

















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/u70/Apache_Beam_The_Solution_for_Portable_and_Evolutive_Data_intensive_Applications?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
Apache Beam介绍
分享
点赞
0
收藏
0
下载 4
Apache Beam提供了统一的大数据编程抽象,提供了不同的执行引擎支持,比如Spark/Flink/Storm等等,本篇介绍了大数据领域的几个常见编程范式(实时和批处理),并引申出Beam的API,如何做到统一的编程模型。
展开查看详情
1 .Apache Beam: portable and evolutive data-intensive applications Ismaël Mejía - @iemejia Talend
2 .Who am I? @iemejia Software Engineer Apache Beam PMC / Committer ASF member Integration Software Big Data / Real-Time Open Source / Enterprise 2
3 .New products We are hiring ! 3
4 .Introduction: Big data state of affairs 4
5 .Before Big Data (early 2000s) The web pushed data analysis / infrastructure boundaries ● Huge data analysis needs (Google, Yahoo, etc) ● Scaling DBs for the web (most companies) DBs (and in particular RDBMS) had too many constraints and it was hard to operate at scale. Solution: We need to go back to basics but in a distributed fashion 5
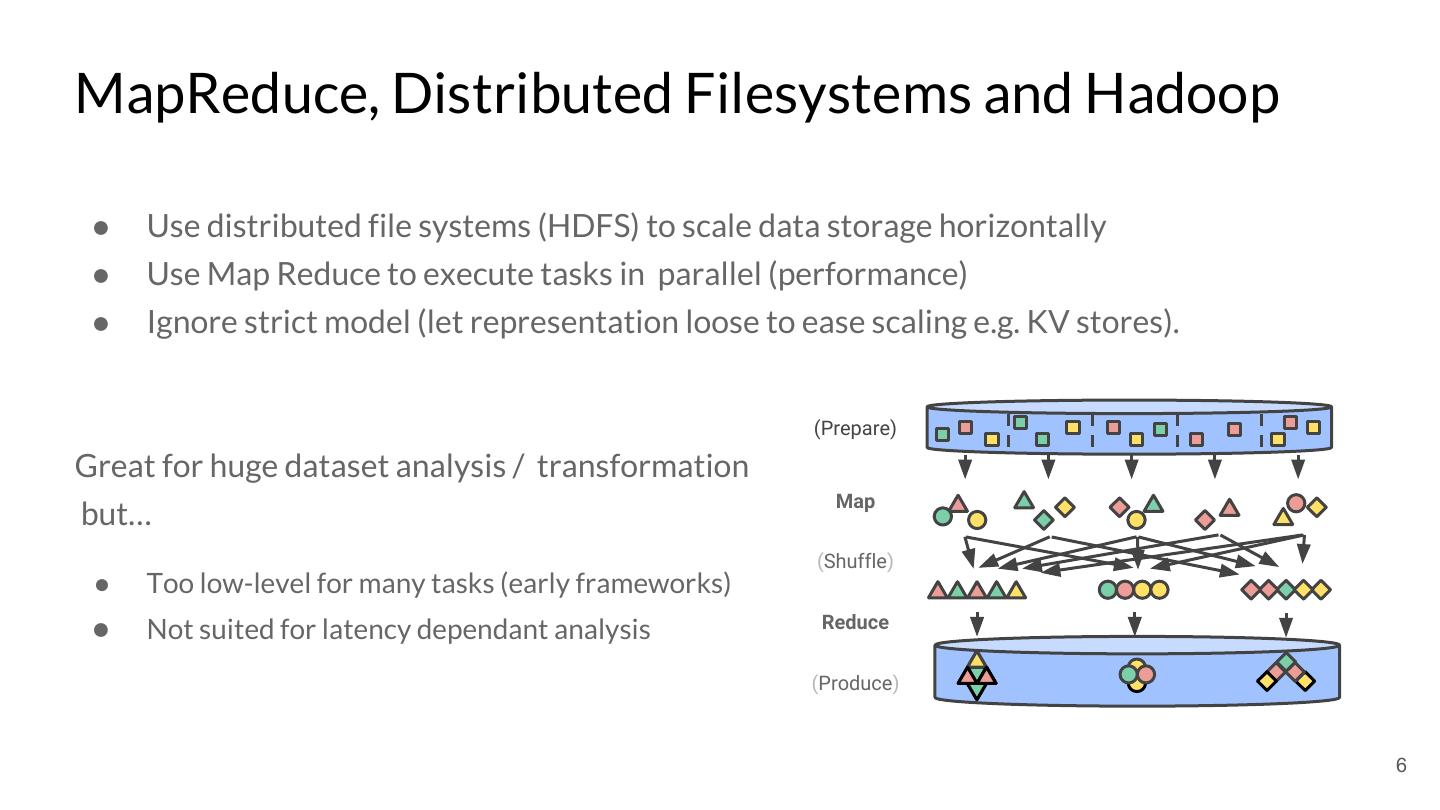
6 .MapReduce, Distributed Filesystems and Hadoop ● Use distributed file systems (HDFS) to scale data storage horizontally ● Use Map Reduce to execute tasks in parallel (performance) ● Ignore strict model (let representation loose to ease scaling e.g. KV stores). (Prepare) Great for huge dataset analysis / transformation Map but… (Shuffle) ● Too low-level for many tasks (early frameworks) Reduce ● Not suited for latency dependant analysis (Produce) 6
7 .The distributed database Cambrian explosion … and MANY others, all of them with different properties, utilities and APIs 7
8 .Distributed databases API cycle NewSQL let's reinvent NoSQL, because our own thing SQL is too limited SQL is back, because it is awesome 8 (yes it is an over-simplification but you get it)
9 .The fundamental problems are still the same or worse (because of heterogeneity) … ● Data analysis / processing from systems with different semantics ● Data integration from heterogeneous sources ● Data infrastructure operational issues Good old Extract-Transform-Load (ETL) is still an important need 9
10 .The fundamental problems are still the same "Data preparation accounts for about 80% of the work of data scientists" [1] [2] 1 Cleaning Big Data: Most Time-Consuming, Least Enjoyable Data Science Task 2 Sculley et al.: Hidden Technical Debt in Machine Learning Systems 10
11 .and evolution continues ... ● Latency needs: Pseudo real-time needs, distributed logs. ● Multiple platforms: On-premise, cloud, cloud-native (also multi-cloud). ● Multiple languages and ecosystems: To integrate with ML tools Software issues: New APIs, new clusters, different semantics, … and of course MORE data stores ! 11
12 .Apache Beam 12
13 .Apache Beam origin Colossus BigTable PubSub Dremel Google Cloud Dataflow Spanner Megastore Millwheel Flume Apache Beam MapReduce
14 .What is Apache Beam? Apache Beam is a unified programming model designed to provide efficient and portable data processing pipelines
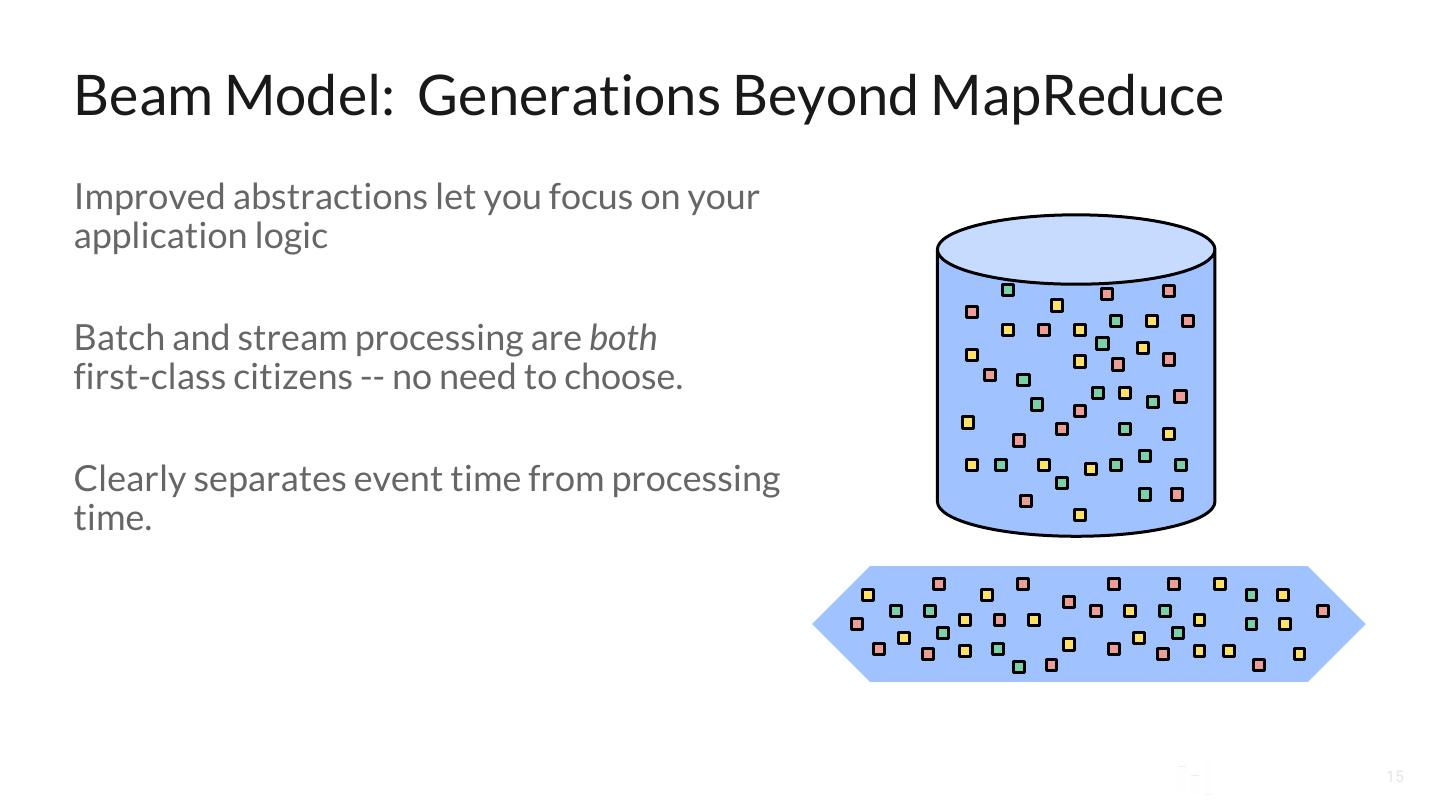
15 .Beam Model: Generations Beyond MapReduce Improved abstractions let you focus on your application logic Batch and stream processing are both first-class citizens -- no need to choose. Clearly separates event time from processing time. 15
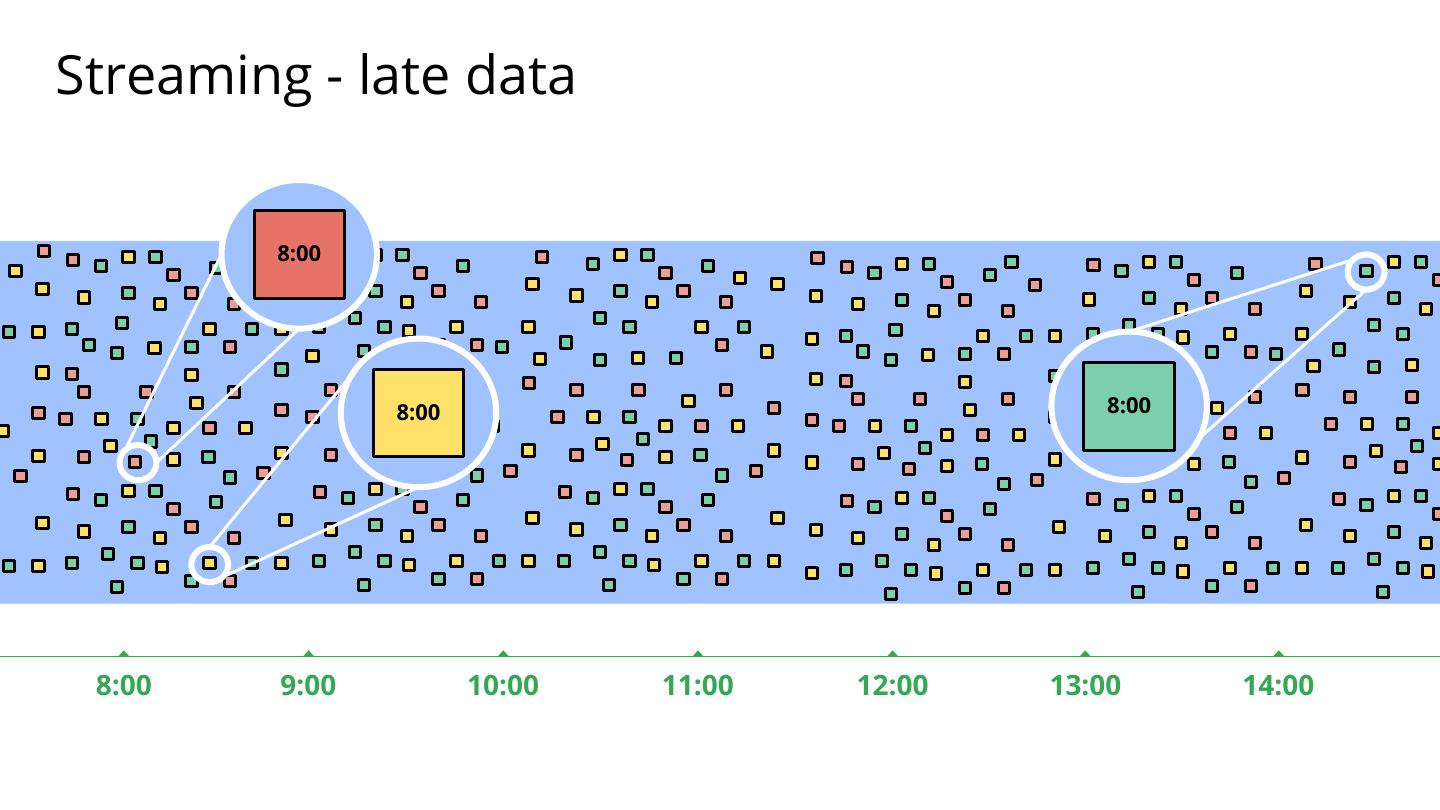
16 .Streaming - late data 8:00 8:00 8:00 8:00 9:00 10:00 11:00 12:00 13:00 14:00
17 .Processing Time vs. Event Time 17
18 .Beam Model: Asking the Right Questions What results are calculated? Where in event time are results calculated? When in processing time are results materialized? How do refinements of results relate? 18
19 .Beam Pipelines PTransform PCollection 19
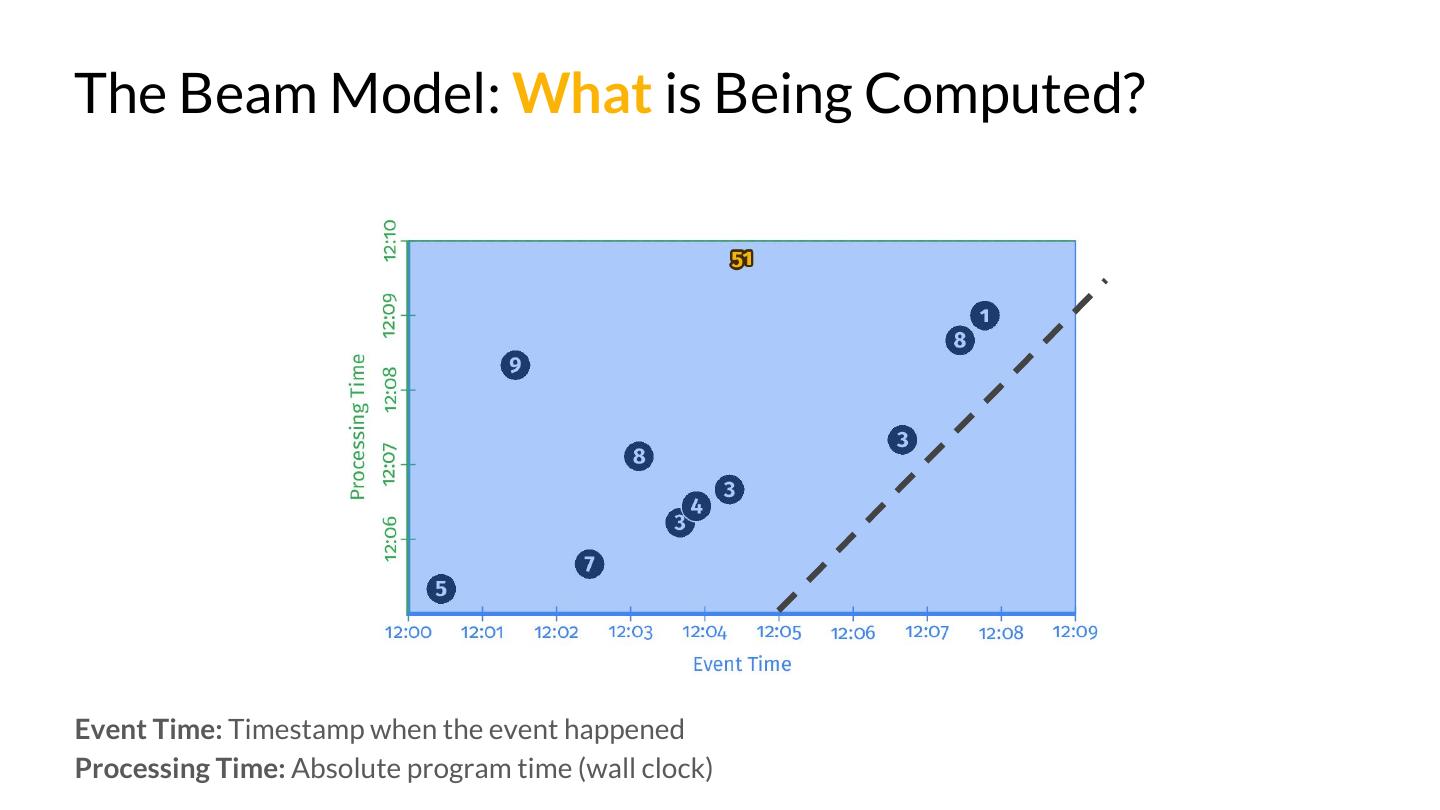
20 .The Beam Model: What is Being Computed? PCollection<KV<String, Integer>> scores = input .apply(Sum.integersPerKey()); scores = (input | Sum.integersPerKey())
21 .The Beam Model: What is Being Computed? Event Time: Timestamp when the event happened Processing Time: Absolute program time (wall clock)
22 .The Beam Model: Where in Event Time? PCollection<KV<String, Integer>> scores = input .apply(Window.into(FixedWindows.of(Duration.standardMinutes(2))) .apply(Sum.integersPerKey()); scores = (input | beam.WindowInto(FixedWindows(2 * 60)) | Sum.integersPerKey())
23 . The Beam Model: Where in Event Time? ● Split infinite data into finite chunks Input Processing Time 12:00 12:02 12:04 12:06 12:08 12:10 Output Event Time 12:00 12:02 12:04 12:06 12:08 12:10
24 .The Beam Model: Where in Event Time?
25 .The Beam Model: When in Processing Time? PCollection<KV<String, Integer>> scores = input .apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)) .triggering(AtWatermark())) .apply(Sum.integersPerKey()); scores = (input | beam.WindowInto(FixedWindows(2 * 60) .triggering(AtWatermark()) | Sum.integersPerKey())
26 .The Beam Model: When in Processing Time?
27 .The Beam Model: How Do Refinements Relate? PCollection<KV<String, Integer>> scores = input .apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)) .triggering(AtWatermark() .withEarlyFirings(AtPeriod(Duration.standardMinutes(1))) .withLateFirings(AtCount(1))) .accumulatingFiredPanes()) .apply(Sum.integersPerKey()); scores = (input | beam.WindowInto(FixedWindows(2 * 60) .triggering(AtWatermark() .withEarlyFirings(AtPeriod(1 * 60)) .withLateFirings(AtCount(1)) .accumulatingFiredPanes()) | Sum.integersPerKey())
28 .The Beam Model: How Do Refinements Relate?
29 .Customizing What Where When How 1 2 3 4 Classic Windowed Streaming Streaming Batch Batch + Accumulation 29
相关推荐
3秒后跳转登录页面
去登陆

