

















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
并行处理-SIMD
本章节主要介绍了并行处理的相关知识,并行性的方法包括了SISD, SIMD, MIMD等等,就SIMD做了主要介绍一条指令同时作用于多个操作数,通过例子说明:矩阵乘法->浮点重->摩尔定律,介绍了amdahl定律。
展开查看详情
1 .CS 61C: Great Ideas in Computer Architecture Lecture 18: Parallel Processing – SIMD Krste Asanović & Randy Katz http:// inst.eecs.berkeley.edu /~cs61c
2 .61C Survey It would be nice to have a review lecture every once in a while, actually showing us how things fit in the bigger picture CS 61c Lecture 18: Parallel Processing - SIMD 2
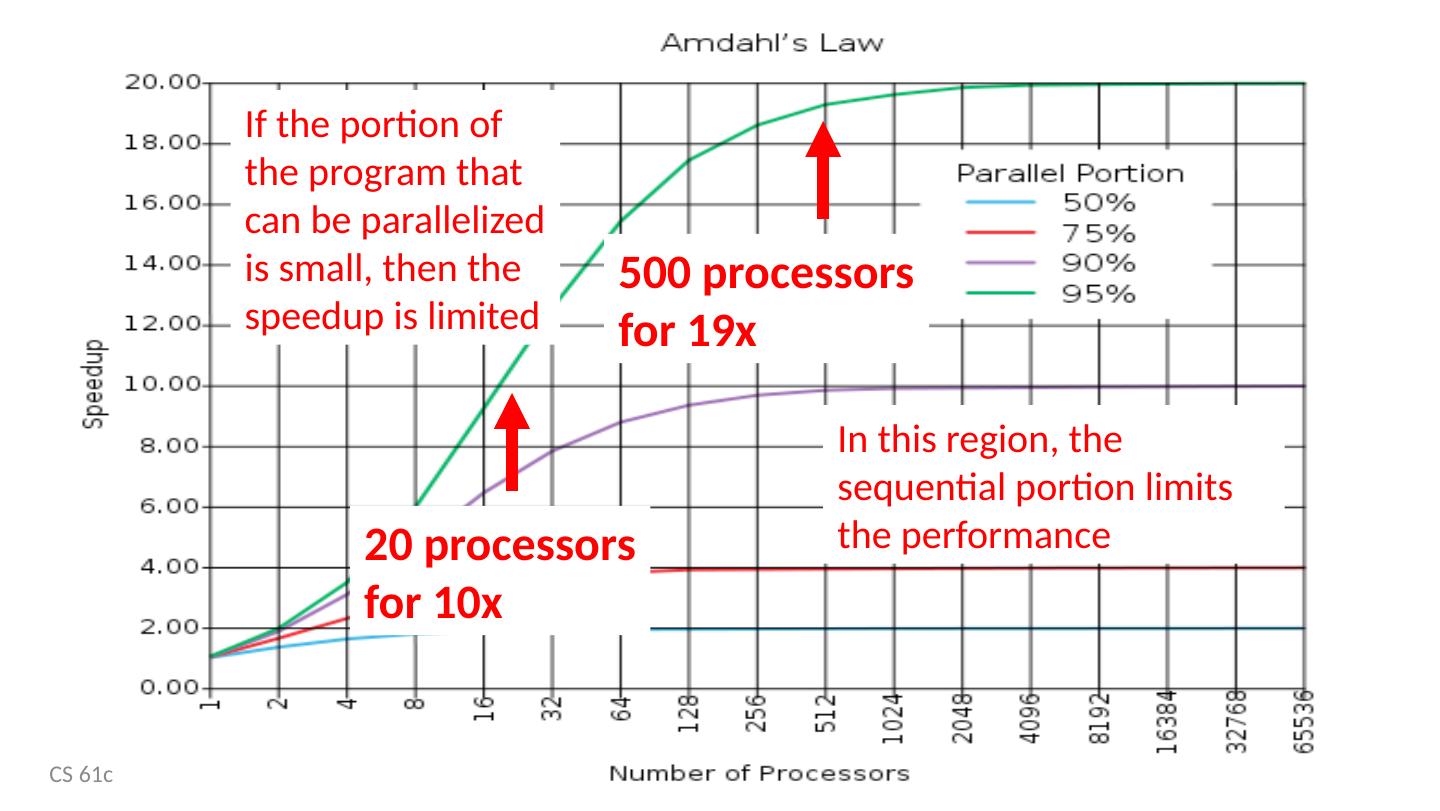
3 .Agenda 61C – the big picture Parallel processing Single instruction, multiple data SIMD matrix multiplication Amdahl’s law Loop unrolling Memory access strategy - blocking And in Conclusion, … CS 61c Lecture 18: Parallel Processing - SIMD 3
4 .61C Topics so far … What we learned: Binary numbers C Pointers Assembly language Datapath architecture Pipelining Caches Performance evaluation Floating point What does this buy us? Promise: execution speed Let’s check! CS 61c Lecture 18: Parallel Processing - SIMD 4
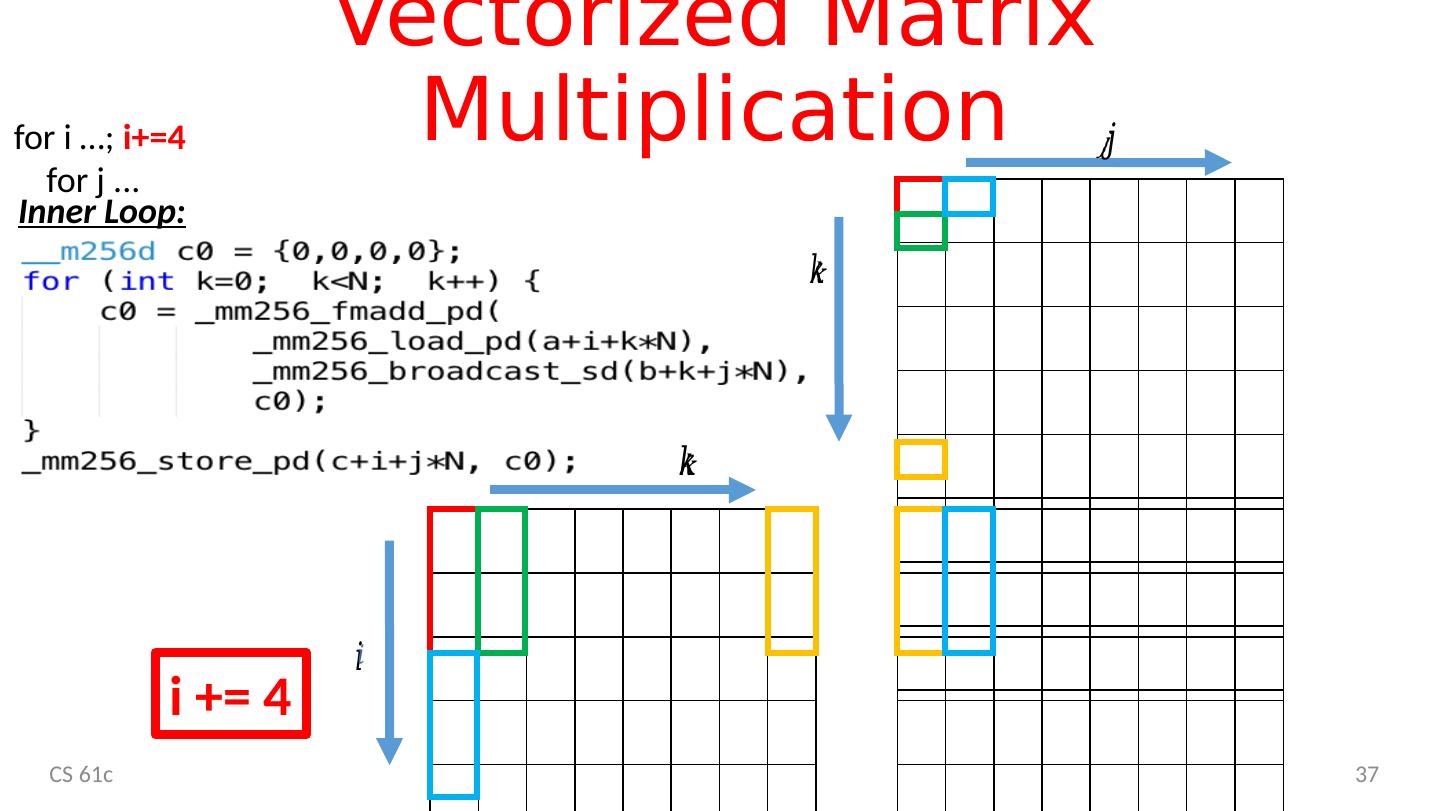
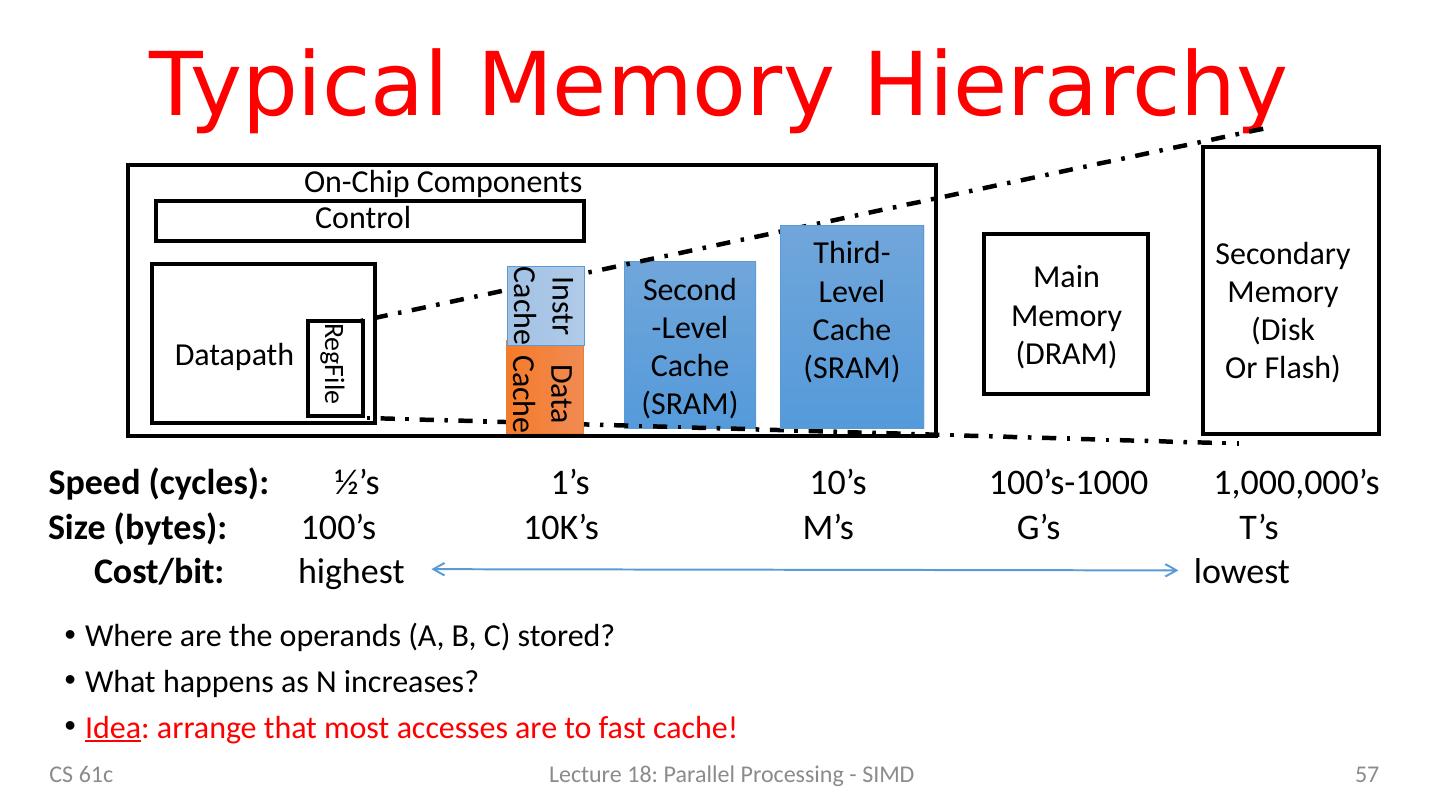
5 .Reference Problem Matrix multiplication Basic operation in many engineering, data, and imaging processing tasks Image filtering, noise reduction, … Many closely related operations E.g. stereo vision (project 4) dgemm double-precision floating-point matrix multiplication CS 61c Lecture 18: Parallel Processing - SIMD 5
6 .Application Example: Deep Learning Image classification (cats …) Pick “best” vacation photos Machine translation Clean up accent Fingerprint verification Automatic game playing CS 61c Lecture 18: Parallel Processing - SIMD 6
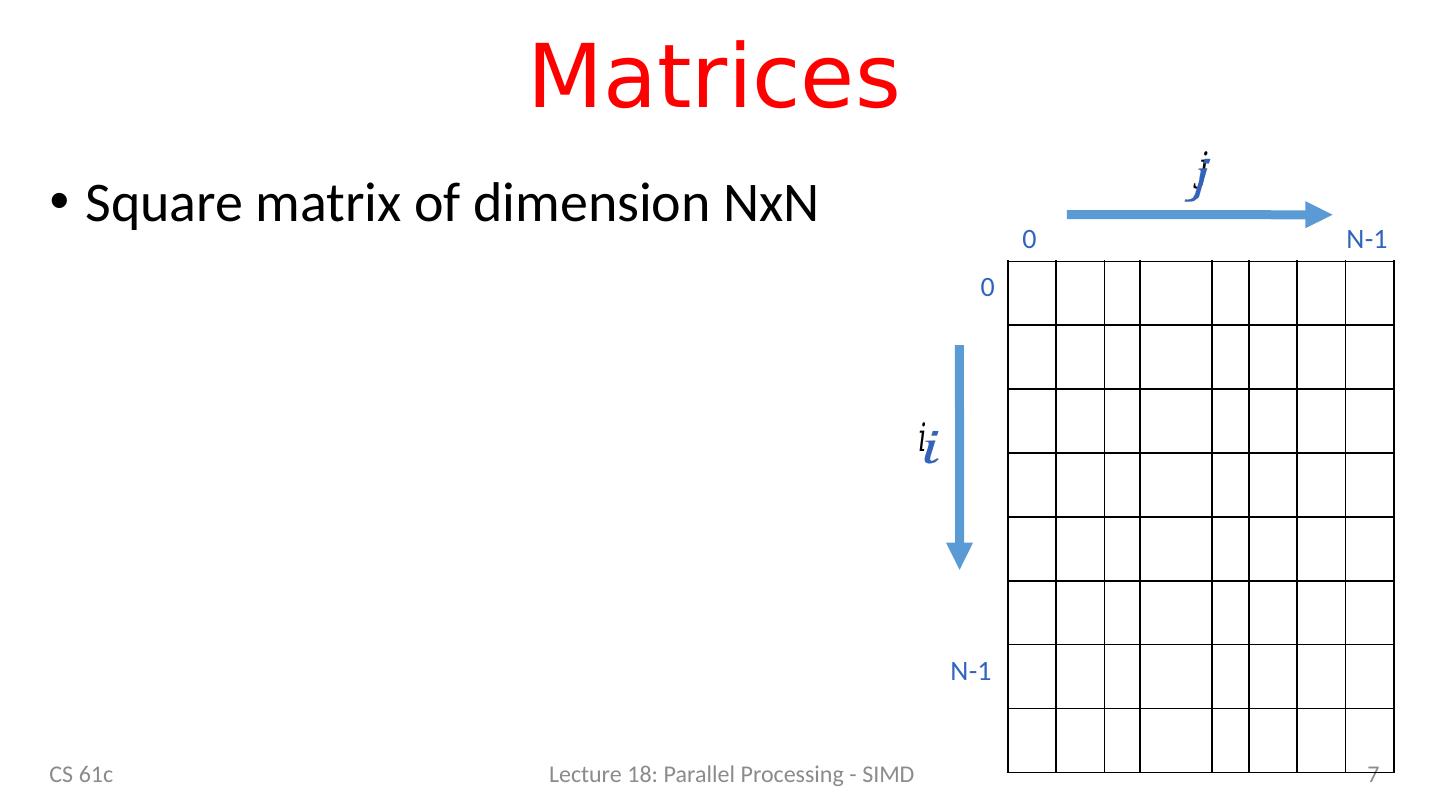
7 .Matrices CS 61c Lecture 18: Parallel Processing - SIMD 7 N-1 N-1 0 0 Square matrix of dimension NxN
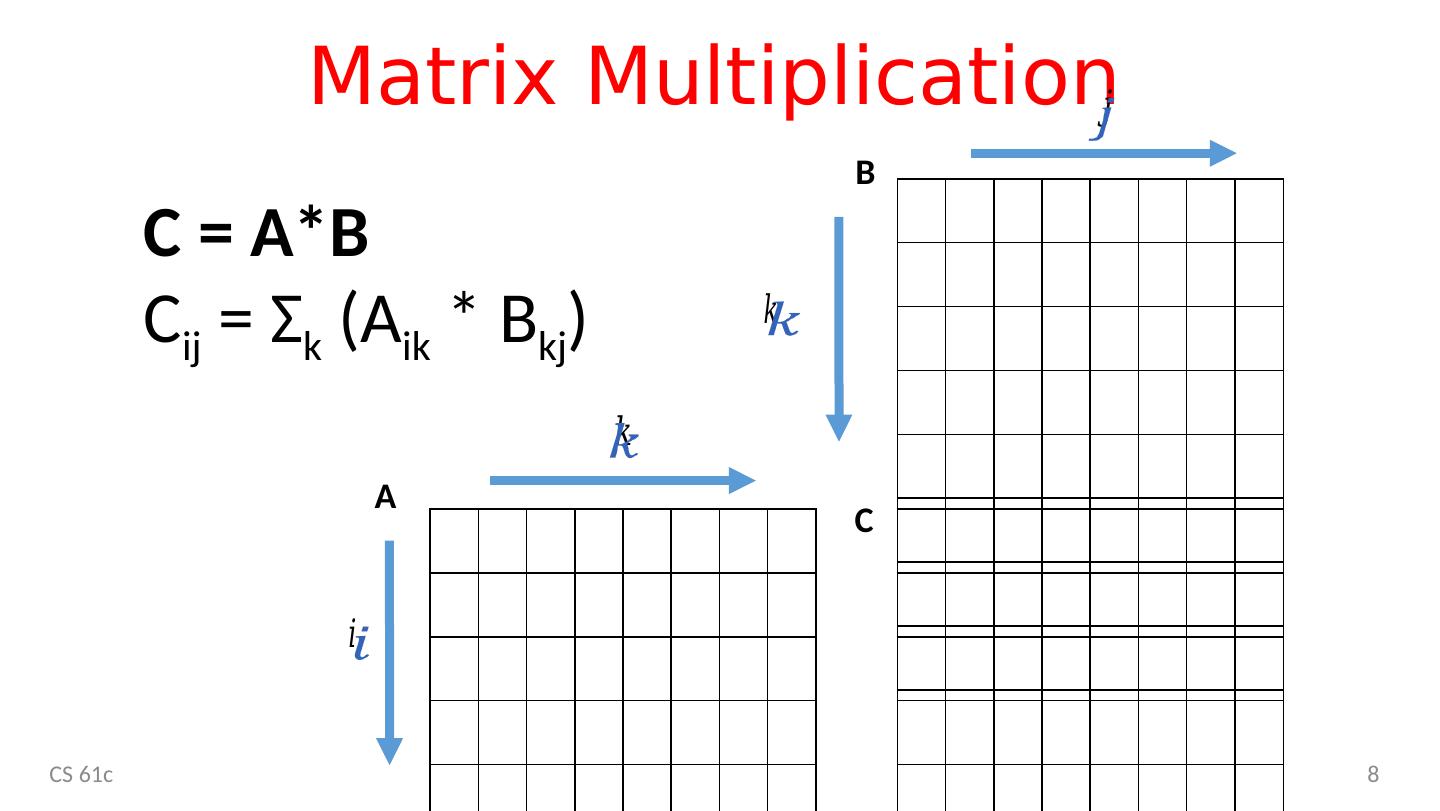
8 .Matrix Multiplication CS 61c 8 C = A*B C ij = Σ k ( A ik * B kj ) A B C
9 .Reference: Python Matrix multiplication in Python CS 61c Lecture 18: Parallel Processing - SIMD 9 N Python [ Mflops ] 32 5.4 160 5.5 480 5.4 960 5.3 1 MFLOP = 1 Million floating-point operations per second ( fadd , fmul ) dgemm (N …) takes 2*N 3 flops
10 .C c = a * b a, b, c are N x N matrices CS 61c Lecture 18: Parallel Processing - SIMD 10
11 .Timing Program Execution CS 61c Lecture 18: Parallel Processing - SIMD 11
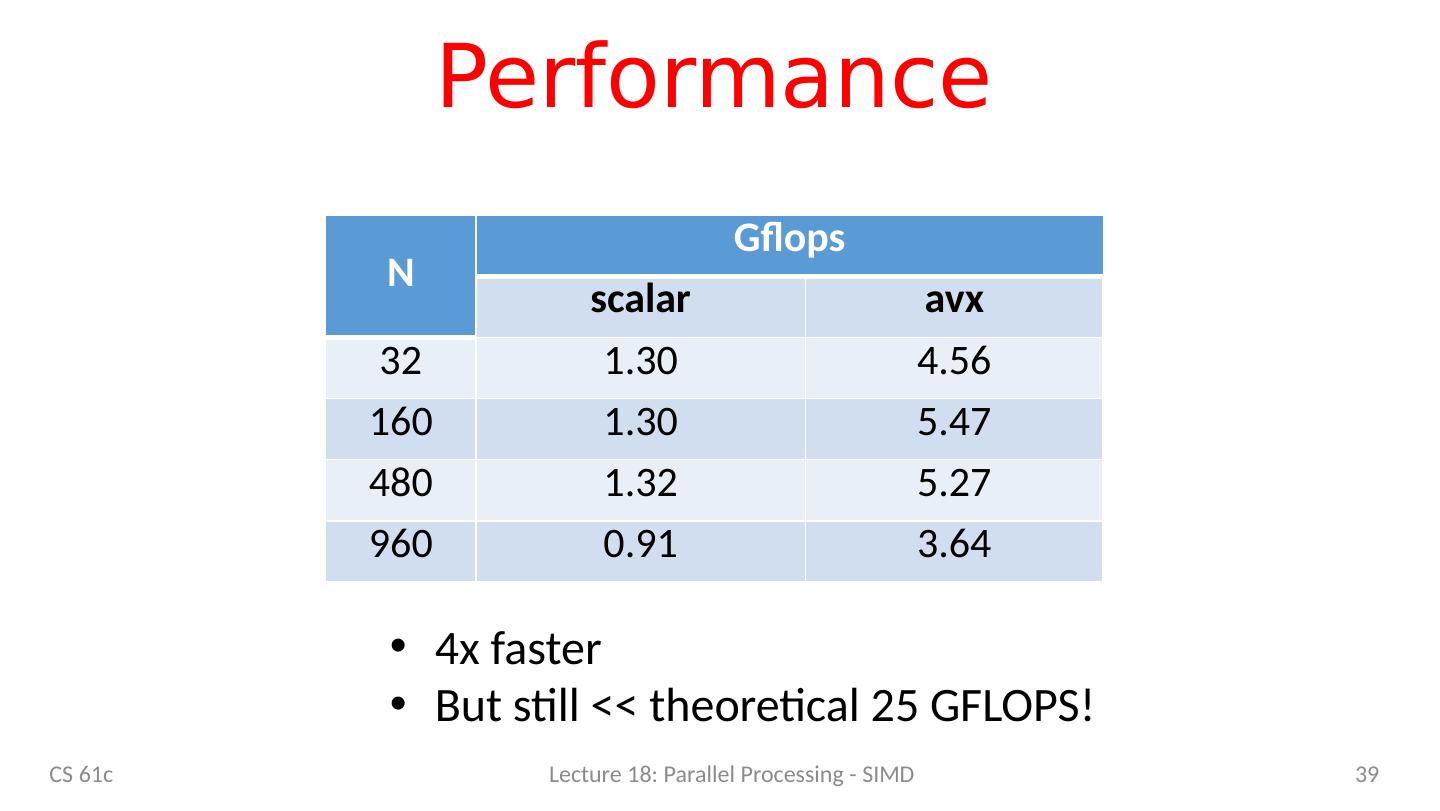
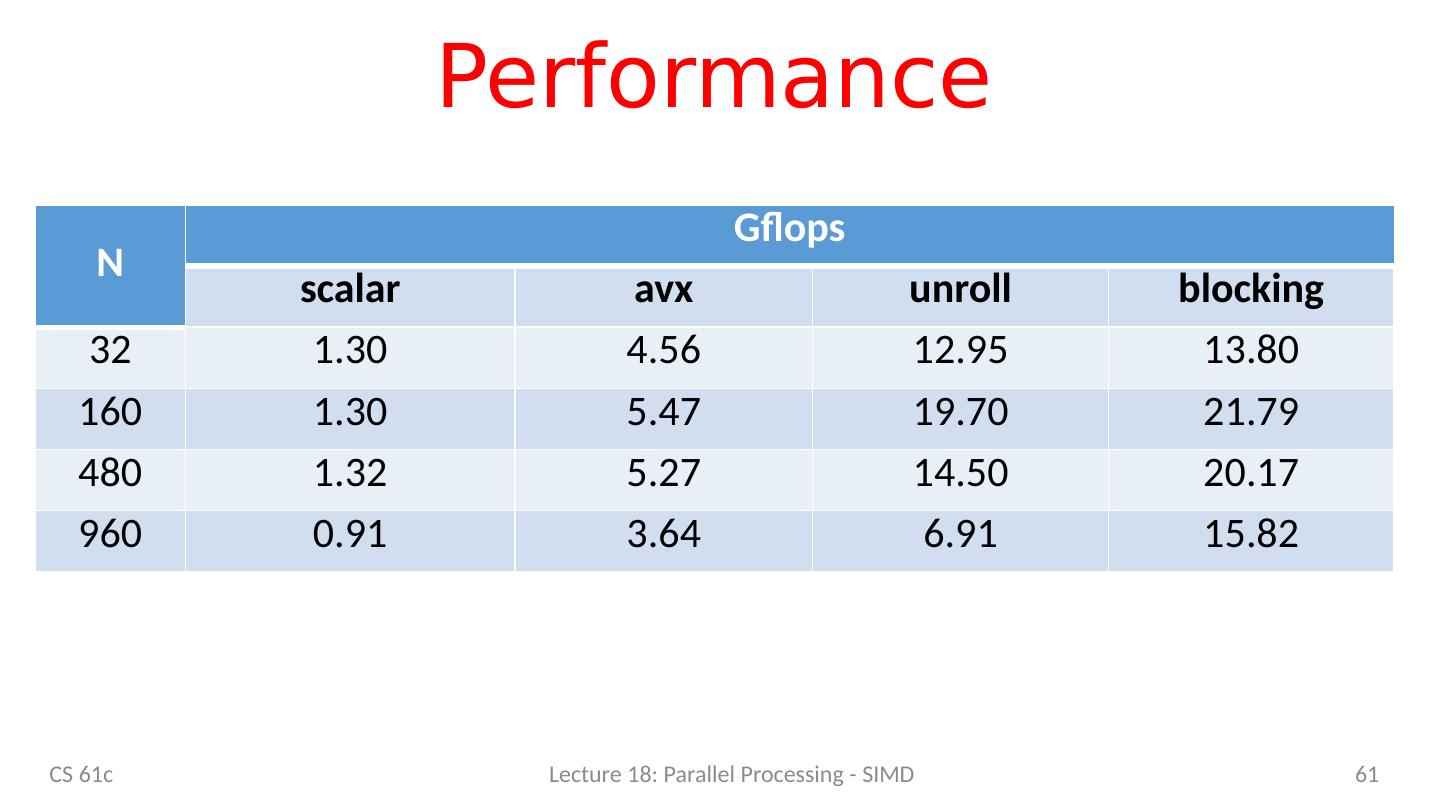
12 .C versus Python CS 61c Lecture 18: Parallel Processing - SIMD 12 N C [ G FLOPS] Python [GFLOPS] 32 1.30 0.0054 160 1.30 0.0055 480 1.32 0.0054 960 0.91 0.0053 Which class gives you this kind of power? We could stop here … but why? Let’s do better! 240x!
13 .Agenda 61C – the big picture Parallel processing Single instruction, multiple data SIMD matrix multiplication Amdahl’s law Loop unrolling Memory access strategy - blocking And in Conclusion, … CS 61c Lecture 18: Parallel Processing - SIMD 13
14 .Why Parallel Processing? CPU Clock Rates are no longer increasing Technical & economic challenges Advanced cooling technology too expensive or impractical for most applications Energy costs are prohibitive Parallel processing is only path to higher speed Compare airlines: Maximum speed limited by speed of sound and economics Use more and larger airplanes to increase throughput And smaller seats … CS 61c Lecture 18: Parallel Processing - SIMD 14
15 .Using Parallelism for Performance Two basic ways: Multiprogramming run multiple independent programs in parallel “Easy” Parallel computing run one program faster “Hard” We’ll focus on parallel computing in the next few lectures 15 CS 61c Lecture 18: Parallel Processing - SIMD
16 .New-School Machine Structures (It’s a bit more complicated!) Parallel Requests Assigned to computer e.g., Search “Katz” Parallel Threads Assigned to core e.g., Lookup, Ads Parallel Instructions >1 instruction @ one time e.g., 5 pipelined instructions Parallel Data >1 data item @ one time e.g., Add of 4 pairs of words Hardware descriptions All gates @ one time Programming Languages 16 Smart Phone Warehouse Scale Computer Software Hardware Harness Parallelism & Achieve High Performance Logic Gates Core Core … Memory (Cache) Input/Output Computer Cache Memory Core Instruction Unit(s ) Functional Unit(s ) A 3 +B 3 A 2 +B 2 A 1 +B 1 A 0 +B 0 Today’s Lecture
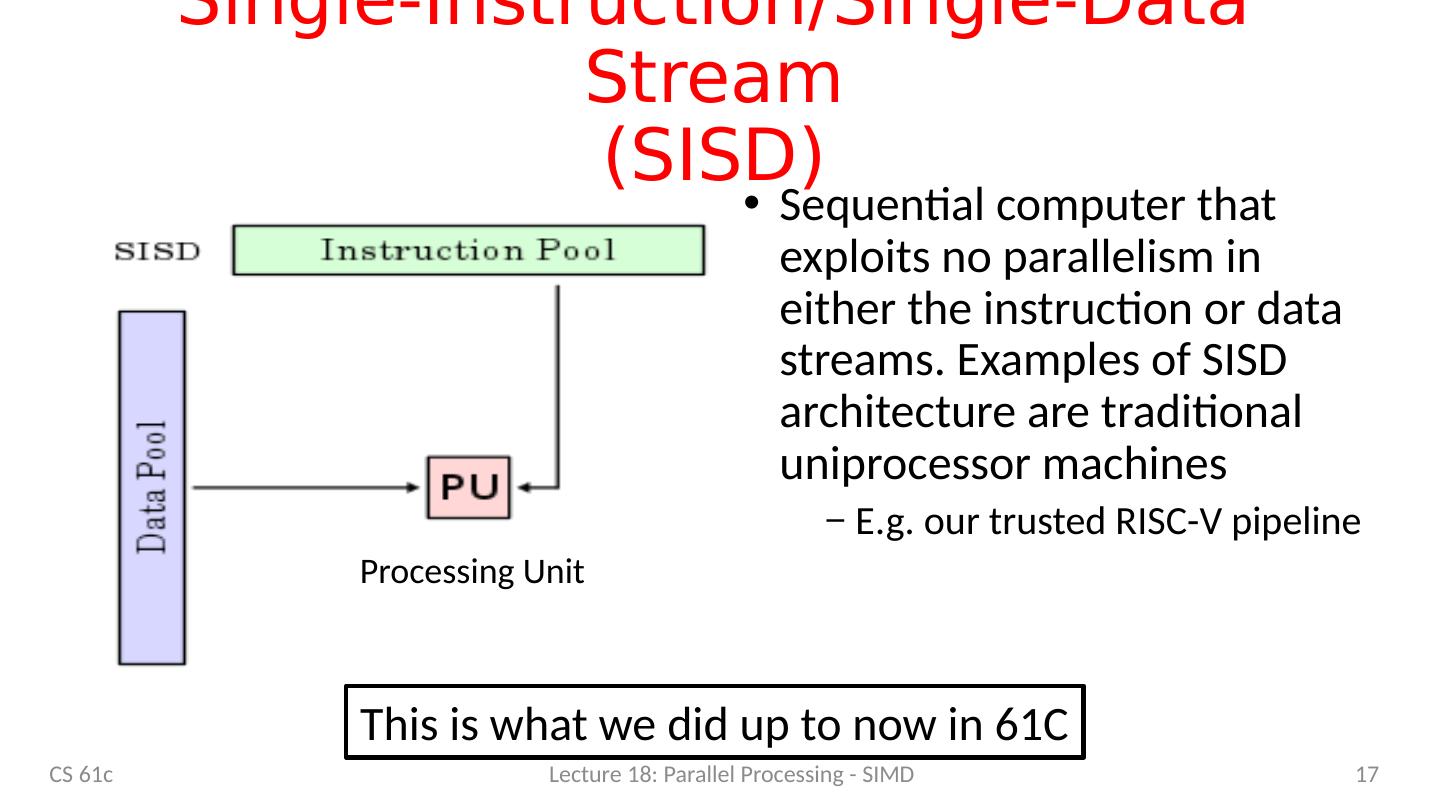
17 .Single-Instruction/Single-Data Stream (SISD) Sequential computer that exploits no parallelism in either the instruction or data streams. Examples of SISD architecture are traditional uniprocessor machines E.g. our trusted RISC-V pipeline 17 Processing Unit CS 61c Lecture 18: Parallel Processing - SIMD This is what we did up to now in 61C
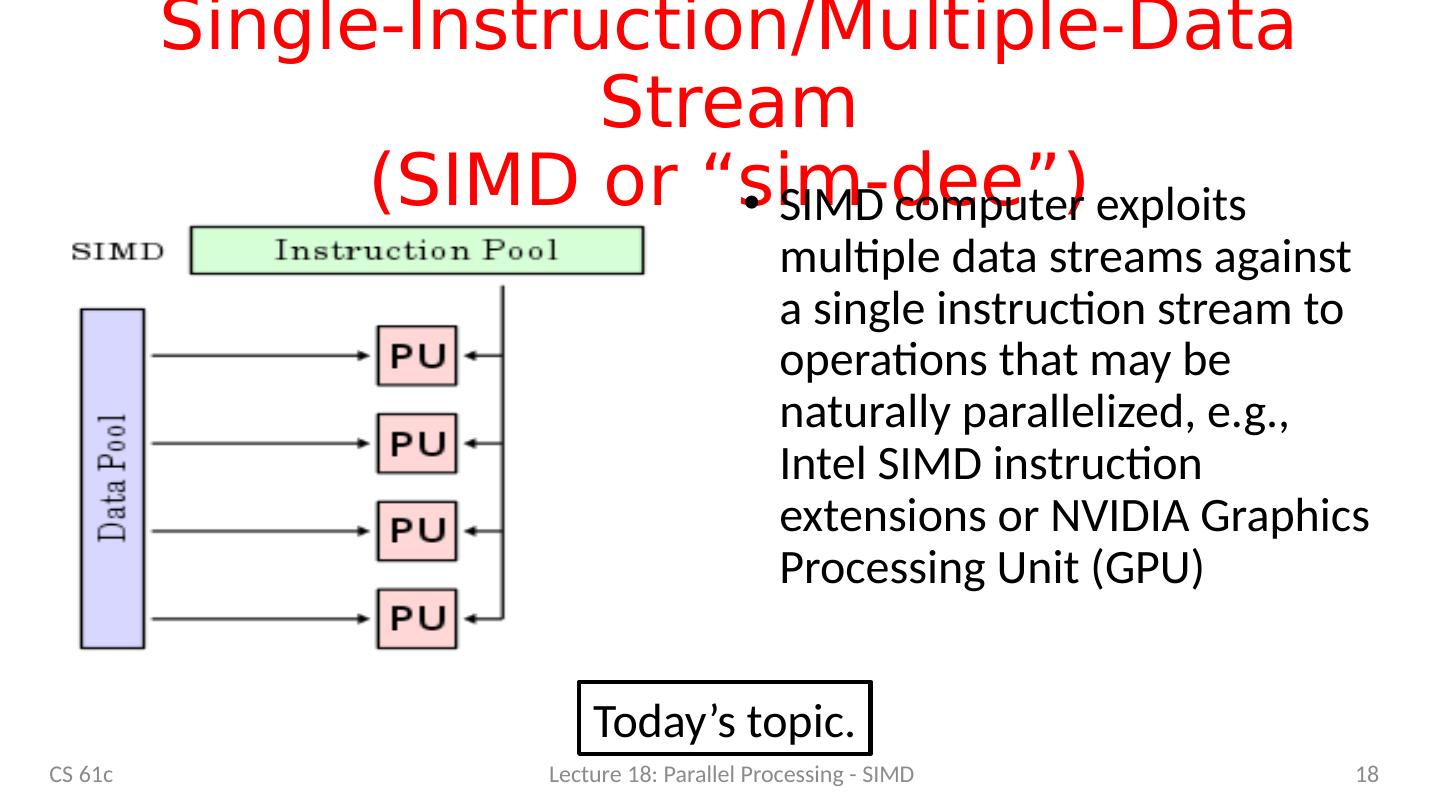
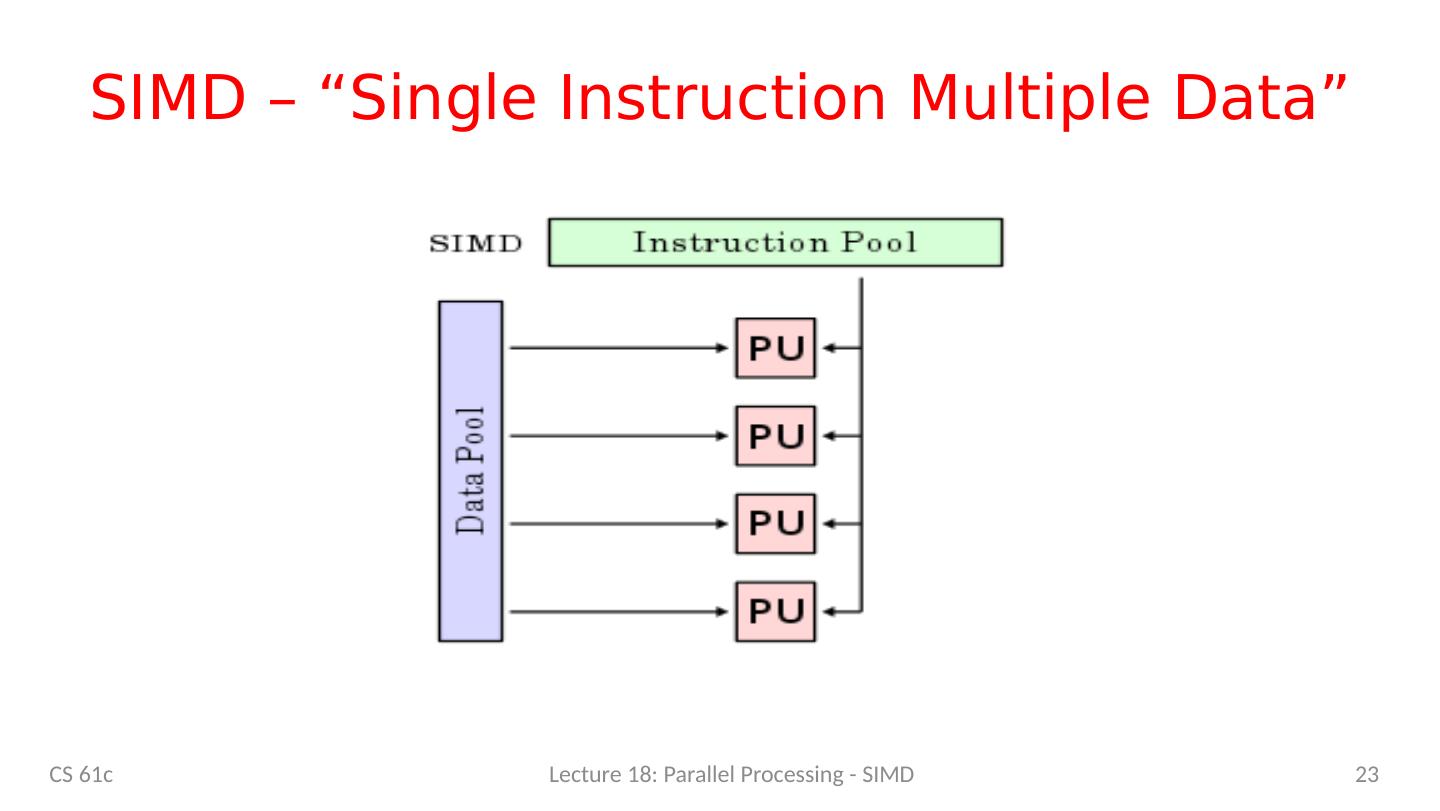
18 .Single-Instruction/Multiple-Data Stream (SIMD or “ sim-dee ” ) SIMD computer exploits multiple data streams against a single instruction stream to operations that may be naturally parallelized, e.g., Intel SIMD instruction extensions or NVIDIA Graphics Processing Unit (GPU) 18 CS 61c Lecture 18: Parallel Processing - SIMD Today’s topic.
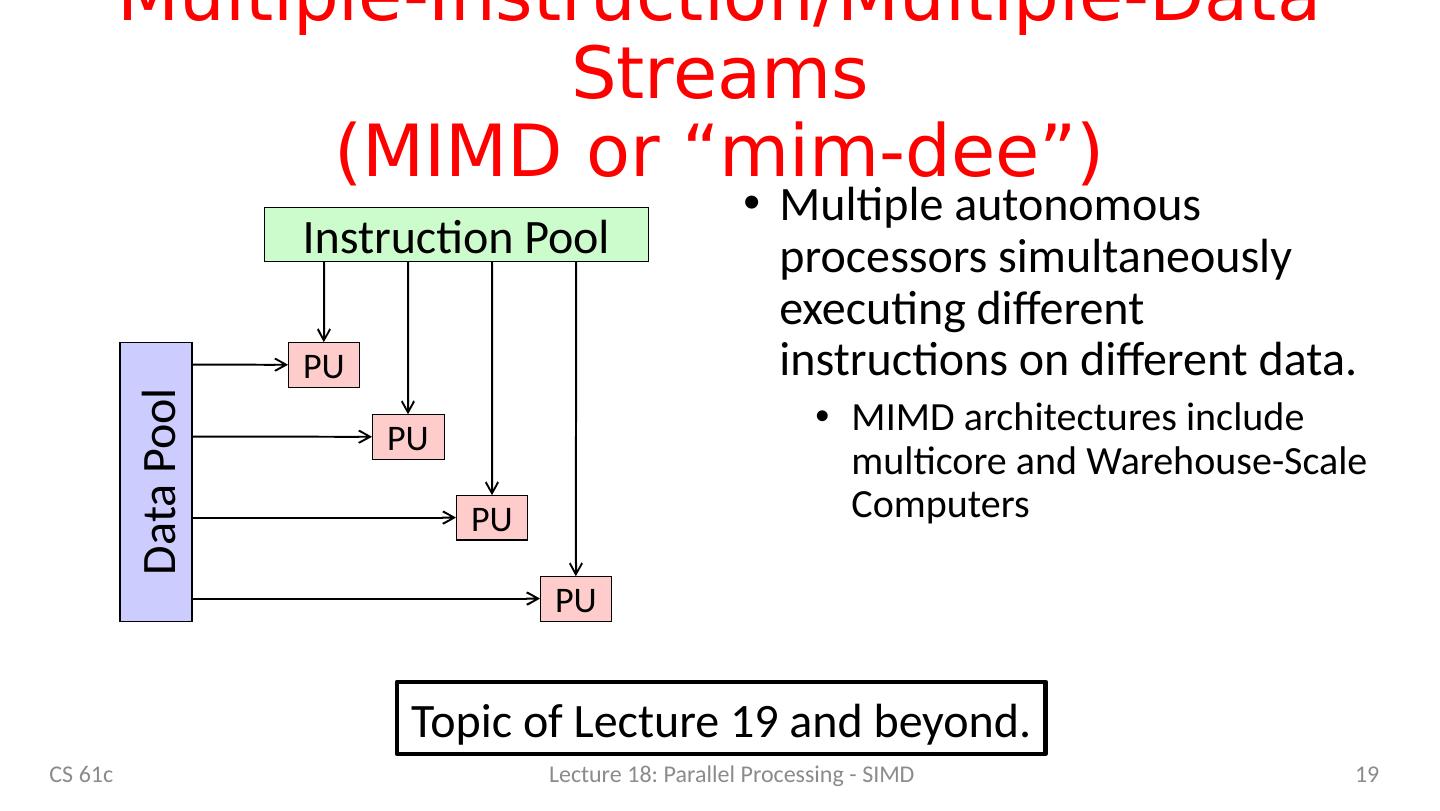
19 .Multiple-Instruction/Multiple-Data Streams (MIMD or “ mim-dee ”) Multiple autonomous processors simultaneously executing different instructions on different data. MIMD architectures include multicore and Warehouse-Scale Computers 19 Instruction Pool PU PU PU PU Data Pool CS 61c Lecture 18: Parallel Processing - SIMD Topic of Lecture 19 and beyond.
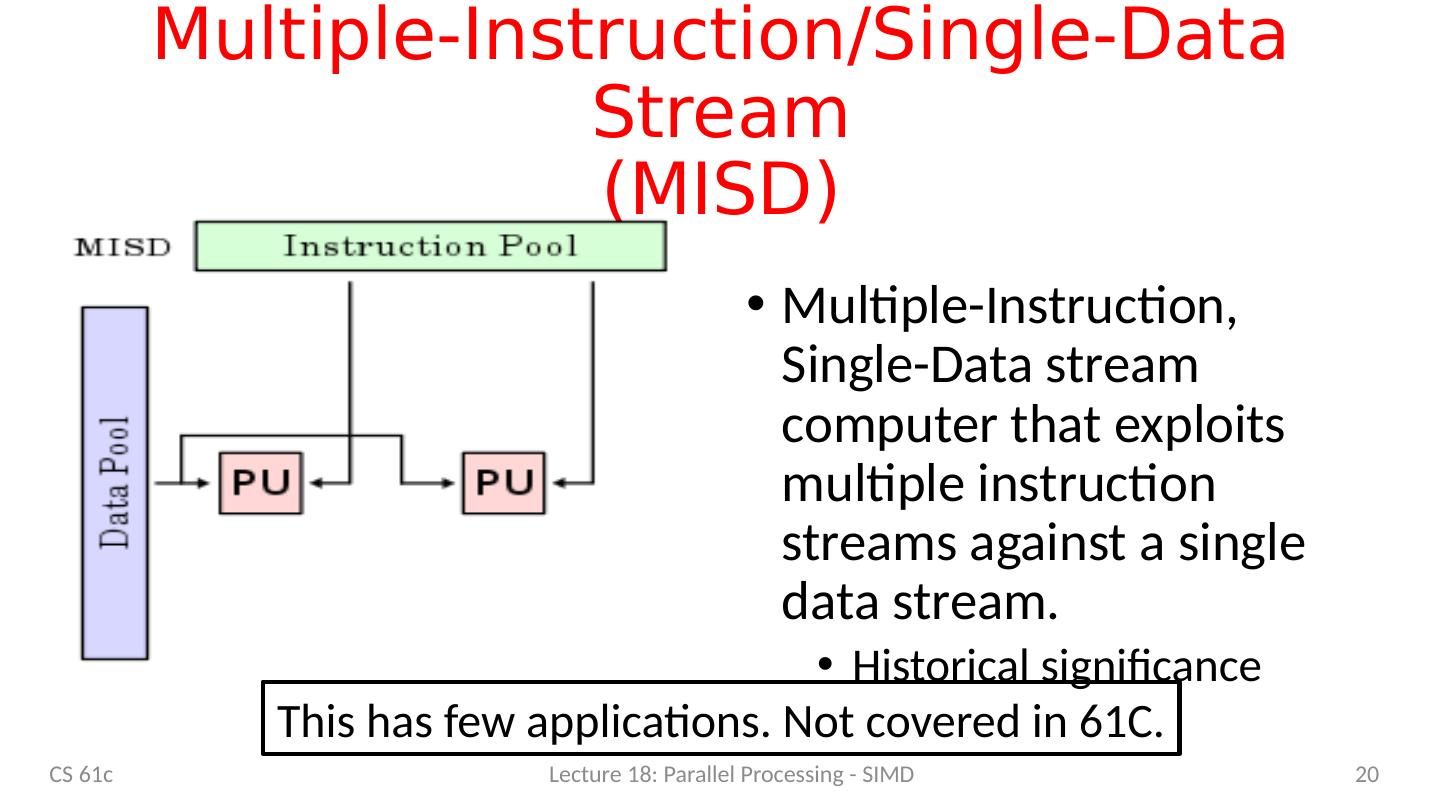
20 .Multiple-Instruction/Single-Data Stream (MISD ) Multiple-Instruction, Single-Data stream computer that exploits multiple instruction streams against a single data stream. Historical significance 20 CS 61c Lecture 18: Parallel Processing - SIMD This has few applications. Not covered in 61C.
21 .Flynn* Taxonomy, 1966 SIMD and MIMD are currently the most common parallelism in architectures – usually both in same system! Most common parallel processing programming style: Single Program Multiple Data (“SPMD”) Single program that runs on all processors of a MIMD Cross-processor execution coordination using synchronization primitives 21 CS 61c Lecture 18: Parallel Processing - SIMD
22 .Agenda 61C – the big picture Parallel processing Single instruction, multiple data SIMD matrix multiplication Amdahl’s law Loop unrolling Memory access strategy - blocking And in Conclusion, … CS 61c Lecture 18: Parallel Processing - SIMD 22
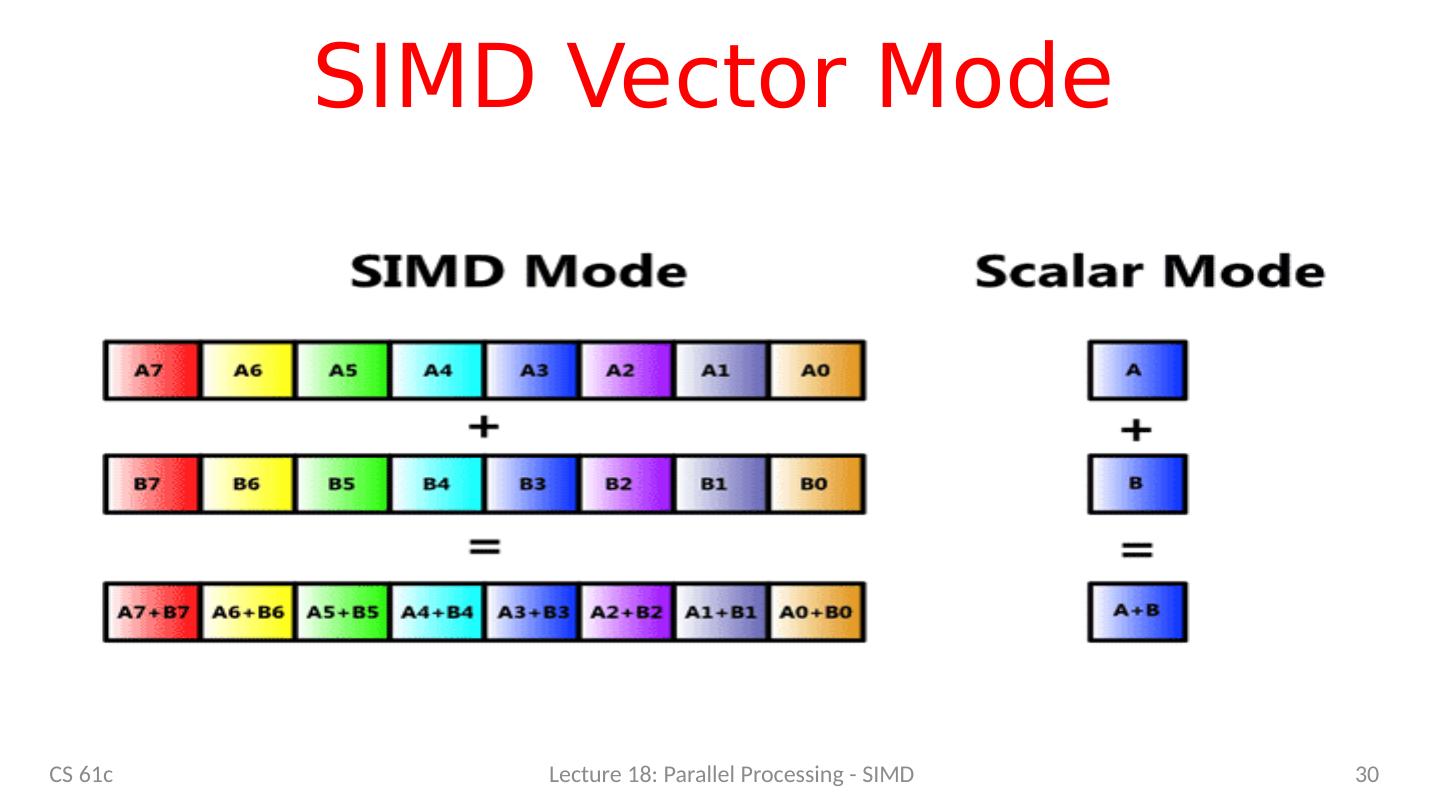
23 .SIMD – “Single Instruction Multiple Data” 23 CS 61c Lecture 18: Parallel Processing - SIMD
24 .SIMD Applications & Implementations Applications Scientific computing Matlab , NumPy Graphics and video processing Photoshop, … Big Data Deep learning Gaming … Implementations x86 ARM RISC-V vector extensions CS 61c Lecture 18: Parallel Processing - SIMD 24
25 .25 First SIMD Extensions: MIT Lincoln Labs TX-2, 1957 CS 61c
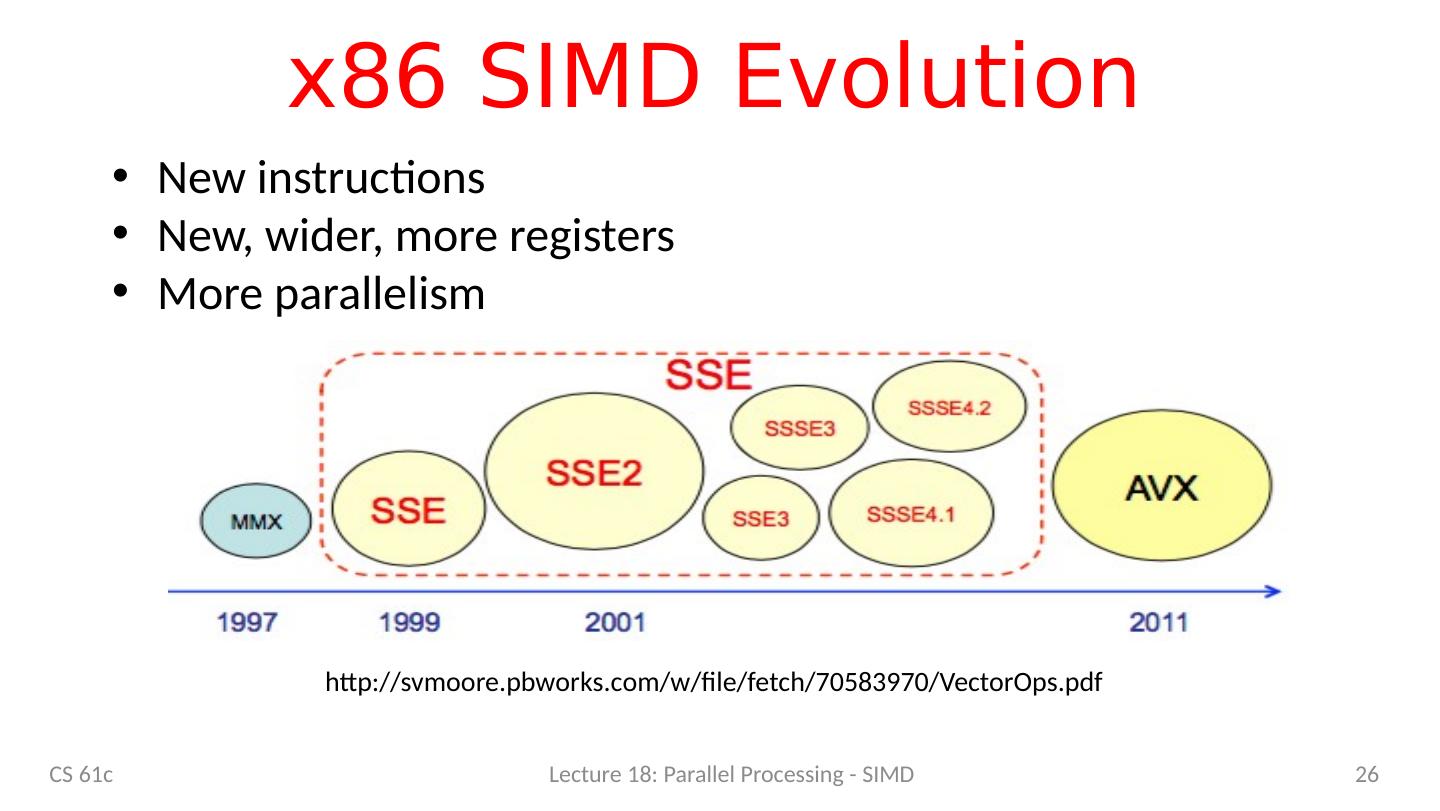
26 .x86 SIMD Evolution CS 61c Lecture 18: Parallel Processing - SIMD 26 http:// svmoore.pbworks.com /w/file/fetch/70583970/ VectorOps.pdf New instructions New, wider, more registers More parallelism
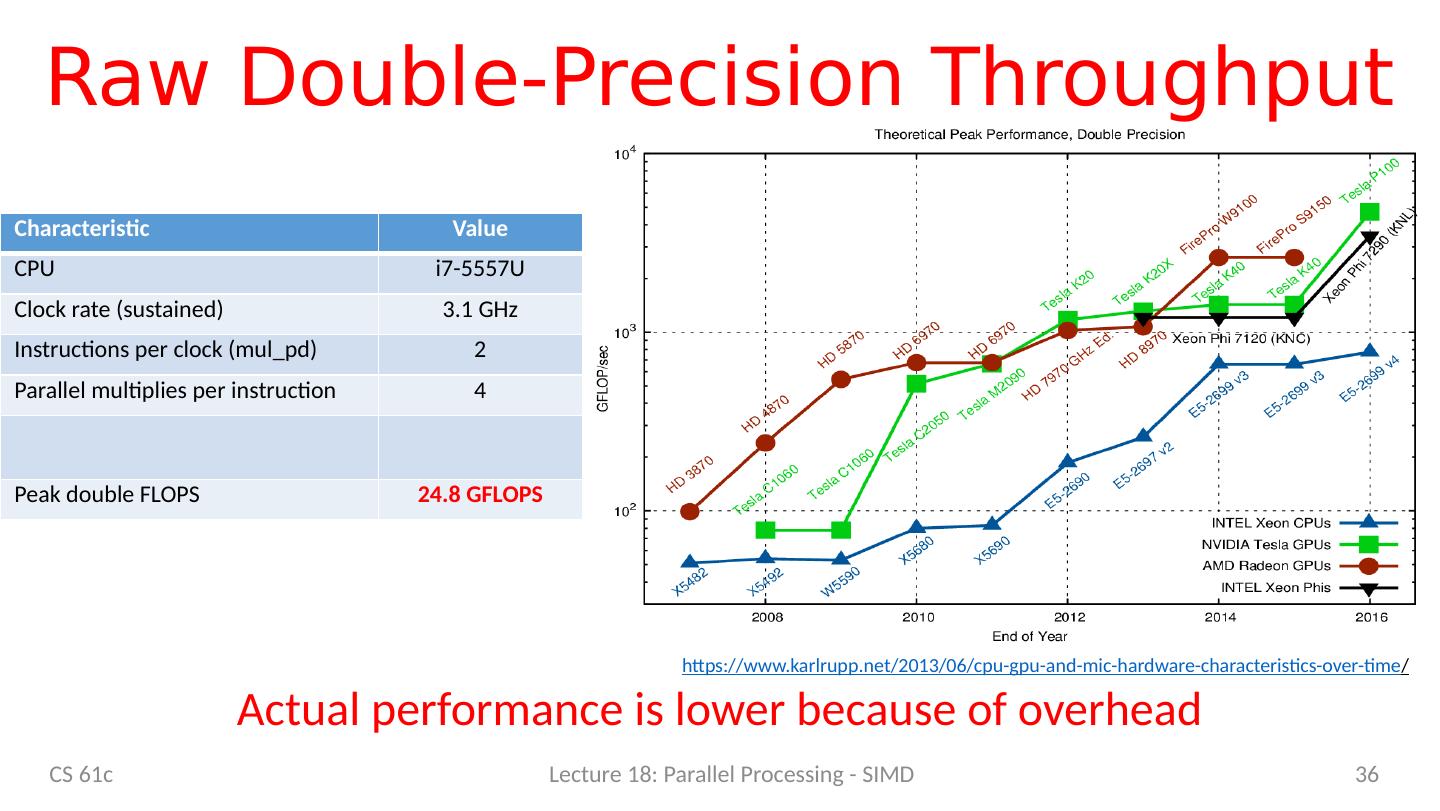
27 .Laptop CPU Specs $ sysctl -a | grep cpu hw.physicalcpu : 2 hw.logicalcpu : 4 machdep.cpu.brand_string : Intel(R ) Core(TM) i7-5557U CPU @ 3.10GHz machdep.cpu.features : FPU VME DE PSE TSC MSR PAE MCE CX8 APIC SEP MTRR PGE MCA CMOV PAT PSE36 CLFSH DS ACPI MMX FXSR SSE SSE2 SS HTT TM PBE SSE3 PCLMULQDQ DTES64 MON DSCPL VMX EST TM2 SSSE3 FMA CX16 TPR PDCM SSE4.1 SSE4.2 x2APIC MOVBE POPCNT AES PCID XSAVE OSXSAVE SEGLIM64 TSCTMR AVX1.0 RDRAND F16C machdep.cpu.leaf7_features : SMEP ERMS RDWRFSGS TSC_THREAD_OFFSET BMI1 AVX2 BMI2 INVPCID SMAP RDSEED ADX IPT FPU_CSDS CS 61c Lecture 18: Parallel Processing - SIMD 27
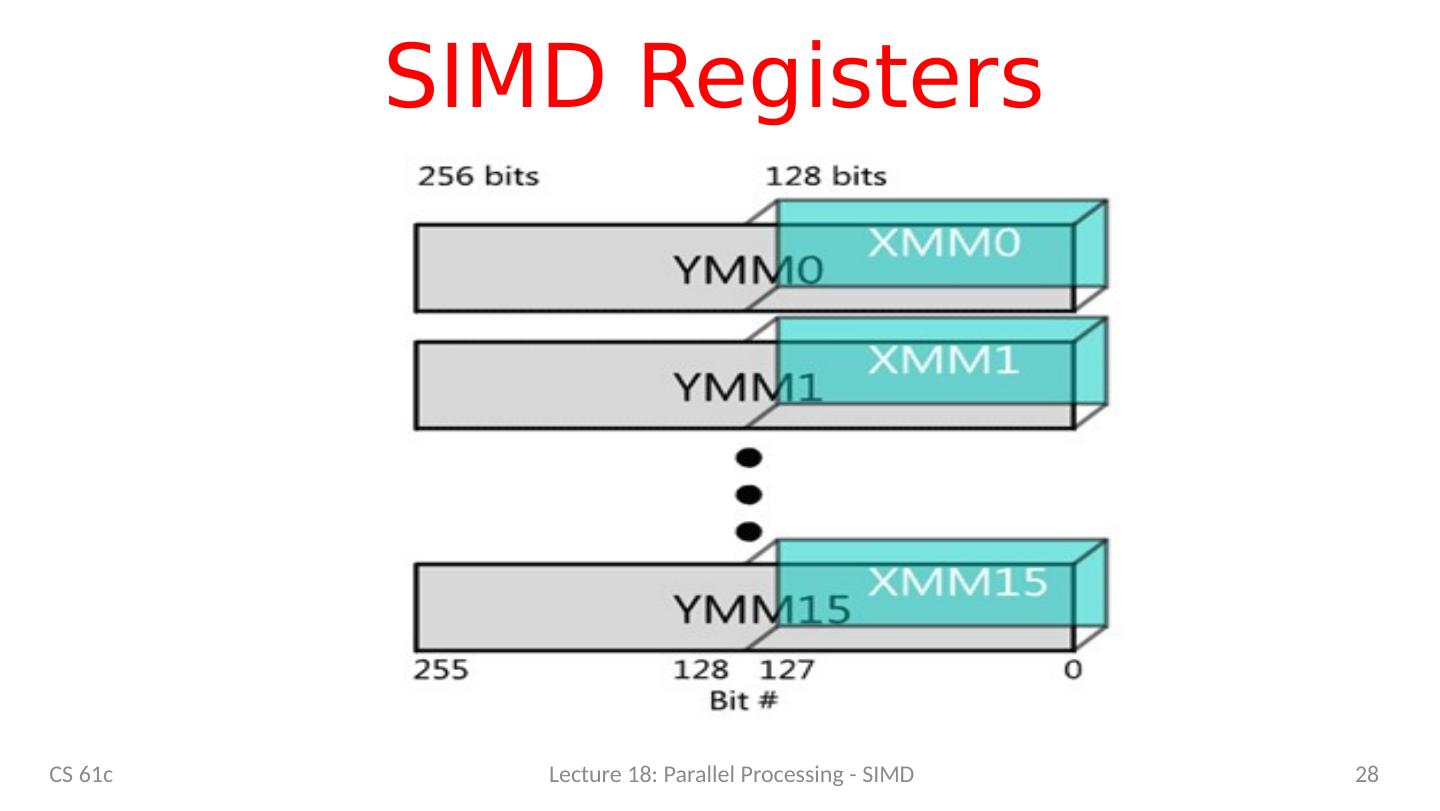
28 .SIMD Registers CS 61c Lecture 18: Parallel Processing - SIMD 28
29 .SIMD Data Types CS 61c Lecture 18: Parallel Processing - SIMD 29 (Now also AVX-512 available)
3秒后跳转登录页面
去登陆

