展开查看详情
1 .scala在喜⻢马拉雅数据平台的使⽤用
数据组 陈涛
2018.10
�
2 .Outline
» 数据计算平台XQL
» 监控系统Spoor
» 打包部署实践
�
3 .数据计算平台XQL
» ⽬目前现状
» 研发背景
» 框架相关
�
4 .XQL ⽬目前现状
» 使⽤用内存10T
» 每天1w+计算任务
» ⽬目前⽀支撑全公司的80%以上的数据分析需求和⼤大部分的etl需求
�
5 .XQL 研发背景
» 数据源众多 (mysql,hbase,hdfs,es…)
» 我司早期埋点数据⽤用json归档,没有合适的分析⼯工具
» 分析师⼤大部分只会sql,不不会写代码
» sql复杂之后可读性差
�
6 .XQL 研发背景
» spark thriftserver
» spark jobserver
» apache zeppelin
�
7 .XQL 研发背景
» scala技术栈
» 合适的dsl语法降低分析师的编程负担
» 依托于spark,进⾏行行深度定制化
�
8 .XQL 语法介绍
Without XQL
XQL
�
9 .框架实践
» akka remote
» akka cluster
» spark
» spark + akka
» parboiled2
�
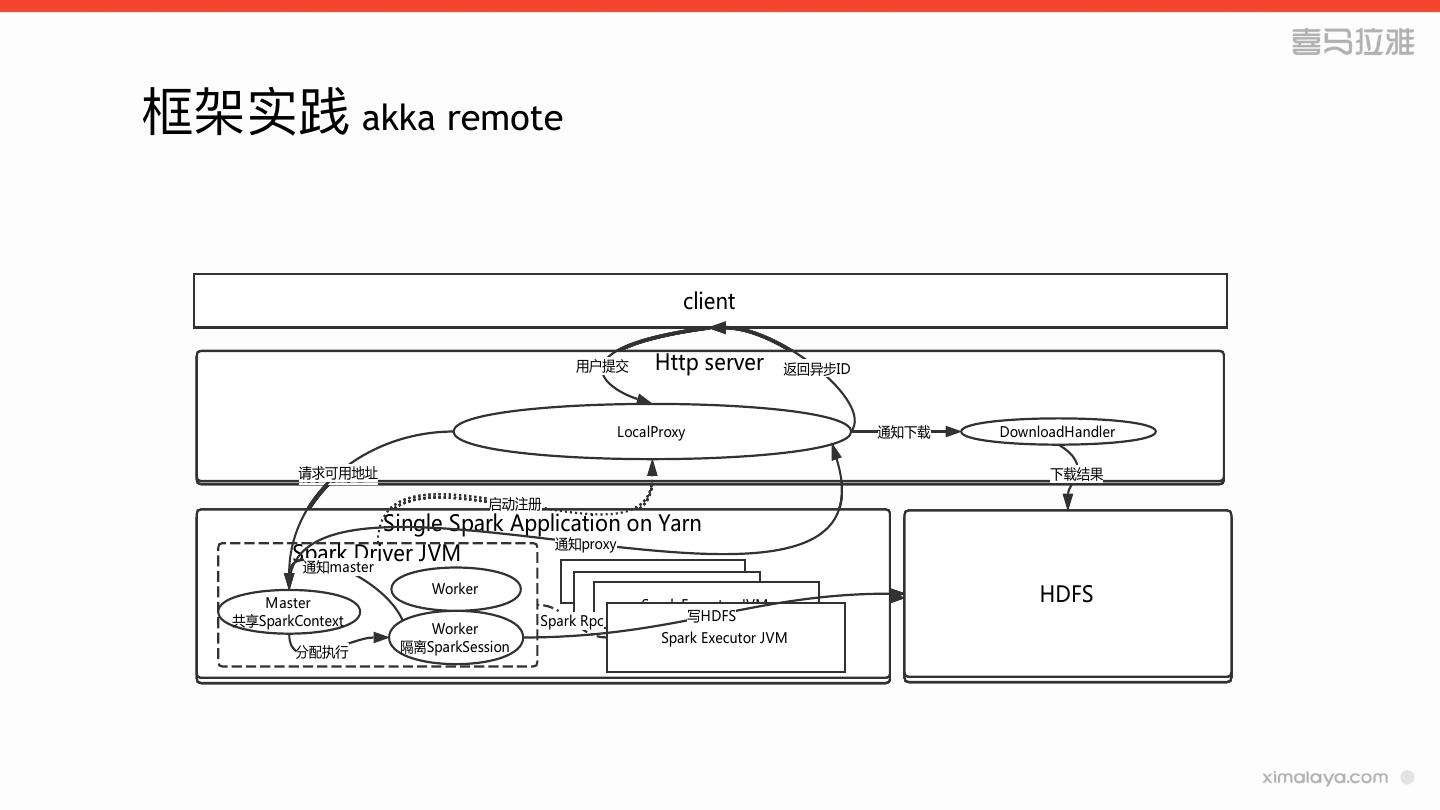
10 .框架实践 akka remote
client
用户提交 Http server 返回异步ID
LocalProxy 通知下载 DownloadHandler
请求可用地址
请求可用地址 下载结果
启动注册
启动注册
Single Spark Application on Yarn
通知proxy
Spark Driver
通知master
JVM
通知master
Spark
Spark Executor
Executor JVM
JVM
Master
Master
Worker
Worker Spark Executor
Spark Executor JVM
Spark
JVM
Executor JVM
HDFS
Spark Executor
写HDFS JVM
共享SparkContext
共享SparkContext Spark Rpc
Spark Rpc 写HDFS
Worker
Worker Spark
Spark Executor
Executor JVM
JVM
分配执行 隔离SparkSession
隔离SparkSession
分配执行
�
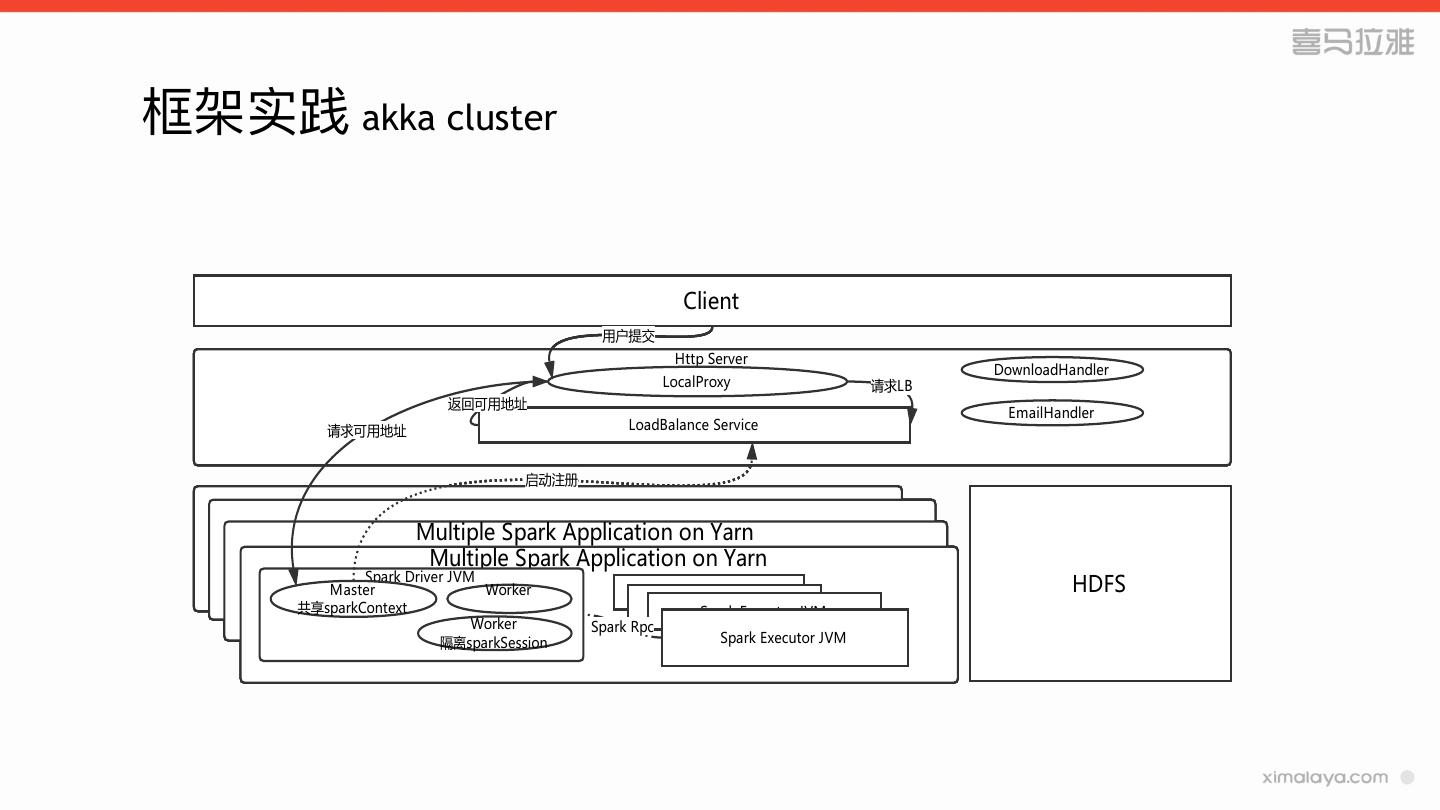
11 .框架实践 akka cluster
Client
用户提交
Http Server
DownloadHandler
LocalProxy 请求LB
返回可用地址
返回可用地址
EmailHandler
请求可用地址 LoadBalance Service
启动注册
Multiple Spark Application on Yarn
Multiple Spark Application on Yarn
Spark Driver JVM
Master Worker Spark Executor JVM HDFS
共享sparkContext Spark Executor JVM
Spark Executor JVM
Worker Spark Rpc
隔离sparkSession Spark Executor JVM
�
12 .框架实践 akka cluster
» akka cluster参数调优
» failure-detector.threshold -> 12.0
» failure-detector.acceptable-heartbeat-pause -> 20s
» failure-detector.min-std-deviation -> 150ms
» jvm参数调优
» -XX:+UseG1GC
» -XX:+ExplicitGCInvokesConcurrent
�
13 .框架实践 其他
» spark
» 利利⽤用同名package降低打包成本
» 定制⾃自⼰己的⼀一些扩展包
» spark + akka
» https://github.com/cjuexuan/mynote/issues/20
» https://issues.apache.org/jira/browse/SPARK-10548
» https://issues.apache.org/jira/browse/SPARK-13747
» parboiled2
» 适合简单的dsl解析,如果是sql解析更更推荐Antlr
�
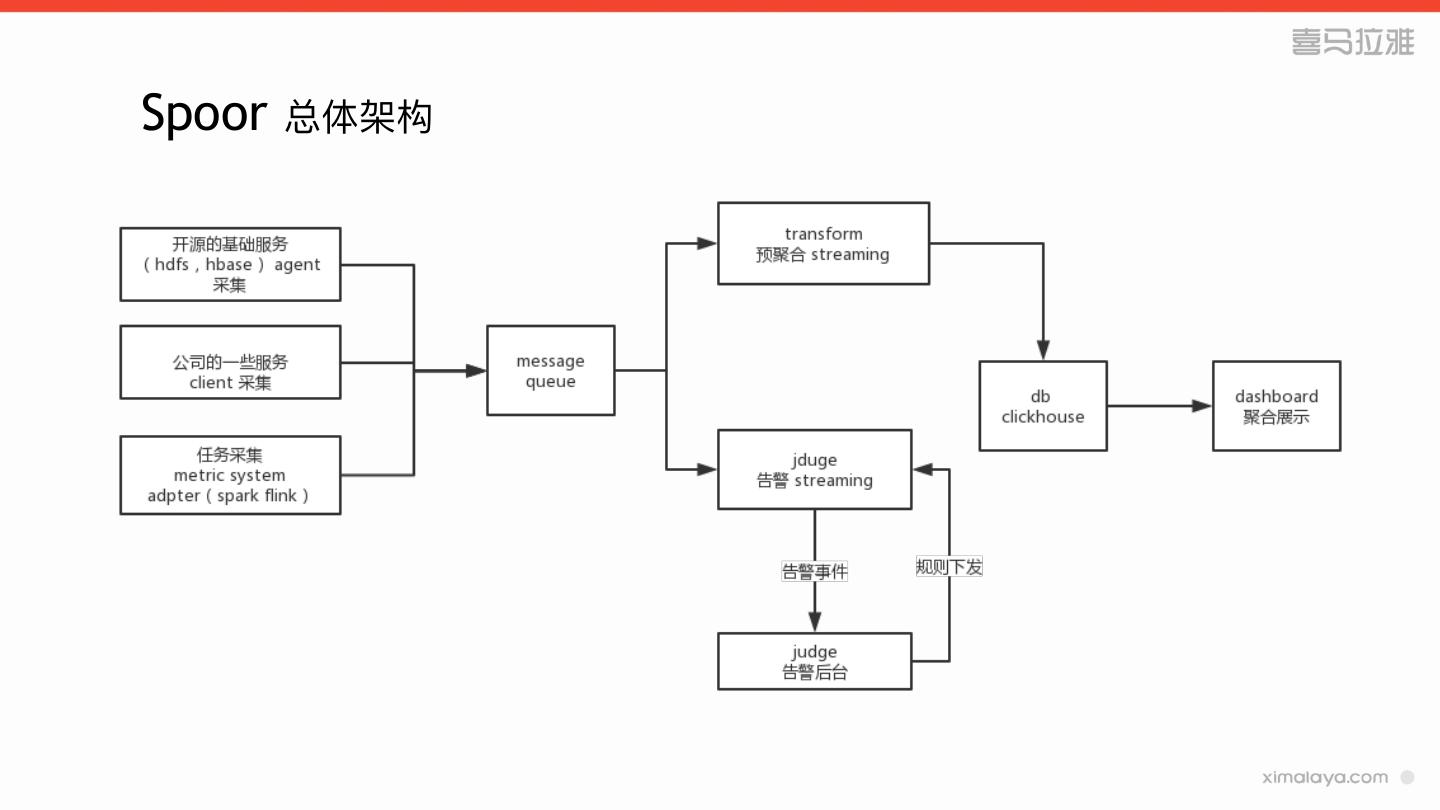
14 .监控平台Spoor
» 总体架构
» 技术栈
» 告警模块
» 对接spark metric sytem
�
17 .Spoor 技术栈
» scala
» akka cluster ⽤用于配置下发
» akka http ⽤用于内部rest接⼝口
» akka actor⽤用于告警模块
» spark structure streaming⽤用于数据预聚合和规则引擎判断
�
18 .Spoor 告警模块
» 合并的策略略(服务,指标,机器器等维度)
» 每个组⼀一个actor,kafka的消息按照组进⾏行行分发
» actor接收到alert之后修改group的alert state
» 利利⽤用scheduler周期去collect group的state
» 策略略外部可配置,不不断传递给下游的策略略合并
» 如果所有策略略都没有命中,则不不合并
�
20 .Spoor 对接spark metric系统
» 实现spark的sink接⼝口
» 在spark的submit时动态修改metric参数
» 动态⽣生成配置⽂文件,通过dist file传到⽤用户的classpath
» ⽤用户正常调⽤用,不不⼊入侵业务逻辑
�
21 .Spoor 对接主流⼤大数据框架
» hdfs,yarn
» http jmx
» hbase
» http jmx
» hadmin serverLoad
» es
» http , transport client
» kafka
» jmx
�
22 .打包部署实践
» 打包发布流程
» 核⼼心需求
» ⾃自⼒力力更更⽣生
�
24 .打包部署 核⼼心需求
» maven的profile⻛风格加载配置
» 同步run.sh脚本
» ⽀支持制作docker镜像
�
26 .THANKS
--------- Q&A Section --------
喜⻢马拉雅FM
⼤大数据team还在招⼈人
base 上海海
todd.chen@ximalaya.com
�