






































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
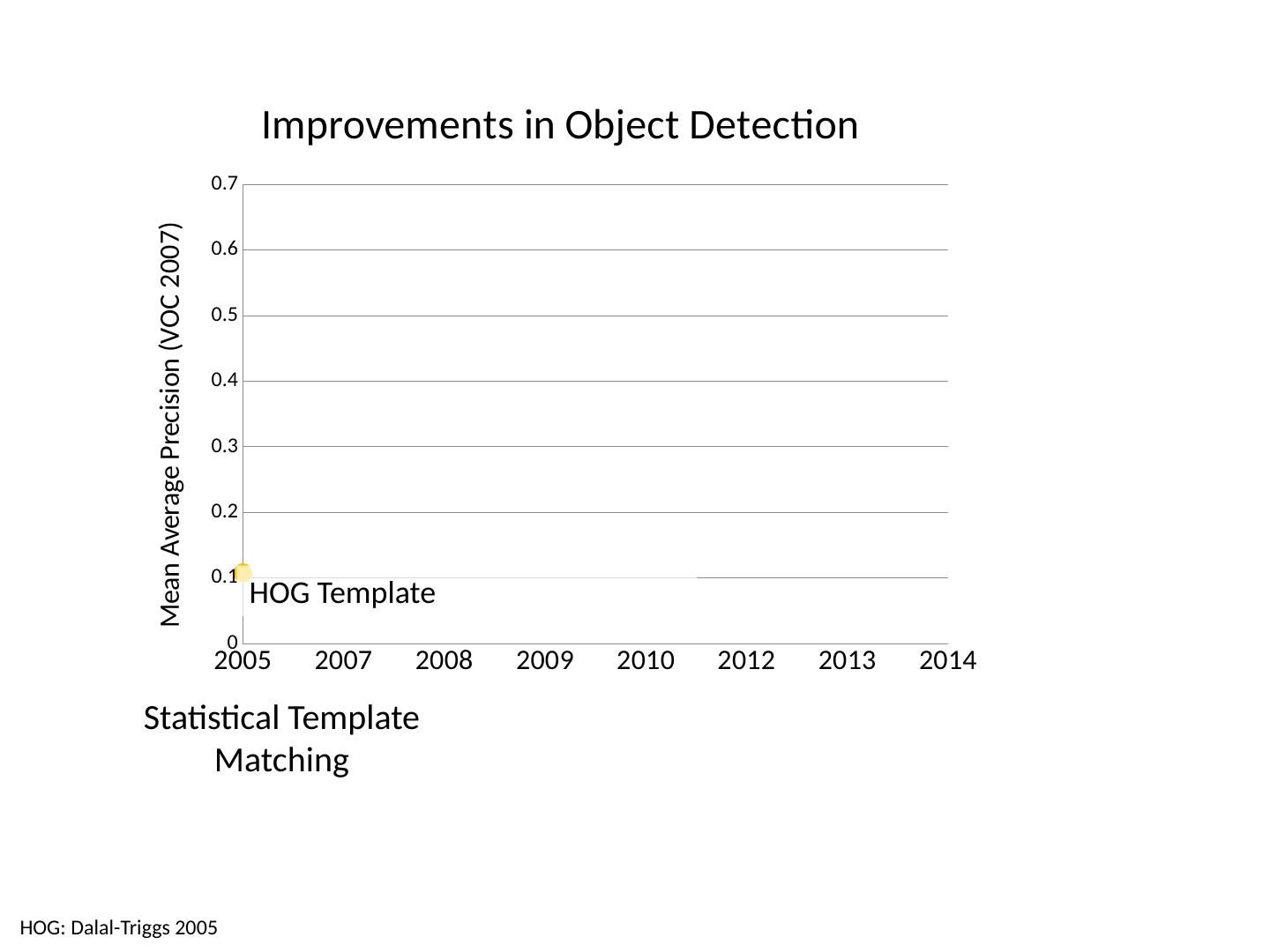
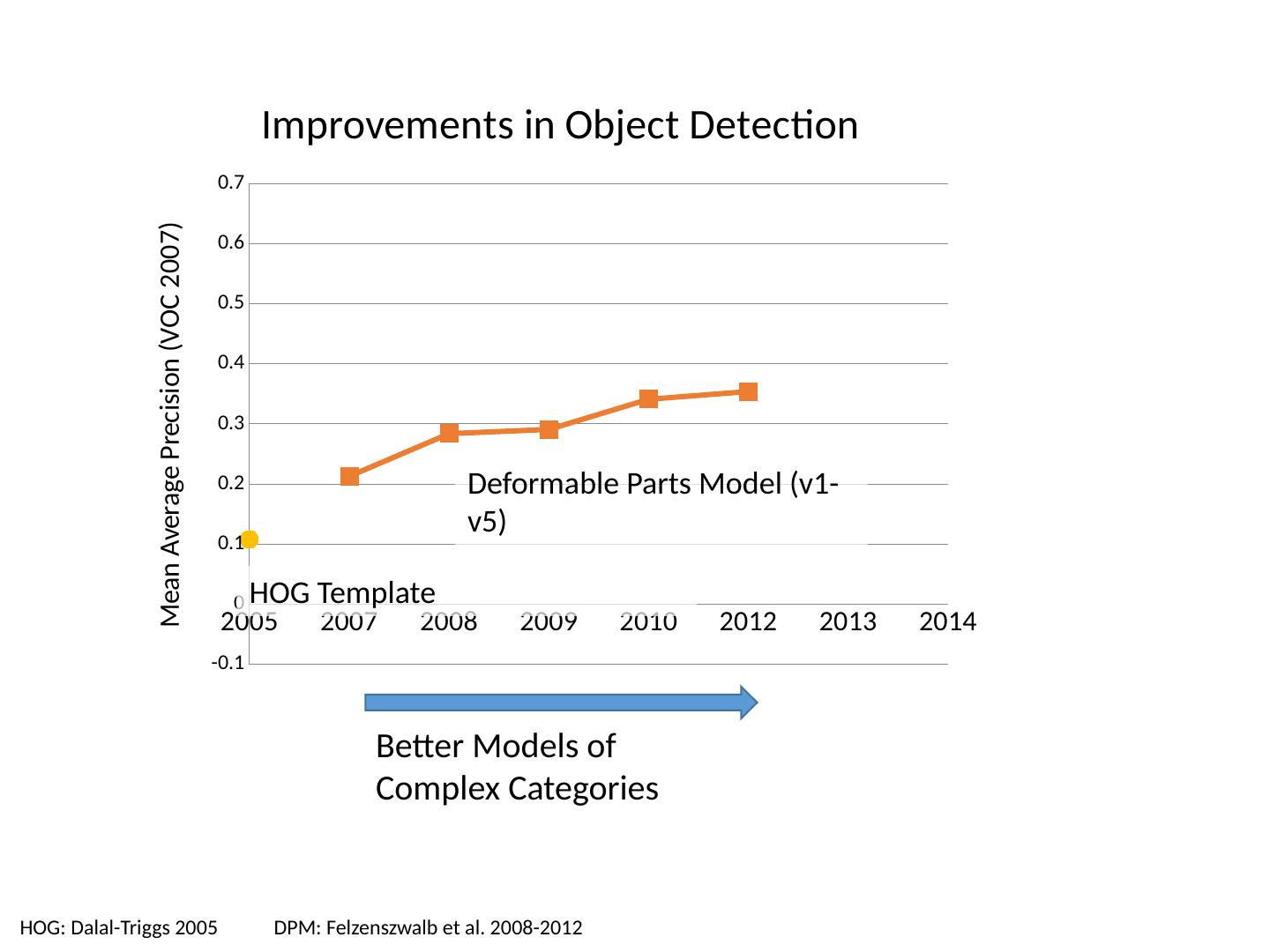
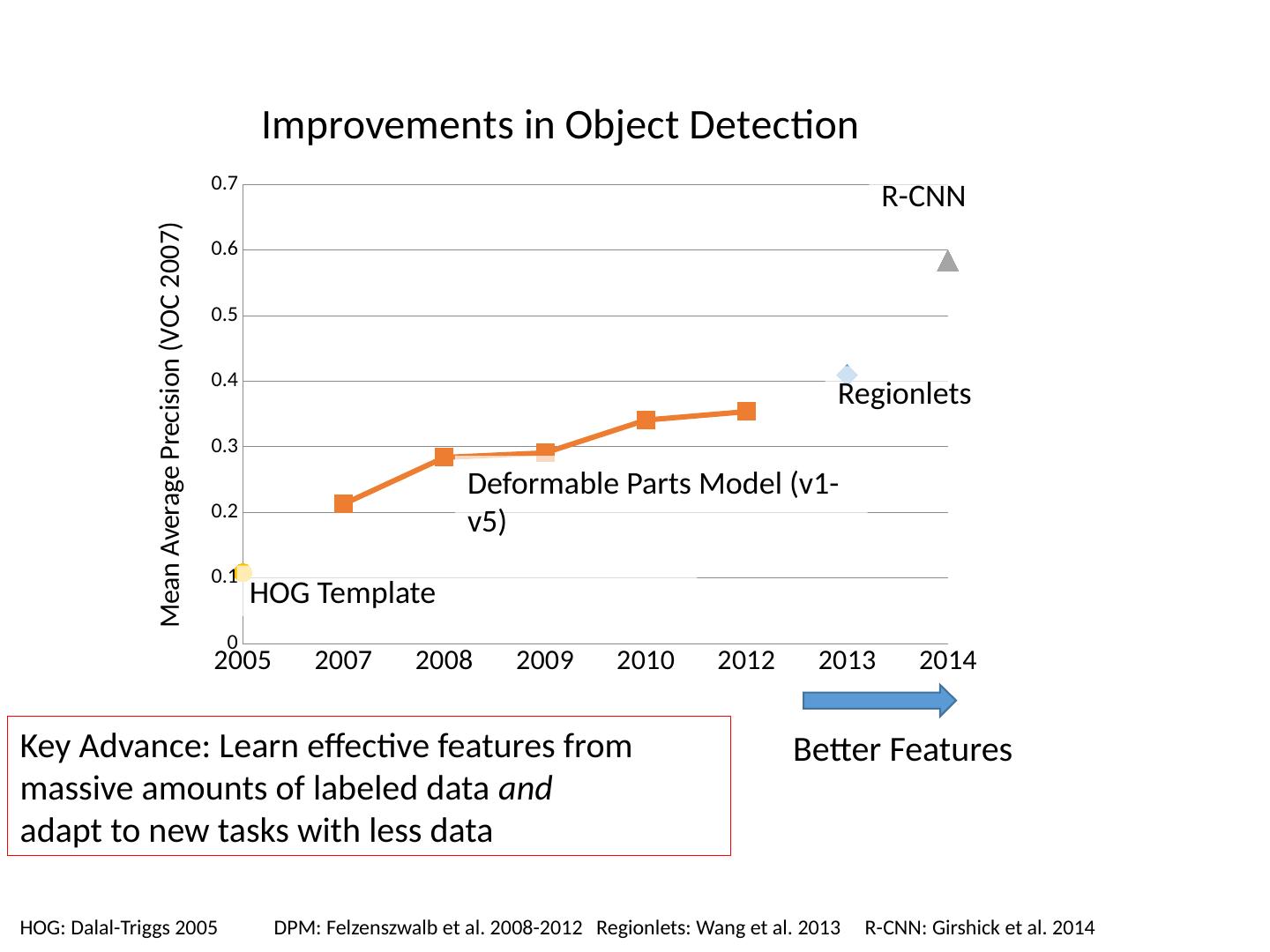
利用统计模板进行对象检测
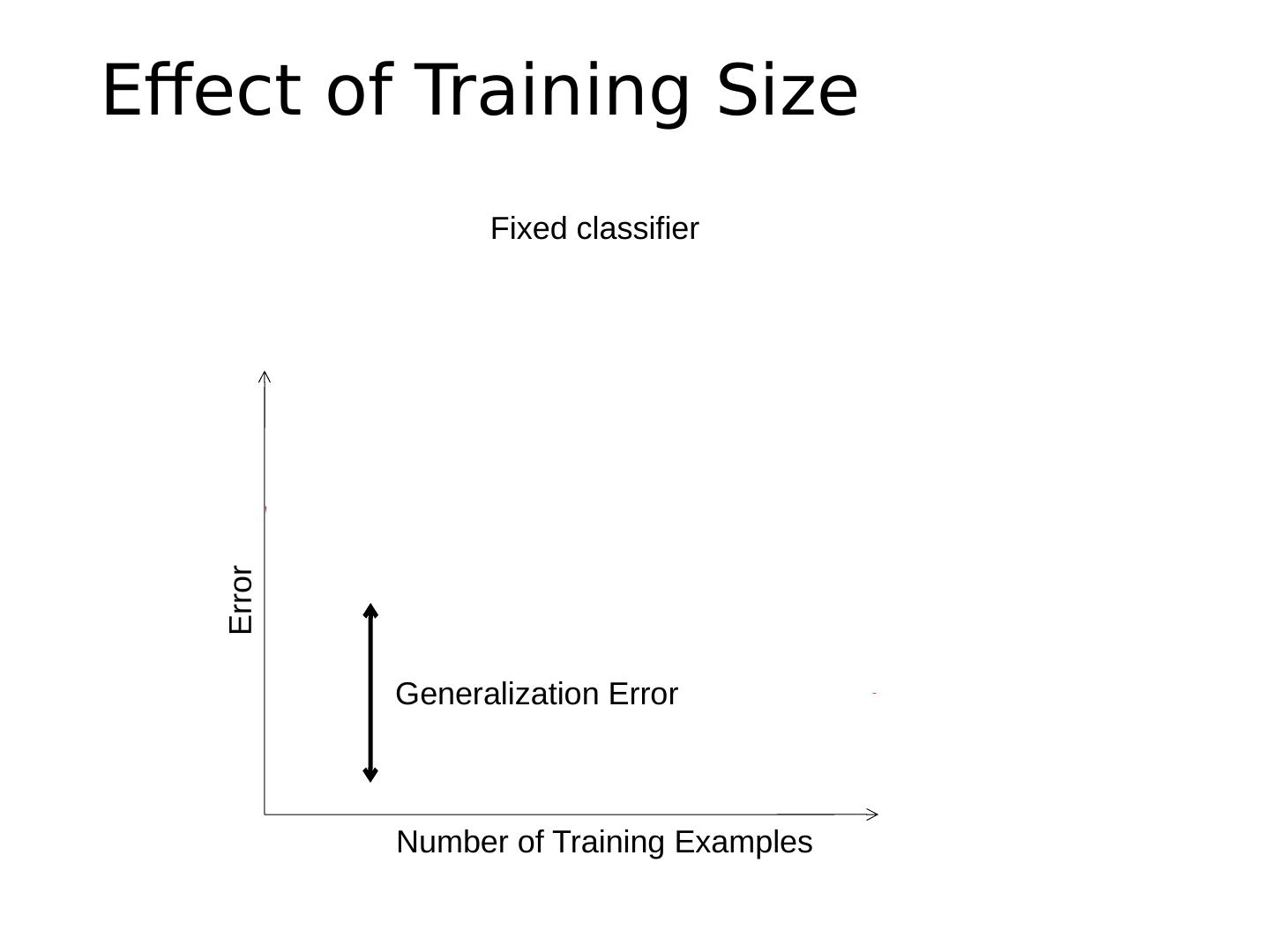
本章讲述审查/完成监督学习,对象类别检测概述,统计模板匹配包括Dalal-Triggs行人检测器、Viola-Jones探测器、R-CNN检测器。首先复习上一讲的内容,基于范例:从具有最相似特性的示例中转移类别标签;线性分类器:对正标签的置信度是特征的加权和;非线性分类器:基于更复杂的特征函数的预测;生成分类器:指定最能解释特征的标签(使特征最有可能出现)。以及对相关模板的介绍。
展开查看详情
1 .Object Detection with Statistical Template Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem, J. Hays
2 .Administrative stuffs HW 5 is out Due 11:59pm on Wed, November 16 Scene categorization Please s tart early Final project proposal Feedback via email s
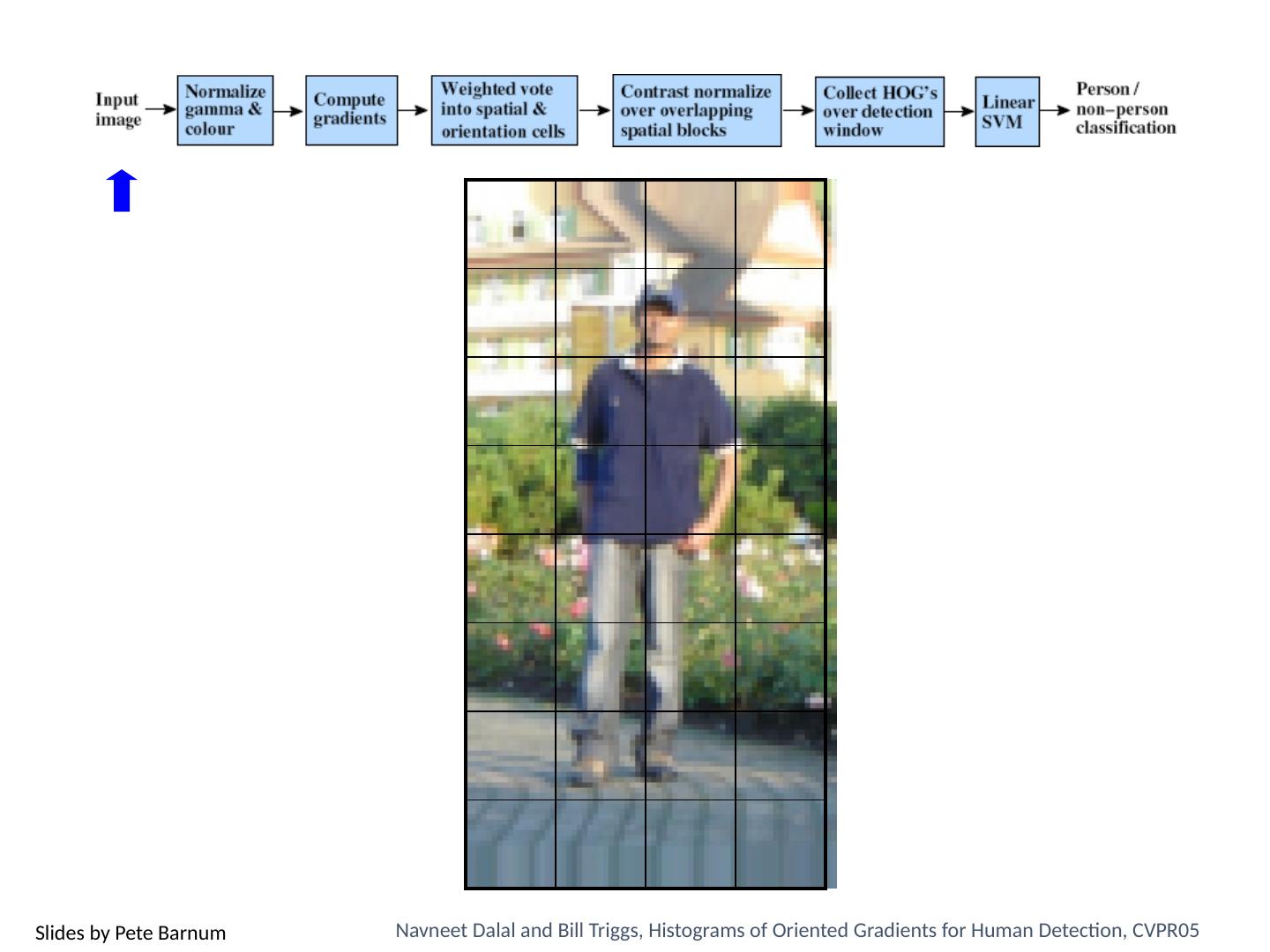
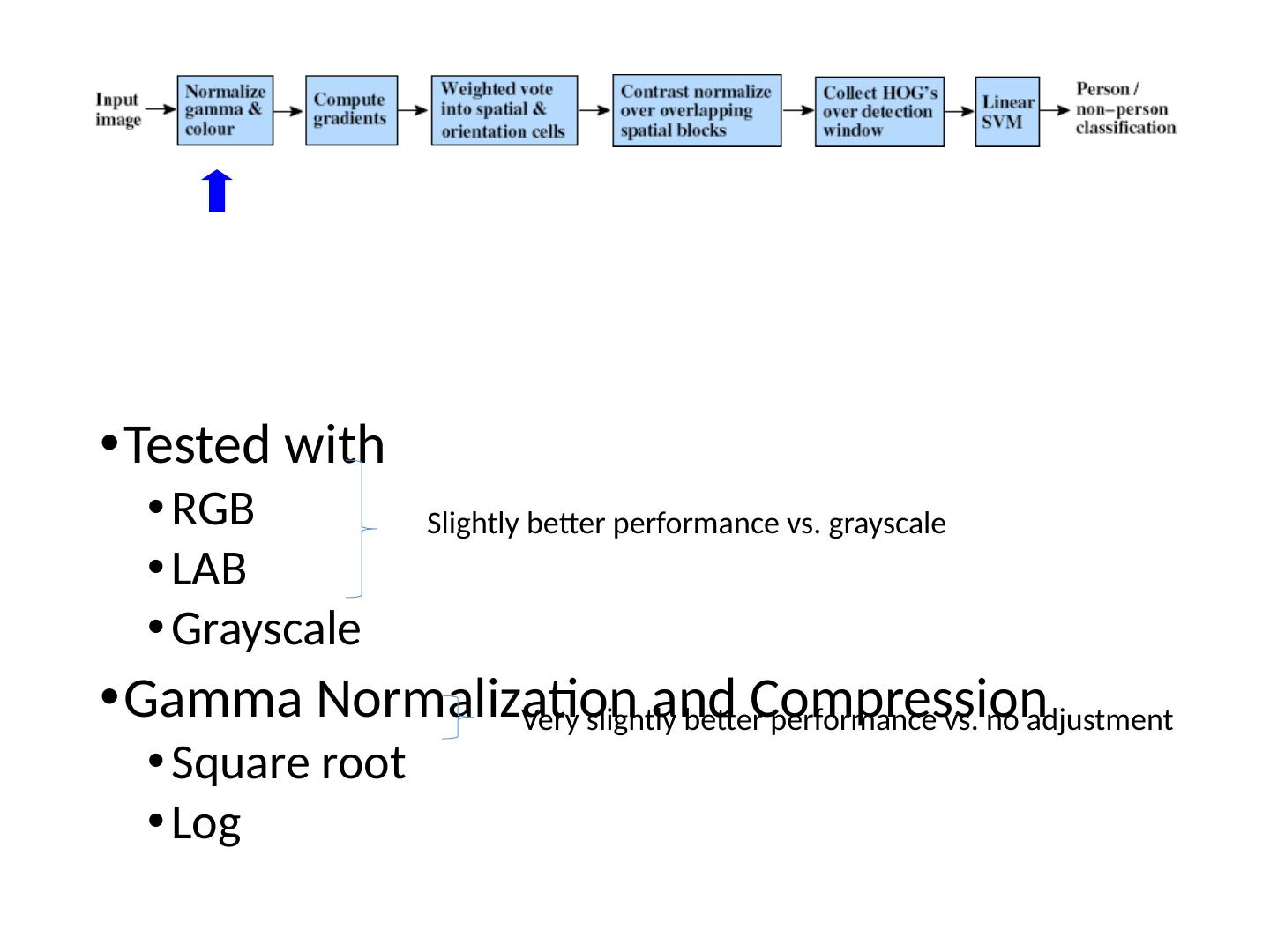
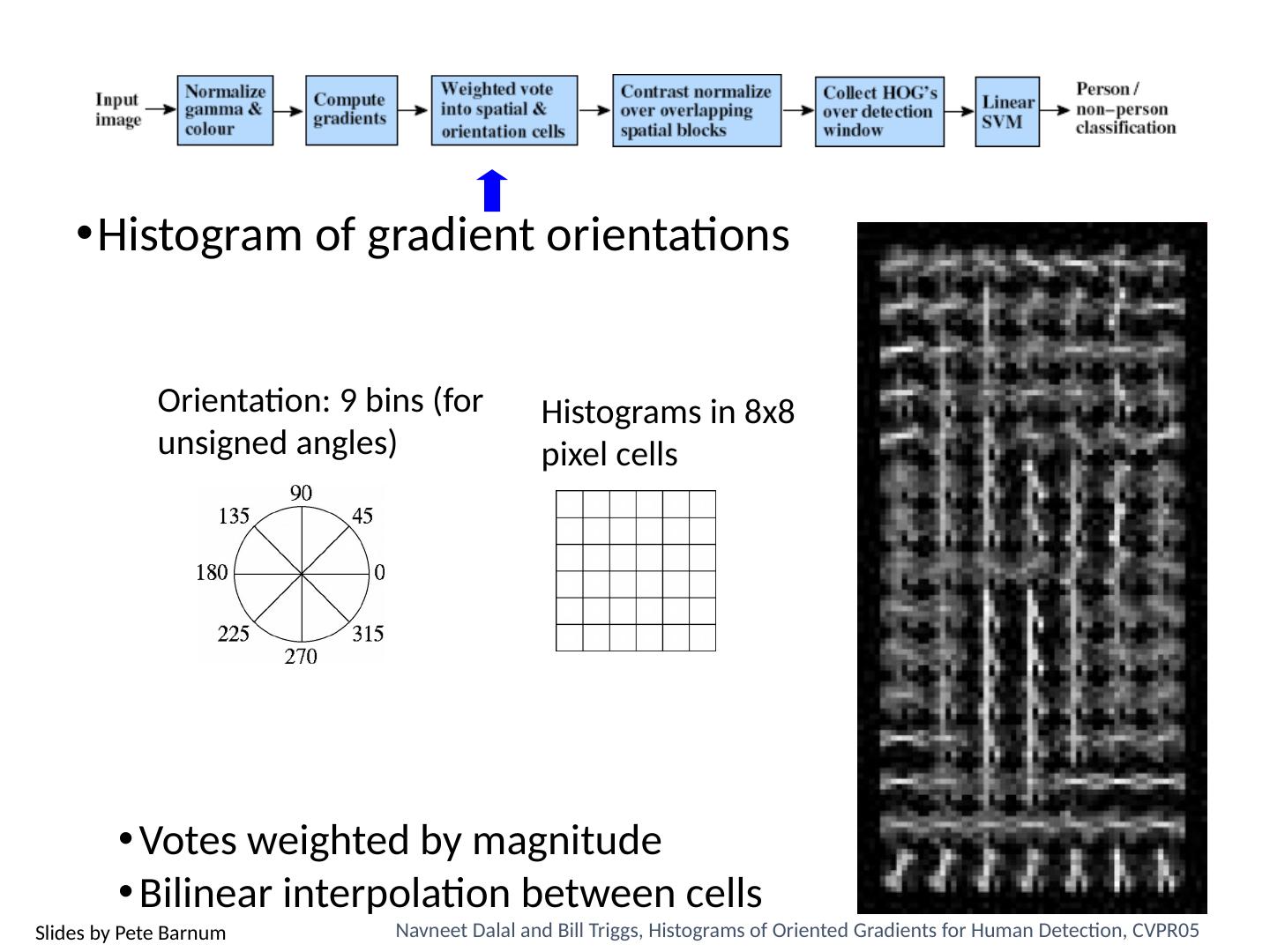
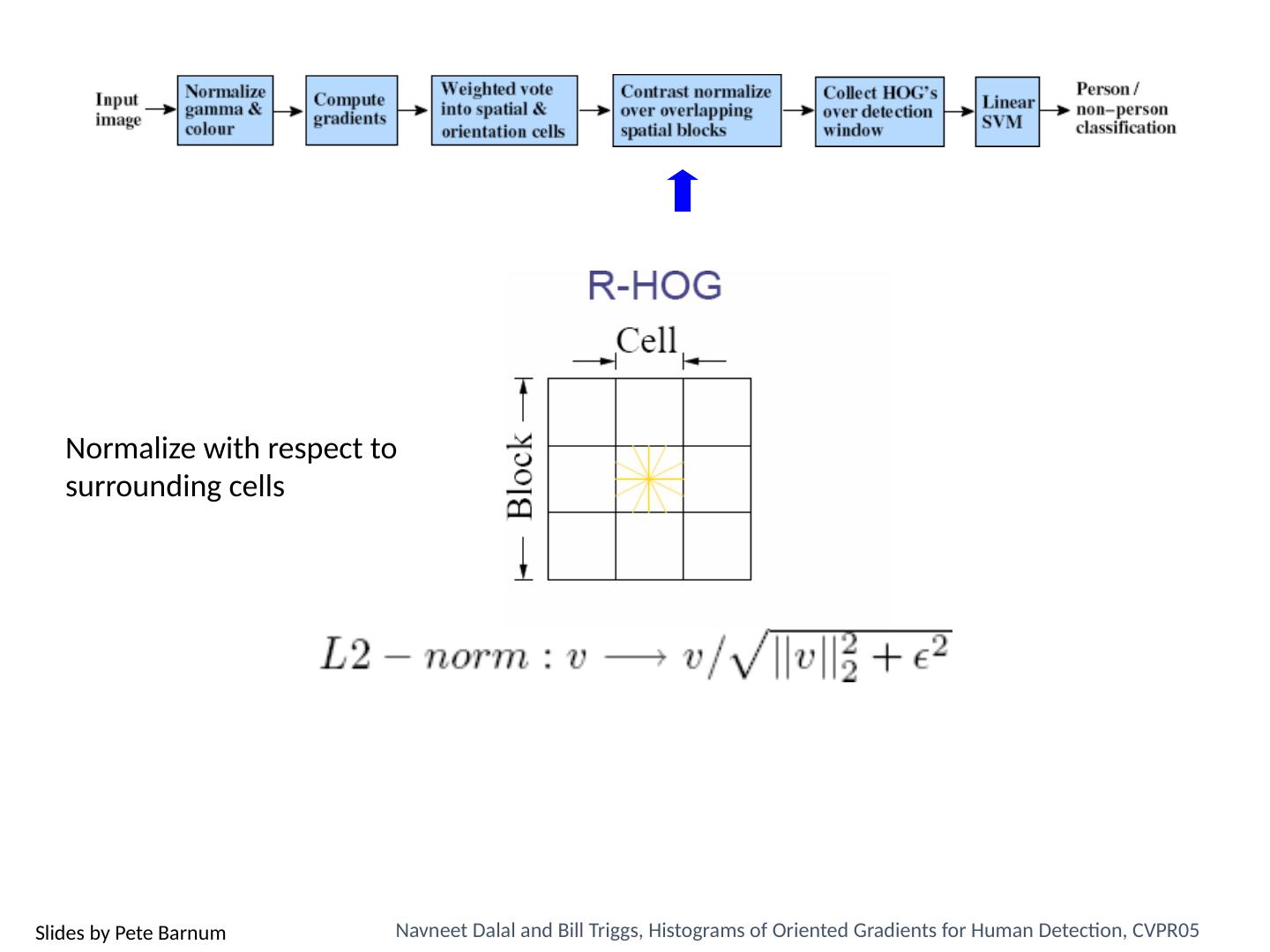
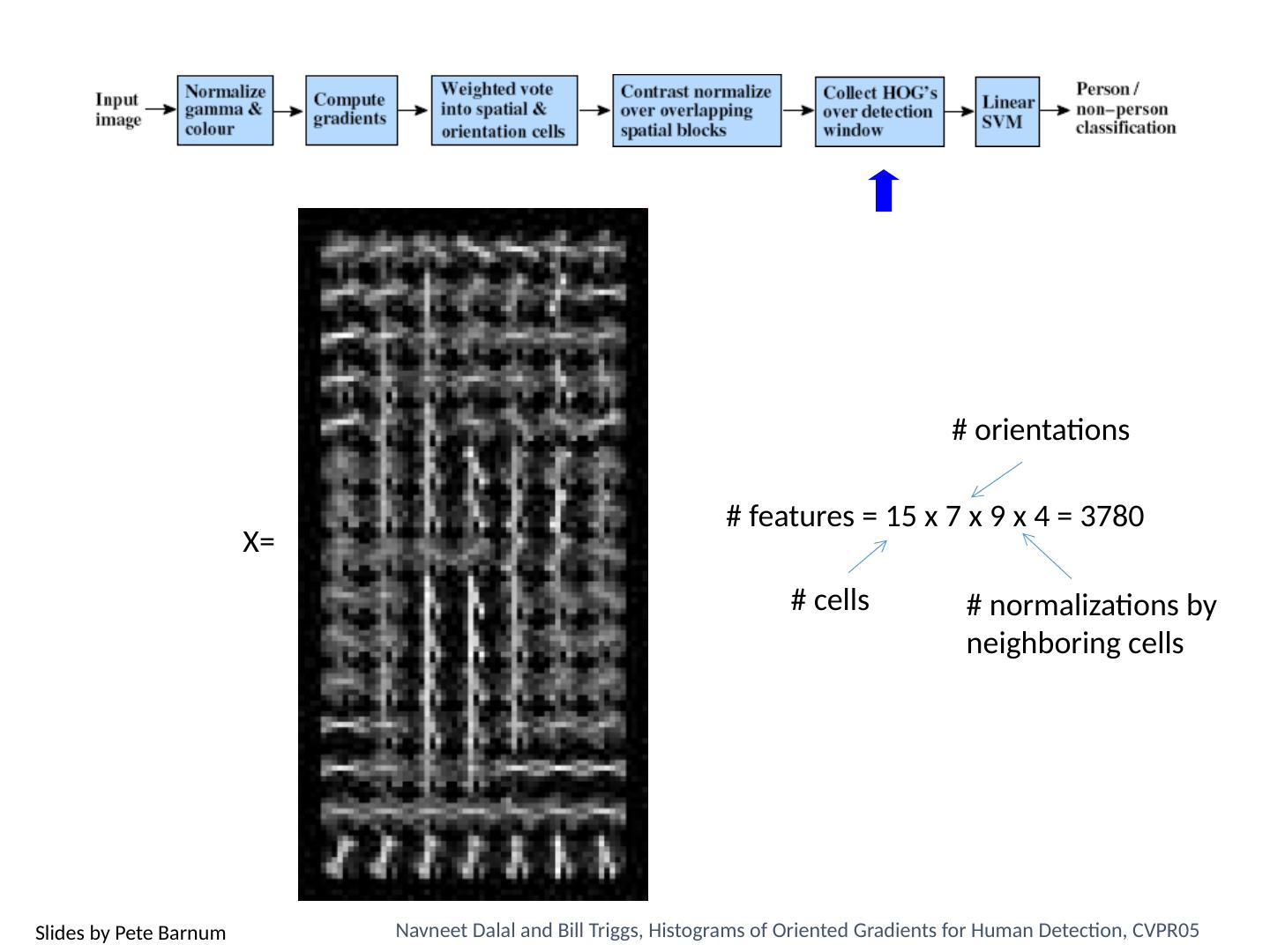
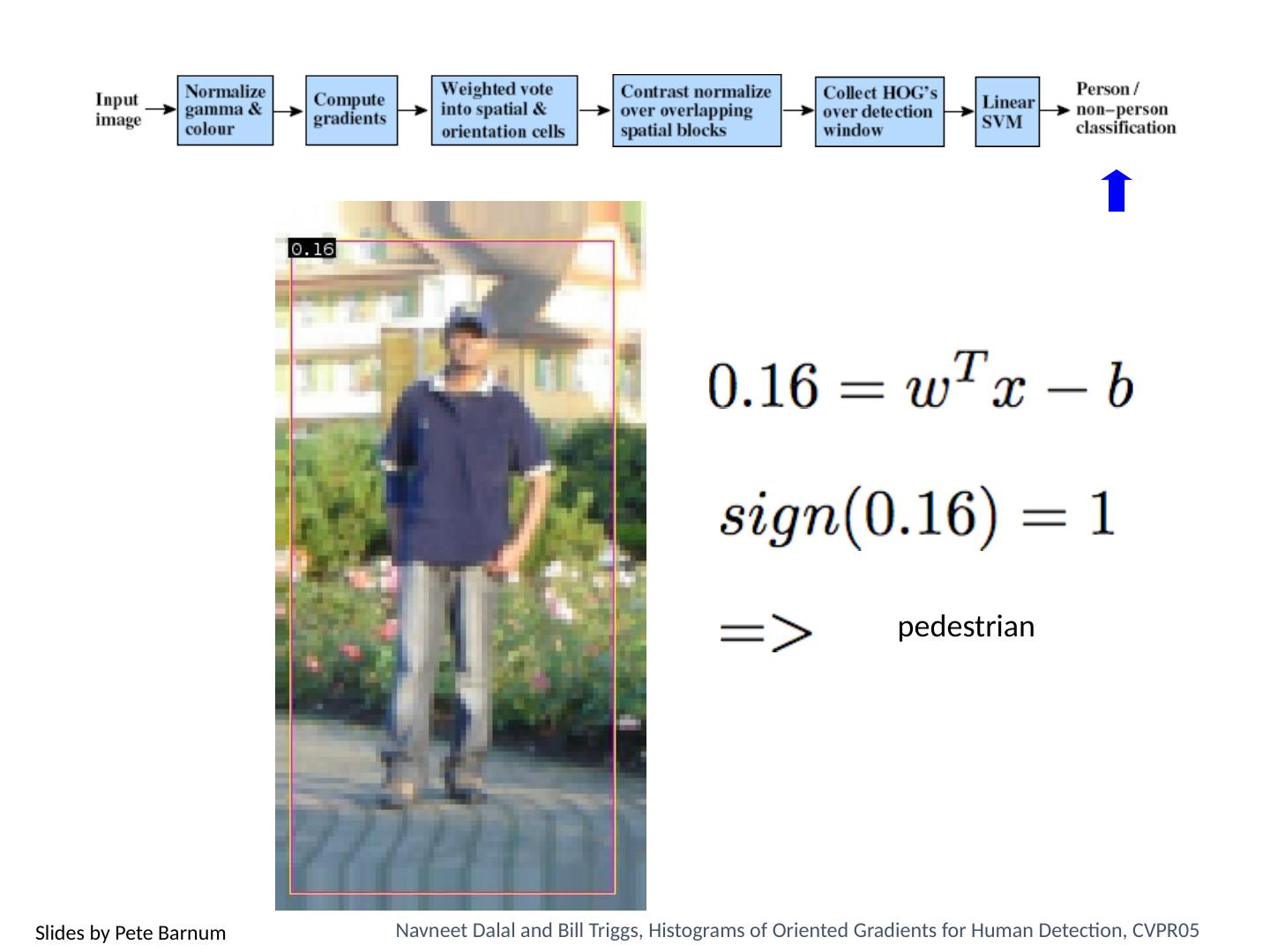
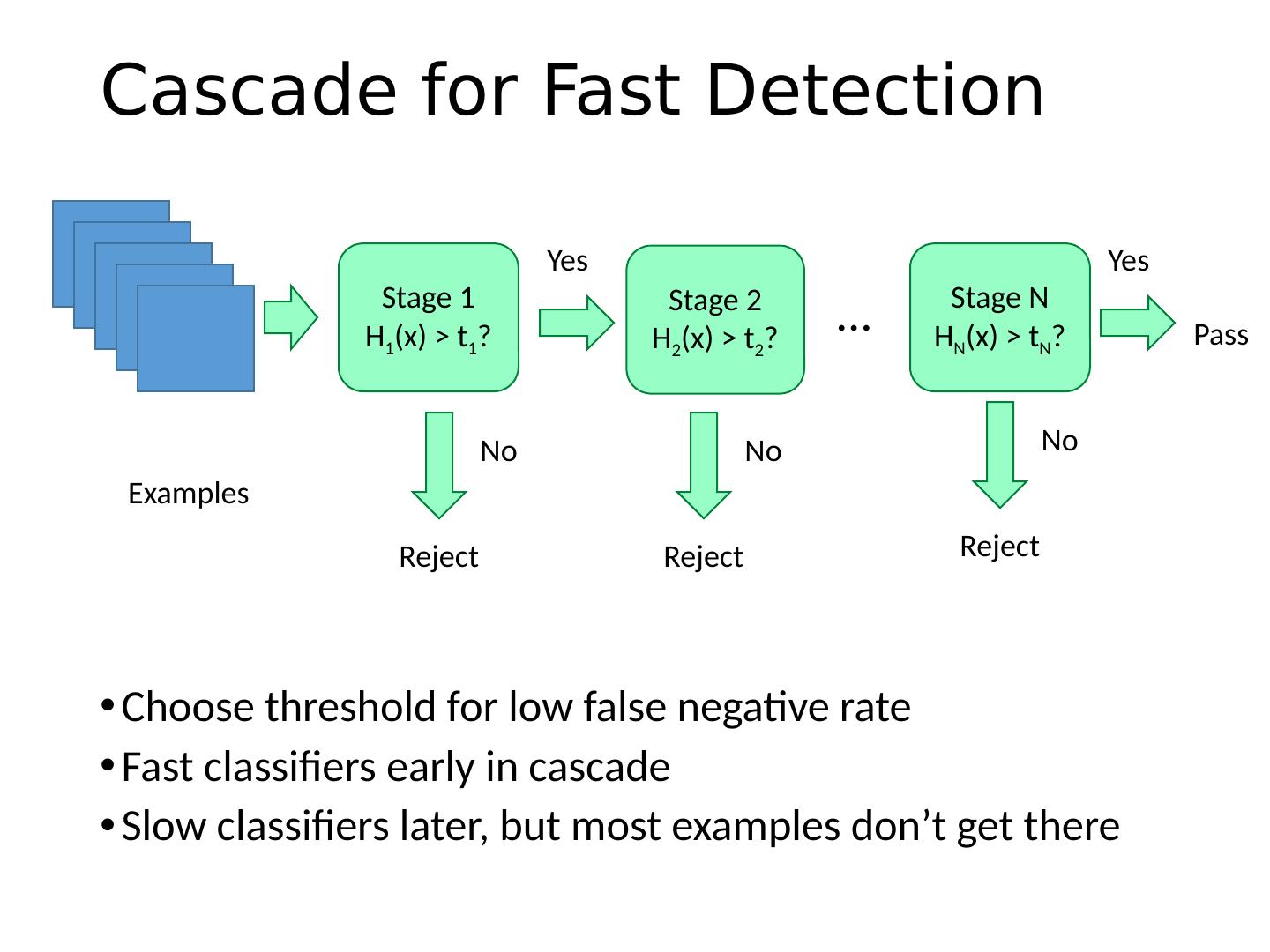
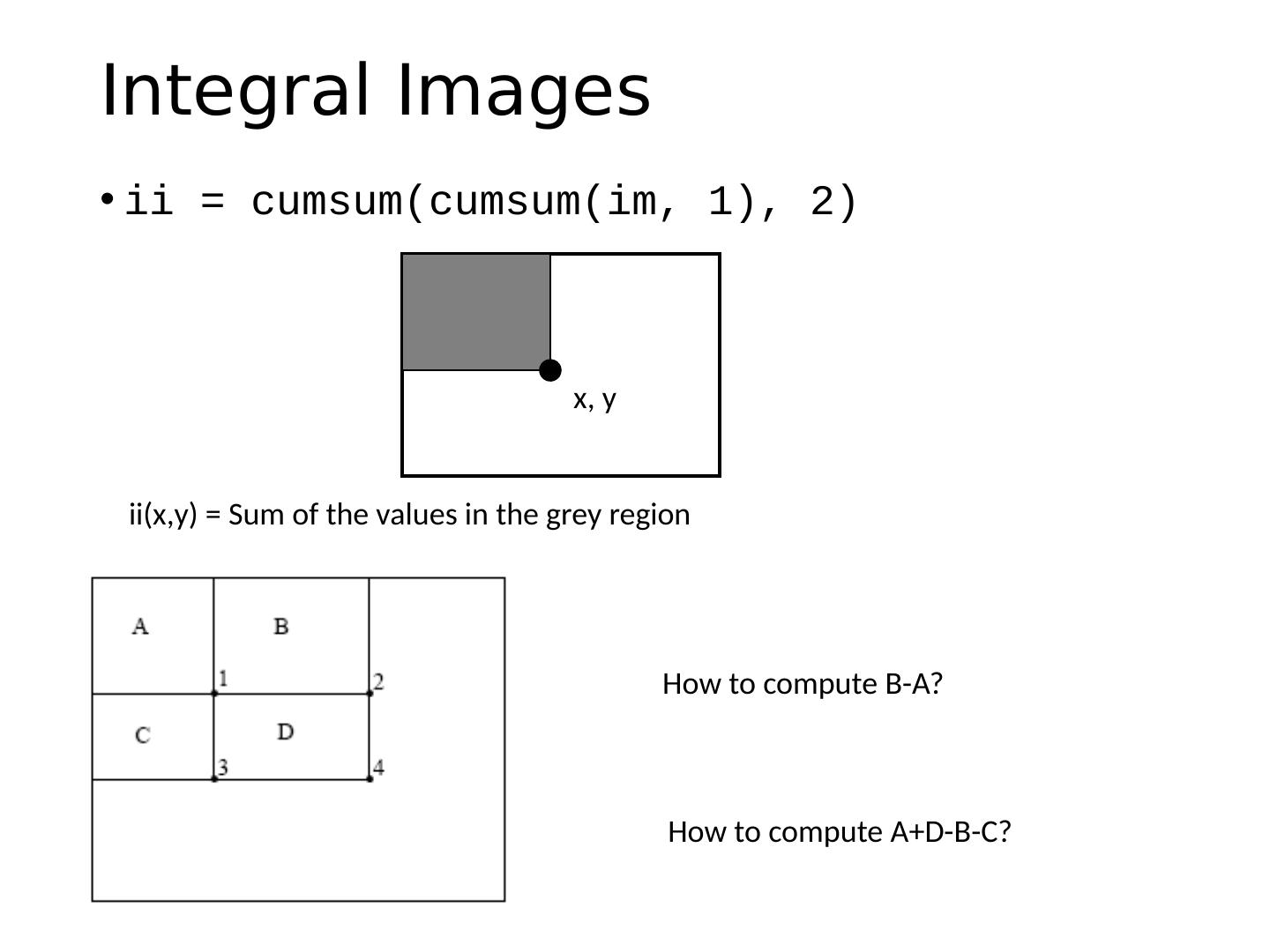
3 .Today’s class Review/finish supervised learning Overview of object category detection Statistical template matching Dalal-Triggs pedestrian detector (basic concept) Viola-Jones detector (cascades, integral images) R-CNN detector (object proposals/CNN)
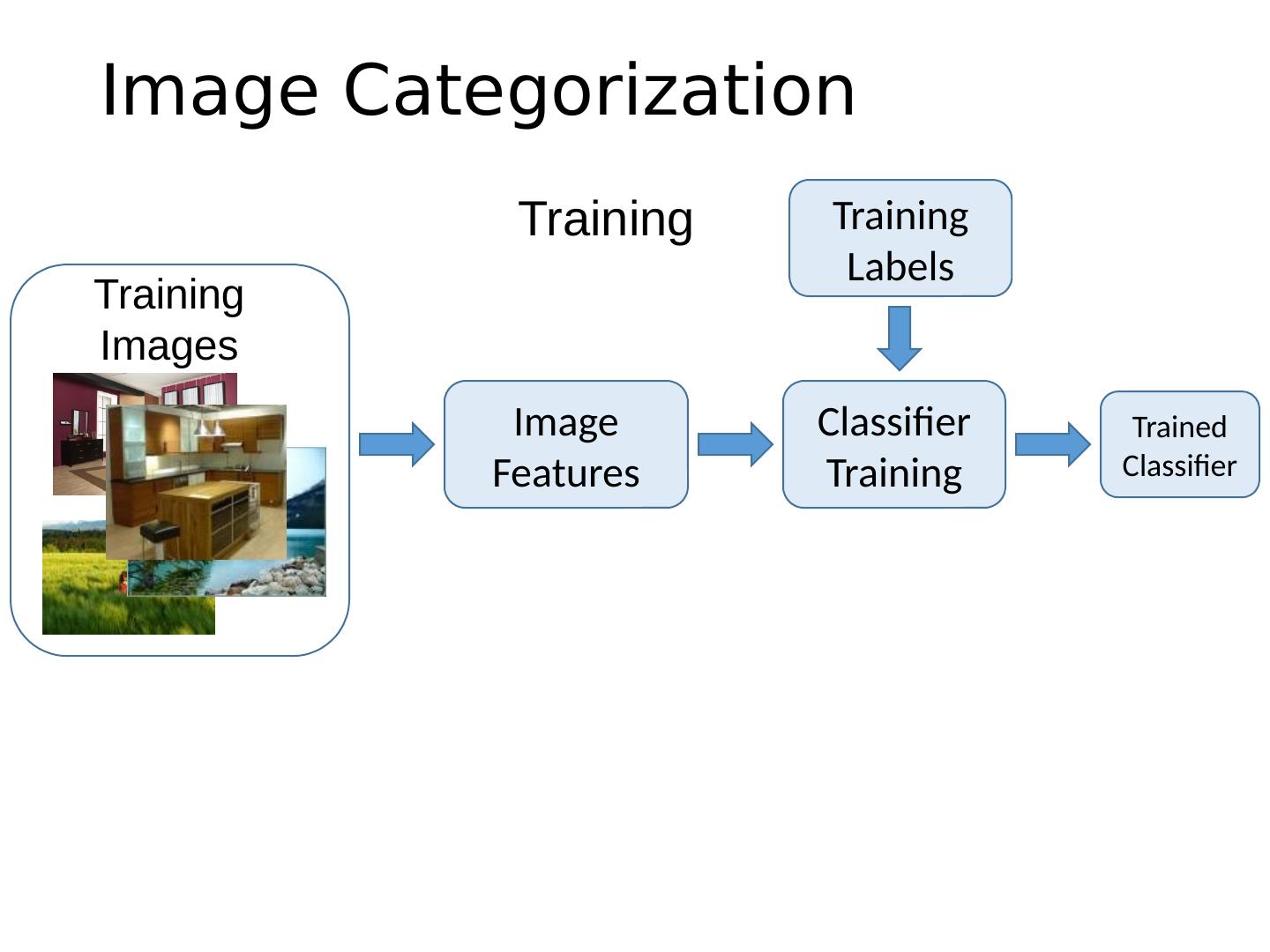
4 .Image Categorization Training Labels Training Images Classifier Training Training Image Features Trained Classifier
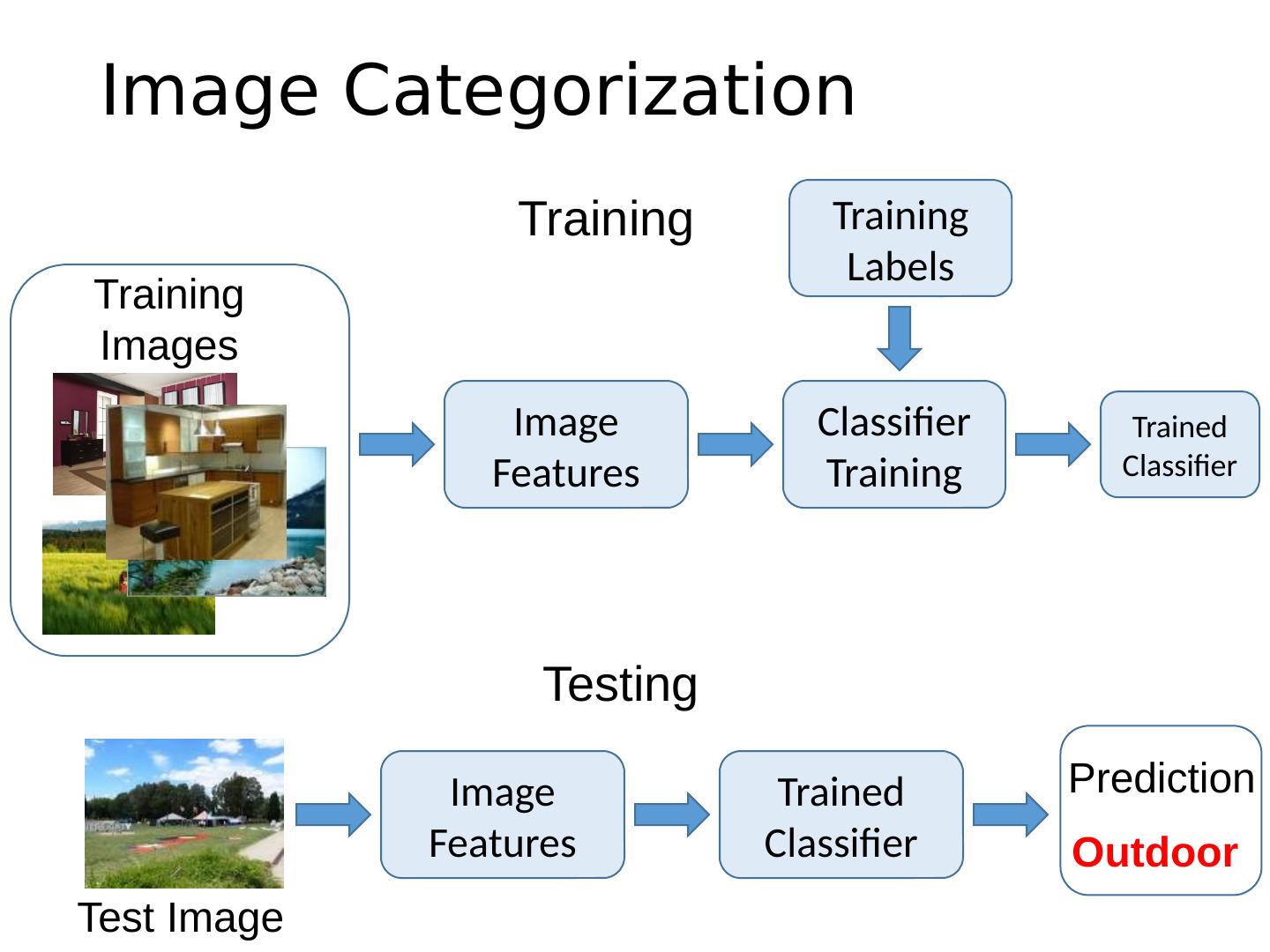
5 .Image Categorization Training Labels Training Images Classifier Training Training Image Features Image Features Testing Test Image Trained Classifier Trained Classifier Outdoor Prediction
6 .Image features : map images to feature space Classifiers : map feature space to label space x x x x x x x x o o o o o x2 x1 x x x x o o o o o o o x x x x x x x x o o o o o x2 x1 x x x x o o o o o o o x x x x x x x x o o o o o x2 x1 x x x x o o o o o o o
7 .Different types of classification Exemplar-based : transfer category labels from examples with most similar features What similarity function? What parameters? Linear classifier : confidence in positive label is a weighted sum of features What are the weights? Non-linear classifier : predictions based on more complex function of features What form does the classifier take? Parameters? Generative classifier : assign to the label that best explains the features (makes features most likely) What is the probability function and its parameters? Note: You can always fully design the classifier by hand, but usually this is too difficult. Typical solution: learn from training examples.
8 .Exemplar-based Models Transfer the label(s) of the most similar training examples
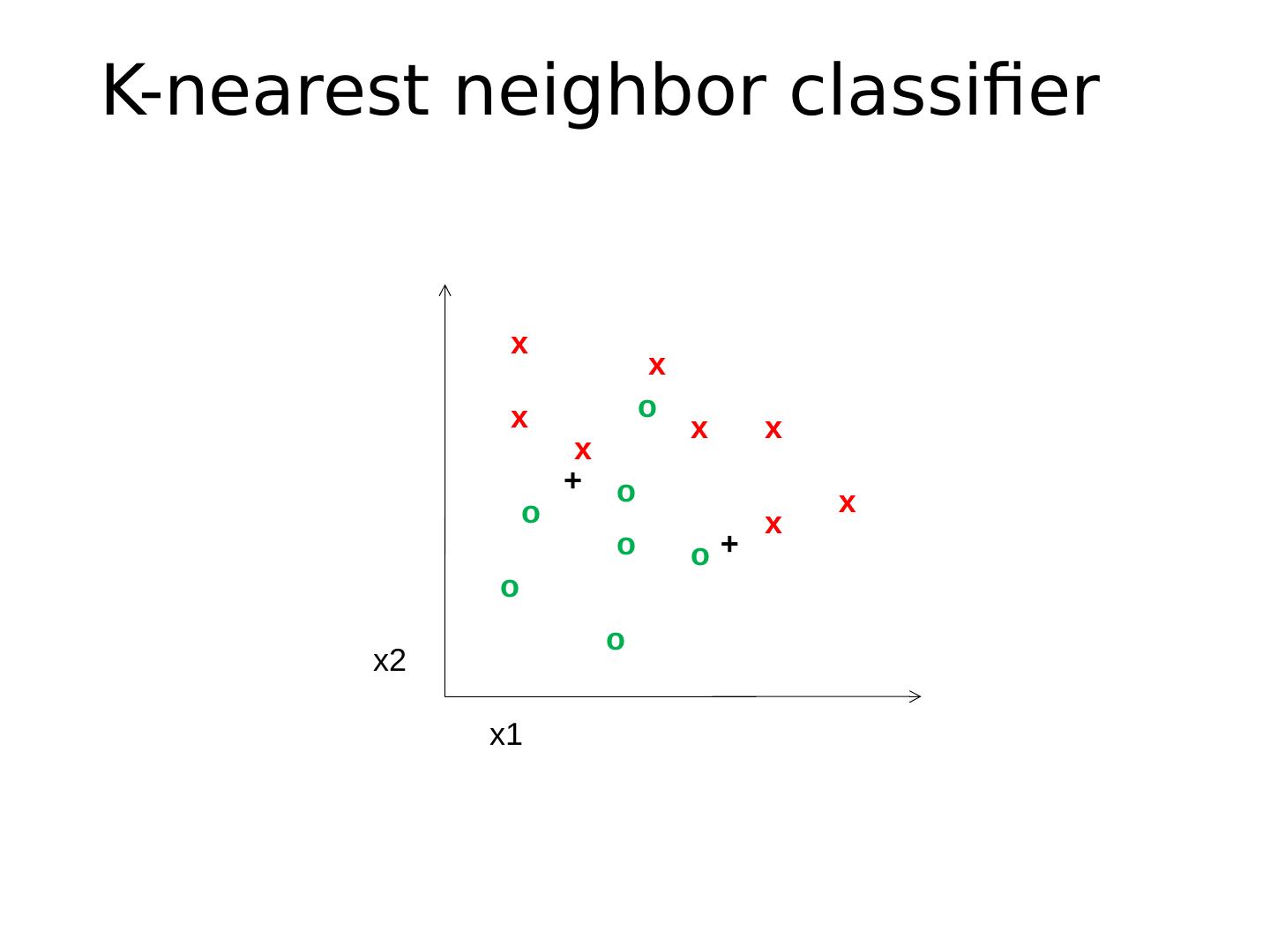
9 .K-nearest neighbor classifier x x x x x x x x o o o o o o o x2 x1 + +
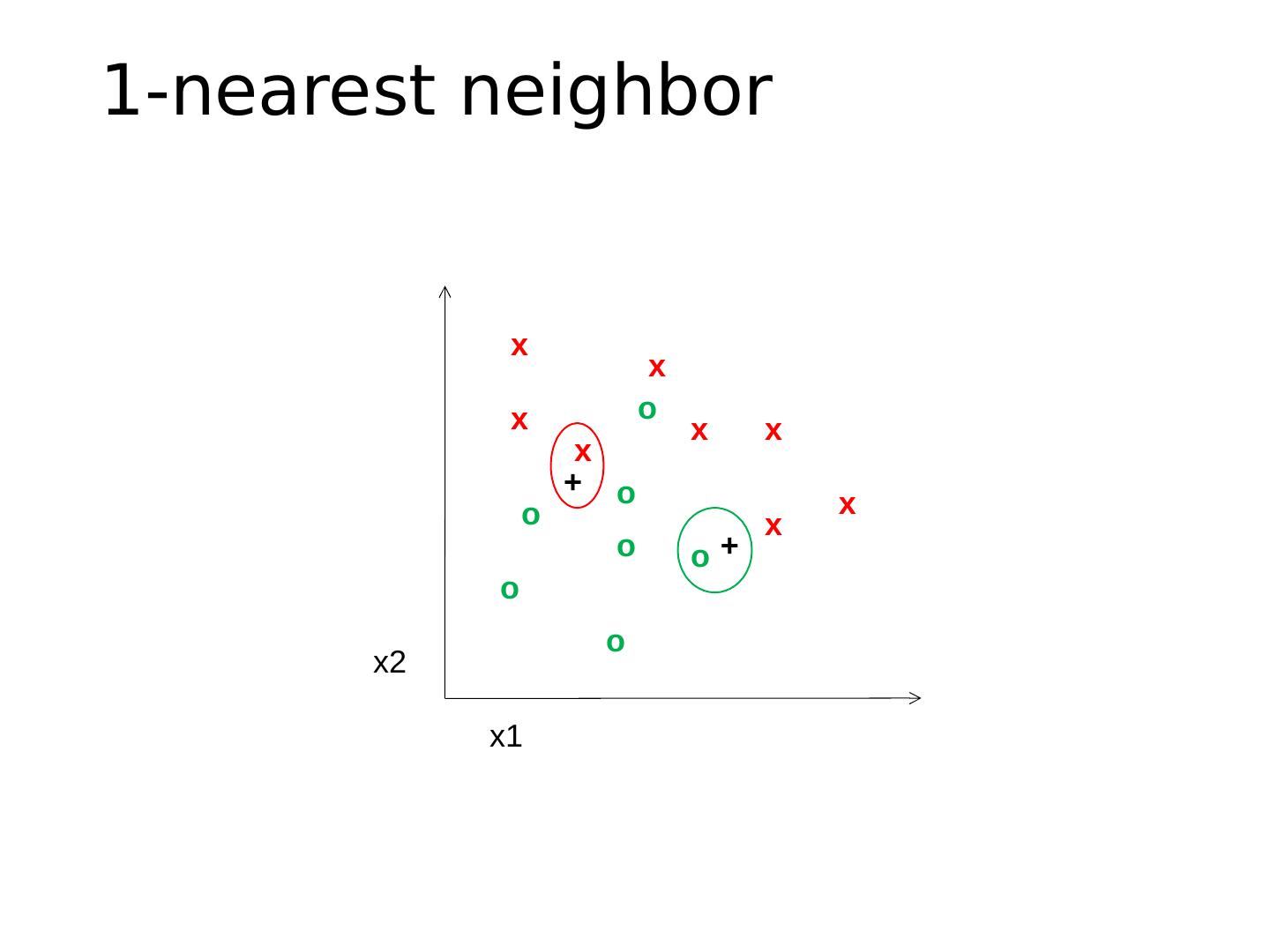
10 .1-nearest neighbor x x x x x x x x o o o o o o o x2 x1 + +
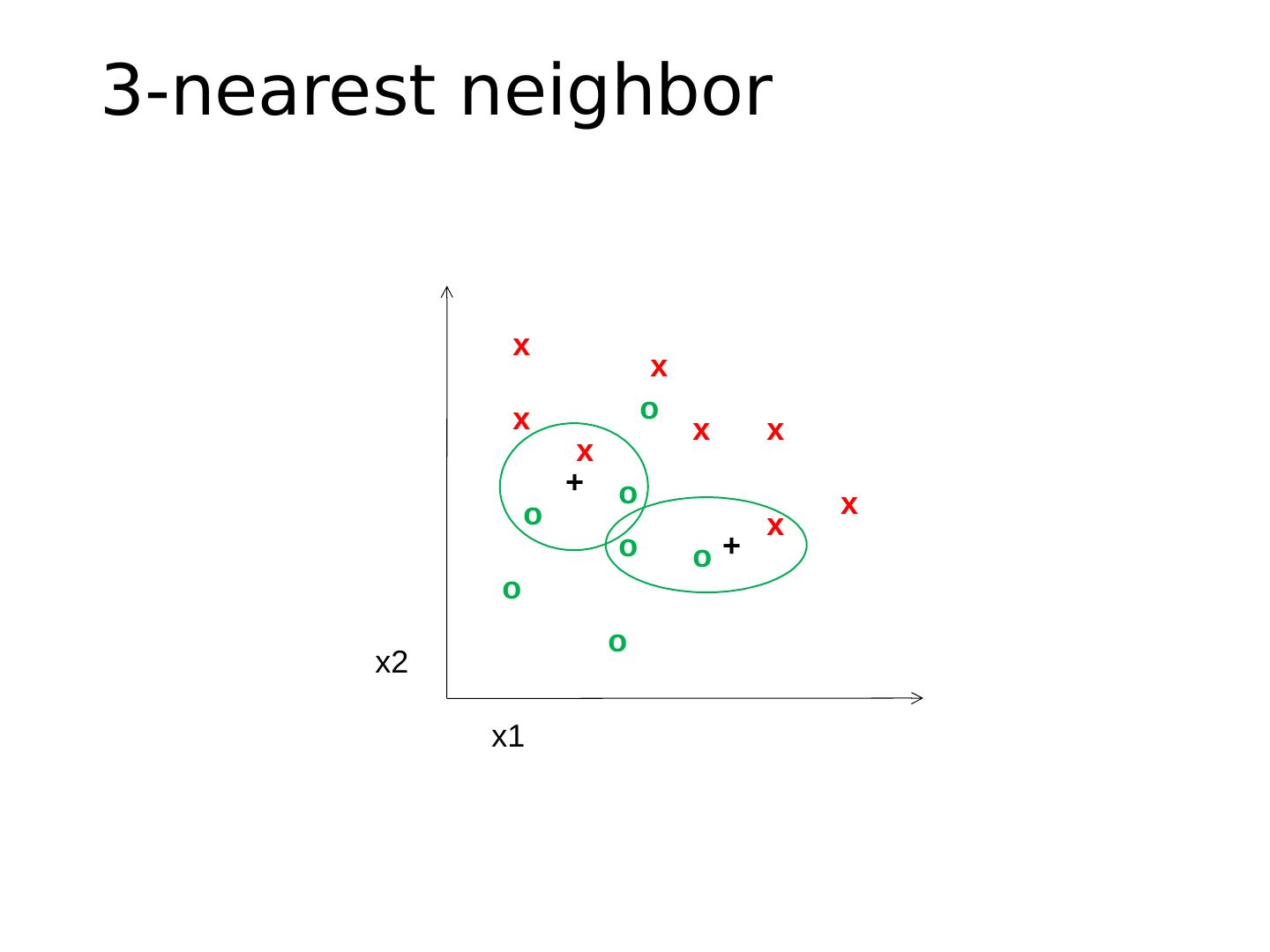
11 .3-nearest neighbor x x x x x x x x o o o o o o o x2 x1 + +
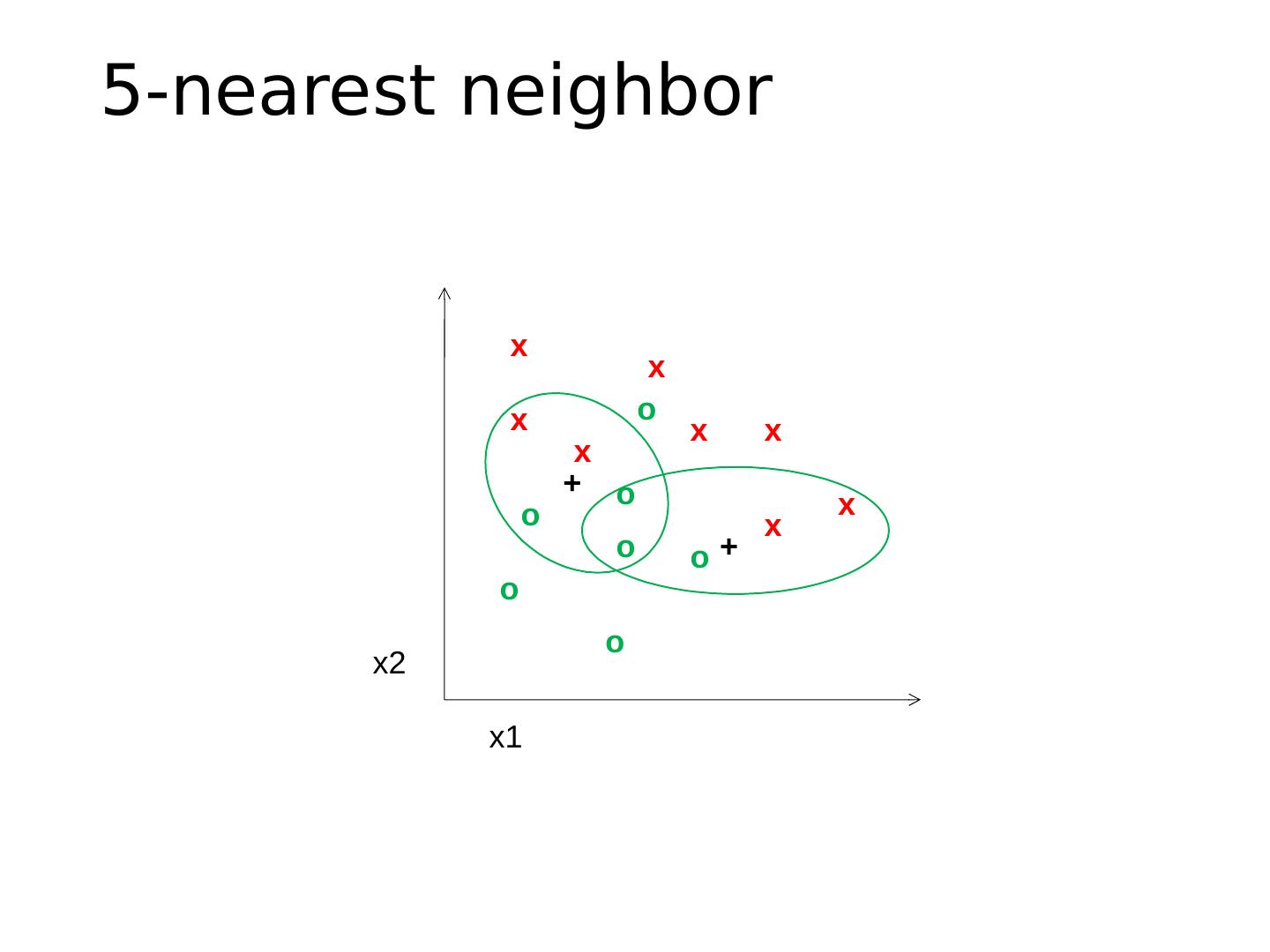
12 .5-nearest neighbor x x x x x x x x o o o o o o o x2 x1 + +
13 .Using K-NN Simple, a good one to try first Higher K gives smoother functions No training time (unless you want to learn a distance function) With infinite examples, 1-NN provably has error that is at most twice Bayes optimal error
14 .Discriminative classifiers Learn a simple function of the input features that confidently predicts the true labels on the training set Training Goals Accurate classification of training data Correct classifications are confident Classification function is simple
15 .Classifiers: Logistic Regression Objective Parameterization Regularization Training Inference x x x x x x x x o o o o o x2 x1 The objective function of most discriminative classifiers includes a loss term and a regularization term .
16 .Using Logistic Regression Quick, simple classifier (good one to try first) Use L2 or L1 regularization L1 does feature selection and is robust to irrelevant features but slower to train
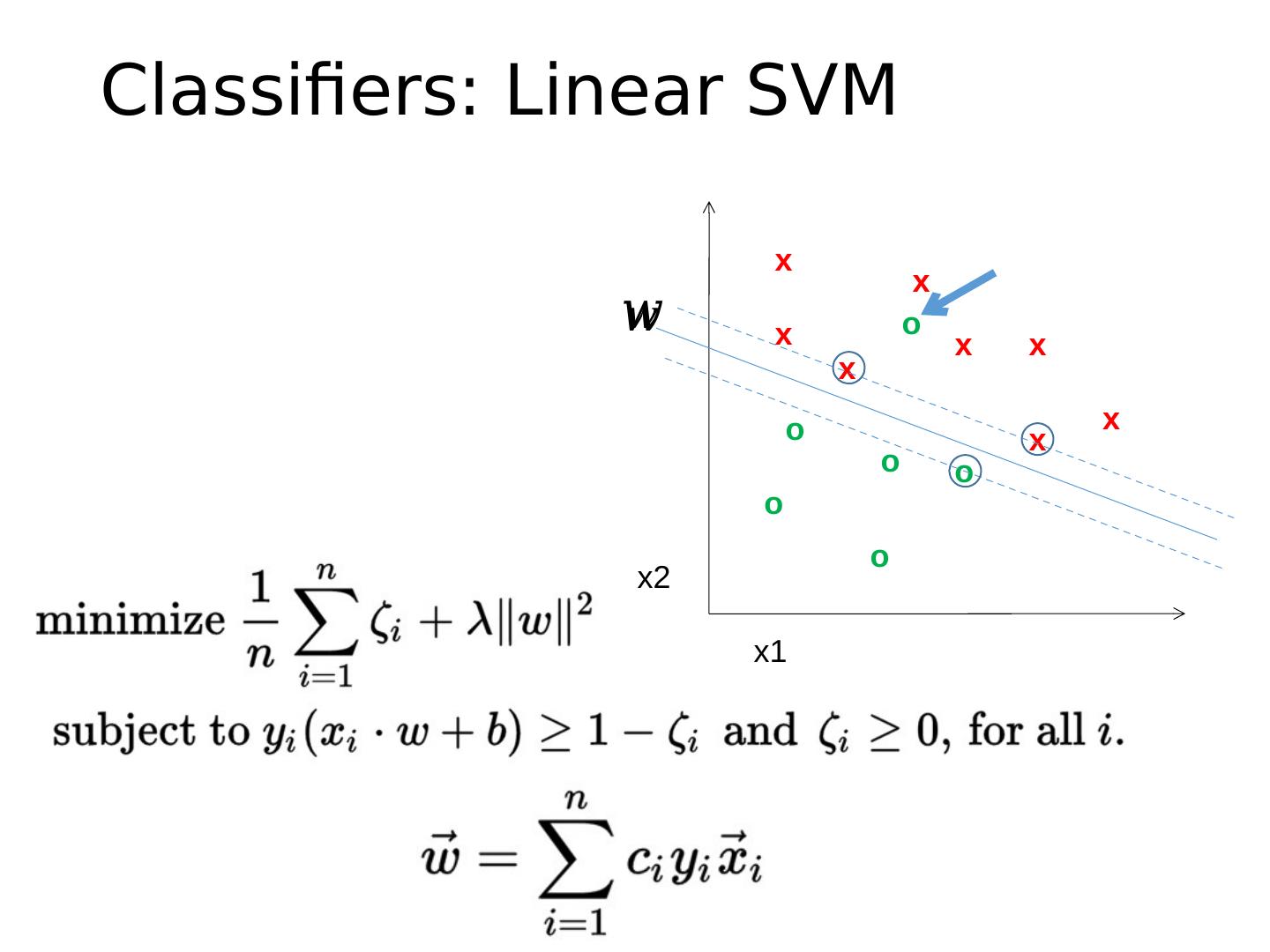
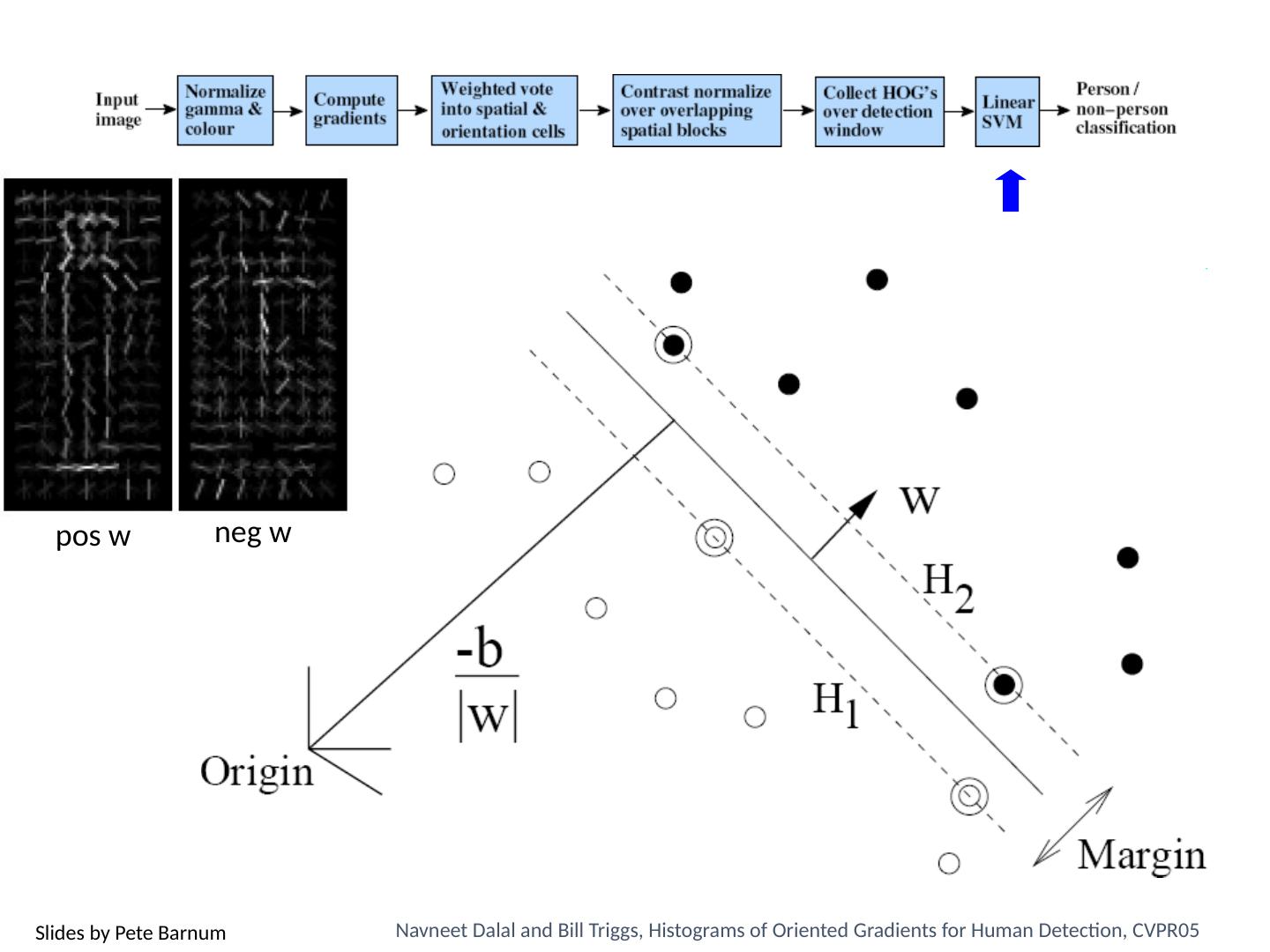
17 .Classifiers: Linear SVM x x x x x x x x o o o o o o x2 x1
18 .Classifiers: Kernelized SVM x x x x o o o x x x x x o o o x x 2 Kernel trick: - implicitly mapping their inputs into high-dimensional feature spaces
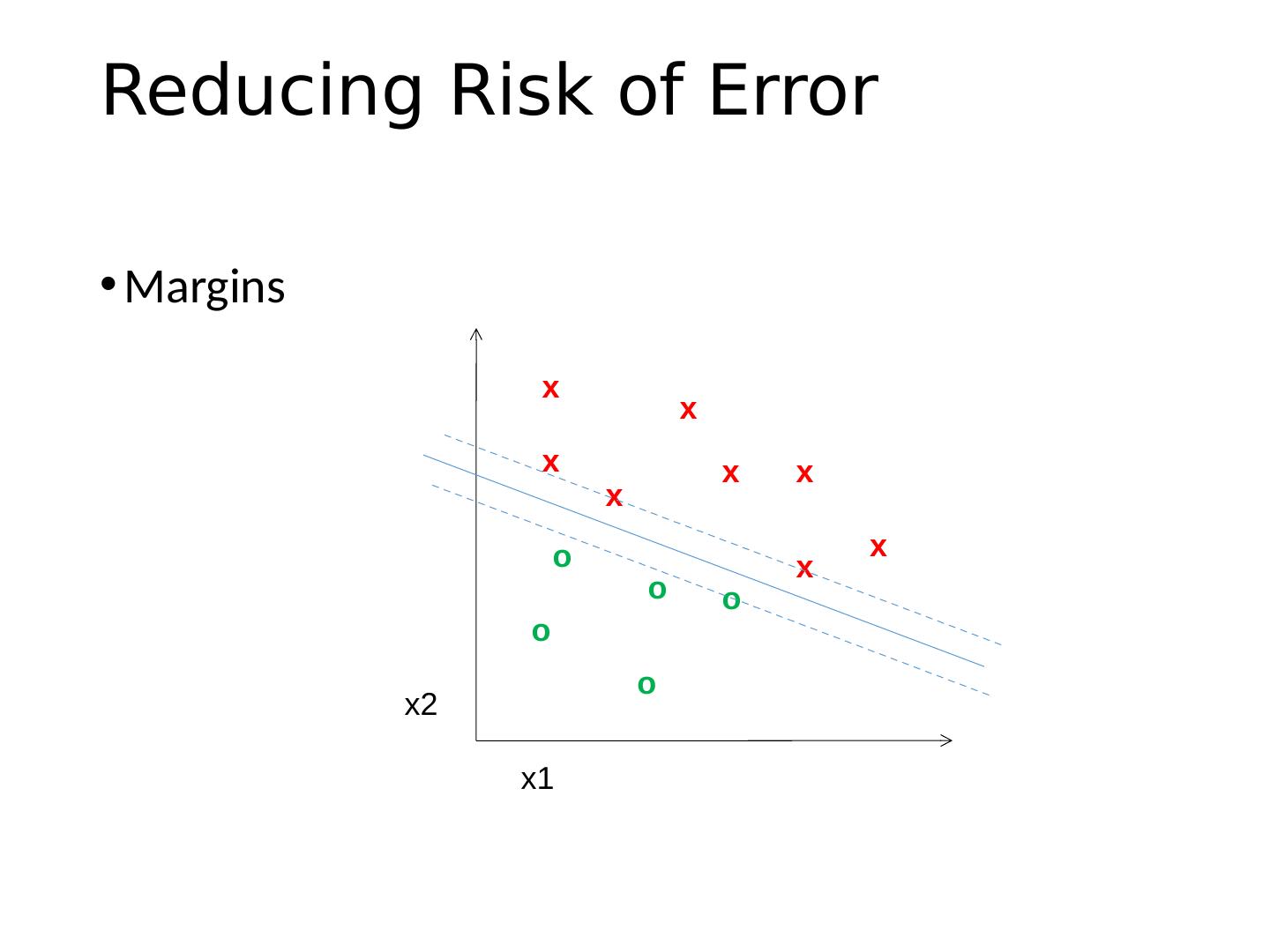
19 .Using SVMs Good general purpose classifier Generalization depends on margin, so works well with many weak features No feature selection Usually requires some parameter tuning Choosing kernel Linear: fast training/testing – start here RBF: related to neural networks, nearest neighbor Chi-squared, histogram intersection: good for histograms (but slower, esp. chi-squared) Can learn a kernel function
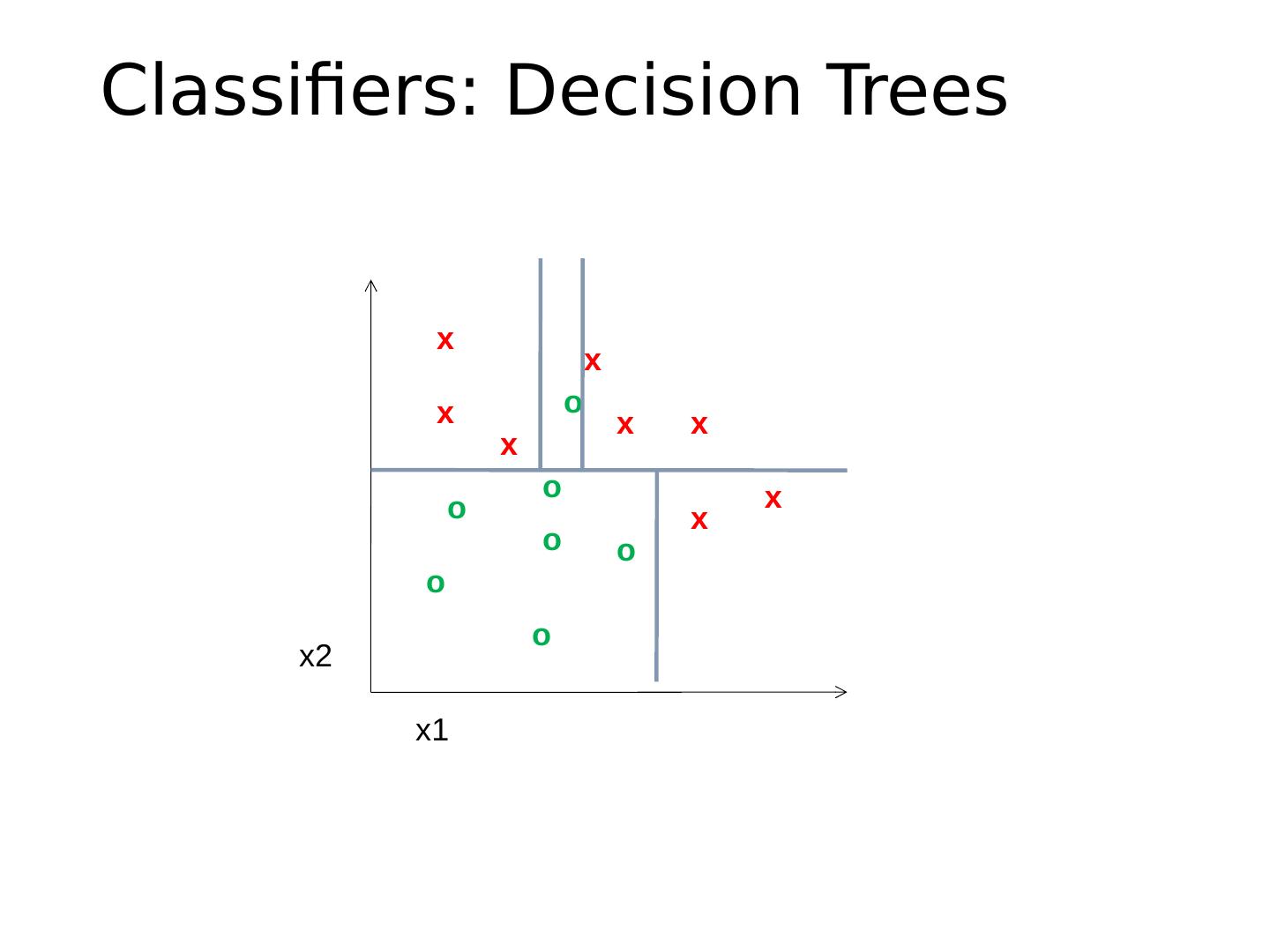
20 .Classifiers: Decision Trees x x x x x x x x o o o o o o o x2 x1
21 .Ensemble Methods: Boosting figure from Friedman et al. 2000
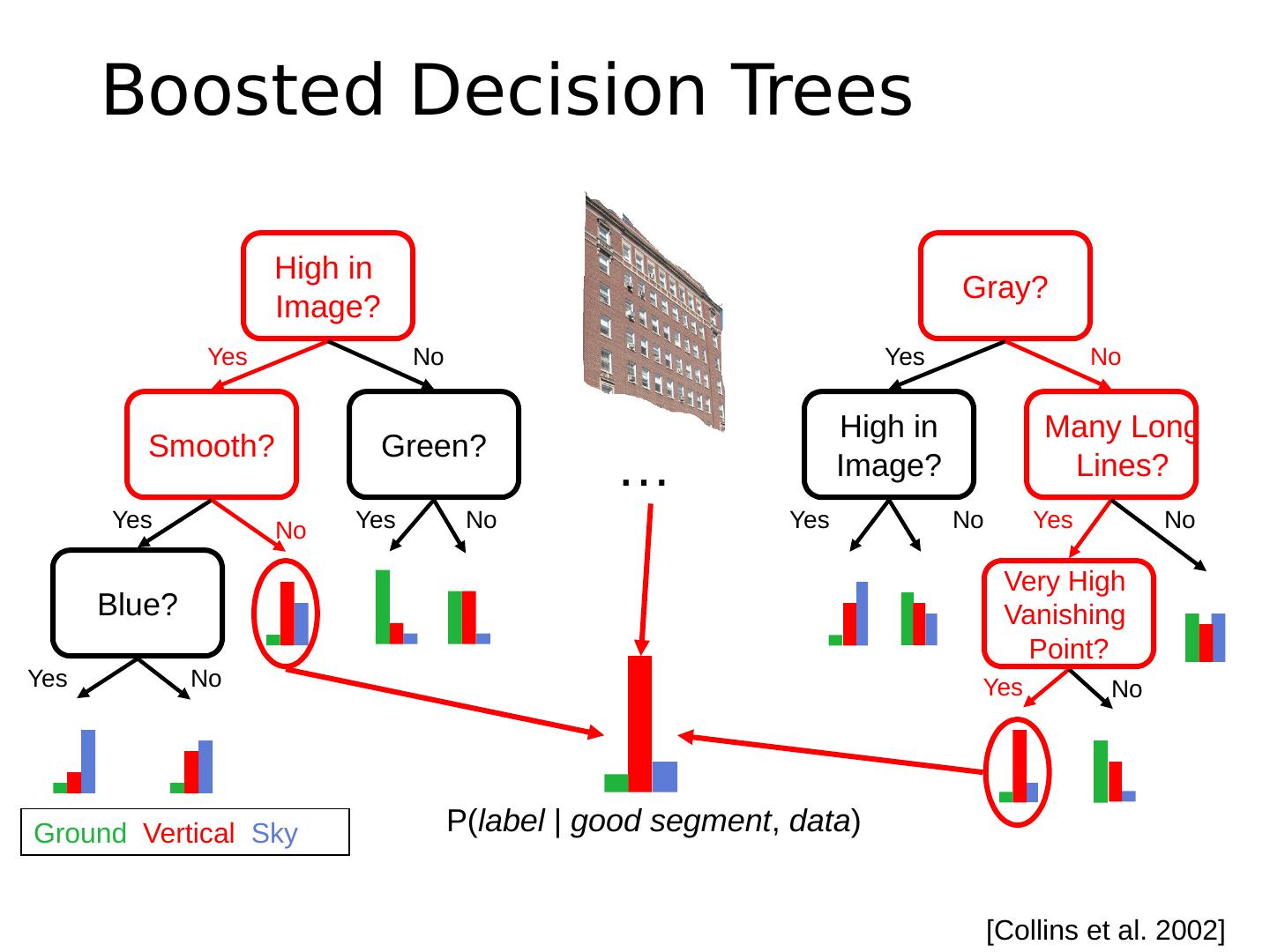
22 .Boosted Decision Trees … Gray? High in Image? Many Long Lines? Yes No No No No Yes Yes Yes Very High Vanishing Point? High in Image? Smooth? Green? Blue? Yes No No No No Yes Yes Yes Ground Vertical Sky [Collins et al. 2002] P( label | good segment , data )
23 .Using Boosted Decision Trees Flexible: can deal with both continuous and categorical variables How to control bias/variance trade-off Size of trees Number of trees Boosting trees often works best with a small number of well-designed features Boosting “stubs” can give a fast classifier
24 .Generative classifiers Model the joint probability of the features and the labels Allows direct control of independence assumptions Can incorporate priors Often simple to train (depending on the model) Examples Naïve Bayes Mixture of Gaussians for each class
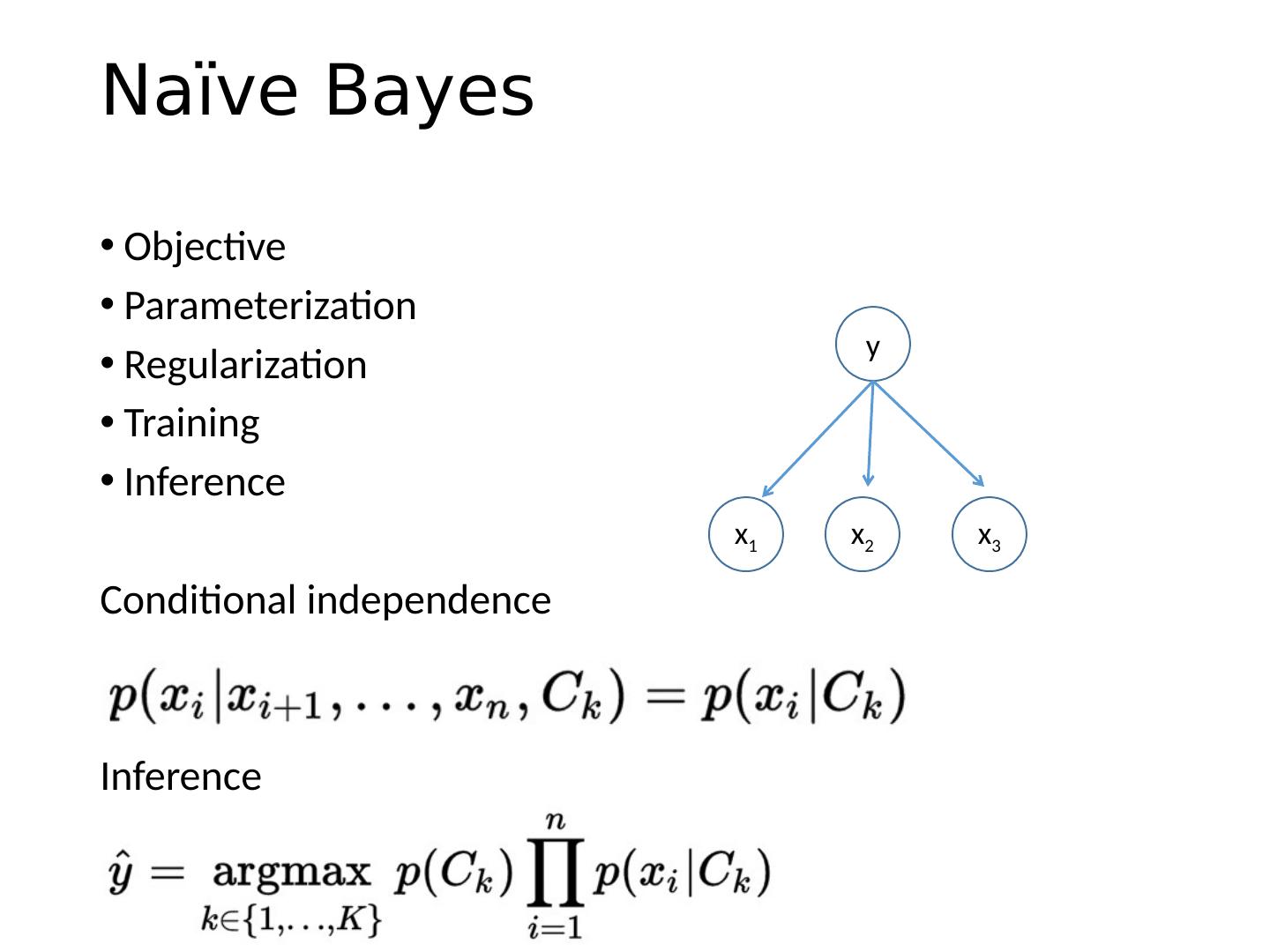
25 .Naïve Bayes Objective Parameterization Regularization Training Inference Conditional independence Inference x 1 x 2 x 3 y
26 .Using Naïve Bayes Simple thing to try for categorical data Very fast to train/test
27 .Web-based demo SVM Neural Network Random Forest
28 .Many classifiers to choose from SVM Neural networks Naïve Bayes Bayesian network Logistic regression Randomized Forests Boosted Decision Trees K-nearest neighbor RBMs Deep networks Etc. Which is the best one?
29 .No Free Lunch Theorem
3秒后跳转登录页面
去登陆

