





































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
利用闪存优化在Cosco基础上的Spark Shuffle
分享
点赞
1
收藏
1
直播间链接 https://developer.aliyun.com/live/43188
利用闪存优化在Cosco基础上的Spark Shuffle
吴一
Databicks开源项目组软件工程师,主要参与开源社区Spark和公司产品Databricks Runtime的研发。最近两年专注于Spark及大数据技术领域,现在是Spark社区的活跃贡献(GitHub@Ngone51)。
Cosco是由FaceBook推出的一种高效且可靠的shufflle服务。Cosco建立在分布式内存共享池的内存聚合基础之上,相较于Spark内置的shufflle,能提供更高效的磁盘利用率。本次议题将会介绍如何通过增加少量闪存来进一步提升shuffle的效率:闪存减少了内存使用,而更大的预写(聚合)缓冲区则进一步减少了磁盘IO。通过严谨的实验和分析,我们还证明了,即使是对于shuffle这种一次写入/一次读取的作业,动态地利用内存和闪存也能保护闪存的持久性。
本次议题还将讨论闪存如何集成到Cosco的架构中和所采用的部署模式,以及通过在大规模生产环境中部署所汲取到的经验教训和潜在的未来工作。

展开查看详情
1 .
2 . 吴一 Software Engineer@Databricks Ngone51@Github yi.wu@databricks.com
3 .Flash for Spark Shuffle with Cosco Original talk: https://databricks.com/session_na20/flash-for-apache-spark-shuffle-with-cosco Aaron Gabriel Feldman Software Engineer at Facebook
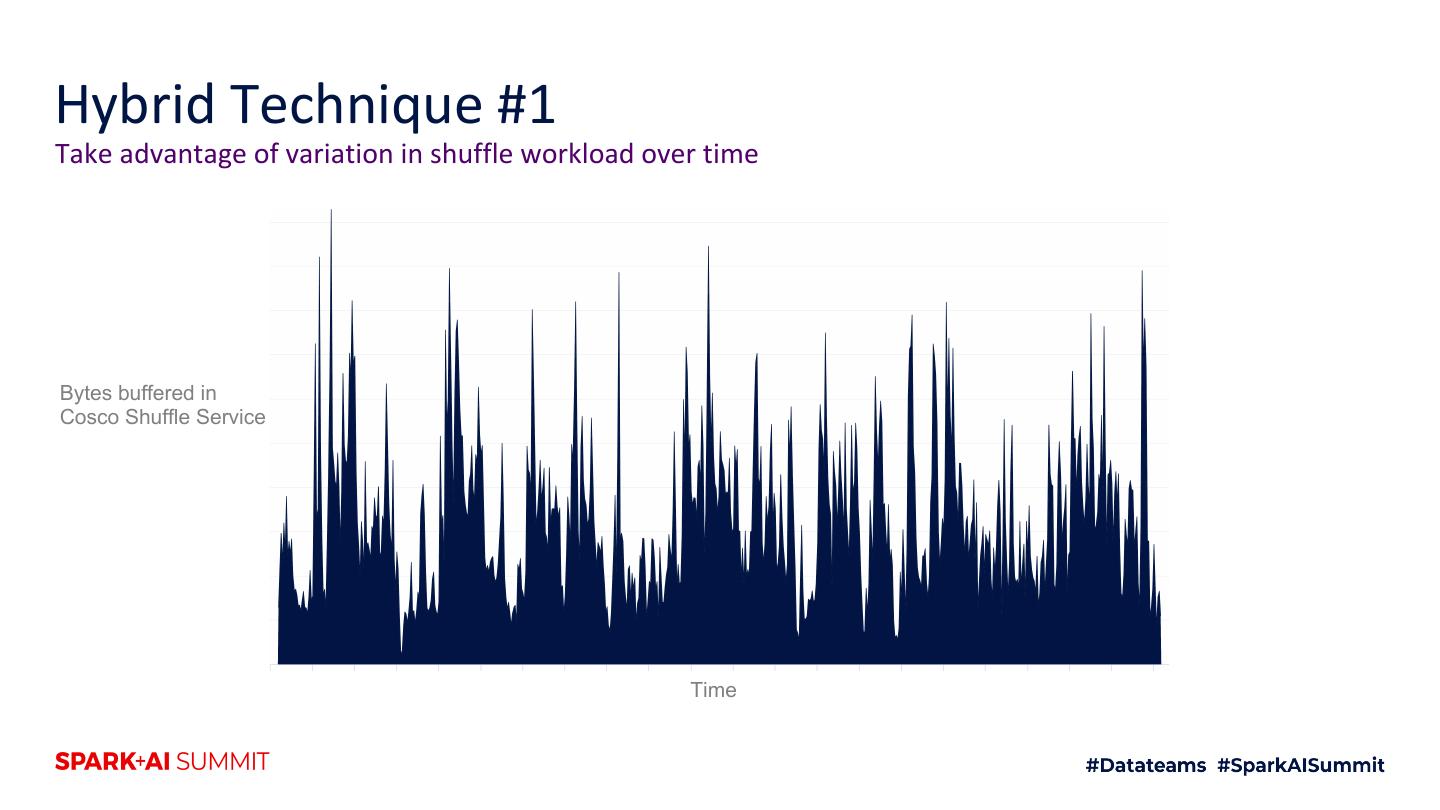
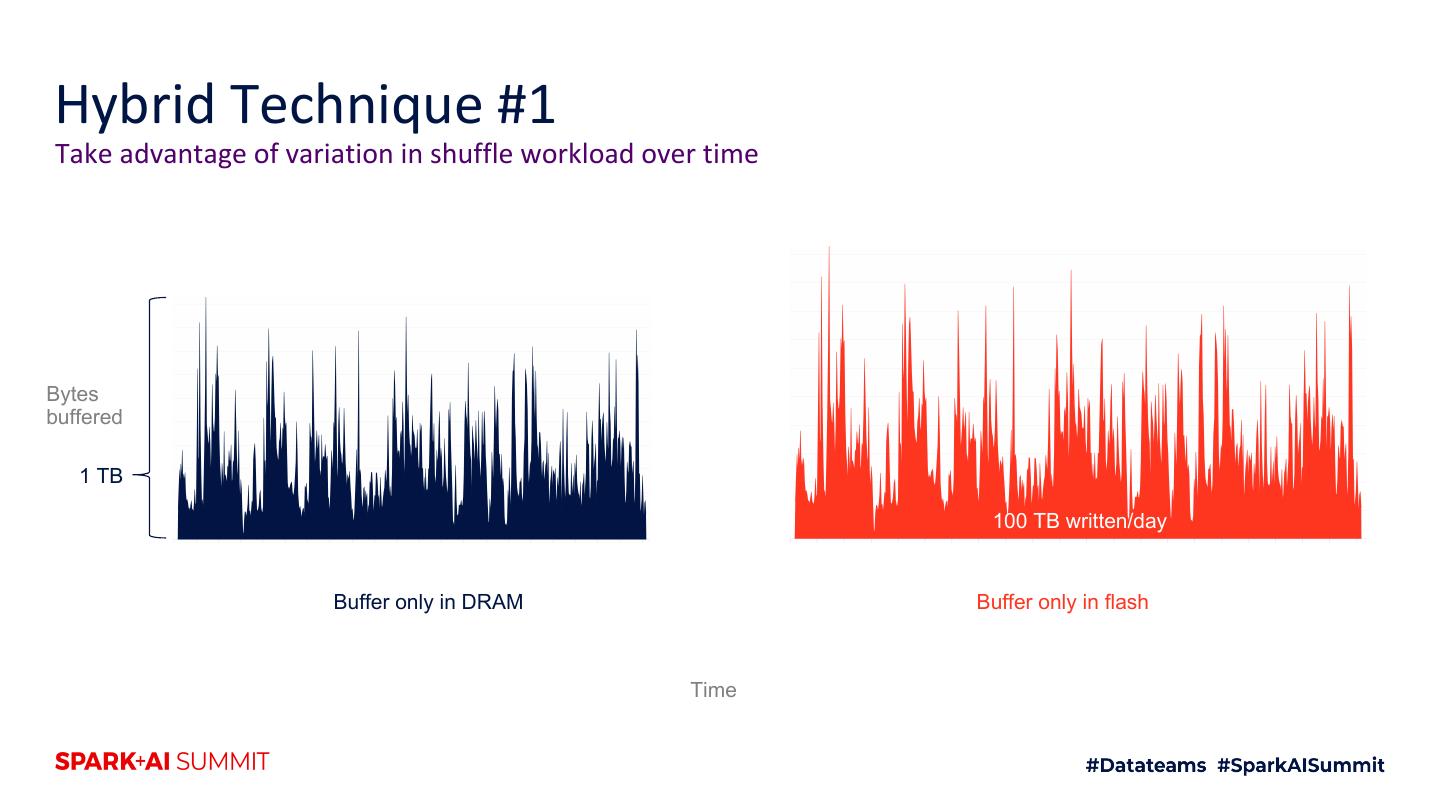
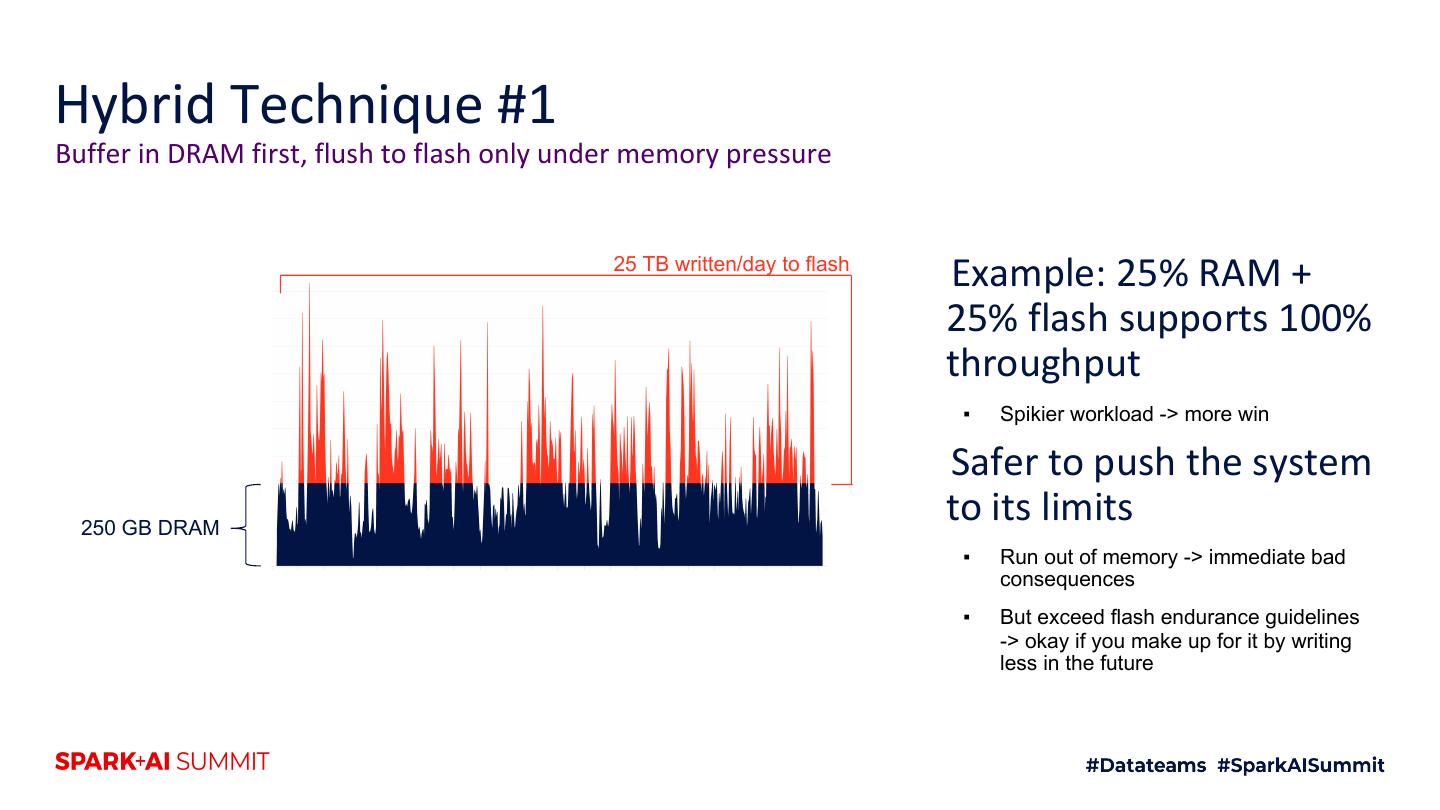
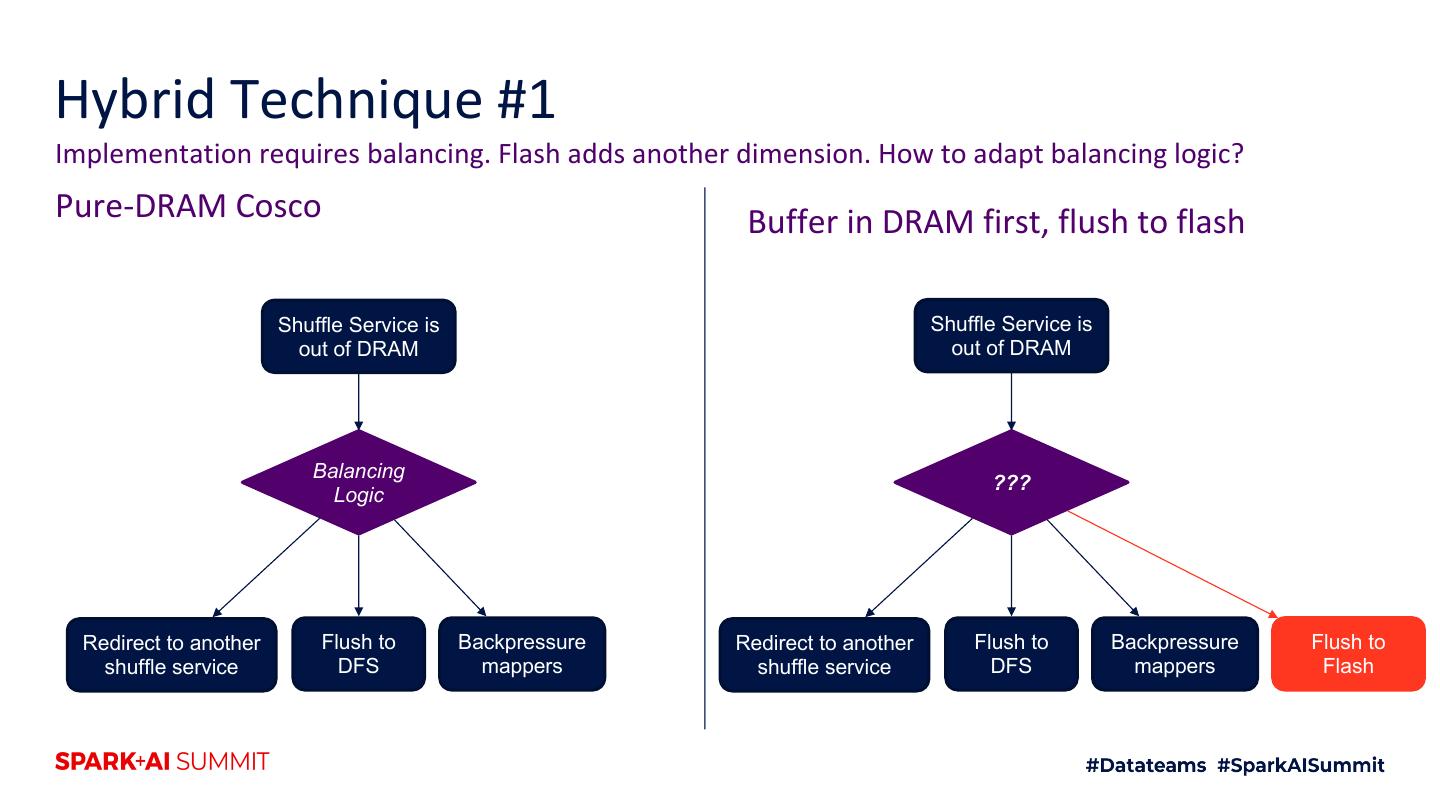
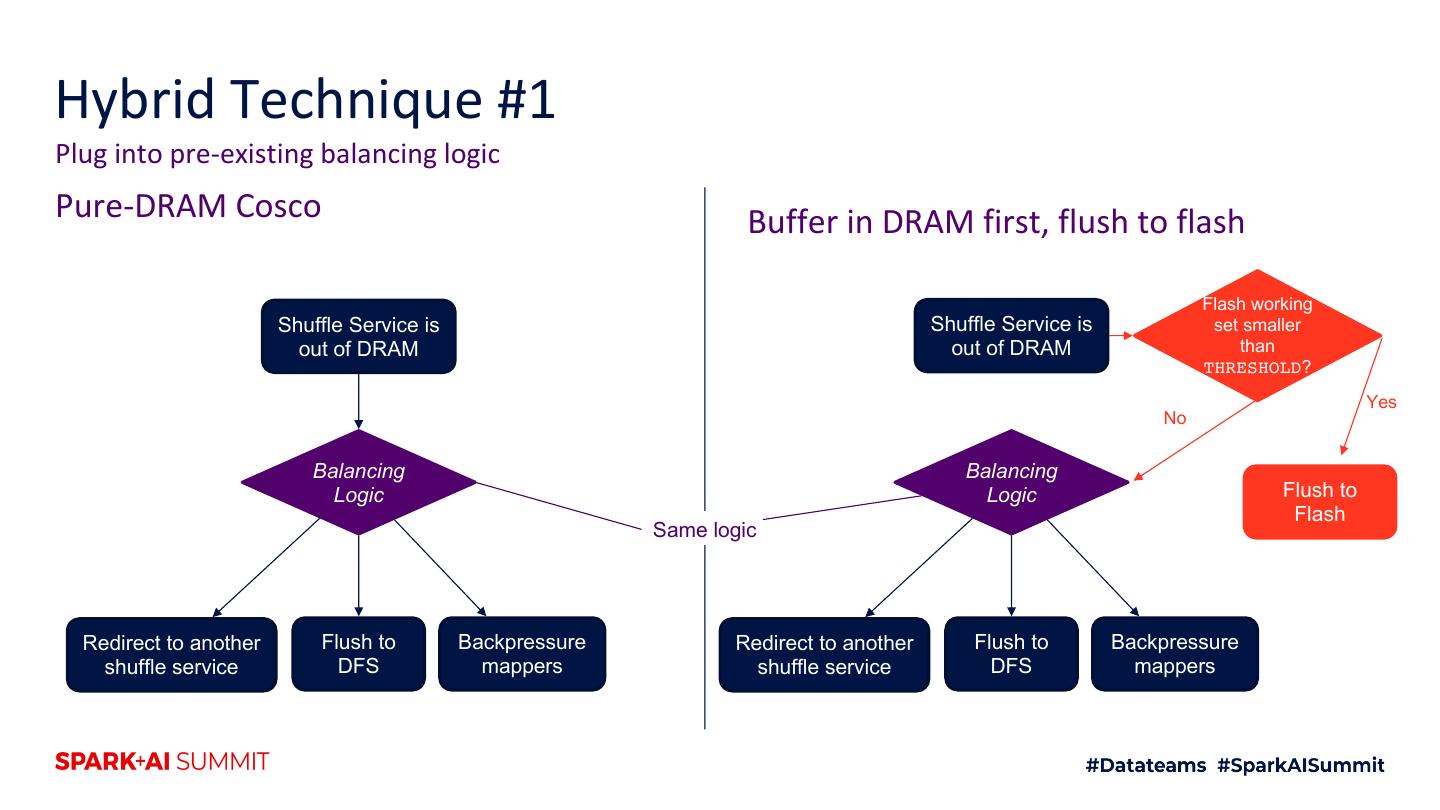
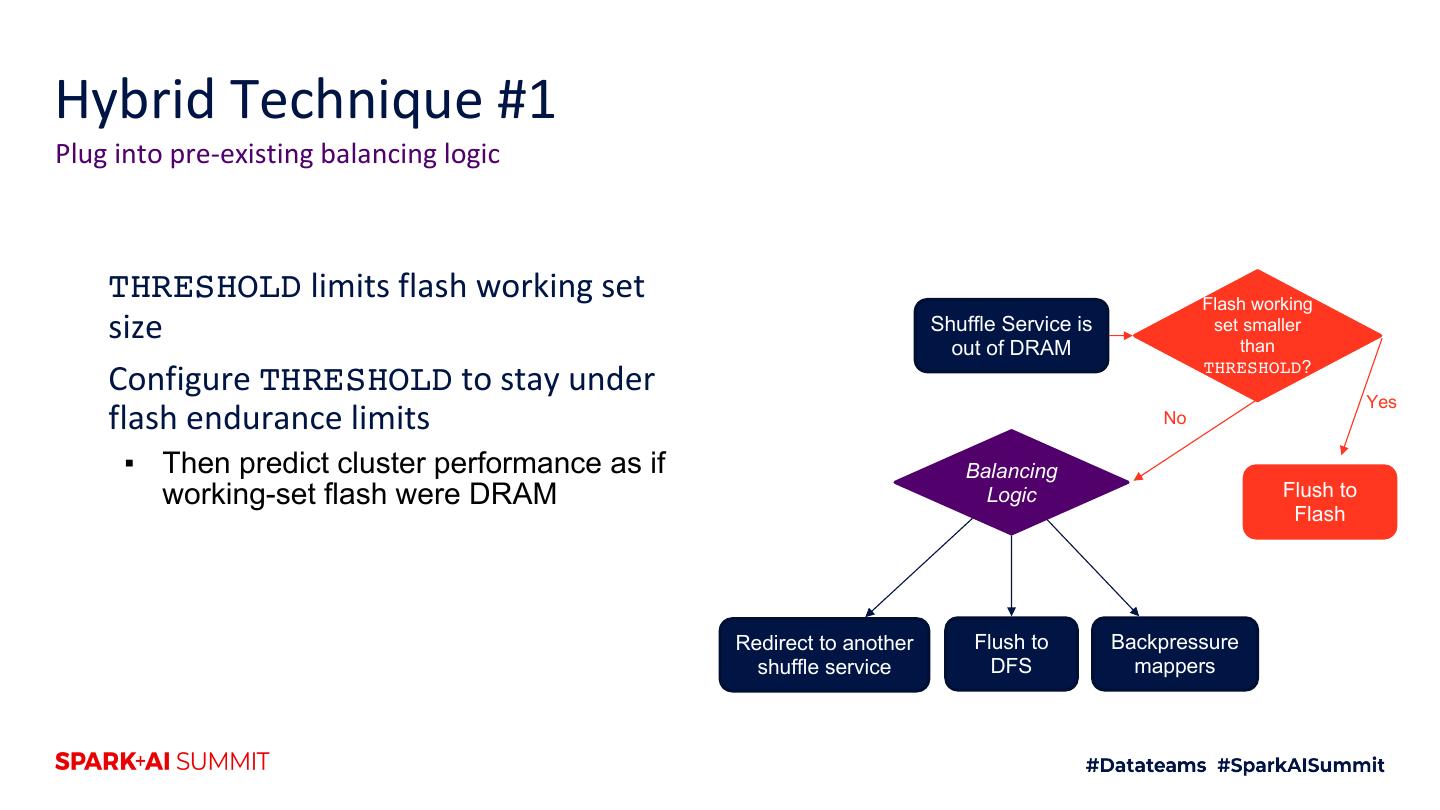
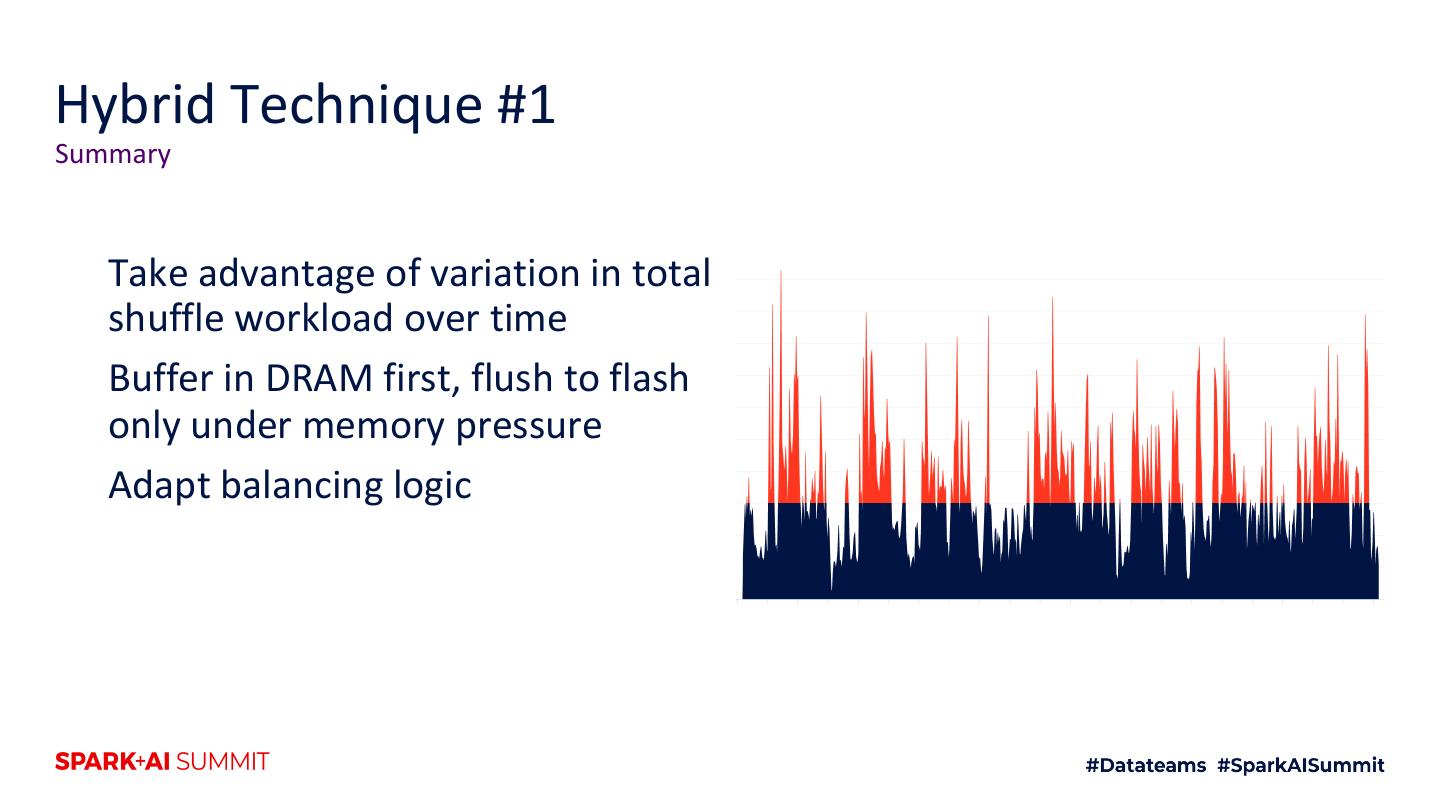
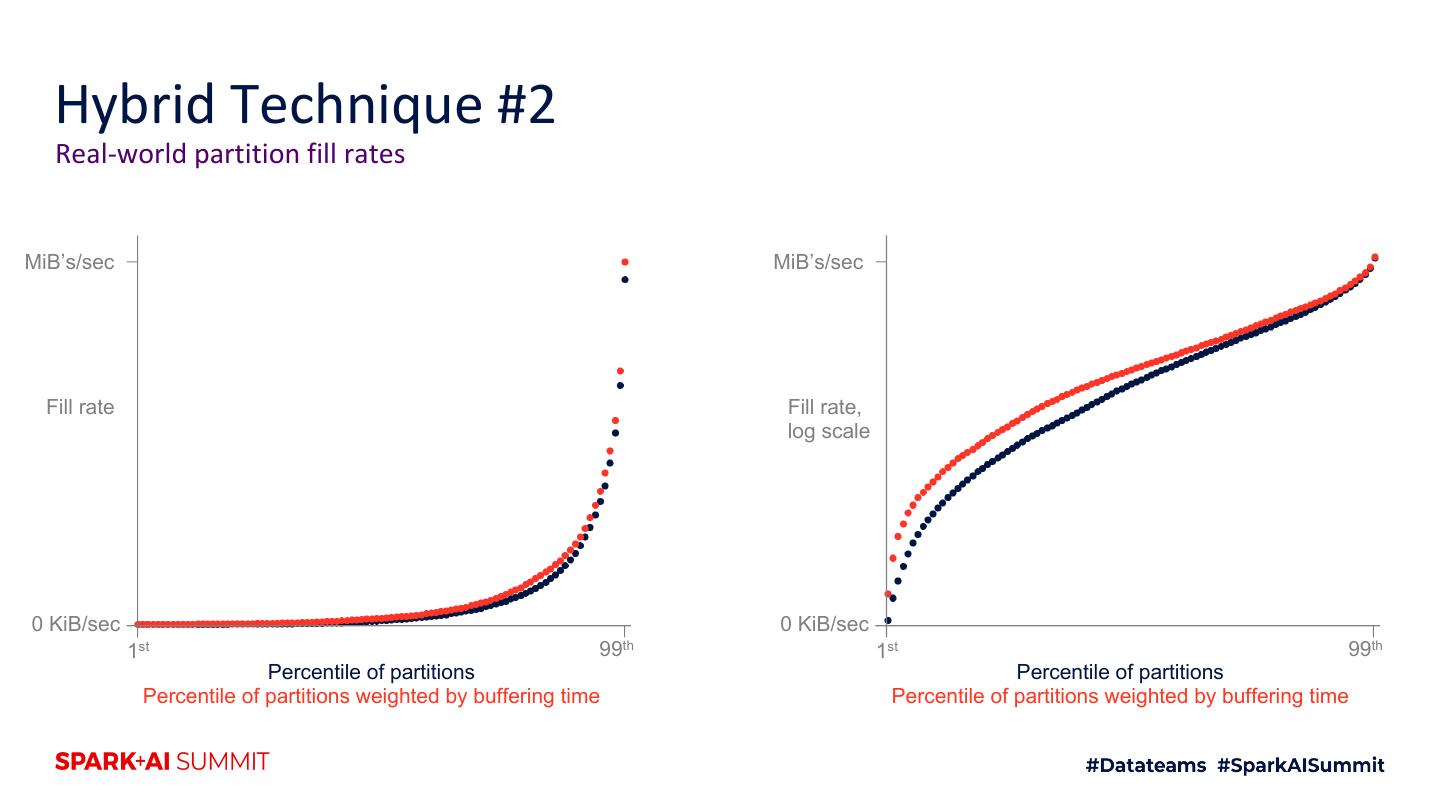
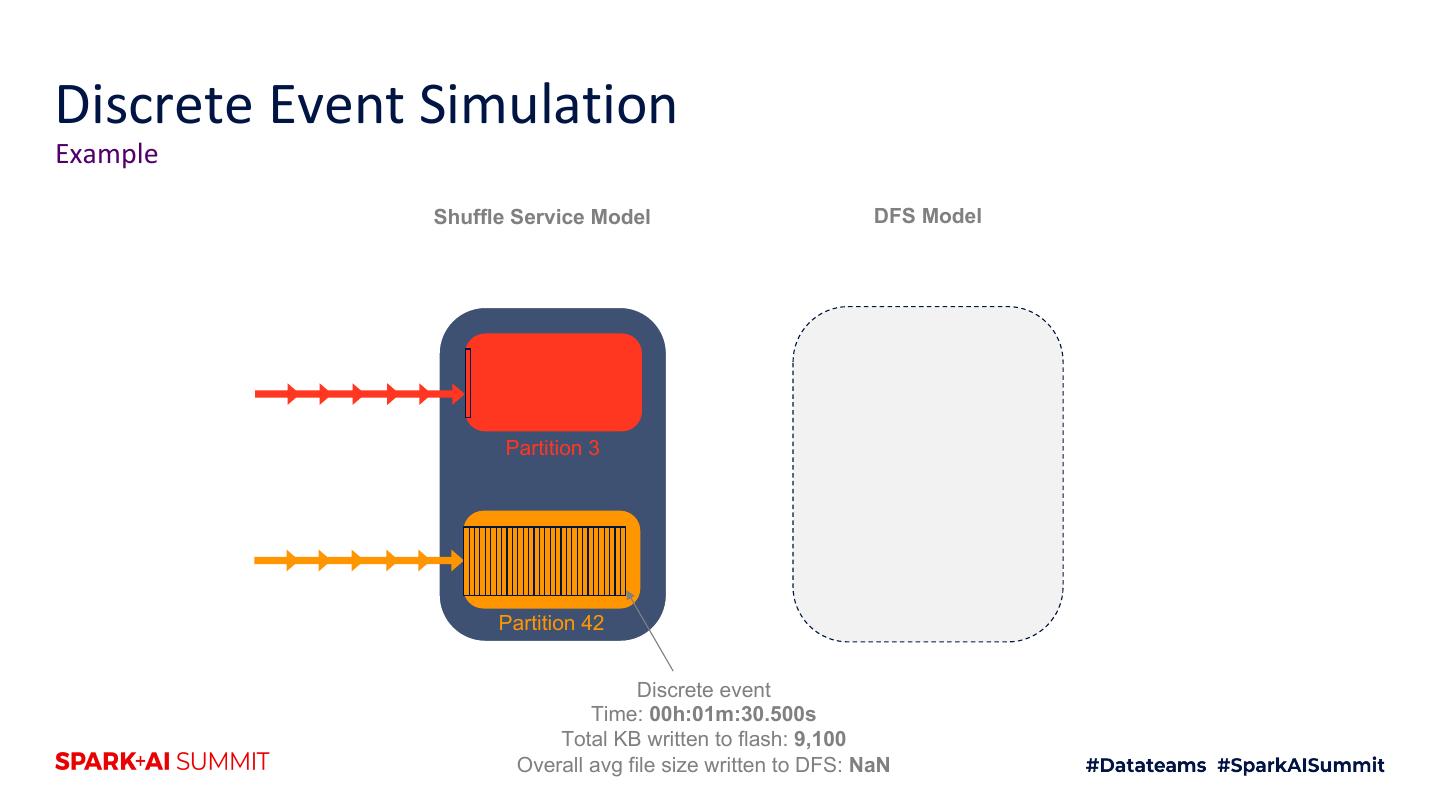
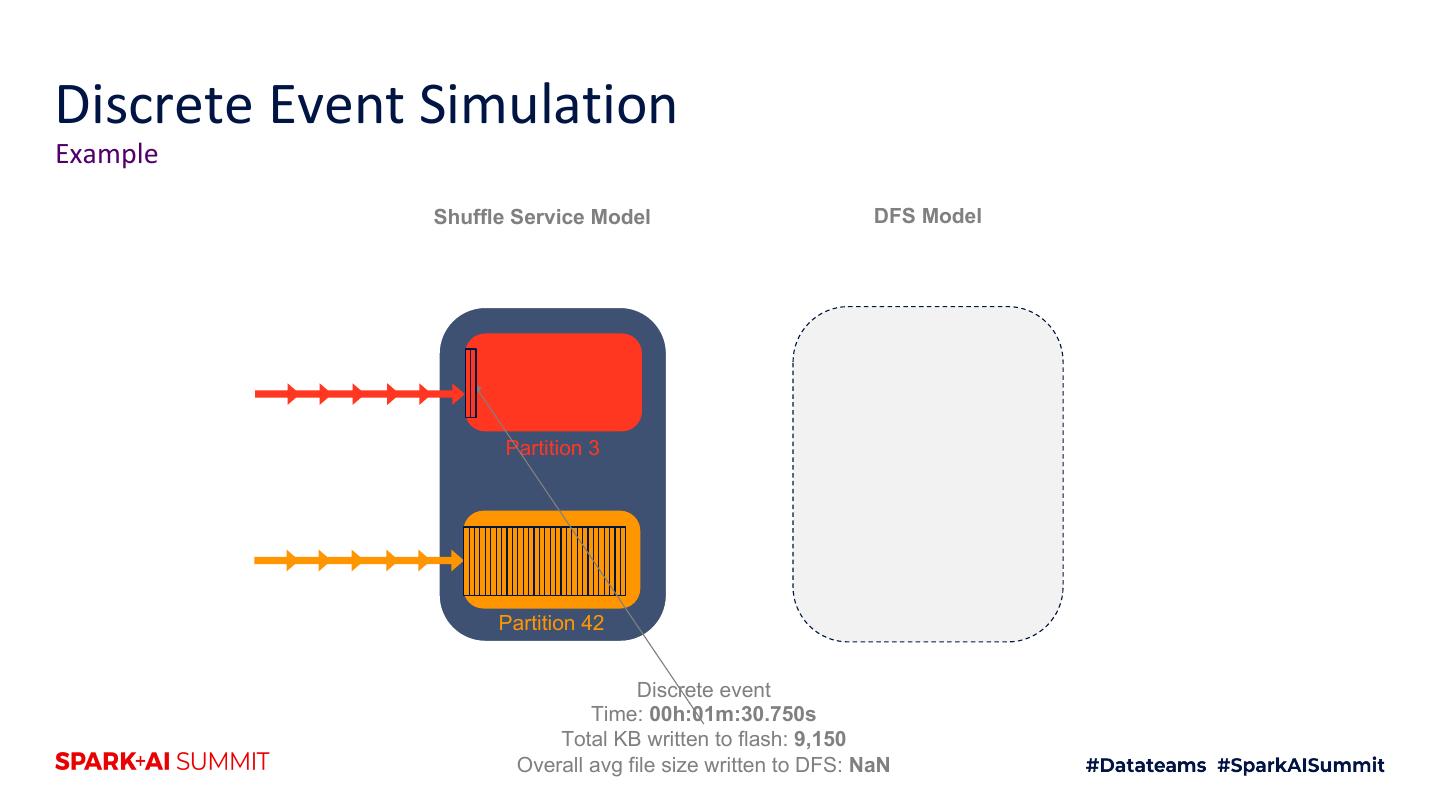
4 .Agenda 1. Motivation 2. Intro to shuffle architecture 3. Flash 4. Hybrid RAM + flash techniques 5. Future improvements 6. Testing techniques
5 .扫描下⽅⼆维码留下您的问题 Your feedback is important to us. Don’t forget to rate and review the sessions.
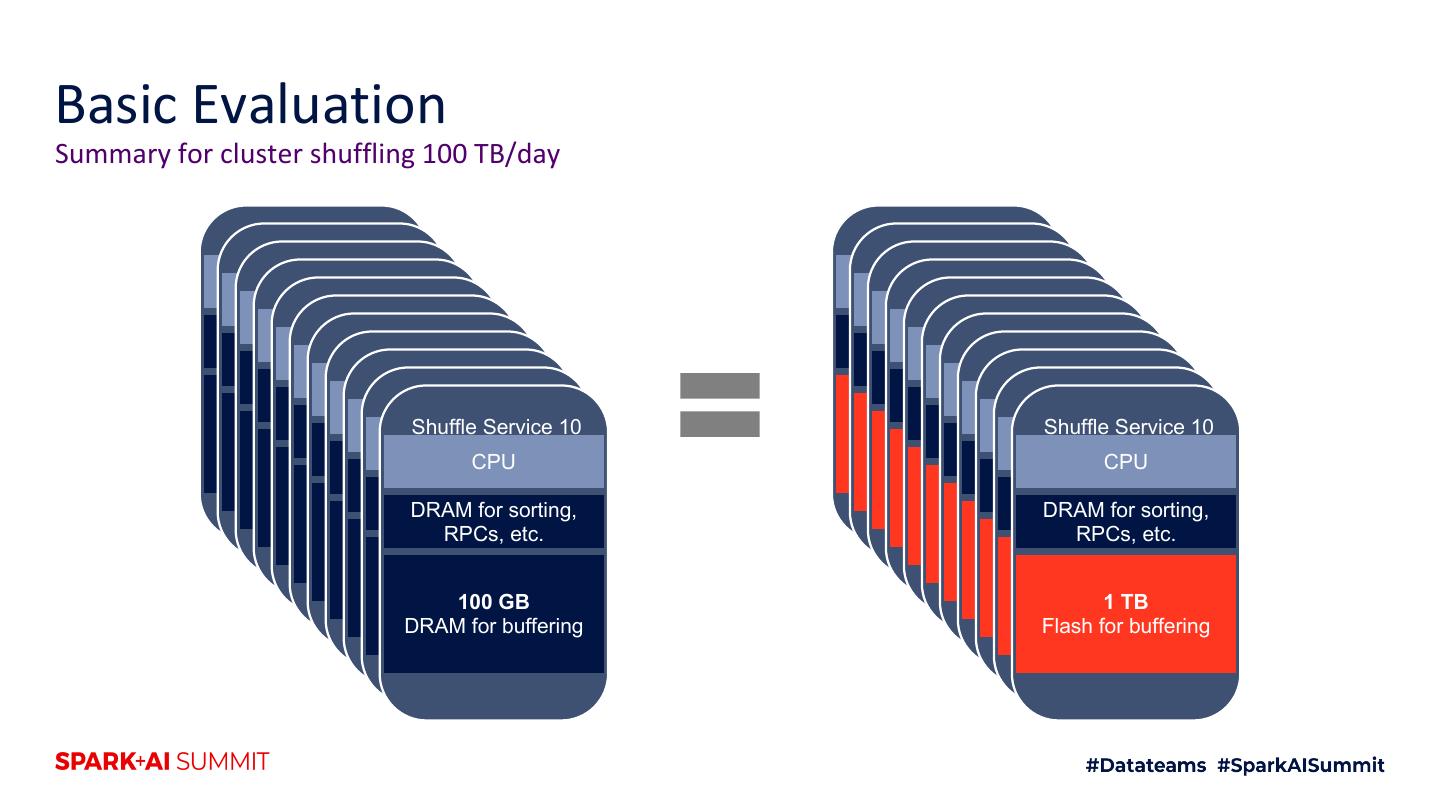
6 .Why should you care? IO efficiency ▪ Cosco is a service that improves IO efficiency (disk service time) by 3x for shuffle data Compute efficiency ▪ Flash supports more workload with less Cosco hardware Query latency is less of a focus ▪ Cosco helps shuffle-heavy queries, but query latency has not been our focus. We have been focused on batch workloads. ▪ Flash unlocks new possibilities to improve query latency, but that is future work Techniques for development and analysis ▪ Hopefully, some of these are applicable outside of Cosco
7 .Intro to Shuffle Architecture
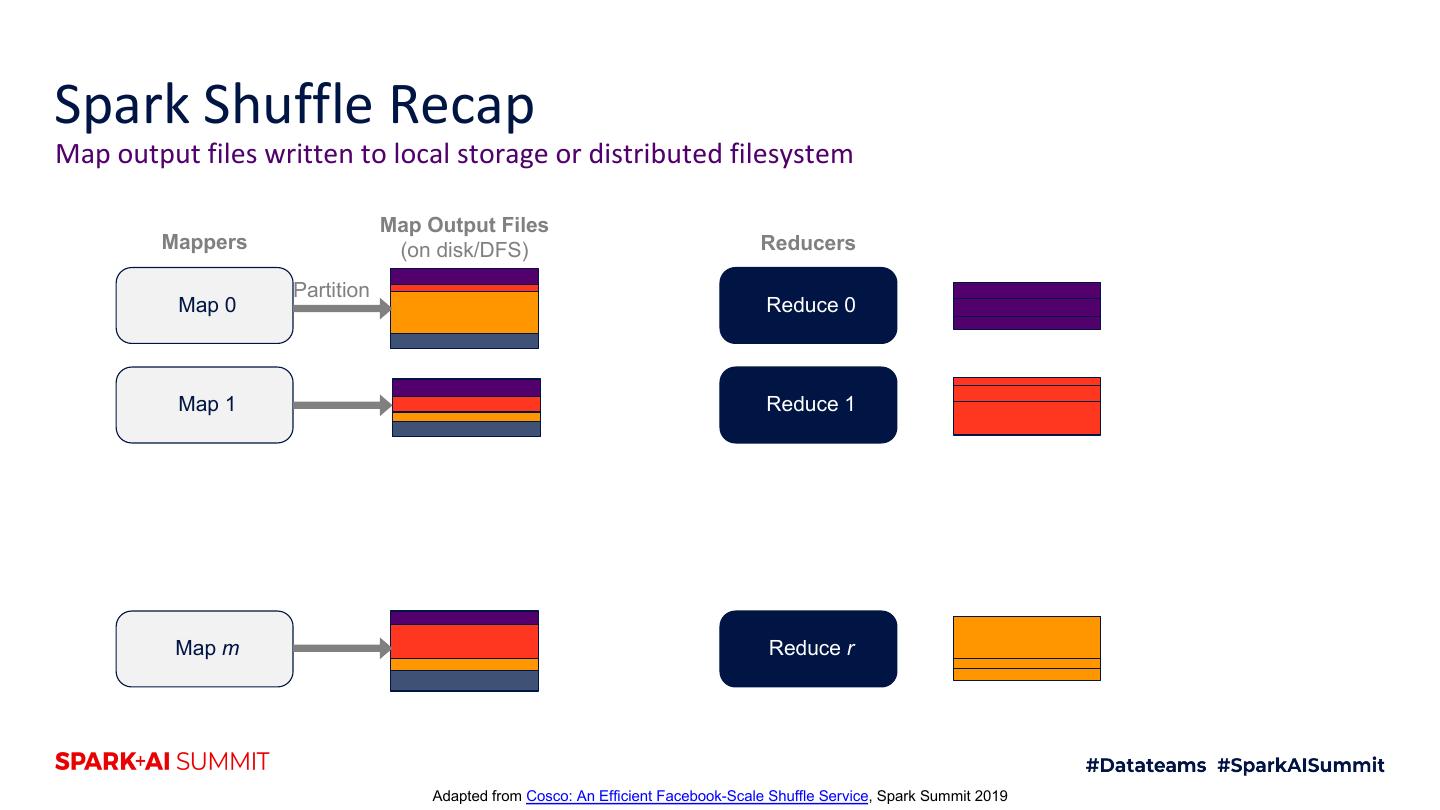
8 .Spark Shuffle Recap Map output files written to local storage or distributed filesystem Map Output Files Mappers (on disk/DFS) Reducers Partition Map 0 Reduce 0 Map 1 Reduce 1 Map m Reduce r Adapted from Cosco: An Efficient Facebook-Scale Shuffle Service, Spark Summit 2019
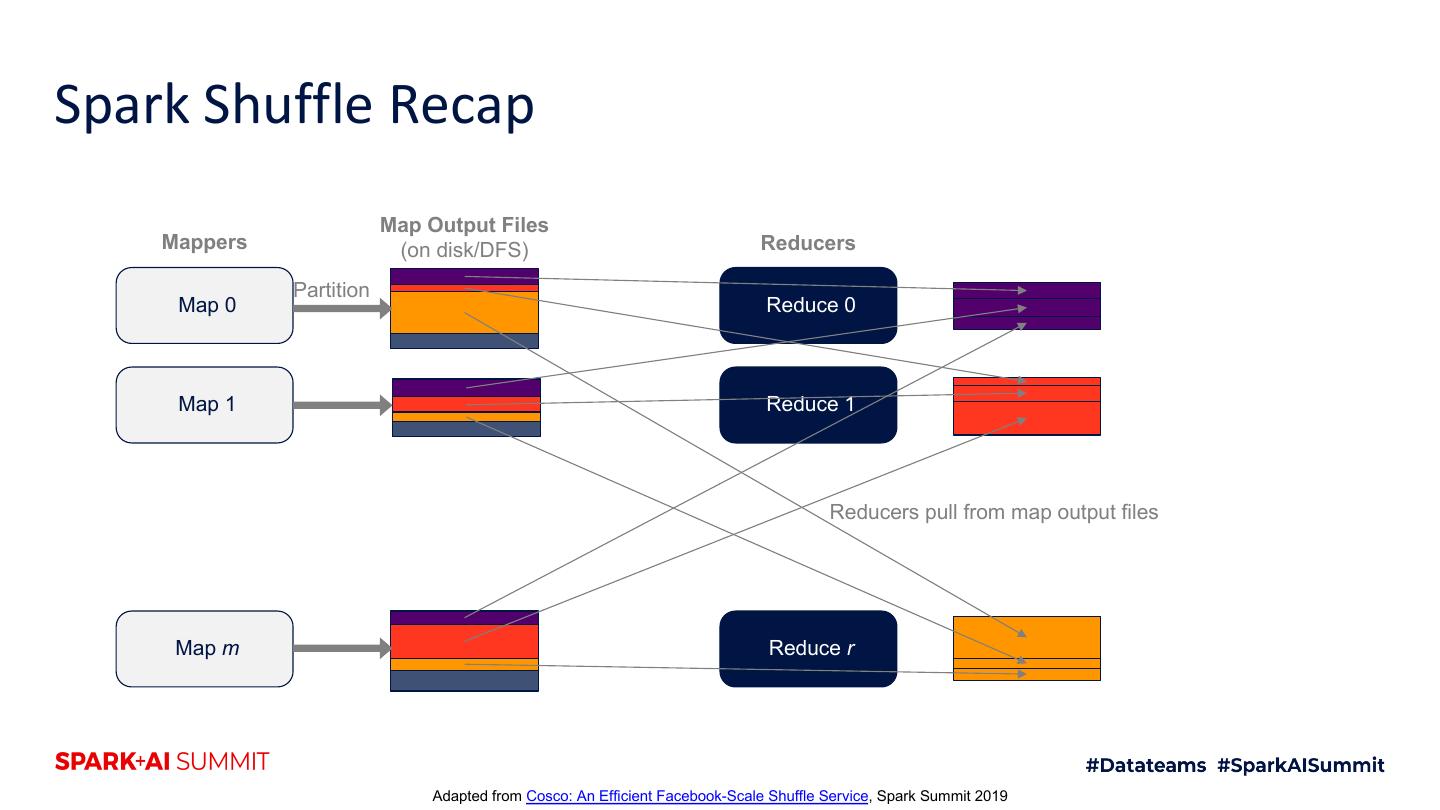
9 .Spark Shuffle Recap Map Output Files Mappers (on disk/DFS) Reducers Partition Map 0 Reduce 0 Map 1 Reduce 1 Reducers pull from map output files Map m Reduce r Adapted from Cosco: An Efficient Facebook-Scale Shuffle Service, Spark Summit 2019
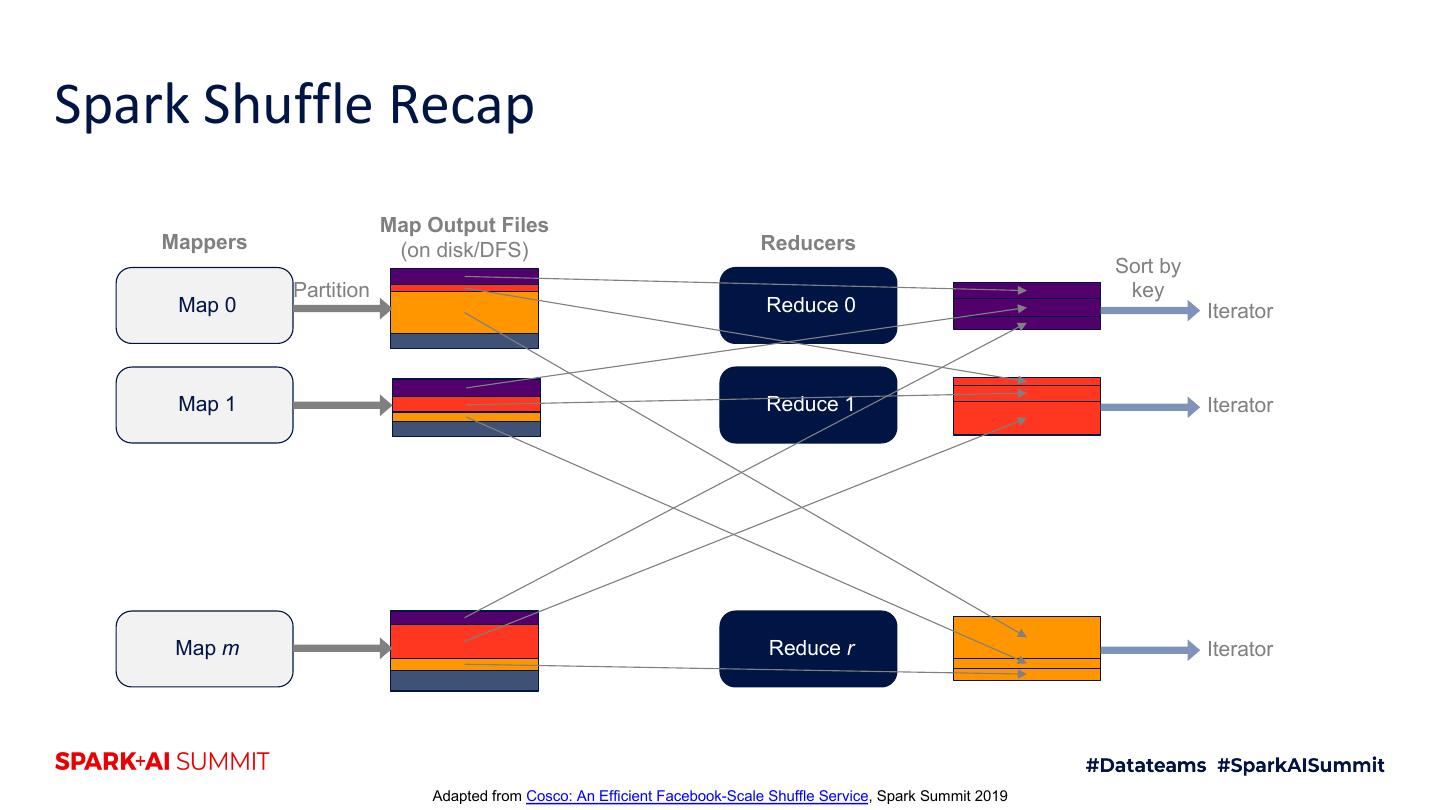
10 .Spark Shuffle Recap Map Output Files Mappers (on disk/DFS) Reducers Sort by Partition key Map 0 Reduce 0 Iterator Map 1 Reduce 1 Iterator Map m Reduce r Iterator Adapted from Cosco: An Efficient Facebook-Scale Shuffle Service, Spark Summit 2019
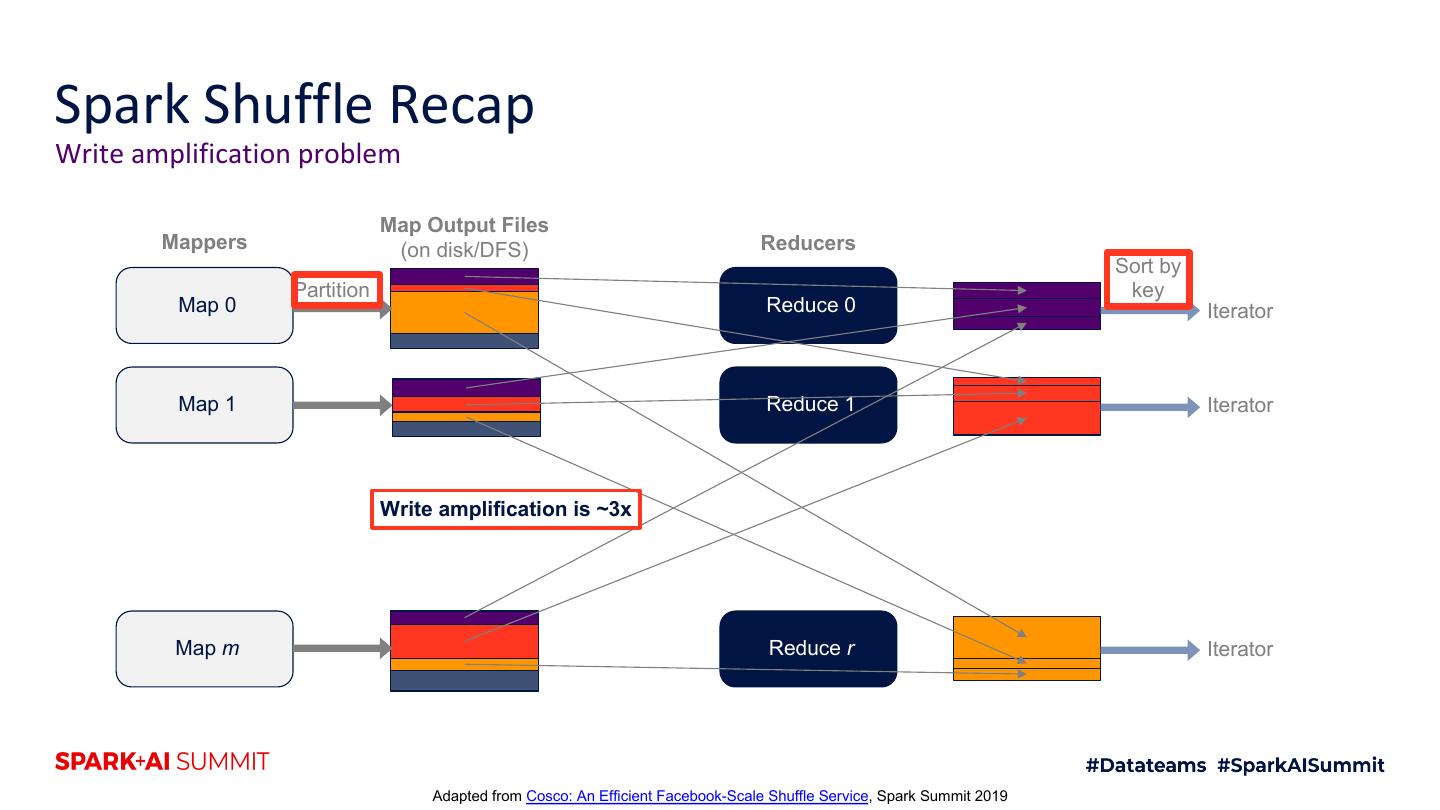
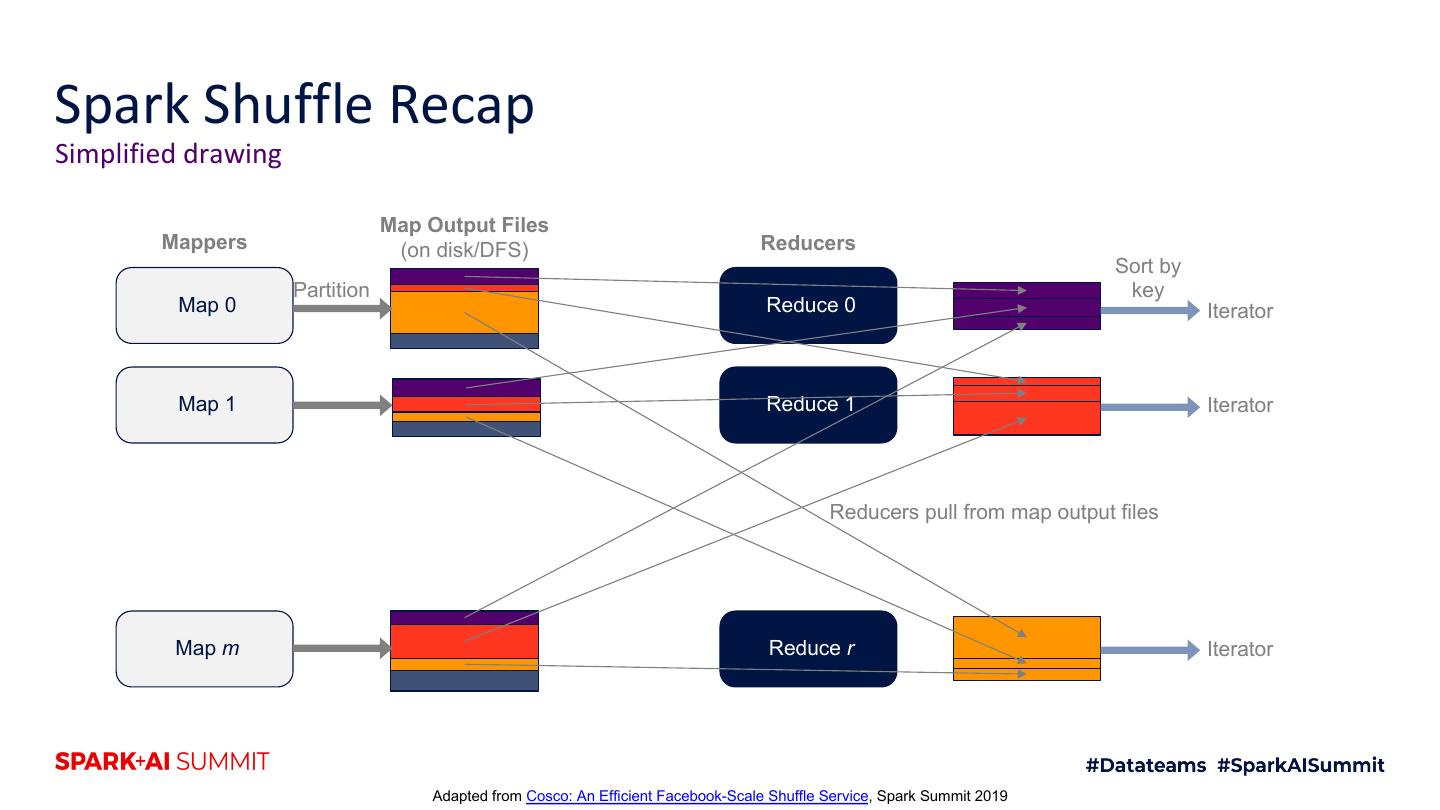
11 .Spark Shuffle Recap Write amplification problem Map Output Files Mappers (on disk/DFS) Reducers Sort by Partition key Map 0 Reduce 0 Iterator Map 1 Reduce 1 Iterator Write amplification is ~3x Map m Reduce r Iterator Adapted from Cosco: An Efficient Facebook-Scale Shuffle Service, Spark Summit 2019
12 .Spark Shuffle Recap And small IOs problem Map Output Files Mappers (on disk/DFS) Reducers Sort by Partition key Map 0 Reduce 0 Iterator Map 1 Reduce 1 Iterator MxR Write amplification is ~3x Avg IO size is ~200 KiB Map m Reduce r Iterator Adapted from Cosco: An Efficient Facebook-Scale Shuffle Service, Spark Summit 2019
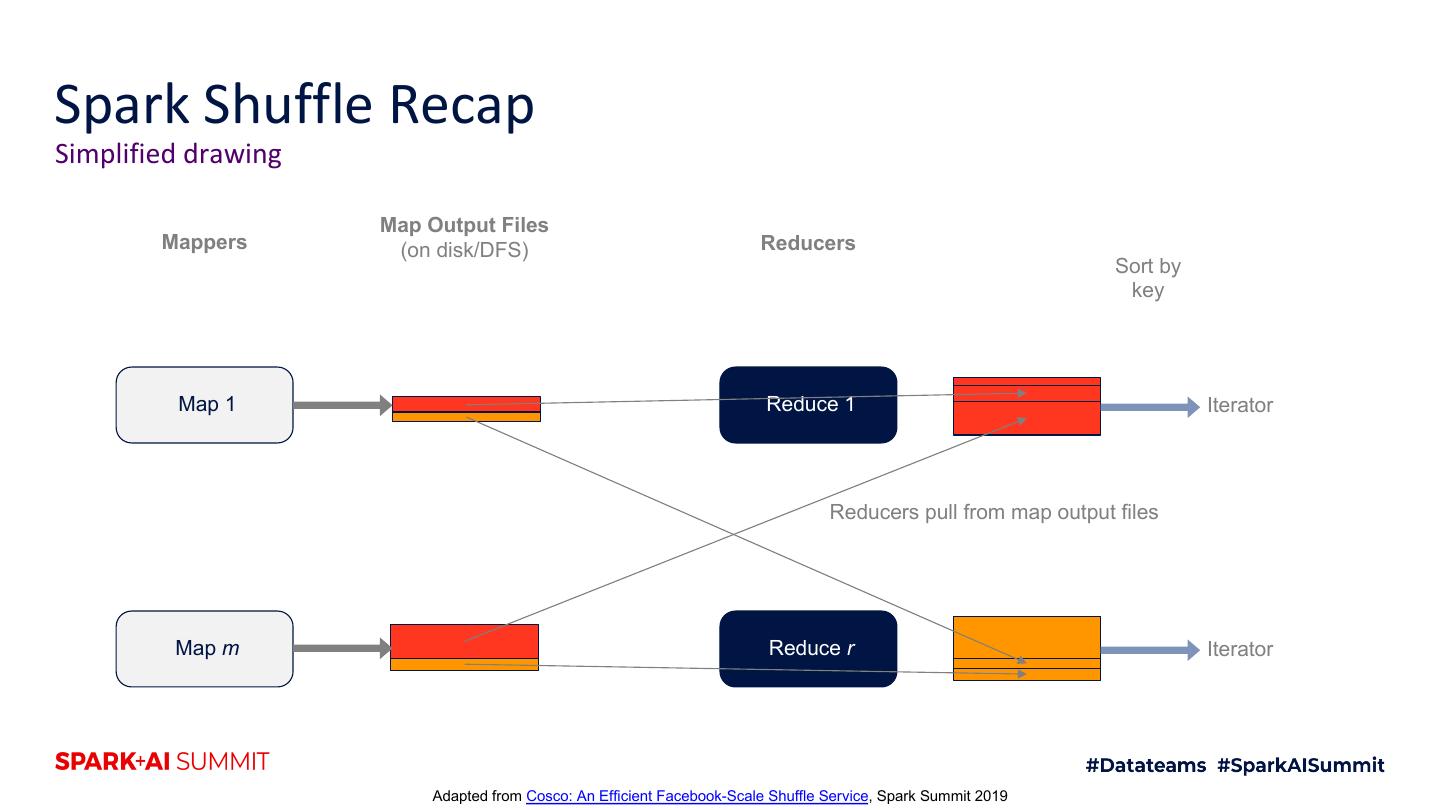
13 .Spark Shuffle Recap Simplified drawing Map Output Files Mappers (on disk/DFS) Reducers Sort by Partition key Map 0 Reduce 0 Iterator Map 1 Reduce 1 Iterator Reducers pull from map output files Map m Reduce r Iterator Adapted from Cosco: An Efficient Facebook-Scale Shuffle Service, Spark Summit 2019
14 .Spark Shuffle Recap Simplified drawing Map Output Files Mappers (on disk/DFS) Reducers Sort by key Map 1 Reduce 1 Iterator Reducers pull from map output files Map m Reduce r Iterator Adapted from Cosco: An Efficient Facebook-Scale Shuffle Service, Spark Summit 2019
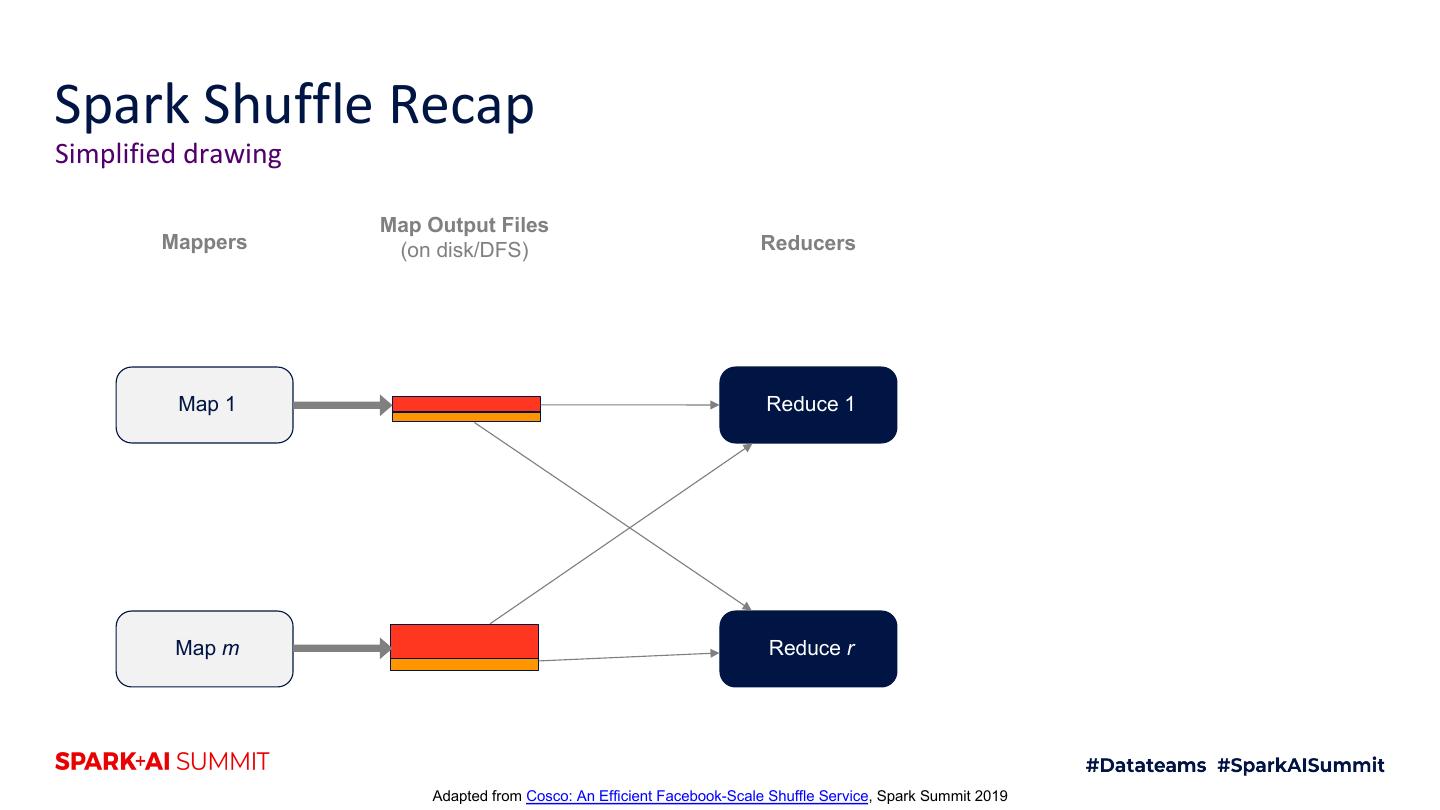
15 .Spark Shuffle Recap Simplified drawing Map Output Files Mappers (on disk/DFS) Reducers Map 1 Reduce 1 Map m Reduce r Adapted from Cosco: An Efficient Facebook-Scale Shuffle Service, Spark Summit 2019
16 .Spark Shuffle Recap Simplified drawing Map Output Files Mappers (on disk/DFS) Reducers Map 1 Reduce 1 Map m Reduce r Adapted from Cosco: An Efficient Facebook-Scale Shuffle Service, Spark Summit 2019
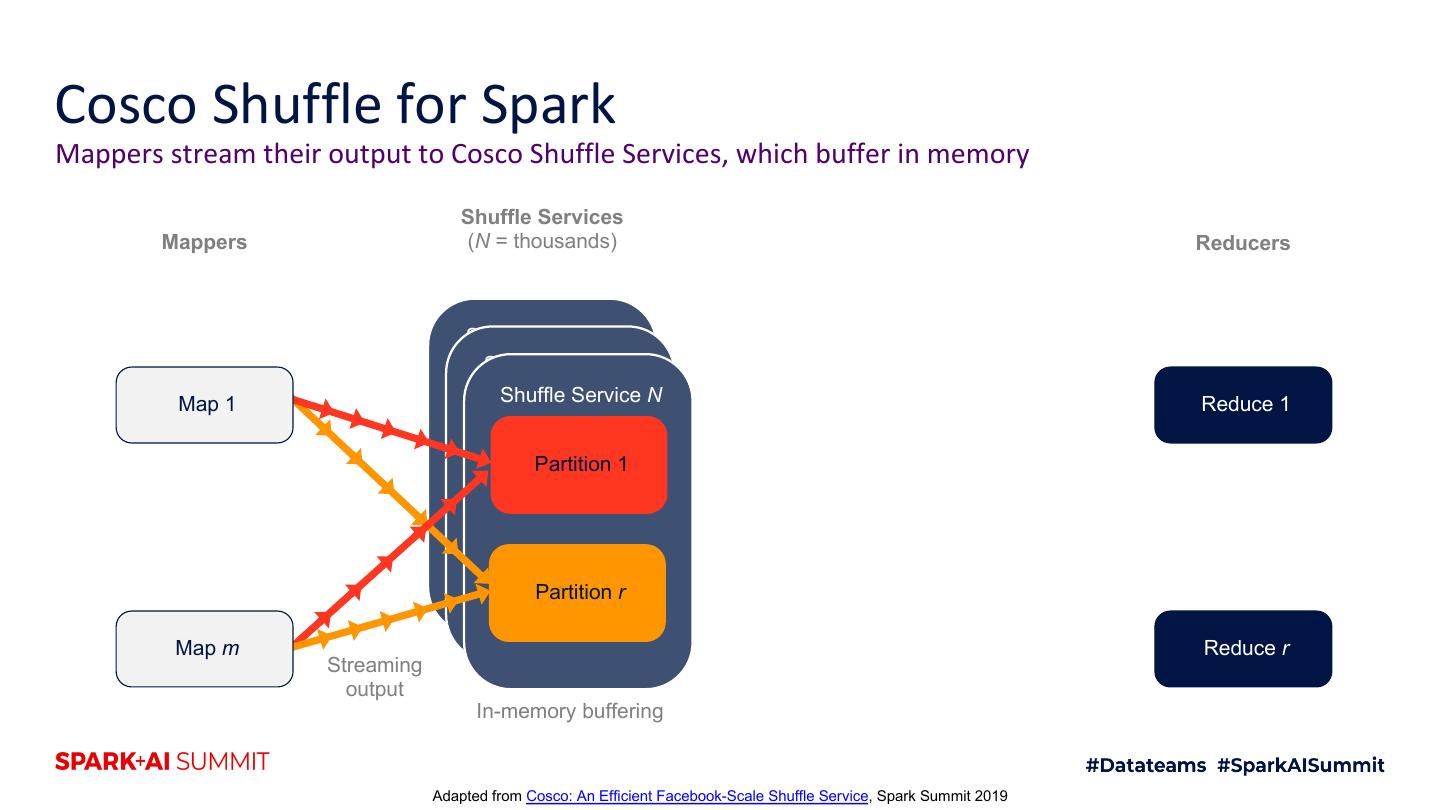
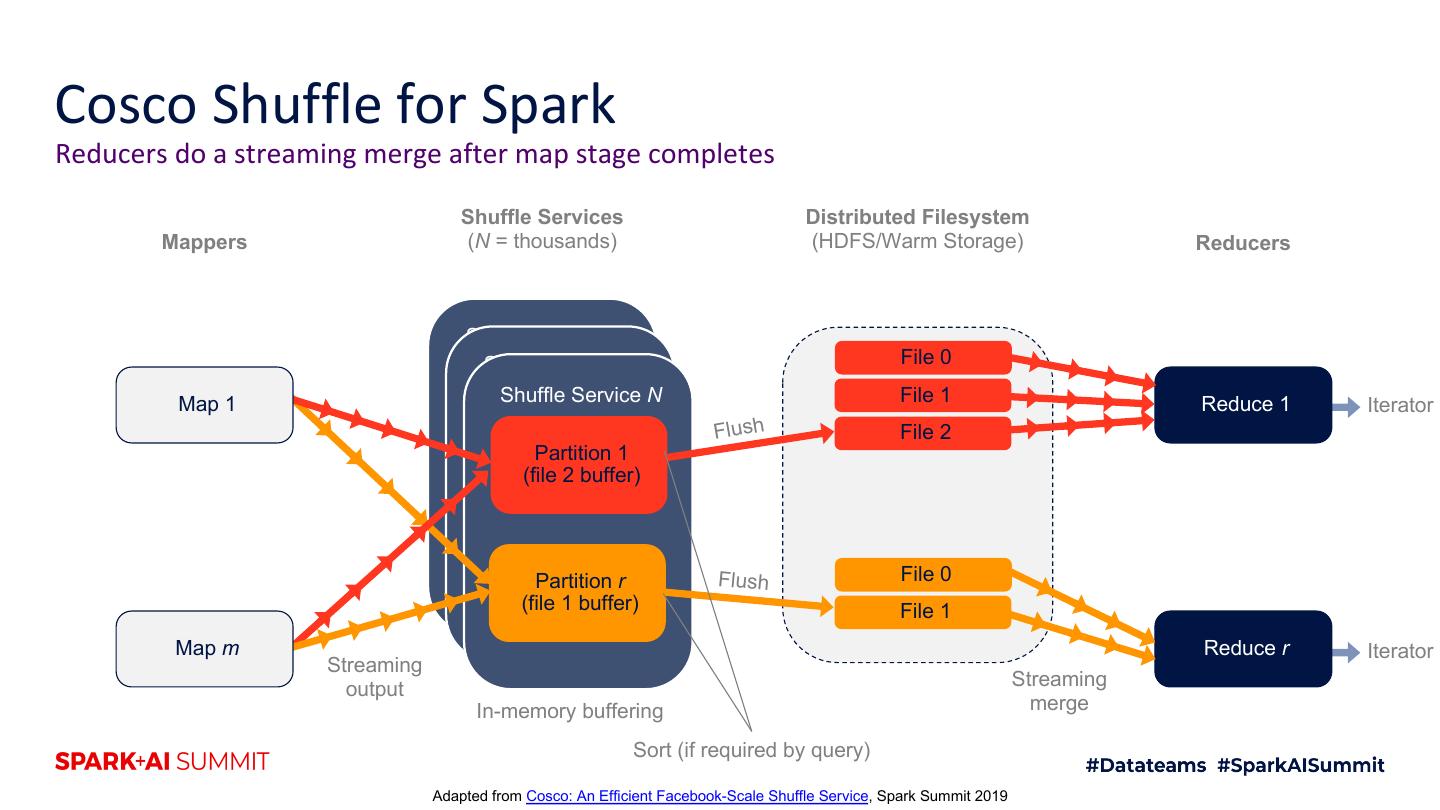
17 .Cosco Shuffle for Spark Mappers stream their output to Cosco Shuffle Services, which buffer in memory Shuffle Services Mappers (N = thousands) Reducers Shuffle Service 1 Shuffle Service 2 Map 1 Shuffle Service N Reduce 1 Partition 1 Partition r Map m Reduce r Streaming output In-memory buffering Adapted from Cosco: An Efficient Facebook-Scale Shuffle Service, Spark Summit 2019
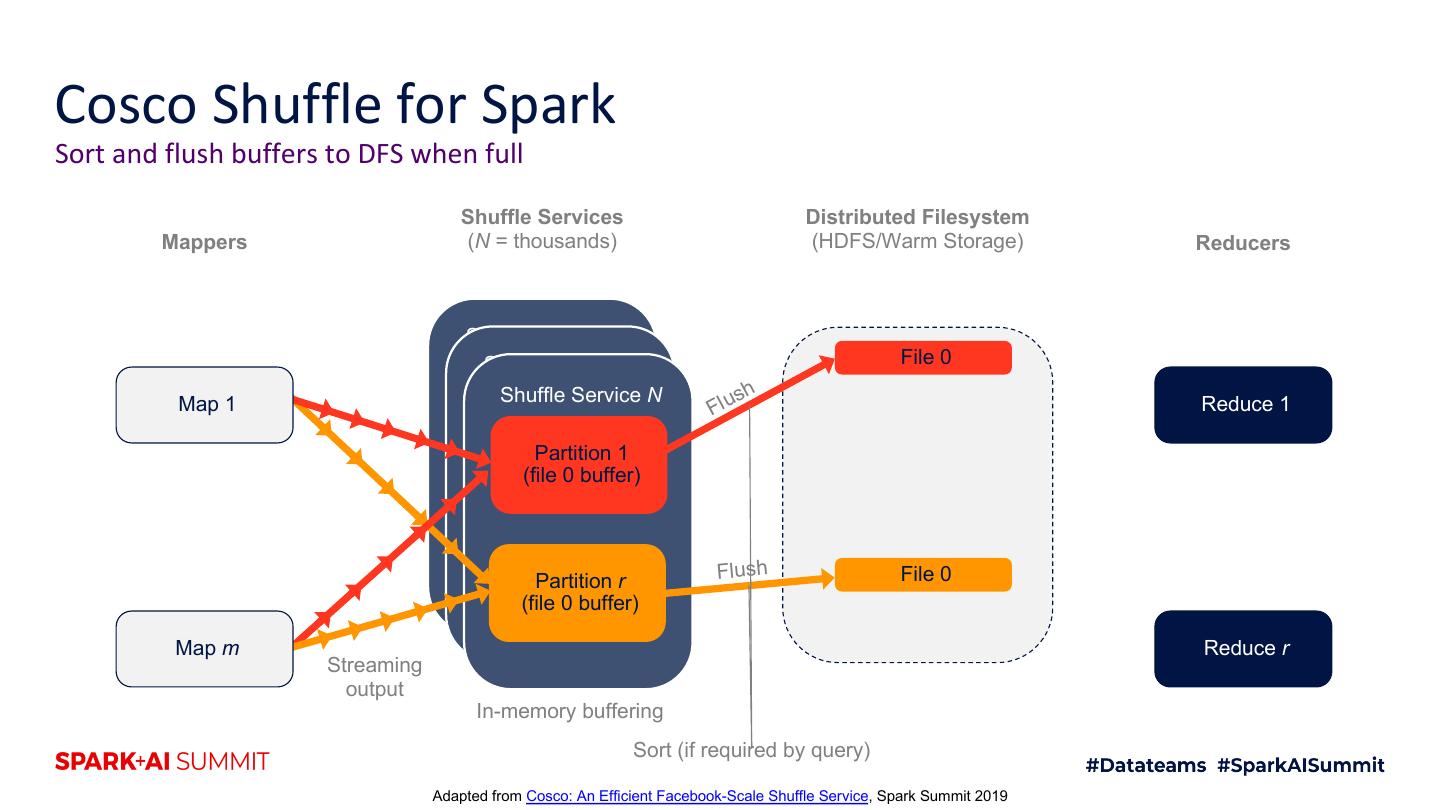
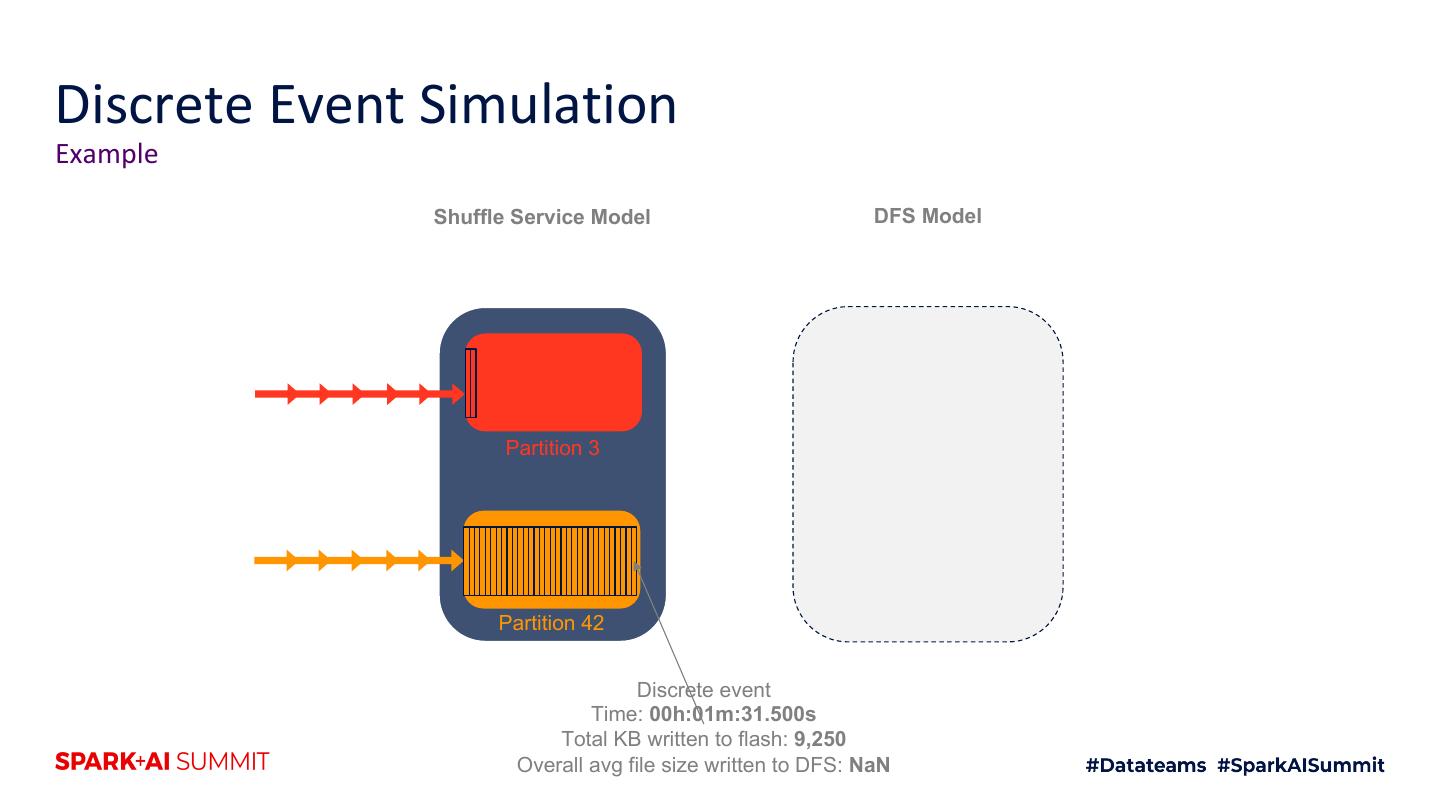
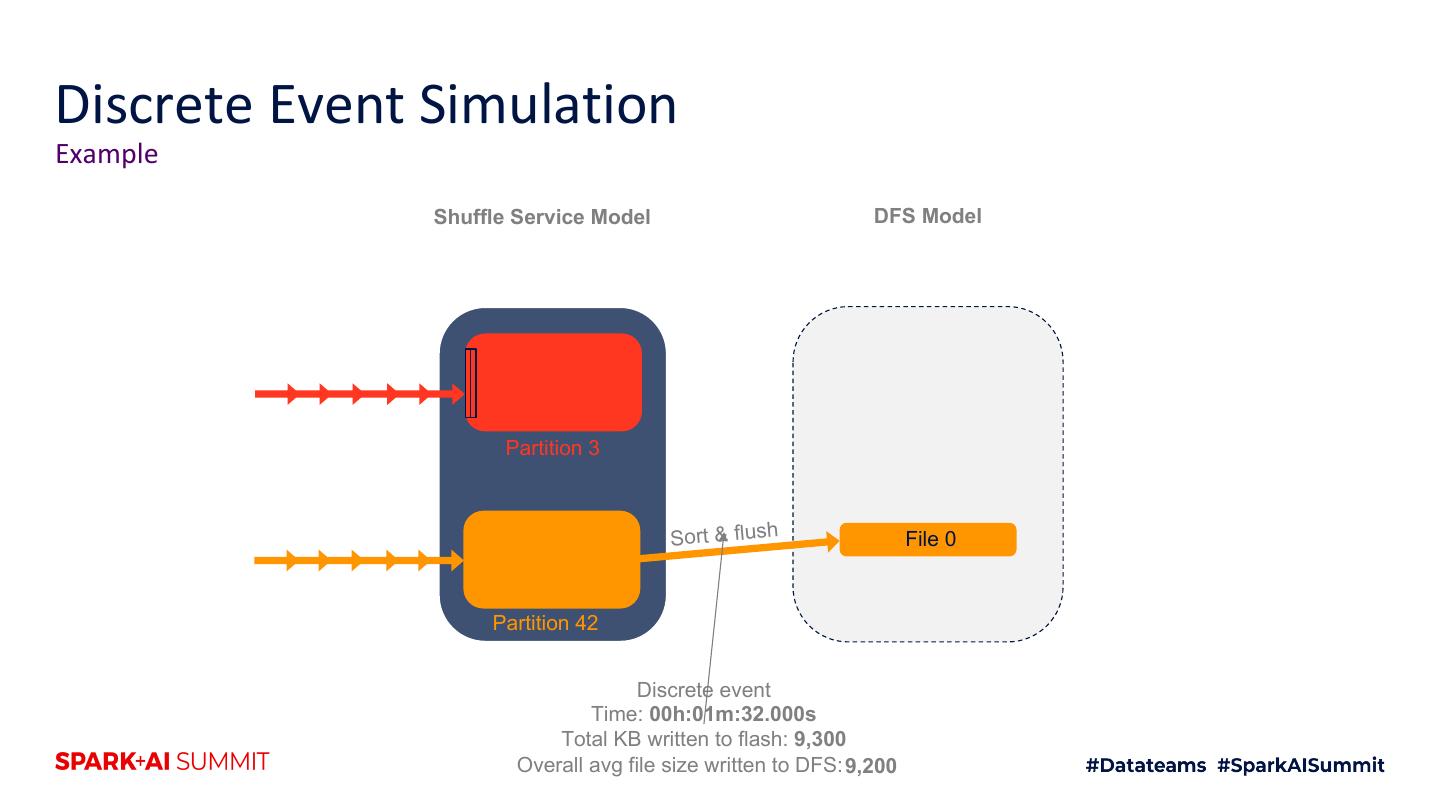
18 .Cosco Shuffle for Spark Sort and flush buffers to DFS when full Shuffle Services Distributed Filesystem Mappers (N = thousands) (HDFS/Warm Storage) Reducers Shuffle Service 1 Shuffle Service 2 File 0 Shuffle Service N s h Map 1 Flu Reduce 1 Partition 1 (file 0 buffer) Partition r Flush File 0 (file 0 buffer) Map m Reduce r Streaming output In-memory buffering Sort (if required by query) Adapted from Cosco: An Efficient Facebook-Scale Shuffle Service, Spark Summit 2019
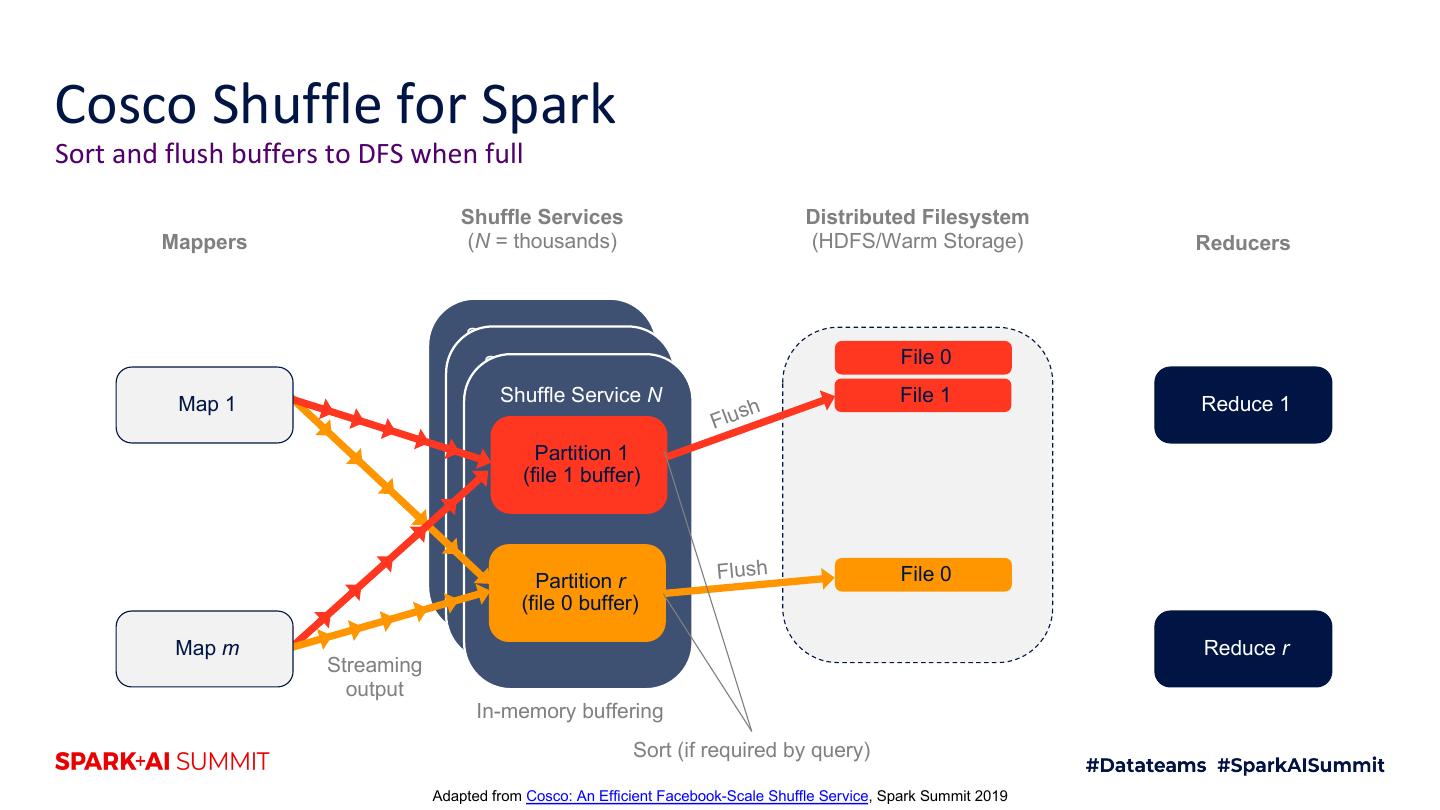
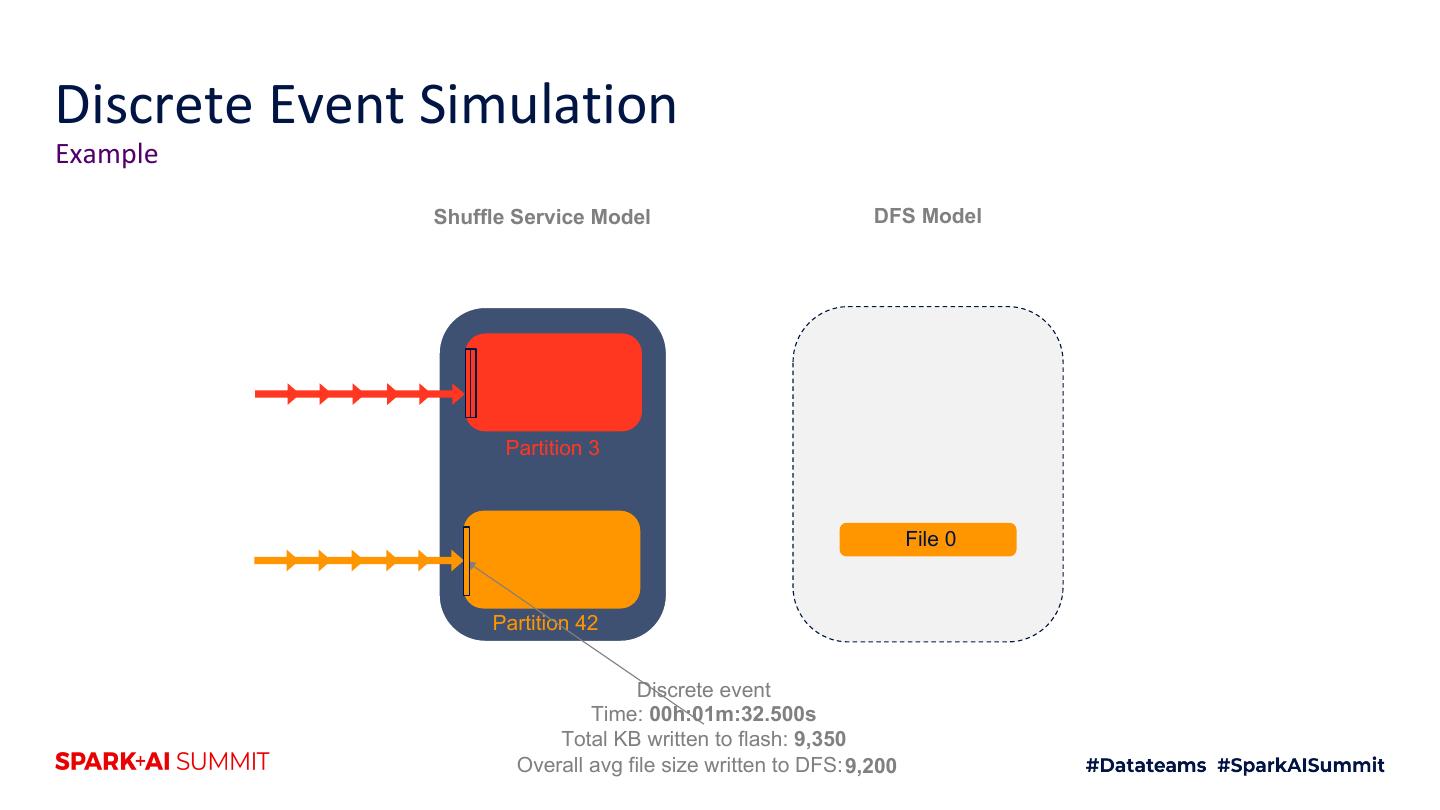
19 .Cosco Shuffle for Spark Sort and flush buffers to DFS when full Shuffle Services Distributed Filesystem Mappers (N = thousands) (HDFS/Warm Storage) Reducers Shuffle Service 1 Shuffle Service 2 File 0 Map 1 Shuffle Service N File 1 Reduce 1 h Flus Partition 1 (file 1 buffer) Partition r Flush File 0 (file 0 buffer) Map m Reduce r Streaming output In-memory buffering Sort (if required by query) Adapted from Cosco: An Efficient Facebook-Scale Shuffle Service, Spark Summit 2019
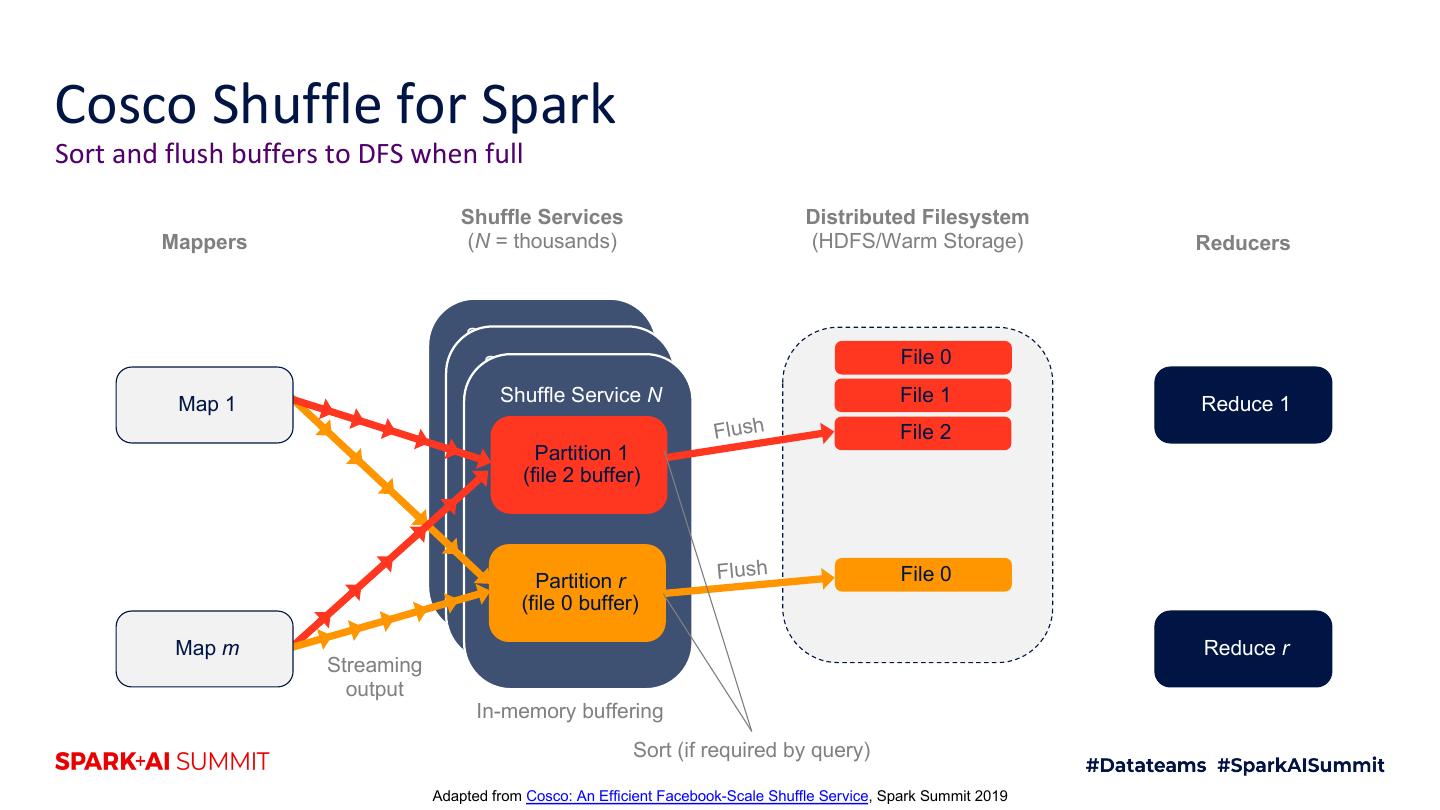
20 .Cosco Shuffle for Spark Sort and flush buffers to DFS when full Shuffle Services Distributed Filesystem Mappers (N = thousands) (HDFS/Warm Storage) Reducers Shuffle Service 1 Shuffle Service 2 File 0 Map 1 Shuffle Service N File 1 Reduce 1 Flush File 2 Partition 1 (file 2 buffer) Partition r Flush File 0 (file 0 buffer) Map m Reduce r Streaming output In-memory buffering Sort (if required by query) Adapted from Cosco: An Efficient Facebook-Scale Shuffle Service, Spark Summit 2019
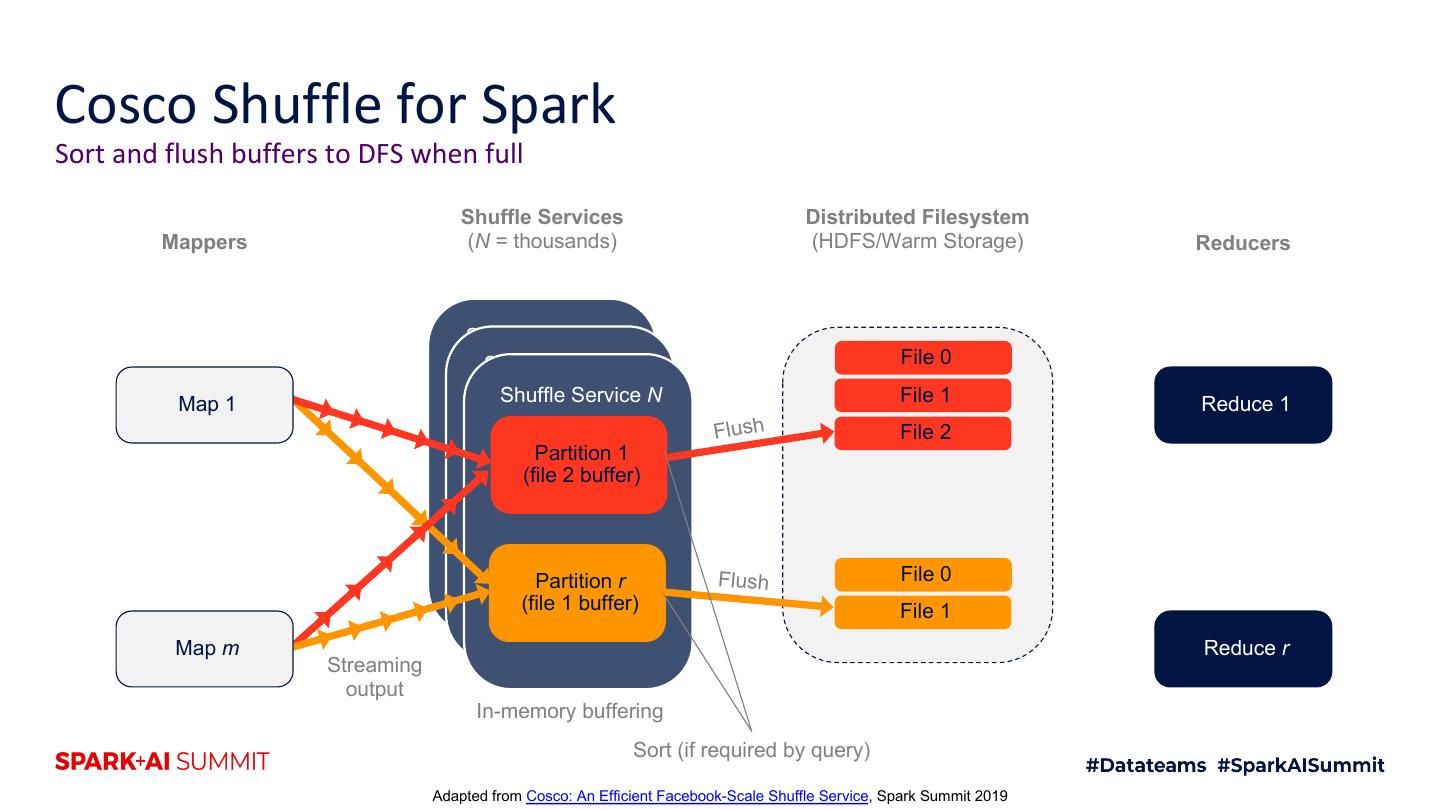
21 .Cosco Shuffle for Spark Sort and flush buffers to DFS when full Shuffle Services Distributed Filesystem Mappers (N = thousands) (HDFS/Warm Storage) Reducers Shuffle Service 1 Shuffle Service 2 File 0 Map 1 Shuffle Service N File 1 Reduce 1 Flush File 2 Partition 1 (file 2 buffer) Partition r Flush File 0 (file 1 buffer) File 1 Map m Reduce r Streaming output In-memory buffering Sort (if required by query) Adapted from Cosco: An Efficient Facebook-Scale Shuffle Service, Spark Summit 2019
22 .Cosco Shuffle for Spark Reducers do a streaming merge after map stage completes Shuffle Services Distributed Filesystem Mappers (N = thousands) (HDFS/Warm Storage) Reducers Shuffle Service 1 Shuffle Service 2 File 0 Map 1 Shuffle Service N File 1 Reduce 1 Iterator Flush File 2 Partition 1 (file 2 buffer) Partition r Flush File 0 (file 1 buffer) File 1 Map m Reduce r Iterator Streaming output Streaming In-memory buffering merge Sort (if required by query) Adapted from Cosco: An Efficient Facebook-Scale Shuffle Service, Spark Summit 2019
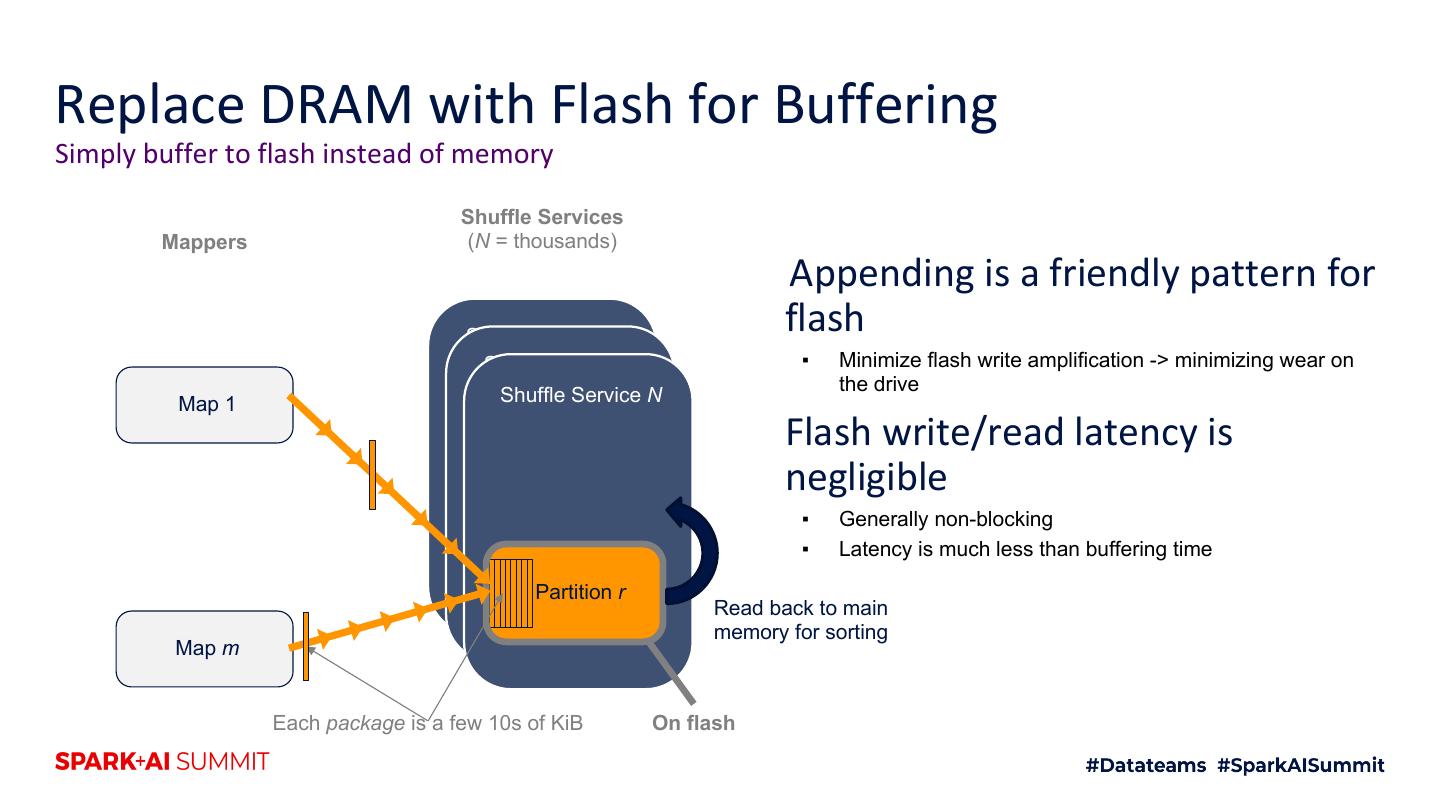
23 .Replace DRAM with Flash for Buffering
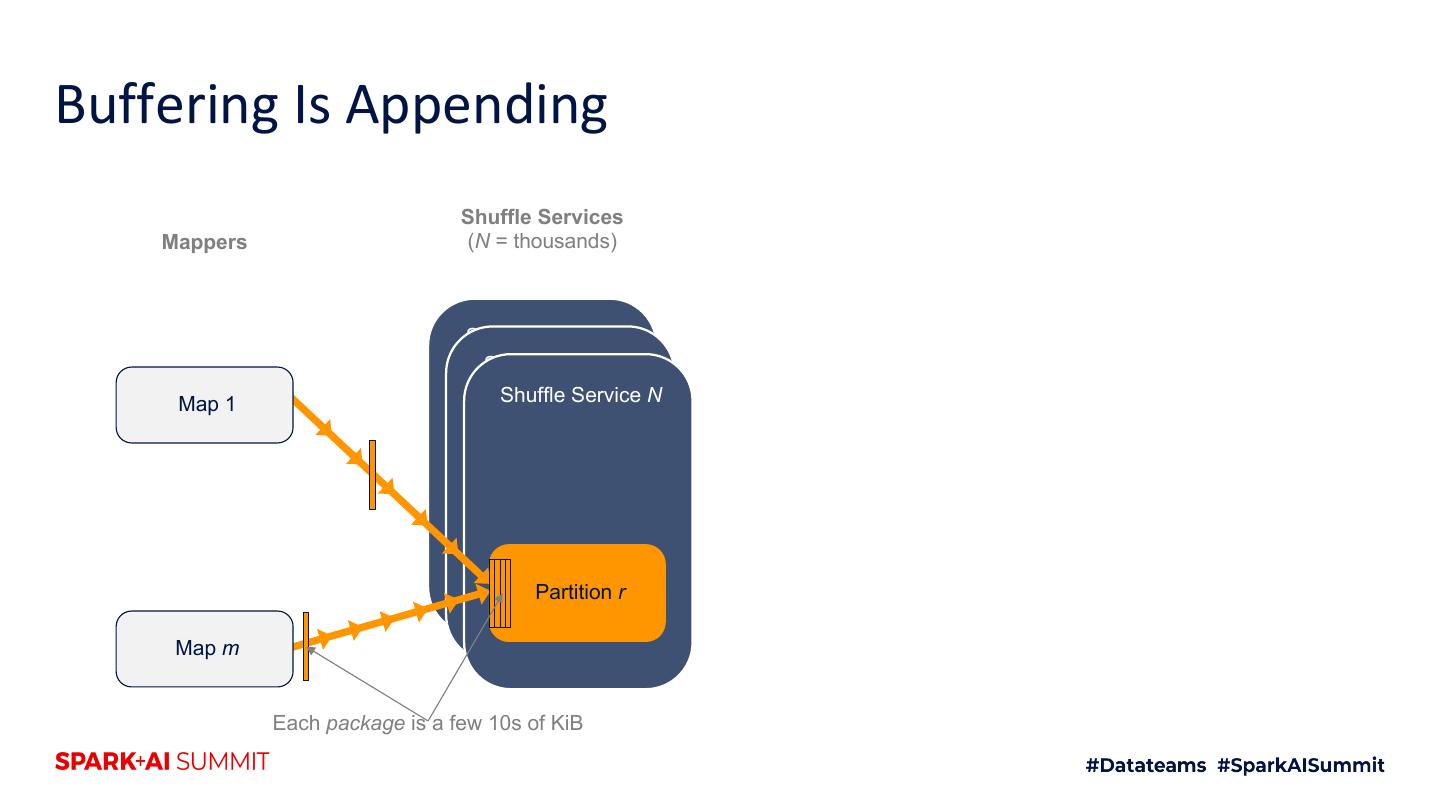
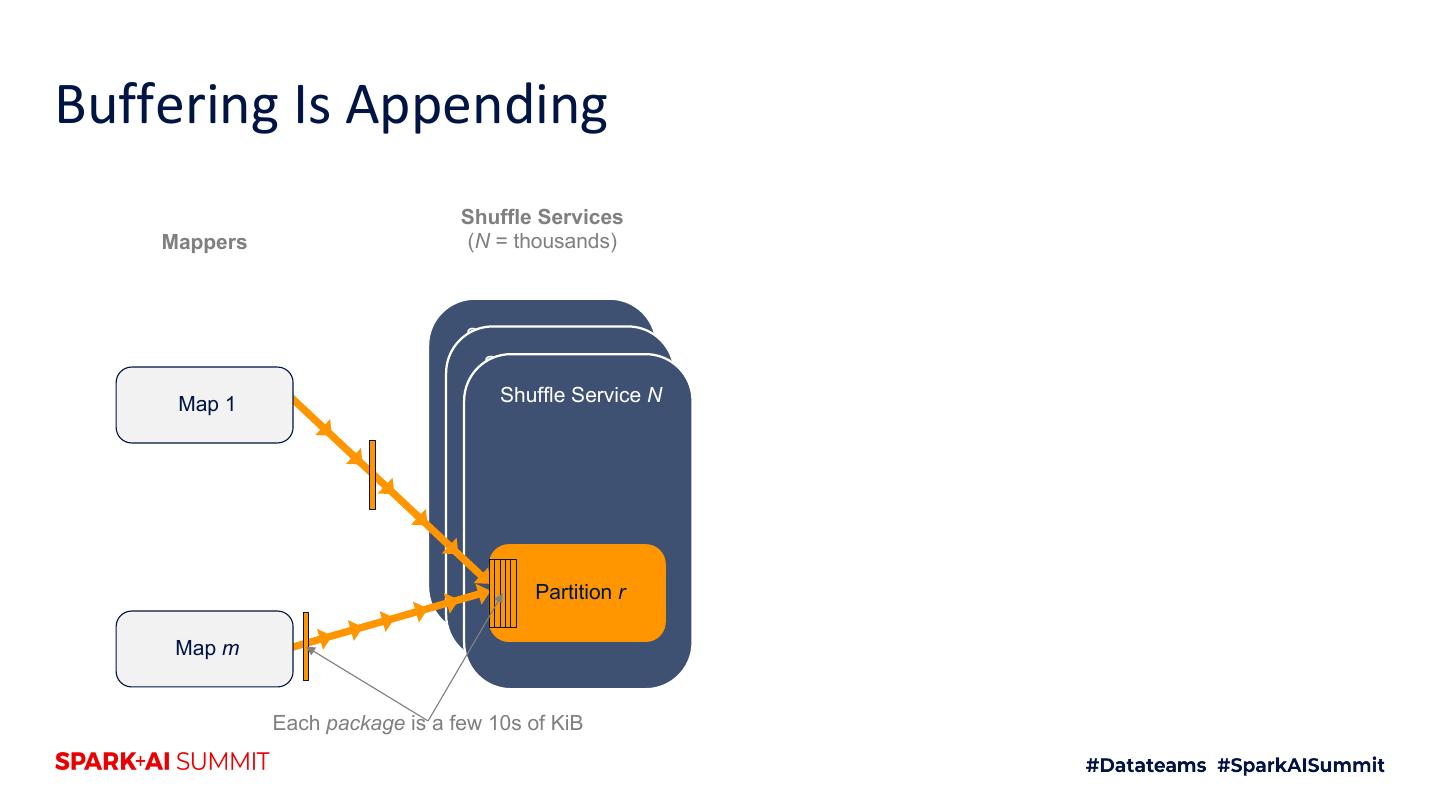
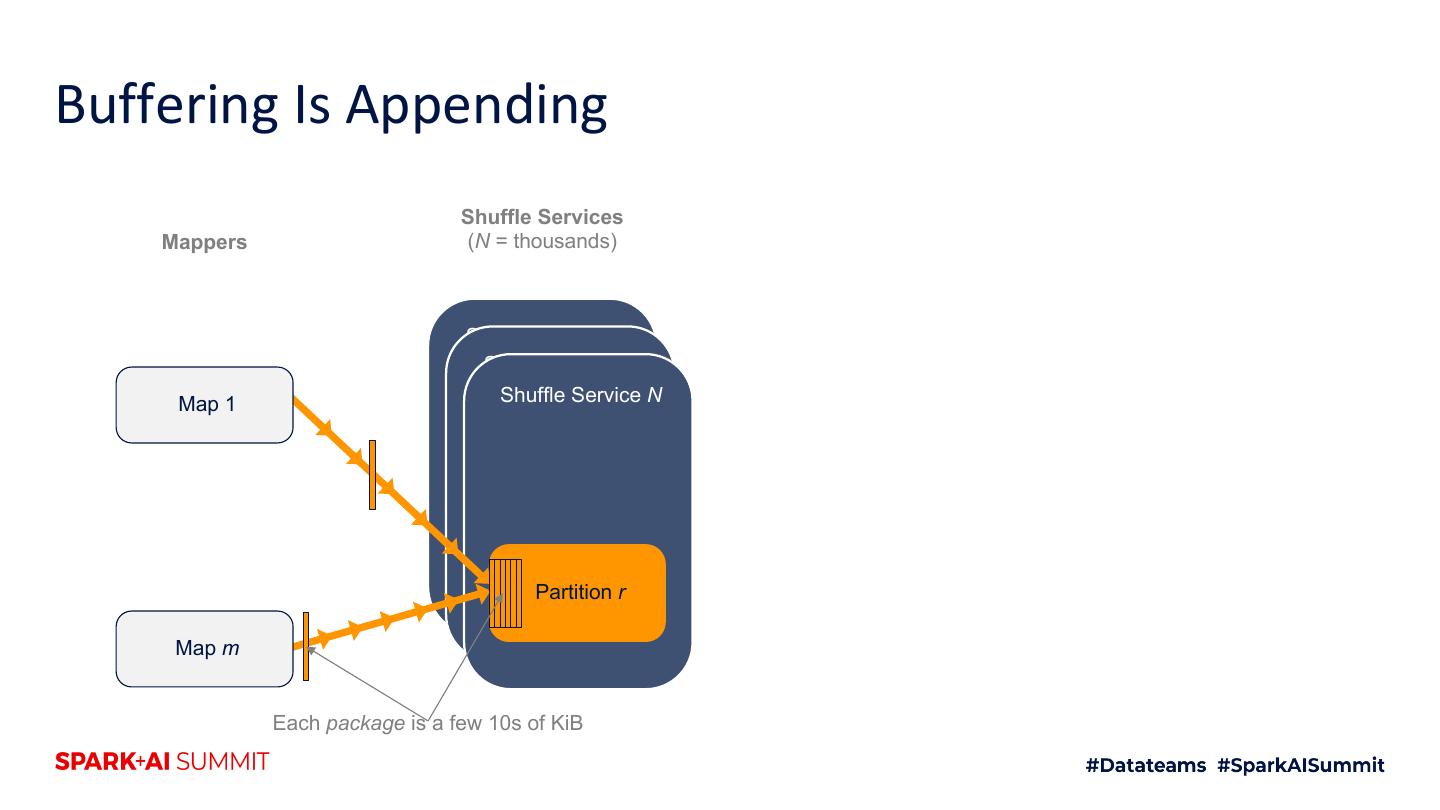
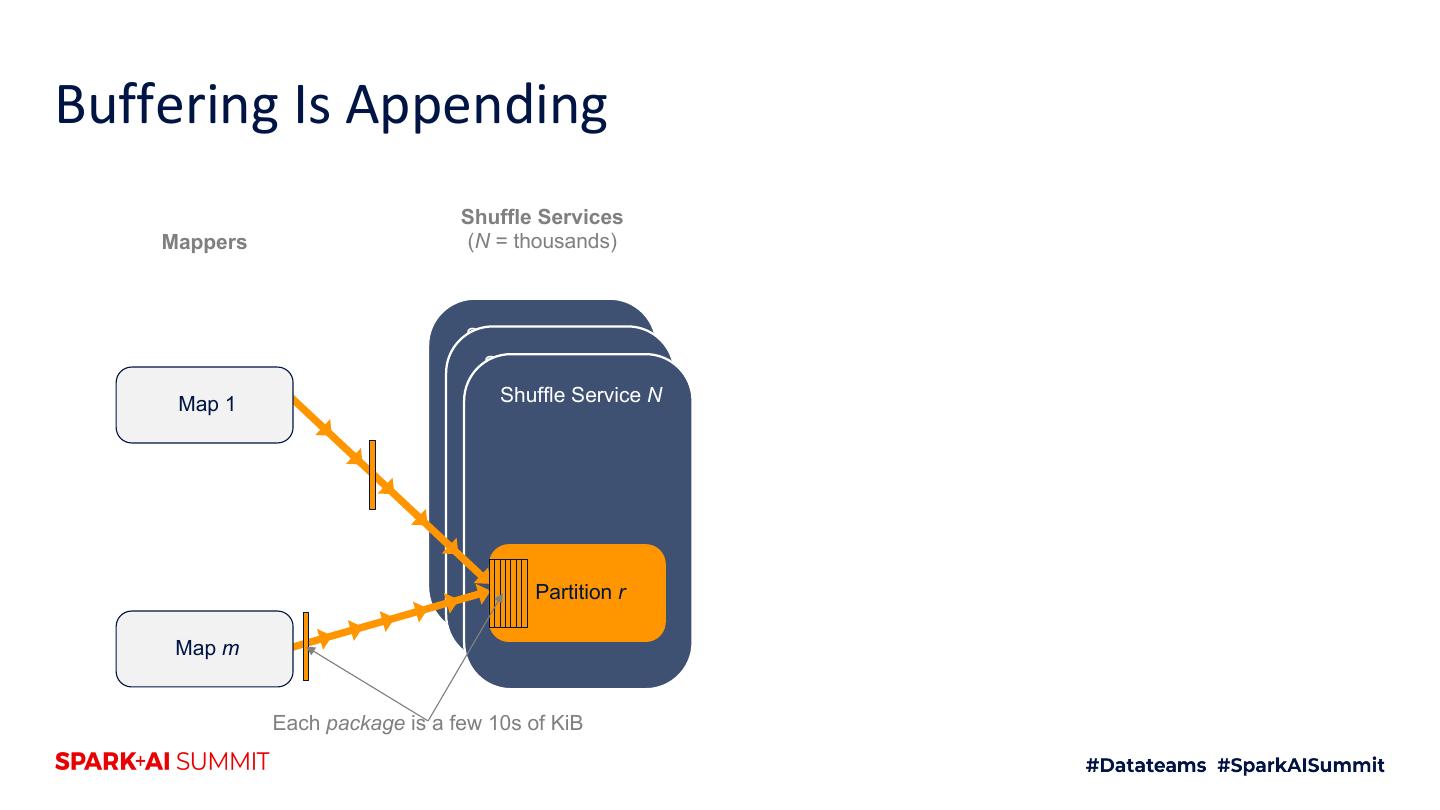
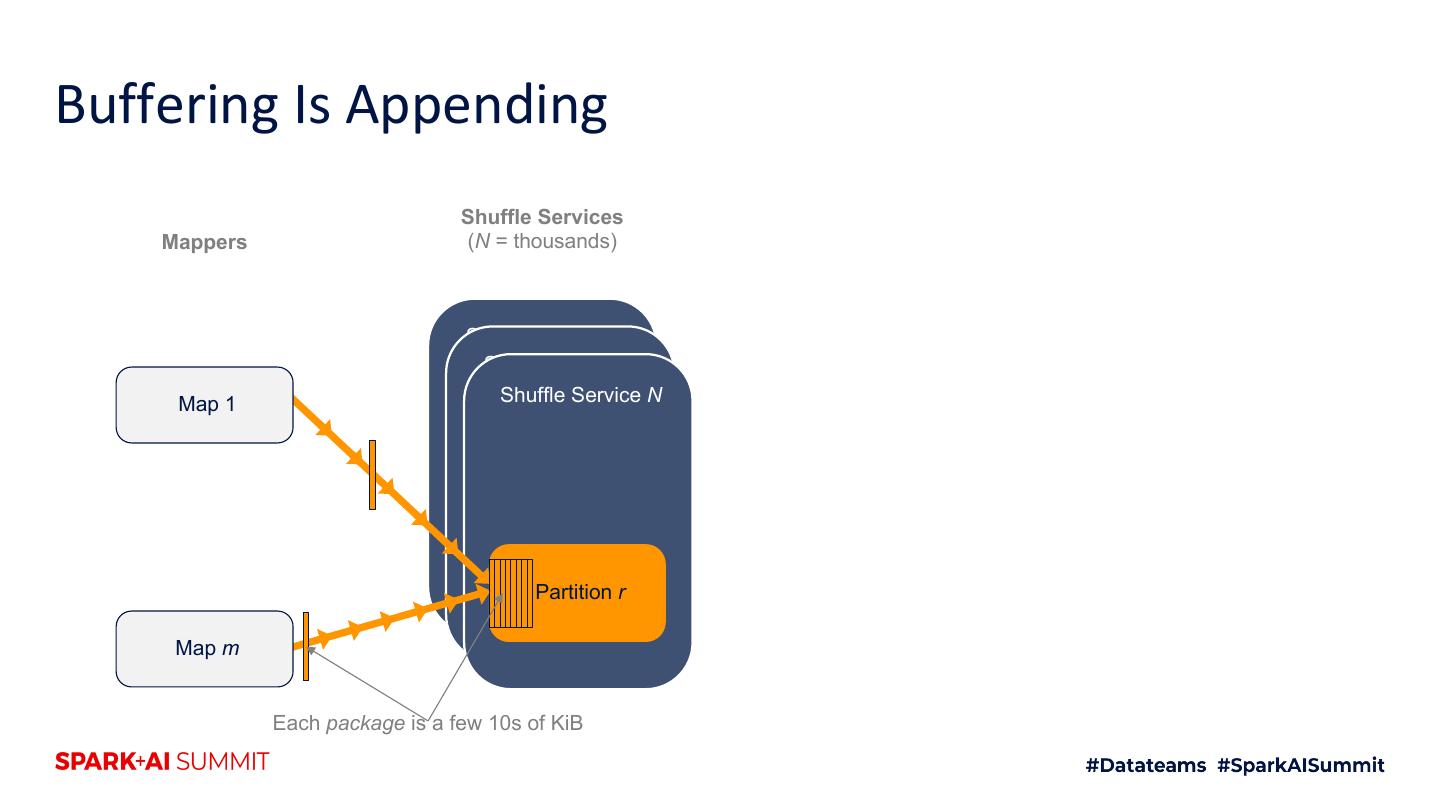
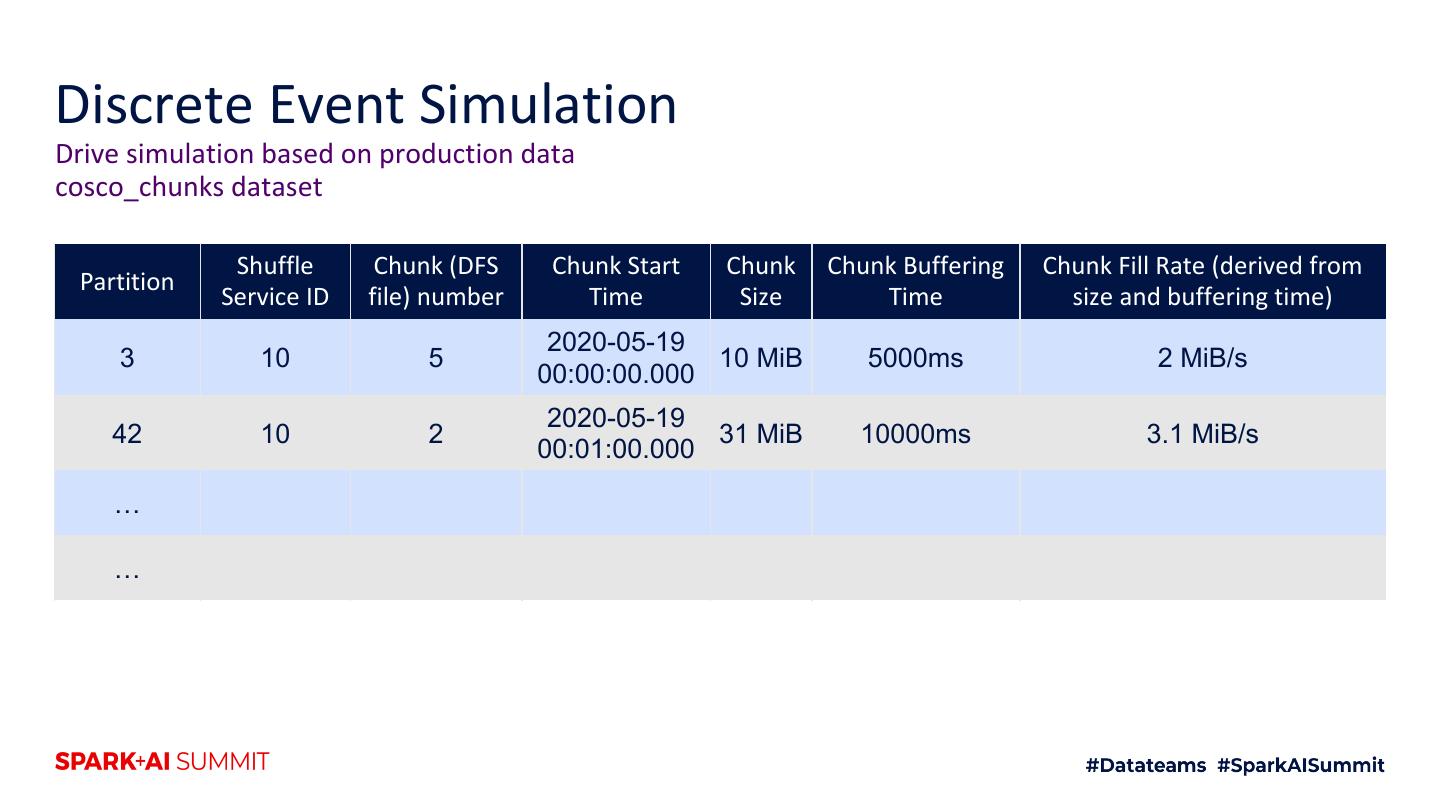
24 .Buffering Is Appending Shuffle Services Mappers (N = thousands) Shuffle Service 1 Shuffle Service 2 Map 1 Shuffle Service N Partition r Map m Each package is a few 10s of KiB
25 .Buffering Is Appending Shuffle Services Mappers (N = thousands) Shuffle Service 1 Shuffle Service 2 Map 1 Shuffle Service N Partition r Map m Each package is a few 10s of KiB
26 .Buffering Is Appending Shuffle Services Mappers (N = thousands) Shuffle Service 1 Shuffle Service 2 Map 1 Shuffle Service N Partition r Map m Each package is a few 10s of KiB
27 .Buffering Is Appending Shuffle Services Mappers (N = thousands) Shuffle Service 1 Shuffle Service 2 Map 1 Shuffle Service N Partition r Map m Each package is a few 10s of KiB
28 .Buffering Is Appending Shuffle Services Mappers (N = thousands) Shuffle Service 1 Shuffle Service 2 Map 1 Shuffle Service N Partition r Map m Each package is a few 10s of KiB
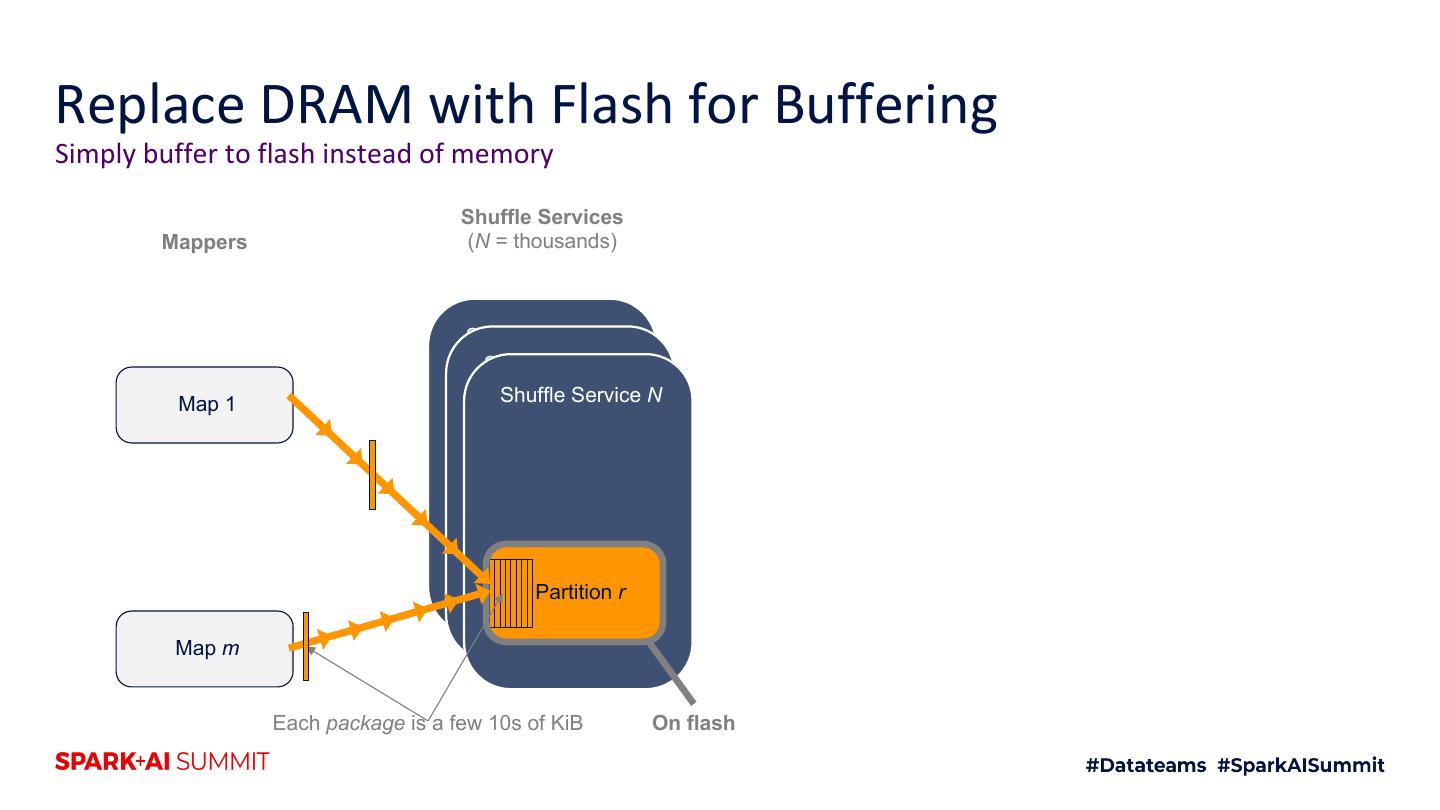
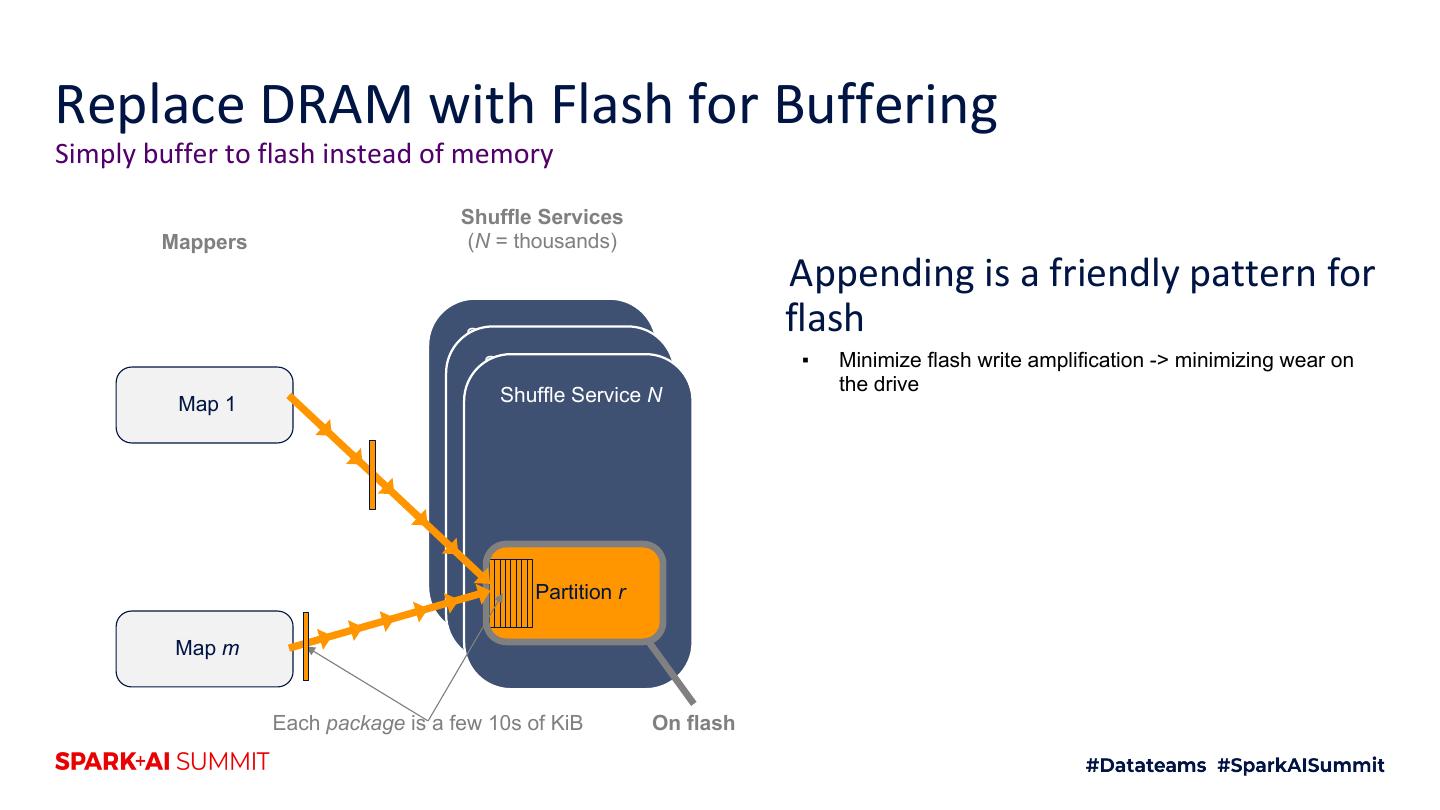
29 .Replace DRAM with Flash for Buffering Simply buffer to flash instead of memory Shuffle Services Mappers (N = thousands) Shuffle Service 1 Shuffle Service 2 Map 1 Shuffle Service N Partition r Map m Each package is a few 10s of KiB On flash
1点赞
1收藏
3秒后跳转登录页面
去登陆

