

















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
快看漫画个性化推荐探索与实践
一、业务介绍
二、技术挑战
三、技术探索
四、总结与未来规划
展开查看详情
1 .快看漫画个性化推荐探索与实践 夏博 2019年9月
2 .目录 一、业务介绍 二、技术挑战 三、技术探索 四、总结与未来规划
3 .目录 一、业务介绍 二、技术挑战 三、技术探索 四、总结与未来规划
4 .了解快看漫画 中国新生代内容社区和原创IP平台 截至2019年7月总用户量已经突破2亿,注 册用户量突破1亿,月活突破4000万 绝大多数用户属于高活跃、高粘性的95后、 00后 被 QuestMobile 等机构评为“最受 00 后 欢迎的产品
5 .快看漫画推荐业务 内容形式 推荐业务场景 人 长漫画 首页个性 发现页推 世界页推 帖底相关 短漫画 推荐tab 荐tab 荐tab 推荐 图文帖子 精准匹配 视频帖子 … 内容
6 .目录 一、业务介绍 二、技术挑战 三、技术探索 四、总结与未来规划
7 .内容形式多样 挑战: 长内容 短内容 技术上如何捕捉长内容的 连续性、周期性、多兴趣 点等特点? 漫画、小说等 短视频、新闻资讯、 快看漫画既有长内容又有 大块时间,阅 用户帖子等 短内容,如何较好的融合 读周期长 碎片化时间,阅读时 两类内容? 连续性、周期 间短 性、多章节多 兴趣点通常单一 兴趣点
8 .内容风格独特 挑战: 图像 文本 如何进行漫画类图像内容 理解? 独特社区文化,新生代文 漫画图像 帖子内容 化“暗语”,给文本内容理解 帖子图片 弹幕 带来挑战 评论
9 .目录 一、业务介绍 二、技术挑战 三、技术探索 四、总结与未来规划
10 . 算法方面的探索 系统架构方面的探索
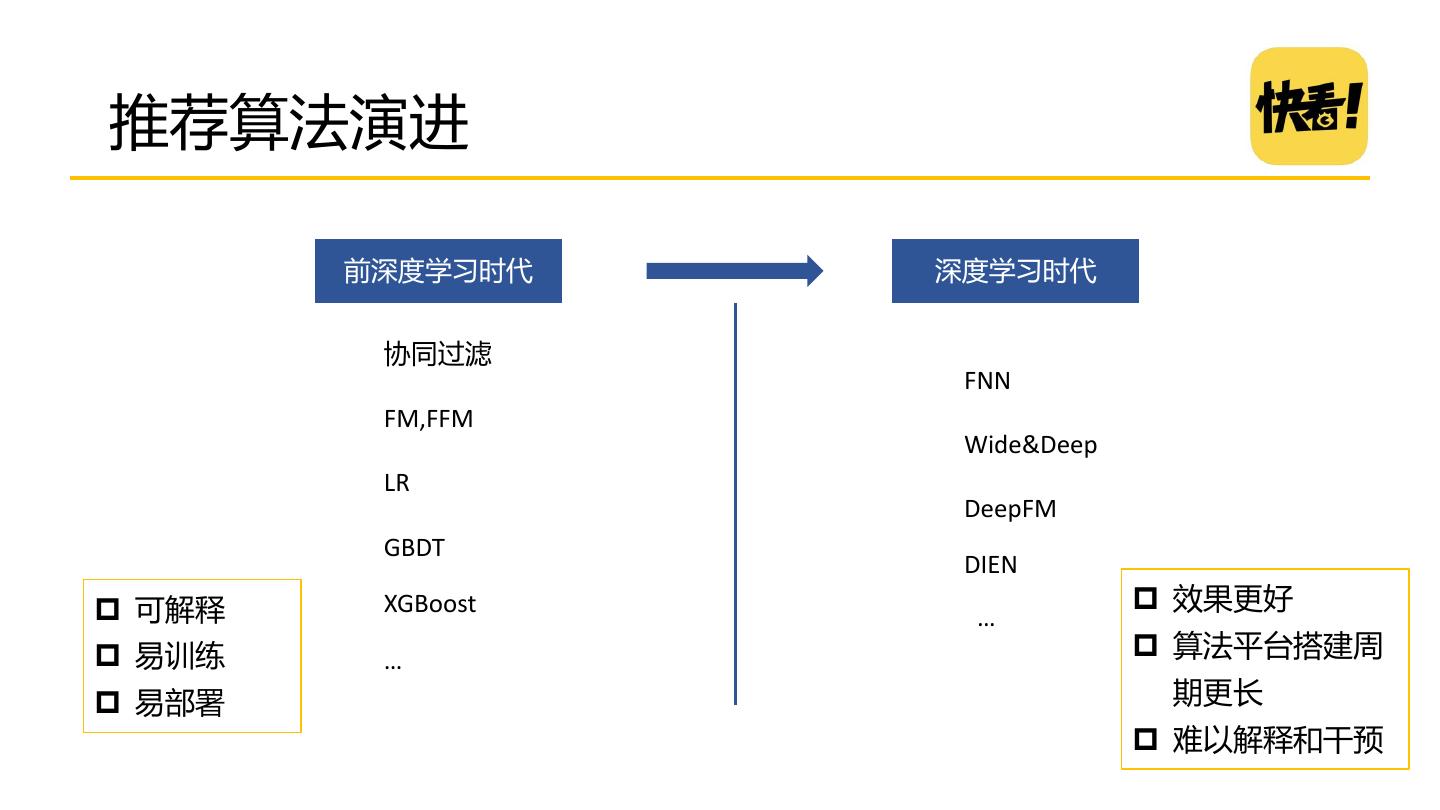
11 .推荐算法演进 前深度学习时代 深度学习时代 协同过滤 FNN FM,FFM Wide&Deep LR DeepFM GBDT DIEN 可解释 XGBoost 效果更好 … 易训练 … 算法平台搭建周 易部署 期更长 难以解释和干预
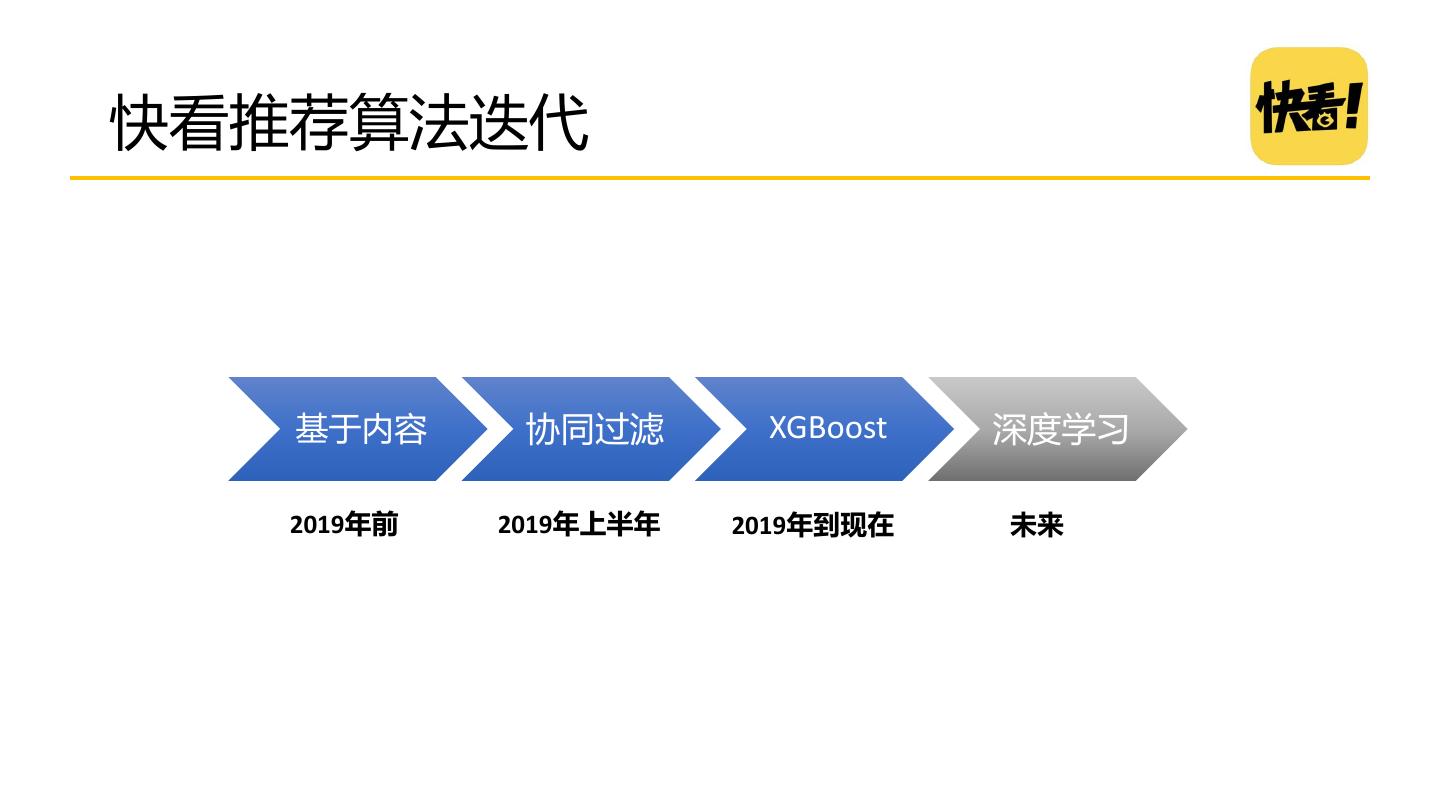
12 .快看推荐算法迭代 基于内容 协同过滤 XGBoost 深度学习 2019年前 2019年上半年 2019年到现在 未来
13 .基于内容的推荐 内容理解 标签 推荐 结果 兴趣模型 用户偏好 优点: 基于已有标签快速实现推 阅读历史 荐功能 可解释性强
14 .快看漫画标签体系 作品基础维度 彩色 单元剧 用户分发维度 搞笑 中性 内容创作维度 青少年 日常 现代 青春 青春成长 治愈 学生 校园 兄妹 逗比 阳光
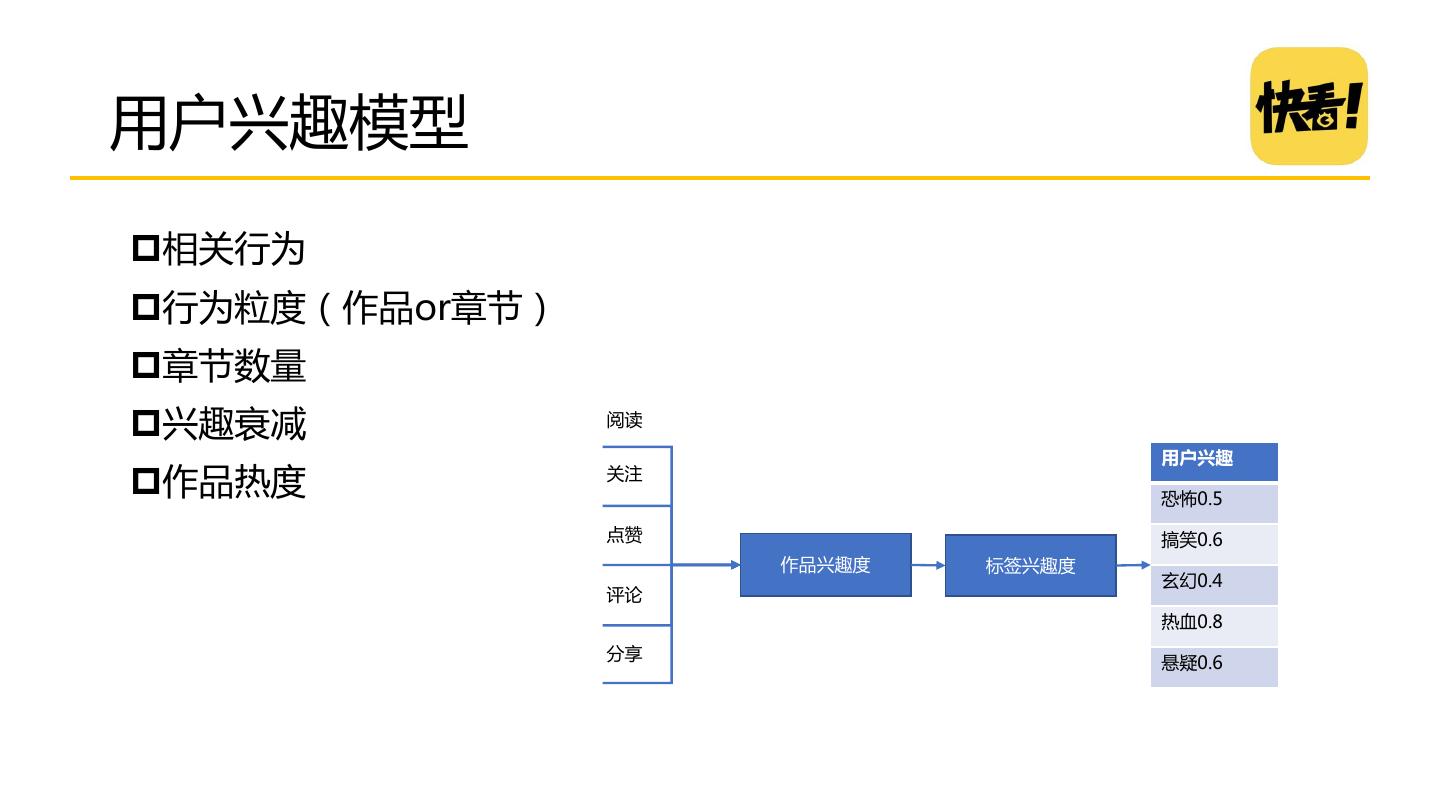
15 .用户兴趣模型 相关行为 行为粒度(作品or章节) 章节数量 兴趣衰减 阅读 用户兴趣 作品热度 关注 恐怖0.5 点赞 搞笑0.6 作品兴趣度 标签兴趣度 玄幻0.4 评论 热血0.8 分享 悬疑0.6
16 .基于内容推荐总结 缺点: 非常依赖标签 推荐粒度较粗,召回不足 DAU人均阅读 缺乏新颖性 次数率提升35%
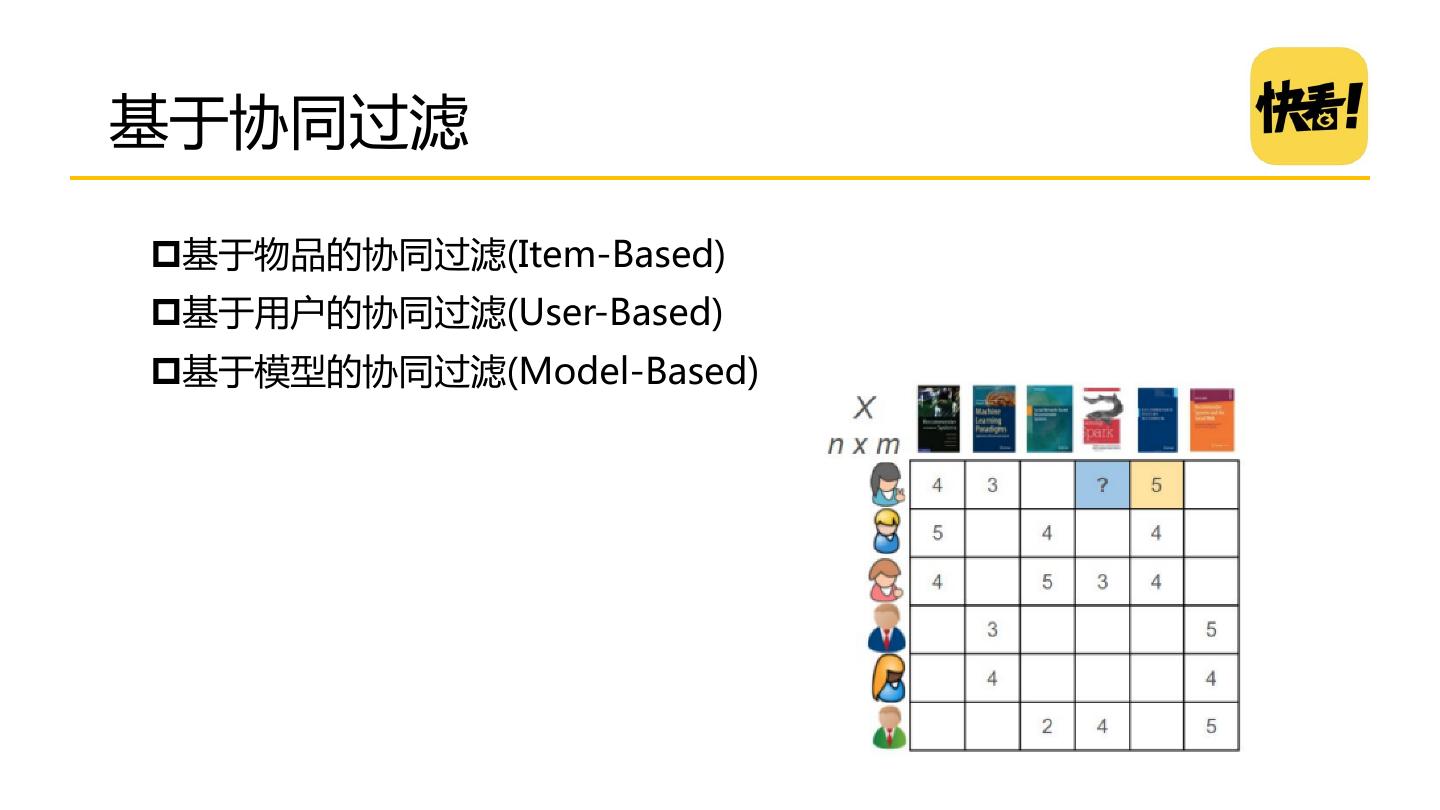
17 .基于协同过滤 基于物品的协同过滤(Item-Based) 基于用户的协同过滤(User-Based) 基于模型的协同过滤(Model-Based)
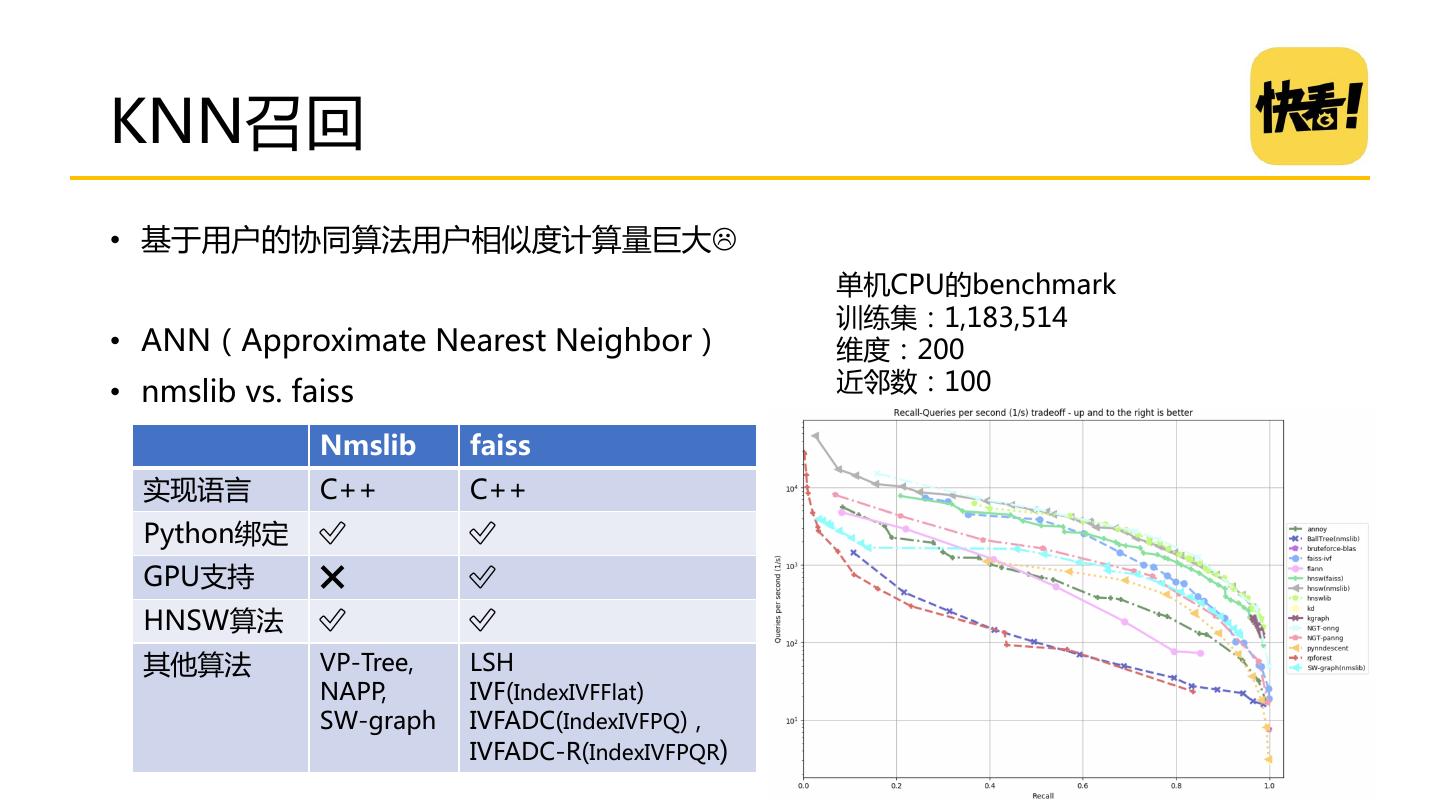
18 .KNN召回 • 基于用户的协同算法用户相似度计算量巨大 单机CPU的benchmark 训练集:1,183,514 • ANN(Approximate Nearest Neighbor) 维度:200 • nmslib vs. faiss 近邻数:100 Nmslib faiss 实现语言 C++ C++ Python绑定 ✅ ✅ GPU支持 ❌ ✅ HNSW算法 ✅ ✅ 其他算法 VP-Tree, LSH NAPP, IVF(IndexIVFFlat) SW-graph IVFADC(IndexIVFPQ) , IVFADC-R(IndexIVFPQR)
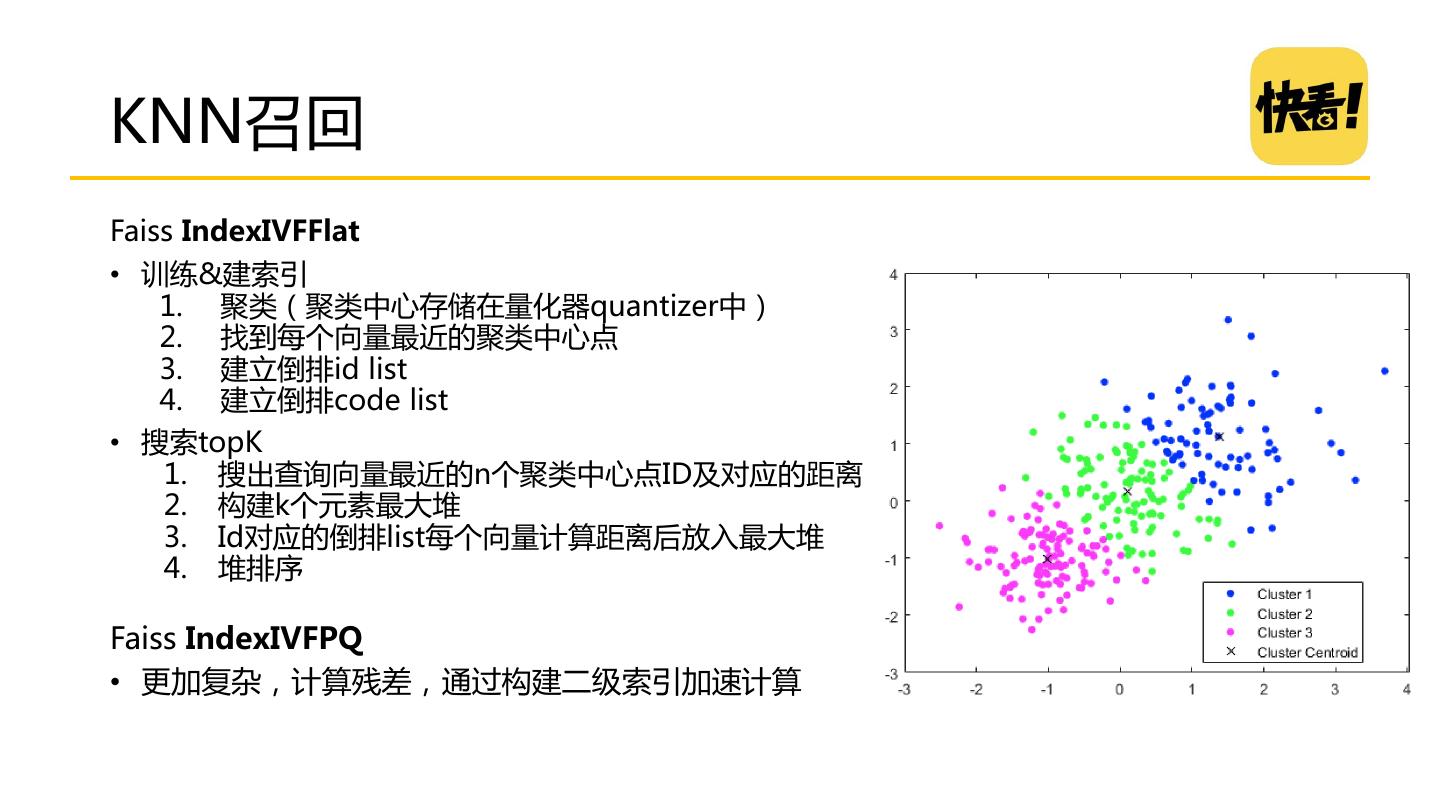
19 .KNN召回 Faiss IndexIVFFlat • 训练&建索引 1. 聚类(聚类中心存储在量化器quantizer中) 2. 找到每个向量最近的聚类中心点 3. 建立倒排id list 4. 建立倒排code list • 搜索topK 1. 搜出查询向量最近的n个聚类中心点ID及对应的距离 2. 构建k个元素最大堆 3. Id对应的倒排list每个向量计算距离后放入最大堆 4. 堆排序 Faiss IndexIVFPQ • 更加复杂,计算残差,通过构建二级索引加速计算
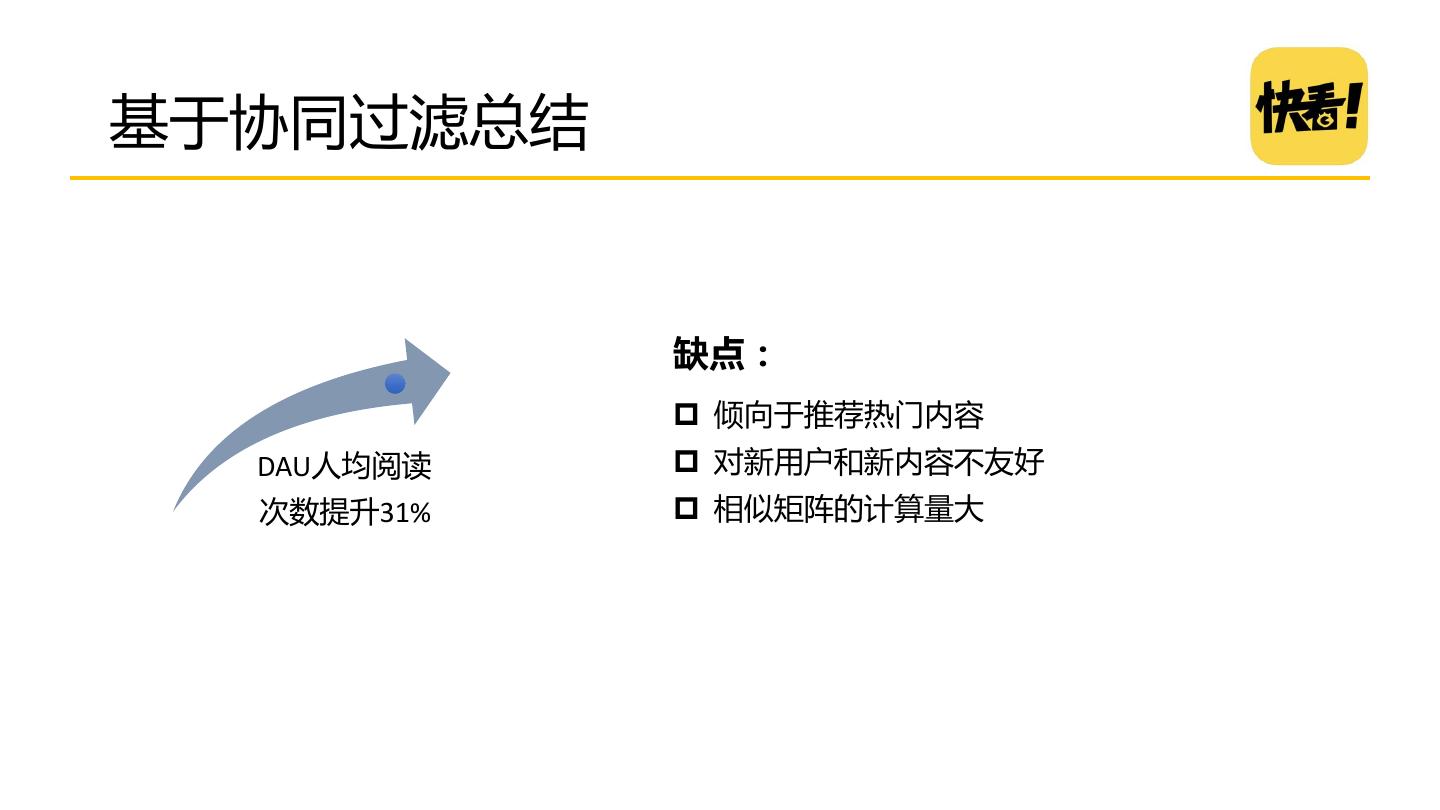
20 .基于协同过滤总结 缺点: 倾向于推荐热门内容 DAU人均阅读 对新用户和新内容不友好 次数提升31% 相似矩阵的计算量大
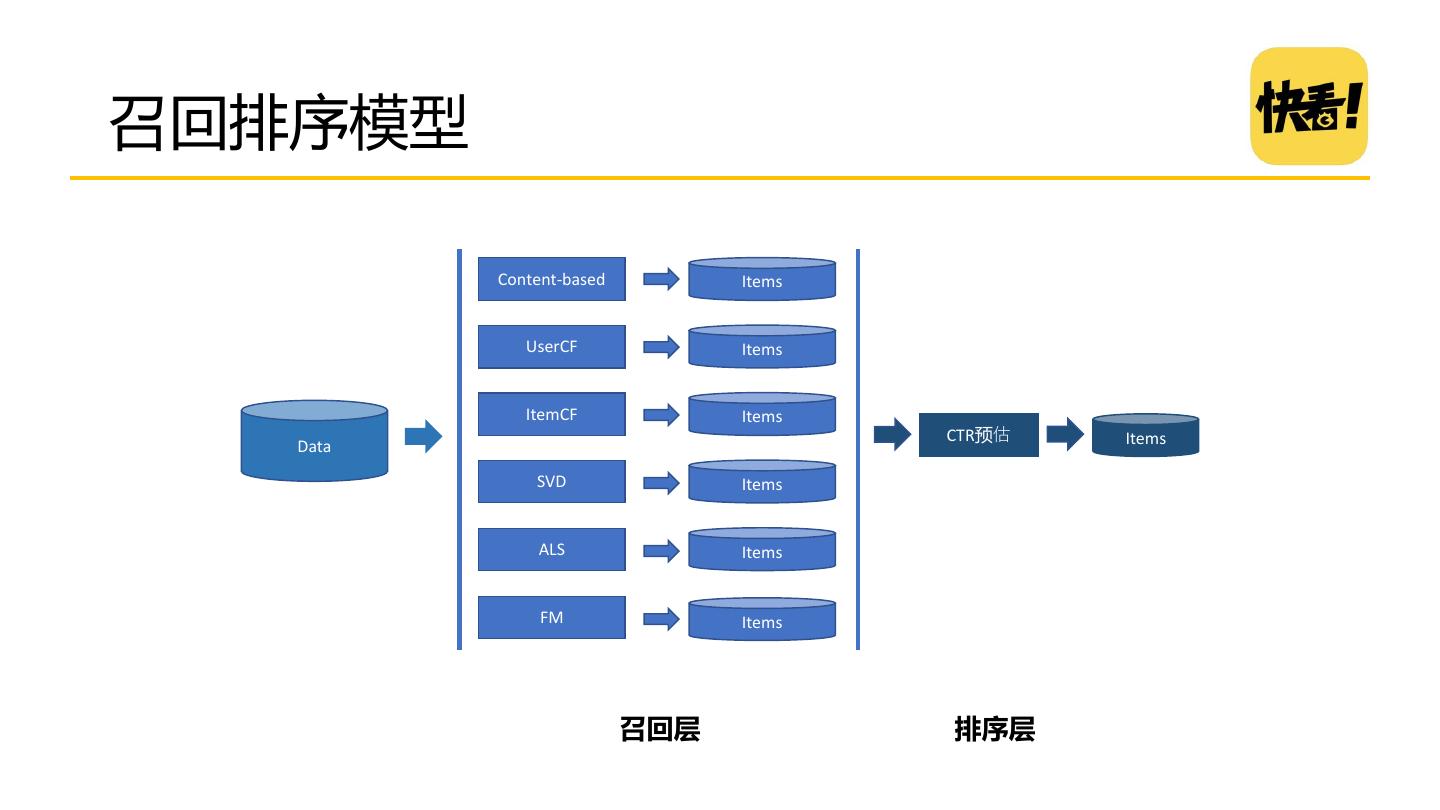
21 .召回排序模型 Content-based Items UserCF Items ItemCF Items CTR预估 Items Data SVD Items ALS Items FM Items 召回层 排序层
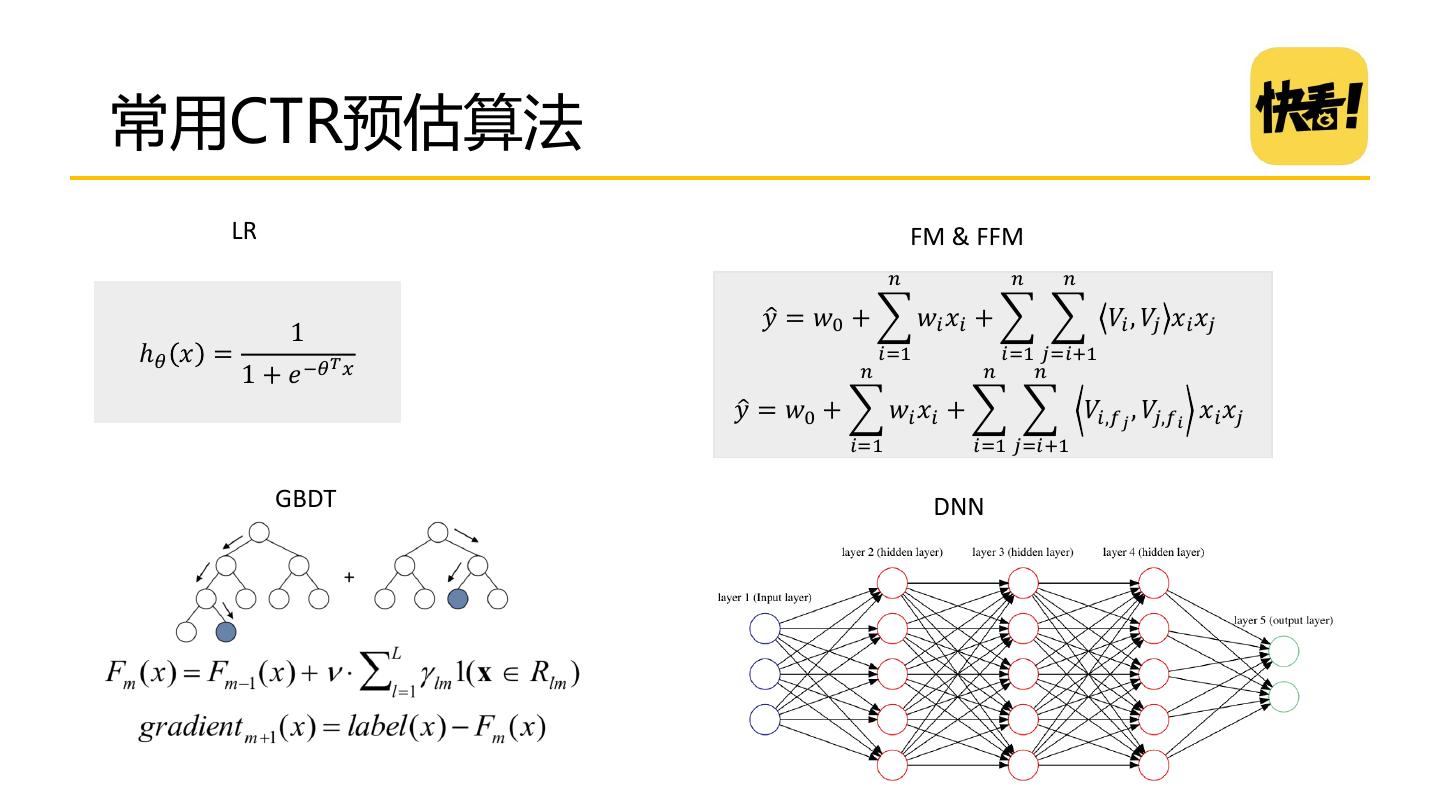
22 .常用CTR预估算法 LR FM & FFM 𝑛 𝑛 𝑛 𝑦 = 𝑤0 + 𝑤𝑖 𝑥𝑖 + 𝑉𝑖 , 𝑉𝑗 𝑥𝑖 𝑥𝑗 1 ℎ𝜃 𝑥 = 𝑇𝑥 𝑖=1 𝑖=1 𝑗=𝑖+1 1 + 𝑒 −𝜃 𝑛 𝑛 𝑛 𝑦 = 𝑤0 + 𝑤𝑖 𝑥𝑖 + 𝑉𝑖,𝑓𝑗 , 𝑉𝑗,𝑓𝑖 𝑥𝑖 𝑥𝑗 𝑖=1 𝑖=1 𝑗=𝑖+1 GBDT DNN
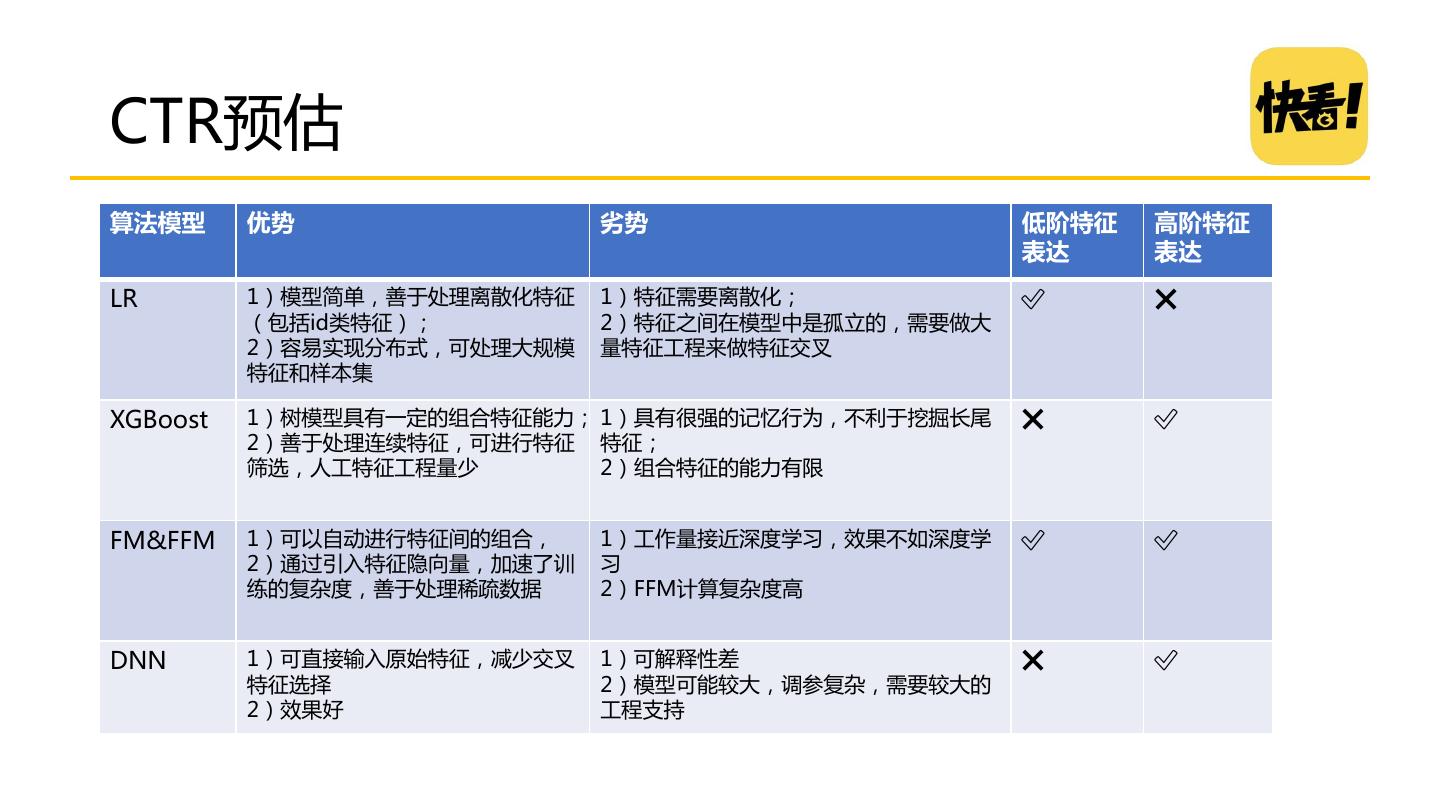
23 .CTR预估 算法模型 优势 劣势 低阶特征 高阶特征 表达 表达 LR 1)模型简单,善于处理离散化特征 1)特征需要离散化; ✅ ❌ (包括id类特征); 2)特征之间在模型中是孤立的,需要做大 2)容易实现分布式,可处理大规模 量特征工程来做特征交叉 特征和样本集 XGBoost 1)树模型具有一定的组合特征能力; 1)具有很强的记忆行为,不利于挖掘长尾 ❌ ✅ 2)善于处理连续特征,可进行特征 特征; 筛选,人工特征工程量少 2)组合特征的能力有限 FM&FFM 1)可以自动进行特征间的组合, 1)工作量接近深度学习,效果不如深度学 ✅ ✅ 2)通过引入特征隐向量,加速了训 习 练的复杂度,善于处理稀疏数据 2)FFM计算复杂度高 DNN 1)可直接输入原始特征,减少交叉 1)可解释性差 ❌ ✅ 特征选择 2)模型可能较大,调参复杂,需要较大的 2)效果好 工程支持
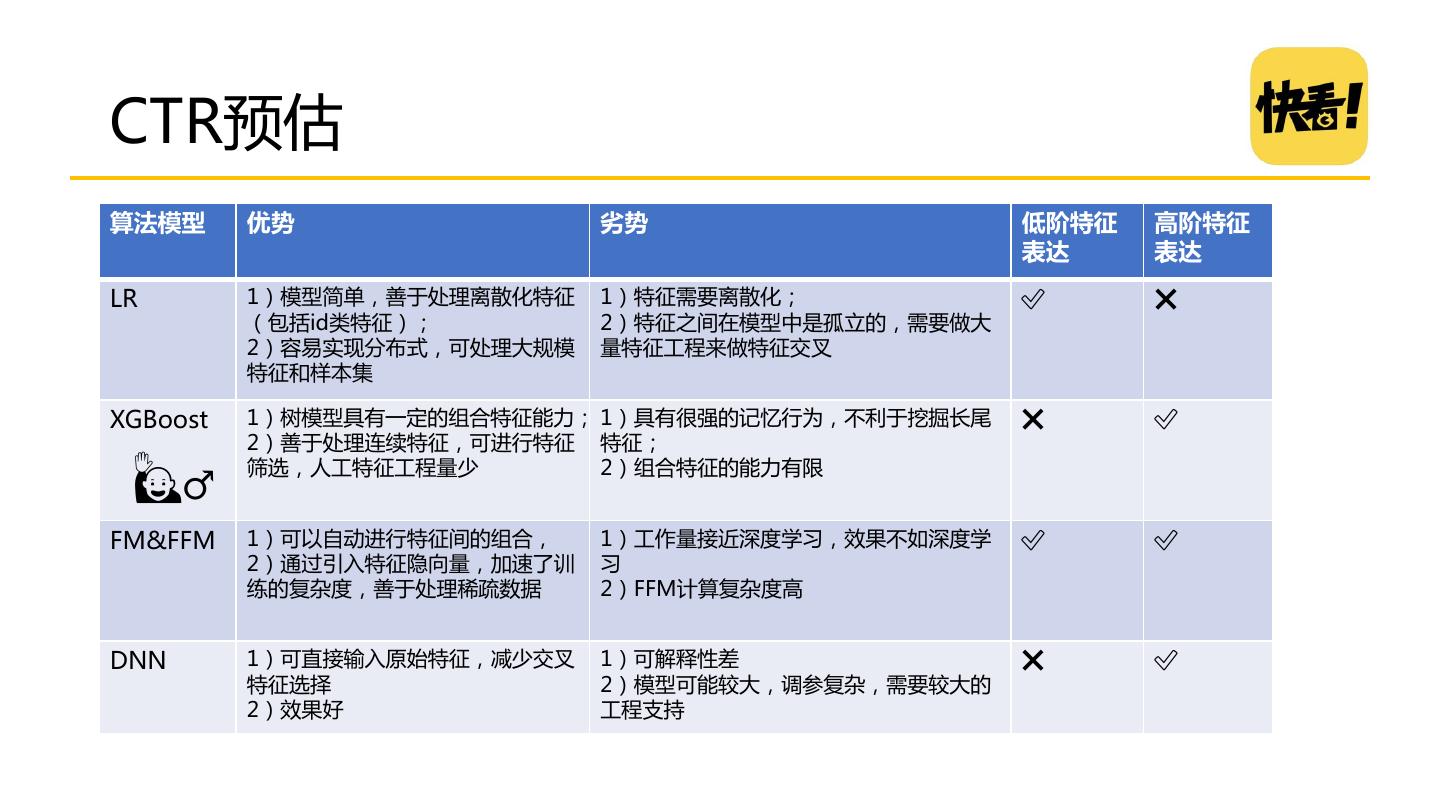
24 .CTR预估 算法模型 优势 劣势 低阶特征 高阶特征 表达 表达 LR 1)模型简单,善于处理离散化特征 1)特征需要离散化; ✅ ❌ (包括id类特征); 2)特征之间在模型中是孤立的,需要做大 2)容易实现分布式,可处理大规模 量特征工程来做特征交叉 特征和样本集 XGBoost 1)树模型具有一定的组合特征能力; 1)具有很强的记忆行为,不利于挖掘长尾 ❌ ✅ 2)善于处理连续特征,可进行特征 特征; 🙋♂ 筛选,人工特征工程量少 2)组合特征的能力有限 FM&FFM 1)可以自动进行特征间的组合, 1)工作量接近深度学习,效果不如深度学 ✅ ✅ 2)通过引入特征隐向量,加速了训 习 练的复杂度,善于处理稀疏数据 2)FFM计算复杂度高 DNN 1)可直接输入原始特征,减少交叉 1)可解释性差 ❌ ✅ 特征选择 2)模型可能较大,调参复杂,需要较大的 2)效果好 工程支持
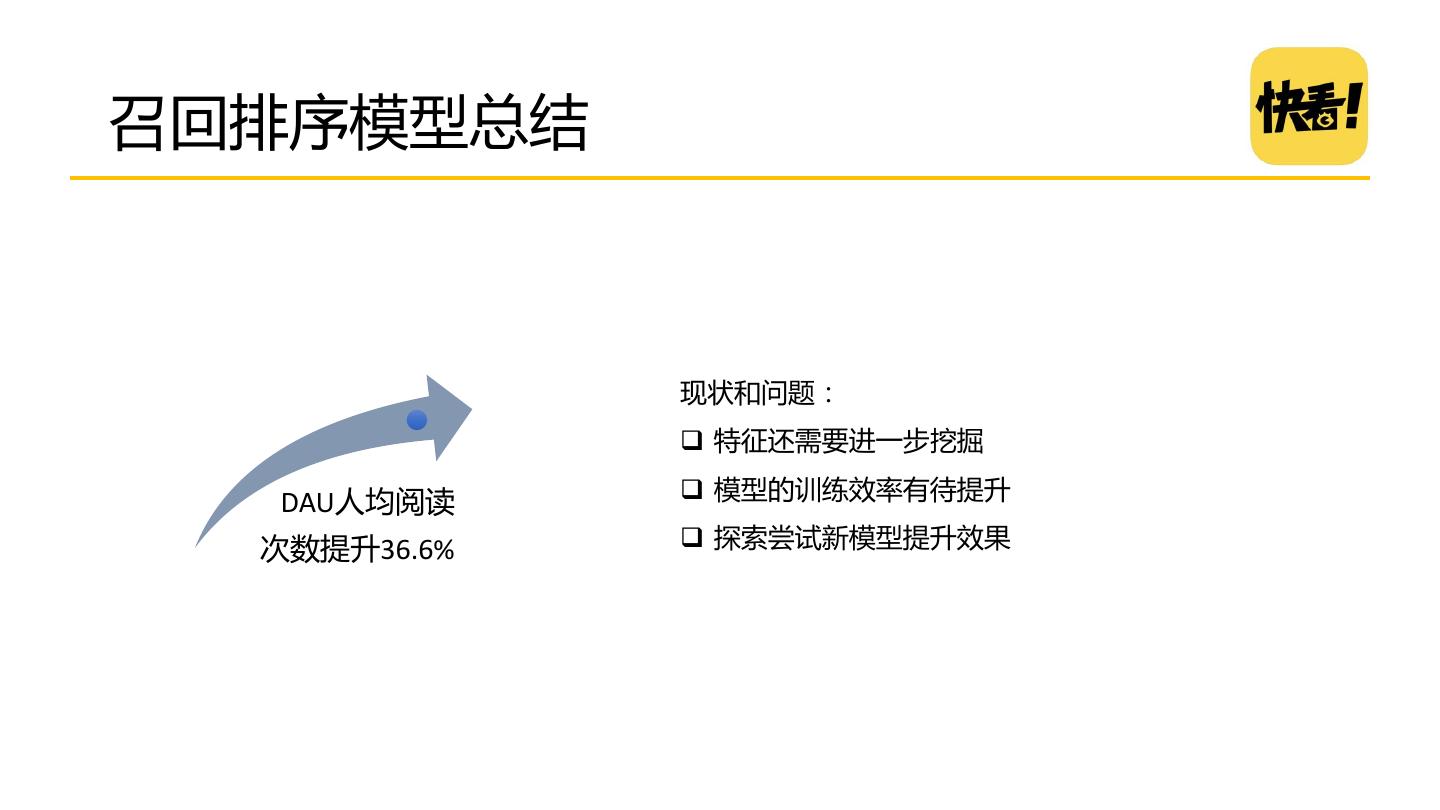
25 .召回排序模型总结 现状和问题: 特征还需要进一步挖掘 DAU人均阅读 模型的训练效率有待提升 次数提升36.6% 探索尝试新模型提升效果
26 . 算法方面的探索 系统架构方面的探索
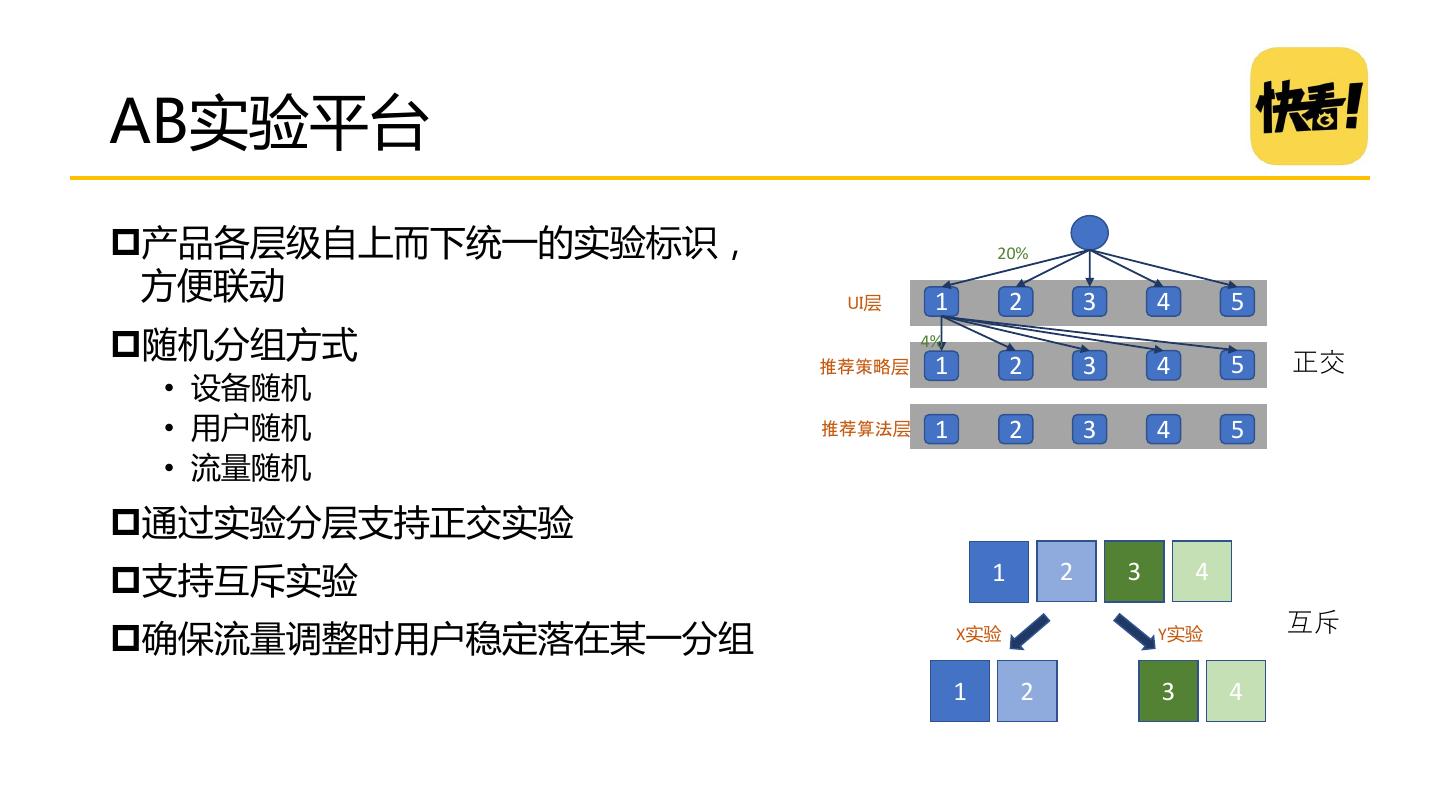
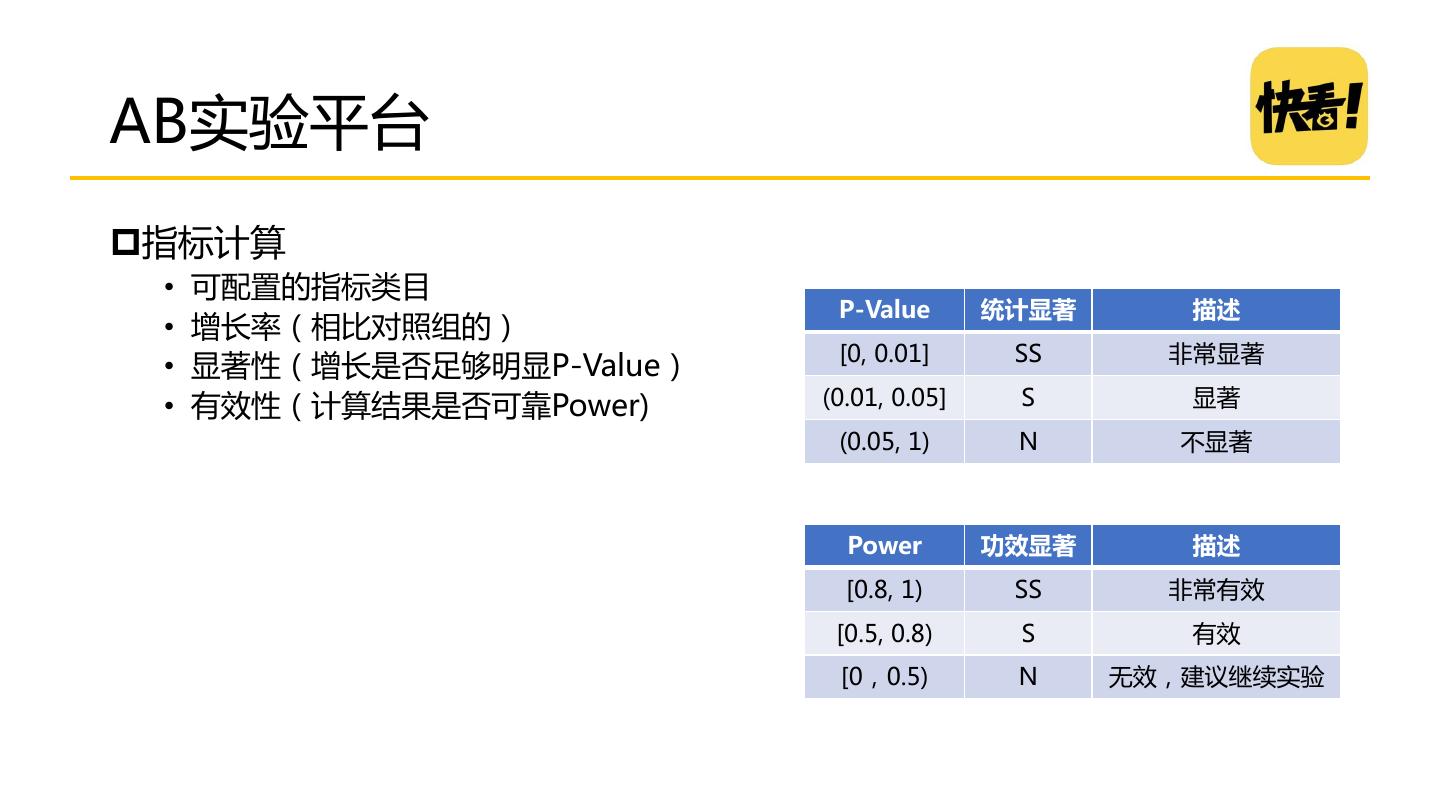
27 .架构的重要性 算法是大脑,架构是骨架,如果没有好的推荐系统架构,算法很难 落地 好的推荐系统需要具备的特质: 实时响应请求 及时、准确、全面的记录用户反馈 优雅降级 快速迭代推荐策略、算法
28 .经典Netflix推荐系统架构 离线层 o 不用实时数据,不提供实时服务 近线层(准实时层) o 使用实时数据,不保证实时服务(秒级) o 近在线计算的完成是为了响应用户事件, 增量学习算法很 适合应用在接近在线计算中 在线层 o 使用实时数据,要保证实时服务(毫秒级) o 在线服务的各组件要满足SLA对可用性和响应时间的要求
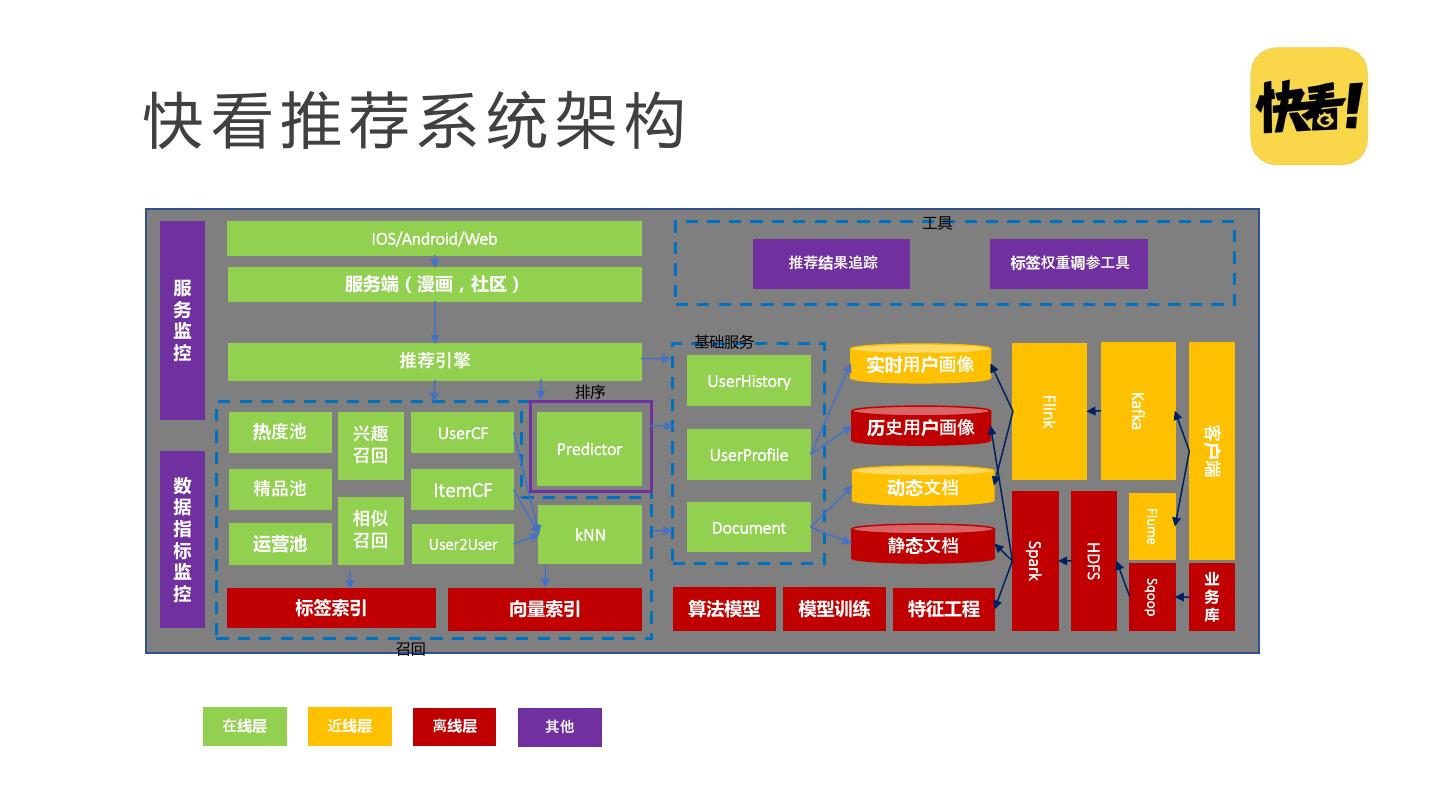
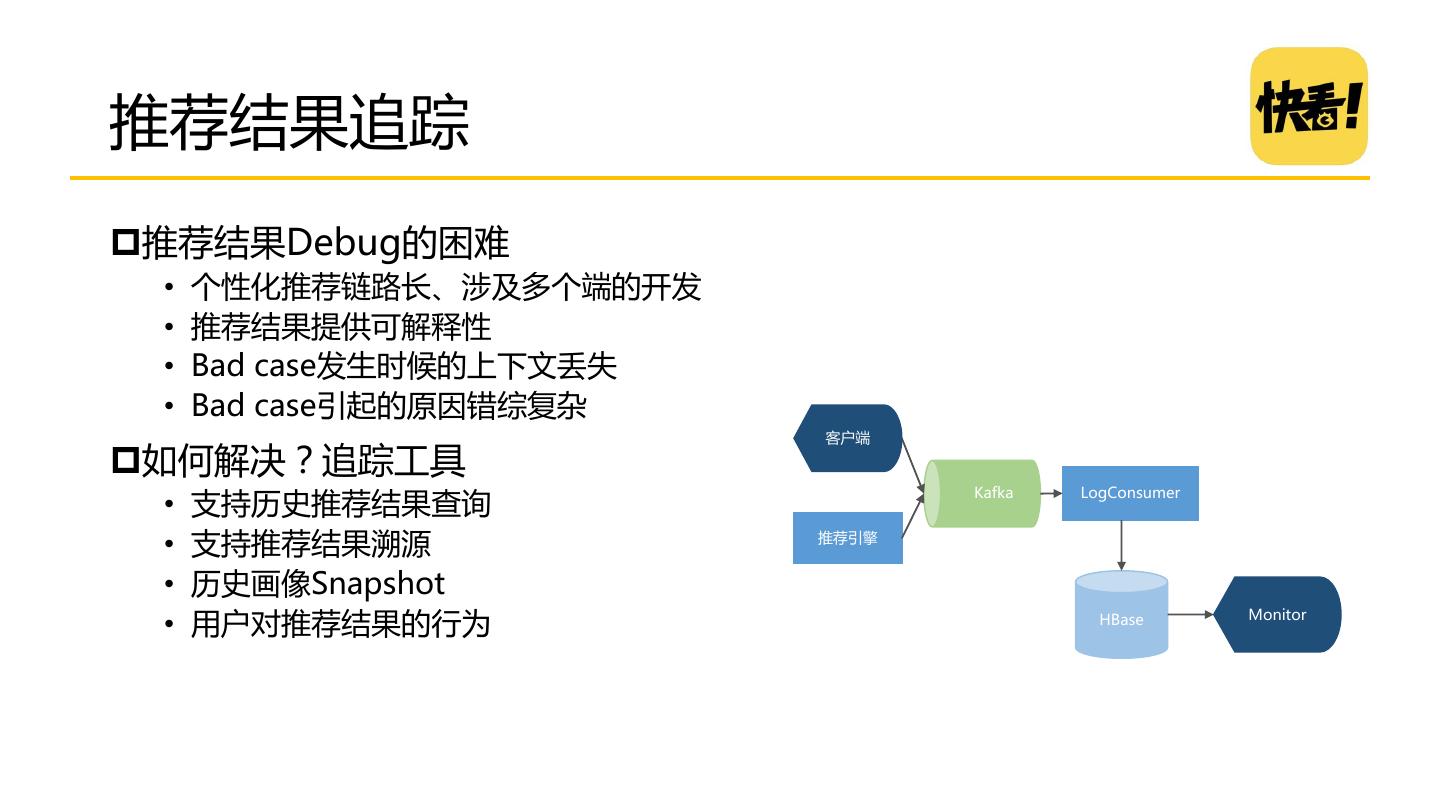
29 .快看推荐系统架构 工具 IOS/Android/Web 推荐结果追踪 标签权重调参工具 服 服务端(漫画,社区) 务 监 基础服务 控 推荐引擎 实时用户画像 UserHistory 排序 Kafka Flink 热度池 历史用户画像 客户端 兴趣 UserCF 召回 Predictor UserProfile 数 精品池 ItemCF 动态文档 据 Flume 相似 指 kNN Document 标 运营池 召回 User2User 静态文档 Spark HDFS 监 业 Sqoop 控 务 标签索引 向量索引 算法模型 模型训练 特征工程 库 召回 在线层 近线层 离线层 其他
3秒后跳转登录页面
去登陆

