
























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/u231/Floyds_algorithm_bst?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
Floyd's Algorithm and BSTs
分享
点赞
3
收藏
0
下载 0
在本章节中介绍了Floyd构建堆的算法,理解它的工作原理是什么以及它是如何实现运作的。另外回顾字典/集合:了解如何成为它们和ADT的客户端,考虑实现的权衡。此外还回顾二叉查找树:了解如何插入、删除和遍历树等等操作。
展开查看详情
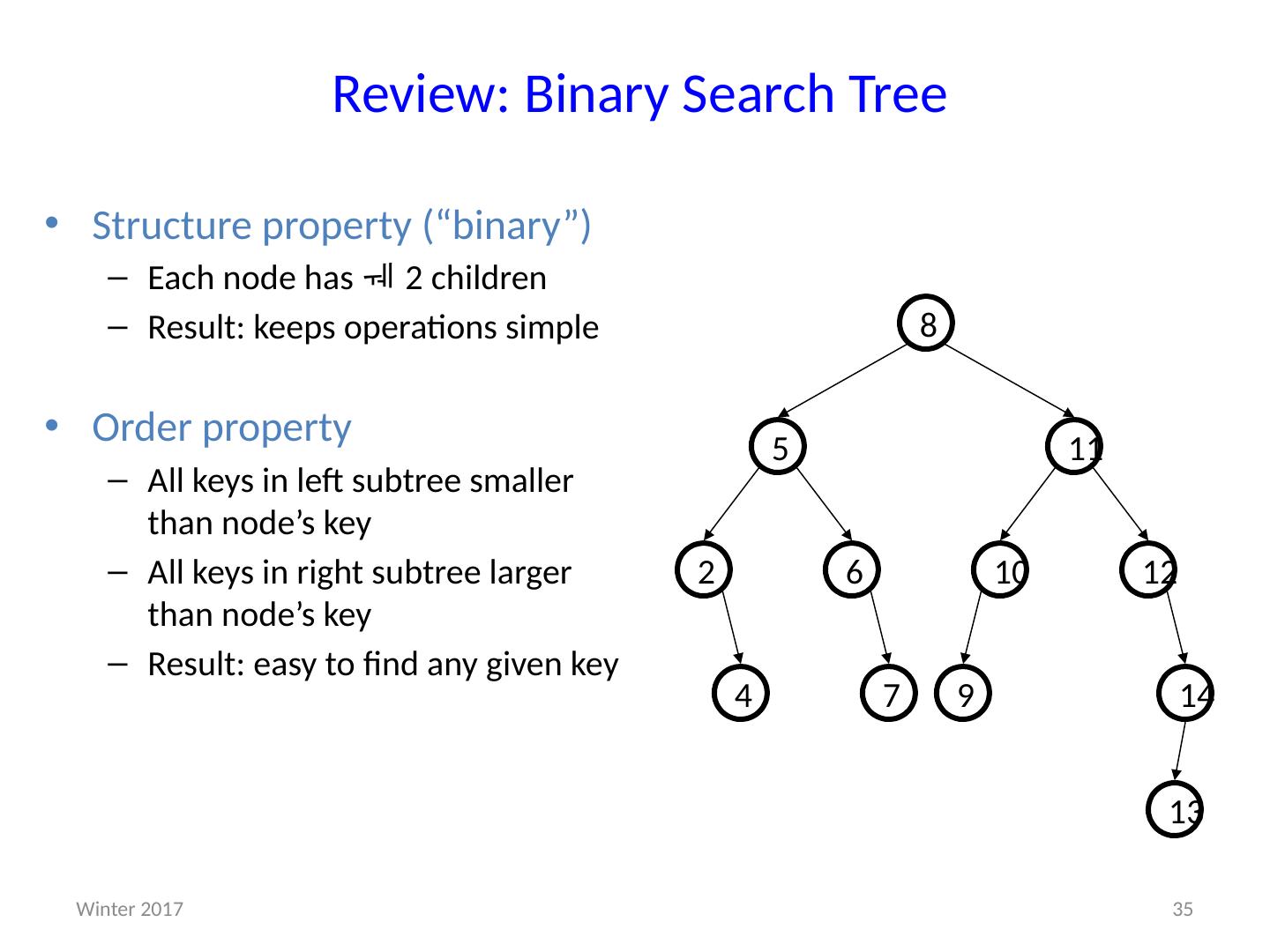
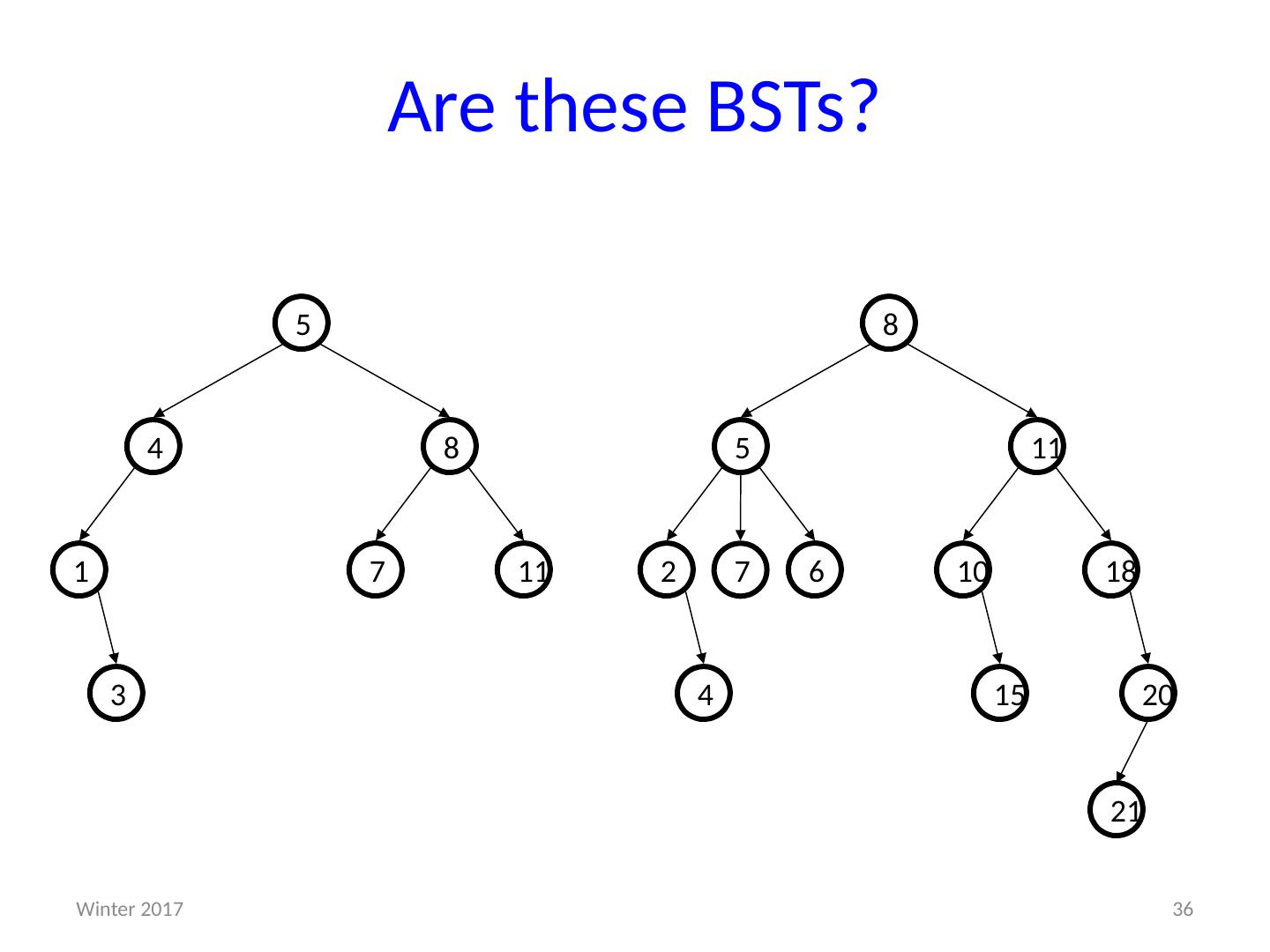
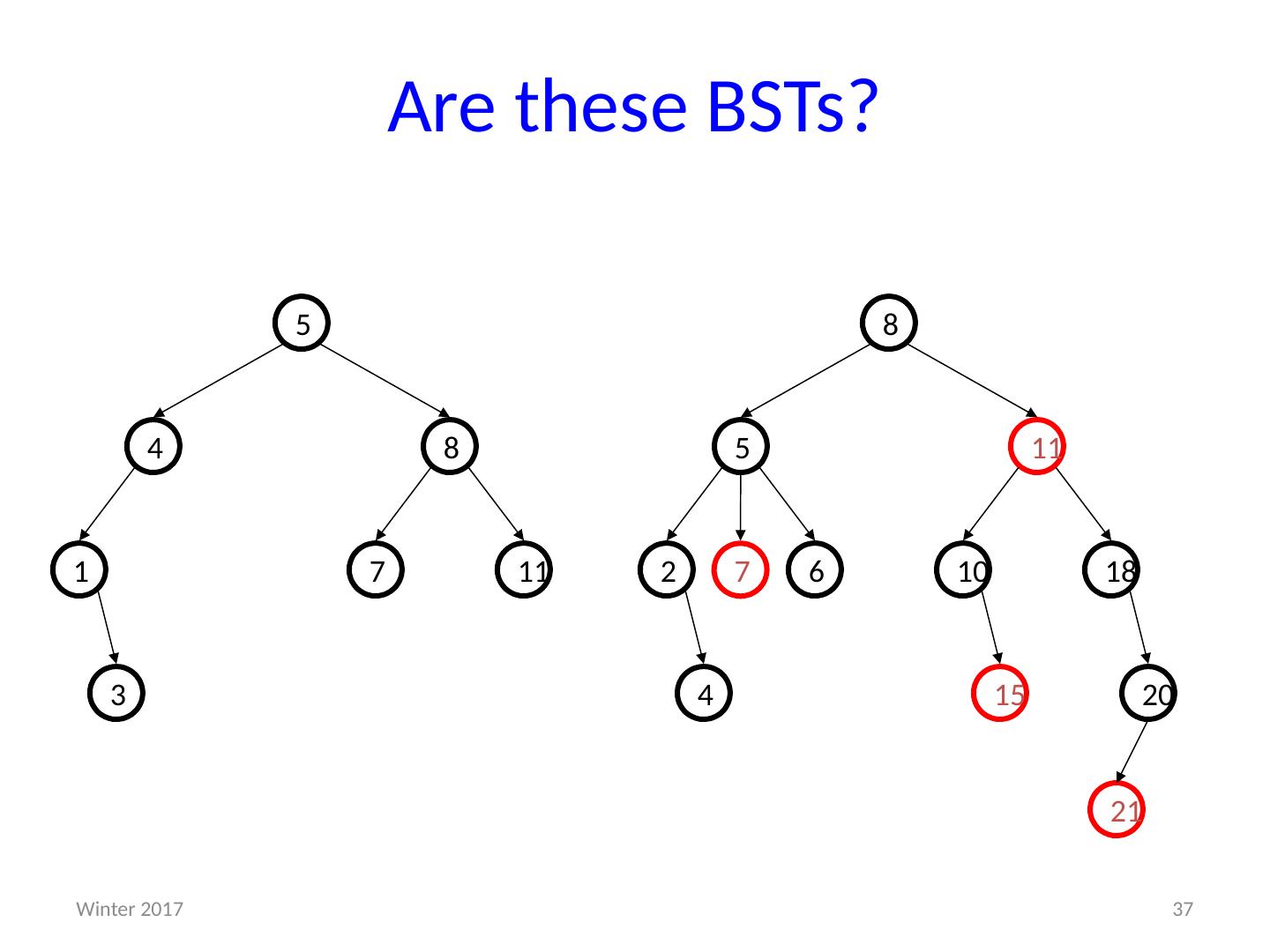
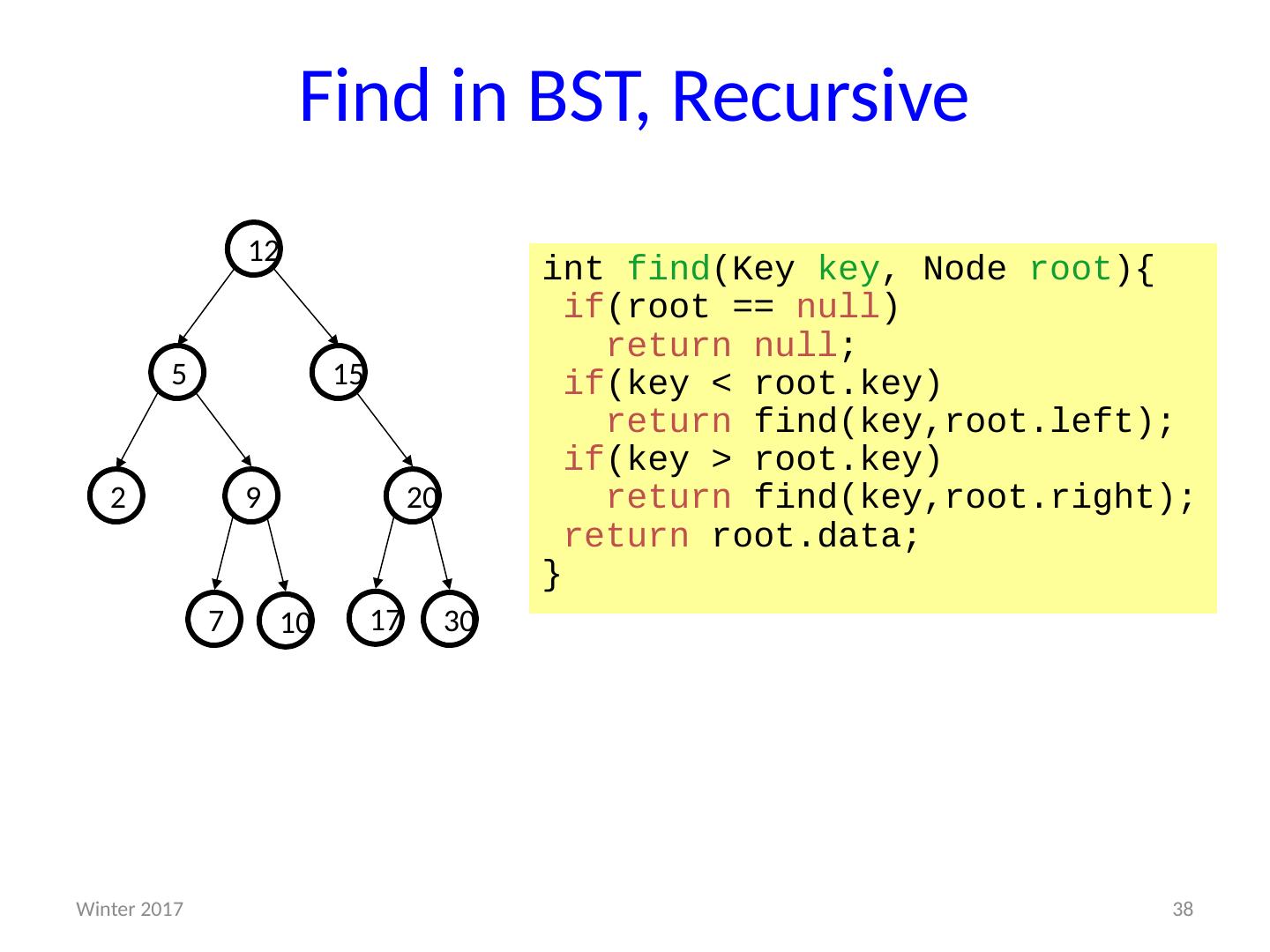
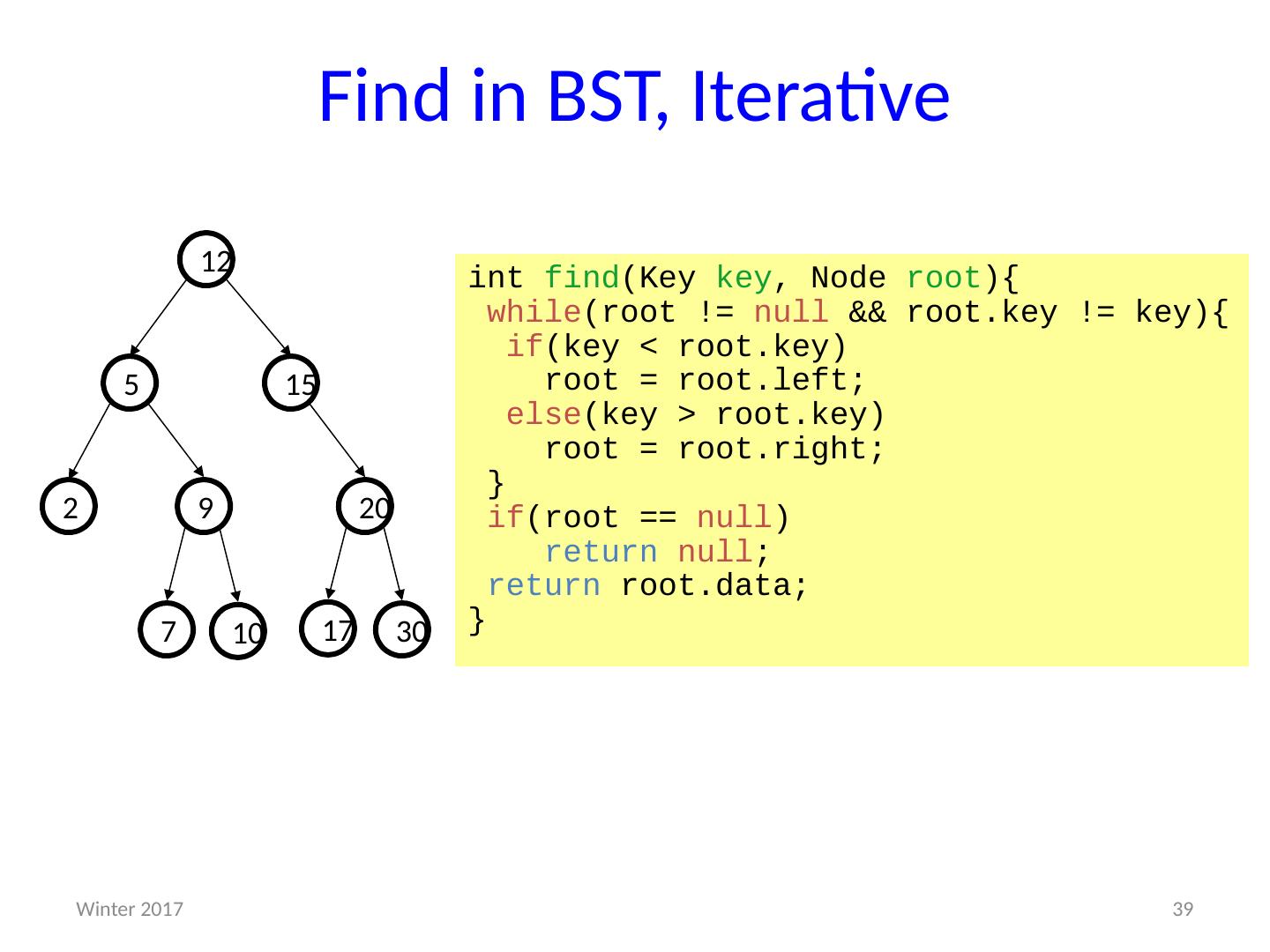
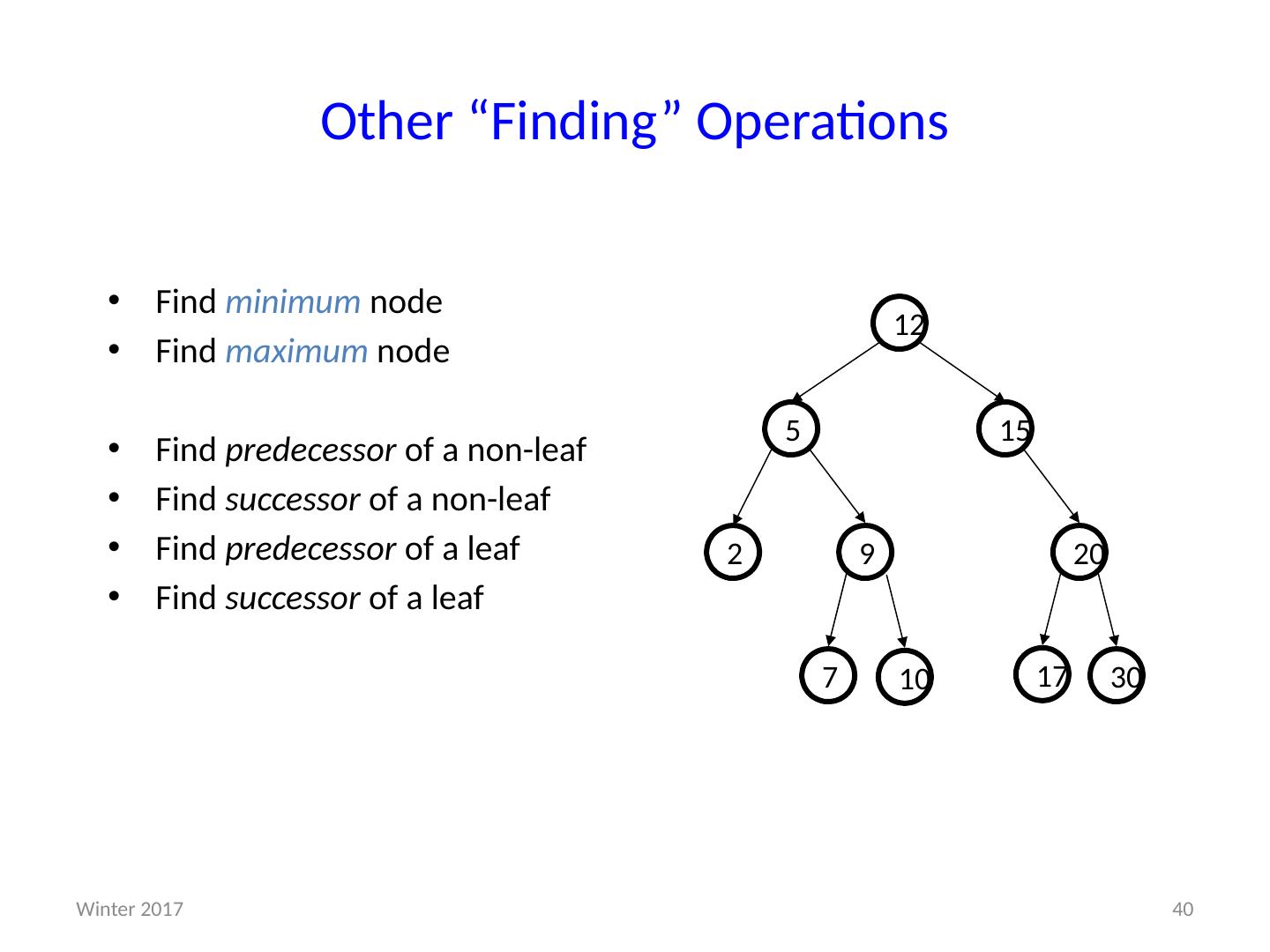
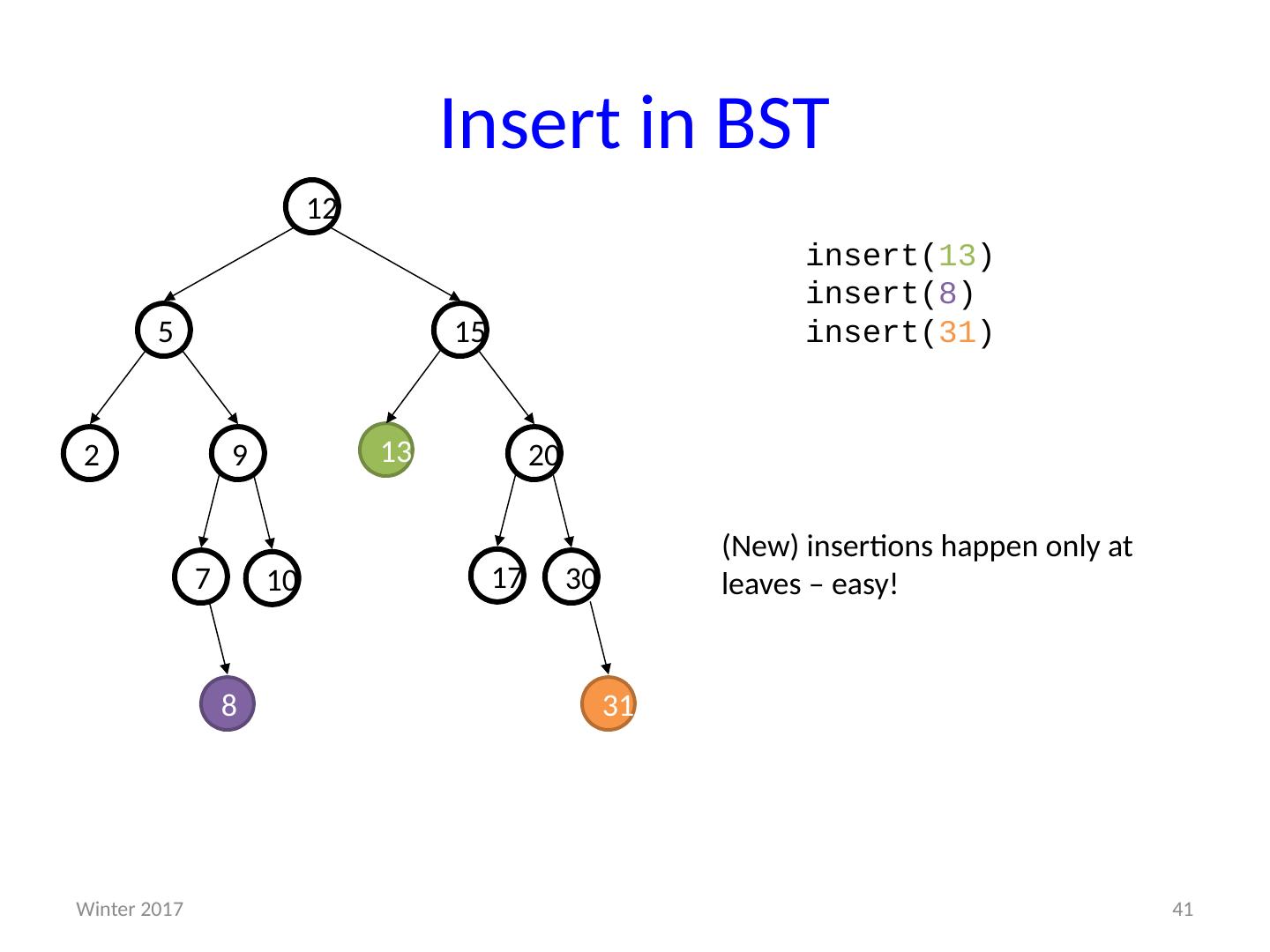
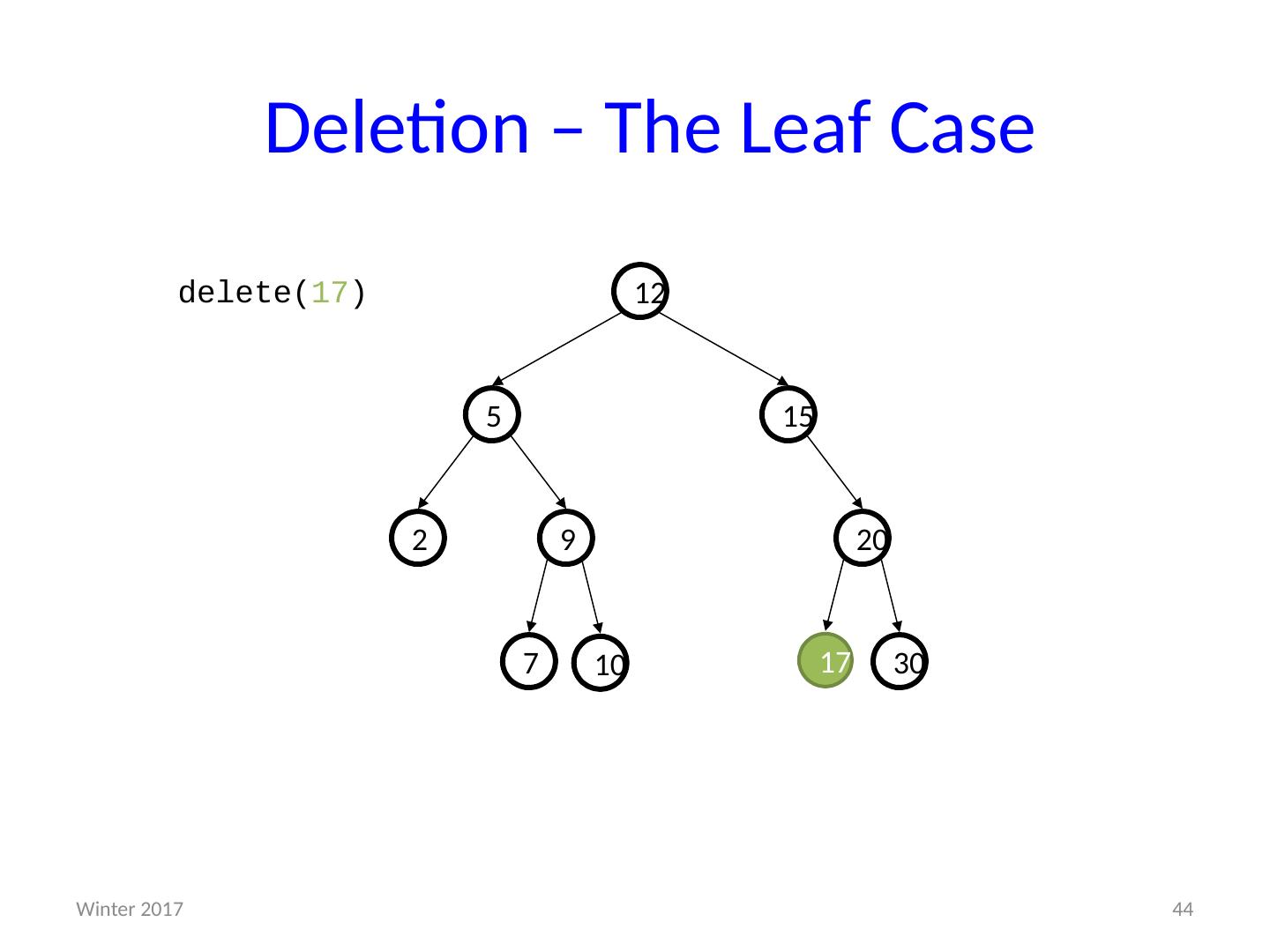
1 .CSE373: Data Structures & Algorithms More Heaps; D ictionaries; Binary Search Trees Riley Porter Winter 2016 1 Winter 2017
2 .Review of last time: Heaps Heaps follow the following two properties: Structure property: A complet e binary tree Heap order property : The priority of the children is always a greater value than the parents (greater value means less priority / less importance) Winter 2017 2 CSE373: Data Structures & Algorithms 15 30 80 20 10 99 60 40 80 20 10 50 700 85 not a heap a heap 450 3 1 75 50 8 6 0 n ot a hea p 10 10
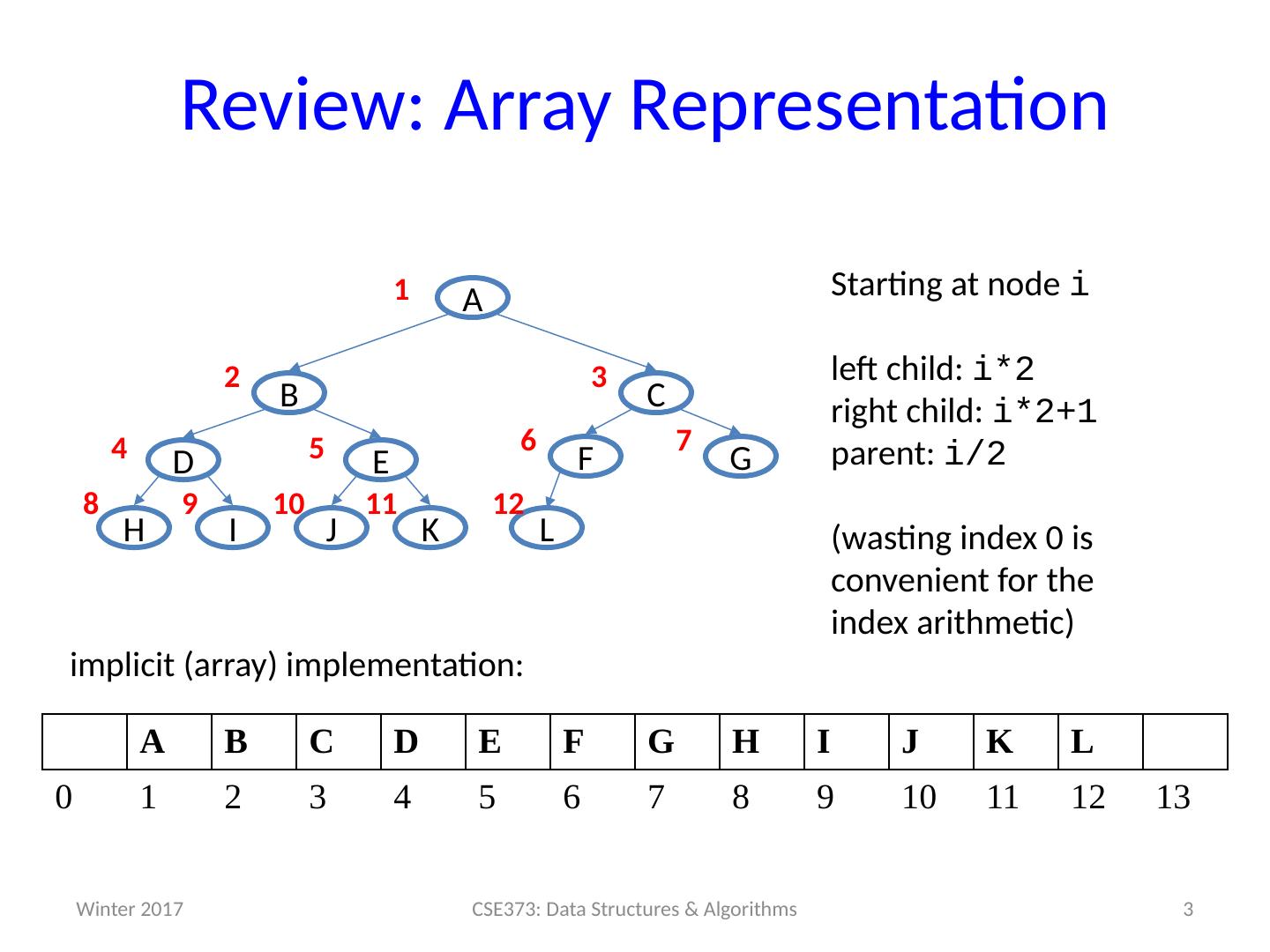
3 .3 Review: Array Representation G E D C B A J K H I F L Starting at node i left child : i *2 right child : i *2+1 parent : i /2 (wasting index 0 is convenient for the index arithmetic) 7 1 2 3 4 5 6 9 8 10 11 12 A B C D E F G H I J K L 0 1 2 3 4 5 6 7 8 9 10 11 12 13 implicit (array) implementation: 2 * i (2 * i)+1 └ i / 2 ┘ CSE373: Data Structures & Algorithms Winter 2017
4 .Review: Heap Operations insert: add the new value at the next valid place in the structure (2) fix the ordering property by percolating value up to the right position deleteMin : remove smallest value at root plug vacant spot at root with value from the last spot in the tree, keeping the structure valid (3) fix the ordering property by percolating the value down to the right position 4 CSE373: Data Structures & Algorithms Winter 2017
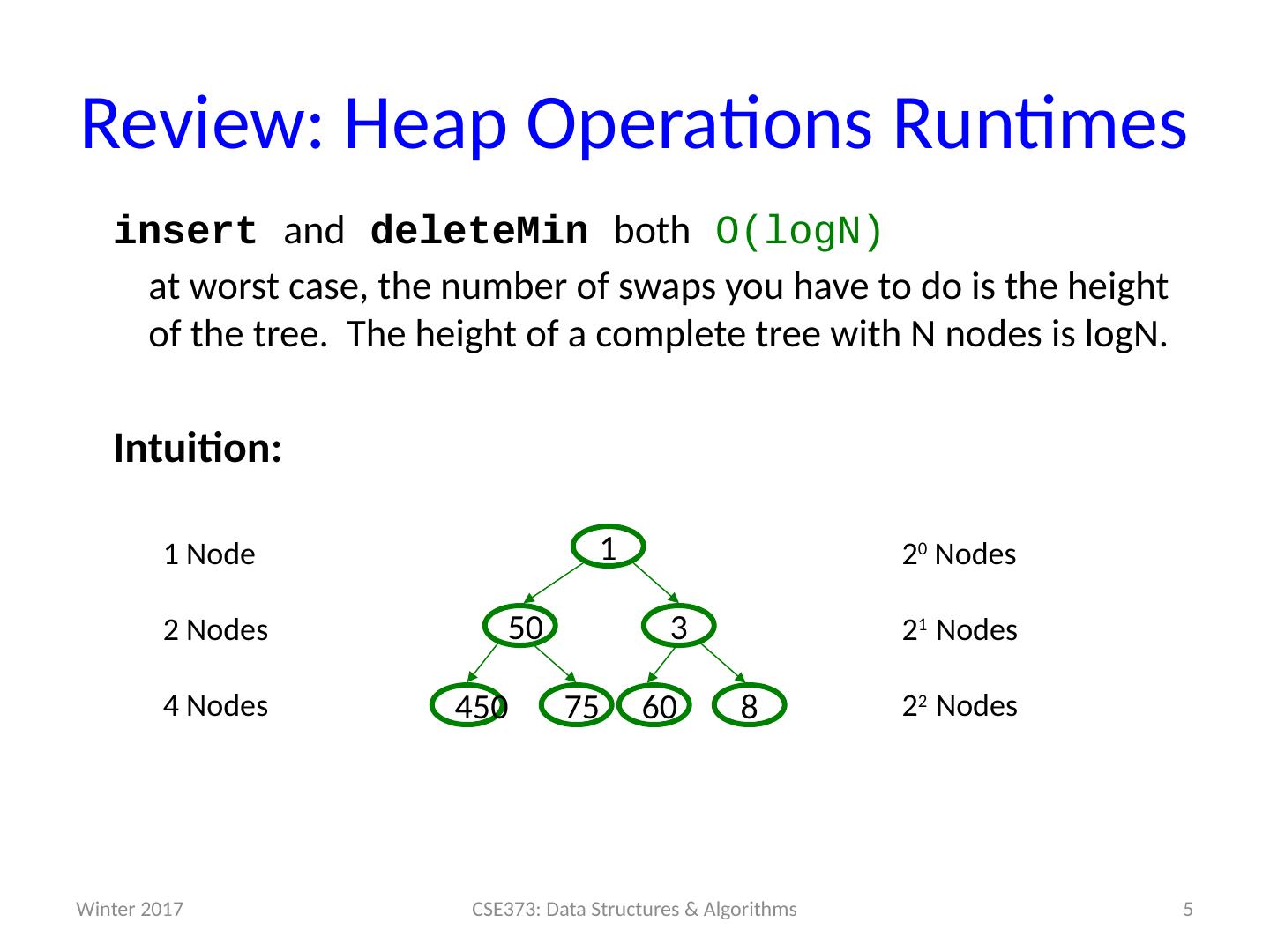
5 .Review: Heap Operations Runtimes insert and deleteMin both O( logN ) at worst case, the number of swaps you have to do is the height of the tree. The height of a complete tree with N nodes is logN . Intuition: 5 CSE373: Data Structures & Algorithms Winter 2017 450 3 1 75 50 8 6 0 1 Node 2 Nodes 4 Nodes 2 0 Nodes 2 1 Nodes 2 2 Nodes
6 .Build Heap Suppose you have n items to put in a new (empty) priority queue Call this operation buildHeap n distinct insert s works (slowly) Only choice if ADT doesn’t provide buildHeap explicitly O ( n log n ) Why would an ADT provide this unnecessary operation? Convenience Efficiency: an O ( n ) algorithm called Floyd’s Method Common tradeoff in ADT design: how many specialized operations 6 CSE373: Data Structures & Algorithms Winter 2017
7 .Floyd’s Method Intuition : if you have a lot of values to insert all at once, you can optimize by inserting them all and then doing a pass for swapping Put the n values anywhere to make a complete structural tree Treat it as a heap and fix the heap-order property Bottom-up: leaves are already in heap order, work up toward the root one level at a time 7 CSE373: Data Structures & Algorithms void buildHeap () { for ( i = size/2; i >0; i --) { val = arr [ i ]; hole = percolateDown ( i,val ); arr [hole] = val ; } } Winter 2017
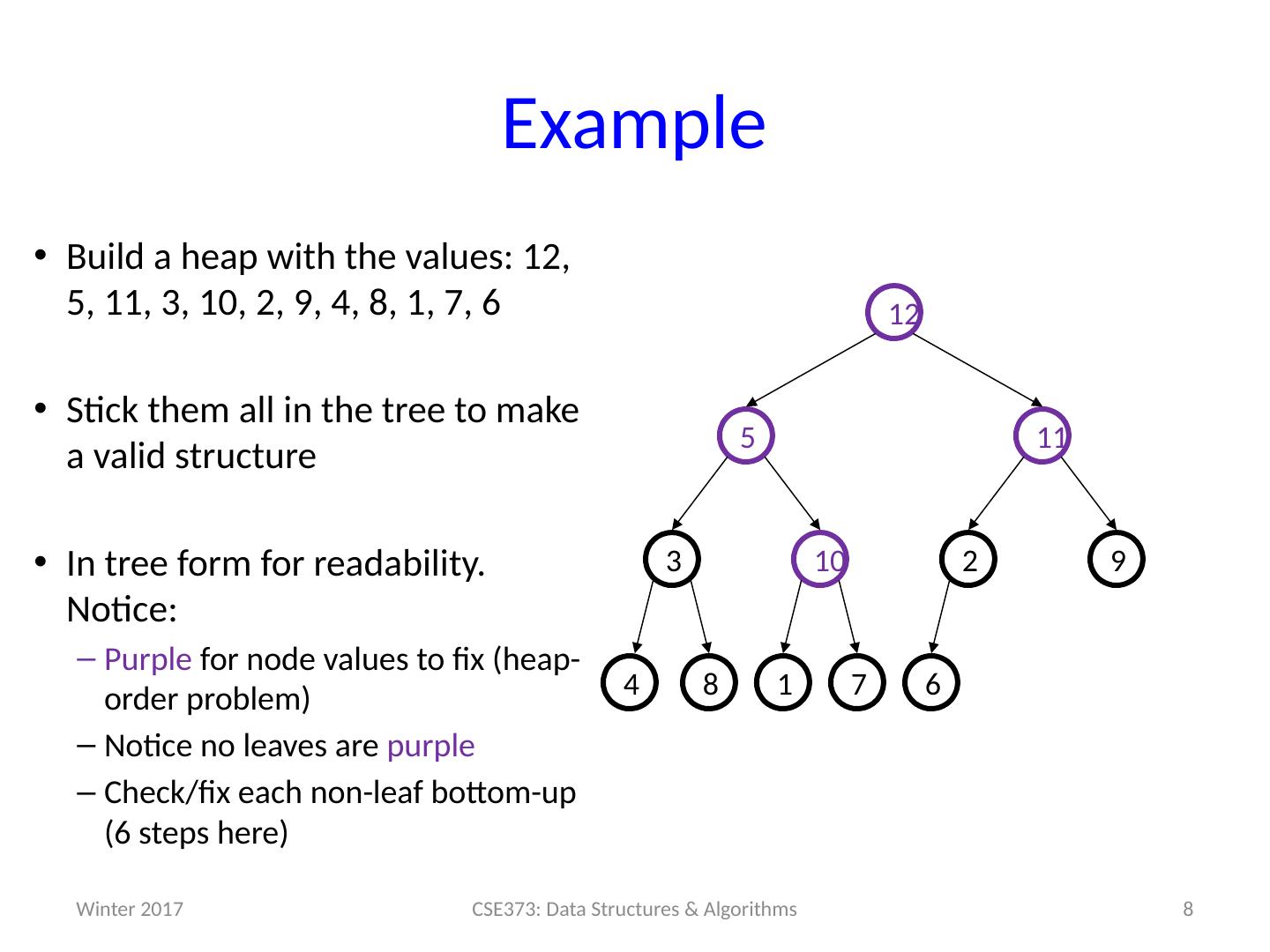
8 .Example Build a heap with the values: 12, 5, 11, 3, 10, 2, 9, 4, 8, 1, 7, 6 Stick them all in the tree to make a valid structure In tree form for readability. Notice: Purple for node values to fix (heap -order problem) Notice no leaves are purple Check/fix each non-leaf bottom-up (6 steps here) 8 CSE373: Data Structures & Algorithms 6 7 1 8 9 2 10 3 11 5 12 4 Winter 2017
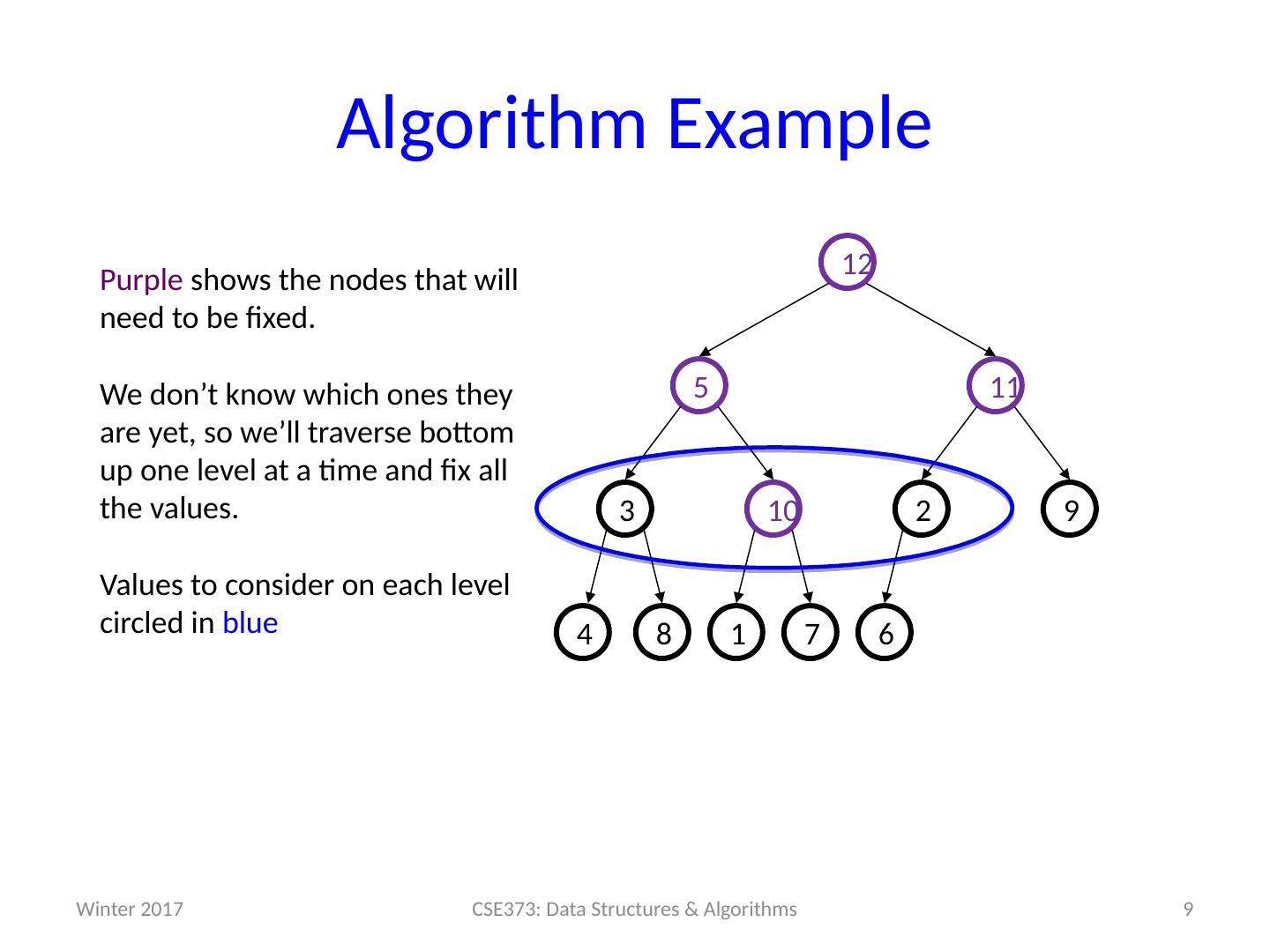
9 .Algorithm Example 9 CSE373: Data Structures & Algorithms 6 7 1 8 9 2 10 3 11 5 12 4 Winter 2017 Purple shows the nodes that will need to be fixed. We don’t know which ones they are yet, so we’ll traverse bottom up one level at a time and fix all the values. Values to consider on each level circled in blue
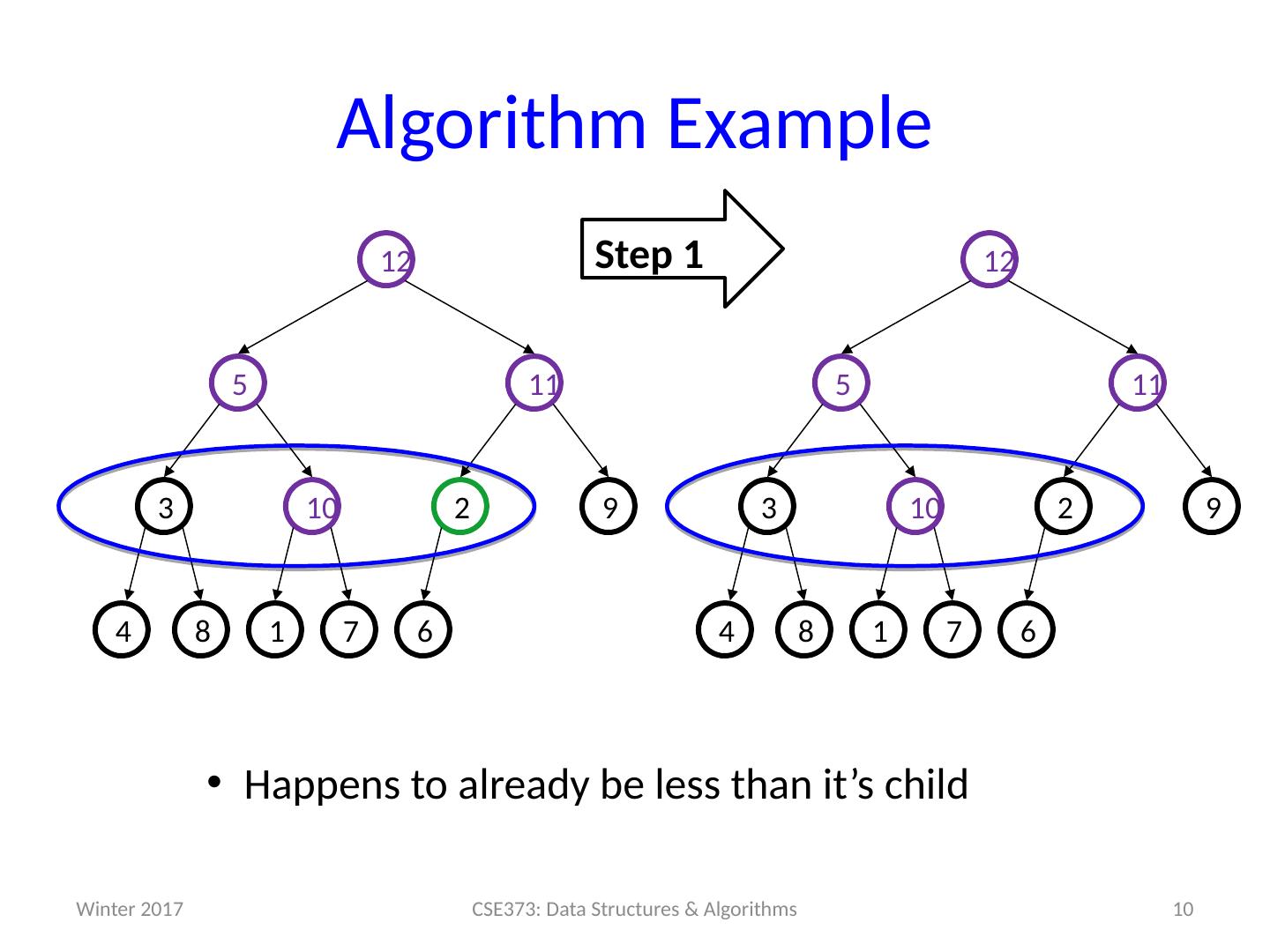
10 .Algorithm Example 10 CSE373: Data Structures & Algorithms 6 7 1 8 9 2 10 3 11 5 12 4 6 7 1 8 9 2 10 3 11 5 12 4 Step 1 Happens to already be less than it’s child Winter 2017
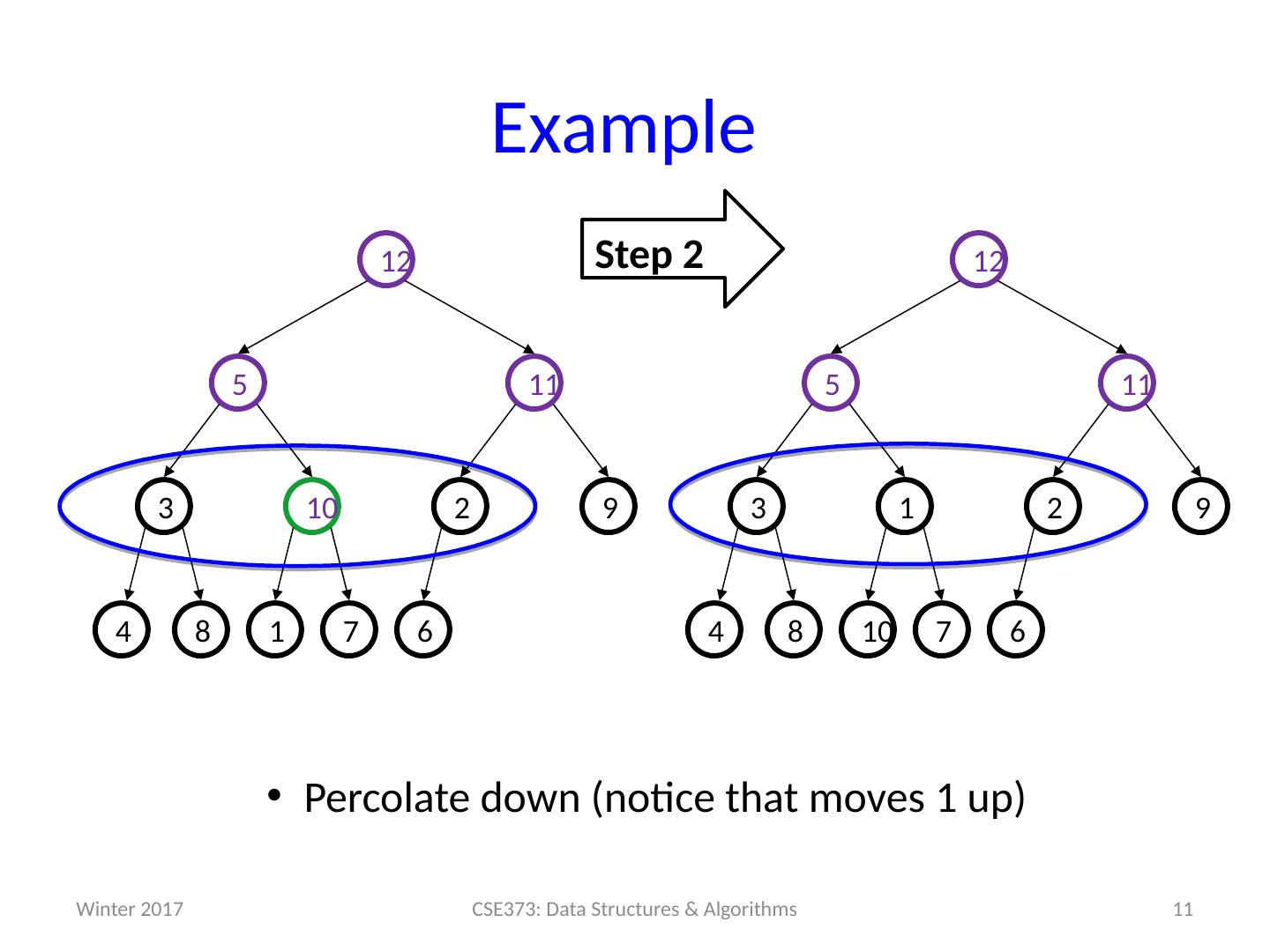
11 .Example 11 CSE373: Data Structures & Algorithms 6 7 1 8 9 2 10 3 11 5 12 4 Step 2 Percolate down (notice that moves 1 up) 6 7 10 8 9 2 1 3 11 5 12 4 Winter 2017
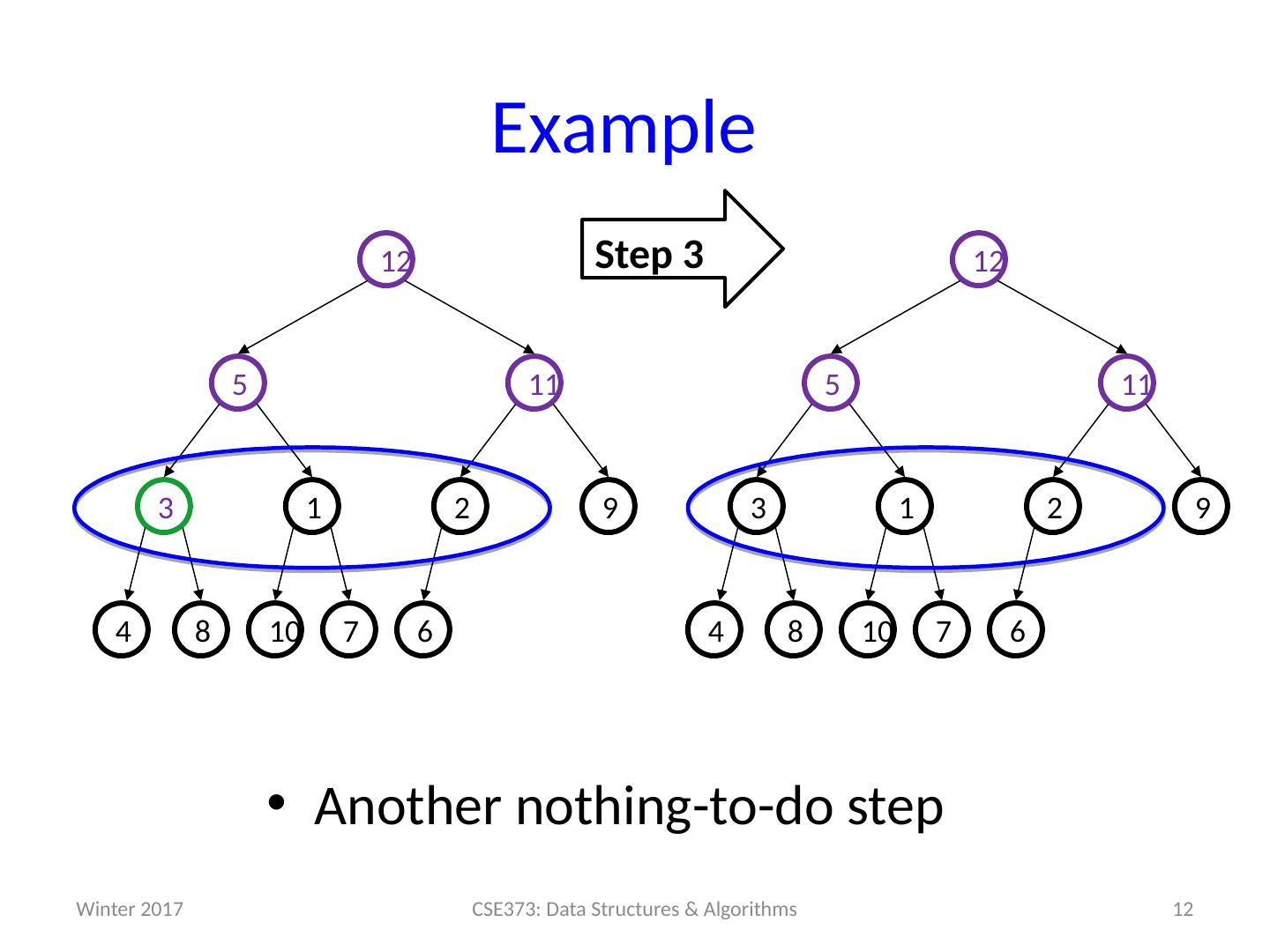
12 .Example 12 CSE373: Data Structures & Algorithms Step 3 Another nothing-to-do step 6 7 10 8 9 2 1 3 11 5 12 4 6 7 10 8 9 2 1 3 11 5 12 4 Winter 2017
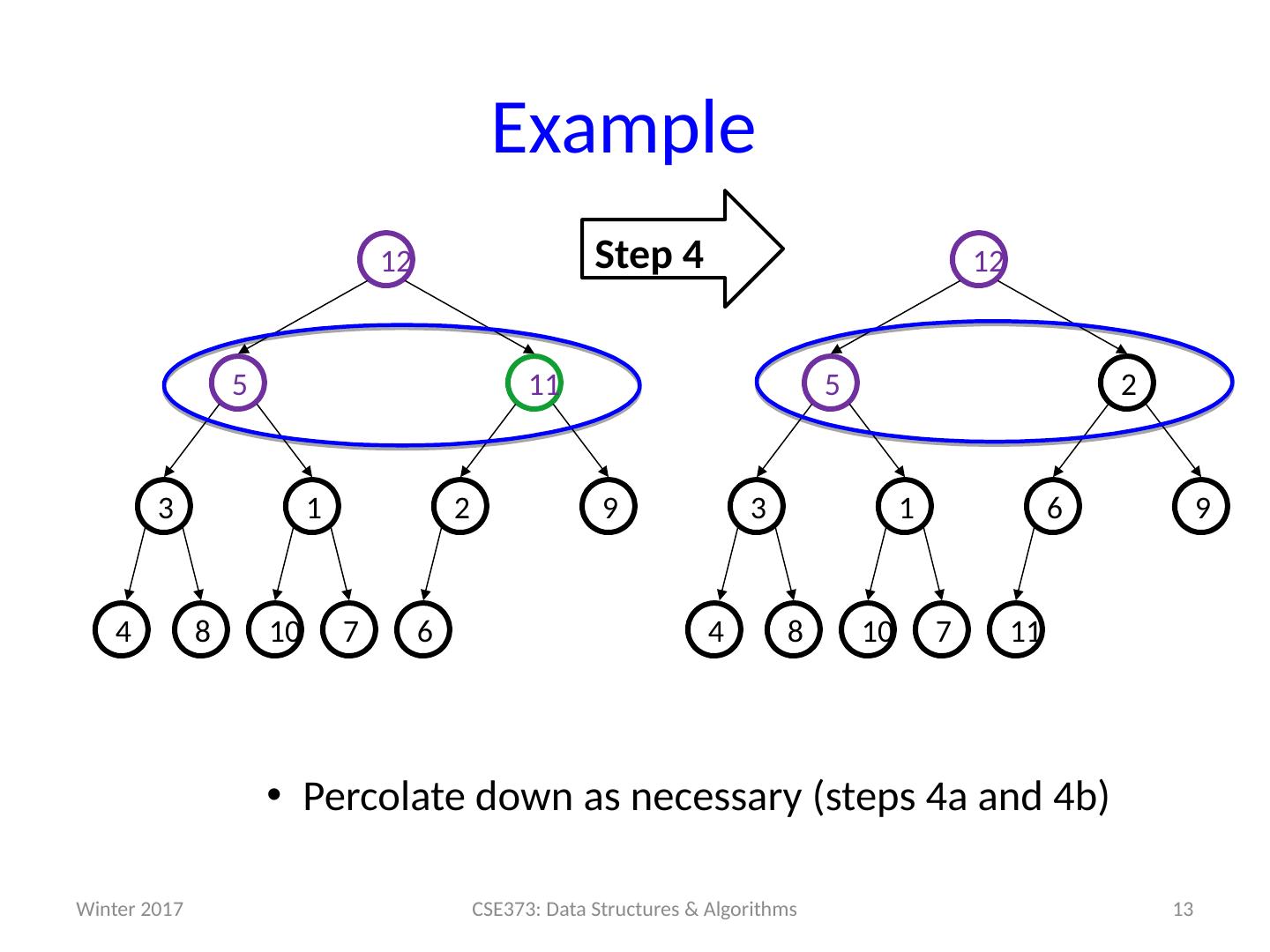
13 .Example 13 CSE373: Data Structures & Algorithms Step 4 Percolate down as necessary (steps 4a and 4b) 11 7 10 8 9 6 1 3 2 5 12 4 6 7 10 8 9 2 1 3 11 5 12 4 Winter 2017
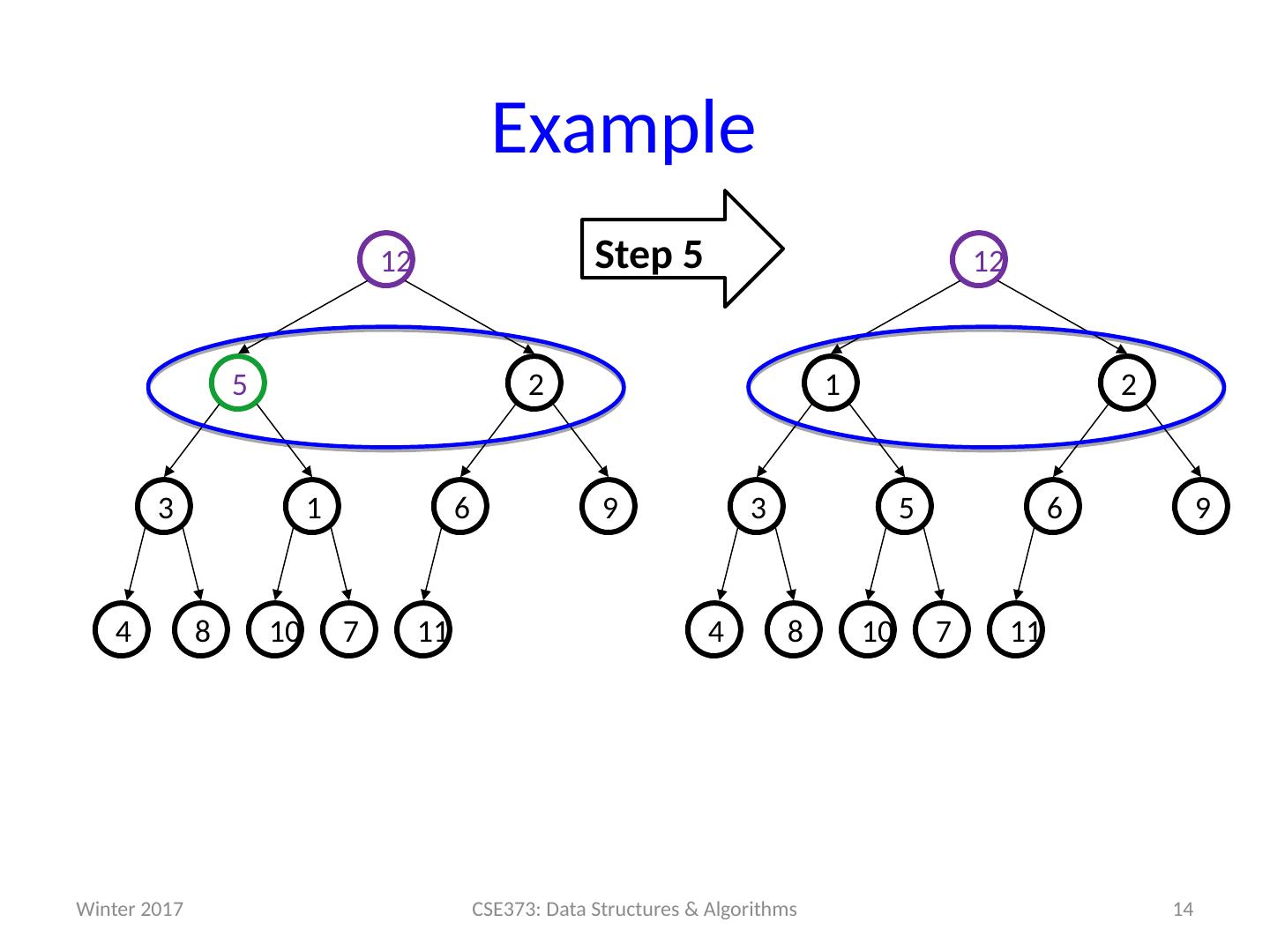
14 .Example 14 CSE373: Data Structures & Algorithms Step 5 11 7 10 8 9 6 5 3 2 1 12 4 11 7 10 8 9 6 1 3 2 5 12 4 Winter 2017
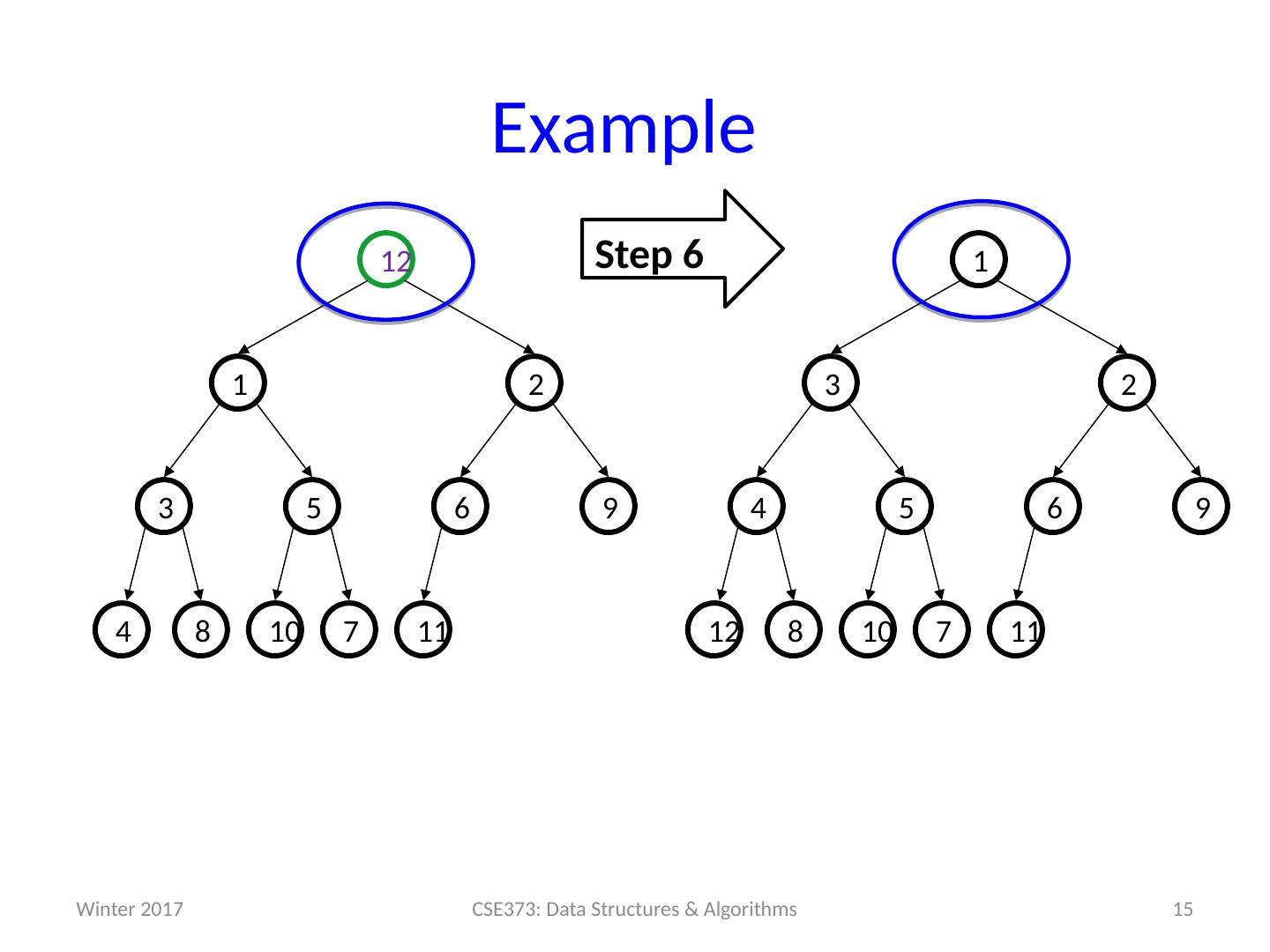
15 .Example 15 CSE373: Data Structures & Algorithms Step 6 11 7 10 8 9 6 5 4 2 3 1 12 11 7 10 8 9 6 5 3 2 1 12 4 Winter 2017
16 .But is it right? “Seems to work” Let’s prove it restores the heap property (correctness) Then let’s prove its running time (efficiency) 16 CSE373: Data Structures & Algorithms void buildHeap () { for ( i = size/2; i >0; i --) { val = arr [ i ]; hole = percolateDown ( i,val ); arr [hole] = val ; } } Winter 2017
17 .Correctness Loop Invariant : For all j > i , arr [j] is less than its children True initially: If j > size/2 , then j is a leaf Otherwise its left child would be at position > size True after one more iteration: loop body and percolateDown make arr [ i ] less than children without breaking the property for any descendants So after the loop finishes, all nodes are less than their children 17 CSE373: Data Structures & Algorithms void buildHeap () { for ( i = size/2; i >0; i --) { val = arr [ i ]; hole = percolateDown ( i,val ); arr [hole] = val ; } } Winter 2017
18 .Efficiency Easy argument: buildHeap is O ( n log n ) where n is size size/2 loop iterations Each iteration does one percolateDown , each is O ( log n ) This is correct, but there is a more precise (“tighter”) analysis of the algorithm… 18 CSE373: Data Structures & Algorithms void buildHeap () { for ( i = size/2; i >0; i --) { val = arr [ i ]; hole = percolateDown ( i,val ); arr [hole] = val ; } } Winter 2017
19 .Efficiency Better argument: buildHeap is O ( n ) where n is size size/2 total loop iterations: O ( n ) 1/2 the loop iterations percolate at most 1 step 1/4 the loop iterations percolate at most 2 steps 1/8 the loop iterations percolate at most 3 steps … ((1/2) + (2/4) + (3/8) + (4/16) + (5/32) + …) < 2 (page 4 of Weiss) So at most 2(size/2) total percolate steps: O ( n ) 19 CSE373: Data Structures & Algorithms void buildHeap () { for ( i = size/2; i >0; i --) { val = arr [ i ]; hole = percolateDown ( i,val ); arr [hole] = val ; } } Winter 2017
20 .Lessons from buildHeap Without buildHeap , our ADT already let clients implement their own in O ( n log n ) worst case Worst case is inserting better priority values later By providing a specialized operation internal to the data structure (with access to the internal data), we can do O ( n ) worst case Intuition: Most data is near a leaf, so better to percolate down Can analyze this algorithm for: Correctness: Non-trivial inductive proof using loop invariant Efficiency: First analysis easily proved it was O( n log n ) Tighter analysis shows same algorithm is O ( n ) 20 CSE373: Data Structures & Algorithms Winter 2017
21 .What we’re skipping merge: g iven two priority queues, make one priority queue How might you merge binary heaps: If one heap is much smaller than the other? If both are about the same size ? Different pointer-based data structures for priority queues support logarithmic time merge operation (impossible with binary heaps) Leftist heaps, skew heaps, binomial queues Worse constant factors Trade-offs! 21 CSE373: Data Structures & Algorithms Winter 2017
22 .Take a breath Let’s talk about more ADTs and Data Structures: Dictionaries/Maps (and briefly Sets) Binary Search Trees Clear your mind with this picture of a kitten: 22 CSE373: Data Structures & Algorithms Winter 2017
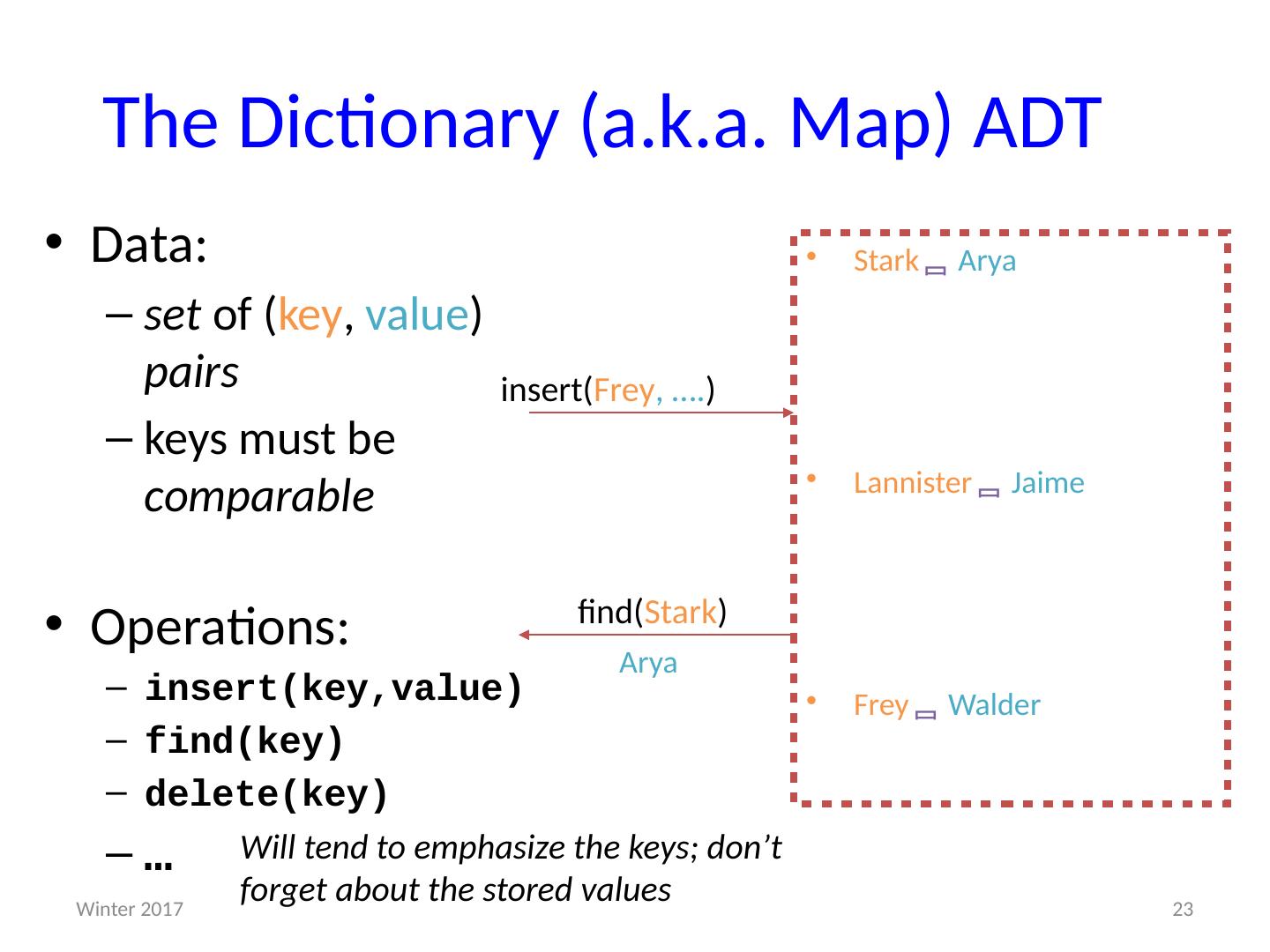
23 .The Dictionary (a.k.a. Map) ADT Data: set of ( key , value ) pairs keys must be comparable Operations: insert( key,value ) find(key) delete(key) … Stark Arya Lannister Jaime Frey Wa lder insert( Frey , …. ) find( Stark ) Arya Will tend to emphasize the keys; don’t forget about the stored values 23 Winter 2017
24 .Comparison: The Set ADT The Set ADT is like a Dictionary without any values A key is present or not (no duplicates) For find , insert , delete , there is little difference In dictionary, values are “just along for the ride” So same data-structure ideas work for dictionaries and sets But if your Set ADT has other important operations this may not hold union , intersection , is_subset N otice these are binary operators on sets 24 binary operation: a rule for combining two objects of a given type, to obtain another object of that type Winter 2017
25 .Applications Lots of fast look-up uses in search: inverted indexes, storing a phone directory, etc Routing information through a Network Operating systems looking up information in page tables Compilers looking up information in symbol tables Databases storing data in fast searchable indexes Biology genome maps 25 Any time you want to store information according to some key and be able t o retrieve it efficiently. Lots of programs do that! Winter 2017
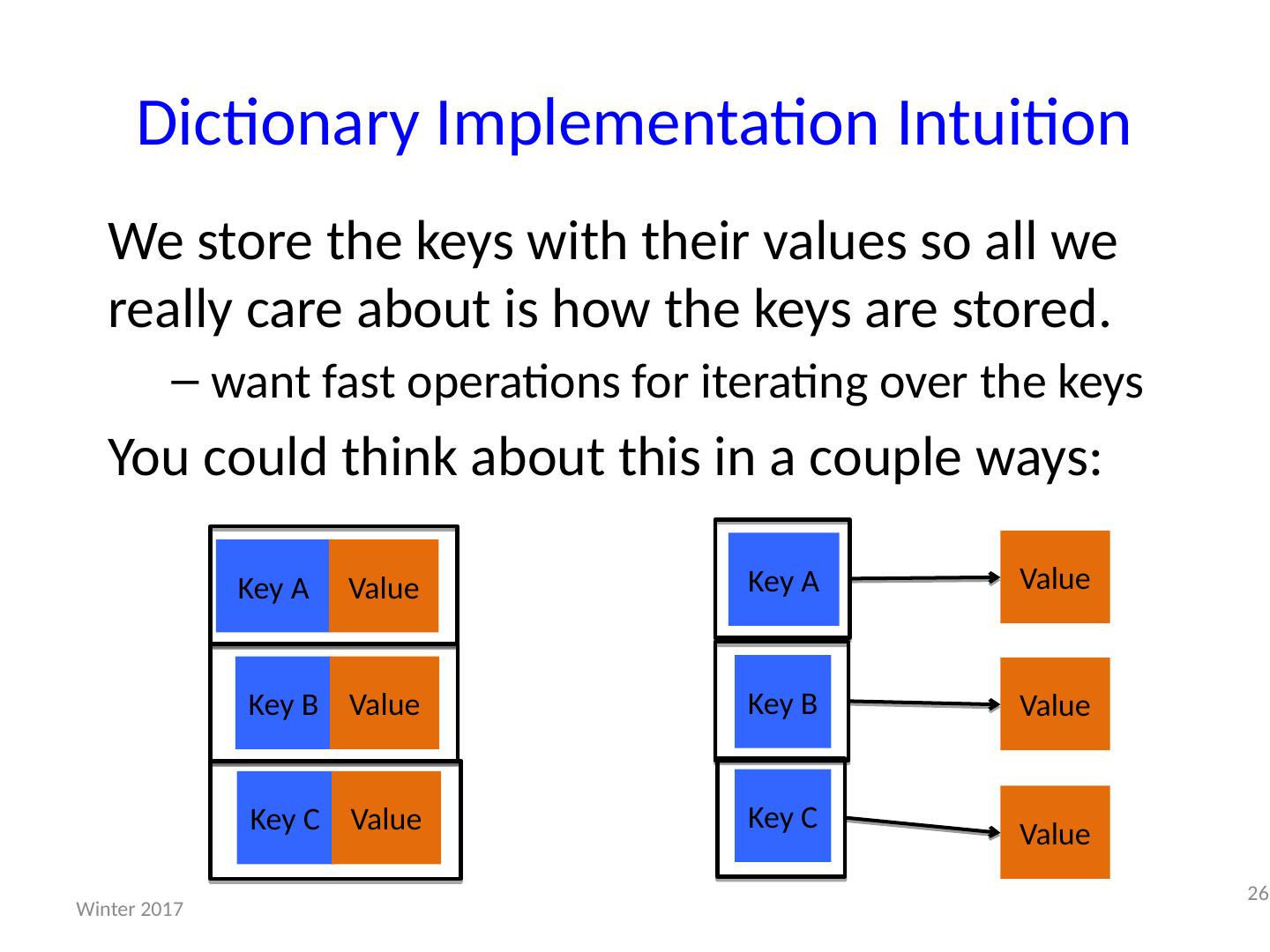
26 .Dictionary Implementation Intuition We store the keys with their values so all we really care about is how the keys are stored. want fast operations for iterating over the keys You could think about this in a couple ways: 26 Winter 2017 Key A Value Key B Value Key C Value Key A Value Key B Value Key C Value
27 .Simple implementations For dictionary with n key/value pairs insert find delete Unsorted linked-list Unsorted array Sorted linked list Sorted array * Unless we need to check for duplicates 27 O(1)* O(n) O(n) O(1)* O(n) O(n) O(n) O(n) O(n) O(n) O( logn ) O(n) We’ll see a Binary Search Tree (BST) probably does better, but not in the worst case unless we keep it balanced Winter 2017
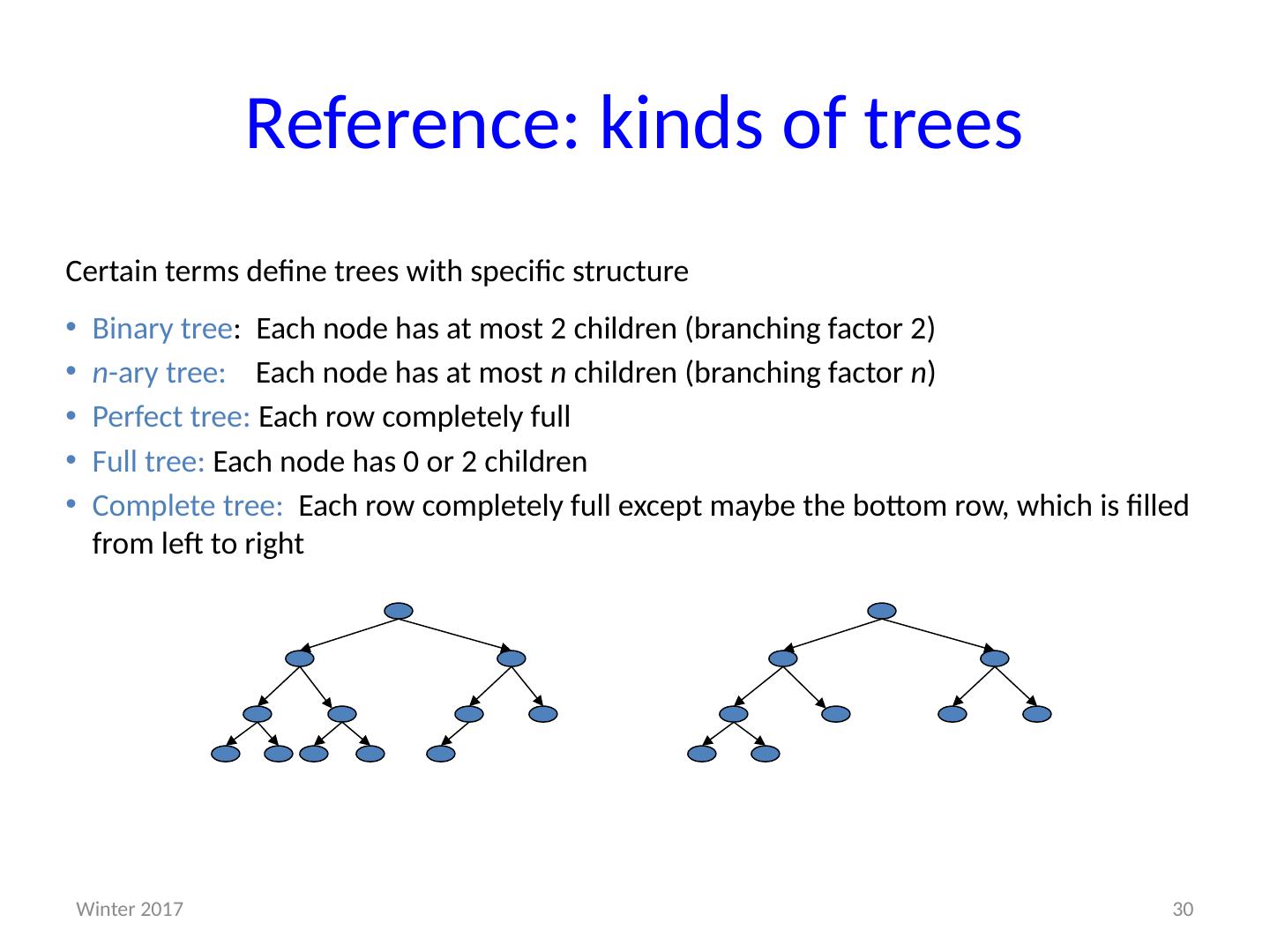
28 .Implementations we’ll see soon There are many good data structures for (large) dictionaries AVL trees (next week) Binary search trees with guaranteed balancing B-Trees (an extra topic we might have time for) Also always balanced, but different and shallower B ≠ Binary; B-Trees generally have large branching factor Hashtables (in two weeks) Not tree-like at all Skipping: Other, really cool, balanced trees (e.g., red-black, splay) 28 Winter 2017
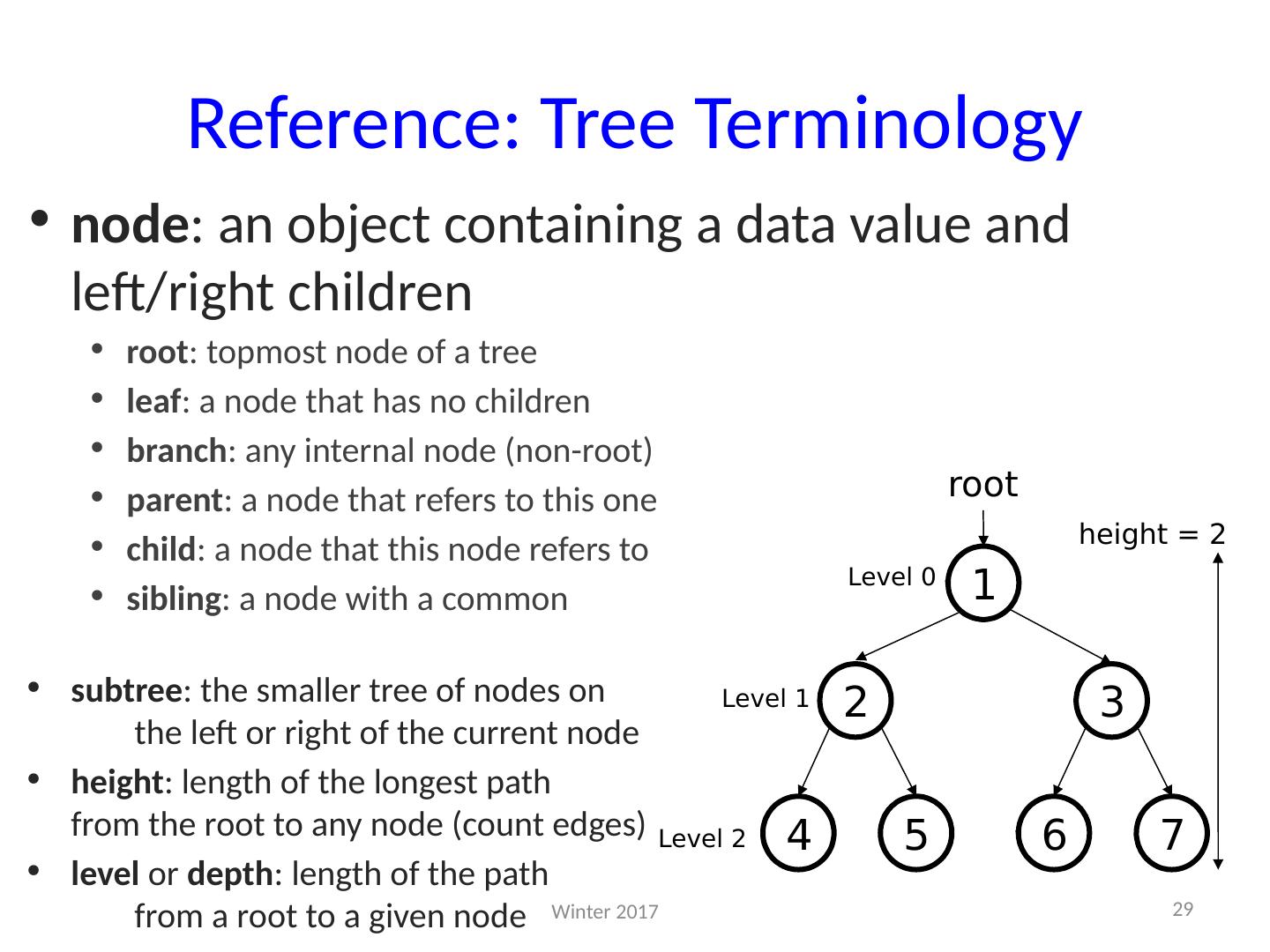
29 .Reference: Tree Terminology node : an object containing a data value and left/right children root : topmost node of a tree leaf : a node that has no children branch : any internal node (non-root) parent : a node that refers to this one child : a node that this node refers to sibling : a node with a common subtree : the smaller tree of nodes on the left or right of the current node height : length of the longest path from the root to any node (count edges) level or depth : length of the path from a root to a given node 7 6 3 2 1 5 4 root height = 2 Level 0 Level 1 Level 2 29 Winter 2017
3秒后跳转登录页面
去登陆

