



























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
MapReduce and Spark
本章节主要介绍MapReduce和Spark,MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算;而Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。介绍了两者的定义,由来,特点。
展开查看详情
1 .MapReduce and Spark (and MPI) (Lecture 22, cs262a) Ali Ghodsi and Ion Stoica, UC Berkeley April 11, 2018
2 .Context (1970s—1990s) Supercomputers the pinnacle of computation Solve important science problems, e.g., Airplane simulations Weather prediction … Large national racing for most powerful computers In quest for increasing power large scale distributed/parallel computers (1000s of processors) Question: how to program these supercomputers?
3 .Shared memory vs. Message passing Message passing : exchange data explicitly via IPC Application developers define protocol and exchanging format, number of participants, and each exchange Client s end( msg ) MSG Client recv ( msg ) MSG MSG IPC Shared memory : all multiple processes to share data via memory Applications must locate and and map shared memory regions to exchange data Client s end( msg ) Client recv ( msg ) Shared Memory
4 .Shared memory vs. Message passing Easy to program; just like a single multi-threaded machines Hard to write high perf. apps: Cannot control which data is local or remote (remote mem. access much slower) Hard to mask failures Message passing: can write very high perf. apps Hard to write apps: Need to manually decompose the app, and move data Need to manually handle failures
5 .MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers, and parallel programmers Used to create parallel programs based on message passing Portable : one standard, many implementations Available on almost all parallel machines in C and Fortran De facto standard platform for the HPC community
6 .Groups, Communicators, Contexts Group : a fixed ordered set of k processes, i.e., 0, 1, .., k-1 Communicator : specify scope of communication Between processes in a group Between two disjoint groups Context : partition of comm. space A message sent in one context cannot be received in another context This image is captured from: “Writing Message Passing Parallel Programs with MPI”, Course Notes , Edinburgh Parallel Computing Centre The University of Edinburgh
7 .Synchronous vs. Asynchronous Message Passing A synchronous communication is not complete until the message has been received An asynchronous communication completes before the message is received
8 .Communication Modes Synchronous : completes once ack is received by sender Asynchronous : 3 modes Standard send : completes once the message has been sent, which may or may not imply that the message has arrived at its destination Buffered send : completes immediately, if receiver not ready, MPI buffers the message locally Ready send : completes immediately, if the receiver is ready for the message it will get it, otherwise the message is dropped silently
9 .Blocking vs. Non-Blocking Blocking , means the program will not continue until the communication is completed Synchronous communication Barriers: wait for every process in the group to reach a point in execution Non-Blocking , means the program will continue, without waiting for the communication to be completed
10 .MPI library Huge (125 functions) Basic (6 functions)
11 .MPI Basic Many parallel programs can be written using just these six functions, only two of which are non-trivial; MPI_INIT MPI_FINALIZE MPI_COMM_SIZE MPI_COMM_RANK MPI_SEND MPI_RECV
12 .Skeleton MPI Program (C) # include < mpi.h > m ain( int argc , char** argv ) { MPI_Init (& argc , & argv ); /* main part of the program */ / * Use MPI function call depend on your data * partitioning and the parallelization architecture */ MPI_Finalize (); }
13 .A minimal MPI program (C) # include “ mpi.h ” #include < stdio.h > int main( int argc , char * argv []) { MPI_Init (& argc , & argv ); printf ( “ Hello, world!
14 .A minimal MPI program (C) #include “ mpi.h ” provides basic MPI definitions and types. MPI_Init starts MPI MPI_Finalize exits MPI Notes: Non-MPI routines are local; this “ printf ” run on each process MPI functions return error codes or MPI_SUCCESS
15 .Improved Hello (C) # include < mpi.h > #include < stdio.h > int main( int argc , char * argv []) { int rank, size; MPI_Init (& argc , & argv ); /* rank of this process in the communicator */ MPI_Comm_rank (MPI_COMM_WORLD, &rank); /* get the size of the group associates to the communicator */ MPI_Comm_size ( MPI_COMM_WORLD, &size); printf ("I am %d of %d
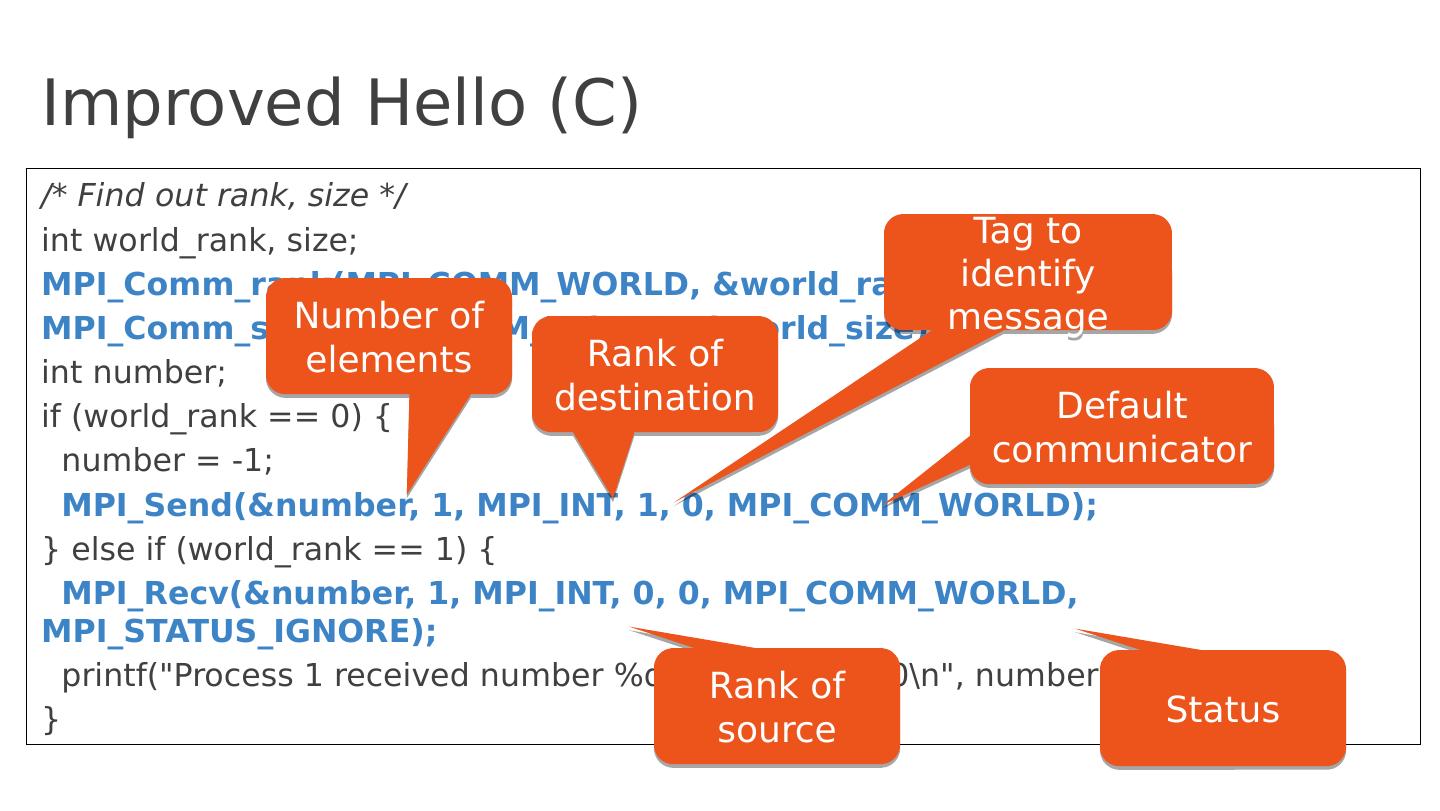
16 .Improved Hello (C) /* Find out rank, size */ int world_rank , size; MPI_Comm_rank (MPI_COMM_WORLD, & world_rank ); MPI_Comm_size (MPI_COMM_WORLD, & world_size ); int number; if ( world_rank == 0) { number = -1; MPI_Send (&number, 1, MPI_INT, 1, 0, MPI_COMM_WORLD); } else if ( world_rank == 1) { MPI_Recv (&number, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE) ; printf ("Process 1 received number %d from process 0
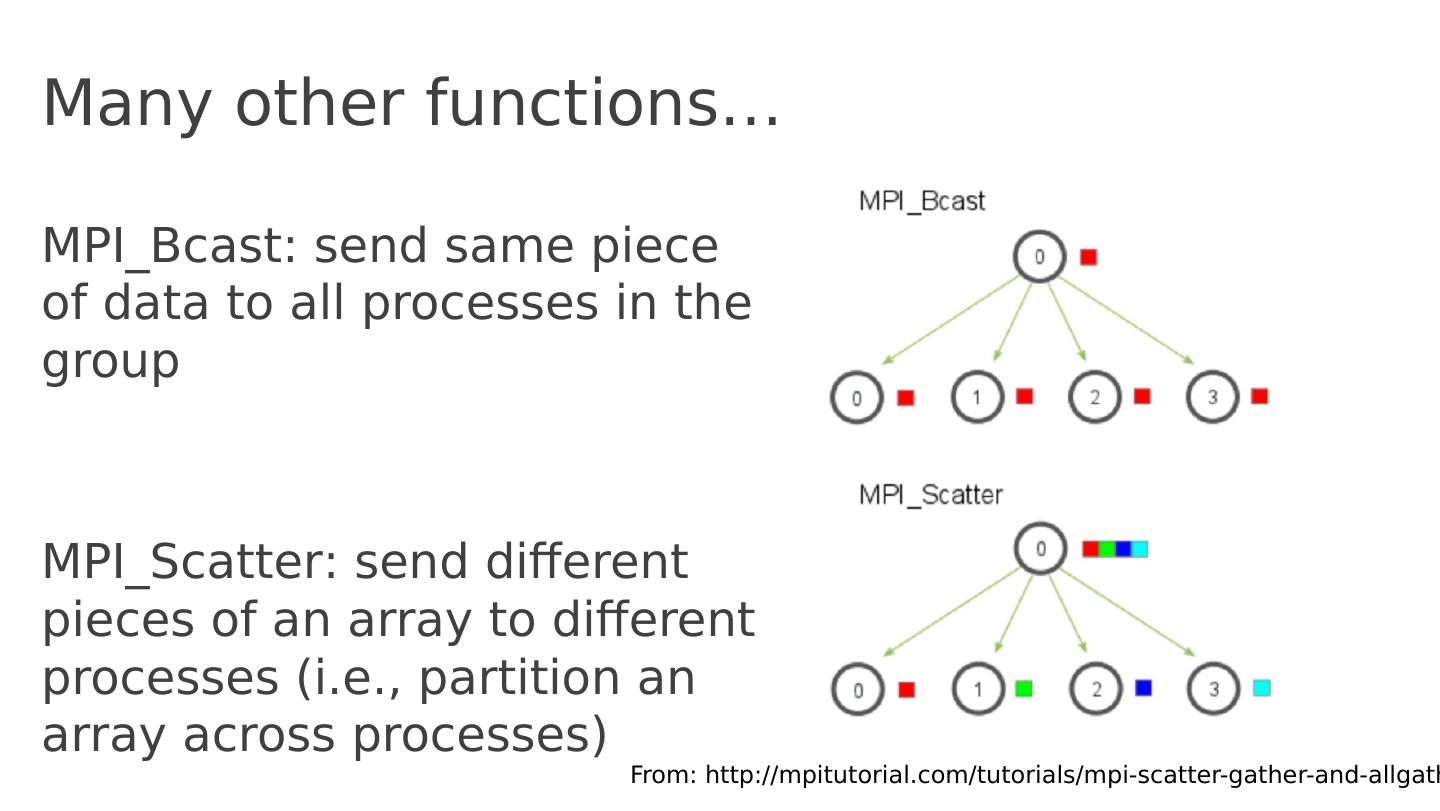
17 .Many other functions … MPI_Bcast : send same piece of data to all processes in the group MPI_Scatter : send different pieces of an array to different processes (i.e., partition an array across processes) From: http :// mpitutorial.com /tutorials/ mpi -scatter-gather-and- allgather /
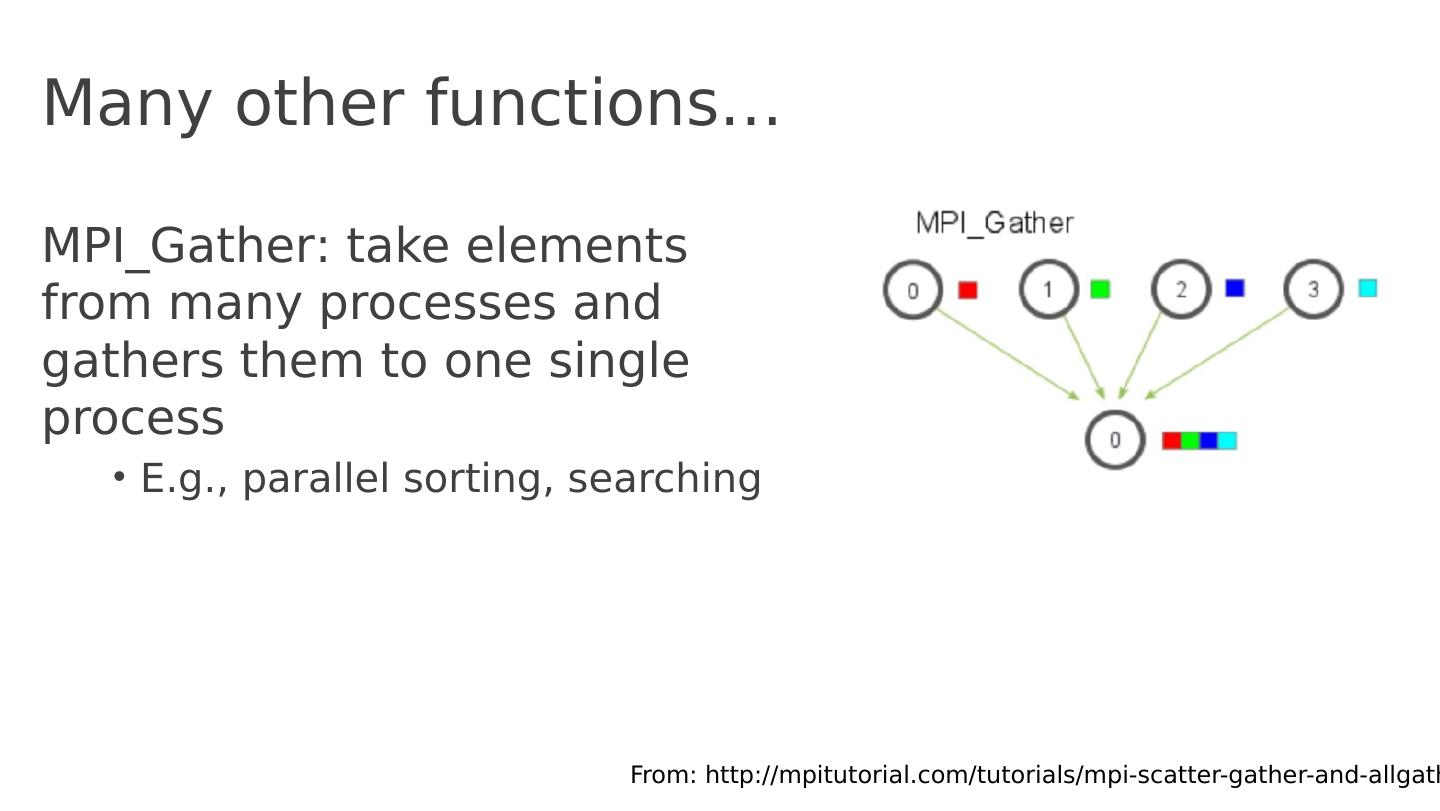
18 .Many other functions … MPI_Gather : take elements from many processes and gathers them to one single process E.g., parallel sorting, searching From: http :// mpitutorial.com /tutorials/ mpi -scatter-gather-and- allgather /
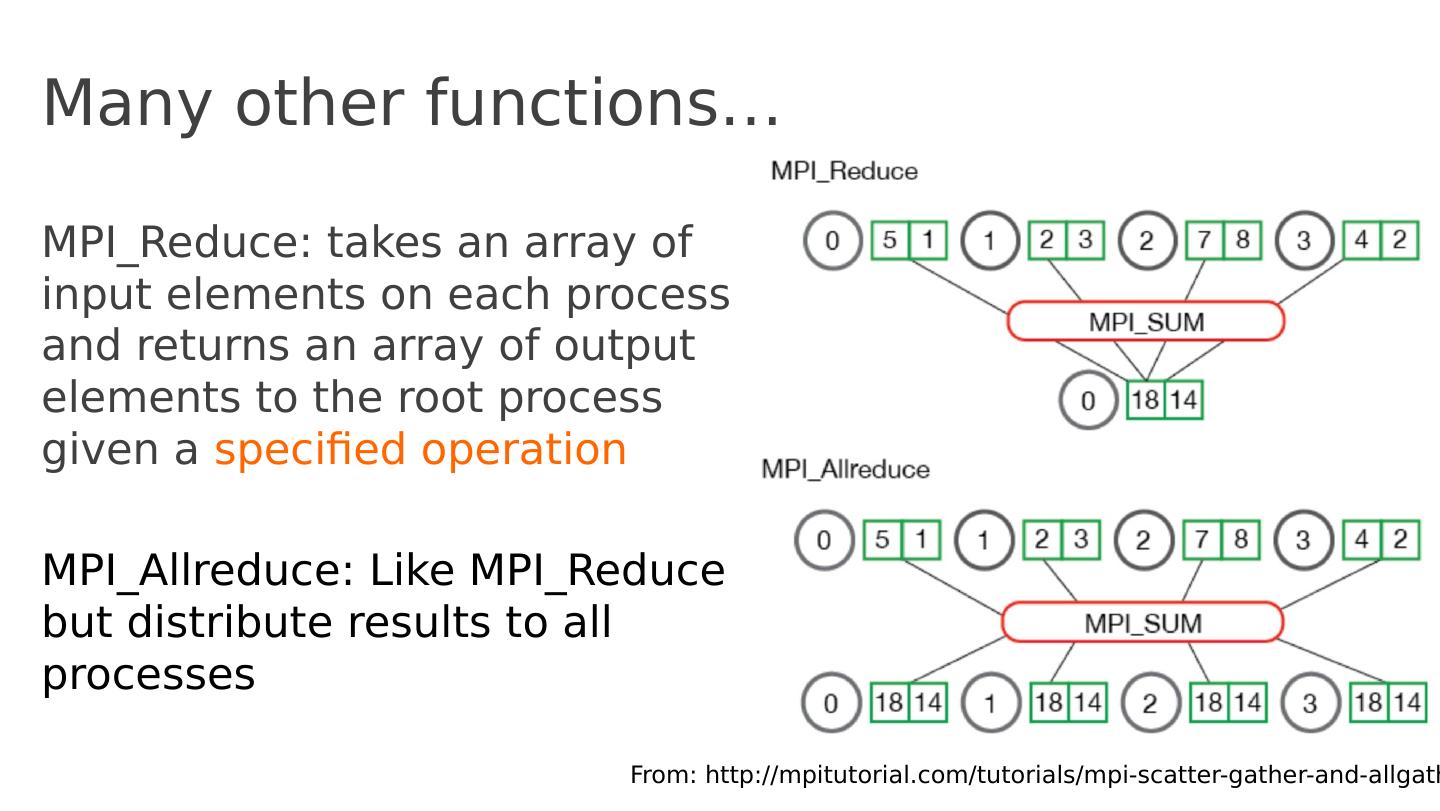
19 .Many other functions … MPI_Reduce : takes an array of input elements on each process and returns an array of output elements to the root process given a specified operation MPI_Allreduce : Like MPI_Reduce but distribute results to all processes From: http :// mpitutorial.com /tutorials/ mpi -scatter-gather-and- allgather /
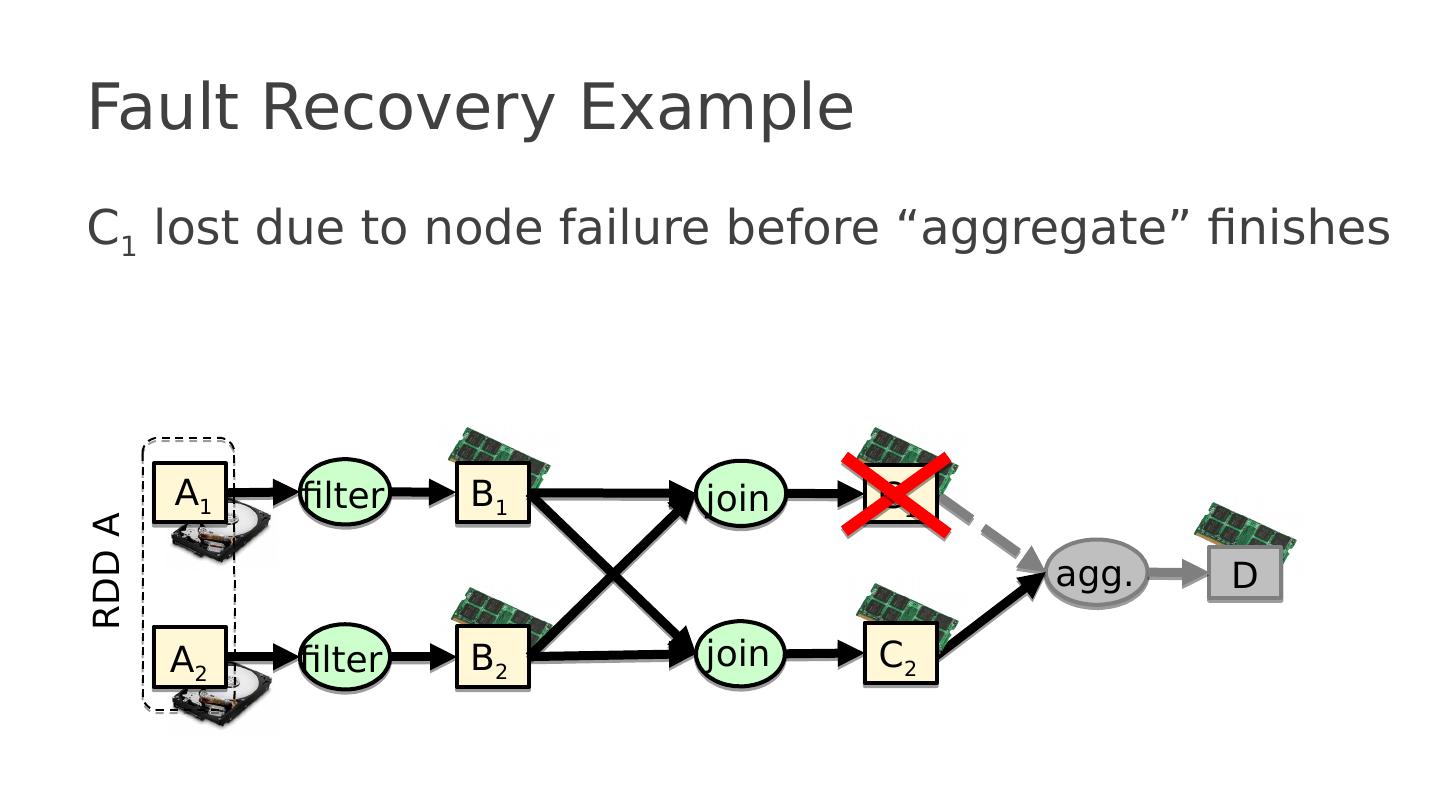
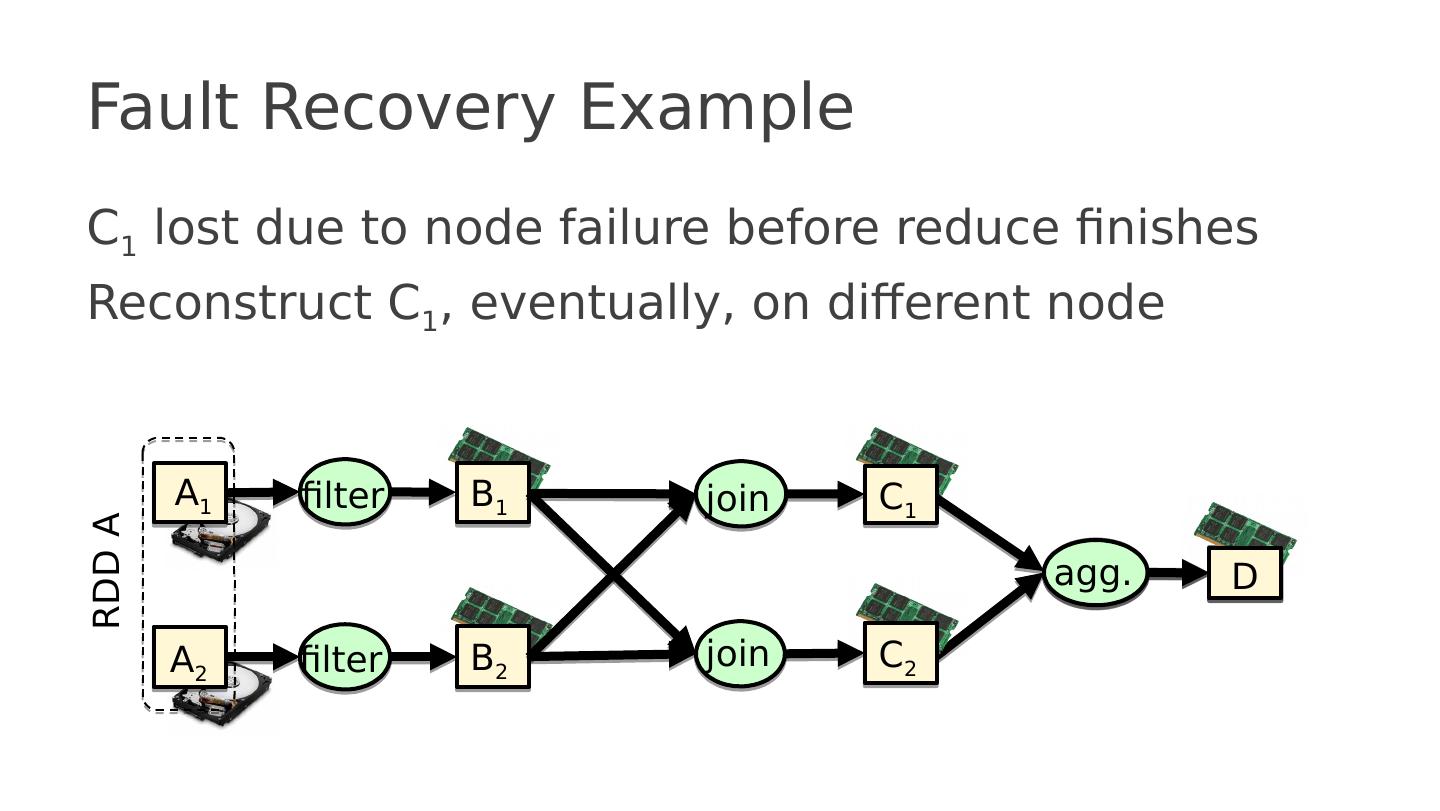
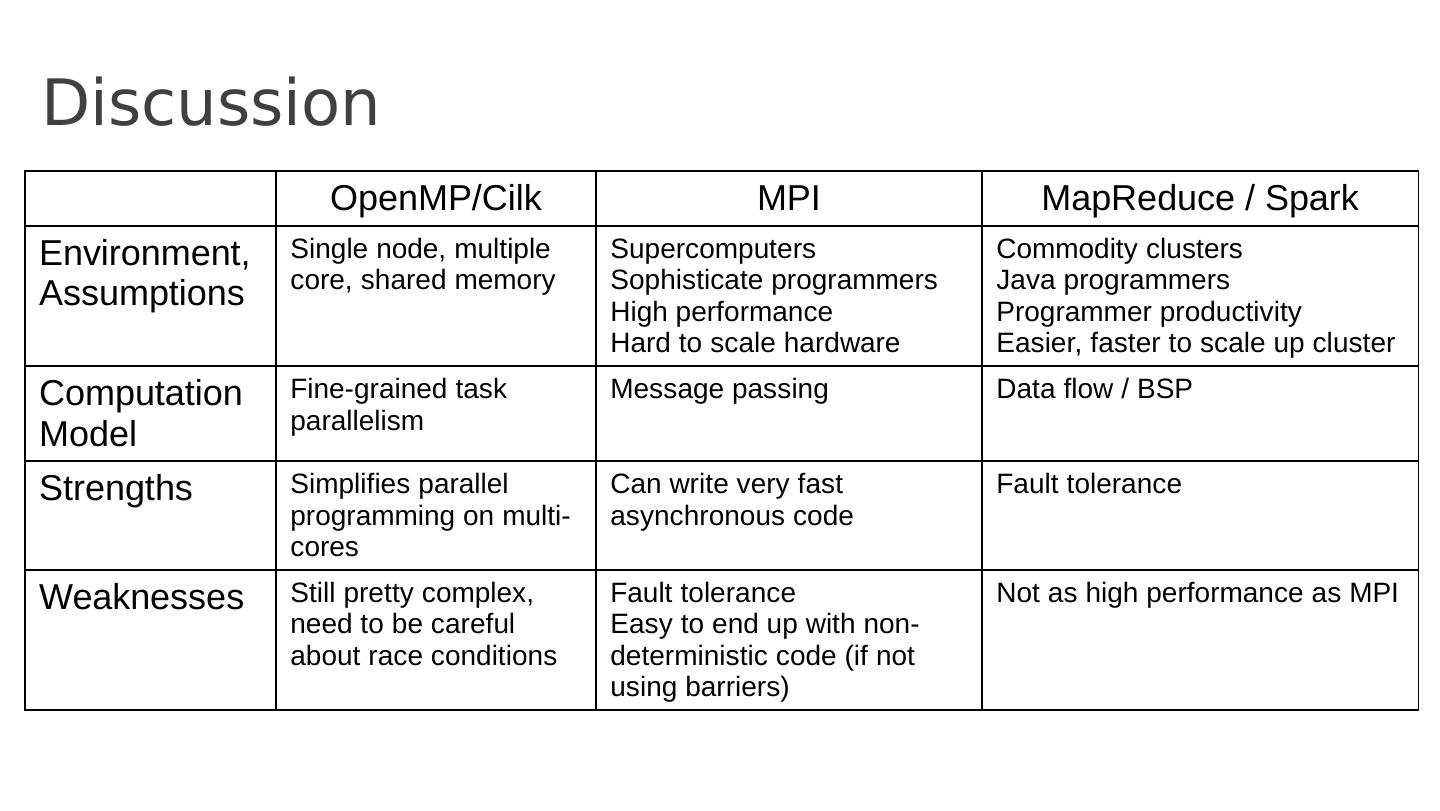
20 .MPI Discussion Gives full control to programmer Exposes number of processes Communication is explicit, driven by the program Assume Long running processes Homogeneous (same performance) processors Little support for failures, no straggler mitigation Summary : achieve high performance by hand-optimizing jobs but requires experts to do so, and little support for fault tolerance
21 .Today’s Papers MapReduce: Simplified Data Processing on Large Clusters, Jeffrey Dean and Sanjay Ghemawat , OSDI’04 http://static.googleusercontent.com /media/research.google.com/en//archive/mapreduce-osdi04. pdf Spark: Cluster Computing with Working Sets, Matei Zaharia , Mosharaf Chowdhury , Michael J. Franklin, Scott Shenker , Ion Stoica, NSDI’12 https://people.csail.mit.edu/matei/papers/2010/ hotcloud_spark.pdf
22 .Context (end of 1990s) Internet and World Wide Web taking off Search as a killer applications Need to index and process huge amounts of data Supercomputers very expensive; also designed for computation intensive workloads vs data intensive workloads Data processing: highly parallel
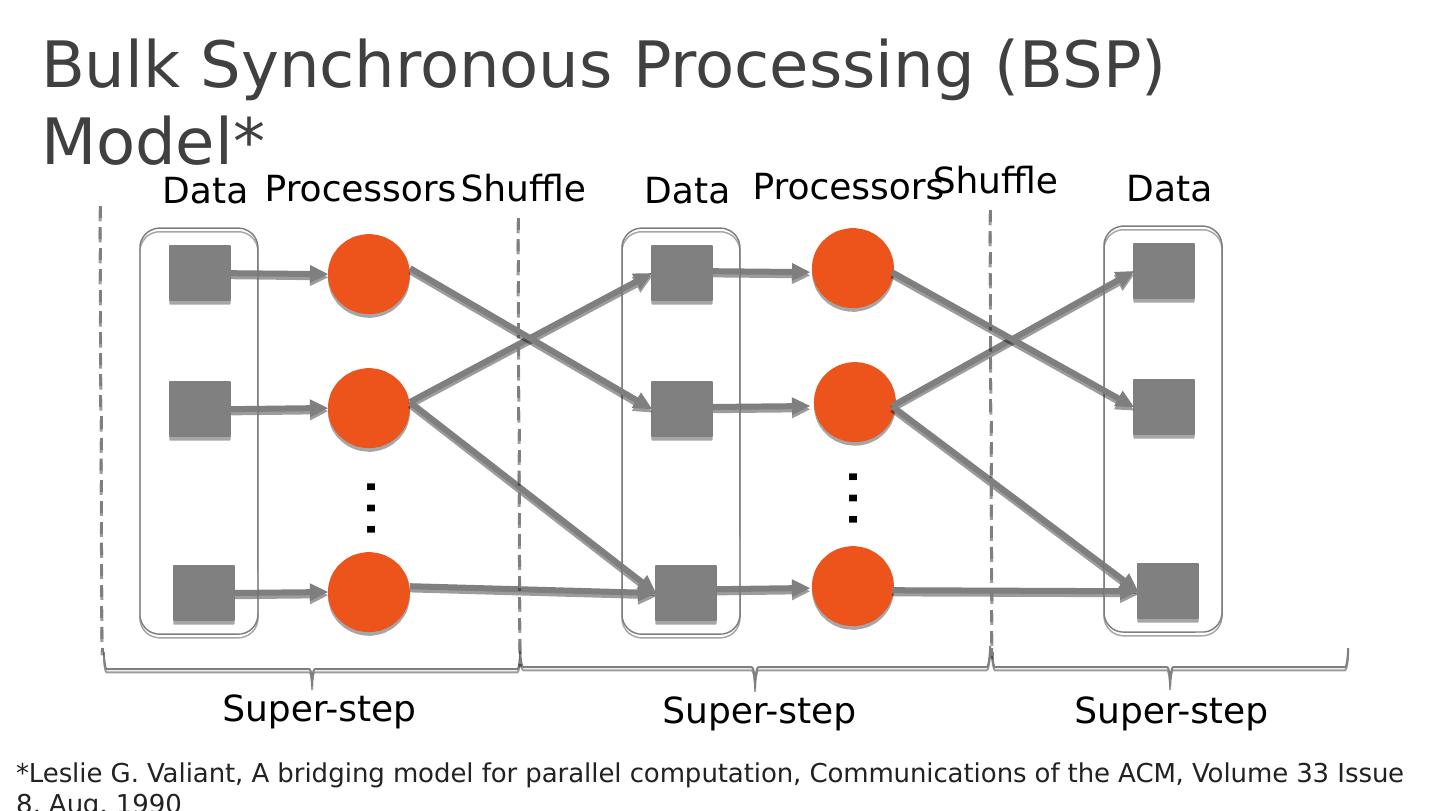
23 .Bulk Synchronous Processing (BSP) Model* S uper-step Processors … Super-step Processors … Data Data Shuffle Data Super-step Shuffle *Leslie G. Valiant, A bridging model for parallel computation, Communications of the ACM, Volume 33 Issue 8, Aug. 1990
24 .MapReduce as a BSP System Super-step (Map phase) Maps … Super-step (Reduce phase) Reduce … Partitions Partitions Shuffle
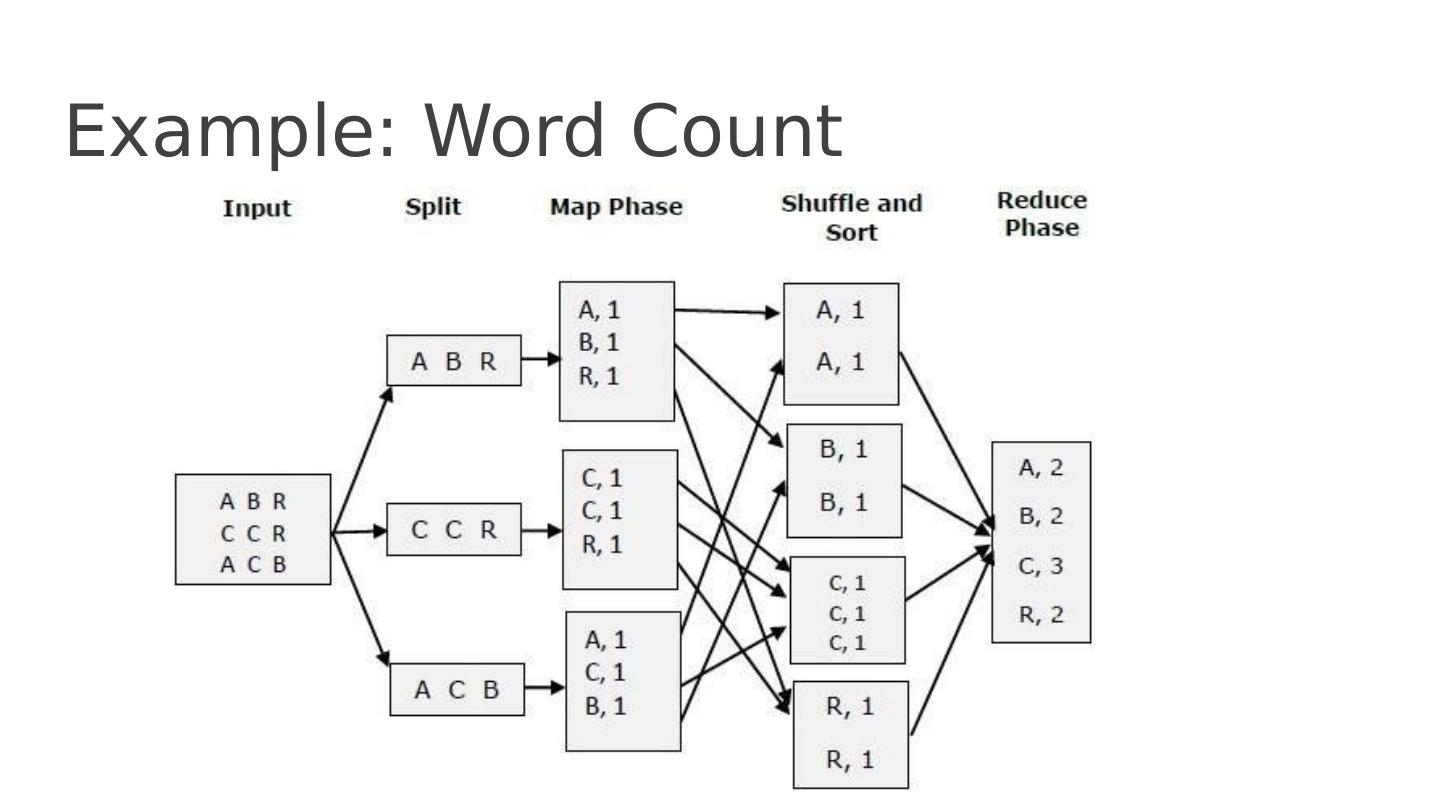
25 .Example: W ord Count
26 .Context (2000s) MapReduce and Hadoop de facto standard for big data processing great for batch jobs … but not effective for Interactive computations Iterative computations 26
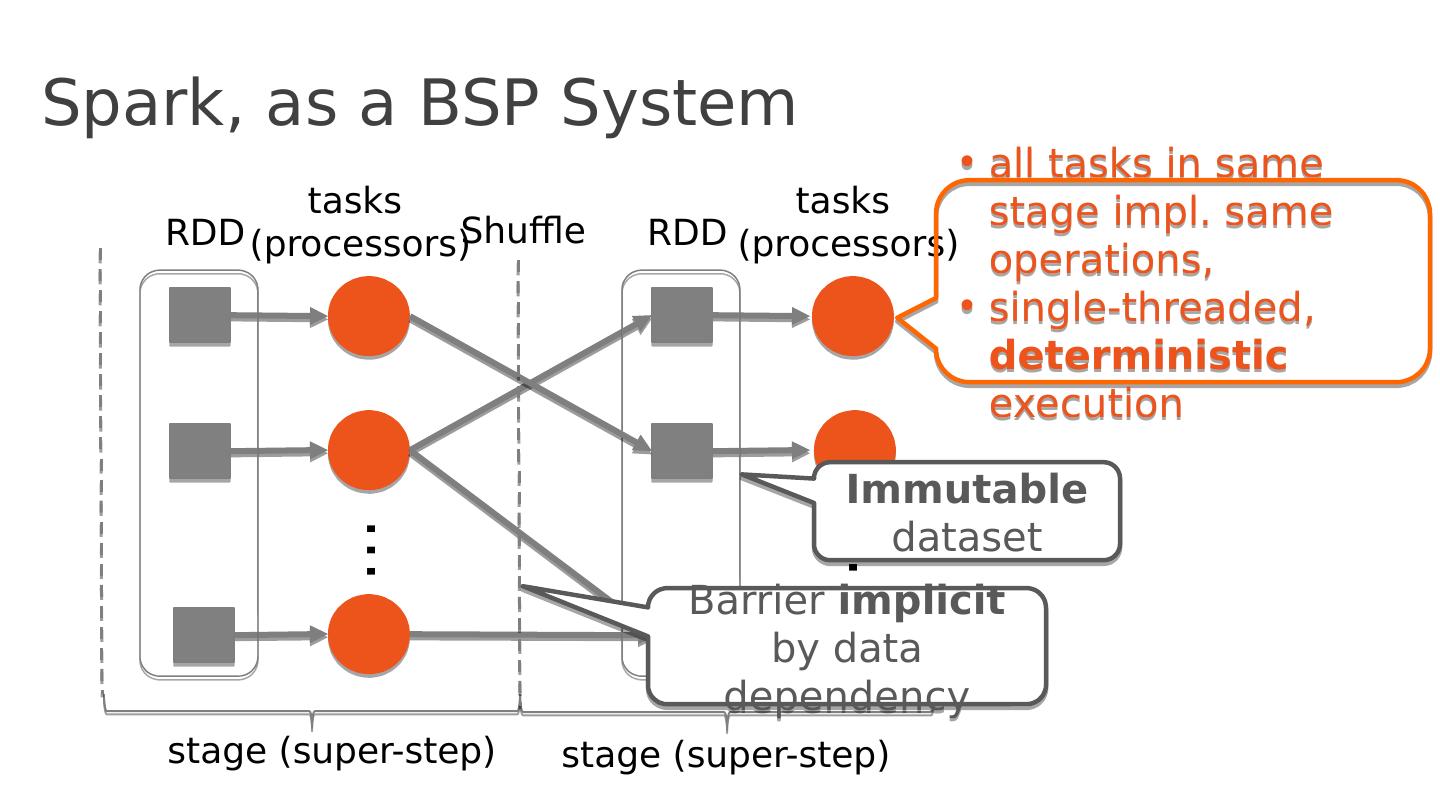
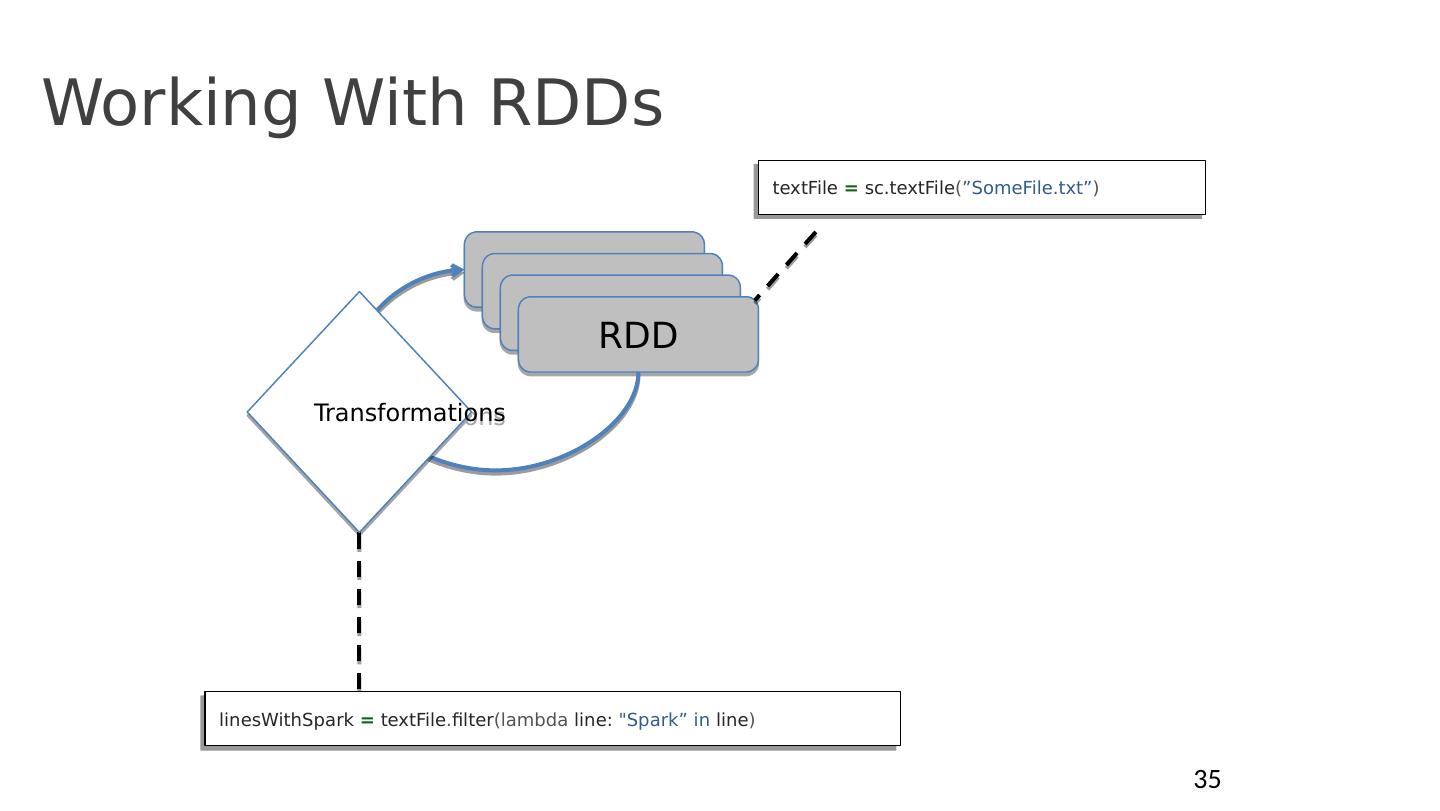
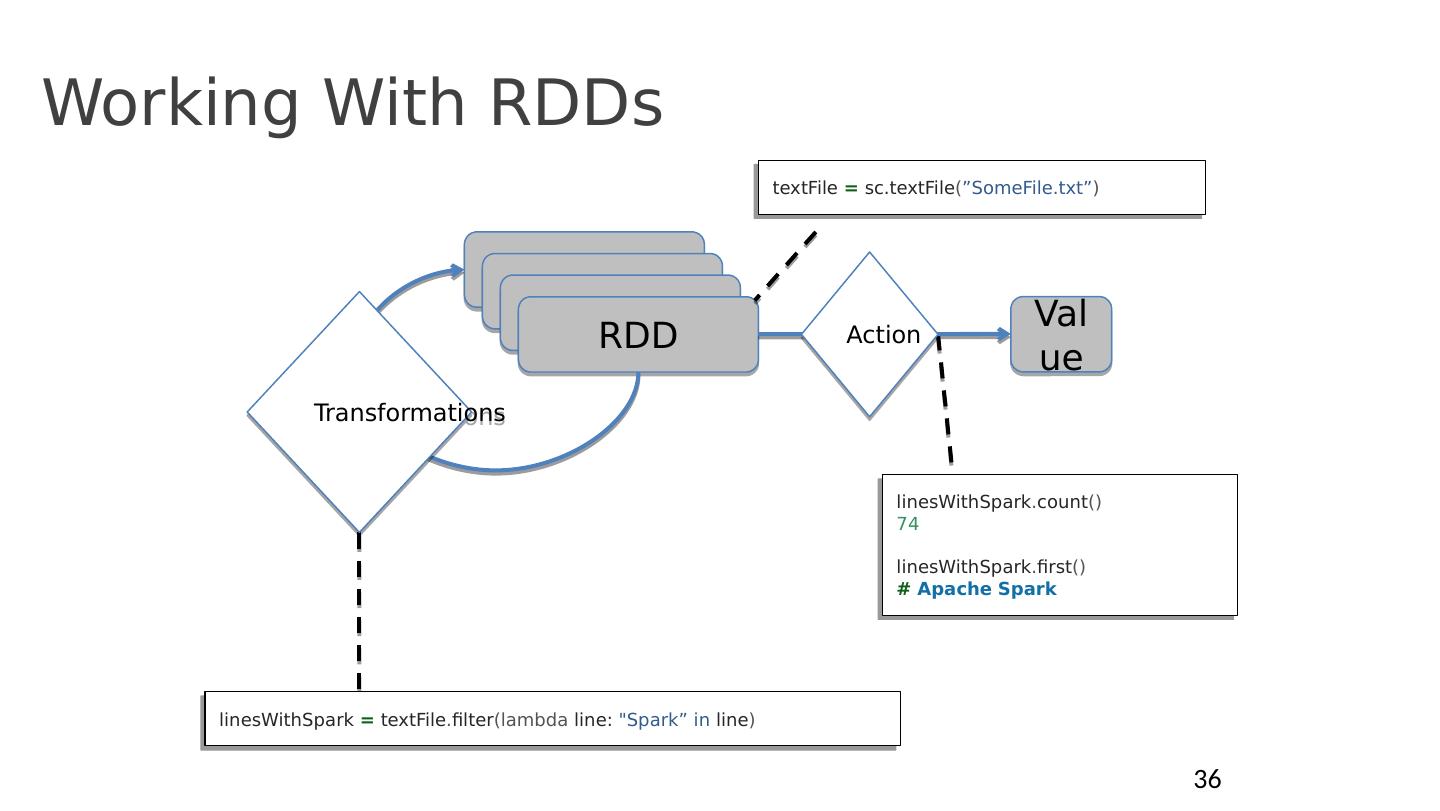
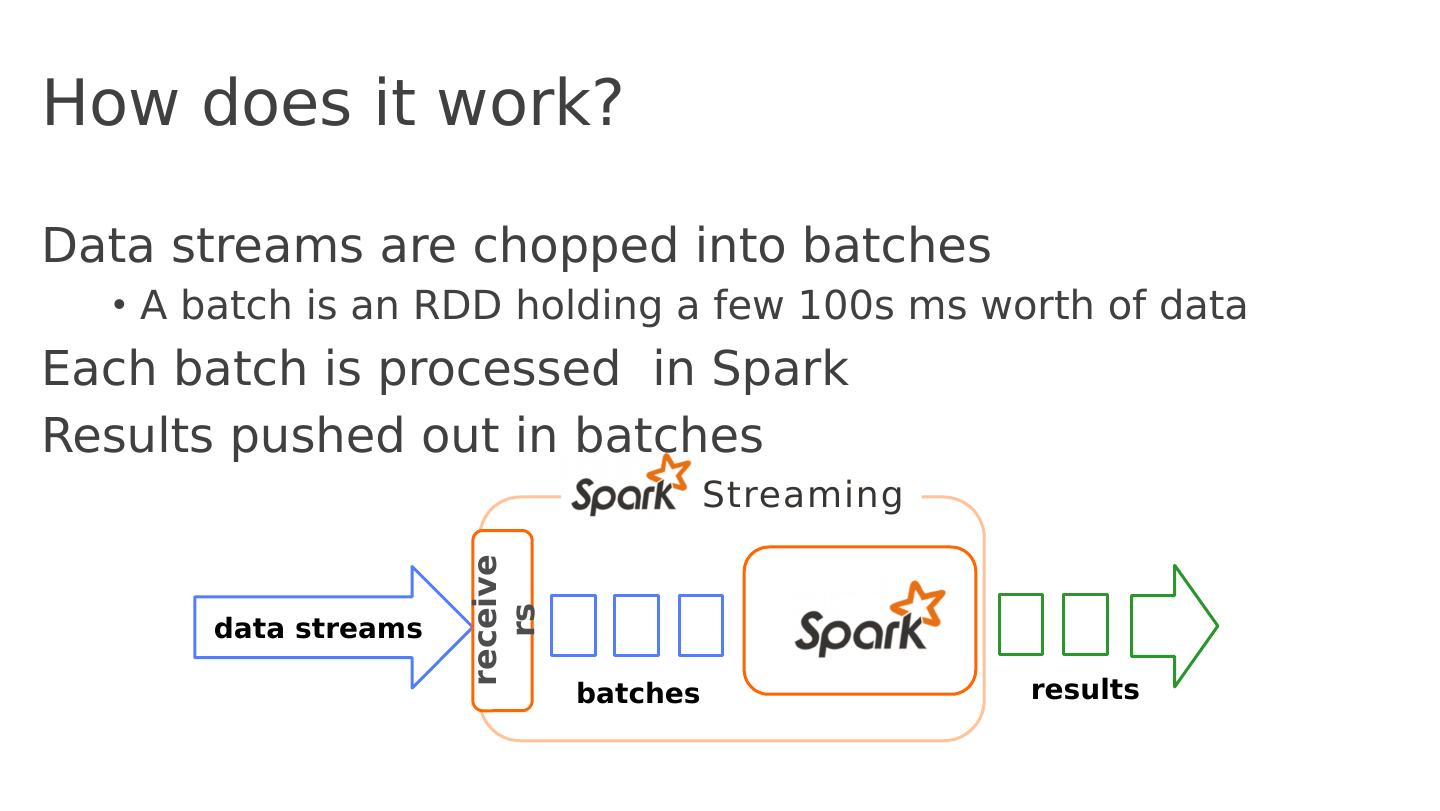
27 .Spark, as a BSP System s tage (super-step) t asks (processors) … s tage (super-step) t asks (processors) … RDD RDD Shuffle a ll tasks in same stage impl . same operations, single-threaded, deterministic execution Immutable dataset Barrier implicit by data dependency
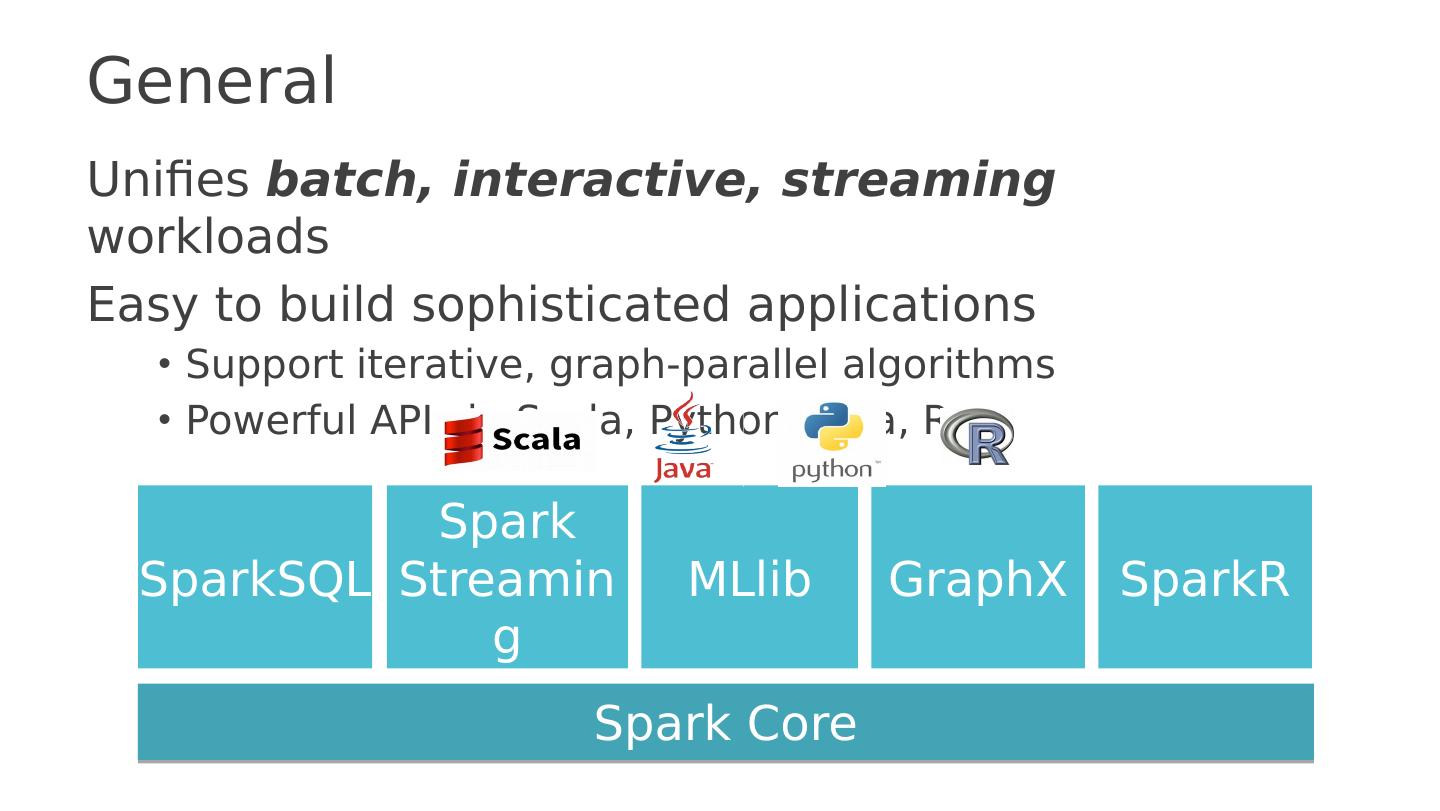
28 .Spark, really a generalization of MapReduce DAG computation model vs two stage computation model (Map and Reduce) Tasks as threads vs. tasks as JVMs Disk-based vs. memory-optimized So for the rest of the lecture, we’ll talk mostly about Spark
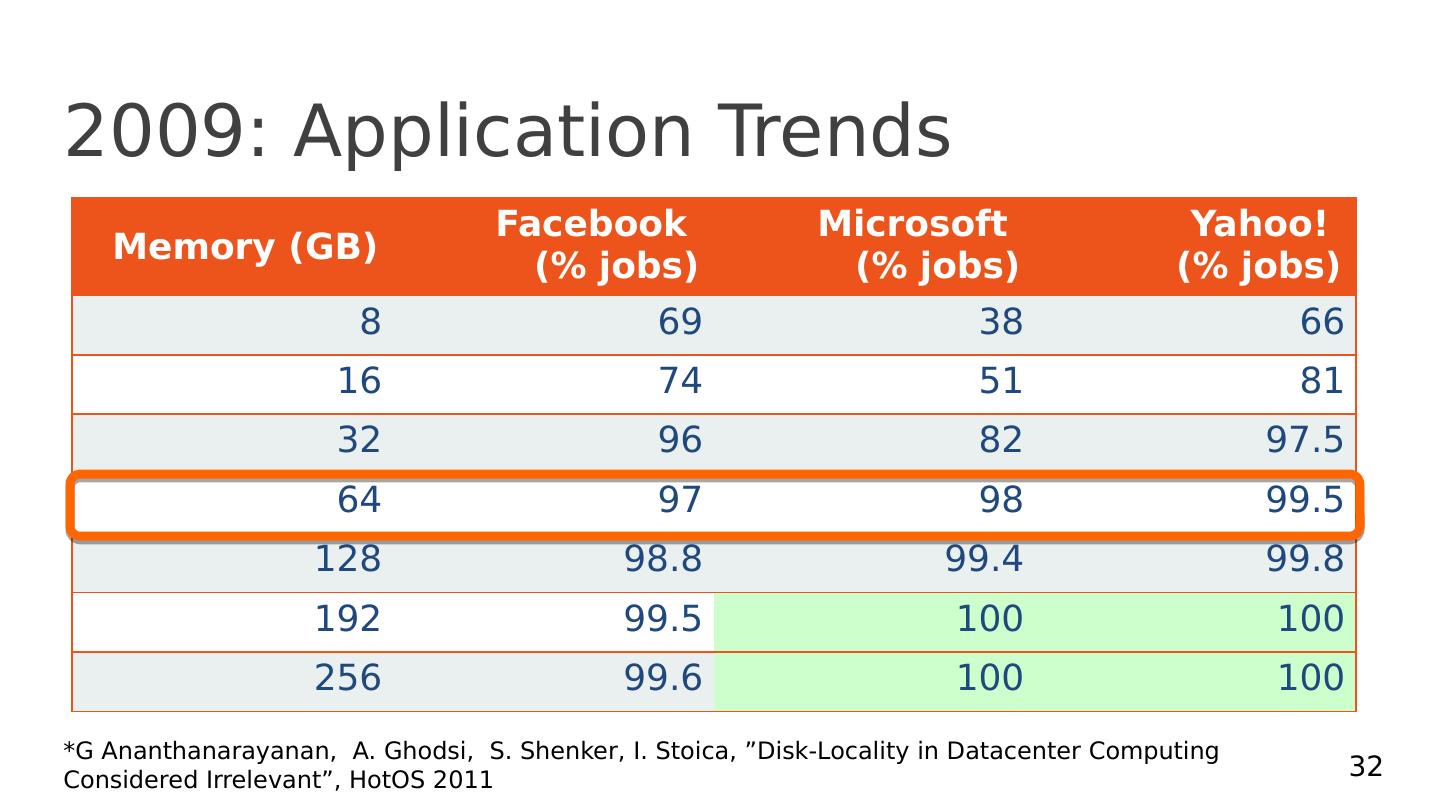
29 .More context (2009): Application Trends Iterative computations , e.g., Machine Learning More and more people aiming to get insights from data Interactive computations , e.g., ad-hoc analytics SQL engines like Hive and Pig drove this trend 29
3秒后跳转登录页面
去登陆

