




















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
What's New in Upcoming Apache Spark 2.4
The new features of the upcoming Apache Spark 2.4
展开查看详情
1 . Upcoming V What's New in Apache Spark 2.4? Xiao Li San Jose | 2018
2 .About Me • Software Engineer at Databricks • Apache Spark Committer and PMC Member • Previously, IBM Master Inventor • Spark SQL, Database Replication, Information Integration • Ph.D. in University of Florida • Github: gatorsmile
3 .Databricks Unified Analytics Platform DATABRICKS WORKSPACE Notebooks Jobs Models APIs Dashboards End to end ML lifecycle DATABRICKS RUNTIME Databricks Delta ML Frameworks Reliable & Scalable Simple & Integrated DATABRICKS CLOUD SERVICE
4 . Databricks Customers Across Industries Financial Services Healthcare & Pharma Media & Entertainment Data & Analytics Services Technology Public Sector Retail & CPG Consumer Services Marketing & AdTech Energy & Industrial IoT
5 .Major Features on Upcoming Spark 2.4 Barrier Spark on Scala PySpark Structured Execution Kubernetes 2.12 Improvement Streaming Image Native Avro Built-in source Higher-order Various SQL Source Support Improvement Functions Features 5
6 .Major Features on Upcoming Spark 2.4 Barrier Spark on Native Avro Image Built-in source Execution Kubernetes Support Source Improvement PySpark Higher-order Scala Structured Various SQL Improvement Functions 2.12 Streaming Features 6
7 .Apache Spark: The First Unified Analytics Engine Uniquely combines Data & AI technologies Runtime Delta Spark Core Engine Big Data Processing Machine Learning ETL + SQL +Streaming MLlib + SparkR
8 .The cross? ?? Continuous Horovod Processing Distributed Pandas UDF TensorFlow Structured Streaming tf.data tf.transform Keras TF XLA AI/ML Project Tungsten TensorFlow TensorFrames ML Pipelines API Caffe/PyTorch/MXNet TensorFlowOnSpark GraphLab 50+ Data Sources xgboost CaffeOnSpark scikit-learn DataFrame-based APIs LIBLINEAR glmnet Python/Java/R interfaces Map/Reduce RDD pandas/numpy/scipy R 8
9 .Project Hydrogen: Spark + AI A gang scheduling to Apache Spark that embeds a distributed DL job as a Spark stage to simplify the distributed training workflow. [SPARK-24374] • Launch the tasks in a stage at the same time • Provide enough information and tooling to embed distributed DL workloads • Introduce a new mechanism of fault tolerance (When any task failed in the middle, Spark shall abort all the tasks and restart the stage) 9
10 .Project Hydrogen: Spark + AI Barrier Optimized Accelerator Execution Data Aware Mode Exchange Scheduling Demo: Project Hydrogen: https://vimeo.com/274267107 & https://youtu.be/hwbsWkhBeWM 10
11 .Timeline Spark 2.4 • [SPARK-24374] barrier execution mode (basic scenarios) • (Databricks) Horovod integration w/ barrier mode Spark 2.5/3.0 • [SPARK-24374] barrier execution mode • [SPARK-24579] optimized data exchange • [SPARK-24615] accelerator-aware scheduling
12 .Major Features on Upcoming Spark 2.4 Barrier Spark on Native Avro Image Built-in source Execution Kubernetes Support Source Improvement PySpark Higher-order Scala Structured Various SQL Improvement Functions 2.12 Streaming Features 12
13 .Pandas UDFs Spark 2.3 introduced vectorized Pandas UDFs that use Pandas to process data. Faster data serialization and execution using vectorized formats • Grouped Aggregate Pandas UDFs • pandas.Series -> a scalar • returnType: primitive data type • [SPARK-22274] [SPARK-22239] 13
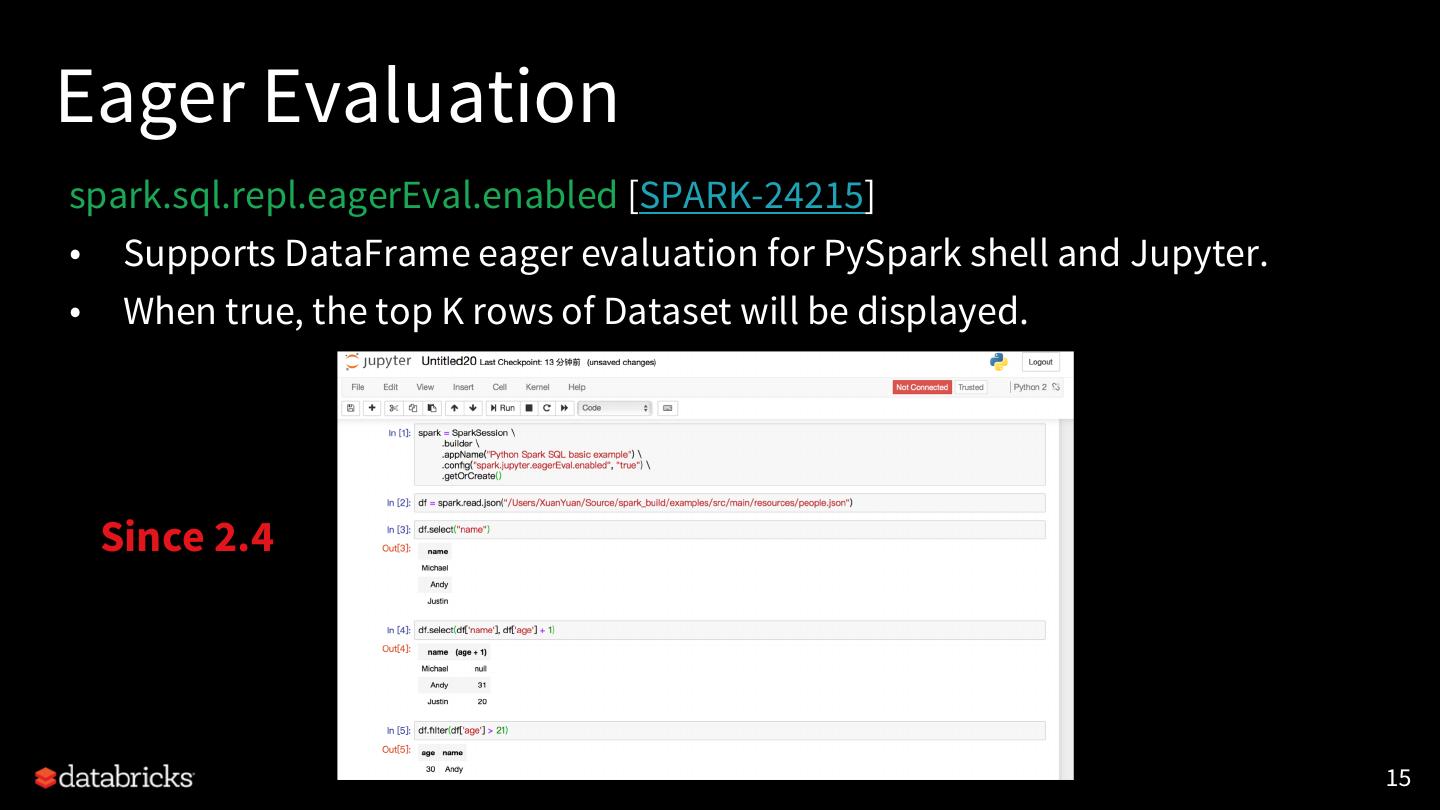
14 .Eager Evaluation spark.sql.repl.eagerEval.enabled [SPARK-24215] • Supports DataFrame eager evaluation for PySpark shell and Jupyter. • When true, the top K rows of Dataset will be displayed. Prior to 2.4 14
15 .Eager Evaluation spark.sql.repl.eagerEval.enabled [SPARK-24215] • Supports DataFrame eager evaluation for PySpark shell and Jupyter. • When true, the top K rows of Dataset will be displayed. Since 2.4 15
16 .Other Notable Features [SPARK-24396] Add Structured Streaming ForeachWriter for Python [SPARK-23030] Use Arrow stream format for creating from and collecting Pandas DataFrames [SPARK-24624] Support mixture of Python UDF and Scalar Pandas UDF [SPARK-23874] Upgrade Apache Arrow to 0.10.0 • Allow for adding BinaryType support [ARROW-2141] [SPARK-25004] Add spark.executor.pyspark.memory limit 16
17 .Major Features on Upcoming Spark 2.4 Barrier Spark on Native Avro Image Built-in source Execution Kubernetes Support Source Improvement PySpark Higher-order Scala Structured Various SQL Improvement Functions 2.12 Streaming Features 17
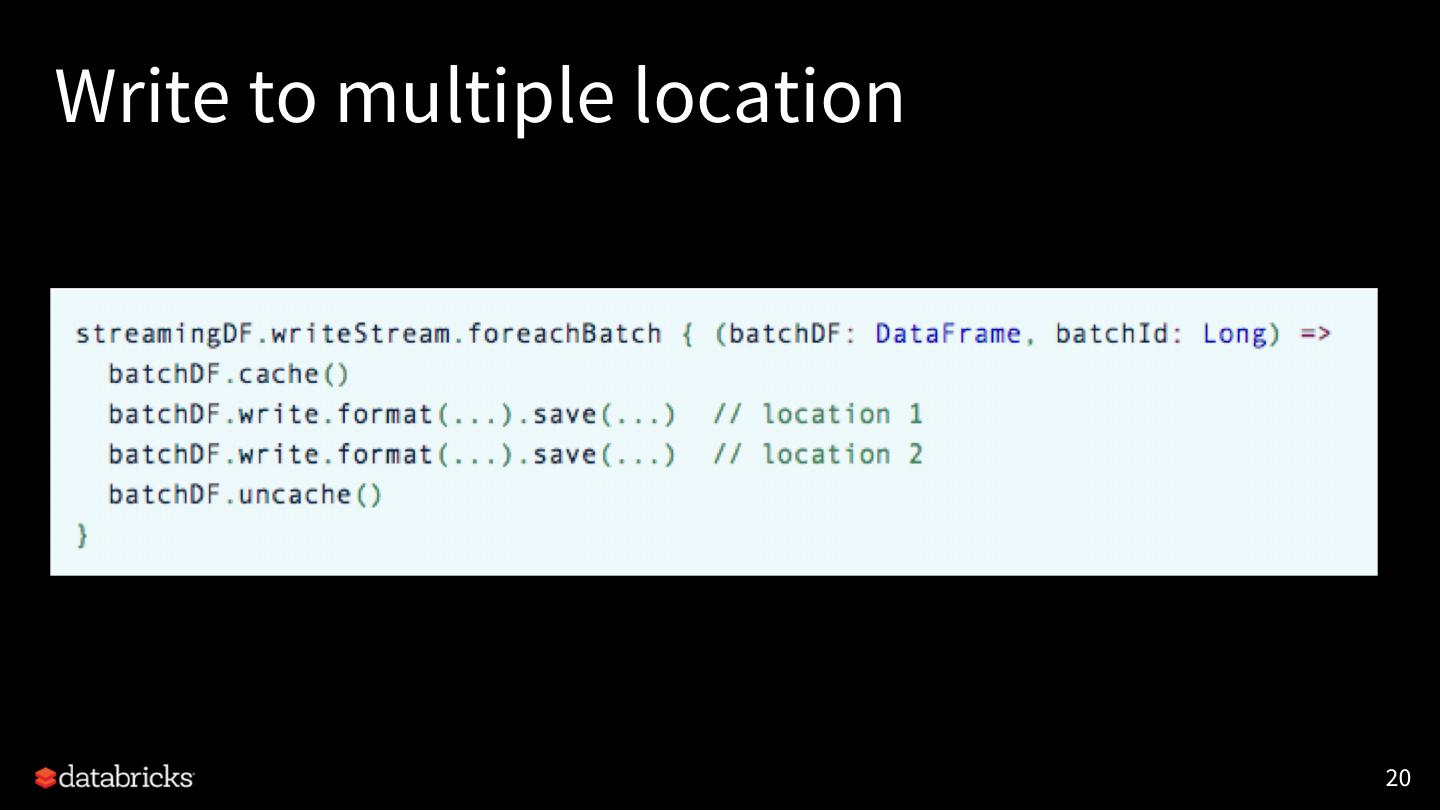
18 .Flexible Streaming Sink [SPARK-24565] Exposing output rows of each microbatch as a DataFrame foreachBatch(f: Dataset[T] => Unit) • Scala/Java/Python APIs in DataStreamWriter. • Reuse existing batch data sources • Write to multiple locations • Apply additional DataFrame operations 18
19 .Reuse existing batch data sources 19
20 .Write to multiple location 20
21 .Structured Streaming [SPARK-24662] Support for the LIMIT operator for streams in Append and Complete output modes. [SPARK-24763] Remove redundant key data from value in streaming aggregation [SPARK-24156] Faster generation of output results and/or state cleanup with stateful operations (mapGroupsWithState, stream-stream join, streaming aggregation, streaming dropDuplicates) when there is no data in the input stream. [SPARK-24730] Support for choosing either the min or max watermark when there are multiple input streams in a query. 21
22 .Kafka Client 2.0.0 [SPARK-18057] Upgraded Kafka client version from 0.10.0.1 to 2.0.0 [SPARK-25005] Support “kafka.isolation.level” to read only committed records from Kafka topics that are written using a transactional producer. 22
23 .Major Features on Upcoming Spark 2.4 Barrier Spark on Native Avro Image Built-in source Execution Kubernetes Support Source Improvement PySpark Higher-order Scala Structured Various SQL Improvement Functions 2.12 Streaming Features 23
24 .AVRO • Apache Avro (https://avro.apache.org) • A data serialization format • Widely used in the Spark and Hadoop ecosystem, especially for Kafka-based data pipelines. • Spark-Avro package (https://github.com/databricks/spark-avro) • Spark SQL can read and write the avro data. • Inlining Spark-Avro package [SPARK-24768] • Better experience for first-time users of Spark SQL and structured streaming • Expect further improve the adoption of structured streaming 24
25 .AVRO [SPARK-24811] from_avro/to_avro functions to read and write Avro data within a DataFrame instead of just files. Example: 1. Decode the Avro data into a struct 2. Filter by column `favorite_color` 3. Encode the column `name` in Avro format 25
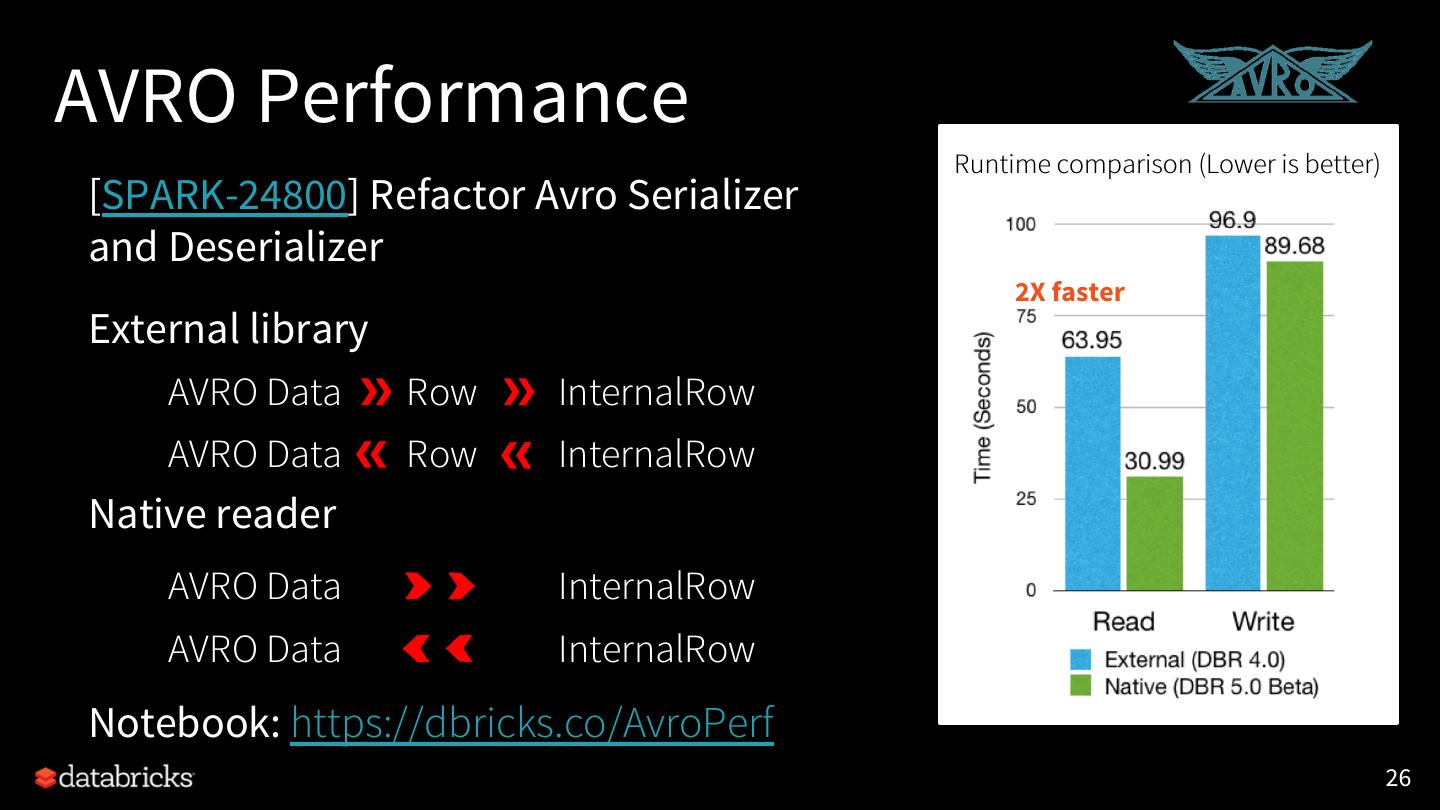
26 .AVRO Performance Runtime comparison (Lower is better) [SPARK-24800] Refactor Avro Serializer and Deserializer 2X faster External library AVRO Data Row InternalRow AVRO Data Row InternalRow Native reader AVRO Data InternalRow AVRO Data InternalRow Notebook: https://dbricks.co/AvroPerf 26
27 .AVRO Logical Types Avro upgrade from 1.7.7 to 1.8. Options: [SPARK-24771] • compression Logical type support: • ignoreExtension • Date [SPARK-24772] • recordNamespace • Decimal [SPARK-24774] • recordName • Timestamp [SPARK-24773] • avroSchema 27
28 .Major Features on Upcoming Spark 2.4 Barrier Spark on Native Avro Image Built-in source Execution Kubernetes Support Source Improvement PySpark Higher-order Scala Structured Various SQL Improvement Functions 2.12 Streaming Features 28
29 .Image schema data source [SPARK-22666] Spark datasource for image format • Partition discovery [new] • Loading recursively from directory [new] • dropImageFailures path wildcard matching • Path wildcard matching 29
相关推荐

加关注
3秒后跳转登录页面
去登陆

