展开查看详情
3 .大纲 引言 基本术语 假设空间 归纳偏好 发展历程 应用现状 阅读材料
4 .机器学习 “假设用 来评估计算机程序在某任务类 上的性能,若一个程序通过利用经验 在 中任务上获得了性能改善,则我们就说关于 和 ,该程序对 进行了学习” 机器学习致力于研究 如何 通过计算的手段,利用经验来改善系统自身的性能,从而在计算机上从数据中产生“模型”, 用于 对新的情况给出判断。
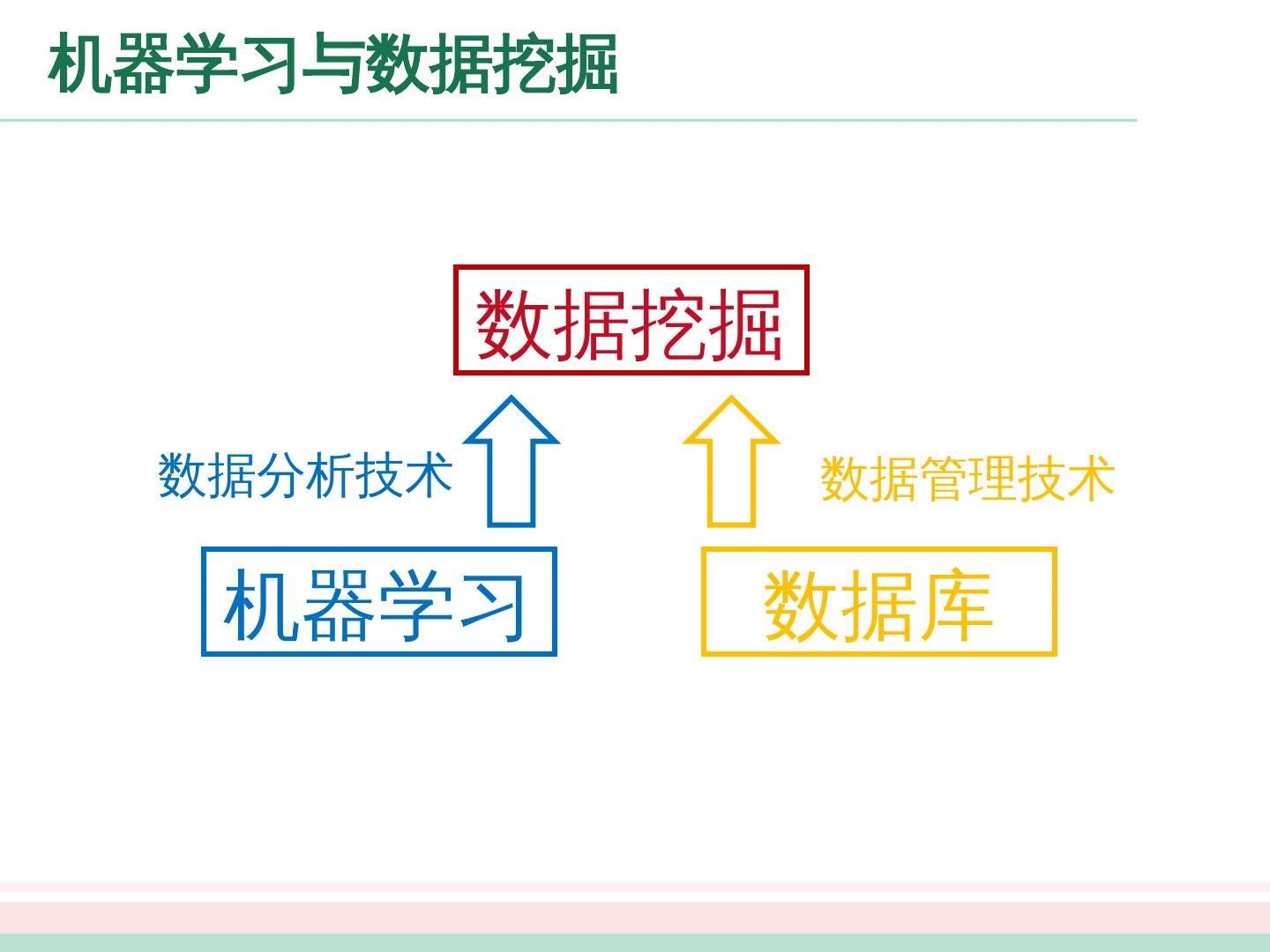
5 .机器学习与数据 挖掘 数据挖掘 机器学习 数据库 数据分析技术 数据管理技术
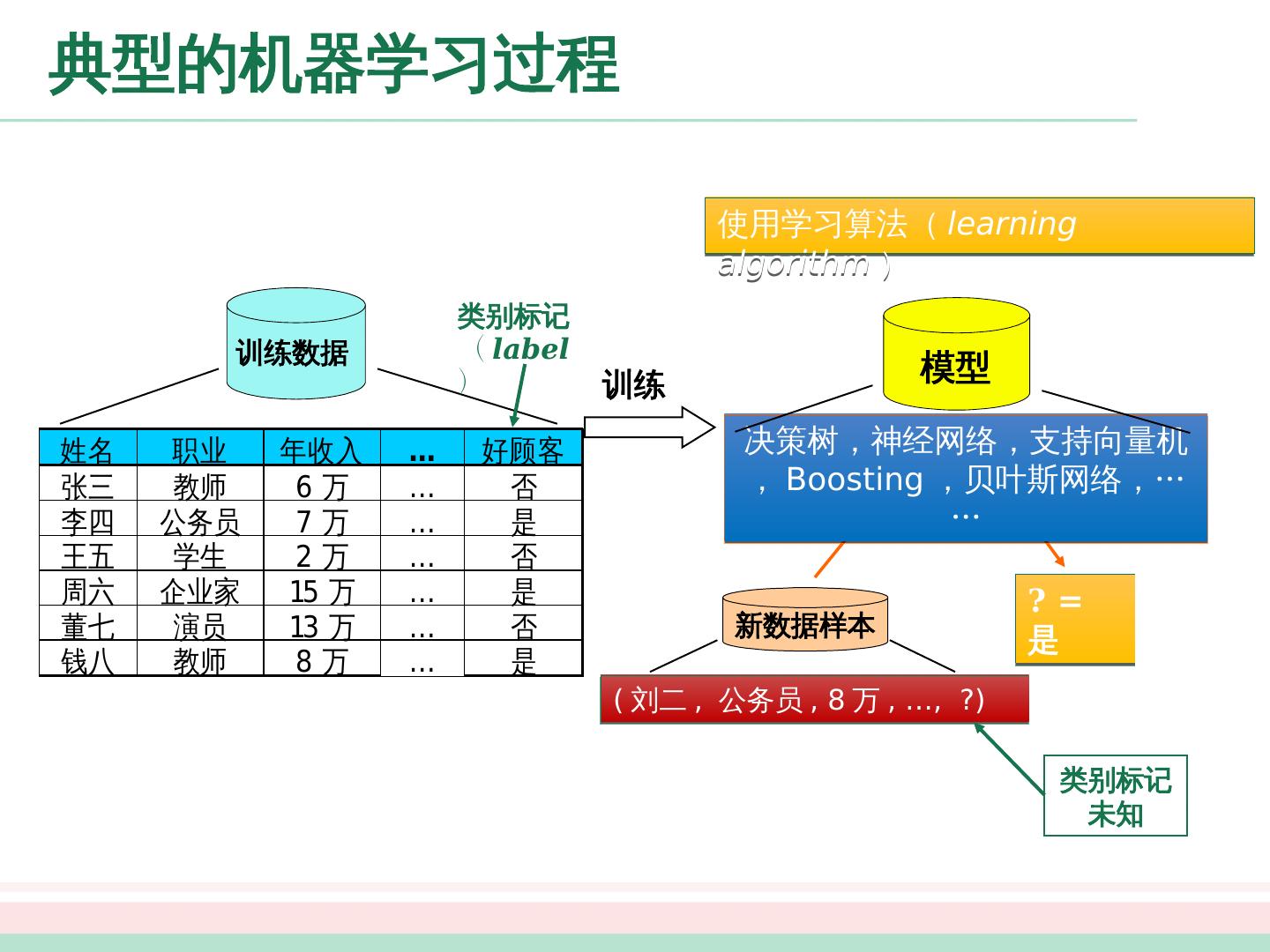
6 .典型的机器学习 过程 决策树,神经网络,支持向量机, Boosting ,贝叶斯网络, …… 模型 训练数据 类别标记 ( label ) 训练 ? = 是 新数据样本 ( 刘二 , 公务员 , 8 万 , …, ?) 类别标记未知 使用学习算法 ( learning algorithm )
7 .典型的机器学习 过程 决策树,神经网络,支持向量机, Boosting ,贝叶斯网络, …… 模型 训练数据 类别标记 ( label ) 训练 ? = 是 新数据样本 ( 刘二 , 公务员 , 8 万 , …, ?) 类别标记未知 使用学习算法 ( learning algorithm )
8 .基本术语 - 数据 训练集 测试集 特征 标记
9 .基本术语 - 任务 预测目标: 分类 : 离散值 二 分类 : 好瓜 ; 坏瓜 多 分类 : 冬瓜 ; 南 瓜 ; 西 瓜 回归 : 连续值 瓜 的成熟度 聚类 : 无标记信息
10 .基本术语 - 任务 有无标记信息 监督学习 : 分类、回归 无监督学习:聚类 半 监督学习:两者结合
11 .基本术语 - 泛化能力 机器学习的目标是使得学到的模型能很好的适用于 “新样本” , 而 不仅仅是训练 集合,我们 称模型适用于新样本的能力为泛化 (generalization) 能力。 通常假设样本空间中的样本服从一个未知分布 , 样本从这个分布中独立获得,即“独立同分布” ( i.i.d ) 。一般而言训练样本越多越有可能通过学习获得强泛化能力的模型
12 .基本术语 - 泛化能力 机器学习的目标是使得学到的模型能很好的适用于 “新样本” , 而 不仅仅是训练 集合,我们 称模型适用于新样本的能力为泛化 (generalization) 能力。 通常假设样本空间中的样本服从一个未知分布 , 样本从这个分布中独立获得,即“独立同分布” ( i.i.d ) 。一般而言训练样本越多越有可能通过学习获得强泛化能力的模型
13 .假设空间 在模型空间中搜索不违背训练集的假设 假设空间大小: 3*3 * 4+1=37 ( 色泽 =?) ( 敲声 =?) 好瓜
14 .假设空间 在模型空间中搜索不违背训练集的假设 假设空间大小: 3*3 * 4+1=37 ( 色泽 =?) ( 敲声 =?) 好瓜
15 .归纳偏好 假设空间中有三个与训练集一致的假设,但他们对 ( 色泽 = 青绿 ; 敲 声 = 沉闷 ) 的瓜会预测出不同的结果: 好瓜 坏 瓜 坏 瓜 选取哪个假设作为学习模型?
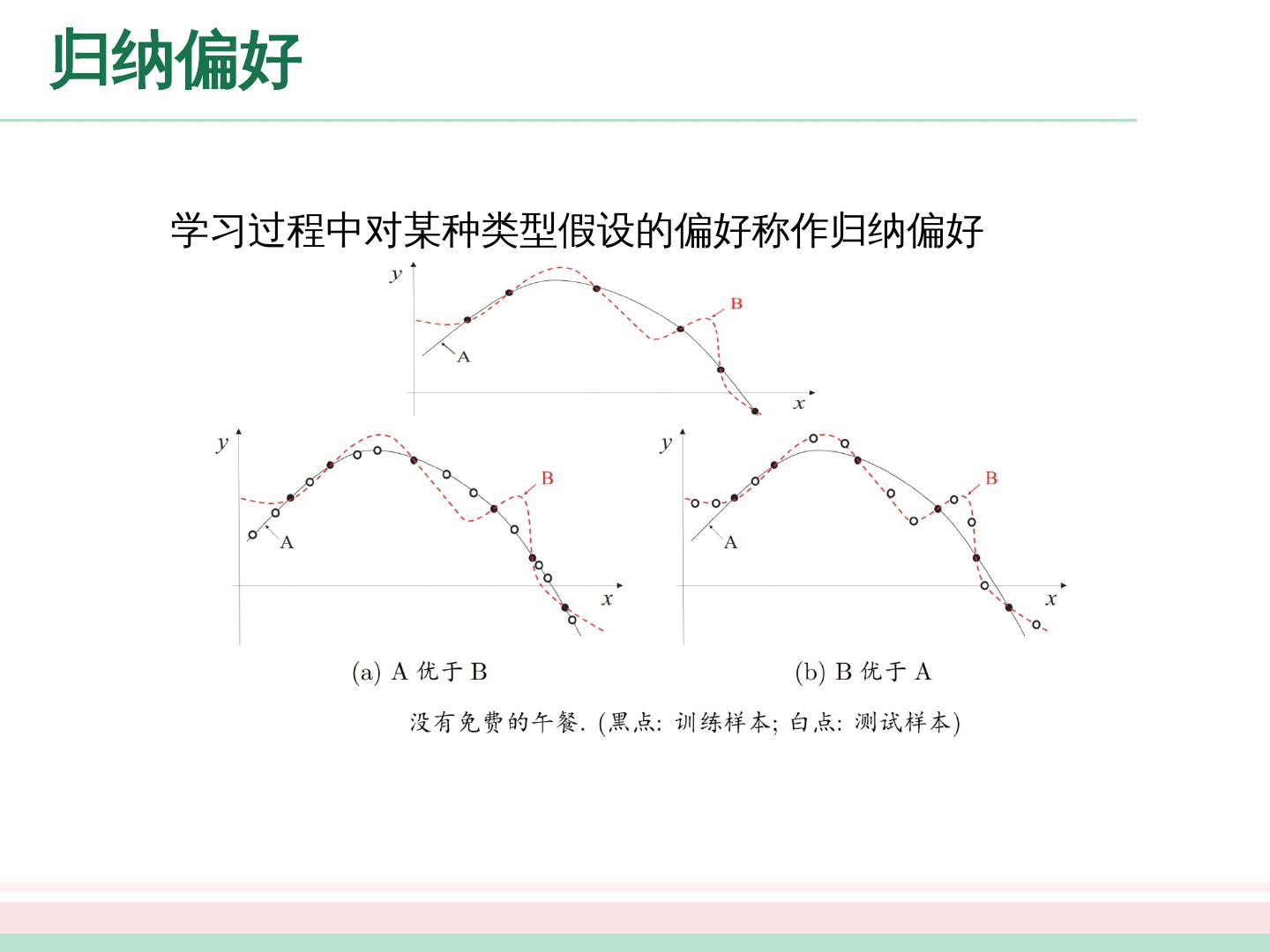
16 .归纳偏好 学习过程中对某种类型假设的偏好称作归纳偏好 A or B? ?
17 .归纳偏好 归纳偏好可看作学习算法自身在一个可能很庞大的假设空间中对假设进行选择的启发式或“价值观” . “奥卡姆剃刀”是一种常用的、自然科学研究中最基本的原则,即“若有多个假设与观察一致,选最简单的那个” . 具体的现实问题中,学习算法本身所做的假设是否成立,也即算法的归纳偏好是否与问题本身匹配,大多数时候直接决定了算法能否取得好的性能 .
18 .NoFreeLunch 一个算法 如果 在某些问题 上 比 另一个算法 好,必然 存在另一些问题 , 比 好 , 也即没有免费的午餐定理。 简单起见,假设样本空间 和假设空间 离散 , 令 代表算法 基于训练数据 X 产生假设 h 的概率,在令 f 代表要学的目标函数, 在训练 集之外所有样本上的总误差为 为指示函数,若 为真取值 1 ,否则取值 0
19 .NoFreeLunch 考虑二分类问题,目标函数可以为任何函数 ,函数空间为 ,对所有可能 f 按均匀分布对误差求和 , 有: 总误差与学习算法无关! 实际问题中,并非所有问题出现的可能性 都 相同 脱离具体问题,空谈“什么学习算法更好”毫无意义
20 .NoFreeLunch 考虑二分类问题,目标函数可以为任何函数 ,函数空间为 ,对所有可能 f 按均匀分布对误差求和 , 有: 总误差与学习算法无关! 实际问题中,并非所有问题出现的可能性 都 相同 脱离具体问题,空谈“什么学习算法更好”毫无意义
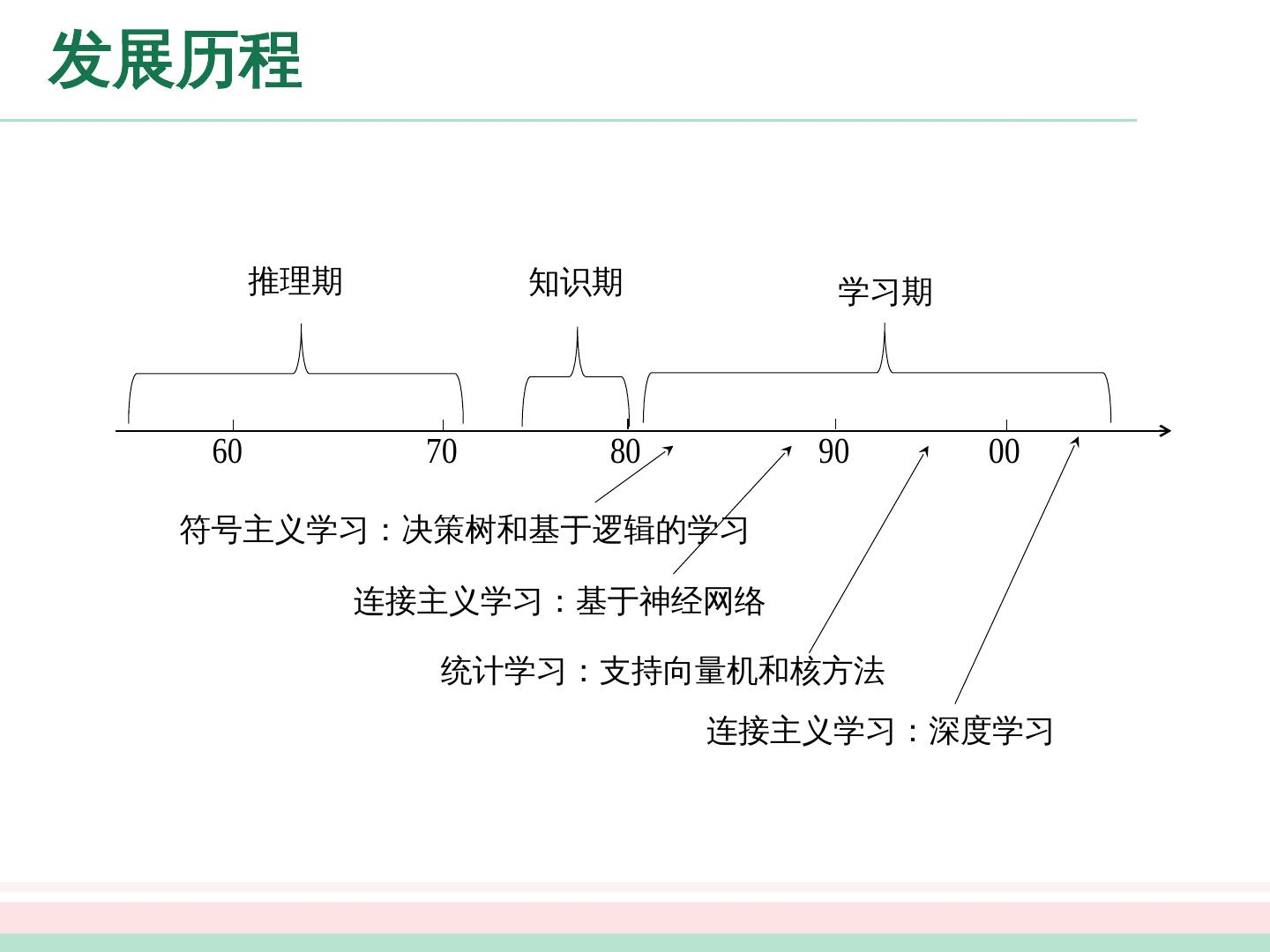
21 .发展历程 推理期 : A. Newell 和 H. Simon 的“逻辑理论家” (Logic Theorist) 程序以及伺候的“通用问题求解” (General Problem Solving) 程序等在当时取得了令人振奋的结果。 2006 年卡耐基梅隆大学宣告成立第一个“机器学习系”,机器学习奠基人之一 T.Mitchell 教授任系主任。 知识期: 大量专家系统问世,在很多应用领域取得大量成果; 但是由人来总结知识再交给计算机相当困难 。
22 .发展历程 学习 期: 符号主义学习 决策树:以信息论为基础,最小化信息熵,模拟了人类对概念进行判定的树形流程 基于逻辑的学习:使用一节逻辑进行知识表示,通过修改扩充逻辑表达式对数据进行归纳 连接主义学习 神经网络 统计学习 支持向量 机及核方法
23 .发展历程 推理期 知识期 学习期 符号主义学习:决策树和基于逻辑的学习 连接主义学习:基于神经网络 统计学习:支持向量机和核方法 连接主义学习:深度学习
24 .发展历程 推理期 知识期 学习期 符号主义学习:决策树和基于逻辑的学习 连接主义学习:基于神经网络 统计学习:支持向量机和核方法 连接主义学习:深度学习
25 .应用现状 计算机领域最活跃的研究分支之一: NASA_JPL 科学家在 Science 撰文指出机器学习对科学研究起到越来越大的支撑作用 DARPA 启动 PAL 计划,将机器学习的重要性提高到国家安全的高度来考虑 2006 年卡耐基梅隆大学宣告成立第一个“机器学习系”,机器学习奠基人之一 T.Mitchell 教授任系主任。 与 普通人的生活密切相关: 天气预报、能源勘探、环境监测、搜索引擎、自动驾驶汽车 等
26 .应用现状 影响 到人类社会的政治生活: 2012 美国大选期间 奥巴 马麾下的机器学习团队,对社交网络等各类数据进行分析,为其提示下一步的竞选行动。 具有 自然科学探索色彩: P.Kanerva 在二十世纪八十年代中期提出 SDM(Sparse Distributed Memory) 模型时并没有刻意模仿脑生理结构,但后来神经科学的研究发现, SDM 的稀疏编码机制在视觉、听觉、嗅觉功能的脑皮层中广泛存在,促进 理解 “人类如何学习”
27 .应用现状 影响 到人类社会的政治生活: 2012 美国大选期间 奥巴 马麾下的机器学习团队,对社交网络等各类数据进行分析,为其提示下一步的竞选行动。 具有 自然科学探索色彩: P.Kanerva 在二十世纪八十年代中期提出 SDM(Sparse Distributed Memory) 模型时并没有刻意模仿脑生理结构,但后来神经科学的研究发现, SDM 的稀疏编码机制在视觉、听觉、嗅觉功能的脑皮层中广泛存在,促进 理解 “人类如何学习”
28 .阅读材料 [ Mitchell, 1997 ] 是第一本机器学习专门教材 . [ Duda et al., 2001; Alpaydin, 2004; Flach, 2012] 为出色的入门读物 . [Hastie et al., 2009] 为进阶读物 , [Bishop, 2006] 适合于贝叶斯学习偏好者 . [Shalev-Shwartz and Ben-David, 2014] 适合于理论偏好者 . 《 机器学习 : 一种人工智能途径 》 [Michalski et al., 1983 ] 汇集了 20 位学者撰写 16 篇文章,是机器学习早期最重要的文献 . [Dietterich, 1997] 对机器学习领域的发展进行了评述和展望。
29 .阅读材料 机器学习领域最重要 的 国际 学术 会议是国际机器学习会议 (ICML) 、国际神经信息处理系统会议 (NIPS) 和国际学习理论会议 (COLT), 重要的区域性会议主要有欧洲机器学习会议 (ECML) 和亚洲机器学习会议 (ACML); 最重要 的 国际 学术 期刊是 Journal of Maching Learning Research 和 Machine Learning. 国内不少书记包含机器学习方面的内容,例如 [ 陆汝钤 ,1996].[ 李航 ,2012] 是一统计学习为主题的读物 . 国内机器学习领域最重要的活动是两年一次的中国机器学习大会 (CCML) 以及每年举行的“机器学习及其应用”研讨会 (MLA).