基于 Druid 的 Apache Kylin 存储引擎实践
分享
点赞
7
收藏
6
下载 27
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
在2018年8月的Apache Kylin meetup@北京活动上,美团点评工程师做了关于使用 Druid 做为 Apache Kylin 存储引擎的实践,并更新了 Kylin 在美团点评的使用现状。
展开查看详情
1 .基于Druid的Kylin存储引擎实践
美团点评
康凯森
�
2 .⼤纲
• Kylin On HBase 问题
• Kylin 新存储引擎探索
•Kylin On Druid
�
3 .Kylin 服务现状
973 Cube 380万 次查询/天
数据量 Cube存储 TP 50 TP 90
8.9万亿 971TB 200ms 1.2s
覆盖所有主要业务线
�
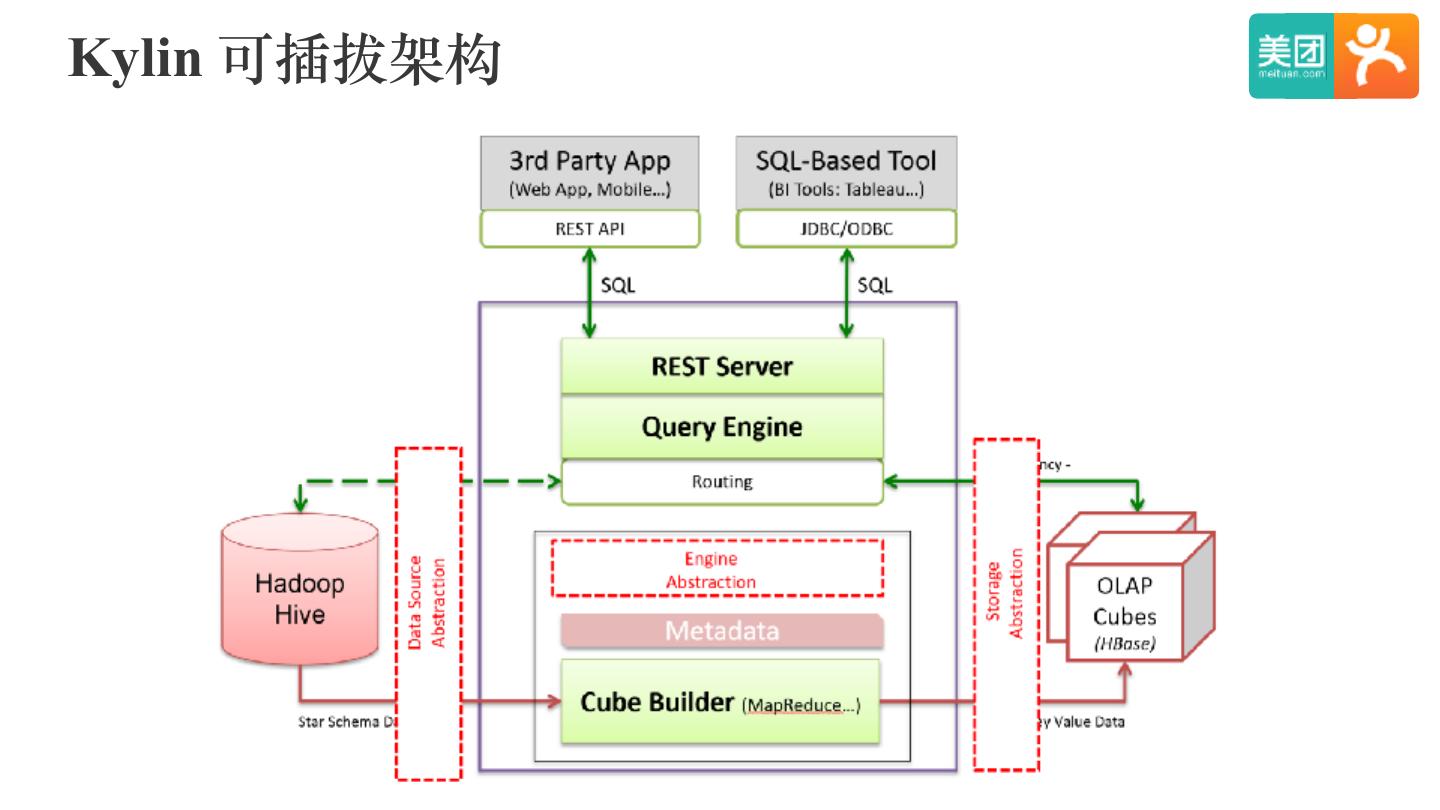
4 .Kylin On HBase 问题
• 同⼀SQL
• 同⼀Cube
• 同⼀集群
唯⼀不同点:Kylin维度在HBase的Rowkey中位置不同
�
5 . Kylin On HBase 问题
• 每次读取所有指标列:
Scan性能相⽐列存
相差10倍多
• 单⼀Rowkey索引:
前缀和后缀Filter
性能相差上千倍
�
6 .Kylin On HBase 问题的可能解
• 列存:更⾼效的Scan
• 索引:更⾼效的Filter
�
7 .列存的优点
• ⾼效IO:只读取必需的列
• ⾼效编码和压缩:每列数据类型⼀致,格式⼀致
• 向量化执⾏
�
10 .Kylin 新存储引擎思路⼀
基于Spark + File演进
�
11 .Kylin 新存储引擎思路⼆
基于File Format演进新存储引擎
�
12 . 第⼀步
探索⼀个适合Kylin的存储格式
�
14 .Parquet File Format 2.3.1
• 列存
• Min,Max索引
• Dictionary 过滤
• ⽆ PageIndex
�
15 .Kylin On Parquet POC
• 构建:单节点每分钟导⼊百万条数据
• 压缩:存储空间⽐HBase节省10%
• Scan 查询:部分列时是HBase的2~6倍;全部列时是HBase的80%
• Filter 查询:前缀查询明显不如HBase,后缀查询有⼀定优势
�
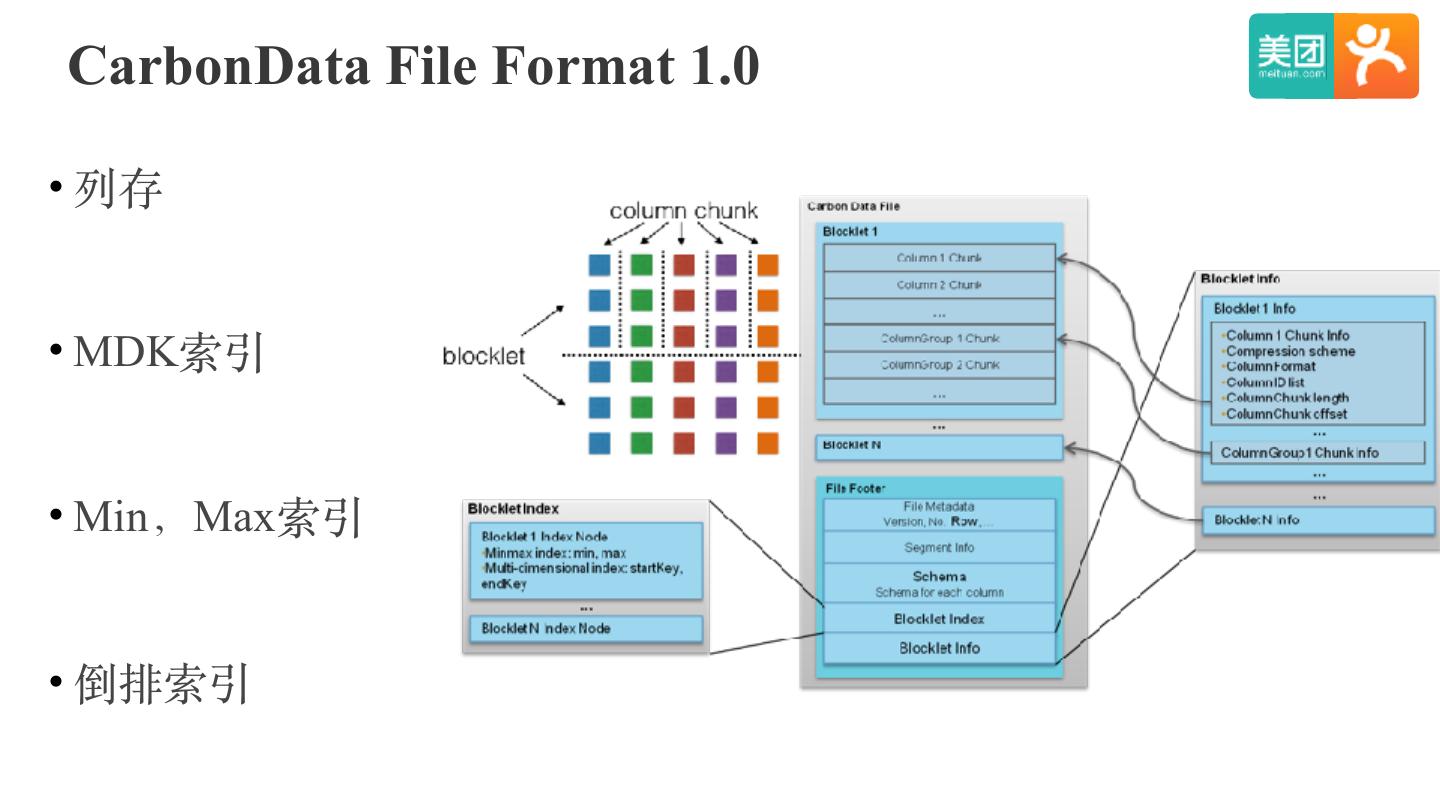
16 .CarbonData File Format 1.0
• 列存
• MDK索引
• Min,Max索引
• 倒排索引
�
17 .Why Not Kylin On Carbondata 1.0
• 没有OutputFormat
• 和 Spark 耦合较深
• 尚不成熟(2017-05)
�
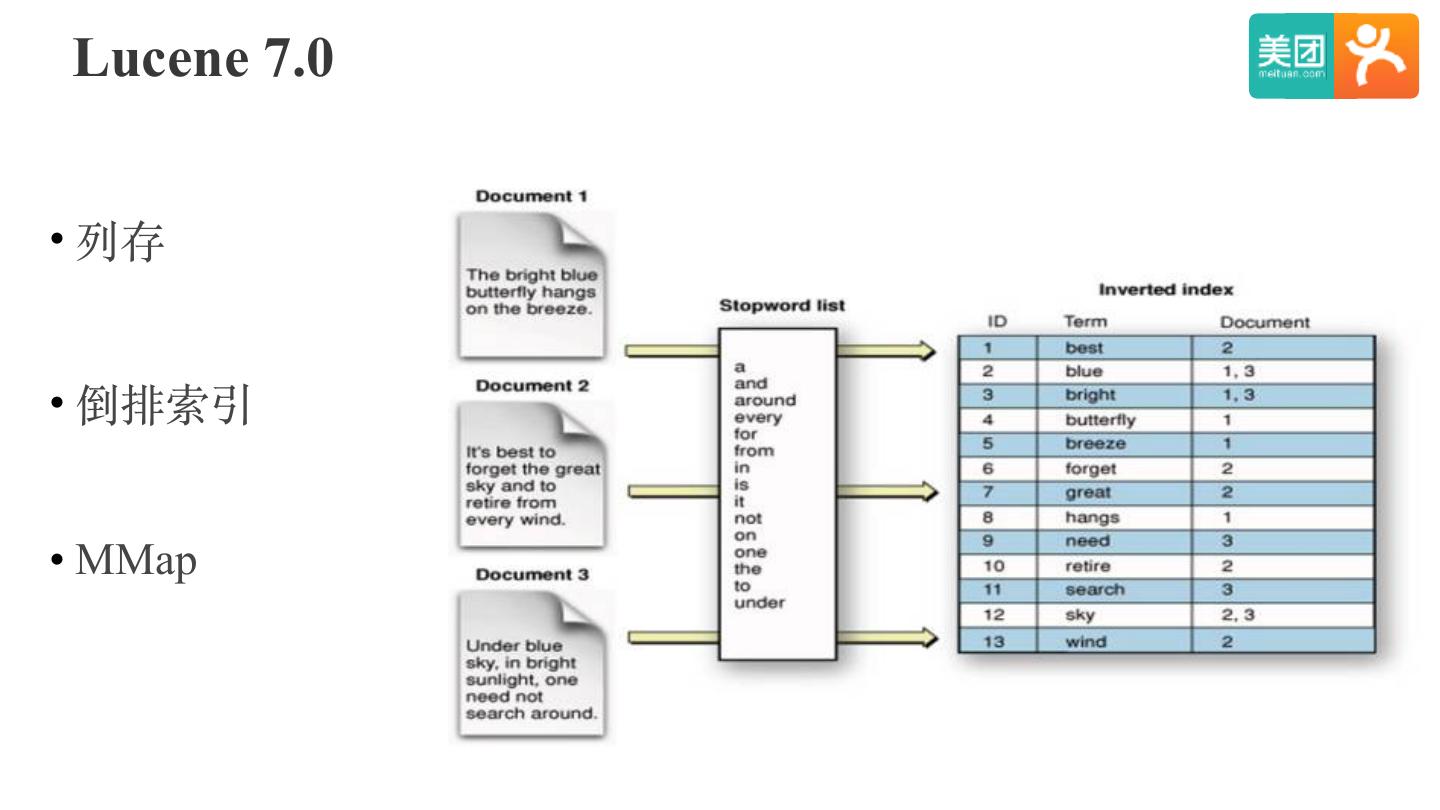
18 .Lucene 7.0
• 列存
• 倒排索引
• MMap
�
19 .Kylin On Lucene POC
• 构建:导⼊速度是HBase的1/3
• 压缩:存储是HBase的4倍
• Scan查询:部分列时性能优于HBase
• Filter查询:过滤性能明显优于HBase, 不过点查询性能⽐HBase差
�
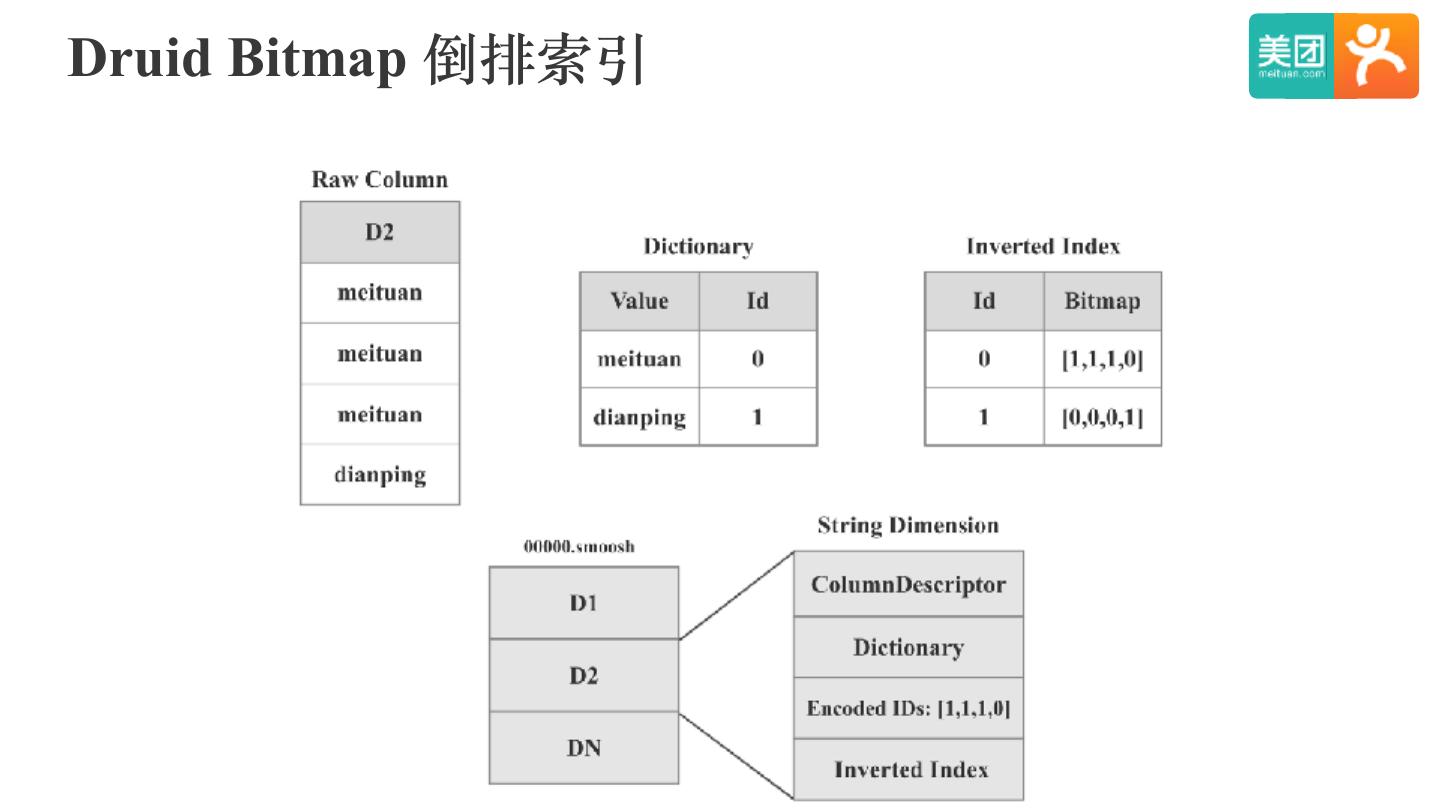
20 .Druid Segment File Format
• 列式存储
• Bitmap倒排索引
• MMap
�
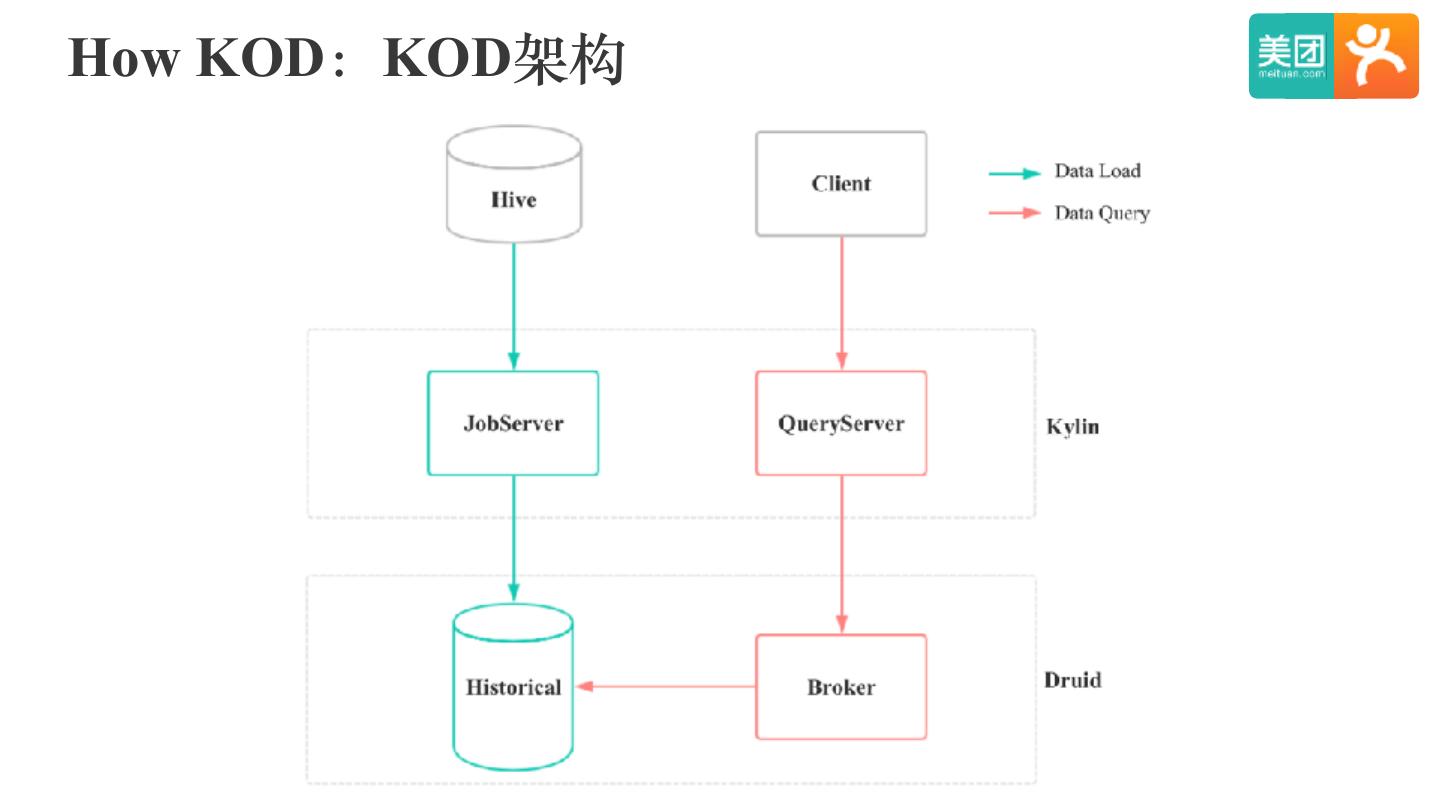
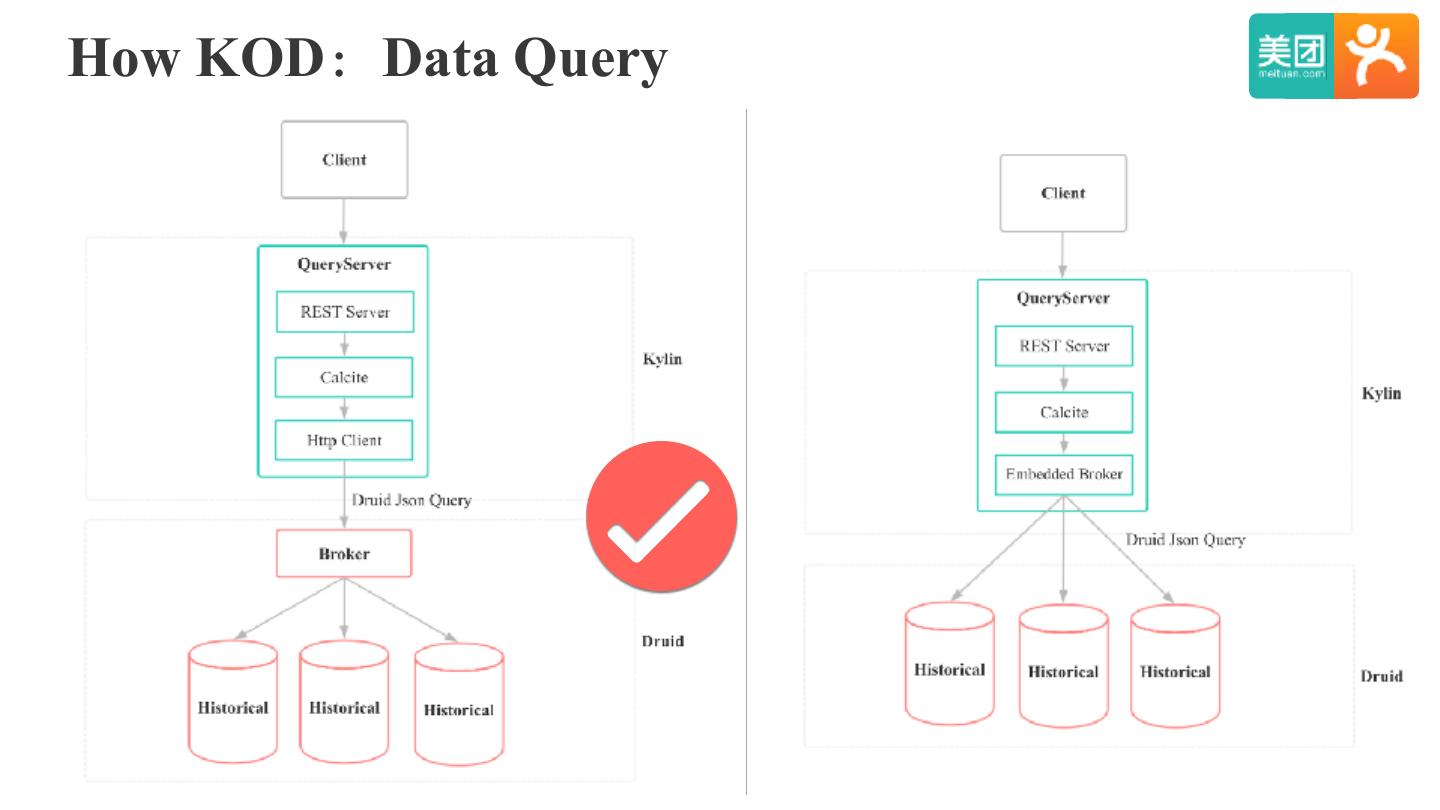
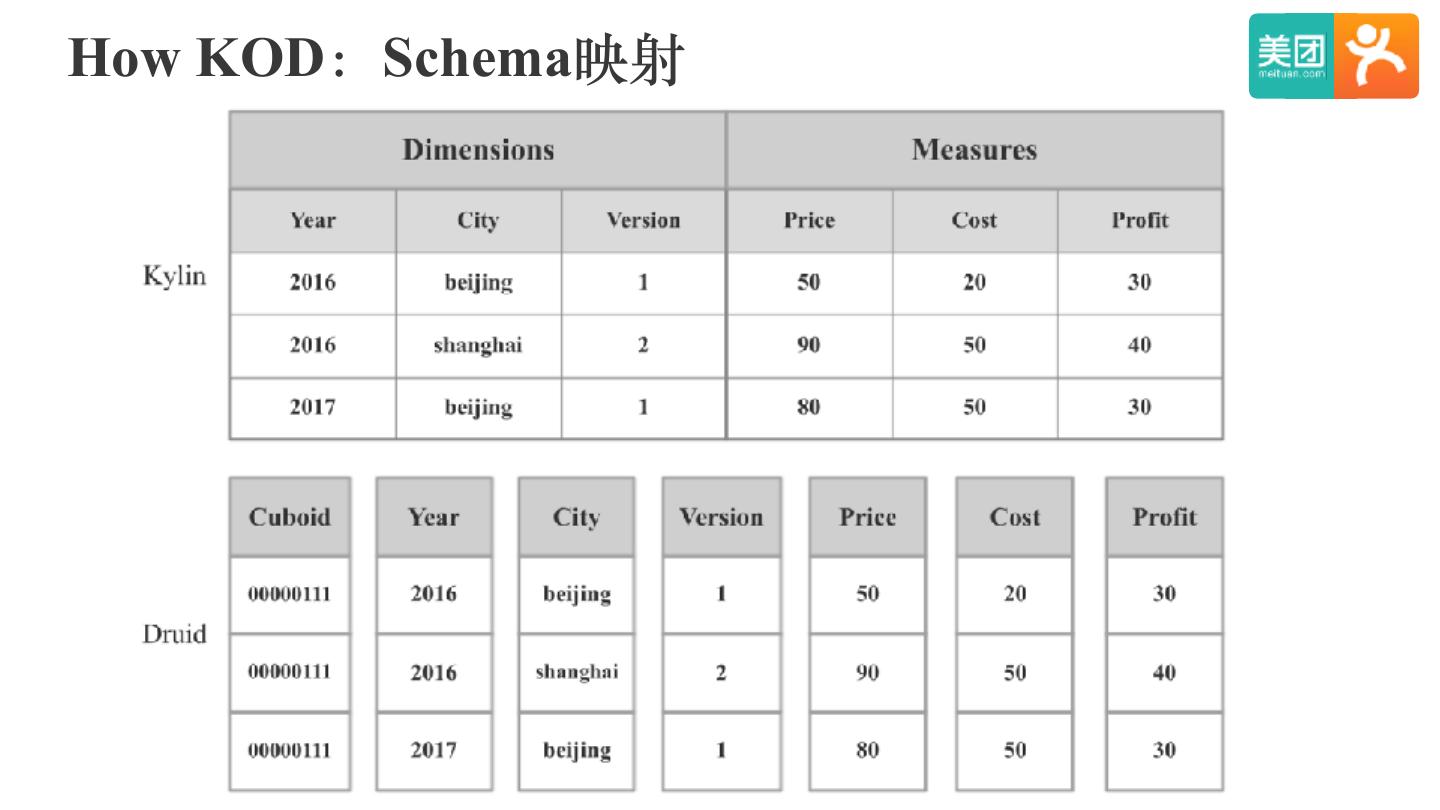
22 .Kylin On Druid POC
前缀过滤
后缀过滤
�
23 .Why Kylin On Druid
• Parquet: 索引粒度较粗,Filter 性能不⾜
•CarbonData: 与Spark耦合较深,集成难度⼤
• Lucene: 存储膨胀率较⾼
�
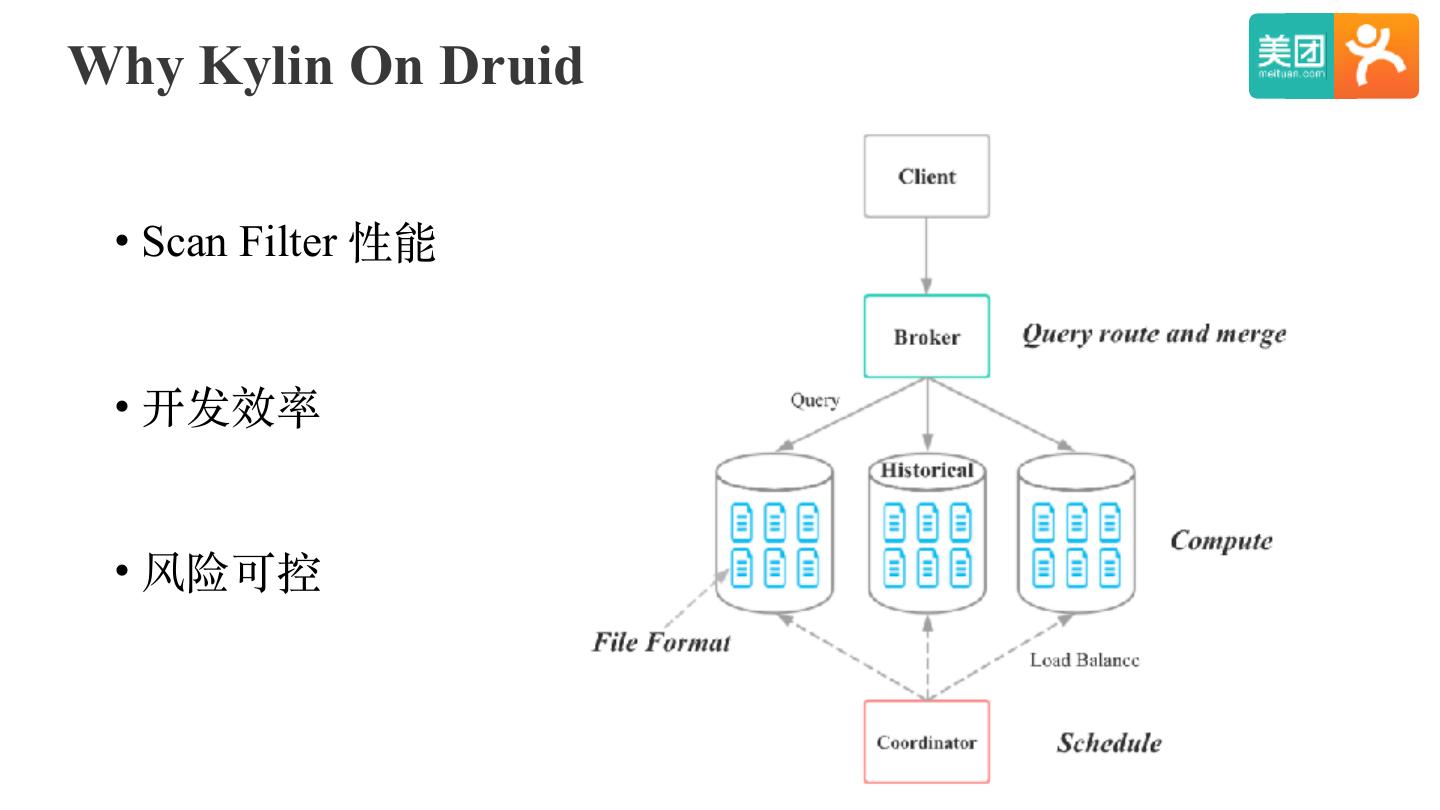
24 .Why Kylin On Druid
• Scan Filter 性能
• 开发效率
• 风险可控
�
25 .⼤纲
• Kylin On HBase 问题
• Kylin 新存储引擎探索
•Kylin On Druid
�