展开查看详情
1 .Map Reduce & Hadoop June 3, 2015 HS Oh, HR Lee, JY Choi YS Lee, SH Choi
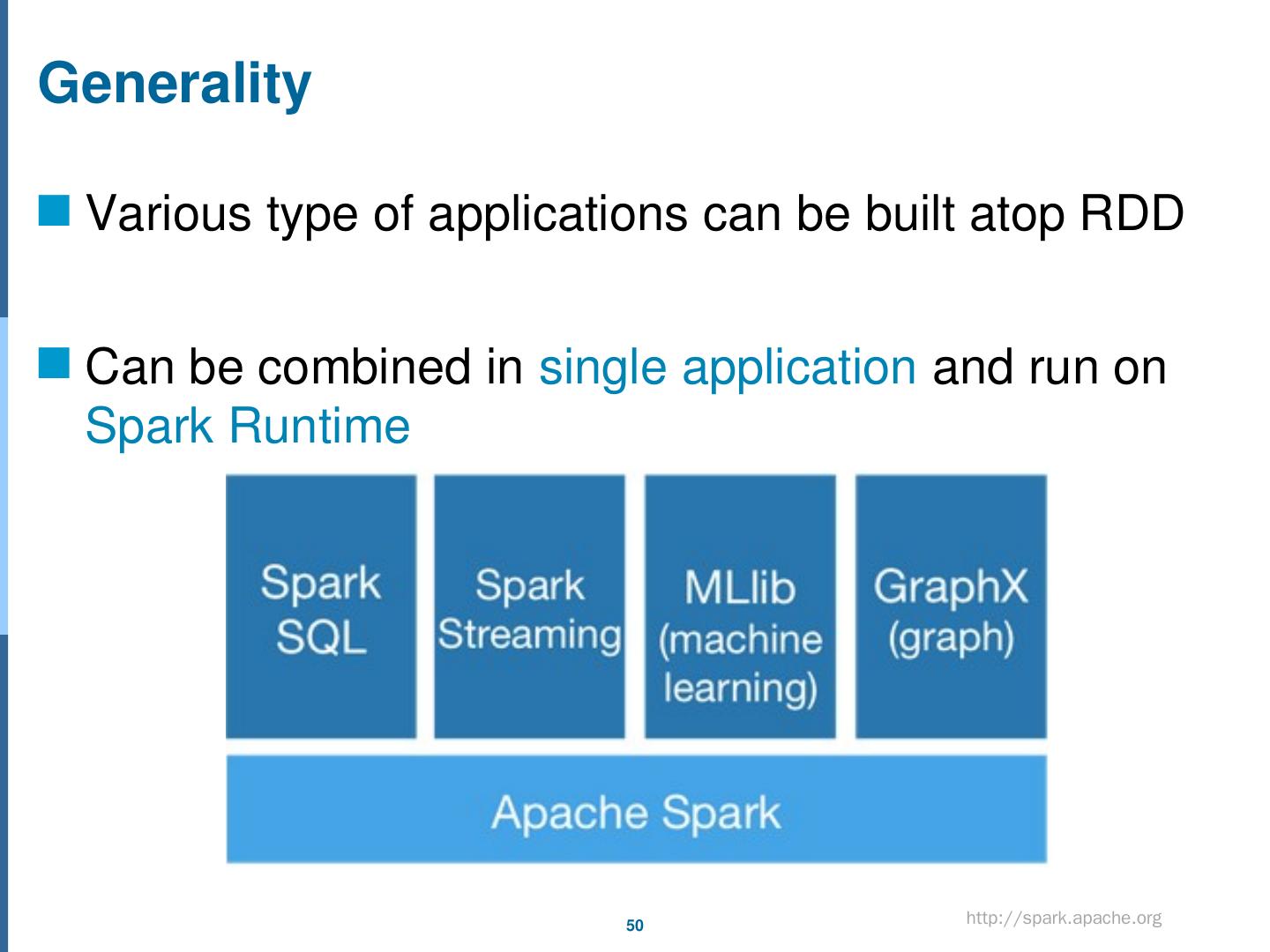
2 .Outline Part1 Introduction to Hadoop MapReduce Tutorial with Simple Example Hadoop v2.0: YARN Part2 MapReduce Hive Stream Data Processing: Storm Spark Up-to-date Trends
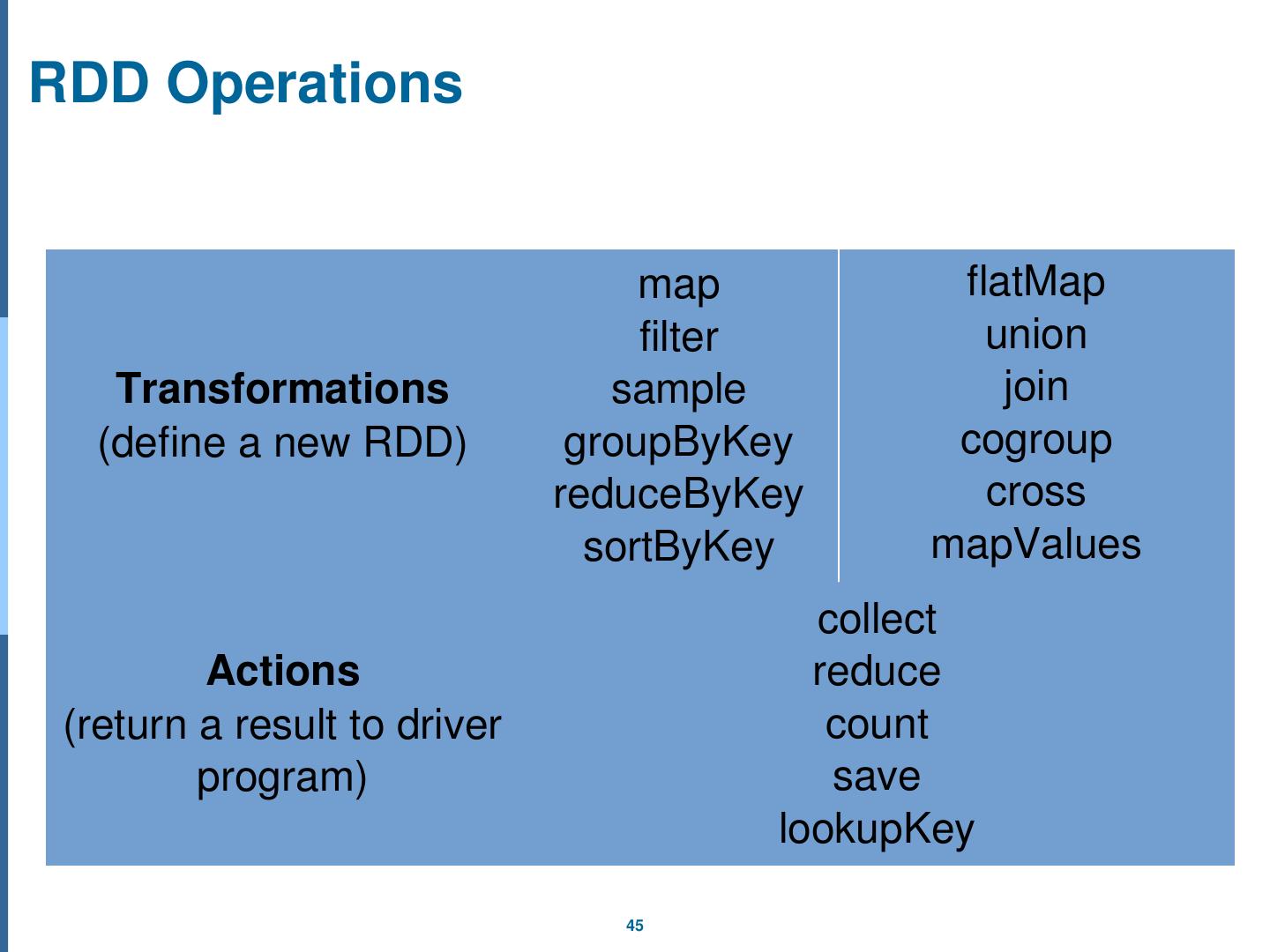
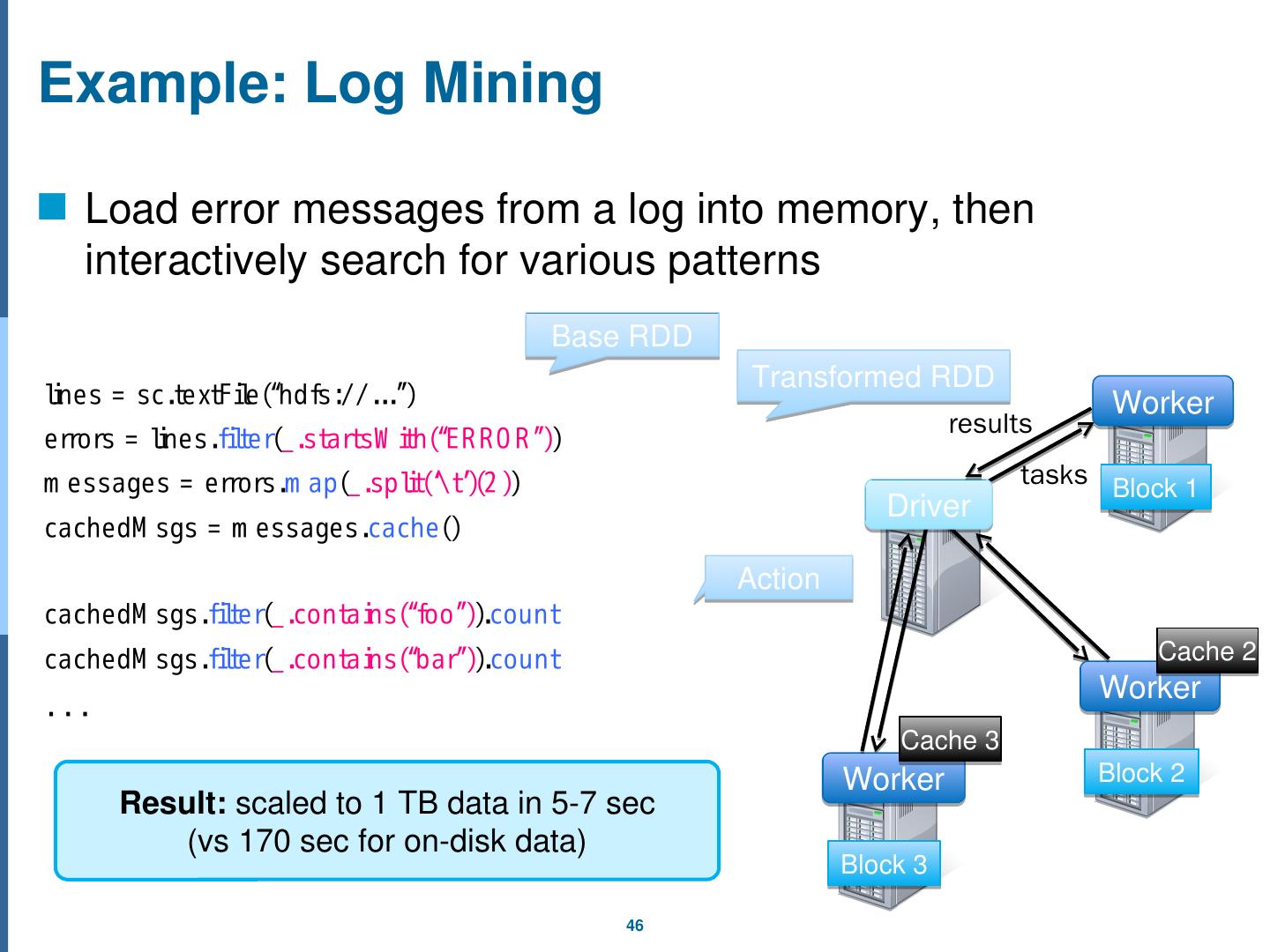
3 .MapReduce Overview Task flow Shuffle configurables Combiner Partitioner Custom Partitioner Example Number of Maps and Reduces How to write MapReduce functions
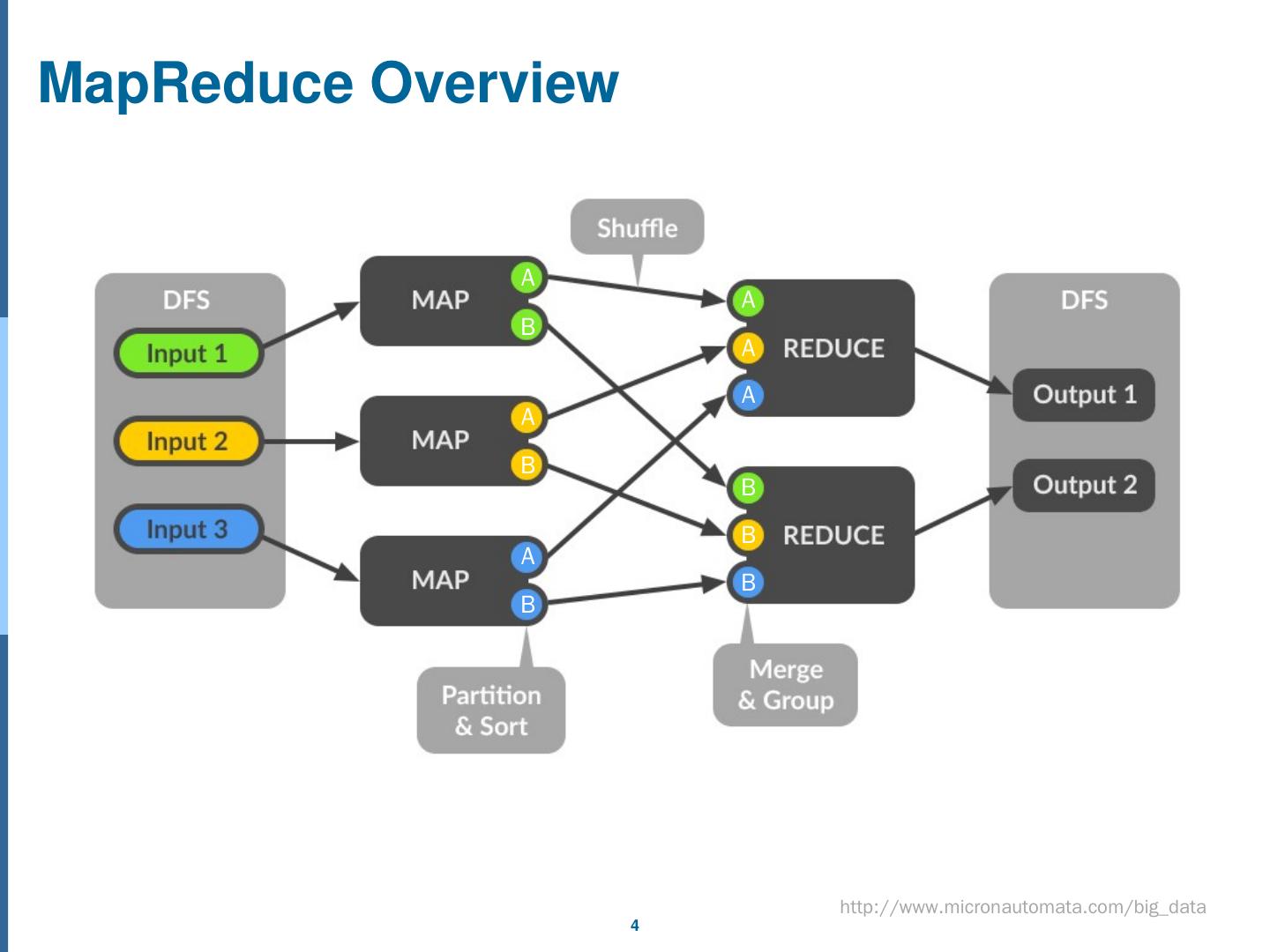
4 .MapReduce Overview http://www.micronautomata.com/big_data A A A A A A B B B B B B
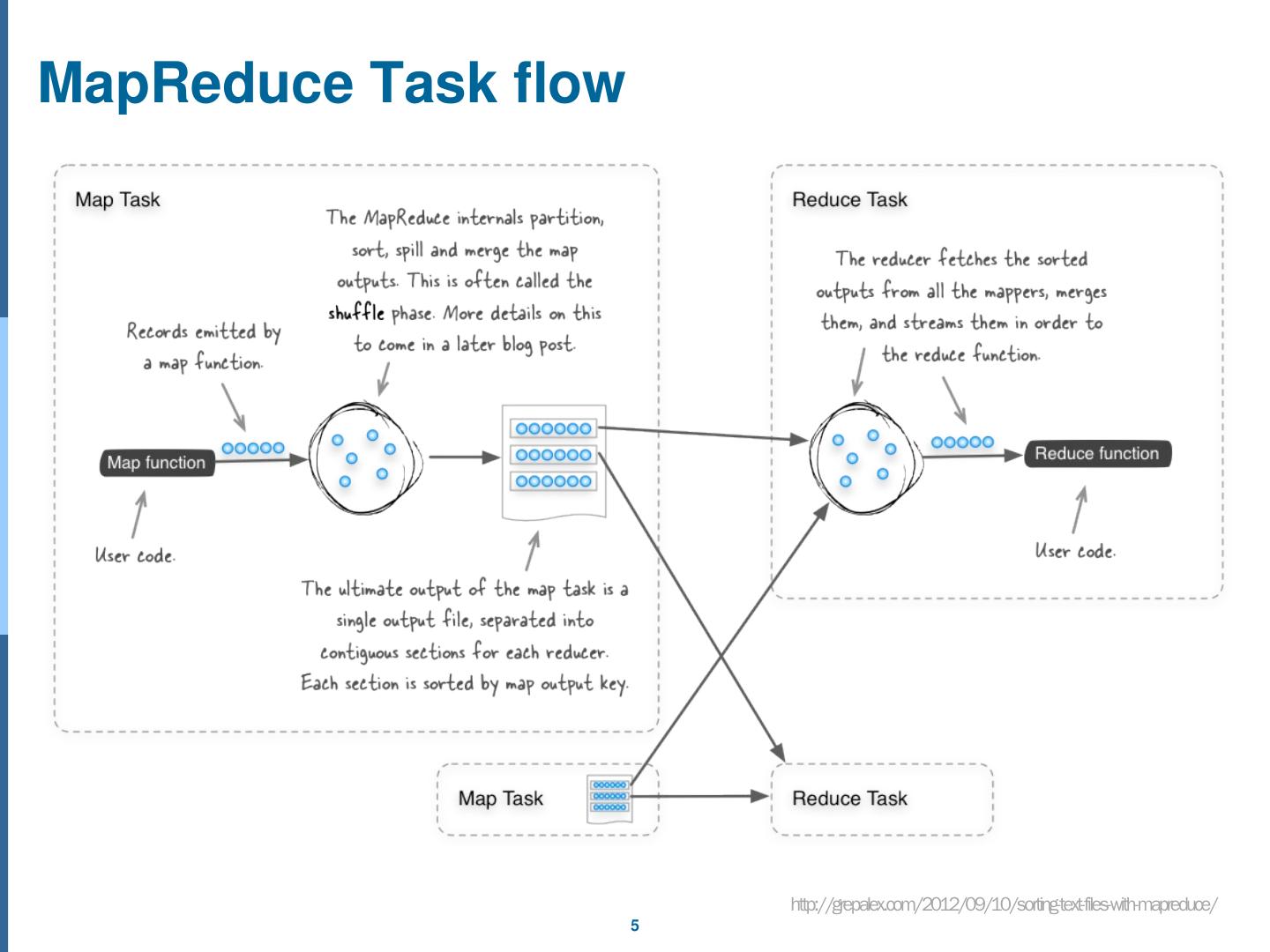
5 .MapReduce Task flow http://grepalex.com/2012/09/10/sorting-text-files-with-mapreduce/
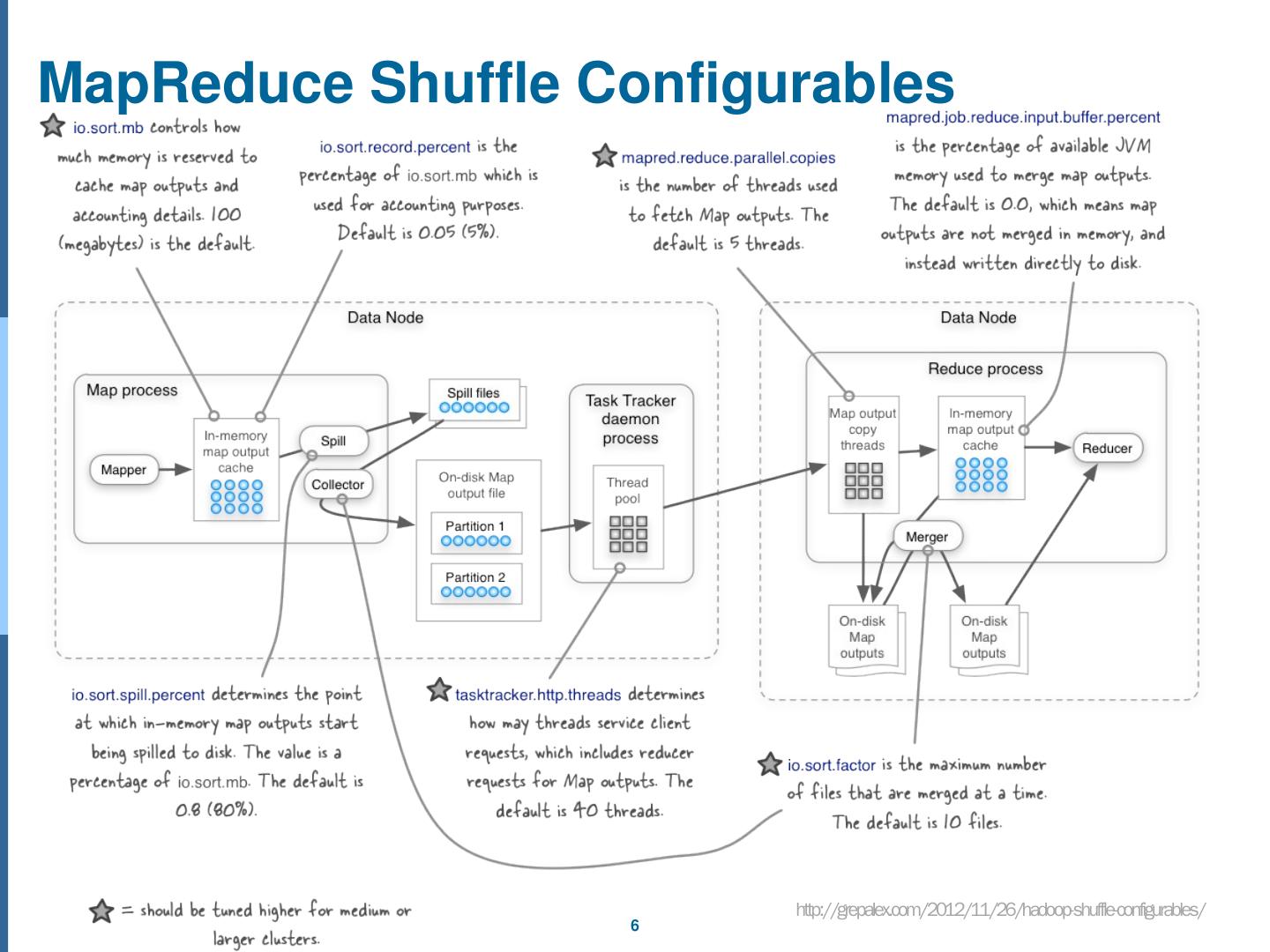
6 .MapReduce Shuffle C onfigurables http://grepalex.com/2012/11/26/hadoop-shuffle-configurables/
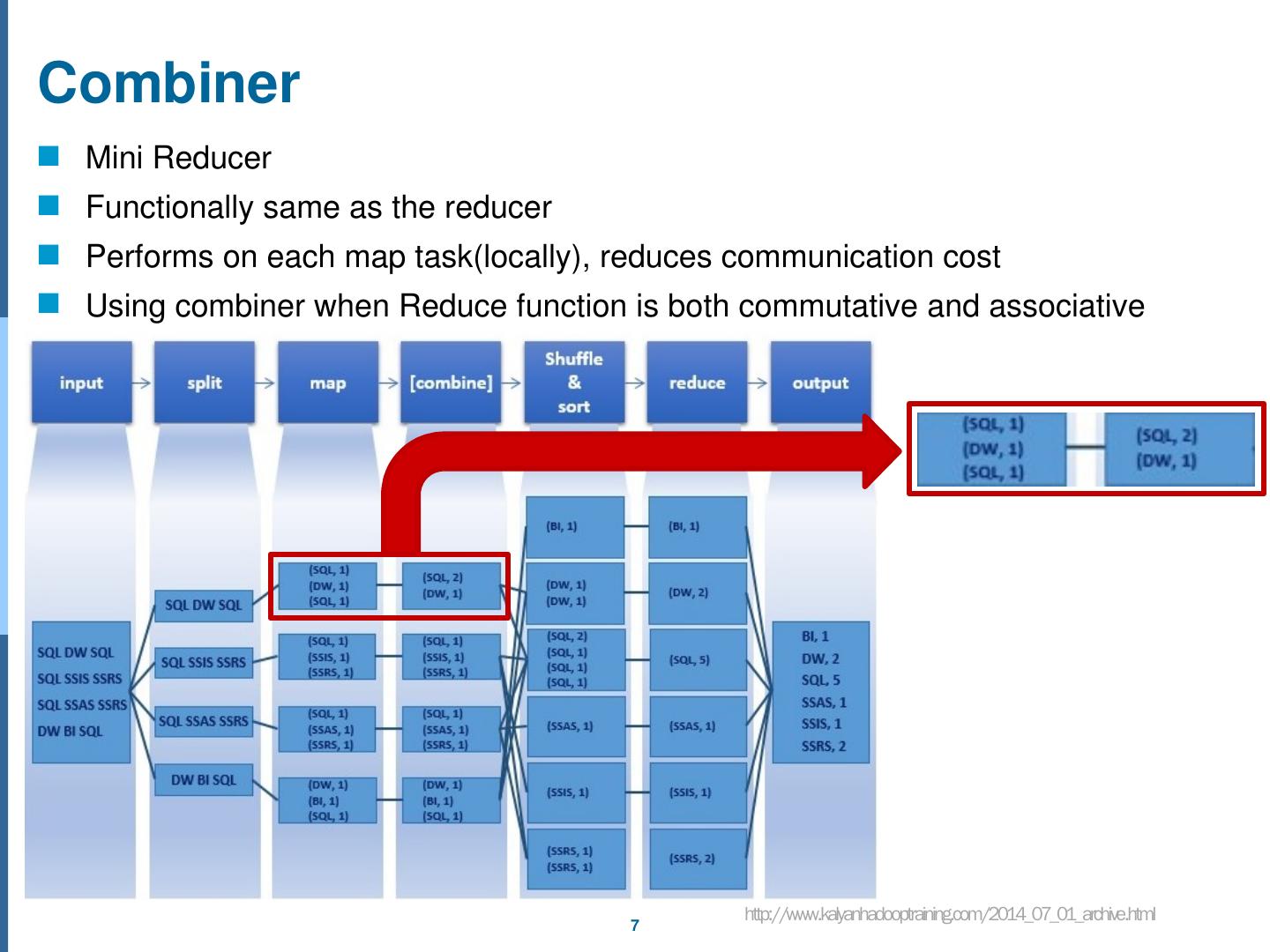
7 .Combiner Mini Reducer Functionally same as the reducer Performs on each map task(locally), reduces communication cost Using combiner when Reduce function is both commutative and associative http://www.kalyanhadooptraining.com/2014_07_01_archive.html
8 .Partitioner Divides Map’s output key, value pair by rule Default strategy is hashing HashPartitioner public class HashPartitioner <K2, V2> implements Partitioner <K2, V2> { public void configure ( JobConf job) {} public int getPartition (K2 key, V2 value, int numReduceTasks ) return ( key. hashCode () & Integer . MAX_VALUE ) % numReduceTasks ; } }
9 .Custom Partitioner Example Input with name, age, sex, and score Map outputs divide by range of age public static class AgePartitioner extends Partitioner <Text, Text> { @Override public int getPartition (Text key, Text value, int numReduceTasks ) { String [] nameAgeScore = value.toString ().split(" "); String age = nameAgeScore [1]; int ageInt = Integer .parseInt (age); //this is done to avoid performing mod with 0 if ( numReduceTasks == 0) return 0; //if the age is <20, assign partition 0 if ( ageInt <=20){ return 0; } //else if the age is between 20 and 50, assign partition 1 if ( ageInt >20 && ageInt <=50){ return 1 % numReduceTasks ; } //otherwise assign partition 2 else return 2 % numReduceTasks ; } } http://hadooptutorial.wikispaces.com/Custom+partitioner
10 .Number of Maps and Reduces The number of Maps = DFS blocks To adjust DFS block size to adjust the number of maps Right level of parallelism for maps → 10~100 maps/node mapred.map.tasks parameter is just a hint The number of Reduces Suggested values Set # of reduce tasks a little bit less than # of total slot A task time between 5 and 15 min Create the fewest files possible conf.setNumReduceTasks ( int num ) http://wiki.apache.org/hadoop/HowManyMapsAndReduces
11 .How to write MapReduce functions [1/2] Java Word Count Example public void map( LongWritable key, Text value, OutputCollector <Text, IntWritable > output, Reporter reporter) throws IOException { String line = value.toString (); StringTokenizer tokenizer = new StringTokenizer (line); while ( tokenizer.hasMoreTokens ()) { word.set ( tokenizer.nextToken ()); output.collect (word, one); } } public void reduce(Text key, Iterator< IntWritable > values, OutputCollector <Text, IntWritable > output, Reporter reporter) throws IOException { int sum = 0; while ( values.hasNext ()) { sum += values.next ().get(); } output.collect (key, new IntWritable (sum)); } Input part Output part Input part Output part http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
12 .How to write MapReduce functions [2/2] Python Word Count Example Mapper.py #!/ usr /bin/python import sys for line in sys.stdin : for word in line.strip ().split(): print "%s\ t%d " % (word, 1) How to excute bin/Hadoop jar share/Hadoop/tools/lib/Hadoop-streaming-2.4.0.jar -files /home/ hduser /Mapper.py, /home/hduser/Reducer.py -mapper /home/hduser/Mapper.py -reducer /home/hduser/Reducer.py -input /input/count_of_monte_cristo.txt -output /output Reducer.py #!/ usr /bin/python import sys current_word = None current_count = 1 for line in sys.stdin : word, count = line.strip ().split(t) if current_word : if word == current_word : current_count += int (count) else: print "%s\ t%d " % ( current_word , current_count ) current_count = 1 current_word = word if current_count > 1: print "%s\ t%d " % ( current_word , current_count ) http://dogdogfish.com/2014/05/19/hadoop-wordcount-in-python/
13 .Hive & Stream Data Processing: Storm Hadoop Ecosystem
14 .The World of Big Data Tools DAG Model For Iterations / Learning For Query For Streaming MapReduce Model Graph Model BSP / Collective Model Hadoop MPI HaLoop Twister Spark Harp Flink REEF Dryad / DryadLINQ Pig / PigLatin Hive Tez SparkSQL (Shark) MRQL S4 Storm Samza Spark Streaming Drill Giraph Hama GraphLab GraphX From Bingjing Zhang
15 .Hive Data warehousing on top of Hadoop Designed to enable easy data summarization ad-hoc querying analysis of large volumes of data HiveQL statements are automatically translated into MapReduce jobs
16 .Advantages Higher level query language Simplifies working with large amounts of data Lower learning curve than Pig or MapReduce HiveQL is much closer to SQL than Pig Less trial and error than Pig
17 .Disadvantages Updating data is complicated Mainly because of using HDFS Can add records Can overwrite partitions No real time access to data Use other means like HBase or Impala High latency
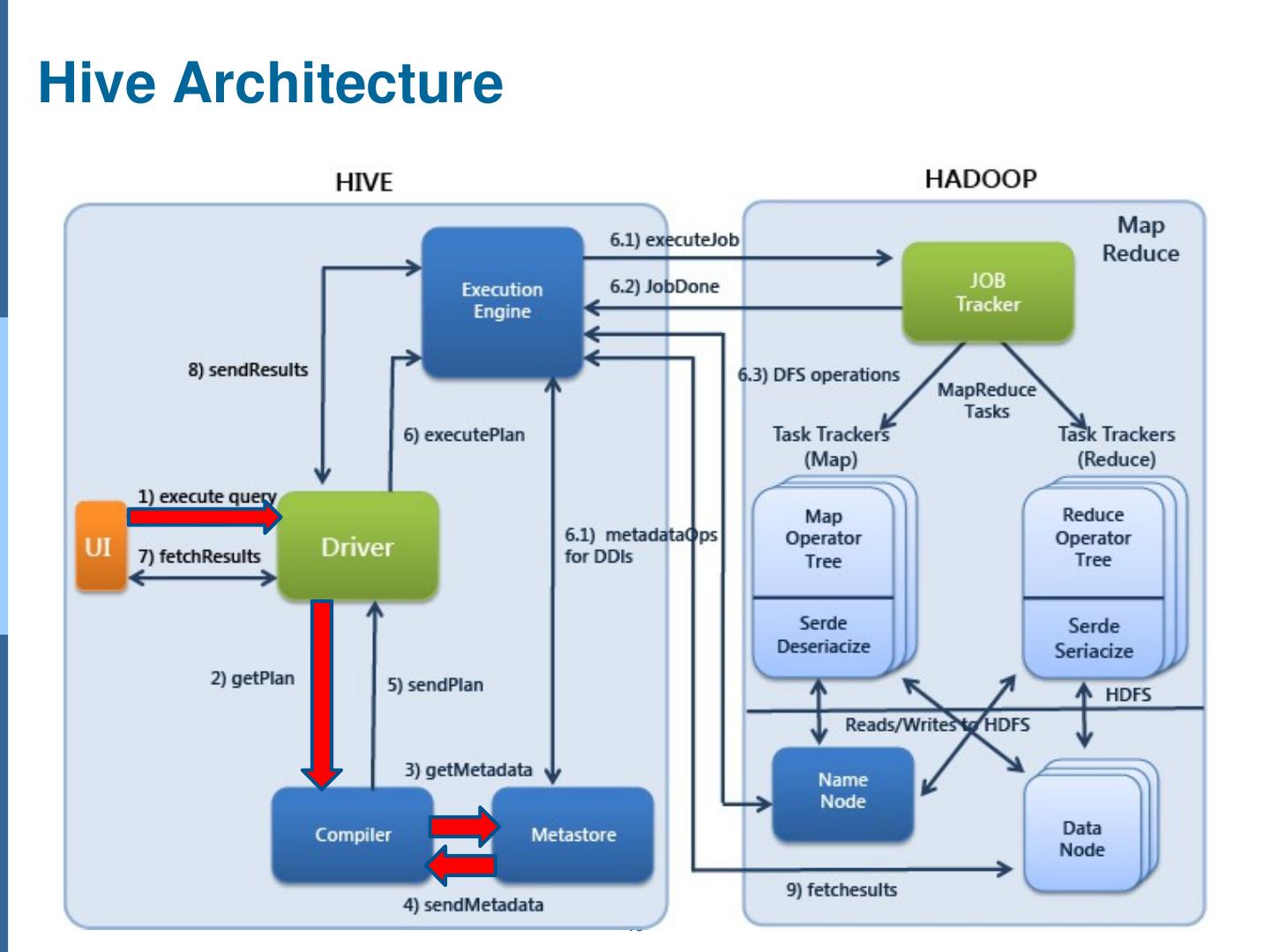
20 .Parser Semantic Analyzer Logical Plan Generator Query Plan Generator Compiler
21 .Parser Semantic Analyzer Logical Plan Generator Query Plan Generator Compiler
22 .While based on SQL, HiveQL does not strictly follow the full SQL-92 standard. HiveQL offers extensions not in SQL, including multitable inserts and create table as select, but only offers basic support for indexes. HiveQL lacks support for transactions and materialized views, and only limited subquery support. Support for insert, update, and delete with full ACID functionality was made available with release 0.14. HiveQL
23 .Datatypes in Hive Primitive datatypes TINYINT SMALLINT INT BIGINT BOOLEAN FLOAT DOUBLE STRING
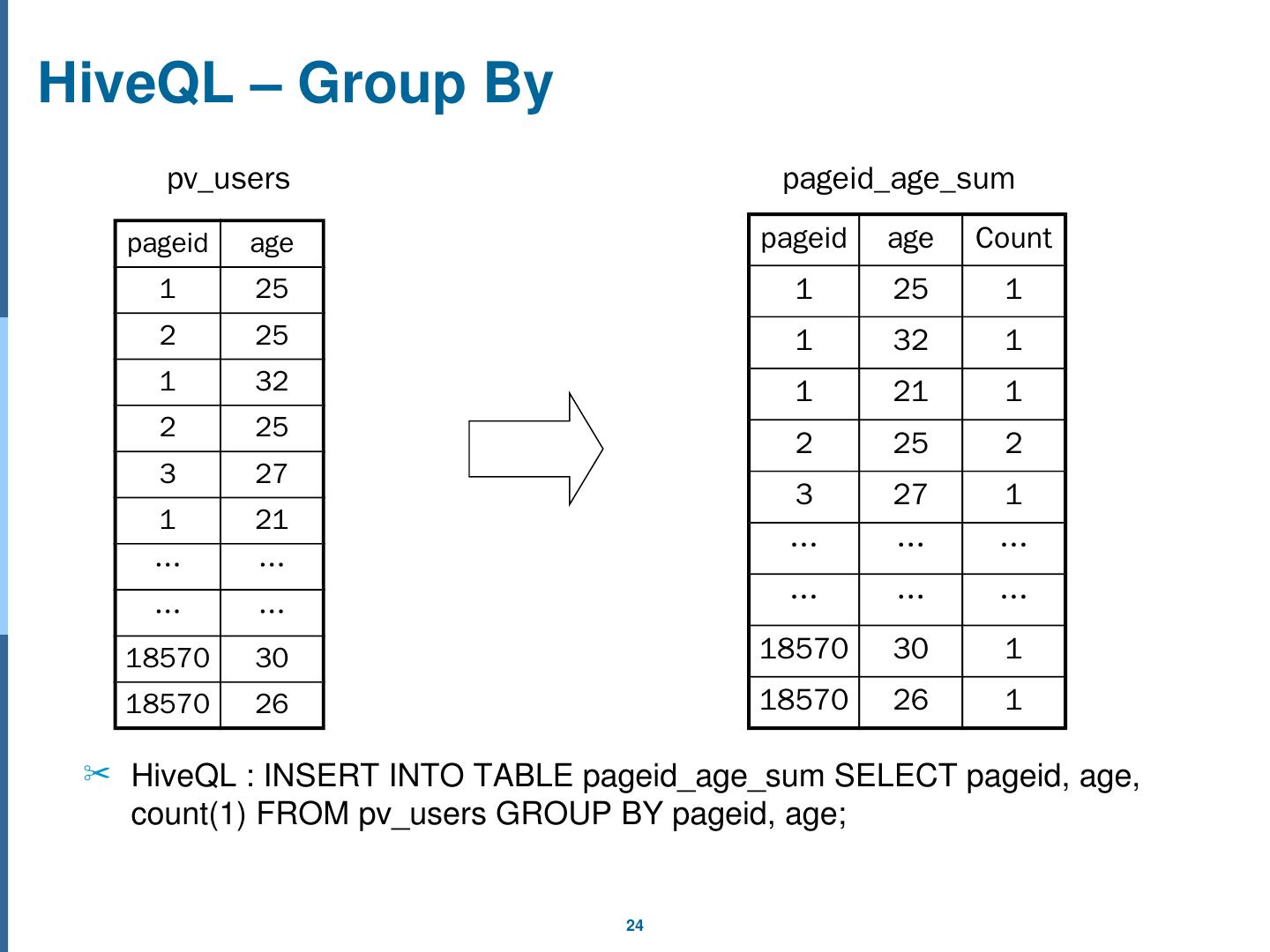
24 .HiveQL – Group By HiveQL : INSERT INTO TABLE pageid_age_sum SELECT pageid , age, count(1) FROM pv_users GROUP BY pageid , age; pageid age 1 25 2 25 1 32 2 25 3 27 1 21 … … … … 18570 30 18570 26 pv_users pageid age Count 1 25 1 1 32 1 1 21 1 2 25 2 3 27 1 … … … … … … 18570 30 1 18570 26 1 pageid_age_sum
25 .HiveQL – Group By in MapReduce pageid age 1 25 2 25 1 32 pageid age Count 1 25 1 1 32 1 1 21 1 pageid age 2 25 3 27 1 21 key value <1,25> 1 <2,25> 1 <1,32> 1 key value < 2 , 25 > 1 < 3 ,2 7 > 1 <1,21> 1 key value <1,25> 1 <1,32> 1 <1,21> 1 key value <2,25> 1 <2,25> 1 2 25 2 pageid age 18570 30 18570 26 … key value <18570,30> 1 <18570,26> 1 … key value <18570,30> 1 <18570,26> 1 key value <3,27> 1 … 3 27 1 18570 30 1 18570 26 1 … Map Shuffle Reduce
26 .Stream Data Processing
27 .Distributed Stream Processing Engine Stream data Unbounded sequence of event tuples E.g., sensor data, stock trading data, web traffic data, … Since large volume of data flows from many sources, centralized systems can no longer process in real time.
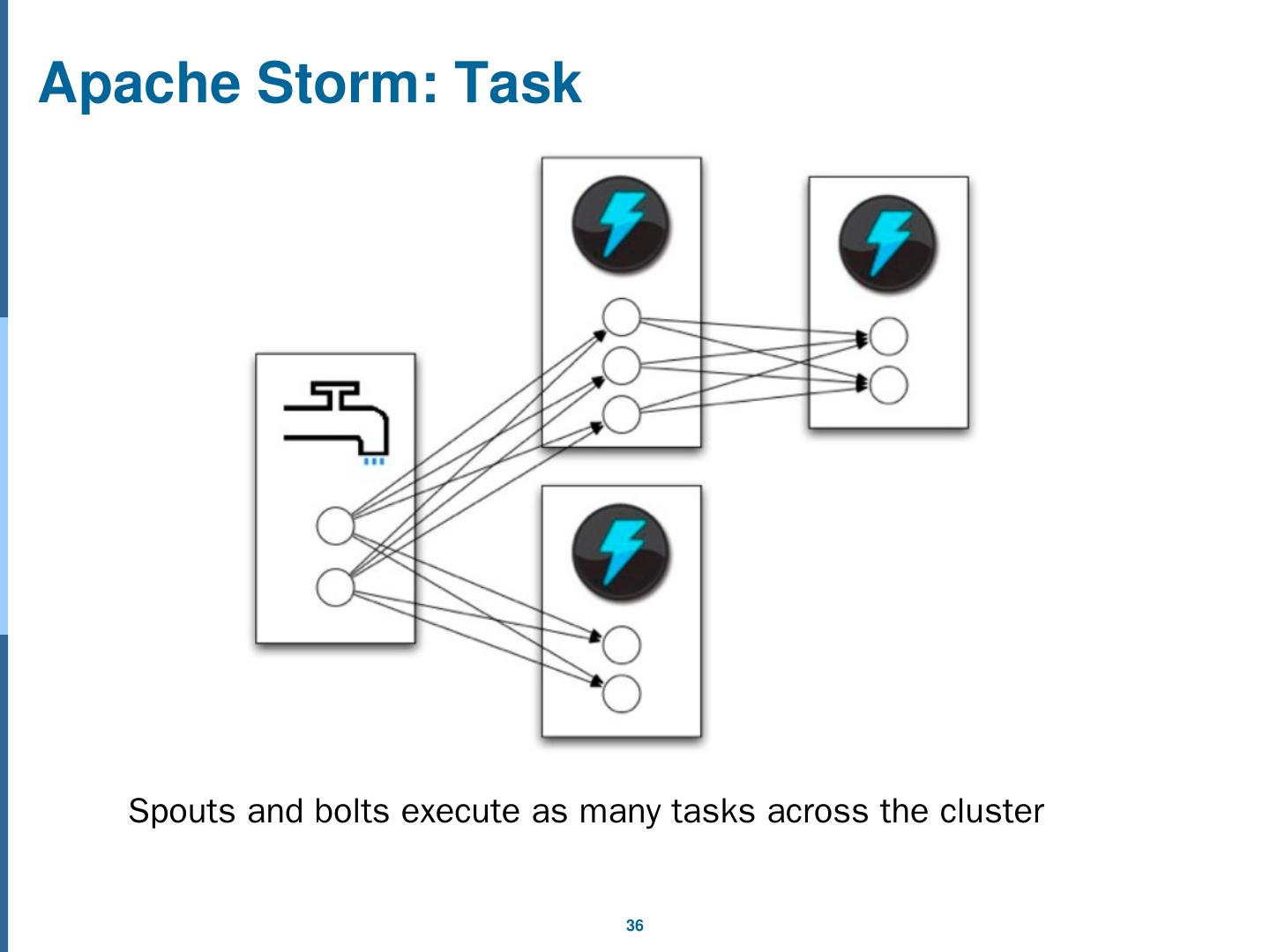
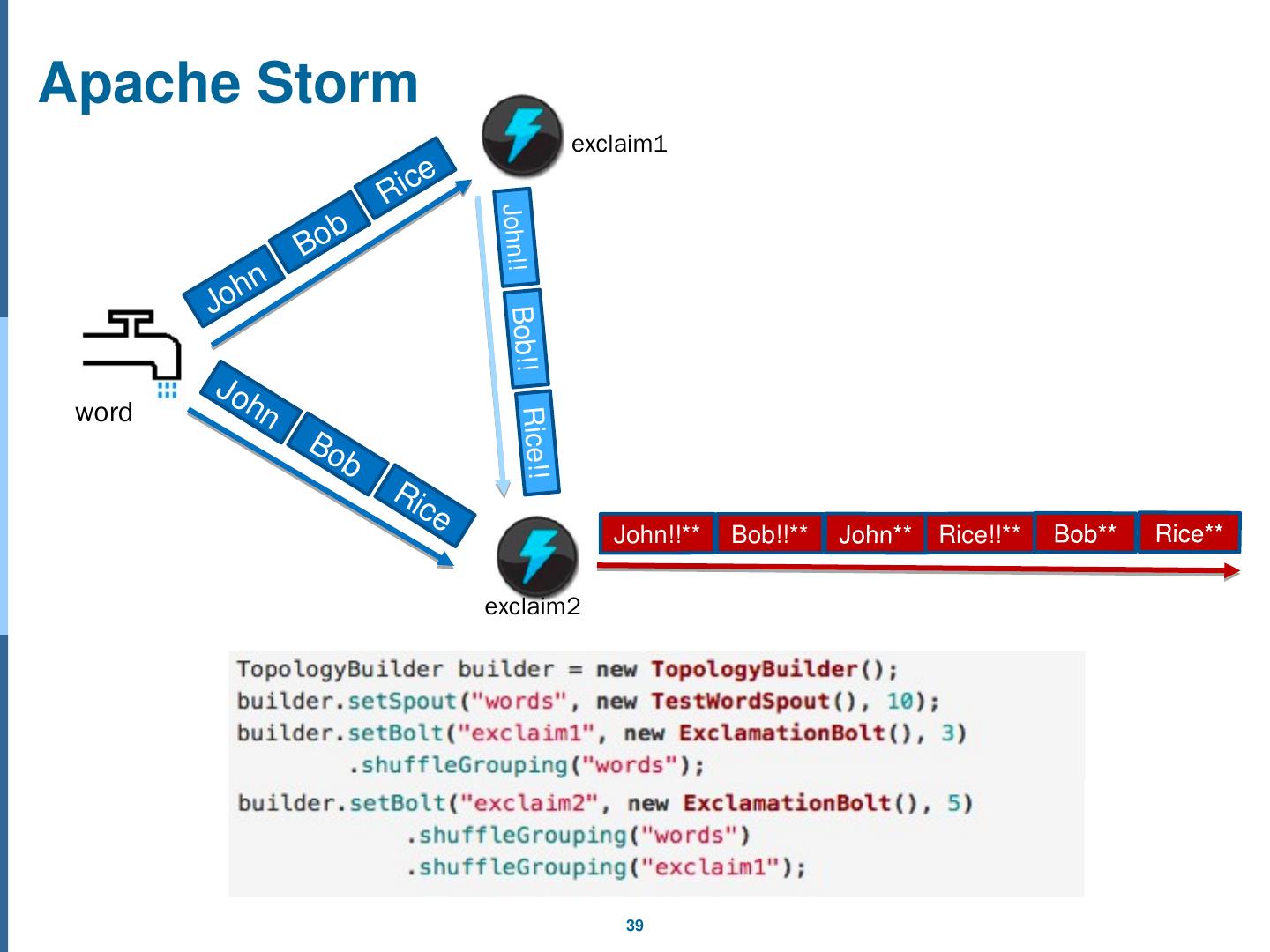
28 .Distributed Stream Processing Engine General Stream Processing Model Stream processing involves processing data before storing . c.f. Batch systems(like Hadoop) provide processing data after storing. Processing Element (PE): A processing unit in stream engine Generally stream processing engine creates a logical network of stream processing elements(PE) connected in directed acyclic graph(DAG).
29 .Distributed Stream Processing Engine