展开查看详情
1 .Perceptron Learning Algorithm
Perceptron Learning Algorithm
Jia Li
Department of Statistics
The Pennsylvania State University
Email: jiali@stat.psu.edu
http://www.stat.psu.edu/∼jiali
Jia Li http://www.stat.psu.edu/∼jiali
�
2 .Perceptron Learning Algorithm
Separating Hyperplanes
Construct linear decision boundaries that explicitly try to
separate the data into different classes as well as possible.
Good separation is defined in a certain form mathematically.
Even when the training data can be perfectly separated by
hyperplanes, LDA or other linear methods developed under a
statistical framework may not achieve perfect separation.
Jia Li http://www.stat.psu.edu/∼jiali
�
3 .Perceptron Learning Algorithm
Jia Li http://www.stat.psu.edu/∼jiali
�
4 .Perceptron Learning Algorithm
Review of Vector Algebra
A hyperplane or affine set L is defined by the linear equation:
L = {x : f (x) = β0 + β T x = 0} .
For any two points x1 and x2 lying in L, β T (x1 − x2 ) = 0, and
hence β ∗ = β/ β is the vector normal to the surface of L.
For any point x0 in L, β T x0 = −β0 .
The signed distance of any point x to L is given by
1
β ∗T (x − x0 ) = (β T x + β0 )
β
1
= f (x) .
f (x)
Hence f (x) is proportional to the signed distance from x to
the hyperplane defined by f (x) = 0.
Jia Li http://www.stat.psu.edu/∼jiali
�
5 .Perceptron Learning Algorithm
Jia Li http://www.stat.psu.edu/∼jiali
�
6 .Perceptron Learning Algorithm
Rosenblatt’s Perceptron Learning
Goal: find a separating hyperplane by minimizing the distance
of misclassified points to the decision boundary.
Code the two classes by yi = 1, −1.
If yi = 1 is misclassified, β T xi + β0 < 0. If yi = −1 is
misclassified, β T xi + β0 > 0.
Since the signed distance from xi to the decision boundary is
β T xi +β0
β , the distance from a misclassified xi to the decision
T
boundary is −yi (β βxi +β0 ) .
Denote the set of misclassified points by M.
The goal is to minimize:
D(β, β0 ) = − yi (β T xi + β0 ) .
i∈M
Jia Li http://www.stat.psu.edu/∼jiali
�
7 .Perceptron Learning Algorithm
Stochastic Gradient Descent
To minimize D(β, β0 ), compute the gradient (assuming M is
fixed):
∂D(β, β0 )
= − yi xi ,
∂β
i∈M
∂D(β, β0 )
= − yi .
∂β0
i∈M
Stochastic gradient descent is used to minimize the piecewise
linear criterion.
Adjustment on β, β0 is done after each misclassified point is
visited.
Jia Li http://www.stat.psu.edu/∼jiali
�
8 .Perceptron Learning Algorithm
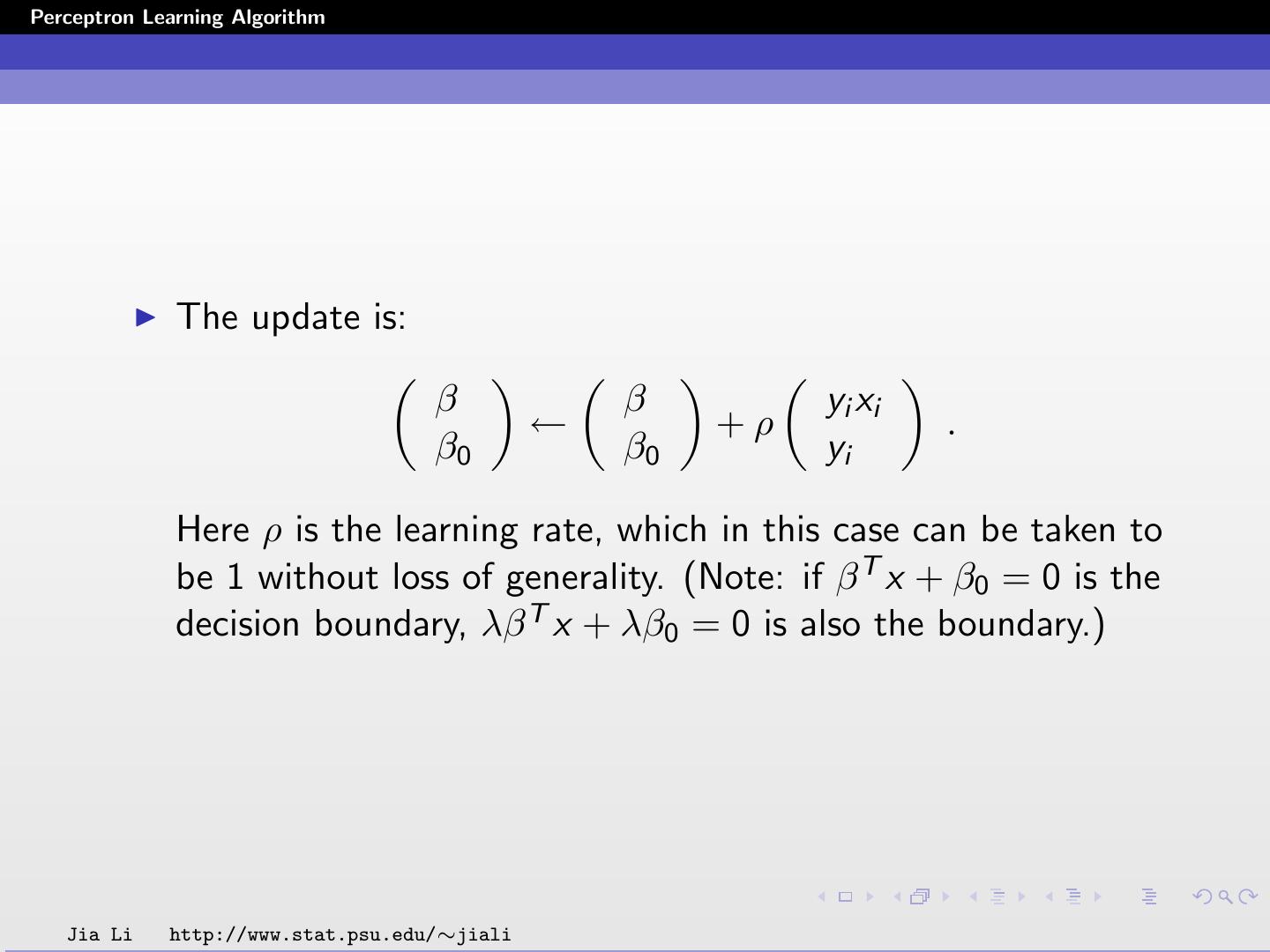
The update is:
β β yi xi
← +ρ .
β0 β0 yi
Here ρ is the learning rate, which in this case can be taken to
be 1 without loss of generality. (Note: if β T x + β0 = 0 is the
decision boundary, λβ T x + λβ0 = 0 is also the boundary.)
Jia Li http://www.stat.psu.edu/∼jiali
�
9 .Perceptron Learning Algorithm
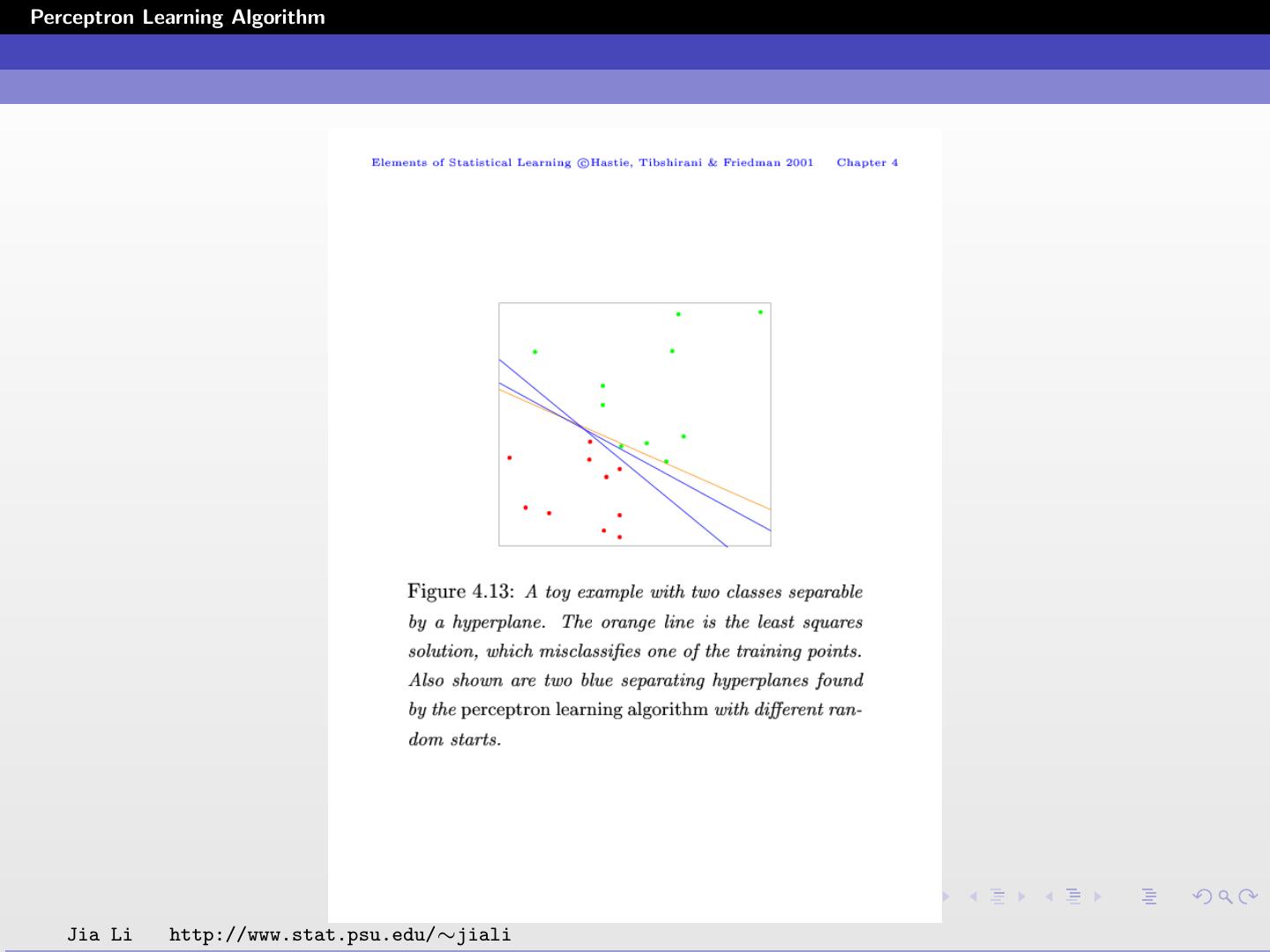
Issues
If the classes are linearly separable, the algorithm converges to
a separating hyperplane in a finite number of steps.
A number of problems with the algorithm:
When the data are separable, there are many solutions, and
which one is found depends on the starting values.
The number of steps can be very large. The smaller the gap,
the longer it takes to find it.
When the data are not separable, the algorithm will not
converge, and cycles develop. The cycles can be long and
therefore hard to detect.
Jia Li http://www.stat.psu.edu/∼jiali
�
10 .Perceptron Learning Algorithm
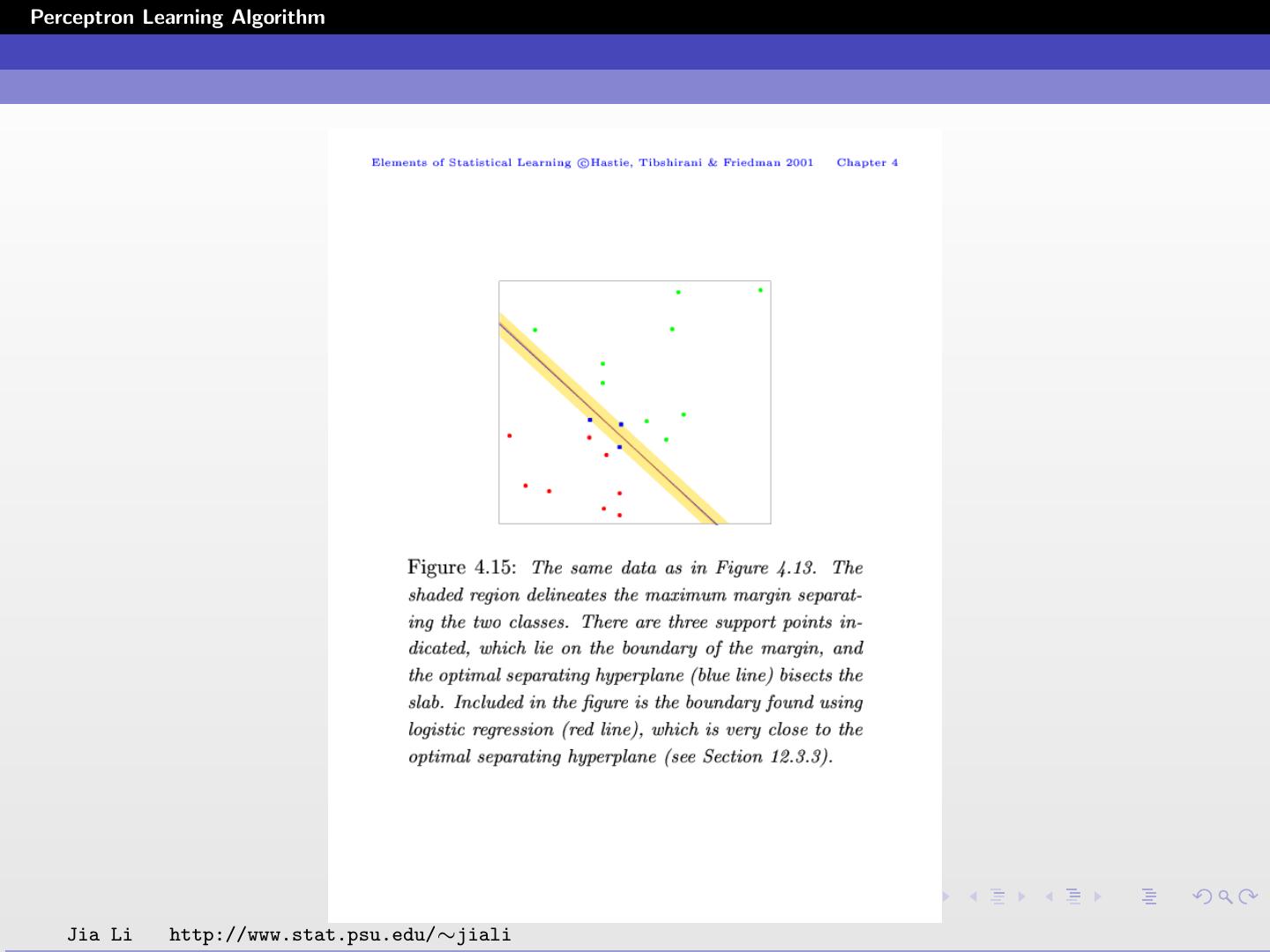
Optimal Separating Hyperplanes
Suppose the two classes can be linearly separated.
The optimal separating hyperplane separates the two classes
and maximizes the distance to the closest point from either
class.
There is a unique solution.
Tend to have better classification performance on test data.
The optimization problem:
max C
β,β0
1
subject to yi (β T xi + β0 ) ≥ C , i = 1, ..., N
β
Every point is at least C away from the decision boundary
β T x + β0 = 0.
Jia Li http://www.stat.psu.edu/∼jiali
�
11 .Perceptron Learning Algorithm
Jia Li http://www.stat.psu.edu/∼jiali
�
12 .Perceptron Learning Algorithm
For any solution of the optimization problem, any positively
scaled multiple is a solution as well. We can set β = 1/C .
The optimization problem is equivalent to:
1 2
min β
β,β0 2
subject to yi (β T xi + β0 ) ≥ 1, i = 1, ..., N
This is a convex optimization problem.
Jia Li http://www.stat.psu.edu/∼jiali
�
13 .Perceptron Learning Algorithm
The Lagrange sum is:
N
1 2
LP = min β − ai [yi (β T xi + β0 ) − 1] .
β,β0 2
i=1
Setting the derivatives to zero, we obtain:
N
β = ai yi xi ,
i=1
N
0 = ai yi .
i=1
Jia Li http://www.stat.psu.edu/∼jiali
�
14 .Perceptron Learning Algorithm
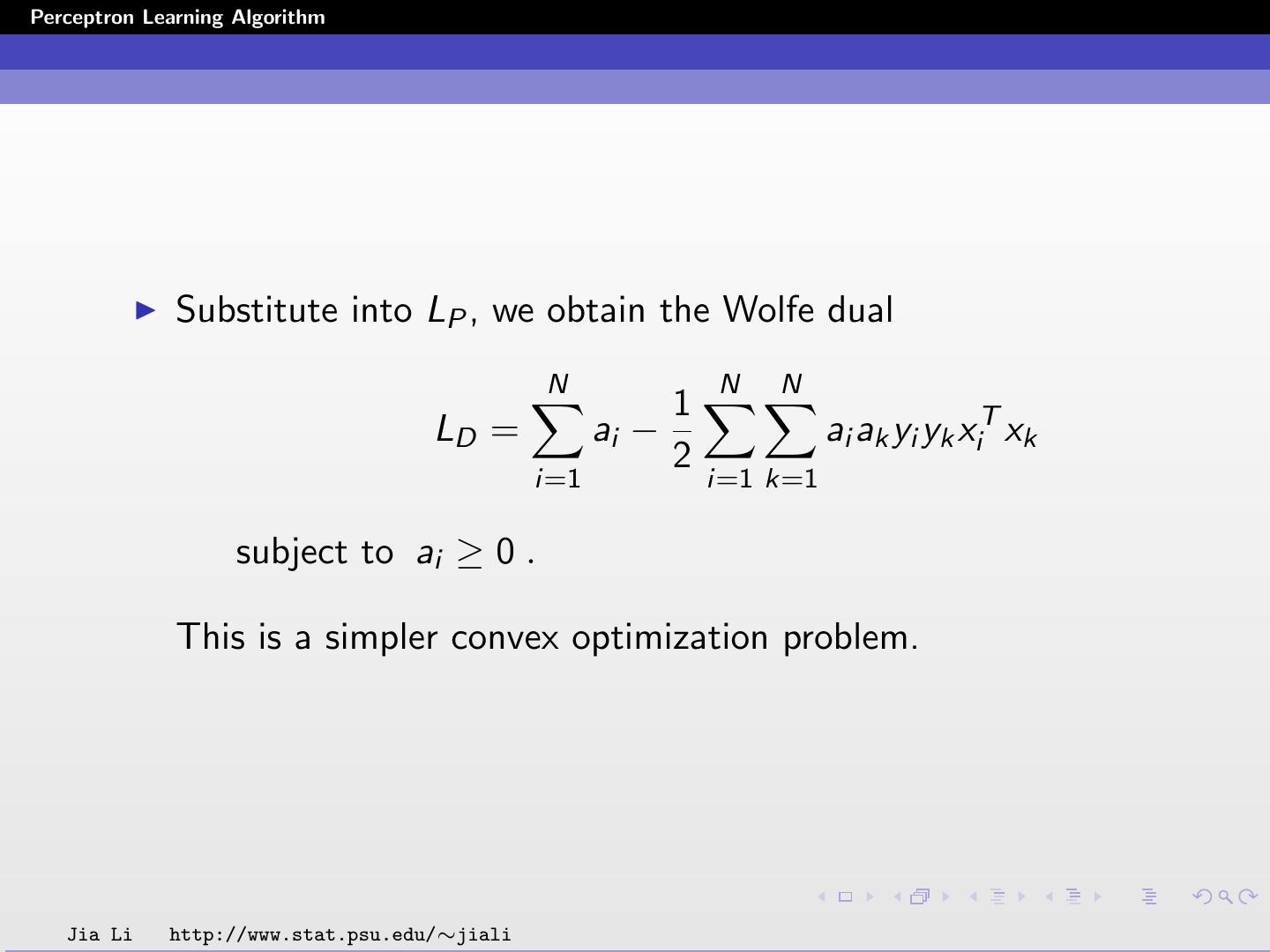
Substitute into LP , we obtain the Wolfe dual
N N N
1
LD = ai − ai ak yi yk xiT xk
2
i=1 i=1 k=1
subject to ai ≥ 0 .
This is a simpler convex optimization problem.
Jia Li http://www.stat.psu.edu/∼jiali
�
15 .Perceptron Learning Algorithm
The Karush-Kuhn-Tucker conditions require:
ai [yi (β T xi + β0 ) − 1] = 0 ∀i .
If ai > 0, then yi (β T xi + β0 ) = 1, that is, xi is on the
boundary of the slab.
If yi (β T xi + β0 ) > 1, that is, xi is not on the boundary of the
slab, ai = 0.
The points xi on the boundary of the slab are called support
points.
The solution vector β is a linear combination of the support
points:
β= ai yi xi .
i:ai >0
Jia Li http://www.stat.psu.edu/∼jiali
�