1 .搜索引擎从0到1 荷花@有赞 hehua@youzan.com
2 .About me • ⽑毛夏君,花名"荷花" • 来⾃自有赞PaaS团队 • 带领有赞搜索平台从0到1的建设 • 全程参与有赞搜索系统的设计和开发 2
3 .Abstract • 构建完整的搜索引擎 • 索引的读写 • 使⽤用要点和案例例分析 • 有赞的实践 3
4 . 构建完整的搜索引擎 • 引擎选择 • sphinx • lucene/solr/elasticsearch • redisearch • bleve/groonga/pgsql fulltext search • … 4
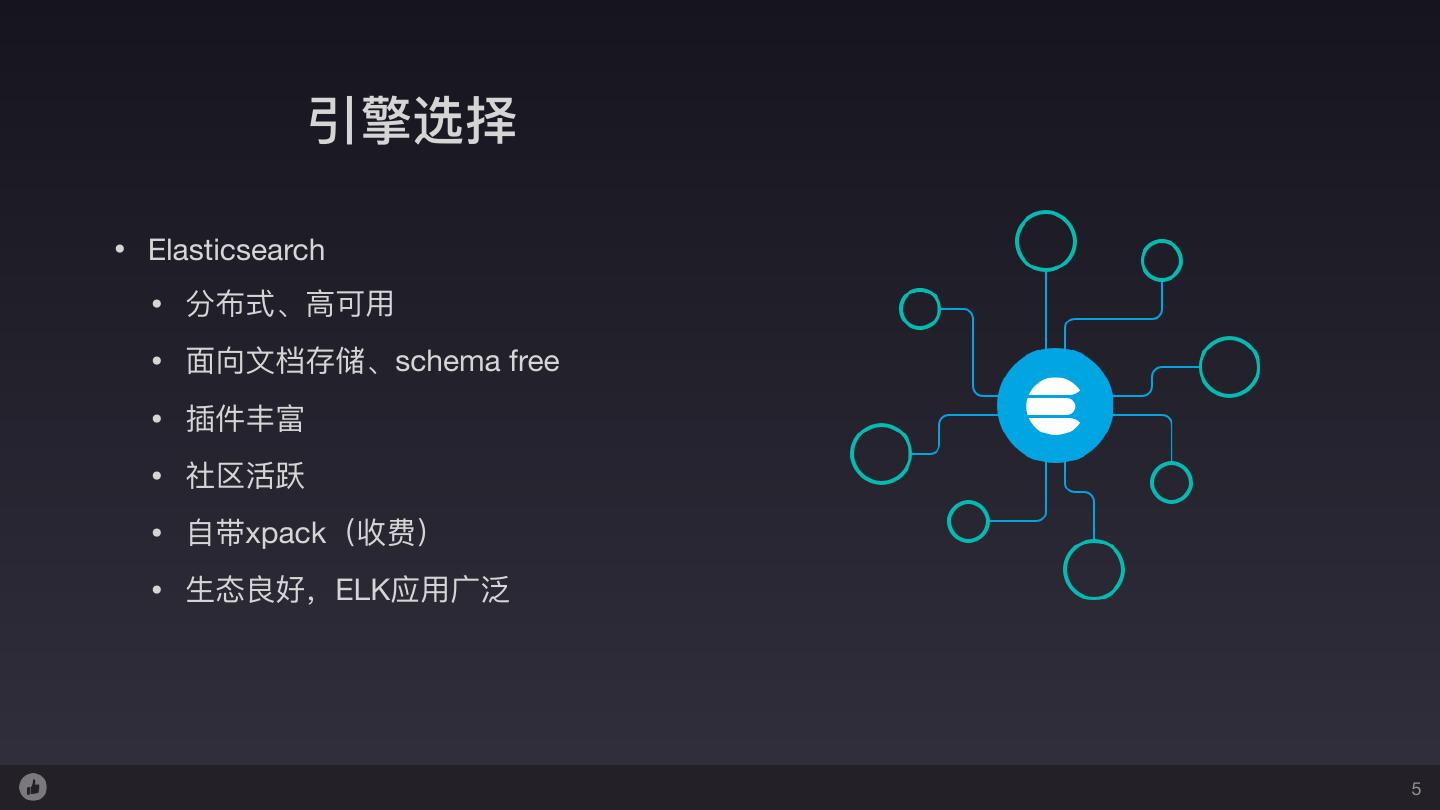
5 . 引擎选择 • Elasticsearch • 分布式、⾼高可⽤用 • ⾯面向⽂文档存储、schema free • 插件丰富 • 社区活跃 • ⾃自带xpack(收费) • ⽣生态良好,ELK应⽤用⼴广泛 5
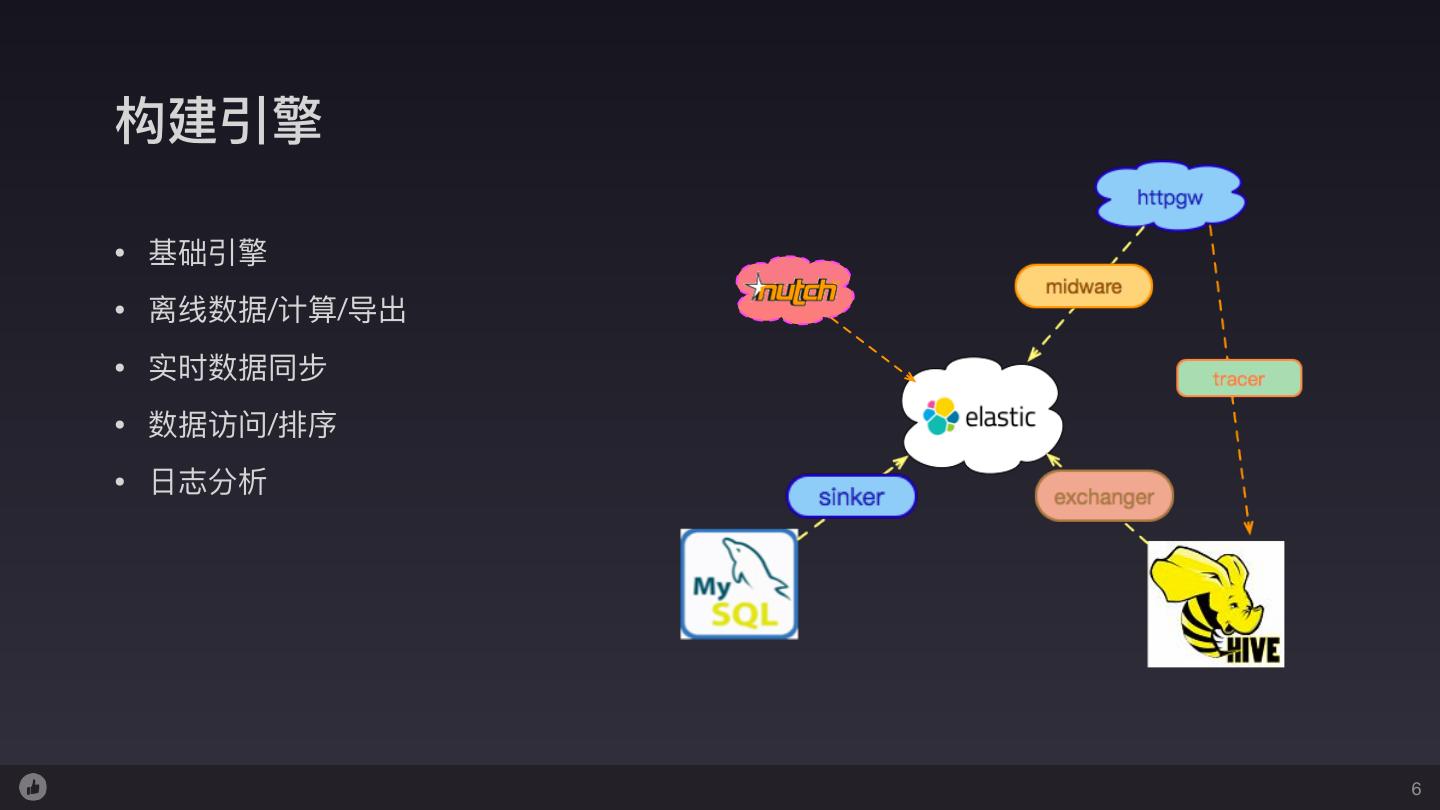
6 .构建引擎 • 基础引擎 • 离线数据/计算/导出 • 实时数据同步 • 数据访问/排序 • ⽇日志分析 6
7 .索引数据的写操作 • 先将数据写⼊入Lucene的内存⽂文件 • 然后在translog中记录,避免HW 失败 • 新增/更更新数据都追加写到新段中 • 主分⽚片写成功后同步到从分⽚片 • 视客户端调⽤用⽅方式,若异步写则 接受到请求后即返回,若同步写 则等待主从写成功后ack 7
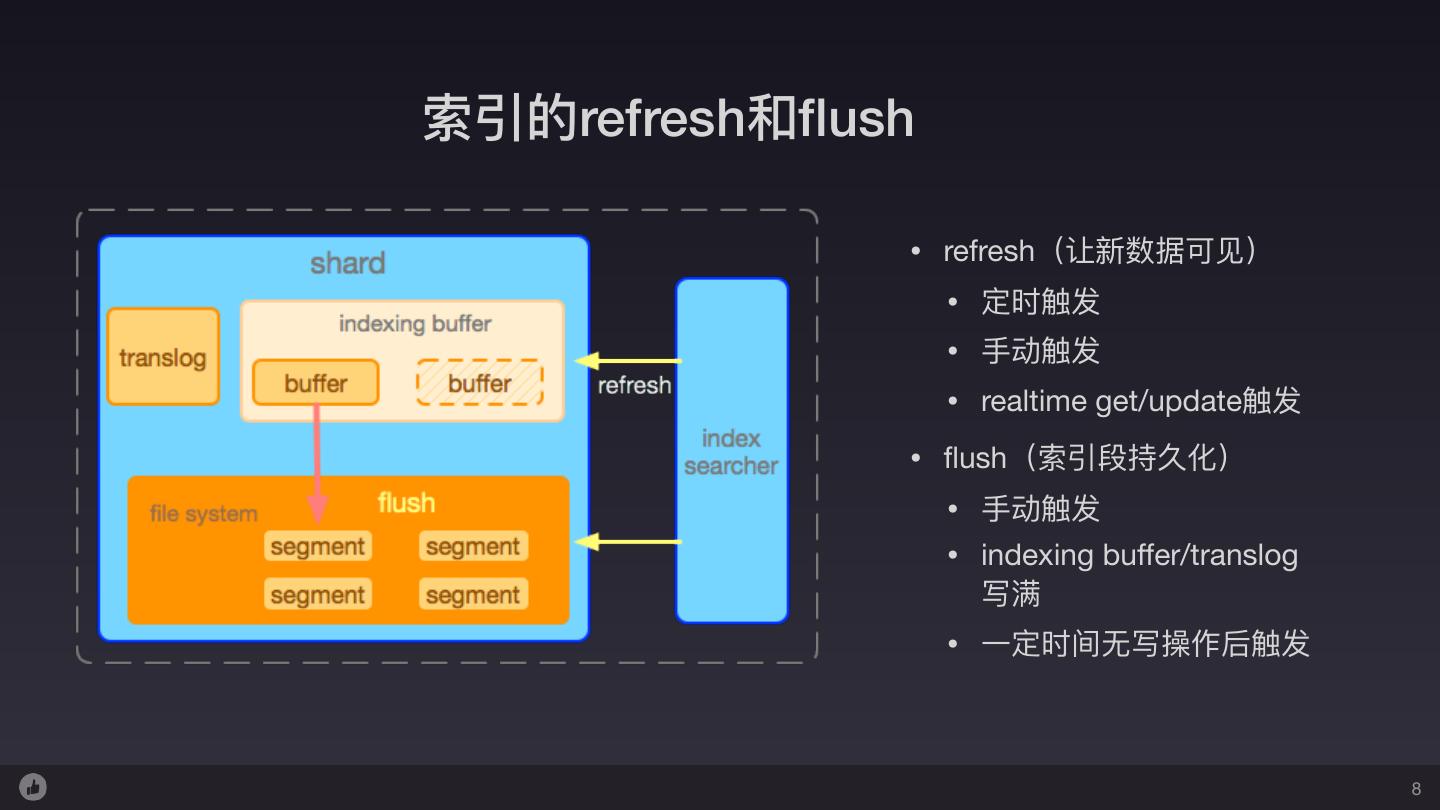
8 .索引的refresh和flush • refresh(让新数据可⻅见) • 定时触发 • ⼿手动触发 • realtime get/update触发 • flush(索引段持久化) • ⼿手动触发 • indexing buffer/translog 写满 • ⼀一定时间⽆无写操作后触发 8
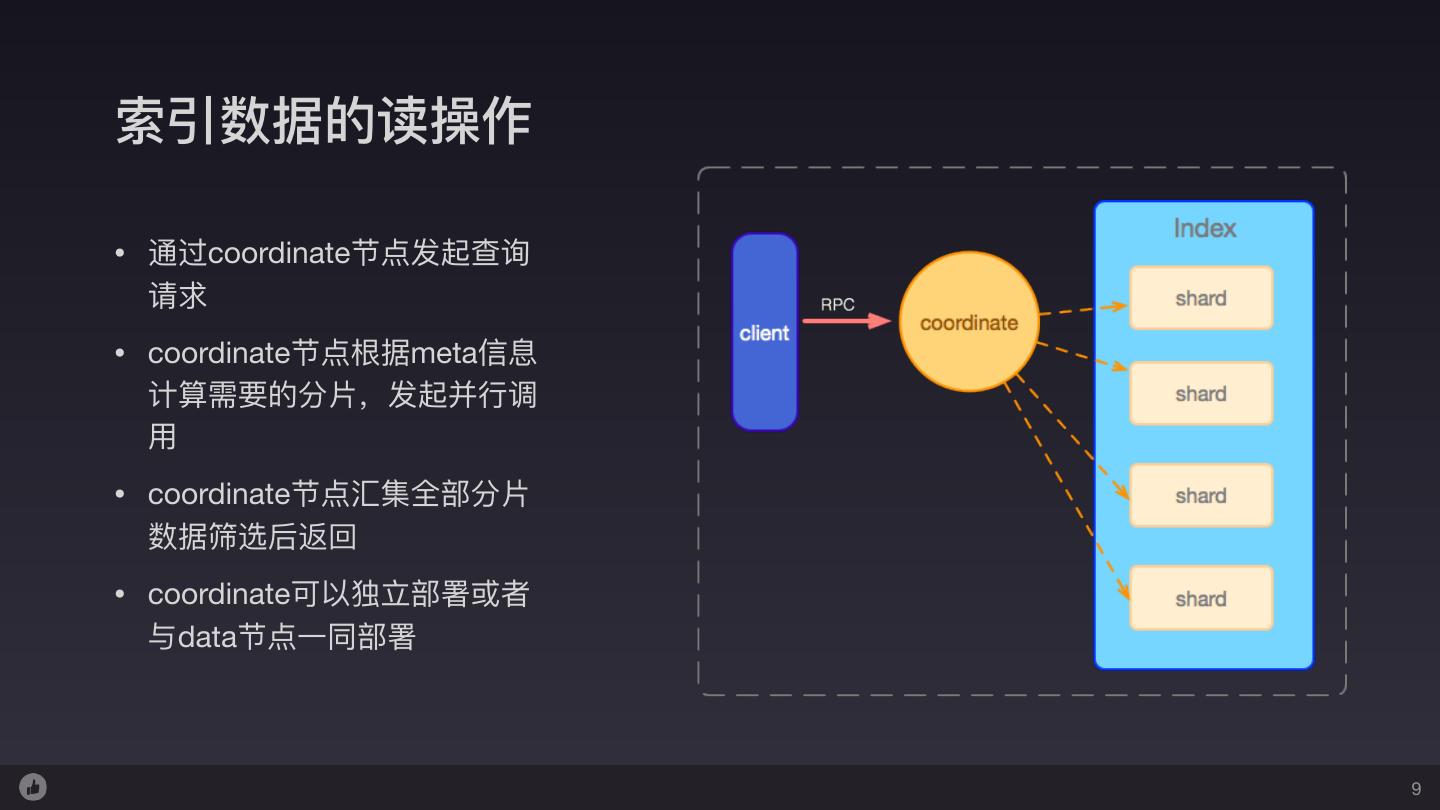
9 .索引数据的读操作 • 通过coordinate节点发起查询 请求 • coordinate节点根据meta信息 计算需要的分⽚片,发起并⾏行行调 ⽤用 • coordinate节点汇集全部分⽚片 数据筛选后返回 • coordinate可以独⽴立部署或者 与data节点⼀一同部署 9
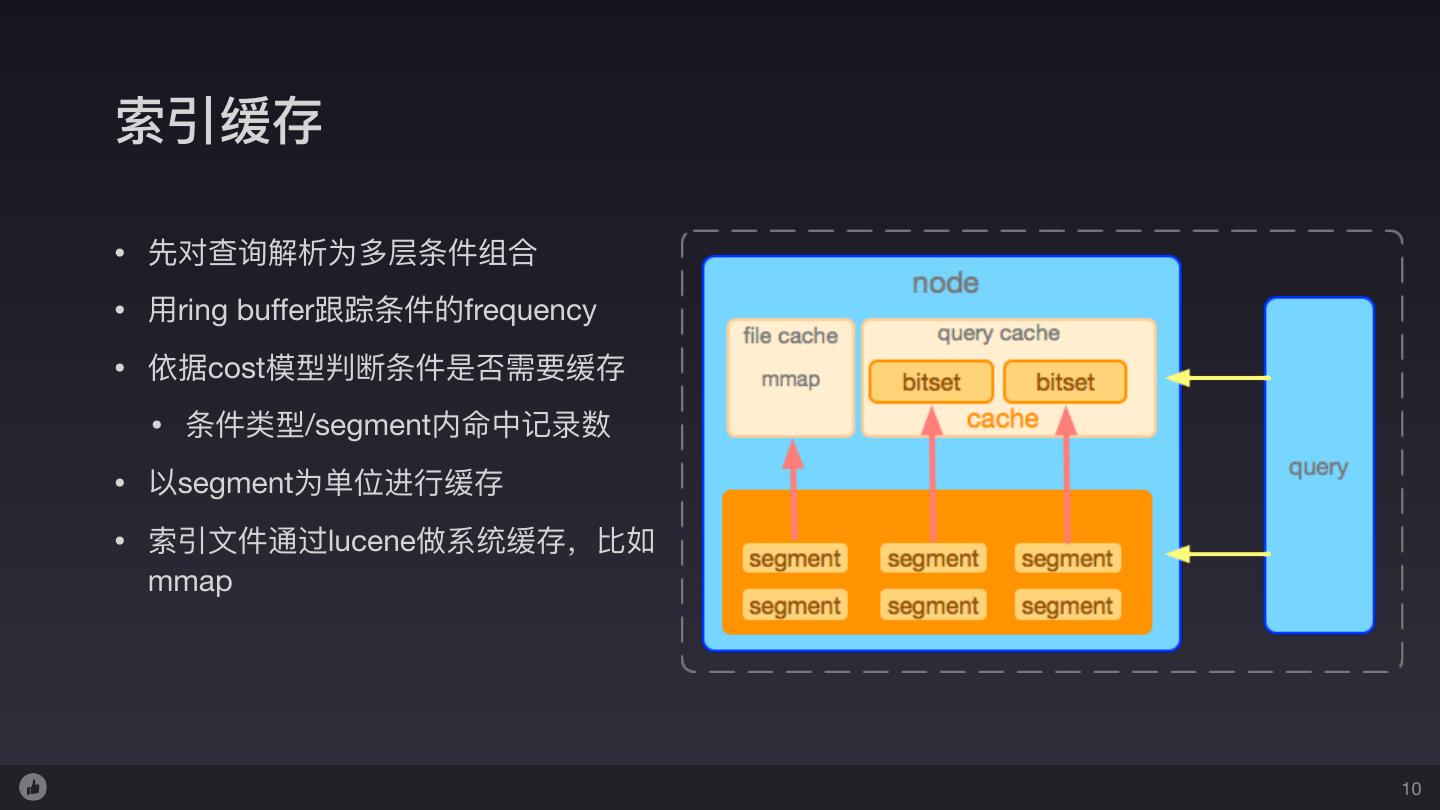
10 .索引缓存 • 先对查询解析为多层条件组合 • ⽤用ring buffer跟踪条件的frequency • 依据cost模型判断条件是否需要缓存 • 条件类型/segment内命中记录数 • 以segment为单位进⾏行行缓存 • 索引⽂文件通过lucene做系统缓存,⽐比如 mmap 10
11 . 使⽤用要点 • 使⽤用合理理的分⽚片数 • 控制删改操作量量 • 避免过多使⽤用⾼高成本查询(terms/range/geo_distance, etc.) • 适当的隔离 11
12 .案例例分析-range query • query cache飙升 • 索引qps正常 • 检查query • 可疑的range条件 • ⼤大量量细微差异的查询导致缓存不不⾜足 • 善⽤用script query • 合理理使⽤用技术栈 12
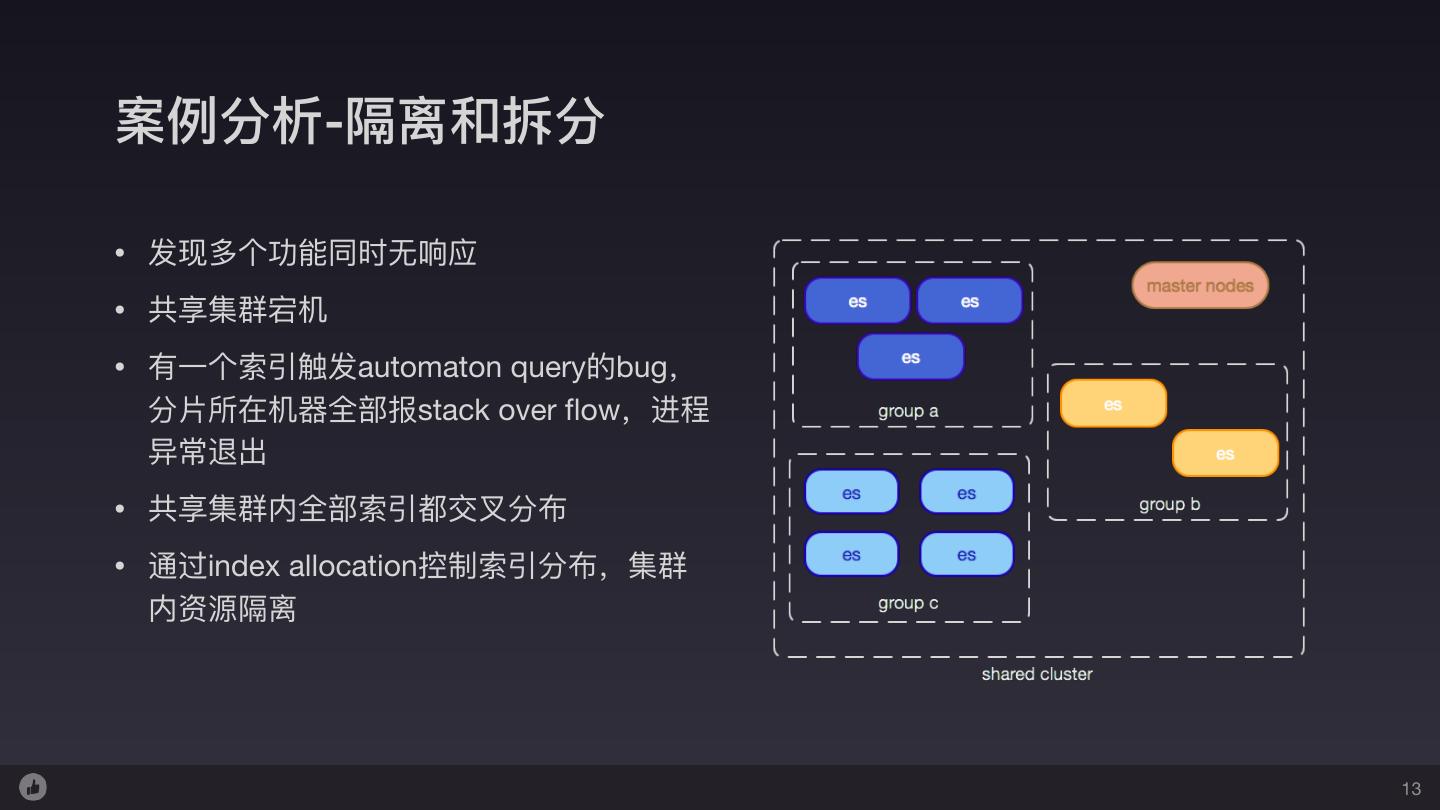
13 .案例例分析-隔离和拆分 • 发现多个功能同时⽆无响应 • 共享集群宕机 • 有⼀一个索引触发automaton query的bug, 分⽚片所在机器器全部报stack over flow,进程 异常退出 • 共享集群内全部索引都交叉分布 • 通过index allocation控制索引分布,集群 内资源隔离 13
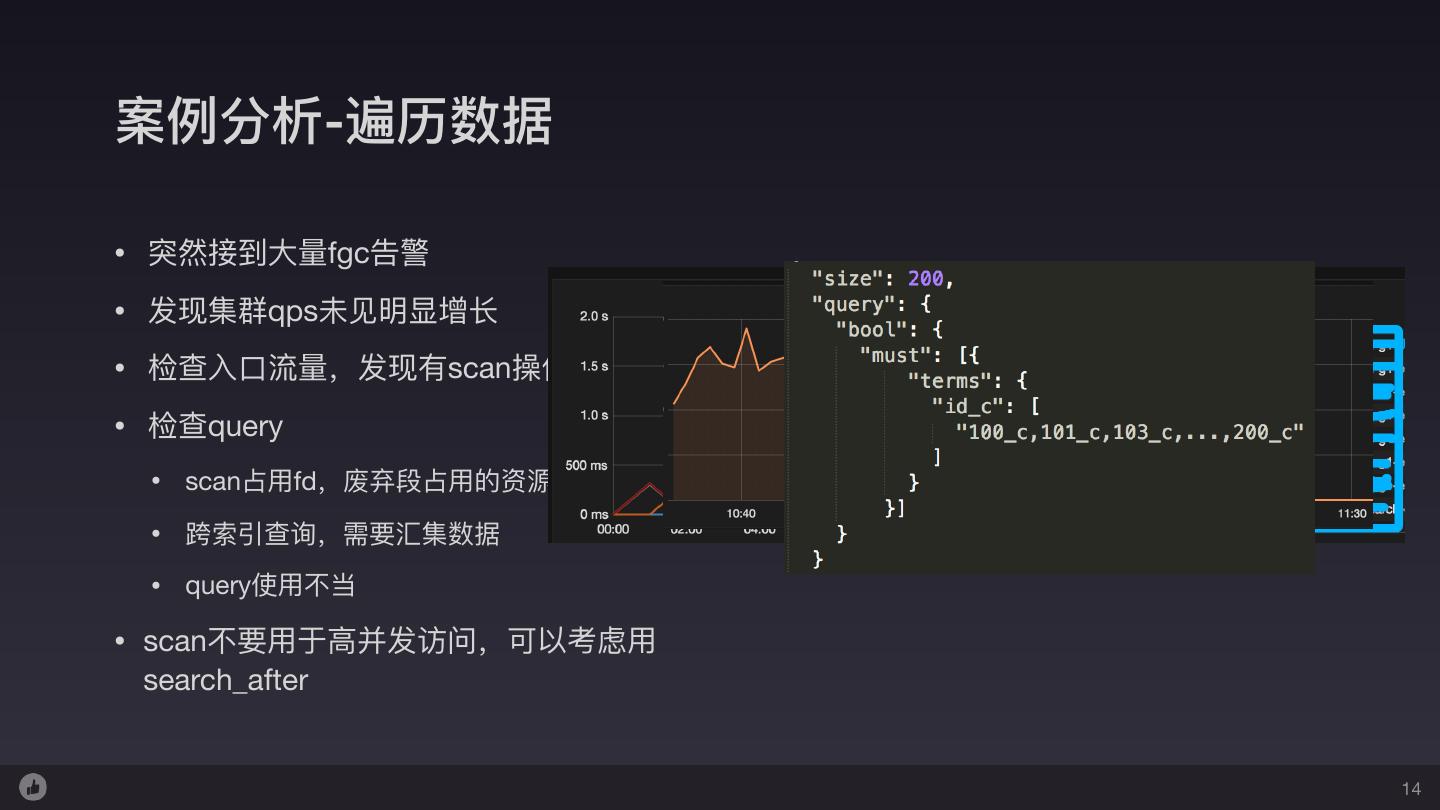
14 .案例例分析-遍历数据 • 突然接到⼤大量量fgc告警 • 发现集群qps未⻅见明显增⻓长 • 检查⼊入⼝口流量量,发现有scan操作有明显增⻓长 • 检查query • scan占⽤用fd,废弃段占⽤用的资源⽆无法回收 • 跨索引查询,需要汇集数据 • query使⽤用不不当 • scan不不要⽤用于⾼高并发访问,可以考虑⽤用 search_after 14
15 . 有赞的实践-部署 • 系统 • ulimit/vm.max_map_count/heap size/gc/⼤大⻚页 • 服务设置 • mem_lock/ping/min_master_nodes • node.attr/cluster.routing.allocation.* • 索引设置 • 设置template配置默认参数, shards/replicas/refresh • strict mapping/dynamic templates • index.routing.allocation.* 15
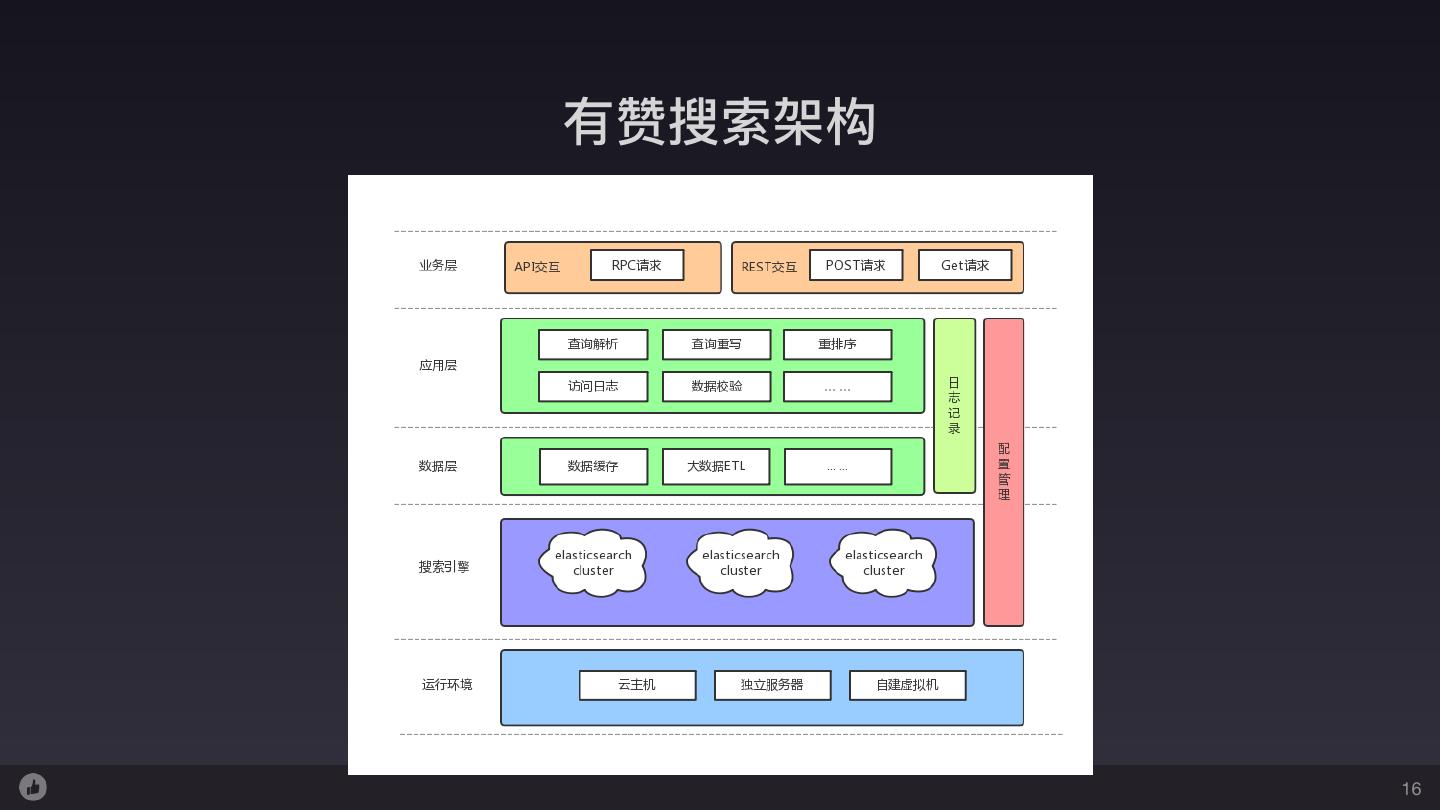
16 .有赞搜索架构 16
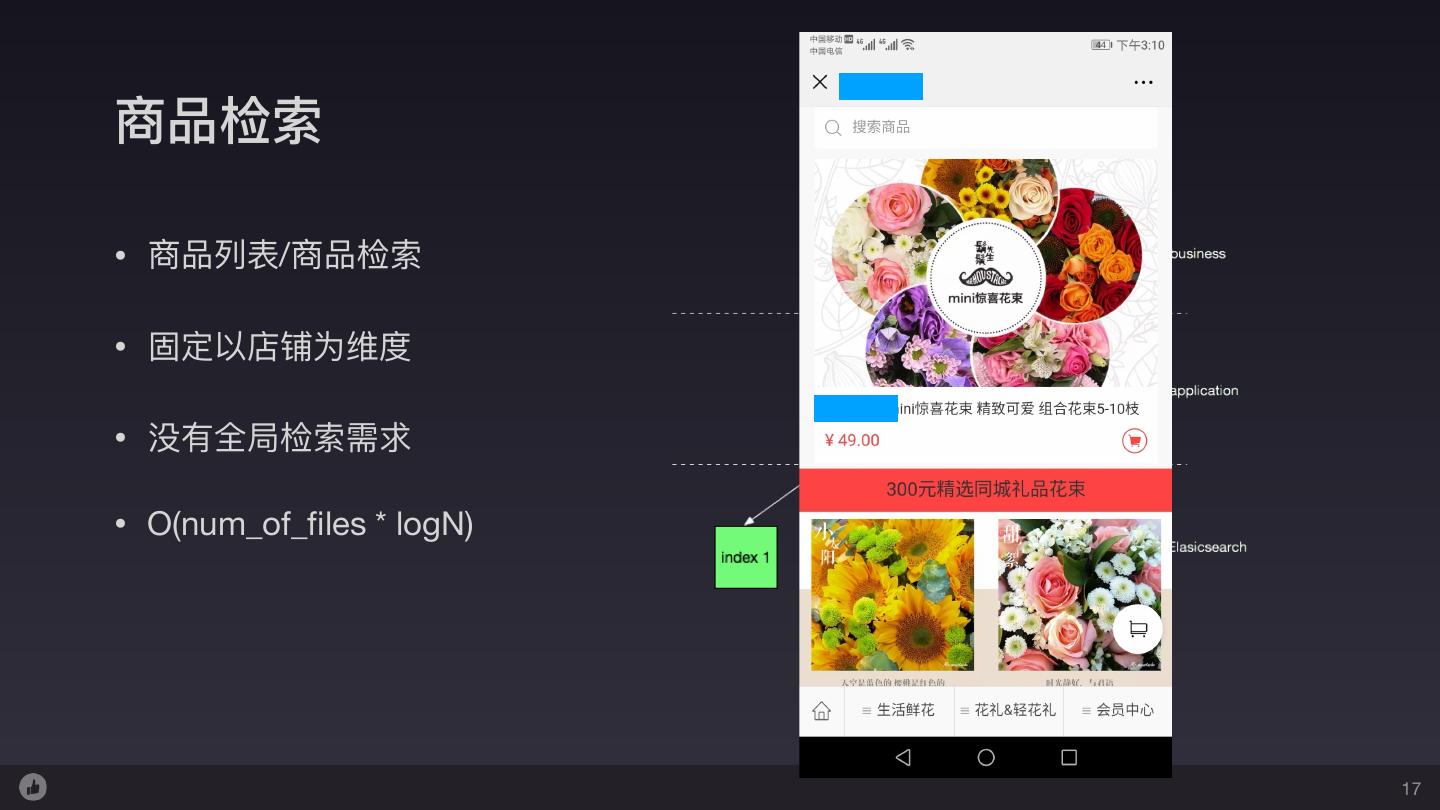
17 .商品检索 • 商品列列表/商品检索 • 固定以店铺为维度 • 没有全局检索需求 • O(num_of_files * logN) 17
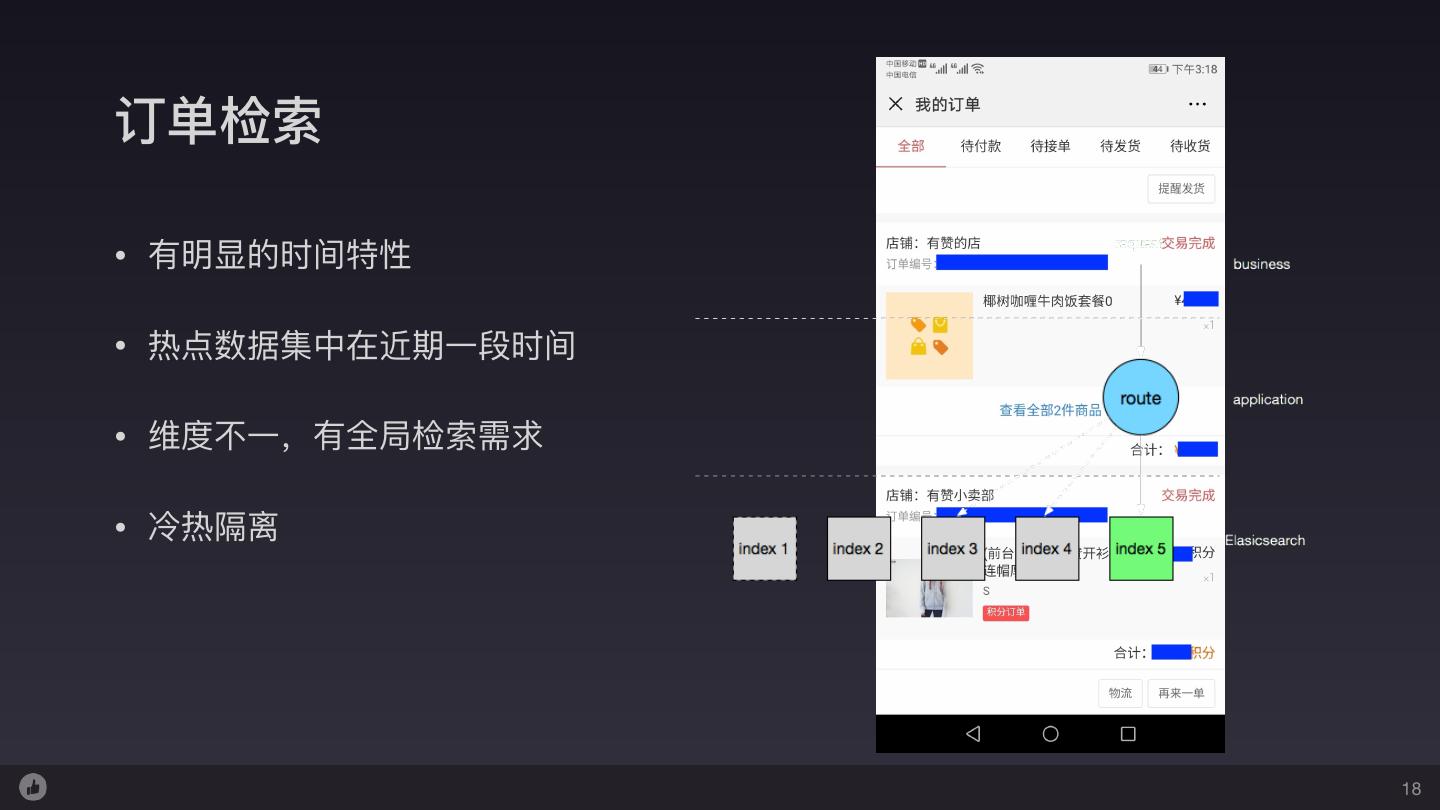
18 .订单检索 • 有明显的时间特性 • 热点数据集中在近期⼀一段时间 • 维度不不⼀一,有全局检索需求 • 冷热隔离 18
19 .集群管理理 • 监控 • cerebro / grafana / head / ⾃自定义插件 • 隔离 • [index/cluster].routing.allocation • include / exclude / total_shards_per_node • watermark • 数据管理理 • node.attr / allocation awareness • reindex / snapshot / auto balance 19
20 .集群管理理 • 扩容⼀一台master机器器 • 扩容⼀一倍data机器器 • 副本数翻倍,等待init结束 • 开始暂存增量量数据 • data’下线 • master’下线,修改ping地址,补充机器器启 动为⼀一个新的master cluster • data’修改ping地址启动,加⼊入新集群 • 恢复增量量数据 • 结束 20
确定删除吗?