























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
9.张浩&郭文杰-DORIS在韵达物流领域应用实践
张浩: 韵达科技高级工程师, 负责公司实时计算任务和平台研发工作,为实时计算提供大规模、高效、稳定的运行平台。
郭文杰:数据模型工程师,负责公司基于Doris的分拨数字产品模型设计
议题介绍
韵达数据中台在实时场景下遇到的问题与技术选型
基于Doris的系统架构及业务架构
基于Doris构建高效的分拨效能数据模型
展开查看详情
1 .Apache Doris在韵达物流领域应用实践 韵达科技 主讲人:张浩 郭文杰
2 .AGENDA ① 韵达科技简介 ② 平台选型 ③ 业务场景分享 ④ 小结
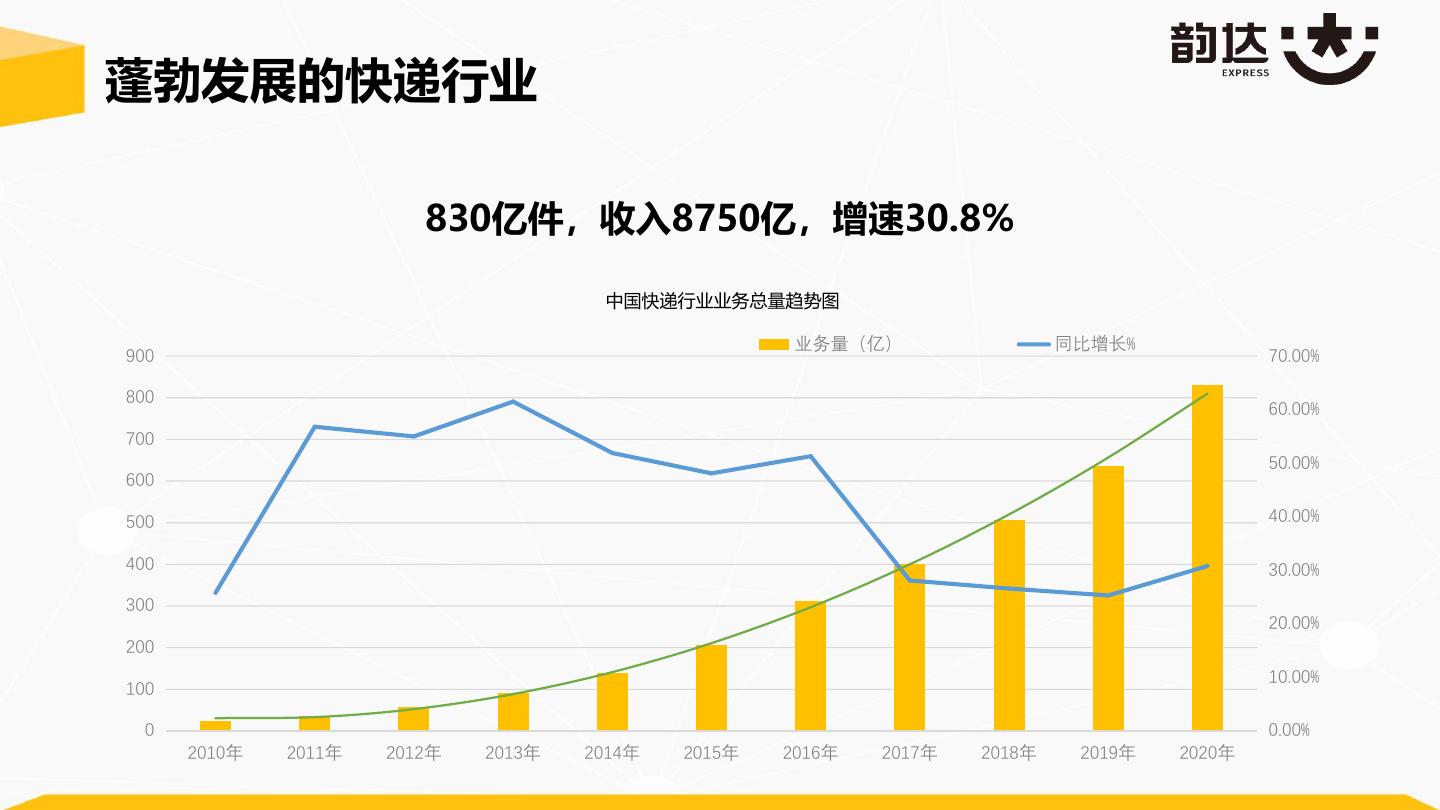
3 .蓬勃发展的快递行业 830亿件,收入8750亿,增速30.8% 中国快递行业业务总量趋势图 业务量(亿) 同比增长% 900 70.00% 800 60.00% 700 50.00% 600 500 40.00% 400 30.00% 300 20.00% 200 10.00% 100 0 0.00% 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年
4 .科技提升服务质量 智能硬件 大数据服务 智慧物联 智能决策 智慧互联 安全与监控
5 .数据驱动服务 韵达快递 韵达快运 韵达供应链 韵达国际 韵达科技 数字驱动 智能运营 端到端服务能力 全方位物流服务 创新引领 韵镖侠 韵 观 自 白 智 北 天 微 玛 智 动 掌 星 马 跑 斗 矶 笑 雅 网 分 柜 台 拣 统一口径 统一平台 统一服务 数据中台 业务中台
6 .AGENDA ① 韵达科技简介 ② 平台选型 ③ 业务场景分享 ④ 小结
7 .平台需求 交互式分析平台 复杂分析支持 • 直接面向用户 • 百亿级数据量 • 通用SQL语法 • 明细级多表join • 查询快捷 • 高效精确去重 • 丰富数据模型 便于运维 接口丰富 • 动态分区 • 数据导入方便 • 集群易扩展 • 与常用组件对接方便 • 存储成本低 • 外部表 • 社区活跃
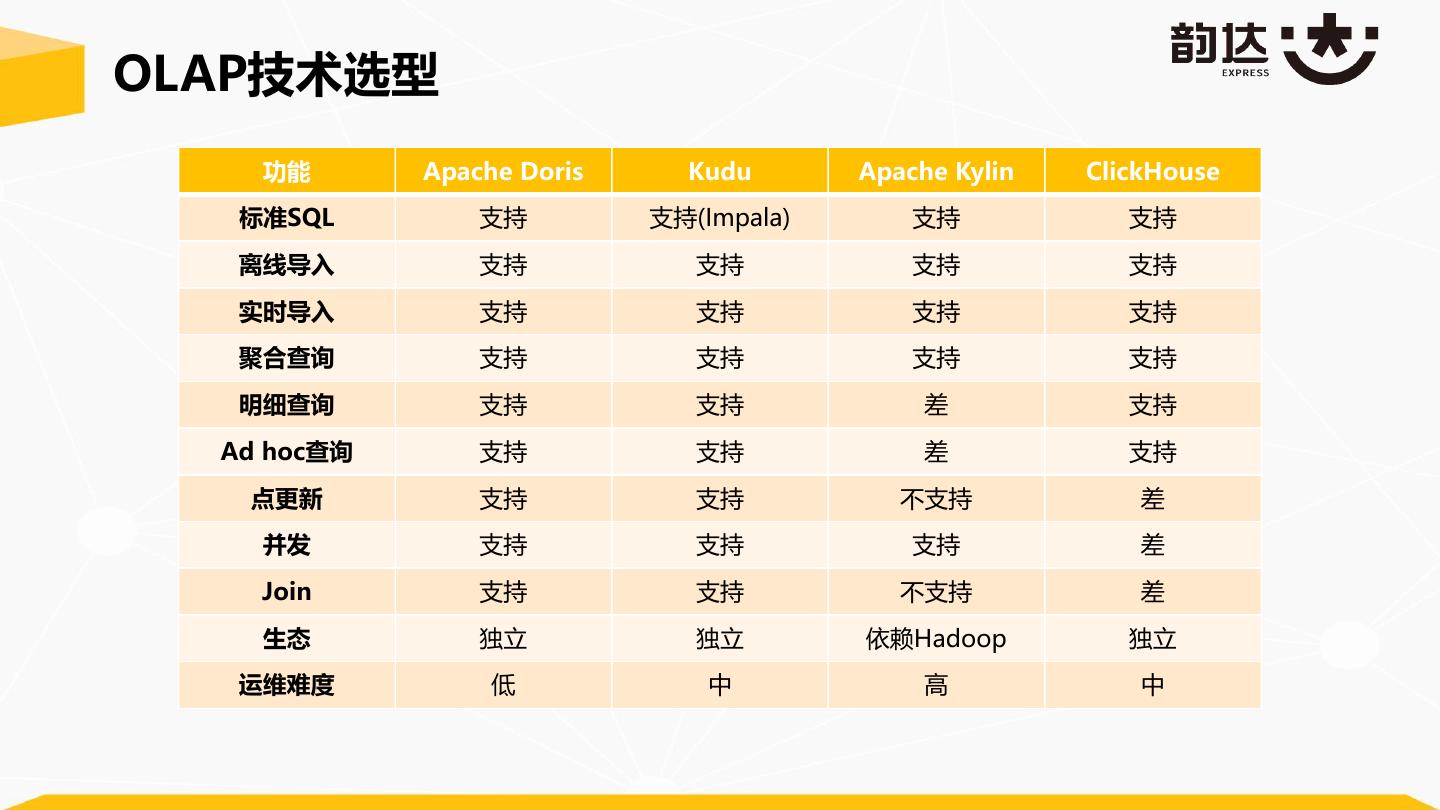
8 .OLAP技术选型 功能 Apache Doris Kudu Apache Kylin ClickHouse 标准SQL 支持 支持(Impala) 支持 支持 离线导入 支持 支持 支持 支持 实时导入 支持 支持 支持 支持 聚合查询 支持 支持 支持 支持 明细查询 支持 支持 差 支持 Ad hoc查询 支持 支持 差 支持 点更新 支持 支持 不支持 差 并发 支持 支持 支持 差 Join 支持 支持 不支持 差 生态 独立 独立 依赖Hadoop 独立 运维难度 低 中 高 中
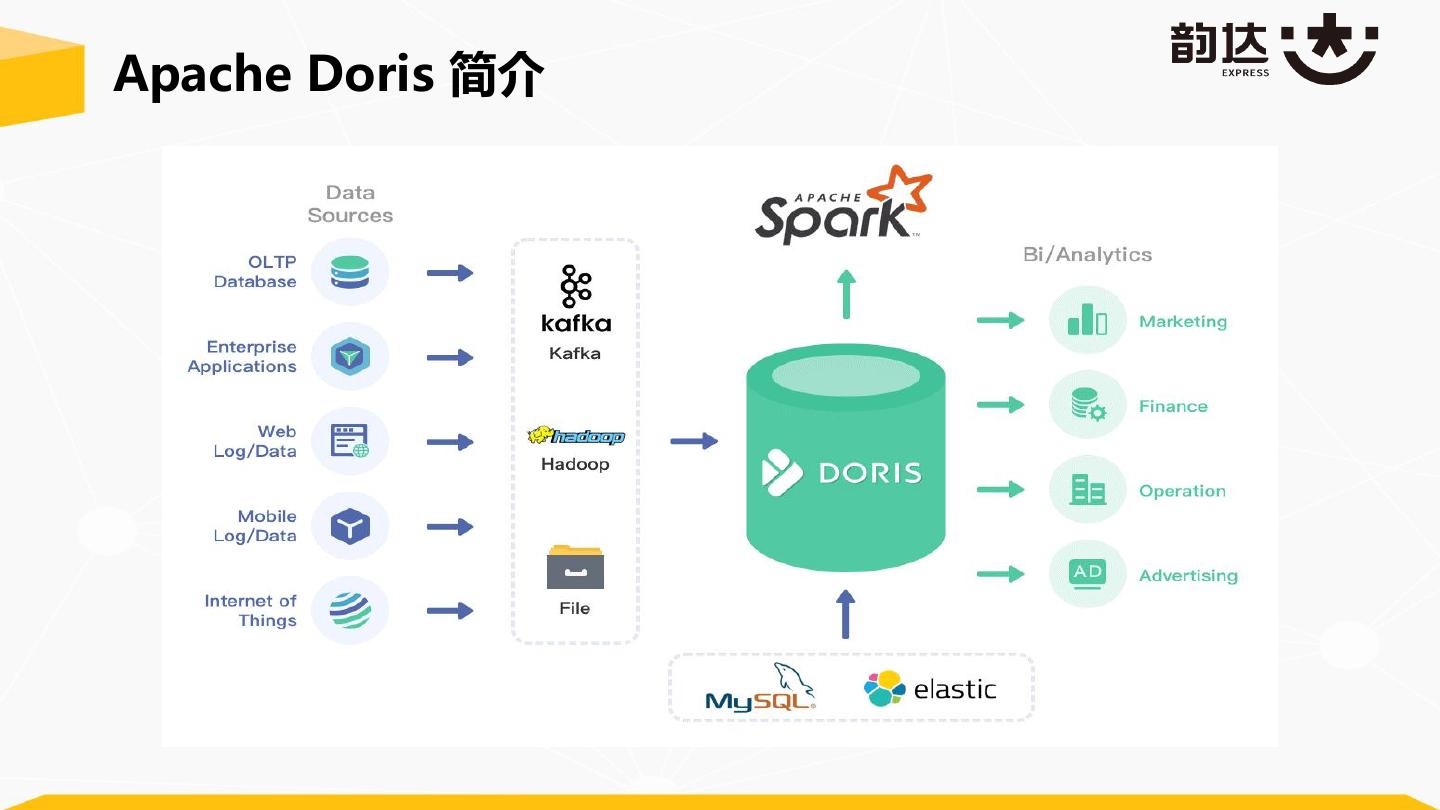
9 .Apache Doris 简介
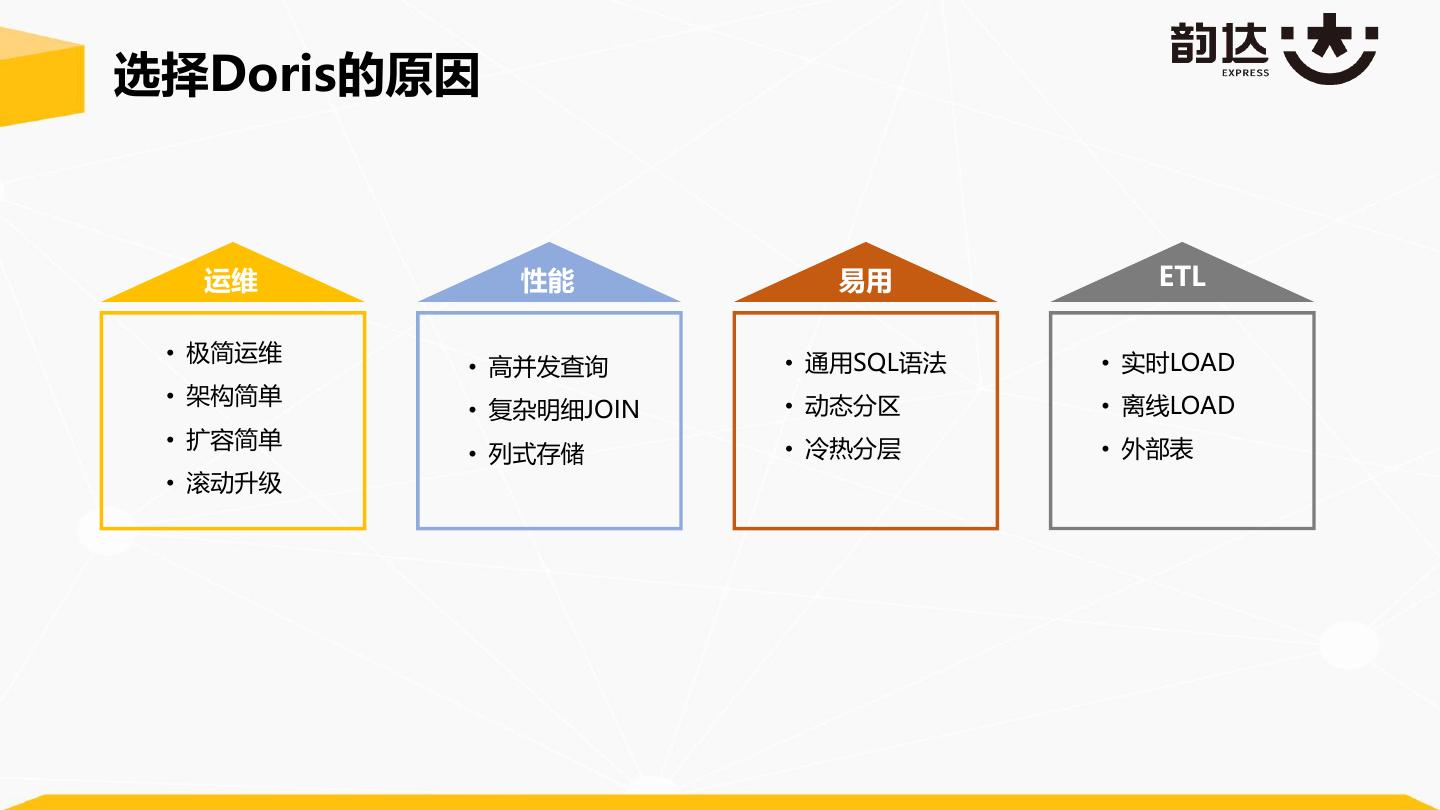
10 .选择Doris的原因 运维 性能 易用 ETL • 极简运维 • 通用SQL语法 • 实时LOAD • 高并发查询 • 架构简单 • 动态分区 • 离线LOAD • 复杂明细JOIN • 扩容简单 • 冷热分层 • 外部表 • 列式存储 • 滚动升级
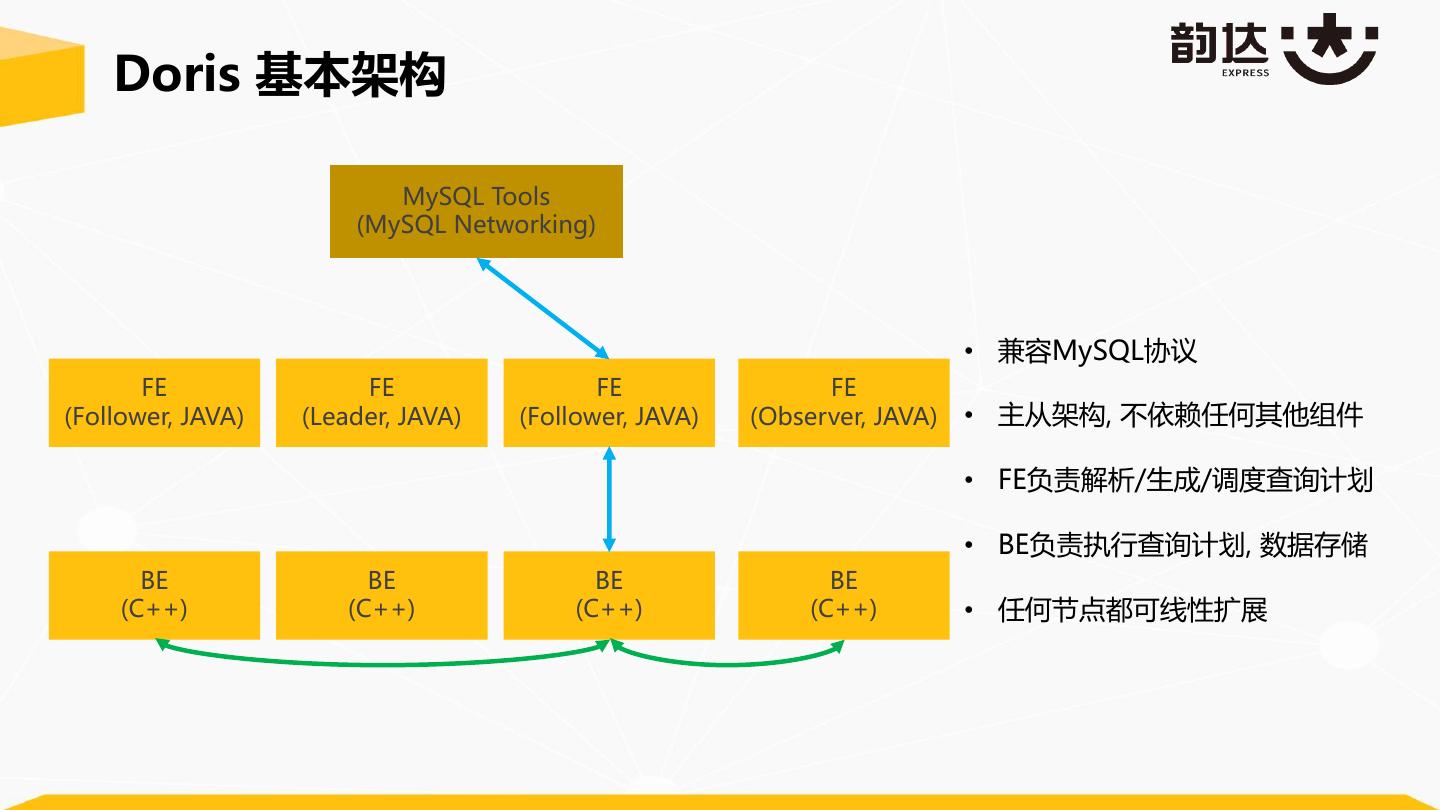
11 . Doris 基本架构 MySQL Tools (MySQL Networking) • 兼容MySQL协议 FE FE FE FE (Follower, JAVA) (Leader, JAVA) (Follower, JAVA) (Observer, JAVA) • 主从架构, 不依赖任何其他组件 • FE负责解析/生成/调度查询计划 • BE负责执行查询计划, 数据存储 BE BE BE BE (C++) (C++) (C++) (C++) • 任何节点都可线性扩展
12 .Doris的数据模型 Aggregate • 相同Key列, 对其Value列聚合 value列聚合方式(sum,min,max,replace,replace_if_not_null,bitmap_union,hll_union) Unique • Key唯一, 不聚合, 实现精准去重 Duplicate • 没有主键, 不做聚合,写多少行表里有多少行
13 .Doris的数据导入方式 • Routine Load • S3 Load • Stream Load • Mini Load • Broker Load • Spark Load • ODBC • Spark Doris Connector • Insert into • Flink Doris Connector
14 .Doris的数据导入方式 Broker Load 用于导入Hive, HDFS 离线数据 Routine Load 用于导入Kafka数据, SQL语法直接导入 Stream Load 结合Flink, 使用http协议导入 ODBC 用于导入MySQL数据, 和MySQL维表Join Insert into 结合DolphinScheduler在Doris跑批
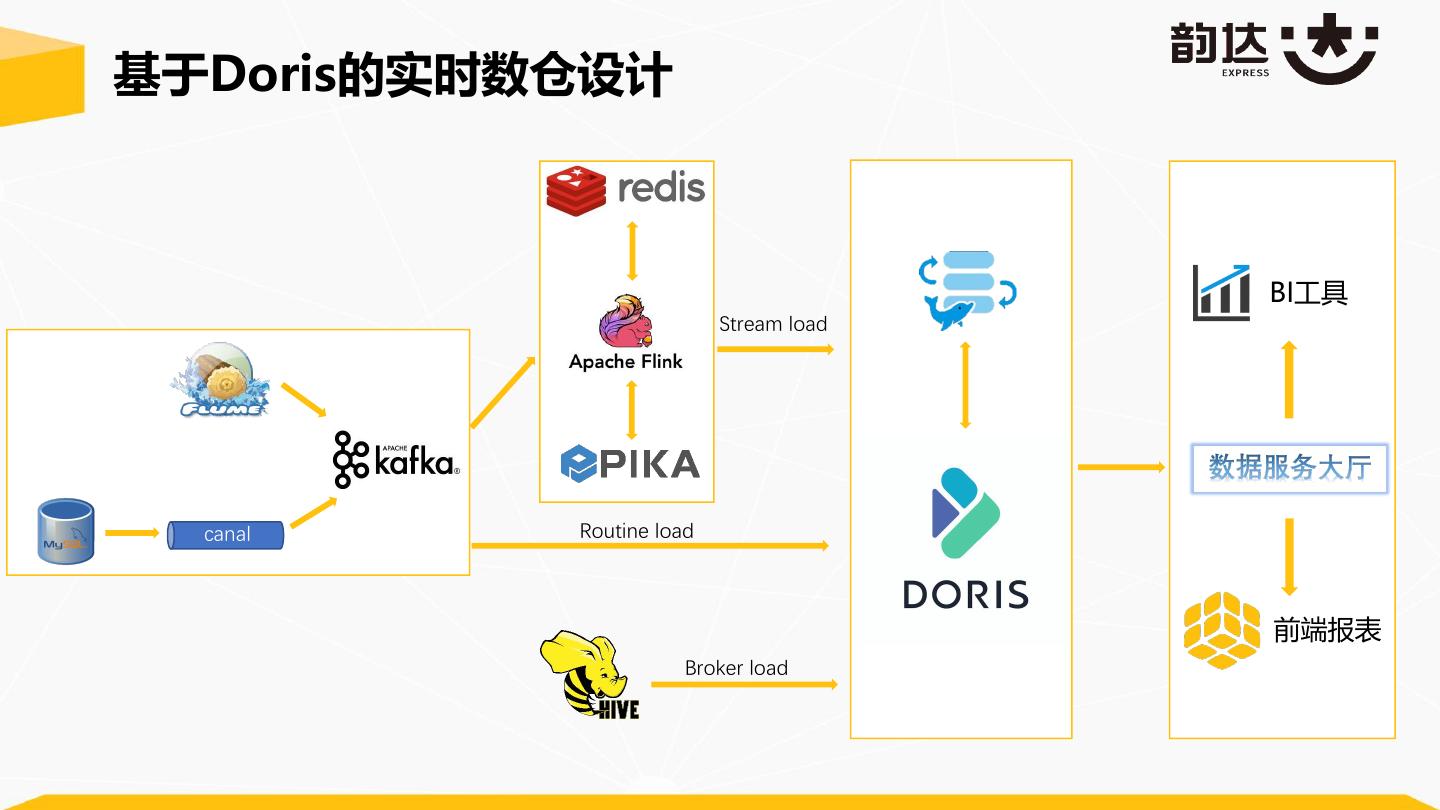
15 .基于Doris的实时数仓设计 BI工具 Stream load canal Routine load 前端报表 Broker load
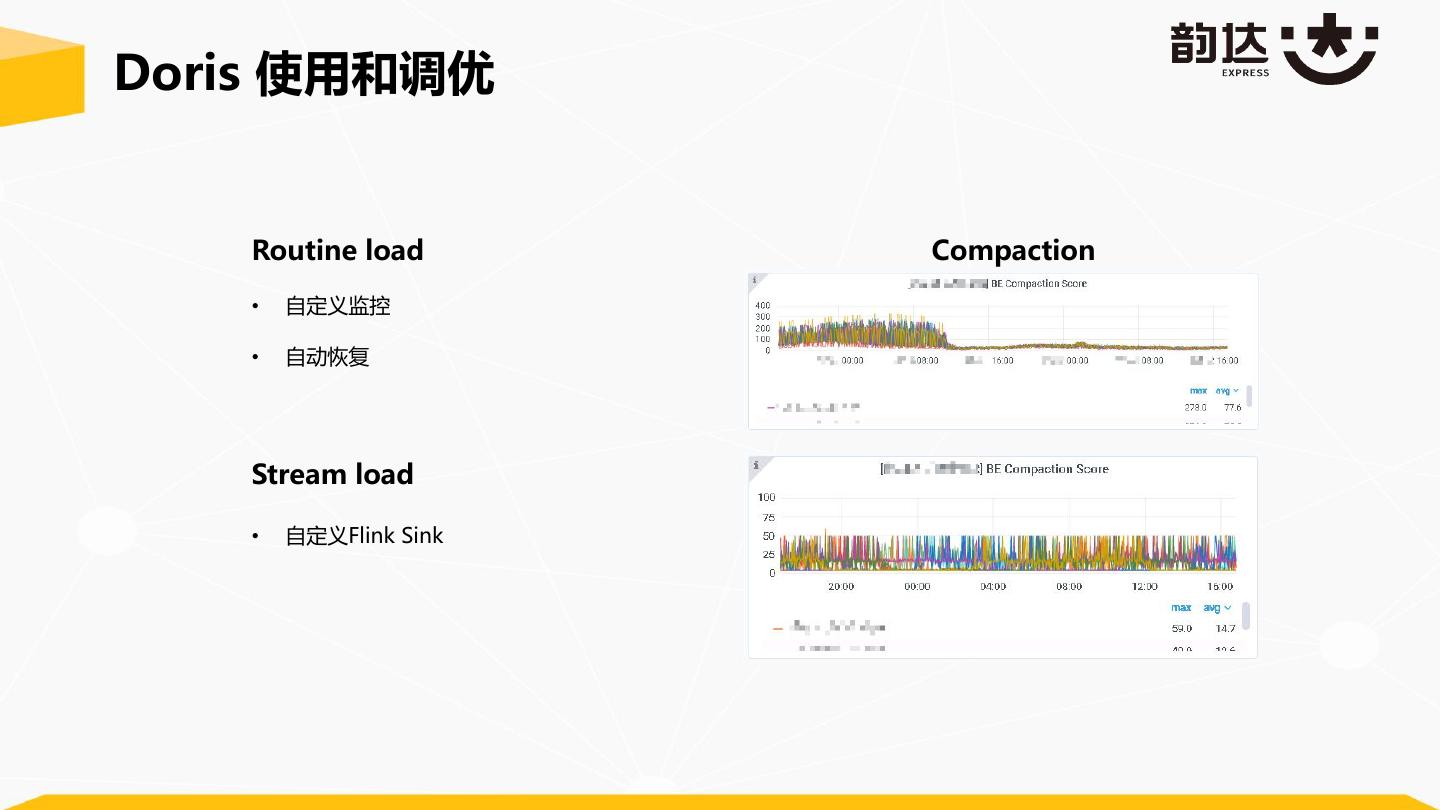
16 .Doris 使用和调优 Routine load Compaction • 自定义监控 • 自动恢复 Stream load • 自定义Flink Sink
17 .AGENDA ① 韵达科技简介 ② 平台选型 ③ 业务场景分享 ④ 小结
18 .业务场景介绍 海量数据 时效要求高 • 百亿级扫描数据 • 日跑批/小时跑批升级到实时,准实时 • 多个明细数据源(扫描,订单,预测..) • 近7日回算周期 接口响应时间秒级 数据准确性保障 • 秒级接口响应 • 实时数据与离线数据误差不超过5%
19 .业务场景介绍 业务痛点 u 时效性:明细级数据15分钟更新,而数据准确性要求和离线数据相比基本没有差异 u 数据量大,多表Join:7-15日回算周期,涉及多张大表,每张表需要用不同逻辑去重 u 接口稳定:海量数据实时写入的同时,保证复杂逻辑的执行稳定,还要对外提供高效的接口 u 业务口径一致:多个应用数十个指标的口径保持一致,保证数据一致性 ……
20 .Aggregate模型应用 聚合类型 适用场景 备注 sum 票件量统计 Flink写入时借助Redis做去重 min 最早进出站时间 max 最晚进出站时间,大包标识,最大重量 replace 一般不适用 必须写入该字段, 否则变空值 replace_if_not_null 数据最后一条更新记录 整型去重精度为100%,适用于 bitmap_union 票件量的去重统计,时间切片 单号去重统计 • 数据入到表里就已经聚合成了需要的业务信息,不再需要写复杂的逻辑去跑批
21 .物化视图和Bitmap 物化视图解决了什么问题? 1. 汇总数据和基表数据的实时统一 2. 查询时自动命中物化视图表,相比普通视图提升了计算效率 Bitmap解决了什么问题? 1. 0 ~ 264-1 范围内精确去重 2. 相比distinct,计算效率大幅提升,数据入表即已实现去重
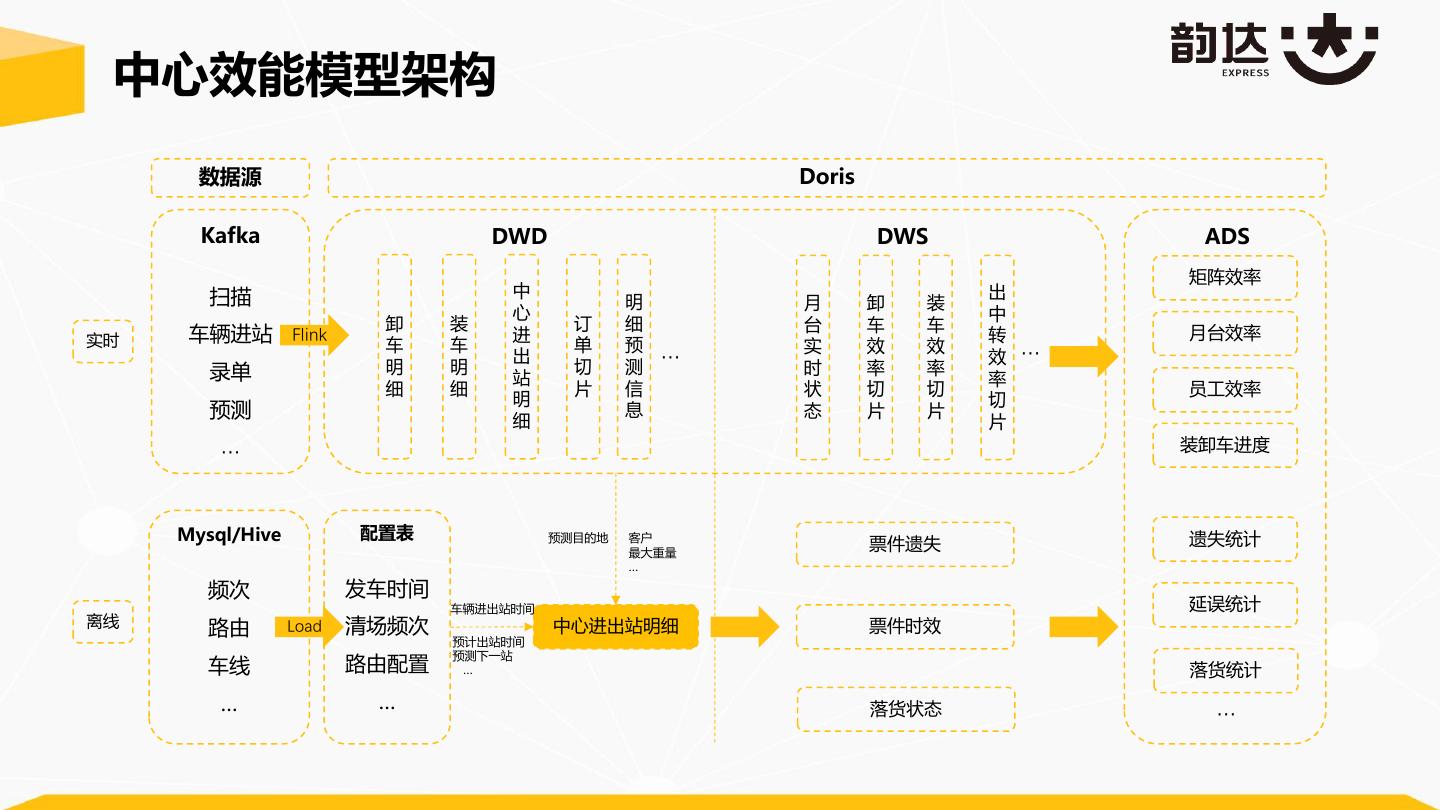
22 . 中心效能模型架构 数据源 Doris Kafka DWD DWS ADS 矩阵效率 扫描 中 出 明 月 卸 装 心 中 卸 装 订 细 台 车 车 实时 车辆进站 Flink 车 车 进 单 预 转 月台效率 实 效 效 明 明 出 切 测 … 时 率 率 效 … 录单 站 率 细 细 片 信 状 切 切 员工效率 明 切 预测 细 息 态 片 片 片 装卸车进度 … Mysql/Hive 配置表 预测目的地 客户 遗失统计 最大重量 票件遗失 … 频次 发车时间 车辆进出站时间 延误统计 离线 清场频次 路由 Load 中心进出站明细 票件时效 预计出站时间 预测下一站 车线 路由配置 … 落货统计 … … 落货状态 …
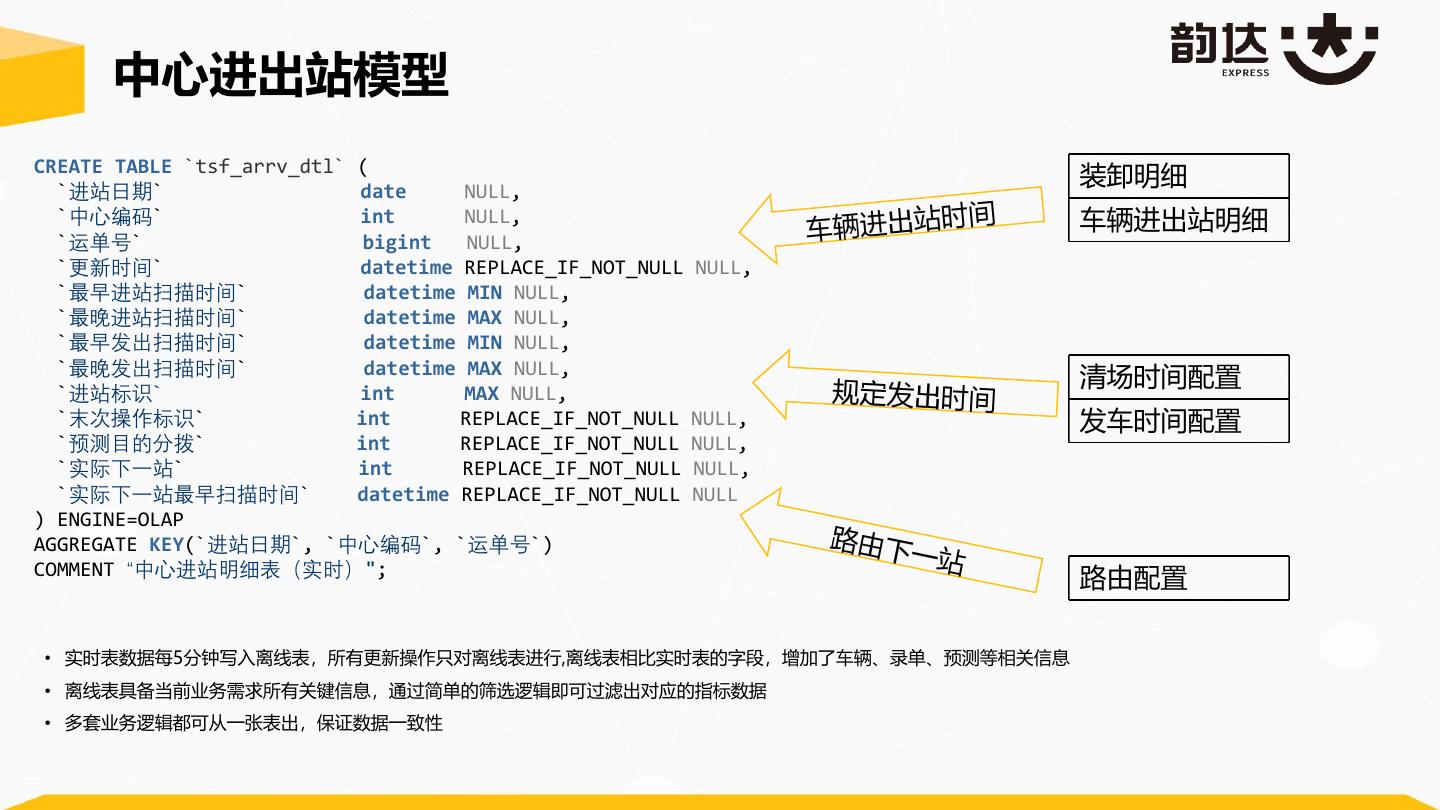
23 . 中心进出站模型 CREATE TABLE `tsf_arrv_dtl` ( `进站日期` date NULL, 装卸明细 `中心编码` int NULL, 车辆进出站明细 `运单号` bigint NULL, `更新时间` datetime REPLACE_IF_NOT_NULL NULL, `最早进站扫描时间` datetime MIN NULL, `最晚进站扫描时间` datetime MAX NULL, `最早发出扫描时间` datetime MIN NULL, `最晚发出扫描时间` datetime MAX NULL, 清场时间配置 `进站标识` int MAX NULL, `末次操作标识` int REPLACE_IF_NOT_NULL NULL, 发车时间配置 `预测目的分拨` int REPLACE_IF_NOT_NULL NULL, `实际下一站` int REPLACE_IF_NOT_NULL NULL, `实际下一站最早扫描时间` datetime REPLACE_IF_NOT_NULL NULL ) ENGINE=OLAP AGGREGATE KEY(`进站日期`, `中心编码`, `运单号`) COMMENT “中心进站明细表(实时)"; 路由配置 • 实时表数据每5分钟写入离线表,所有更新操作只对离线表进行,离线表相比实时表的字段,增加了车辆、录单、预测等相关信息 • 离线表具备当前业务需求所有关键信息,通过简单的筛选逻辑即可过滤出对应的指标数据 • 多套业务逻辑都可从一张表出,保证数据一致性
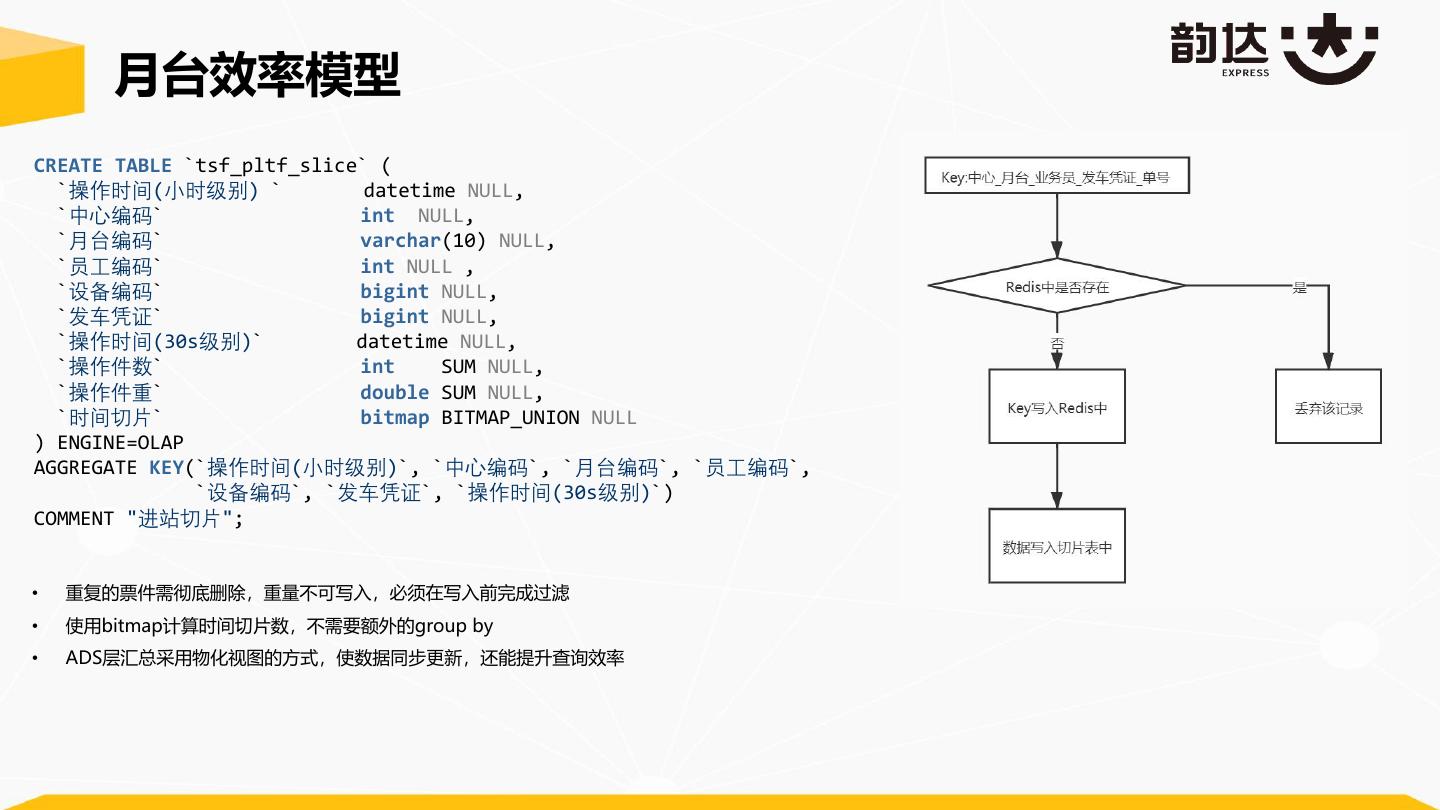
24 . 月台效率模型 CREATE TABLE `tsf_pltf_slice` ( `操作时间(小时级别) ` datetime NULL, `中心编码` int NULL, `月台编码` varchar(10) NULL, `员工编码` int NULL , `设备编码` bigint NULL, `发车凭证` bigint NULL, `操作时间(30s级别)` datetime NULL, `操作件数` int SUM NULL, `操作件重` double SUM NULL, `时间切片` bitmap BITMAP_UNION NULL ) ENGINE=OLAP AGGREGATE KEY(`操作时间(小时级别)`, `中心编码`, `月台编码`, `员工编码`, `设备编码`, `发车凭证`, `操作时间(30s级别)`) COMMENT "进站切片"; • 重复的票件需彻底删除,重量不可写入,必须在写入前完成过滤 • 使用bitmap计算时间切片数,不需要额外的group by • ADS层汇总采用物化视图的方式,使数据同步更新,还能提升查询效率
25 . 月台实时状态模型 CREATE TABLE `pltf_curr_status` • 直接对外提供接口,月台情况秒级更新,大屏实时显示月台变化 ( `中心编码` int • 配合5分钟统计的装卸车进度汇总,车辆装卸情况准实时更新,为分拨赋能 ,`月台编码` varchar(20) ,`最晚操作时间` datetime max ,`发车凭证编码` bigint replace_if_not_null ,`操作员工` bigint replace_if_not_null ,`更新时间` datetime replace_if_not_null )AGGREGATE key (`中心编码`, `月台编码`) COMMENT‘中心各月台实时状态’; 数字孪生主看板 展示指标: • 月台/交叉带实时状态 – 秒级 • 车辆详细信息 – 分钟级 • 车辆装卸车进度 --分钟级 • 员工操作效率 --分钟级 • 吞吐量 --分钟级 …
26 .Doris在韵达应用现状 • Doris在韵达目前主要用于分拨数据的实时分析。 • 涵盖分拨中心90%的核心指标,满足多部门数据产品,保证集团数据一致性。 • 其它系统报表迁移Doris持续进行中。 数据量 调度数 核心指标数 亿级 100+ 100+
27 .AGENDA ① 韵达科技简介 ② 平台选型 ③ 业务场景分享 ④ 小结
28 .数据时效性对比 Doris与Greenplum,Kudu的耗时对比: 在韵达相同业务场景下,Doris跑批时效约是Kudu的1/2,是Greenplum的1/10。 落货统计 实时时效 三错 月台效率 Greenplum Kudu Doris
29 . 开发难度降低 Greenplum: Doris: select 建表: ship_id CREATE TABLE `票件进站信息表` ,扫描时间 as 最早进站时间 ( from( `中心编码` int select ,`运单号` bigint 运单号 ,`最早进站时间` datetime min ,扫描时间 )AGGREGATE key (`中心编码`, `运单号`) ,row_number()over(partition by 运单号,分拨编码 order by 扫描时间 asc) rn DISTRIBUTED BY HASH(`中心编码`) BUCKETS 1 from 扫描表 PROPERTIES ( where time between '2021-06-01' and '2021-06-02' …); and 扫描类型 in ('卸车','称重') ) as c where c.rn=1 Kudu: Redis Greenplum Kudu Doris Key:单号+分拨 upsert Kafka明细 Kudu 数据量 大 小 小 value:最早时间 需要大量 大量计算由Flink+redis 开发量 row_number+join 去重少,写入即所得 完成,开发难度较高 操作,重复计算
3秒后跳转登录页面
去登陆

