










































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
计算机结构
本章节主要介绍计算机存储器,内存等的相关信息,介绍了图书馆/计算机存储器的局部性原则,利用局部性的内存层次的结构(速度/大小/每比特的成本),缓存-内存层次结构中较低级别的复制以及直接映射到使用标记字段和有效位查找缓存中的块。
展开查看详情
1 .CS 61C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 1 Instructors: Krste Asanović & Randy H. Katz http:// inst.eecs.berkeley.edu /~cs61c/ 1 10/11/17 Fall 2017 - Lecture #14
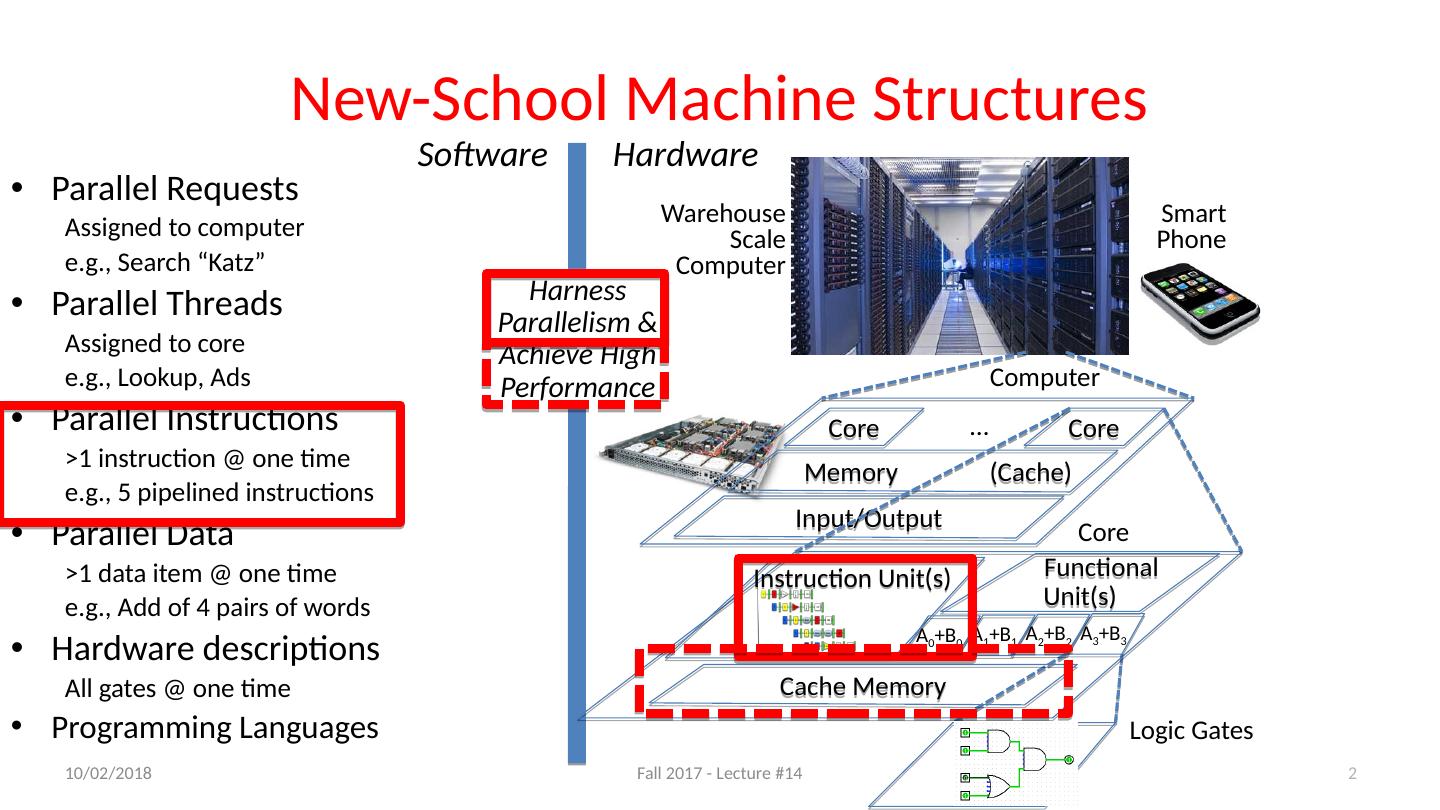
2 .New-School Machine Structures 2 Parallel Requests Assigned to computer e.g., Search “Katz” Parallel Threads Assigned to core e.g., Lookup, Ads Parallel Instructions >1 instruction @ one time e.g., 5 pipelined instructions Parallel Data >1 data item @ one time e.g., Add of 4 pairs of words Hardware descriptions All gates @ one time Programming Languages Smart Phone Warehouse Scale Computer Software Hardware Harness Parallelism & Achieve High Performance Logic Gates Core Core … Memory (Cache) Input/Output Computer Cache Memory Core Instruction Unit(s ) Functional Unit(s ) A 3 +B 3 A 2 +B 2 A 1 +B 1 A 0 +B 0 10/11/17 Fall 2017 - Lecture #14
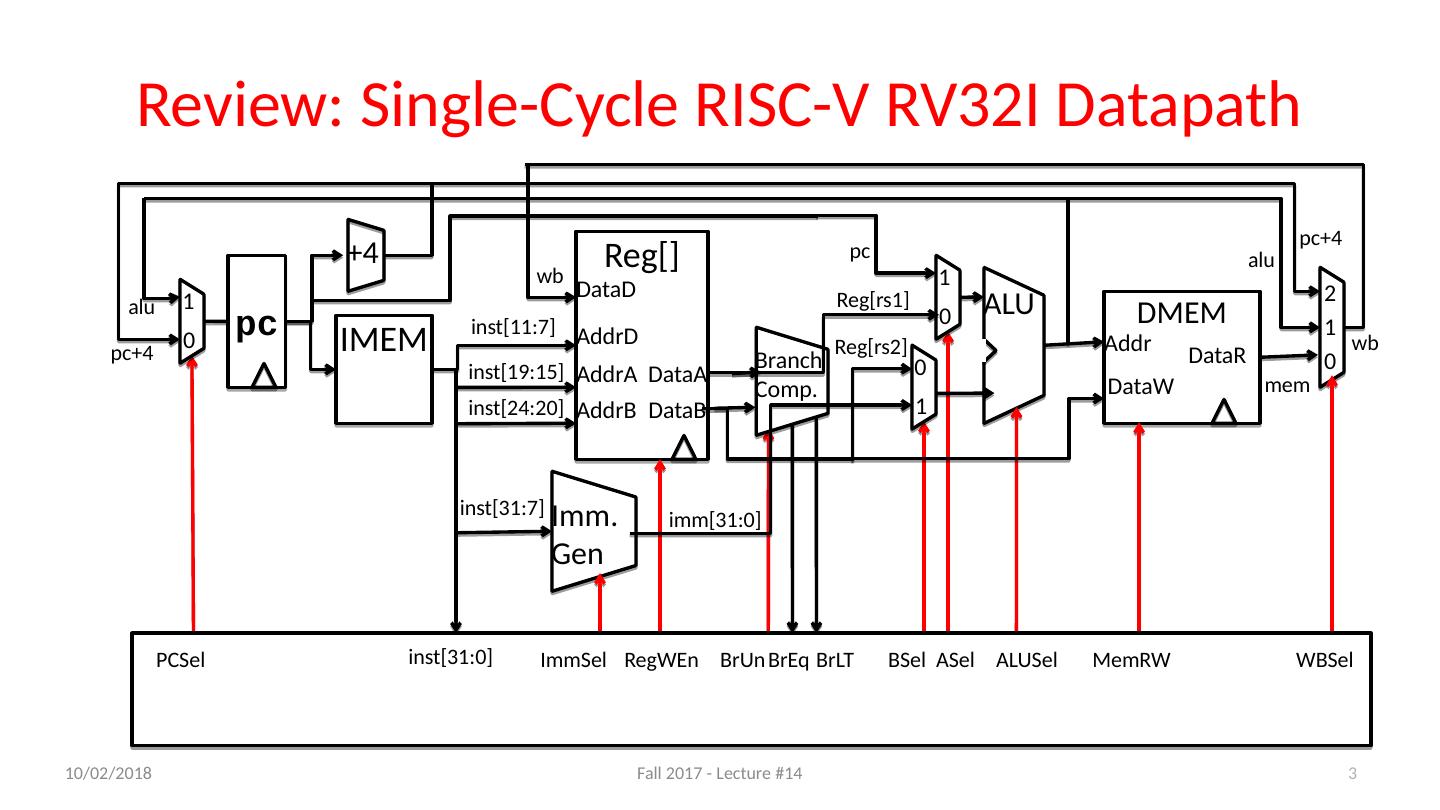
3 .Review: Single-Cycle RISC-V RV32I Datapath IMEM ALU Imm . Gen +4 DMEM Branch Comp. Reg [] AddrA AddrB DataA AddrD DataB DataD Addr DataW DataR 1 0 0 1 2 1 0 pc 0 1 inst [11:7] inst [19:15] inst [24:20] inst [31:7] pc+4 alu mem wb alu pc+4 Reg [rs1] pc imm [31:0] Reg [rs2] inst [31:0] ImmSel RegWEn BrUn BrEq BrLT ASel BSel ALUSel MemRW WBSel PCSel wb 3 10/11/17 Fall 2017 - Lecture #14
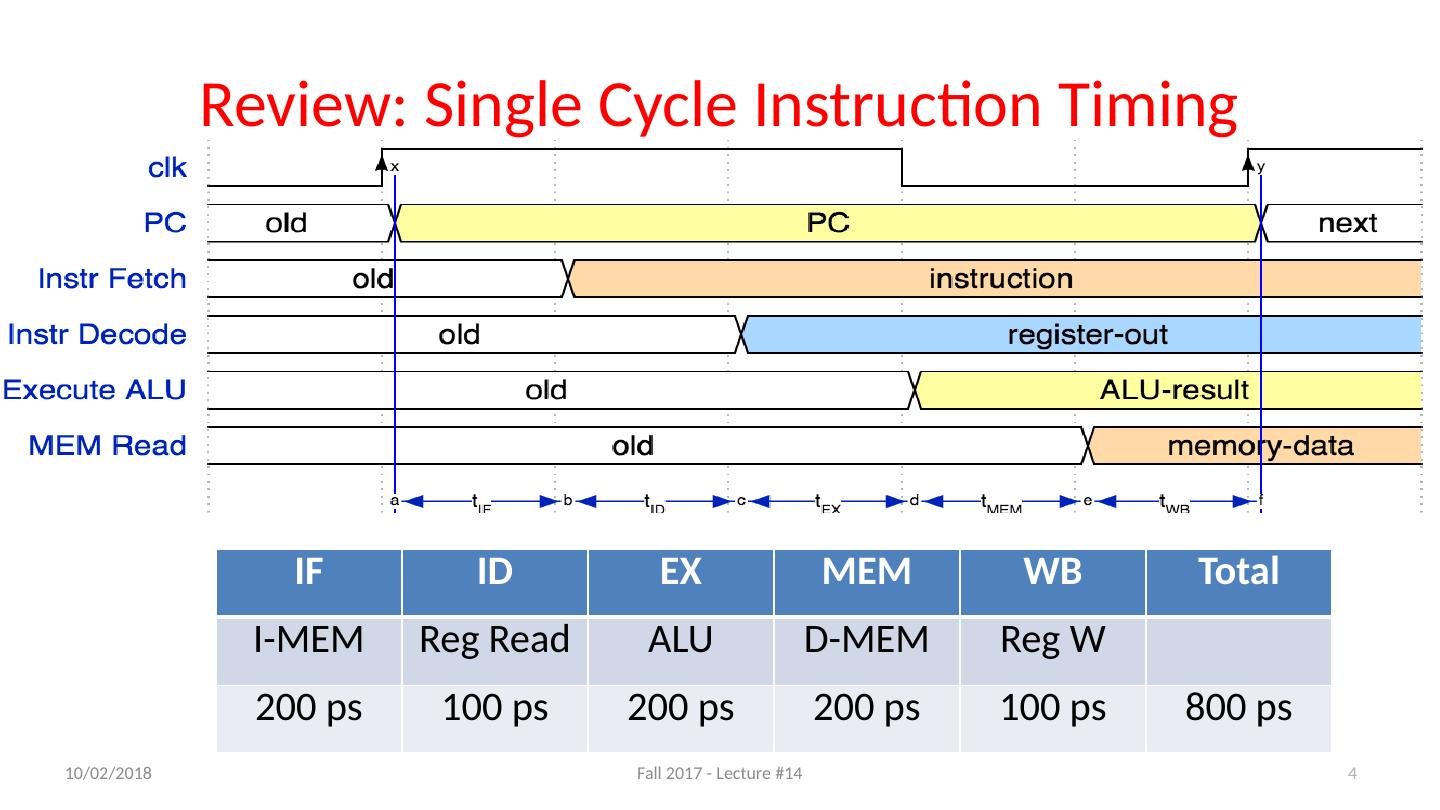
4 .Review: Single Cycle Instruction Timing IF ID EX MEM WB Total I-MEM Reg Read ALU D-MEM Reg W 200 ps 100 ps 200 ps 200 ps 100 ps 800 ps 4 10/11/17 Fall 2017 - Lecture #14
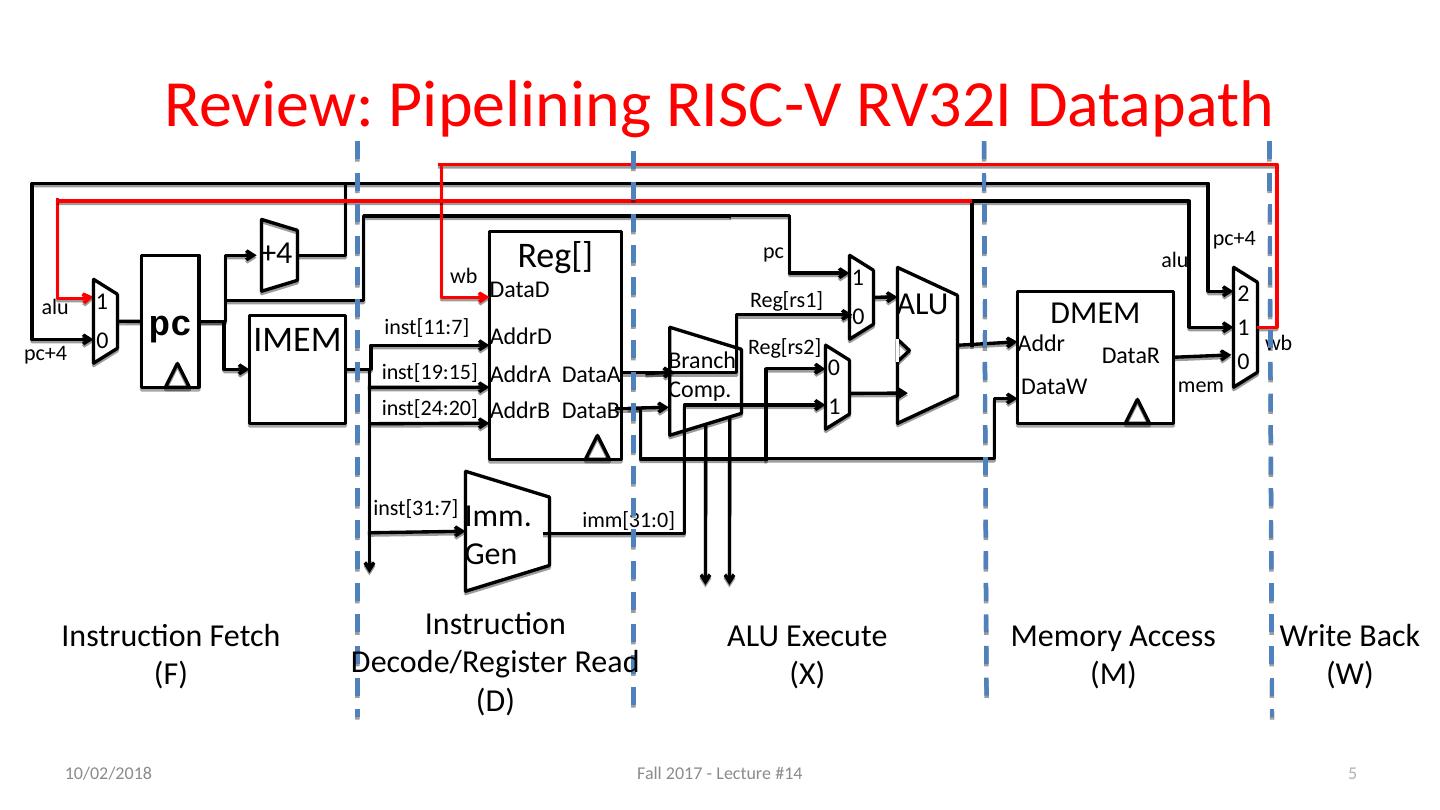
5 .Review: Pipelining RISC-V RV32I Datapath IMEM ALU Imm . Gen +4 DMEM Branch Comp. Reg [] AddrA AddrB DataA AddrD DataB DataD Addr DataW DataR 1 0 0 1 2 1 0 pc 0 1 inst [11:7] inst [19:15] inst [24:20] inst [31:7] pc+4 alu mem wb alu pc+4 Reg [rs1] pc imm [31:0] Reg [rs2] wb Instruction Fetch (F) Instruction Decode/Register Read (D) ALU Execute (X) Memory Access (M) Write Back (W) 5 10/11/17 Fall 2017 - Lecture #14
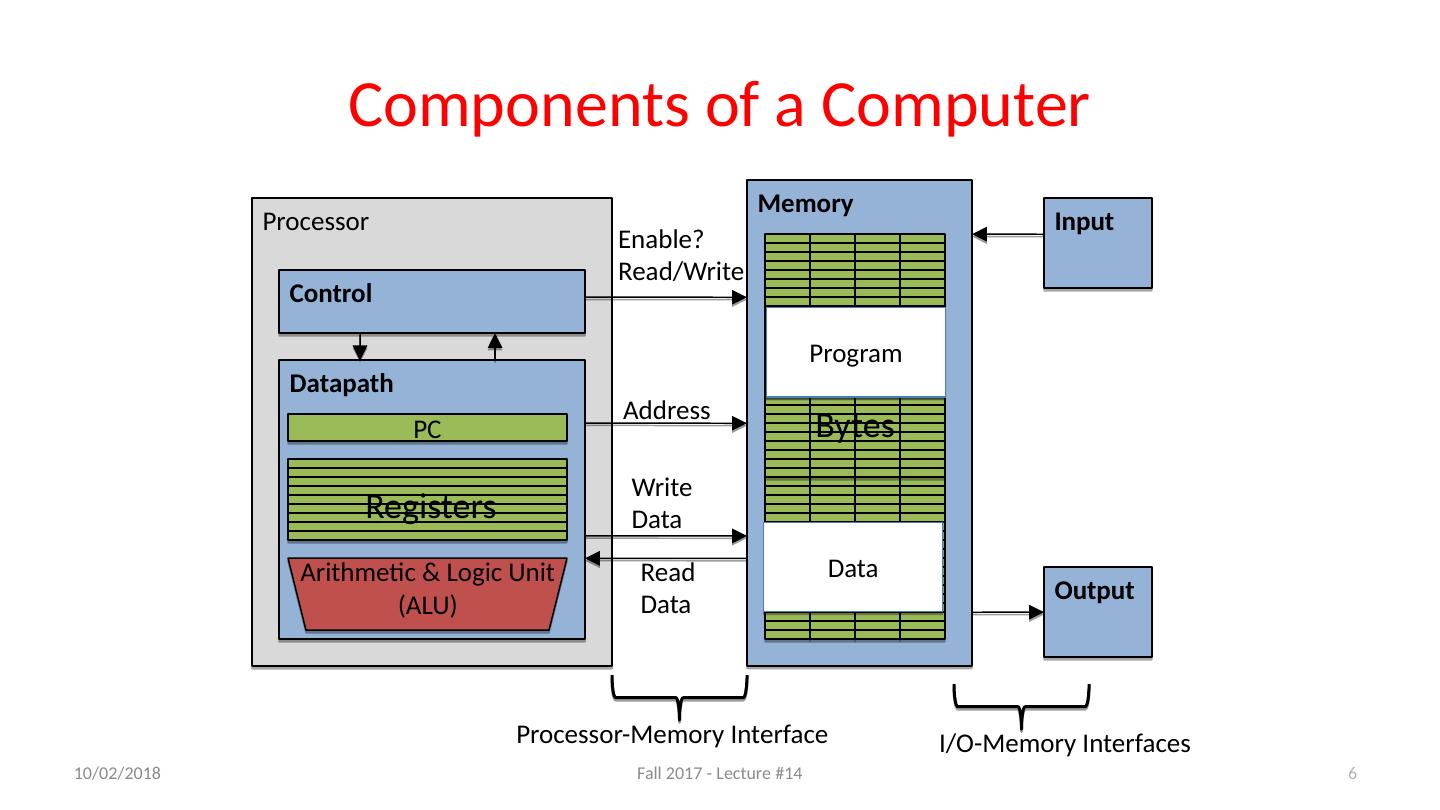
6 .Processor Control Datapath Components of a Computer 6 PC Registers Arithmetic & Logic Unit (ALU) Memory Input Output Bytes Enable? Read/Write Address Write Data ReadData Processor-Memory Interface I/O-Memory Interfaces Program Data 10/11/17 Fall 2017 - Lecture #14
7 .Outline Memory Hierarchy and Latency Caches Principles Basic Cache Organization Different Kinds of Caches Write Back vs. Write Through And in Conclusion … 7 10/11/17 Fall 2017 – Lecture #14
8 .Outline Memory Hierarchy and Latency Caches Principles Basic Cache Organization Different Kinds of Caches Write Back vs. Write Through And in Conclusion … 8 10/11/17 Fall 2017 – Lecture #14
9 .Why are Large Memories Slow? Library Analogy Time to find a book in a large library S earch a large card catalog – (mapping title/author to index number) Round-trip time to walk to the stacks and retrieve the desired book Larger libraries worsen both delays Electronic memories have same issue, plus the technologies used to store a bit slow down as density increases (e.g., SRAM vs. DRAM vs. Disk) However what we want is a large yet fast memory! 10/11/17 Fall 2017 - Lecture #14 9
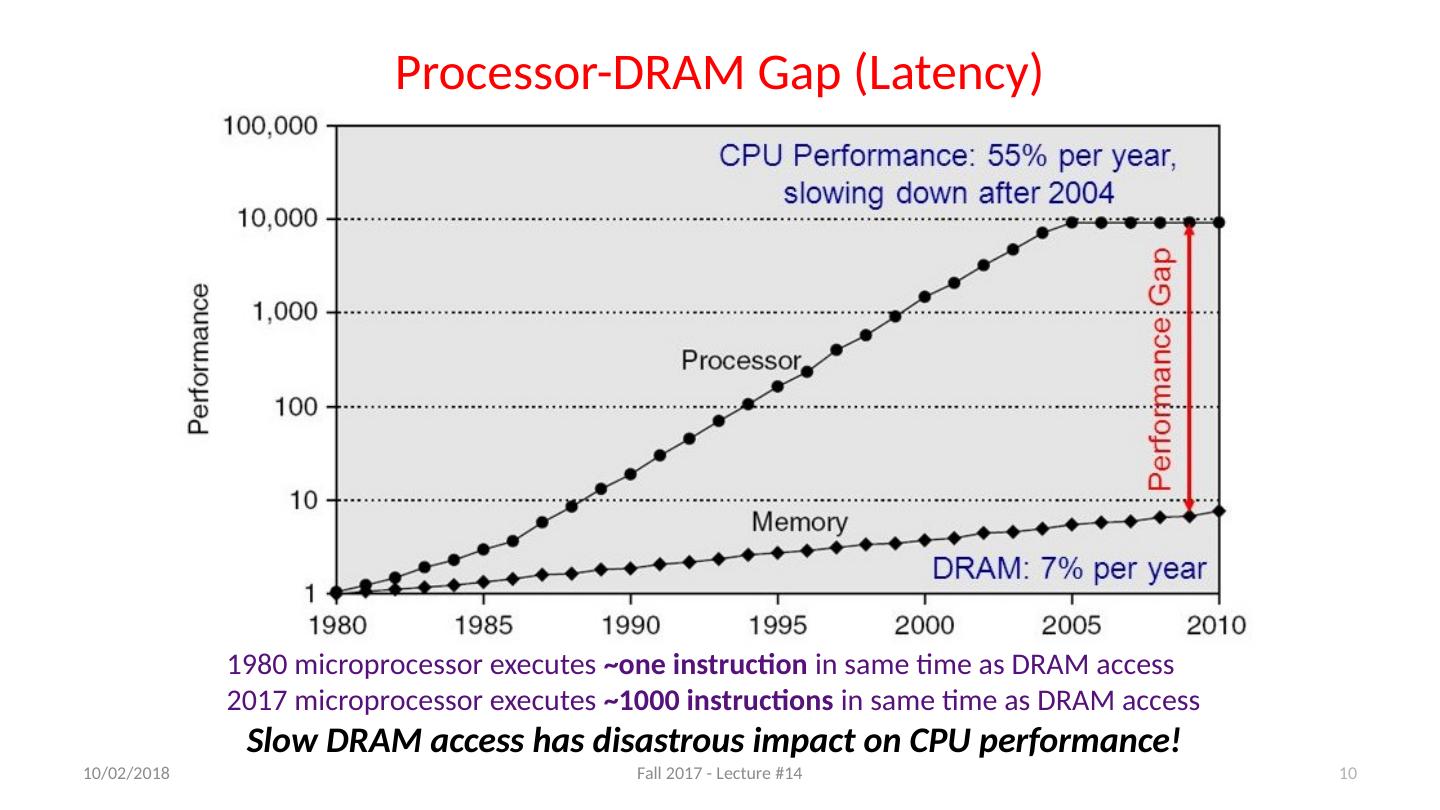
10 .Processor-DRAM Gap (Latency) 1980 microprocessor executes ~one instruction in same time as DRAM access 2017 microprocessor executes ~1000 instructions in same time as DRAM access Slow DRAM access has disastrous impact on CPU performance! 10/11/17 Fall 2017 - Lecture #14 10
11 .What To Do: Library Analogy Write a report using library books E.g., works of J.D. Salinger Go to library, look up relevant books, fetch from stacks, and place on desk in library If need more, check them out and keep on desk But don’t return earlier books since might need them You hope this collection of ~10 books on desk enough to write report, despite 10 being only 0.00001% of books in UC Berkeley libraries 10/11/17 Fall 2017 - Lecture #14 11
12 .Outline Memory Hierarchy and Latency Caches Principles Basic Cache Organization Different Kinds of Caches Write Back vs. Write Through And in Conclusion … 10/11/17 Fall 2017 – Lecture #14 12
13 .Big Idea: Memory Hierarchy Processor Size of memory at each level Increasing distance from processor, decreasing speed Level 1 Level 2 Level n Level 3 . . . Inner Outer Levels in memory hierarchy As we move to outer levels the latency goes up and price per bit goes down. Why? 10/11/17 Fall 2017 - Lecture #14 13
14 .Big Idea: Locality Temporal Locality (locality in time) Go back to same book on desk multiple times If a memory location is referenced, then it will tend to be referenced again soon Spatial Locality (locality in space) When go to book shelf, pick up multiple books on J.D. Salinger since library stores related books together If a memory location is referenced, the locations with nearby addresses will tend to be referenced soon 10/11/17 Fall 2017 - Lecture #14 14
15 .Memory Reference Patterns Donald J. Hatfield, Jeanette Gerald: Program Restructuring for Virtual Memory. IBM Systems Journal 10(3): 168-192 (1971) Time Memory Address (one dot per access) Spatial Locality Temporal Locality 10/11/17 Fall 2017 - Lecture #14 15
16 .Principle of Locality Principle of Locality : Programs access small portion of address space at any instant of time (spatial locality) and repeatedly access that portion (temporal locality) What program structures lead to temporal and spatial locality in instruction accesses? In data accesses? What structures defeat temporal and spatial locality in instruction and data accesses? 10/11/17 Fall 2017 - Lecture #14 16
17 .Memory Reference Patterns Address Time Instruction fetches Stack accesses Data accesses n loop iterations subroutine call subroutine return argument access vector access scalar accesses 10/11/17 Fall 2017 - Lecture #14 17
18 .10/11/17 Fall 2017 - Lecture #14 18
19 .Cache Philosophy Programmer-invisible hardware mechanism gives illusion of speed of fastest memory with size of largest memory Works even if you have no idea what a cache is P erformance-oriented programmers sometimes “reverse engineer” cache organization to design data structures and access patterns optimized for a specific cache design You are going to do that in Project #3 (parallel programming)! 19 10/11/17 Fall 2017 - Lecture #14
20 .Outline Memory Hierarchy and Latency Caches Principles Basic Cache Organization Different Kinds of Caches Write Back vs. Write Through And in Conclusion … 10/11/17 Fall 2017 – Lecture #14 20
21 .Memory Access without Cache Load word instruction: lw t0,0(t1) t1 contains 1022 ten, Memory[1022] = 99 Processor issues address 1022 ten to Memory Memory reads word at address 1022 ten (99) Memory sends 99 to Processor Processor loads 99 into register t0 10/11/17 Fall 2017 - Lecture #14 21
22 .Processor Control Datapath Adding Cache to Computer PC Registers Arithmetic & Logic Unit (ALU) Memory Input Output Bytes Enable? Read/Write Address Write Data ReadData Processor-Memory Interface I/O-Memory Interfaces Program Data Cache 10/11/17 Fall 2017 - Lecture #14 22 Processor organized around words and bytes Memory (including cache) organized around blocks, which are typically multiple words
23 .Memory Access with Cache Load word instruction: lw t0,0(t1) t1 contains 1022 ten, Memory[1022] = 99 With cache: Processor issues address 1022 ten to Cache Cache checks to see if has copy of data at address 1022 ten 2a. If finds a match ( Hit ): cache reads 99, sends to processor 2b. No match ( Miss ): cache sends address 1022 to Memory Memory reads 99 at address 1022 ten Memory sends 99 to Cache Cache replaces word with new 99 Cache sends 99 to processor Processor loads 99 into register t0 10/11/17 Fall 2017 - Lecture #14 23
24 .Administrivia Homework 3 has been released! Link is on the course website Project 1 Part 2 is due Monday This is the same day that Project 2 Part 1 will be released! Midterm 2 is on Oct 31 (Halloween) 24 10/11/17 Fall 2017 - Lecture #14
25 .Break! 25 10/11/17 Fall 2017 - Lecture # 14
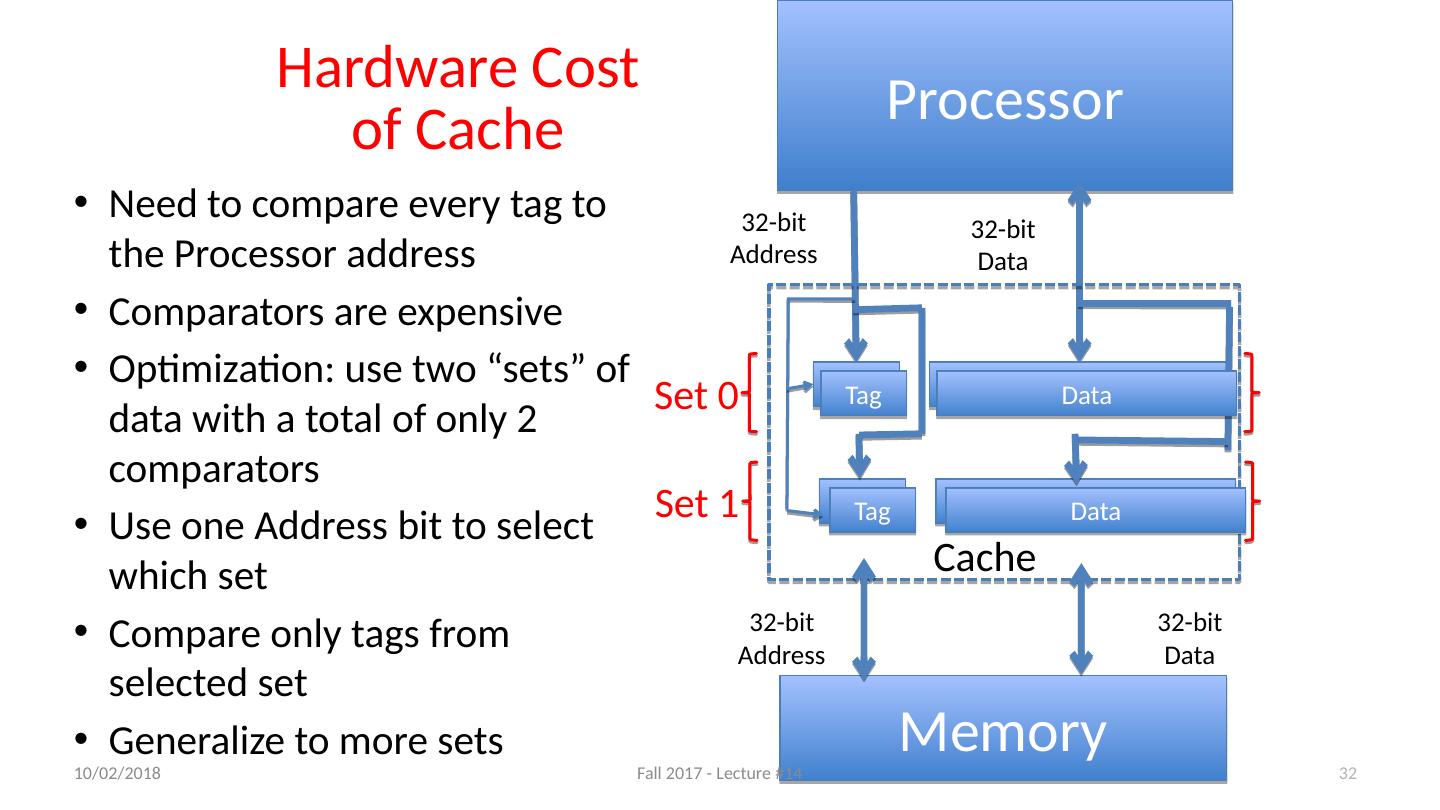
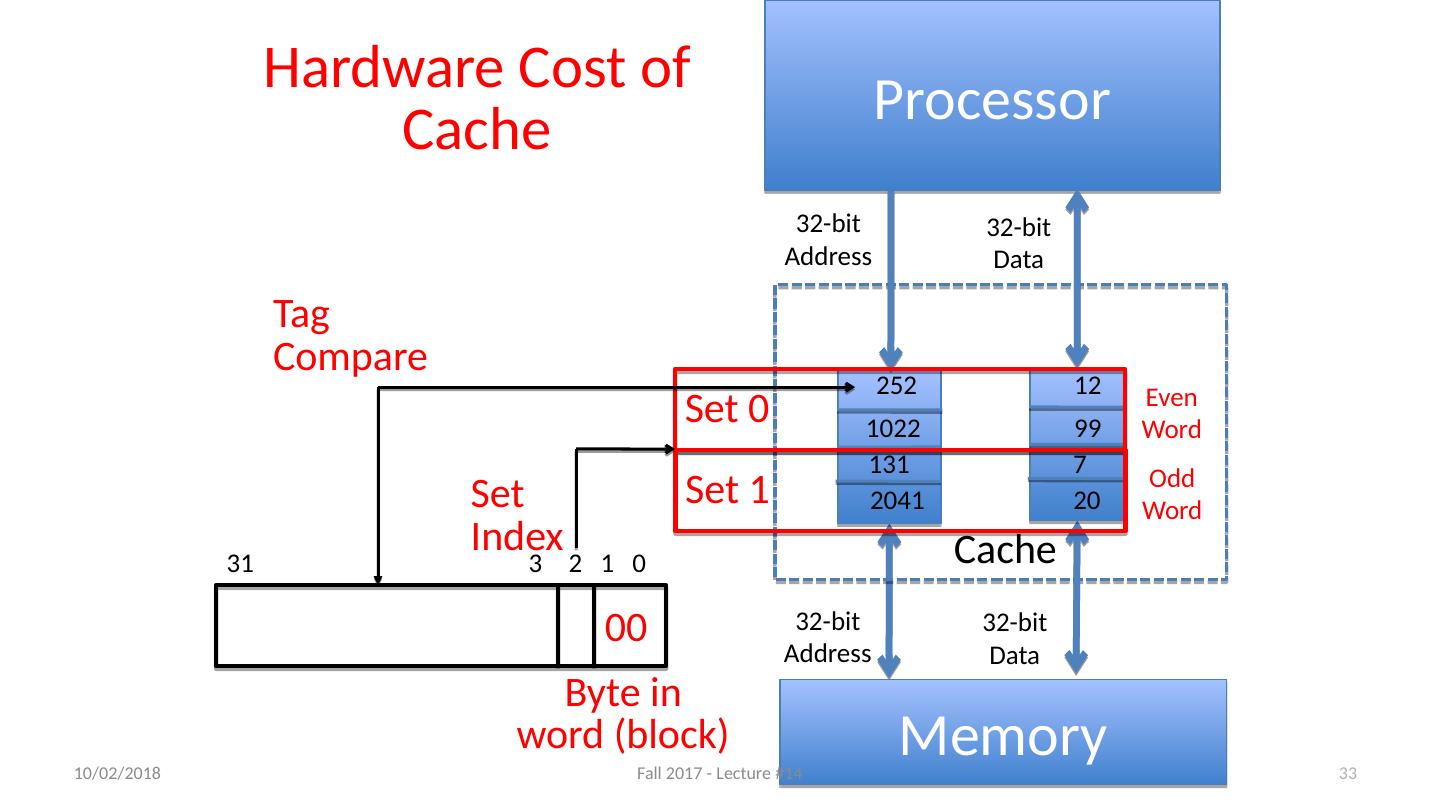
26 .Cache “Tags” Need way to tell if have copy of location in memory so that can decide on hit or miss On cache miss, put memory address of block in “tag address” of cache block 1022 placed in tag next to data from memory (99) Tag Data 252 12 1022 99 131 7 2041 20 From earlier loads or stores 10/11/17 Fall 2017 - Lecture #14 26
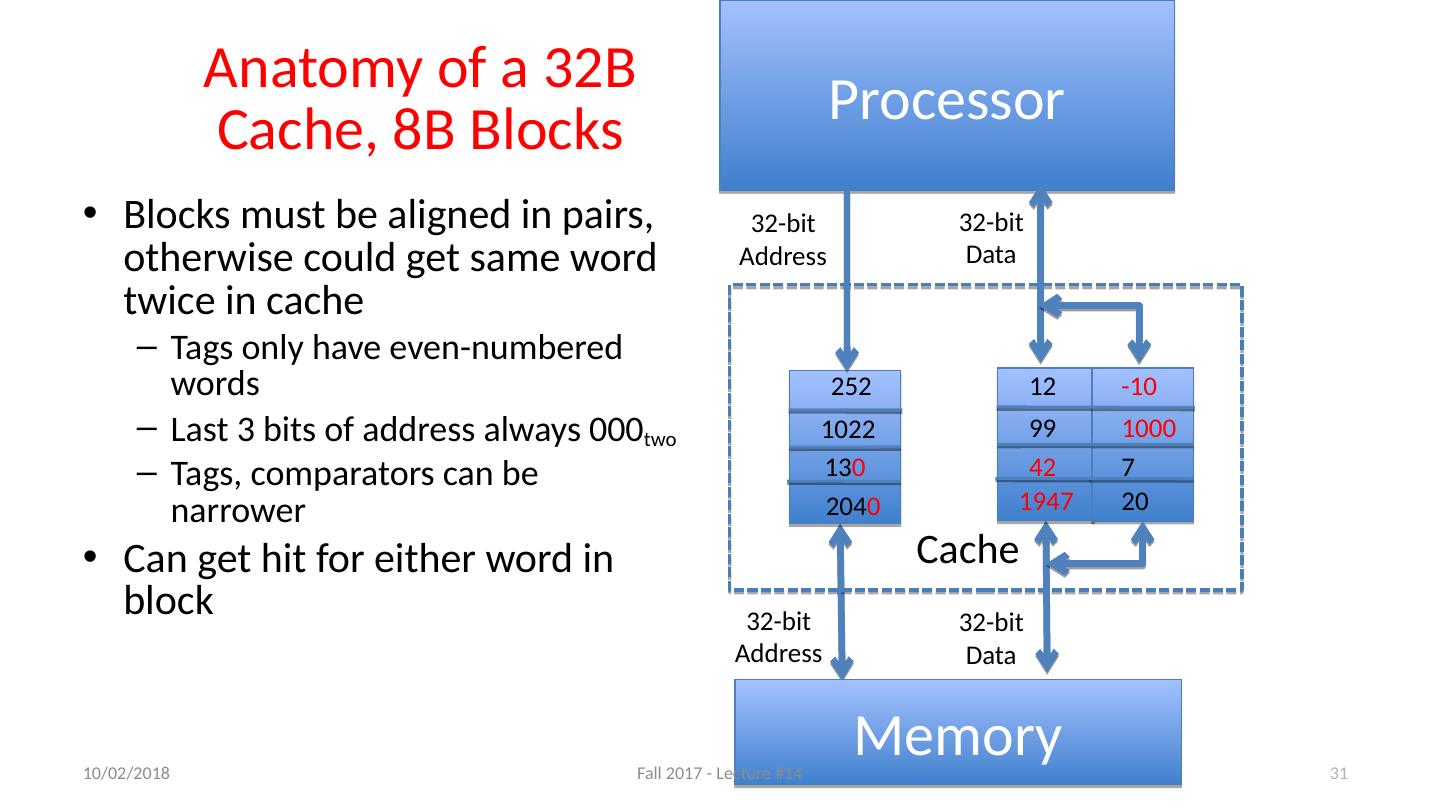
27 .Anatomy of a 16 Byte Cache, with 4 Byte Blocks Operations: Cache Hit Cache Miss Refill cache from memory Cache needs Address Tags to decide if Processor Address is a Cache Hit or Cache Miss Compares all four tags Processor 32-bit Address 32-bit Data Cache 32-bit Address 32-bit Data Memory 1022 99 252 7 20 12 131 2041 10/11/17 Fall 2017 - Lecture #14 27 27
28 .Tag Data 252 12 1022 99 131 7 2041 20 Cache Replacement Suppose processor now requests location 511, which contains 11? Doesn’t match any cache block, so must “evict” a resident block to make room Which block to evict? Replace “victim” with new memory block at address 511 10/11/17 Fall 2017 - Lecture #14 28
29 .Tag Data 252 12 1022 99 511 11 2041 20 Cache Replacement Suppose processor now requests location 511, which contains 11? Doesn’t match any cache block, so must “evict” a resident block to make room Which block to evict? Replace “victim” with new memory block at address 511 10/11/17 Fall 2017 - Lecture #14 29
3秒后跳转登录页面
去登陆

