, 4 2 L - offset, basic LDRH, LDRSB, LDRSH, LDRSW, PRFM Load register, register LDR, LDRSW, 4 2 L - offset, scale by 4/8 PRFM Load register, register LDRH, LDRSH 5 2 I, L - offset, scale by 2 Load register, register LDR, LDRB, 4 2 L - offset, extend LDRH, LDRSB, LDRSH, LDRSW, PRFM Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 24 of 68
25 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics Instruction Group AArch64 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Load register, register LDR, LDRSW, 4 2 L - offset, extend, scale by PRFM 4/8 Load register, register LDRH, LDRSH 5 2 I, L - offset, extend, scale by 2 Load pair, signed immed LDP, LDNP 4 2 L - offset, normal, W-form Load pair, signed immed LDP, LDNP 4 1 L - offset, normal, X-form Load pair, signed immed LDPSW 5 1 I, L - offset, signed words, base! = SP Load pair, signed immed LDPSW 5 1 I, L - offset, signed words, base = SP Load pair, immed post- LDP 4 1 L, I - index, normal Load pair, immed post- LDPSW 5 1 I, L - index, signed words Load pair, immed pre- LDP 4 1 L, I - index, normal Load pair, immed pre- LDPSW 5 1 I, L - index, signed words Table 15: AArch32 Load instructions Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Load, immed offset LDR{T}, 4 2 L 1,2 LDRB{T}, LDRD, LDRH{T}, LDRSB{T}, LDRSH{T} Load, register offset, plus LDR, LDRB, 4 2 L 1.2 LDRD, LDRH, LDRSB, LDRSH Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 25 of 68
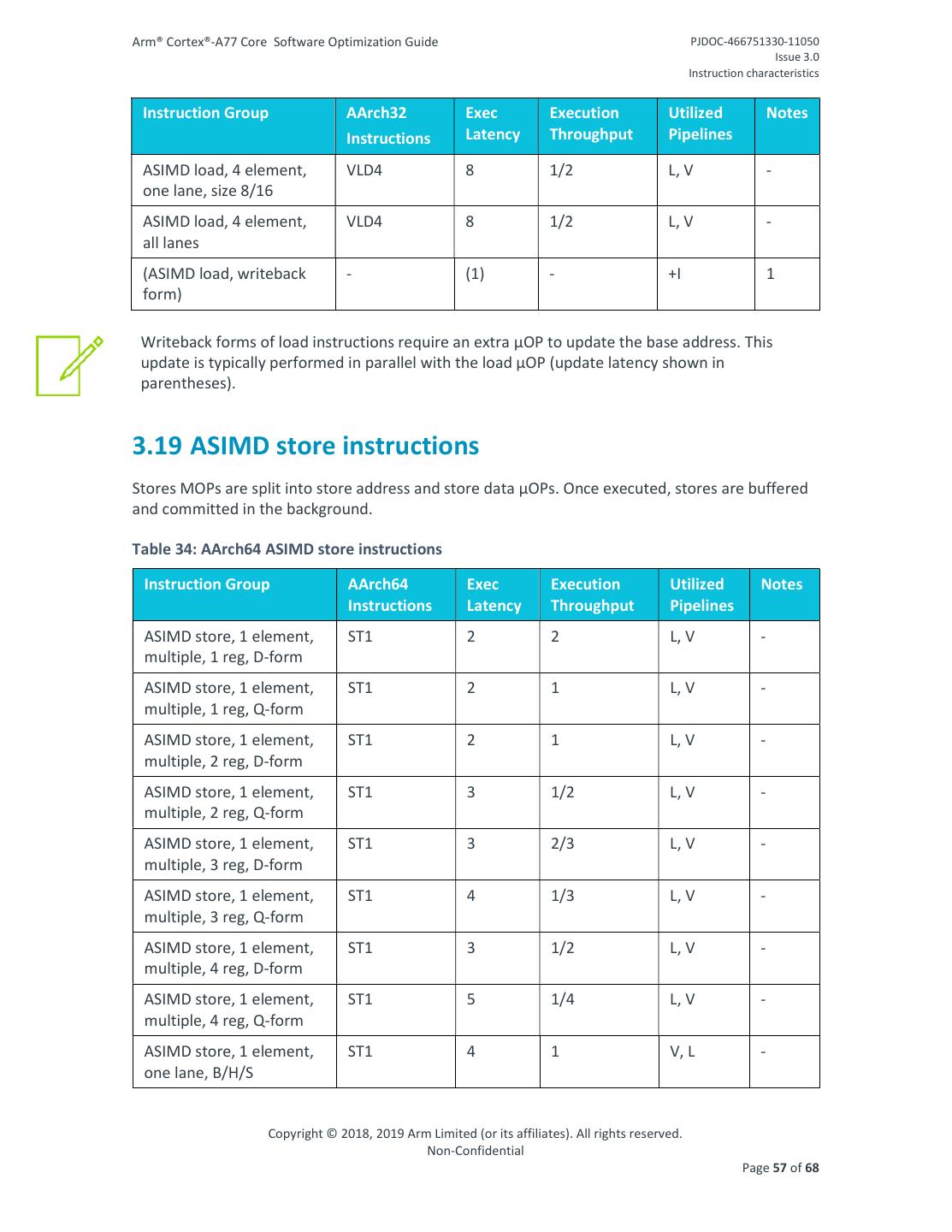
26 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Load, register offset, LDR, LDRB, 5 2 I, L 1,2 minus LDRD, LDRH, LDRSB, LDRSH Load, scaled register LDR, LDRB 4 2 L 1 offset, plus, LSL2 Load, scaled register LDR, LDRB, 5 2 I, L 1 offset, other LDRH, LDRSB, LDRSH Load, immed pre-indexed LDR, LDRB, 4 2 L, I 1,2 LDRD, LDRH, LDRSB, LDRSH Load, register pre- LDR, LDRB, 5 2 I, L, M 3 indexed, shift Rm, plus LDRH, LDRSB, and minus LDRSH Load, register pre- LDRD 4 2 L, I - indexed Load, register pre- LDRD 5 1 1/2 L, I - indexed, cond Load, scaled register pre- LDR, LDRB 4 2 L, I 1 indexed, plus, LSL2 Load, scaled register pre- LDR, LDRB 4 2 L, I - indexed, unshifted Load, immed post- LDR{T}, 4 2 L, I 1,2 indexed LDRB{T}, LDRD, LDRH{T}, LDRSB{T}, LDRSH{T} Load, register post- LDR, LDRB, 5 2 I, L - indexed LDRH{T}, LDRSB{T}, LDRSH{T} Load, register post- LDRD 4 2 L, I - indexed Load, register post- LDRT, LDRBT 5 2 I, L - indexed Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 26 of 68
27 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Load, scaled register LDR, LDRB 4 2 L, M 3 post-indexed Load, scaled register LDRT, LDRBT 4 2 L, M 3 post-indexed Preload, immed offset PLD, PLDW 4 2 L - Preload, register offset, PLD, PLDW 4 2 L - plus Preload, register offset, PLD, PLDW 5 2 I, L - minus Preload, scaled register PLD, PLDW 5 2 I, L - offset, plus LSL2 Preload, scaled register PLD, PLDW 5 2 I, L - offset, other Load multiple, no LDMIA, N 2/R L 1, 4, writeback, base reg not in LDMIB, 5 list LDMDA, LDMDB Load multiple, no LDMIA, 1+ N 2/R I, L 1, 4, writeback, base reg in list LDMIB, 5 LDMDA, LDMDB Load multiple, writeback LDMIA, 1+N 2/R L, I 1, 4, LDMIB, 5 LDMDA, LDMDB, POP (Load, all branch forms) - +1 - +B 6 1. Condition loads have an extra µOP which goes down pipeline I and have 1 cycle extra latency compared to their unconditional counterparts. 2. The throughput of conditional LDRD is 1 as compared to a throughput of 2 for unconditional LDRD. 3. The address update op for addressing forms which use reg scaled reg, or reg extend goes down pipeline ‘I’ if the shift is LSL where the shift value is less than or equal to 4. 4. N is floor [ (num_reg+3)/4]. 5. R is floor [(num_reg +1)/2]. 6. Branch forms are possible when the instruction destination register is the PC. For those cases, an additional branch µOP is required. This adds 1 cycle to the latency. Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 27 of 68
28 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics 3.10 Store instructions The following tables describes performance characteristics for standard store instructions. Stores µOPs are split into address and data µOPs. Once executed, stores are buffered and committed in the background. Table 16: AArch64 Store instructions Instruction Group AArch64 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Store register, unscaled STUR, STURB, 1 2 L, D - immed STURH Store register, immed STR, STRB, 1 2 L, D - post-index STRH Store register, immed STR, STRB, 1 2 L, D - pre-index STRH Store register, immed STTR, STTRB, 1 2 L, D - unprivileged STTRH Store register, unsigned STR, STRB, 1 2 L, D - immed STRH Store register, register STR, STRB, 1 2 L, D - offset, basic STRH Store register, register STR 1 2 L, D - offset, scaled by 4/8 Store register, register STRH 2 3/2 I, L, D - offset, scaled by 2 Store register, register STR, STRB, 1 2 L, D - offset, extend STRH Store register, register STR 1 2 L, D - offset, extend, scale by 4/8 Store register, register STRH 2 3/2 I, L, D - offset, extend, scale by 1 Store pair, immed offset, STP, STNP 1 2 L, D - W-form Store pair, immed offset, STP, STNP 1 1 L, D - X-form Store pair, immed post- STP 1 1 L, D - index, W-form Store pair, immed post- STP 1 1 L, D - index, X-form Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 28 of 68
29 .Arm® Cortex®-A77 Core Software Optimization Guide PJDOC-466751330-11050 Issue 3.0 Instruction characteristics Instruction Group AArch64 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Store pair, immed pre- STP 1 1 L, D - index, W-form Store pair, immed pre- STP 1 1 L, D - index, X-form Table 17: AArch32 Store instructions Instruction Group AArch32 Exec Execution Utilized Notes Instructions Latency Throughput Pipelines Store, immed offset STR{T}, 1 2 L, D - STRB{T}, STRD, STRH{T} Store, register offset, plus STR, STRB, 1 2 L, D - STRD, STRH Store, register offset, STR, STRB, 1 2 L, D - minus STRD, STRH Store, register offset, no STR, STRB 1 2 L, D - shift, plus Store, scaled register STR, STRB 1 2 L, D - offset, plus LSL2 Store, scaled register STR, STRB 2 3/2 I, L, D - offset, other Store, scaled register STR, STRB 2 3/2 I, L, D - offset, minus Store, immed pre- STR, STRB, 1 3/2 I, L, D - indexed STRD, STRH Store, register pre- STR, STRB, 1 3/2 L, D - indexed, plus, no shift STRD, STRH Store, register pre- STR, STRB, 2 1 I, L, D - indexed, minus STRD, STRH Store, scaled register pre- STR, STRB 1 3/2 L, D - indexed, plus LSL2 Store, scaled register pre- STR, STRB 2 1 I, L, D, M 1 indexed, other Copyright © 2018, 2019 Arm Limited (or its affiliates). All rights reserved. Non-Confidential Page 29 of 68
相关推荐

加关注
3秒后跳转登录页面
去登陆

