































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/u181/distributed_systems_and_algorithms09?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
分布式系统和算法:故障和容错
分享
点赞
1
收藏
0
下载 0
分布式系统的一大优势便是容错度高。本章讲述了系统运行时可能出现的错误及其分类、介绍,容错类型,故障检测等内容并举例说明了几种重要协议的应用。
展开查看详情
1 .Faults and fault-tolerance
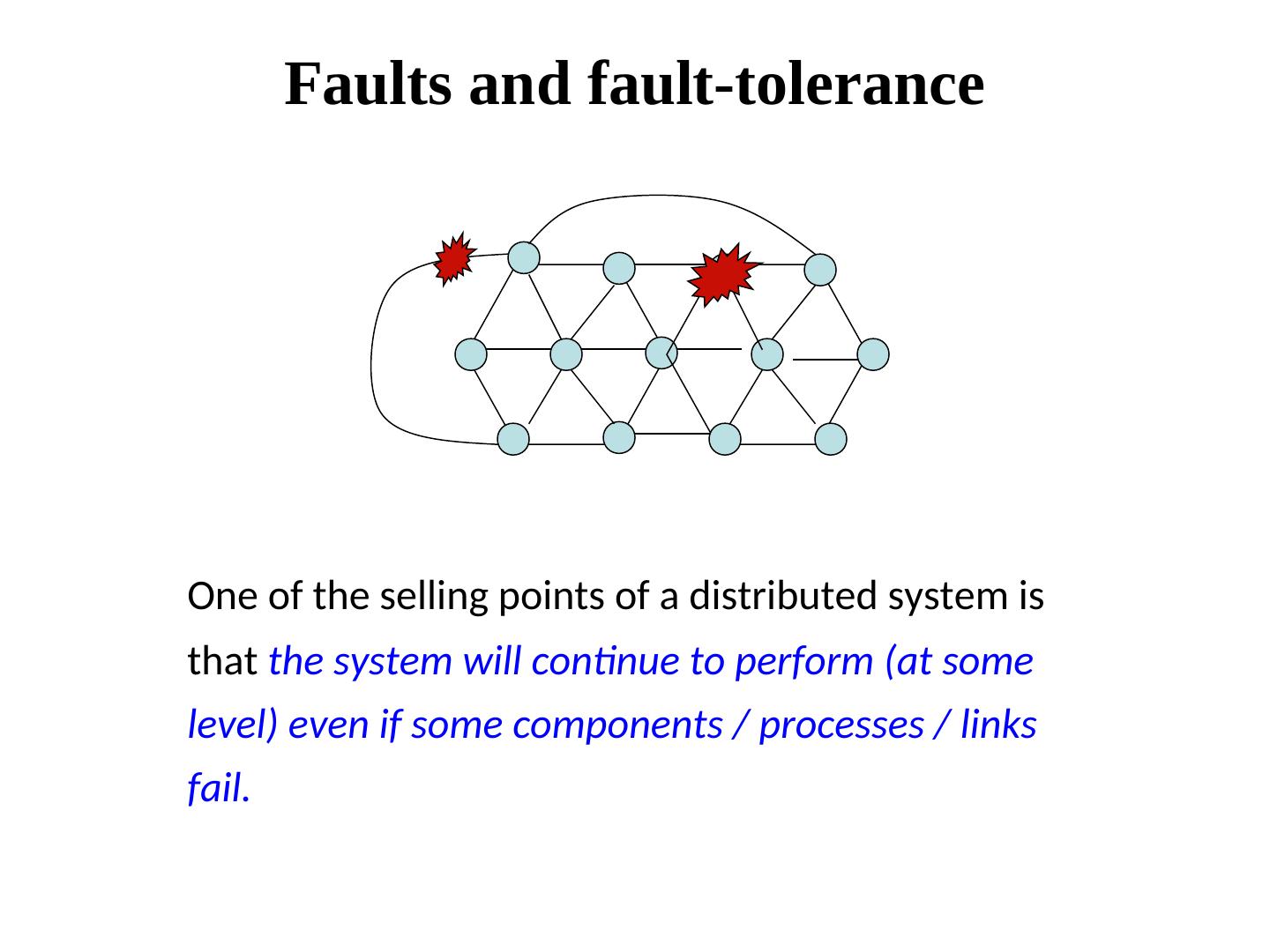
2 . Faults and fault-tolerance One of the selling points of a distributed system is that the system will continue to perform (at some level) even if some components / processes / links fail.
3 . Cause and effect • Study examples of what causes what. • We view the effect of failures at our level of abstraction, and then try to mask it, or recover from it. • Reliability and availability • MTBF (Mean Time Between Failures) and MTTR (Mean Time To Repair) are two commonly used metrics in the engineering world
4 .A classification of failures • Crash failure • Omission failure • Transient failure • Software failure • Security failure • Byzantine failure • Temporal failure • Environmental perturbations
5 . Crash failures Crash failure = the process halts. It is irreversible. Crash failure is a form of “nice” failure. In a synchronous system, it can be detected using timeout, but in a asynchronous system, crash detection becomes tricky. Some failures may be complex and nasty. Fail-stop failure is a simple abstraction that mimics crash failure when process behavior becomes arbitrary. Implementations of fail-stop behavior help detect which processor has failed. If a system cannot tolerate fail-stop failure, then it cannot tolerate crash.
6 . Omission failures Message lost in transit. May happen due to various causes, like – Transmitter malfunction – Buffer overflow – Collisions at the MAC layer – Receiver out of range
7 . Transient failure (Hardware) Arbitrary perturbation of the global state. May be induced by power surge, weak batteries, lightning, radio- frequency interferences, cosmic rays etc. Not Heisenberg (Software) Heisenbugs are a class of temporary internal faults and are intermittent. They are essentially permanent faults whose conditions of activation occur rarely or are not easily reproducible, so they are harder to detect during the testing phase. Over 99% of bugs in IBM DB2 production code are non-deterministic and transient (Jim Gray)
8 . Software failures Coding error or human error On September 23, 1999, NASA lost the $125 million Mars orbiter spacecraft because one engineering team used metric units while another used English units leading to a navigation fiasco, causing it to burn in the atmosphere. Design flaws or inaccurate modeling Mars pathfinder mission landed flawlessly on the Martial surface on July 4, 1997. However, later its communication failed due to a design flaw in the real-time embedded software kernel VxWorks. The problem was later diagnosed to be caused due to priority inversion, when a medium priority task could preempt a high priority one.
9 . Software failures (continued) Memory leak Operating systems may crash when processes fail to entirely free up the physical memory that has been allocated to them. This effectively reduces the size of the available physical memory over time. When this becomes smaller than the minimum memory needed to support an application, it crashes. Incomplete specification (example Y2K) Year = 09 (1909 or 2009 or 2109)? Many failures (like crash, omission etc) can be caused by software bugs too.
10 . Temporal failures Inability to meet deadlines – correct results are generated, but too late to be useful. Very important in real-time systems. May be caused by poor algorithms, poor design strategy or loss of synchronization among the processor clocks.
11 .Environmental perturbations Consider open systems or dynamic systems. Correctness is related to the environment. If the environment changes, then a correct system A system of becomes incorrect. Traffic lights Example of environmental parameters: time of day, network topology, user demand etc. Essentially, distributed Time of day systems are expected to adapt to the environment
12 . Security problems Security loopholes can lead to failure. Code or data may be corrupted by security attacks. In wireless networks, rogue nodes with powerful radios can sometimes impersonate for good nodes and induce faulty actions.
13 . Byzantine failure Anything goes! Includes every conceivable form of erroneous behavior. It is the weakest type of failure. Numerous possible causes. Includes malicious behaviors (like a process executing a different program instead of the specified one) too. Most difficult kind of failure to deal with.
14 .Specification of faulty behavior (Most faulty behaviors can be modeled as a fault action F superimposed on the normal action S. This is for specification purposes only) program example1; define x : boolean (initially x = true); {a, b are messages); do {S}: x → send a {specified action} [] {F}: true → send b {faulty action} od aaaabaaabbaaaaaaa…
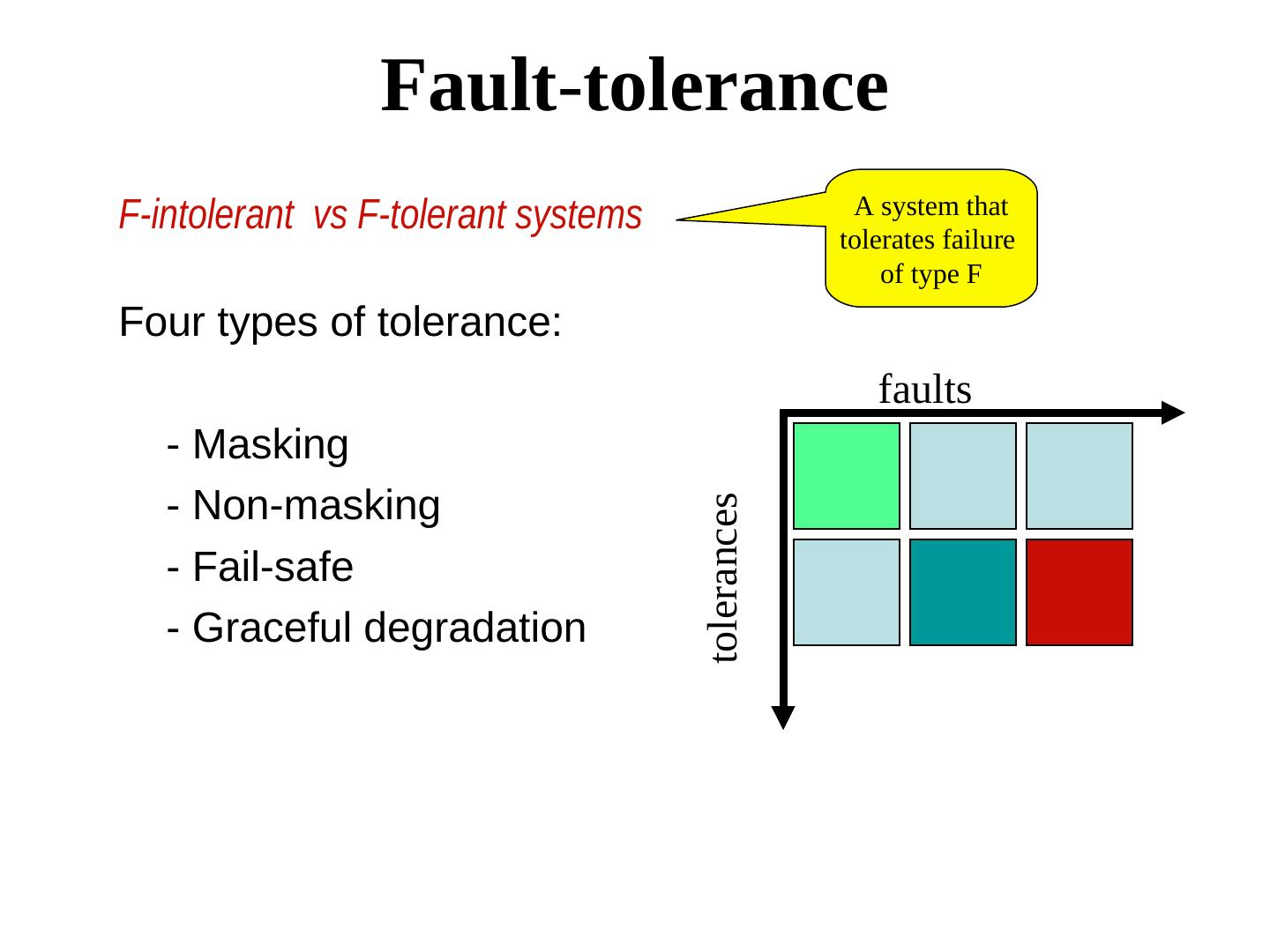
15 . Fault-tolerance F-intolerant vs F-tolerant systems A system that tolerates failure of type F Four types of tolerance: faults - Masking - Non-masking tolerances - Fail-safe - Graceful degradation
16 . Fault-tolerance P is the invariant of the original fault-free system Q Q represents the worst possible behavior of the P system when failures occur. It is called the fault span. Q is closed under S or F.
17 . Fault-tolerance Masking tolerance: P = Q (neither safety nor liveness is violated) Q Non-masking tolerance: P ⊂ Q Q (safety property may be temporarily P violated, but not liveness). Eventually safety property is restored.
18 . Classifying fault-tolerance Masking tolerance. Application runs as it is. The failure does not have a visible impact. All properties (both liveness & safety) continue to hold. Non-masking tolerance. Safety property is temporarily affected, but not liveness. Example 1. Clocks lose synchronization, but recover soon thereafter. Example 2. Multiple processes temporarily enter their critical sections, but thereafter, the normal behavior is restored. Example 3. A transaction crashes, but eventually recovers
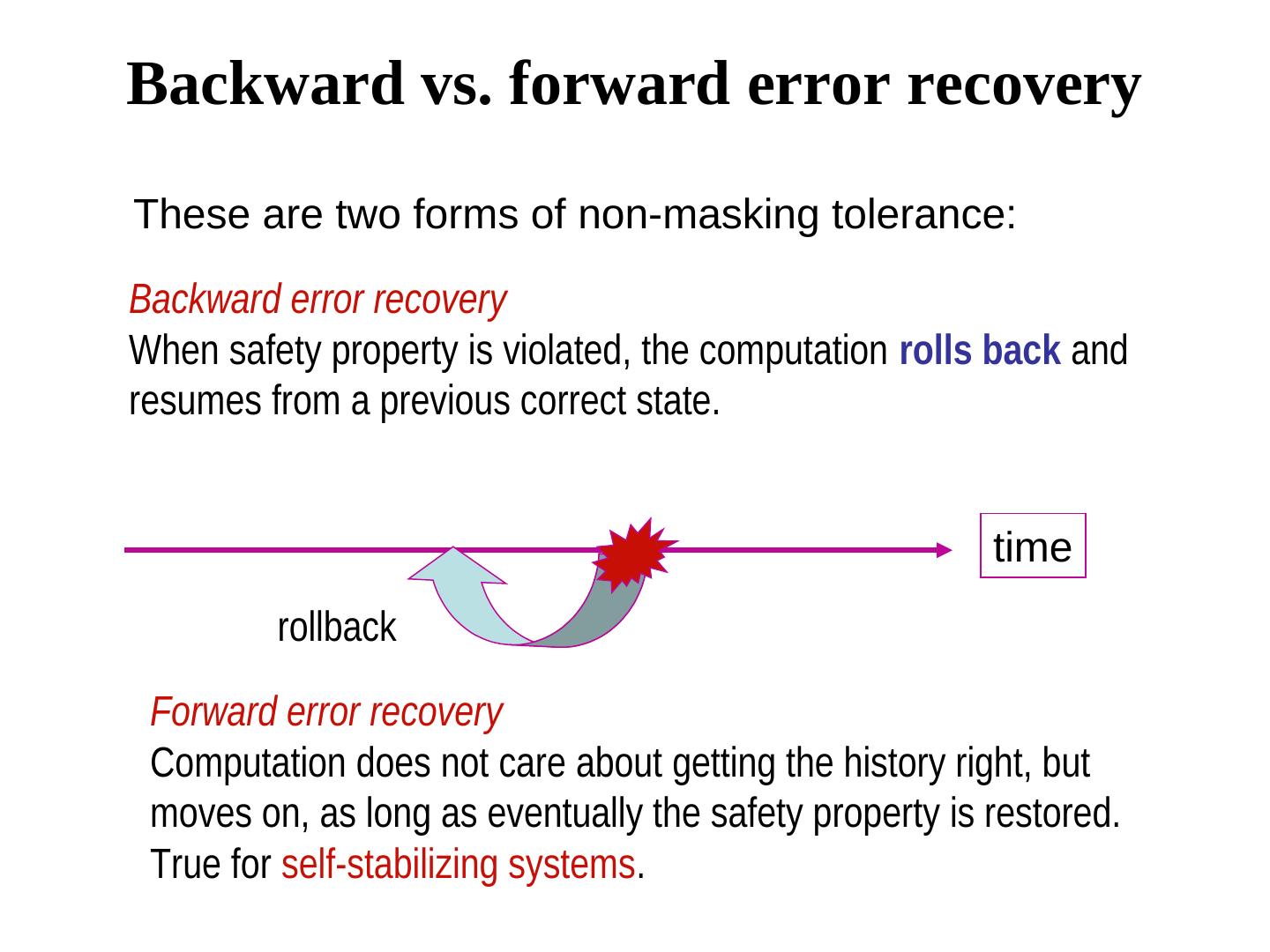
19 .Backward vs. forward error recovery These are two forms of non-masking tolerance: Backward error recovery When safety property is violated, the computation rolls back and resumes from a previous correct state. time rollback Forward error recovery Computation does not care about getting the history right, but moves on, as long as eventually the safety property is restored. True for self-stabilizing systems.
20 . Classifying fault-tolerance Fail-safe tolerance Given safety predicate is preserved, but liveness may be affected Example. Due to failure, no process can enter its critical section for an indefinite period. In a traffic crossing, failure changes the traffic in both directions to red. Graceful degradation Application continues, but in a “degraded” mode. Much depends on what kind of degradation is acceptable. Example. Consider message-based mutual exclusion. Processes will enter their critical sections, but not in timestamp order.
21 . Failure detection The design of fault-tolerant systems will be easier if failures can be detected. Depends on the 1. System model, and 2. The type of failures. Asynchronous models are more tricky. We first focus on synchronous systems only
22 . Detection of crash failures Failure can be detected using heartbeat messages (periodic “I am alive” broadcast) and timeout - if processors speed has a known lower bound - channel delays have a known upper bound. True for synchronous models only. We will address failure detectors for asynchronous systems later.
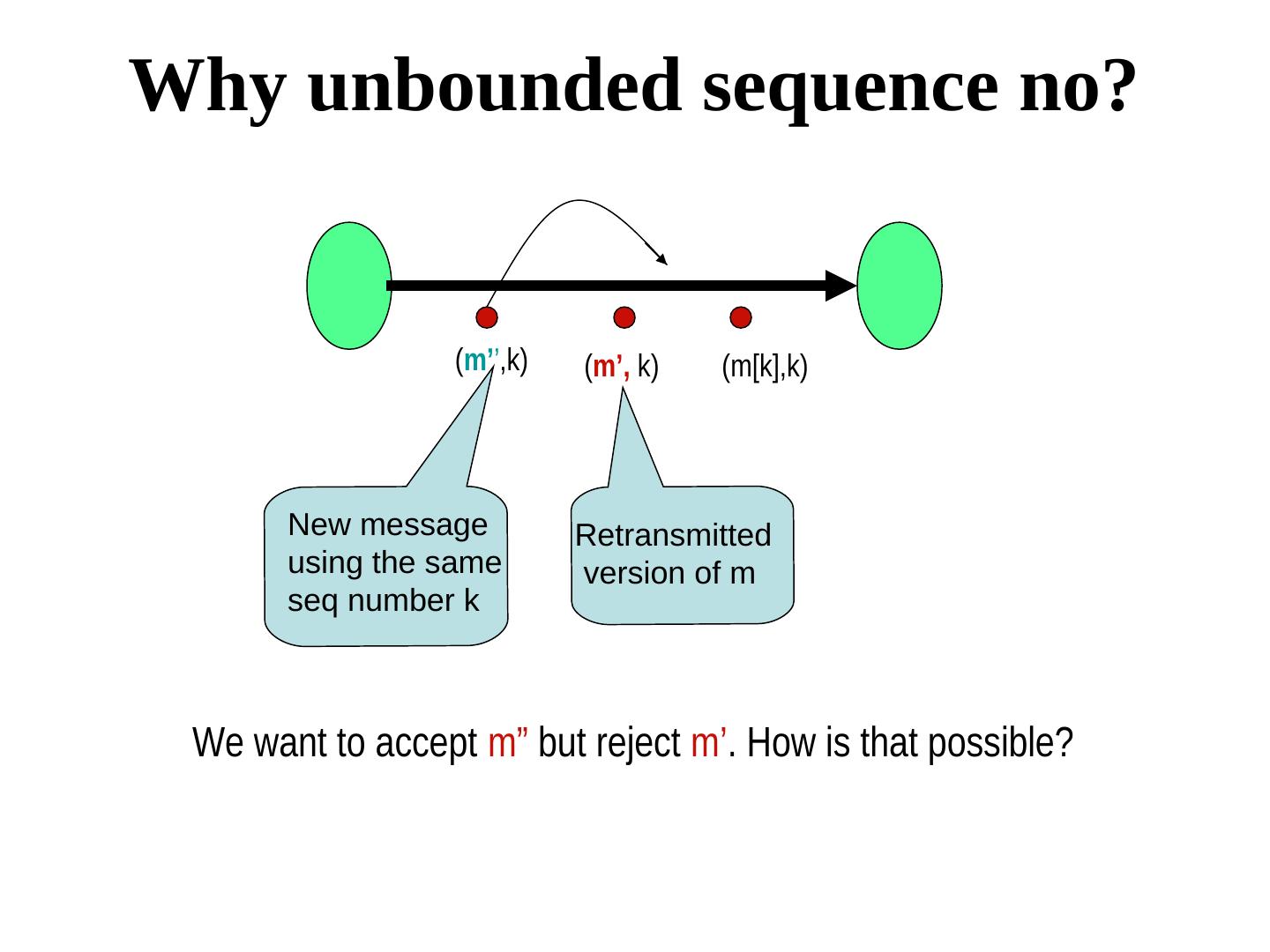
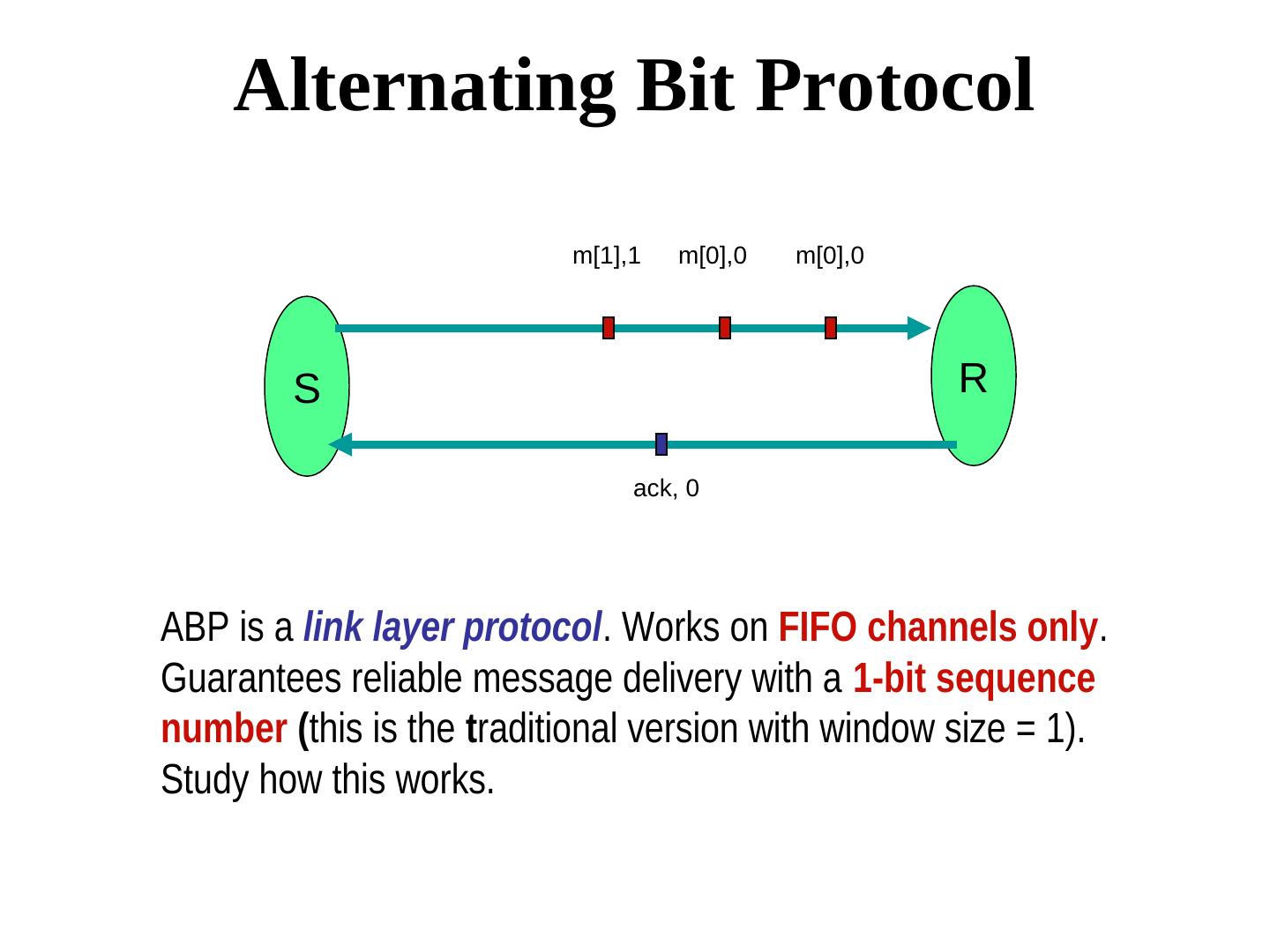
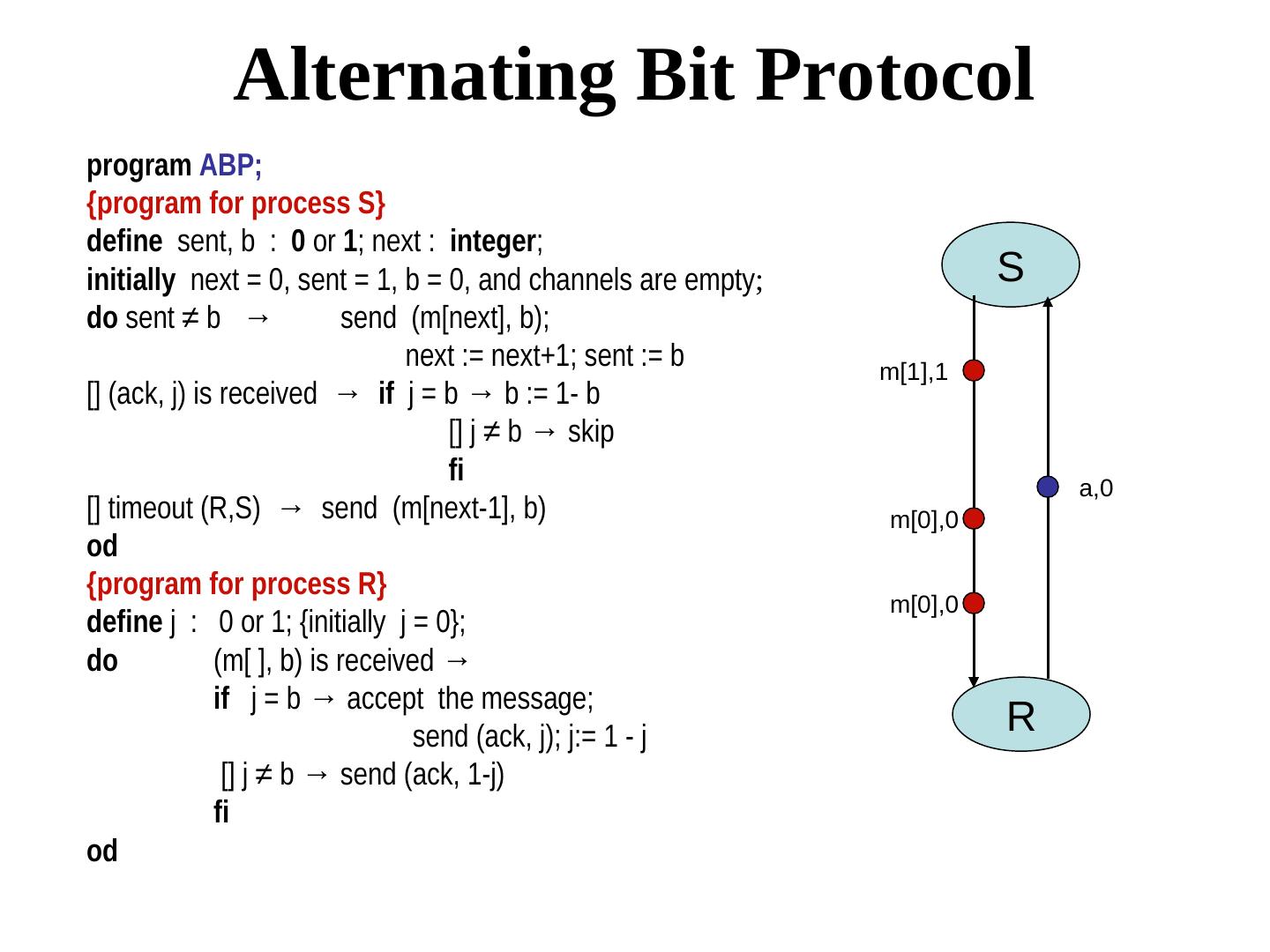
23 . Detection of omission failures For FIFO channels: Use sequence numbers with messages. (1, 2, 3, 5, 6 … ) ⇒ message 5 was received but not message message 5 was received but not message 4 ⇒ message 5 was received but not message message must be is missing Non-FIFO bounded delay channels delay - use timeout (Message 4 should have arrived by now, but it did not) What about non-FIFO channels for which the upper bound of the delay is not known? -- Use sequence numbers and acknowledgments. But acknowledgments may also be lost. We will soon look at a real protocol dealing with omission failure ….
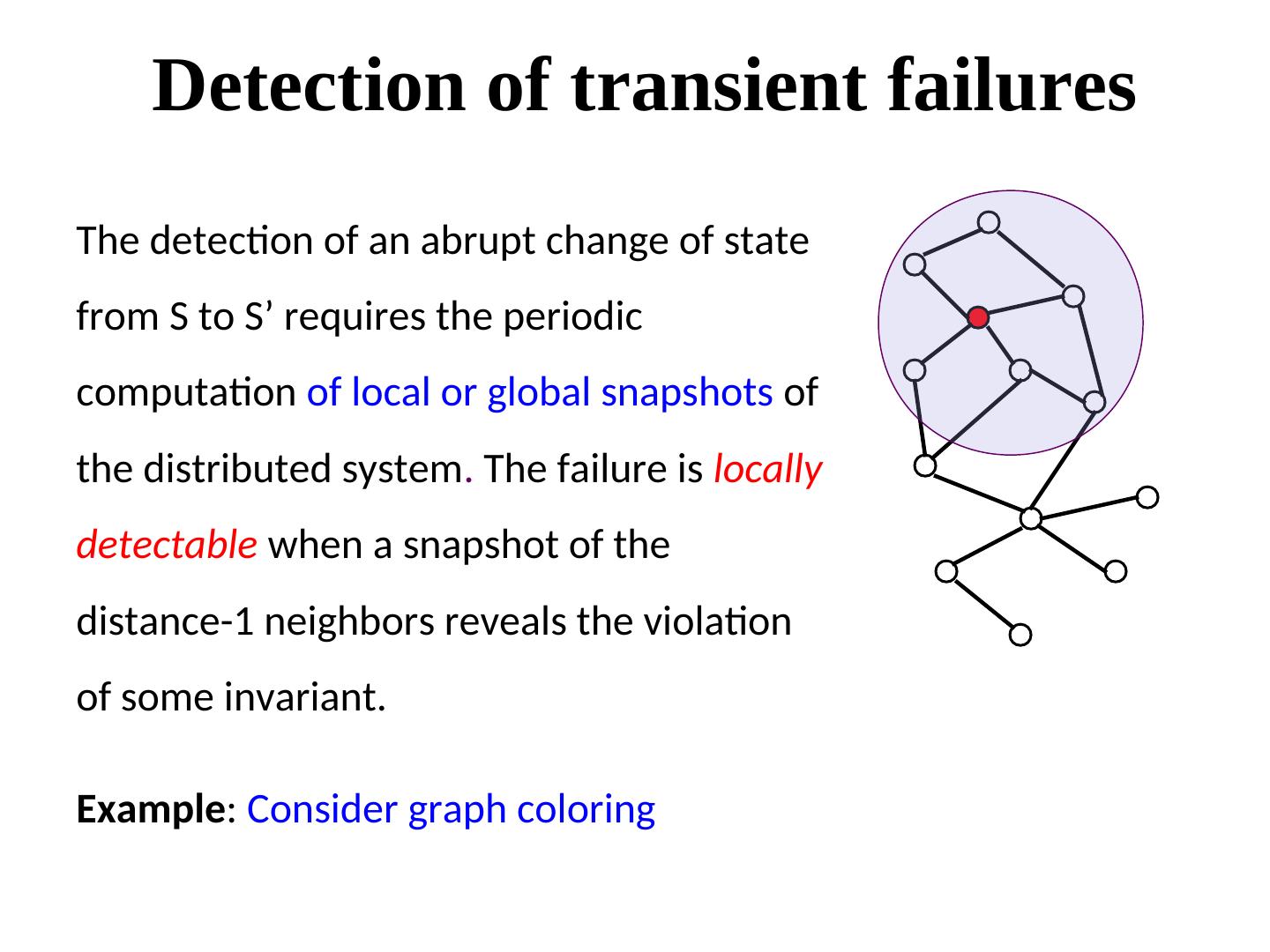
24 . Detection of transient failures The detection of an abrupt change of state from S to S’ requires the periodic computation of local or global snapshots of the distributed system. The failure is locally detectable when a snapshot of the distance-1 neighbors reveals the violation of some invariant. Example: Consider graph coloring
25 . Detection of Byzantine failures A system with 3f+1 processes is considered adequate for (sometimes) detecting (and definitely masking) up to f byzantine faults. More on Byzantine faults later.
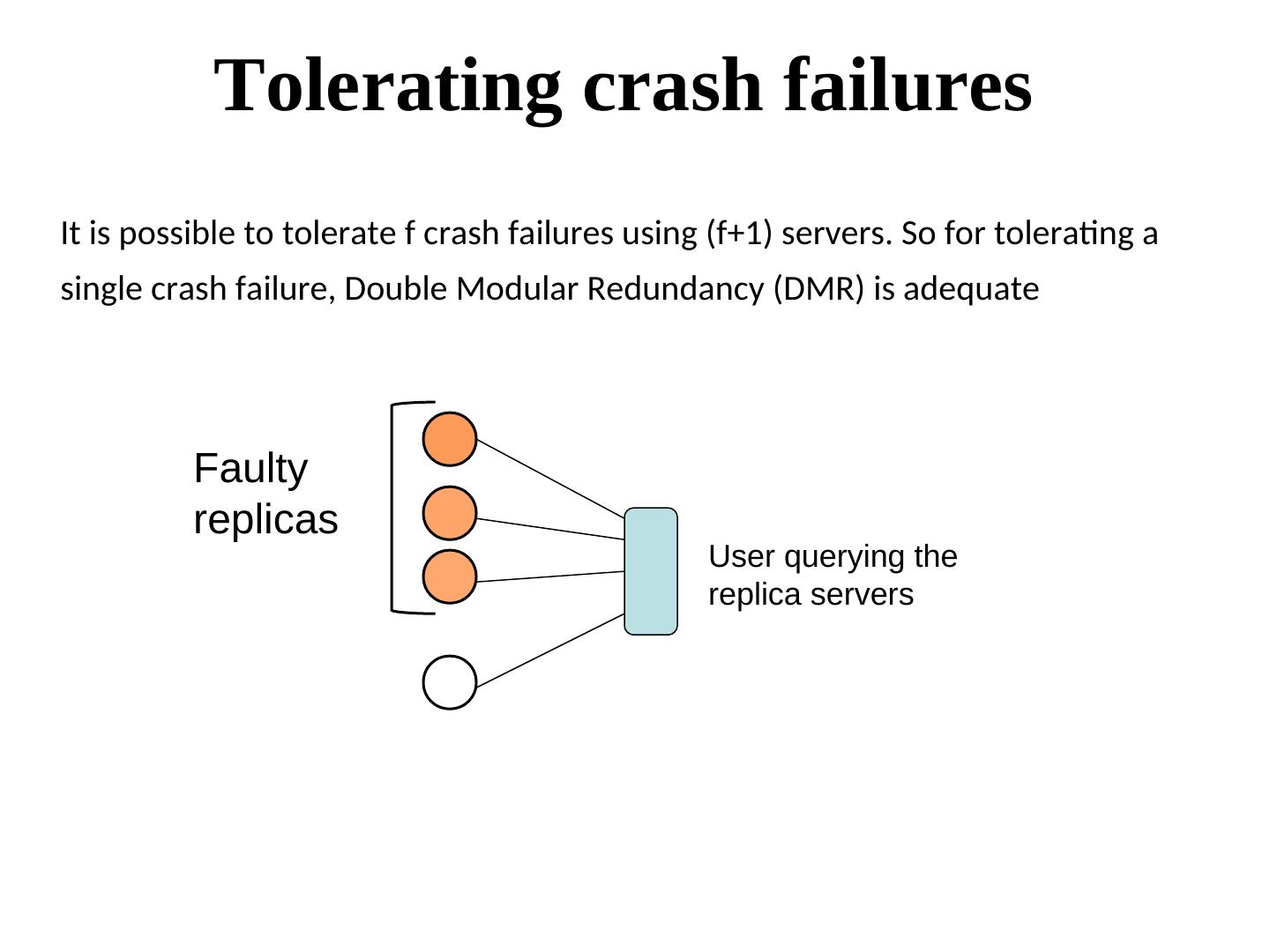
26 . Tolerating crash failures It is possible to tolerate f crash failures using (f+1) servers. So for tolerating a single crash failure, Double Modular Redundancy (DMR) is adequate Faulty replicas User querying the replica servers
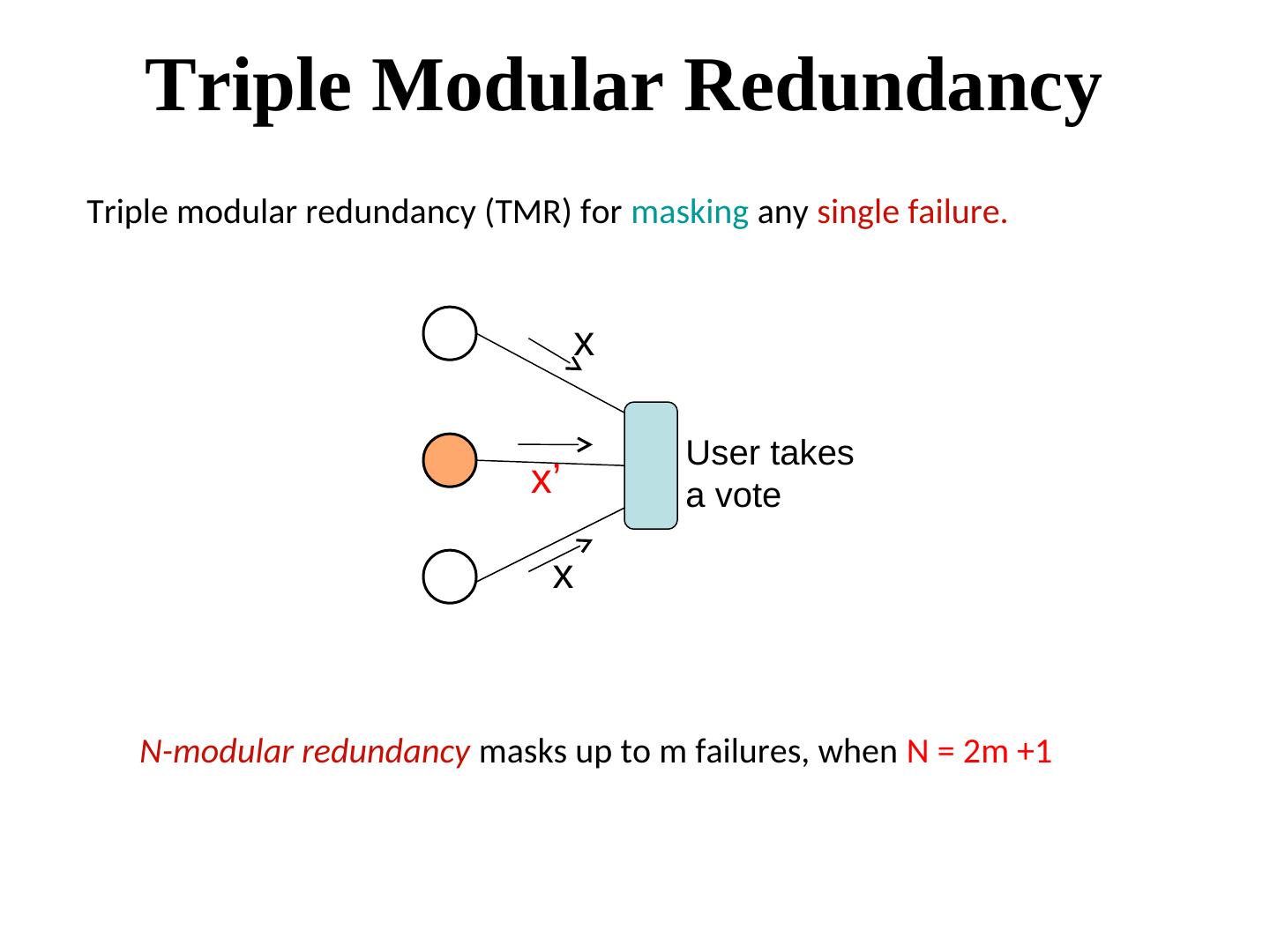
27 . Triple Modular Redundancy Triple modular redundancy (TMR) for masking any single failure. x User takes x’ a vote x N-modular redundancy masks up to m failures, when N = 2m +1
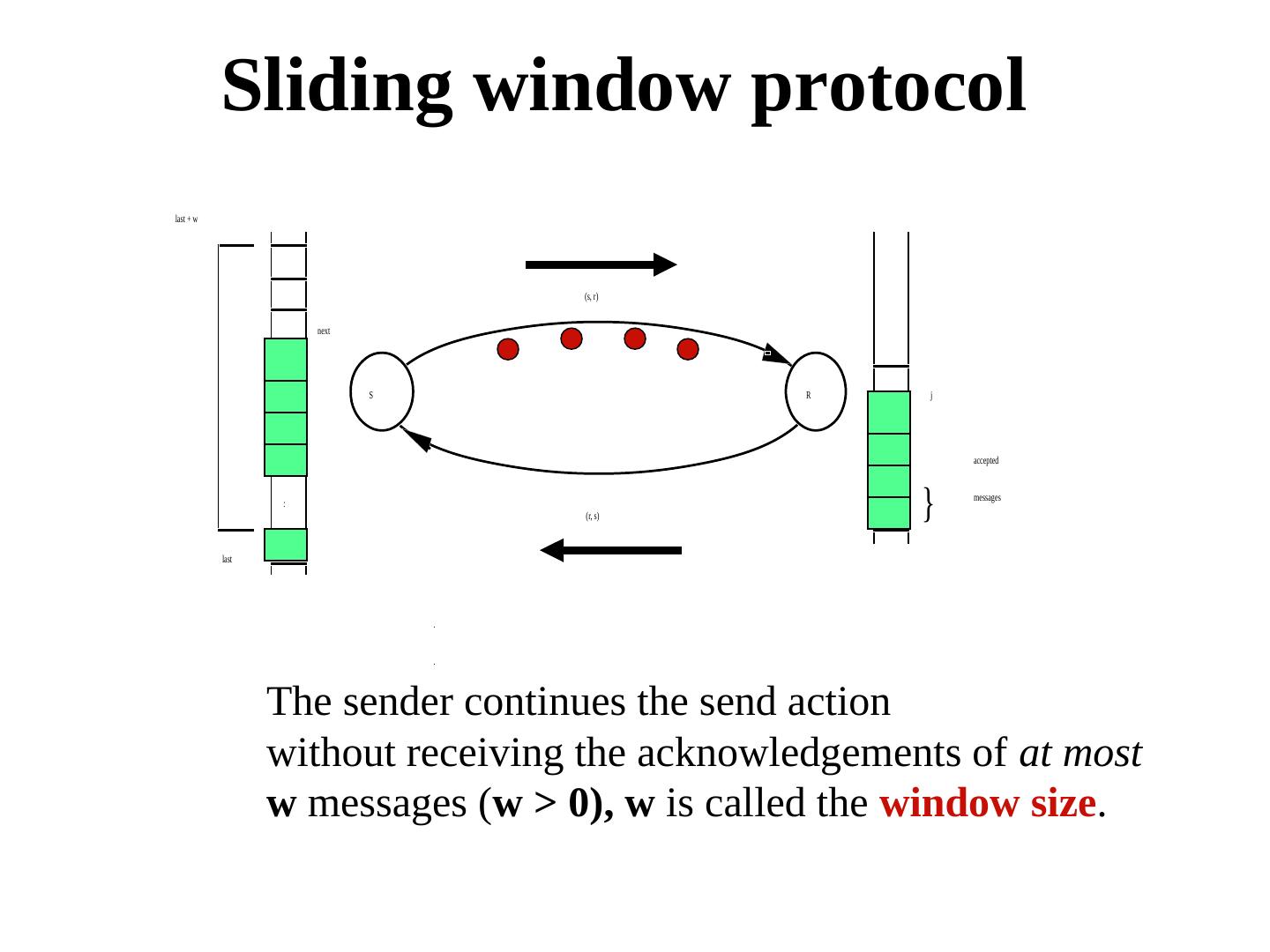
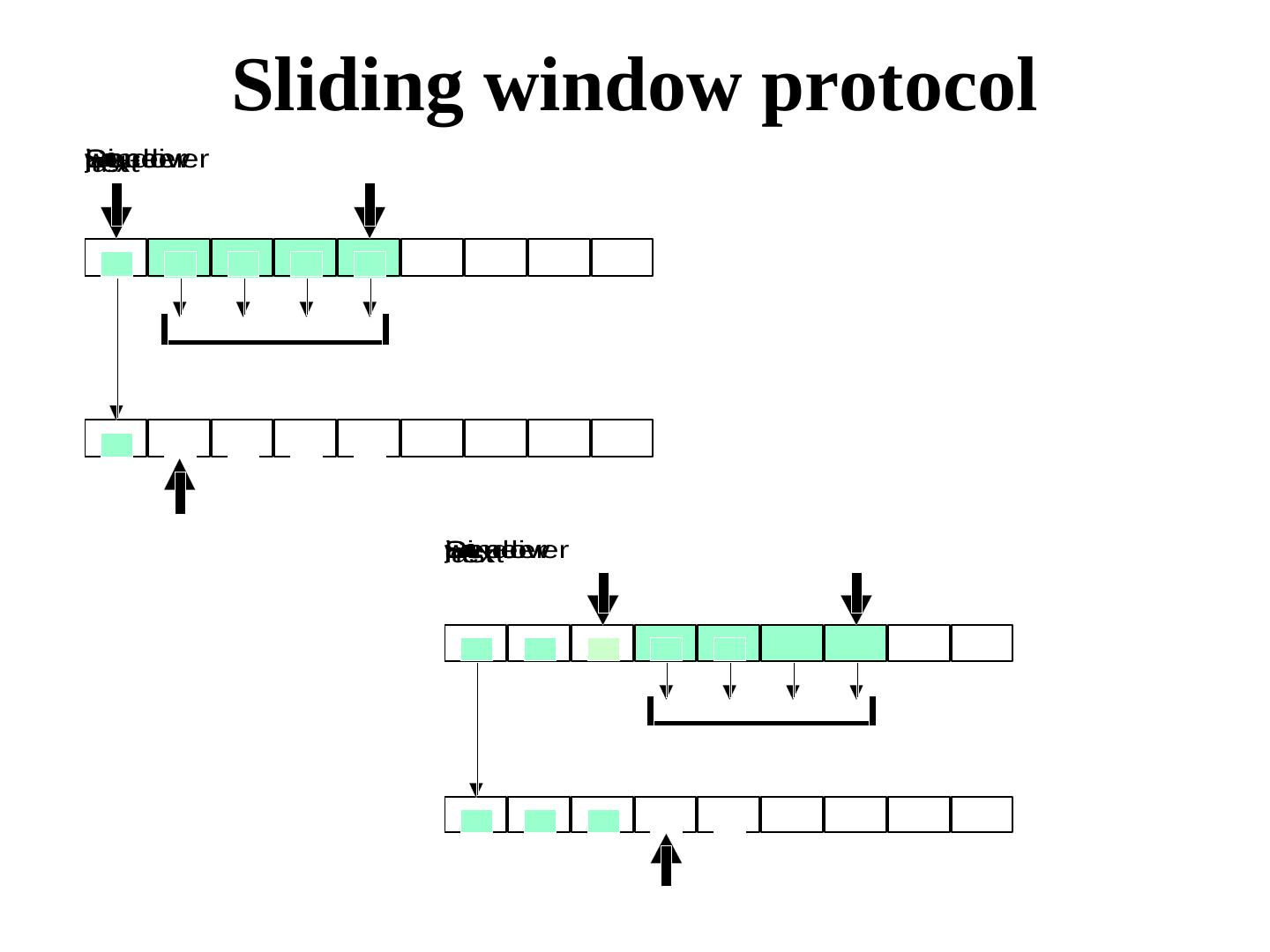
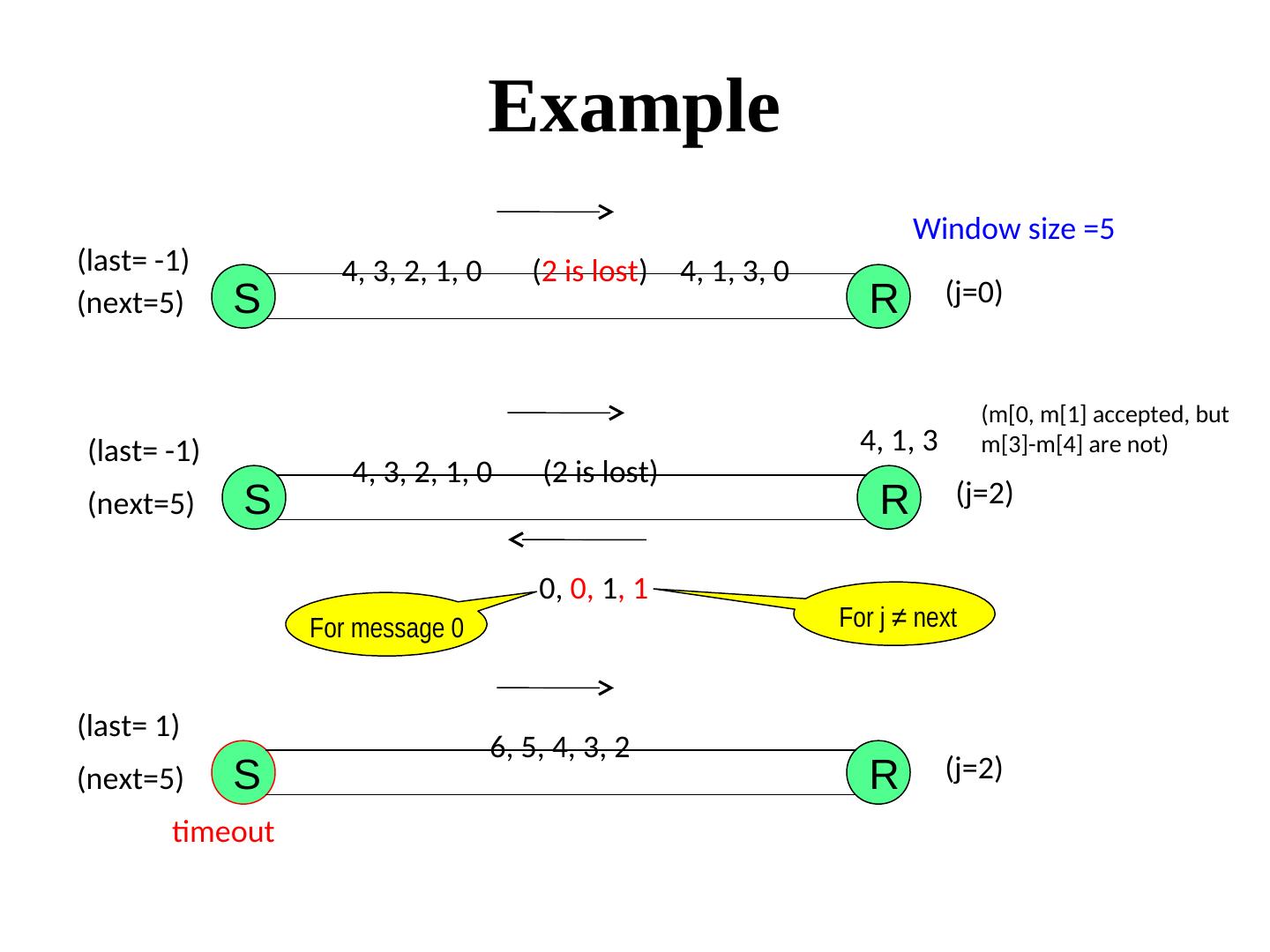
28 . Tolerating omission failures A central issue in networking A router Routers may drop messages, but reliable end-to-end transmission is an important requirement. If the sender B does not receive an ack within a time period, it retransmits (it may so happen that the router was not lost, so a duplicate is generated). This implies, the communication must tolerate Loss, Duplication, and Re-ordering of messages
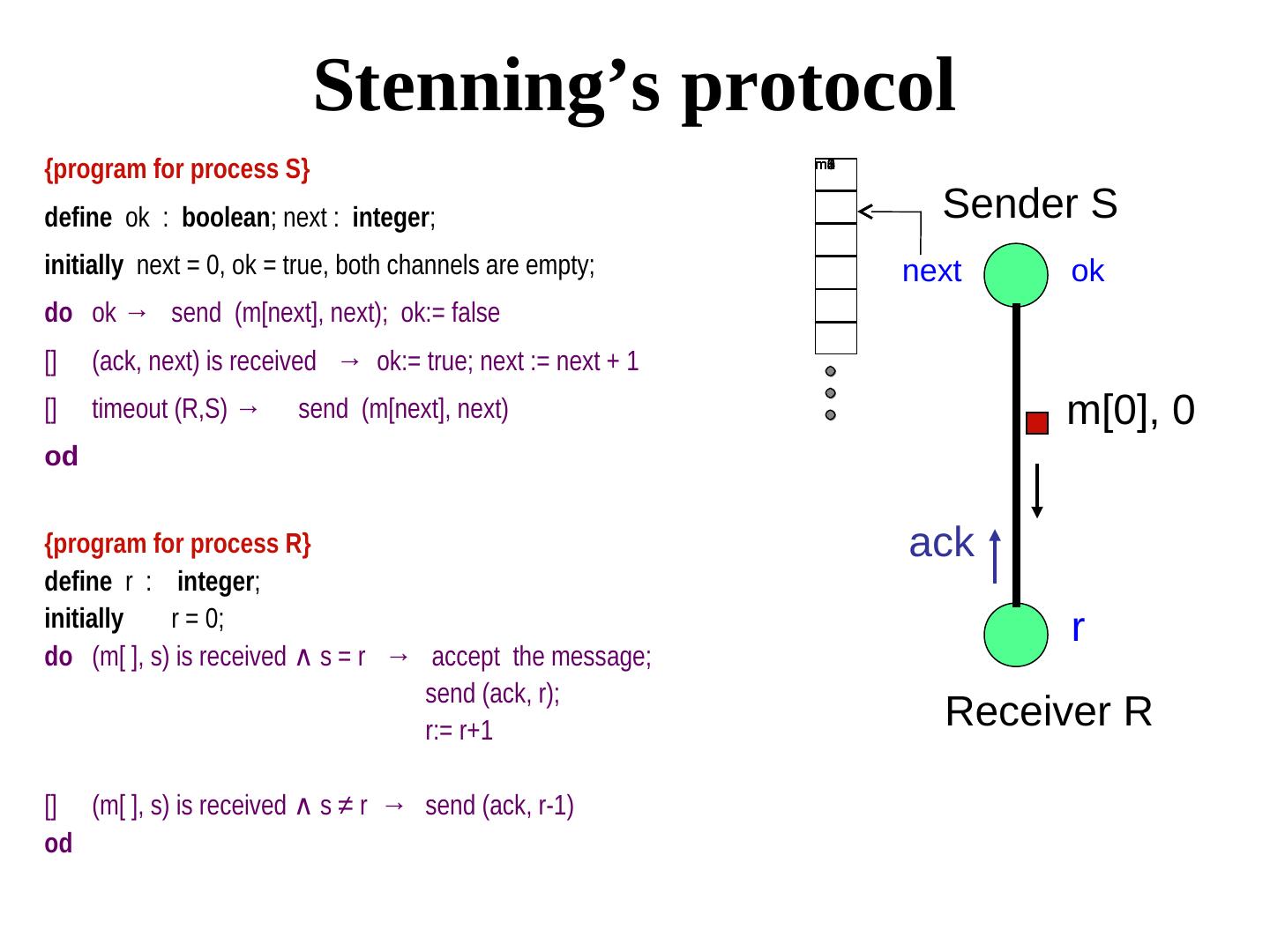
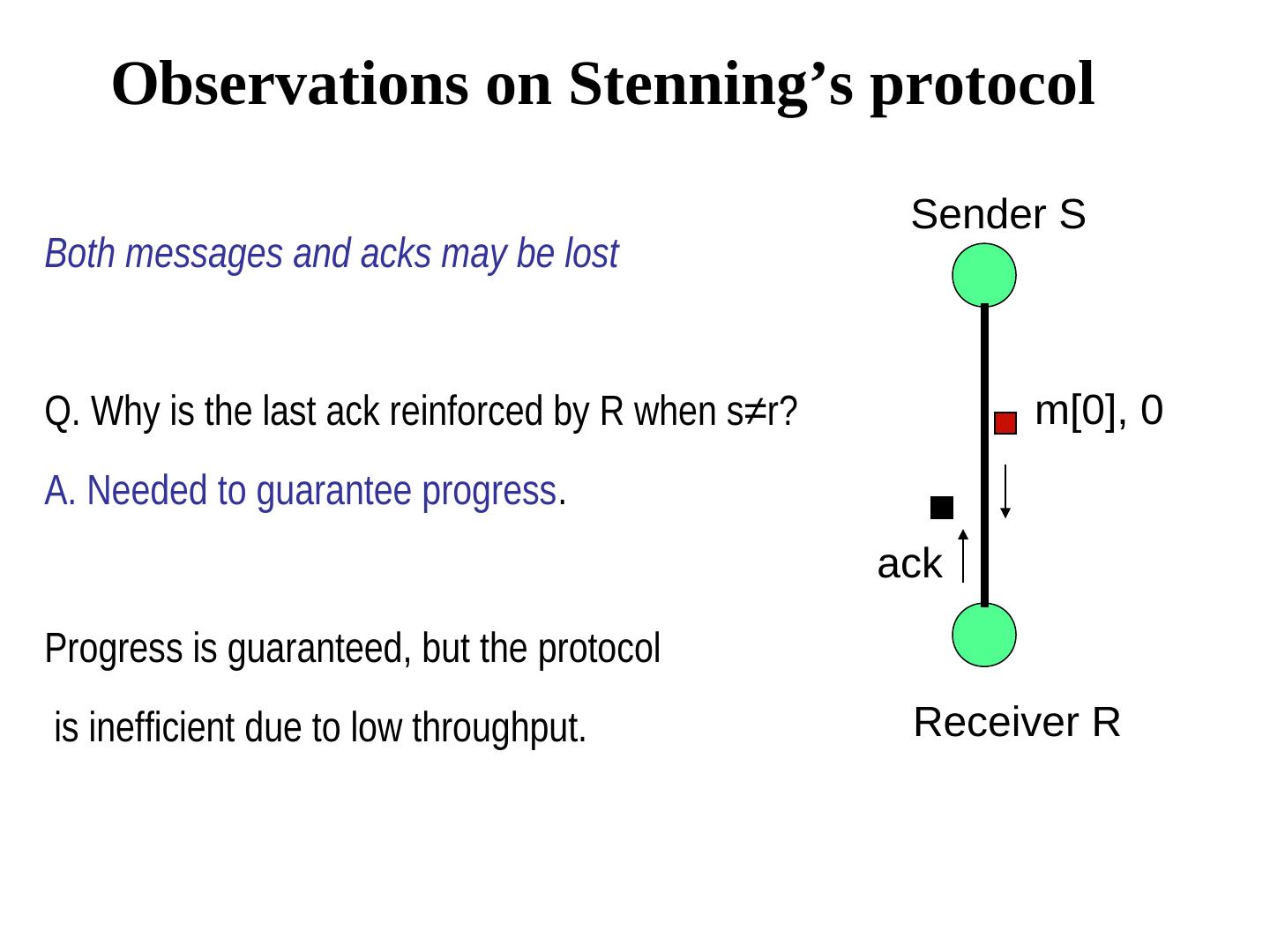
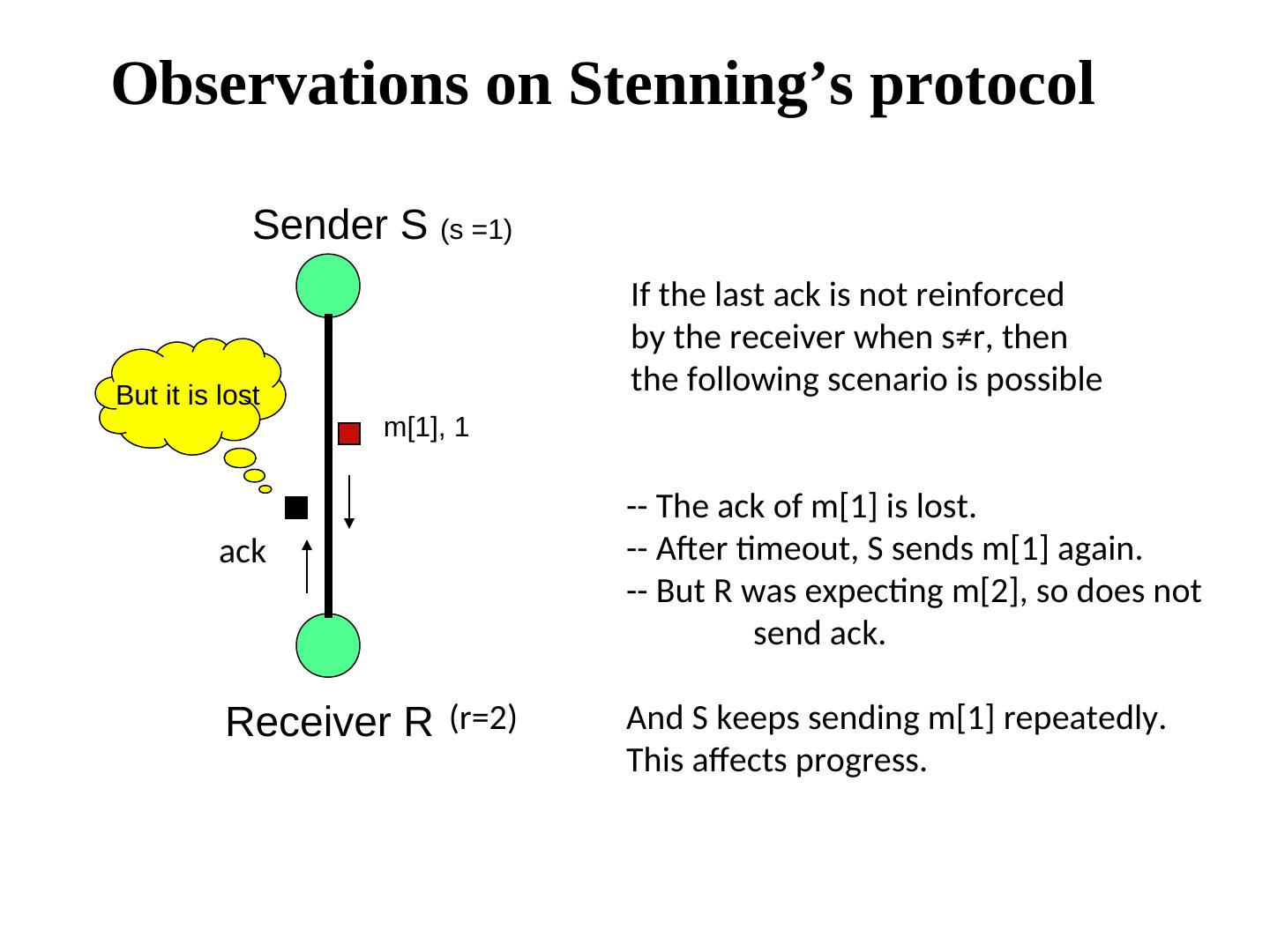
29 . Stenning’s protocol {program for process S} m5 m4 m3 m2 m1 m0 define ok : boolean; next : integer; Sender S initially next = 0, ok = true, both channels are empty; next ok do ok → send (m[next], next); ok:= false [] (ack, next) is received → ok:= true; next := next + 1 [] timeout (R,S) → send (m[next], next) m[0], 0 od {program for process R} ack define r : integer; initially r = 0; r do (m[ ], s) is received ∧ s = r → accept the message; s = r → accept the message; send (ack, r); r:= r+1 Receiver R [] (m[ ], s) is received ∧ s = r → accept the message; s ≠ r → send (ack, r-1) od
3秒后跳转登录页面
去登陆

