






























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Arrow and PySpark Pandas UDF
Introduce PySpark Pandas UDF
展开查看详情
1 .Apache Arrow and Pandas UDF on Apache Spark Takuya UESHIN 2018-12-08, Apache Arrow Tokyo Meetup 2018
2 .About Me - Software Engineer @databricks - Apache Spark Committer - Twitter: @ueshin - GitHub: github.com/ueshin 2
3 .Agenda • Apache Spark and PySpark • PySpark and Pandas • Python UDF and Pandas UDF • Pandas UDF and Apache Arrow • Arrow IPC format and Converters • Handling Communication • Physical Operators • Python worker • Work In Progress • Follow-up Events 3
4 .Agenda • Apache Spark and PySpark • PySpark and Pandas • Python UDF and Pandas UDF • Pandas UDF and Apache Arrow • Arrow IPC format and Converters • Handling Communication • Physical Operators • Physical Operators • Work In Progress • Follow-up Events 4
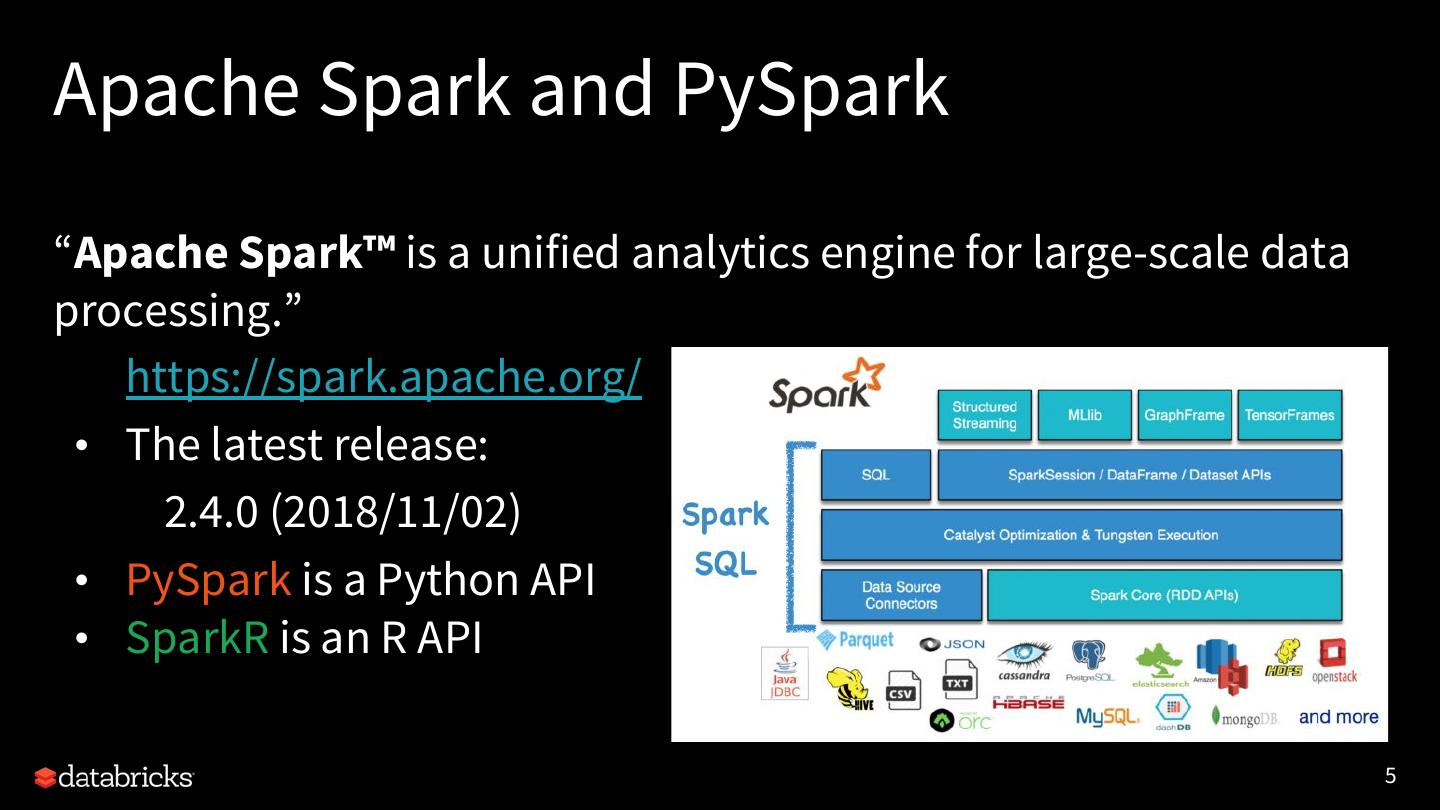
5 .Apache Spark and PySpark “Apache Spark™ is a unified analytics engine for large-scale data processing.” https://spark.apache.org/ • The latest release: 2.4.0 (2018/11/02) • PySpark is a Python API • SparkR is an R API 5
6 .PySpark and Pandas “pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.” • https://pandas.pydata.org/ • The latest release: v0.23.4 Final (2018/08/03) • PySpark supports Pandas >= "0.19.2" 6
7 .PySpark and Pandas PySpark can convert data between PySpark DataFrame and Pandas DataFrame. • pdf = df.toPandas() • df = spark.createDataFrame(pdf) We can use Arrow as an intermediate format by setting config: “spark.sql.execution.arrow.enabled” to “true” (“false” by default). 7
8 .Python UDF and Pandas UDF • UDF: User Defined Function • Python UDF • Serialize/Deserialize data with Pickle • Fetch data block, but invoke UDF row by row • Pandas UDF • Serialize/Deserialize data with Arrow • Fetch data block, and invoke UDF block by block • PandasUDFType: SCALAR, GROUPED_MAP, GROUPED_AGG We don’t need any config, but the declaration is different. 8
9 .Python UDF and Pandas UDF @udf(’double’) def plus_one(v): return v + 1 @pandas_udf(’double’, PandasUDFType.SCALAR) def pandas_plus_one(v): return v + 1 9
10 .Python UDF and Pandas UDF • SCALAR • A transformation: One or more Pandas Series -> One Pandas Series • The length of the returned Pandas Series must be of the same as the input Pandas Series • GROUPED_MAP • A transformation: One Pandas DataFrame -> One Pandas DataFrame • The length of the returned Pandas DataFrame can be arbitrary • GROUPED_AGG • A transformation: One or more Pandas Series -> One scalar • The returned value type should be a primitive data type 10
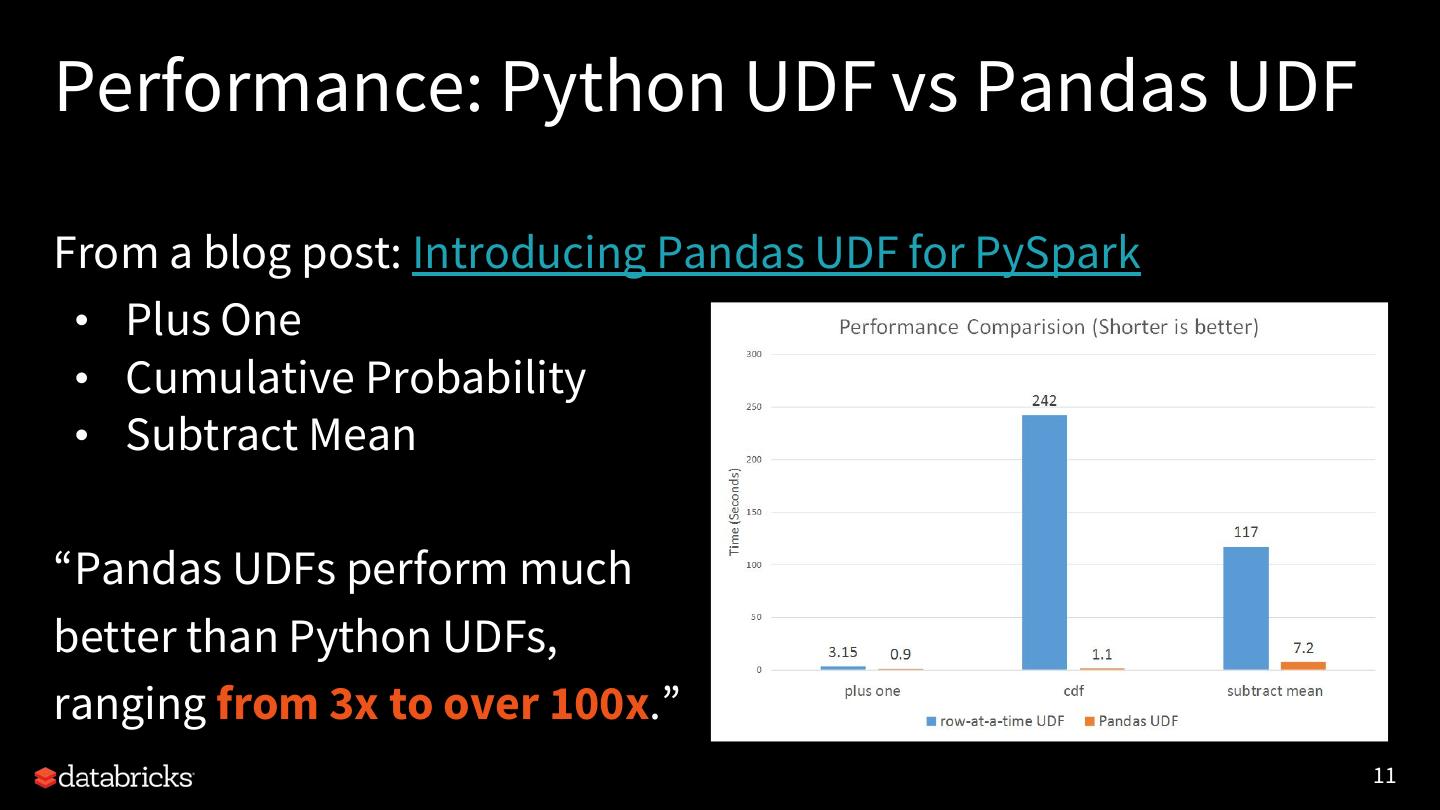
11 .Performance: Python UDF vs Pandas UDF From a blog post: Introducing Pandas UDF for PySpark • Plus One • Cumulative Probability • Subtract Mean “Pandas UDFs perform much better than Python UDFs, ranging from 3x to over 100x.” 11
12 .Agenda • Apache Spark and PySpark • PySpark and Pandas • Python UDF and Pandas UDF • Pandas UDF and Apache Arrow • Arrow IPC format and Converters • Handling Communication • Physical Operators • Python worker • Work In Progress • Follow-up Events 12
13 .Apache Arrow “A cross-language development platform for in-memory data” https://arrow.apache.org/ • The latest release - 0.11.0 (2018/10/08) • Columnar In-Memory • docs/memory_layout.html PySpark supports Arrow >= "0.8.0" • "0.10.0" is recommended 13
14 .Apache Arrow and Pandas UDF • Use Arrow to Serialize/Deserialize data • Streaming format for Interprocess messaging / communication (IPC) • ArrowWriter and ArrowColumnVector • Communicate JVM and Python worker via Socket • ArrowPythonRunner • worker.py • Physical Operators for each PythonUDFType • ArrowEvalPythonExec • FlatMapGroupsInPandasExec • AggregateInPandasExec 14
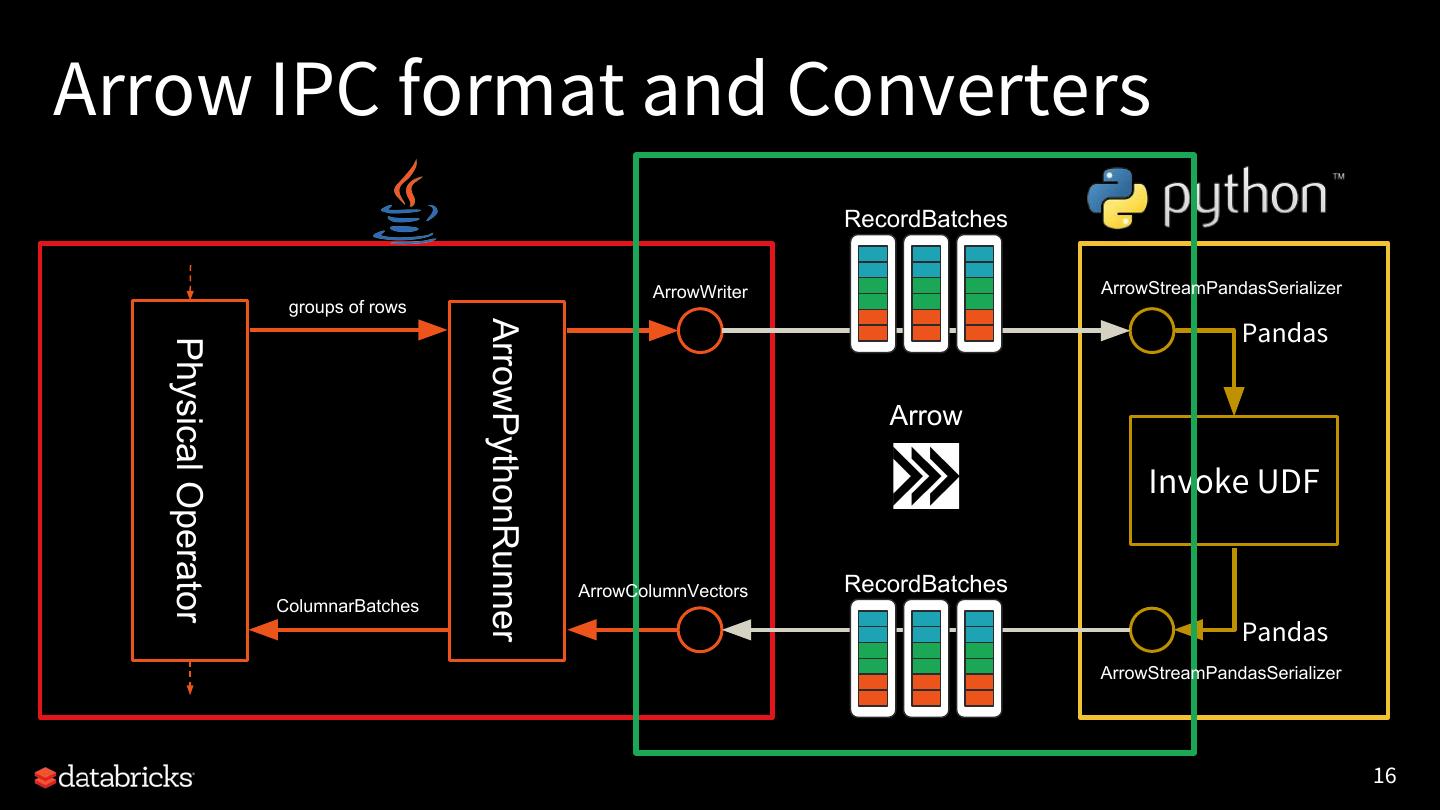
15 .Overview of Pandas UDF execution RecordBatches ArrowWriter ArrowStreamPandasSerializer groups of rows ArrowPythonRunner Pandas Physical Operator Arrow Invoke UDF ArrowColumnVectors RecordBatches ColumnarBatches Pandas ArrowStreamPandasSerializer 15
16 .Arrow IPC format and Converters RecordBatches ArrowWriter ArrowStreamPandasSerializer groups of rows ArrowPythonRunner Pandas Physical Operator Arrow Invoke UDF ArrowColumnVectors RecordBatches ColumnarBatches Pandas ArrowStreamPandasSerializer 16
17 .Encapsulated message format • https://arrow.apache.org/docs/ipc.html • Messages • Schema, RecordBatch, DictionaryBatch, Tensor • Formats • Streaming format – Schema + (DictionaryBatch + RecordBatch)+ • File format – header + (Streaming format) + footer Pandas UDFs use Streaming format. 17
18 .Arrow Converters in Spark in Java/Scala • ArrowWriter [src] • A wrapper for writing VectorSchemaRoot and ValueVectors • ArrowColumnVector [src] • A wrapper for reading ValueVectors, works with ColumnarBatch in Python • ArrowStreamPandasSerializer [src] • A wrapper for RecordBatchReader and RecordBatchWriter 18
19 .Handling Communication RecordBatches ArrowWriter ArrowStreamPandasSerializer groups of rows ArrowPythonRunner Pandas Physical Operator Arrow Invoke UDF ArrowColumnVectors RecordBatches ColumnarBatches Pandas ArrowStreamPandasSerializer 19
20 .Handling Communication ArrowPythonRunner [src] • Handle the communication between JVM and the Python worker • Create or reuse a Python worker • Open a Socket to communicate • Write data to the socket with ArrowWriter in a separate thread • Read data from the socket • Return an iterator of ColumnarBatch of ArrowColumnVectors 20
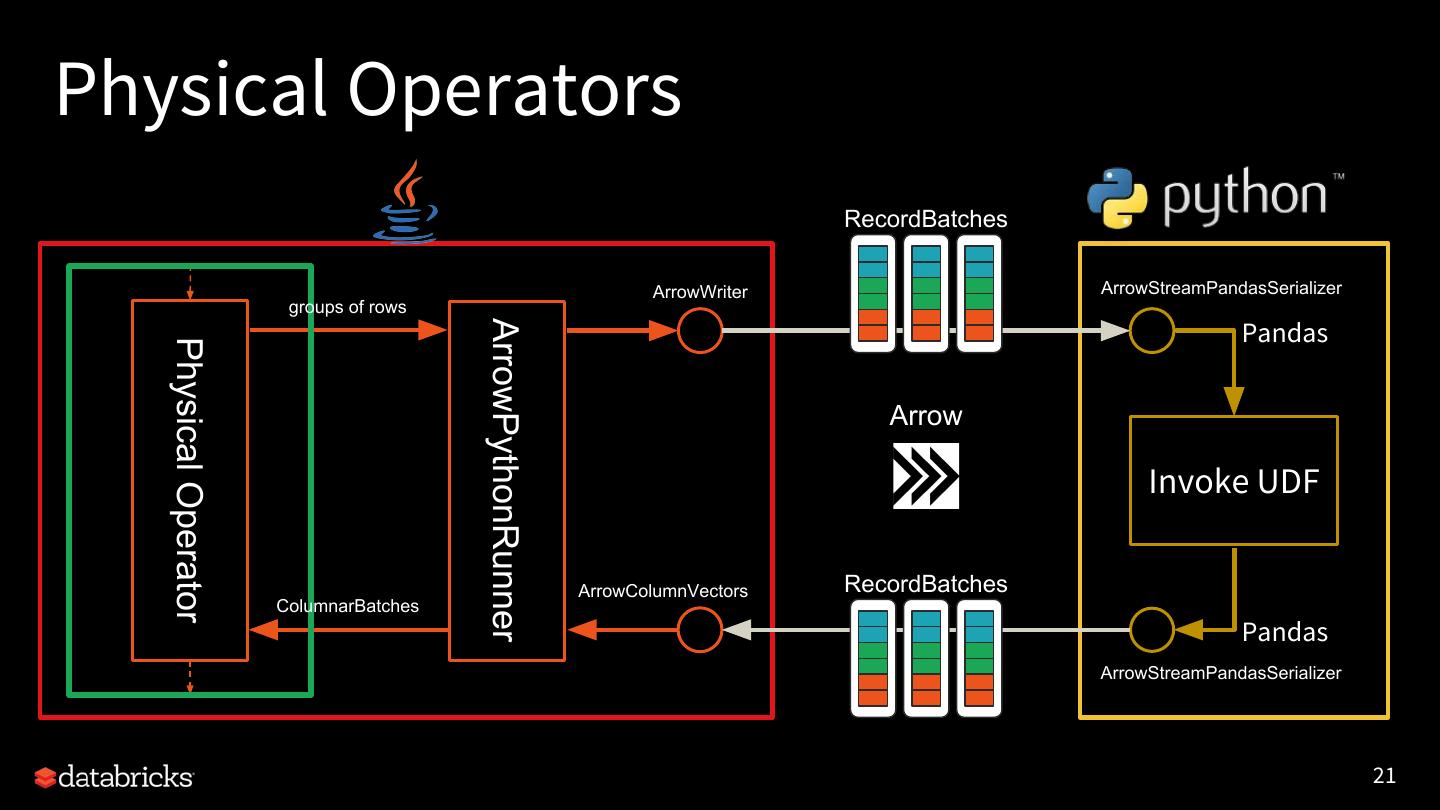
21 .Physical Operators RecordBatches ArrowWriter ArrowStreamPandasSerializer groups of rows ArrowPythonRunner Pandas Physical Operator Arrow Invoke UDF ArrowColumnVectors RecordBatches ColumnarBatches Pandas ArrowStreamPandasSerializer 21
22 .Physical Operators Create a RDD to execute the UDF. • There are several operators for each PythonUDFType • Group input data and pass to ArrowPythonRunner • SCALAR: every configured number of rows – “spark.sql.execution.arrow.maxRecordsPerBatch” (10,000 by default) • GROUP_XXX: every group • Read the result iterator of ColumnarBatch • Return the iterator of rows over ColumnarBatches 22
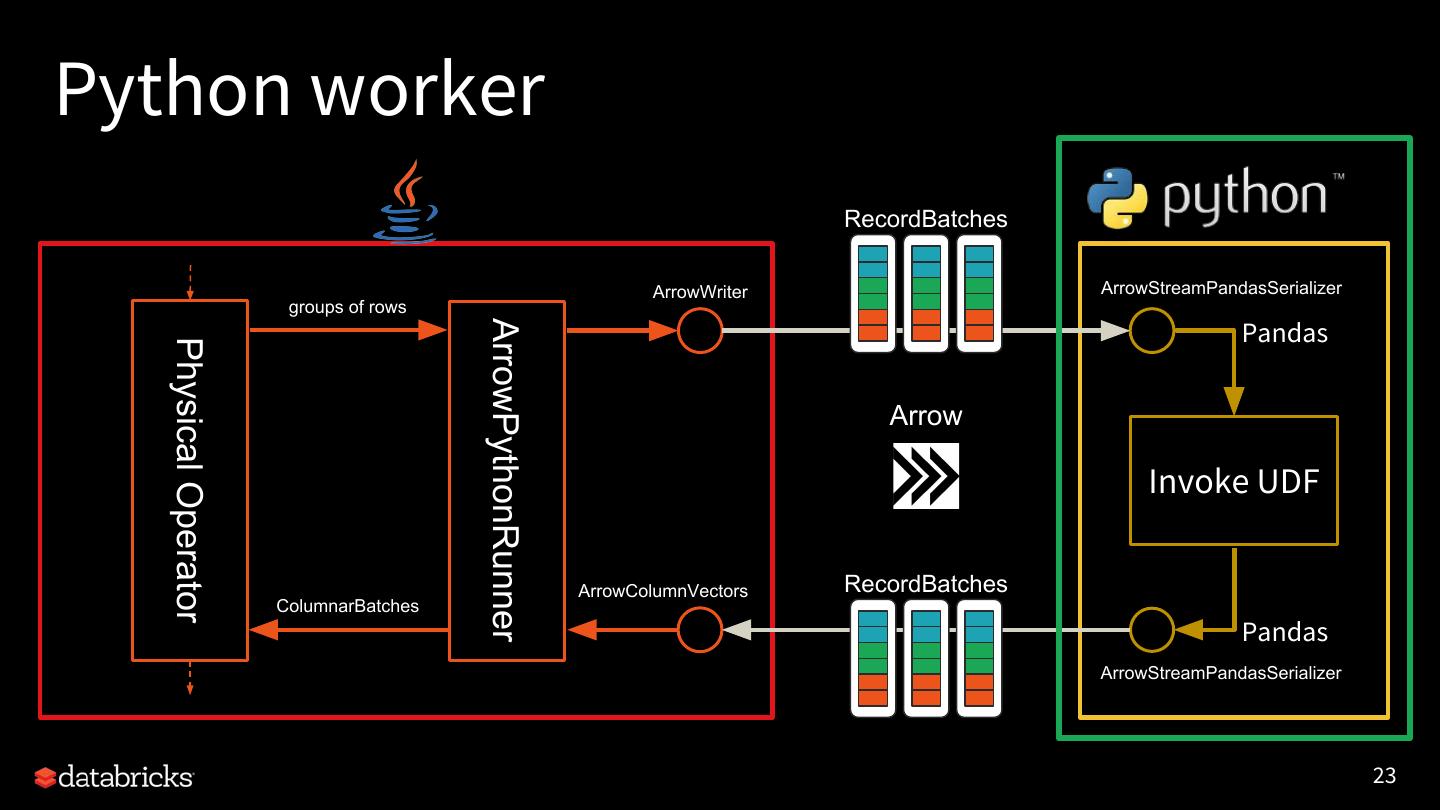
23 .Python worker RecordBatches ArrowWriter ArrowStreamPandasSerializer groups of rows ArrowPythonRunner Pandas Physical Operator Arrow Invoke UDF ArrowColumnVectors RecordBatches ColumnarBatches Pandas ArrowStreamPandasSerializer 23
24 .Python worker worker.py [src] • Open a Socket to communicate • Set up a UDF execution for each PythonUDFType • Create a map function – prepare the arguments – invoke the UDF – check and return the result • Execute the map function over the input iterator of Pandas DataFrame • Write back the results 24
25 .Agenda • Apache Spark and PySpark • PySpark and Pandas • Python UDF and Pandas UDF • Pandas UDF and Apache Arrow • Arrow IPC format and Converters • Handling Communication • Physical Operators • Python worker • Work In Progress • Follow-up Events 25
26 .Work In Progress We can track issues related to Pandas UDF. • [SPARK-22216] Improving PySpark/Pandas interoperability • 37 subtasks in total • 3 subtasks are in progress • 4 subtasks are open 26
27 .Work In Progress • Window Pandas UDF • [SPARK-24561] User-defined window functions with pandas udf (bounded window) • Performance Improvement of toPandas -> merged! • [SPARK-25274] Improve toPandas with Arrow by sending out-of-order record batches • SparkR • [SPARK-25981] Arrow optimization for conversion from R DataFrame to Spark DataFrame 27
28 .Agenda • Apache Spark and PySpark • PySpark and Pandas • Python UDF and Pandas UDF • Pandas UDF and Apache Arrow • Arrow IPC format and Converters • Handling Communication • Physical Operators • Python worker • Work In Progress • Follow-up Events 28
29 .Follow-up Events Spark Developers Meetup • 2018/12/15 (Sat) 10:00-18:00 • @ Yahoo! LODGE • https://passmarket.yahoo.co.jp/event/show/detail/01a98dzxf auj.html 29
相关推荐

加关注
3秒后跳转登录页面
去登陆

