





























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/dbaplus/infra_devops_in_weibo?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
孙燕 - 微博广告全景运维之路
分享
点赞
0
收藏
0
下载 0
微博广告基础运维负责人孙燕分享《微博广告之全景运维之路》
展开查看详情
1 . 微博广告全景运维之路 演讲人:孙燕 2019 中国数据智能管理峰会
2 . 前言 微博广告是微博重要且稳定的收入来源 微博广告服务稳定性为重中之重 微博广告运维担负 资产管理,服务稳定性,故障应急处理,成本控制等责任 2019 中国数据智能管理峰会
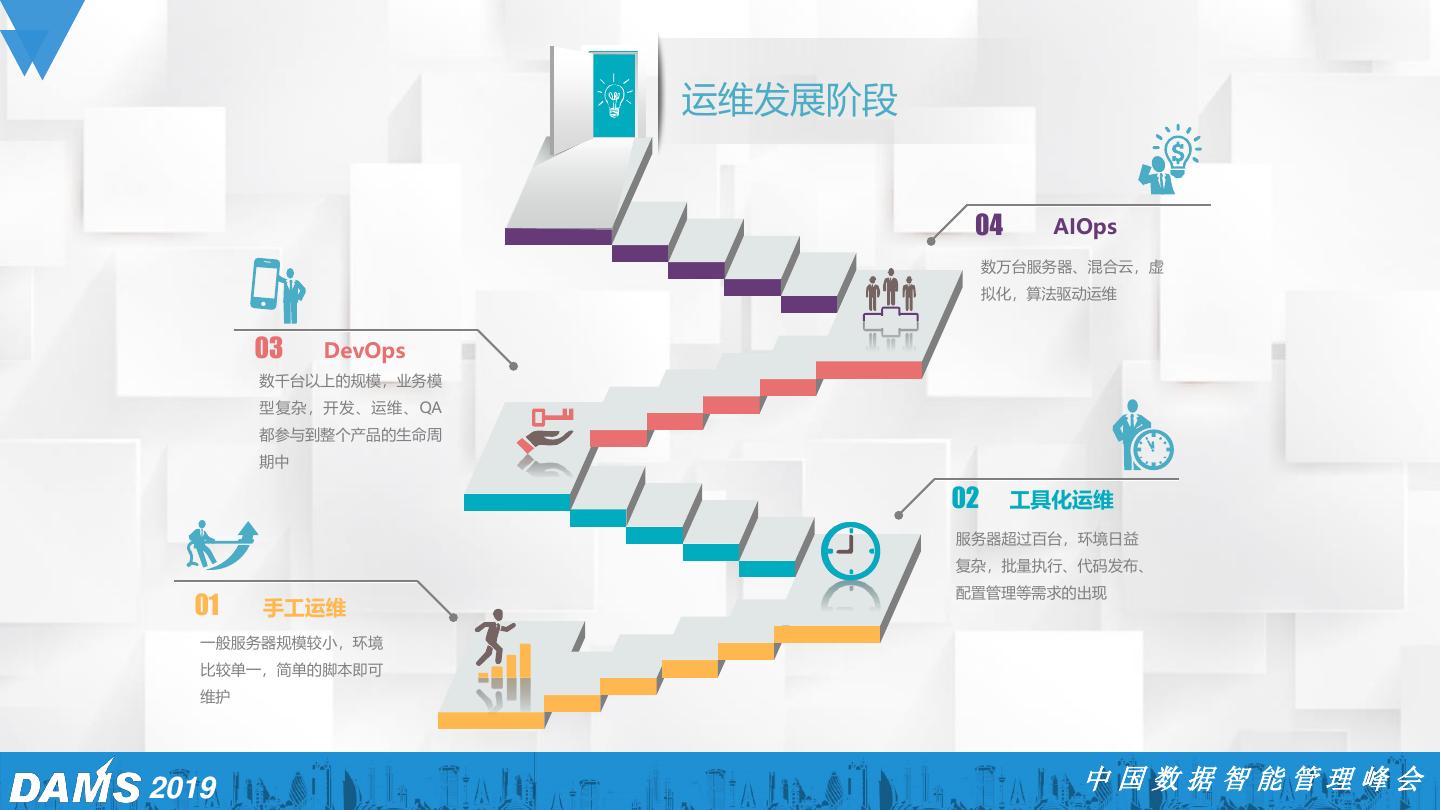
3 . 运维发展阶段 04 AIOps 数万台服务器、混合云,虚 拟化,算法驱动运维 03 DevOps 数千台以上的规模,业务模 型复杂,开发、运维、QA 都参与到整个产品的生命周 期中 02 工具化运维 服务器超过百台,环境日益 复杂,批量执行、代码发布、 配置管理等需求的出现 01 手工运维 一般服务器规模较小,环境 比较单一,简单的脚本即可 维护 2019 中国数据智能管理峰会
4 .微博广告运维痛点 1 服务器数量 3000+ 2 3 业务线及辅助资源多样 资产管理 产品迭代快,依赖关系复杂 虽然有统一的 4 流量变更,切换损失不可接受 CMDB,但线上的 环境不统一 变更、上下线变更 运行环境、依赖版 不能自动同步 上线难度大 本,测试环境和线 上环境不统一 代码托管方式不一 致,无法实现自动 运维成本高 化测试和上线 日常工作繁琐,手 工分配服务器、手 工变更服务,人工 维护配置 2019 中国数据智能管理峰会
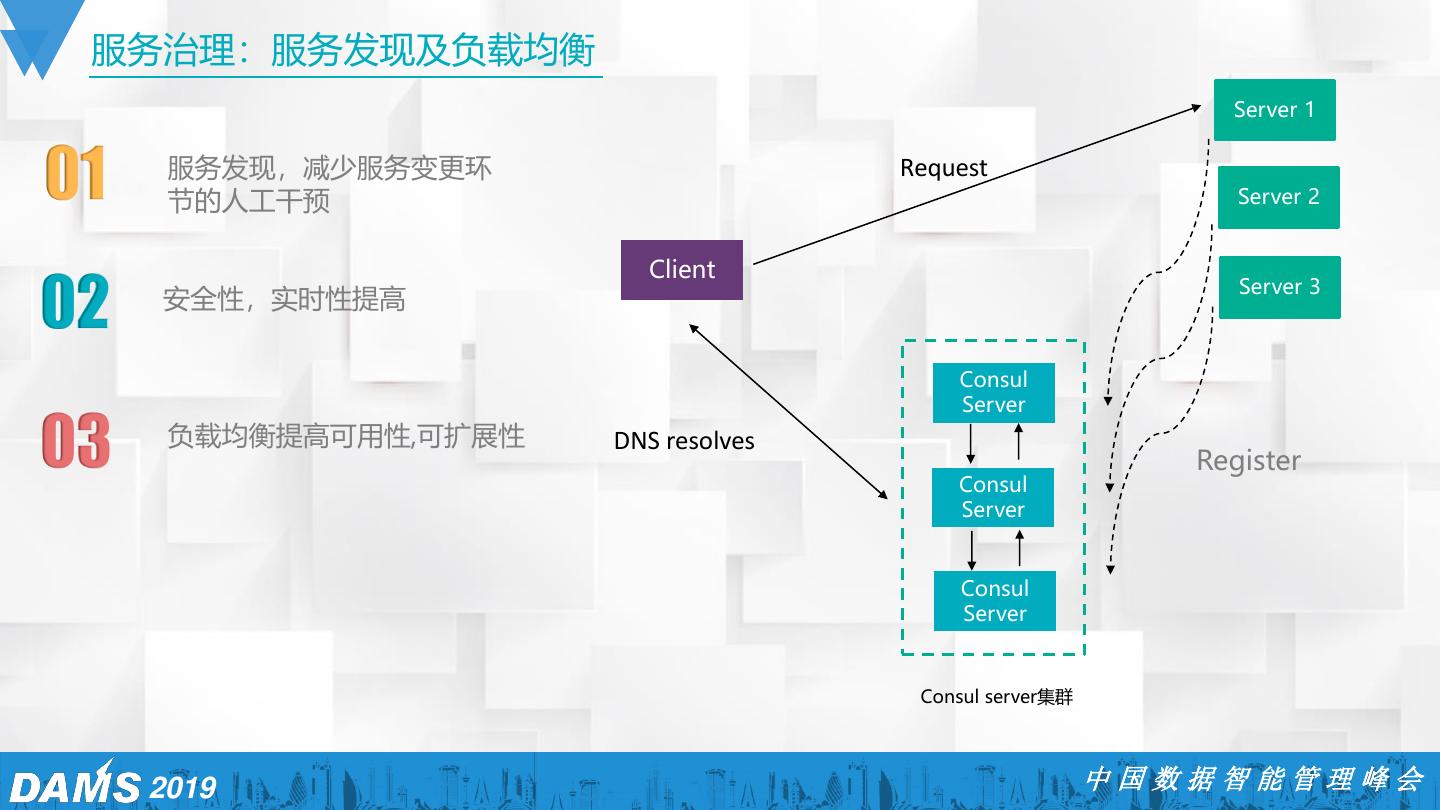
5 .微博广告运维方向 01 02 03 04 运维自动化 弹性计算 智能监控 服务治理 资源管理 、批量运维工具、 自动化扩缩容 、多云适配、 海量指标、 告警收敛、异 自动注册、自动发现、熔 事件收集、配置管理 压测和冗余度评估 、 分级 常检测、故障定位 断机制,负载均衡 水位线 2019 中国数据智能管理峰会
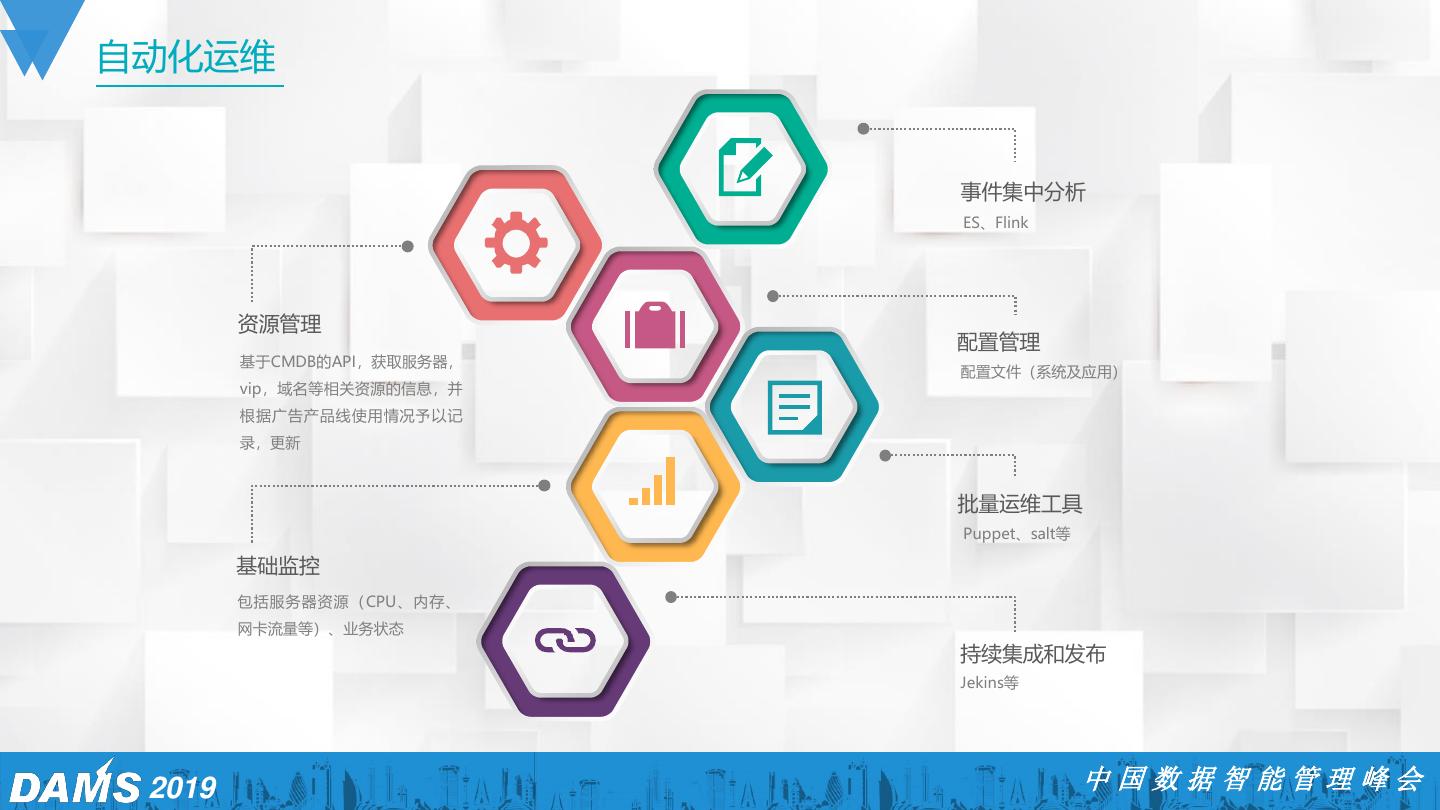
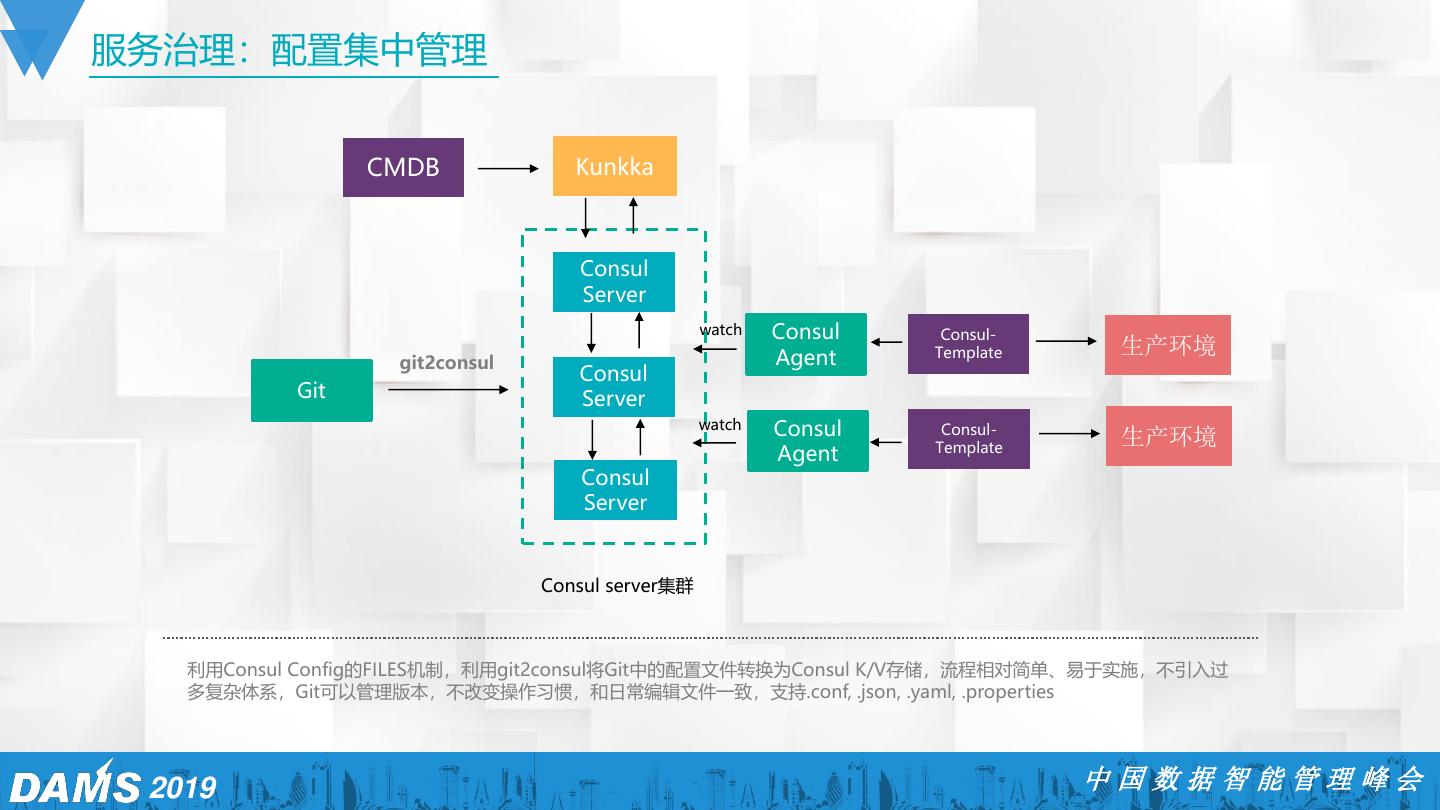
6 .自动化运维 事件集中分析 ES、Flink 资源管理 配置管理 基于CMDB的API,获取服务器, 配置文件(系统及应用) vip,域名等相关资源的信息,并 根据广告产品线使用情况予以记 录,更新 批量运维工具 Puppet、salt等 基础监控 包括服务器资源(CPU、内存、 网卡流量等)、业务状态 持续集成和发布 Jekins等 2019 中国数据智能管理峰会
7 .Kunkka组成 Kunkka自动化运维平台 主机 服务发现 工单系统 文件/命令下发 阿里云/华为云 服务注册 代码仓库 批量管理 VIP管理 服务扩缩容 测试 脚本仓库 DNS管理 服务配置 发布 日志审计 资产管理 配置中心 自动化上线 自助终端 2019 中国数据智能管理峰会
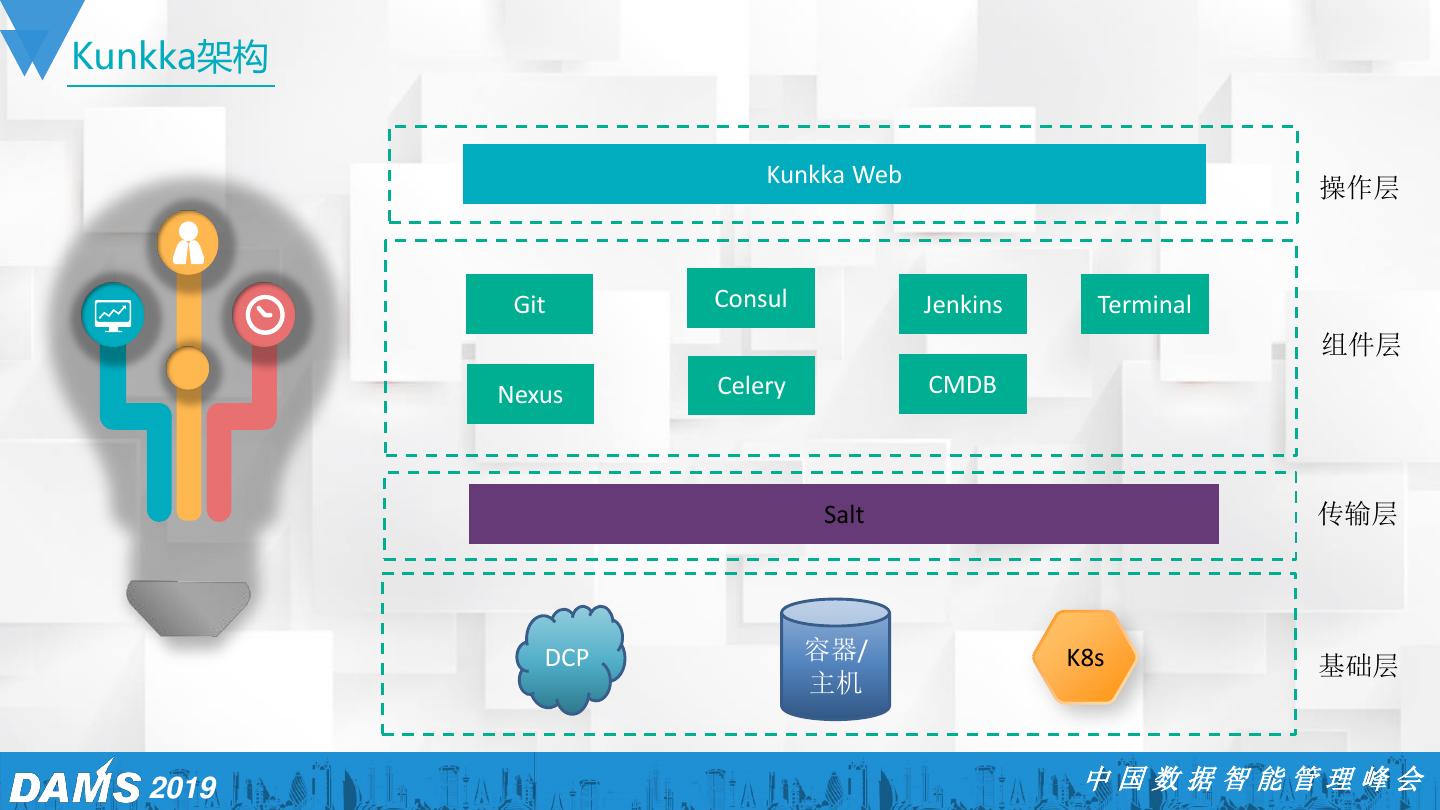
8 .Kunkka架构 Kunkka Web 操作层 Git Consul Jenkins Terminal 组件层 Nexus Celery CMDB Salt 传输层 DCP 容器/ K8s 基础层 主机 2019 中国数据智能管理峰会
9 .自动化上线 CI CD SaltStack 测试环境 Jenkins Slave Jenkins Jenkins Nexus 工单系统 SaltStack Master Slave Jenkins Kunkka 自动化测试 Slave 生产环境 Git 2019 中国数据智能管理峰会
10 . 01 02 03 04 运维自动化 弹性计算 智能监控 服务治理 资源管理 、批量运维工具、 自动化扩缩容 、多云适配、 海量指标、 告警收敛、异 自动注册、自动发现、熔 事件收集、配置管理 压测和冗余度评估 、 分级 常检测、故障定位 断机制,负载均衡 水位线 2019 中国数据智能管理峰会
11 .为什么需要弹性计算 产品方面 A 产品线多,依赖关系复杂,发 布和变更非常频繁 运营(收入)方面 B 大型活动、重要新闻等有计划 的推广需求 技术方面 C 热点事件、突发事件,瞬间峰 值高 2019 中国数据智能管理峰会
12 .传统的业务运维 预估 基础运维 优点: 立项 容量 评审 • 对传统项目而言,整体可控 缺点: • 申请周期太长,无法应对突发事 购买新机器 CMDB 件 • 无法准确预估容量,资源浪费严 重 机房上线 • 资源利用率较低,较难在业务间 共享 产品运维 服务部署 流量引入 报修置换 过期下架 2019 中国数据智能管理峰会
13 .弹性计算:实时动态扩缩容 01 多云适配 私有云、阿里云、华为云 02 在线压力检测 自动压测、容量预估 弹性计算 04 分级别决策 安全线、警戒线、致命线 03消耗度评测 通用评估公示和计算方法 2019 中国数据智能管理峰会
14 .弹性计算架构 业务指标监控 多云对接 私有云 自动压测 镜像市场 阿里云 决策系统 演练 下发通道 华为云 自动扩 扩容模版 缩容 Kunkka Oops DCP混合云平台 云服务商 2019 中国数据智能管理峰会
15 .决策系统 1 业务指标 2 容量预测 • 压测方法:按照一定步长减少业务服务池的实例数量 • 压测指标: 基于历史数据的: • 同比分析 • 环比分析 系统:Load,Cpu_idle,Iowait,Swap 业务:5xx错误比率,接口平均耗时 Action • 容量概况 • 流量趋势 • 辅助API • 扩缩容建议 2019 中国数据智能管理峰会
16 .容量评估方法 CPU ? Avg_Time? QPS? AVG_hits ! Ahits = 0.1 * avg1 + 0.5 * avg2+ 2 * avg3+ 4 * avg4+ 8 * avg5 消耗比 = 当前容量(Ahits)/最大容量(max_Ahtis) avg hits定义:通过各接口的耗时分布,对访问压力进行统一的量化处理,来表示某时刻单机的消耗 计算方法描述:对处于不同区间内的请求数加权求和,来拟合实际的单机消耗量 相比于传统的 QPS、AvgTime、CPU Load 等单一指标更准确。 消耗比 计算公式: 通过压测得出系统中单机最大容量,任意时刻系统的消耗度就是实际单机消耗量与单机最大容量之比。 2019 中国数据智能管理峰会
17 .分级治理:水位线 安全线 警戒线 致命线 水位线一段时间内稳定在安 水位线低于警戒线时,需要 水位线低于致命线时,必须 全线以上时,逐步进行缩容 逐步进行扩容,直到恢复 立即扩容 逐 步 缩 容 逐 步 扩 容 立 即 扩 容 虽然有了各种实时评估指标,但用什么标准决策依然是个难点。为此,我们在系统中引入了消耗比分级水位线。 具体来讲,就是划定三条线:安全线、警戒线和致命线, 消耗比水位线基于历史数据的经验值 2019 中国数据智能管理峰会
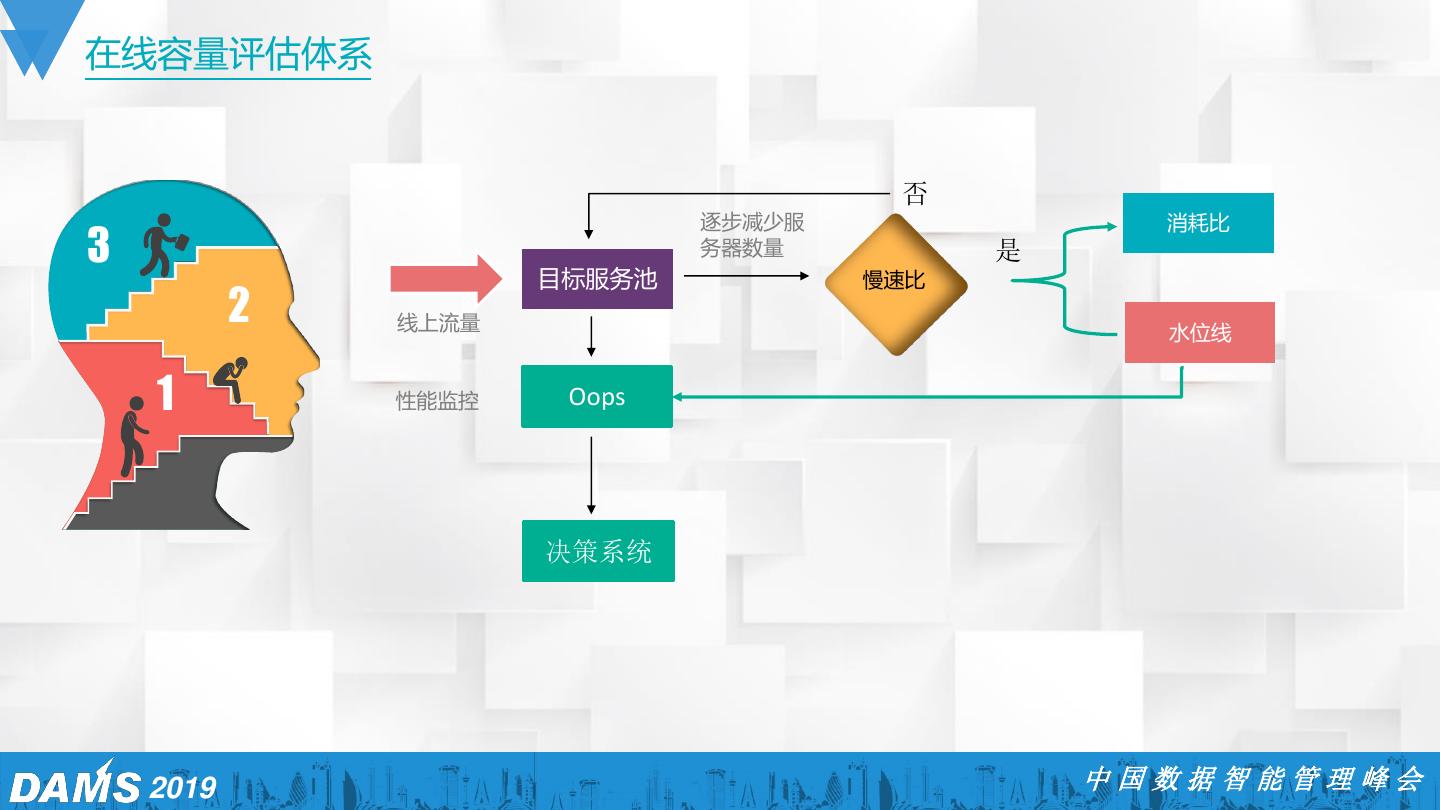
18 .在线容量评估体系 否 逐步减少服 消耗比 3 务器数量 是 目标服务池 慢速比 2 线上流量 水位线 1 性能监控 Oops 决策系统 2019 中国数据智能管理峰会
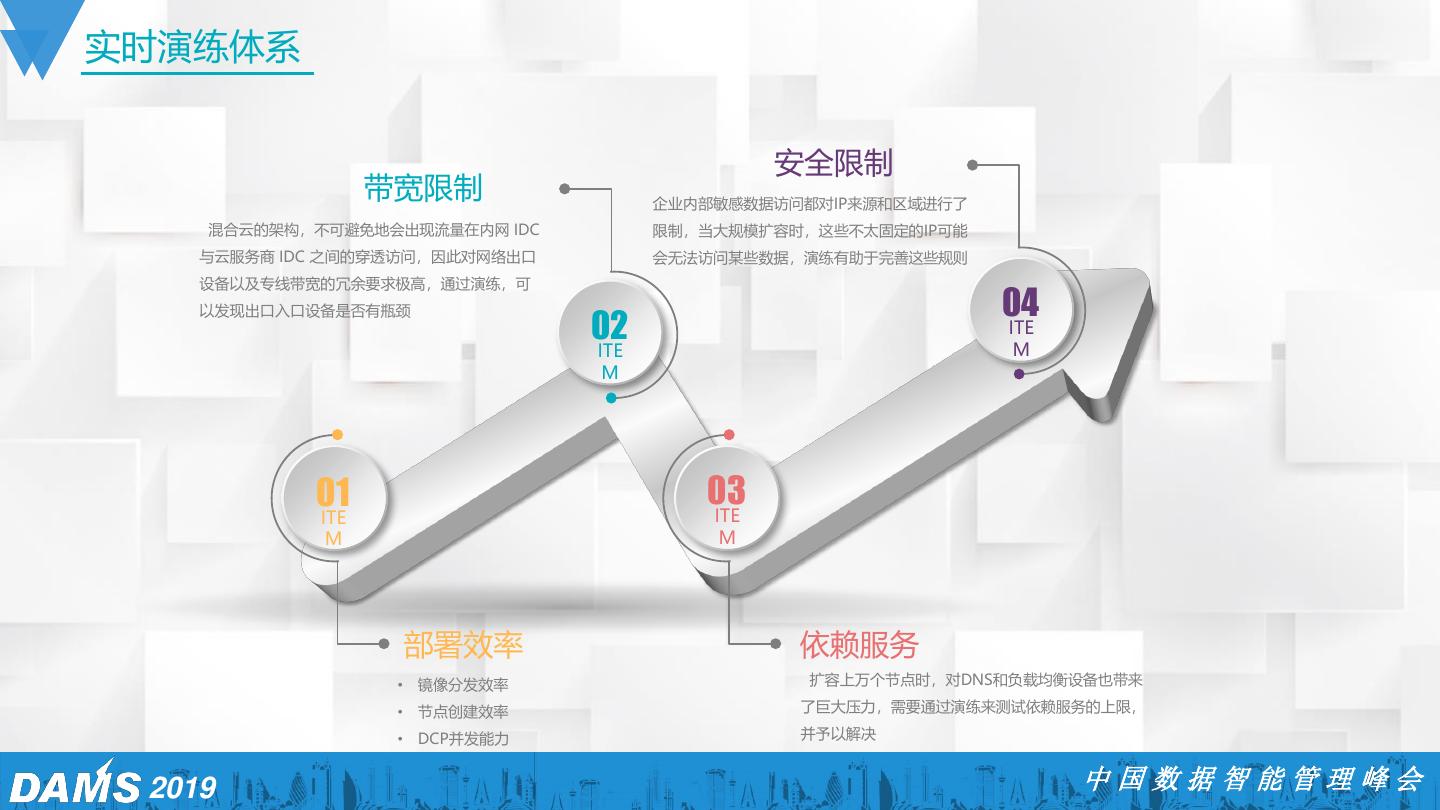
19 .实时演练体系 安全限制 带宽限制 企业内部敏感数据访问都对IP来源和区域进行了 混合云的架构,不可避免地会出现流量在内网 IDC 限制,当大规模扩容时,这些不太固定的IP可能 与云服务商 IDC 之间的穿透访问,因此对网络出口 会无法访问某些数据,演练有助于完善这些规则 设备以及专线带宽的冗余要求极高,通过演练,可 以发现出口入口设备是否有瓶颈 04 02 ITE M ITE M 01 03 ITE ITE M M 部署效率 依赖服务 • 镜像分发效率 扩容上万个节点时,对DNS和负载均衡设备也带来 • 节点创建效率 了巨大压力,需要通过演练来测试依赖服务的上限, • DCP并发能力 并予以解决 2019 中国数据智能管理峰会
20 . 01 02 03 04 运维自动化 弹性计算 智能监控 服务治理 资源管理 、批量运维工具、 自动化扩缩容 、多云适配、 海量指标、 监控告警、异 自动注册、自动发现、熔 事件收集、配置管理 压测和冗余度评估 、 分级 常检测、故障定位 断机制,负载均衡 水位线 2019 中国数据智能管理峰会
21 .监控面临的挑战 海量指标运算 01 监控指标的维度非常多,再加上指标随时间不断变化,监控数据实时性高,当指标多到千万级甚至亿级, 每日要处理百亿级别的数据,秒级查询和展示 实时监控和离线分析 02 大部分监控数据来自日志,但监控不需要精确,所以没有全量收集日志的需求,但离线分析(大数据)需要 准确性,又需要收集和处理全量日志,需要平衡这两种需求,尽量减少线上服务器的消耗 告警问题 03 在复杂环境下,随着告警范围覆盖面日益完善,告警级别分类细致,告警事件过于敏感,容易造成告警风 暴,反而干扰了运维人员对故障的判断 问题定位 04 监控做的越全面,各种可视化、Dashboard也越来越多,如何从众多信息中准确定位故障根源,如果过 滤重复和不相关的信息 2019 中国数据智能管理峰会
22 .Oops整体架构 Graphite Grafana 日志查询 全链路分析 告警 数据可视化 Carbon HBase MySQL TSDB HDFS 数据存储 ElasticSearch ClickHouse Druid Redis Hive Statsd Relay Logstash 数据清洗和计算 Filebeat Logtailer Flink Kafka 数据采集 系统日志 业务日志 性能日志 接口日志 2019 中国数据智能管理峰会
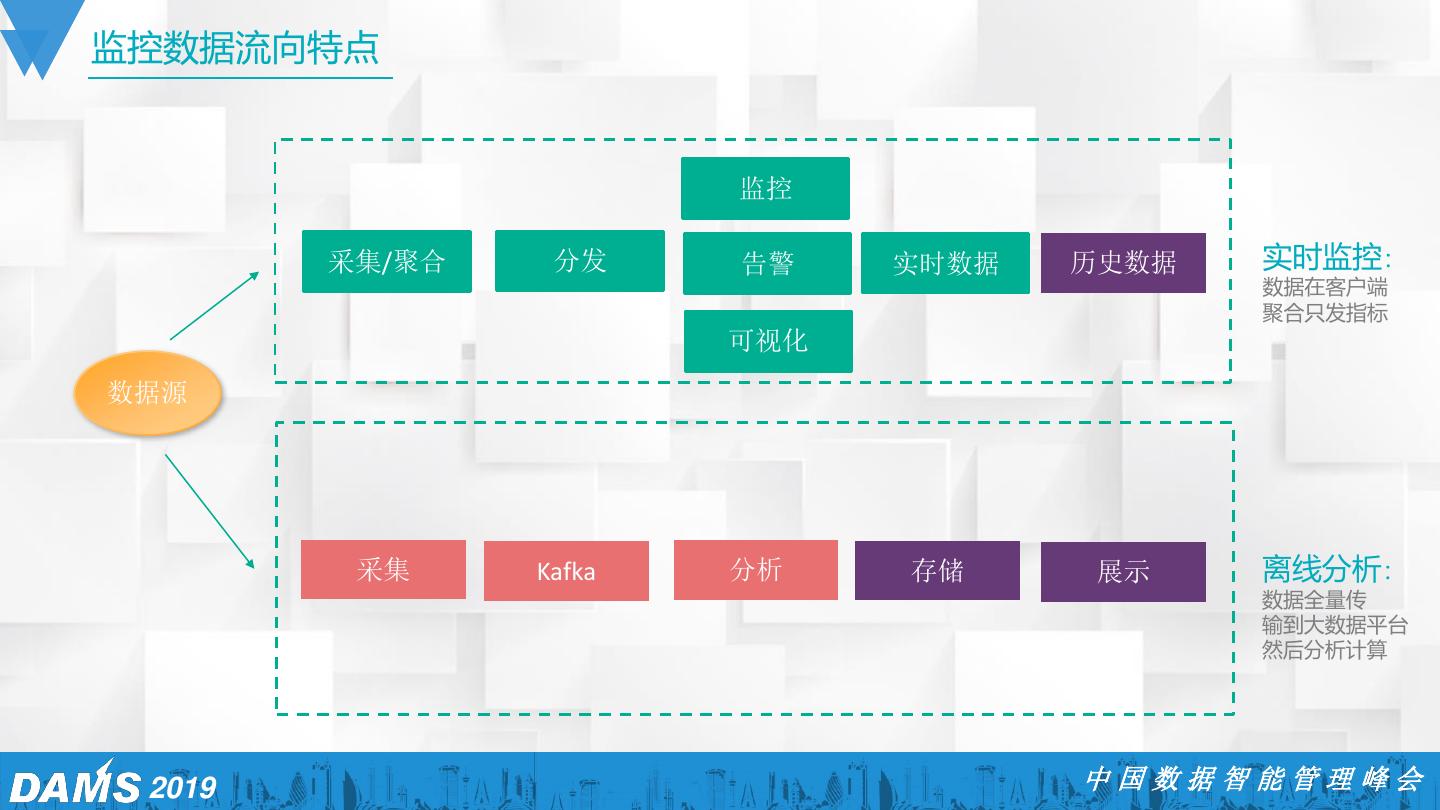
23 .监控数据流向特点 监控 采集/聚合 分发 告警 实时数据 历史数据 实时监控: 数据在客户端 聚合只发指标 可视化 数据源 采集 Kafka 分析 存储 展示 离线分析: 数据全量传 输到大数据平台 然后分析计算 2019 中国数据智能管理峰会
24 .海量指标监控系统流程 App 实时监控计算 内存 Log Agent Proxy Alert 计算节点 relay SSD Framwork 历史计算 TSDB Alert 计算节点 API 在线扩缩容 九宫格 成本分析 Redis 告警中心 Mail/sms Graphite 辅助决策 Grafana WatchD A/B Test 2019 中国数据智能管理峰会
25 .监控指标及九宫格展示 2019 中国数据智能管理峰会
26 .告警的问题 告警数量巨大 01 运维人员需要关注整个所有部分,从系统到服务、到接口等等,维度很多,一 旦有问题,各种策略都会触发报警,报警数量多到一定程度,基本上等于没有 报警 重复告警率高 告警策略一般会周期性执行,一直到告警条件不被满足,如果服务一直不恢复, 02 就会重复报下去,另外,同一个故障也可能引发不同层次的告警 告警有效性不足 03 很多时候,网络抖动、拥堵,负载暂时过高,或者变更等原因,会触发报警,但 这类报警要么不再重现,要么可以自愈 告警模式粗放 04 无论是否重要、优先级如何,告警都通过邮件、短信、App PUSH发送到接收人, 经常会让真正重要的告警淹没在一大堆普通告警中 2019 中国数据智能管理峰会
27 .降低告警的数量 分类和分级 抖动收敛 详细定义告警级别,发送优先 抖动或者毛刺一般不具有重复 级、升级策略等,可有效减少 性,为了防止误报,应该定义 粗放模式下告警接收量 为某段时间内重复多少次才触 发 告警的合 并和收敛 变更忽略 同类合并 生产环境中,有很多自动化上 同一个原因可能会触发一个服 线、定时扩缩容、压测等任务, 务池里面的所有实例都报警, 必然会引发告警,对此类告警 比如同时无法连接数据库,只 可以和运维自动化平台一起来 需要报一次即可 决策是否忽略 2019 中国数据智能管理峰会
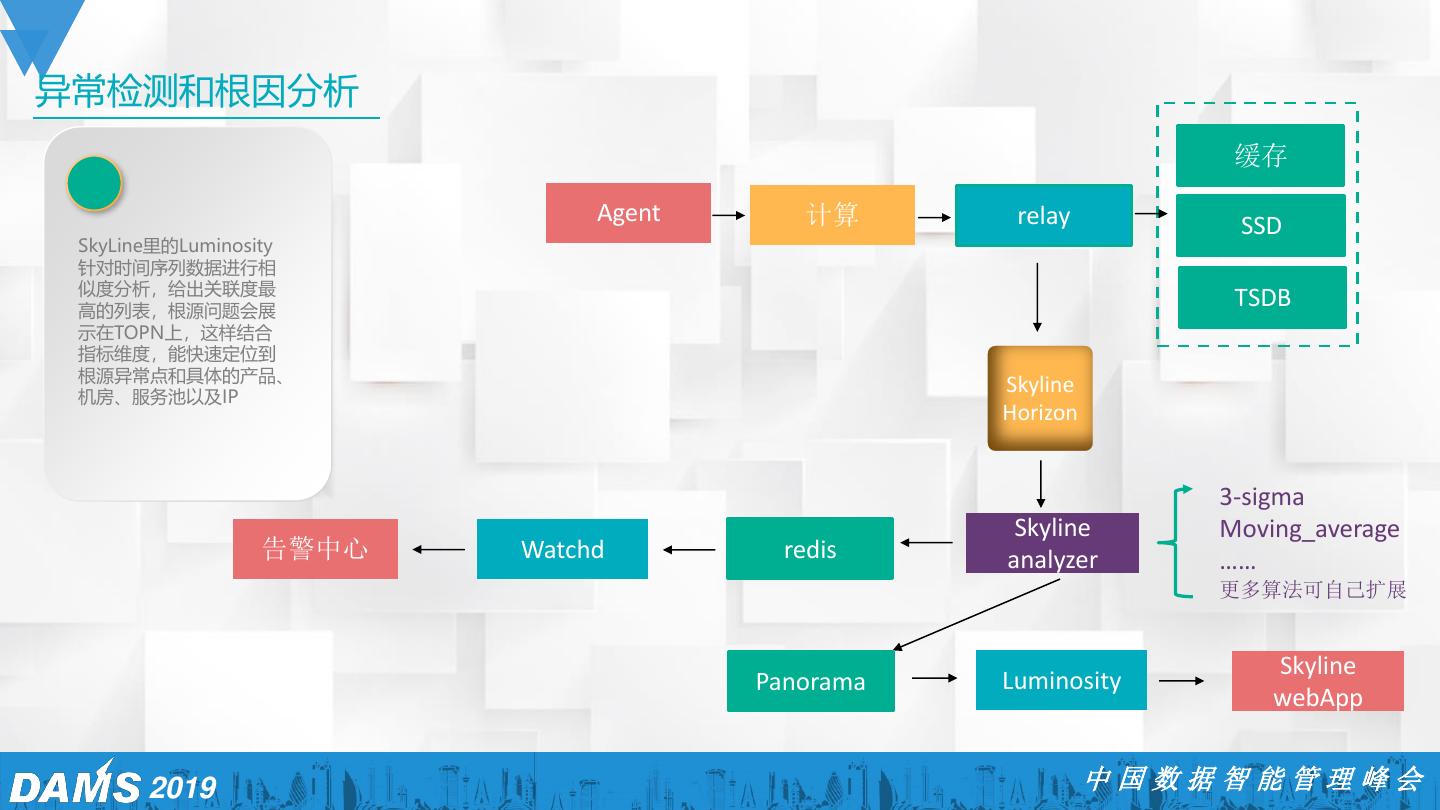
28 .异常检测和根因分析 缓存 Agent 计算 relay SSD SkyLine里的Luminosity 针对时间序列数据进行相 似度分析,给出关联度最 高的列表,根源问题会展 TSDB 示在TOPN上,这样结合 指标维度,能快速定位到 根源异常点和具体的产品、 机房、服务池以及IP Skyline Horizon 3-sigma Skyline Moving_average 告警中心 Watchd redis analyzer …… 更多算法可自己扩展 Skyline Panorama Luminosity webApp 2019 中国数据智能管理峰会
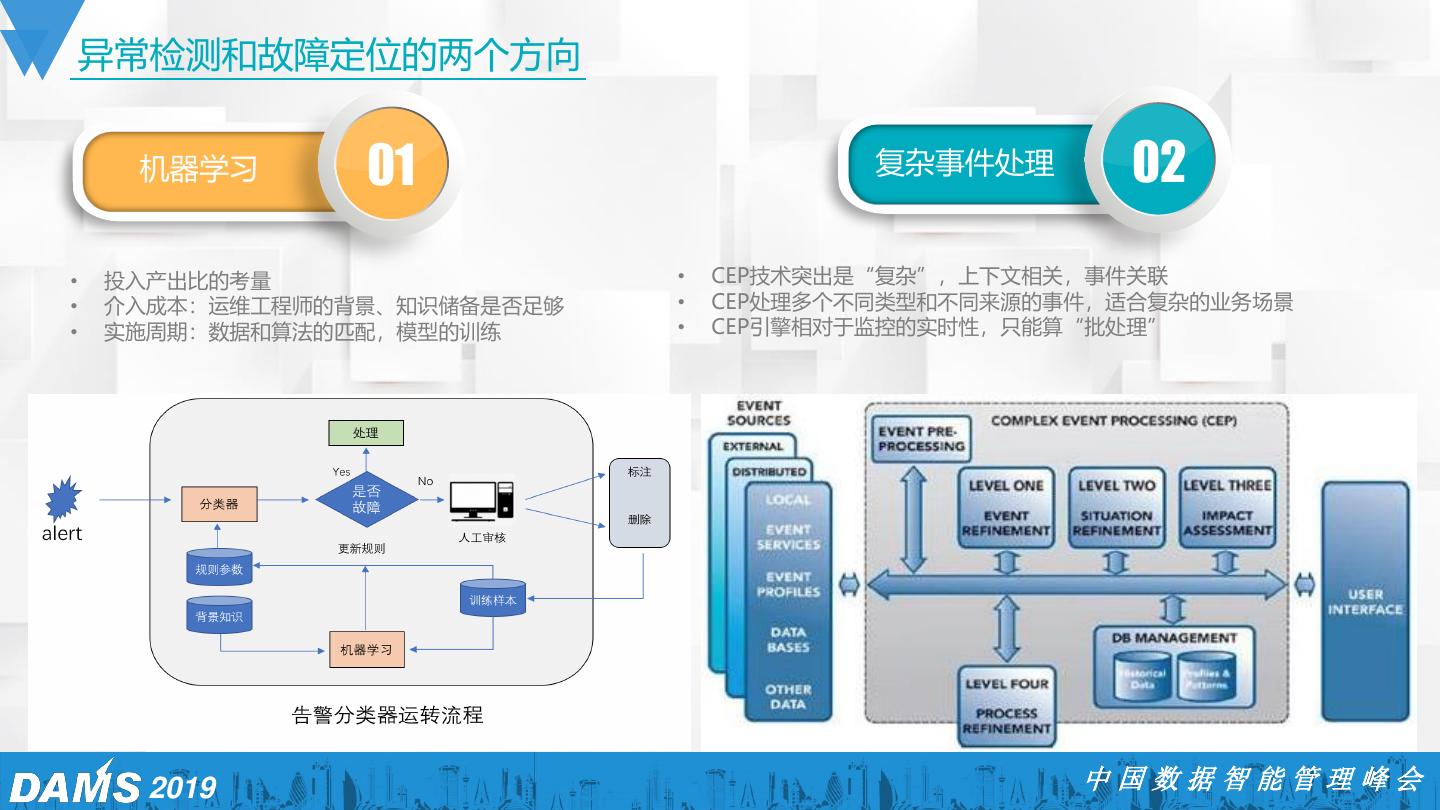
29 .异常检测和故障定位的两个方向 机器学习 01 复杂事件处理 02 • 投入产出比的考量 • CEP技术突出是“复杂”,上下文相关,事件关联 • 介入成本:运维工程师的背景、知识储备是否足够 • CEP处理多个不同类型和不同来源的事件,适合复杂的业务场景 • 实施周期:数据和算法的匹配,模型的训练 • CEP引擎相对于监控的实时性,只能算“批处理” 2019 中国数据智能管理峰会
3秒后跳转登录页面
去登陆

