


































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Native SQL Engine Introduction
议题介绍
Optimized Analytics Package(OAP) 是一个英特尔开源项目结合了许多Spark相关的优化。Native SQL Engine是其中一个重点项目,目标在基于Spark SQL的基础之上,提供Spark列式存储的计算能力,并引入启用Native的方式及Intel AVX的技术,得到更佳的效能。
在此议题中,观众将能了解到详细的Native SQL Engine介绍包含是如何工作的细节及性能的展示,并且同时更新此项目目前的现况及未来的发展方向。
嘉宾介绍
韦廷是一名英特尔资深软件工程师,服务于英特尔大数据软件部6年多的时间。
他致力于大数据及云计算相关领域的解决方案达8年以上的时间,主要工作为大数据在云计算解决方案的研发及客户的支持,目前专注于大数据在Intel技术的結合、研究与发展。
展开查看详情
1 .Binwei Yang, Chendi Xue, Yuan Zhou, Hongze Zhang, Ke Jia Weiting Chen, Carson Wang, Jian Zhang IAGS/MLP/DAS/BDF Contact: weiting.chen@intel.com Last update: May, 2021
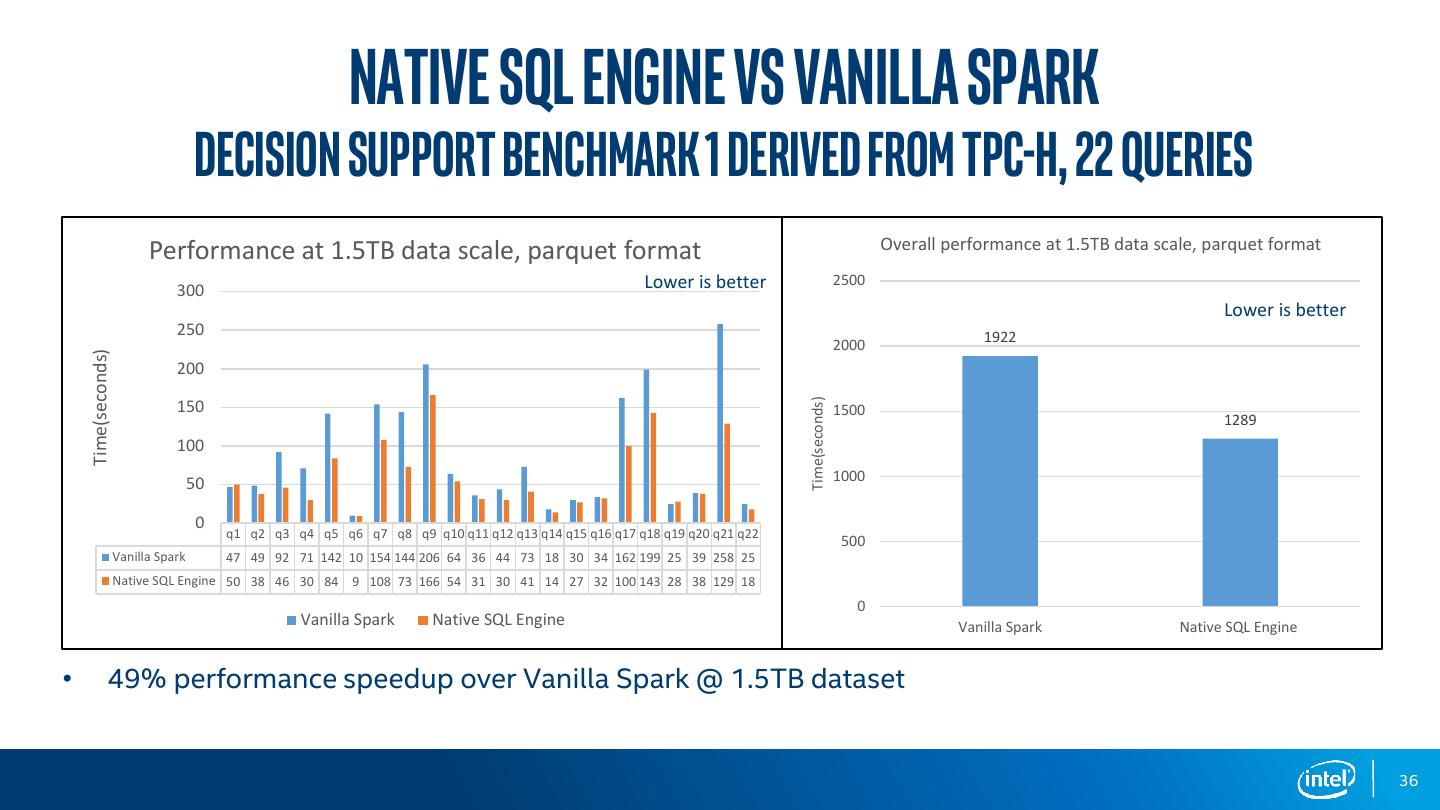
2 .agenda Motivation Core Design - Architecture - Arrow Data Source - Native SQL Engine - Columnar Shuffle Getting Started Performance Summary 2
3 .agenda Motivation Core Design - Architecture - Arrow Data Source - Native SQL Engine - Columnar Shuffle Getting Started Performance Summary 3
4 .Motivation Issues of current Spark SQL Engine ₋ Row based processing, not friendly for SIMD instructions with Intel technologies such as AVX, GPU, FPGA, …etc. ₋ Java GC Overhead ₋ JIT code quality relies on JVM, hard to tune ₋ High overhead of integration with other native libraries Goals ₋ Move the key SQL operations to highly optimized native code with Intel technologies ₋ Easily add accelerators support with Intel products in Spark ₋ Building a friendly end-to-end AI workloads 4
5 . Apache Arrow – Unified Data Format Without Arrow With Arrow • Each system has its own internal memory format • All systems utilize the same memory format • 70-80% computation wasted on serialization and deserialization • No overhead for cross-system communication • Similar functionality implemented in multiple projects • Projects can share functionality(eg, Parquet-to-Arrow reader) Reference: https://arrow.apache.org 5
6 .Apache Arrow – Highly Optimized Lib. Columnar format -> The opportunity for Intel AVX Support Native C++ implementation –> No JVM Overhead Dataframe functions -> SQL Operators such as Filter, Join, Aggregate … Implement Java, python, etc. as interface Share to other projects with a unified interface -> Pandas, Spark, Flink… Using the same interface to offload to other accelerators such as Intel GPU, Intel FPGA 6
7 .spark-27396 pUBLIC APIS FOR EXTENED COLUMNAR PROCESSING https://issues.apache.org/jira/browse/SPARK-27396 ColumnarToRow Existing APIs use RDD[InternalRow] New APIs use RDD[ColumnarBatch] ColumnarProject - def executeColumnar(): RDD[ColumnarBatch] (Expression ColumnarAdd(…)) - def columnarEval(batch: ColumnarBatch): Any - class ColumnarRule RowToColumnar ColumnarToRow/RowToColumnar - Translate RDD[InternalRow] <-> RDD[ColumnarBatch] Exchange The opportunity to support accelerators in Spark LocalTableScan 7
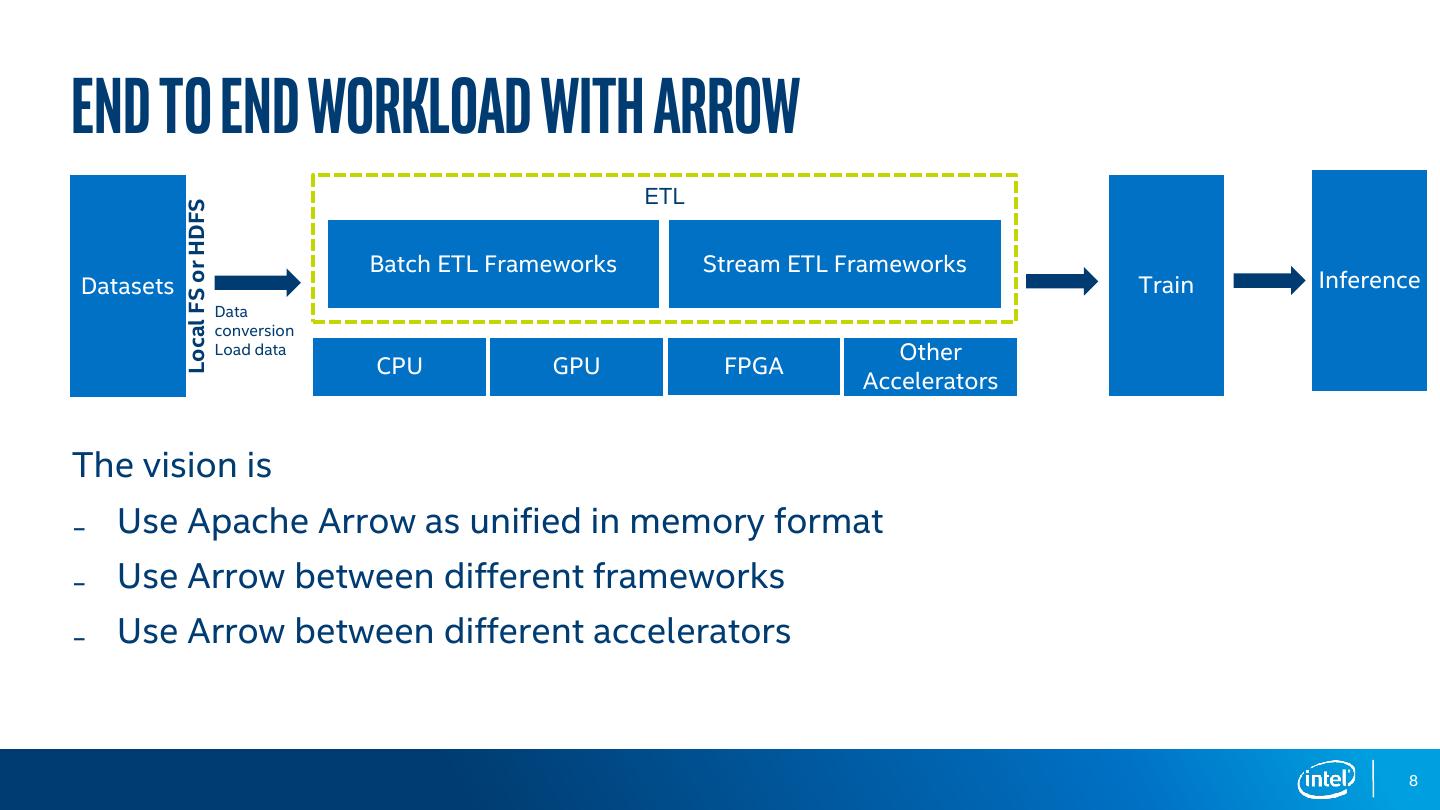
8 .END TO END WORKLOAD with arrow Local FS or HDFS ETL Batch ETL Frameworks Stream ETL Frameworks Datasets Train Inference Data conversion Load data Other CPU GPU FPGA Accelerators The vision is ₋ Use Apache Arrow as unified in memory format ₋ Use Arrow between different frameworks ₋ Use Arrow between different accelerators 8
9 .agenda Motivation Core Design - Architecture - Arrow Data Source - Native SQL Engine - Columnar Shuffle Getting Started Performance Summary 9
10 . Native SQL Engine ARCHITECTURE Spark Application SQL Python APP Java/Scala APP R APP Query Plan Optimization ColumnarRules ColumnarCollapseRules ColumnarAQERules FallbackRules Physical Plan Execution JVM SQL Engine Columnar Plugin ColumnarCompute Memory Row Column UDF Cache Spill Scheduler Conversion WSCG join/sort/aggr/proj/… Mgmt. Memory Native Arrow Data Source Native Compute Columnar Shuffle Plugin Manage / JNI wrapper JNI WRAPPER Operator Spark Streamer / Register pre- Optimal strategy DAOS / HDFS / Parquet / ORC CPP Code Compatible Compressed LLVM (Cost / S3 / KUDU / / CSV / JASON / compiled Batch Gandiva Generator Partition Serialization Support ) LOCALFS / … … kernels Apache Arrow Github Repository: https://github.com/oap-project/native-sql-engine 10
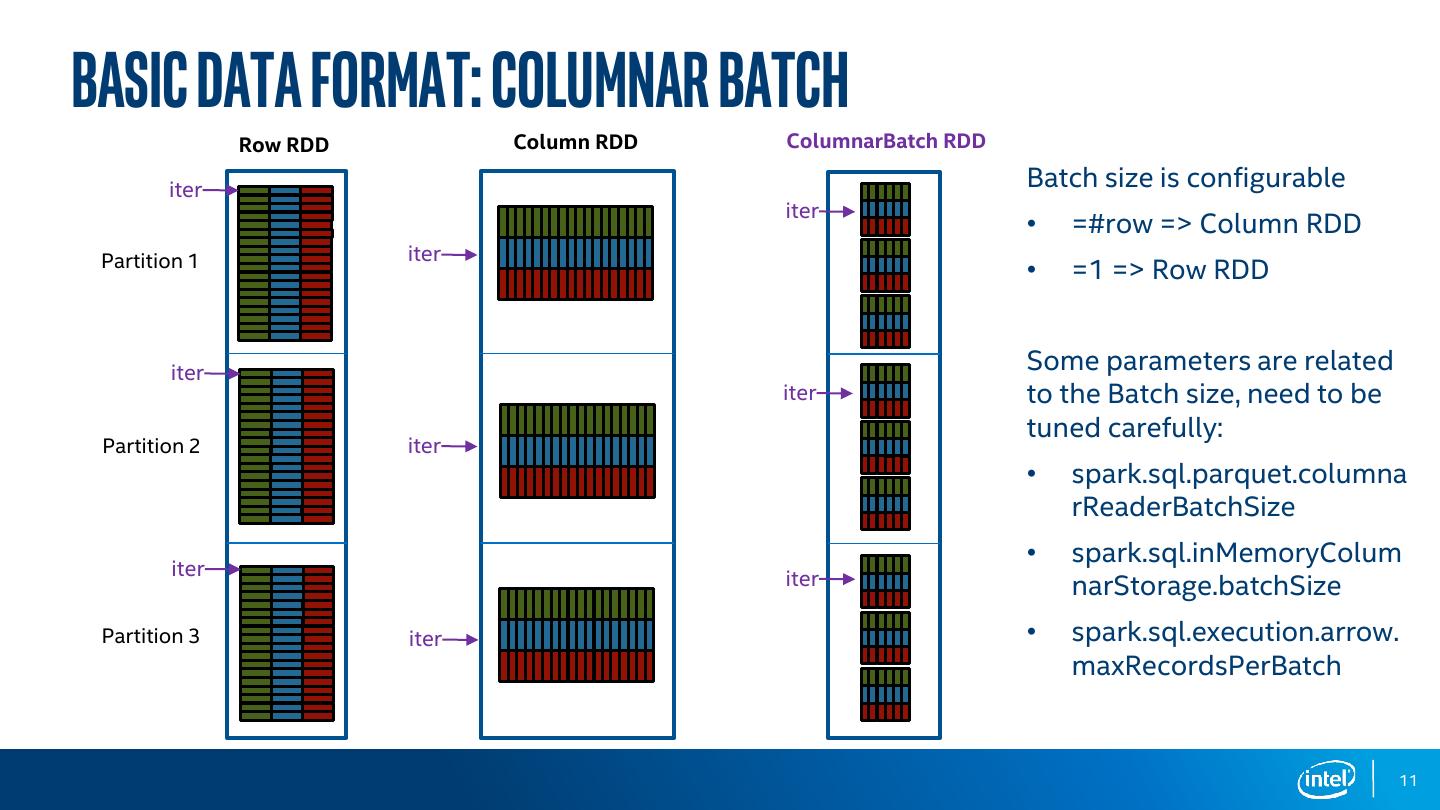
11 .Basic data format: Columnar Batch Row RDD Column RDD ColumnarBatch RDD iter Batch size is configurable iter • =#row => Column RDD Partition 1 iter • =1 => Row RDD iter Some parameters are related iter to the Batch size, need to be tuned carefully: Partition 2 iter • spark.sql.parquet.columna rReaderBatchSize iter • spark.sql.inMemoryColum iter narStorage.batchSize Partition 3 iter • spark.sql.execution.arrow. maxRecordsPerBatch 11
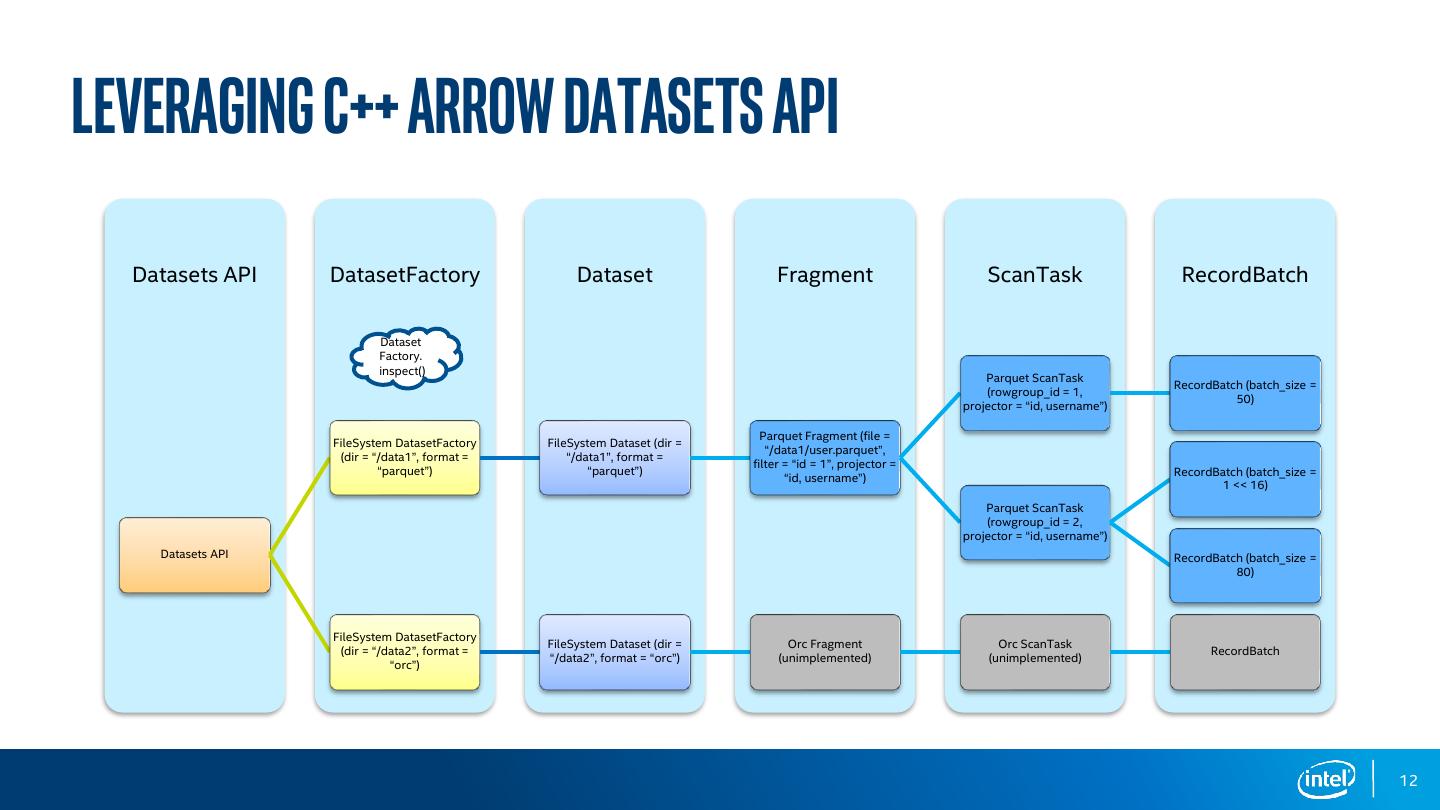
12 .LEVERAGING C++ Arrow datasets API Datasets API DatasetFactory Dataset Fragment ScanTask RecordBatch Dataset Factory. inspect() Parquet ScanTask RecordBatch (batch_size = (rowgroup_id = 1, 50) projector = “id, username”) Parquet Fragment (file = FileSystem DatasetFactory FileSystem Dataset (dir = “/data1/user.parquet”, (dir = “/data1”, format = “/data1”, format = filter = “id = 1”, projector = “parquet”) “parquet”) RecordBatch (batch_size = “id, username”) 1 << 16) Parquet ScanTask (rowgroup_id = 2, projector = “id, username”) Datasets API RecordBatch (batch_size = 80) FileSystem DatasetFactory FileSystem Dataset (dir = Orc Fragment Orc ScanTask (dir = “/data2”, format = RecordBatch “/data2”, format = “orc”) (unimplemented) (unimplemented) “orc”) 12
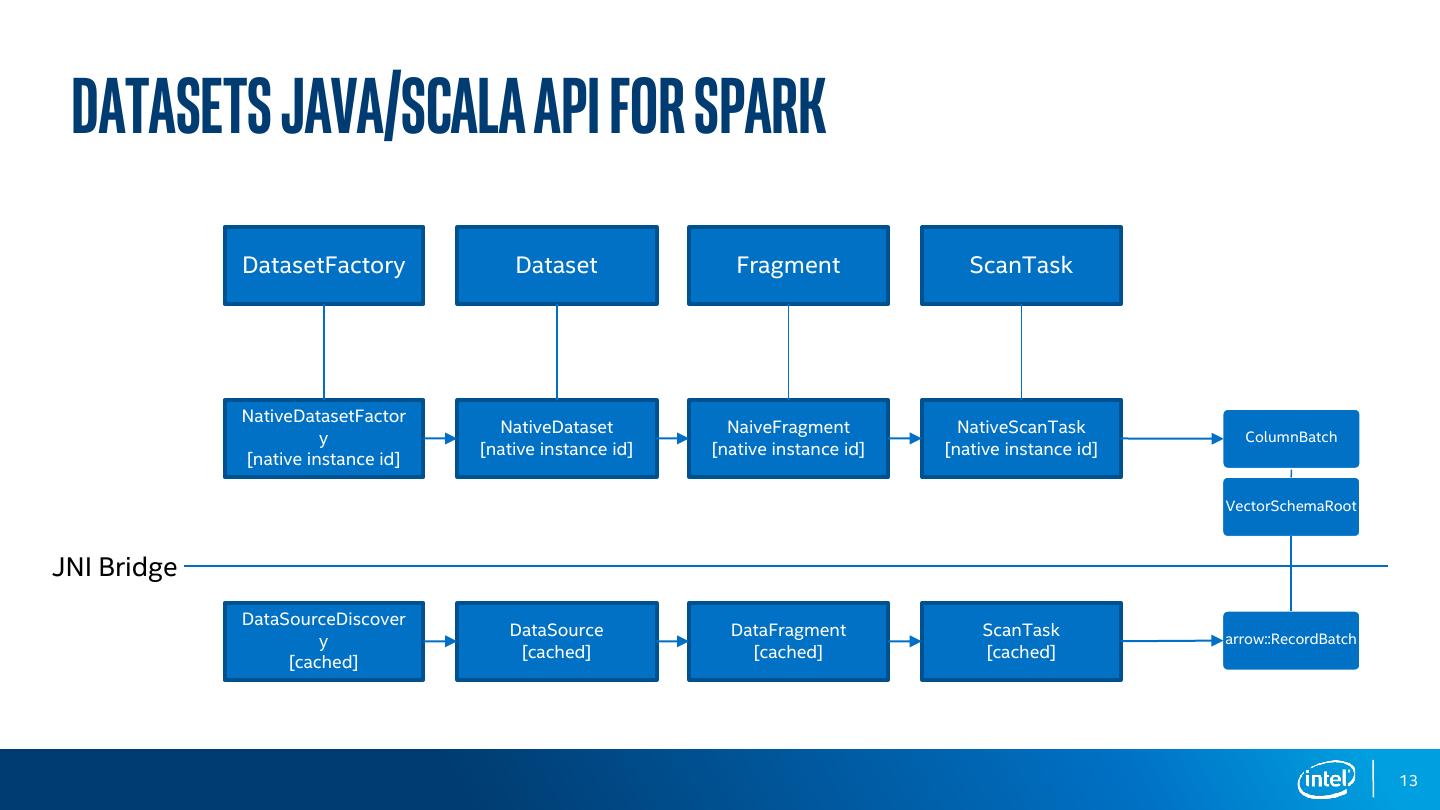
13 . Datasets JAVA/SCALA API for SPARK DatasetFactory Dataset Fragment ScanTask NativeDatasetFactor NativeDataset NaiveFragment NativeScanTask y ColumnBatch [native instance id] [native instance id] [native instance id] [native instance id] VectorSchemaRoot JNI Bridge DataSourceDiscover DataSource DataFragment ScanTask y arrow::RecordBatch [cached] [cached] [cached] [cached] 13
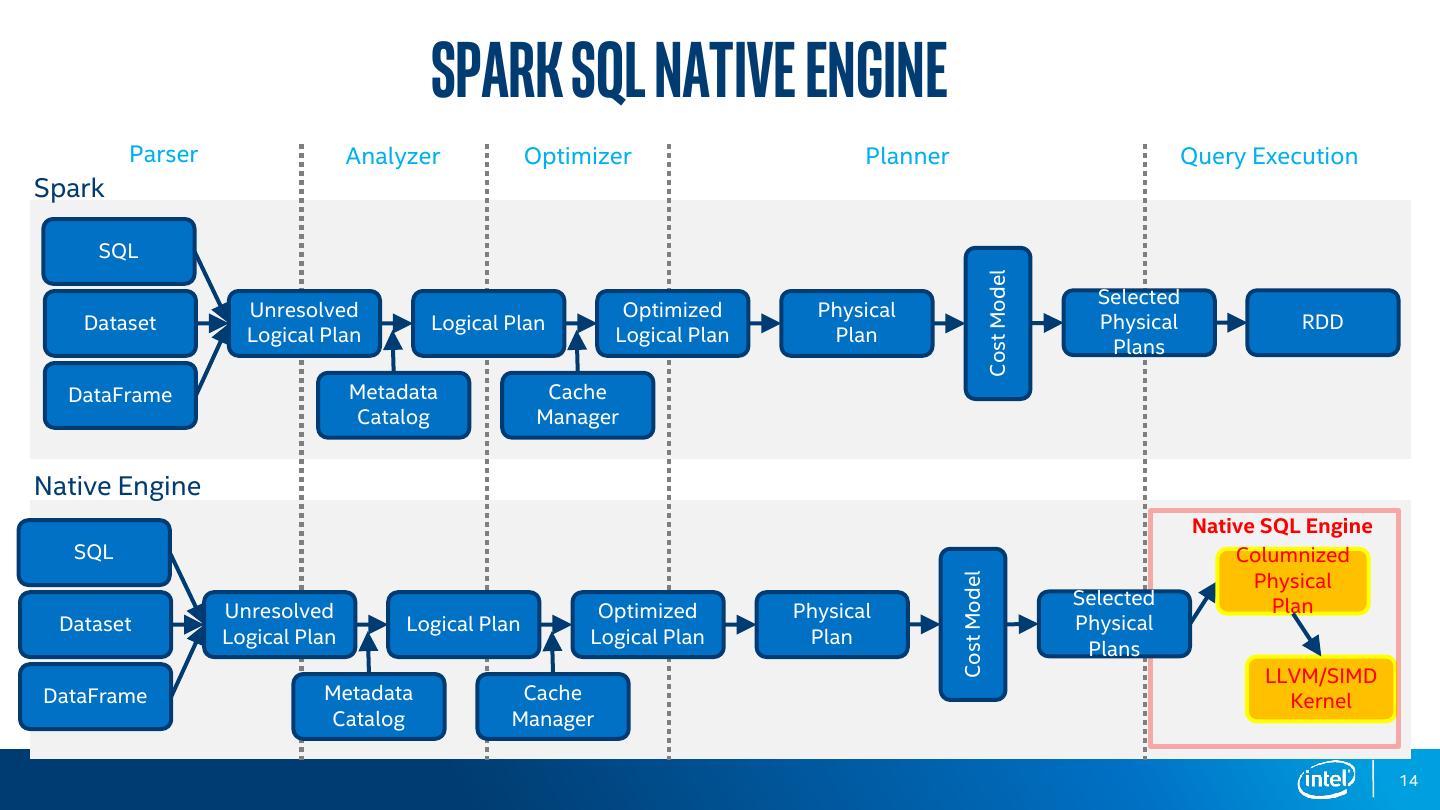
14 . SPARK sql native engine Parser Analyzer Optimizer Planner Query Execution Spark SQL Cost Model Selected Unresolved Optimized Physical Dataset Logical Plan Physical RDD Logical Plan Logical Plan Plan Plans DataFrame Metadata Cache Catalog Manager Native Engine Native SQL Engine SQL Columnized Physical Cost Model Selected Plan Unresolved Optimized Physical Dataset Logical Plan Physical Logical Plan Logical Plan Plan Plans LLVM/SIMD DataFrame Metadata Cache Kernel Catalog Manager 14
15 . Native sql operator What SparkColumnarPlugin does: Spark Executor Context Plug into spark as an extra jar Oap-native-sql Convert Spark Plan to a columnar supported spark plan. Columnar Spark Plan Spark Plan Handle data using ColumnarBatch format → executeColumnar() Use Apache Arrow Compute and Gandiva modules to do ColumnarBased Data Process. expression input output key value spark.sql.extensions com.intel.sparkColumnarPlugin. Expression RecordBatch RecordBatch ColumnarPlugin Tree Unified API JniWrapper Build(schema, expr_tree, return_types) Evaluate(input_record_batch, CodeGenerator *vector<output_record_batch>) 3rd Finish(*ResultIterator<record_batch>) Gandiv Native CPP Party ResultIterator->Next() a Engine ResultIterator->Process(input_record_batch) 15
16 .Java side WorkFlow Expression Build (CodeGen): • Convert a list of expressions into one columnar based function ColumnarBased Evaluation • Pass a columnarBatch to this operator, then return processed columnarBatch using ‘CodeGen’ed function. Expression Spark Expression Tree: Spark Expression Tree: Gandiva Expression Tree: codegen: Alias Alias ResultTreeNode Expression: 1 Add 2 ColumnarAdd 3 AddTreeNode (c_0 + c_1 + c_2 + ….c_9) Add c_9 ColumnarAdd c_9 AddTreeNode int Add c_8 ColumnarAdd c_8 AddTreeNode int Add c_7 ColumnarAdd c_7 AddTreeNode int …… …… …… c_0 c_1 c_0 c_1 int int 4 make(exprTree) Native Projector(.so) Arrow Arrow Arrow Arrow RDD[ColumnarBatch] Parqu RDD[ColumnarBatch] BatchScanExec ColumnProject Next Operator et Evaluation: 5 8 16
17 . Native Side WorkFlow Expr visitor Cache Func_id Expr_vistor_ptr Dependency_ptr Expr tree From Java encodeArrayf_0 Visitor_0 Nullptr unique build splitArrayListf_0f_1f_2 Visitor_1 Visitor_0 uniquef_0 Visitor_2 Visitor_1 {f_0} uniquef_1 Visitor_3 Visitor_1 splitArrayList sumf_2 Visitor_4 Visitor_1 encodeArray {f_0, f_1, f_2} null {f_0} Kernel tree …… sum Action_unique Action_unique Action_sum {f_2} {f_0} {f_1} {f_2} splitArrayList SplitArrayListWithActionKernel encodeArray {f_0, f_1, f_2} EncodeArrayKernel {f_0, f_1, f_2} null {f_0} null {f_0, f_1} Evaluate ColumnarBatch or List[ColumnarBatch] Iterator[ColumnarBatch] Next() Process(columnarBatch) 17
18 . example 1: Columnar conditioned Project ColumnarBased project took 28 sec, and RowBased project took 50 sec. Project added 10 columns into one. 18
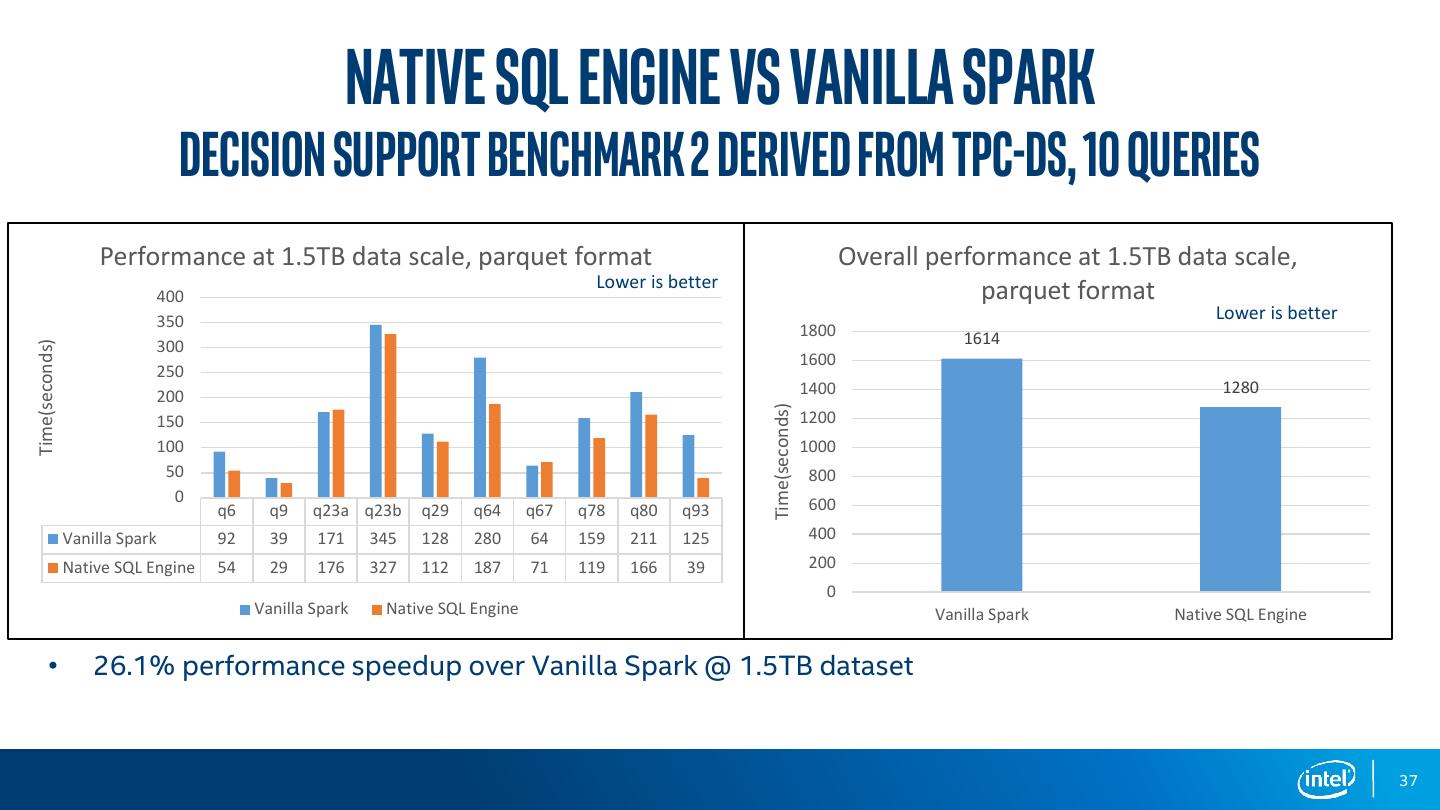
19 .example 2: Columnar GROUPBY aggregate in TPCH Q6 3s ColumnarBased project took 3 sec, and RowBased project took 7 sec for TPCH Q6 HashAggregate took most of exec time, ColumnarBased spent avg 686ms, and Rowbased spend avg 2.5s 19
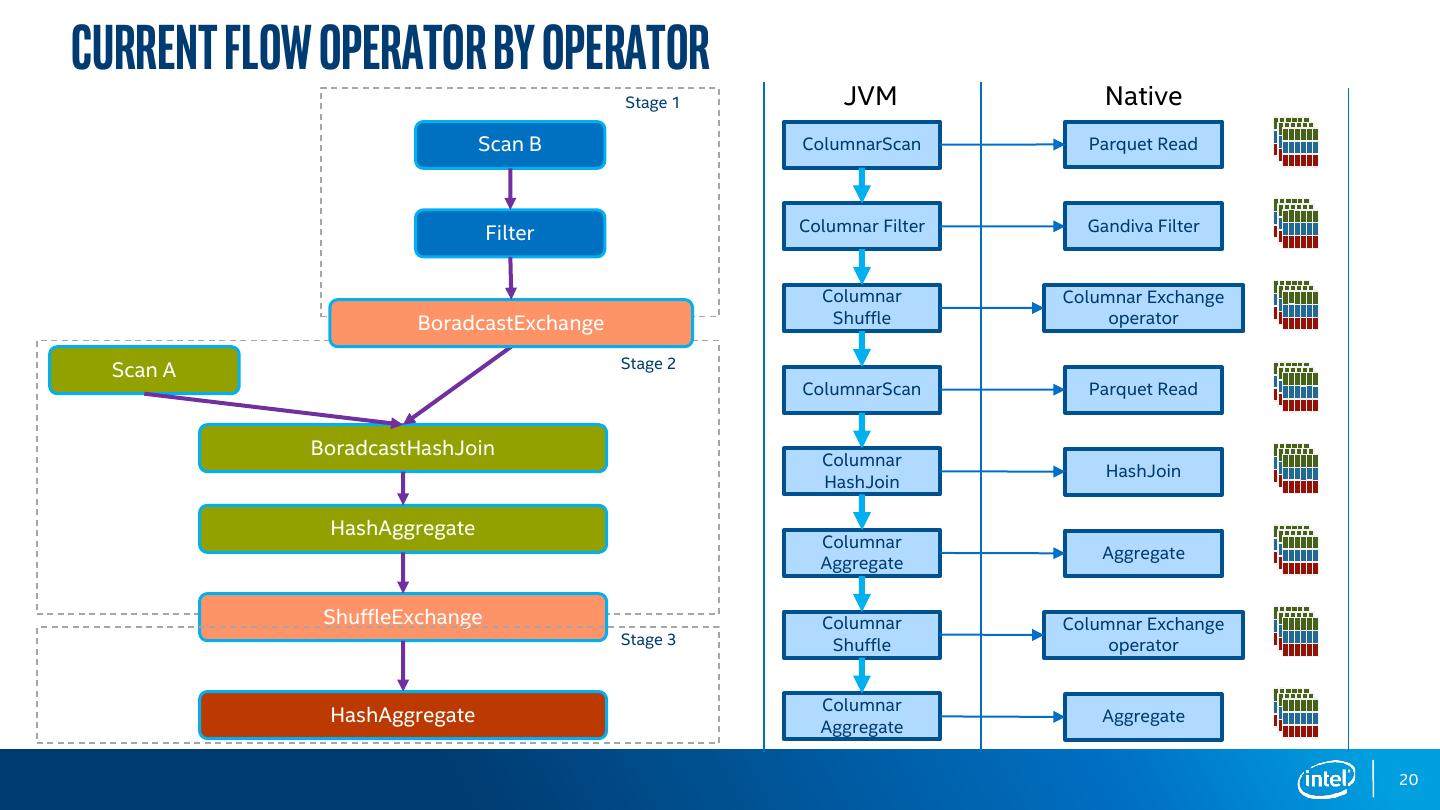
20 .Current Flow Operator By Operator Stage 1 JVM Native Scan B ColumnarScan Parquet Read Filter Columnar Filter Gandiva Filter Columnar Columnar Exchange BoradcastExchange Shuffle operator Scan A Stage 2 ColumnarScan Parquet Read BoradcastHashJoin Columnar HashJoin HashJoin HashAggregate Columnar Aggregate Aggregate ShuffleExchange Columnar Columnar Exchange Stage 3 Shuffle operator Columnar HashAggregate Aggregate Aggregate 20
21 . Whole Stage Offload JVM Native JVM Native Stage1 ColumnarScan Parquet Read Parquet Read Evaluate Columnar Filter Gandiva Filter Gandiva Filter Columnar Columnar Exchange Columnar Columnar Exchange Shuffle operator Shuffle operator Stage2 ColumnarScan Parquet Read Parquet Read Evaluate Columnar HashJoin HashJoin HashJoin Columnar Aggregate Aggregate Aggregate Columnar Columnar Exchange Columnar Columnar Exchange Shuffle operator Shuffle operator Columnar Columnar Aggregate Aggregate Aggregate Aggregate 21
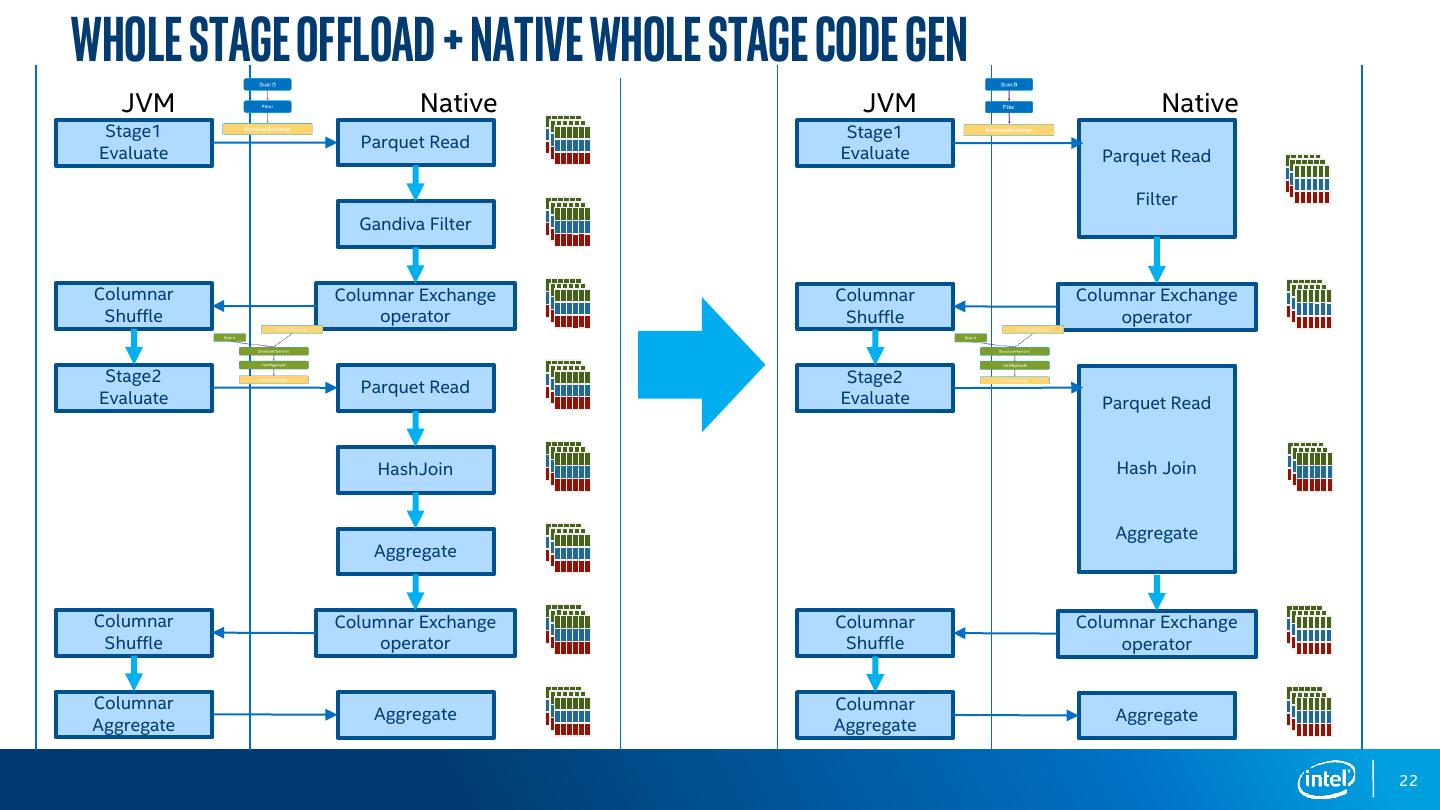
22 .Whole Stage Offload + Native whole stage Code Gen JVM Native JVM Native Stage1 Stage1 Parquet Read Evaluate Evaluate Parquet Read Filter Gandiva Filter Columnar Columnar Exchange Columnar Columnar Exchange Shuffle operator Shuffle operator Stage2 Stage2 Parquet Read Evaluate Evaluate Parquet Read HashJoin Hash Join Aggregate Aggregate Columnar Columnar Exchange Columnar Columnar Exchange Shuffle operator Shuffle operator Columnar Columnar Aggregate Aggregate Aggregate Aggregate 22
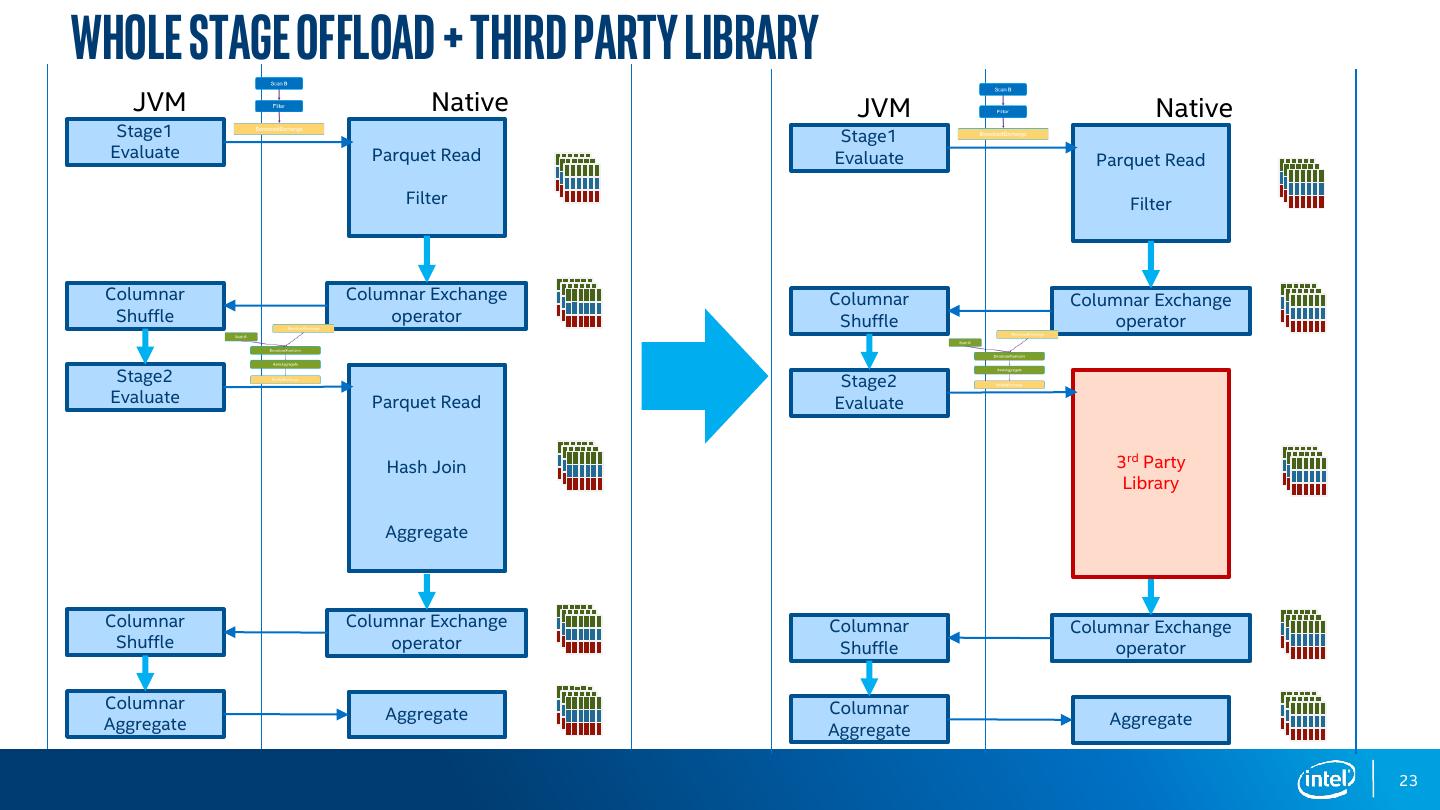
23 .Whole Stage Offload + Third Party Library JVM Native JVM Native Stage1 Stage1 Evaluate Parquet Read Evaluate Parquet Read Filter Filter Columnar Columnar Exchange Columnar Columnar Exchange Shuffle operator Shuffle operator Stage2 Stage2 Evaluate Parquet Read Evaluate Hash Join 3rd Party Library Aggregate Columnar Columnar Exchange Columnar Columnar Exchange Shuffle operator Shuffle operator Columnar Columnar Aggregate Aggregate Aggregate Aggregate 23
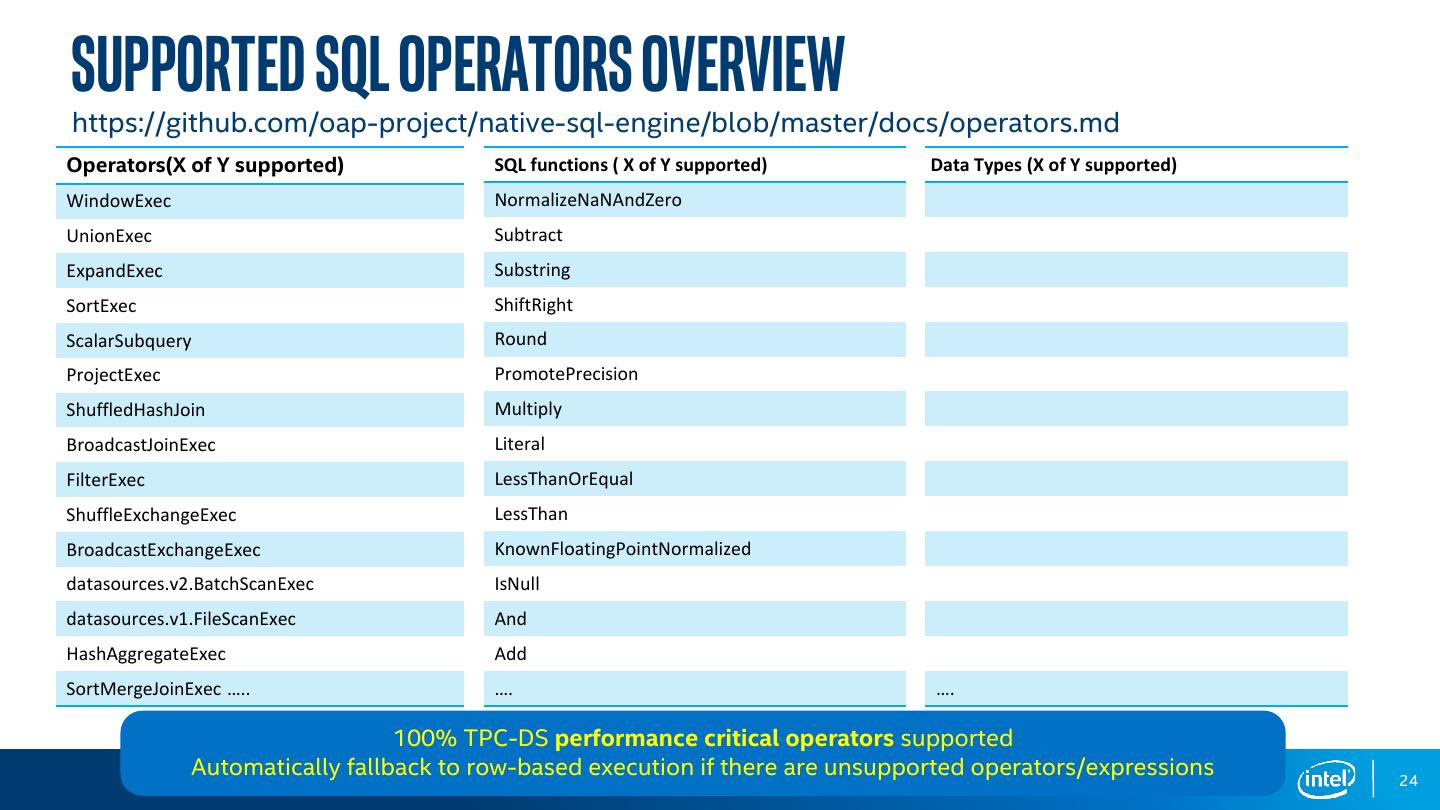
24 .Supported SQL Operators Overview https://github.com/oap-project/native-sql-engine/blob/master/docs/operators.md Operators(X of Y supported) SQL functions ( X of Y supported) Data Types (X of Y supported) WindowExec NormalizeNaNAndZero UnionExec Subtract ExpandExec Substring SortExec ShiftRight ScalarSubquery Round ProjectExec PromotePrecision ShuffledHashJoin Multiply BroadcastJoinExec Literal FilterExec LessThanOrEqual ShuffleExchangeExec LessThan BroadcastExchangeExec KnownFloatingPointNormalized datasources.v2.BatchScanExec IsNull datasources.v1.FileScanExec And HashAggregateExec Add SortMergeJoinExec ….. …. …. 100% TPC-DS performance critical operators supported Automatically fallback to row-based execution if there are unsupported operators/expressions 24
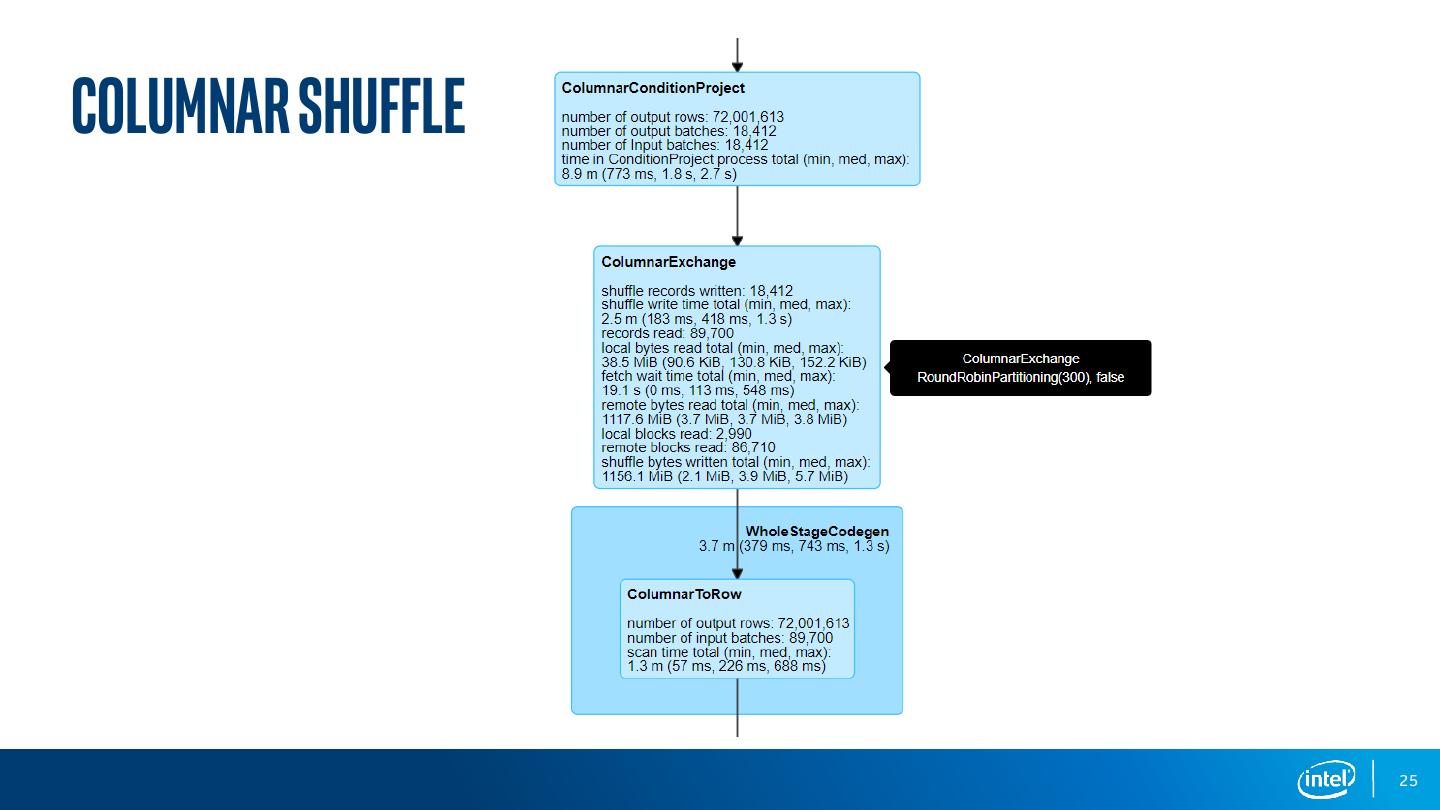
25 .ColumnAR SHUFFLE 25
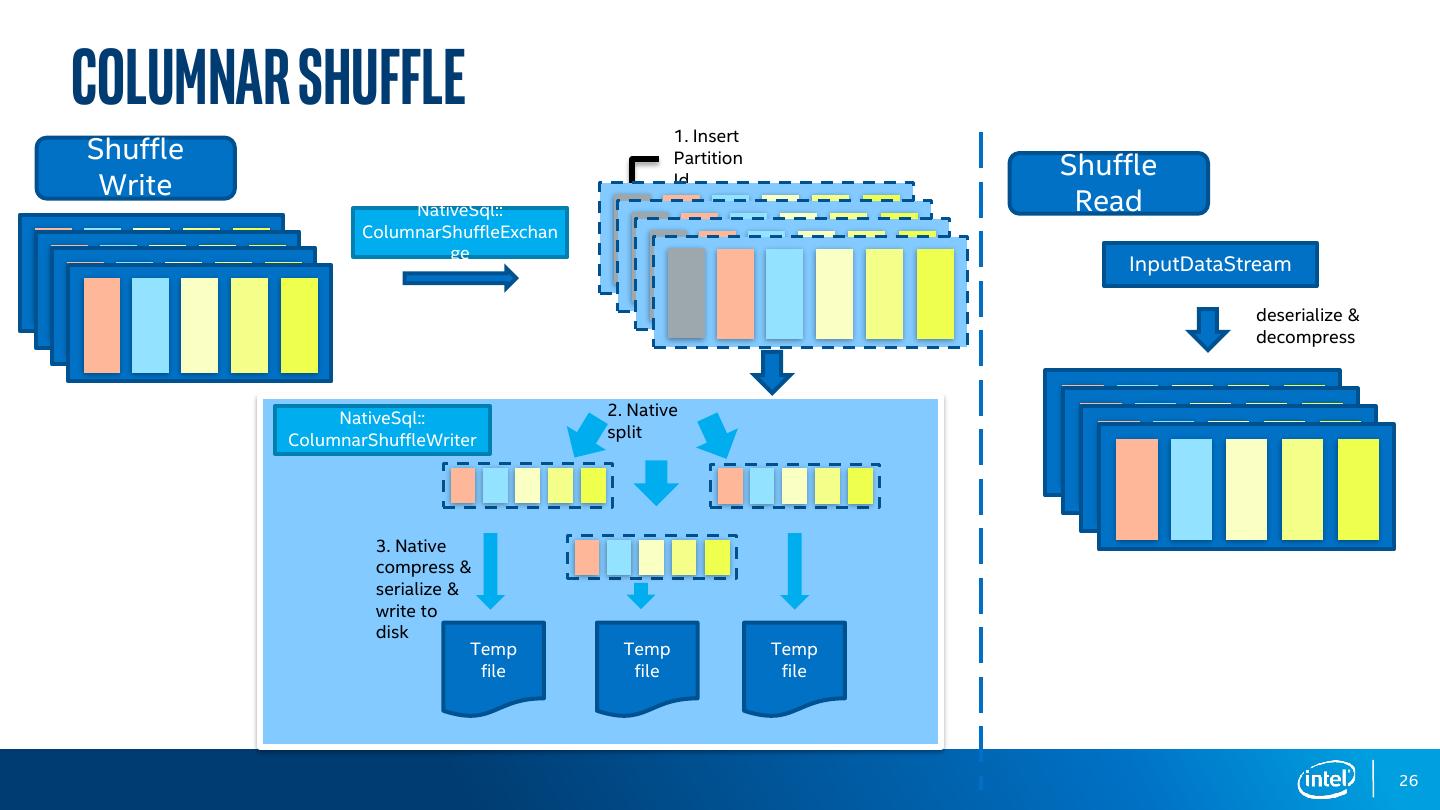
26 .Columnar SHUFFLE 1. Insert Shuffle Partition Shuffle Write Id NativeSql:: Read ColumnarShuffleExchan ge InputDataStream deserialize & decompress NativeSql:: 2. Native ColumnarShuffleWriter split 3. Native compress & serialize & write to disk Temp Temp Temp file file file 26
27 .MemoryManagement Storage spark.memory.storageFraction spark.memory.offHeap.size Execution Balance between Storage and Execution Memory • If none of its space is insufficient but the other is free, then it will borrow the other’s space • If both parties doesn’t have enough space, evict storage memory using LRU mechanism 27
28 .agenda Motivation Core Design - Architecture - Arrow Data Source - Native SQL Engine - Columnar Shuffle Getting Started Performance Summary 28
29 .method1: use fat jar Download Fat Jars from https://mvnrepository.com/artifact/com.intel.oap Use fat jar is a quick way to run Native SQL Engine on your environment. You only need to download below two jar files and add them when running spark-shell, spark-submit, …etc: 1. Arrow Data Source Jar: https://repo1.maven.org/maven2/com/intel/oap/spark-arrow-datasource-standard/1.1.0/spark-arrow-datasource- standard-1.1.0-jar-with-dependencies.jar 2. Native SQL Jar: https://repo1.maven.org/maven2/com/intel/oap/spark-columnar-core/1.1.0/spark-columnar-core-1.1.0-jar-with- dependencies.jar Please notices to use the fat jar files, you must ensure your environment is fulfilled below requirements: • Use GCC9.3.0 • Use LLVM 7.0.1 Reference: https://github.com/oap-project/native-sql-engine/blob/master/README.md 29
3秒后跳转登录页面
去登陆

