















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
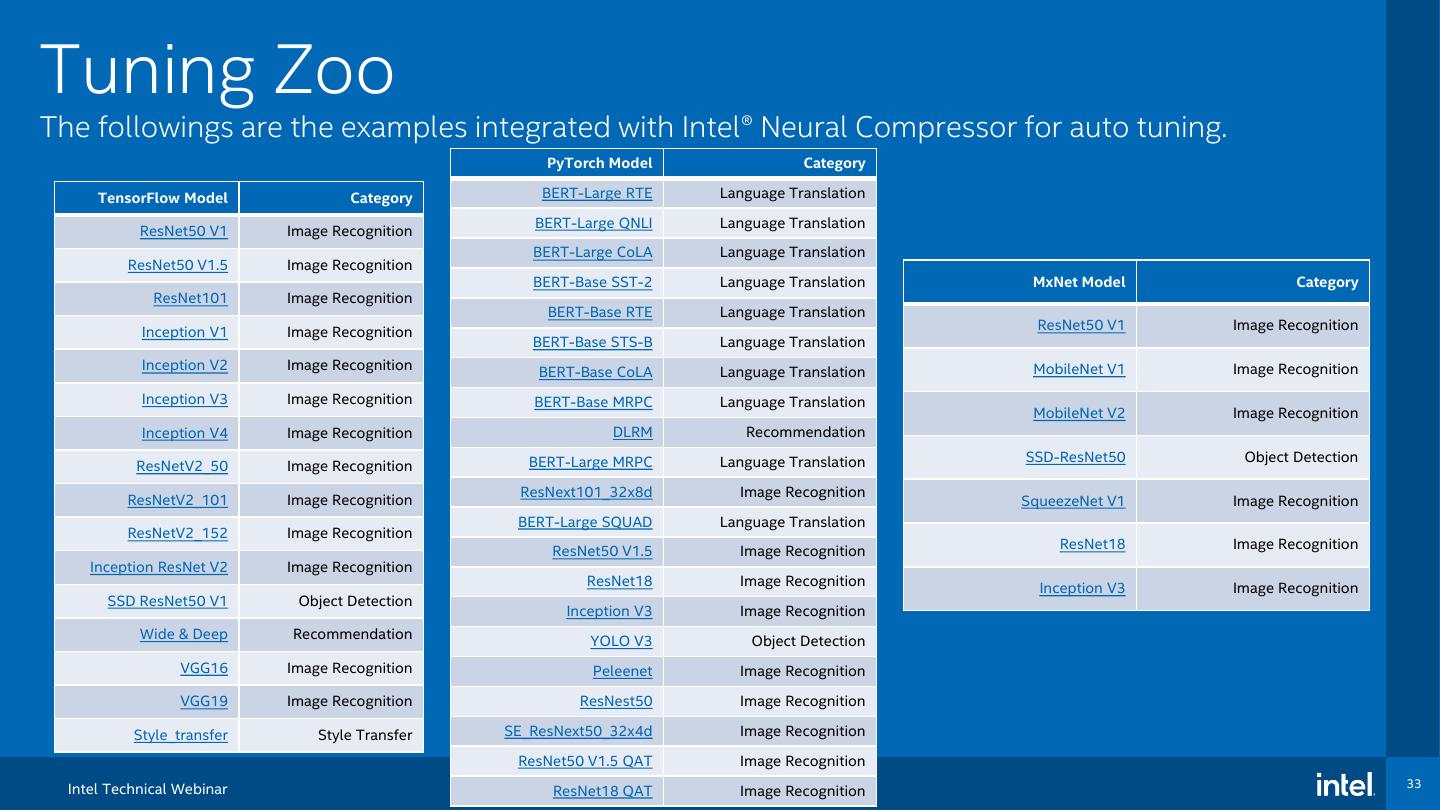
AI机器学习模型推理加速!
在 CPU 上加速 AI 推理速度,是 AI 项目落地时常见的需求。现在大家已经不再争论跑AI,到底是 GPU 好,还是应该开发更专用的 AI 加速芯片了,因为 CPU 也成了越来越多企业用户的选择,那么我们到底需要用什么样的“姿势”,才能用好 CPU 的这项能力?
本次活动我们特别邀请到Intel的嘉宾,为大家带来基于TensorFlow的 AI 模型推理加速及优化主题的分享。通过学习如何使用 Intel® Deep Learning Boost 技术和 Intel® AI Analytics Toolkit 软件工具包,简洁方便的在 CPU 上实现低精度 TensorFlow 模型推理加速。
展开查看详情
1 .应用Intel® AI软硬件技术, 在CPU上加速 Tensorflow*模型推理 张建宇, AI SSE Intel Software and Advanced Technology Group (SATG)
2 . Notices & Disclaimers Intel technologies may require enabled hardware, software or service activation. Learn more at intel.com or from the OEM or retailer. Your costs and results may vary. Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy. Optimization Notice: Intel's compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice Revision #20110804. https://software.intel.com/en-us/articles/optimization-notice Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. See backup for configuration details. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See configuration disclosure for details. No product or component can be absolutely secure. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. © Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others. Intel Technical Webinar 2
3 .Agenda • Intel® Deep Learning Boost • Intel® oneAPI AI Analytics Toolkit • Intel® Optimization for TensorFlow* • Intel® Neural Compressor • Demo
4 .向量化 Vectorization - SIMD: Single Instruction Multiple Data ISA Length Num of FP32 AVX 128 bits 4 AVX2 256 bits 8 AVX512 512 bits 16 a c1 = a1 + b1 c2 = a2 + b2 + c3 = a3 + b3 b ……. = c c16 = a16 + b16 c = _mm512_add_ps(a, b) Intel Technical Webinar 4
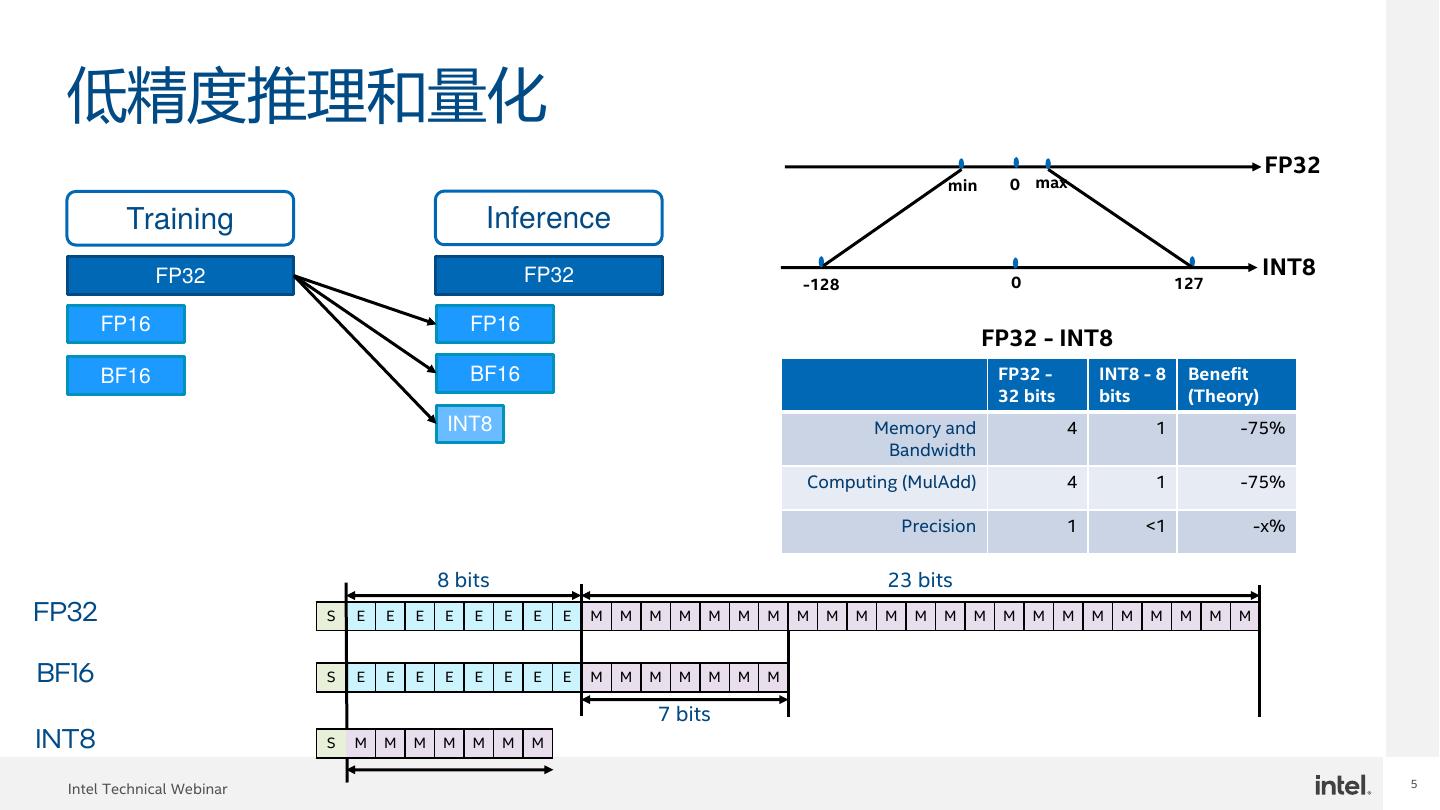
5 . 低精度推理和量化 FP32 min 0 max Training Inference FP32 FP32 INT8 -128 0 127 FP16 FP16 FP32 - INT8 BF16 BF16 FP32 - INT8 - 8 Benefit 32 bits bits (Theory) INT8 Memory and 4 1 -75% Bandwidth Computing (MulAdd) 4 1 -75% Precision 1 <1 -x% 8 bits 23 bits FP32 S E E E E E E E E M M M M M M M M M M M M M M M M M M M M M M M BF16 S E E E E E E E E M M M M M M M 7 bits INT8 S M M M M M M M 5 Intel Technical Webinar
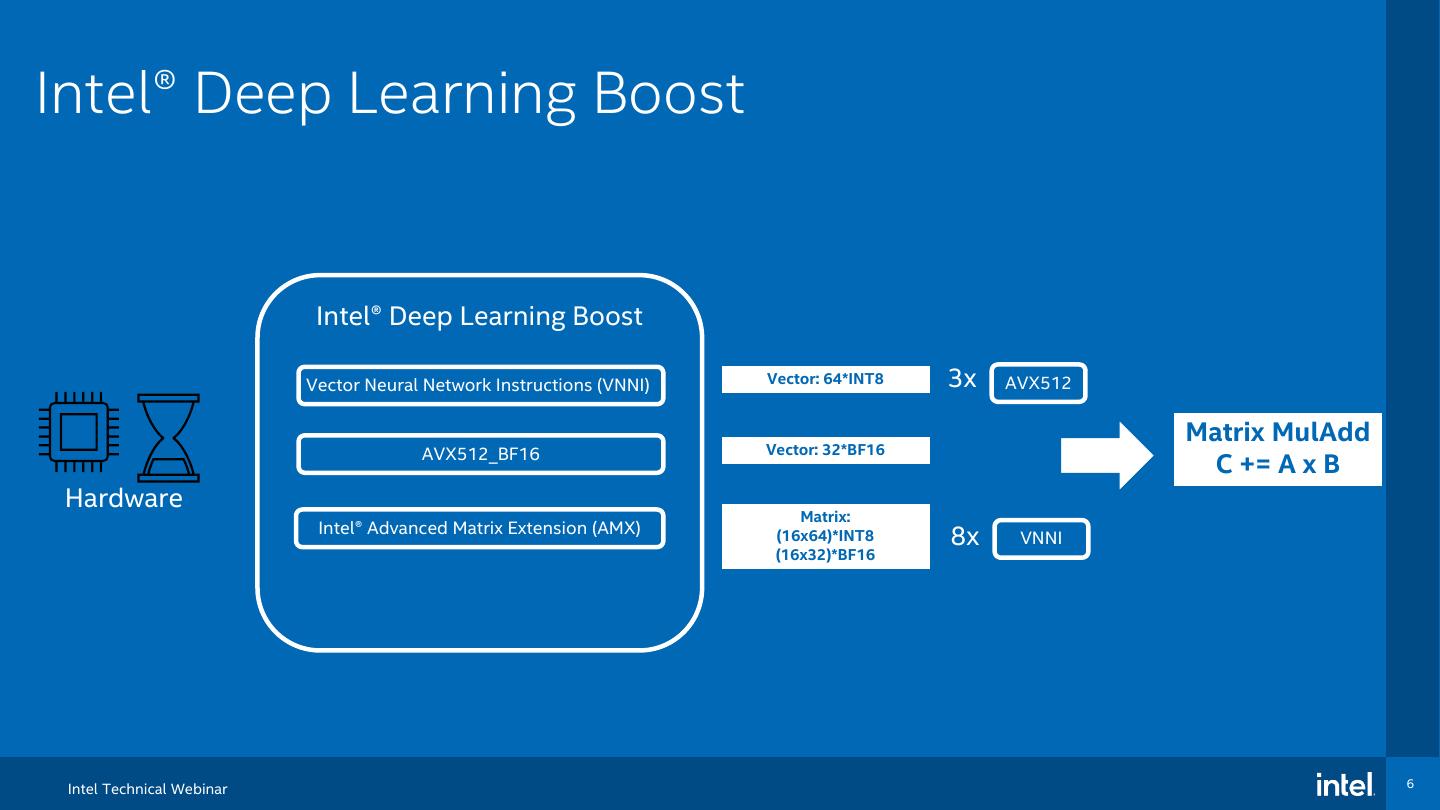
6 .Intel® Deep Learning Boost Intel® Deep Learning Boost Vector Neural Network Instructions (VNNI) Vector: 64*INT8 3x AVX512 Matrix MulAdd AVX512_BF16 Vector: 32*BF16 C += A x B Hardware Matrix: Intel® Advanced Matrix Extension (AMX) (16x64)*INT8 8x VNNI (16x32)*BF16 Intel Technical Webinar 6
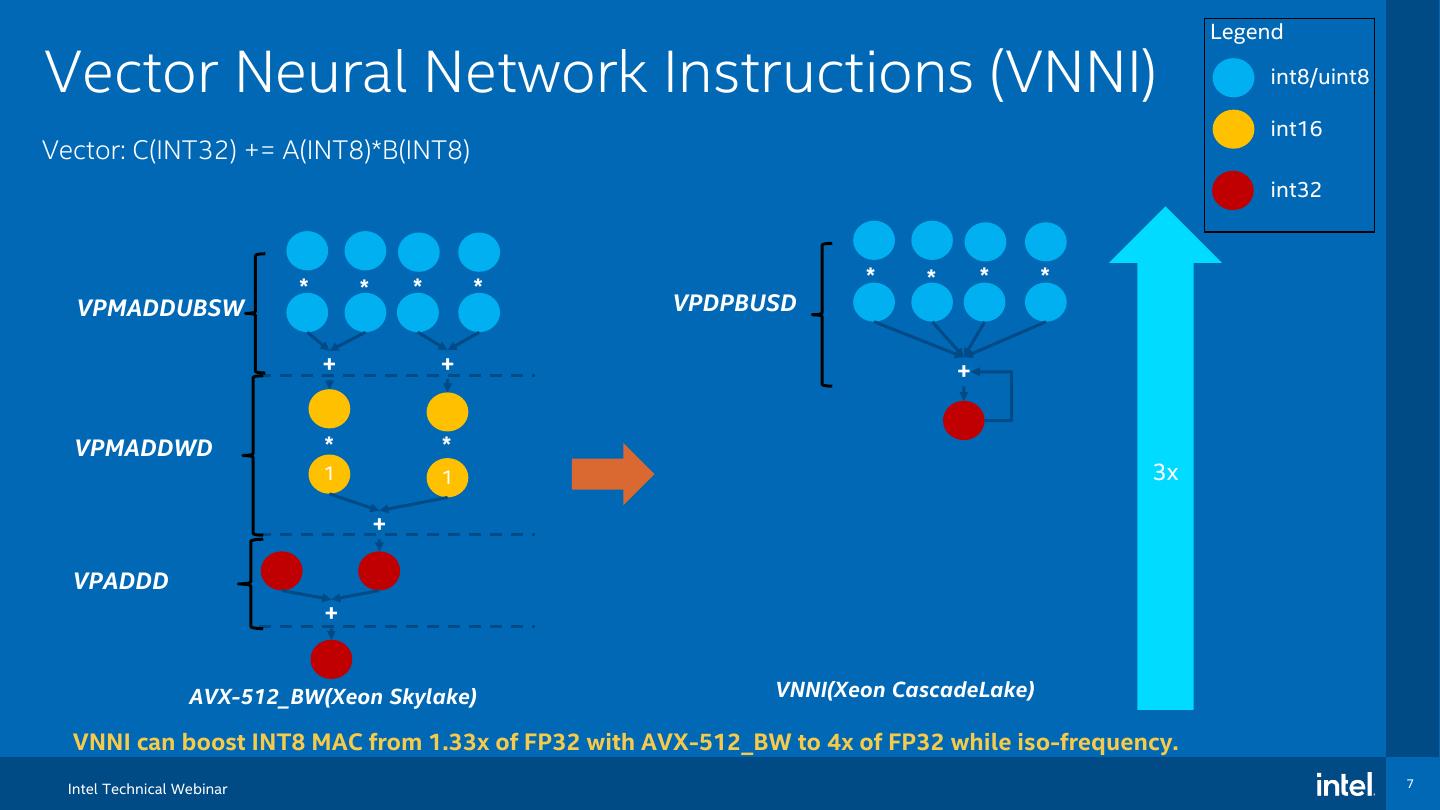
7 . Legend Vector Neural Network Instructions (VNNI) int8/uint8 int16 Vector: C(INT32) += A(INT8)*B(INT8) int32 * * * * * * * * VPMADDUBSW VPDPBUSD + + + VPMADDWD * * 1 1 3x + VPADDD + AVX-512_BW(Xeon Skylake) VNNI(Xeon CascadeLake) VNNI can boost INT8 MAC from 1.33x of FP32 with AVX-512_BW to 4x of FP32 while iso-frequency. Intel Technical Webinar 7
8 .Intel® Advanced Matrix Extension (AMX) Tile0-7: AMX 16*64 Bytes 2048 int8 Tile C Tile A Tile B += x 8x operations / cycle / core VNNI 256 int8 Intel Technical Webinar 8
9 .Intel® Xeon Generation Intel® Xeon® Scalable CodeName VNNI AVX512_BF16 AMX Processors 2nd Cascade Lake 3rd Cooper Lake 3rd Ice Lake Next-Gen (coming) Sapphire Rapids Intel Technical Webinar 9
10 .Agenda • Intel® Deep Learning Boost • Intel® oneAPI AI Analytics Toolkit • Intel® Optimization for TensorFlow* • Intel® Neural Compressor • Demo
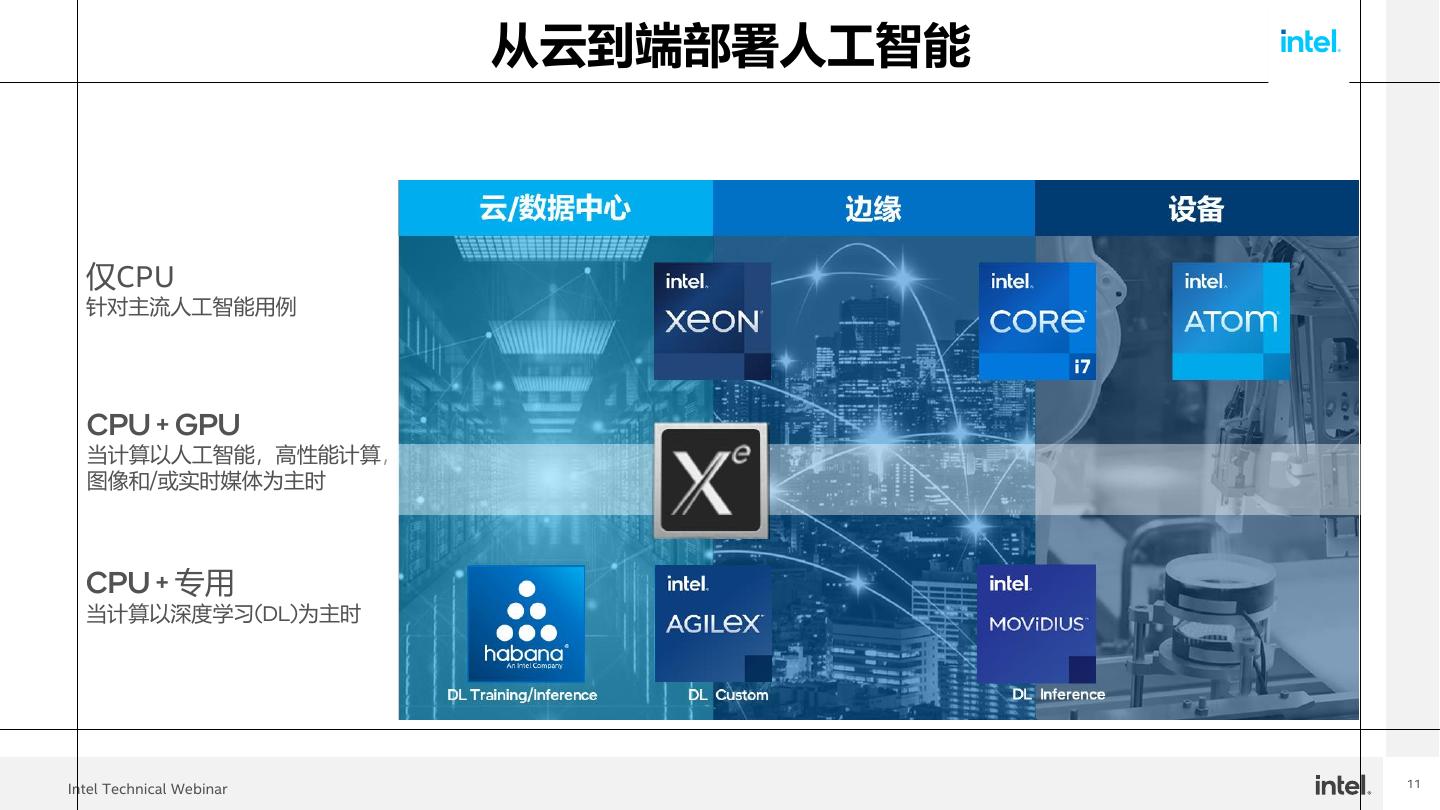
11 . 从云到端部署人工智能 仅CPU 针对主流人工智能用例 CPU + GPU 当计算以人工智能,高性能计算, 图像和/或实时媒体为主时 CPU + 专用 当计算以深度学习(DL)为主时 11 Intel Technical Webinar
12 . oneAPI CPU->XPU 拓展传统优势 • 充分挖掘硬件的价值 • 快速自信地开发高性能代码 • 基于行业标准和开放式规范 • 面向未来的编程模型提供了选择的 自由 software.intel.com/oneapi 12 Intel Technical Webinar
13 .AI Software Stack for Intel® XPUs Intel offers a robust software stack to maximize performance of diverse workloads E2E Workloads Model Zoo for Intel® Neural Open Model DL/ML Tools (Census, NYTaxi, Intel® Mortgage…) Compressor Zoo Architecture Scikit- pandas numpy Model learn DL/ML Optimizer numba xgboost TensorFlow PyTorch Middleware & Inference Frameworks Modin scipy daal4Py Engine DPC++ / Libraries & oneMKL oneDAL oneTBB oneCCL oneDNN oneVPL DPPY Compiler XPUs** VPU *OpenVINO® toolkit can use models trained with TF and Pytorch, default or Intel-optimized versions **VPU and GNA are supported only by OpenVINO 13 Intel Technical Webinar
14 .AI Software Stack for Intel XPUs Intel offers a Robust Software Stack to Maximize Performance of Diverse Workloads E2E Workloads Model Zoo for Intel® Neural Open Model DL/ML Tools (Census, NYTaxi, Intel® Mortgage…) IntelCompressor ® oneAPI Architecture Intel Zoo ® AI Analytics Toolkit OpenVINO ™ Toolkit Develop DL models in Frameworks, pandas ML &Scikit- numpy Analytics in Python learn Model Deploy DL DL/ML Optimizer numba xgboost TensorFlow PyTorch models Middleware & Inference Frameworks Modin scipy daal4Py Engine DPC++ / Intel® oneAPI Base Toolkit Libraries & oneMKL oneDAL oneTBB oneCCL oneDNN oneVPL DPPY Kernel Selection, Write, Customize Kernels Compiler Full Set of Intel oneAPI cross-architecture AI ML & DL Software Solutions 14 Intel Technical Webinar
15 .Intel® AI Analytics Toolkit Powered by oneAPI Intel® AI Analytics Toolkit Accelerate End-to-End Performance for Data Science DEEP Learning machine learning and AI Workloads Intel® Extension for Scikit- Intel® Optimization for learn (oneDAL) TensorFlow Who Uses It? Intel-optimized XGBoost Intel® Optimization for Data scientists, AI Researchers, Machine and Deep Learning PyTorch developers Model Zoo for Intel® Architecture Data Analytics Top Features/Benefits Intel® Distribution of Modin Intel® Neural Deep learning performance for training and inference with Compressor Intel® Distribution for Python Intel optimized DL frameworks, pretrained models and low- precision tools Drop-in acceleration for machine learning and analytics Core Python workflows with compute-intensive Python libraries Intel-Opt Intel-Opt Intel-Opt Intel-Opt 15 DPPY Seamless scaling of data pipelines across multi-cores, multi- NumPy SciPy Numba Pandas nodes to optimize end-to-end solutions with cross- architecture support (Intel CPUs, GPUs) Choose the best accelerated technology – the software doesn’t decide for you Learn More: intel.com/oneAPI-AIKit 15 Intel Technical Webinar
16 .开始学习Intel® oneAPI AI Analytics Toolkit Overview Installation Hands on Learning Support ▪ Visit Intel® oneAPI AI ▪ Download the AI Kit ▪ Code Samples ▪ Machine Learning & ▪ Ask questions and Analytics Toolkit (AI from Intel, Anaconda Analytics Blogs share information with ▪ Build, test and Kit) for more details or any of your favorite others through the remotely run ▪ Intel AI Blog site and up-to-date package managers Community Forum workloads on the product information ▪ Webinars & articles ▪ Get started quickly Intel® DevCloud for ▪ Discuss with experts at ▪ Release Notes with the AI Kit Docker free. No software AI Frameworks Forum Container downloads. No configuration steps. ▪ Installation Guide No installations. ▪ Utilize the Getting Started Guide Download Now 16 Intel Technical Webinar
17 .Agenda • Intel® Deep Learning Boost • Intel® oneAPI AI Analytics Toolkit • Intel® Optimization for TensorFlow* • Intel® Neural Compressor • Demo
18 .Intel®Optimizations for TensorFlow* 1. Operator optimizations: Replace default (Eigen) kernels by highly- optimized kernels (using Intel® oneDNN) 2. Graph optimizations: Fusion, batch normalization 3. System optimizations: Threading model 18 18 Intel Technical Webinar
19 .Intel®oneAPI Deep Neural Network Library (oneDNN) An open-source cross-platform performance library for deep learning applications • Includes optimized versions of key deep learning functions • Abstracts out instruction set and other complexities of performance optimizations • Same API for both Intel CPUs and GPUs, use the best technology for the job • Supports Linux, Windows and macOS • Open source for community contributions More information as well as sources: https://github.com/oneapi-src/oneDNN 19 Intel Technical Webinar
20 .Intel® oneDNN overview Feature: Intel® oneDNN Convolution 2D/3D Direct Convolution/Deconvolution, Depthwise ▪ Highly vectorized and threaded building blocks separable convolution 2D Winograd convolution ▪ Performance critical functions Inner Product 2D/3D Inner Production ▪ Training (float32, bfloat16) and inference (float32, Pooling 2D/3D Maximum int8) 2D/3D Average (include/exclude padding) ▪ CNNs (1D, 2D and 3D), RNNs (plain, LSTM, GRU) Normalization 2D/3D LRN across/within channel, 2D/3D Batch normalization Portability: Eltwise (Loss/activation) ReLU(bounded/soft), ELU, Tanh; Softmax, Logistic, linear; square, sqrt, abs, exp, gelu, swish ▪ Compilers: Intel C++ compiler/Clang/GCC/MSVC* Data manipulation Reorder, sum, concat, View ▪ OS: Linux*, Windows*, Mac* RNN cell RNN cell, LSTM cell, GRU cell ▪ Threading: OpenMP*, TBB Fused primitive Conv+ReLU+sum, BatchNorm+ReLU Data type f32, bfloat16, s8, u8 20 Intel Technical Webinar
21 .Tensorflow优化:Operator optimizations ▪ Replace default (Eigen) kernels by Forward Backward highly-optimized kernels (using Conv2D Conv2DGrad Intel® oneDNN) Relu, TanH, ELU ReLUGrad, TanHGrad, ▪ Intel® oneDNN has optimized a set of ELUGrad TensorFlow operations. MaxPooling MaxPoolingGrad AvgPooling AvgPoolingGrad ▪ Library is open-source (https://github.com/oneapi- BatchNorm BatchNormGrad src/oneDNN) and downloaded LRN LRNGrad automatically when building MatMul, Concat TensorFlow. 21 Intel Technical Webinar
22 . $ python tf_cnn_benchmarks.py --device=cpu --mkl=True --data_format=NHWC \ --kmp_affinity=‘granularity=fine,noverbose,compact,1,0’ --kmp_blocktime=1 \ --kmp_settings=1 --num_warmup_batches=20 --batch_size=256 --num_batches=50 \ --model=resnet50 --num_intra_threads=56 --num_inter_threads=2 --forward_only=false \ --trace_file='tf_timeline_training_benchmark_latest.json' 22 Intel Technical Webinar
23 .Tensorflow优化:Graph optimizations: fusion Input Filter Input Filter Bias Conv2D Bias Conv2DWithBias BiasAdd Before Merge After Merge 23 23 Intel Technical Webinar
24 .Tensorflow优化:System optimizations: load balancing ▪ TensorFlow* graphs offer opportunities for parallel execution. ▪ Threading model, Tune your Intel® oneDNN 1. intra_op_parallelism_threads • max number of threads to use for executing an operator config = tf.ConfigProto() config.intra_op_parallelism_threads = 56 • This should be set to the number of physical cores config.inter_op_parallelism_threads = 2 2. inter_op_parallelism_threads tf.Session(config=config) • max number of operators that can be executed in parallel • A good guideline we have found empirically is to set this to 2 3. OMP_NUM_THREADS • oneDNN equivalent of intra_op_parallelism_threads • the maximum number of threads available for the OpenMP runtime. A good guideline is to set it equal to the number of physical cores 4. KMP_AFFINITY - usage: [<modifier>,...]<type>[,<permute>][,<offset>] os.environ[“KMP_AFFINITY”] = “granularity=fine,compact,1,0” os.environ[“KMP_BLOCKTIME”] = “1” 5. KMP_BLOCKTIME, KMP_SETTINGS os.environ[“KMP_SETTINGS”] = “0” ▪ More details: os.environ[“OMP_NUM_THREADS”] = “56” • https://github.com/IntelAI/models • https://software.intel.com/en-us/articles/maximize-tensorflow-performance-on-cpu-considerations-and-recommendations-for-inference 24 Intel Technical Webinar
25 .安装Intel Optimization for Tensorflow ▪ Intel Optimization for Tensorflow is included in Intel® AI Analytics Toolkite. If you have AI Analytics toolkit, Intel-Tensorflow conda environment can be activated. ▪ Install via Pip: pip install intel-tensorflow==2.8.0 ▪ For Stock-tensorflow: pip install tensorflow==2.8.0 Need to enable oneDNN using: export TF_ENABLE_ONEDNN_OPTS=1 ▪ With Conda: conda install tensorflow -c intel 25 Intel Technical Webinar
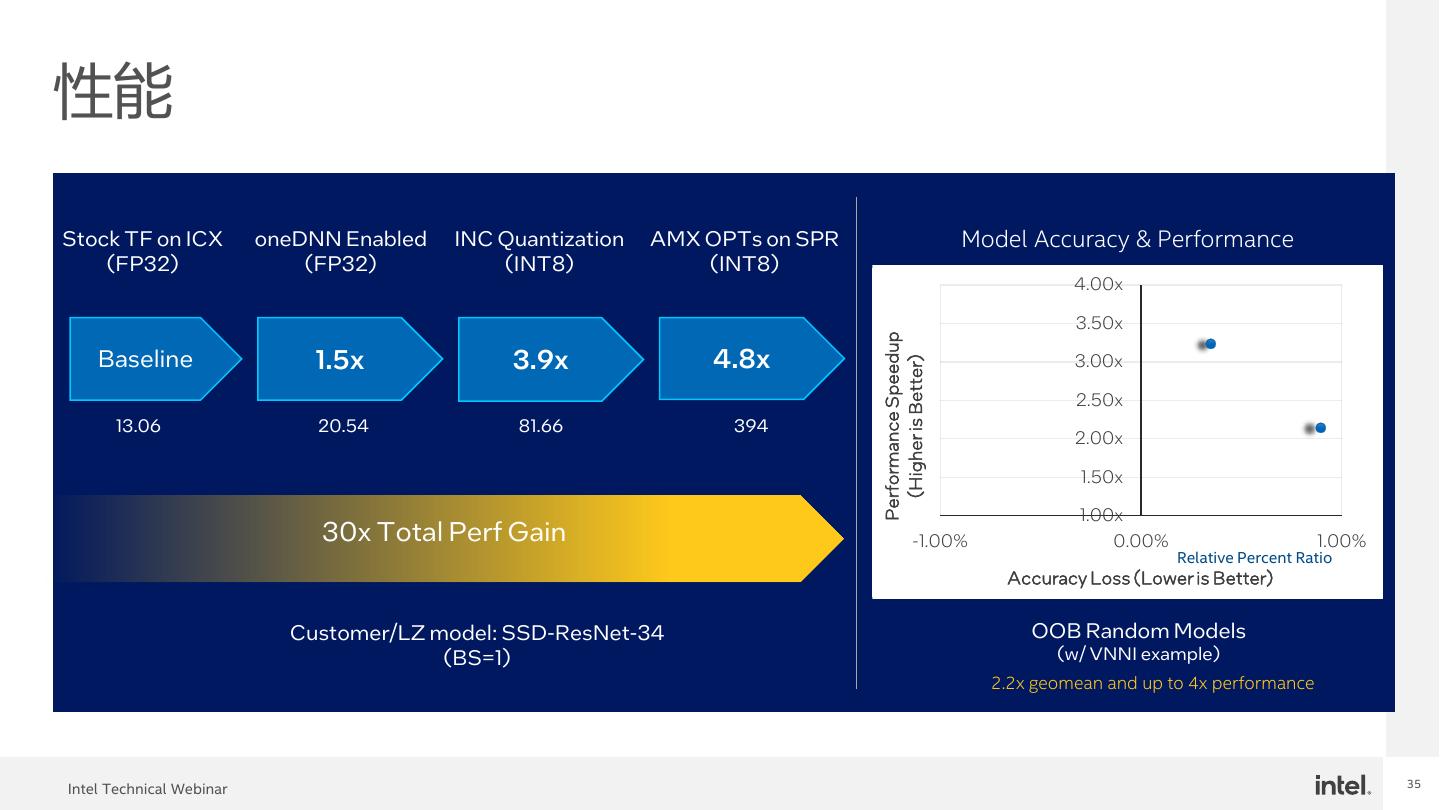
26 . 30x AI 性能提升,基于优化软件和 下一代至强处理器 one Intel® Next-Gen Intel® DNN Neural Xeon® Compressor Scalable Processor 13.06 20.54 81.66 394 Baseline 1.5x 3.9x 4.8x (FP32) (FP32) (int8) (int8) Official TensorFlow on 3rd Gen TensorFlow with Model quantization with Intel® AMX optimization Intel® Xeon® Scalable Processor oneDNN enabled Intel® Neural compressor on Sapphire Rapids 3rd Gen Intel® Xeon™ Scalable Processors Next-Gen Xeon SSD-ResNet-34 Inference Throughput (Batch Size =1) Results may vary. See www.intel.com/InnovationEventClaims for workloads and configurations. For workloads and configurations visit www.intel.com/InnovationEventClaims. Results may vary. 26 Intel Technical Webinar
27 .Agenda • Intel® Deep Learning Boost • Intel® oneAPI AI Analytics Toolkit • Intel® Optimization for TensorFlow* • Intel® Neural Compressor • Demo
28 .量化的挑战和解决方案 Matrix MulAdd C += A x B Vector Neural Network Instructions (VNNI) Vector: 64*INT8 3x AVX512 Intel® Deep AVX512_BF16 Vector: 32*BF16 Learning Boost Hardware Matrix: Intel® Advanced Matrix Extension (AMX) (16x64)*INT8 8x VNNI (16x32)*BF16 Simple python API + YAML Complex Intel® Neural Compressor Automatic accuracy-driven tuning strategies Accuracy Intel Technical Webinar 28
29 .深度学习推理优化方法 Quantization Knowledge Distillation FP32 FP32 FP32 INT8 INT8 INT8 FP32 FP32 INT8 INT8 Mix Precision Graphic Optimization FP32 FP32 FP32 INT8 INT8 INT8 FP32 FP32 BF16 BF16 Graphic Optimization Conv2D Pruning Conv2D BatchNorm BatchNorm Relu Relu Intel Technical Webinar 29
3秒后跳转登录页面
去登陆

